Day 2 Scraping the web
Today’s session will be dedicated to getting data from the web. This process is also called scraping since we scrape data off from the surface and remodel it for our inferences. The following picture shows you the web scraping cheat sheet that outlines the process of scraping the web. On the left side, you can see the first step in scraping the web which is requesting the information from the server. This is basically what is going under the hood when you make requests using a browser. The response is the website, usually stored in an XML document, which is then the starting point for your subsequent queries and data extraction.
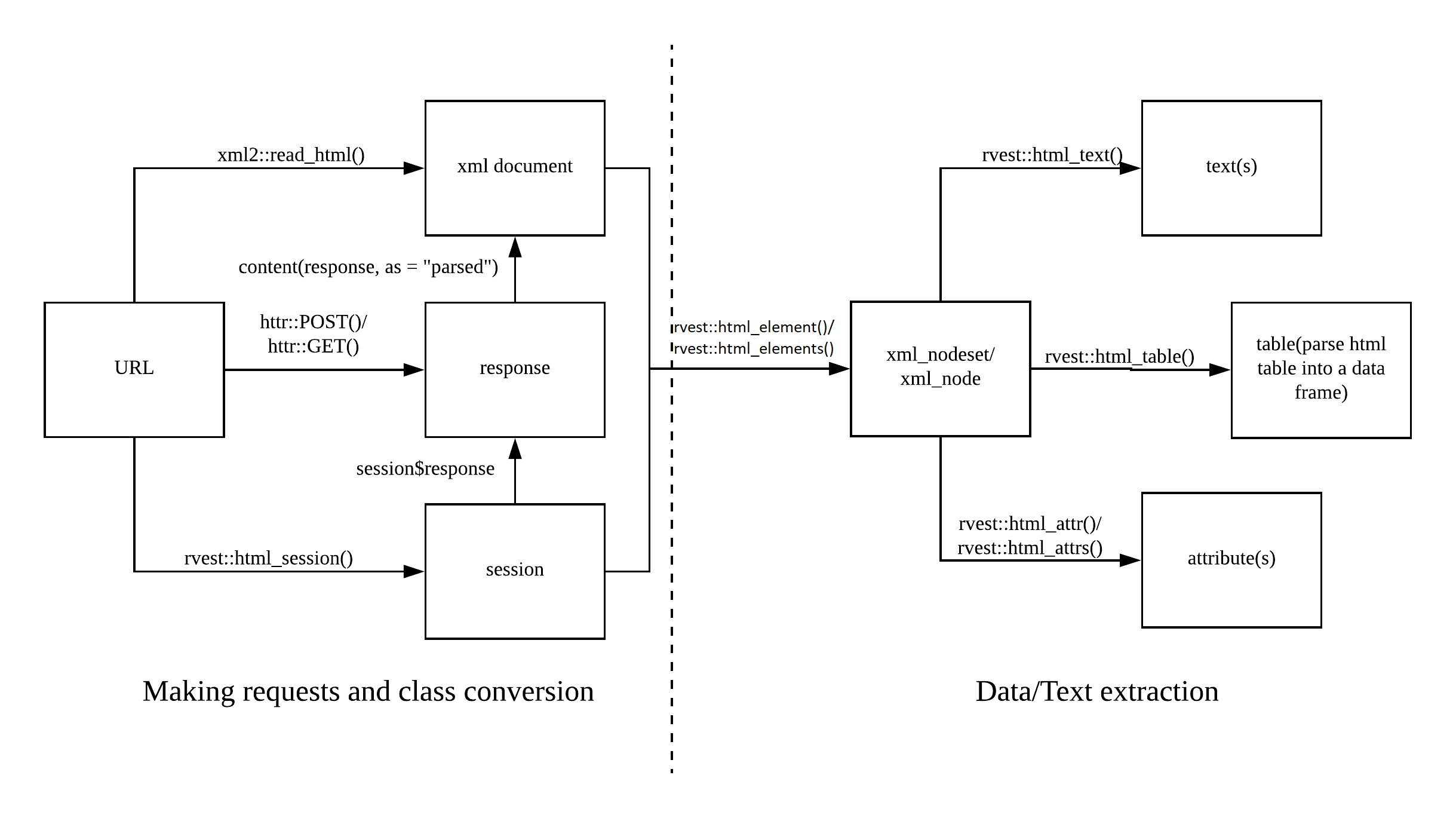
Web scraping cheat sheet
In today’s session, you will learn different techniques to get your hands on data. In particular, this will encompass making simple URL requests with read_html(), using session()s to navigate around on a web page, submitting html_form()s to fill in forms on a web page, and making structured requests to APIs.
