Chapter 5 “Fighting words”
A common task in the quantitative analysis of text is to determine how documents differ from each other concerning word usage. This is usually achieved by identifying words that are particular for one document but not for another. These words are referred to by Monroe, Colaresi, and Quinn (2008) as fighting words or, by Grimmer, Roberts, and Stewart (2022), discriminating words. To use the techniques that will be presented today, an already existing organization of the documents is assumed.
In the following, I will present multiple methods according to which you can identify words that are related to different groups and can be used to distinguish them. I will present the methods and their implementation in R ordered from rather simple to more complicated. The order is inspired by Monroe, Colaresi, and Quinn (2008). The methods have in common that, at their heart, they determine how often a word appears in a group of documents. Thereafter, the “importance” of a word in distinguishing the groups is determined through several weighting procedures.
5.1 Counting words per document
The most simple approach to determine which words are more correlated to a certain group of documents is by merely counting them and determining their proportion in the document groups. For illustratory purposes, I use fairytales from H.C. Andersen which are contained in the hcandersenr package.
library(tidyverse)
library(lubridate)
library(tidytext)
fairytales <- hcandersenr::hcandersen_en |>
filter(book %in% c("The princess and the pea",
"The little mermaid",
"The emperor's new suit"))
fairytales_tidy <- fairytales |>
unnest_tokens(output = token, input = text)5.1.1 Naive approach: raw counts
For a first, naive analysis, I can merely count the times the terms appear in the texts. Since the text is in tidytext format, I can do so using means from traditional tidyverse packages. I will then visualize the results with a bar plot.
fairytales_top10 |>
ggplot() +
geom_col(aes(x = n, y = reorder_within(token, n, book))) +
scale_y_reordered() +
labs(y = "token") +
facet_wrap(vars(book), scales = "free") +
theme(strip.text.x = element_blank())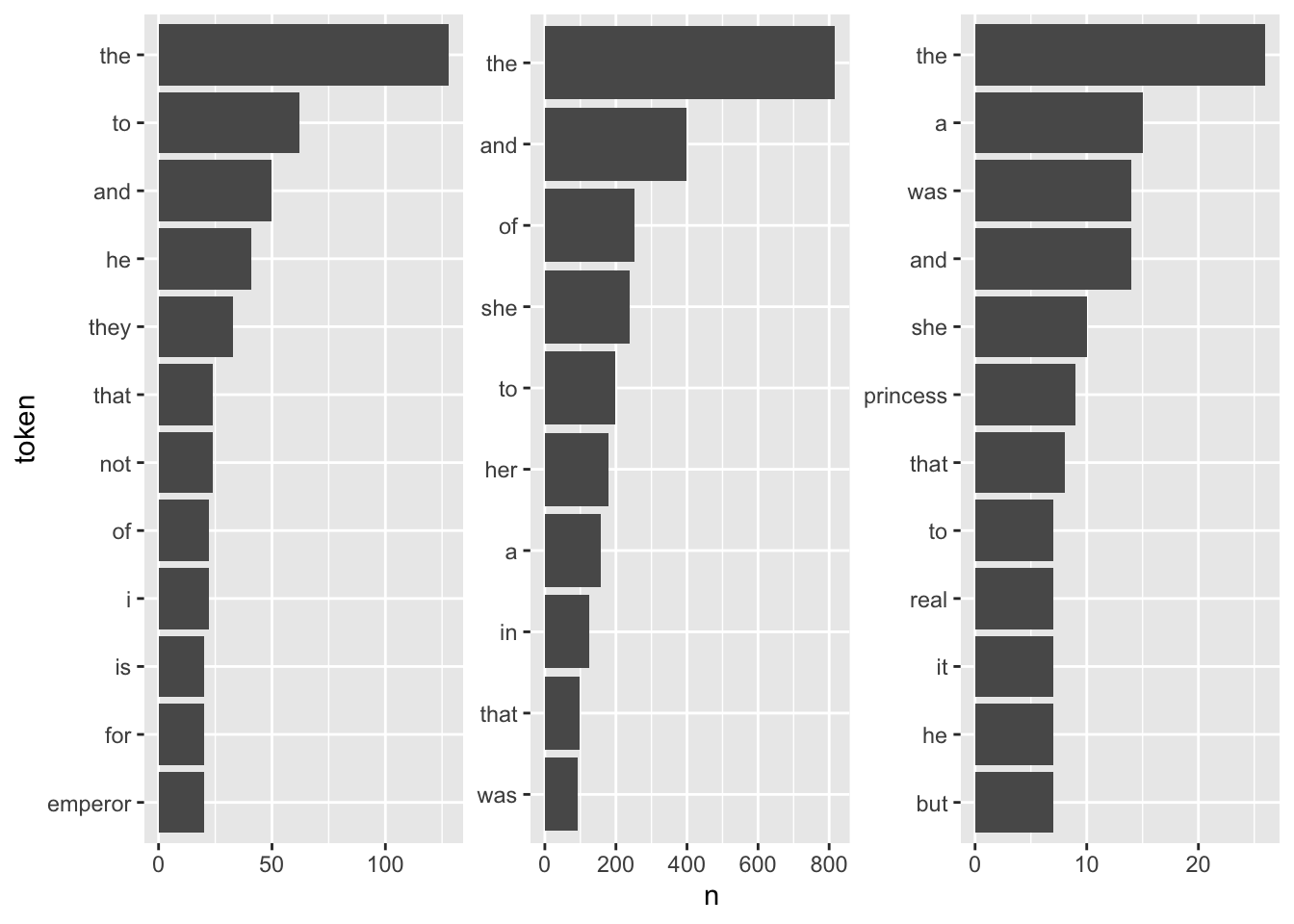
It is quite hard to draw inferences on which plot belongs to which book since the plots are crowded with stopwords. However, there are pre-made stopword lists I can harness to remove the noise and perhaps catch a bit more signal for determining the books.
library(stopwords)
fairytales_top10_nostop <- fairytales_tidy |>
anti_join(get_stopwords(), by = c("token" = "word")) |>
group_by(book) |>
count(token) |>
slice_max(n, n = 10, with_ties = FALSE)fairytales_top10_nostop |>
