library(tidyverse)
library(PNWColors)
library(patchwork)
library(ggExtra)
library(brms)
library(tidybayes)
library(GGally)
library(ggridges)21 Dichotomous Predicted Variable
This chapter considers data structures that consist of a dichotomous predicted variable. The early chapters of the book were focused on this type of data, but now we reframe the analyses in terms of the generalized linear model…
The traditional treatment of these sorts of data structure is called “logistic regression.” In Bayesian software it is easy to generalize the traditional models so they are robust to outliers, allow different variances within levels of a nominal predictor, and have hierarchical structure to share information across levels or factors as appropriate. (Kruschke, 2015, pp. 621–622)
21.1 Multiple metric predictors
“We begin by considering a situation with multiple metric predictors, because this case makes it easiest to visualize the concepts of logistic regression” (p. 623).
The 3D wireframe plot in Figure 21.1 is technically beyond the scope of our current ggplot2 paradigm. But we will discuss an alternative in the end of Section 21.1.2.
21.1.1 The model and implementation in JAGS brms.
Load the primary packages.
Our statistical model will follow the form
\[\begin{align*} \mu & = \operatorname{logistic}(\beta_0 + \beta_1 x_1 + \beta_2 x_2) \\ y & \sim \operatorname{Bernoulli}(\mu) \end{align*}\]
where
\[\operatorname{logistic}(x) = \frac{1}{[1 + \exp(-x)]}.\]
The generic brms code for logistic regression using the Bernoulli likelihood looks like so.
fit <- brm(
data = my_data,
family = bernoulli,
y ~ 1 + x1 + x2,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b)))Note that this syntax presumes the predictor variables have already been standardized.
We’d be remiss not to point out that you can also specify the model using the binomial distribution. That code would look like this.
fit <- brm(
data = my_data,
family = binomial,
y | trials(1) ~ 1 + x1 + x2,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b)))As long as the data are not aggregated, the results of these two should be the same within simulation variance. In brms, the default link for both family = bernoulli and family = binomial models is logit, which is exactly what we want, here. Also, note the additional | trials(1) syntax on the left side of the model formula. You could get away with omitting this in older versions of brms. But newer versions prompt users to specify how many of trials each row in the data represents. This is because, as with the baseball data we’ll use later in the chapter, the binomial distribution includes an \(n\) parameter. When working with un-aggregated data like what we’re about to do, below, it’s presumed that \(n = 1\).
We won’t be making our version of Figure 21.1 until a little later in the chapter. However, we can go ahead and make our version of the model diagram in Kruschke’s Figure 21.2. Before we do, let’s discuss the issues of plot colors and theme. For this chapter, we’ll take our color palette from the PNWColors package (Lawlor, 2020), which provides color palettes inspired by the beauty of my birthplace,the US Pacific Northwest. Our color palette will be "Mushroom".
pm <- pnw_palette(name = "Mushroom", n = 8)
pm
Our overall plot theme will be a "Mushroom" infused extension of theme_linedraw().
theme_set(
theme_linedraw() +
theme(text = element_text(color = pm[1]),
axis.text = element_text(color = pm[1]),
axis.ticks = element_line(color = pm[1]),
legend.background = element_blank(),
legend.box.background = element_blank(),
legend.key = element_rect(fill = pm[8]),
panel.background = element_rect(color = pm[8], fill = pm[8]),
panel.border = element_rect(colour = pm[1]),
panel.grid = element_blank(),
strip.background = element_rect(fill = pm[1], color = pm[1]),
strip.text = element_text(color = pm[8]))
)Now make Figure 21.2.
# Normal density
p1 <- tibble(x = seq(from = -3, to = 3, by = 0.1)) |>
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = pm[5]) +
annotate(geom = "text",
x = 0, y = 0.2,
label = "normal",
color = pm[1], size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = 0.6,
label = c("italic(M)[0]", "italic(S)[0]"),
color = pm[1], family = "Times", hjust = 0, parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = "white", fill = pm[8], linewidth = 1))
# Second normal density
p2 <- tibble(x = seq(from = -3, to = 3, by = 0.1)) |>
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = pm[5]) +
annotate(geom = "text",
x = 0, y = 0.2,
label = "normal",
color = pm[1], size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = 0.6,
label = c("italic(M[j])", "italic(S[j])"),
color = pm[1], family = "Times", hjust = 0, parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = "white", fill = pm[8], linewidth = 1))
## An annotated arrow
# Save our custom arrow settings
my_arrow <- arrow(angle = 20, length = unit(0.35, "cm"), type = "closed")
p3 <- tibble(x = 0.5,
y = 1,
xend = 0.85,
yend = 0) |>
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow, color = pm[1]) +
annotate(geom = "text",
x = 0.55, y = 0.4,
label = "'~'",
color = pm[1], family = "Times", parse = TRUE, size = 10) +
xlim(0, 1) +
theme_void()
# Another annotated arrow
p4 <- tibble(x = 0.5,
y = 1,
xend = 1/3,
yend = 0) |>
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow, color = pm[1]) +
annotate(geom = "text",
x = c(0.3, 0.48), y = 0.4,
label = c("'~'", "italic(j)"),
color = pm[1], family = "Times", parse = TRUE, size = c(10, 7)) +
xlim(0, 1) +
theme_void()
# Likelihood formula
p5 <- tibble(x = 0.5,
y = 0.5,
label = "logistic(beta[0]+sum()[italic(j)]~beta[italic(j)]~italic(x)[italic(ji)])") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# A third annotated arrow
p6 <- tibble(x = c(0.375, 0.6),
y = c(1/2, 1/2),
label = c("'='", "italic(i)")) |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = c(10, 7)) +
geom_segment(x = 0.5, xend = 0.5,
y = 1, yend = 0,
arrow = my_arrow) +
xlim(0, 1) +
theme_void()
# Bar plot of Bernoulli data
p7 <- tibble(x = 0:1,
d = (dbinom(x, size = 1, prob = 0.6)) / max(dbinom(x, size = 1, prob = 0.6))) |>
ggplot(aes(x = x, y = d)) +
geom_col(fill = pm[5], width = 0.4) +
annotate(geom = "text",
x = 0.5, y = 0.2,
label = "Bernoulli",
color = pm[1], size = 7) +
annotate(geom = "text",
x = 0.5, y = 0.94,
label = "mu[italic(i)]",
color = pm[1], family = "Times", parse = TRUE, size = 7) +
xlim(-0.75, 1.75) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = pm[8], fill = pm[8]))
# The final annotated arrow
p8 <- tibble(x = c(0.375, 0.625),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)")) |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = c(10, 7)) +
geom_segment(x = 0.5, xend = 0.5,
y = 1, yend = 0,
arrow = my_arrow, color = pm[1]) +
xlim(0, 1) +
theme_void()
# Some text
p9 <- tibble(x = 1,
y = 0.5,
label = "italic(y[i])") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = 7) +
xlim(0, 2) +
theme_void()
# Define the layout
layout <- c(
area(t = 1, b = 2, l = 1, r = 2),
area(t = 1, b = 2, l = 3, r = 4),
area(t = 3, b = 3, l = 1, r = 2),
area(t = 3, b = 3, l = 3, r = 4),
area(t = 4, b = 4, l = 1, r = 4),
area(t = 5, b = 5, l = 2, r = 3),
area(t = 6, b = 7, l = 2, r = 3),
area(t = 8, b = 8, l = 2, r = 3),
area(t = 9, b = 9, l = 2, r = 3))
# Combine, adjust, and display
(p1 + p2 + p3 + p4 + p5 + p6 + p7 + p8 + p9) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))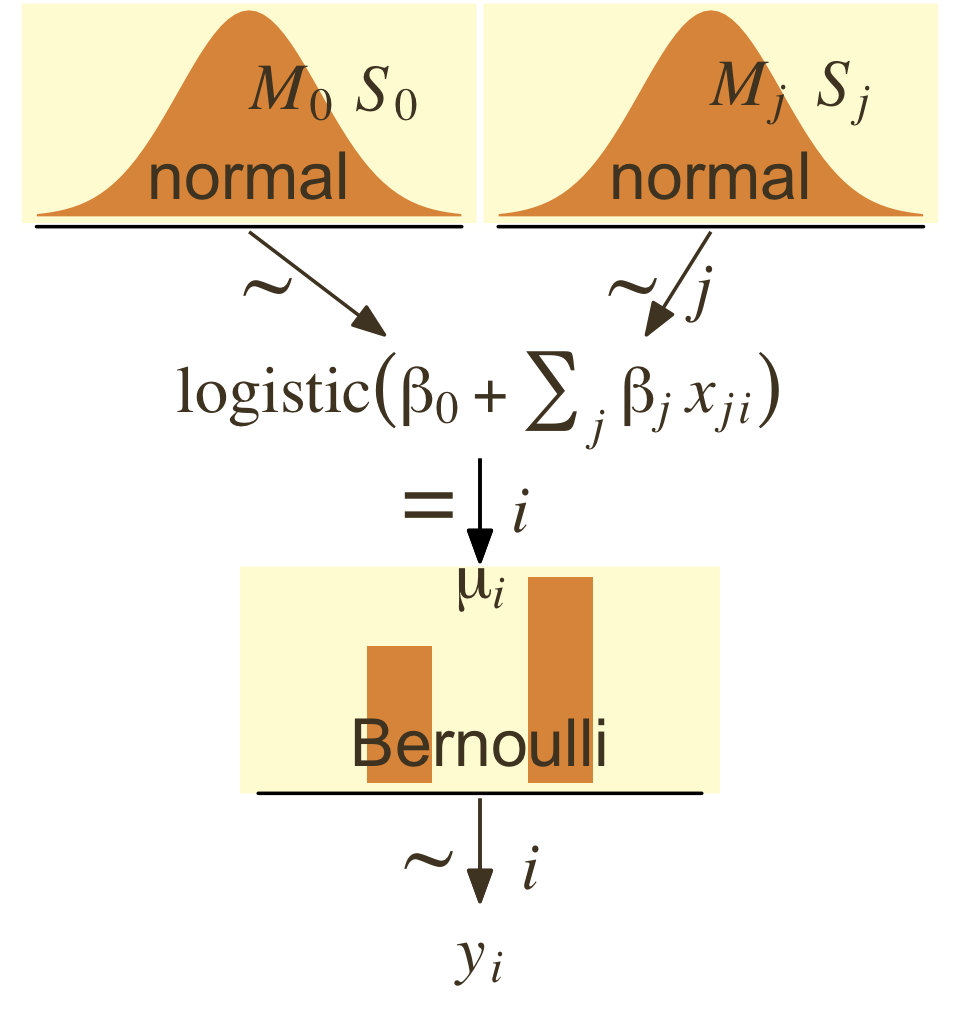
21.1.2 Example: Height, weight, and gender.
Load the height/weight data.
my_data <- read_csv("data.R/HtWtData110.csv")
glimpse(my_data)Rows: 110
Columns: 3
$ male <dbl> 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, …
$ height <dbl> 63.2, 68.7, 64.8, 67.9, 68.9, 67.8, 68.2, 64.8, 64.3, 64.7, 66.…
$ weight <dbl> 168.7, 169.8, 176.6, 246.8, 151.6, 158.0, 168.6, 137.2, 177.0, …Let’s standardize our predictors.
my_data <- my_data |>
mutate(height_z = (height - mean(height)) / sd(height),
weight_z = (weight - mean(weight)) / sd(weight))Before we fit a model, we might take a quick look at the data to explore the relations among the continuous variables weight and height and the dummy variable male. The ggMarginal() function from the ggExtra package (Attali & Baker, 2022) will help us get a sense of the multivariate distribution by allowing us to add marginal densities to a scatter plot.
p <- my_data |>
ggplot(aes(x = weight, y = height, fill = male == 1)) +
geom_point(aes(color = male == 1),
alpha = 3/4) +
scale_color_manual(values = pm[c(3, 6)]) +
scale_fill_manual(values = pm[c(3, 6)]) +
theme(legend.position = "none")
p |>
ggMarginal(data = my_data,
alpha = 0.8,
colour = pm[1],
groupFill = TRUE,
type = "density")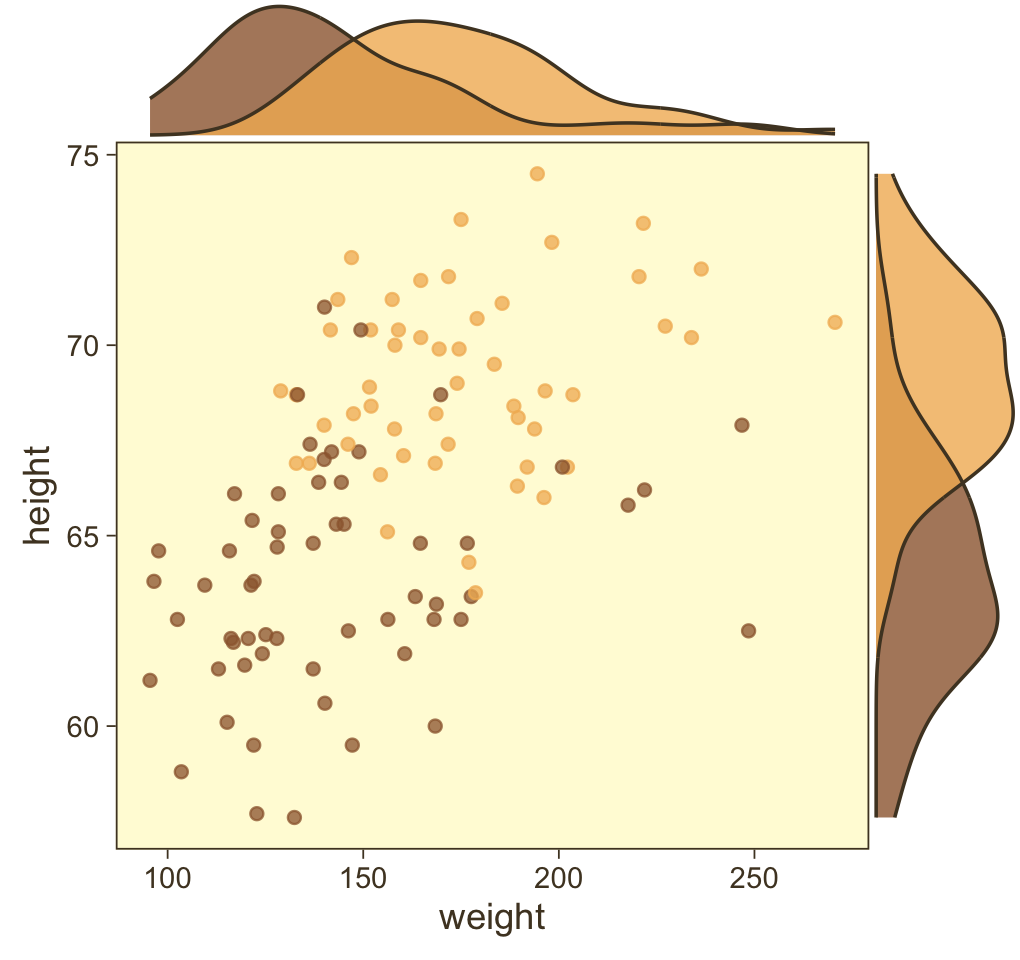
Looks like the data for which male == 1 are concentrated in the upper right and those for which male == 0 are more so in the lower left. What we’d like is a model that would tell us the optimal dividing line(s) between our male categories with respect to those predictor variables.
