Pharmacy Primer for T-SQL Database Interrogation
2021-05-22
1 Introduction
1.1 Scope
This document will focus on the three S’s of SQL-based database interrogation: syntax, schema, and strategy. Given the technical pursuits of being a SQL practitioner, this process begins with slightly more abstract theoretical material and progressively incorporates itself into the application domain (i.e., the real-world processes being analyzed). First, we will go through query examples to illustrate basic SQL syntax to help users conceptualize, execute, and interpret basic queries. Next will be gradual incorporation of query examples highlighting practical aspects of the Epic Clarity database schema, so users can begin systematically navigating this large database and tailoring SQL queries to meet specific requirements. Lastly, we will cover data strategy which incorporates more complex examples that require an ensemble of techniques.
1.2 Soapbox Disclaimer
Note that the three S’s does not include project design, data analysis, or project management in general; the bookends of any meaningful quality improvement or research project. Having virtually unlimited access to data for projects is exciting and can improve professional development and satisfaction; and I hope your SQL skills help to impact higher-level pharmacy decision-making. However, I would be remiss if I didn’t mention the hazards of data access aside from the hopefully obvious security concerns. Fortunately, for each of these hazards there’s a countermeasure:
| Hazard | Countermeasure |
|---|---|
| Disconnect between the data acquisition and design/analysis processes of a project | Establish at least a basic understanding about the project with requester (may sometimes include managing expectations and actively seeking information, even if a very specific request is made). |
| Lack of knowledge about the topic under investigation | Independently investigate the topic; dedicate time with data requester or subject matter experts (SME’s) to understand process. Projects without necessary background knowledge or SME should solicit caution; proper framing of results and managing expectations becomes more important. |
| Lack of data validation process | Apply systematic, re-iterative approach that includes use of ground truths whenever possible for observation- and aggregate-level data (e.g., results from other related internal projects with manually validated data, external literature or other benchmarks, selective chart review). Understand provenance and limitation of data points; use experience to develop understanding of “safe” situations to guide more individualized approach for different types of data projects. |
| Overreliance on query results for drawing conclusions | Exercise scientific restraint and skepticism (scientific discovery doesn’t come easily and for observational methods is not assured even with many data points and large sample sizes — bias eats sample size for breakfast). |
| Not vetting data results with stakeholders (i.e., a party who is or perceived to be affected by a change or information) | Communicate with project manager or data requester; apply situational awareness about department mission, objectives, and priorities; discuss with manager or trusted mentor. |
Database querying will play an important role in many projects, but its limitations must always be known and carefully considered by the project team. Having performed data queries for hundreds of tasks and projects, I still approach every single job with unrelenting skepticism about the data’s veracity. Not for philosophical reasons or force of habit, but because it still amazes me how hasty (or lack of) data validation for a seemingly simple data query can make the difference between very useful and completely useless results (assuming the analyst, requester, or other customer catches the mistakes!). Hopefully, this document illustrates for you the uncertainty factor with data acquisition and not only helps you obtain data, but also helps you efficiently and consistently establish confidence in your data.
1.3 What is SQL?
Structured Query Language (SQL) is a declarative programming language (user declares what is to be done, as opposed to how to do it; is supposed to be more human-readable, as opposed to more machine-readable). It is a domain-specific language, as opposed to a general-purpose language, used for managing data held in relational database management systems (RDBMS). Standard SQL is governed by ISO/IEC (ISO/IEC Joint Technical Committee 1/SC 32 2016). There were many proprietary extensions of SQL established prior to adoption of the ANSI/ISO standard (e.g., Microsoft T-SQL which will be focus of this learning material). As a result, there is significant variation across the SQL dialects and tools, albeit the core syntax of them is similar. Example SQL queries utilized in these learning materials will generally adhere to standard SQL with some exception. As a pharmacist, the difference between T-SQL and standard SQL is unlikely to be relevant, unless you are investigating SQL topics (e.g., on stackoverflow.com) or collaborating on data projects outside HFHS utilizing different SQL tools.
For SQL there are multiple “sublanguages” or categories of SQL statements: data control language (DCL) for access/security, data definition language (DDL) for creating tables or table indices, and data manipulation language (DML) for querying or modifying data. As SQL practitioners, your focus will be database interrogation, DBI (the querying of databases), as opposed to database administration, DBA (the storage and organization of data into databases). Therefore, we will be mostly learning the DML aspect of SQL (more specifically what some would call “DQL,” or data query language) with some DDL.
