Capítulo 8 Escalonamento
Davi Moreira, Mônica Rocabado
\(~\)
8.1 O que é escalonamento?
O escalonamento é um método de comparação de similaridade de casos em um conjunto de dados Wiki. O método pode ser utilizado tanto no forma de aprendizado computacional supervisionado quanto não supervisionado. Reduzindo a dimensionalidade dos dados, é possível apresentar as obervações sob análise em pontos mapeados no espaço cartesiano. Tais pontos são conhecidos como pontos ideais.
Nas ciências sociais, o uso do escalonamento para extração de posições políticas/ideológicas de partidos, políticos e eleitores é uma área extremamente promissora (Izumi and Moreira 2018). O teste de modelos de competição partidária, por exemplo, depende do conhecimento das posições dos principais atores envolvidos no jogo político.
Existem diversos modelos que estimam os pontos ideais de atores políticos através do modo como votam, por exemplo analisando os registros de de votações nominais (Clinton, Jackman, and Rivers 2004; Poole and Rosenthal 1991, 2006). Entre eles, destaca-se o DW-Nominate (Dynamic Weighted NOMINAl Three-step Estimation), cujos resultados de análise dos pontos ideais dos congressistas estadunidenses são sintetizados pelo Projeto Voteview. Nele, a proximidade de dois congressistas mostra quão semelhantes são seus registros de votação.
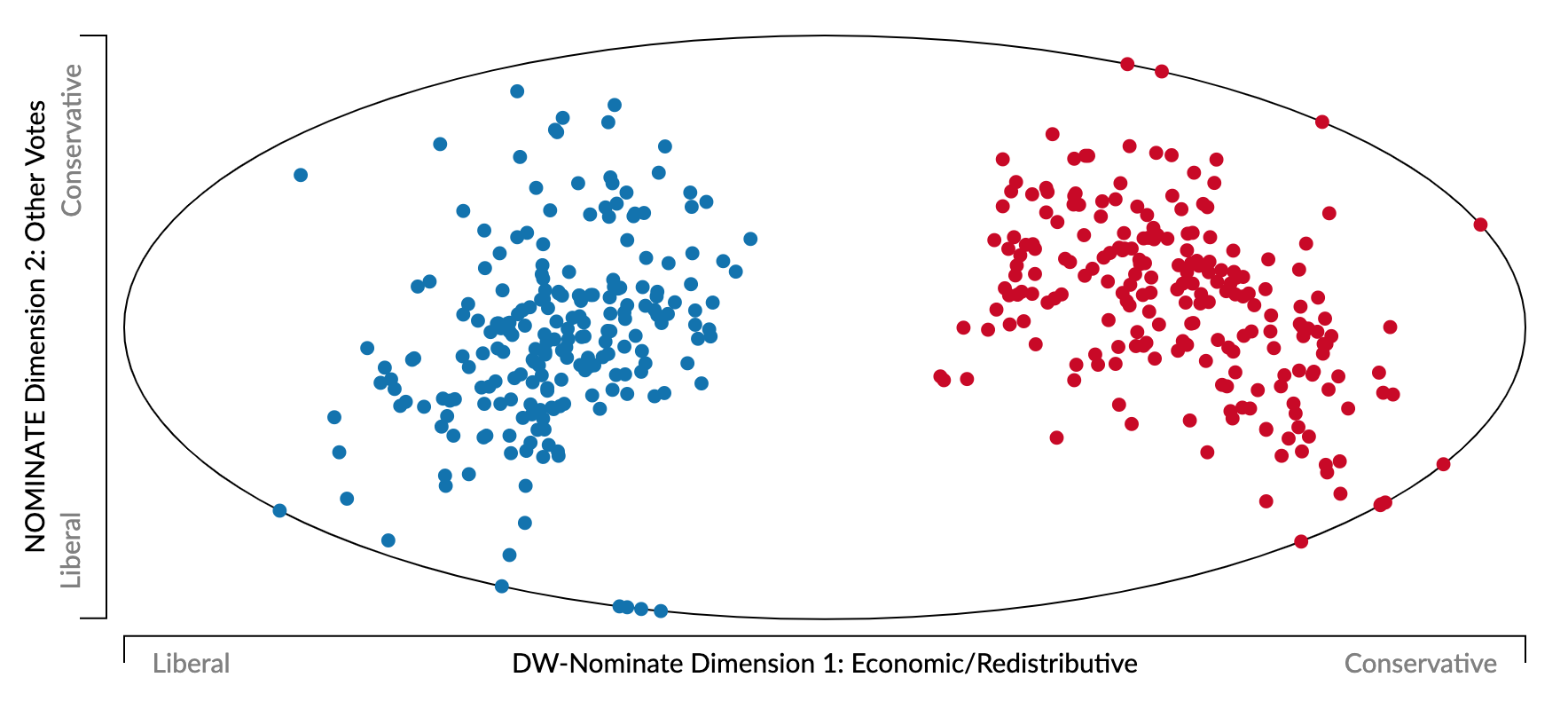
dw-nominate
Uma vez realizado o escalonamento, é possível interpretar o que significa cada dimensão em relação a um tópico específico. No caso acima, vemos que o eixo \(x\) representa a dimensão liberal-conservadora referente às votações de matérias na área econômica/redistributiva, enquanto o eixo \(y\) representa a dimensão liberal-conservadora nas demais votações realizadas. Vemos, por exemplo, que em relação ao eixo \(x\) os congressistas democratas e republicanos apresentam comportamento bastante distinto entre si.