Our first logistic model with family = bernoulli uses only weight_z as a predictor.
fit21.1 <- brm(
data = my_data,
family = bernoulli,
male ~ 1 + weight_z,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b)),
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
file = "fits/fit21.01")Here’s the model summary.
print(fit21.1) Family: bernoulli
Links: mu = logit
Formula: male ~ 1 + weight_z
Data: my_data (Number of observations: 110)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.08 0.22 -0.50 0.34 1.00 6604 5167
weight_z 1.18 0.27 0.67 1.74 1.00 6028 5132
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).Now let’s get ready to make our version of Figure 21.3. First, we extract the posterior draws.
draws <- as_draws_df(fit21.1)Now we wrangle a bit to make the top panel of Figure 21.3.
length <- 200
n_draw <- 20
set.seed(21)
draws |>
# Take 20 random samples of the posterior draws
slice_sample(n = n_draw) |>
# Add in a sequence of weight_z
expand_grid(weight_z = seq(from = -2, to = 3.5, length.out = length)) |>
# Compute the estimates of interest
mutate(male = plogis(b_Intercept + b_weight_z * weight_z),
weight = weight_z * sd(my_data$weight) + mean(my_data$weight),
thresh = -b_Intercept / b_weight_z * sd(my_data$weight) + mean(my_data$weight)) |>
# Plot
ggplot(aes(x = weight)) +
geom_hline(yintercept = 0.5, color = pm[7], linewidth = 1/2) +
geom_vline(aes(xintercept = thresh, group = .draw),
color = pm[6], linetype = 2, linewidth = 2/5) +
geom_line(aes(y = male, group = .draw),
alpha = 2/3, color = pm[1], linewidth = 1/3) +
geom_point(data = my_data,
aes(y = male),
alpha = 1/3, color = pm[1]) +
labs(y = "male",
title = "Data with Post. Pred.") +
coord_cartesian(xlim = range(my_data$weight))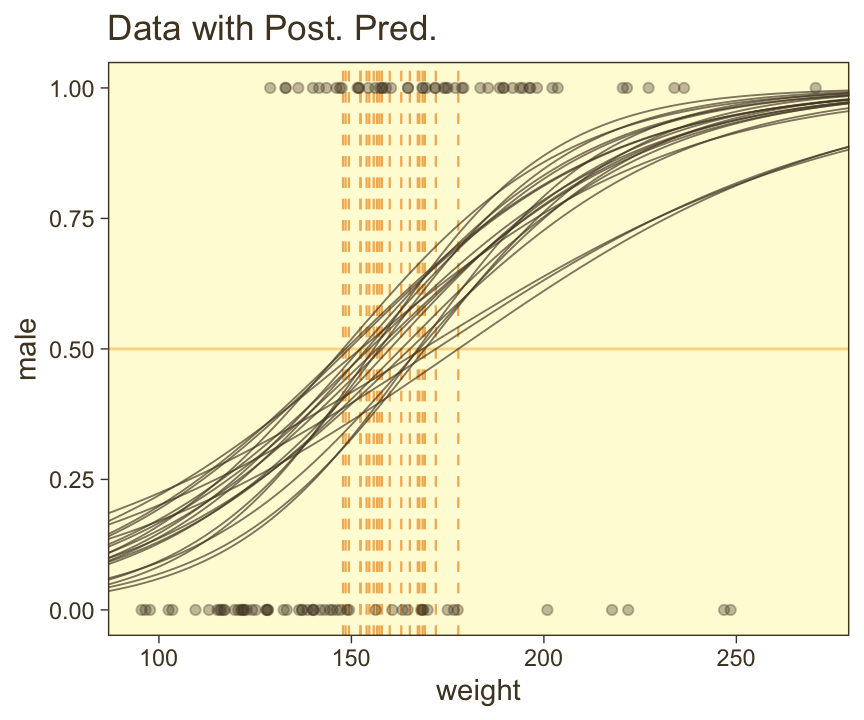
We should discuss those thresholds (i.e., the vertical lines) a bit. Kruschke:
The spread of the logistic curves indicates the uncertainty of the estimate; the steepness of the logistic curves indicates the magnitude of the regression coefficient. The \(50\%\) probability threshold is marked by arrows that drop down from the logistic curve to the \(x\)-axis, near a weight of approximately \(160\) pounds. The threshold is the \(x\) value at which \(\mu = 0.5\), which is \(x = -\beta_0 / \beta_1\). (p. 626)
It’s important to realize that when you compute the thresholds with \(-\beta_0 / \beta_1\), this returns the values on the scale of the predictor. In our case, the predictor was weight_z. But since we wanted to plot the data on the scale of the unstandardized variable, weight, we have to convert the thresholds to that metric by multiplying their values by \(s_\text{weight}\) and then add the product to \(\overline{\text{weight}}\). If you study it closely, you’ll see that’s what we did when computing the thresh values, above.
Now here we show the marginal distributions in our versions of the lower panels of Figure 21.3.
draws <- draws |>
# Convert the parameter draws to their natural metric following Equation 21.1 (pp. 624--625)
transmute(Intercept = b_Intercept - (b_weight_z * mean(my_data$weight) / sd(my_data$weight)),
weight = b_weight_z / sd(my_data$weight)) |>
pivot_longer(cols = everything())
# Plot
draws |>
ggplot(aes(x = value)) +
stat_halfeye(point_interval = mode_hdi, .width = 0.95,
color = pm[1], fill = pm[7], normalize = "panels",
point_color = pm[4], point_size = 2.5, shape = 15,
size = 2, slab_color = pm[1], slab_size = 1/2) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
facet_wrap(~ name, scales = "free")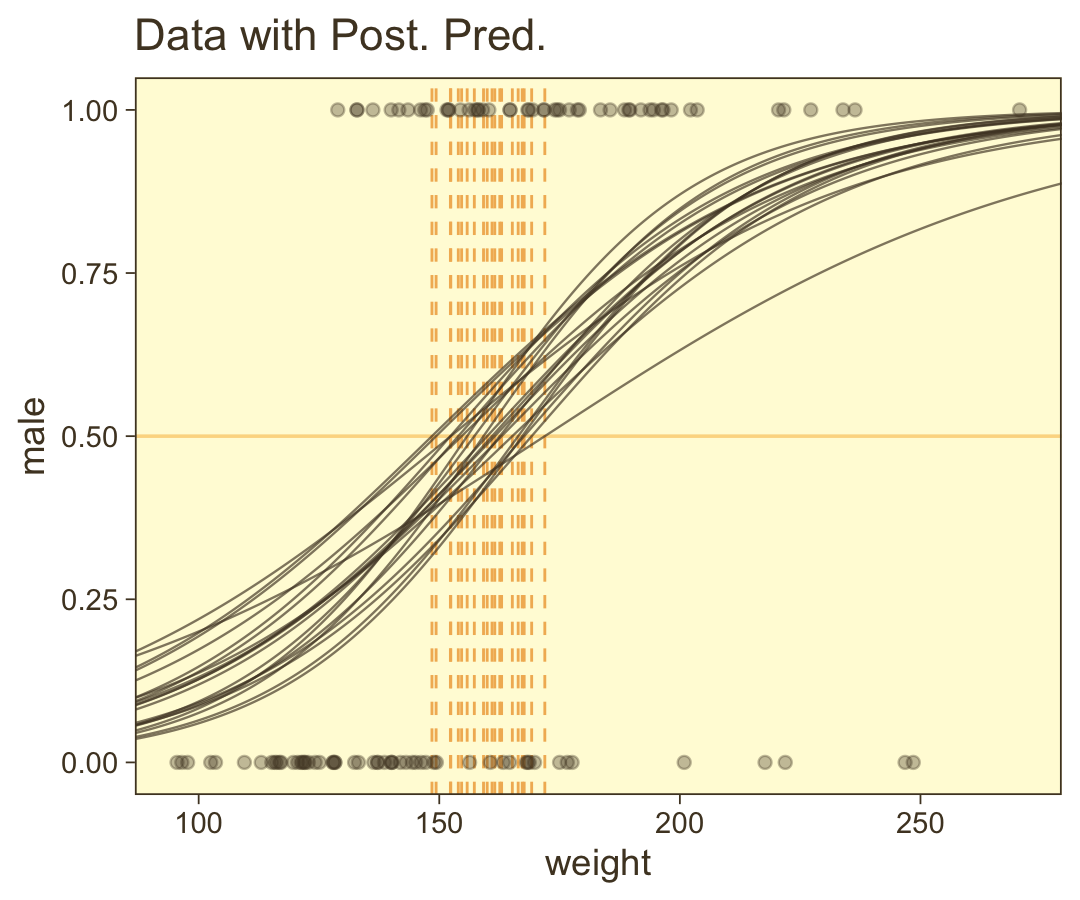
And here are those exact posterior mode and 95% HDI values.
draws |>
group_by(name) |>
mode_hdi() |>
mutate_if(is.double, .funs = round, digits = 3)# A tibble: 2 × 7
name value .lower .upper .width .point .interval
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 Intercept -5.26 -7.74 -2.99 0.95 mode hdi
2 weight 0.033 0.018 0.048 0.95 mode hdi If you look back at our code for the lower marginal plots for Figure 21.3, you’ll notice we did a whole lot of argument tweaking within tidybayes::stat_halfeye(). We have a lot of marginal densities ahead of us in this chapter, so we might streamline our code with those settings saved in a custom function. As the vibe I’m going for in those settings is based on some of the plots in Chapter 16 of Wilke’s (2019), Fundamentals of data visualization, we’ll call our function stat_wilke().
stat_wilke <- function(.width = 0.95,
shape = 15, point_size = 2.5, point_color = pm[4],
slab_color = pm[1], fill = pm[7], color = pm[1],
slab_size = 1/2, size = 2, ...) {
stat_halfeye(point_interval = mode_hdi, .width = .width,
shape = shape, point_size = point_size, point_color = point_color,
slab_color = slab_color, fill = fill, color = color,
slab_size = slab_size, size = size,
normalize = "panels",
...)
}Now fit the two-predictor model using both weight_z and height_z.
fit21.2 <- brm(
data = my_data,
family = bernoulli,
male ~ 1 + weight_z + height_z,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b)),
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
file = "fits/fit21.02")Here’s the model summary.
print(fit21.2) Family: bernoulli
Links: mu = logit
Formula: male ~ 1 + weight_z + height_z
Data: my_data (Number of observations: 110)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.35 0.30 -0.94 0.22 1.00 5816 5414
weight_z 0.67 0.35 0.01 1.39 1.00 7381 6001
height_z 2.62 0.51 1.69 3.71 1.00 5321 4745
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).Before we make our plots for Figure 21.4, we’ll need to extract the posterior samples and transform a little.
draws <- as_draws_df(fit21.2) |>
mutate(b_weight = b_weight_z / sd(my_data$weight),
b_height = b_height_z / sd(my_data$height),
Intercept = b_Intercept - ((b_weight_z * mean(my_data$weight) / sd(my_data$weight)) +
(b_height_z * mean(my_data$height) / sd(my_data$height)))) |>
select(.draw, b_weight, b_height, Intercept)
head(draws)# A tibble: 6 × 4
.draw b_weight b_height Intercept
<int> <dbl> <dbl> <dbl>
1 1 0.0277 0.685 -50.8
2 2 0.0231 0.663 -48.3
3 3 0.0231 0.620 -45.3
4 4 0.0174 0.525 -37.8
5 5 0.00414 0.466 -31.7
6 6 0.00876 0.802 -55.7Here’s our version of Figure 21.4.a.
set.seed(21) # We need this for the `slice_sample()` function
draws |>
slice_sample(n = 20) |>
expand_grid(weight = c(80, 280)) |>
# This follows the Equation near the top of p. 629
mutate(height = (-Intercept / b_height) + (-b_weight / b_height) * weight) |>
# Now plot
ggplot(aes(x = weight, y = height)) +
geom_line(aes(group = .draw),
alpha = 2/3, color = pm[7], linewidth = 2/5) +
geom_text(data = my_data,
aes(label = male, color = male == 1)) +
scale_color_manual(values = pm[c(4, 1)]) +
ggtitle("Data with Post. Pred.") +
coord_cartesian(xlim = range(my_data$weight),
ylim = range(my_data$height)) +
theme(legend.position = "none")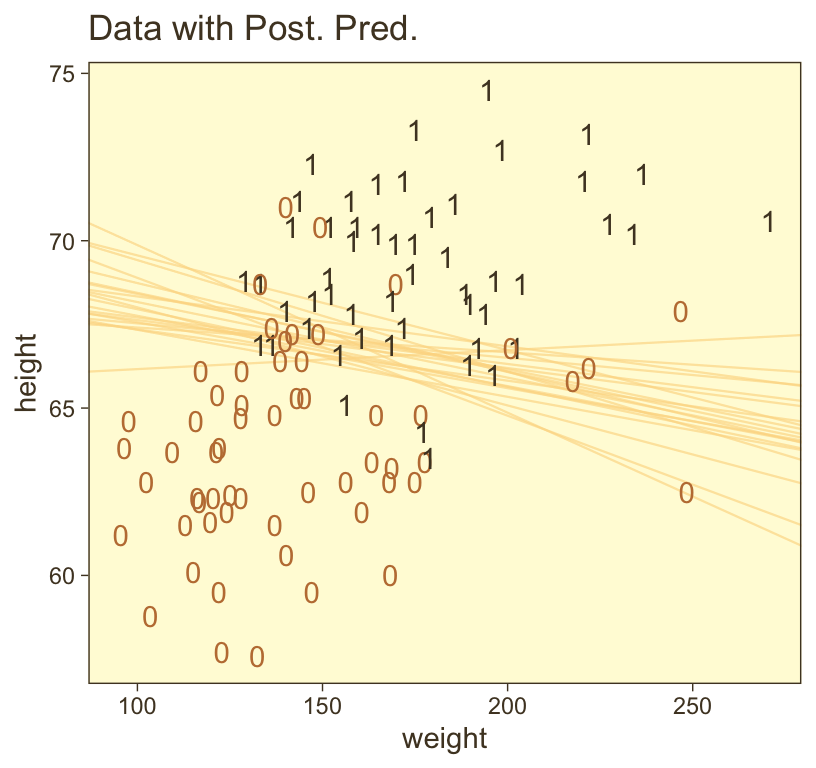
With just a tiny bit more wrangling, we’ll be ready to make the bottom panels of Figure 21.4.
draws |>
pivot_longer(cols = -.draw) |>
mutate(name = factor(str_remove(name, "b_"),
levels = c("Intercept", "weight", "height"))) |>
ggplot(aes(x = value)) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
facet_wrap(~ name, scales = "free")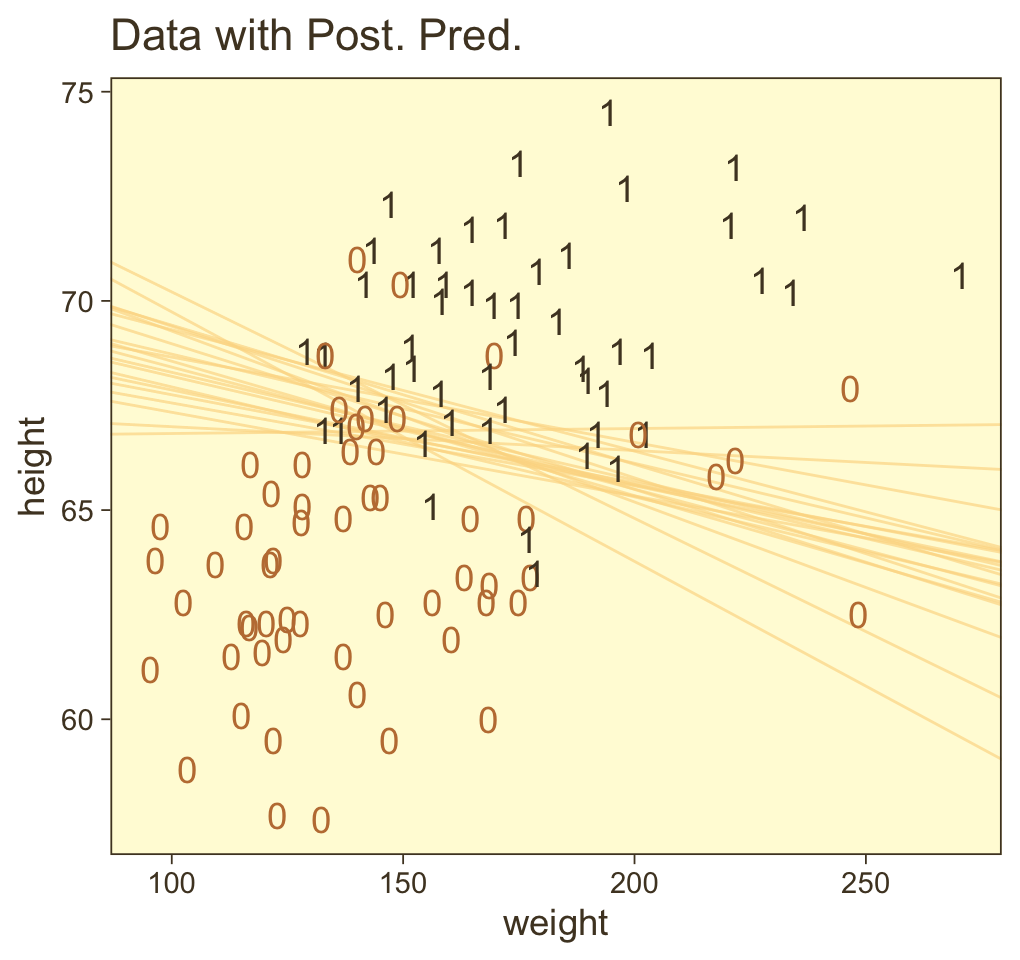
Did you notice our use of stat_wilke()? By now, you know how to use mode_hdi() to return those exact summary values if you’d like them.
Now remember how we backed away from Figure 21.1? Well, when you have a logistic regression with two predictors, there is a reasonable way to express those three dimensions on a two-dimensional grid. Now we have the results from fit21.2, let’s try it out.
