4.5 Juntando dados
A junção (joining) e a união (binding) de dados são processos fundamentais na manipulação e análise de dados em R. Eles são essenciais para combinar informações de diferentes fontes ou tabelas, o que permite realizar análises mais completas e significativas.
A junção de dados permite:
• Combinar Informações Complementares: Muitas vezes, os dados relevantes para uma análise estão distribuídos em diferentes tabelas ou arquivos. A junção e a união permitem combinar essas fontes de dados em um único conjunto coerente.
• Enriquecer Dados: Ao unir dados de diferentes fontes, é possível enriquecer um dataset original com informações adicionais, como adicionar dados demográficos a um conjunto de dados de vendas para análises mais profundas.
4.5.1 Juntando linhas
O R nos permite juntar linhas quando precisamos combinar conjuntos de dados que têm a mesma estrutura (ou seja, as mesmas colunas), mas contêm dados diferentes.
A função mais usada para isso é a bind_rows(), do pacote dplyr. Caso as colunas tenham exatamente os mesmos nomes e tipo, o bind_rows() consegue fazer a união perfeitamente.
Lembrete: O R possui a função nativa rbind (), que corresponde à função bind_rows() do dplyr
Vamos testar a junção de linhas com dois dataframes referentes a dados Airbnb em Minas Gerais. Queremos juntar a tabela referente aos dados de Belo Horizonte com a tabela de dados sobre Ouro Preto.
O primeiro dataframe (BHair) corresponde a uma tabela de 100 linhas e 4 colunas com informações sobre unidades Airbnb em Belo Horizonte.
| X | url | address | location.lat | location.lng |
|---|---|---|---|---|
| 1 | https://www.airbnb.com/rooms/15677909 | Belo Horizonte | -19.99636 | -44.04467 |
| 2 | https://www.airbnb.com/rooms/1011116016079460730 | Belo Horizonte | -19.98734 | -44.03149 |
| 3 | https://www.airbnb.com/rooms/1048772607162009300 | Belo Horizonte | -19.99400 | -44.01400 |
| 4 | https://www.airbnb.com/rooms/6687784 | Belo Horizonte | -19.89753 | -44.01633 |
| 5 | https://www.airbnb.com/rooms/1150086536583269687 | Belo Horizonte | -20.05900 | -43.98900 |
| 6 | https://www.airbnb.com/rooms/1085731432923449528 | Belo Horizonte | -20.05540 | -43.98328 |
| 7 | https://www.airbnb.com/rooms/825640321009966341 | Belo Horizonte | -20.00058 | -43.97209 |
| 8 | https://www.airbnb.com/rooms/820977218643665725 | Belo Horizonte | -20.00064 | -43.97230 |
| 9 | https://www.airbnb.com/rooms/1136518508115343403 | Belo Horizonte | -20.01300 | -44.01200 |
| 10 | https://www.airbnb.com/rooms/906427794641339249 | Belo Horizonte | -19.99800 | -44.02000 |
Já o segundo dataframe (OPair) corresponde a uma tabela de 100 linhas e 4 colunas com informações sobre unidades Airbnb em Ouro Preto. Repare que o número de colunas e o nome das variáveis são os mesmos nos dois dataframes.
| X | url | address | location.lat | location.lng |
|---|---|---|---|---|
| 1 | https://www.airbnb.com/rooms/823041675798025171 | Ouro Preto | -20.51100 | -43.57400 |
| 2 | https://www.airbnb.com/rooms/836055458674161628 | Ouro Preto | -20.35583 | -43.69931 |
| 3 | https://www.airbnb.com/rooms/28892091 | Ouro Preto | -20.33004 | -43.75723 |
| 4 | https://www.airbnb.com/rooms/959274307285383721 | Ouro Preto | -20.37854 | -43.70886 |
| 5 | https://www.airbnb.com/rooms/945078104216829991 | Ouro Preto | -20.42500 | -43.33100 |
| 6 | https://www.airbnb.com/rooms/1100821263179101301 | Ouro Preto | -20.52300 | -43.69700 |
| 7 | https://www.airbnb.com/rooms/1092881830865462081 | Ouro Preto | -20.47662 | -43.54989 |
| 8 | https://www.airbnb.com/rooms/1081793622311133572 | Ouro Preto | -20.40396 | -43.51048 |
| 9 | https://www.airbnb.com/rooms/53106928 | Ouro Preto | -20.38751 | -43.50523 |
| 10 | https://www.airbnb.com/rooms/904946291235370243 | Ouro Preto | -20.35442 | -43.41671 |
Utilizaremos a função bind_rows() para unir os dois conjuntos de dados em um novo dataframe, que chamamos de airbnb. O data frame resultante possui 200 linhas (100+100) e 5 colunas.
