Capítulo 1 CLASE 1
1.1 ¿Que es una base de datos?
El término ha sido utilizado para referirse a cualquier cosa, desde una colección de nombres y direcciones hasta un complejo sistema de recuperación y almacenamiento de datos que se basa en interfaces de usuarios y una red de computadoras y servidores. Hay tantas definiciones para la palabra base de datos como libros sobre éstas.
Una base de datos es una colección de datos ordenados en un formato que puede ser fácilmente accesible.
Para gestionar las bases de datos, utilizamos una aplicación de software llamada SISTEMA DE GESTIÓN DE BASES DE DATOS o DBMS por sus siglas en inglés. Entonces, nos conectamos a DBMS y damos instrucciones para consultar o modificar datos. El DBMS ejecuta el intrsucciont y devuelve el resultado.
A lo largo de los años se ha implementado una serie de modelos de base de datos para almacenar y administrar la información. Varios de los modelos más comunes incluyen los siguientes:
1.1.1 Modelo No Relacional
Antes de la introducción del modelo relacional por parte de Ted Codd, existían bases de datos no relacionales, como bases de datos jerárquicas o similares a redes. Después del desarrollo de los sistemas de gestión de bases de datos relacionales, los modelos no relacionales todavía se utilizaban en aplicaciones técnicas o científicas. Por ejemplo, ejecutar sistemas CAD (diseño asistido por computadora) para componentes estructurales o de máquinas en tecnología relacional es bastante difícil. Dividir objetos técnicos en una multitud de tablas resultó problemático, ya que las manipulaciones geométricas, topológicas y gráficas tenían que ejecutarse en tiempo real.
El advenimiento de Internet y numerosas aplicaciones basadas en la web ha proporcionado un gran impulso a la relevancia de los conceptos de datos no relacionales frente a los relacionales, ya que administrar aplicaciones de Big Data con tecnología de bases de datos relacionales es difícil o imposible.
Si bien “no relacional” sería una mejor descripción que NoSQL, este último se ha establecido con los investigadores y proveedores de bases de datos en el mercado durante los últimos años.
NoSQL El término NoSQL ahora se utiliza para cualquier enfoque de gestión de datos no relacional que cumpla con dos criterios:
- Primero: los datos no se almacenan en tablas.
- En segundo lugar: el lenguaje de la base de datos no es SQL.
NoSQL también se interpreta a veces como “No solo SQL” para expresar que otras tecnologías además de la tecnología de datos relacionales se utilizan en aplicaciones web distribuidas masivamente. Las tecnologías NoSQL son especialmente necesarias si el servicio web requiere alta disponibilidad. Al final del cruso veremos “No solo SQL.”
1.1.2 Modelo Relacional
Si alguna vez tiene la oportunidad de ver un libro acerca de base de datos relacionales, es muy posible que vea el nombre de E. F. (Ted) Codd, a quien se hace referencia en el contexto del modelo relacional. En 1970, Codd publicó su trabajo más importante A Relational Model Of Data For Large Shared Data Banks (Un modelo relacional de datos para grandes bancos de datos compartidos), en el diario Communications of the ACM, volumen 13, número 6 (junio de 1970). Codd define una estructura de datos relacional que protege los datos y permite que sean manipulados de manera que es previsible y resistente al error. El modelo relacional, el cual se basa principalmente en los principios matemáticos de la teoría de conjuntos y lógica de predicados, apoya la recuperación de datos sencilla, aplica la integración de datos (la precisión y coherencia de los datos), y proporciona una estructura de base de datos independiente de las aplicaciones al acceder a los datos almacenados.
Para trabajar sobre modelo relacionales se trabaja con el lenguaje SQL. El lenguaje estructurado de consultas (SQL, Structured Query Language) apoya la creación y mantenimiento de la base de datos relacional y la gestión de los datos dentro de la base de datos.
