Capítulo 2 CLASE 2
2.1 Modelo Físico
Es la implementación del modelo lógico en MySQL.
2.2 Normalización de datos
La parte central de los principios del modelo relacional es el concepto de normalización, una técnica para producir un conjunto de relaciones que poseen un conjunto de ciertas propiedades que mi- nimizan los datos redundantes y preservan la integridad de los datos almacenados tal como se mantienen (añadidos, actualizados y eliminados). El proceso fue desarrollado por E. F. Codd en 1972, y el nombre es un chiste político debido a que el presidente Nixon estaba “normalizando” relaciones con China en ese momento. Codd imaginó que si las relaciones con un país pueden normalizarse, entonces seguramente podría normalizar las relaciones de la base de datos. La normalización se define por un conjunto de normas, que se conocen como formas normales, que proporcionan una directriz específica de cómo los datos son organizados para evitar anomalías que den lugar a inconsistencias y pérdida de los datos tal como se mantienen almacenados en la base de datos.
Cuando Codd presentó por primera vez la normalización, incluía tres formas normales.
Elección de un identificador único Un identificador único es un atributo o conjunto de atributos que únicamente identifican cada fila de datos en una relación. El identificador único eventualmente se convertirá en la clave principal de la tabla creada en la base de datos física desde la relación de normalización, pero muchos usan los términos identificador único y clave principal de manera intercambiable
2.2.1 Primera forma normal
La primera forma normal, que proporciona la fundación para la segunda y tercera forma normal, incluye las siguientes directrices:
Cada atributo de una tupla contiene sólo un valor.
Cada tupla en una relación contiene el mismo número de atributos.
Cada tupla es diferente, lo que significa que la combinación de los valores de todos los atributos de una tupla dada no puede ser como ninguna otra tupla en la misma relación.
Como se ve en la figura:
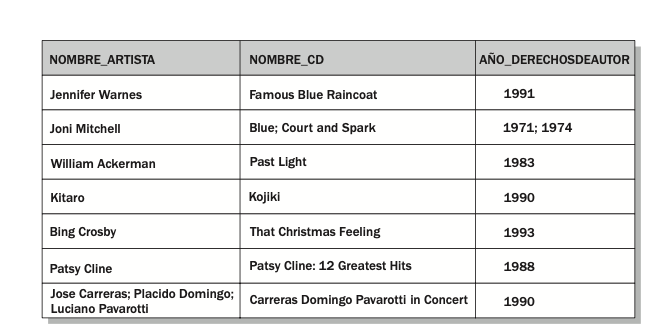
la segunda tupla y la última tupla violan la primera forma normal.Para normalizar la relación mostrada en la figura anterior, debe crear relaciones adicionales que separen los datos de modo que cada atributo contenga un solo valor como se muestra en la figura:
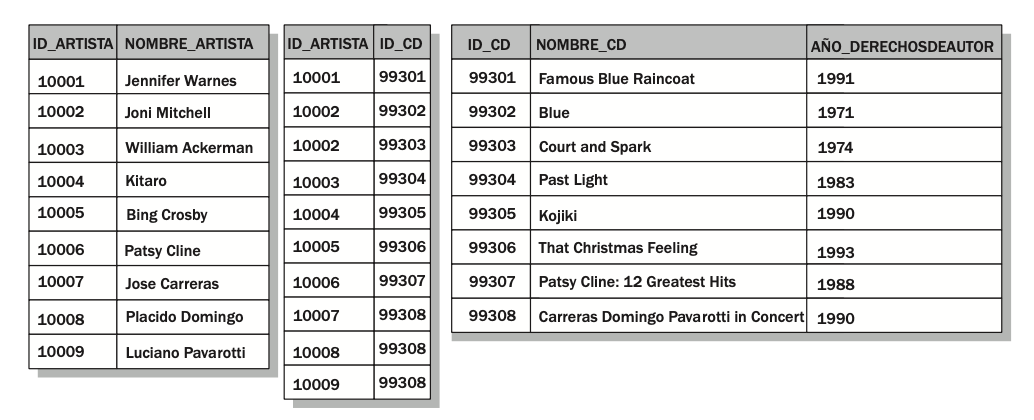
Ahora los datos se ajustan a la primera forma normal.