First, we need a grid of values for our two predictors, weight_z and height_z.
length <- 100
nd <- crossing(weight_z = seq(from = -3.5, to = 3.5, length.out = length),
height_z = seq(from = -3.5, to = 3.5, length.out = length))Second, we plug those values into fitted() and wrangle.
f <- fitted(fit21.2,
newdata = nd,
scale = "linear") |>
data.frame() |>
# Note we're only working with the posterior mean, here
transmute(prob = Estimate |> inv_logit_scaled()) |>
bind_cols(nd) |>
mutate(weight = (weight_z * sd(my_data$weight) + mean(my_data$weight)),
height = (height_z * sd(my_data$height) + mean(my_data$height)))
glimpse(f)Rows: 10,000
Columns: 5
$ prob <dbl> 7.043966e-06, 8.479752e-06, 1.020819e-05, 1.228894e-05, 1.479…
$ weight_z <dbl> -3.5, -3.5, -3.5, -3.5, -3.5, -3.5, -3.5, -3.5, -3.5, -3.5, -…
$ height_z <dbl> -3.500000, -3.429293, -3.358586, -3.287879, -3.217172, -3.146…
$ weight <dbl> 33.45626, 33.45626, 33.45626, 33.45626, 33.45626, 33.45626, 3…
$ height <dbl> 53.24736, 53.51234, 53.77731, 54.04229, 54.30727, 54.57224, 5…Third, we’re ready to plot. Here we’ll express the third dimension, probability, on a color spectrum.
f |>
ggplot(aes(x = weight, y = height)) +
geom_raster(aes(fill = prob),
interpolate = TRUE) +
geom_text(data = my_data,
aes(label = male, color = male == 1),
show.legend = FALSE) +
scale_y_continuous(position = "right") +
scale_color_manual(values = pm[c(8, 1)]) +
scale_fill_gradientn(colours = pnw_palette(name = "Mushroom", n = 101),
limits = c(0, 1)) +
coord_cartesian(xlim = range(my_data$weight),
ylim = range(my_data$height)) +
theme(legend.position = "left")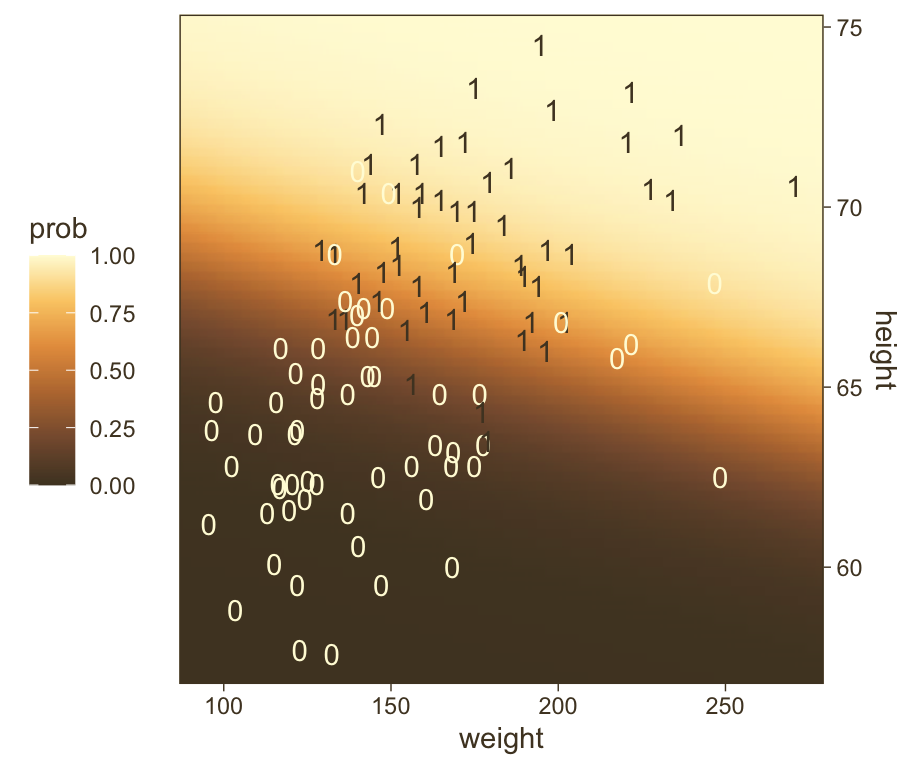
If you look way back to Figure 21.1 (p. 623), you’ll see the following formula at the top:
\[y \sim \operatorname{dbern}(m), m = \operatorname{logistic}(0.018 x_1 + 0.7 x_2 - 50).\]
Now while you keep your finger on that equation, take another look at the last line in Kruschke’s Equation 21.1,
\[ \operatorname{logit}(\mu) = \underbrace{\zeta_0 - \sum_j \frac{\zeta_j}{s_{x_j}} \overline x_j}_{\beta_0} + \sum_j \underbrace{\frac{\zeta_j}{s_{x_j}} \overline x_j}_{\beta_j}, \]
where the \(\zeta\)’s are the parameters from the model based on standardized predictors. Our fit21.2 was based on standardized weight and height values (i.e., weight_z and height_z), yielding model coefficients in the \(\zeta\) metric. Here we use the formula above to convert our fit21.2 estimates to their unstandardized \(\beta\) metric. For simplicity, we’ll just take their means.
as_draws_df(fit21.2) |>
transmute(beta_0 = b_Intercept - ((b_weight_z * mean(my_data$weight) / sd(my_data$weight)) +
((b_height_z * mean(my_data$height) / sd(my_data$height)))),
beta_1 = b_weight_z / sd(my_data$weight),
beta_2 = b_height_z / sd(my_data$height)) |>
summarise_all(.funs = \(x) mean(x) |> round(digits = 3))# A tibble: 1 × 3
beta_0 beta_1 beta_2
<dbl> <dbl> <dbl>
1 -49.8 0.019 0.7Within rounding error, those values are the same ones in the formula at the top of Kruschke’s Figure 21.1! That is, our last plot was a version of Figure 21.1.
Hopefully this helps make sense of what the thresholds in Figure 21.4.a represented. But do note a major limitation of this visualization approach. By expressing the threshold with multiple lines drawn from the posterior in Figure 21.4.a, we expressed the uncertainty inherent in the posterior distribution. However, for this probability plane approach, we’ve taken a single value from the posterior, the mean (i.e., the Estimate), to compute the probabilities. Though beautiful, our probability-plane plot does a poor job expressing the uncertainty in the model. If you’re curious how one might include uncertainty into a plot like this, check out the intriguing blog post by Adam Pearce, Communicating model uncertainty over space.
21.2 Interpreting the regression coefficients
In this section, I’ll discuss how to interpret the parameters in logistic regression. The first subsection explains how to interpret the numerical magnitude of the slope coefficients in terms of “log odds.” The next subsection shows how data with relatively few \(1\)’s or \(0\)’s can yield ambiguity in the parameter estimates. Then an example with strongly correlated predictors reveals tradeoffs in slope coefficients. Finally, I briefly describe the meaning of multiplicative interaction for logistic regression. (p. 629)
21.2.1 Log odds.
When the logistic regression formula is written using the logit function, we have \(\operatorname{logit}(\mu) = \beta_0 + \beta_1 x_1 + \beta_2 x_2\). The formula implies that whenever \(x_1\) goes up by \(1\) unit (on the \(x_1\) scale), then \(\operatorname{logit}(\mu)\) goes up by an amount \(\beta_1\). And whenever \(x_2\) goes up by \(1\) unit (on the \(x_2\) scale), then \(\operatorname{logit}(\mu)\) goes up by an amount \(\beta_2\). Thus, the regression coefficients are telling us about increases in \(\operatorname{logit}(\mu)\). To understand the regression coefficients, we need to understand \(\operatorname{logit}(\mu)\). (pp. 629–630)
Given the logit function is the inverse of the logistic, which itself is
\[\operatorname{logistic}(x) = \frac{1}{1 + \exp(−x)},\]
and given the formula
\[\operatorname{logit}(\mu) = \log \left (\frac{\mu}{1 - \mu} \right),\]
where
\[0 < \mu < 1,\]
it may or may not be clear that the results of our logistic regression models have a nonlinear relation with the actual parameter of interest, \(\mu\), which, recall, is the probability our criterion variable is 1 (e.g., male == 1). To get a sense of that nonlinear relation, we might make a plot.
tibble(mu = seq(from = 0, to = 1, length.out = 300)) |>
mutate(logit_mu = log(mu / (1 - mu))) |>
ggplot(aes(x = mu, y = logit_mu)) +
geom_line(color = pm[3], linewidth = 1.5) +
labs(x = expression(mu~"(i.e., the probability space)"),
y = expression(logit~mu~"(i.e., the parameter space)")) +
theme(legend.position = "none")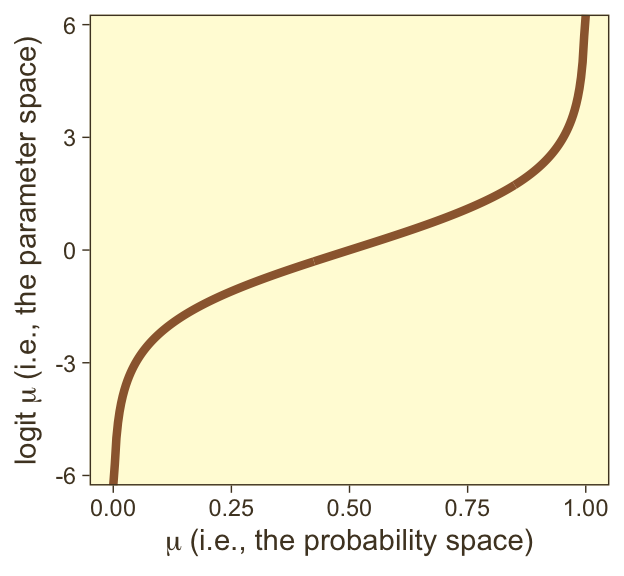
So whereas our probability space is bound between 0 and 1, the parameter space shoots off into negative and positive infinity. Also,
\[\operatorname{logit}(\mu) = \log \left (\frac{p(y = 1)}{p(y = 0)} \right ).\]
Thus, “the ratio, \(p(y = 1) / p(y = 0)\), is called the odds of outcome 1 to outcome 0, and therefore \(\operatorname{logit}(\mu)\) is the log odds of outcome 1 to outcome 0” (p. 630).
Here’s a table layout of the height/weight examples in the middle of page 630.
tibble(b0 = -50,
b1 = 0.02,
b2 = 0.7,
weight = 160,
inches = c(63:64, 67:68)) |>
mutate(logit_mu = b0 + b1 * weight + b2 * inches) |>
mutate(log_odds = logit_mu) |>
mutate(p_male = 1 / (1 + exp(-log_odds))) |>
knitr::kable()| b0 | b1 | b2 | weight | inches | logit_mu | log_odds | p_male |
|---|---|---|---|---|---|---|---|
| -50 | 0.02 | 0.7 | 160 | 63 | -2.7 | -2.7 | 0.0629734 |
| -50 | 0.02 | 0.7 | 160 | 64 | -2.0 | -2.0 | 0.1192029 |
| -50 | 0.02 | 0.7 | 160 | 67 | 0.1 | 0.1 | 0.5249792 |
| -50 | 0.02 | 0.7 | 160 | 68 | 0.8 | 0.8 | 0.6899745 |
Thus, a regression coefficient in logistic regression indicates how much a \(1\) unit change of the predictor increases the log odds of outcome \(1\). A regression coefficient of \(0.5\) corresponds to a rate of probability change of about \(12.5\) percentage points per \(x\)-unit at the threshold \(x\) value. A regression coefficient of \(1.0\) corresponds to a rate of probability change of about \(24.4\) percentage points per \(x\)-unit at the threshold \(x\) value. When \(x\) is much larger or smaller than the threshold \(x\) value, the rate of change in probability is smaller, even though the rate of change in log odds is constant. (pp. 630–631)
21.2.2 When there are few 1’s or 0’s in the data.
In logistic regression, you can think of the parameters as describing the boundary between the \(0\)’s and the \(1\)’s. If there are many \(0\)’s and \(1\)’s, then the estimate of the boundary parameters can be fairly accurate. But if there are few \(0\)’s or few \(1\)’s, the boundary can be difficult to identify very accurately, even if there are many data points overall. (p. 631)
As far as I can tell, Kruschke must have used \(n = 500\) to simulate the data he displayed in Figure 21.5. Using the coefficient values he displayed in the middle of page 631, here’s an attempt at replicating them.
b0 <- -3
b1 <- 1
n <- 500
set.seed(21)
d_rare <- tibble(x = rnorm(n, mean = 0, sd = 1)) |>
mutate(mu = b0 + b1 * x) |>
mutate(y = rbinom(n, size = 1, prob = 1 / (1 + exp(-mu))))
glimpse(d_rare)Rows: 500
Columns: 3
$ x <dbl> 0.793013171, 0.522251264, 1.746222241, -1.271336123, 2.197389533, 0…
$ mu <dbl> -2.2069868, -2.4777487, -1.2537778, -4.2713361, -0.8026105, -2.5668…
$ y <int> 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…We’re ready to fit the model. So far, we’ve been following along with Kruschke by using the Bernoulli distribution (i.e., family = bernoulli) in our brms models. Let’s get frisky and use the \(n = 1\) binomial distribution, here. You’ll see it yields the same results.
fit21.3 <- brm(
data = d_rare,
family = binomial,
y | trials(1) ~ 1 + x,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b)),
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
file = "fits/fit21.03")Recall that when you use the binomial distribution in newer versions of brms, you need to use the trials() syntax to tell brm() how many trials each row in the data corresponds to. Anyway, behold the summary.
print(fit21.3) Family: binomial
Links: mu = logit
Formula: y | trials(1) ~ 1 + x
Data: d_rare (Number of observations: 500)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -3.01 0.24 -3.49 -2.56 1.00 3039 3873
x 1.03 0.20 0.65 1.41 1.00 2890 4077
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).Looks like the model did a good job recapturing those data-generating b0 and b1 values. Now make the top left panel of Figure 21.5.
draws <- as_draws_df(fit21.3)
# Unclear if Kruschke still used 20 draws or not
n_draw <- 20
length <- 100
set.seed(21)
draws |>
# Take 20 random samples of the posterior draws
slice_sample(n = n_draw) |>
# Add in a sequence of `x`
expand_grid(x = seq(from = -3.5, to = 3.5, length.out = length)) |>
# Compute the estimates of interest
mutate(y = plogis(b_Intercept + b_x * x),
thresh = -b_Intercept / b_x) |>
# Plot
ggplot(aes(x = x)) +
geom_hline(yintercept = 0.5, color = pm[7], linewidth = 1/2) +
geom_vline(aes(xintercept = thresh, group = .draw),
color = pm[6], linetype = 2, linewidth = 2/5) +
geom_line(aes(y = y, group = .draw),
alpha = 2/3, color = pm[1], linewidth = 1/3) +
geom_point(data = d_rare,
aes(y = y),
alpha = 1/3, color = pm[1]) +
ggtitle("Data with Post. Pred.") +
coord_cartesian(xlim = range(d_rare$x))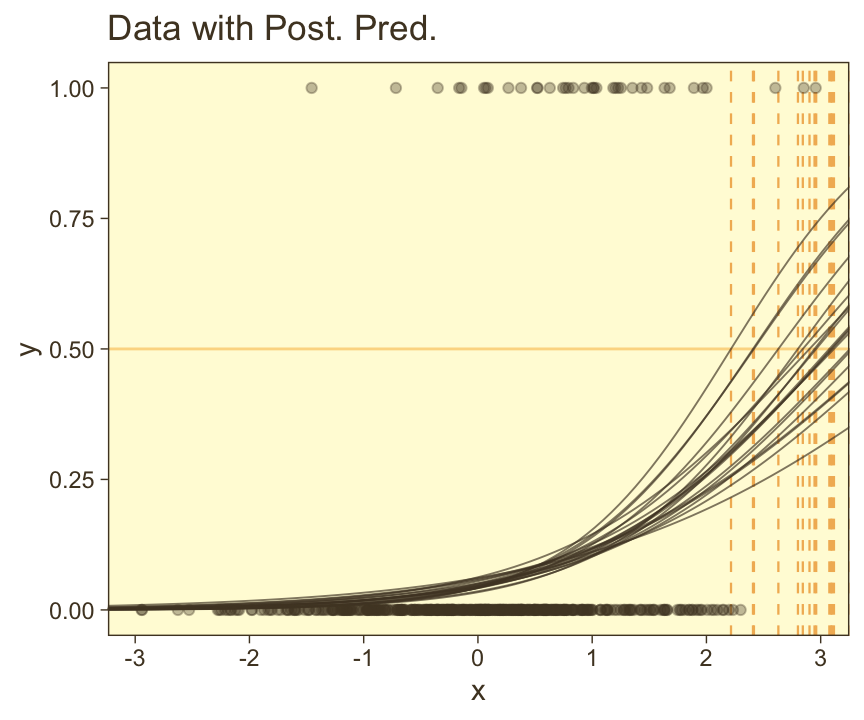
Here are the two subplots at the bottom, left.
draws |>
mutate(Intercept = b_Intercept,
x = b_x) |>
pivot_longer(cols = c(Intercept, x)) |>
ggplot(aes(x = value)) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
facet_wrap(~ name, scales = "free")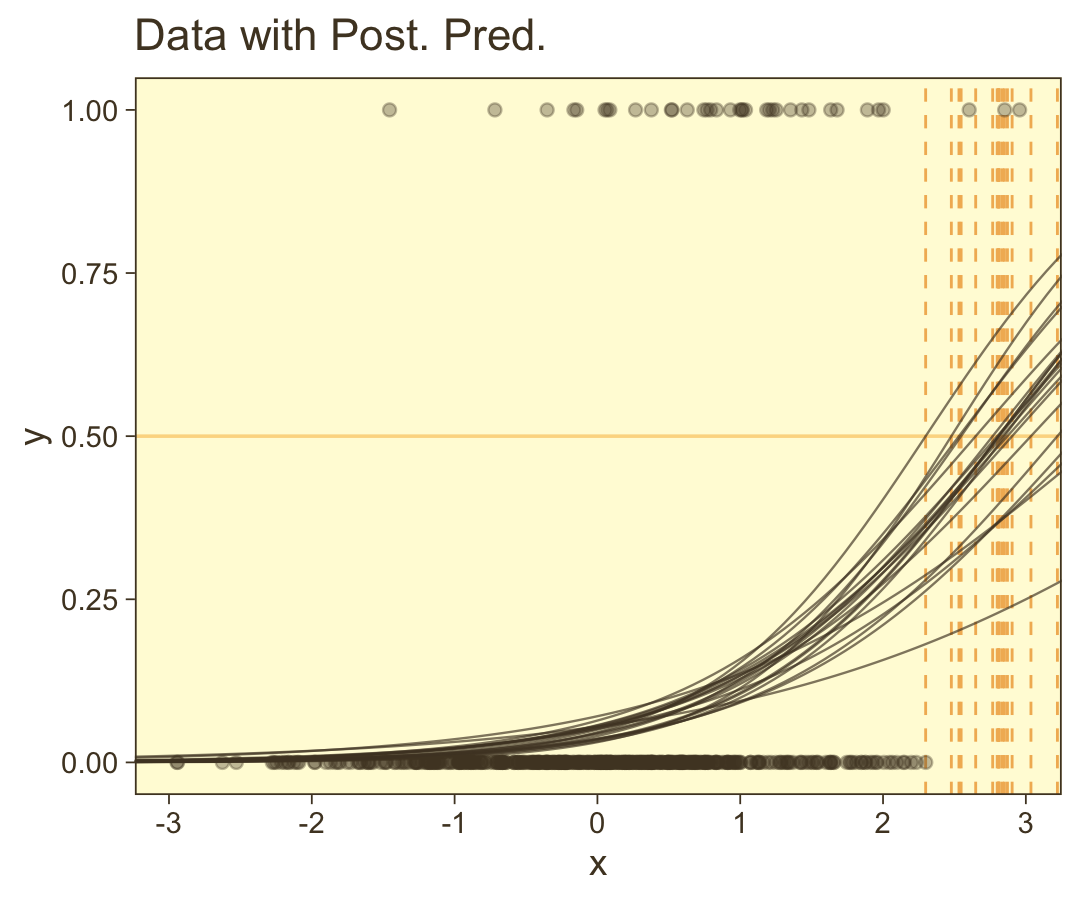
Since our data were simulated without the benefit of knowing how Kruschke set his seed and such, our results will only approximate those in the text.