2.1 Making requests
The most basic form of making a request is by using read_html() from the xml2 package.
#install.packages("rvest")
library(rvest) # this also loads the xml2 package
library(tidyverse)
page <- read_html("https://en.wikipedia.org/wiki/Tidyverse")
page %>% str()## List of 2
## $ node:<externalptr>
## $ doc :<externalptr>
## - attr(*, "class")= chr [1:2] "xml_document" "xml_node"#page %>% as.character() %>% write_lines("wiki.html")This is perfectly fine for making requests to static pages where you do not need to take any further action. Sometimes, however, this is not enough, and you want to accept cookies or move on the page.
2.1.1 session()
However, the slickest way to do this is by using a session(). In a session, R behaves like a normal browser, stores cookies, allows you to navigate between pages, by going session_forward() or session_back(), session_follow_link()s on the page itself or session_jump_to() a different URL, or submit form()s with session_submit().
First, you start the session by simply calling session().
my_session <- session("https://scrapethissite.com/")Some servers may not want robots to make requests and block you for this reason. To circumnavigate this, we can set a “user agent” in a session. The user agent contains data that the server receives from us when we make the request. Hence, by adapting it we can trick the server into thinking that we are humans instead of robots. Let’s check the current user agent first:
my_session$response$request$options$useragent## [1] "libcurl/7.79.1 r-curl/4.3.2 httr/1.4.3"Not very human. We can set it to a common one using the httr package (which powers rvest).
user_a <- httr::user_agent("Mozilla/5.0 (Macintosh; Intel Mac OS X 12_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36")
session_with_ua <- session("https://scrapethissite.com/", user_a)
session_with_ua$response$request$options$useragent## [1] "Mozilla/5.0 (Macintosh; Intel Mac OS X 12_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"You can check the response using session$response$status_code – 200 is good.
my_session$response$status_code## [1] 200When you want to save a page from the session, do so using read_html().
page <- read_html(session_with_ua)If you want to open a new URL, hit session_jump_to().
library(magrittr)
session_with_ua %<>% session_jump_to("https://www.scrapethissite.com/pages/")
session_with_ua## <session> https://www.scrapethissite.com/pages/
## Status: 200
## Type: text/html; charset=utf-8
## Size: 10603Once you are familiar with CSS selectors – which will be introduced tomorrow – you can also click buttons on the page:
session_with_ua %<>% session_jump_to("https://www.scrapethissite.com/") %>%
session_follow_link(css = ".btn-default")## Navigating to /pages/session_with_ua## <session> https://www.scrapethissite.com/pages/
## Status: 200
## Type: text/html; charset=utf-8
## Size: 10603Wanna go back – session_back(); thereafter you can go session_forward(), too.
session_with_ua %<>%
session_back()
session_with_ua## <session> https://www.scrapethissite.com/
## Status: 200
## Type: text/html; charset=utf-8
## Size: 8117session_with_ua %<>%
session_forward()
session_with_ua## <session> https://www.scrapethissite.com/pages/
## Status: 200
## Type: text/html; charset=utf-8
## Size: 10603You can look at what your scraper has done with session_history().
session_with_ua %>% session_history()## https://www.scrapethissite.com/
## https://www.scrapethissite.com/pages/
## https://www.scrapethissite.com/
## - https://www.scrapethissite.com/pages/2.1.2 Forms
Sometimes we also want to provide certain input, e.g., to provide login credentials or to scrape a website more systematically. That information is usually provided using so-called forms. A <form> element can contain different other elements such as text fields or checkboxes. Basically, we use html_form() to extract the form, html_form_set() to define what we want to submit, and html_form_submit() to finally submit it. For a basic example, wesearch for something on Google.
