Chapter 2 Comparative survey research
Cross-national and cross-cultural comparative surveys are a very important resource for the Social Sciences. According to the Overview of Comparative Surveys Worldwide, more than 90 cross-national comparative surveys have been conducted around the world since 1948.
Even though surveys can aim to fulfill different purposes, generally they aim to estimate population means, totals or distributions or relationships between variables. A comparative survey will aim to compare these levels or relationships across groups (national or otherwise).
](bar_graph.png)
Figure 2.1: Comparative percentages by country regarding immigration tolerance, from the European Social Survey Round 7. Source: Dimiter Toshkov 2020
Figure 2.1 shows a rather common application of a comparative survey. The groups, in this case European countries, are compared on their percentage shares on the answer to the question about allowing more immigrants.
However, what we see in this graph is only the final abstraction of very long process that typically surveys, and most particularly cross-national surveys, must go through. This process is sometimes called survey lifecycle and goes from design to dissemination.
](lifecycle.png)
Figure 2.2: Survey Lifecycle. Source: Cross Cultural Survey Guidelines
2.1 Survey Error
Survey error is any error arising from the survey process that contributed to the deviation of an estimate from its true parameter values. (Biemer 2016)
But regardless of how much we can try to prevent it, survey errors in one form or another will always occur. And survey errors might affect the estimates and their comparability.
This applies both to when we compare data from different surveys and comparisons of sub-groups within the same survey.
The comparability of survey measurements is an issue that should be thoughtfully considered before drawing substantive conclusions from comparative surveys.
](trump_pence.jpg)
Figure 2.3: Slighty problematic survey question. Source: badsurveyq
Survey error can be classified in two components:
Random error is caused by any factors that randomly affect measurement of the variable
Systematic error is caused by any factors that systematically affect measurement of the variable
Survey group comparability problems come from systematic error or “Bias”1.
What is particular about comparative surveys is that there are at least two different survey statistics. Therefore, each one of these statistics is subject to different sources of error. If the overall statistics are differently affected by the error, this will cause some form of “bias” in the comparison.
In other words, besides substantive differences between survey statistics, there might be systematic differences caused by survey error.
2.2 Total Survey Error framework
Total survey error is the accumulation of all errors that may arise in the design, collection, processing and analysis of survey data.
The Total Survey Error offers an elegant framework to describe survey errors and the several sources of error that are rooted within the survey lifecycle.
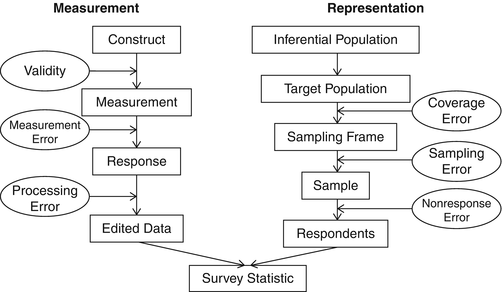
Figure 2.4: Source: Groves and Lyberg (2010)
As it can be seen in figure 2.4, there is a “representation” and a “measurement” side.
Systematic representation errors include:
- coverage error
- sampling error
- nonresponse
Systematic error in measurement include:
- validity
- processing
- measurement error
Measurement error includes: response error, interviewer-induced response effects, social desirability, methods effects, response styles.
Here we will focus on the Measurement side
2.3 The “Bias” framework
The TSE error classification is analogous to the “Bias” framework in the field of cross-cultural psychology. Under this framework, Vijver and Leung (1997) distinguished between “construct”, “item”, and “method” bias which are essencially similar to the TSE’s validity, measurement error and all the remaining errors.
The bias framework is developed from the perspective of cross-cultural psychology and attempts to provide a comprehensive taxonomy of all systematic sources of error that can challenge the inferences drawn from cross-cultural studies (Vijver and Leung 1997, 2000; Van de Vijver and Poortinga 1997; Vijver and Tanzer 2004).
2.3.1 Construct Bias
Construct bias is present if the underlying construct measured is not the same across cultures.
- It can occur if a construct is differently defined or only has a partial overlap across cultural groups.
Example:
Varying definitions of happiness in Western and East Asian cultures (Uchida, Norasakkunkit, and Kitayama 2004). In Western cultures, happiness tends to be defined in terms of individual achievement, whereas in East Asian cultures happiness is defined in terms of interpersonal connectedness.
