4.1 Filtrando dados
Filtrar dados no R é uma tarefa essencial para a análise de dados, pois permite selecionar subconjuntos específicos de um conjunto de dados com base em condições definidas. Isso é útil em várias etapas da análise de dados, desde a preparação e limpeza dos dados até a visualização e modelagem estatística.
A filtragem de dados permite:
• Remover Dados Irrelevantes: Filtrar ajuda a excluir linhas que não são relevantes para a análise, como valores ausentes ou dados redundantes.
• Tratar Valores Anômalos: Identificar e remover outliers ou valores que não fazem sentido no contexto da análise.
• Isolar Subconjuntos Específicos: Focar em uma população específica dentro do conjunto de dados, como filtrar por região geográfica, grupo etário, ou qualquer outra variável relevante.
• Reduzir Tamanho dos Dados: Trabalhar com um subconjunto dos dados pode acelerar o processamento e a análise, especialmente em conjuntos de dados grandes.
• Focar em Variáveis Específicas: Concentração em variáveis específicas pode facilitar a execução de análises estatísticas e modelagem.
4.1.1 Usando o comando subset
A filtragem de variáveis pode ser feita através do comando subset.
Repare que o novo dataframe adultos contém 4314 observações, pois abarca apenas os indivíduos mais jovens que 60 anos.
## 'data.frame': 4314 obs. of 19 variables:
## $ X : int 1 2 3 4 5 6 7 8 9 10 ...
## $ status : chr "bom" "bom" "ruim" "bom" ...
## $ tempo_empresa : int 9 17 10 0 0 1 29 9 0 0 ...
## $ moradia : chr "alugada" "alugada" "própria" "alugada" ...
## $ tempo_emprestimo: int 60 60 36 60 36 60 60 12 60 48 ...
## $ idade : int 30 58 46 24 26 36 44 27 32 41 ...
## $ estado_civil : chr "casada(o)" "viúva(o)" "casada(o)" "solteira(o)" ...
## $ registros : chr "não" "não" "sim" "não" ...
## $ trabalho : chr "autônomo" "fixo" "autônomo" "fixo" ...
## $ despesas : int 73 48 90 63 46 75 75 35 90 90 ...
## $ renda : int 129 131 200 182 107 214 125 80 107 80 ...
## $ ativos : int 0 0 3000 2500 0 3500 10000 0 15000 0 ...
## $ dividas : int 0 0 0 0 0 0 0 0 0 0 ...
## $ valor_emprestimo: int 800 1000 2000 900 310 650 1600 200 1200 1200 ...
## $ preco_do_bem : int 846 1658 2985 1325 910 1645 1800 1093 1957 1468 ...
## $ dif : int 46 658 985 425 600 995 200 893 757 268 ...
## $ aut : chr "sim" "não" "sim" "não" ...
## $ naoaut : chr "não" "sim" "não" "sim" ...
## $ idadeQ : chr "Jovem adultos" "Adultos" "Adultos" "Jovem adultos" ...O comando subset permite selecionar apenas as colunas desejadas
#Selecionar colunas moradia, status e idade
dadosfilt<-subset(dados, select=c("moradia","status","idade"))
head(dadosfilt)## moradia status idade
## 1 alugada bom 30
## 2 alugada bom 58
## 3 própria ruim 46
## 4 alugada bom 24
## 5 alugada bom 26
## 6 própria bom 36Digamos que queremos montar uma tabela apenas com indivíduos cuja moradia é própria ou alugada.
#Filtrar apenas indivíduos de moradia alugada
dadosmoradia<-subset(dados, moradia == "alugada")
unique(dadosmoradia$moradia)## [1] "alugada"Para estabelecermos mais de uma condição podemos usar os comandos | ou &. O comando | é traduzido como “ou”, ou seja, mostra que apenas uma das condições deve ser respeitada. Já o comando & é traduzido com “e”, ou seja, mostra que as duas condição devem ser respeitadas ao mesmo tempo.
Vamos testar os dois comandos. Utilizamos o código abaixo para especificar que queremos filtrar indivíduos que moram em moradia alugadas ou têm um trabalho fixo. Repare que a tabela resultante mostra os indivíduos que moram de aluguel ou os indivíduos que trabalham fixo (e não necessariamente moram de aluguel).
# Subset por condições múltiplas, utilizando o |
subset(dados, moradia == "alugada" | trabalho == "fixo")
Em seguida, substituimos o comando | por &. A tabela resultante filtra apenas os indivíduos que moram em moradia alugada e, ao mesmo tempo, possuem um trabalho fixo.
# Subset por condições múltiplas, utilizando o &
subset(dados, moradia == "alugada" & trabalho == "fixo")
### Usando o comando select
O comando select no R é frequentemente associado ao pacote dplyr, que é parte do tidyverse. O dplyr é amplamente utilizado para manipulação de dados e select é usado para selecionar colunas específicas de um data frame.
Permite selecionar colunas da base de dados. A função pode receber apenas o nome das colunas, ou colunas que comecem ou terminem com a palavra especificada pelas funções starts_with()e ends_with(). Os operadores ou :, complementar !, e & e intervalo : também são aceitos para espeficar a seleção.
Primeiro, um exemplo mais simples em que selecionaremos as variáveis estado civil, moradia e status.
## estado_civil moradia status
## Length:4454 Length:4454 Length:4454
## Class :character Class :character Class :character
## Mode :character Mode :character Mode :characterPodemos utilizar o operador complementar ! para excluir variáveis da base. Vamos utilizá-lo para excluir as variáveis moradia e status.