google <- read_html("http://www.google.com")
search <- html_form(google) %>% pluck(1)
search %>% str()## List of 5
## $ name : chr "f"
## $ method : chr "GET"
## $ action : chr "http://www.google.com/search"
## $ enctype: chr "form"
## $ fields :List of 10
## ..$ ie :List of 4
## .. ..$ type : chr "hidden"
## .. ..$ name : chr "ie"
## .. ..$ value: chr "ISO-8859-1"
## .. ..$ attr :List of 3
## .. .. ..$ name : chr "ie"
## .. .. ..$ value: chr "ISO-8859-1"
## .. .. ..$ type : chr "hidden"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ hl :List of 4
## .. ..$ type : chr "hidden"
## .. ..$ name : chr "hl"
## .. ..$ value: chr "fr"
## .. ..$ attr :List of 3
## .. .. ..$ value: chr "fr"
## .. .. ..$ name : chr "hl"
## .. .. ..$ type : chr "hidden"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ source:List of 4
## .. ..$ type : chr "hidden"
## .. ..$ name : chr "source"
## .. ..$ value: chr "hp"
## .. ..$ attr :List of 3
## .. .. ..$ name : chr "source"
## .. .. ..$ type : chr "hidden"
## .. .. ..$ value: chr "hp"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ biw :List of 4
## .. ..$ type : chr "hidden"
## .. ..$ name : chr "biw"
## .. ..$ value: NULL
## .. ..$ attr :List of 2
## .. .. ..$ name: chr "biw"
## .. .. ..$ type: chr "hidden"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ bih :List of 4
## .. ..$ type : chr "hidden"
## .. ..$ name : chr "bih"
## .. ..$ value: NULL
## .. ..$ attr :List of 2
## .. .. ..$ name: chr "bih"
## .. .. ..$ type: chr "hidden"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ q :List of 4
## .. ..$ type : chr "text"
## .. ..$ name : chr "q"
## .. ..$ value: chr ""
## .. ..$ attr :List of 8
## .. .. ..$ class : chr "lst"
## .. .. ..$ style : chr "margin:0;padding:5px 8px 0 6px;vertical-align:top;color:#000"
## .. .. ..$ autocomplete: chr "off"
## .. .. ..$ value : chr ""
## .. .. ..$ title : chr "Recherche Google"
## .. .. ..$ maxlength : chr "2048"
## .. .. ..$ name : chr "q"
## .. .. ..$ size : chr "57"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ btnG :List of 4
## .. ..$ type : chr "submit"
## .. ..$ name : chr "btnG"
## .. ..$ value: chr "Recherche Google"
## .. ..$ attr :List of 4
## .. .. ..$ class: chr "lsb"
## .. .. ..$ value: chr "Recherche Google"
## .. .. ..$ name : chr "btnG"
## .. .. ..$ type : chr "submit"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ btnI :List of 4
## .. ..$ type : chr "submit"
## .. ..$ name : chr "btnI"
## .. ..$ value: chr "J'ai de la chance"
## .. ..$ attr :List of 5
## .. .. ..$ class: chr "lsb"
## .. .. ..$ id : chr "tsuid1"
## .. .. ..$ value: chr "J'ai de la chance"
## .. .. ..$ name : chr "btnI"
## .. .. ..$ type : chr "submit"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ iflsig:List of 4
## .. ..$ type : chr "hidden"
## .. ..$ name : chr "iflsig"
## .. ..$ value: chr "AJiK0e8AAAAAYrrjogSg05vkCdLVnO4hilR_DN7_B24p"
## .. ..$ attr :List of 3
## .. .. ..$ value: chr "AJiK0e8AAAAAYrrjogSg05vkCdLVnO4hilR_DN7_B24p"
## .. .. ..$ name : chr "iflsig"
## .. .. ..$ type : chr "hidden"
## .. ..- attr(*, "class")= chr "rvest_field"
## ..$ gbv :List of 4
## .. ..$ type : chr "hidden"
## .. ..$ name : chr "gbv"
## .. ..$ value: chr "1"
## .. ..$ attr :List of 4
## .. .. ..$ id : chr "gbv"
## .. .. ..$ name : chr "gbv"
## .. .. ..$ type : chr "hidden"
## .. .. ..$ value: chr "1"
## .. ..- attr(*, "class")= chr "rvest_field"
## - attr(*, "class")= chr "rvest_form"search_something <- search %>% html_form_set(q = "something")
resp <- html_form_submit(search_something, submit = "btnG")
