8.2 Avaliação
Para a avaliação do curso, faremos uma série de exercícios baseados nas aulas ministradas, a partir de duas bases de dados.
As bases de dados para o exercício consistem em dados coletados do Spotify em em Junho 2020. Os dados originais podem ser encontrados aqui.
Para a avaliação vocês utilizarão dois arquivos: Arquivo 1 e Arquivo 2
O arquivo spot1.csv traz informações como o nome da música, artista, duração (milisegundos), ano de lançamento,popularidade.
## id track_name artist_name genre
## 1 000xQL6tZNLJzIrtIgxqSl Still Got Time ZAYN Dance
## 2 004XT7kCZUEJkVIZjmBdDi Life Rolls On Slightly Stoopid Reggae
## 3 005lwxGU1tms6HGELIcUv9 I Kissed A Girl Katy Perry Dance
## 4 007n10xGvSbc7dKgAORVIq Brokenheartsville Joe Nichols Country
## 5 007reLkuOQhAJypiC5sVyX Power and the Glory Jimmy Cliff Reggae
## 6 00AxNl4D4jHL2AEf1W55j5 What The Hell Did I Say Dierks Bentley Country
## 7 00B7TZ0Xawar6NZ00JFomN Best Life (feat. Chance The Rapper) Cardi B Rap
## 8 00bnP8RyknzZMkNlEAO2ih Ghetto Story Cham Reggae
## 9 00bOhb4584JjyfTiXX81mO The Weight The Staple Singers Jazz
## 10 00CcJObzGJw76LjLDyEO6I Anxiety Nobuo Uematsu Anime
## duration_ms year popularity explicit
## 1 188491 2017 64 0
## 2 219107 2015 54 0
## 3 179640 2008 67 0
## 4 231347 2011 50 0
## 5 311333 1983 34 0
## 6 207333 2016 53 0
## 7 284856 2018 61 1
## 8 251640 2006 45 0
## 9 275640 1968 58 0
## 10 242373 1997 40 0O arquivo spot2.csv traz medidas que classificam cada música de acordo com suas características como “dançabilidade”
## id acousticness danceability energy instrumentalness liveness
## 1 000xQL6tZNLJzIrtIgxqSl 0.131000 0.748 0.627 0.00e+00 0.0852
## 2 004XT7kCZUEJkVIZjmBdDi 0.001630 0.644 0.749 8.63e-01 0.0735
## 3 005lwxGU1tms6HGELIcUv9 0.002230 0.699 0.760 0.00e+00 0.1320
## 4 007n10xGvSbc7dKgAORVIq 0.126000 0.458 0.677 5.87e-04 0.0944
## 5 007reLkuOQhAJypiC5sVyX 0.030700 0.683 0.423 0.00e+00 0.2450
## 6 00AxNl4D4jHL2AEf1W55j5 0.000668 0.579 0.804 1.19e-06 0.1980
## 7 00B7TZ0Xawar6NZ00JFomN 0.287000 0.620 0.625 0.00e+00 0.3140
## 8 00bnP8RyknzZMkNlEAO2ih 0.338000 0.613 0.563 0.00e+00 0.3810
## 9 00bOhb4584JjyfTiXX81mO 0.424000 0.629 0.387 0.00e+00 0.0479
## 10 00CcJObzGJw76LjLDyEO6I 0.902000 0.243 0.117 8.42e-01 0.2630
## loudness speechiness tempo valence
## 1 -6.029 0.0644 120.963 0.5240
## 2 -6.531 0.0336 174.065 0.7550
## 3 -3.173 0.0677 129.996 0.6960
## 4 -4.327 0.0310 208.056 0.4880
## 5 -14.597 0.0332 89.336 0.9380
## 6 -4.777 0.0265 107.985 0.2910
## 7 -7.438 0.5530 167.911 0.6650
## 8 -8.206 0.3580 103.371 0.7750
## 9 -13.667 0.0386 76.003 0.4970
## 10 -19.072 0.0378 139.014 0.0397A entrega da avaliação deverá ser feita em formato de script R. É importante que o script seja limpo e organizado, descrevendo seus passo e cada exercício. Veja um exemplo abaixo:
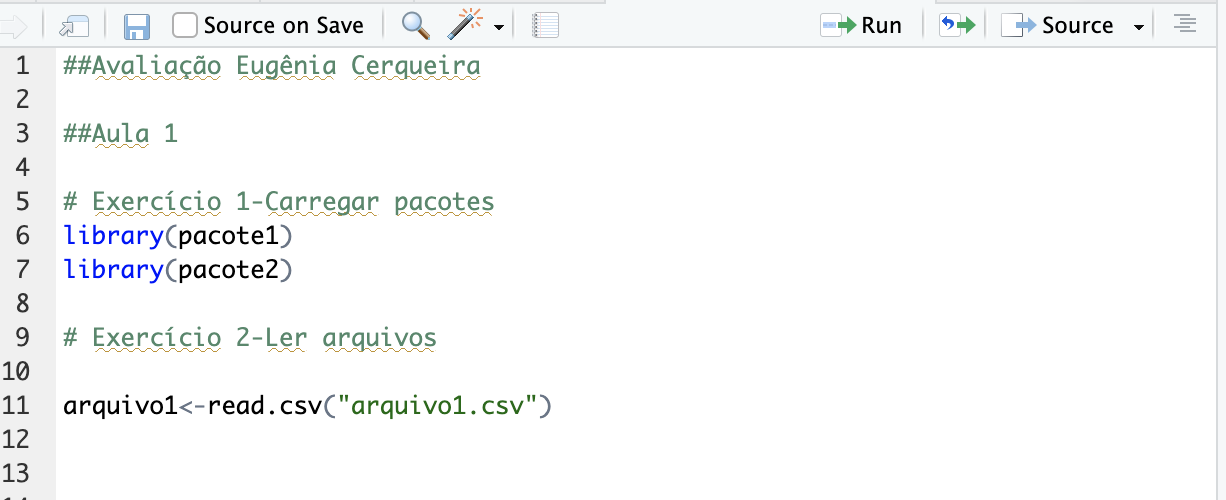
8.2.1 Aula 1
Exercício 1- Carregar os pacotes necessários para a realização dos exercícios
-tidyverse (ou carregar separadamente dplyr, forcats, janitor e ggplot2)
-gt
Exercício 2- Carregar os arquivos spot1.csv e spot2.csv
