7 Interactions
Every model so far in [McElreath’s text] has assumed that each predictor has an independent association with the mean of the outcome. What if we want to allow the association to be conditional?… To model deeper conditionality—where the importance of one predictor depends upon another predictor—we need interaction. Interaction is a kind of conditioning, a way of allowing parameters (really their posterior distributions) to be conditional on further aspects of the data. (p. 210)
7.1 Building an interaction.
“Africa is special” (p. 211). Let’s load the rugged data to see one of the reasons why.
library(rethinking)## Warning: package 'ggplot2' was built under R version 3.5.2data(rugged)
d <- ruggedAnd here we switch out rethinking for brms.
detach(package:rethinking, unload = T)
library(brms)
rm(rugged)We’ll continue to use tidyverse-style syntax to wrangle the data.
library(tidyverse)
# make the log version of criterion
d <-
d %>%
mutate(log_gdp = log(rgdppc_2000))
# extract countries with GDP data
dd <-
d %>%
filter(complete.cases(rgdppc_2000))
# split the data into countries in Africa and not in Africa
d.A1 <-
dd %>%
filter(cont_africa == 1)
d.A0 <-
dd %>%
filter(cont_africa == 0)The first two models predicting log_gdp are univariable.
b7.1 <-
brm(data = d.A1, family = gaussian,
log_gdp ~ 1 + rugged,
prior = c(prior(normal(8, 100), class = Intercept),
prior(normal(0, 1), class = b),
prior(uniform(0, 10), class = sigma)),
iter = 2000, warmup = 1000, chains = 4, cores = 4,
seed = 7)
b7.2 <-
update(b7.1,
newdata = d.A0)In the text, McElreath more or less dared us to figure out how to make Figure 7.2. Here’s the brms-relevant data wrangling.
nd <-
tibble(rugged = seq(from = 0, to = 6.3, length.out = 30))
f_b7.1 <-
fitted(b7.1, newdata = nd) %>%
as_tibble() %>%
bind_cols(nd)
f_b7.2 <-
fitted(b7.2, newdata = nd) %>%
as_tibble() %>%
bind_cols(nd)
# here we'll put both in a single data object, with `f_b7.1` stacked atop `f_b7.2`
f <-
full_join(f_b7.1, f_b7.2) %>%
mutate(cont_africa = rep(c("Africa", "not Africa"), each = 30))For this chapter, we’ll take our plot theme from the ggthemes package.
# install.packages("ggthemes", dependencies = T)
library(ggthemes)Here’s the plot code for our version of Figure 7.2.