2.2.2 Segunda forma normal
Para comprender la segunda forma normal, primero debe entender el concepto de dependencia funcional. Para esta definición se usarán dos atributos arbitrarios, llamados A y B. El atributo B es funcionalmente dependiente (dependiente para abreviar) del atributo A si en cualquier momento no hay más que un valor del atributo B asociado con el valor dado al atributo A. Si se dice que el atributo B es funcionalmente dependiente del atributo A, también estaremos diciendo que el atributo A determina al atributo B, o que A es un factor determinante (identificador único) del atributo B.
En la figura:.
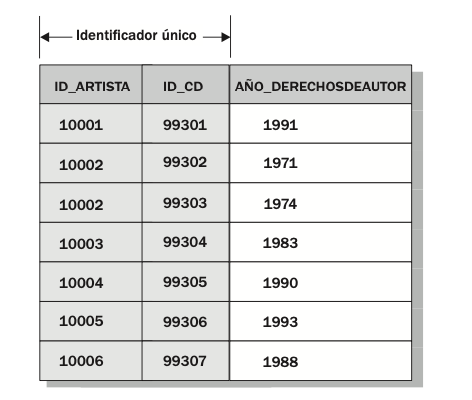
AÑO_DERECHOSDEAUTOR depende de ID_CD, ya que sólo puede haber un valor de AÑO_DERECHOSDEAUTOR para cualquier CD. Dicho de otra manera, ID_CD es un factor determinante de AÑO_DERECHOS- DEAUTOR
La segunda forma normal expone que una relación debe estar en la primera forma normal y que todos los atributos en la relación dependen del identificador único completo. En la figura 1-4, si la combinación de ID_ARTISTA y ID_CD es seleccionada como identificador único, enton- ces AÑO_DERECHOSDEAUTOR violaría la segunda forma normal porque sólo dependería de ID_CD en lugar de la combinación ID_CD y ID_ARTISTA. A pesar de que la relación se ajusta a la primera forma normal, se violaría la segunda forma normal. De nuevo, la solución sería separar los datos en relaciones diferentes, como se vio en la figura:
2.2.3 Tercera forma normal
La tercera forma normal, como la segunda forma normal, depende de la relación del identificador único. Para adherir a las directrices de la tercera forma normal, una relación debe estar en la segunda forma normal y sin un atributo clave (atributos que no sean parte de algún candidato clave) deben ser independiente el uno del otro y depender del identificador único. Por ejemplo, el identificador único en la relación mostrada en la figura siguiente es el atributo ID_ARTISTA
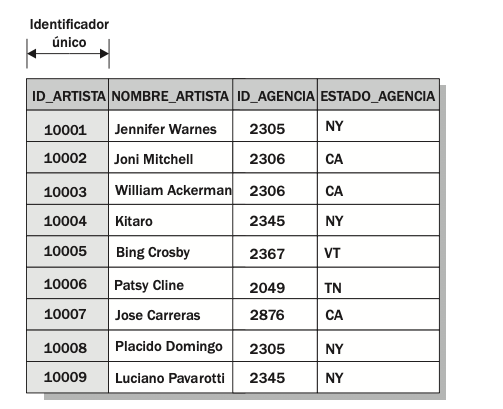 Los atributos NOMBRE_ARTISTA e ID_AGENCIA dependen del identificador único y son in- dependientes uno del otro. Sin embargo, el atributo ESTADO_AGENCIA depende del atributo ID_AGENCIA, y por lo tanto viola las condiciones de la tercera forma normal. Este atributo se adapta mejor en una relación que incluye datos sobre las agencias.
Los atributos NOMBRE_ARTISTA e ID_AGENCIA dependen del identificador único y son in- dependientes uno del otro. Sin embargo, el atributo ESTADO_AGENCIA depende del atributo ID_AGENCIA, y por lo tanto viola las condiciones de la tercera forma normal. Este atributo se adapta mejor en una relación que incluye datos sobre las agencias.
2.3 Relaciones
Hasta ahora el enfoque en este capítulo se ha centrado en la relación y la manera de normalizar los datos. Sin embargo, un componente importante de cualquier base de datos relacional es de qué forma esas relaciones se asocian entre sí. Esas asociaciones, o relaciones, se vinculan en forma significativa, lo que contribuye a garantizar la integridad de los datos de modo que una acción realizada en una relación no repercuta negativamente en los datos de otra relación.