ggplot() +
geom_col(aes(x = n, y = reorder_within(token, n, book))) +
scale_y_reordered() +
labs(y = "token") +
facet_wrap(vars(book), scales = "free") +
scale_x_continuous(breaks = scales::pretty_breaks()) +
theme(strip.text.x = element_blank())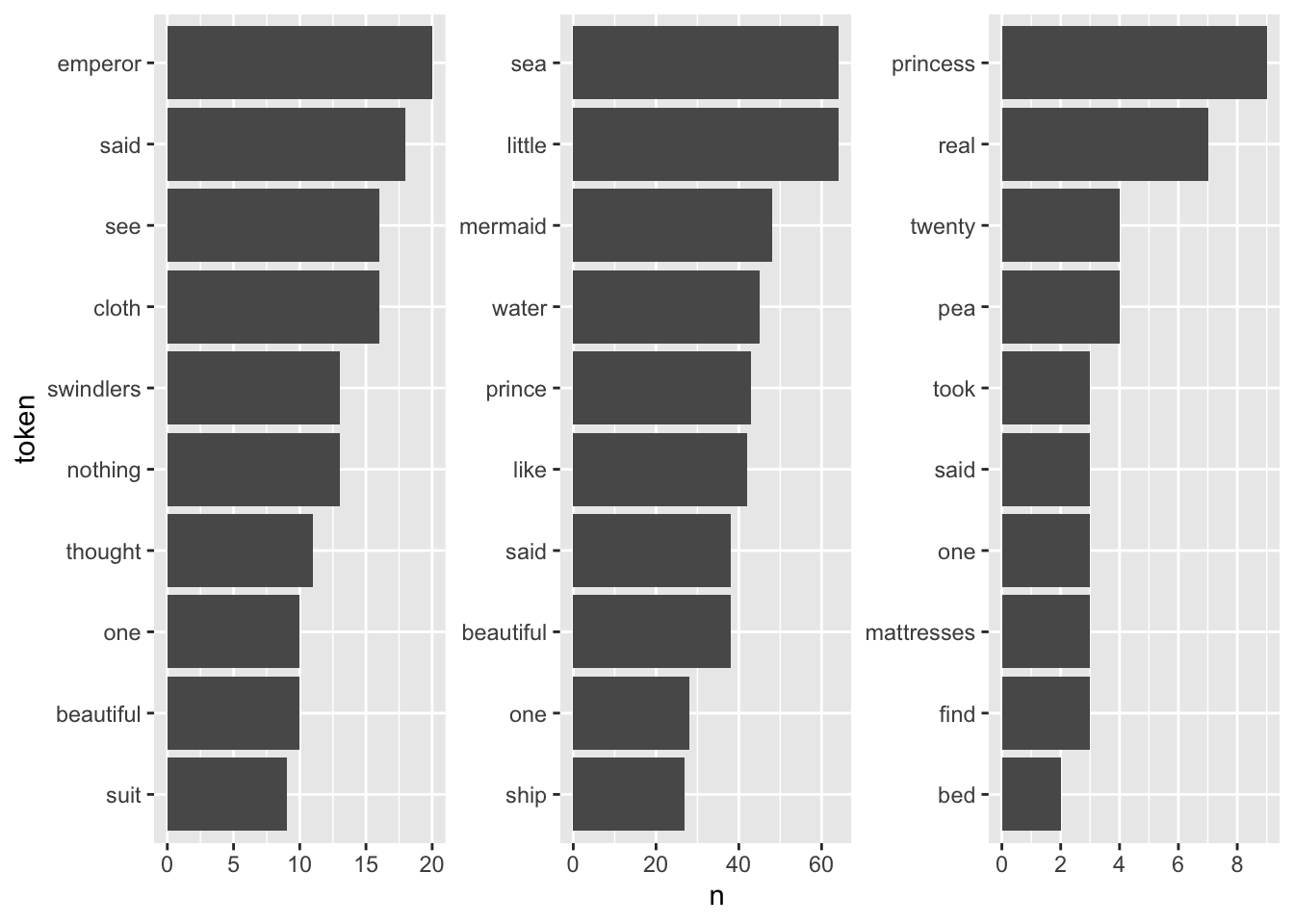
This already looks quite nice, it is quite easy to see which plot belongs to the respective book.
5.1.2 TF-IDF
A better explanation for words that are particular to a group of documents is the ones that appear often in one group but rarely in the other one(s). So far, the measure of term frequency only accounts for how often terms are used in the respective document. I can take into account how often it appears in other documents by including the inverse document frequency. The resulting measure is called tf-idf and describes “the frequency of a term adjusted for how rarely it is used.” (Silge and Robinson 2016: 31) If a term is rarely used overall but appears comparably often in a singular document, it might be safe to assume that it plays a bigger role in that document.
The tf-idf of a word in a document is commonly3 calculated as follows:
\[w_{i,j}=tf_{i,j}\times ln(\frac{N}{df_{i}})\]
–> \(tf_{i,j}\): number of occurrences of term \(i\) in document \(j\)
–> \(df_{i}\): number of documents containing \(i\)
–> \(N\): total number of documents