read_html(resp)## {html_document}
## <html lang="fr">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body jsmodel="hspDDf">\n<header id="hdr"><script nonce="qp8qChP5MHuwdgze ...vals <- list(q = "web scraping", hl = "en")
search <- search %>% html_form_set(!!!vals)
resp <- html_form_submit(search)
read_html(resp)## {html_document}
## <html lang="en-FR">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body jsmodel="hspDDf">\n<header id="hdr"><script nonce="NYyTGkAMB2tO8kFZ ...If you are working with a session, the workflow is as follows:
- Extract the form.
- Set it.
- Start your session on the page with the form.
- Submit the form using
session_submit().
google_form <- read_html("http://www.google.com") %>%
html_form() %>%
pluck(1) #another way to do [[1]]
search_something <- google_form %>% html_form_set(q = "something")
google_session <- session("http://www.google.com") %>%
session_submit(search_something, submit = "btnG")
google_session %>%
read_html()## {html_document}
## <html lang="fr">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body jsmodel="hspDDf">\n<header id="hdr"><script nonce="ieDt7f6OGGog10-q ...2.1.3 Scraping hacks
Some web pages are a bit fancier than the ones we have looked at so far (i.e., they use JavaScript). rvest works nicely for static web pages, but for more advanced ones you need different tools such as RSelenium. This, however, goes beyond the scope of this tutorial.
A web page may sometimes give you time-outs (i.e., it doesn’t respond within a given time). This can break your loop. Wrapping your code in safely() or insistently() from the purrr package might help. The former moves on and notes down what has gone wrong, the latter keeps sending requests until it has been successful. They both work easiest if you put your scraping code in functions and wrap those with either insistently() or safely().
Sometimes a web page keeps blocking you. Consider using a proxy server.
my_proxy <- httr::use_proxy(url = "http://example.com",
user_name = "myusername",
password = "mypassword",
auth = "one of basic, digest, digest_ie, gssnegotiate, ntlm, any")
my_session <- session("https://scrapethissite.com/", my_proxy)Find more useful information – including the stuff we just described – and links on this GitHub page.
2.2 Application Programming Interfaces (APIs)
While web scraping (or screen scraping, as you extract the stuff that appears on your screen) is certainly fun, it should be seen as a last resort. More and more web platforms provide so-called Application Programming Interfaces (APIs).
“An application programming interface (API) is a connection between computers or between computer programs.” (Wikipedia)
There are a bunch of different sorts of APIs, but the most common one is the REST API. REST stands for “Representational State Transfer” and describes a set of rules the API designers are supposed to obey when developing their particular interface. You can make different requests, such as GET content, POST a file to a server – PUT is similar, or request to DELETE a file. We will only focus on the GET part.
