Chapter 3 The Rasch Model
3.1 Basics
We can Run the Rasch model via TAM:
\(Pr(X_{si}=1|\theta_s, \delta_i) = \frac{exp(\theta_s-\delta_i)}{1+exp(\theta_s-\delta_i)}\).
Here, \(\theta_s\) denotes the estimated ability level of student s, \(\delta_i\) is the estimated difficulty level of item i and both estimates are in logits. \(Pr(X=1|\theta_s, \delta_i)\) can be read as the probability of a “correct response” or of a respondent endorsing the “higher” category (if the item is scored dichotomously) for a item i given a student’s ability and item i's difficulty.
TAM will provide estimates for item difficulty and student ability along with a host of other data.
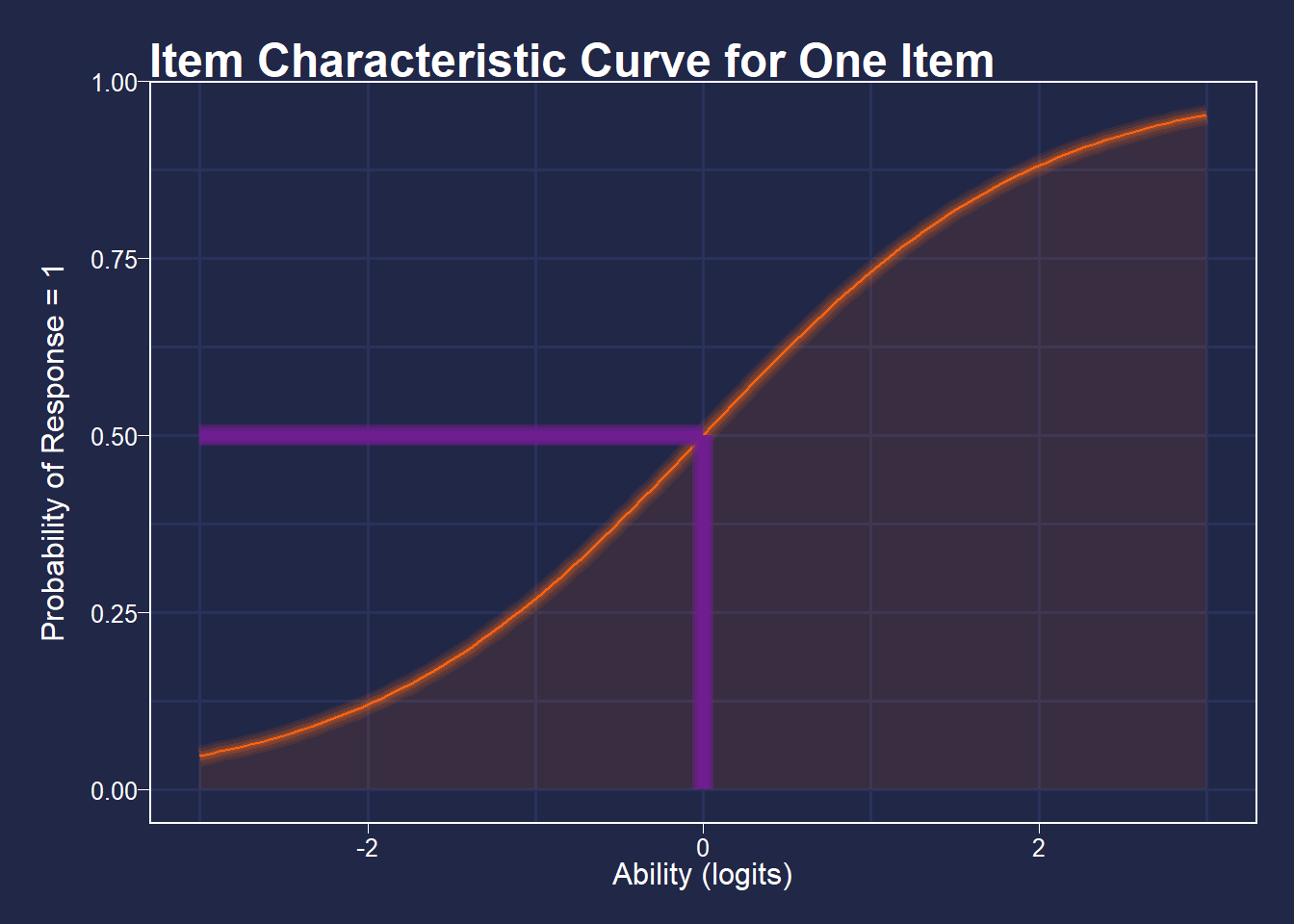
Item difficulties are defined as the point at which a person has a 50% chance of getting an item correct, defined in logits (log of the odds). So, if for an item a person of ability 0 logits has a 50% chance of getting a item correct, that item’s difficulty is defined as 0 logits.
See the figure below for a visualization of this.
3.2 Packages Necessary for running the Rasch model
Install the packages below. TAM is a collection of functions to run a variety of Rasch-type models. WrightMap will help us visualize model estimated item difficulties and model estimated person abilities. We can use the Wright map to help us answer questions such as, “do our items match our population of interest such that we have items that garner information about students at all ranges of the ability distribution?” or “do we have too many easy or hard items and not enough items in the middle of the ability range (are the items well targeted)?” Let’s get into it.
If you need to install TAM or the WrightMap package, note the quotes and capitalizations:
install.packages("TAM")
install.packages("WrightMap")We need to load the packages.Additionally, we’ll use some packages from the tidyverse
library(TAM)
library(WrightMap)
library(tidyverse)3.3 Reading in Data
The data for this session will be downloaded from an online repository (github). We need to read it in to your R session. This means that it is something you can now work with in R. The .csv file will be read in as something called a data frame or (dataframe). This is a type of object in R that’s essentially a spreadsheet that your’re used to working with.
hls <- read_csv("https://raw.githubusercontent.com/danielbkatz/DBER_Rasch/master/data/dichotomous.csv")
# The first column are IDs that we'll get rid of
hls <- hls[-1]If you would like to download the data first, and are reading it in locally,
hls <- read.csv("data/hls_dic_scale.csv")3.4 Check out the data set
Let’s explore hls just a little. It has 15 columns (the items, and 1000 rows, the people). Each item is titled “V1…vN.” There is no missing data.
dim(hls)## [1] 1000 15str(hls)## tibble [1,000 x 15] (S3: tbl_df/tbl/data.frame)
## $ V1 : num [1:1000] 0 0 0 0 1 0 0 0 0 1 ...
## $ V2 : num [1:1000] 0 0 0 0 0 0 0 1 0 0 ...
## $ V3 : num [1:1000] 0 0 0 0 0 0 1 1 1 0 ...
## $ V4 : num [1:1000] 0 0 1 0 1 0 0 0 0 1 ...
## $ V5 : num [1:1000] 0 0 0 0 1 0 0 0 0 0 ...
## $ V6 : num [1:1000] 1 1 1 1 1 0 1 0 1 1 ...
## $ V7 : num [1:1000] 1 1 1 0 1 1 0 1 0 1 ...
## $ V8 : num [1:1000] 1 1 1 0 1 1 1 0 0 1 ...
## $ V9 : num [1:1000] 1 0 1 0 0 1 1 0 0 1 ...
## $ V10: num [1:1000] 1 1 1 1 1 1 1 1 1 1 ...
## $ V11: num [1:1000] 0 0 0 0 1 0 1 0 0 0 ...
## $ V12: num [1:1000] 1 1 1 0 1 0 1 0 1 1 ...
## $ V13: num [1:1000] 1 1 1 1 1 1 1 1 1 1 ...
## $ V14: num [1:1000] 1 1 1 1 1 1 1 0 0 0 ...
## $ V15: num [1:1000] 1 1 1 1 1 0 1 0 0 1 ...head(hls)## # A tibble: 6 x 15
## V1 V2 V3 V4 V5 V6 V7 V8 V9
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0 0 0 0 0 1 1 1 1
## 2 0 0 0 0 0 1 1 1 0
## 3 0 0 0 1 0 1 1 1 1
## 4 0 0 0 0 0 1 0 0 0
## 5 1 0 0 1 1 1 1 1 0
## 6 0 0 0 0 0 0 1 1 1
## # ... with 6 more variables: V10 <dbl>, V11 <dbl>,
## # V12 <dbl>, V13 <dbl>, V14 <dbl>, V15 <dbl>If you want to see the whole dataset, view the data frame:
View(hls)3.5 Running the Rasch model
This command runs a Rasch model on the selected data frame. Here, mod1 is an object in R that “holds” the data from our Rasch model (along with a lot of other information). It’s essentially a large list. This is the main computation step, now we just select information that is stored in mod1 or run mod1 through further computation.
Note that the dataframe hls has to contain only items and no other information.
mod1 <- tam(hls)## ....................................................
## Processing Data 2021-03-05 08:48:37
## * Response Data: 1000 Persons and 15 Items
## * Numerical integration with 21 nodes
## * Created Design Matrices ( 2021-03-05 08:48:37 )
## * Calculated Sufficient Statistics ( 2021-03-05 08:48:37 )
## ....................................................
## Iteration 1 2021-03-05 08:48:37
## E Step
## M Step Intercepts |----
## Deviance = 14773.234
## Maximum item intercept parameter change: 0.399105
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.078497
## ....................................................
## Iteration 2 2021-03-05 08:48:37
## E Step
## M Step Intercepts |---
## Deviance = 14690.1844 | Absolute change: 83.0496 | Relative change: 0.00565341
## Maximum item intercept parameter change: 0.021879
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.033763
## ....................................................
## Iteration 3 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14688.5292 | Absolute change: 1.6552 | Relative change: 0.00011269
## Maximum item intercept parameter change: 0.014713
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.023636
## ....................................................
## Iteration 4 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.7687 | Absolute change: 0.7605 | Relative change: 5.177e-05
## Maximum item intercept parameter change: 0.010151
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.016163
## ....................................................
## Iteration 5 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.4204 | Absolute change: 0.3483 | Relative change: 2.372e-05
## Maximum item intercept parameter change: 0.007002
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.01092
## ....................................................
## Iteration 6 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.2608 | Absolute change: 0.1595 | Relative change: 1.086e-05
## Maximum item intercept parameter change: 0.004829
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.007322
## ....................................................
## Iteration 7 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1876 | Absolute change: 0.0733 | Relative change: 4.99e-06
## Maximum item intercept parameter change: 0.003331
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.004888
## ....................................................
## Iteration 8 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1538 | Absolute change: 0.0338 | Relative change: 2.3e-06
## Maximum item intercept parameter change: 0.0023
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.003254
## ....................................................
## Iteration 9 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1382 | Absolute change: 0.0156 | Relative change: 1.06e-06
## Maximum item intercept parameter change: 0.001589
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.002164
## ....................................................
## Iteration 10 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1309 | Absolute change: 0.0073 | Relative change: 5e-07
## Maximum item intercept parameter change: 0.001098
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.001439
## ....................................................
## Iteration 11 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1275 | Absolute change: 0.0034 | Relative change: 2.3e-07
## Maximum item intercept parameter change: 0.00076
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.000957
## ....................................................
## Iteration 12 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1259 | Absolute change: 0.0016 | Relative change: 1.1e-07
## Maximum item intercept parameter change: 0.000526
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.000637
## ....................................................
## Iteration 13 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1251 | Absolute change: 8e-04 | Relative change: 5e-08
## Maximum item intercept parameter change: 0.000365
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.000425
## ....................................................
## Iteration 14 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1248 | Absolute change: 4e-04 | Relative change: 2e-08
## Maximum item intercept parameter change: 0.000253
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.000284
## ....................................................
## Iteration 15 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1246 | Absolute change: 2e-04 | Relative change: 1e-08
## Maximum item intercept parameter change: 0.000176
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.00019
## ....................................................
## Iteration 16 2021-03-05 08:48:37
## E Step
## M Step Intercepts |--
## Deviance = 14687.1245 | Absolute change: 1e-04 | Relative change: 1e-08
## Maximum item intercept parameter change: 0.000122
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 0.000127
## ....................................................
## Iteration 17 2021-03-05 08:48:37
## E Step
## M Step Intercepts |-
## Deviance = 14687.1245 | Absolute change: 0 | Relative change: 0
## Maximum item intercept parameter change: 8.5e-05
## Maximum item slope parameter change: 0
## Maximum regression parameter change: 0
## Maximum variance parameter change: 8.5e-05
## ....................................................
## Item Parameters
## xsi.index xsi.label est
## 1 1 V1 1.7931
## 2 2 V2 2.9362
## 3 3 V3 1.8480
## 4 4 V4 1.9376
## 5 5 V5 1.1392
## 6 6 V6 -0.3249
## 7 7 V7 0.2917
## 8 8 V8 0.1005
## 9 9 V9 0.3164
## 10 10 V10 -2.7690
## 11 11 V11 2.3171
## 12 12 V12 -1.3863
## 13 13 V13 -3.1003
## 14 14 V14 -0.5554
## 15 15 V15 -0.2020
## ...................................
## Regression Coefficients
## [,1]
## [1,] 0
##
## Variance:
## [,1]
## [1,] 1.028
##
##
## EAP Reliability:
## [1] 0.691
##
## -----------------------------
## Start: 2021-03-05 08:48:37
## End: 2021-03-05 08:48:37
## Time difference of 0.03499699 secsIf we want to see some basic results from mod1, we can use summary
summary(mod1)## ------------------------------------------------------------
## TAM 3.5-19 (2020-05-05 22:45:39)
## R version 3.6.0 (2019-04-26) x86_64, mingw32 | nodename=LAPTOP-K7402PLE | login=katzd
##
## Date of Analysis: 2021-03-05 08:48:37
## Time difference of 0.03499699 secs
## Computation time: 0.03499699
##
## Multidimensional Item Response Model in TAM
##
## IRT Model: 1PL
## Call:
## tam.mml(resp = resp)
##
## ------------------------------------------------------------
## Number of iterations = 17
## Numeric integration with 21 integration points
##
## Deviance = 14687.12
## Log likelihood = -7343.56
## Number of persons = 1000
## Number of persons used = 1000
## Number of items = 15
## Number of estimated parameters = 16
## Item threshold parameters = 15
## Item slope parameters = 0
## Regression parameters = 0
## Variance/covariance parameters = 1
##
## AIC = 14719 | penalty=32 | AIC=-2*LL + 2*p
## AIC3 = 14735 | penalty=48 | AIC3=-2*LL + 3*p
## BIC = 14798 | penalty=110.52 | BIC=-2*LL + log(n)*p
## aBIC = 14747 | penalty=59.64 | aBIC=-2*LL + log((n-2)/24)*p (adjusted BIC)
## CAIC = 14814 | penalty=126.52 | CAIC=-2*LL + [log(n)+1]*p (consistent AIC)
## AICc = 14720 | penalty=32.55 | AICc=-2*LL + 2*p + 2*p*(p+1)/(n-p-1) (bias corrected AIC)
## GHP = 0.49064 | GHP=( -LL + p ) / (#Persons * #Items) (Gilula-Haberman log penalty)
##
## ------------------------------------------------------------
## EAP Reliability
## [1] 0.691
## ------------------------------------------------------------
## Covariances and Variances
## [,1]
## [1,] 1.028
## ------------------------------------------------------------
## Correlations and Standard Deviations (in the diagonal)
## [,1]
## [1,] 1.014
## ------------------------------------------------------------
## Regression Coefficients
## [,1]
## [1,] 0
## ------------------------------------------------------------
## Item Parameters -A*Xsi
## item N M xsi.item AXsi_.Cat1 B.Cat1.Dim1
## 1 V1 1000 0.182 1.793 1.793 1
## 2 V2 1000 0.074 2.936 2.936 1
## 3 V3 1000 0.175 1.848 1.848 1
## 4 V4 1000 0.164 1.938 1.938 1
## 5 V5 1000 0.280 1.139 1.139 1
## 6 V6 1000 0.566 -0.325 -0.325 1
## 7 V7 1000 0.440 0.292 0.292 1
## 8 V8 1000 0.479 0.100 0.100 1
## 9 V9 1000 0.435 0.316 0.316 1
## 10 V10 1000 0.915 -2.769 -2.769 1
## 11 V11 1000 0.123 2.317 2.317 1
## 12 V12 1000 0.760 -1.386 -1.386 1
## 13 V13 1000 0.936 -3.100 -3.100 1
## 14 V14 1000 0.612 -0.555 -0.555 1
## 15 V15 1000 0.541 -0.202 -0.202 1
##
## Item Parameters in IRT parameterization
## item alpha beta
## 1 V1 1 1.793
## 2 V2 1 2.936
## 3 V3 1 1.848
## 4 V4 1 1.938
## 5 V5 1 1.139
## 6 V6 1 -0.325
## 7 V7 1 0.292
## 8 V8 1 0.100
## 9 V9 1 0.316
## 10 V10 1 -2.769
## 11 V11 1 2.317
## 12 V12 1 -1.386
## 13 V13 1 -3.100
## 14 V14 1 -0.555
## 15 V15 1 -0.2023.6 Item Difficulties
We’ll extract difficulties (xsi) from the mod1 object (mod1 is like a large list, and we can index it like we do with vectors, dataframes, etc). List objects can be indexed with double brackets (i.e. to get the first object in a list called list, then we can go with: list[[1]] or by name, list[["name"]] or list name). List objects can be vectors, dataframes, arrays, or another list (among other things). In TAM, the mod1 object created involves all of these things.