Note that the \(ln\) is included so that words that appear in all documents – and do therefore not have discriminatory power – will automatically get a value of 0. This is because \(ln(1) = 0\). On the other hand, if a term appears in, say, 4 out of 20 documents, its idf is \(ln(20/4) = ln(5) = 1.6\).
The tidytext package provides a neat implementation for calculating the tf-idf called bind_tfidf(). It takes as input the columns containing the term, the document, and the document-term counts n.
fairytales_top10_tfidf <- fairytales_tidy |>
group_by(book) |>
count(token) |>
bind_tf_idf(token, book, n) |>
slice_max(tf_idf, n = 10)fairytales_top10_tfidf |>
ggplot() +
geom_col(aes(x = tf_idf, y = reorder_within(token, tf_idf, book))) +
scale_y_reordered() +
labs(y = "token") +
facet_wrap(vars(book), scales = "free") +
theme(strip.text.x = element_blank(),
axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank())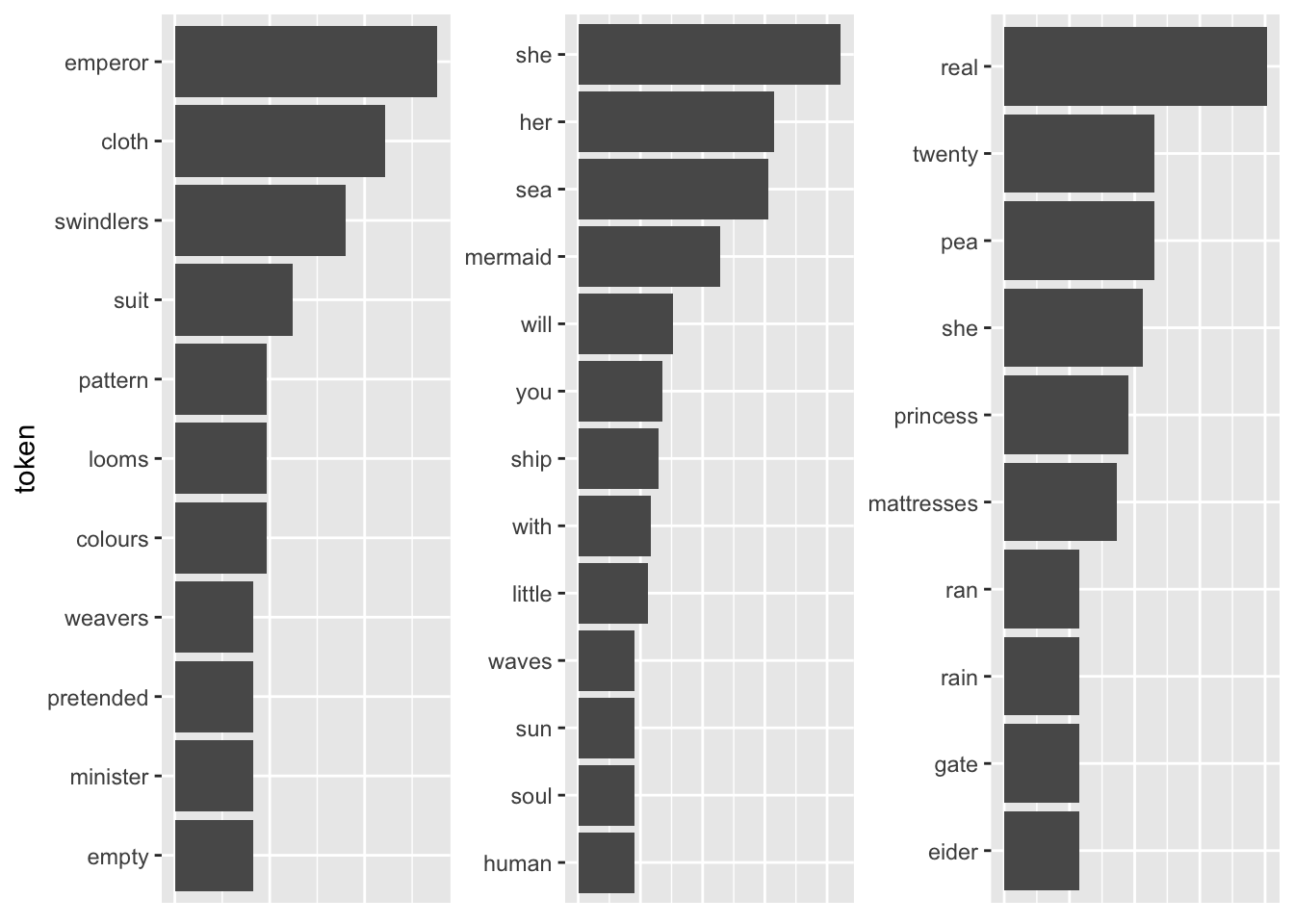
Pretty good already! All the fairytales can be clearly identified. A problem with this representation is that I cannot straightforwardly interpret the x-axis values (they can be removed by uncommenting the last three lines). A way to mitigate this is using odds.
Another shortcoming becomes visible when I take the terms with the highest TF-IDF as compared to all other fairytales.