Okay, now we need to simulate the complimentary data, those for which \(y = 1\) is a less-rare event.
b0 <- 0
b1 <- 1
n <- 500
set.seed(21)
d_not_rare <- tibble(x = rnorm(n, mean = 0, sd = 1)) |>
mutate(mu = b0 + b1 * x) |>
mutate(y = rbinom(n, size = 1, prob = 1 / (1 + exp(-mu))))
glimpse(d_not_rare)Rows: 500
Columns: 3
$ x <dbl> 0.793013171, 0.522251264, 1.746222241, -1.271336123, 2.197389533, 0…
$ mu <dbl> 0.793013171, 0.522251264, 1.746222241, -1.271336123, 2.197389533, 0…
$ y <int> 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0…Fitting this model is just like before.
fit21.4 <- update(
fit21.3,
newdata = d_not_rare,
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
file = "fits/fit21.04")Behold the summary.
print(fit21.4) Family: binomial
Links: mu = logit
Formula: y | trials(1) ~ 1 + x
Data: d_not_rare (Number of observations: 500)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 0.08 0.10 -0.11 0.28 1.00 8030 5420
x 0.91 0.11 0.68 1.14 1.00 6444 5270
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).Here’s the code for the main plot in Figure 21.5.b.
draws <- as_draws_df(fit21.4)
set.seed(21)
p1 <- draws |>
slice_sample(n = n_draw) |>
expand_grid(x = seq(from = -3.5, to = 3.5, length.out = length)) |>
mutate(y = plogis(b_Intercept + b_x * x),
thresh = -b_Intercept / b_x) |>
ggplot(aes(x = x, y = y)) +
geom_hline(yintercept = 0.5, color = pm[7], linewidth = 1/2) +
geom_vline(aes(xintercept = thresh, group = .draw),
color = pm[6], linetype = 2, linewidth = 2/5) +
geom_line(aes(group = .draw),
alpha = 2/3, color = pm[1], linewidth = 1/3) +
geom_point(data = d_rare,
alpha = 1/3, color = pm[1]) +
ggtitle("Data with Post. Pred.") +
coord_cartesian(xlim = c(-3, 3))Now make the two subplots at the bottom.
p2 <- draws |>
mutate(Intercept = b_Intercept,
x = b_x) |>
pivot_longer(cols = c(Intercept, x)) |>
ggplot(aes(x = value)) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
facet_wrap(~ name, scales = "free")This time we’ll combine them with patchwork.
p3 <- plot_spacer()
p1 / (p2 + p3 + plot_layout(widths = c(2, 1))) +
plot_layout(height = c(4, 1))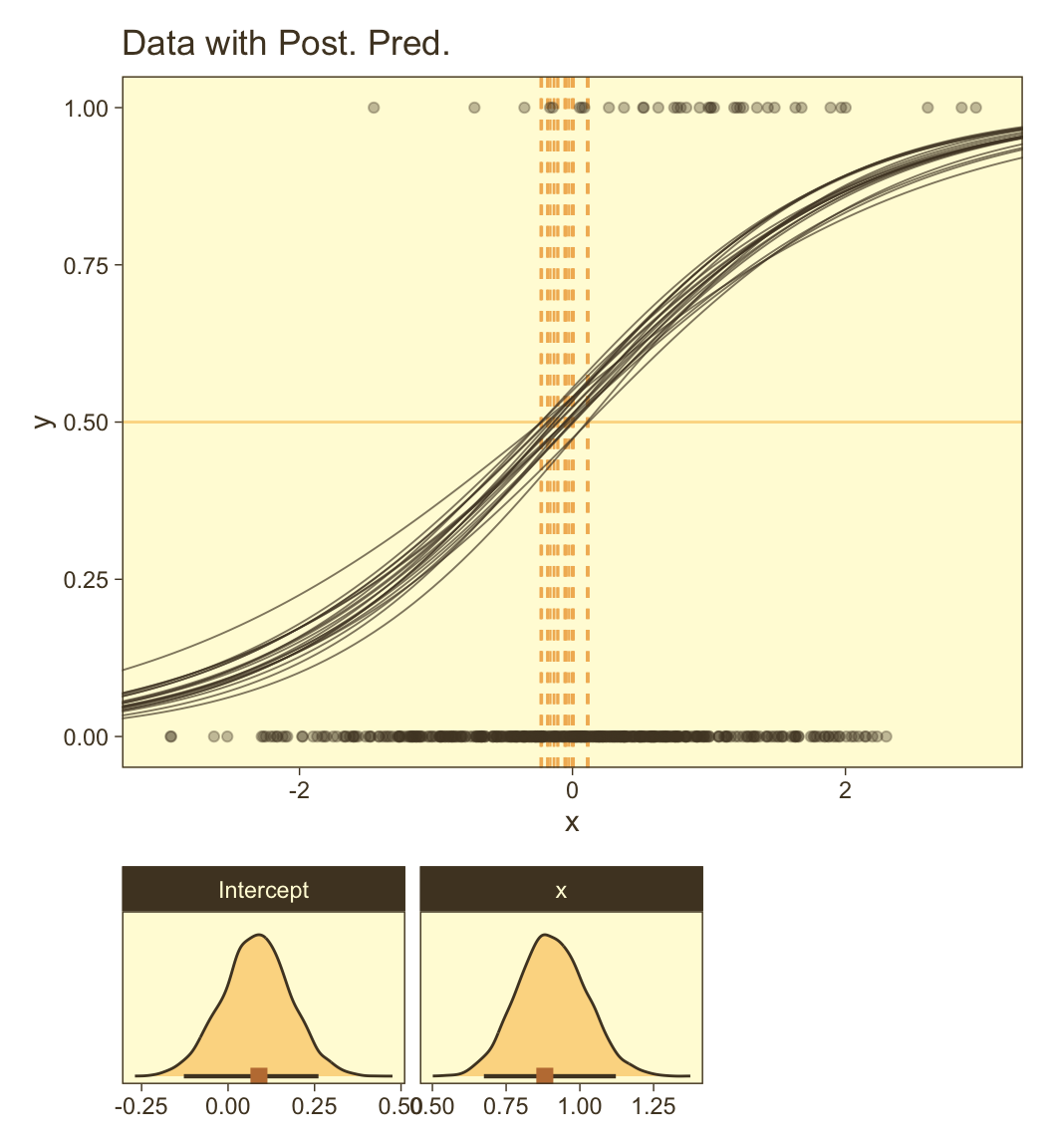
You can see in Figure 21.5 that the estimate of the slope (and of the intercept) is more certain in the right panel than in the left panel. The \(95\%\) HDI on the slope, \(\beta_1\), is much wider in the left panel than in the right panel, and you can see that the logistic curves in the left panel have greater variation in steepness than the logistic curves in the right panel. The analogous statements hold true for the intercept parameter.
Thus, if you are doing an experimental study and you can manipulate the \(x\) values, you will want to select \(x\) values that yield about equal numbers of \(0\)’s and \(1\)’s for the \(y\) values overall. If you are doing an observational study, such that you cannot control any independent variables, then you should be aware that the parameter estimates may be surprisingly ambiguous if your data have only a small proportion of \(0\)’s or \(1\)’s. (pp. 631–632)
21.2.3 Correlated predictors.
“Another important cause of parameter uncertainty is correlated predictors. This issue was previously discussed at length, but the context of logistic regression provides novel illustration in terms of level contours” (p. 632).
As far as I can tell, Kruschke chose about \(n = 200\) for the data in this example. After messing around with correlations for a bit, it seems \(\rho_{x_1, x_2} = 0.975\) looks about right. We can simulate multivariate Gaussian data with a particular correlation with the MASS::mvrnorm() function. Since we’ll be using standardized \(x\)-variables, we’ll need to specify our \(n\), the desired correlation matrix, and a vector of means. Then we’ll be ready to do the actual simulation with mvrnorm().
n <- 200
# Correlation matrix
s <- matrix(c(1, 0.975,
0.975, 1),
nrow = 2, ncol = 2)
# Mean vector
m <- c(0, 0)
# Simulate
set.seed(21)
d <- MASS::mvrnorm(n = n, mu = m, Sigma = s) |>
data.frame() |>
set_names(str_c("x", 1:2))Let’s confirm the correlation coefficient.
d |>
summarise(r = cor(x1, x2)) r
1 0.9730091Solid. Now we’ll use the \(\beta\) values from page 633 to simulate the data set by including our dichotomous criterion variable, y.
b0 <- 0
b1 <- 1
b2 <- 1
set.seed(21)
d <- d |>
mutate(mu = b0 + b1 * x1 + b2 * x2) |>
mutate(y = rbinom(n, size = 1, prob = 1 / (1 + exp(-mu))))Fit the model with the highly-correlated predictors.
fit21.5 <- brm(
data = d,
family = binomial,
y | trials(1) ~ 1 + x1 + x2,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b)),
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
file = "fits/fit21.05")Behold the summary.
print(fit21.5) Family: binomial
Links: mu = logit
Formula: y | trials(1) ~ 1 + x1 + x2
Data: d (Number of observations: 200)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.04 0.18 -0.39 0.32 1.00 3766 3639
x1 -0.06 0.71 -1.44 1.34 1.00 2955 3405
x2 2.07 0.76 0.59 3.59 1.00 2851 3070
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).We did a good job recapturing Kruschke’s \(\beta\)s in terms of our posterior means, but notice how large those posterior \(\textit{SD}\)s are for \(\beta_1\) and \(\beta_2\). To get a better sense, let’s look at them in a coefficient plot before continuing on with the text.
as_draws_df(fit21.5) |>
pivot_longer(cols = b_Intercept:b_x2) |>
ggplot(aes(x = value, y = name)) +
stat_gradientinterval(point_interval = mode_hdi, .width = c(0.5, 0.95),
color = pm[1], fill = pm[4]) +
labs(x = NULL, y = NULL) +
theme(axis.text.y = element_text(hjust = 0),
axis.ticks.y = element_blank())
Them are some sloppy estimates! But we digress. Here’s our version of Figure 21.6.a.
set.seed(21)
as_draws_df(fit21.5) |>
slice_sample(n = 20) |>
expand_grid(x1 = c(-4, 4)) |>
# This follows the equation near the top of p. 629
mutate(x2 = (-b_Intercept / b_x2) + (-b_x1 / b_x2) * x1) |>
# Now plot
ggplot(aes(x = x1, y = x2)) +
geom_line(aes(group = .draw),
alpha = 2/3, color = pm[7], linewidth = 2/5) +
geom_text(data = d,
aes(label = y, color = y == 1),
size = 2.5) +
scale_color_manual(values = pm[c(4, 1)]) +
ggtitle("Data with Post. Pred.") +
coord_cartesian(xlim = c(-3, 3),
ylim = c(-3, 3)) +
theme(legend.position = "none")
It can be easy to under-appreciate how sensitive this plot is to the seed you set for sample_n(). To give a better sense of the uncertainty in the posterior for the threshold, here we show the plot for several different seeds.
# Make a custom function
different_seed <- function(i) {
set.seed(i)
as_draws_df(fit21.5) |>
slice_sample(n = 20) |>
expand_grid(x1 = c(-4, 4)) |>
mutate(x2 = (-b_Intercept / b_x2) + (-b_x1 / b_x2) * x1)
}
# Set your seeds
tibble(seed = 1:9) |>
# Pump those seeds into the `different_seed()` function
mutate(sim = map(.x = seed, .f = different_seed)) |>
unnest(sim) |>
mutate(seed = str_c("seed: ", seed)) |>
# Plot
ggplot(aes(x = x1, y = x2)) +
geom_line(aes(group = .draw),
alpha = 2/3, color = pm[7], linewidth = 2/5) +
geom_text(data = d,
aes(label = y, color = y == 1),
size = 1.5) +
scale_color_manual(values = pm[c(4, 1)]) +
ggtitle("Data with Post. Pred.") +
coord_cartesian(xlim = c(-3, 3),
ylim = c(-3, 3)) +
theme(legend.position = "none") +
facet_wrap(~ seed)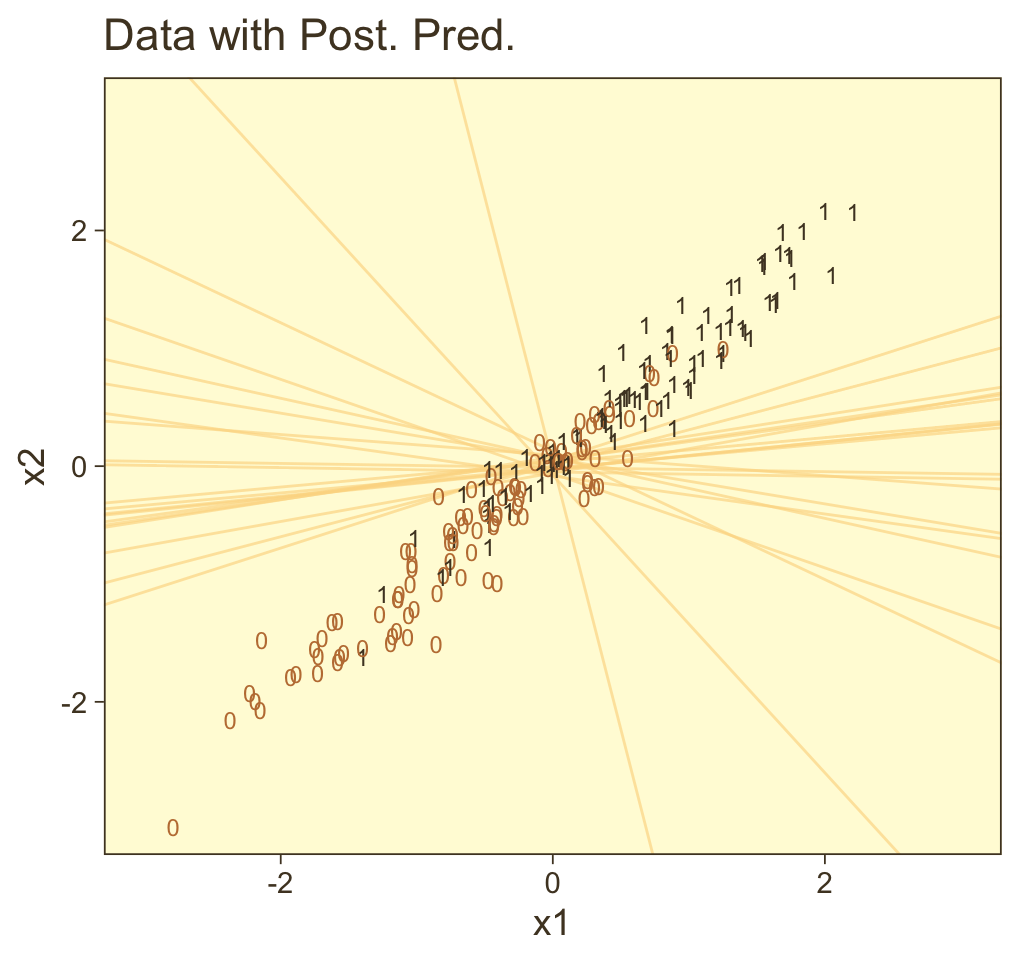
To make our version of the pairs plots in Figure 21.6.b, we’ll bring back some of our old tricks with GGally. First, we define our custom settings for the upper triangle, the diagonal, and lower triangle.