dd %>%
mutate(cont_africa = ifelse(cont_africa == 1, "Africa", "not Africa")) %>%
ggplot(aes(x = rugged)) +
geom_smooth(data = f,
aes(y = Estimate, ymin = Q2.5, ymax = Q97.5,
fill = cont_africa, color = cont_africa),
stat = "identity",
alpha = 1/4, size = 1/2) +
geom_point(aes(y = log_gdp, color = cont_africa),
size = 2/3) +
scale_colour_pander() +
scale_fill_pander() +
scale_x_continuous("Terrain Ruggedness Index", expand = c(0, 0)) +
ylab("log GDP from year 2000") +
theme_pander() +
theme(text = element_text(family = "Times"),
legend.position = "none") +
facet_wrap(~cont_africa)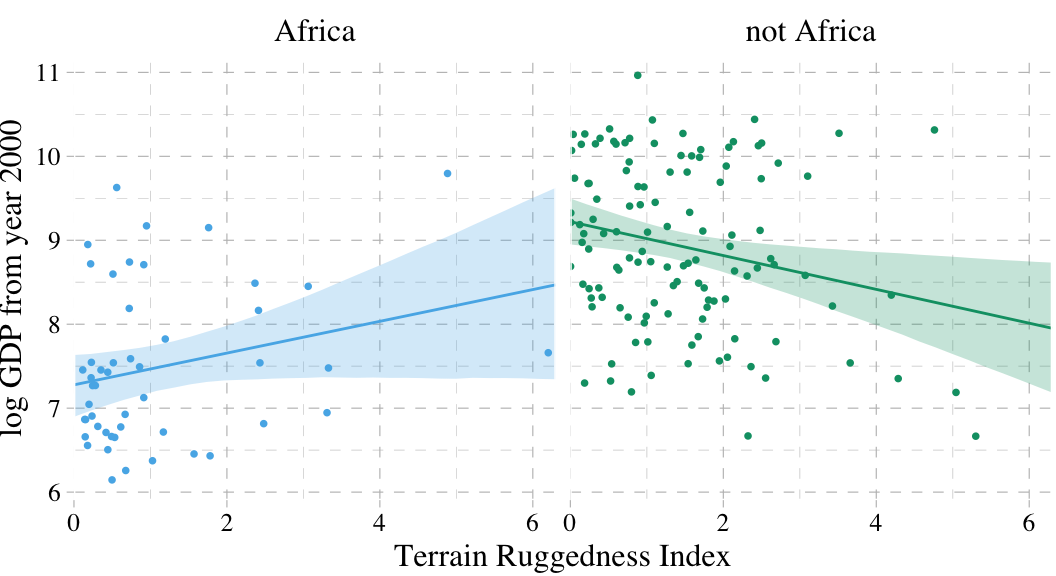
7.1.1 Adding a dummy variable doesn’t work.
Here’s our model with all the countries, but without the cont_africa dummy.
b7.3 <-
update(b7.1,
newdata = dd)Now we’ll add the dummy.
b7.4 <-
update(b7.3,
newdata = dd,
formula = log_gdp ~ 1 + rugged + cont_africa) Using the skills from Chapter 6, let’s compute the information criteria for the two models. Note how with the add_criterion() function, you can compute both the LOO and the WAIC at once.
b7.3 <- add_criterion(b7.3, c("loo", "waic"))
b7.4 <- add_criterion(b7.4, c("loo", "waic"))Here we’ll compare the models with the loo_compare() function, first by the WAIC and then by the LOO.
loo_compare(b7.3, b7.4,
criterion = "waic")## elpd_diff se_diff
## b7.4 0.0 0.0
## b7.3 -31.7 7.3loo_compare(b7.3, b7.4,
criterion = "loo")## elpd_diff se_diff
## b7.4 0.0 0.0
## b7.3 -31.7 7.3Happily, the WAIC and the LOO are in agreement. The model with the dummy, b7.4, fit the data much better. Here are the WAIC model weights.
model_weights(b7.3, b7.4,
weights = "waic") %>%
round(digits = 3)## b7.3 b7.4
## 0 1As in the text, almost all the weight went to the multivariable model, b7.4. Before we can plot that model, we need to wrangle a bit.
nd <-
tibble(rugged = seq(from = 0, to = 6.3, length.out = 30) %>%
rep(., times = 2),
cont_africa = rep(0:1, each = 30))
f <-
fitted(b7.4, newdata = nd) %>%
as_tibble() %>%
bind_cols(nd) %>%
mutate(cont_africa = ifelse(cont_africa == 1, "Africa", "not Africa"))Behold our Figure 7.3.
dd %>%
mutate(cont_africa = ifelse(cont_africa == 1, "Africa", "not Africa")) %>%
ggplot(aes(x = rugged)) +
geom_smooth(data = f,
aes(y = Estimate, ymin = Q2.5, ymax = Q97.5,
fill = cont_africa, color = cont_africa),
stat = "identity",
alpha = 1/4, size = 1/2) +
geom_point(aes(y = log_gdp, color = cont_africa),
size = 2/3) +
scale_colour_pander() +
scale_fill_pander() +
scale_x_continuous("Terrain Ruggedness Index", expand = c(0, 0)) +
ylab("log GDP from year 2000") +
theme_pander() +
theme(text = element_text(family = "Times"),
legend.position = c(.69, .94),
legend.title = element_blank(),
legend.direction = "horizontal")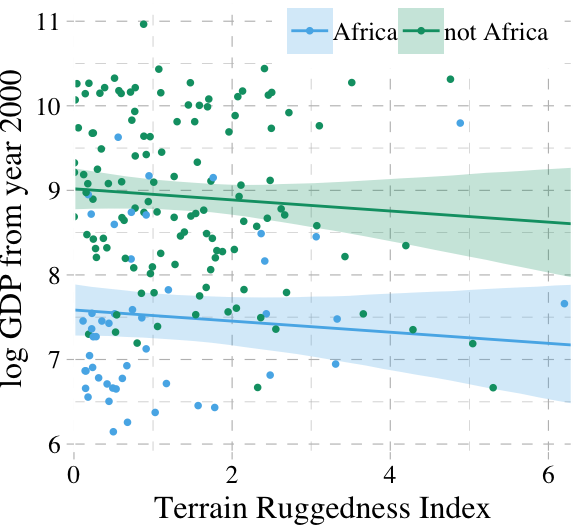
7.1.2 Adding a linear interaction does work.
Yes, it sure does. But before we fit, here’s the equation:
\[\begin{align*} \text{log_gdp}_i & \sim \text{Normal} (\mu_i, \sigma) \\ \mu_i & = \alpha + \gamma_i \text{rugged}_i + \beta_2 \text{cont_africa}_i \\ \gamma_i & = \beta_1 + \beta_3 \text{cont_africa}_i \end{align*}\]Fit the model.
