Chapter 4 Dictionary-based sentiment analysis
So far, you have learned how you can bring text into a representation that allows for systematic analysis (Chapter 2) and how you can discover which terms can be used to discriminate between groups (Chapter 5). Performing quantitative social science however also requires actually measuring things. In the remainder of this course, I will put a stronger emphasis on techniques that can be used to accomplish this.
According to Grimmer, Roberts, and Stewart (2022), measurement encompasses the following steps for the researcher:
- “Define the conceptualization we want to measure.
- Locate a source of data that contains implications of the identified concept.
- Generate a way to translate data into a latent representation.
- Label the representation and connect it to the identified concept.
- Validate the resulting measure.” (p. 173)
Today, I will start with an easy yet commonly used way to measure the presence of certain conceptualizations in text: dictionary-based text analysis. The intuition of dictionary-based text analysis is that the presence and salience of a conceptualization in a given text can be determined by counting words that are a priori defined to be related to the conceptualization. Probably the most common use case is so-called sentiment analysis. Its goal is to determine whether the tone of a text is positive or negative. A classic application in the industry is the automatic determination of the sentiment of customer reviews.
4.1 Sentiment analysis using tidytext principles
Today’s example is similar: I will use a data set containing 25,000 IMDb reviews and use tidytext to determine whether they are rather positive or negative. In this case, the movie titles are not included. Hence, I cannot draw inferences on how different movies were perceived by the audience. If I had this information though, it would of course be straightforward by just averaging the respective values.
First, I load the required packages and the data.
library(tidyverse)
library(tidytext)
library(SnowballC)
imdb_data <- read_csv("data/imdb_reviews.csv")
glimpse(imdb_data)## Rows: 25,000
## Columns: 2
## $ text <chr> "Once again Mr. Costner has dragged out a movie for far long…
## $ sentiment <chr> "negative", "negative", "negative", "negative", "negative", …Note that the data also contains a column named “sentiment” which contains the true sentiment value. This will be helpful to assess the validity of my measurement later.
The next step is to bring the documents (each document is a review in this case) into a representation that lends itself well to the automated analysis of the words that are contained, the tidytext format. However, in order for me to bring it into the proper format, I will first look at the dictionaries.
4.1.1 Available dictionaries
The tidytext package comes with a number of freely available dictionaries. Each dictionary has its own particularities and using the “right” dictionary always depends a bit on the task at hand. The dictionaries are stored in tibbles which contain two columns. word always refers to the word. sentiment refers to a discrete sentiment value (e.g., “positive”), and value to a numeric sentiment value (e.g., for AFINN the positivity/negativity of a word is measured on a scale from -5 – the most negative – to +5 – the most positive). For today’s example, I will use AFINN (Nielsen 2011) and bing (Hu and Liu 2004).
#get_sentiments(lexicon = "nrc")
walk(c("bing", "loughran", "afinn", "nrc"), ~get_sentiments(lexicon = .x) |>
head() |>
print())## # A tibble: 6 × 2
## word sentiment
## <chr> <chr>
## 1 2-faces negative
## 2 abnormal negative
## 3 abolish negative
## 4 abominable negative
## 5 abominably negative
## 6 abominate negative
## # A tibble: 6 × 2
## word sentiment
## <chr> <chr>
## 1 abandon negative
## 2 abandoned negative
## 3 abandoning negative
## 4 abandonment negative
## 5 abandonments negative
## 6 abandons negative
## # A tibble: 6 × 2
## word value
## <chr> <dbl>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2
## # A tibble: 6 × 2
## word sentiment
## <chr> <chr>
## 1 abacus trust
## 2 abandon fear
## 3 abandon negative
## 4 abandon sadness
## 5 abandoned anger
## 6 abandoned fearGiven this structure of the dictionaries, I can analyze the sentiment of my documents by taking the following steps:
- Clean the data and bring them into the
tidytextformat; the column containing the terms needs to be named “word” for easier joining. - Use a
dplyr::inner_join()to join the dictionary tibble. - Summarize the sentiment values for each document (if categorical: count occurrences of different categories per document, use the modal value; if numerical: average values)
4.1.2 Step 1: Preprocessing
imdb_tidy <- imdb_data |>
rowid_to_column("doc_id") |> # to identify documents later
unnest_tokens(output = word, input = text) |>
mutate(word = wordStem(word, language = "en"))
imdb_tidy |> glimpse()## Rows: 5,801,976
## Columns: 3
## $ doc_id <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
## $ sentiment <chr> "negative", "negative", "negative", "negative", "negative", …
## $ word <chr> "onc", "again", "mr", "costner", "has", "drag", "out", "a", …Now I have created a nice tibble containing the IMDb reviews of the 20th century in a tidy format. Note that the words were stemmed. Therefore, I will have to stem the words in the sentiment dictionary as well, since they need to match. I will use both the bing (categorizing words in “positive” and “negative”) and the AFINN (continuous scale ranging from -5 to +5) dictionary.