We’ll access item difficulties via indexing with the $. In other words, access mod1 and extract the object xsi which exists in mod1 as a datframe.
Assign those values to an object in the environment called diffic using <-, the assignment operator, like before
diffic <- mod1$xsidiffic## xsi se.xsi
## V1 1.7931307 0.08796069
## V2 2.9362293 0.12572913
## V3 1.8480436 0.08918914
## V4 1.9375978 0.09130044
## V5 1.1392412 0.07679369
## V6 -0.3249306 0.07031216
## V7 0.2917034 0.07025640
## V8 0.1004752 0.06985392
## V9 0.3164109 0.07033607
## V10 -2.7690071 0.11837091
## V11 2.3171095 0.10185622
## V12 -1.3863076 0.08015772
## V13 -3.1003020 0.13381930
## V14 -0.5553981 0.07135170
## V15 -0.2019536 0.06998711In the table below, we can see the item difficulties in logits in the column xsi and the standard error for each item se.xsi. One way to think of what the standard error tells us is whether item difficulties may overlap or not.
xsi values indicate more difficult items. For instance, item Hls9 is harder than Hls8. The values are identified by constraining the mean of item difficulties to zero.
| xsi | se.xsi | |
|---|---|---|
| V1 | 1.7931307 | 0.0879607 |
| V2 | 2.9362293 | 0.1257291 |
| V3 | 1.8480436 | 0.0891891 |
| V4 | 1.9375978 | 0.0913004 |
| V5 | 1.1392412 | 0.0767937 |
| V6 | -0.3249306 | 0.0703122 |
| V7 | 0.2917034 | 0.0702564 |
| V8 | 0.1004752 | 0.0698539 |
| V9 | 0.3164109 | 0.0703361 |
| V10 | -2.7690071 | 0.1183709 |
| V11 | 2.3171095 | 0.1018562 |
| V12 | -1.3863076 | 0.0801577 |
| V13 | -3.1003020 | 0.1338193 |
| V14 | -0.5553981 | 0.0713517 |
| V15 | -0.2019536 | 0.0699871 |
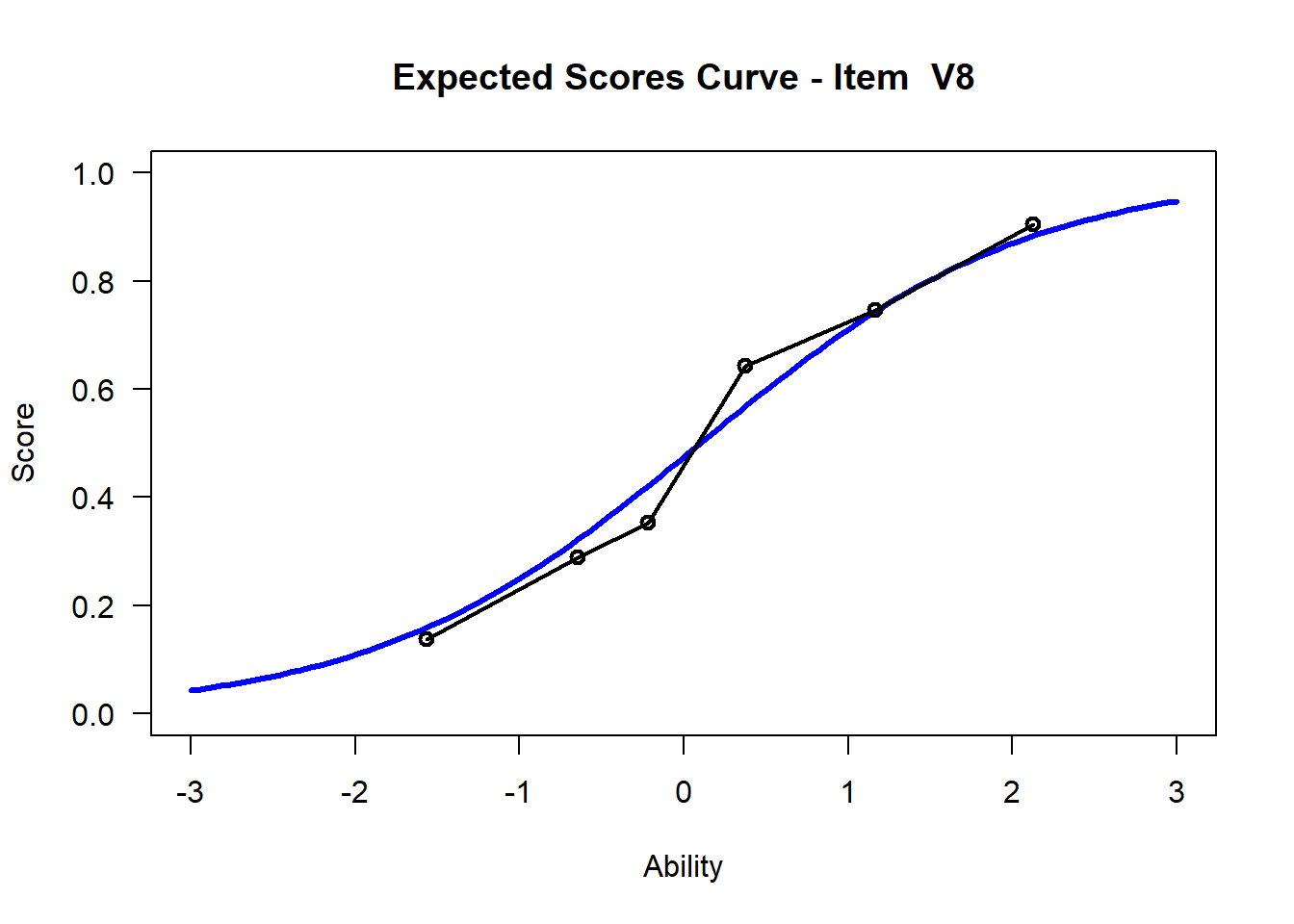
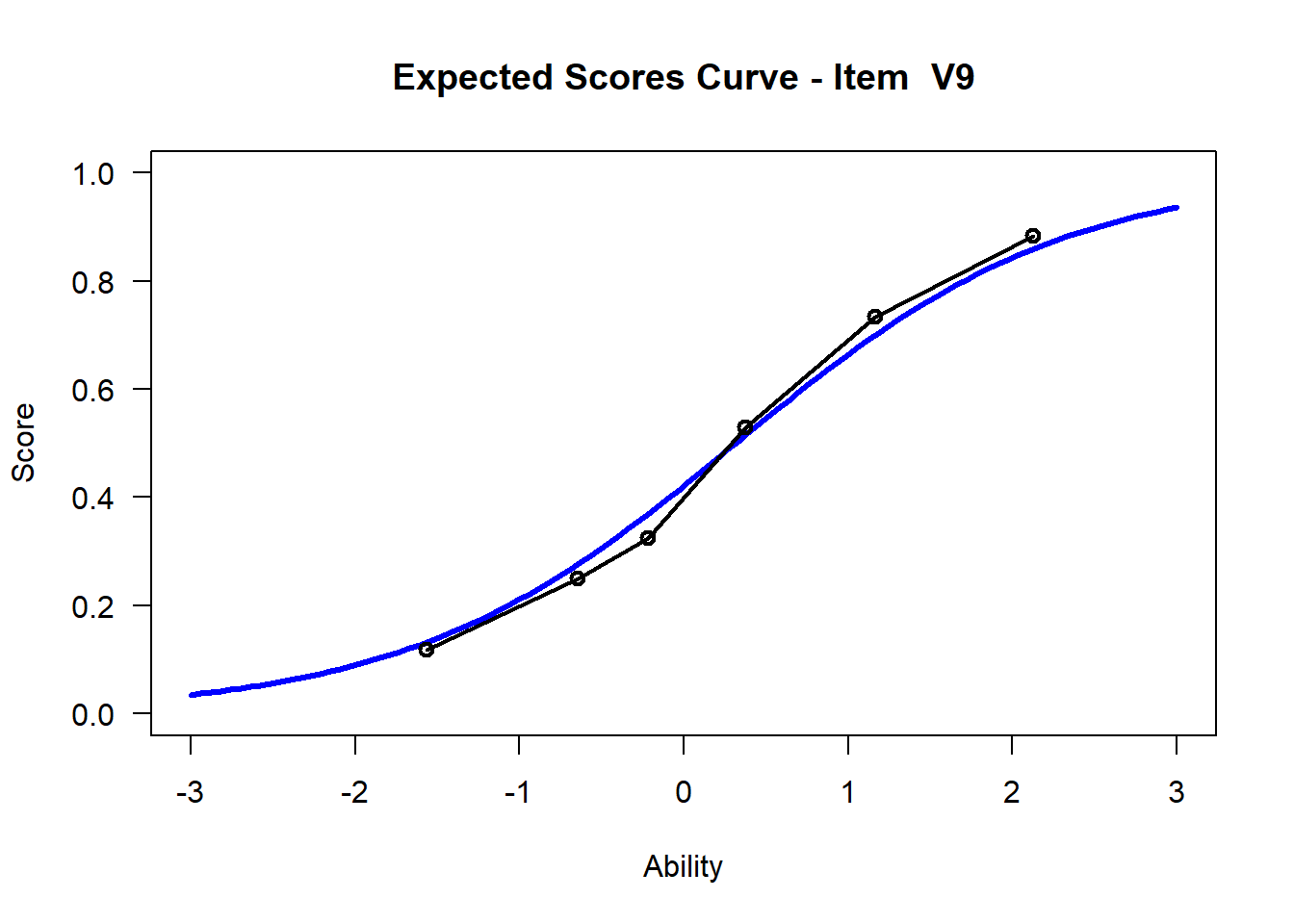
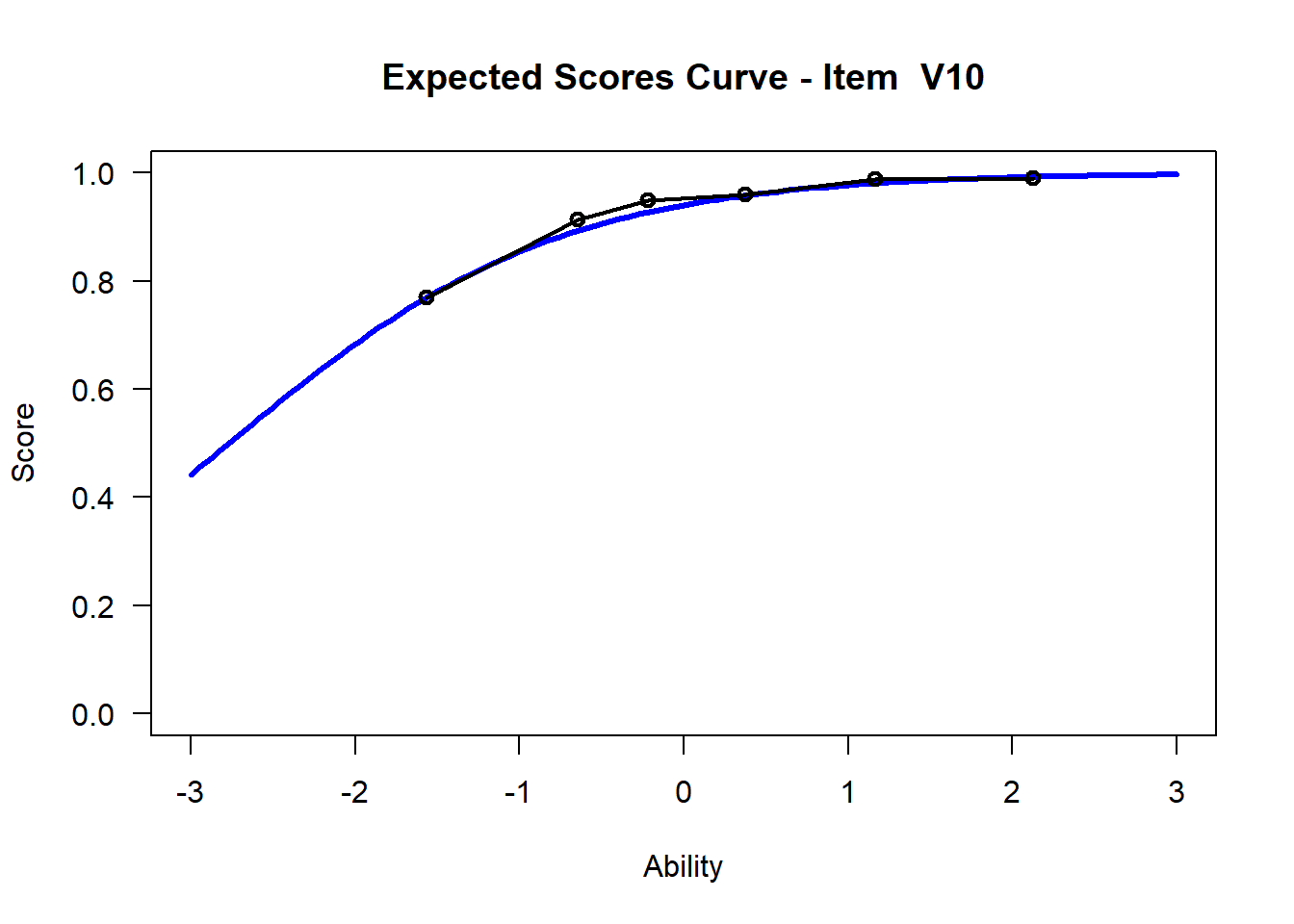
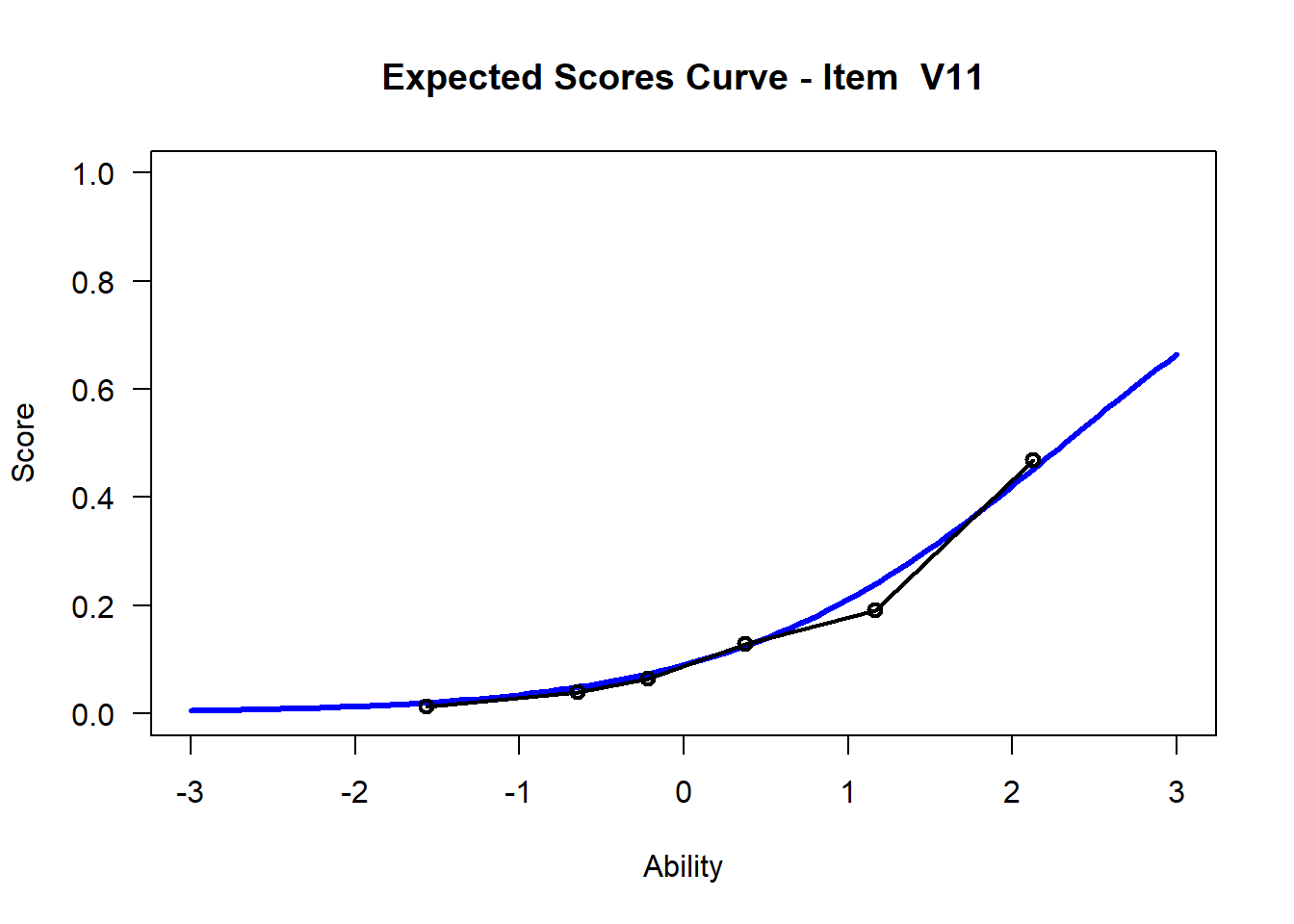
3.7 Visualize - Get Item Characteristic Curves
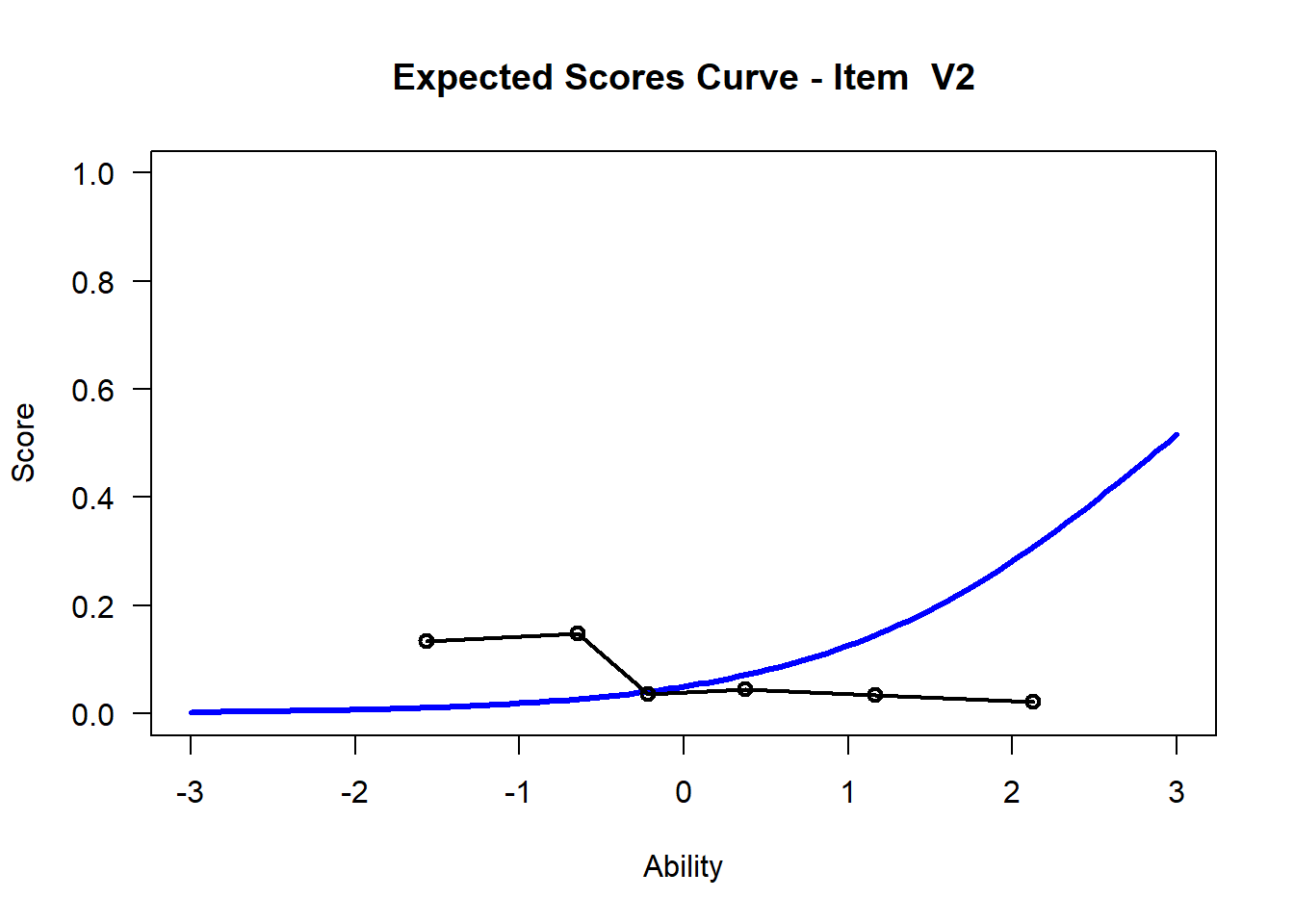
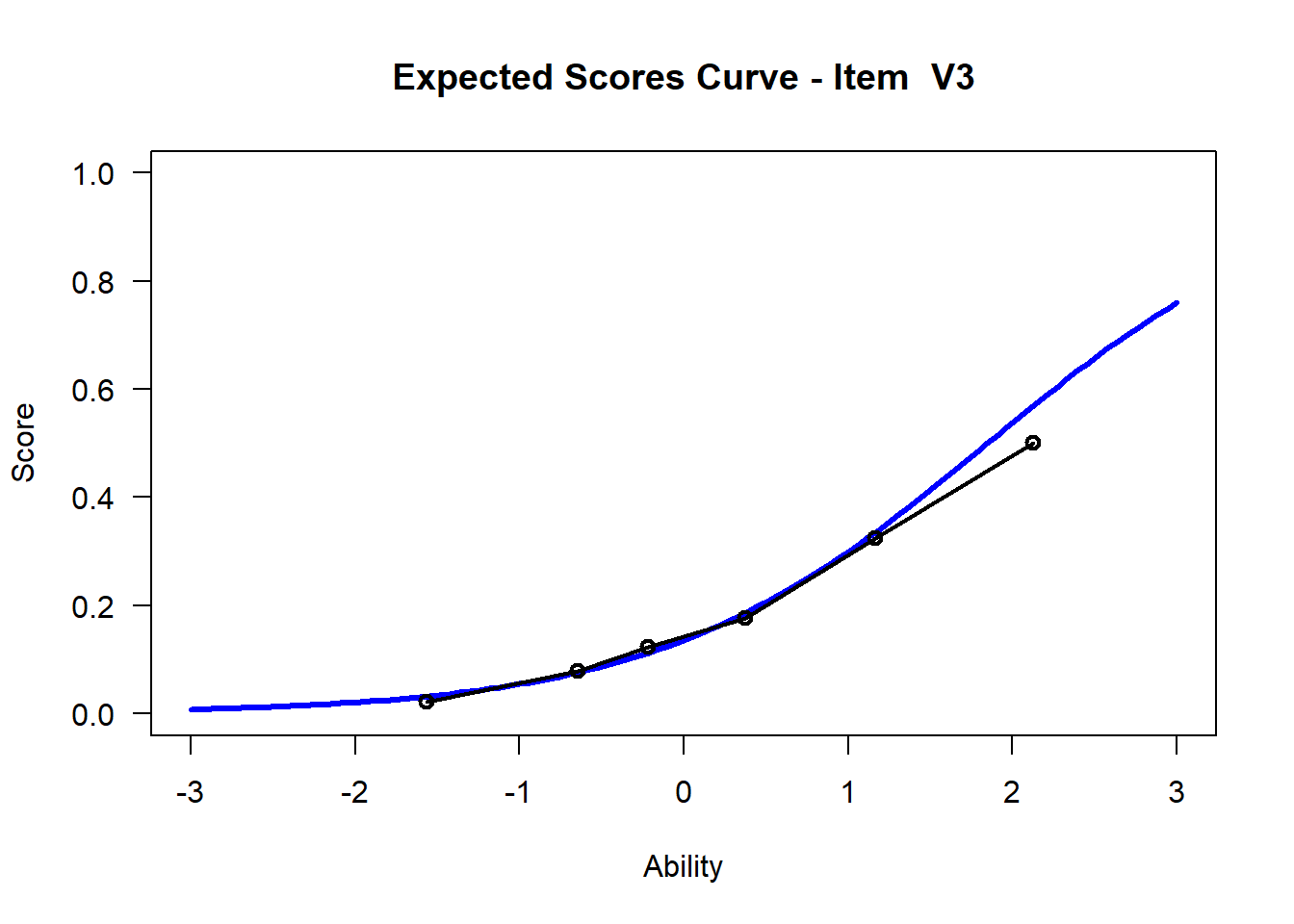
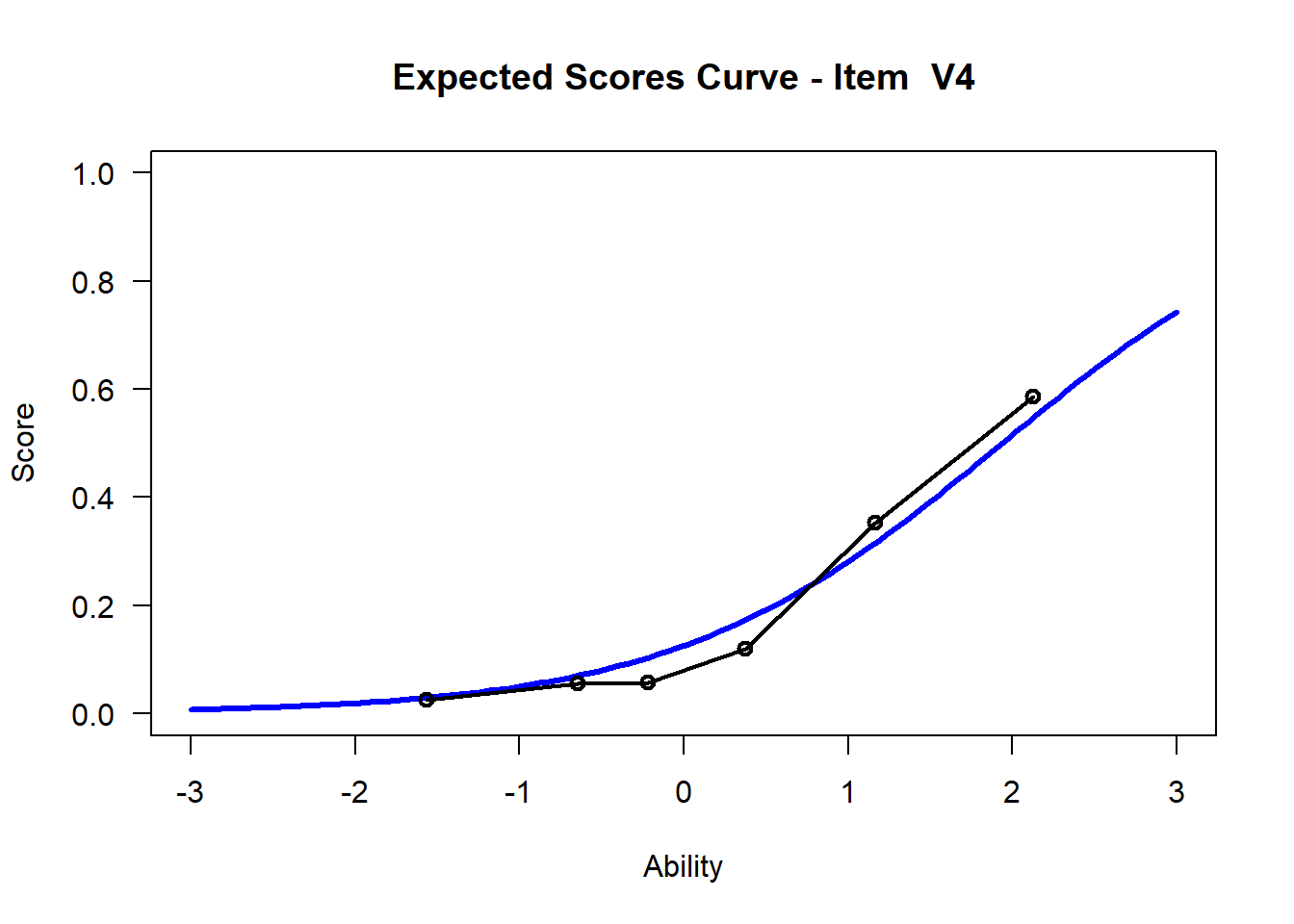
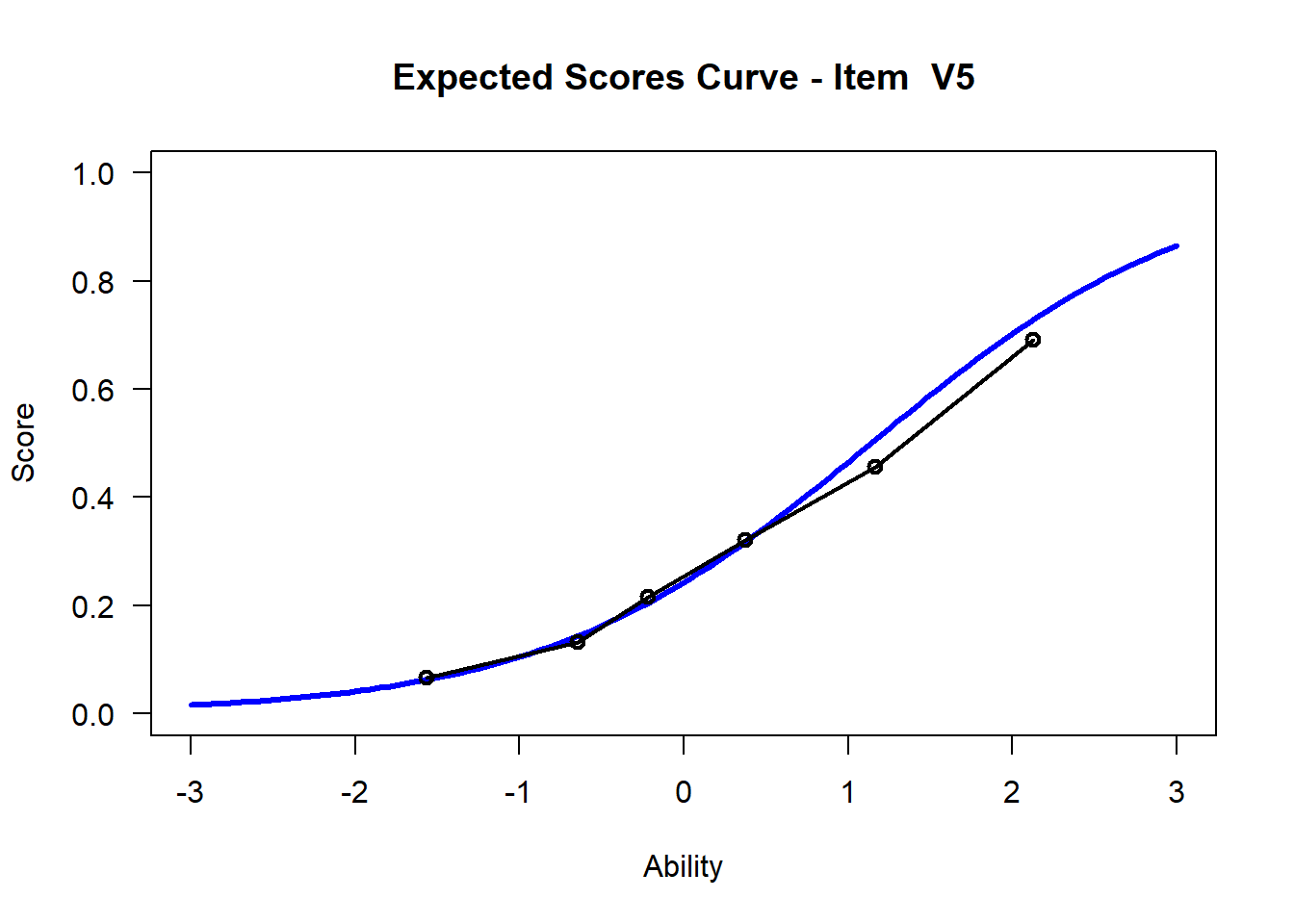
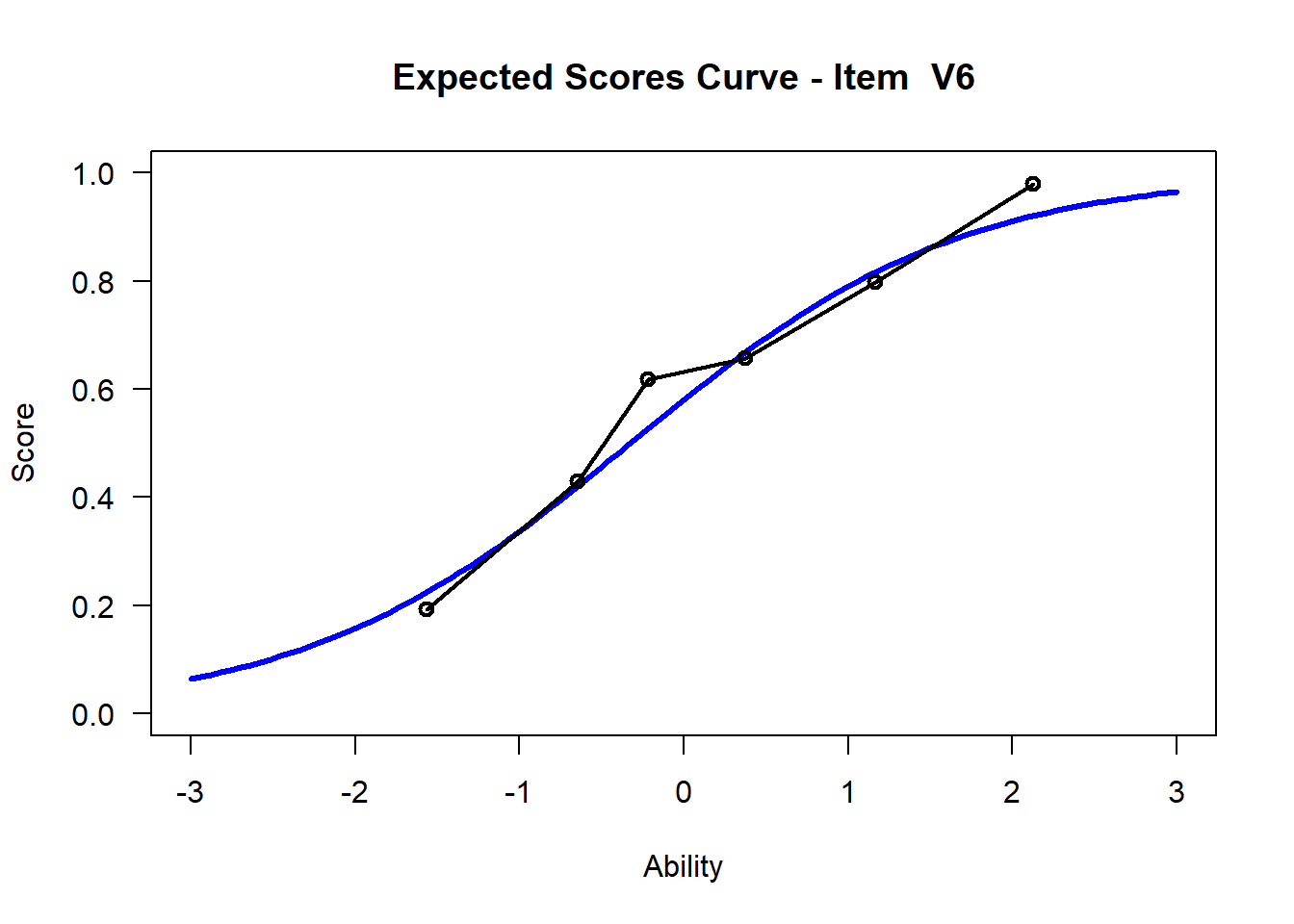
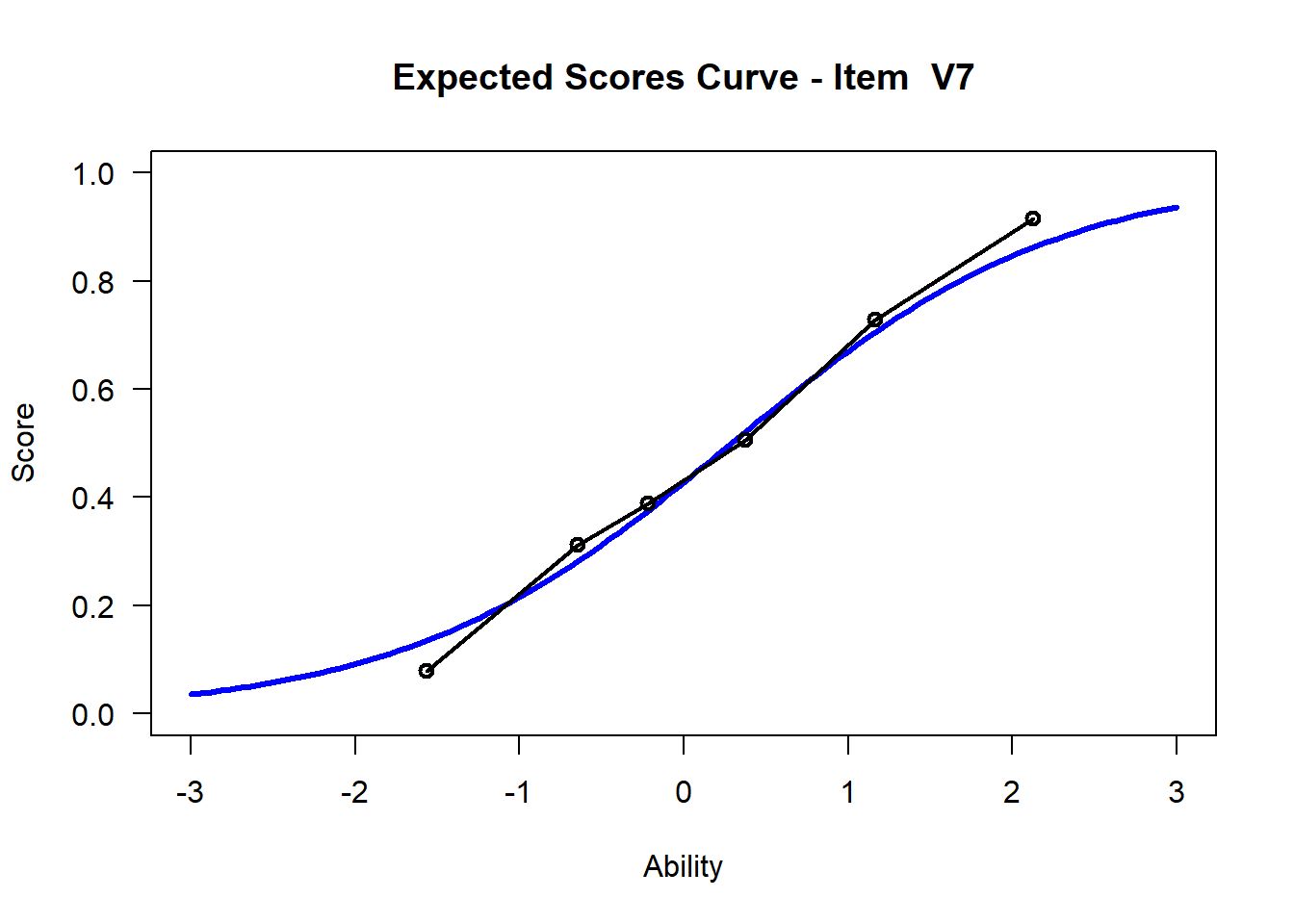