SELECT *
FROM products
WHERE category= ‘food’
ORDER BY price
Algunos RDBMS:
Los datos se almacenan en una relación en tuplas (filas). Una tupla es un conjunto de datos cuyos valores hacen una instancia de cada atributo definido por esa relación. Cada tupla representa un registro de datos relacionados. (De hecho, el conjunto de datos se conoce en ocasiones como registro.) Por ejemplo, en la figura:
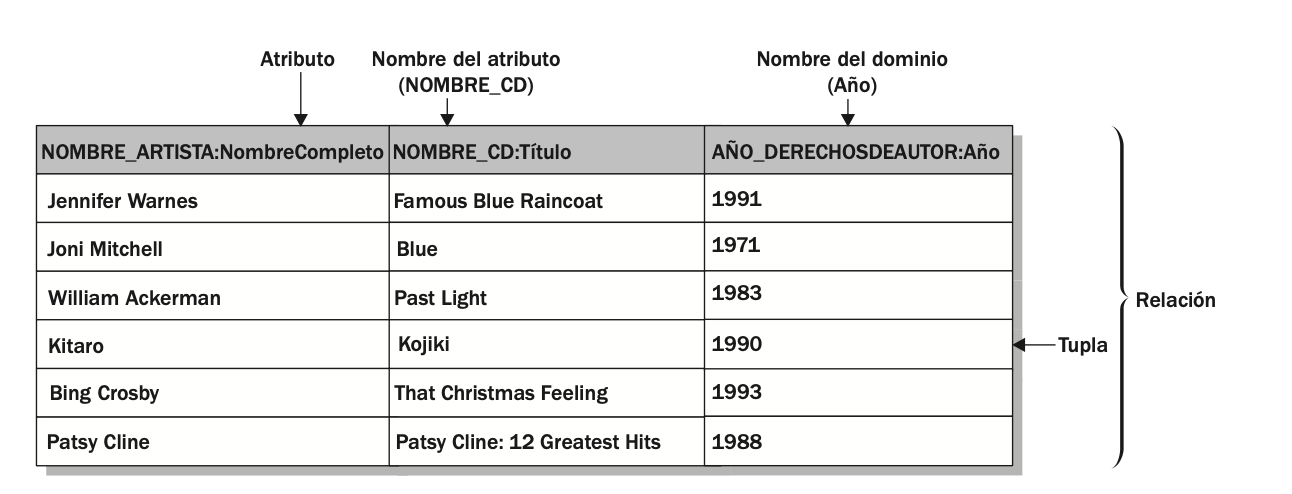
la segunda tupla de arriba hacia abajo contiene el valor “Joni Mitchell” para el atributo NOMBRE_ARTISTA, el valor “Blue” para el atributo NOMBRE_CD y el valor “1971” para el atributo AÑO_DERECHOSDEAUTOR. Estos tres valores juntos forman una tupla.
1.2 Diseño Bases de datos
El proceso de creación de un modelo para los datos que desea almacenar en una base de datos, consta de 4 pasos:
- Comprender y analizar los requisitos comerciales.
- Crear un modelo conceptual del negocio.
- Construir modelo lógico.
- Construir modelo físico.
1.2.1 Modelo conceptual
Primero necesitamos crear un modelo conceptual que represente la entidades o conceptos de un negocio y su relación relaciones entre sí.
Necesitamos una forma de ver visualmente estas entidades y sus relaciones. Existen dos formas de hacer esto: podemos usar la relación de entidad o Diagramas UML. Ambas son formas de expresar conceptos visualmente. Los diagramas de relación entre entidades se utilizan a menudo para el modelado de datos, UML es la abreviatura de lenguajes de modelado unificados.
Podemos utilizar herramientas en línea como ‘draw.io’ y construimos el modelo conceptual de un curso.
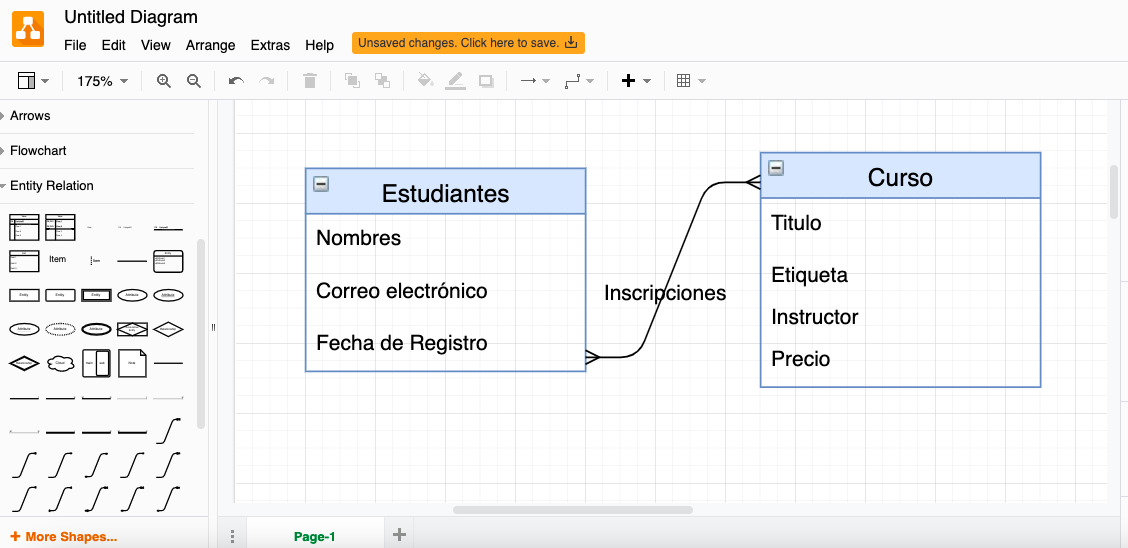 El modelo conceptual nos brinda una visión general de muy alto nivel del dominio empresarial
y las entidades involucradas en el dominio. En este punto no
Necesitamos muchos detalles sobre el tipo de cada atributo, tampoco nos importa
qué sistema de gestión de bases de datos vamos a utilizar para implementar este modelo.
A continuación, usaremos este modelo conceptual para construir un modelo lógico.