Para o caso brasileiro, uma iniciativa similar é o Radar Parlamentar, que utiliza a análise de componentes principais (PCA) para estimação dos “pontos ideais” dos partidos em votações nominais no Congresso Nacional.
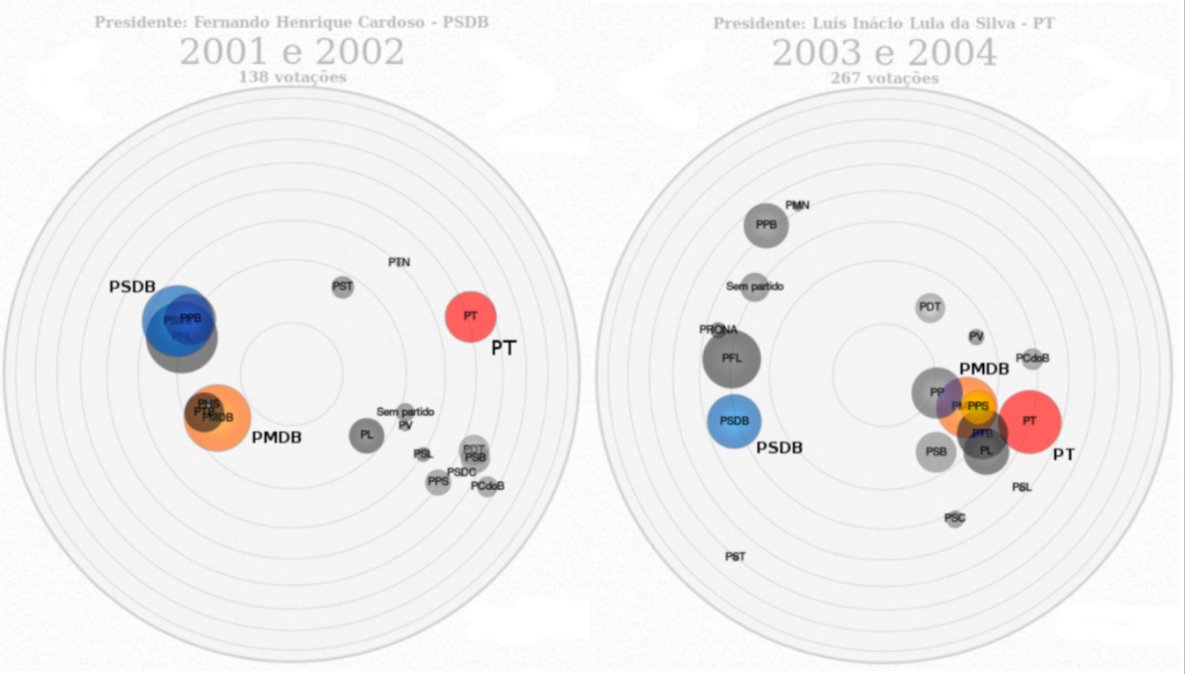
Radar Parlamentar
Note que, mesmo analisando dados de natureza similar, os pontos ideais dos partidos obtidos através das votações nominais refletem algo diferente de uma escala liberal/conservadora. Do lado esquerdo, é possível identificar o PMDB (atual MDB) com padrão de votação muito próximo do PSDB nos dois últimos anos do segundo mandato do ex-presidente Fernando Henrique Cardoso. Por sua vez, do lado direito, a análise dos dois primeiros anos do primeiro mandato do ex-presidente Luiz Inácio Lula da Silva, mostra o PMDB com padrão de votação alinhado ao PT. Logo, ao invés de identificarmos um padrão liberal/conservador ou ideológico (esquerda/direita) para o caso do eixo \(x\), identificamos um provável reflexo da relação governo-oposição que, reconhecidamente, orienta o processo decisório nacional (Leoni 2002; Zucco 2009; Limongi and Figueiredo 1998).
Como vimos até aqui, analisar o posicionamento de representantes políticos através de votações nominais é apenas uma pequena amostra da atividade no interior do parlamento. Além disso, seu resultado pode ser fruto dos incentivos promovidos pelo sistema de governo e não representar necessariamente um retrato verídico do posicionamento dos atores. Logo, o emprego da abordagem do texto como dado para a estimação de posições a partir de conteúdo político como fonte primária é uma alternativa à limitação de outras fontes.
A utilização de palavras é parte elementar de como a política se materializa.
Pode-se dizer que é no espaço entre a ação e a fala que a política reside. Antes de qualquer votação nominal, por exemplo, parlamentares discutem a matéria em plenário. Partidos apresentam suas ideias em programas. Cidadãos discutem política nas redes sociais. Em resumo, é por meio de palavras – sejam elas escritas ou faladas – que os indivíduos expressam suas preferências políticas e é através de seu uso estratégico que a política se materializa (Moreira 2020).