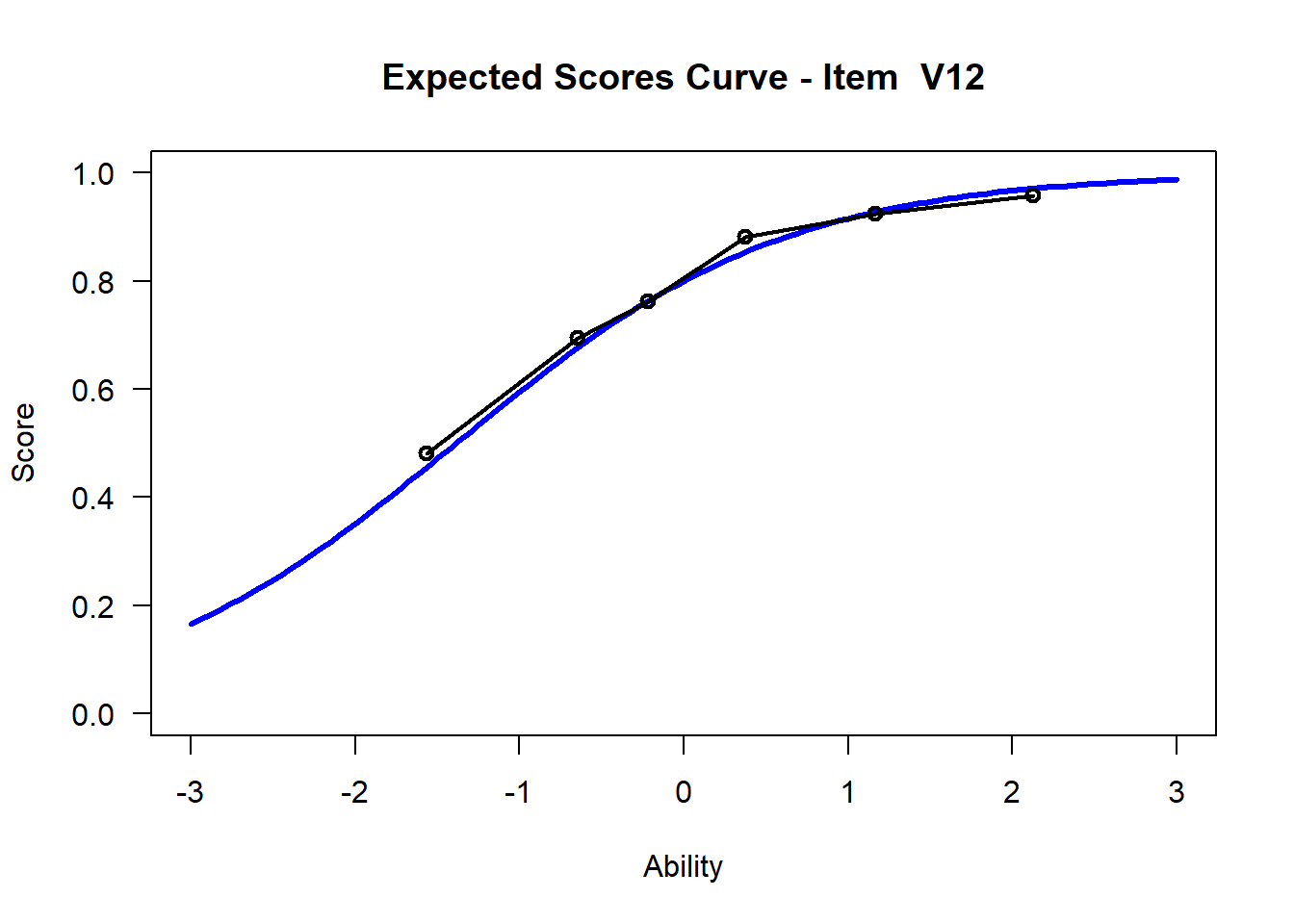
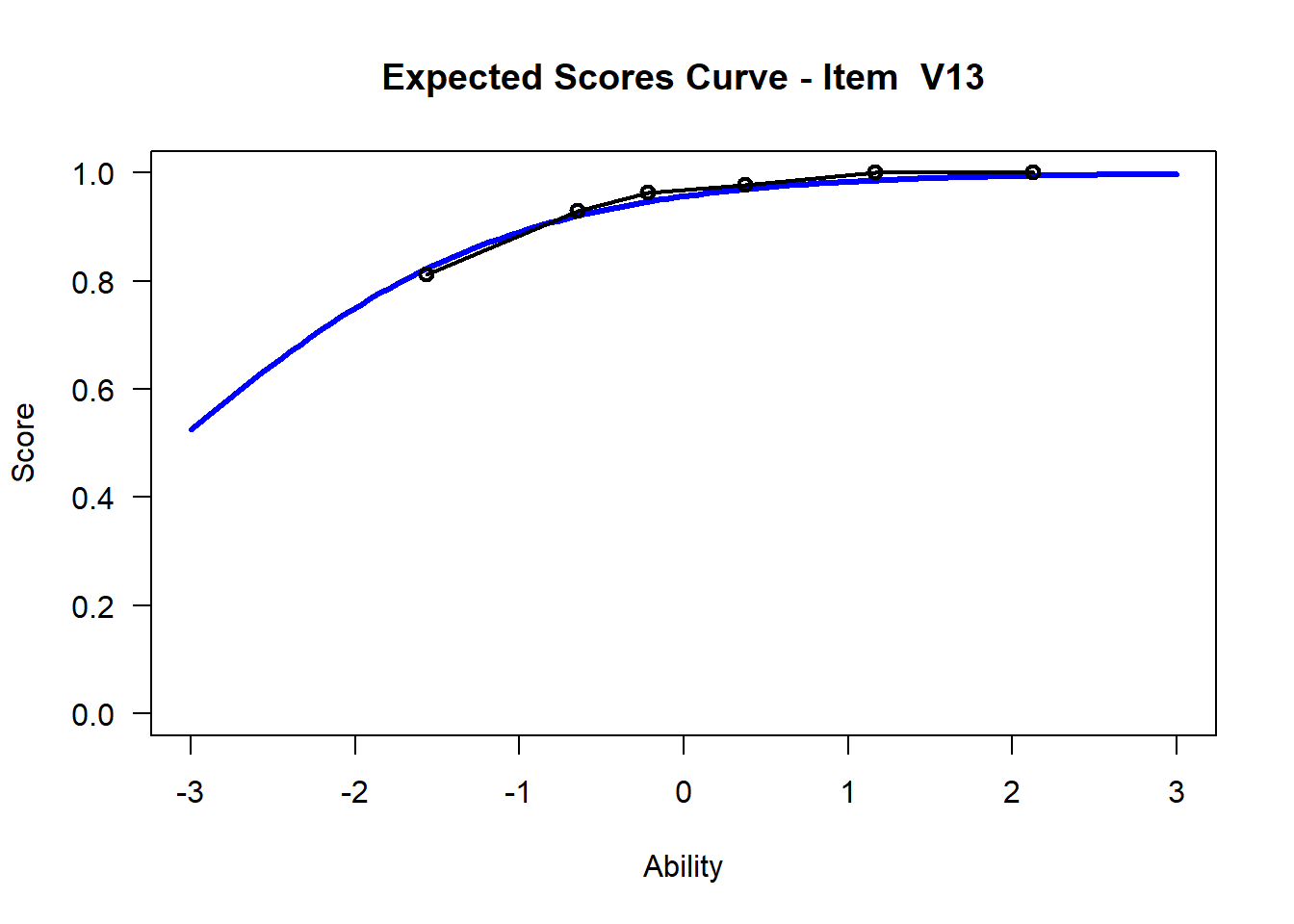
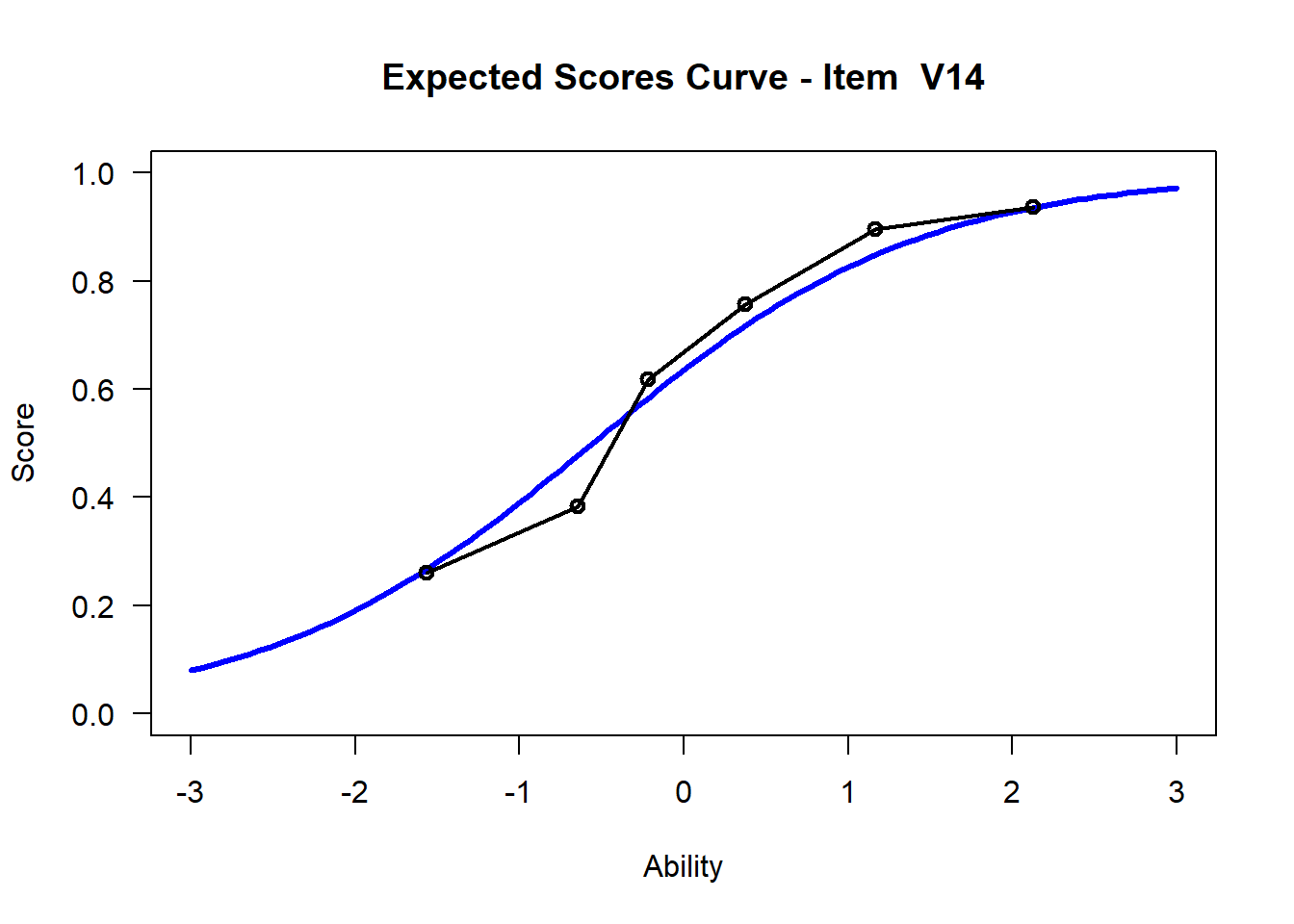
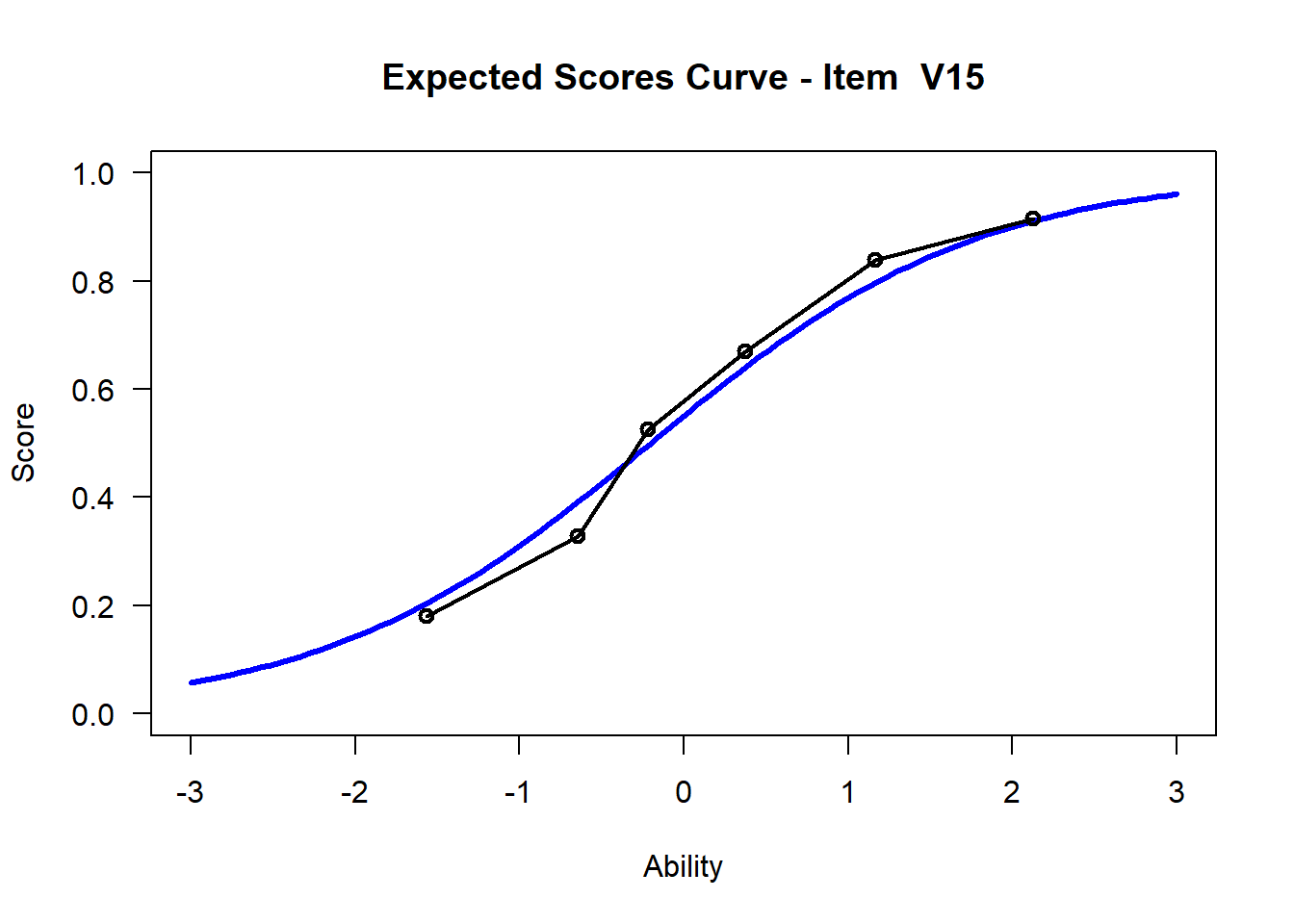
We may want to visualize each item characteristic curve (ICC) for each item. These plots plot the expected value (blue, smooth line) given that the data fits the Rasch model, and the observed black line (a binned solution). Each plot represents a single item. They visualize the probability of a respondent getting the item correct given their ability level. For instance, for item V1, the blue line shows that a person at 1 logit (x-axis) has something like a 30% probability of getting the item correct (predicted).
plot(mod1)## Iteration in WLE/MLE estimation 1 | Maximal change 1.2824
## Iteration in WLE/MLE estimation 2 | Maximal change 0.2808
## Iteration in WLE/MLE estimation 3 | Maximal change 0.01
## Iteration in WLE/MLE estimation 4 | Maximal change 0.0012
## Iteration in WLE/MLE estimation 5 | Maximal change 1e-04
## Iteration in WLE/MLE estimation 6 | Maximal change 0
## ----
## WLE Reliability= 0.666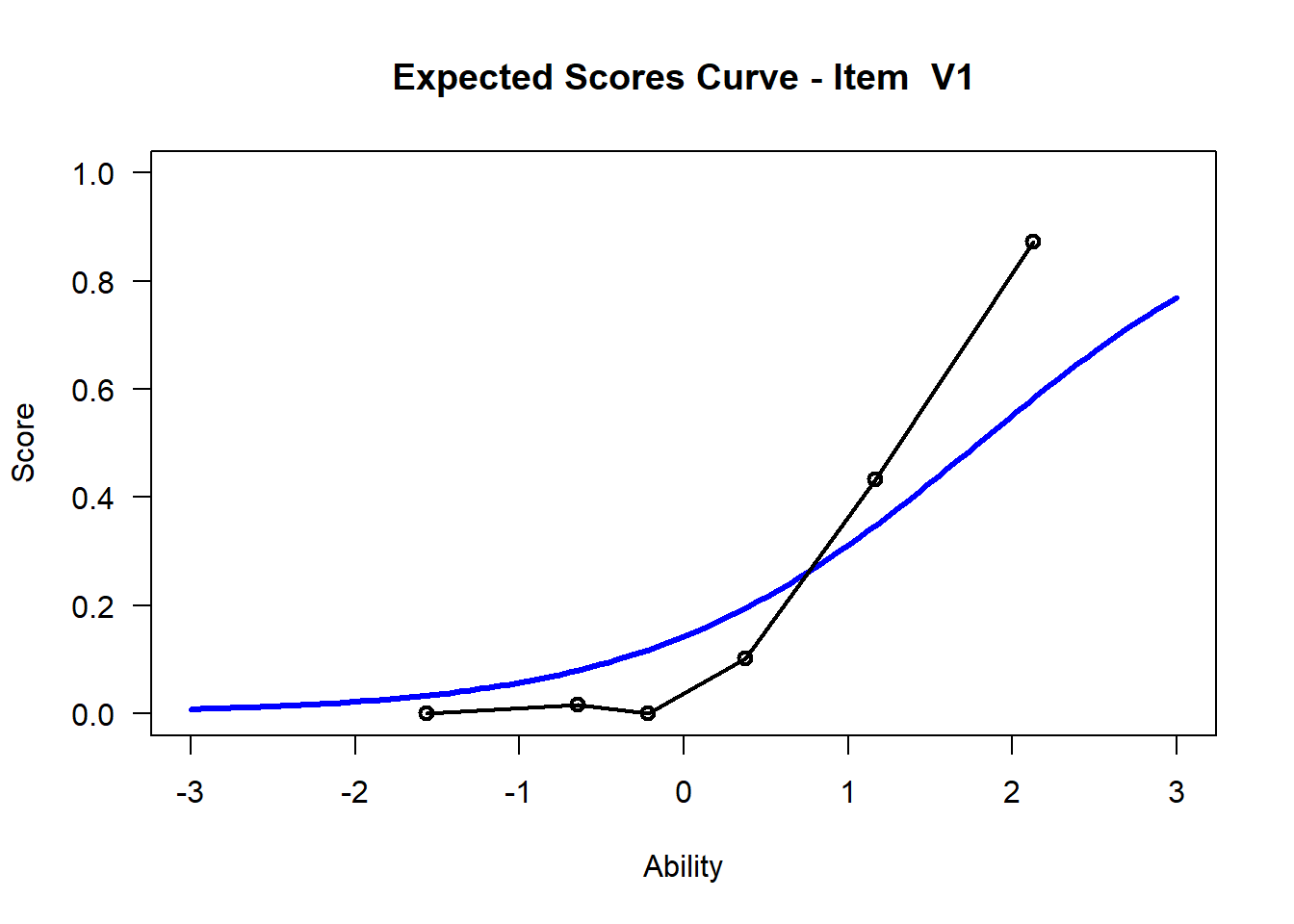
## ....................................................
## Plots exported in png format into folder:
## C:/Users/katzd/Desktop/Rprojects/Rasch_BIOME/DBER_Rasch-data/PlotsNote that for items V1 and V2, the black line, the observed probabilities, deviate quite a lot from the blue lines, the expected probabilities. Contrast this with item V5. For item V1, the black line seems to be steeper than the blue line, whereas for V2, the black line is quite a bit shallower. These lines hint at different types of item misfit, which we’ll introduce later. Roughly, in the shallower case, we’re not able to differentiate between respondents very easily - it probably means there is too much randomness. In the steep case, it might be too easy to differentiate - the item isn’t informative.
3.8 Summarizing the distribution of difficulties
We can visualize and summarize the distribution of item difficulties below, but there will be a better way, called a Wright Map, that we’ll introduce later.