my_upper <- function(data, mapping, ...) {
ggplot(data = data, mapping = mapping) +
geom_point(size = 1/2, shape = 1, alpha = 1/4, color = pm[2])
}
my_diag <- function(data, mapping, ...) {
ggplot(data = data, mapping = mapping) +
stat_wilke() +
scale_x_continuous(NULL, breaks = NULL) +
scale_y_continuous(NULL, breaks = NULL) +
coord_cartesian(ylim = c(-0.01, NA))
}
my_lower <- function(data, mapping, ...) {
# Get the x and y data to use the other code
x <- eval_data_col(data, mapping$x)
y <- eval_data_col(data, mapping$y)
# Compute the correlations
corr <- cor(x, y, method = "p", use = "pairwise")
abs_corr <- abs(corr)
# Plot the cor value
ggally_text(
label = formatC(corr, digits = 2, format = "f"),
mapping = aes(),
color = pm[1], size = 4) +
scale_x_continuous(NULL, breaks = NULL) +
scale_y_continuous(NULL, breaks = NULL) +
theme(panel.background = element_rect(fill = pm[8]))
}Now we wrangle and plot.
as_draws_df(fit21.5) |>
transmute(`Intercept~(beta[0])` = b_Intercept,
`x1~(beta[1])` = b_x1,
`x2~(beta[2])` = b_x2) |>
ggpairs(upper = list(continuous = my_upper),
diag = list(continuous = my_diag),
lower = list(continuous = my_lower),
labeller = label_parsed)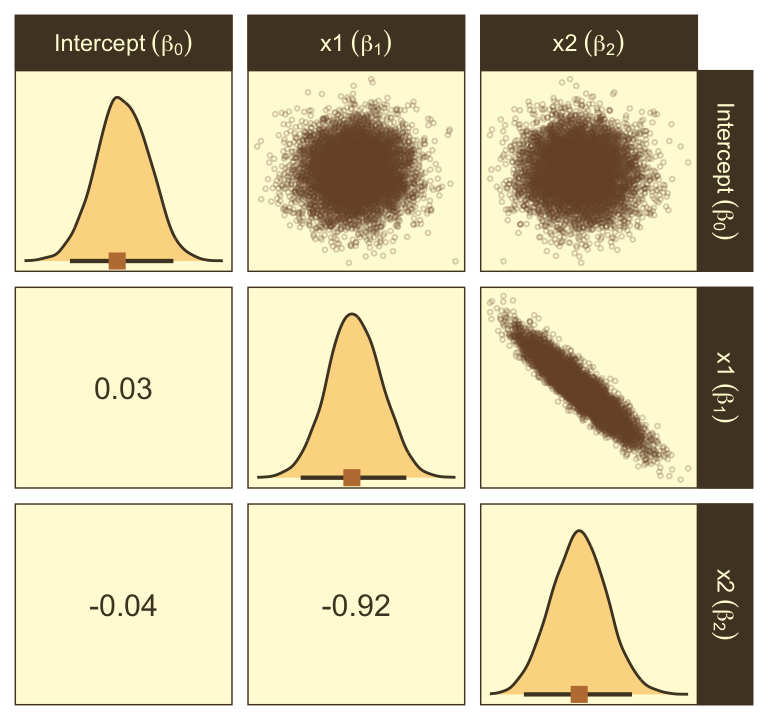
21.2.4 Interaction of metric predictors.
“There may be applications in which it is meaningful to consider a multiplicative interaction of metric predictors” (p. 633). Kruschke didn’t walk through an analysis in this section, but it’s worth the practice. Let’s simulate data based on the formula he gave in Figure 21.7, top right.
n <- 500
b0 <- 0
b1 <- 0
b2 <- 0
b3 <- 4
set.seed(21)
d <- tibble(x1 = rnorm(n, mean = 0, sd = 1),
x2 = rnorm(n, mean = 0, sd = 1)) |>
mutate(mu = b1 * x1 + b2 * x2 + b3 * x1 * x2 - b0) |>
mutate(y = rbinom(n, size = 1, prob = 1 / (1 + exp(-mu))))To fit the interaction model, let’s go back to the Bernoulli likelihood.
fit21.6 <- brm(
data = d,
family = bernoulli,
y ~ 1 + x1 + x2 + x1:x2,
prior = c(prior(normal(0, 2), class = Intercept),
prior(normal(0, 2), class = b)),
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
file = "fits/fit21.06")Looks like the model did a nice job recapturing the data-generating parameters.
print(fit21.6) Family: bernoulli
Links: mu = logit
Formula: y ~ 1 + x1 + x2 + x1:x2
Data: d (Number of observations: 500)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.18 0.13 -0.42 0.07 1.00 8306 5913
x1 -0.21 0.17 -0.55 0.12 1.00 8166 5172
x2 -0.02 0.16 -0.35 0.29 1.00 7561 6326
x1:x2 4.28 0.43 3.46 5.16 1.00 7163 6300
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).I’m not quite sure how to expand Kruschke’s equation from the top of page 629 to our interaction model. But no worries. We can take a slightly different approach to show the consequences of our interaction model on the probability \(y = 1\). First, we define our newdata and then get the Estimates from fitted(). Then we wrangle as usual.
length <- 100
nd <- crossing(x1 = seq(from = -3.5, to = 3.5, length.out = length),
x2 = seq(from = -3.5, to = 3.5, length.out = length))
f <- fitted(fit21.6,
newdata = nd,
scale = "linear") |>
data.frame() |>
transmute(prob = Estimate |> plogis())Now all we have to do is integrate our f results with the nd and original d data and then we can plot.
f |>
bind_cols(nd) |>
ggplot(aes(x = x1, y = x2)) +
geom_raster(aes(fill = prob),
interpolate = TRUE) +
geom_text(data = d,
aes(label = y, color = y == 1),
show.legend = FALSE, size = 2.75) +
scale_x_continuous(expand = c(0, 0)) +
scale_y_continuous(expand = c(0, 0)) +
scale_color_manual(values = pm[c(8, 1)]) +
scale_fill_gradientn("m", colours = pnw_palette(name = "Mushroom", n = 101),
limits = c(0, 1)) +
coord_cartesian(xlim = range(nd$x1),
ylim = range(nd$x2))
Instead of a simple threshold line, we get to visualize our interaction as a checkerboard-like probability plane. If you look back to Figure 21.7, you’ll see this is our 2D version of Kruschke’s wire-frame plot on the top right.
21.3 Robust logistic regression
With the robust logistic regression approach,
we will describe the data as being a mixture of two different sources. One source is the logistic function of the predictor(s). The other source is sheer randomness or “guessing,” whereby the \(y\) value comes from the flip of a fair coin: \(y \sim \operatorname{Bernoulli}(\mu = 1/2)\). We suppose that every data point has a small chance, \(\alpha\), of being generated by the guessing process, but usually, with probability \(1 - \alpha\), the \(y\) value comes from the logistic function of the predictor. With the two sources combined, the predicted probability that \(y = 1\) is
\[\mu = \alpha \cdot \frac{1}{2} + (1 - \alpha) \cdot \operatorname{logistic} \bigg ( \beta_0 + \sum_j \beta_j x_j \bigg )\]
Notice that when the guessing coefficient is zero, then the conventional logistic model is completely recovered. When the guessing coefficient is one, then the y values are completely random. (p. 635)
Here’s what Kruschke’s \(\operatorname{Beta}(1, 9)\) prior for \(\alpha\) looks like.
tibble(x = seq(from = 0, to = 1, length.out = 200)) |>
ggplot(aes(x = x, y = dbeta(x, 1, 9))) +
geom_area(fill = pm[4]) +
scale_x_continuous(NULL, breaks = 0:5 / 5, expand = c(0, 0)) +
scale_y_continuous(NULL, breaks = NULL, expand = expansion(mult = c(0, 0.05))) +
ggtitle(expression("Beta"*(1*", "*9)))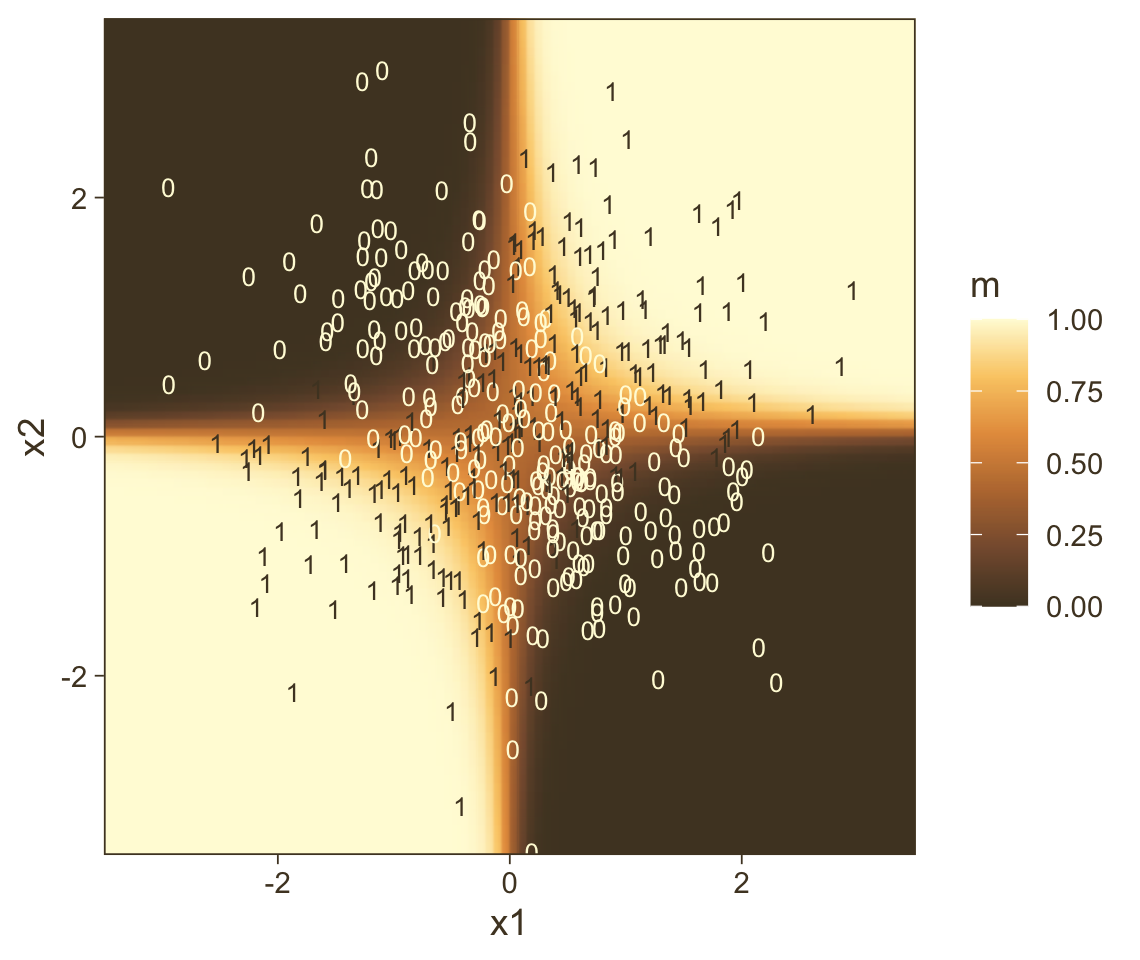
To fit the brms analogue to Kruschke’s robust logistic regression model, we’ll need to adopt what Bürkner calls the non-linear syntax, which you can learn about in detail with his (2022) vignette, Estimating non-linear models with brms.
fit21.7 <- brm(
data = my_data,
family = bernoulli(link = identity),
bf(male ~ a * 0.5 + (1 - a) * 1 / (1 + exp(-1 * (b0 + b1 * weight_z))),
a + b0 + b1 ~ 1,
nl = TRUE),
prior = c(prior(normal(0, 2), nlpar = b0),
prior(normal(0, 2), nlpar = b1),
prior(beta(1, 9), nlpar = a, lb = 0, ub = 1)),
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
file = "fits/fit21.07")And just for clarity, you can do the same thing with family = binomial(link = identity), too. Just don’t forget to specify the number of trials with trials(). But to explain what’s going on with our syntax, above, I think it’s best to quote Bürkner at length:
When looking at the above code, the first thing that becomes obvious is that we changed the
formulasyntax to display the non-linear formula including predictors (i.e., [weight_z]) and parameters (i.e., [a,b0, andb1]) wrapped in a call to [thebf()function]. This stands in contrast to classical R formulas, where only predictors are given and parameters are implicit. The argument [a + b0 + b1 ~ 1] serves two purposes. First, it provides information, which variables informulaare parameters, and second, it specifies the linear predictor terms for each parameter. In fact, we should think of non-linear parameters as placeholders for linear predictor terms rather than as parameters themselves (see also the following examples). In the present case, we have no further variables to predict [a,b0, andb1] and thus we just fit intercepts that represent our estimates of [\(\alpha\), \(\beta_0\), and \(\beta_1\)]. The formula [a + b0 + b1 ~ 1] is a short form of [a ~ 1, b0 ~ 1, b1 ~ 1] that can be used if multiple non-linear parameters share the same formula. Settingnl = TRUEtells brms that the formula should be treated as non-linear.In contrast to generalized linear models, priors on population-level parameters (i.e., ‘fixed effects’) are often mandatory to identify a non-linear model. Thus, brms requires the user to explicitely specify these priors. In the present example, we used a [
beta(1, 9)prior on (the population-level intercept of)a, while we used anormal(0, 4)prior on both (population-level intercepts of)b0andb1]. Setting priors is a non-trivial task in all kinds of models, especially in non-linear models, so you should always invest some time to think of appropriate priors. Quite often, you may be forced to change your priors after fitting a non-linear model for the first time, when you observe different MCMC chains converging to different posterior regions. This is a clear sign of an idenfication problem and one solution is to set stronger (i.e., more narrow) priors. (emphasis in the original)
Now, behold the summary.
print(fit21.7) Family: bernoulli
Links: mu = identity
Formula: male ~ a * 0.5 + (1 - a) * 1/(1 + exp(-1 * (b0 + b1 * weight_z)))
a ~ 1
b0 ~ 1
b1 ~ 1
Data: my_data (Number of observations: 110)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
a_Intercept 0.20 0.09 0.03 0.39 1.00 2032 1091
b0_Intercept 0.34 0.45 -0.42 1.37 1.00 3300 2853
b1_Intercept 2.61 0.88 1.11 4.54 1.00 2406 3076
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).Here’s a quick and dirty look at the conditional effects for weight_z.
conditional_effects(fit21.7) |>
plot(points = TRUE,
line_args = list(color = pm[2], fill = pm[6]),
point_args = list(alpha = 3/4, color = pm[1]))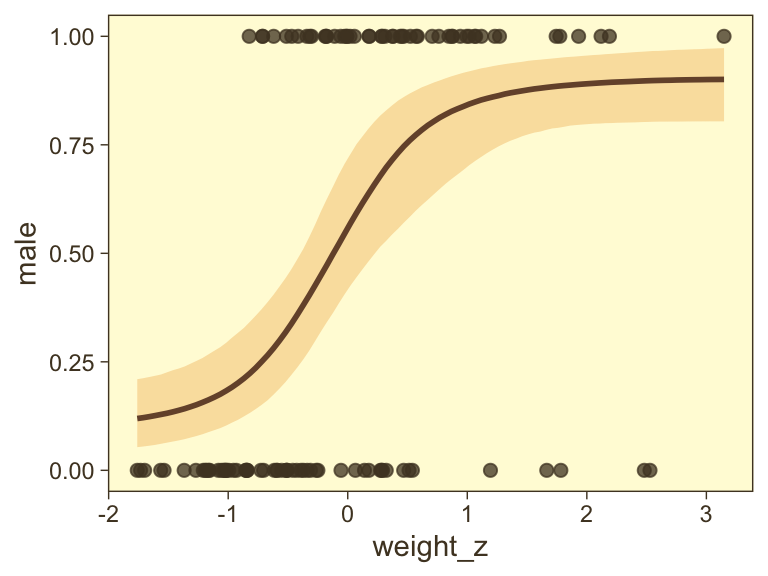
The way we prep for our version of Figure 21.8 is a minor extension what we did for Figure 21.3, above. Here we make the top panel. The biggest change, from before, is our adjusted formula for computing male.
draws <- as_draws_df(fit21.7)
set.seed(21)
p1 <- draws |>
slice_sample(n = n_draw) |>
expand_grid(weight_z = seq(from = -2, to = 3.5, length.out = length)) |>
# Compare this to Kruschke's mu[i] code at the top of page 636
mutate(male = 0.5 * b_a_Intercept + (1 - b_a_Intercept) * plogis(b_b0_Intercept + b_b1_Intercept * weight_z),
weight = weight_z * sd(my_data$weight) + mean(my_data$weight),
thresh = -b_b0_Intercept / b_b1_Intercept * sd(my_data$weight) + mean(my_data$weight)) |>
ggplot(aes(x = weight, y = male)) +
geom_hline(yintercept = 0.5, color = pm[7], linewidth = 1/2) +
geom_vline(aes(xintercept = thresh, group = .draw),
color = pm[6], linetype = 2, linewidth = 2/5) +
geom_line(aes(group = .draw),
alpha = 2/3, color = pm[1], linewidth = 1/3) +
geom_point(data = my_data,
alpha = 1/3, color = pm[1]) +
labs(y = "male",
title = "Data with Post. Pred.") +
coord_cartesian(xlim = range(my_data$weight))Here we make the marginal-distribution plots for our versions of the lower panels of Figure 21.8.