Hay tres tipos principales de relaciones:
- Una a una Una relación entre dos relaciones en la cual una tupla en la primera relación esté relacionada con al menos una tupla en la segunda relación, y una tupla en la segunda relación esté relacionada con al menos una tupla en la primera relación.
- Una a varias Una relación entre dos relaciones en la cual una tupla en la primera relación esté relacionada con ninguna, una o más tuplas en la segunda relación, pero una tupla en la se- gunda relación esté relacionada con al menos una tupla en la primera relación.
- Varias a varias Una relación entre dos relaciones en la cual una tupla en la primera relación esté relacionada con ninguna, una o más tuplas en la segunda relación, y una tupla en la segun- da relación esté relacionada con ninguna, una o más tuplas en la primera relación.
Las bases de datos relacionales sólo apoyan una relación una a varias directamente. Una relación varias a varias se implementa físicamente agregando una tercera relación entre la primera y la segunda para crear dos relaciones una a varias. En la Figura:
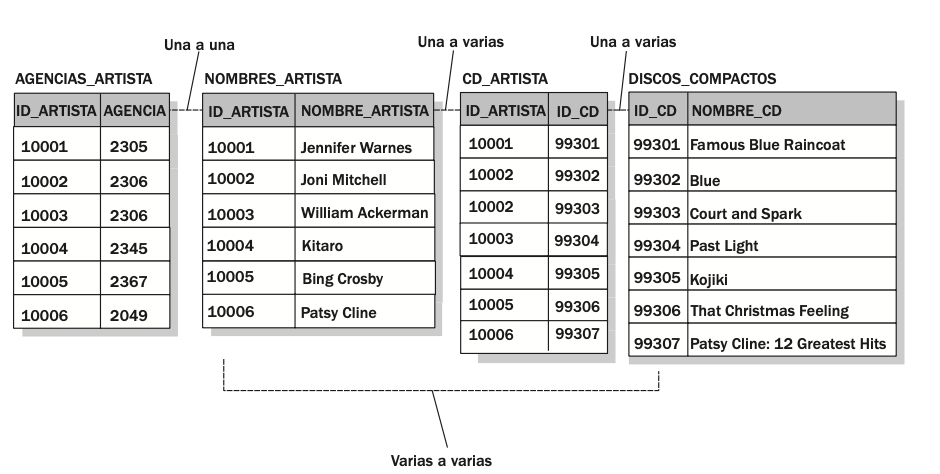
la relación CD_ARTISTA se agregó entre las relaciones NOMBRES_ARTISTA y DISCOS_COMPACTOS. Una relación una a una se aplica físicamente al igual que una relación una a varias, excepto que se añade una limitación para evitar duplicar los registros que coinciden en los “muchos” lados de la relación. En la figura 1-6 se añadió una limitación única en el atributo ID_ARTISTA para evitar que un artista aparezca en más de una agencia.
2.4 PASO A PASO: Normalización de datos e identificación de relaciones
- Revise la relación en la siguiente ilustración:
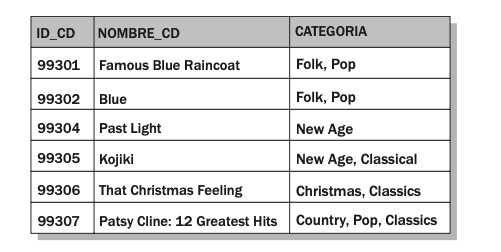
Identifique cualquier elemento que no se ajuste a las tres formas normales. Encontrará que el atributo CATEGORIA contiene más de un valor por tupla, que viola la primera forma normal.
Normalice los datos de acuerdo a las formas normales. Proyecte el modelo de datos que incluya las relaciones, atributos y tuplas apropiadas. Consejo: Su modelo incluirá tres tablas, una para la lista de CD, otra para la lista de las categorías de música (por ejemplo, Pop), y otra que asocie los CD con las apropiadas categorías de música.
En la ilustración que dibujó, identifique las relaciones ó propongalas. Recuerde que cada CD se puede asociar con una o más categorías, y cada categoría se puede asociar con cero, uno o más CD.