The methods below use no packages to visualize and summarize.
hist(diffic$xsi, breaks=10)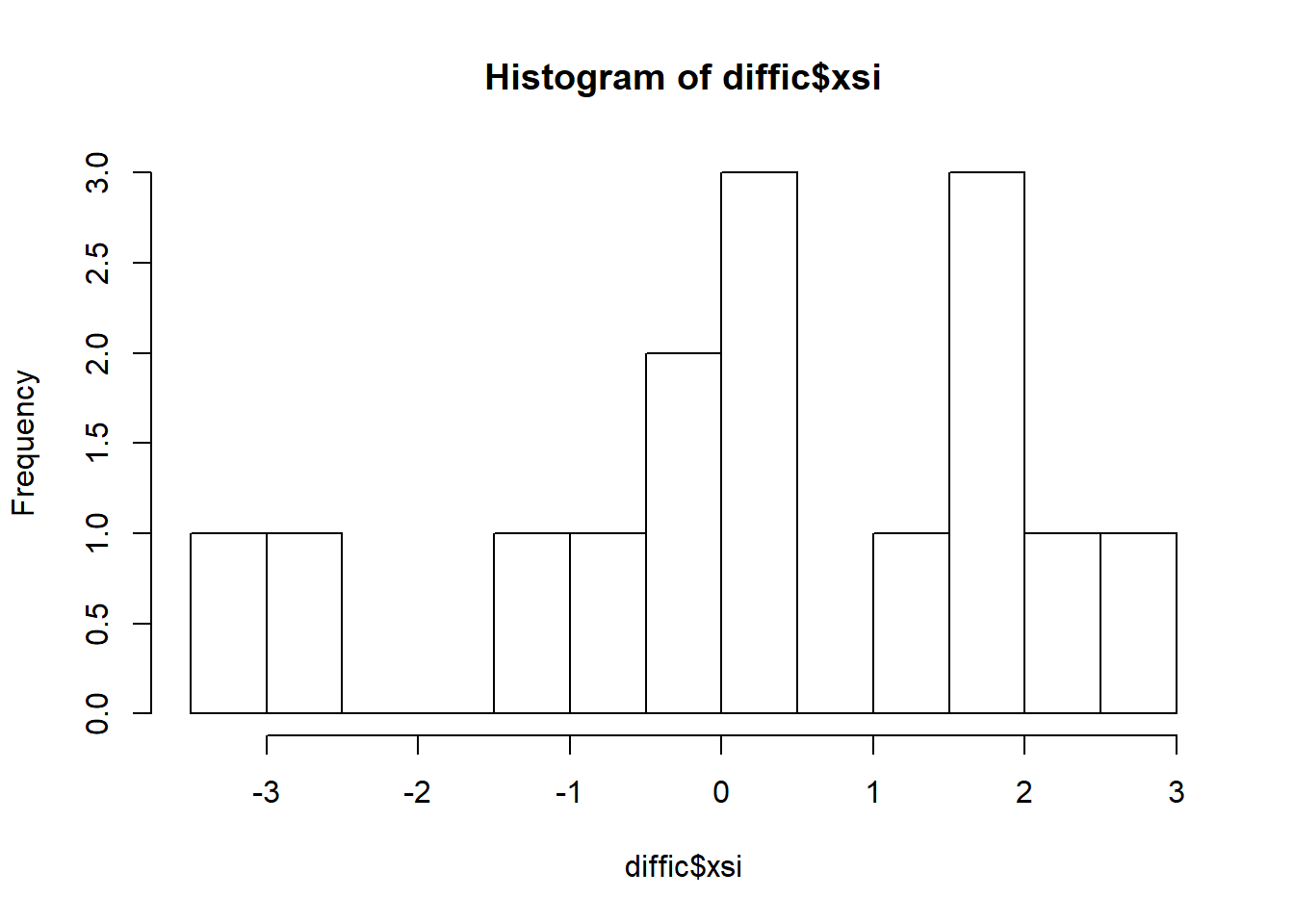
# If you want to see the items as a scatter plot
plot(diffic$xsi, main="Scatter Plot of Item Difficulties", xlab="Item Number", ylab = "Difficulty in Logits", pch=9)
axis(side=1, at = c(1:15))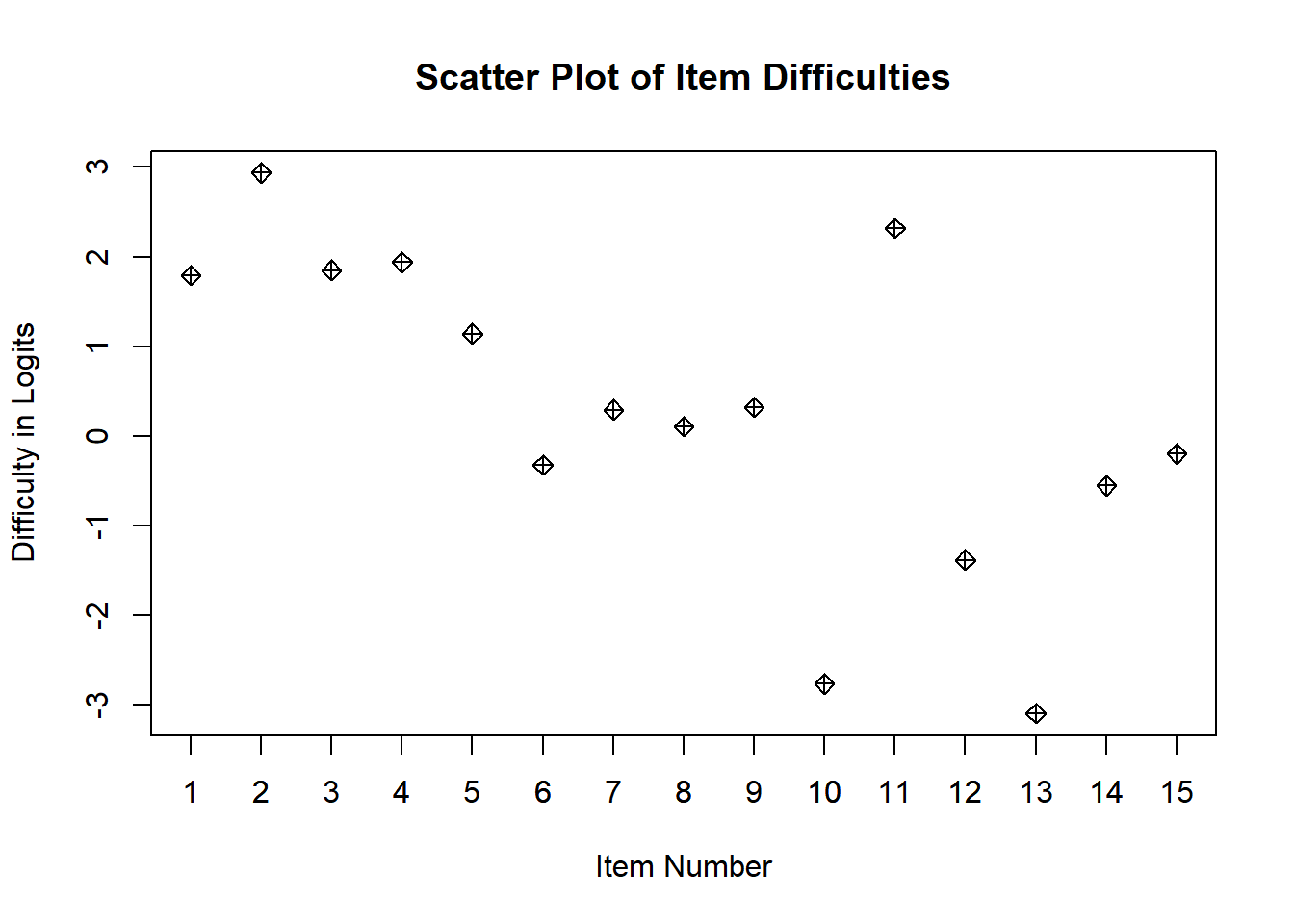
Let’s make that difficulty plot look a bit nicer - but we can’t really
# create a histogram to get a sense - since we only have 15 items, it's not that useful
ggplot(diffic, aes(x = xsi)) +
geom_histogram(bins=15) +
ggtitle("Distribution of Item Difficulties")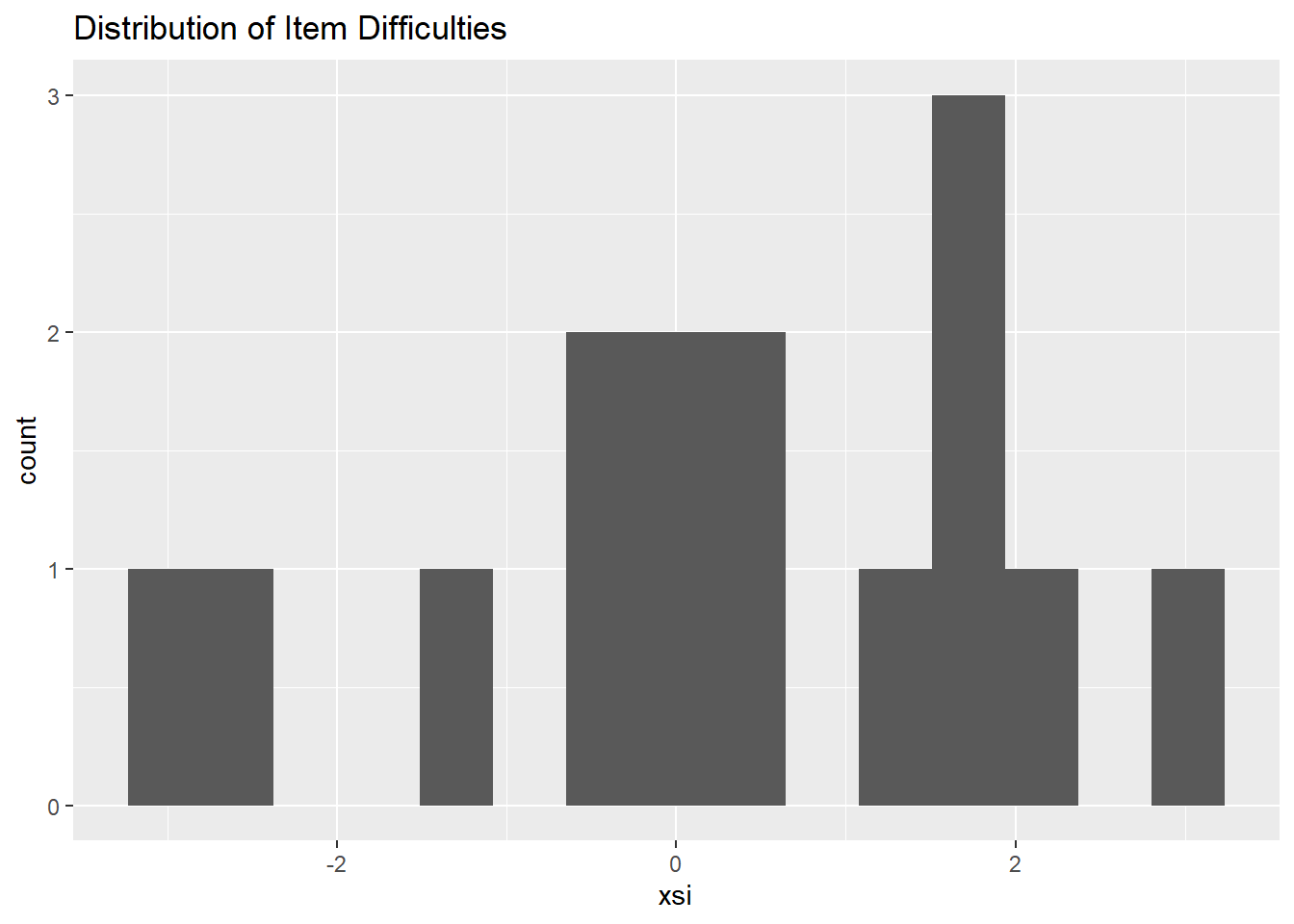
What might be more useful is looking at item difficulties vs their standard errors. Luckily, in this dataset, items were ordered from easiest to hardest. We see that items with larger standard errors are the hard items and the easiest items. This is because we have fewer students in the tails of the distribution - thus less information for each item - hence larger standard errors.
We’ll get into this more later!
ggplot(diffic, aes(x = xsi, y=se.xsi)) + geom_point() +
ggtitle("Item difficulties and their standard error") +
xlab("Estimated Item Difficulties") +
ylab("Estimated Item Standard Errors")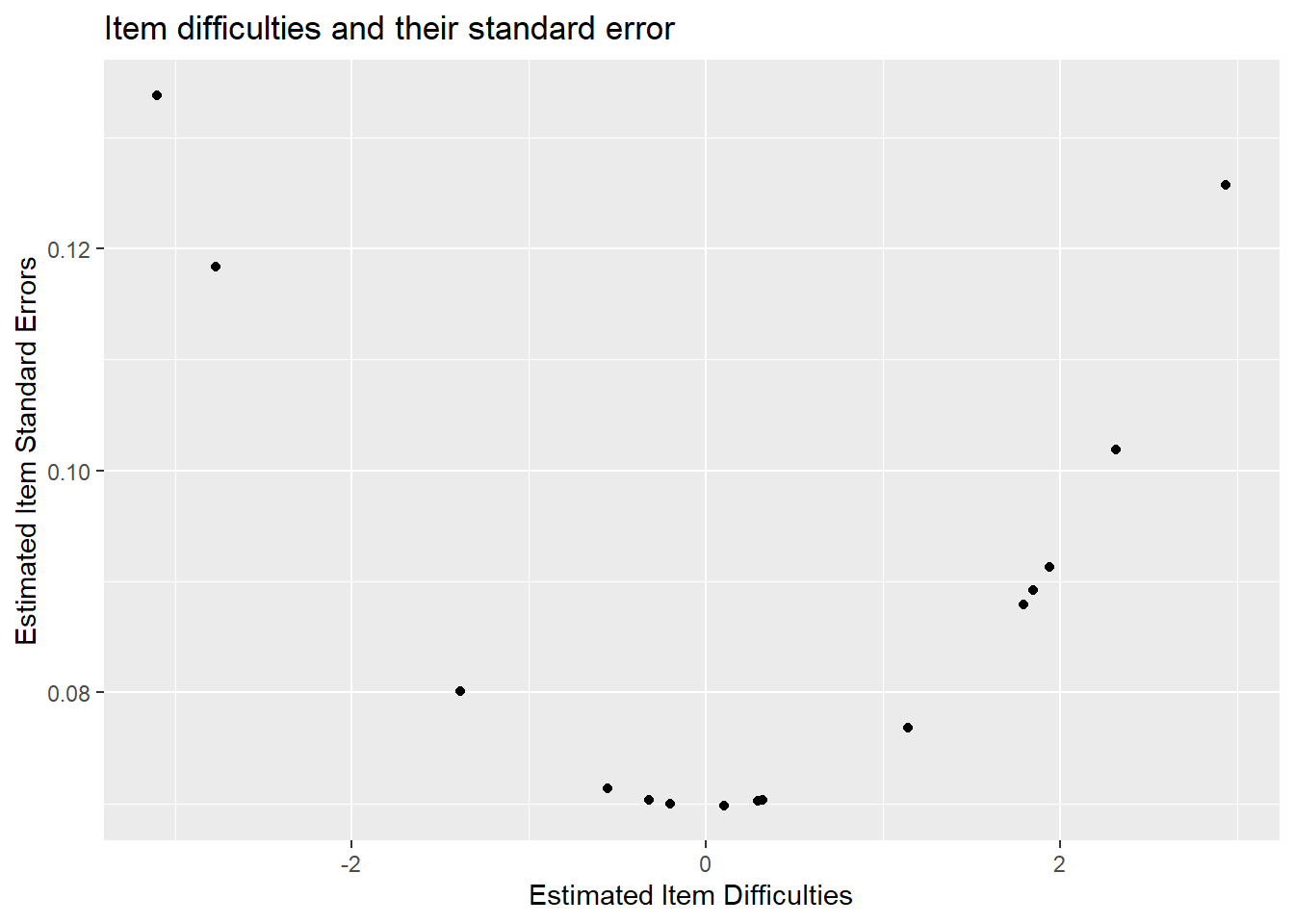
Another way we can get an idea of dispersion - the empirical item means and standard deviations.
mean(diffic$xsi)## [1] 0.2894695sd(diffic$xsi)## [1] 1.7781923.8.1 Exercise:
- Which item is the hardest? The easiest?
- Which item has the lowest standard error - what is it’s difficulty - don’t use the plot.
3.9 Item Fit
Let’s find out if the data fit the model. Use the tam.fit function to compute fit statistics, then display. We note that items V1 and V2 have outfits that are drastically different from the items’ infit values. We also note that infit values of V1 and V2 are different from any of the other items. We note that V1 is “over fitting,” it’s outfit and infit values being well below 1, while V2 is “underfitting.” This means that item V1 is too predictable - the amount of information is well predicted from other items which means it provides little new information above and beyond the other items. On the other hand, the underfitting V2 item has too much randomness.