APIs offer you a structured way to communicate with the platform via your machine. In our use case, this means that you can get the data you want in a usually well-structured format and without all the “dirt” that you need to scrape off tediously (enough web scraping metaphors for today). With APIs, you can generally quite clearly define what you want and how you want it. In R, we achieve this by using the httr (Wickham 2020) package. Moreover, using APIs does not bear the risk of acquiring the information you are not supposed to access and you also do not need to worry about the server not being able to handle the load of your requests (usually, there are rate limits in place to address this particular issue). However, it’s not all fun and games with APIs: they might give you their data in a special format, both XML and JSON are common. The former is the one rvest uses as well, the latter can be tamed using jsonlite (Ooms, Temple Lang, and Hilaiel 2020) which is to be introduced as well. Moreover, you usually have to ask the platform for permission and perhaps pay to get it. Once you have received the keys you need, you can tell R to fill them automatically, similar to how your browser knows your Amazon password, etc.; usethis (Wickham et al. 2021) can help you with such tasks. An overview of currently existing APIs can be found on The Programmable Web
The best thing that can happen with APIs: some of them are so popular that people have already written specific R packages for working with them – an overview can be found on the ROpenSci website. One example of this is Twitter and the rtweet package (Kearney 2019) which will be introduced in the end. Less work for us, great.
2.2.1 Obtaining their data
API requests are performed using URLs. Those start with the basic address of the API (e.g., https://api.nytimes.com), followed by the endpoint that you want to use (e.g., /lists). They also contain so-called headers which are provided as key-value pairs. Those headers can contain for instance authentification tokens or different search parameters. A request to the New York Times API to obtain articles for January 2019 would then look like this: https://api.nytimes.com/svc/archive/v1/2019/1.json?api-key=yourkey.
At most APIs, you will have to register first. As we will play with the New York Times API, do this here.
2.2.1.1 Making queries
A basic query is performed using the GET() function. However, first, you need to define the call you want to make. The different keys and values they can take can be found in the API documentation. Of course, there is also a neater way to deal with the key problem. We will show it later.
library(httr)
key <- "xxx"
nyt_headlines <- modify_url(
url = "https://api.nytimes.com/",
path = "svc/news/v3/content/nyt/business.json",
query = list(`api-key` = key))
response <- GET(nyt_headlines)When it comes to the NYT news API, there is the problem that the type of section is specified not in the query but in the endpoint path itself. Hence, if we were to scrape the different sections, we would have to change the path itself, e.g., through str_c().
The Status: code you want to see here is 200 which stands for success. If you want to put it inside a function, you might want to break the function once you get a non-successful query. http_error() or http_status() are your friends here.
response %>% http_error()## [1] TRUEresponse %>% http_status()## $category
## [1] "Client error"
##
## $reason
## [1] "Unauthorized"
##
## $message
## [1] "Client error: (401) Unauthorized"content() will give you the content of the request.
response %>% content() %>% glimpse()What you see is also the content of the call – which is what we want. It is in a format that we cannot work with right away, though, it is in JSON.
2.2.1.2 JSON
The following unordered list is stolen from this blog entry:
- The data are in name/value pairs
- Commas separate data objects
- Curly braces {} hold objects
- Square brackets [] hold arrays
- Each data element is enclosed with quotes “” if it is a character, or without quotes if it is a numeric value
writeLines(rawToChar(response$content))jsonlite helps us to bring this output into a data frame.
library(jsonlite)
response %>%
content(as = "text") %>%
fromJSON()## $fault
## $fault$faultstring
## [1] "Invalid ApiKey"
##
## $fault$detail
## $fault$detail$errorcode
## [1] "oauth.v2.InvalidApiKey"2.2.1.3 Dealing with authentification
Well, as we saw before, we would have to put our official NYT API key publicly visible in this script. This is bad practice and should be avoided, especially if you work on a joint project (where everybody uses their code) or if you put your scripts in public places (such as GitHub). The usethis package can help you here.