p2 <- draws |>
mutate(Intercept = b_b0_Intercept - (b_b1_Intercept * mean(my_data$weight) / sd(my_data$weight)),
weight = b_b1_Intercept / sd(my_data$weight),
guessing = b_a_Intercept) |>
pivot_longer(cols = c(Intercept, weight, guessing)) |>
mutate(name = factor(name, levels = c("Intercept", "weight", "guessing"))) |>
ggplot(aes(x = value)) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
xlab(NULL) +
facet_wrap(~ name, scales = "free", ncol = 3)Now combine them with patchwork and behold the glory.
p1 / p2 +
plot_layout(height = c(4, 1))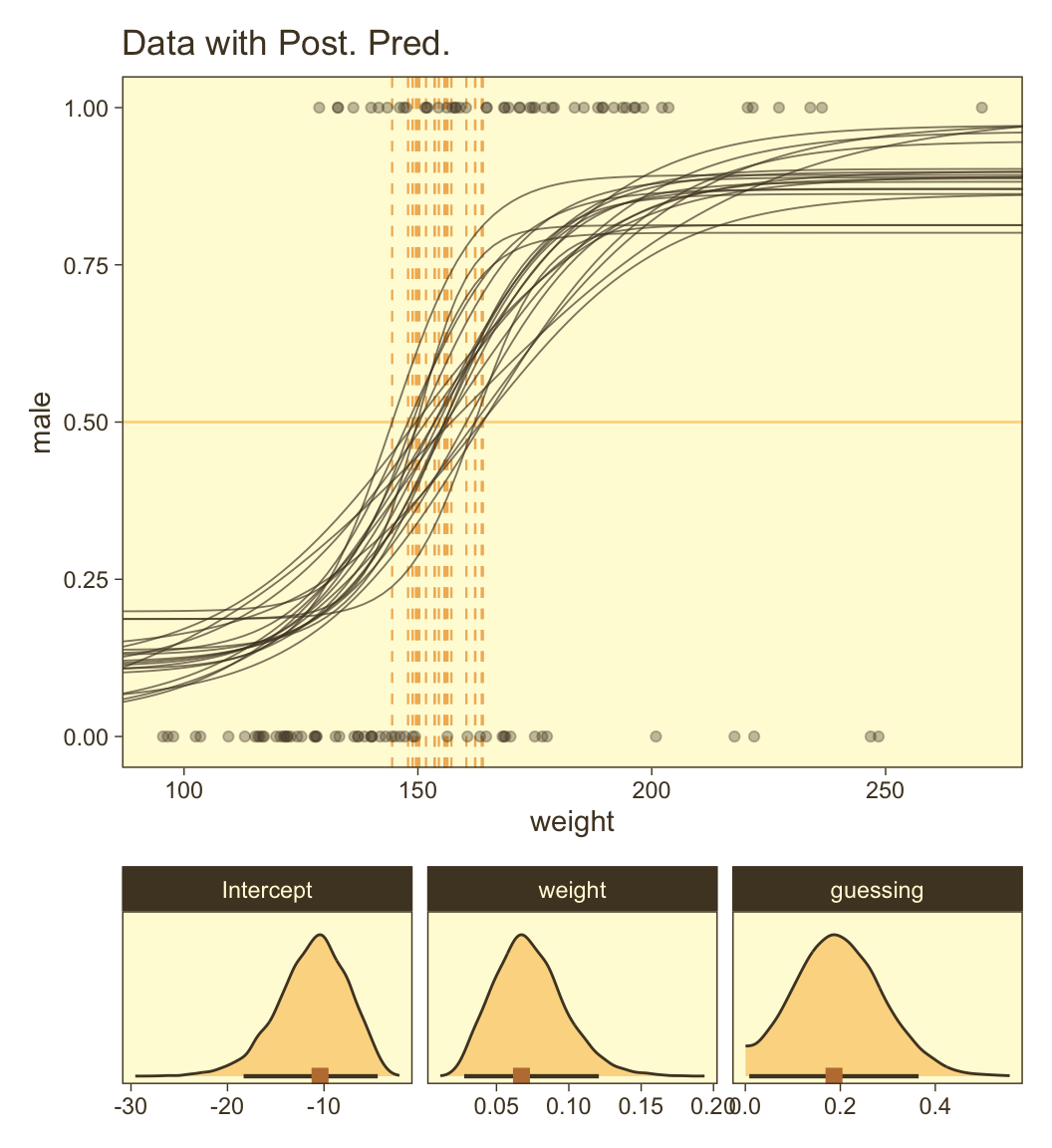
Here are the ggpairs() plots.
as_draws_df(fit21.7) |>
transmute(`Intercept~(beta[0])` = b_b0_Intercept,
`weight~(beta[1])` = b_b1_Intercept,
guessing = b_a_Intercept) |>
ggpairs(upper = list(continuous = my_upper),
diag = list(continuous = my_diag),
lower = list(continuous = my_lower),
labeller = label_parsed)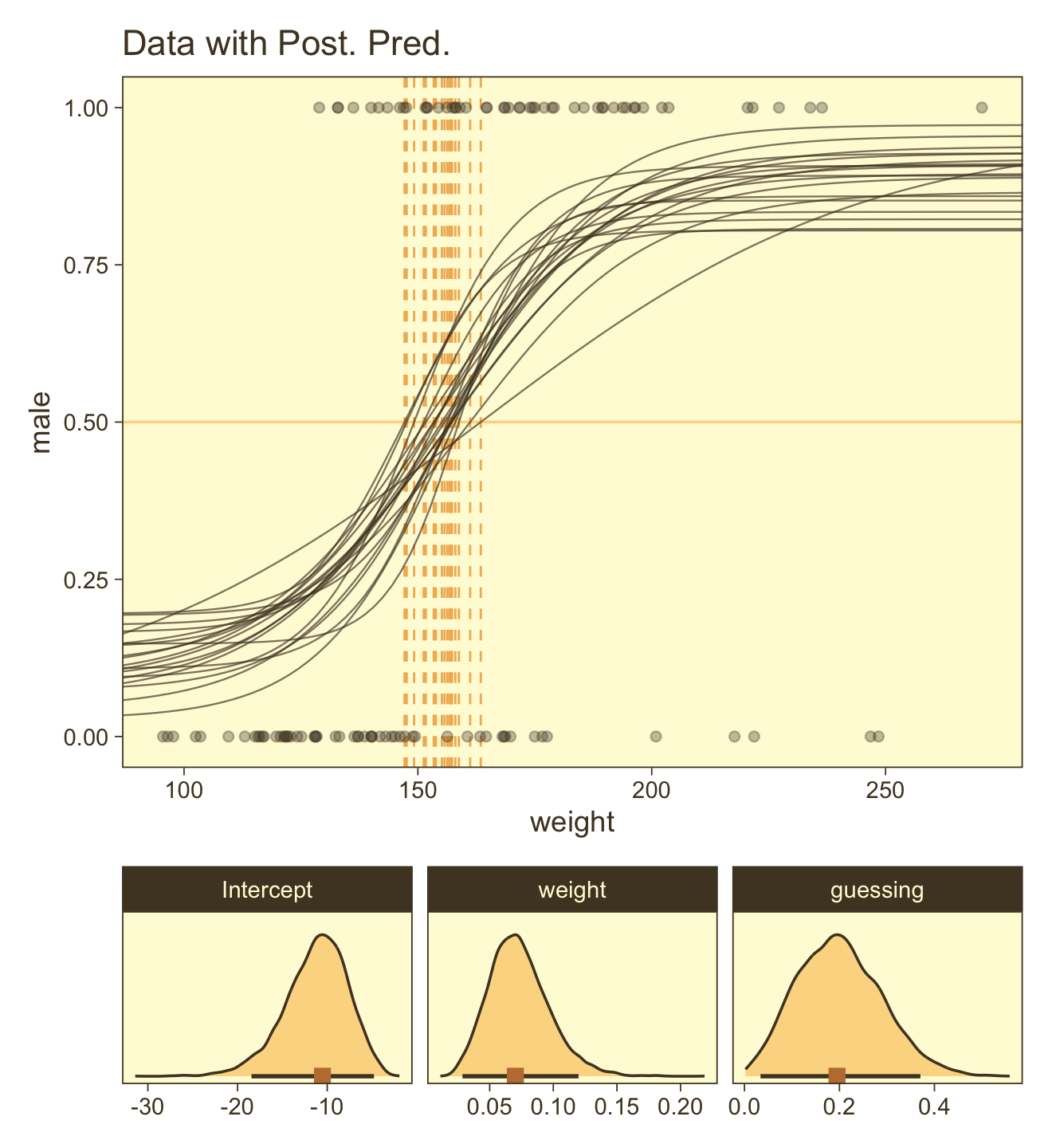
Look at how that sweet Stan-based HMC reduced the correlation between \(\beta_0\) and \(\beta_1\).
For more on this approach to robust logistic regression in brms and an alternative suggested by Andrew Gelman, check out a thread from the Stan Forums, Translating robust logistic regression from rstan to brms. Yet do note that subsequent work suggests Gelman’s alternative approach is not as robust as originally thought (see here).
21.4 Nominal predictors
“We now turn our attention from metric predictors to nominal predictors” (p. 636).
21.4.1 Single group.
If we have just a single group and no other predictors, that’s just an intercept-only model. Back in the earlier chapters we thought of such a model as
\[\begin{align*} y & \sim \operatorname{Bernoulli}(\theta) \\ \theta & \sim \operatorname{Beta}(a, b). \end{align*}\]
Now we’re expressing the model as
\[\begin{align*} y & \sim \operatorname{Bernoulli}(\mu) \\ \mu & \sim \operatorname{logistic}(\beta_0). \end{align*}\]
For that \(\beta_0\), we typically use a Gaussian prior of the form
\[\beta_0 \sim \operatorname{Normal}(M_0, S_0).\]
To further explore what this means, we might make the model diagram in Figure 21.10.
p1 <- tibble(x = seq(from = -3, to = 3, by = 0.1)) |>
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = pm[5]) +
annotate(geom = "text",
x = 0, y = 0.2,
label = "normal",
color = pm[1], size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = 0.6,
label = c("italic(M)[0]", "italic(S)[0]"),
color = pm[1], family = "Times", hjust = 0, parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = pm[8], fill = pm[8]))
# An annotated arrow
p2 <- tibble(x = 0.5,
y = 1,
xend = 0.5,
yend = 0) |>
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow, color = pm[1]) +
annotate(geom = "text",
x = 0.4, y = 0.4,
label = "'~'",
color = pm[1], family = "Times", parse = TRUE, size = 10) +
xlim(0, 1) +
theme_void()
# Likelihood formula
p3 <- tibble(x = 0.5,
y = 0.5,
label = "logistic(beta[0])") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# A second annotated arrow
p4 <- tibble(x = 0.375,
y = 1/2,
label = "'='") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = 10) +
geom_segment(x = 0.5, xend = 0.5,
y = 1, yend = 0,
arrow = my_arrow, color = pm[1]) +
xlim(0, 1) +
theme_void()
# Bar plot of Bernoulli data
p5 <- tibble(x = 0:1,
d = (dbinom(x, size = 1, prob = 0.6)) / max(dbinom(x, size = 1, prob = 0.6))) |>
ggplot(aes(x = x, y = d)) +
geom_col(fill = pm[5], width = 0.4) +
annotate(geom = "text",
x = 0.5, y = 0.2,
label = "Bernoulli",
color = pm[1], size = 7) +
annotate(geom = "text",
x = 0.5, y = 0.94,
label = "mu",
color = pm[1], family = "Times", parse = TRUE, size = 7) +
xlim(-0.75, 1.75) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = pm[8], fill = pm[8]))
# Another annotated arrow
p6 <- tibble(x = c(0.375, 0.625),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)")) |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = c(10, 7)) +
geom_segment(x = 0.5, xend = 0.5,
y = 1, yend = 0,
arrow = my_arrow, color = pm[1]) +
xlim(0, 1) +
theme_void()
# Some text
p7 <- tibble(x = 1,
y = 0.5,
label = "italic(y[i])") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = 7) +
xlim(0, 2) +
theme_void()
# Define the layout
layout <- c(
area(t = 1, b = 2, l = 2, r = 7),
area(t = 3, b = 3, l = 2, r = 7),
area(t = 4, b = 4, l = 1, r = 6),
area(t = 5, b = 5, l = 1, r = 6),
area(t = 6, b = 7, l = 1, r = 6),
area(t = 8, b = 8, l = 1, r = 6),
area(t = 9, b = 9, l = 1, r = 6))
# Combine, adjust, and display
(p1 + p2 + p3 + p4 + p5 + p6 + p7) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))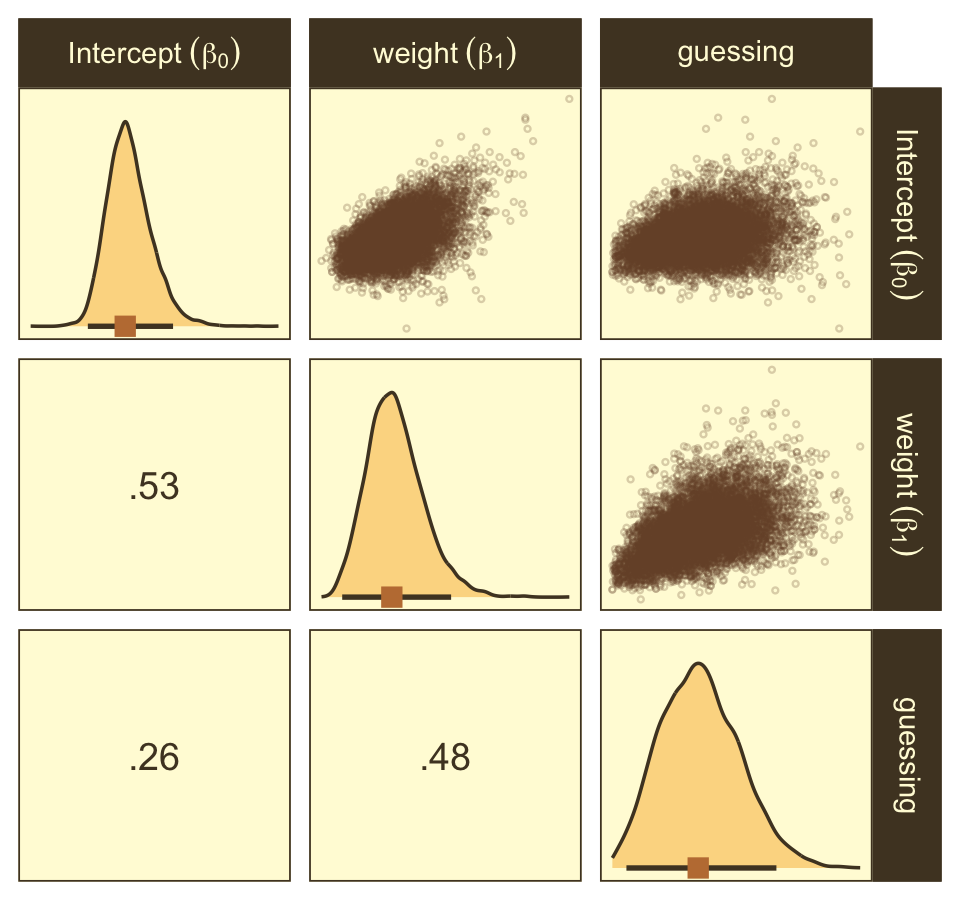
In a situation where we don’t have strong prior substantive knowledge, we often set \(M_0 = 0\), which puts the probability mass around \(\theta = 0.5\), a reasonable default hypothesis. Often times \(S_0\) is some modest single-digit integer like 2 or 4. To get a sense of how different Gaussians translate to the beta distribution, we’ll recreate Figure 21.11.
crossing(m_0 = 0:1,
s_0 = c(0.5, 1, 2)) |>
mutate(key = str_c("mu == logistic(beta %~%", " N(", m_0, ", ", s_0, "))"),
sim = pmap(.l = list(2e6, m_0, s_0), .f = rnorm)) |>
unnest(sim) |>
mutate(sim = plogis(sim)) |>
ggplot(aes(x = sim, y = after_stat(density))) +
geom_histogram(color = pm[8], fill = pm[7],
linewidth = 1/3, bins = 20, boundary = 0) +
geom_line(stat = "density", color = pm[3], linewidth = 1) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(expression(mu)) +
facet_wrap(~ key, scales = "free_y", labeller = label_parsed)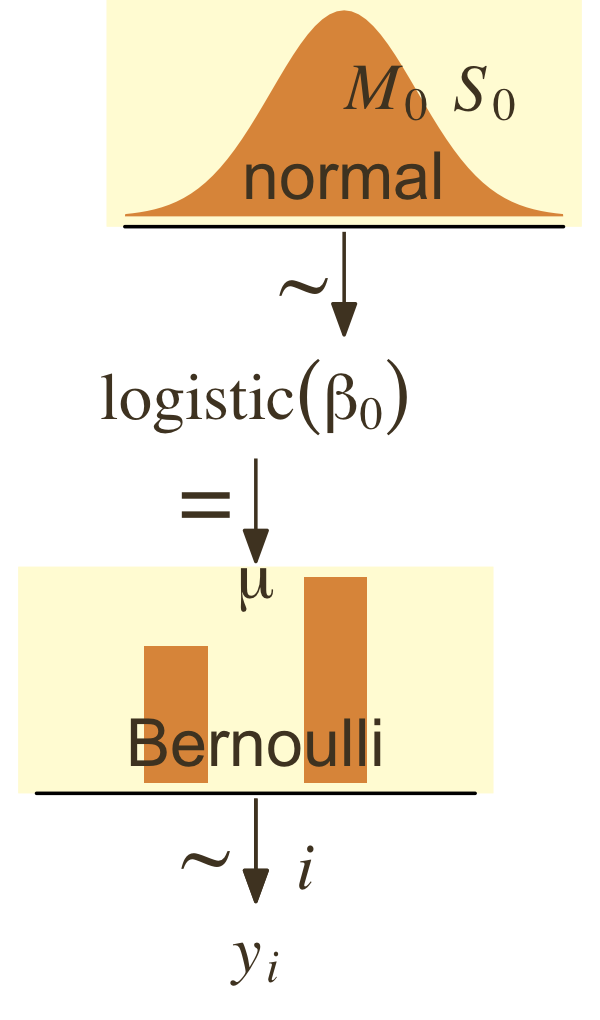
So the prior distribution doesn’t even flatten out until you’re somewhere between \(S_0 = 1\) and \(S_0 = 2\). Just for kicks, here we break that down a little further.