tfidf_vs_full <- hcandersenr::hcandersen_en |>
unnest_tokens(output = token, input = text) |>
count(token, book) |>
bind_tf_idf(book, token, n) |>
filter(book %in% c("The princess and the pea",
"The little mermaid",
"The emperor's new suit"))
plot_tf_idf <- function(df, group_var){
df |>
group_by({{ group_var }}) |>
slice_max(tf_idf, n = 10, with_ties = FALSE) |>
ggplot() +
geom_col(aes(x = tf_idf, y = reorder_within(token, tf_idf, {{ group_var }}))) +
scale_y_reordered() +
labs(y = "token") +
facet_wrap(vars({{ group_var }}), scales = "free") +
#theme(strip.text.x = element_blank()) +
theme(axis.title.x=element_blank(),
axis.text.x=element_blank(),
axis.ticks.x=element_blank())
}
plot_tf_idf(tfidf_vs_full, book)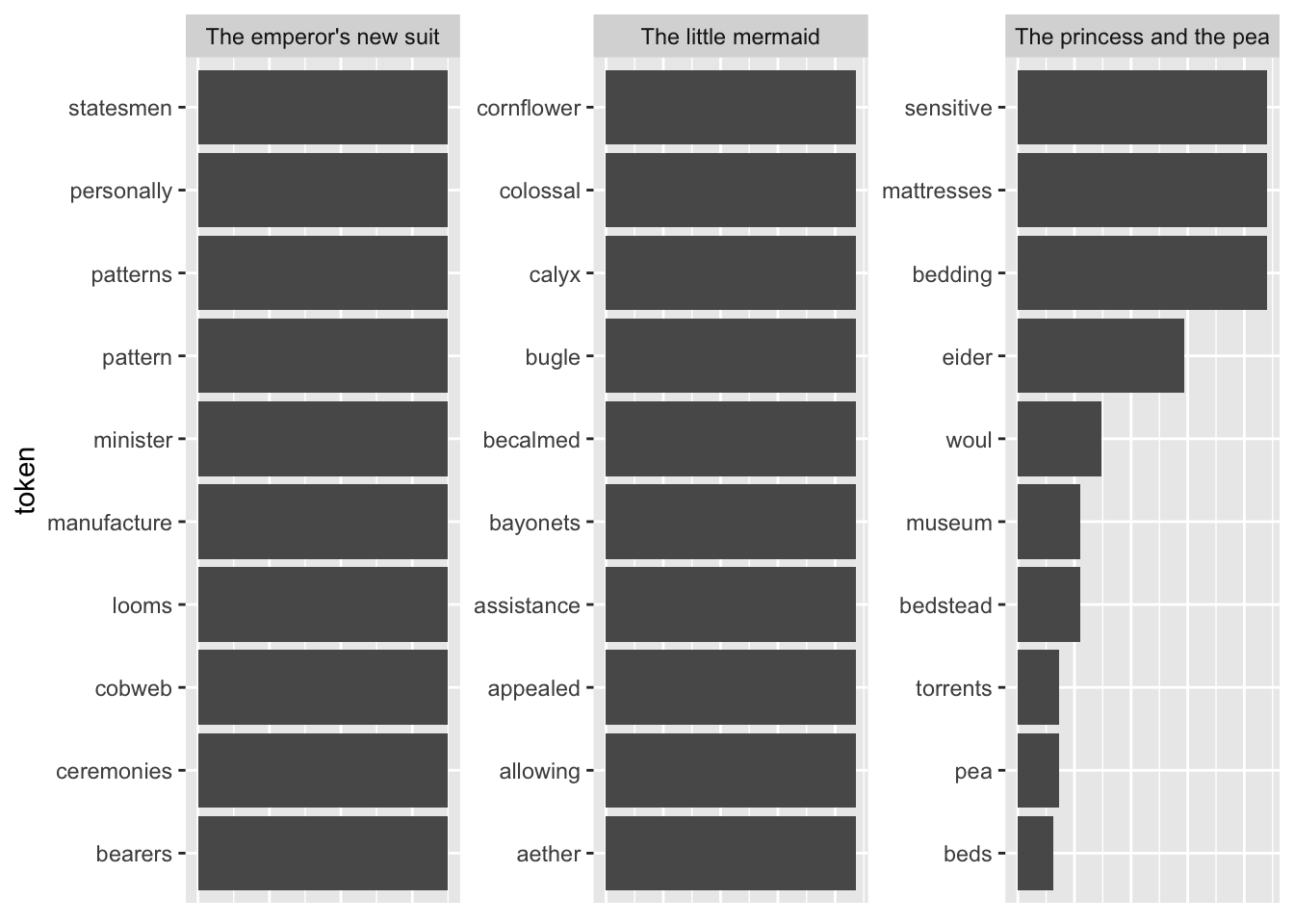
The tokens are far too specific to make any sense. Introducing a lower threshold (i.e., limiting the analysis to terms that appear at least x times in the document) might mitigate that. Yet, this threshold is of course arbitrary.