4.1.3 Step 2: Sentiment Analysis using dplyr::inner_join()
in the next step, I just add the sentiment values to the respective documents. Each matching term will have the respective sentiment value added. Note that I have to change the column name “sentiment” in the original tibble because there is the column “sentiment” present in the dictionary.
imdb_afinn <- imdb_tidy |>
rename(sentiment_gold = sentiment) |>
inner_join(afinn_stemmed)
glimpse(imdb_afinn)## Rows: 585,808
## Columns: 4
## $ doc_id <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2…
## $ sentiment_gold <chr> "negative", "negative", "negative", "negative", "negati…
## $ word <chr> "drag", "terrif", "rescu", "care", "ghost", "forgotten"…
## $ value <dbl> -1, 4, 2, 2, -1, -1, 2, 2, -2, -2, 2, -1, -2, 4, -1, 3,…## Joining with `by = join_by(word)`## Warning in inner_join(rename(imdb_tidy, sentiment_gold = sentiment), bing_stemmed): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 267 of `x` matches multiple rows in `y`.
## ℹ Row 1568 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship =
## "many-to-many"` to silence this warning.## Rows: 753,106
## Columns: 4
## $ doc_id <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2…
## $ sentiment_gold <chr> "negative", "negative", "negative", "negative", "negati…
## $ word <chr> "drag", "terrif", "just", "ghost", "realiz", "time", "c…
## $ sentiment <chr> "negative", "positive", "positive", "negative", "positi…4.1.4 Step 3: Summarize values
In the case of numerical sentiment values, this step is rather simple: group by the document and average the values.
imdb_afinn_summary <- imdb_afinn |>
group_by(doc_id) |>
summarize(mean_value = mean(value))
glimpse(imdb_afinn_summary)## Rows: 24,997
## Columns: 2
## $ doc_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
## $ mean_value <dbl> 0.4444444, -0.2173913, -0.8636364, 0.4516129, 0.6666667, 0.…In the case of the categorical values, it requires a bit more code. First, I need to replace the categorical values with numerical ones. Then, I can do the same operation as above.
imdb_bing_summary <- imdb_bing |>
mutate(value = case_when(sentiment == "negative" ~ -1,
sentiment == "positive" ~ 1)) |>
group_by(doc_id) |>
summarize(mean_value = mean(value, na.rm = TRUE))
glimpse(imdb_bing_summary)## Rows: 25,000
## Columns: 2
## $ doc_id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, …
## $ mean_value <dbl> 0.25000000, 0.12500000, -0.28000000, 0.09523810, 0.17948718…Et voilà, I have performed a first sentiment classification just using tidy commands. The next step would now be to validate the results, i.e., to check whether my measures come to the same conclusions as to the gold standard the data set came with. This will be described in the chapter on Supervised Classification. However, a first basic comparison would be to plot the words that contribute much to the classification into the respective category. The contribution of a word is here operationalized as its sentiment value times its occurrence.