To review, an item’s fit starts with its residuals.A residual is the observed response minus the expected response. The expected response is the probability of a student endorsing and item category or getting an item correct. The observed response is the student’s actual response. So, if a student is expected to get an item right with a probability of 40%, and the student gets the item right, then the residual is \(1 - .40 = .60\).
To get outfit:
\[Z_{si}=\frac{X_{si}-E(X_{si})}{Var(X_{si})}\]
Where \(X_{si}\) is the observed response of the s to item i. \(E(X_{si})\) is the expected response of student s to item i. This is just the result of the Rasch model - the probability of getting an item correct or selecting an item category. \(Var(X_{si})\) is simply \(E(X_{si})(1-E(X_{si}))\).
Outfit of item i, is then:
\[Outfit_i = \frac{\sum_s Z_{si}^2}{n}\]
And, Infit, of item i is calculated:
\[Infit_i = \frac{\sum_s Z_{si}^2 W_{si}}{\sum_sW_{si}}\]
Note, that W are item specific weights coming from \(Var(X_{si})\).
We don’t need to do this manually, and can instead use TAM.
However, outfit is “outlier” sensitive whereas “infit” is not. This implies that for V2 there might be a few responses that are particularly random/unexpected.
fit <- tam.fit(mod1)## Item fit calculation based on 15 simulations
## |**********|
## |----------|str(fit)## List of 3
## $ itemfit:'data.frame': 15 obs. of 9 variables:
## ..$ parameter : Factor w/ 15 levels "V1","V10","V11",..: 1 8 9 10 11 12 13 14 15 2 ...
## ..$ Outfit : num [1:15] 0.635 3.619 1.024 0.962 1.044 ...
## ..$ Outfit_t : num [1:15] -8.247 16.695 0.464 -0.677 1.198 ...
## ..$ Outfit_p : num [1:15] 1.62e-16 1.42e-62 6.43e-01 4.99e-01 2.31e-01 ...
## ..$ Outfit_pholm: num [1:15] 2.27e-15 2.12e-61 1.00 1.00 1.00 ...
## ..$ Infit : num [1:15] 0.834 1.235 1.031 0.98 1.035 ...
## ..