# Wrangle
tibble(m_0 = 0,
s_0 = c(1.25, 1.5, 1.75)) |>
mutate(key = str_c("mu == logistic(beta %~%", " N(", m_0, ", ", s_0, "))"),
sim = pmap(list(1e7, m_0, s_0), rnorm)) |>
unnest(sim) |>
mutate(sim = plogis(sim)) |>
# Plot
ggplot(aes(x = sim, y = after_stat(density))) +
geom_histogram(bins = 20, boundary = 0,
color = pm[8], fill = pm[7], linewidth = 1/3) +
geom_line(stat = "density", color = pm[3], linewidth = 1) +
scale_y_continuous(NULL, breaks = NULL) +
xlab(expression(mu)) +
facet_wrap(~ key, labeller = label_parsed, ncol = 3, scales = "free_y")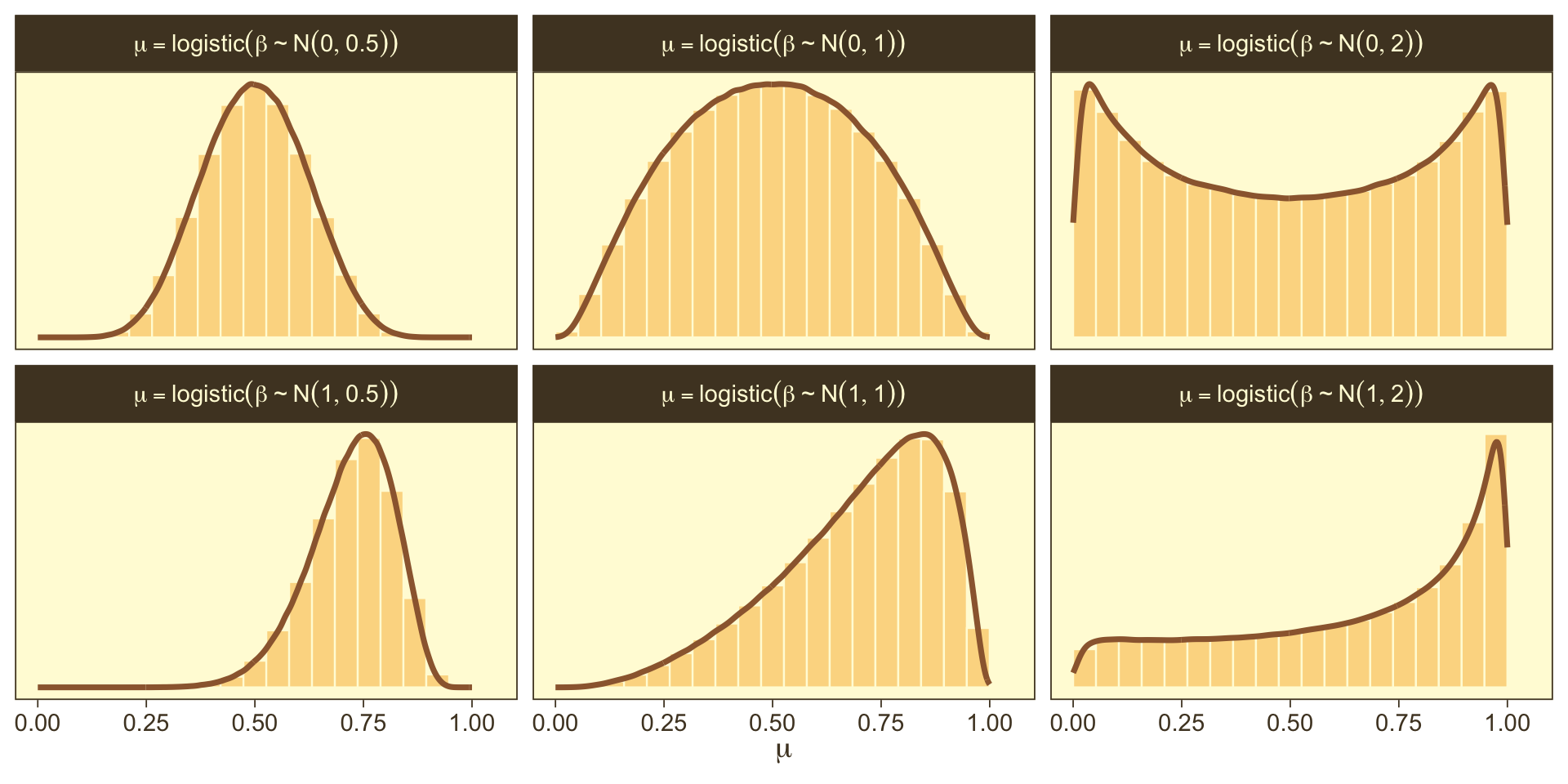
Here’s the basic brms analogue to Kruschke’s JAGS code from the bottom of page 639.
fit <- brm(
data = my_data,
family = bernoulli(link = identity),
y ~ 1,
prior(beta(1, 1), class = Intercept, lb = 0, ub = 1))Here’s the brms analogue to Kruschke’s JAGS code at the top of page 641.
fit <- brm(
data = my_data,
family = bernoulli,
y ~ 1,
prior(normal(0, 2), class = Intercept))21.4.2 Multiple groups.
If there’s only one group, we don’t need a grouping variable. But that’s a special case. Now we show the more general approach with multiple groups.
21.4.2.1 Example: Baseball again.
Load the baseball data.
my_data <- read_csv("data.R/BattingAverage.csv")
glimpse(my_data)Rows: 948
Columns: 6
$ Player <chr> "Fernando Abad", "Bobby Abreu", "Tony Abreu", "Dustin Ack…
$ PriPos <chr> "Pitcher", "Left Field", "2nd Base", "2nd Base", "1st Bas…
$ Hits <dbl> 1, 53, 18, 137, 21, 0, 0, 2, 150, 167, 0, 128, 66, 3, 1, …
$ AtBats <dbl> 7, 219, 70, 607, 86, 1, 1, 20, 549, 576, 1, 525, 275, 12,…
$ PlayerNumber <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17…
$ PriPosNumber <dbl> 1, 7, 4, 4, 3, 1, 1, 3, 3, 4, 1, 5, 4, 2, 7, 4, 6, 8, 9, …21.4.2.2 The model.
I’m not aware that Kruschke’s modeling approach for this example will work well within the brms paradigm. Accordingly, our version of the hierarchical model diagram in Figure 21.12 will differ in important ways from the one in the text.
# Bracket
p1 <- tibble(x = 0.4,
y = 0.25,
label = "{_}") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[3], family = "Times", size = 10) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# Normal density
p2 <- tibble(x = seq(from = -3, to = 3, by = 0.1)) |>
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = pm[5]) +
annotate(geom = "text",
x = 0, y = 0.2,
label = "normal",
color = pm[1], size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = 0.6,
label = c("italic(M)[0]", "italic(S)[0]"),
color = pm[1], family = "Times", hjust = 0, parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = "white", fill = pm[8], linewidth = 1))
# Second normal density
p3 <- tibble(x = seq(from = -3, to = 3, by = 0.1)) |>
ggplot(aes(x = x, y = (dnorm(x)) / max(dnorm(x)))) +
geom_area(fill = pm[5]) +
annotate(geom = "text",
x = 0, y = 0.2,
label = "normal",
color = pm[1], size = 7) +
annotate(geom = "text",
x = c(0, 1.5), y = 0.6,
label = c("0", "sigma[beta]"),
color = pm[1], family = "Times", hjust = 0, parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = "white", fill = pm[8], linewidth = 1))
# Plain arrow
p4 <- tibble(x = 0.4,
y = 1,
xend = 0.4,
yend = 0.25) |>
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow, color = pm[1]) +
xlim(0, 1) +
theme_void()
# Likelihood formula
p5 <- tibble(x = 0.5,
y = 0.3,
label = "logistic(beta[0]+sum()[italic(j)]*beta['['*italic(j)*']']*italic(x)['['*italic(j)*']'](italic(i)))") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = 7) +
scale_x_continuous(expand = c(0, 0), limits = c(0, 1)) +
ylim(0, 1) +
theme_void()
# Two annotated arrows
p6 <- tibble(x = c(0.2, 0.8),
y = 1,
xend = c(0.37, 0.63),
yend = 0.1) |>
ggplot(aes(x = x, xend = xend,
y = y, yend = yend)) +
geom_segment(arrow = my_arrow, color = pm[1]) +
annotate(geom = "text",
x = c(0.22, 0.66, 0.77), y = 0.55,
label = c("'~'", "'~'", "italic(j)"),
color = pm[1], family = "Times", parse = TRUE, size = c(10, 10, 7)) +
xlim(0, 1) +
theme_void()
# Binomial density
p7 <- tibble(x = 0:7) |>
ggplot(aes(x = x,
y = (dbinom(x, size = 7, prob = 0.625)) / max(dbinom(x, size = 7, prob = 0.625)))) +
geom_col(fill = pm[5], width = 0.4) +
annotate(geom = "text",
x = 3.5, y = 0.2,
label = "binomial",
size = 7) +
annotate(geom = "text",
x = 7, y = 0.85,
label = "italic(N)[italic(i)*'|'*italic(j)]",
family = "Times", parse = TRUE, size = 7) +
coord_cartesian(xlim = c(-1, 8),
ylim = c(0, 1.2)) +
theme_void() +
theme(axis.line.x = element_line(linewidth = 0.5),
plot.background = element_rect(color = pm[8], fill = pm[8]))
# One annotated arrow
p8 <- tibble(x = c(0.375, 0.5),
y = c(0.75, 0.3),
label = c("'='", "mu[italic(i)*'|'*italic(j)]")) |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = c(10, 7)) +
geom_segment(x = 0.5, xend = 0.5,
y = 1, yend = 0.425,
arrow = my_arrow, color = pm[1]) +
xlim(0, 1) +
theme_void()
# Another annotated arrow
p9 <- tibble(x = c(0.375, 0.625),
y = c(1/3, 1/3),
label = c("'~'", "italic(i)*'|'*italic(j)")) |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = c(10, 7)) +
geom_segment(x = 0.5, xend = 0.5,
y = 1, yend = 0,
arrow = my_arrow, color = pm[1]) +
xlim(0, 1) +
theme_void()
# Some text
p10 <- tibble(x = 1,
y = 0.5,
label = "italic(y[i])['|'][italic(j)]") |>
ggplot(aes(x = x, y = y, label = label)) +
geom_text(color = pm[1], family = "Times", parse = TRUE, size = 7) +
xlim(0, 2) +
theme_void()
# Define the layout
layout <- c(
area(t = 1, b = 2, l = 6, r = 8),
area(t = 4, b = 5, l = 1, r = 3),
area(t = 4, b = 5, l = 5, r = 7),
area(t = 3, b = 4, l = 6, r = 8),
area(t = 7, b = 8, l = 1, r = 7),
area(t = 6, b = 7, l = 1, r = 7),
area(t = 11, b = 12, l = 3, r = 5),
area(t = 9, b = 11, l = 3, r = 5),
area(t = 13, b = 14, l = 3, r = 5),
area(t = 15, b = 15, l = 3, r = 5))
# Combine, adjust, and display
(p1 + p2 + p3 + p4 + p5 + p6 + p7 + p8 + p9 + p10) +
plot_layout(design = layout) &
ylim(0, 1) &
theme(plot.margin = margin(0, 5.5, 0, 5.5))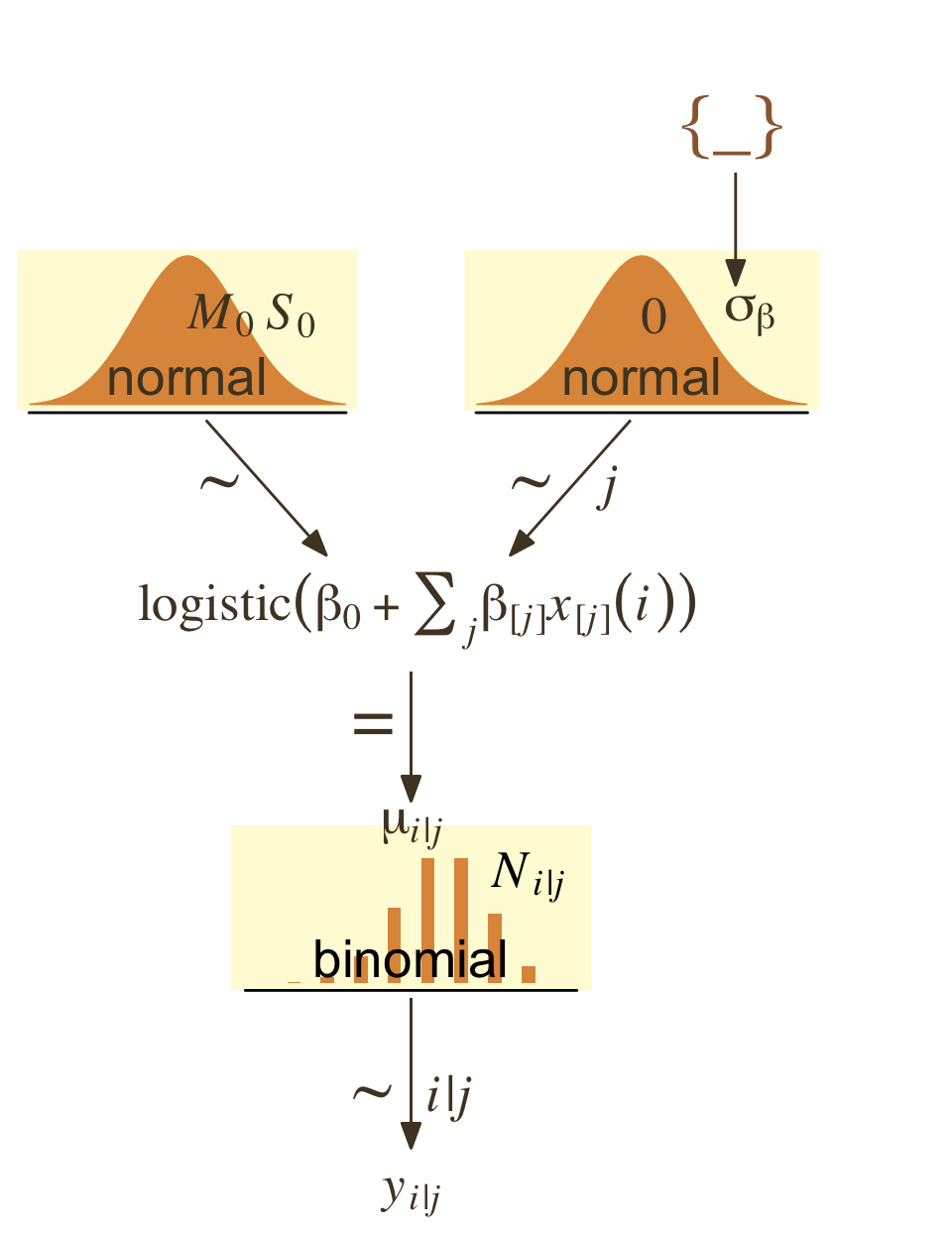
I recommend we fit a hierarchical aggregated-binomial regression model in place of the one Kruschke used. With this approach, we might express the statistical model as
\[\begin{align*} \text{Hits}_i & \sim \operatorname{Binomial}(\text{AtBats}_i, p_i) \\ \operatorname{logit}(p_i) & = \beta_0 + \beta_{\text{PriPos}_i} + \beta_{\text{PriPos:Player}_i} \\ \beta_0 & \sim \operatorname{Normal}(0, 2) \\ \beta_\text{PriPos} & \sim \operatorname{Normal}(0, \sigma_\text{PriPos}) \\ \beta_\text{PriPos:Player} & \sim \operatorname{Normal}(0, \sigma_\text{PriPos:Player}) \\ \sigma_\text{PriPos} & \sim \operatorname{HalfCauchy}(0, 1) \\ \sigma_\text{PriPos:Player} & \sim \operatorname{HalfCauchy}(0, 1). \end{align*}\]
Here’s how to fit the model with brms. Notice we’re finally making good use of the trials() syntax. This is because we’re fitting an aggregated binomial model. Instead of our criterion variable Hits being a vector of 0’s and 1’s, it’s the number of successful trials given the total number of trials, which is listed in the AtBats vector. Aggregated binomial.
fit21.8 <- brm(
data = my_data,
family = binomial(link = logit),
Hits | trials(AtBats) ~ 1 + (1 | PriPos) + (1 | PriPos:Player),
prior = c(prior(normal(0, 2), class = Intercept),
prior(cauchy(0, 1), class = sd)),
iter = 2500, warmup = 500, chains = 4, cores = 4,
seed = 21,
control = list(adapt_delta = 0.99),
file = "fits/fit21.08")21.4.2.3 Results.
