8 中文文本分析
代码提供: 张柏珊 王楠
主要内容:
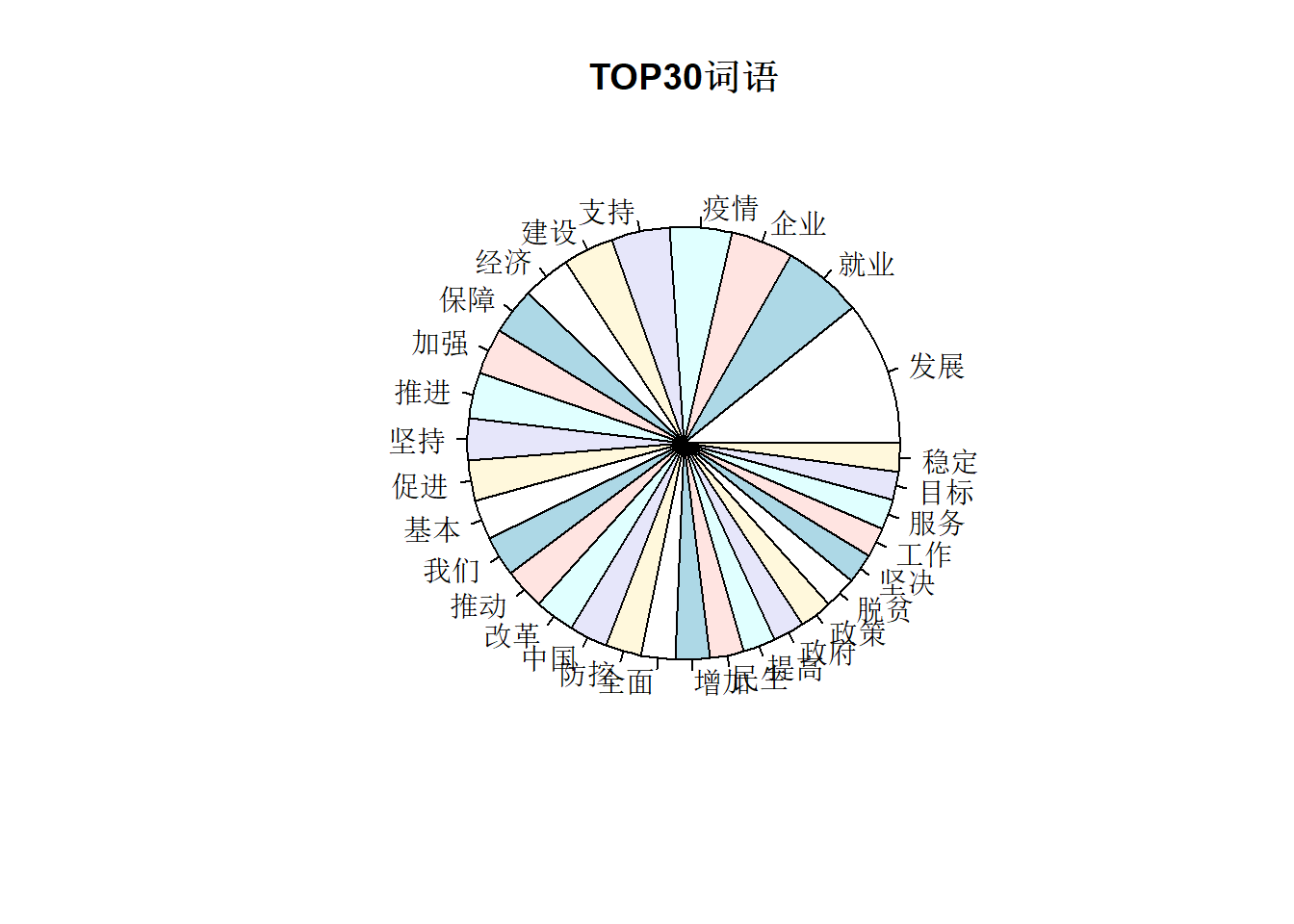
-1.安装拓展包和导入 -2.分词 -3.运用SQL -4.词云 -5.词频可视化
8.1 安装拓展包和导入
8.2 结巴分词处理
8.2.1 制作词表
8.2.1.1 标停止词
engine1 <- worker(user = "users.txt",stop_word = "stopwords.txt")
stopwords_CN <- c("被","怎么","还是","多少","得", "吗","给",
"年","月","还","个","能", "日","什么","做","没","啊",
"的", "了", "在", "是", "我", "有", "和", "就","不",
"人", "都", "一", "一个", "上", "也", "很", "到", "说",
"要", "去", "你","会", "着", "没有", "看", "好",
"自己", "这", "等","各位代表")
library('jiebaR')8.2.1.2 变量seg保存文章所有的词语
seg <- qseg[f]## Warning in `[.qseg`(qseg, f): Quick mode is depreciated, and is scheduled to be