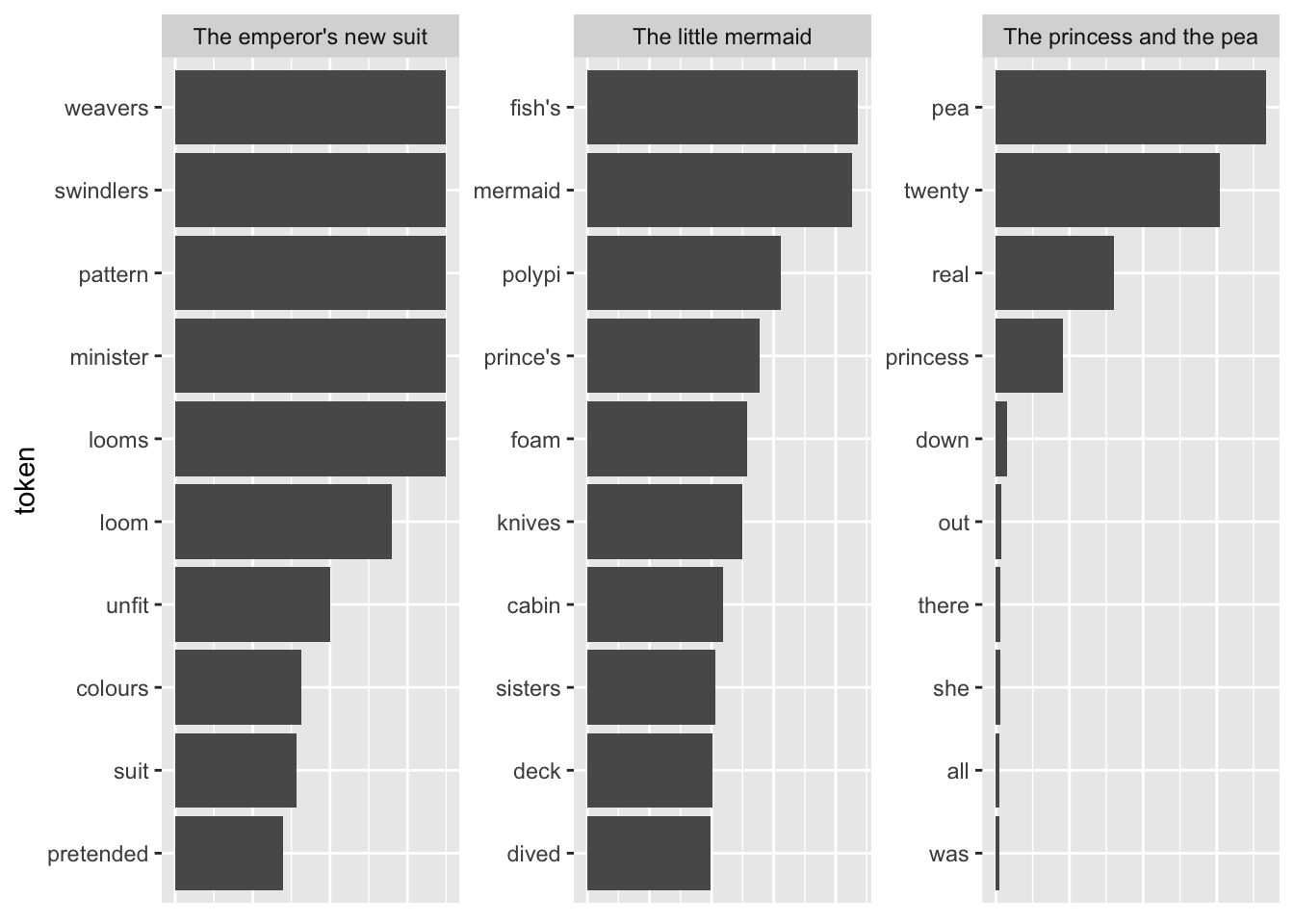
This looks a bit better already, yet the threshold is of course arbitrary and not generalizable. Choosing a higher threshold will take away more specific terms, lower thresholds might make the results overly specific.
5.2 Further links
- Chapter on TF-IDF inTidy text mining with R.
- Introduction to tidylo.
- More on the rationale behind log-odds by Qiushi Yan
5.3 Exercise
The following code was used to download the latest 200 tweets of the members of the U.S. Congress.
library(tidyverse)
library(rvest)
#library(rtweet)
library(lubridate)
rep_overview <- read_html("https://pressgallery.house.gov/member-data/members-official-twitter-handles") |>
html_table() |>
pluck(1)
colnames(rep_overview) <- rep_overview[2, ]
rep_overview <- slice(rep_overview, -1, -2) |>
janitor::clean_names() |>
mutate(twitter_handle = str_remove(twitter_handle, "\\@"))
tweet_overview_us_rep <- map(
rep_overview$twitter_handle,
~{
Sys.sleep(5)
get_timeline(.x, n = 200)
}
)
tweets_relevant <- tweet_overview_us_rep |> bind_rows() |>
mutate(date = date(created_at)) |>
filter(date > ymd("2022-05-01"))
tweets_2022 <- tweet_overview_us_rep |> bind_rows() |>
mutate(date = date(created_at)) |>
filter(date >= ymd("2022-01-01"))- On May 2, 2022, documents from the supreme court were leaked that show an upcoming decision on one of the major hot-button issues in American politics. Which topic? Can you figure that out from the data? (Hints: Create two groups with Tweets that were posted before and on/after May 2nd; don’t use the full date but reduce them to say April 20 to May 1 for group “before”; perhaps remove hashtags and infrequent words (words with n <= 15)?; use some of the methods outlined above and try to identify the issue.