#usethis::edit_r_environ() # save key there
Sys.getenv("nyt_key")Hence, if we now search for articles – find the proper parameters here, we provide the key by using the Sys.getenv function. So, if somebody wants to work with your code and their own key, all they need to make sure is that they have the API key stored in the environment with the same name.
modify_url(
url = "http://api.nytimes.com/svc/search/v2/articlesearch.json",
query = list(q = "Trump",
pub = "20161101",
end_date = "20161110",
`api-key` = Sys.getenv("nyt_key"))
) %>%
GET()## Response [http://api.nytimes.com/svc/search/v2/articlesearch.json?q=Trump&pub=20161101&end_date=20161110&api-key=qekEhoGTXqjsZnXpqHns0Vfa2U6T7ABf]
## Date: 2022-06-28 10:19
## Status: 200
## Content-Type: application/json
## Size: 190 kB2.2.2 rtweet
Twitter is quite popular among social scientists. The main reason for this is arguably its data accessibility. For R users, the package you want to use is rtweet by Michael Kearney (find an overview of the different packages and their capabilities here). There is a great and quite complete presentation demonstrating its capabilities. This presentation is a bit outdated. The main difference to the package these days is that you will not need to register an app upfront anymore. All you need is a Twitter account. When you make your first request, a browser window will open where you log on to Twitter, authorize the app, and then you can just go for it. There are certain rate limits, too, which you will need to be aware of when you try to acquire data. Rate limits and the parameters you need to specify can be found in the extensive documentation.
In the following, we will just link to the respective vignettes. Please, feel free to play around with the functions yourself. As a starting point, we provide you with the list of all British MPs and some tasks in exercise 3. A first introduction gives this vignette.
library(rtweet)
uk_mps <- lists_members(
list_id = "217199644"
)2.4 Exercises
- Start a session with the tidyverse Wikipedia page. Adapt your user agent to some sort of different value. Proceed to Hadley Wickham’s page. Go back. Go forth. Check the
session_history()to see if it has worked.
Solution. Click to expand!
tidyverse_wiki <- "https://en.wikipedia.org/wiki/Tidyverse"
hadley_wiki <- "https://en.wikipedia.org/wiki/Hadley_Wickham"
user_agent <- httr::user_agent("Hi, I'm Felix and I try to steal your data.")wiki_session <- session(tidyverse_wiki, user_agent)
wiki_session %<>% session_jump_to(hadley_wiki) %>%
session_back() %>%
session_forward()
wiki_session %>% session_history()- Start a session on “https://www.scrapethissite.com/pages/advanced/?gotcha=login”, fill out, and submit the form. Any value for login and password will do. (Disclaimer: you have to add the URL as an “action” attribute after creating the form, see this tutorial. –
login_form$action <- url)
url <- "https://www.scrapethissite.com/pages/advanced/?gotcha=login"
#extract and set login form here
login_form$action <- url # add url as action attribute
# submit form
base_session <- session("https://www.scrapethissite.com/pages/advanced/?gotcha=login") %>%
session_submit(login_form) Solution. Click to expand!
url <- "https://www.scrapethissite.com/pages/advanced/?gotcha=login"
#extract and set login form here
login_form <- read_html(url) %>%
html_form() %>%
pluck(1) %>%
html_form_set(user = "123",
pass = "456")
login_form$action <- url # add url as action attribute
# submit form
base_session <- session("https://www.scrapethissite.com/pages/advanced/?gotcha=login") %>%
session_submit(login_form)
base_session %>% read_html() %>% html_text()base_session %>% read_html() %>% html_elements(".col-md-offset-4") %>% html_text2()- Scrape 10 profile timelines from the following list. Check the documentation for instructions.
Solution. Click to expand!
library(rtweet)
uk_mps <- lists_members(
list_id = "217199644"
)
# get 10 profiles
sample_uk_mps <- uk_mps %>%
slice_sample(n = 10) %>%
pull(screen_name)
# get timelines
## using purrr::map
timelines <- sample_uk_mps %>%
map(get_timeline)
## using for-loop
timelines <- vector(mode = "list", length = length(sample_uk_mps))
for (i in seq_along(sample_uk_mps)){
timelines[[i]] <- get_timeline(user = sample_uk_mps[[i]])
}