O emprego de técnicas que dependem quase exclusivamente de recursos computacionais tem tornado a tarefa de estimar posições políticas a partir de textos acessíveis a qualquer pesquisador. Atualmente, as duas técnicas mais populares são: o Wordscores, método de aprendizado computacional supervisionado (Laver, Benoit, and Garry 2003) e o Wordfish, método de aprendizado computacional não supervisionado (slapin_scaling_2008-1?).
8.2 Wordscores
O Wordscores é um algoritmo supervisionado para estimar posições políticas (Laver, Benoit, and Garry 2003). Nessa família de algoritmos, dados de entrada e as saídas esperadas são apresentados ao computador. Chamamos esse conjunto de entradas e saídas de training set. A partir desse conjunto de informações o algoritmo “aprende” a classificar novos documentos, o conjunto do test set.
Assim, no Wordscores temos dois conjuntos de textos. O primeiro é formado pelos textos de referência (training set). Nele temos documentos cujas posições políticas são definidas, a priori, em uma dimensão conhecida pelo analista. Essa dimensão pode estar associada à escala ideológica esquerda-direita, mas também pode refletir a relação governo-oposição, a relação entre de aprovação-desaprovação de um tema, ou outra escala qualquer que faça sentido substantivamente. O segundo conjunto é formado pelos textos cujas posições políticas são desconhecidas (test set), mas gostaríamos de conhecer.
Diante de qualquer documento, observamos apenas o número de vezes que cada palavra aparece em cada texto. De modo intuitivo, o algoritmo classifica os documentos do test set em um contínuo entre os documentos de referência (training set) a partir da similaridade da frequência relativa de palavras.
Três etapas são necessárias para implementação do Wordscores:
Escolher os textos de referência e definir quais são suas posições relativas. Essa etapa é fundamental e envolve o conhecimento substantivo do contexto no qual os dados são gerados. Em primeiro lugar, é importante que os textos de referência utilizem o mesmo léxico que os textos a serem classificados. Por exemplo, se queremos classificar discursos de parlamentares, é recomendável que os textos de referência também sejam discursos de parlamentares. Em segundo, é necessário selecionar textos que cubram todo o espectro ideológico ou a dimensão na qual os demais serão posicionados. Idealmente, é recomendável escolher textos que ocupem os extremos da escala, além da posição central. Em terceiro, os textos de referência devem possuir um conjunto diversificado de palavras. Assim, devemos evitar o uso de documentos curtos como textos de referência, porque os documentos do test set serão analisados no contexto do universo de palavras dos textos de referência (training set). Após a escolha dos textos, devemos atribuir valores às suas posições políticas. Por exemplo, se nossos textos de referência são discursos de um partido de esquerda, um de direita e um de centro, podemos respectivamente atribuir os valores de -1, 1, e 0 para cada partido. Com isso, completamos nosso training set.
A segunda etapa é gerar scores para as palavras dos textos de referência - por isso o nome WordScore 😉. Esse score é a média da posição política atribuída a priori (-1, 1 ou 0, no exemplo acima) ponderada pela probabilidade de observar um documento, dado que estamos analisando uma palavra em particular (Grimmer and Stewart 2013; Izumi and Moreira 2018).
Com o score para todas as palavras no universo dos textos de referência podemos estimar a posição política dos textos não analisados (test set). Essa terceira etapa nada mais é do que calcular o score médio das palavras ponderando pela frequência relativa de palavras em cada documento do test set. Vamos ver o exemplo contido nos tutoriais do pacote
quanteda.
Iremos aplicar o Wordscores nos manifestos das eleições federais alemãs de 2013 e 2017. Para as eleições de 2013, foram atribuídas as avaliações médias de especialistas obtidas na Pesquisa de Especialistas de Chapel Hill de 2014 para os cinco principais partidos. Através do Wordscores pode-se estimar as posições/avalições médias dos partidos políticos em 2017. Para carregar os dados será necessário realizar o download através do pacote quanteda.corpora, recomenda-se que instale os pacotes quanteda.textmodels, quanteda.textplots e quanteda.corpora através do devtools.
library(quanteda)
library(quanteda.textmodels)
library(quanteda.textplots)
library(quanteda.corpora)
# carregando dados ----
corp_ger <- quanteda.corpora::download(url = "https://www.dropbox.com/s/uysdoep4unfz3zp/data_corpus_germanifestos.rds?dl=1")A base, como é possível ver pelos metadados, possui informações sobre o documento, um resumo da estrutura lexical (tokens, setença), o ano e partido referente ao texto, e o score atribuído pelos especialistas em 2013 aos documentos dos partidos, estando vazios (NA) os valores em 2017.