## remove in v0.11.0. If you want to keep this feature, please submit a issue on
## GitHub page to let me know.## Warning in file.exists(code) && .GlobalEnv$quick_worker$write == T: 'length(x)
## = 88 > 1' in coercion to 'logical(1)'8.3 运用SQL
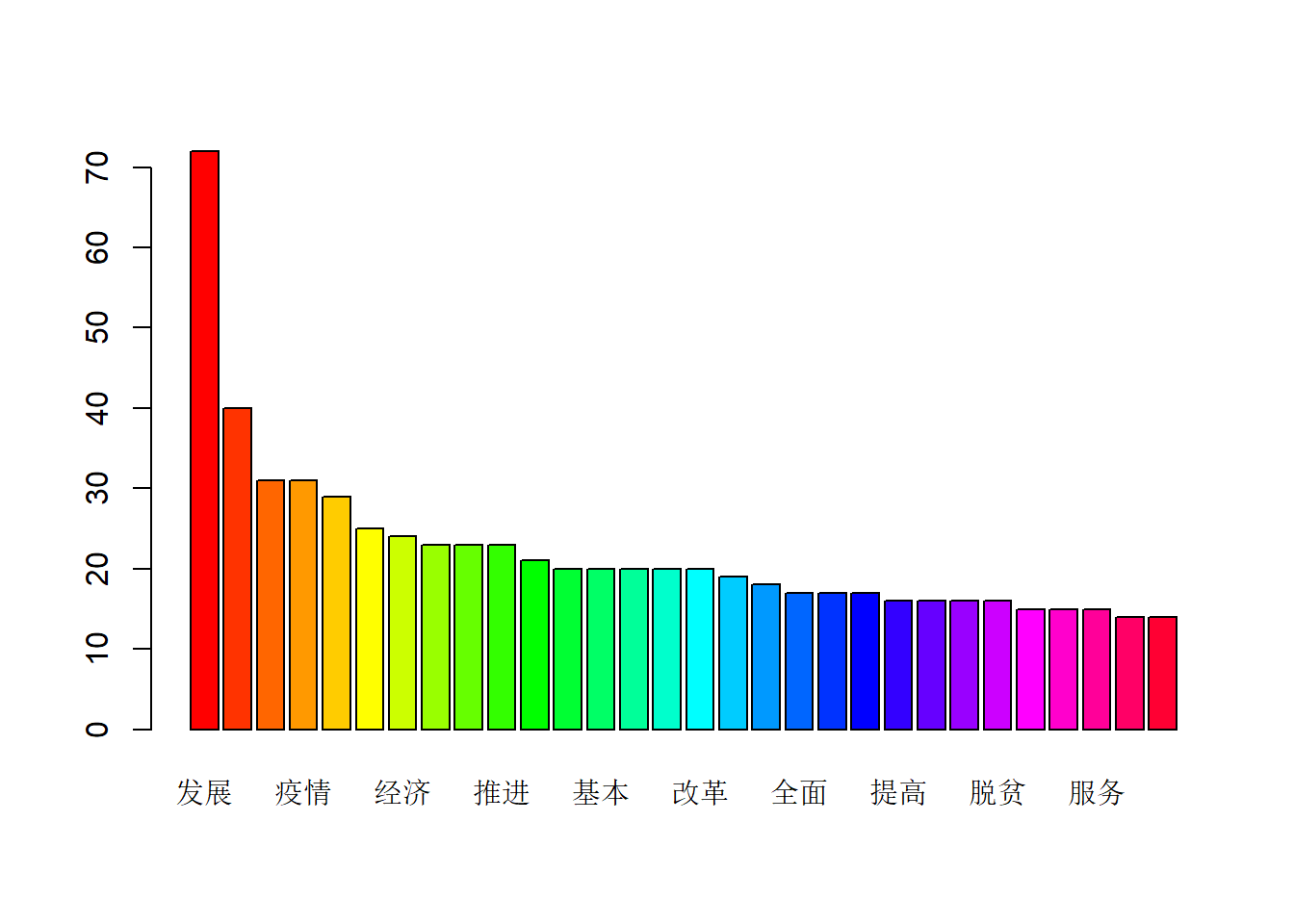
8.3.1 安装并载入sqldf程序包 >group by“根据一定的规则进行分组”,通过一定的规则将一个数据集划分成若干个笑的区域,然后针对若干个小区域进行数据处理 >count(1)来计数 >select检索数据
library(sqldf)## Loading required package: gsubfn## Loading required package: proto## Loading required package: RSQLitem2 <- sqldf('select seg,count(1)as freg from m1 group by seg')
class(m2)## [1] "data.frame"