1 R语言基础
As the Cantonese say, yauh peng, yauh leng, which means “both inexpensive and beautiful.” Why use anything else?1
1.1 R基本对象和属性
1.1.1 工作环境
如何获取当前工作路径,以及当前环境中有哪些对象,还有你这个工作路径中还有什么其他文件.在RStudio中,设置路径可以用Ctrl+Shift+h或者点击Session > Set Working Directory > Choose Directory
setwd(path) # 设置路径
setwd("d:\\rfiles\\myfiles") # 第一种格式
setwd("d:/rfiles/myfiles") # 第二种格式
setwd("..") # 设置到上一级
setwd('weibo') # 设置到下一级,如果当前路径存在这样一个文件夹
getwd() # 得到路径
ls() # 查看当前环境的变量然后我比较常用的两个命令,一个是清空当前环境中所有对象,一个是清屏(把代码清理掉,看着舒服),但好像是在RStudio里面的快捷键,是Crtl+L.
rm(list = ls()) # 清空当前环境所有对象1.1.2 R语言赋值符号
R语言接受 <-和=两个赋值符号,但是最好使用前者,因为“<-是固定只有赋值一种功能,而=是赋值加指定参数两个功能。这两个混用报错的情况见链接.
1.1.3 五种基本对象
我们在 R 语言里所操作和接触的所有东西 ,都被叫做对象(object),R 语言有五种最基本的对象 ,它们是最底层、最基础的对象.
- 字符型(character)
- 数值型(numeric)
- 整型(integer)
- 复数型(complex number)
- 逻辑型(logical)(True/False)
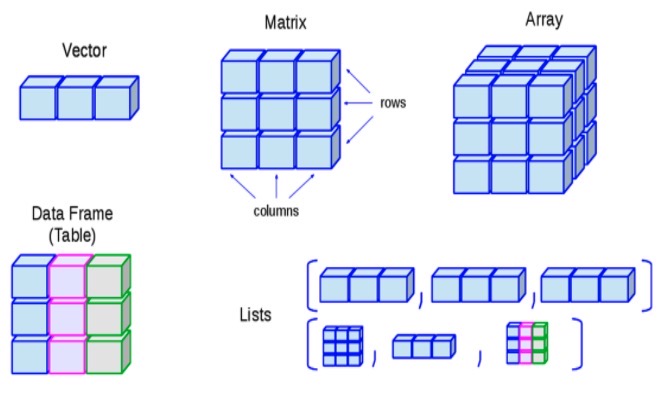
最基本的对象就是向量了,可以用vector()函数创建一个空向量,向量只能包含相同类型(class)元素,但列表里可以装不同类型的元素.每个对象有不同的用法,具体看这个菜鸟R语言教程.大体如下图.
# 查看对象种类
typeof(1)
## [1] "double"
typeof(1L)
## [1] "integer"1.1.4 特殊对象
- Inf:无穷大,当然也可以得到负无穷大.
- NaN(Not a Number):缺失值,或者未定义的数,比如0/0.
- NA(Not available):也是缺失值,一般需要数据处理删去这种东西.
- NaN是NA,NA不是NaN
1/0 # Inf
## [1] Inf
0/0 # NaN
## [1] NaNNA的一些操作
a <- NA # NA
class(a)
## [1] "logical"
length(a)
## [1] 1
NA > 5
## [1] NA
10 == NA
## [1] NA
NA + 10
## [1] NA
NA / 2
## [1] NA
NA == NA # 疑惑
## [1] NA对于最后的一个操作的一种解释,这个例子来自R for data science
# Let x be Mary's age. We don't know how old she is.
x <- NA
# Let y be John's age. We don't know how old he is.
y <- NA
# Are John and Mary the same age?
x == y
## [1] NA1.2 R语言基础算术
数字加减乘除,取余数等
123 + 569 # 相加
## [1] 692
123 - 5 #相减
## [1] 118
12*5 # 乘法
## [1] 60
12^5 # 乘方
## [1] 248832
sqrt(2) # 开根号
## [1] 1.414214除法涉及整除和取余数
22/5 # 除法
## [1] 4.4
22 %/% 5 # 整除
## [1] 4
22 %% 5 # 整除求余
## [1] 21.3 对象的属性
R语言中对象可以有属性,但有些对象没有属性,一般常见的属性有:
- 名称(names)、维度名称(dimnames)
- 维度(dimensions)
- 类(class)
- 长度(length)
- 用户自定义的属性(一般是包里面的对象)
如果要查看一个对象的属性,调用函数attribute()即可.下面是一个矩阵的例子,矩阵按列排的.
c <- matrix(c(1:12),nrow = 3,ncol = 4)
c
## [,1] [,2] [,3] [,4]
## [1,] 1 4 7 10
## [2,] 2 5 8 11
## [3,] 3 6 9 12
attributes(c)
## $dim
## [1] 3 41.3.1 因子对象
分类型数据(category data)经常要把数据分成不同的水平或因子(factor)。比如,学生的性别包含男和女两个因子。因子代表变量的不同可能的水平(即使在数据中不出现)。在统计模型统计分析中十分有用,例如将0,1转换为’yes’,’no’就很方便,在R里可以使用factor函数来创建因子,函数形式如下
factor(x = character(), levels, labels = levels, exclude = NA, ordered = is.ordered(x))
# 无序
factor(c("女","男","男","女","女","女","男"))
## [1] 女 男 男 女 女 女 男
## Levels: 男 女
# 有序因子
score <- c("B","C","D","B","A","D","A")
ordered(score,levels=c("D","C","B","A"))
## [1] B C D B A D A
## Levels: D < C < B < AReferences
R Programming for Data Science by Roger D. Peng↩︎
Here is the citation. See (茆诗松, 王静龙, and 濮晓龙 2006)↩︎