| Text | Types | Tokens | Sentences | year | party | ref_score |
|---|---|---|---|---|---|---|
| AfD 2013 | 450 | 944 | 43 | 2013 | AfD | NA |
| CDU-CSU 2013 | 7615 | 46535 | 2527 | 2013 | CDU-CSU | 5.92 |
| FDP 2013 | 7953 | 42298 | 2375 | 2013 | FDP | 6.53 |
| Gruene 2013 | 13839 | 93595 | 5126 | 2013 | Gruene | 3.61 |
| Linke 2013 | 8451 | 43382 | 1850 | 2013 | Linke | 1.23 |
| SPD 2013 | 8360 | 47348 | 2532 | 2013 | SPD | 3.76 |
| AfD 2017 | 5947 | 18754 | 715 | 2017 | AfD | NA |
| CDU-CSU 2017 | 4890 | 21510 | 1256 | 2017 | CDU-CSU | NA |
| FDP 2017 | 8676 | 37609 | 1925 | 2017 | FDP | NA |
| Gruene 2017 | 13353 | 72645 | 3220 | 2017 | Gruene | NA |
| Linke 2017 | 11830 | 65728 | 2755 | 2017 | Linke | NA |
| SPD 2017 | 8400 | 41938 | 2401 | 2017 | SPD | NA |
Para aplicar o WordScores temos que processar os dados, como visto no Capítulo 6. Logo, iremos transformar o corpus em tokens, os tokens em DFM e tratar a base para remover informações não relevantes para análise (stopwords).
# tokenize
toks_ger <- tokens(corp_ger, remove_punct = TRUE)
# dfm
dfmat_ger <- dfm(toks_ger) %>%
dfm_remove(pattern = stopwords("de"))Com a base tratada e preparada, podemos utilizar o WordScores em nossa DFM através da função textmodel_wordscores() do pacote quanteda.textmodels. Como anteriormente mencionado, a base que estamos utilizando já possui um score de referência para utilizarmos como critério.
tmod_ws <- textmodel_wordscores(dfmat_ger, y = docvars(corp_ger, "ref_score"),
smooth = 1)Como é possível ver abaixo, a função classificou os termos de acordo com a classificação pré definida de 2013, mas ainda não nos deu o score dos textos por ano.
##
## Call:
## textmodel_wordscores.dfm(x = dfmat_ger, y = docvars(corp_ger,
## "ref_score"), smooth = 1)
##
## Reference Document Statistics:
## score total min max mean median
## AfD 2013 NA 455 0 23 0.01093 0
## CDU-CSU 2013 5.92 23060 0 245 0.55373 0
## FDP 2013 6.53 20603 0 186 0.49473 0
## Gruene 2013 3.61 45759 0 398 1.09879 0
## Linke 2013 1.23 21011 0 234 0.50453 0
## SPD 2013 3.76 23150 0 214 0.55589 0
## AfD 2017 NA 9899 0 108 0.23770 0
## CDU-CSU 2017 NA 10753 0 136 0.25821 0
## FDP 2017 NA 19358 0 261 0.46483 0
## Gruene 2017 NA 40982 0 1086 0.98408 0
## Linke 2017 NA 33347 0 788 0.80074 0
## SPD 2017 NA 20836 0 186 0.50032 0
##
## Wordscores:
## (showing first 30 elements)
## alternative deutschland wahlprogramm
## 3.291 4.741 3.296
## währungspolitik fordern geordnete
## 4.530 3.255 4.241
## auflösung euro-währungsgebietes braucht
## 3.337 4.241 4.153
## euro ländern schadet
## 3.329 4.227 3.912
## wiedereinführung nationaler währungen
## 4.464 4.578 4.241
## schaffung kleinerer stabilerer
## 4.289 4.426 4.241
## währungsverbünde dm darf
## 4.241 4.241 3.871
## tabu änderung europäischen
## 4.159 4.227 4.359
## verträge staat ausscheiden
## 3.553 4.792 3.698
## ermöglichen volk demokratisch
## 4.355 4.241 2.271Agora que temos os scores por termos colocados, vamos estimar a posição dos documentos
desconhecidos de 2017 através da função predict(). Nota-se que para isso, o processo
anterior é necessário.
pred_ws <- predict(tmod_ws, se.fit = TRUE, newdata = dfmat_ger)Com o objeto pred_ws podemos utilizar a função textplot_scale1d() para visualizar
os pontos ideais estimados e seus intervalos de confiança. Vemos o posicionamento do
manifesto dos partidos em 2013 e em 2017, de acordo com a estimação a partir do score
pré-estabelecido dos especialistas.