$ Infit_t : num [1:15] -3.437 2.305 0.604 -0.346 0.965 ...
## ..$ Infit_p : num [1:15] 0.000589 0.021159 0.545702 0.729449 0.334344 ...
## ..$ Infit_pholm : num [1:15] 0.00884 0.29622 1 1 1 ...
## $ time : POSIXct[1:2], format: "2021-03-05 08:48:57" ...
## $ CALL : language tam.fit(tamobj = mod1)
## - attr(*, "class")= chr "tam.fit"View(fit$itemfit)| parameter | Outfit | Outfit_t | Outfit_p | Outfit_pholm | Infit | Infit_t | Infit_p | Infit_pholm |
|---|---|---|---|---|---|---|---|---|
| V1 | 0.6348193 | -8.2470850 | 0.0000000 | 0 | 0.8340363 | -3.4365960 | 0.0005891 | 0.0088361 |
| V2 | 3.6191206 | 16.6953650 | 0.0000000 | 0 | 1.2351540 | 2.3051395 | 0.0211588 | 0.2962226 |
| V3 | 1.0244030 | 0.4639721 | 0.6426677 | 1 | 1.0314371 | 0.6042125 | 0.5457024 | 1.0000000 |
| V4 | 0.9622681 | -0.6767866 | 0.4985413 | 1 | 0.9800337 | -0.3458590 | 0.7294487 | 1.0000000 |
| V5 | 1.0441221 | 1.1979991 | 0.2309174 | 1 | 1.0353141 | 0.9654005 | 0.3343443 | 1.0000000 |
| V6 | 1.0008682 | 0.0221932 | 0.9822939 | 1 | 1.0025780 | 0.0904614 | 0.9279206 | 1.0000000 |
| V7 | 0.9645949 | -1.3434885 | 0.1791139 | 1 | 0.9769153 | -0.8673938 | 0.3857263 | 1.0000000 |
| V8 | 0.9740113 | -1.0067846 | 0.3140383 | 1 | 0.9742177 | -0.9916475 | 0.3213695 | 1.0000000 |
| V9 | 0.9784955 | -0.8048260 | 0.4209201 | 1 | 0.9819962 | -0.6720271 | 0.5015665 | 1.0000000 |
| V10 | 1.0126241 | 0.1624851 | 0.8709238 | 1 | 1.0023939 | 0.0535191 | 0.9573183 | 1.0000000 |
| V11 | 0.9541706 | -0.6728552 | 0.5010394 | 1 | 0.9950074 | -0.0557559 | 0.9555363 | 1.0000000 |
| V12 | 1.0421713 | 1.0261736 | 0.3048098 | 1 | 1.0151186 | 0.3826206 | 0.7020011 | 1.0000000 |
| V13 | 0.8270982 | -1.7376315 | 0.0822758 | 1 | 0.9918696 | -0.0471409 | 0.9624009 | 1.0000000 |
| V14 | 0.9615502 | -1.3792037 | 0.1678320 | 1 | 0.9771779 | -0.8110648 | 0.4173285 | 1.0000000 |
| V15 | 0.9824680 | -0.6776275 | 0.4980079 | 1 | 0.9821499 | -0.6802111 | 0.4963708 | 1.0000000 |
3.9.1 Exercise:
- Which items fit best? Which items fit worst?
- How many, if any items, are outside the traditional bounds of mean-square item fit [.75, 1.33]?