imdb_afinn_pos_contribution <- imdb_afinn |>
group_by(word) |>
summarize(contribution = sum(value)) |>
slice_max(contribution, n = 10)
imdb_afinn_neg_contribution <- imdb_afinn |>
group_by(word) |>
summarize(contribution = sum(value)) |>
slice_min(contribution, n = 10)imdb_bing_pos_contribution <- imdb_bing |>
mutate(value = case_when(sentiment == "negative" ~ -1,
sentiment == "positive" ~ 1)) |>
group_by(word) |>
summarize(contribution = sum(value)) |>
slice_max(contribution, n = 10)
imdb_bing_neg_contribution <- imdb_bing |>
mutate(value = case_when(sentiment == "negative" ~ -1,
sentiment == "positive" ~ 1)) |>
group_by(word) |>
summarize(contribution = sum(value)) |>
slice_min(contribution, n = 10)It can be visualized in a smart bar plot:
bind_rows(imdb_afinn_pos_contribution |> mutate(dic = "AFINN"),
imdb_afinn_neg_contribution |> mutate(dic = "AFINN"),
imdb_bing_pos_contribution |> mutate(dic = "Bing"),
imdb_bing_neg_contribution |> mutate(dic = "Bing")) |>
mutate(word = reorder_within(word, contribution, dic)) |>
ggplot() +
geom_col(aes(contribution, word), show.legend = FALSE) +
scale_y_reordered() +
facet_wrap(vars(dic), scales = "free")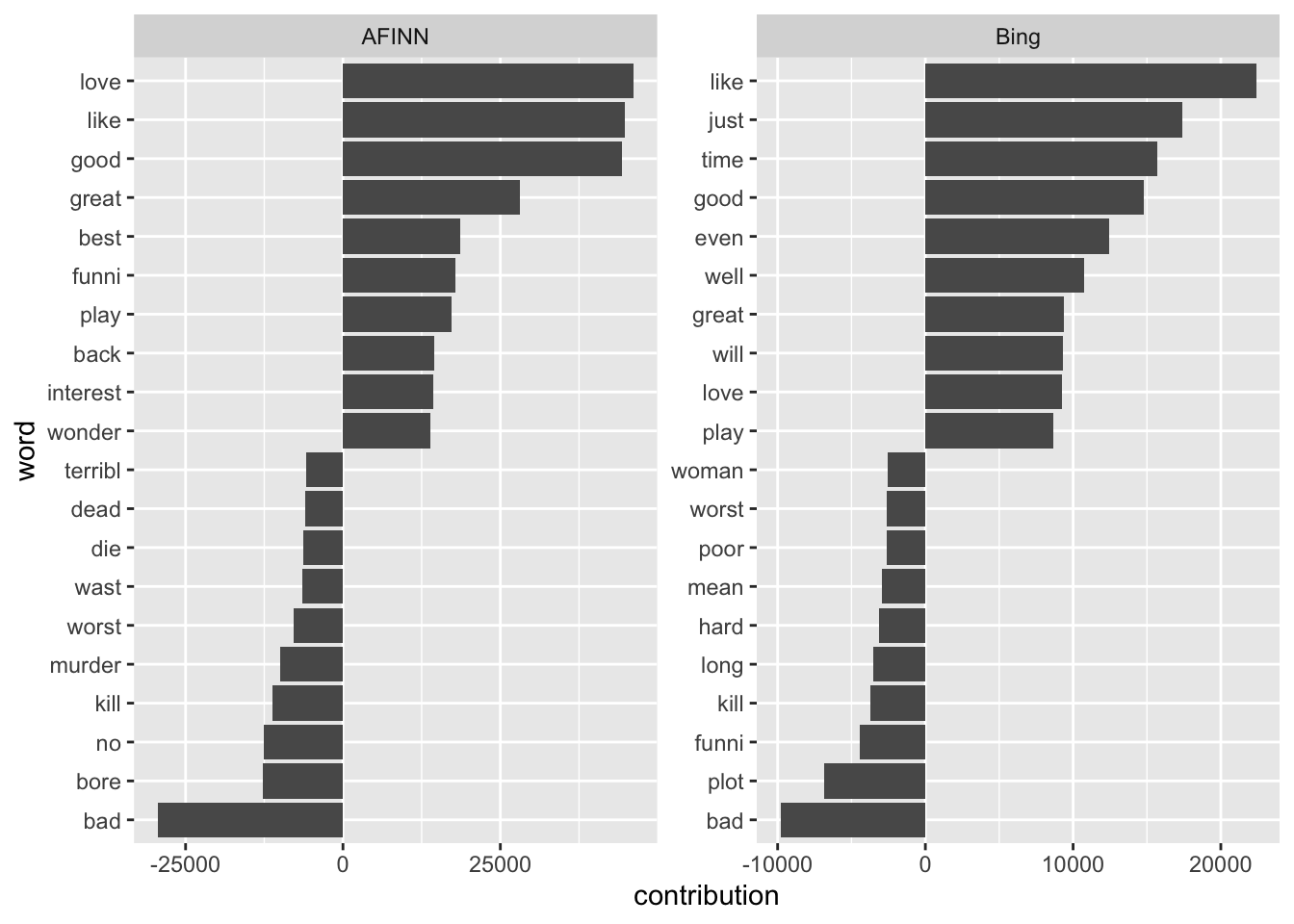
4.3 Exercises
Take this Twitter data set. Filter out all tweets dealing with abortion.