1.4 Microsoft SQL Server Management Studio (SSMS): Getting Started
1.4.1 Connect to Database Engine Server: Claritysnap
SSMS is the main tool for performing T-SQL queries. Assuming you have database access, the first thing to do when starting up an SSMS session is to connect to an instance of the database engine Claritysnap, the workhorse server for HFHS pharmacy SQL practitioners. Assuming the user has been granted access through the HFHS provisioning process (ask your manager if you are not aware of the process), the Connect to Database Enginge activity will use automatically Windows Authentication based on your HFHS corporate information. For instructions on establishing a database connection visit the Microsoft tutorial for this topic.
1.4.2 Connect to Relational Databases: Clarity and Warehouse
Within the Claritysnap server are two main databases that we are most concerned with: Clarity and Warehouse. Clarity is the primary production area for Epic data storage and is a relational database management system (RDBMS). Warehouse contains procured tables based on primary data from Clarity — as well as many other non-Epic data sources — and is a dimensional database managed by the HFHS Enterprise Data Warehouse (EDW) team. Think of Warehouse tables as more user-friendly, turn-key-ready versions of the Clarity source data. Besides detracting from the objective of learning SQL, the main disadvantage of Warehouse tables is determining the data provenance (i.e., the Clarity table/column sources and related manipulations) which affects reliability and confidence in the data. (That information is often documented and available but requires SQL skills to interpret anyways!) This document will use the Clarity database since it better illustrates key SQL concepts and is the primary data source, but it should be known that Warehouse tables can be very useful, particularly if the user has weak domain knowledge in the area under investigation or doesn’t have the time or skills to execute the analysis in SQL.
To successfully connect with Clarity or Warehouse and begin executing T-SQL queries, after establishing a connection to the Claritysnap server you need to establish the database context, which can be done by performing any of the following actions:
1. Use a fully qualified schema table name in your queries (clarity.dbo.<table name>).
While in a script window, select the Clarity option from the Available Databases dropdown in SSMS as shown below:
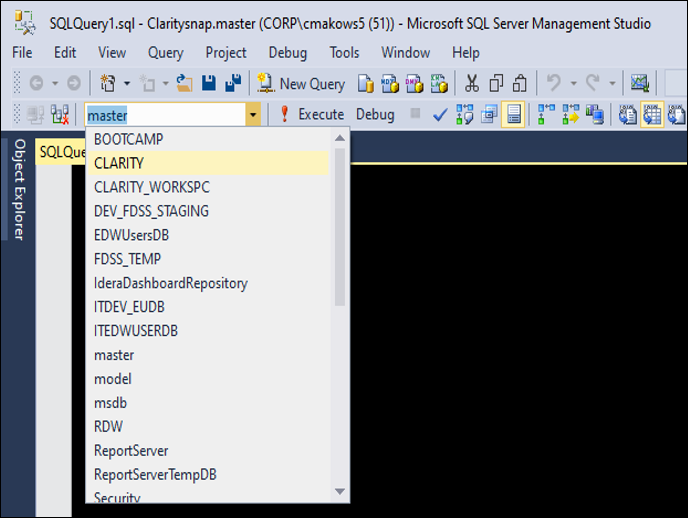
While in a script window, include the code
USE claritybefore reference to any Clarity tables (placing the command towards the top of the query script is generally a good practice).
1.4.3 Basic Environmental Customizations
There is much potential customization within SSMS. So much of programming in general is about loose conventions and community preferences. You may be ambivalent now, but once you begin coding more you’ll surely develop some preferences, or at least some tendencies. To that end, below I have included some SSMS customizations that may be immediately useful:
- Add line numbers to the query script. Useful for troubleshooting errors message which sometimes reference script line numbers or referencing code for oneself or communicating with others. Below is the menu sequence for activating this feature:
- Tools → Options → Text Editor → Transact-SQL → General → Settings (Line numbers)
- Modifying tab sizes. Helps support whatever coding style you may develop; which isn’t just relevant to SQL. This feature may sound like minutiae, but its utility will become clearer as you attempt to write more literate, easy-to-follow SQL code with systematic use of white space (note: SQL syntax is agnostic of white space; however, some programming languages actually have spacing/indentation requirements as part of their syntax). Below is the menu sequence for modifying tab sizes:
- Tools → Options → Text Editor → Transact-SQL → Tabs
- Modifying background and text fonts. Ultimately you want proper contrast between background and font colors (e.g., light gray font on black background). White background tends to be harder on the eyes. There is actual science and even more opinions available on this topic if you want to nerd out and investigate. Personally, I prefer silver or grey font against black background, with Consolas font, but I recommend that you just start adjusting the settings and develop your own opinion.