3.10 Optional - Visualizing Item Fit
If you’d like, we can use default WrightMap functionality to plot item fit statistics. In the fit object, itemfit is a dataframe containing various fit statistics. We’ll plot infit with a lowerbound of .75 (in mean-square error units) and an upper bound of 1.33
The nice thing is that you can create unique fitbounds for each item (such that it’s sensitive to sample size). However, if we want all the same fit values, we have to just repeat the fit value (in our case, there are 15 items).
infit <- fit$itemfit$Infit
upper_bound <- rep(x = 1.33, times =15) # this repeats 1.33 fifteen times
lower_bound <- rep(x = .75, times = 15)
# running fitgraph
fitgraph(fitEst = infit, fitLB = lower_bound, fitUB = upper_bound, itemLabels = names(hls))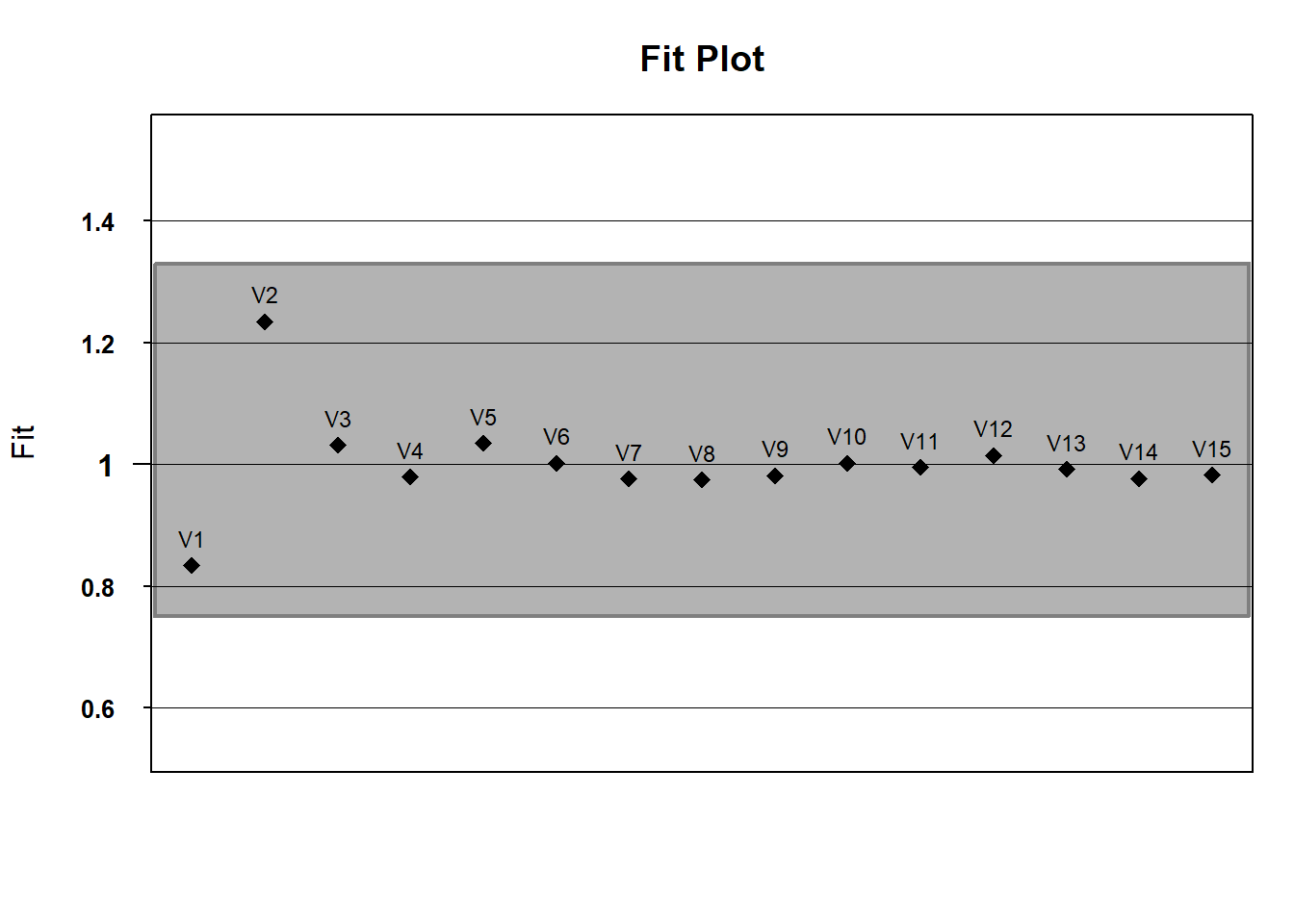
# what about outfit?
outfit <- fit$itemfit$Outfit
fitgraph(fitEst = outfit, fitLB = lower_bound, fitUB = upper_bound, itemLabels = names(hls))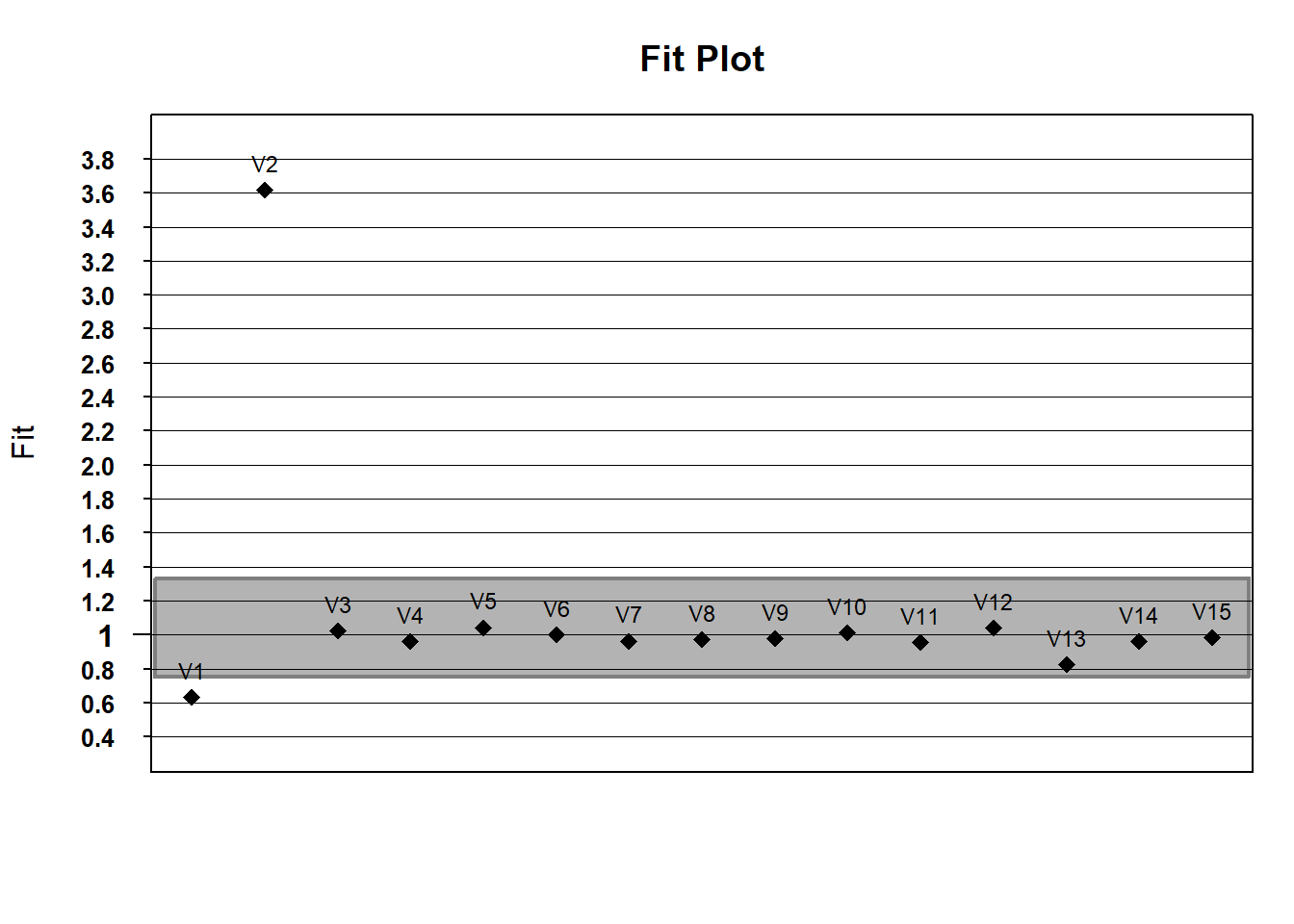 If you wanted to do this with ggplot - play with the code to try to change the fit limits or plot outfit instead of infit.
If you wanted to do this with ggplot - play with the code to try to change the fit limits or plot outfit instead of infit.
# put the fit data in a dataframe
fit_stats <- fit$itemfit
fit_stats %>%
ggplot(aes(x=parameter, y = infit)) +
geom_point() +
geom_hline(yintercept = 1.2) +
geom_hline(yintercept = .8) +
scale_y_continuous(breaks = scales::pretty_breaks(n = 15)) +
ggtitle("Item Fit Statistics for Lab 3 Data")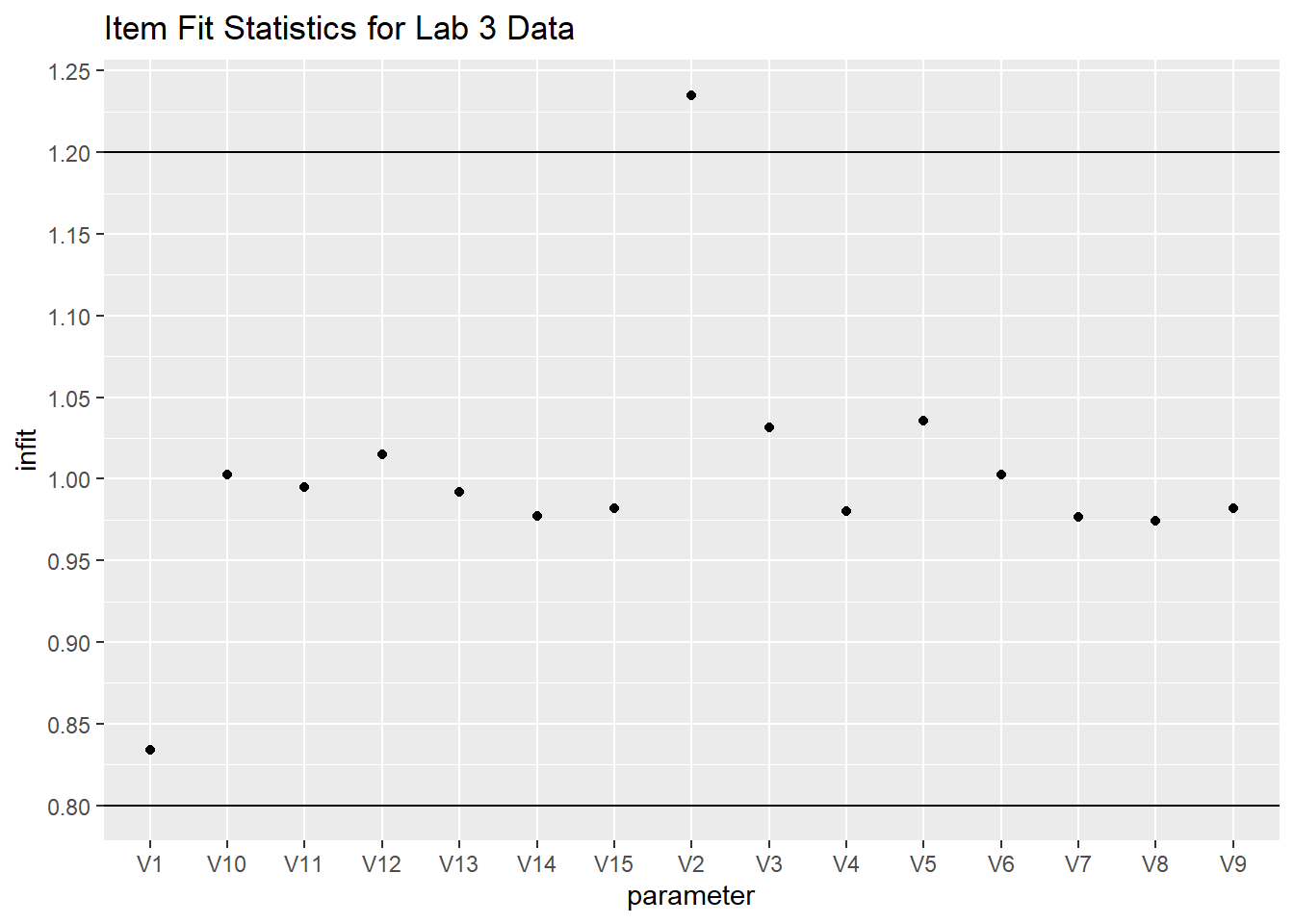
3.11 Optional Understanding the Rasch model
This chapter uses the model results from the previous chapter’s model runs. It’s seperated as it’s supplementary. TAM also provides some descriptive statistics.
item_prop <- mod1$itemitem_prop| item | N | M | xsi.item | AXsi_.Cat1 | B.Cat1.Dim1 | |
|---|---|---|---|---|---|---|
| V1 | V1 | 1000 | 0.182 | 1.7930554 | 1.7930554 | 1 |
| V2 | V2 | 1000 | 0.074 | 2.9361446 | 2.9361446 | 1 |
| V3 | V3 | 1000 | 0.175 | 1.8479678 | 1.8479678 | 1 |
| V4 | V4 | 1000 | 0.164 | 1.9375212 | 1.9375212 | 1 |
| V5 | V5 | 1000 | 0.280 | 1.1391729 | 1.1391729 | 1 |
| V6 | V6 | 1000 | 0.566 | -0.3249806 | -0.3249806 | 1 |
| V7 | V7 | 1000 | 0.440 | 0.2916454 | 0.2916454 | 1 |
| V8 | V8 | 1000 | 0.479 | 0.1004197 | 0.1004197 | 1 |
| V9 | V9 | 1000 | 0.435 | 0.3163527 | 0.3163527 | 1 |
| V10 | V10 | 1000 | 0.915 | -2.7690302 | -2.7690302 | 1 |
| V11 | V11 | 1000 | 0.123 | 2.3170294 | 2.3170294 | 1 |
| V12 | V12 | 1000 | 0.760 | -1.3863445 | -1.3863445 | 1 |
| V13 | V13 | 1000 | 0.936 | -3.1003226 | -3.1003226 | 1 |
| V14 | V14 | 1000 | 0.612 | -0.5554452 | -0.5554452 | 1 |
| V15 | V15 | 1000 | 0.541 | -0.2020052 | -0.2020052 | 1 |
Note, the total number of people who answered an item correctly is a sufficient statistic for calculating an item’s difficulty. Said another way, the number of correct answers, or, number of people who endorse a category increases monotonically with the item difficulty (of course, this does not mean you can just replace the Rasch model with a sum score since we’re using the Rasch model to test whether summing items at all is a reasonable thing to do).
To see this, we can find the total number of people who endorsed the “agree” category for each Hls item above. The table provides the proportion who endorsed the higher category in the M column. For instance, item Hls1 had 15.77% of people endorse the “agree” category (1= agree, 0= disagree). In the N column, we see that 317 people answered the item in total.
That means that \(317*.1577\) = 50 people answering the item correctly. Note, the estimated difficulty found in the column is 2.43 logits.
# Confirm that the total number of endorsements (coded 1) is 50 for Hls1: sum down the column containing all answers to Hls1 in the raw data.
apply(hls[1], 2, sum)## V1
## 182However, we see that for item Hls5, 27% of people endorsed that item and the estimated mean item difficulty in xsi.item is 1.50 logits.
The correlation between total number of endorsements per item and the estimated item difficulty can be computed as follows.