-Utilizar a função read.csv() ou Import Dataset.
8.2.2 Aula 2
Exercício 1- Gerar as estatísticas resumo dos arquivos spot1 e spot2
-Utilizar a função summary()
Exercício 2- Filtrar apenas as músicas a partir do ano 1950
-Utilizar a função subset ou filter
Exercício 3- Criar uma variável nova classificando a data de lançamento das músicas a cada 20 anos
-Utilizar o dataframe spot1
-Usar o comando ifelse() para criar uma nova variável “year2” a partir da variável original “year”.
-Usar os períodos de tempo para criar quatro categorias chamadas: “1950-1969”, “1970-1989”,“1990-2009” e “2010-2020”.
8.2.3 Aula 3
Exercício 1-Juntar as duas tabelas spot1 e spot2
-Utilizar a função left_join()
-Chamar a nova tabela de spotj
Exercício 2-Criar uma nova tabela selecionando apenas as músicas explícitas
-Utilizar a função subset() ou filter() para filtrar a base de dados.
-Chamar a nova tabela de spotexp
Exercício 3-Criar uma nova tabela adicionando apenas os gêneros musicais: Alternative, Country, Dance, Folk, Pop, Rock
-Salvar a tabela com spotj (substituindo a tabela criada no Exercício 1)
-Utilizar a função filter() para filtrar a base de dados.
-Lembrar do comando %in% da função filter.
Exercício 4-Recodificar a categoria Dance, da variável genre, para Pop
-Utilizar o pacote forcats e a função fct_recode() para transformar a variável Dance em Pop.
8.2.4 Aula 4
Atenção: todos exercícios da Aula 4 e 5 devem ser feitos com a tabela spotj, criada no exercício 3.
Exercício 1- Criar uma tabela de frequência por gênero musical
-Utilizar o comando summarize() do pacote dplyr
Exercício 2- Adicionar à tabela acima a média de danceability por gênero musical
-Utilizar o comando summarize() do pacote dplyr
Exercício 3-Adicionar à tabela acima a proporção por gênero musical
-Utilizar o comando mutate() do pacote dplyr
Exercício 4-Criar uma tabela cruzada de gênero x década de lançamento
-Utilizar a função tabyl() do pacote janitor
-Utilizar as variáveis genre e year2
Exercício 5-Utilizar o pacote gt para apresentar as duas tabelas acima
-Lembrar de renomear os nomes de cada coluna
-Adicionar fonte.
8.2.5 Aula 5
Exercício 1- Criar um gráfico de pontos da “dançabilidade” x popularidade das músicas do gênero Rock.
-Antes de fazer o gráfico, filtrar apenas o gênero “Rock”
-Utilizar as variáveis popularity e danceability
-Utilizar a função geom_point()
-Lembrar de ajustar os elementos de apresentação do gráfico (nome dos eixos etc.)
Exercício 2- Criar um gráfico de barras simples mostrando a média de popularidade por gênero
-Utilizar as variáveis genre e popularity
-Utilizar a função geom_bar()
-Utilizar os comandos stat e fun para fazer a média
-Lembrar de ajustar os elementos de apresentação do gráfico (nome dos eixos etc.)
Exercício 3-Criar um gráfico de barras empilhado cruzando a proporção de músicas por gênero e o período de lançamento da música
-Utilizar as variáveis genre e year
-Utilizar a função geom_bar()
-Lembrete: utilizar o comando position=fill
-Lembrar de ajustar os elementos de apresentação do gráfico (nome dos eixos, legenda etc.)