- Tools → Options → Environment → Fonts and Colors
1.5 Epic Clarity Data Dictionary
This section of the chapter deals with another valuable resource for navigating the Clarity database: the Epic Clarity Data Dictionary. Connecting to a database through Microsoft SSMS provides the keys to the car, but it does not provide a map or directions to the data. Following that metaphor, if the Epic Clarity schema is the map then the Clarity Data Dictionary is the directions. The data dictionary is simply a structured document representing standard characteristics about each Clarity table, its columns, and a variety of other information for DBIs and DBAs. It the most important single resource for Epic Clarity DBIs.
1.5.1 Accessing the Data Dictionary
The official source of the Epic Clarity Data Dictionary is actually in the Epic Production system (the same area where users access actual patient charts). I call it the “official version” because there may be compressed HTML versions (aka, .chm file) of the data dictionary in circulation. These versions are helpful for offline information and are generally similar to the data dictionary in the Epic production system. Due to occasional differences, though, I recommend working from the production version, particularly as you progress and become more reliant on schematic information from the data dictionary, plus there is information in the production version that isn’t found in the .chm versions. Below are instructions for locating the data dictionary:
Locate the Report Management area under the main Epic activity button as shown below.
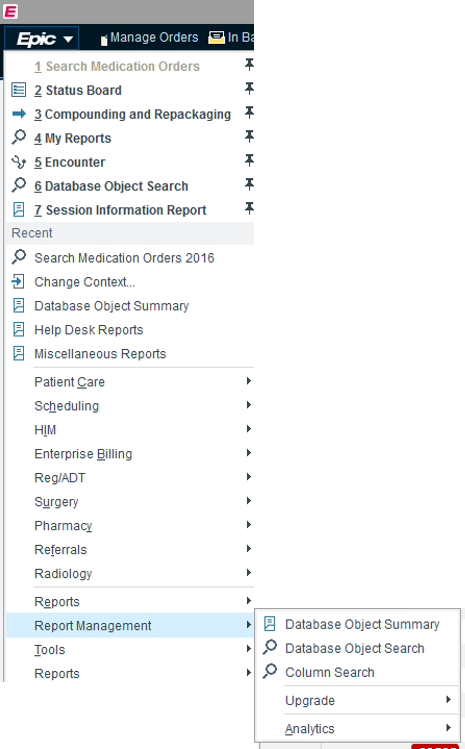
Search for database tables or other objects using one of three options below available under Report Management.
Database Object Summary: browsing from general directory.
Database Object Search: searching by table name.
Column Search: searching by column name.
1.5.2 Contents of the Data Dictionary
The anatomy of the data dictionary will make more sense as we progress through various relational database concepts. For the beginning DBI, most of the useful information is available through the left Summary tab within the Table Summary view. Below are some of the most immediately useful sections within that Summary tab:
Description: basic description of the table content. Very important when exploring and trying to determine relevance of content or better understand the Epic production system.
Primary Key: primary key information for understanding the row uniqueness of the table (to be covered more in Relational Database Schemas: Tables, Rows, Columns, and Keys).
Index Information: indexed columns for the table (to be covered more when discussing query optimization).
Column Information: definitions and relevant details about the column, including the data type, the INI item (useful for determining where this data resides in the Epic production system), and if the column has been or will be deprecated (i.e., moved to a different column or even a different table).
Foreign Key Information: foreign key information for understanding references to other tables (to be covered more in Relational Database Schemas: Tables, Rows, Columns, and Keys).
1.6 Other Useful Resources
Programming in general tends to be a very auto-didactic endeavor — learning SQL is no different. Part of supporting an effective learning routine is obviously consulting with useful references. Below are a few references I highly recommend for practicing or learning about SQL. They cover everything from official documentation of T-SQL syntax to practical querying techniques to solutions within the SQL community for various problems.
General SQL References
- Microsoft Transact-SQL Reference (Database Engine).
- Itzik Ben-Gan
- T-SQL Fundamentals (Ben-gan 2016)
- T-SQL Querying (Developer Reference) (Ben-gan 2015)
- Would recommend this title if you were to pick one
- T-SQL Window Functions: For data analysis and beyond (Developer Reference) (Ben-gan 2019)
- More advanced title
- SQL for Smarties: Advanced SQL Programming by Joe Celko (Celko 2014)
- Much more advanced title.
SQL Tutorials
Troubleshooting/FAQs
- Stack Exchange Network: Stack Overflow.
- Quality Google search will point to various SQL blogs (not worth referencing them all, since their utility depends on the topic or question).