# create a column in the item_prop object that has the total number of endorsements for each item
item_prop <- mutate(item_prop, total_endorsed =N*M)
cor(item_prop$xsi.item, item_prop$total_endorsed)## [1] -0.994751We see that the correlation between item difficulties and total endorsements per item is nearly perfect -.97. As the number of endorsements go down, the estimated difficulty of the item increase.
ggplot(item_prop, aes(x=total_endorsed, y=xsi.item)) +
geom_point() +
ylab("Estimated Item Difficulties (logits)") +
xlab("Total Number of Endorsements for an item") +
ggtitle("Relationship between estimated item difficulty and total endorsements")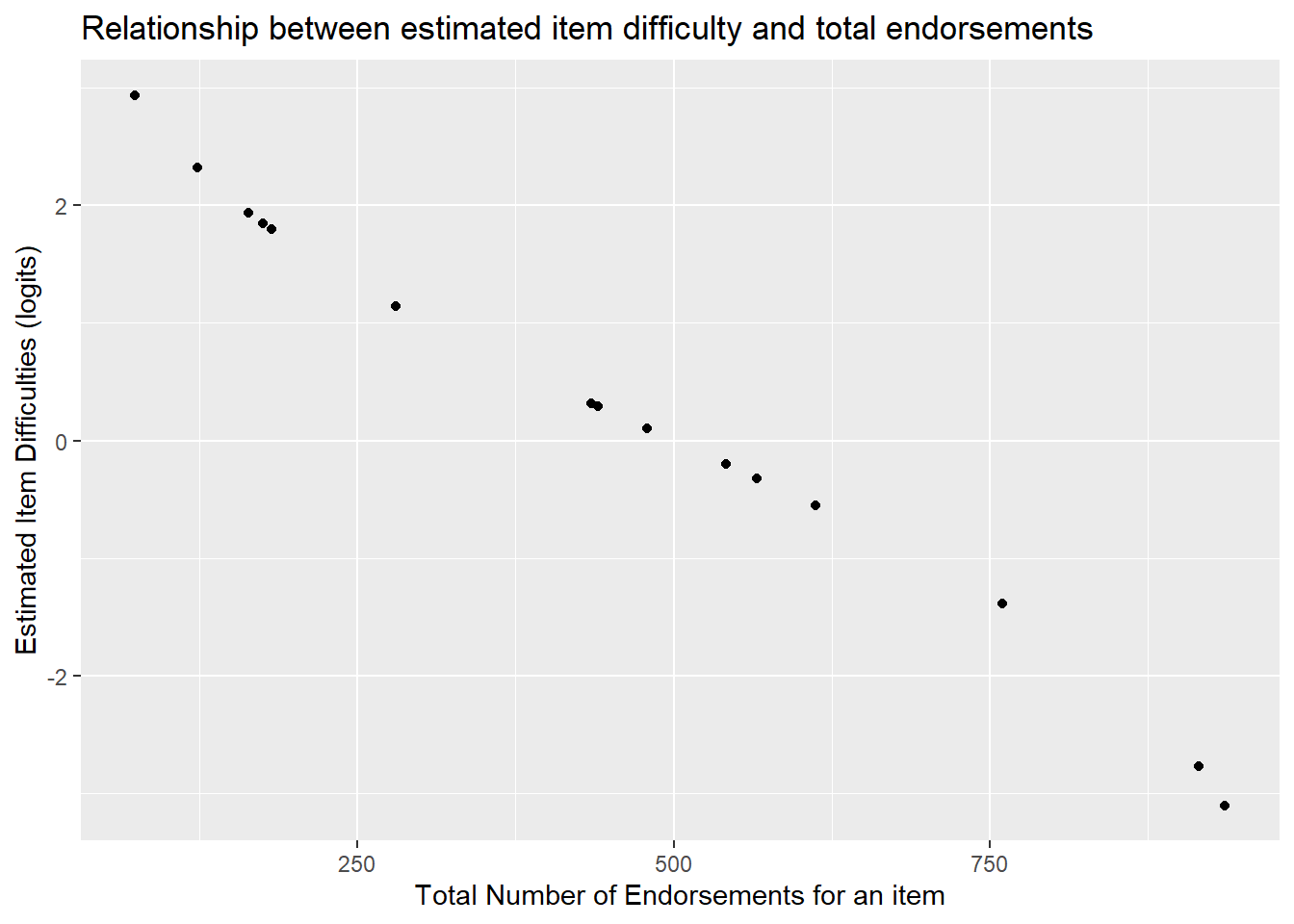
3.12 Person Abilities
Person abilities are also of interest. We can look at the person side of the model by computing person abilities.
Compute person abilities using the
tam.wlefunction and assign to an object calledabil.Extract person abilities (\(\theta_p\)) from
abilto create an object in theenvironmentcalledPersonAbilitywhich will essentially be a column vector.
Note: You may want more information than this at times (such as standard errors) so you may not always want to subset this way.
#generates a data frame - output related to estimation
abil <- tam.wle(mod1)## Iteration in WLE/MLE estimation 1 | Maximal change 1.2824
## Iteration in WLE/MLE estimation 2 | Maximal change 0.2808
## Iteration in WLE/MLE estimation 3 | Maximal change 0.01
## Iteration in WLE/MLE estimation 4 | Maximal change 0.0012
## Iteration in WLE/MLE estimation 5 | Maximal change 1e-04
## Iteration in WLE/MLE estimation 6 | Maximal change 0
## ----
## WLE Reliability= 0.666See the first few rows of Abil. Notice you get:
pid: person id assigned by TAM.N.items: Number of items the person was given (this becomes interesting when you have linked test forms where students may not all see the same number of items)PersonScores: Number of items the student got right or endorsed (in the survey case).PersonMax: Max total that person could have gotten right/selected an option fortheta: estimated person abilityerror: estimated measurement errorWLE.rel: estimated person seperation reliability.
head(Abil)
# or
View(Abil)| pid | N.items | PersonScores | PersonMax | theta | error | WLE.rel |
|---|---|---|---|---|---|---|
| 1 | 15 | 9 | 15 | 0.9846072 | 0.6445392 | 0.666301 |
| 2 | 15 | 8 | 15 | 0.5861029 | 0.6396378 | 0.666301 |
| 3 | 15 | 10 | 15 | 1.3941069 | 0.6580203 | 0.666301 |
| 4 | 15 | 5 | 15 | -0.6435504 | 0.6827321 | 0.666301 |
| 5 | 15 | 12 | 15 | 2.2922517 | 0.7261986 | 0.666301 |
| 6 | 15 | 6 | 15 | -0.2146746 | 0.6565507 | 0.666301 |
The column in the abil data.frame corresponding to person estimates is the theta column. Pull out the ability estimates, theta, column if you would like, though, this creates a list. This makes it a little easier for a few basic tasks below.
PersonAbility <- abil$theta# Only the first 6 rows, shown
head(PersonAbility)## [1] 0.9846072 0.5861029 1.3941069 -0.6435504 2.2922517
## [6] -0.2146746You can export those estimated abilites to a .csv to save (you can also save directly in R, if you need to). This writes abil as a csv file to your output directory that we created earlier using the here package.
write.csv(abil, here("output", "HLSmod1_thetas.csv")3.13 Quick descriptives for person ability - we’ll use WrightMap to bring this all together
hist(PersonAbility)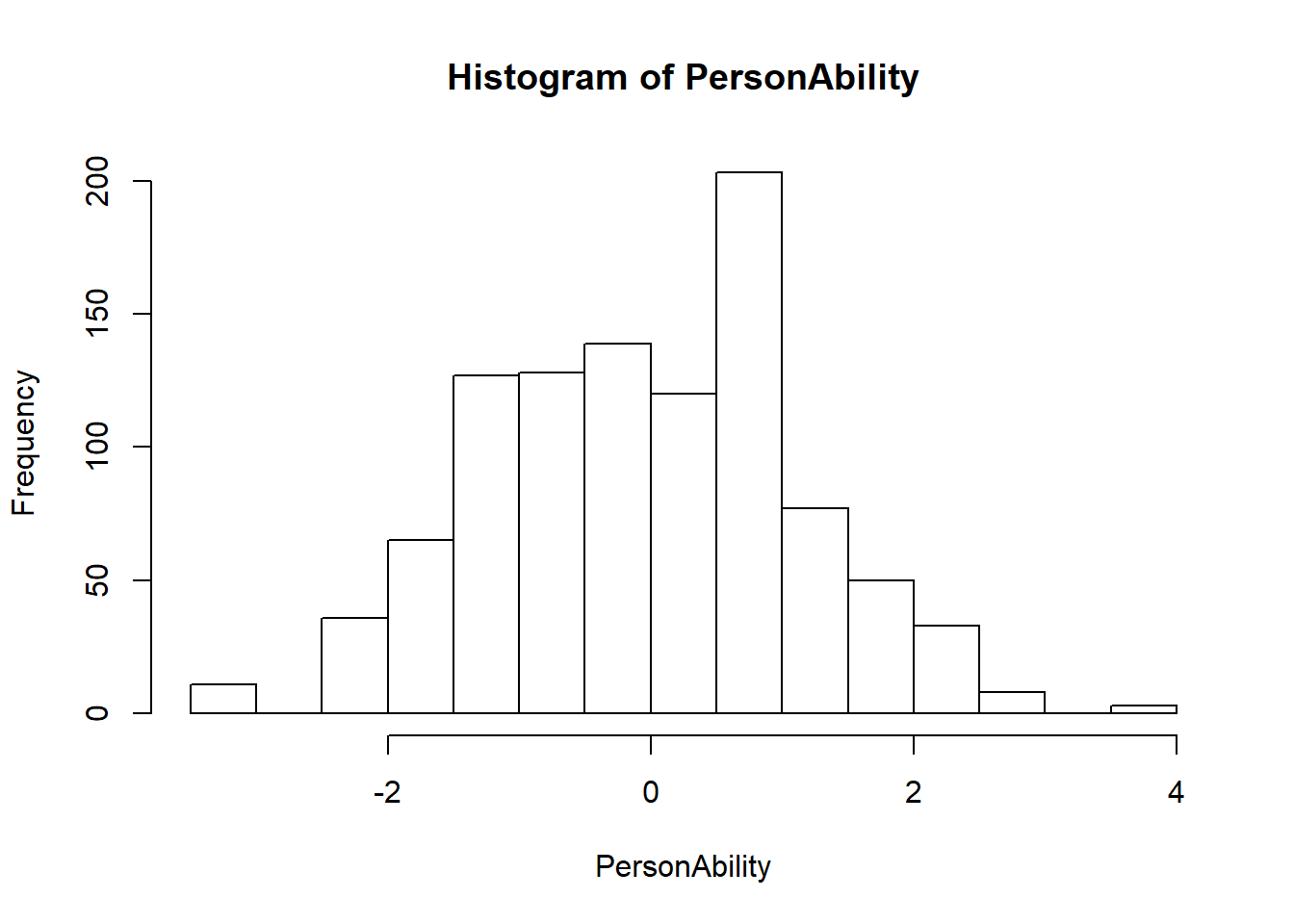
mean(PersonAbility)## [1] 0.001822466sd(PersonAbility)## [1] 1.2051163.14 Wright Map
To visualize the relationship between item difficulty and person ability distributions, call the WrightMap package installed previously. We’ll generate a simple WrightMap. We’ll clean it up a little bit by removing some elements
library(WrightMap)
IRT.WrightMap(mod1)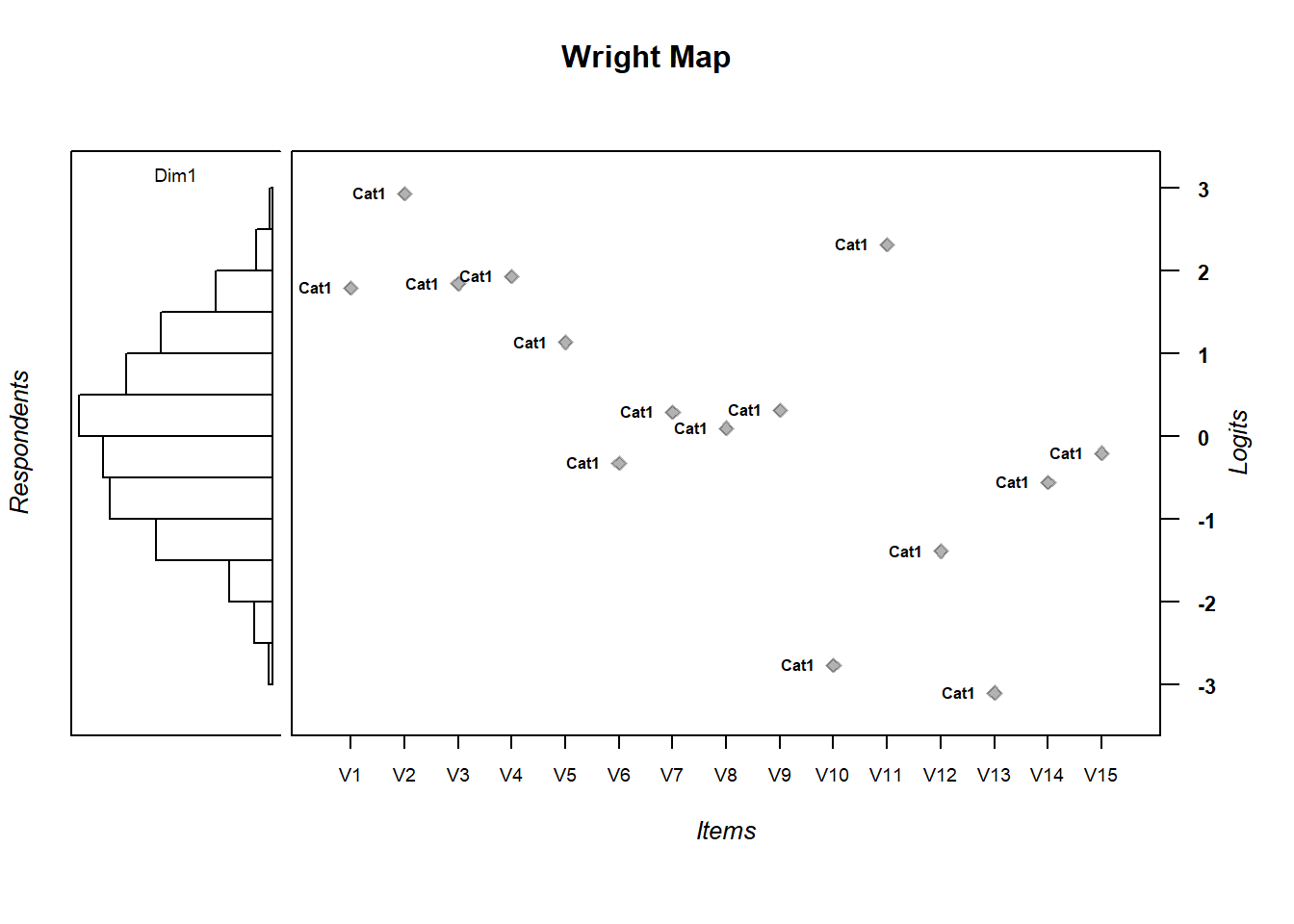
IRT.WrightMap(mod1, show.thr.lab=FALSE)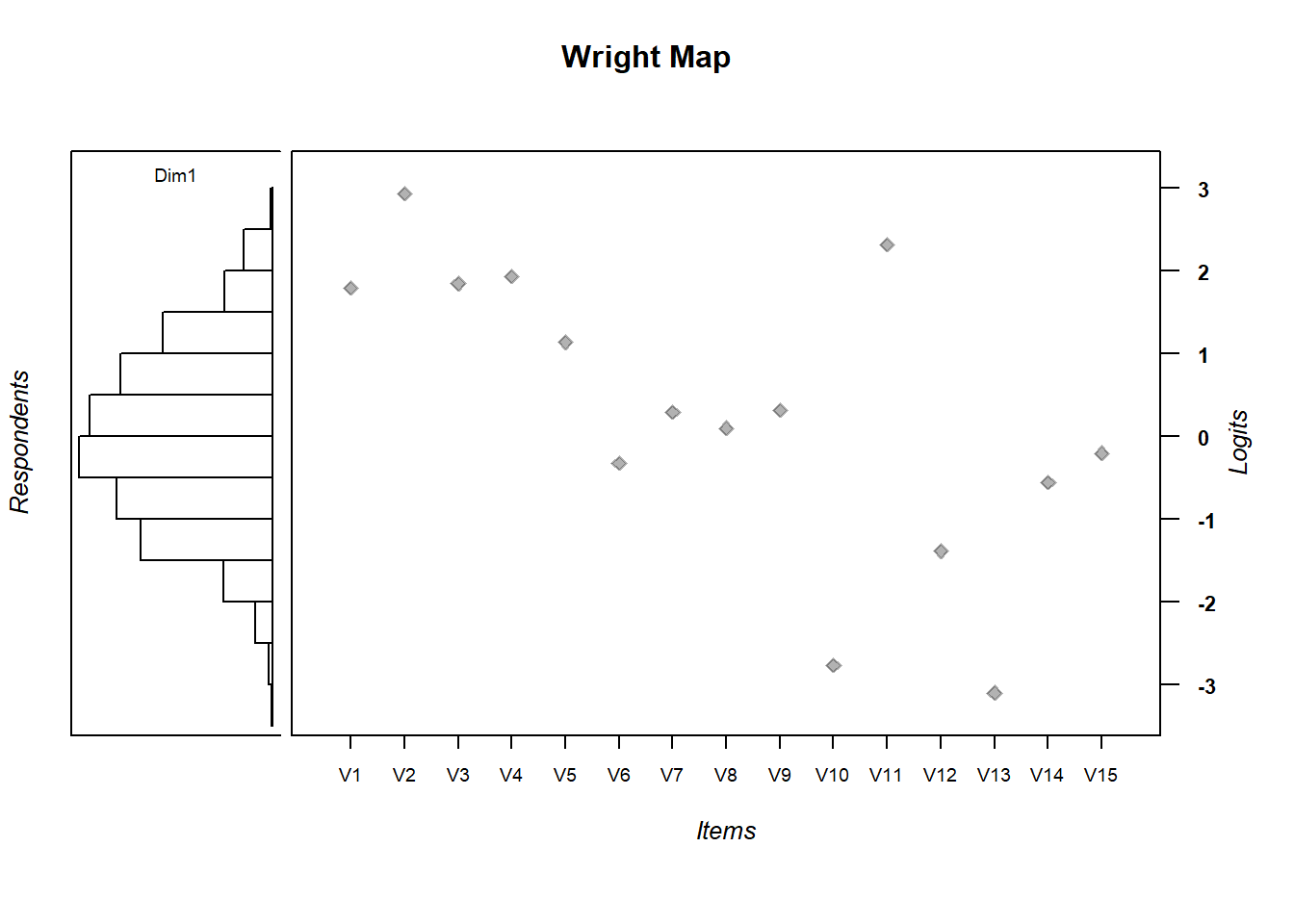
3.14.1 Exercise:
- Are the items appropriately targeted to the ability level of the population?
- Why do you think?