| X | url | address | location.lat | location.lng |
|---|---|---|---|---|
| 1 | https://www.airbnb.com/rooms/15677909 | Belo Horizonte | -19.99636 | -44.04467 |
| 2 | https://www.airbnb.com/rooms/1011116016079460730 | Belo Horizonte | -19.98734 | -44.03149 |
| 3 | https://www.airbnb.com/rooms/1048772607162009300 | Belo Horizonte | -19.99400 | -44.01400 |
| 4 | https://www.airbnb.com/rooms/6687784 | Belo Horizonte | -19.89753 | -44.01633 |
| 5 | https://www.airbnb.com/rooms/1150086536583269687 | Belo Horizonte | -20.05900 | -43.98900 |
| 6 | https://www.airbnb.com/rooms/1085731432923449528 | Belo Horizonte | -20.05540 | -43.98328 |
| 7 | https://www.airbnb.com/rooms/825640321009966341 | Belo Horizonte | -20.00058 | -43.97209 |
| 8 | https://www.airbnb.com/rooms/820977218643665725 | Belo Horizonte | -20.00064 | -43.97230 |
| 9 | https://www.airbnb.com/rooms/1136518508115343403 | Belo Horizonte | -20.01300 | -44.01200 |
| 10 | https://www.airbnb.com/rooms/906427794641339249 | Belo Horizonte | -19.99800 | -44.02000 |
4.5.2 Juntando colunas
Juntando colunas no rbase
No R base, podemos juntar data frames por colunas usando funções base como merge() e cbind().
Cbind (column bind) une colunas lado a lado, criando um novo data frame ou matriz. Todos os objetos combinados devem ter o mesmo número de linhas.
Juntando dados no dplyr
O pacote dplyr oferece várias funções diferentes de join (left_join(), right_join(), inner_join(), full_join()). .Left join
Para ilustrar operações de junção, consideraremos primeiro o tipo mais comum, uma “junção à esquerda”, através do comando left_join().
No esquema abaixo, os dois data frames compartilham uma coluna comum, V1. Podemos combinar os dois data frames em um único data frame, correspondendo as linhas do primeiro data frame com as do segundo data frame que compartilham o mesmo valor da variável V1.
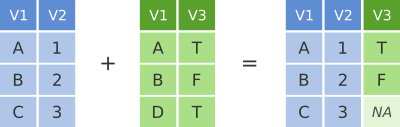
Figure 4.1: O left join usa o primeiro dataframa como base
Vamos unir os dados de Airbnb sobre BH com uma nova coluna, informando o tipo de locação. Primeiro, vamos carregar o segundo arquivo. O dataframe BHair2 traz informações complementares (sobre o tipo de unidade de locação) sobre as 100 unidades Airbnb de Belo Horizonte listadas no dataframe BHair.
Dataframe BHair2
| X | url | roomType |
|---|---|---|
| 1 | https://www.airbnb.com/rooms/15677909 | Entire rental unit |
| 2 | https://www.airbnb.com/rooms/1011116016079460730 | Private room in home |
| 3 | https://www.airbnb.com/rooms/1048772607162009300 | Entire home |
| 4 | https://www.airbnb.com/rooms/6687784 | Entire rental unit |
| 5 | https://www.airbnb.com/rooms/1150086536583269687 | Entire home |
| 6 | https://www.airbnb.com/rooms/1085731432923449528 | Entire home |
| 7 | https://www.airbnb.com/rooms/825640321009966341 | Tiny home |
| 8 | https://www.airbnb.com/rooms/820977218643665725 | Entire home |
| 9 | https://www.airbnb.com/rooms/1136518508115343403 | Entire rental unit |
| 10 | https://www.airbnb.com/rooms/906427794641339249 | Private room in rental unit |
Agora vamos unir os arquivos BHair e BHair2. No exemplo abaixo, a função left_join() é utilizada como um comando individual para criar um novo dataframe chamado BHbnb.