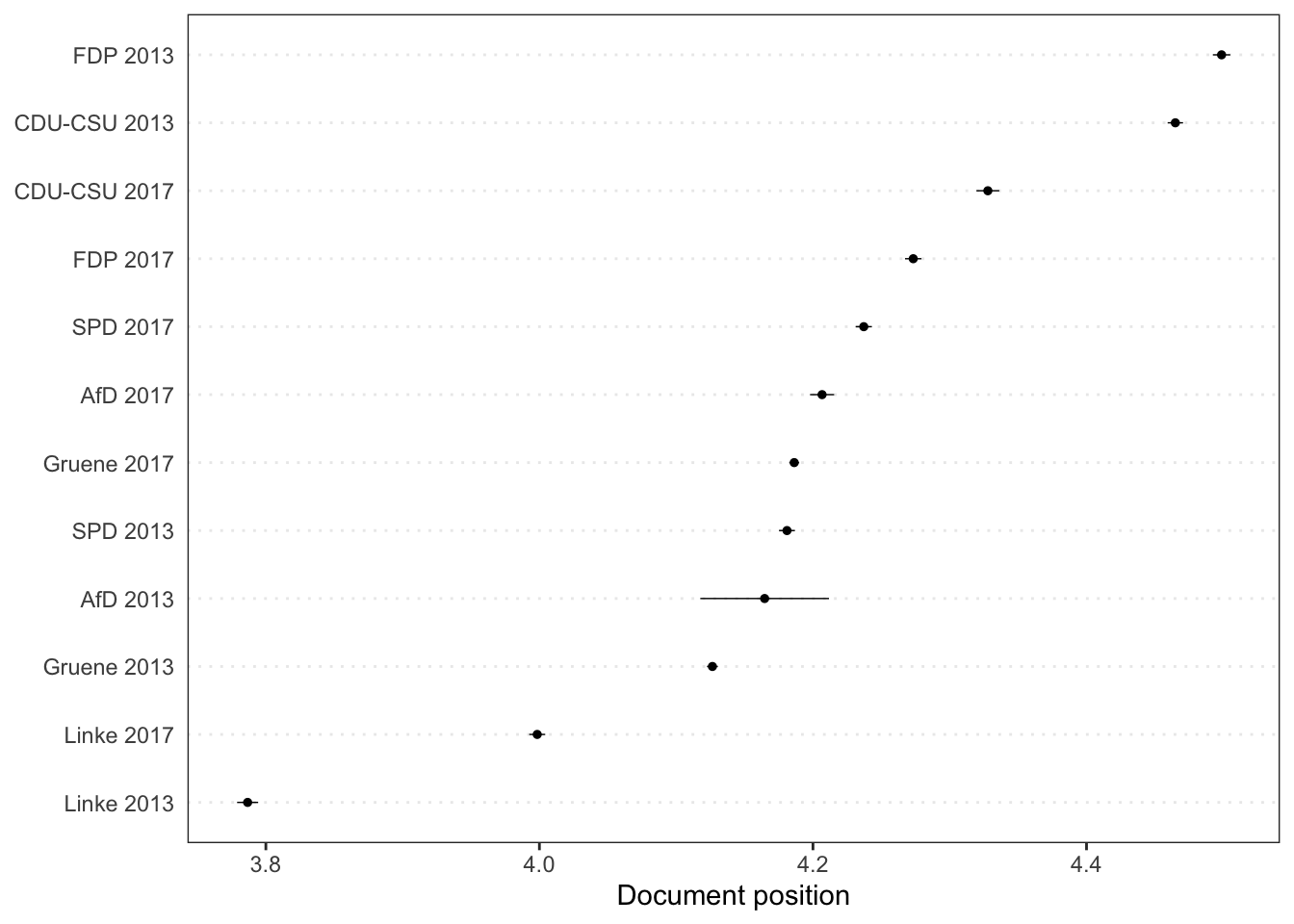
8.2.1 Críticas e potenciais problemas
Como (Izumi and Moreira 2018) apontam, embora o Wordscores constitua um grande avanço na análise quantitativa de textos, ele não é livre de problemas. Sua principal fragilidade é o fato de depender fortemente da escolha dos textos de referência (training set). É possível que com a escolha diferentes textos de referência, um mesmo pesquisador encontre resultados diferentes para um mesmo corpus. Uma segunda limitação, como apontado por (Lowe n.d.), é a possibilidade de as diferenças entre os textos estarem mais relacionadas com o estilo linguístico do autor do que com as posições políticas. Como todas as palavras adicionam a mesma quantidade de informação sobre o documento, temos que palavras politicamente relevantes em um contexto sejam igualmente ponderadas a palavras pouco informativas.
8.3 Wordfish
O segundo modelo mais popular para estimar posições políticas a partir do texto como dado é o Wordfish (slapin_scaling_2008-1?). Ao contrário do Wordscores, esse é um algoritmo não supervisionado, pois não depende da escolha de textos de referência (taining set) para realiar o escalonamento. Logo, o Wordfish não apresenta a limitação de diferentes pesquisadores chegarem a resultados distintos a partir do mesmo conjunto de dados. Outra vantagem em relação ao Wordscores é o fato de ele não atribuir o mesmo peso para todas as palavras. O Wordfish estima a importância das palavras para discriminar as posições políticas. Assim, palavras politicamente relevantes em uma dimensão têm peso maior na tarefa de localizar os documentos no espectro político.
O Wordfish é baseado em modelos da Teoria da Resposta ao Item (TRI), tal como aqueles utilizados para estimação de pontos ideais a partir de votações nominais (Clinton, Jackman, and Rivers 2004). Mas, em vez de utilizar votos nominais dados a projetos, ele opera com a frequência relativa de palavras. Nesse sentido, o pressuposto é que o uso relativo das palavras forneça informações relevantes sobre as posições políticas dos atores. Outro aspecto importante é a existência de um pressuposto de que a probabilidade de observamos uma palavra em um documento é independente da posição das outras palavras no mesmo documento. Embora esse pressuposto seja falso, ele é frequentemente utilizado na abordagem do texto como dado. Vamos conhecer mais do modelo Wordfish novamente através de um exemplo do pacote quanteda.
Nesse exemplo, serão utilzados os os discursos orçamentários irlandeses de 2010 através do objeto data_corpus_irishbudget2010 que acompanha o pacote quanteda. O processo é similar ao anterior, sendo necessária o processamento e transformação da base numa DFM.
dfmat_irish <- dfm(data_corpus_irishbudget2010, remove_punct = TRUE)Vamos então aplicar o modelo do Wordfish através da função textmodel_wordfish() presente no pacote quanteda. Para tanto, devemos indicar o argumento dir, identificação global da dimensão, para orientar a alocação dos documentos no eixo \(x\). No caso abaixo, estamos indicando os documentos de índice 6 e 5 como referência para o modelo.
tmod_wf <- textmodel_wordfish(dfmat_irish, dir = c(6,5))O modelo estima os pontos ideais dos documentos, theta (\(\theta\)), e calcula o se, que é o erro padrão da estimativa pontual theta.
|
Visualizando o resultado através da função textplot_scale1d() presente no pacote quanteda.textplots temos a posição estimada dos discursos dos parlamentares no caso da discussão sobre o orçamento irlandes sem a necessidade de um score pré definido.
textplot_scale1d(tmod_wf)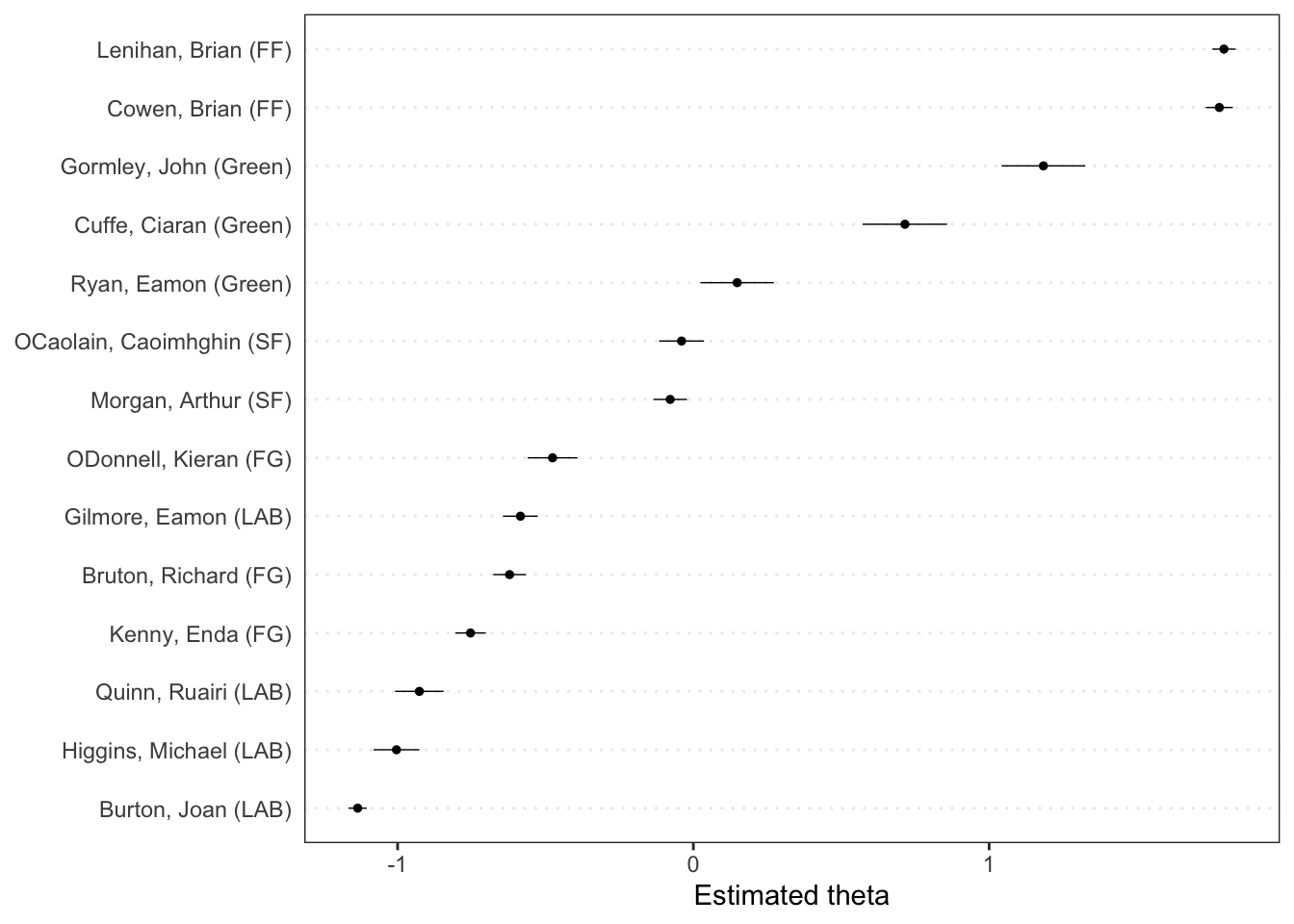
Podemos aprimorar a visualização ao agrupar os resultados por partido.
textplot_scale1d(tmod_wf, groups = docvars(dfmat_irish, "party"))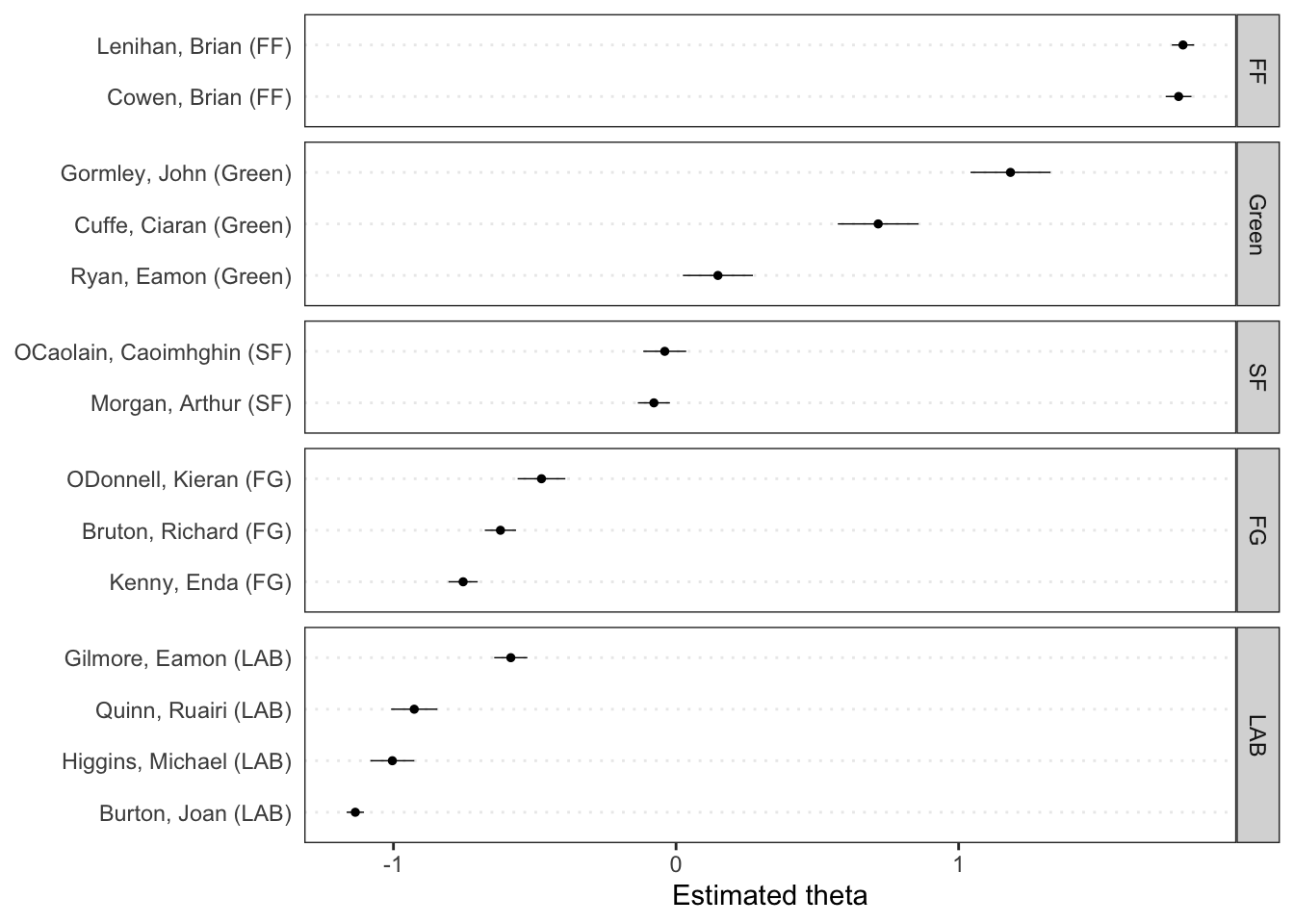
Podemos ainda visualizar a posição estimada das palavras (tokens) da nossa DFM, dando destaque para algumas selecionadas. O psi (\(\psi\)) estimado representa os efeitos fixos por palavra (estimated word fixed effects e o beta (\(\beta\)) estimado representa o efeito marginal (estimated feature marginal effects). Logo, são scores estimados e atribuídos aos termos da DFM que podemos visualizar no gráfico abaixo.
textplot_scale1d(tmod_wf, margin = "features",
highlighted = c("government", "global", "children",
"bank", "economy", "the", "citizenship",
"productivity", "deficit"))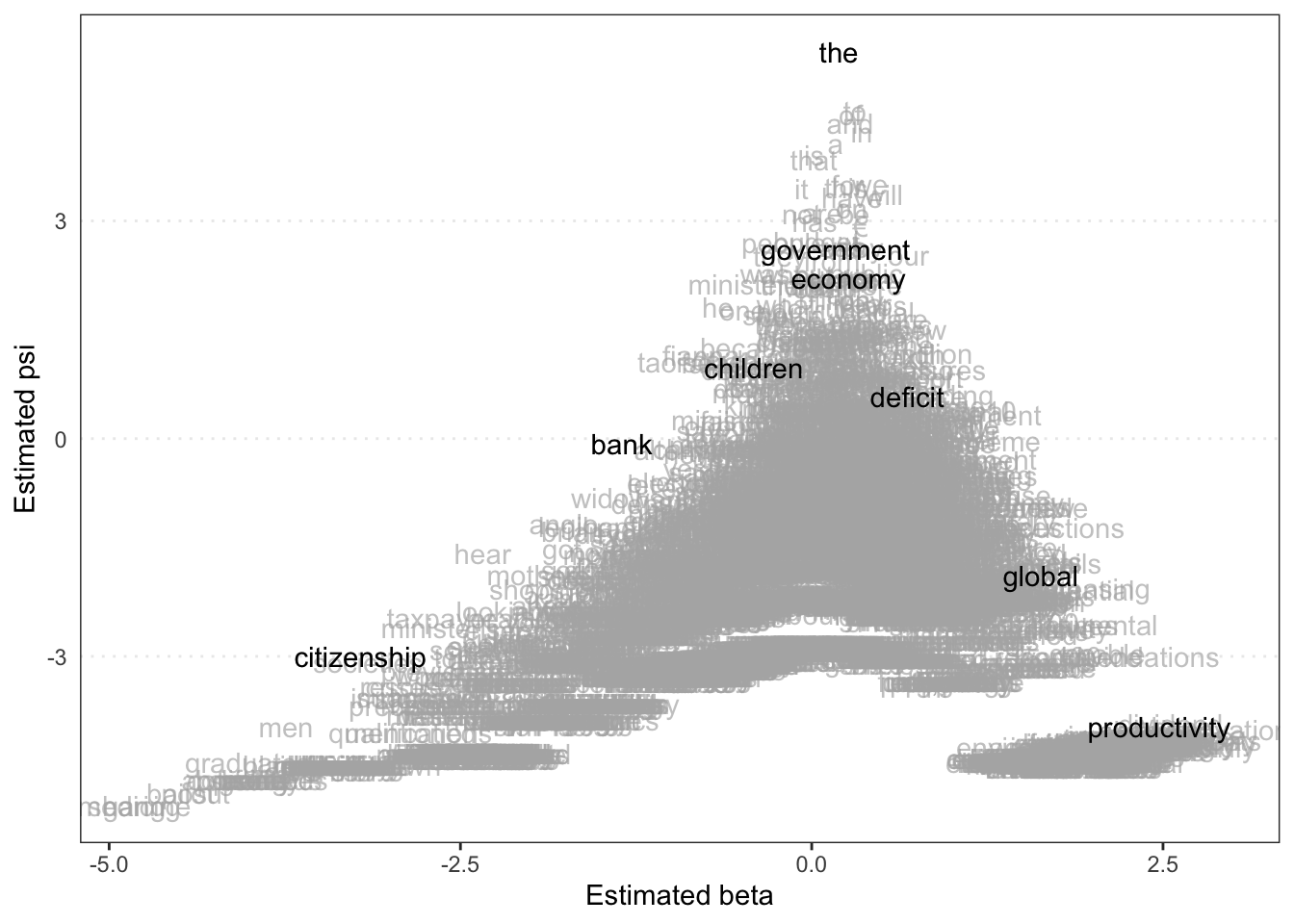
8.3.1 Críticas e potenciais problemas
A principal limitação do Wordfish para extração de posições ideológicas gerais é o fato de ele necessitar que os documentos cubram uma grande quantidade de temas para que a diversidade lexical permita a estimação de preferências políticas. Assim, se eventualmente parlamentares focarem seus discursos em determinadas áreas temáticas, como a variação no uso das palavras não será determinada pelas preferências políticas, mas pelos tópicos, a diferença nas posições estimadas também refletirá essa característica (Lauderdale and Herzog 2016) e o Wordfish não apresentará resultados consistentes com o objetivo de obter o posicionamento ideologico geral dos atores. Outro aspecto, compartilhado com o Wordscore, é a possível mudança nos resultados a depender do tratamento dado aos textos no pré-processamento.
8.4 Exercícios
Com o acervo de pronunciamentos realizados do dia de aprovação do impeachment da Presidenta Dilma Rousseff, use o Wordfish através do pacote quanteda para estimar o posicionamento dos partidos e analisar os resultados obtidos. Não se esqueça que será necessário processar os dados antes de aplicar o modelo.