Solution. Click to expand!
tweets <- read_csv("https://www.dropbox.com/s/fjf5wx7kdqiwniw/congress_tweets_2022.csv?dl=1") |>
mutate(date_group = case_when(date >= ymd("2022-05-02") ~ "after",
between(date, ymd("2022-04-15"), ymd("2022-05-01")) ~ "before")) ## Rows: 76114 Columns: 5
## ── Column specification ──────────────────────────────────────────────
## Delimiter: ","
## chr (2): twitter_handle, text
## lgl (2): is_retweet, is_quote
## date (1): date
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.tf_idf_min15 <- tweets |>
#mutate(text = str_remove_all(text, "\\#.* ")) |>
drop_na(date_group) |>
unnest_tokens(token, text) |>
count(token, date_group) |>
filter(n > 15) |>
bind_tf_idf(token, date_group, n)
tf_idf_min15 |>
group_by(date_group) |>
slice_max(tf_idf, n = 10, with_ties = FALSE) |>
ggplot() +
geom_col(aes(x = tf_idf, y = reorder_within(token, tf_idf, date_group))) +
scale_y_reordered() +
labs(y = "token") +
facet_wrap(vars(date_group), scales = "free") +
#theme(strip.text.x = element_blank()) +
theme(axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank())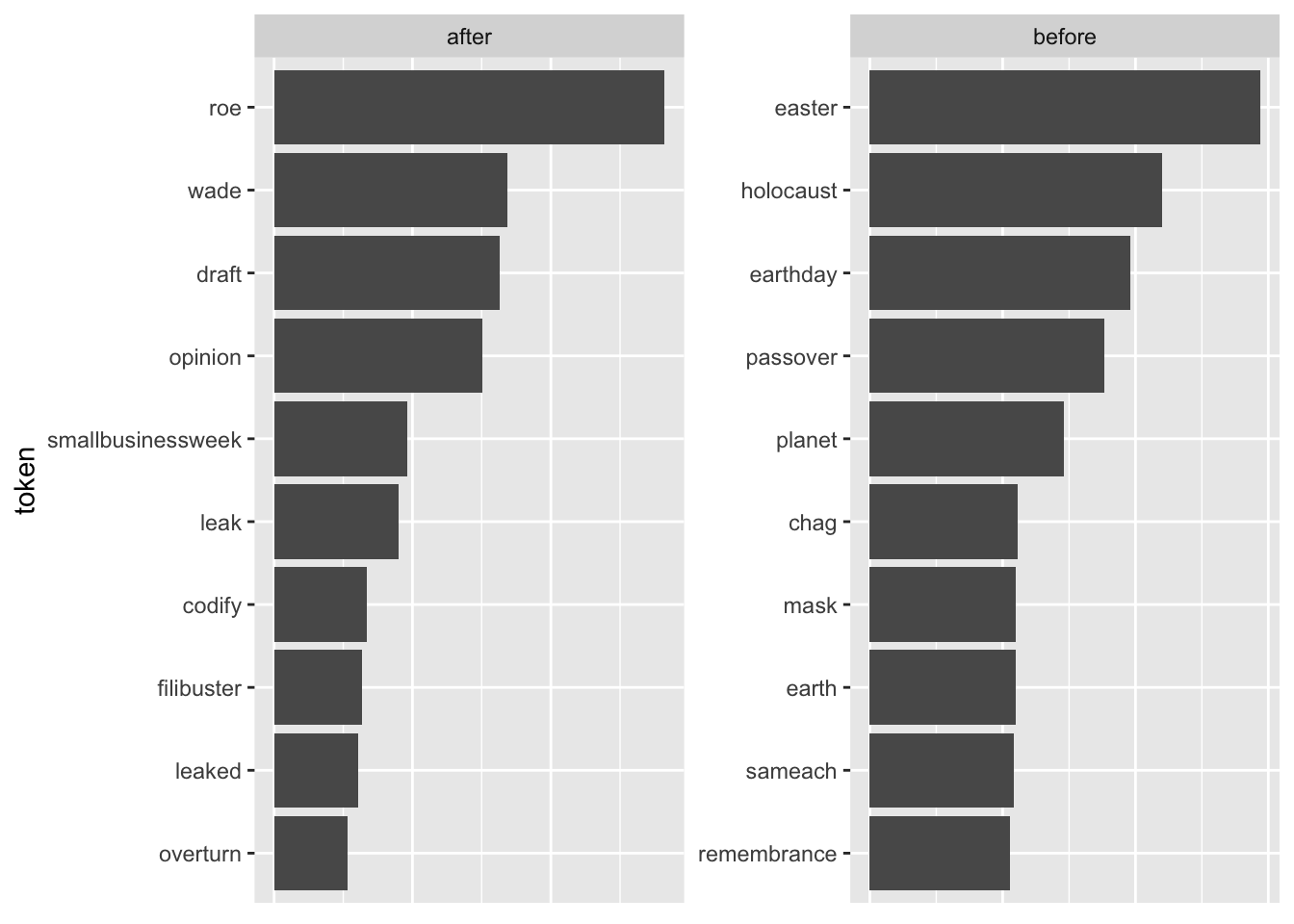
- As we are talking hot-button issue here, how did the language Republican and Democratic House members used differ? [You can get an overview of the name, the Twitter handle, and the party leaning of the House members by running the following code (note that you may have to install
rvestandjanitorfirst).]
Solution. Click to expand!
library(tidyverse)
library(rvest)
library(janitor)
library(tidytext)
rep_overview <- read_html("https://pressgallery.house.gov/member-data/members-official-twitter-handles") |>
html_table() |>
pluck(1)
colnames(rep_overview) <- rep_overview[3, ]
rep_overview <- slice(rep_overview, 4:nrow(rep_overview)) |>
clean_names() |>
mutate(twitter_handle = str_remove(twitter_handle, "\\@"))
tweets_w_party <- tweets |>
left_join(rep_overview |> select(twitter_handle, party))
tf_idf_min15_party <- tweets_w_party |>
drop_na(party) |>