As entradas (inputs) são os dataframes BHair e BHair2. O primeiro dataframe listado é o dataframe de base e o segundo é o dataframe que será unido a ele.
O terceiro argumento by = é onde especificamos a coluna em cada dataframe que será utilizada para alinhar os dois dataframes. No nosso caso corresponde à coluna “url”, coluna comum aos dois dataframes.
O dataframe resultante, BHbnb, tem 7 colunas ao total e é composto pelas colunas dos dois dataframes. Repare como a coluna X, que era comum aos dois dataframes foi renomeada para X.x e X.y.
Dataframe BHbnb
| X.x | url | address | location.lat | location.lng | X.y | roomType |
|---|---|---|---|---|---|---|
| 1 | https://www.airbnb.com/rooms/15677909 | Belo Horizonte | -19.99636 | -44.04467 | 1 | Entire rental unit |
| 2 | https://www.airbnb.com/rooms/1011116016079460730 | Belo Horizonte | -19.98734 | -44.03149 | 2 | Private room in home |
| 3 | https://www.airbnb.com/rooms/1048772607162009300 | Belo Horizonte | -19.99400 | -44.01400 | 3 | Entire home |
| 4 | https://www.airbnb.com/rooms/6687784 | Belo Horizonte | -19.89753 | -44.01633 | 4 | Entire rental unit |
| 5 | https://www.airbnb.com/rooms/1150086536583269687 | Belo Horizonte | -20.05900 | -43.98900 | 5 | Entire home |
| 6 | https://www.airbnb.com/rooms/1085731432923449528 | Belo Horizonte | -20.05540 | -43.98328 | 6 | Entire home |
| 7 | https://www.airbnb.com/rooms/825640321009966341 | Belo Horizonte | -20.00058 | -43.97209 | 7 | Tiny home |
| 8 | https://www.airbnb.com/rooms/820977218643665725 | Belo Horizonte | -20.00064 | -43.97230 | 8 | Entire home |
| 9 | https://www.airbnb.com/rooms/1136518508115343403 | Belo Horizonte | -20.01300 | -44.01200 | 9 | Entire rental unit |
| 10 | https://www.airbnb.com/rooms/906427794641339249 | Belo Horizonte | -19.99800 | -44.02000 | 10 | Private room in rental unit |
Lembrando que também é possível fazer o join entre dois dataframes mesmo se as colunas de referência tiverem nomes diferentes. Para isso utilizamos by = c(“coluna_1” = “coluna_2”)
#Juntando os dataframes por colunas com nomes diferentes
join<-left_join(x, y, by = c("coluna_x" = "coluna_y"))Right join
A função right_join() funciona da mesma forma que o left_join(), porém o dataframe de base será o segundo dataframe (direita).
Inner join
Um inner join é o mais restritivo dos joins - ele retona apenas as linhas que combinam em ambos os dataframes. Isso significa que o número linhas no dataframe base pode, de fato, reduzir. Ajustes em relação a qual dataframe será o base (escrito primeiro na função) não irá impactar quais linhas serão retornadas, mas vai impactar na ordem das colunas e linhas, e quais colunas de identificadores serão mantidas.
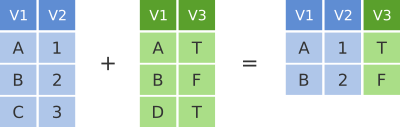
Figure 4.2: O inner join filtra apenas os valores das linhas comuns aos dois dataframes
Full join
Um full join é o mais inclusivo dos joins - ele retorna todas as linhas de ambos os dataframes.
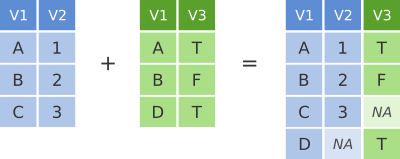
Figure 4.3: O full join retorna os valores dos dois dataframes
Salvar arquivo
Não esquecer de salvar as modificações que fizemos na nossa base de dados hoje. Podemos salvar como .csv ou como objeto RDS. Para salvar como csv utilizar o código:
Ou para salvar como RDS
Não se esqueça de carregar o arquivo modificado na próxima aula!