El modelo conceptual nos brinda una visión general de muy alto nivel del dominio empresarial
y las entidades involucradas en el dominio. En este punto no
Necesitamos muchos detalles sobre el tipo de cada atributo, tampoco nos importa
qué sistema de gestión de bases de datos vamos a utilizar para implementar este modelo.
A continuación, usaremos este modelo conceptual para construir un modelo lógico.
1.2.2 Modelo lógico
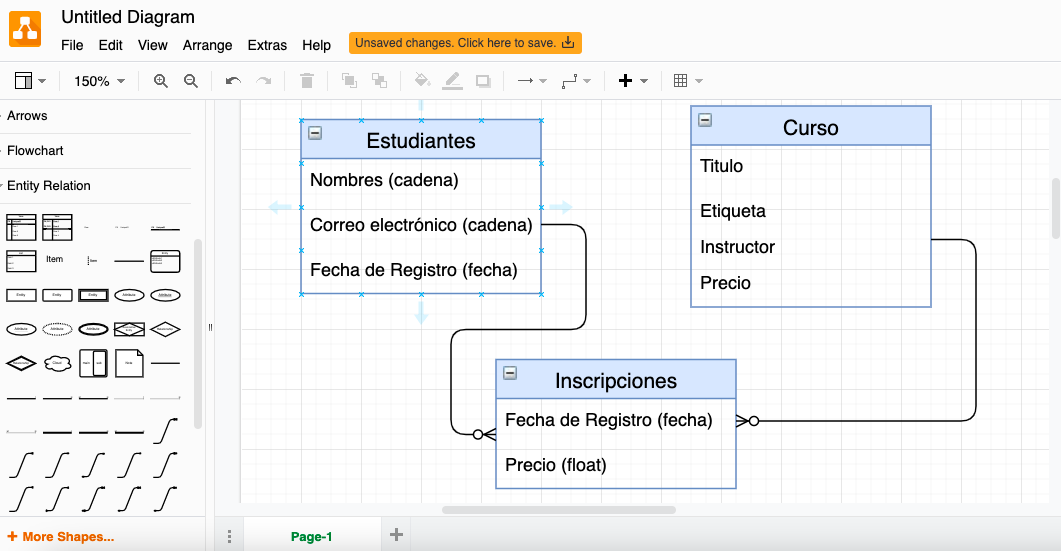
Ahora vamos a refinar el modelo conceptual para crear un modelo de datos o una estructura de datos para almacenar nuestros datos. Este modelo lógico es independiente de las tecnologías de bases de datos, por eso lo llamamos modelo lógico de datos. Es solo un modelo de datos abstracto que muestra claramente las relaciones de nuestras entidades. El modelo físico es la implementación de un modelo lógico para una tecnología de base de datos específica. Esto será mostrado en el capítulo 1.3.
1.3 Aprenda acerca de SQL
Ahora que tiene un conocimiento fundamental del modelo relacional, es el momento para introducirlo a SQL y sus características básicas. Como recordará de la sección “Entienda las bases de datos relacionales” vista anteriormente en este capítulo, SQL se basa en el modelo relacional, aunque no se trate de una aplicación exacta. Mientras el modelo relacional proporciona las bases teóricas de la base de datos relacional, es el lenguaje SQL el que apoya la aplicación física de esa base de datos.
SQL, el lenguaje relacional casi universalmente aplicado, es diferente de otros lenguajes computacionales como C, COBOL y Java, los cuales son de procedimiento. Un lenguaje de pro- cedimiento define cómo las operaciones de una aplicación deben realizarse y el orden en el cual se realizan. Un lenguaje de no procedimiento, por otro lado, se refiere a los resultados de una operación; el entorno fundamental del software determina cómo se procesan las operaciones. Esto no quiere decir que SQL respalda a la funcionalidad de no procedimiento. Por ejemplo, los proce- dimientos almacenados, agregados a varios productos RDBMS hace algunos años, son parte del estándar SQL:2006 y proporciona capacidades parecidas a procedimiento.Muchos de los proveedores de RDBMS añadieron extensiones a SQL para proporcionar esas capacidades de procedimiento, como Transact-SQL encontrado en Sybase y Microsoft SQL Server y PL/SQL encontrado en Oracle.
A menudo SQL se considera como un sublenguaje de datos porque se utiliza con frecuencia en asociación con la aplicación de lenguajes de progra- mación como C y Java, lenguajes que no fueron diseñados para la manipulación de datos alma- cenados en una base de datos.
1.3.1 La evolución de SQL
A principios de la década de 1970, después que se publicó el artículo de E. F. Codd, IBM comenzó a desarrollar un lenguaje y un sistema de base de datos que podría usarse para la aplicación de ese modelo. Cuando se definió por primera vez, el lenguaje fue denominado Lenguaje de consulta estructurado (en inglés, SEQUEL, Structured English Query Language). Cuando se descubrió que SEQUEL era propiedad de una marca comercial de Hawker-Siddeley Aircraft Company en el Rei- no Unido, el nombre se cambió a SQL. Cuando se pasó la voz de que IBM estaba desarrollando un sistema de base de datos relacional basado en SQL, otras compañías comenzaron a desarrollar sus propios productos basados en SQL. De hecho, Relational Software, Inc., ahora Oracle Corpo- ration, lanzó el sistema de base de datos antes de que IBM lanzara el suyo al mercado. Conforme más proveedores lanzaron sus productos, SQL comenzó a surgir como el lenguaje estándar de base de datos relacional.