b7.5 <-
update(b7.4,
formula = log_gdp ~ 1 + rugged*cont_africa) For kicks, we’ll just use the LOO to compare the last three models.
b7.5 <- add_criterion(b7.5, c("loo", "waic"))
l <- loo_compare(b7.3, b7.4, b7.5,
criterion = "loo")
print(l, simplify = F)## elpd_diff se_diff elpd_loo se_elpd_loo p_loo se_p_loo looic se_looic
## b7.5 0.0 0.0 -234.8 7.3 5.1 0.9 469.6 14.6
## b7.4 -3.1 2.9 -237.9 7.4 4.0 0.8 475.8 14.8
## b7.3 -34.8 7.3 -269.6 6.5 2.5 0.3 539.2 12.9And recall, if we want those LOO difference scores in the traditional metric like McElreath displayed in the text, we can do a quick conversion with algebra and cbind().
cbind(loo_diff = l[, 1] * -2,
se = l[, 2] * 2)## loo_diff se
## b7.5 0.00000 0.000000
## b7.4 6.24989 5.813487
## b7.3 69.69437 14.647744And we can weight the models based on the LOO rather than the WAIC, too.
model_weights(b7.3, b7.4, b7.5,
weights = "loo") %>%
round(digits = 3)## b7.3 b7.4 b7.5
## 0.000 0.042 0.9587.1.2.1 Overthinking: Conventional form of interaction.
The conventional equation for the interaction model might look like:
\[\begin{align*} \text{log_gdp}_i & \sim \text{Normal} (\mu_i, \sigma) \\ \mu_i & = \alpha + \beta_1 \text{rugged}_i + \beta_2 \text{cont_africa}_i + \beta_3 \text{rugged}_i \times \text{cont_africa}_i \end{align*}\]Instead of the y ~ 1 + x1*x2 approach, which will work fine with brm(), you can use this more explicit syntax.
b7.5b <-
update(b7.5,
formula = log_gdp ~ 1 + rugged + cont_africa + rugged:cont_africa) From here on, I will default to this style of syntax for interactions.
Since this is the same model, it yields the same information criteria estimates within simulation error. Here we’ll confirm that with the LOO.
b7.5b <- add_criterion(b7.5b, c("loo", "waic"))
b7.5$loo##
## Computed from 4000 by 170 log-likelihood matrix
##
## Estimate SE
## elpd_loo -234.8 7.3
## p_loo 5.1 0.9
## looic 469.6 14.6
## ------
## Monte Carlo SE of elpd_loo is 0.0.
##
## Pareto k diagnostic values:
## Count Pct. Min. n_eff
## (-Inf, 0.5] (good) 169 99.4% 1235
## (0.5, 0.7] (ok) 1 0.6% 1767
## (0.7, 1] (bad) 0 0.0% <NA>
## (1, Inf) (very bad) 0 0.0% <NA>
##
## All Pareto k estimates are ok (k < 0.7).
## See help('pareto-k-diagnostic') for details.b7.5b$loo##
## Computed from 4000 by 170 log-likelihood matrix
##
## Estimate SE
## elpd_loo -234.8 7.3
## p_loo 5.1 0.9
## looic 469.6 14.6
## ------
## Monte Carlo SE of elpd_loo is 0.0.
##
## Pareto k diagnostic values:
## Count Pct. Min. n_eff
## (-Inf, 0.5] (good) 169 99.4% 1202
## (0.5, 0.7] (ok) 1 0.6% 1590
## (0.7, 1] (bad) 0 0.0% <NA>
## (1, Inf) (very bad) 0 0.0% <NA>
##
## All Pareto k estimates are ok (k < 0.7).
## See help('pareto-k-diagnostic') for details.7.1.3 Plotting the interaction.
Here’s our prep work for the figure.