Before we start plotting, review the model summary.
print(fit21.8) Family: binomial
Links: mu = logit
Formula: Hits | trials(AtBats) ~ 1 + (1 | PriPos) + (1 | PriPos:Player)
Data: my_data (Number of observations: 948)
Draws: 4 chains, each with iter = 2500; warmup = 500; thin = 1;
total post-warmup draws = 8000
Multilevel Hyperparameters:
~PriPos (Number of levels: 9)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.32 0.10 0.19 0.57 1.00 3071 4708
~PriPos:Player (Number of levels: 948)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.14 0.01 0.12 0.15 1.00 3657 5456
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -1.18 0.11 -1.40 -0.95 1.00 2245 3354
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).If you look closely at our model versus the one in the text, you’ll see ours has fewer parameters. As a down-the-line consequence, our model doesn’t support a direct analogue to the plot at the top of Figure 21.13. However, we can come close. Rather than modeling the position-based probabilities as multiple draws of beta distributions, we can simply summarize our probabilities by their posterior distributions.
# Define our new data, `nd`
nd <- my_data |>
group_by(PriPos) |>
summarise(AtBats = mean(AtBats) |> round(digits = 0)) |>
# To help join with the draws
mutate(name = str_c("V", 1:n()))
# Push the model through `fitted()` and wrangle
fitted(fit21.8,
newdata = nd,
re_formula = Hits | trials(AtBats) ~ 1 + (1 | PriPos),
scale = "linear",
summary = FALSE) |>
data.frame() |>
pivot_longer(cols = everything()) |>
mutate(probability = plogis(value)) |>
left_join(nd, by = "name") |>
# Plot
ggplot(aes(x = probability, y = PriPos)) +
geom_vline(xintercept = fixef(fit21.8)[1] |> plogis(), color = pm[6]) +
geom_density_ridges(color = pm[1], fill = pm[7], linewidth = 1/2,
rel_min_height = 0.005, scale = 0.9) +
geom_jitter(data = my_data,
aes(x = Hits / AtBats),
alpha = 1/6, color = pm[1], height = 0.025, size = 1/6) +
scale_x_continuous("Hits / AtBats", breaks = 0:5 / 5, expand = c(0, 0)) +
coord_cartesian(xlim = c(0, 1),
ylim = c(1, 9.5)) +
ggtitle("Data with Posterior Predictive Distrib.") +
theme(axis.text.y = element_text(hjust = 0),
axis.ticks.y = element_blank())
For kicks and giggles, we depicted the grand mean probability as the vertical line in the background with geom_vline().
However, we can make our plot more directly analogous to Kruschke’s if we’re willing to stretch a little. Recall that Kruschke used the beta distribution with the \(\omega-\kappa\) parameterization in both his statistical model and his plot code–both of which you can find detailed in his Jags-Ybinom-Xnom1fac-Mlogistic.R. file. We didn’t use the beta distribution in our brm() model and the parameters from that model didn’t have as direct correspondences to the beta distribution the way those from Kruschke’s JAGS model did. However, recall that we can re-parameterize the beta distribution in terms of its mean \(\mu\) and sample size \(n\), following the form
\[\begin{align*} \alpha & = \mu n \\ \beta & = (1 - \mu) n . \end{align*}\]
When we take the inverse logit of our intercepts, we do get vales in a probability metric. We might consider inserting those probabilities into the \(\mu\) parameter. Furthermore, we can take our AtBats sample sizes and insert them directly into \(n\). As before, we’ll use the average sample size per position.
# Wrangle like a boss
nd |>
add_epred_draws(fit21.8,
ndraws = 20,
re_formula = Hits | trials(AtBats) ~ 1 + (1 | PriPos),
dpar = "mu") |>
# Use the equations from above
mutate(alpha = mu * AtBats,
beta = (1 - mu) * AtBats) |>
mutate(ll = qbeta(0.025, shape1 = alpha, shape2 = beta),
ul = qbeta(0.975, shape1 = alpha, shape2 = beta)) |>
mutate(theta = map2(.x = ll, .y = ul,
.f = \(ll, ul) seq(from = ll, to = ul, length.out = 100))) |>
unnest(theta) |>
mutate(density = dbeta(theta, shape1 = alpha, shape2 = beta)) |>
group_by(.draw) |>
mutate(density = density / max(density)) |>
# Plot
ggplot(aes(y = PriPos)) +
geom_ridgeline(aes(x = theta, height = -density, group = interaction(PriPos, .draw)),
alpha = 2/3, color = adjustcolor(pm[1], alpha.f = 1/3),
fill = NA, linewidth = 1/3, min_height = NA) +
geom_jitter(data = my_data,
aes(x = Hits / AtBats, size = AtBats),
alpha = 1/6, color = pm[1], height = 0.05, shape = 1) +
scale_x_continuous("Hits / AtBats", expand = c(0, 0)) +
scale_size_continuous(range = c(1/4, 4)) +
labs(y = NULL,
title = "Data with Posterior Predictive Distrib.") +
coord_flip(xlim = c(0, 1),
ylim = c(0.67, 8.67)) +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
axis.ticks.x = element_blank(),
legend.position.inside = c(0.956, 0.8))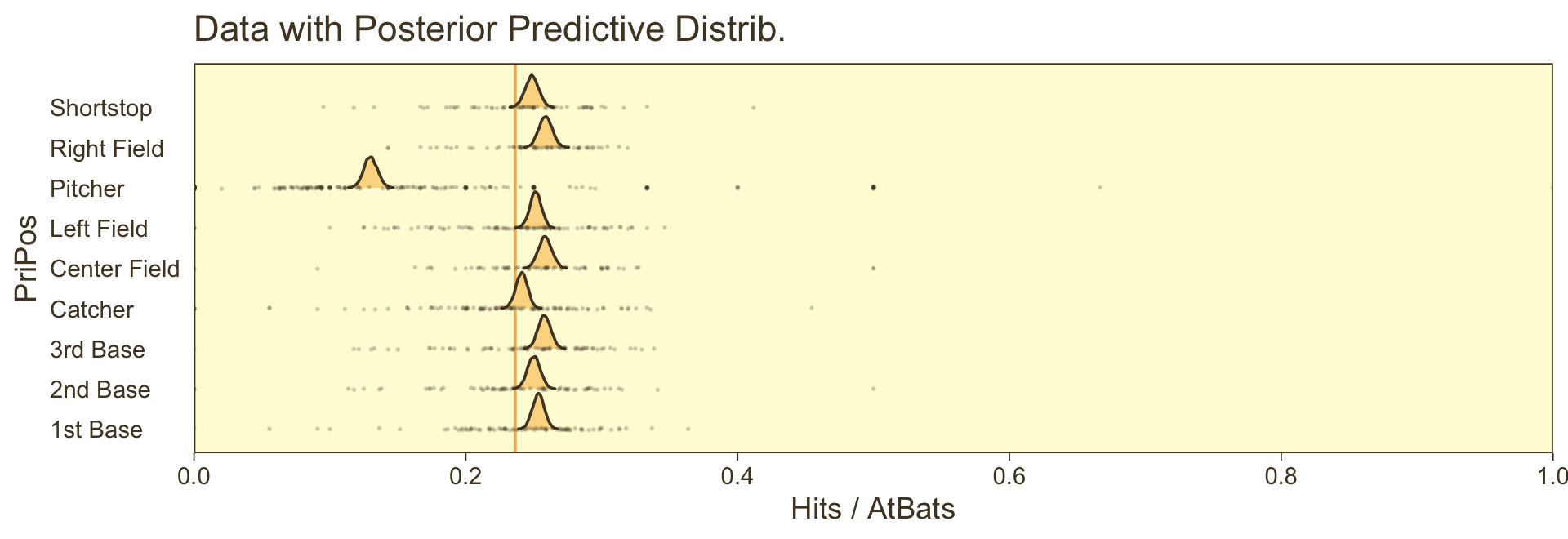
⚠️ Since we didn’t actually presume the beta distribution anywhere in our brm() statistical model, I would not attempt to present this workflow in a scientific outlet. Go with the previous plot. This attempt seems dishonest. But it is kinda fun to see how far we can push our results. ⚠️
Happily, our contrasts will be less contentious. Here’s the initial wrangling.
# Define our subset of positions
positions <- c("1st Base", "Catcher", "Pitcher")
# Redefine `nd`
nd <- my_data |>
filter(PriPos %in% positions) |>
group_by(PriPos) |>
summarise(AtBats = mean(AtBats) |> round(0))
# Push the model through `fitted()` and wrangle
f <- fitted(fit21.8,
newdata = nd,
re_formula = Hits | trials(AtBats) ~ 1 + (1 | PriPos),
scale = "linear",
summary = FALSE) |>
data.frame() |>
set_names(positions)
# What did we do?
head(f) 1st Base Catcher Pitcher
1 -1.046248 -1.149345 -1.975936
2 -1.106469 -1.155328 -1.875289
3 -1.086128 -1.169836 -1.922121
4 -1.087369 -1.124628 -1.883061
5 -1.104407 -1.155220 -1.854039
6 -1.073023 -1.124804 -1.882417Here we make are our versions of the middle two panels of Figure 21.13.
p1 <- f |>
# Compute the differences and put the data in the long format
mutate(`Pitcher vs. Catcher` = Pitcher - Catcher,
`Catcher vs. 1st Base` = Catcher - `1st Base`) |>
pivot_longer(cols = contains("vs.")) |>
mutate(name = factor(name, levels = c("Pitcher vs. Catcher", "Catcher vs. 1st Base"))) |>
ggplot(aes(x = value)) +
geom_vline(xintercept = 0, color = pm[6]) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
xlab("Difference (in b)") +
facet_wrap(~ name, scales = "free")Now make our versions of the bottom two panels of Figure 21.13.
p2 <- f |>
# Transform before computing the differences
mutate_all(.funs = plogis) |>
mutate(`Pitcher vs. Catcher` = Pitcher - Catcher,
`Catcher vs. 1st Base` = Catcher - `1st Base`) |>
pivot_longer(cols = contains("vs.")) |>
mutate(name = factor(name, levels = c("Pitcher vs. Catcher", "Catcher vs. 1st Base"))) |>
ggplot(aes(x = value)) +
geom_vline(xintercept = 0, color = pm[6]) +
stat_wilke() +
scale_y_continuous(NULL, breaks = NULL) +
xlab("Difference (in probability)") +
facet_wrap(~ name, scales = "free")Combine and display.
p1 / p2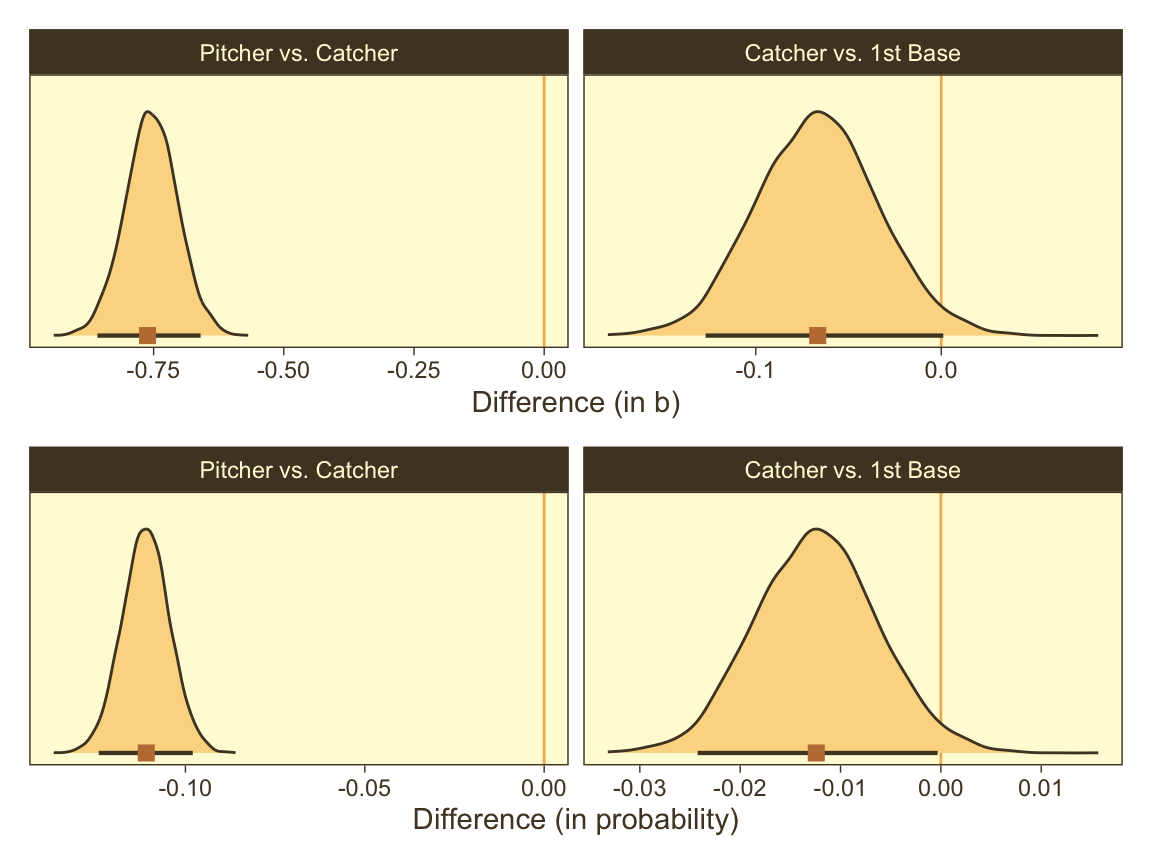
Note how our distributions are described as differences in probability, rather than in \(\omega\).
Session info
sessionInfo()R version 4.4.3 (2025-02-28)
Platform: aarch64-apple-darwin20
Running under: macOS Ventura 13.4
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggridges_0.5.6 GGally_2.2.1 tidybayes_3.0.7 brms_2.22.0
[5] Rcpp_1.0.14 ggExtra_0.10.1 patchwork_1.3.0 PNWColors_0.1.0
[9] lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4
[13] purrr_1.0.4 readr_2.1.5 tidyr_1.3.1 tibble_3.2.1
[17] ggplot2_3.5.1 tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] gridExtra_2.3 inline_0.3.19 sandwich_3.1-1
[4] rlang_1.1.5 magrittr_2.0.3 multcomp_1.4-26
[7] matrixStats_1.4.1 compiler_4.4.3 loo_2.8.0
[10] reshape2_1.4.4 vctrs_0.6.5 pkgconfig_2.0.3
[13] arrayhelpers_1.1-0 crayon_1.5.3 fastmap_1.1.1
[16] backports_1.5.0 labeling_0.4.3 utf8_1.2.4
[19] promises_1.3.0 rmarkdown_2.29 tzdb_0.4.0
[22] bit_4.0.5 xfun_0.49 jsonlite_1.8.9
[25] later_1.3.2 parallel_4.4.3 R6_2.6.1
[28] stringi_1.8.4 RColorBrewer_1.1-3 StanHeaders_2.32.10
[31] estimability_1.5.1 assertthat_0.2.1 rstan_2.32.6
[34] knitr_1.49 zoo_1.8-12 bayesplot_1.11.1
[37] httpuv_1.6.15 Matrix_1.7-2 splines_4.4.3
[40] timechange_0.3.0 tidyselect_1.2.1 rstudioapi_0.16.0
[43] abind_1.4-8 yaml_2.3.8 codetools_0.2-20
[46] miniUI_0.1.1.1 curl_6.0.1 pkgbuild_1.4.4
[49] lattice_0.22-6 plyr_1.8.9 shiny_1.8.1.1
[52] withr_3.0.2 bridgesampling_1.1-2 posterior_1.6.0
[55] coda_0.19-4.1 evaluate_1.0.1 survival_3.8-3
[58] ggstats_0.6.0 RcppParallel_5.1.7 ggdist_3.3.2
[61] pillar_1.10.2 tensorA_0.36.2.1 checkmate_2.3.2
[64] stats4_4.4.3 distributional_0.5.0 generics_0.1.3
[67] vroom_1.6.5 hms_1.1.3 rstantools_2.4.0
[70] munsell_0.5.1 scales_1.3.0 xtable_1.8-4
[73] emo_0.0.0.9000 glue_1.8.0 emmeans_1.10.3
[76] tools_4.4.3 mvtnorm_1.2-5 grid_4.4.3
[79] QuickJSR_1.1.3 colorspace_2.1-1 nlme_3.1-167
[82] cli_3.6.4 svUnit_1.0.6 Brobdingnag_1.2-9
[85] V8_4.4.2 gtable_0.3.6 digest_0.6.37
[88] TH.data_1.1-2 htmlwidgets_1.6.4 farver_2.1.2
[91] htmltools_0.5.8.1 lifecycle_1.0.4 mime_0.12
[94] bit64_4.0.5 MASS_7.3-64