En 1986, el American National Standards Institute (ANSI) dio a conocer el primer estándar publicado para el lenguaje (SQL-86), el cual fue adoptado por la International Organization for Standardization (ISO) en 1987. El estándar se actualizó en 1989, 1992, 2003, 2006, y el trabajo con- tinúa. Ha crecido con el tiempo (el estándar original estaba muy por debajo de 1 000 páginas, mien- tras que la versión de SQL:2006 tiene más de 3 700 páginas). El estándar se escribió en partes para permitir la publicación programada de revisiones y facilitar el trabajo paralelo por diferentes comités.
Con la llegada de la programación orientada a objetos (junto con los avances tecnológicos en el hardware y software y la creciente complejidad de aplicaciones) se hizo cada vez más evidente que un lenguaje puramente relacional era insuficiente para satisfacer las demandas del mundo real. De preocupación específica fue el hecho que SQL no podía respaldar tipos de datos complejos y definidos por el usuario ni la extensibilidad requerida para aplicaciones más complejas.
Impulsados por la competencia natural de la industria, los proveedores RDBMS se encargaron de aumentar sus productos e incorporar la funcionalidad orientada a objetos en sus sistemas. El estándar SQL:2006 sigue el ejemplo y extiende el modelo relacional con capacidades orientadas a objetos, como métodos, encapsulación, y tipos de datos complejos y definidos por el usuario, lo que hace a SQL un lenguaje de base de datos relacional a objeto. (SQL/XML) se amplió considerablemente y se reeditó con SQL:2006, y todas las de- más partes se tomaron de SQL:2003.
1.4 Tipos de instrucciones de SQL
Aunque SQL se considera un sublenguaje debido a su naturaleza de no procesamiento, aun así es un lenguaje completo que le permite crear y mantener objetos en una base de datos, asegurar esos objetos y manipular la información dentro de los objetos. Un método común usado para categorizar las instrucciones SQL es dividirlas de acuerdo con las funciones que realizan. Basado en este método, SQL se separa en tres tipos de instrucciones:
Lenguaje de definición de datos (DDL, Data Definition Language) Las instrucciones DDL se usan para crear, modificar o borrar objetos en una base de datos como tablas, vistas, esquemas, dominios, activadores, y almacenar procedimientos. Las palabras clave en SQL más frecuentemente asociadas con las instrucciones DDL son CREATE, ALTER y DROP. Por ejemplo, se usa la instrucción CREATE TABLE para crear una tabla, la instrucción ALTER TABLE para modificar las características de una tabla, y la instrucción DROP TABLE para borrar la definición de la tabla de la base de datos.
SQL incrustado: En este método, las instrucciones SQL están codificadas (incrustadas) directamente en el lenguaje de programación anfitrión. Por ejemplo, las instrucciones SQL se pueden incrustar en el código C de la aplicación. Antes que el código se compile, un pre- procesador analiza las instrucciones SQL y las desglosa desde el código C. El código SQL se convierte en una forma que RDBMS puede entender, y el código C restante se compila como lo haría normalmente.
Unión de módulo: Este método permite crear bloques de instrucciones SQL (módulos) que están separados del lenguaje de programación anfitrión. Una vez que el módulo es creado, es una combinación entre una aplicación y un vinculador. Un módulo contiene, entre otras cosas, procedimientos, y son los procedimientos los que contienen las instrucciones SQL reales.
Interfaz convocatoria a nivel (CLI, Call-level interface) Una CLI permite invocar instrucciones SQL a través de una interfaz mediante la aprobación de instrucciones SQL como valores argumentativos para las subrutinas. Las instrucciones no están precompiladas como en el SQL incrustado y la Unión de módulo. En lugar de eso, son ejecutadas directamente por los RDBMS.
1.5 PASO A PASO: Instalación de MYSQL
Instale MYSQL en su equipo.
Abra el cliente GUI (interfaz gráfica de usuario) que le permita invocar directamente las instrucciones SQL. Cuando abra el GUI, es posible que se le pida un nombre de usuario y contraseña. Cuándo y si se le pide puede variar dependiendo del producto que utiliza, si se conecta a través de la red, si el RDBMS se configura como un sistema autónomo, y otras variables específicas del producto. Además, un producto como SQL Server ofrece seguridad integrada con el sistema operativo, por lo que es posible que sólo se le pida un nombre de servidor.
Ejecute la instrucción SELECT en la aplicación de entrada de la ventana. Me doy cuenta que aún no se cubren las instrucciones SELECT, pero la sintaxis básica es relativamente fácil:
SELECT * FROM
El marcador de posición
El propósito de este ejercicio es simplemente comprobar que tiene conectividad con los datos almacenados en el RDBMS. La mayoría de los productos incluyen información de muestra, y esa información es con la que intentará conectarse. Compruebe la documentación del producto o consulte con el administrador de bases de datos para verificar si existe una base de datos que pueda acceder.