## X tempo_empresa tempo_emprestimo idade estado_civil
## Min. : 1 Min. : 0.000 Min. : 6.00 Min. :18.00 Length:4454
## 1st Qu.:1114 1st Qu.: 2.000 1st Qu.:36.00 1st Qu.:28.00 Class :character
## Median :2228 Median : 5.000 Median :48.00 Median :36.00 Mode :character
## Mean :2228 Mean : 7.987 Mean :46.44 Mean :37.08
## 3rd Qu.:3341 3rd Qu.:12.000 3rd Qu.:60.00 3rd Qu.:45.00
## Max. :4454 Max. :48.000 Max. :72.00 Max. :68.00
##
## registros trabalho despesas renda ativos
## Length:4454 Length:4454 Min. : 35.00 Min. : 6.0 Min. : 0
## Class :character Class :character 1st Qu.: 35.00 1st Qu.: 90.0 1st Qu.: 0
## Mode :character Mode :character Median : 51.00 Median :125.0 Median : 3000
## Mean : 55.57 Mean :141.7 Mean : 5404
## 3rd Qu.: 72.00 3rd Qu.:170.0 3rd Qu.: 6000
## Max. :180.00 Max. :959.0 Max. :300000
## NA's :381 NA's :47
## dividas valor_emprestimo preco_do_bem dif aut
## Min. : 0 Min. : 100 Min. : 105 Min. : 0.0 Length:4454
## 1st Qu.: 0 1st Qu.: 700 1st Qu.: 1117 1st Qu.: 142.0 Class :character
## Median : 0 Median :1000 Median : 1400 Median : 300.0 Mode :character
## Mean : 343 Mean :1039 Mean : 1463 Mean : 423.9
## 3rd Qu.: 0 3rd Qu.:1300 3rd Qu.: 1692 3rd Qu.: 594.0
## Max. :30000 Max. :5000 Max. :11140 Max. :10140.0
## NA's :18
## naoaut idadeQ
## Length:4454 Length:4454
## Class :character Class :character
## Mode :character Mode :character
##
##
##
## 4.1.2 Usando o comando filter
A função filter do pacote dplyr é usada para selecionar linhas de um data frame com base em condições lógicas, da mesma forma que o subset.
## [1] "bom"Esta função também possui um operador especial denotado por %in% que permite filtrar uma variável categórica de acordo com um vetor de categorias.
Vamos utilizar o operador %in% para filtrar apenas as modalidades alugada, própria e pais da variável moradia.
## [1] "alugada" "própria" "pais"4.1.3 Filtrando linhas e colunas
Para filtrar linhas e colunas utilizamos a seguinte gramática:
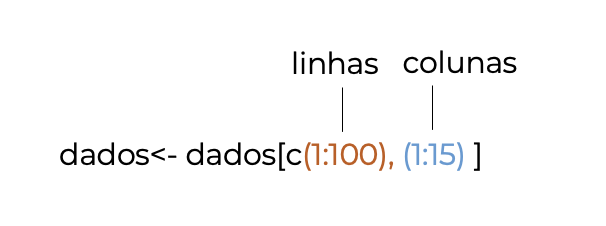
Vamos carregar a base de dados adultos.csv, que traz informações sobre 200 indivíduos.
Digamos que queremos selecionar apenas as 100 primeiras linhas. O operador : indica que queremos remover da linha 1 até a linha 100 (1:100). Poderíamos também precisar o número específico das linhas queremos manter, no entanto esse método não é prático quando queremos remover um número grande de elementos.
Como queremos selecionar apenas as linhas, deixamos a parte depois da vírgula vazia.
## X age workclass fnlwgt education education_num marital_status
## 1 1 39 State-gov 77516 Bachelors 13 Never-married
## 2 2 50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse
## 3 3 38 Private 215646 HS-grad 9 Divorced
## 4 4 53 Private 234721 11th 7 Married-civ-spouse
## 5 5 28 Private 338409 Bachelors 13 Married-civ-spouse
## 6 6 37 Private 284582 Masters 14 Married-civ-spouse
## occupation relationship race sex capital_gain capital_loss hours_per_week
## 1 Adm-clerical Not-in-family White Male 2174 0 40
## 2 Exec-managerial Husband White Male 0 0 13
## 3 Handlers-cleaners Not-in-family White Male 0 0 40
## 4 Handlers-cleaners Husband Black Male 0 0 40
## 5 Prof-specialty Wife Black Female 0 0 40
## 6 Exec-managerial Wife White Female 0 0 40
## native_country more_than_50k
## 1 United-States no
## 2 United-States no
## 3 United-States no
## 4 United-States no
## 5 Cuba no
## 6 United-States noPara filtrar colunas, utilizamos a mesma sintaxe, porém deixamos a primeira parte antes da vírgula vazia.
## X age workclass fnlwgt education education_num marital_status
## 1 1 39 State-gov 77516 Bachelors 13 Never-married
## 2 2 50 Self-emp-not-inc 83311 Bachelors 13 Married-civ-spouse
## 3 3 38 Private 215646 HS-grad 9 Divorced
## 4 4 53 Private 234721 11th 7 Married-civ-spouse
## 5 5 28 Private 338409 Bachelors 13 Married-civ-spouse
## 6 6 37 Private 284582 Masters 14 Married-civ-spouse
## occupation relationship race
## 1 Adm-clerical Not-in-family White
## 2 Exec-managerial Husband White
## 3 Handlers-cleaners Not-in-family White
## 4 Handlers-cleaners Husband Black
## 5 Prof-specialty Wife Black
## 6 Exec-managerial Wife White