library(tidyverse)
library(rvest)
library(janitor)
library(tidytext)
rep_overview <- read_html("https://pressgallery.house.gov/member-data/members-official-twitter-handles") |>
html_table() |>
pluck(1)
colnames(rep_overview) <- rep_overview[3, ]
rep_overview <- slice(rep_overview, 4:nrow(rep_overview)) |>
clean_names() |>
mutate(twitter_handle = str_remove(twitter_handle, "\\@"))
keywords <- c("abortion", "prolife", " roe ", " wade ", "roevswade", "baby", "fetus", "womb", "prochoice")
tweets_abortion <- read_csv("https://www.dropbox.com/s/fjf5wx7kdqiwniw/congress_tweets_2022.csv?dl=1") |>
left_join(rep_overview |> select(twitter_handle, party)) |>
filter(str_detect(text, pattern = str_c(keywords, collapse = "|")) &
party %in% c("D", "R"))
tweets_abortion_tidy <- tweets_abortion |>
select(date, text, party) |>
rowid_to_column("doc_id") |>
unnest_tokens(word, text)- Which party’s members tweeted more negatively? Try two strategies:
- take the average of the overall terms depending on the party.
- determine individual Tweets’ sentiment and then compare shares between parties.
- do the results differ?
- Look at the contributing words. Why is it difficult to draw exact inferences here?
Solution. Click to expand!
#1
#a
sent_per_party <- tweets_abortion_tidy |>
inner_join(get_sentiments("afinn")) |>
mutate(word_sent = case_when(value > 0 ~ "positive",
value < 0 ~ "negative"))
sent_per_party |>
ggplot() +
geom_bar(aes(word_sent)) +
facet_wrap(vars(party))
#b
sent_per_doc <- tweets_abortion_tidy |>
inner_join(get_sentiments("afinn")) |>
group_by(doc_id, party) |>
summarize(mean_sent = mean(value)) |>
mutate(tweet_sent = case_when(mean_sent > 0 ~ "positive",
mean_sent < 0 ~ "negative",
TRUE ~ "neutral"))
sent_per_doc |>
ggplot() +
geom_bar(aes(tweet_sent)) +
facet_wrap(vars(party))
#2
tweets_abortion_tidy_contribution <- tweets_abortion_tidy |>
inner_join(get_sentiments("afinn")) |>
group_by(party, word) |>
summarize(contribution = sum(value))
bind_rows(
tweets_abortion_tidy_contribution |>
filter(party == "D") |>
slice_max(contribution, n = 10, with_ties = FALSE) |>
mutate(type = "pos"),
tweets_abortion_tidy_contribution |>
filter(party == "D") |>
slice_min(contribution, n = 10, with_ties = FALSE) |>
mutate(type = "neg"),
tweets_abortion_tidy_contribution |>
filter(party == "R") |>
slice_max(contribution, n = 10, with_ties = FALSE) |>
mutate(type = "pos"),
tweets_abortion_tidy_contribution |>
filter(party == "R") |>
slice_min(contribution, n = 10, with_ties = FALSE) |>
mutate(type = "neg")
) |>
mutate(word = reorder_within(word, contribution, party)) |>
ggplot() +
geom_col(aes(contribution, word), show.legend = FALSE) +
scale_y_reordered() +
facet_wrap(vars(party, type), scales = "free")