Escriba la instrucción SQL y oprima ENTER. Una vez que ejecute la instrucción, los resultados de la consulta aparecerán en la ventana de sa- lida. En este momento, no se preocupe por el significado de cada palabra en la instrucción SQL o con los resultados de la consulta. Su única preocupación es asegurarse que todo funcione. Si no puede ejecutar la instrucción, consulte con el administrador de bases de datos o la documentación del producto.
Cierre la aplicación GUI sin guardar la consulta.
1.6 Entorno SQL
El entorno SQL es, simplemente, la suma de todas las partes que conforman ese SQL. Cada parte, o componente, trabaja en conjunto con otros componentes para respaldar las operaciones de SQL tales como la creación y modificación de objetos, almacenamiento y consulta de información, o modificación y eliminación de datos. En conjunto, estos componentes forman un modelo en el que un RDBMS puede basarse. Esto no significa, sin embargo, que los proveedores de RDBMS se adhieren estrictamente a este modelo; cuáles componentes implementan, y cómo lo hacen se deja, en su mayor parte, a la discreción de esos proveedores.
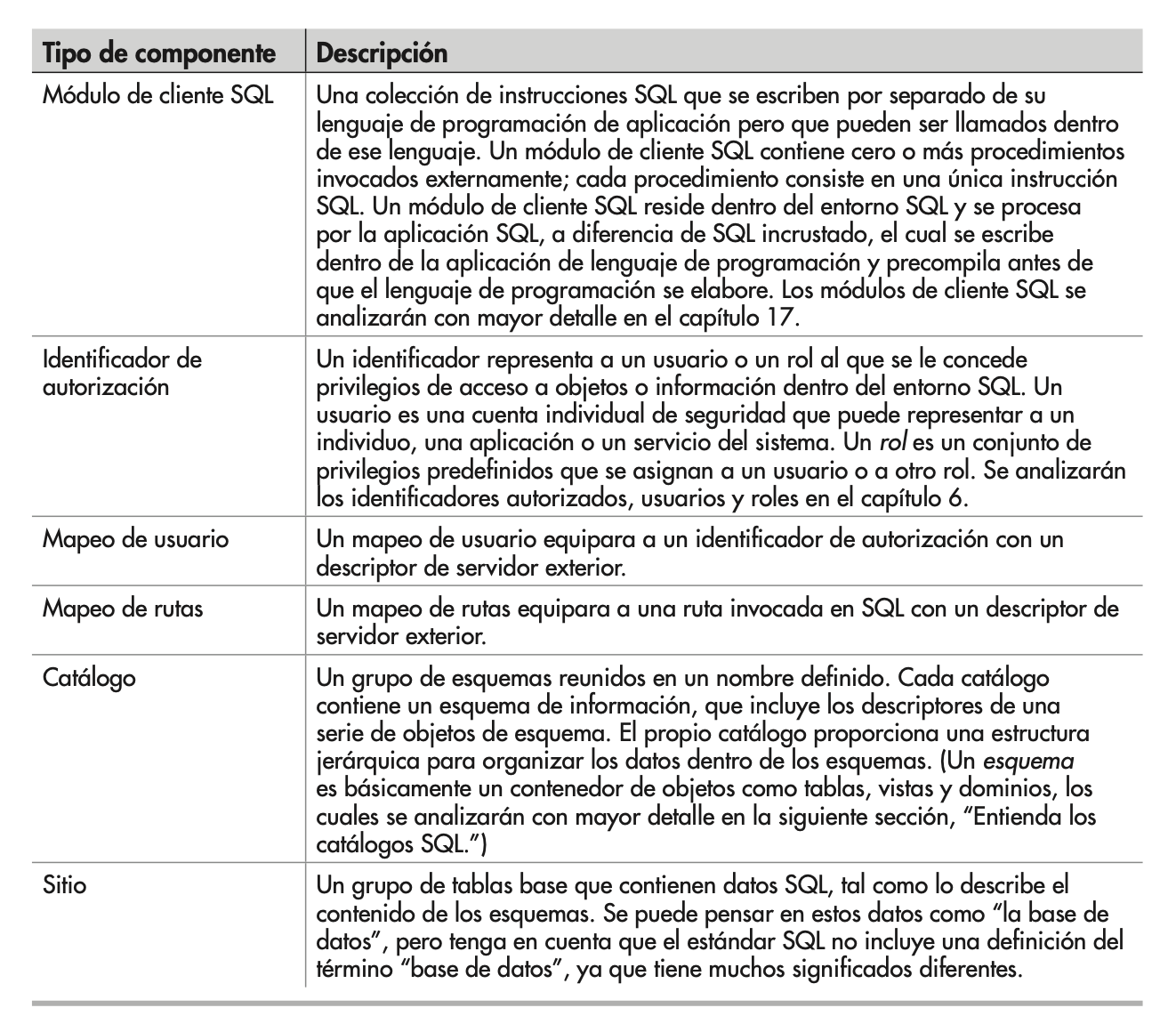
El entorno SQL se compone de seis tipos de componentes, como se muestra en la Figura:
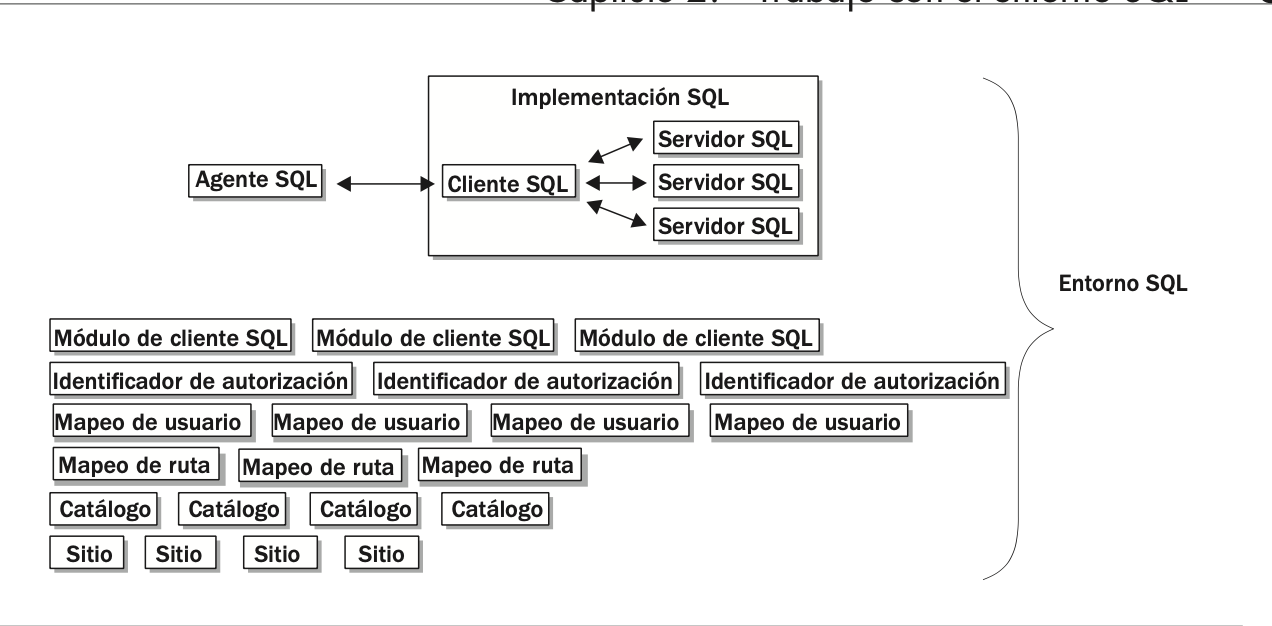
Los clientes SQL y los servidores SQL son parte de la aplicación de SQL y son, por lo tanto, subtipos de ese componente.
Cada tipo de componente realiza una función específica dentro del entorno SQL.

1.6.1 Catálogos SQL
Un catálogo es como una estructura jerárquica con el catálogo como el objeto primario y los esquemas como los objetos secundarios:
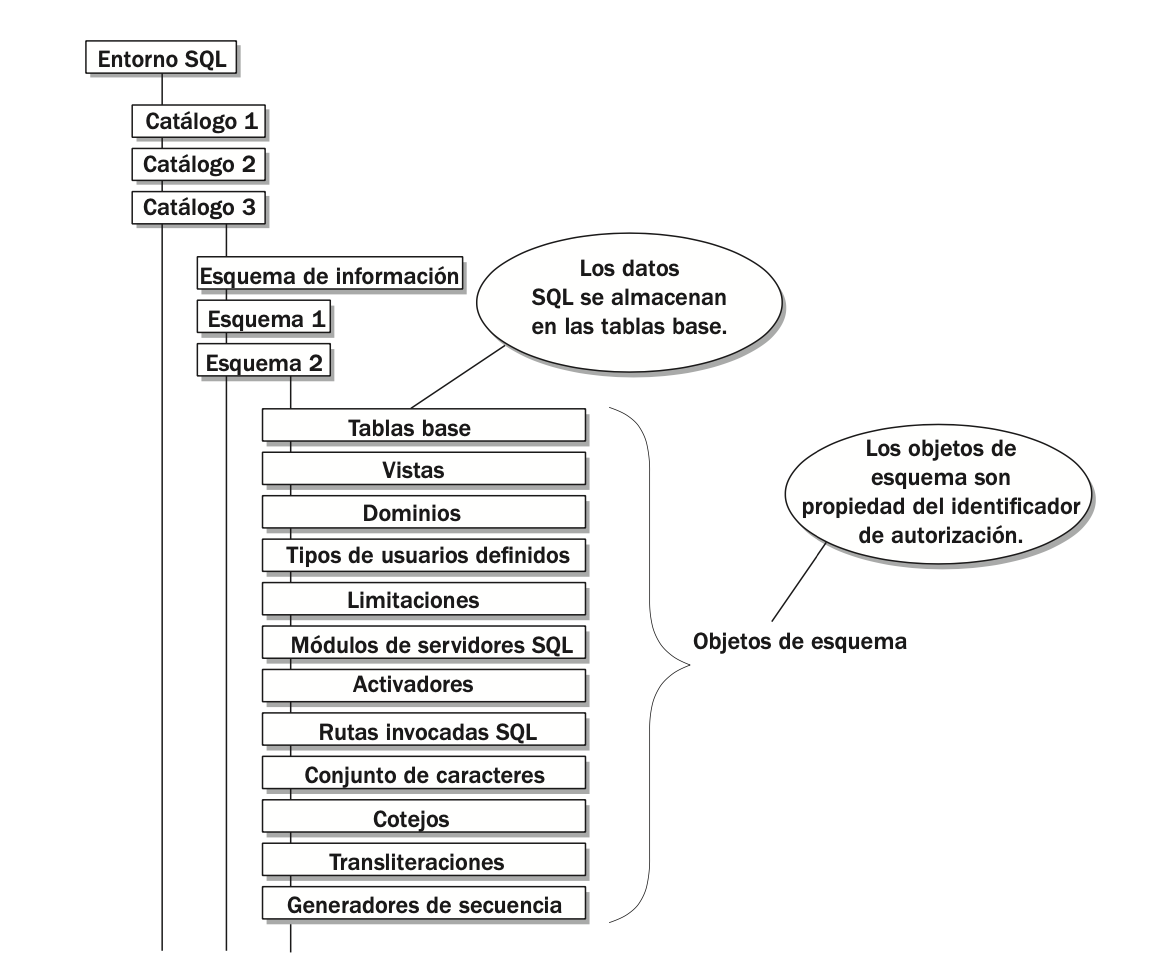
Puede comparar las relaciones entre los objetos en un catálogo a las relaciones entre los archivos y directorios en el sistema operativo de su equipo. El catálogo se representa por un directorio raíz; los esquemas, por subdirectorios, y los objetos de esquema, por archivos dentro de subdirectorios.
1.6.2 ESQUEMAS
Cada catálogo contiene uno o más esquemas. Un esquema es un conjunto de objetos relacionados que se reúnen bajo un nombre común. El esquema actúa como un contenedor de esos objetos, los que a su vez almacenan los datos SQL o realizan otras funciones con datos relacionados. Cada esquema, los objetos contenidos en el esquema y los datos SQL dentro de esos objetos son propiedad del identificador de autorización asociado con ese esquema.
Cada catálogo contiene un esquema especial llamado INFORMATION_SCHEMA. Este esquema contiene las definiciones de una serie de objetos de esquema, la mayoría de vista. Una vista es una tabla virtual que permite observar los datos reunidos de tablas reales. Mediante el uso de esas vis- tas, puede mostrar las definiciones de los objetos en ese catálogo como si se tratara de datos SQL.
1.6.3 Nombrado de objetos en un entorno SQL
Un identificador es un nombre dado a un objeto de SQL. El nombre puede ser de hasta (pero no incluir) 128 caracteres, y debe seguir los convenios definidos. Un identificador se puede asignar a cualquier objeto que se crea con instrucciones SQL, tales como dominios, tablas, columnas, vistas o esquemas. El estándar SQL:2006 define dos tipos de identificadores: identificadores regulares e identificadores delimitados.
Los identificadores regulares son bastante restrictivos y deben seguir convenios específicos:
Los nombres no se distinguen entre mayúsculas y minúsculas. Por ejemplo, Nombres_Artista es lo mismo que NOMBRES_ARTISTA y nombres_artista.
Sólo se permiten letras, dígitos y guiones. Por ejemplo, se pueden crear identificadores tales como Primer_Nombre, 1erNombre o PRIMER_NOMBRE. Observe que el guión bajo es el único carácter válido que se usa como separador entre palabras. Los espacios no son acepta- bles ni tampoco guiones (los guiones se interpretan como operaciones de sustracción).
No se puede utilizar palabras clave reservadas en SQL.
SQL no distingue mayúsculas y minúsculas, por lo que respecta a los identificadores regulares. Todos los nombres se cambian a mayúsculas cuando se almacenan en SQL, que es la razón por la que 1erNombre y 1ERNOMBRE se leen como valores idénticos.
Los identificadores delimitados no son tan restrictivos como los identificadores regulares, pero aún deben seguir convenios específicos:
El identificador debe estar incluido en un conjunto de comillas dobles, como el identificador “NombresArtista.”
Las comillas no se almacenan en la base de datos, pero todos los demás caracteres se almace- nan como aparecen en la instrucción SQL.
-Los nombres son sensibles a mayúsculas y minúsculas. Por ejemplo, “Nombres_Artista” no es lo mismo que “nombres_artista” o “NOMBRES_ARTISTA,” pero “NOMBRES_ARTISTA” es lo mismo que NOMBRES_ARTISTA y Nombres_Artista (porque los identificadores regu- lares se cambian a mayúsculas).
La mayoría de los caracteres están permitidos, incluyendo espacios.
Se pueden utilizar palabras clave reservadas a SQL.
1.7 Creación de un esquema
Se empezará con la instrucción CREATE SCHEMA, ya que los esquemas están en la parte superior de la jerarquía de SQL, en términos de los objetos que el estándar le permite crear.
CREATE SCHEMA < nombre de la cláusula >
[ < conjunto de caracteres o ruta > ]
[ < elementos del esquema > ]
Los corchetes angulados contienen información que sirve como un marcador de posición para un valor o una cláusula en relación con esa información. Por ejemplo, < nombre de la cláusula > es el marcador de posición para palabras clave y valores relacionados con el nombramiento del esquema. Por otro lado, las llaves significan que la cláusula es opcional. No es necesario especificar un conjunto de caracteres, ruta o el elemento del esquema.
Echemos un vistazo a la sintaxis de la instrucción CREATE SCHEMA pieza por pieza. Las palabras clave CREATE SCHEMA activan la aplicación de SQL con el tipo de instrucción que se ejecuta. Esto continúa con el marcador de posición
< nombre del esquema >
AUTHORIZATION < identificador de autorizació >
< nombre del esquema > AUTHORIZATION < identificador de autorización >
El valor < identificador de autorización > especifica quién es el propietario del esquema y sus objetos. Si ninguno se especifica, el valor predetermina el del usuario actual. Si no se especifica el valor < nombre del esquema >, se crea un nombre que se base en el identificador de autorización.
La siguiente cláusula, < conjunto de caracteres o ruta >, le permite definir un conjunto de caracteres predeterminados, una ruta predeterminada, o ambos. El nombre del conjunto de caracteres se precede por las palabras clave DEFAULT CHARACTER SET y especifican un conjunto de caracteres predeterminados para el nuevo esquema. La ruta especifica una orden para buscar rutinas invocadas por SQL (procedimientos y funciones) que se crean como parte de la instrucción CREATE SCHEMA.
La cláusula < elementos del esquema > se compone de varios tipos de instrucciones de SQL que se pueden incluir en la instrucción CREATE SCHEMA. En su mayor parte, esta cláusula permite crear objetos de esquema tales como tablas, vistas, dominios y activadores. La ventaja de esto es que los objetos se añaden correctamente al esquema cuando se crea, todo en un solo paso.
Ahora que ha visto la sintaxis para la instrucción CREATE SCHEMA, veamos un ejemplo. El siguiente código crea un esquema llamado INVENTARIO. La instrucción también especifica un nombre de identificador de autorización MNGR y un conjunto de caracteres llamado Latino1.
CREATE SCHEMA INVENTARIO AUTHORIZATION MNGR
DEFAULT CHARACTER SET Latino1
CREATE TABLE ARTISTAS
( ID_ARTISTA INTEGER, NOMBRE_ARTISTA CHARACTER (20) );
Observe que el código de ejemplo incluye la instrucción CREATE TABLE. Éste es uno de los elementos que se puede especificar como parte de la cláusula < elementos del esquema >. Se pueden incluir tantas instrucciones como se quiera. Esta instrucción en particular crea tablas llamadas ARTISTAS que contienen la columna de ID_ARTISTA y la columna NOMBRE_ARTISTA.
1.8 Creación de una base de datos
la mayoría de los productos utilizan la misma sintaxis básica para crear una base de datos objeto:
CREATE DATABASE < nombre de la base de datos > < parámetros adicionales >
1.9 PASO A PASO: La creación de una base de datos y un esquema
Abra la aplicación de cliente que le permita invocar directamente las instrucciones SQL. Si es aplicable, consulte con el administrador de base de datos para asegurarse de que está entrando con las autorizaciones necesarias para crear una base de datos y un esquema. Puede que necesi- te permisos especiales para crear esos objetos. También verifique si hay algunos parámetros que debe incluir cuando se crea la base de datos (por ejemplo, el tamaño del archivo de registro), restricciones en el nombre que utilizará o restricciones de cualquier otro tipo. Asegúrese de comprobar la documentación del producto antes de seguir adelante.
Cree una base de datos llamada INVENTARIO (si el RDBMS respalda esta funcionalidad, en Oracle se crea un nombre de usuario llamado INVENTARIO, que implícitamente crea un es- quema con el mismo nombre). Dependiendo del producto que se use, se ejecutará una instruc- ción que sea similar a la siguiente:
CREATE DATABASE INVENTARIO;Si se requiere incluir parámetros adicionales en la instrucción, lo más probable es que se incluyan en las líneas siguientes a la cláusula CREATE DATABASE. Una vez que se ejecute la instrucción, debe recibir algún tipo de mensaje que indique que la instrucción se ejecutó con éxito.
- Conexión a la nueva base de datos.
USE Inventario
- Cree un esquema llamado CD_INVENTARIO. Cree un esquema bajo su actual identificador de autorización. No incluya ninguno de los elementos del esquema en este momento.
CREATE SCHEMA CD_INVENTARIO;