2.3.2 Method Bias
Sample Bias: is the incomparability of samples due to cross-cultural variations in characteristics, such as different educational levels, students versus the general population, and urban versus rural residents
Instrument bias: involves systematic errors derived from instrument characteristics such as self-report bias in Likert-type scale measures. The systematic tendency of respondents to endorse certain response options on some basis other than the target construct (i.e., response styles) may affect the validity of cross- cultural comparisons (Herk, Poortinga, and Verhallen 2004).
Administration Bias: stems from administration conditions (e.g., data collection modes, group versus individual assessment), ambiguous instructions, interaction between administrators and respondents (e.g., halo effects), and communication problems (e.g., language differences, taboo topic).
2.3.3 Item Bias
Occurs when an item has a different meaning across cultures. An item of a scale is biased if persons with the same target trait level, but coming from different cultures, are not equally likely to endorse the item (Vijver and Leung (1997); Vijver (2013)).
Item bias can arise from poor translation, inapplicability of item contents in different cultures, or from items that trigger additional traits or have words with ambiguous connotations.
2.4 Preventing survey comparability problems
Following the TSE framework, the best way to reduce eventual comparability issues in survey data is to reduce the survey error to the very minimum and assuring that the persistent errors are most likely similar across the groups.
There is a vast literature discussing how to reduce TSE. However, two issues are particularly relevant to cross-cultural/national surveys.
2.4.1 Translation
TRAPD - Translation, Review, Adjudication, Pretesting, and Documentation
This method was proposed by Harkness, Vijver, and Mohler (2003)
Team approach to survey translation:
- Translators produce, independently from each other, initial translations
- Reviewers review translations with the translators
- Adjudicator (one or more) decides whether the translation is ready
- Pretesting is the next step before going out to the field
- Documentation should be constant during the entire process
2.4.2 Question coding system: SQP
It offers an additional way to check question comparability by taking into account the different characteristics of the questions in the original and adapted versions.
References
Biemer, Paul P. 2016. “Total Survey Error Paradigm: Theory and Practice.” In The Sage Handbook of Survey Methodology, 122–41. London: SAGE Publications Ltd. https://doi.org/10.4135/9781473957893.n10.
Groves, R. M., and L. Lyberg. 2010. “Total Survey Error: Past, Present, and Future.” Public Opinion Quarterly 74 (5): 849–79. https://doi.org/10.1093/poq/nfq065.
Harkness, Janet A., Fons J. R. van de Vijver, and Peter Ph. Mohler. 2003. Cross-Cultural Survey Methods. Hoboken, NJ: Wiley.
Herk, Hester van, Ype H Poortinga, and Theo M M Verhallen. 2004. “Response Styles in Rating Scales: Evidence of Method Bias in Data From Six EU Countries.” Journal of Cross-Cultural Psychology 35 (3): 346–60. https://doi.org/10.1177/0022022104264126.
Uchida, Yukiko, Vinai Norasakkunkit, and Shinobu Kitayama. 2004. “Cultural Constructions of Happiness: Theory and Empirical Evidence.” Journal of Happiness Studies 5 (February): 223–39. https://doi.org/10.1007/s10902-004-8785-9.
Van de Vijver, Fons, and Ype Poortinga. 1997. “Towards an Integrated Analysis of Bias in Cross-Cultural Assessment.” European Journal of Psychological Assessment 13 (January): 29–37. https://doi.org/10.1027/1015-5759.13.1.29.
Vijver, Fons J R van de. 2013. “Item Bias.” Major Reference Works. https://doi.org/doi:10.1002/9781118339893.wbeccp309.
Vijver, Fons J R van de, and Kwok Leung. 1997. Methods and data analysis for cross-cultural research. Cross-Cultural Psychology Series, Vol 1. Thousand Oaks, CA, US: Sage Publications, Inc.
Vijver, Fons J R van de, and Kwok Leung. 2000. “Methodological issues in psychological research on culture.” Journal of Cross-Cultural Psychology 31 (1): 33–51. https://doi.org/10.1177/0022022100031001004.
Vijver, Fons van de, and Norbert K Tanzer. 2004. “Bias and equivalence in cross-cultural assessment: An overview.” European Review of Applied Psychology / Revue Européenne de Psychologie Appliquée 54 (2): 119–35. https://doi.org/10.1016/j.erap.2003.12.004.
systematic error and “Bias” are terms used interchangeably in the literature and they refer to deviations that are not due to chance alone.↩︎