unnest_tokens(token, text) |>
count(token, party) |>
filter(n > 15) |>
bind_tf_idf(token, party, n)
tf_idf_min15_party |>
group_by(party) |>
slice_max(tf_idf, n = 10, with_ties = FALSE) |>
ggplot() +
geom_col(aes(x = tf_idf, y = reorder_within(token, tf_idf, party))) +
scale_y_reordered() +
labs(y = "token") +
facet_wrap(vars(party), scales = "free") +
#theme(strip.text.x = element_blank()) +
theme(axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank())- Try to select tweets that are about the issue at hand (i.e., abortion and the leak). Come up with keywords that help you select all relevant tweets. Note that due to the issue and the language concerning it being so partisan, your choice might skew your sample. Focus on tweets posted after the leak. You can check whether you see abortion-related tweets spike using the following code:
tweets_abortion |> count(date) |> ggplot() + geom_line(aes(date, n))
Solution. Click to expand!
keywords <- c("abortion", "prolife", " roe ", "wade ", "roevswade", "baby", "fetus", "womb", "prochoice", "leak")
tweets_abortion <- tweets_w_party |>
filter(str_detect(text, pattern = str_c(keywords, collapse = "|")) &
party %in% c("D", "R"))
tweets_abortion |>
count(party)
tweets_abortion |>
count(date) |>
ggplot() +
geom_line(aes(date, n))
tweets_abortion_new <- tweets_w_party |>
filter(str_detect(text, pattern = str_c(keywords, collapse = "|")) &
date > ymd("2022-05-01") &
party %in% c("D", "R"))
tweets_abortion_new |>
count(party)
tf_idf_abortion <- tweets_abortion_new |>
unnest_tokens(token, text) |>
filter(party %in% c("D", "R")) |>
count(token, party) |>
bind_tf_idf(token, party, n)
tf_idf_abortion |>
group_by(party) |>
slice_max(tf_idf, n = 10, with_ties = FALSE) |>
ggplot() +
geom_col(aes(x = tf_idf, y = reorder_within(token, tf_idf, party))) +
scale_y_reordered() +
labs(y = "token") +
facet_wrap(vars(party), scales = "free") +
#theme(strip.text.x = element_blank()) +
theme(axis.title.x = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank())