Capítulo 7 Mineração e estatísticas básicas
Davi Moreira, Mônica Rocabado
\(~\)
Já vimos como abordar algumas análises básicas. Vamos agora consolidar o conteúdo.
7.1 Análise de frequência

protesto covid-19
No dia 29 de maio de 2021 a população brasileira realizou o maior protesto registrado no período da pandemia da Covid-19. A data marcada como 29M é simbólica por representar a repulsa de grande parcela da população ao modo como o então governo do Presidente Jair Bolsonaro lidava com a pandemia. Os protestos ganharam o mundo e receberam em diferentes partes do globo.
Vamos iniciar este capítulo com a análise de 1000 tweets publicados com o termo “Bolsonaro” no dia 29 de maio de 2021. Os dados do Twitter foram obtidos através do pacote rtweet conforme apresentado no Capítulo 5. Para reproduzir essa análise você pode utilizar a base de dados presente no pacote txt4cs. A especificação do type indica que queremos tweets recentes e populares em nossa análise.
library(rtweet)
tweets <- search_tweets("Bolsonaro", n = 1000, type = "mixed", include_rts = FALSE)Utilizando o pacote quanteda, vamos verificar a frequência de hashtags usando select = "#*". Para tal, devemos processar nossos dados conforme indicado no Capítulo 6: transformar a base em um corpus, depois em tokens, remover pontuações, e criar em uma DFM selecionando apenasas hashtags.
library(quanteda)
library(quanteda.textstats)
#transformando em um corpus
corp_tweets <- corpus(tweets)
#transformando em tokens
toks_tweets <- tokens(corp_tweets, remove_punct = TRUE)
#criando uma DFM com as hashtags
dfmat_tweets <- dfm(toks_tweets, select = "#*")Com a dfmat_tweets iremos obter a frequência das features através da função textstat_frequency do pacote quanteda. No exemplo abaixo estamos especificando as 20 topfeatures conforme o agrupamento por idioma (lang) do tweet. Lembrando que para verificar as variáveis disponíveis no objeto DFM você pode utilizar a função docvars. Com este resultado estaremos obtendo as 20 principais hashtags e o o número de documentos no qual cada feature ocorre (docfreq). No caso, cada tweet é um documento, sendo, portanto, 1000 documentos.
tstat_freq <- textstat_frequency(dfmat_tweets, n = 20, groups = lang)| feature | frequency | rank | docfreq | group |
|---|---|---|---|---|
| #bolsonaro | 1 | 1 | 1 | en |
| #newindia | 1 | 1 | 1 | en |
| #coronavirus | 1 | 1 | 1 | en |
| #brazil | 1 | 1 | 1 | en |
| #india | 1 | 1 | 1 | en |
| #aajtak_ | 1 | 1 | 1 | en |
| #29mforabolsonaro | 6 | 1 | 6 | es |
| #bolsonaro | 3 | 2 | 3 | es |
| #fora | 3 | 2 | 3 | es |
| #guayaquil | 2 | 4 | 1 | es |
| #brasil | 2 | 4 | 2 | es |
| #ecuador | 1 | 6 | 1 | es |
| #quito | 1 | 6 | 1 | es |
| #lasso | 1 | 6 | 1 | es |
| #nebot | 1 | 6 | 1 | es |
| #asamblea | 1 | 6 | 1 | es |
| #fyp | 1 | 6 | 1 | es |
| #reyfelipe | 1 | 6 | 1 | es |
| #politica | 1 | 6 | 1 | es |
| #politics | 1 | 6 | 1 | es |
| #periodismo | 1 | 6 | 1 | es |
| #journalism | 1 | 6 | 1 | es |
| #gye | 1 | 6 | 1 | es |
| #24demayo | 1 | 6 | 1 | es |
| #presidencia | 1 | 6 | 1 | es |
| #cuenca | 1 | 6 | 1 | es |
| #29mforabolsonaro | 31 | 1 | 31 | pt |
| #forabolsonaro | 22 | 2 | 22 | pt |
| #euapoiobolsonaro2022 | 10 | 3 | 9 | pt |
| #forabolsonarogenocida | 9 | 4 | 9 | pt |
| #29mpovonasruas | 9 | 4 | 9 | pt |
| #putinhasmariafifi | 9 | 4 | 9 | pt |
| #impeachmentja | 8 | 7 | 8 | pt |
| #foragenocida | 4 | 8 | 4 | pt |
| #vacinanobracocomidanoprato | 3 | 9 | 3 | pt |
| #impeachmentbolsonarourgente | 3 | 9 | 3 | pt |
| #vacinasalvavidas | 3 | 9 | 3 | pt |
| #vacinasim | 3 | 9 | 3 | pt |
| #vacinaparatodos | 3 | 9 | 3 | pt |
| #bolsonaropresidenteate2026 | 3 | 9 | 3 | pt |
| #impeachment | 3 | 9 | 3 | pt |
| #imprensalixo | 3 | 9 | 3 | pt |
| #maisvacinasmenoscloroquina | 2 | 17 | 2 | pt |
| #29m | 2 | 17 | 2 | pt |
| #fernandocollor | 2 | 17 | 1 | pt |
| #forabolsonaro29m | 2 | 17 | 2 | pt |
| #29mforabolsonaro | 1 | 1 | 1 | und |
| #forabolsonarogenocida | 1 | 1 | 1 | und |
| #29mpovonasruas | 1 | 1 | 1 | und |
Com a base de dados processada, podemos visualizar as hashtags mais frequentes.
dfmat_tweets %>%
textstat_frequency(n = 20) %>%
ggplot(aes(x = reorder(feature, frequency), y = frequency)) +
geom_point() +
coord_flip() +
labs(x = NULL, y = "Frequência") +
theme_minimal()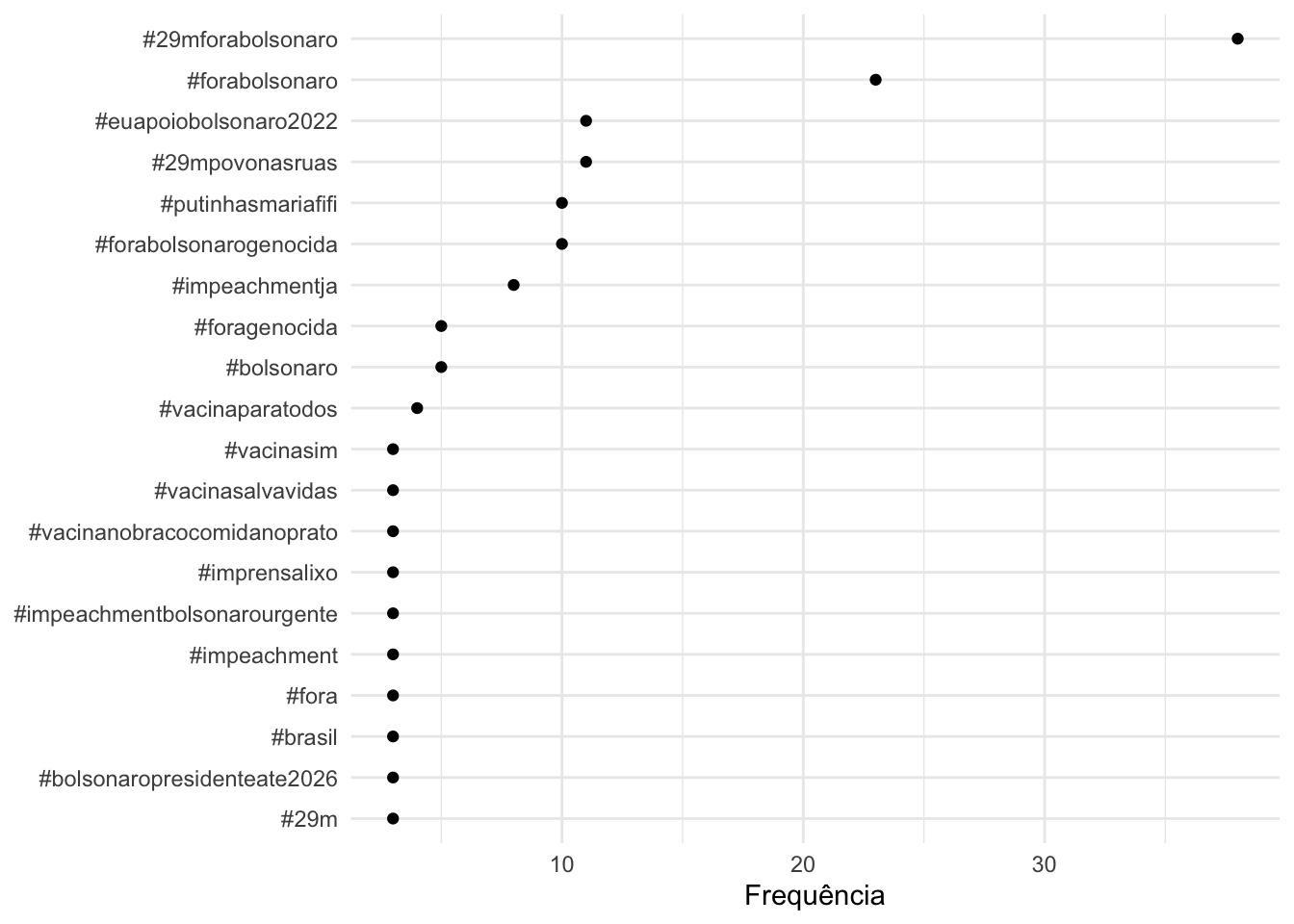
7.2 Nuvem de palavras
Uma forma comum da visualização de frequência na análise de texto é a nuvem de palavras. Para isso vamos aplicar nossa DFM na função textplot_wordcloud() do pacote quanteda
library(quanteda.textplots)
set.seed(132)
textplot_wordcloud(dfmat_tweets, max_words = 100)
Podemos aprimorar a visualização da nuvem de palavras para comparar grupos.
Primeiro, criamos uma nova variável ao nível do documento que atribui faixas de influência através do total de seguidores que o usuário possui. Para isso, criamos a nova variável influencia dentro do corp_tweets e estabelecemos uma condição do que consideramos influente. Tudo o que não corresponder ao critério será considerado “não influente”, no caso estamos utilizando como parâmetro perfis com mais de 1000 seguidores.
docvars(corp_tweets, "influencia") <- factor(
case_when(docvars(corp_tweets, "followers_count") > 1000 ~ "Influente",
TRUE ~ "Não Influente"))Com isto feito, agrupamos a DFM de hashtags:
# criando DFM com as hashtags
dfmat_tweets <- dfm(corp_tweets, select = "#*")
# agrupando DFM
dfmat_corp_language <- dfm_group(dfmat_tweets, groups = influencia)Criamos a worcloud, possibilitando a comparação entre grupos indicando TRUE no argumento comparison.
library(quanteda.textplots)
set.seed(132)
textplot_wordcloud(dfmat_corp_language, comparison = TRUE, max_words = 200)
7.3 tf-idf: term frequency-inverse document frequency
Uma questão central na mineração de texto e processamento de linguagem natural é: como quantificar o assunto de um documento? As possibilidades de respostas são diversas. Entre elas, está a possibilidade de utilizar a análise da frequência das palavras que compõem o documento. Logo, uma primeira medida seria a frequência de um termo (tf) em um documento.
Contudo, há palavras que ocorrem muitas vezes talvez não sejam importantes. Podemos removê-las antes da análise, mas é possível que algumas dessas palavras sejam mais importantes em alguns documentos do que em outros. Por isso, uma alternativa seria examinar a frequência de inversa de um termo no documento (idf), o que diminui o peso de palavras comumente usadas e aumenta o peso de palavras que não são muito usadas em uma coleção de documentos.
Combinando as duas alternativas, calcula-se o tf-idf de um termo. Em outras palavras: a frequência de um termo ajustada pela frequência com que é usado no acervo.
tf-idf: A estatística tf-idf destina-se a medir a importância de uma palavra para um documento em uma coleção de documentos (corpus), por exemplo, para um romance em uma coleção de romances, para um site em uma coleção de sites, um discurso numa coleção de discursos, etc. O método resulta na frequência das palavras mais “relevantes” entre documentos. Quanto mais perto de 1, mais relevante é a palavra.
Vamos ver um exemplo usando os votos proferidos na aprovação do impeachment da ex-presidenta Dilma Rousseff e presente no pacote txt4cs. Através do pacote tidytext, vamos transformar a base em formato token. Em seguida, vamos contar a quantidade de termos utilizados por partido e selecionar apenas PT, PSDB, PSOL e PMDB. O processo de contagem de termos é essencial para função tf-idf.
library(tidytext)
library(tidyverse)
impeachment_words <- impeachment_dilma %>%
unnest_tokens(word, text) %>%
count(partido, word, sort = TRUE) %>%
filter(partido %in% c("PT", "PSDB", "PSOL", "PMDB"))Obtemos o valor do tf-idf através da função bind_tf_idf do pacote tidytext. Note que é relevante definir a base de comparação dos documentos, no caso, partido. Dessa forma iremos obter as palavras mais relevantes para cada partido.
plot_impeachment <- impeachment_words %>%
bind_tf_idf(word, partido, n) %>%
arrange(desc(tf_idf)) Para produzir uma visualização, transformamos os termos e partidos que estão em chr em fator (fct).
plot_impeachment <- plot_impeachment %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
mutate(partido = factor(partido, levels = unique(plot_impeachment$partido)))Com os dados tratados, podemos visualizar graficamente quais os 10 termos mais relevantes e utilizados por cada partido nos textos selecionados:
plot_impeachment %>%
group_by(partido) %>%
top_n(10, tf_idf) %>%
ungroup() %>%
mutate(word = reorder(word, tf_idf)) %>%
ggplot(aes(word, tf_idf, fill = partido)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "tf-idf") +
facet_wrap(~partido, ncol = 2, scales = "free") +
coord_flip()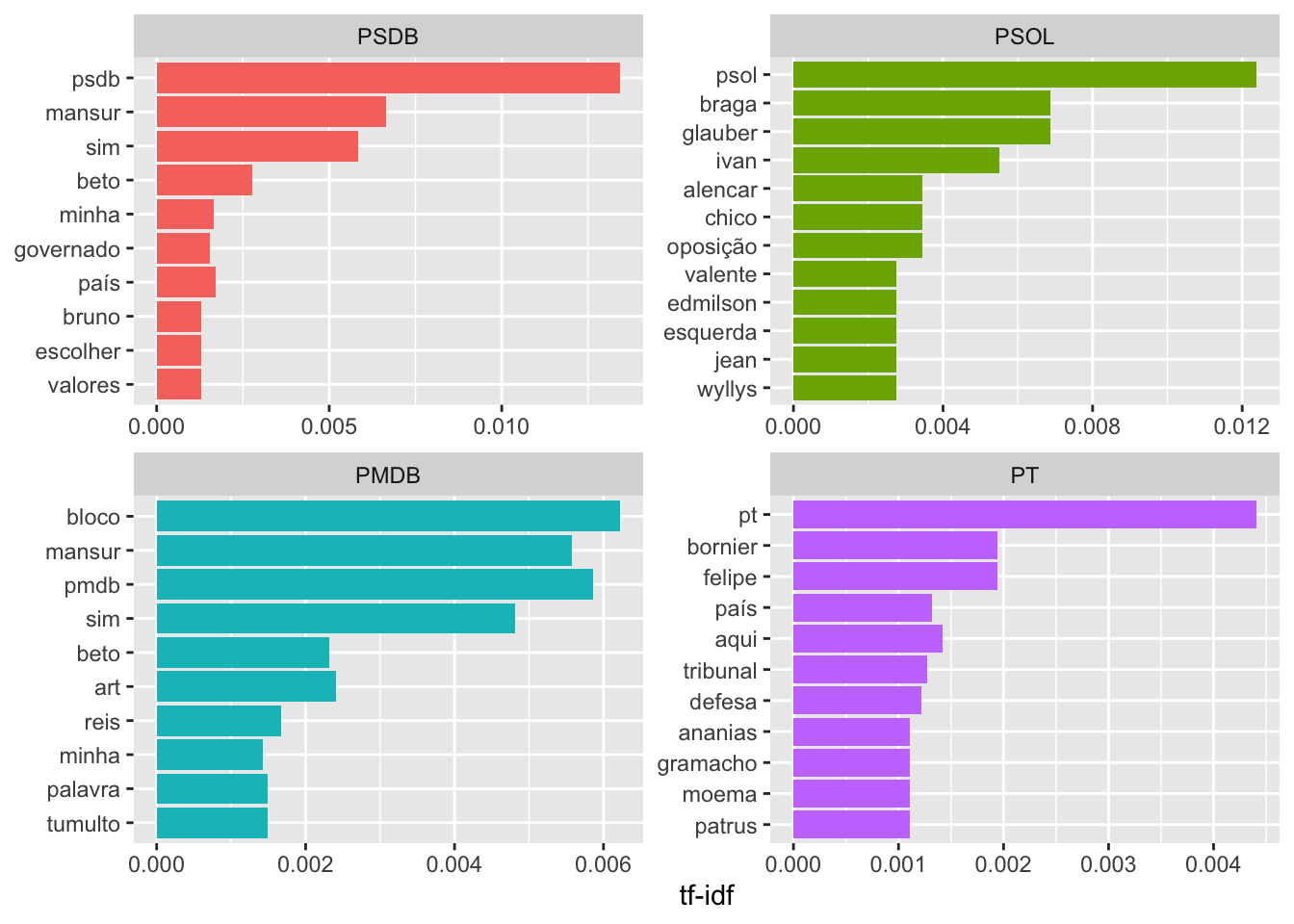
7.4 Rede de n-grams
Interessados em visualizar as relações entre as palavras simultaneamente, através de n-grams podemos organizar as palavras em uma rede. O pacote igraph possui muitas funções poderosas para processar e analisar redes. Uma maneira de criar um objeto igraph a partir de um data.frame é a função graph_from_data_frame().
No exemplo iremos utilizar os votos proferidos na aprovação do processo de impeachment da ex-presidenta Dilma Rousseff (impeachment_dilma) disponível no pacote txt4cs que acompanha esse livro.
library(igraph)
library(ggraph)Iremos transformar essa base de dados com o pacote tidytext em n-grams de dois termos.
impeachment_bigrams <- impeachment_dilma %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2)Como visto no capítulo anterior, para trabalhar com n-grams no tidytext temos que separar as palavras para podermos filtrar as stop_words, utilizaremos a base stop_words presente no pacote tidytext.
bigrams_separated <- impeachment_bigrams %>%
separate(bigram, c("word1", "word2"), sep = " ")
stop_w <- tibble(word = stopwords(source = "stopwords-iso", language = "pt"))
bigrams_filtered <- bigrams_separated %>%
filter(!word1 %in% stop_w$word) %>%
filter(!word2 %in% stop_w$word)Precisamos então contar quantas vezes os termos aparecem juntos para realizar nossa rede de termos.
bigram_counts <- bigrams_filtered %>%
count(word1, word2, sort = TRUE)Escolhemos os termos que tenham uma frequência conjunta maior que 30 vezes, e através da função graph_from_data_frame transformamos a data.frame em formato igraph
library(igraph)
bigram_graph <- bigram_counts %>%
filter(n > 30) %>%
graph_from_data_frame()Estabelecemos uma ordem aleatória e geramos nossa rede de relações. Para isso vamos precisar do pacote ggraph.
library(ggraph)
set.seed(2017)
ggraph(bigram_graph, layout = "fr") +
geom_edge_link() +
geom_node_point() +
geom_node_text(aes(label = name), vjust = 1, hjust = 1)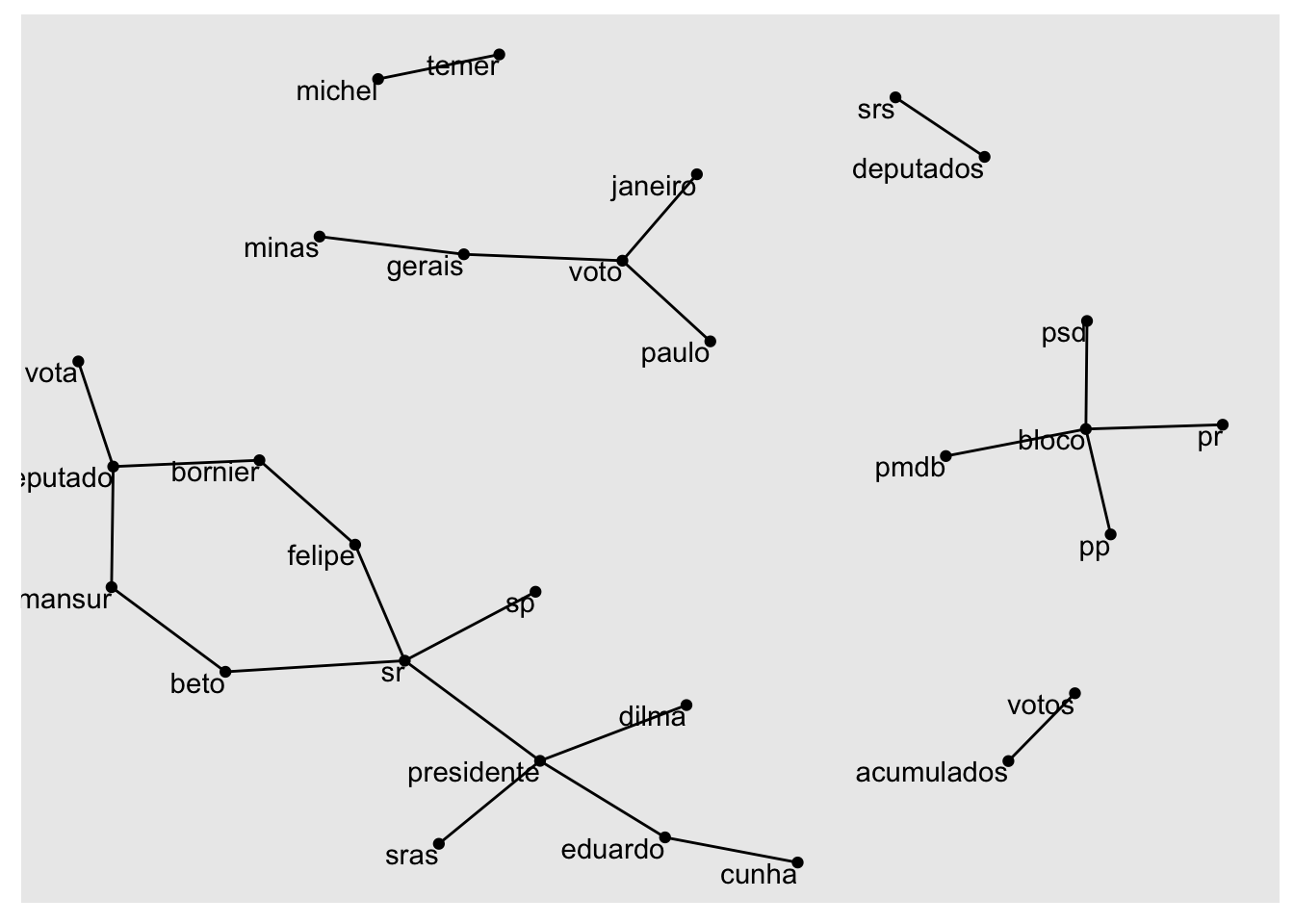
7.5 Correlação pareada
Podemos querer examinar a correlação entre palavras e verificar com que frequência elas aparecem juntas em relação à frequência com que aparecem separadas. Para tanto, vamos analisar o coeficiente \(\phi\), uma medida comum para correlação binária. O foco do coeficiente \(\phi\) é o quão mais provável é a palavra \(X\) e a palavra \(Y\) aparecem juntas em relação a aparecerem separadas. Sua interpretação é similar à correlação linear de Pearson em que 1 significa uma correlação linear perfeitamente positiva e -1 uma correlação linear perfeitamente negativa, caso 0 não há correlação.
A função pairwise_cor() do pacote widyr nos permite encontrar o coeficiente \(\phi\) entre as palavras com base na frequência com que aparecem.
Vamos utilizar o corpus com os votos proferidos no processo de abertura do impeachment contra a presidenta Dilma Rousseff. Seguindo nosso fluxo de trabalho, inicialmente vamos utilizar o pacote tidytext para preparar nossos dados para análise.
library(tidytext)
library(tidyverse)
# separando stop words e palavras selecionadas para posterior remoção
stop_w <- tibble(word = stopwords(source = "stopwords-iso", language = "pt"))
sel_w <- tibble(word = c("sr", "deputado", "v.exa", "deputada"))
# criando objeto com tokens
impeachment_words <- impeachment_dilma %>%
mutate(text = str_remove_all(text, "[[:digit:]]")) %>%
unnest_tokens(word, text) %>%
anti_join(stop_w) %>%
anti_join(sel_w)Agrupamos as palavras e filtramos aquelas que possuem uma frequência maior ou igual a 20. Ao final computamos a correlação pareada com a função pairwise_cor().
library(widyr)
word_cors <- impeachment_words %>%
group_by(word) %>%
filter(n() >= 20) %>%
pairwise_cor(word, partido, sort = TRUE)Podemos visualizar a correlação pareada, focando em palavras de maior interesse, por exemplo: “deus” e “família”. Para tanto, basta filtrar a primeira coluna e assim avaliarmos as principais correlações pareadas existentes.
word_cors %>%
filter(item1 %in% c("deus", "família")) %>%
group_by(item1) %>%
top_n(10) %>%
ungroup() %>%
mutate(item2 = reorder(item2, correlation)) %>%
ggplot(aes(item2, correlation)) +
geom_bar(stat = "identity") +
facet_wrap(~ item1, scales = "free") +
coord_flip()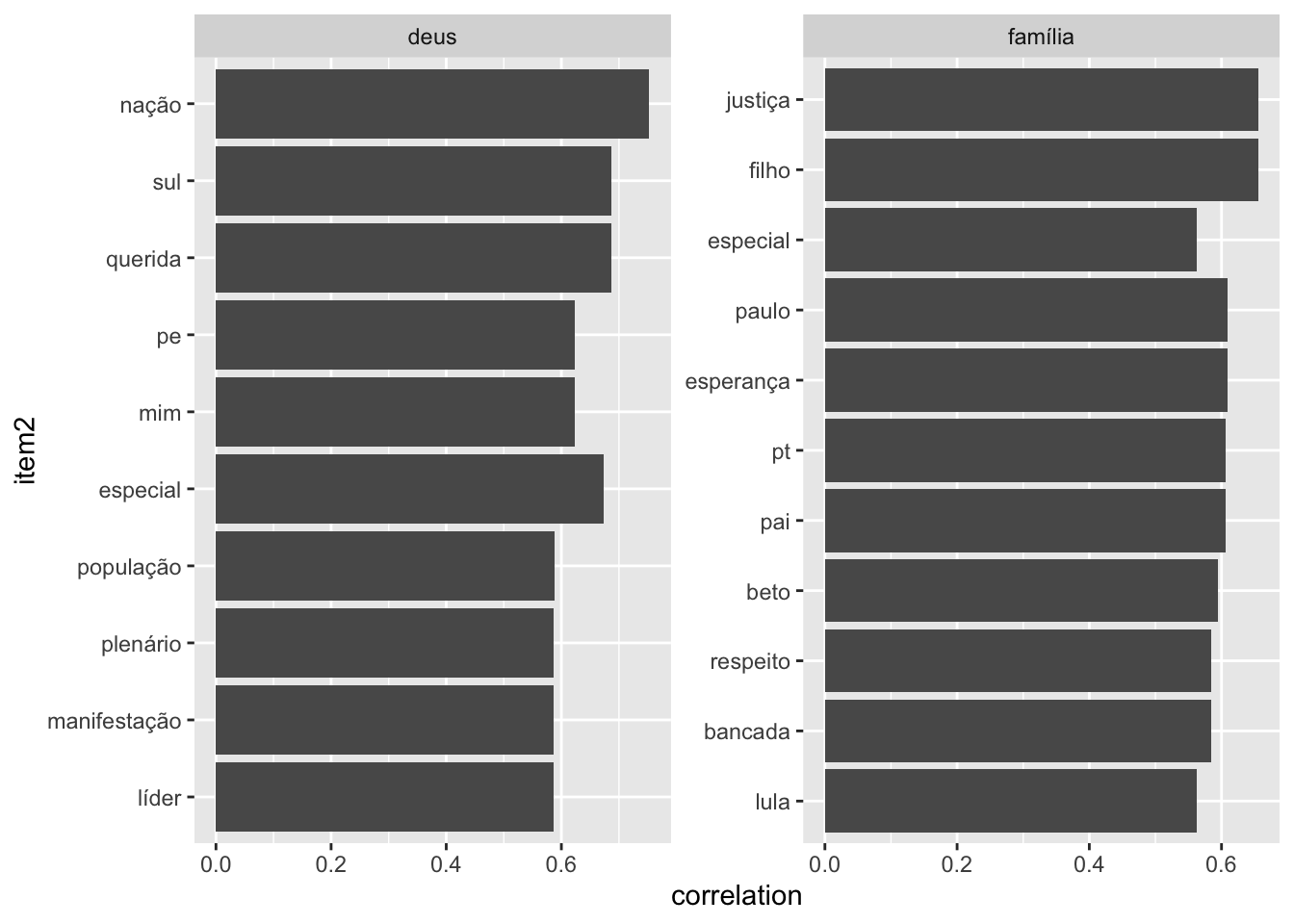
7.6 Diversidade lexical
A diversidade lexical pode ser obtida através de várias medidas com base no número de tokens exclusivos e no comprimento de um documento. Pode ser utilizada para analisar as habilidades lingüísticas de oradores ou autores, ou a complexidade das ideias expressas.
Com a função textstat_lexdiv() do pacote quanteda, a mensuração padrão é a Type-Token Ratio (TTR), mas pode-se optar por outros métodos de cálculo. Essa medida divide o número de “tipos” pelo número total de tokens. Logo, quanto mais próximo a 1, maior a complexidade lexical.
Vamos utilizar o corpus com os votos proferidos no processo de abertura do impeachment contra a presidenta Dilma Rousseff. Seguindo nosso fluxo de trabalho, devemos preparar nossa base para obter uma DFM. Com o objetivo de comparar votos com tamanho similar, vamos contar o número de palavras de cada um e manter na DFM somente aqueles incluídos no intervalo to segundo e terceiro quartís.
library(stringi)
library(stringr)
library(quanteda)
library(quanteda.textstats)
impeachment_dfm <- impeachment_dilma %>%
mutate(text = stri_trans_general(text, "Latin-ASCII")) %>%
mutate(text = str_remove_all(text, "[[:digit:]]")) %>%
corpus(docid_field = "doc_id", text_field = "text") %>%
tokens(remove_punct = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords(source = "stopwords-iso", language = "pt"), min_nchar = 2) %>%
tokens_wordstem(language = "pt") %>%
dfm()Com a DFM pronta, podemos calcular a diversidade lexical através da função tstat_lexdiv(). Em seguida, vamos incluir o resultado da mensuração TTR em nossa base de dados original.
tstat_lexdiv <- textstat_lexdiv(impeachment_dfm)
impeachment_dilma_lexdiv_sel <- impeachment_dilma %>%
mutate(doc_id = as.character(doc_id)) %>%
left_join(tstat_lexdiv, by = c("doc_id" = "document")) %>%
tibble() %>%
arrange(desc(TTR)) Pronto! Vamos conhecer uma amostra aleatória de cinco discursos com maior diversidade lexical:
| nomeOrador | partido | uf | text |
|---|---|---|---|
| MARCELO ÁLVARO ANTÔNIO | PR | MG | O SR. MARCELO ÁLVARO ANT (Bloco/PR-Minas Gerais.) - Sr. Presidente, pela minhas filhas Amanda Dias e Ana Clara, pela minha esposa Janaína, pela minha mãe, pelas famílias de cada um dos brasileiros - quero fazer uma menção especial à minha região do Barreiro, à nossa querida Belo Horizonte -, levando em consideração também a legitimidade dos protestos, as vozes das ruas, a legalidade do processo e a governabilidade do nosso País, eu voto “sim”, Sr. Presidente. Que Deus abençoe o nosso Brasil! (Palmas.) O SR. BETO MANSUR - Deputado Marcelo Álvaro Antônio, do PR de Minas Gerais: voto “sim”. Total: 293 votos. |
| MANOEL JUNIOR | PMDB | PB | O SR. MANOEL JUNIOR (Bloco/PMDB-PB.) - Sr. Presidente, ecoa nesta Casa o clamor das ruas. A Nação exige mudança. A Nação terá mudança. Contra a corrupção, por mais qualidade na saúde, na educação, na segurança do nosso País; pela honra dos meus eleitores da Paraíba, pelos meus companheiros médicos e da área da Saúde, pelos meus conterrâneos de Pedras de Fogo, pela minha querida João Pessoa, pela Paraíba e pelo Brasil, “sim” ao impeachment. (Palmas.) (Manifestação no plenário. Muito bem! Nove! Nove! Nove!) O SR. BETO MANSUR - Deputado Manoel Junior, do PMDB da Paraíba: voto “sim”. Total: 333 votos acumulados. |
| IVAN VALENTE | PSOL | SP | O SR. IVAN VALENTE (PSOL-SP.) - A todo o povo brasileiro, quero dizer que não aceito o corrupto Eduardo Cunha presidindo qualquer processo de impeachment. Ele deveria ser o primeiro impedido. (Manifestação no plenário.) A eleição de Temer, se vingar o impeachment , é uma fraude que deve ser evitada, porque Temer é uma armação para sacrificar os trabalhadores e para abafar a Lava-Jato. O SR. PRESIDENTE (Eduardo Cunha) - Como vota, Deputado? O SR. IVAN VALENTE - Pela democracia e contra o golpe, o PSOL é “não”. O SR. FELIPE BORNIER - Deputado Ivan Valente, do PSOL de São Paulo: voto “não”. Total: 43 votos. |
| EXPEDITO NETTO | PSD | RO | O SR. EXPEDITO NETTO (Bloco/PSD-RO.) - Sr. Presidente, gostaria de cumprimentar todos os nobres companheiros que aqui se encontram e todos que nos assistem pelos meios de comunicação de nosso País. Quero dizer que, hoje, estamos votando o impeachment da Presidente Dilma e, amanhã, estaremos votando o seu, Sr. Presidente. E pode ter certeza de que votarei da mesma forma como voto hoje. Respeitando o povo rondoniense e respeitando o povo brasileiro, eu voto “sim”, contra a corrupção, venha ela de que partido vier. O SR. BETO MANSUR - Deputado Expedito Netto, do PSD de Rondônia: voto “sim”. Total: 97 votos. |
| FÁBIO RAMALHO | PMDB | MG | O SR. FÁBIO RAMALHO (Bloco/PMDB-MG.) - Eu pedi a Deus que me desse sabedoria para votar com dignidade. Eu pedi a Deus que me iluminasse. E, neste momento, em nome de um Estado cujo outro nome é liberdade, Minas Gerais; em nome de milhares de mineiros que me pediram para votar a favor do impeachment ; eu estou aqui para declarar o meu voto, em gratidão ao povo mineiro, à família mineira e, sobretudo, aos milhões de desempregados deste País. Eu voto “sim” por Minas Gerais e pelo Brasil! O SR. BETO MANSUR - Deputado Fábio Ramalho, do PMDB do Estado de Minas Gerais, votou “sim”. Total: 284 votos acumulados. |
Agora, vamos conhecer os cinco discursos com menor diversidade lexical:
| nomeOrador | partido | uf | text |
|---|---|---|---|
| ANDRES SANCHEZ | PT | SP | O SR. ANDRES SANCHEZ (PT-SP.) - Sr. Presidente, este é o meu primeiro mandato. Meu filhos nunca quiseram que eu entrasse na política, e a maioria dos corintianos também não; mas, infelizmente, entrei. Que decepção! Meu voto é “não”. O SR. FELIPE BORNIER - Deputado Andres Sanchez, do PT de São Paulo: voto “não”. Total: 40 votos. |
| MAX FILHO | PSDB | ES | O SR. MAX FILHO (PSDB-ES.) - Sr. Presidente, Srs. Deputados, em homenagem aos princípios da Constituição Federal, da legalidade, da impessoalidade e, sobretudo, da moralidade, da publicidade e da eficiência, meu voto é “sim”. O SR. BETO MANSUR - Deputado Max Filho, do PSDB do Espírito Santo: voto “sim”. Total: 258 votos acumulados. |
| GUILHERME MUSSI | PP | SP | O SR. GUILHERME MUSSI (Bloco/PP-SP.) - Sr. Presidente, senhoras e senhores, pela legalidade, com muita responsabilidade e serenidade, em respeito à minha família, aos meus amigos, a todos os paulistas e aos brasileiros, meu voto é “sim”. O SR. BETO MANSUR - Deputado Guilherme Mussi, do PP de São Paulo: voto “sim”. Total: 168 votos. |
| ROBERTO SALES | PRB | RJ | O SR. ROBERTO SALES (Bloco/PRB-RJ.) - Sr. Presidente, pela unidade do PRB, pela família e para nenhum governo se levantar contra a Nação de Israel, por São Gonçalo, pelo leste fluminense, pelo Rio de Janeiro, voto “sim”. (Palmas.) O SR. BETO MANSUR - Deputado Roberto Sales, do PRB do Rio de Janeiro, voto “sim”. Total: 246 votos. |
| SILAS CÂMARA | PRB | AM | O SR. SILAS CÂMARA (Bloco/PRB-AM.) - Sr. Presidente, pela reconstrução da unidade de uma Nação que tentaram dividir, por amor e carinho ao povo do Amazonas, pela minha família e, acima de tudo, por amor a Deus, o meu voto é “sim”. (Palmas.) O SR. BETO MANSUR - Deputado Silas Câmara, do PRB do Amazonas: voto “sim”. Total: 96 votos. |
| MIGUEL HADDAD | PSDB | SP | O SR. MIGUEL HADDAD (PSDB-SP.) - Sr. Presidente, em respeito aos milhões de brasileiros que foram às ruas pedir o impeachment da Presidente Dilma, representando São Paulo, representando Jundiaí e região, o meu voto é “sim”! (Palmas.) O SR. BETO MANSUR - Deputado Miguel Haddad, do PSDB de São Paulo: voto “sim”. Total: 179 votos. |
| ALEXANDRE LEITE | DEM | SP | O SR. ALEXANDRE LEITE (DEM-SP.) - Sr. Presidente, eu saúdo o Brasil e os brasileiros. Eu saúdo o meu Estado de São Paulo e a minha querida Zona Sul com o voto “sim”, pelo impedimento da Presidente Dilma Vana Rousseff. Tchau, querida! O SR. BETO MANSUR - Deputado Alexandre Leite, do DEM de São Paulo: voto “sim”. Total: 145 votos. |
Com simples processamento dos dados, podemos comparar a diversidade lexical (TTR) de deputados selecionados:
impeachment_dilma_lexdiv_sel %>%
filter(nomeOrador %in% c("PR. MARCO FELICIANO", "PAULO TEIXEIRA",
"ONYX LORENZONI", "JAIR BOLSONARO",
"JEAN WYLLYS ", "TIRIRICA", "GLAUBER BRAGA")) %>%
arrange(TTR) %>%
mutate(nomeOrador = factor(nomeOrador, levels = nomeOrador)) %>%
ggplot(aes(nomeOrador, TTR)) +
geom_bar(stat = "identity", width = .7) +
theme_bw() +
coord_flip() +
theme(axis.title.x = element_blank(),
axis.title.y = element_blank())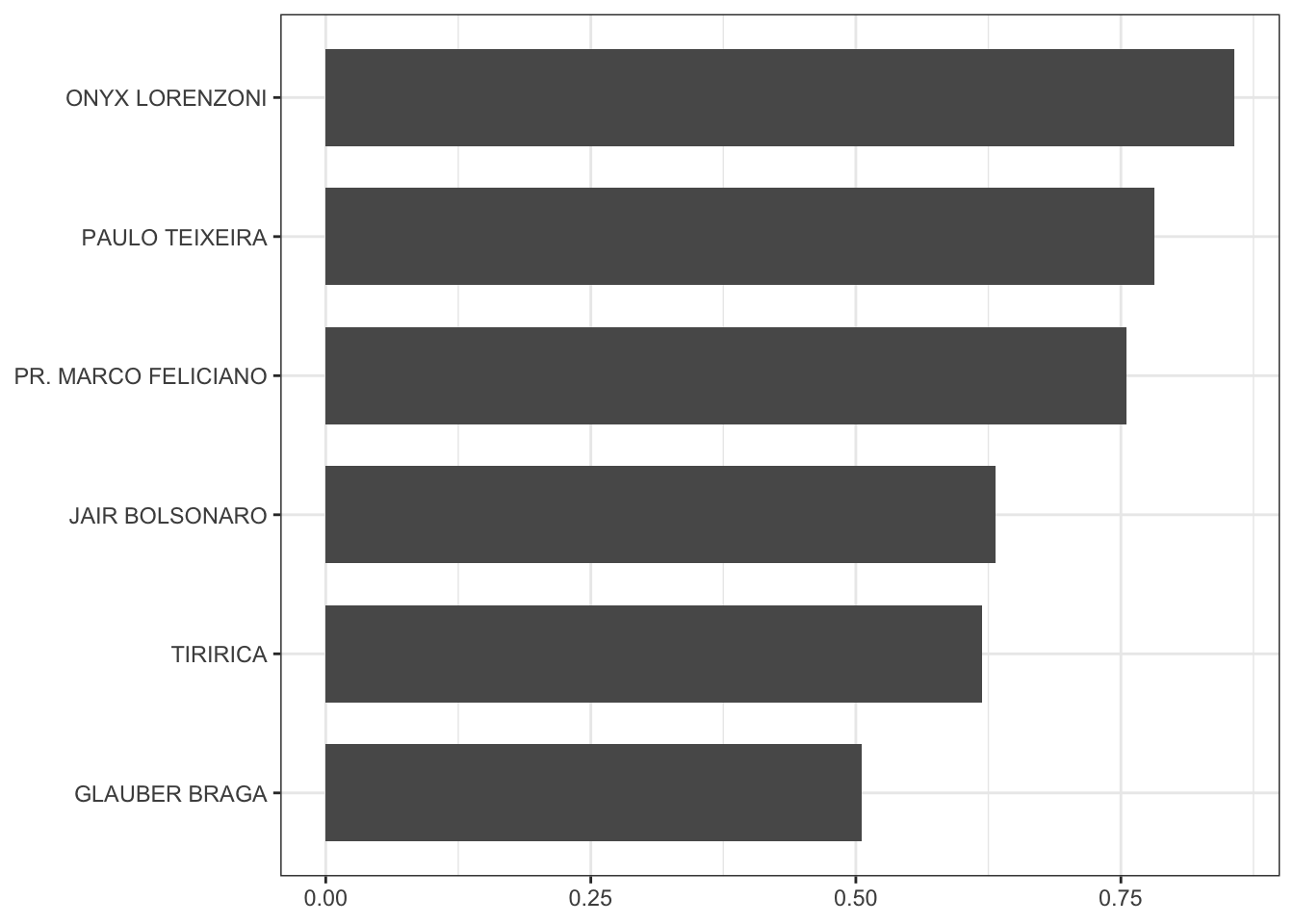
| nomeOrador | partido | uf | text |
|---|---|---|---|
| ONYX LORENZONI | DEM | RS | O SR. ONYX LORENZONI (DEM-RS.) - Diz o hino rio-grandense: “Sirvam nossas façanhas de modelo a toda terra.” Estamos legitimados pelo povo brasileiro para dizer um “basta” para a roubalheira. “sim”, de esperança num novo futuro para o nosso Brasil. O SR. BETO MANSUR - Onyx Lorenzoni, do DEM do Rio Grande do Sul: voto “sim”. Total: 26 votos. |
| PAULO TEIXEIRA | PT | SP | O SR. PAULO TEIXEIRA (PT-SP) - Ao povo brasileiro, “não” ao golpe daqueles que querem tirar uma pessoa que teve 54 milhões de votos nas urnas. Esses que querem tirá-la, não têm votos. Contra o ataque à Constituição e à democracia que está sendo feito aqui nesta tarde em Brasília; e contra a conspiração dirigida pelo réu por corrupção no Supremo Tribunal Federal, Eduardo Cunha, junto com Michel Temer e Aécio Neves, com o objetivo de tirar direitos do povo brasileiro, muitos deles conquistados nos Governos Lula e Dilma, voto “não”, pelo Brasil! O SR. DEPUTADO FELIPE BORNIER - Deputado Paulo Teixeira, do PP de São Paulo: voto “não”. Total: 48 votos. |
| PR. MARCO FELICIANO | PSC | SP | O SR. PR. MARCO FELICIANO (Bloco/PSC) - Com a ajuda de Deus, pela minha família, pelo povo brasileiro, pelos evangélicos da Nação toda, pelos meninos do MBL, pelo Vem Pra Rua Brasil - dizendo que o Olavo tem razão, Sr. Presidente, dizendo “tchau” para essa querida e para o PT, Partido das Trevas -, eu voto “sim” ao impeachment , Sr. Presidente! O SR. BETO MANSUR - Deputado Pr. Marco Feliciano, do PSC de São Paulo: voto “sim”. Total: 187 votos. |
| JAIR BOLSONARO | PSC | RJ | O SR. JAIR BOLSONARO (Bloco/PSC-RJ.) - Neste dia de glória para o povo brasileiro, um nome entrará para a história nesta data pela forma como conduziu os trabalhos desta Casa: Parabéns, Presidente Eduardo Cunha! (Manifestação no plenário.) O SR. PRESIDENTE (Eduardo Cunha) - Como vota, Deputado? O SR. JAIR BOLSONARO (Bloco/PSC-RJ.) - Perderam em 1964. Perderam agora em 2016. Pela família e pela inocência das crianças em sala de aula, que o PT nunca teve… Contra o comunismo, pela nossa liberdade, contra a Folha de S.Paulo , pela memória do Cel. Carlos Alberto Brilhante Ustra, o pavor de Dilma Rousseff! (Apupos no plenário.) O SR. PRESIDENTE (Eduardo Cunha) - Como vota, Deputado? O SR. JAIR BOLSONARO (Bloco/PSC-RJ.) - Pelo Exército de Caxias, pelas nossas Forças Armadas, por um Brasil acima de tudo, e por Deus acima de todos, o meu voto é “sim”! (Manifestação no plenário.) O SR. BETO MANSUR - Deputado Jair Bolsonaro, do PSC do Rio de Janeiro, votou “sim”. Acumulado: 236 votos. |
| TIRIRICA | PR | SP | O SR. TIRIRICA (Bloco/PR-SP.) - Sr. Presidente, pelo meu país, meu voto é “sim”! (Tiririca! Tiririca! Tiririca!) O SR. BETO MANSUR - Tiririca, PR de São Paulo: voto “sim”. Total: 197 votos. |
| GLAUBER BRAGA | PSOL | RJ | O SR. GLAUBER BRAGA (PSOL-RJ.) - Eduardo Cunha, você é um gângster. (Manifestação no plenário.) O que dá sustentação à sua cadeira cheira enxofre. Eu voto por aqueles que nunca escolheram o lado fácil da história. Eu voto por Marighella, eu voto por Plínio de Arruda Sampaio, eu voto por Evandro Lins e Silva, eu voto por Arraes, eu voto por Luís Carlos Prestes. O SR. PRESIDENTE (Eduardo Cunha) - Como vota, Deputado? O SR. GLAUBER BRAGA - Eu voto por Olga Benário. O SR. PRESIDENTE (Eduardo Cunha) - Como vota? O SR. GLAUBER BRAGA - Eu voto por Brizola e Darcy Ribeiro. Eu voto por Zumbi dos Palmares. O SR. PRESIDENTE (Eduardo Cunha) - Como vota, Deputado? O SR. GLAUBER BRAGA - Eu voto “não”! (Palmas.) (Manifestação no plenário: Fora, Cunha!) O SR. FELIPE BORNIER - Deputado Glauber Braga, do PSOL do Rio de Janeiro, votou “não”. Total: 76 votos. |
7.7 Similaridade entre documentos
A função textstat_dist() calcula semelhanças e distâncias entre documentos ou features por diversas medidas. Conjutamente com a função, iremos utilizar a função as.dist() que retorna uma matriz de distância. Afim de obter um cluster hierárquico de análise, iremos também utilizar a função hclust().
Vamos utilizar o corpus com os votos proferidos no processo de abertura do impeachment contra a presidenta Dilma Rousseff. Seguindo nosso fluxo de trabalho, devemos preparar nossa base para obter uma DFM.
impeachment_dfm_group <- impeachment_dilma %>%
mutate(text = stri_trans_general(text, "Latin-ASCII")) %>%
mutate(text = str_remove_all(text, "[[:digit:]]")) %>%
corpus(docid_field = "doc_id", text_field = "text") %>%
tokens(remove_punct = TRUE) %>%
tokens_tolower() %>%
tokens_remove(stopwords(source = "stopwords-iso", language = "pt"), min_nchar = 2) %>%
tokens_wordstem(language = "pt") %>%
dfm() %>%
dfm_select(pattern = c("sr", "total", "deput", "vot", "president", "bet",
"mansur", "palm"), selection = "remove") %>%
dfm_trim(min_docfreq = 0.01, docfreq_type = "prop") %>%
dfm_group(partido)
tstat_dist <- as.dist(textstat_dist(impeachment_dfm_group))
clust <- hclust(tstat_dist)
plot(clust, xlab = "Distance", ylab = NULL)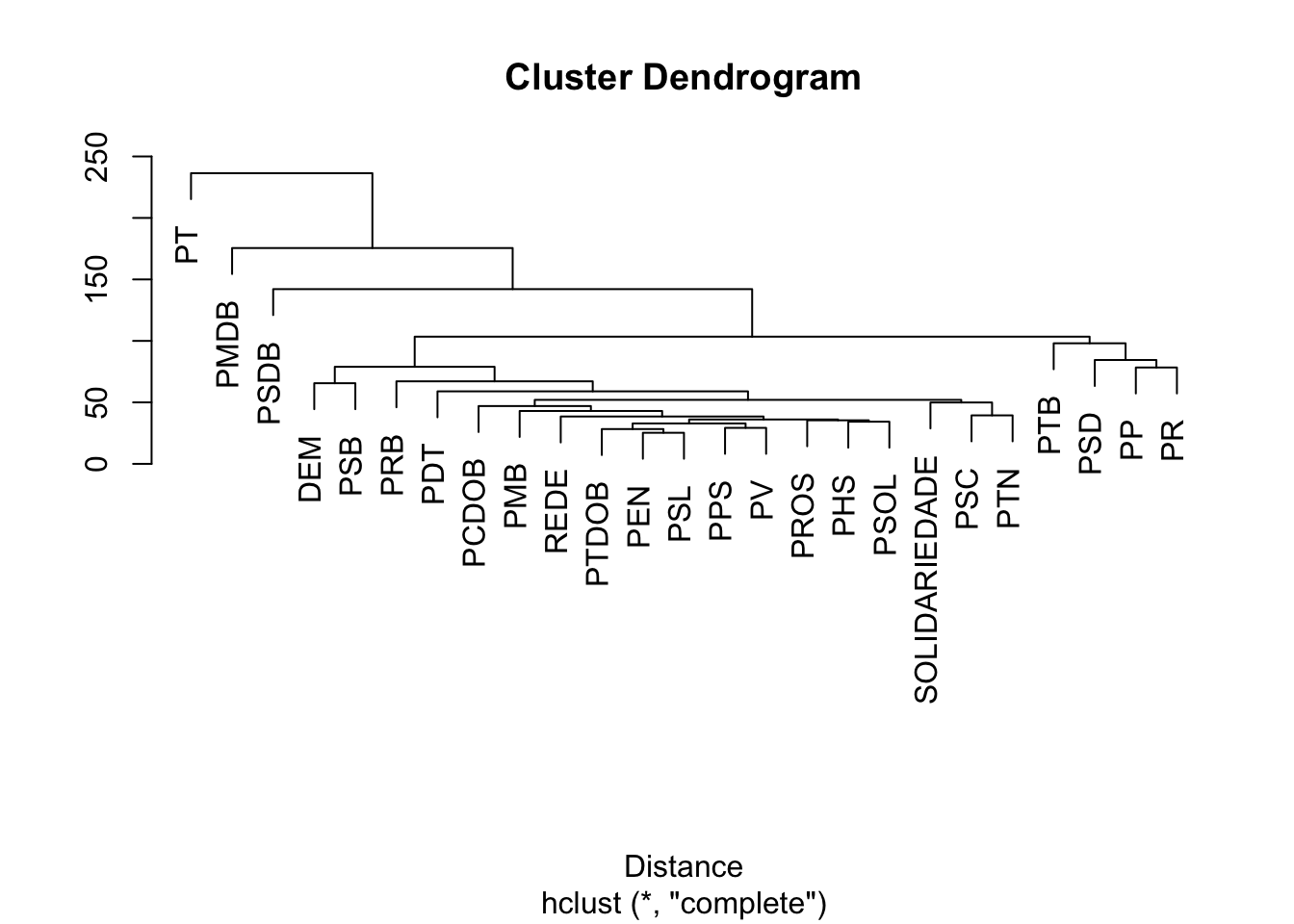
7.8 KEYNESS: Análise de Frequência Relativa
Segundo o implementador original da metodologia (WordSmith), Keyness é uma pontuação de associação para identificar palavras frequentes em documentos em um grupo de referência e de destino. O algorítmo identifica palavras-chave em uma base, comparando padrões de freqüência.
Uma palavra é dita “chave” se:
- ocorre no texto pelo menos tantas vezes quantas o usuário tenha especificado como frequência mínima;
- sua frequência no texto, quando comparada com sua frequência em um corpus de referência, é tal que a probabilidade estatística, conforme calculada por um procedimento apropriado, é menor ou igual a um \(p − valor\) especificado pelo analista.
Keyness positivo e negativo: Uma palavra que é positivamente chave ocorre mais frequentemente do que seria esperado por acaso em comparação com o corpus de referência. Uma palavra que é negativamente chave ocorre com menos frequência do que seria esperado por acaso em comparação com o corpus de referência.
Usando a função textstat_keyness(), você pode comparar frequências de palavras entre documentos de destino e de referência. Como exemplo, vamos replicar o tutorial do pacote quanteda. Analisaremos um corpus de notícias publicadas pelo jornal The Guardian. Os documentos de destino são artigos de notícias publicados em 2016 e os documentos de referência são os publicados em 2012-2015. Caso não tenha, recomendo instalar o pacote quanteda.corpora para obter os dados para o exemplo através de devtools::install_github("quanteda/quanteda.corpora")
library(quanteda)
require(quanteda.textstats)
require(quanteda.textplots)
require(quanteda.corpora)
library(lubridate)
corp_news <- download("data_corpus_guardian")Após baixar os dados, vamos processá-los para obter uma DFM:
toks_news <- tokens(corp_news, remove_punct = TRUE)
dfmat_news <- dfm(toks_news, remove = stopwords('en'))Com a DFM, podemos utilizar a função textstat_keyness() que irá verificar a frequência relativa entre o target (documentos de destino) e os documentos de referência.
tstat_key <- textstat_keyness(dfmat_news,
target = year(docvars(dfmat_news, 'date')) >= 2016)
attr(tstat_key, 'documents') <- c('2016', '2012-2015')
textplot_keyness(tstat_key)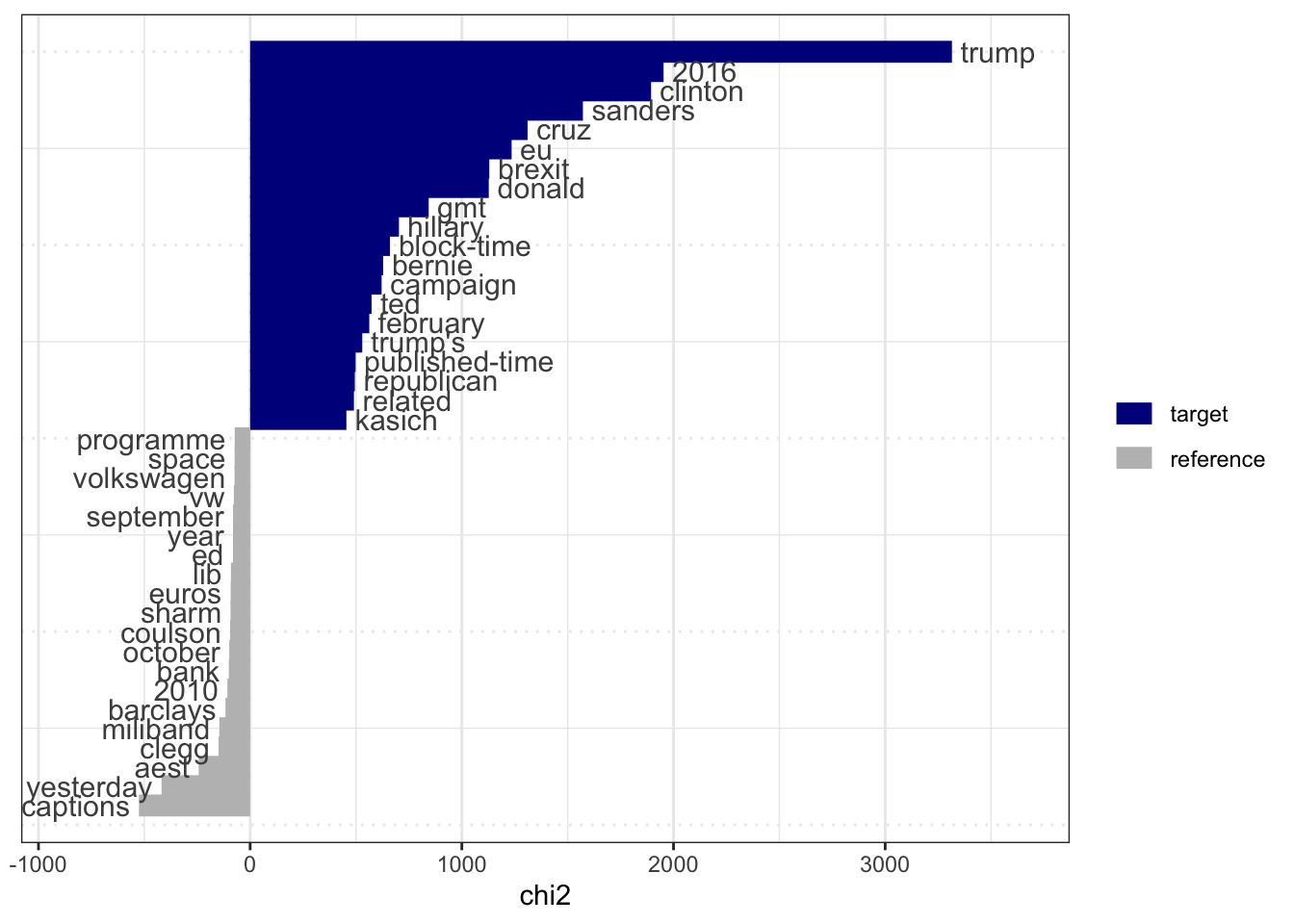
O gráfico acima nos informa que os termos chave em target (2016) são trump, 2016, clinton, sanders, cruz, eu, brexit, em relação aos termos de referência (2012-2015) que são captions, yesterday, aest, clegg, miliband. Percebe-se que os termos chave positivos retratam a eleição presidencial de 2016 nos EUA. Já os termos chave negativos, que ocorrem com menor frequência em 2016 e maior frequência entre 2012 e 2015, se referem às disputas políticas entre Clegg e Miliband no Reino Unido.