f <-
fitted(b7.5, newdata = nd) %>% # we can use the same `nd` data from last time
as_tibble() %>%
bind_cols(nd) %>%
mutate(cont_africa = ifelse(cont_africa == 1, "Africa", "not Africa"))And here’s the code for our version of Figure 7.4.
dd %>%
mutate(cont_africa = ifelse(cont_africa == 1, "Africa", "not Africa")) %>%
ggplot(aes(x = rugged, color = cont_africa)) +
geom_smooth(data = f,
aes(y = Estimate, ymin = Q2.5, ymax = Q97.5,
fill = cont_africa),
stat = "identity",
alpha = 1/4, size = 1/2) +
geom_point(aes(y = log_gdp),
size = 2/3) +
scale_colour_pander() +
scale_fill_pander() +
scale_x_continuous("Terrain Ruggedness Index", expand = c(0, 0)) +
ylab("log GDP from year 2000") +
theme_pander() +
theme(text = element_text(family = "Times"),
legend.position = "none") +
facet_wrap(~cont_africa)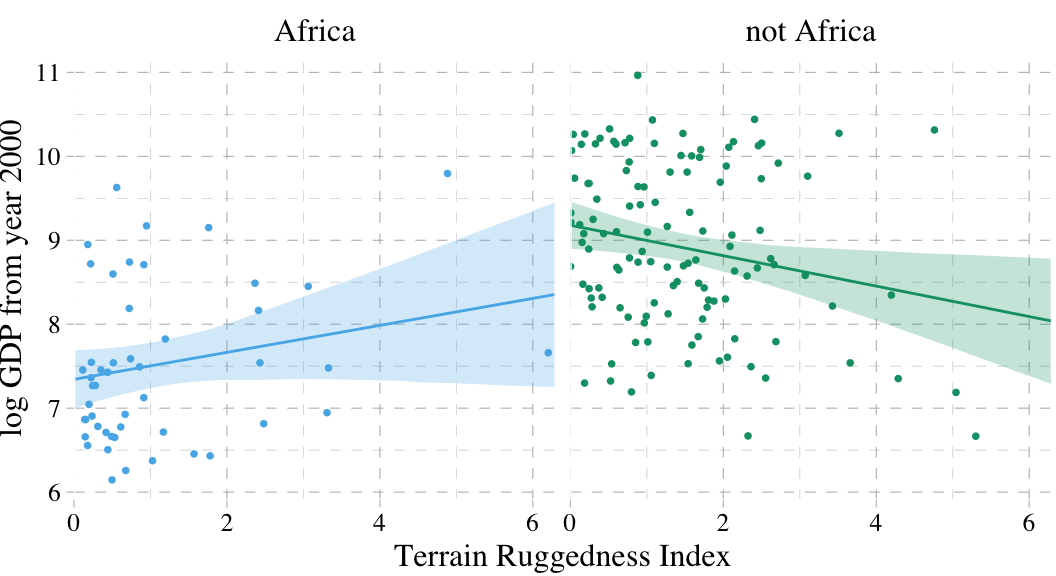
7.1.4 Interpreting an interaction estimate.
Interpreting interaction estimates is tricky. It’s trickier than interpreting ordinary estimates. And for this reason, I usually advise against trying to understand an interaction from tables of numbers along. Plotting implied predictions does far more for both our own understanding and for our audience’s. (p. 219)
7.1.4.1 Parameters change meaning.
In a simple linear regression with no interactions, each coefficient says how much the average outcome, \(\mu\), changes when the predictor changes by one unit. And since all of the parameters have independent influences on the outcome, there’s no trouble in interpreting each parameter separately. Each slope parameter gives us a direct measure of each predictor variable’s influence.
Interaction models ruin this paradise. (p. 220)
Return the parameter estimates.
posterior_summary(b7.5)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept 9.1792393 0.14149466 8.89962531 9.46077896
## b_rugged -0.1813222 0.07712694 -0.33339230 -0.03235624
## b_cont_africa -1.8360291 0.22105654 -2.26477916 -1.40748471
## b_rugged:cont_africa 0.3420525 0.13043028 0.08522017 0.59545682
## sigma 0.9501851 0.05397561 0.85137364 1.06127947
## lp__ -244.4591256 1.63737690 -248.61363845 -242.34571022“Since \(\gamma\) (gamma) doesn’t appear in this table—it wasn’t estimated—we have to compute it ourselves” (p. 221). Like in the text, we’ll do so first by working with the point estimates.
# within Africa
fixef(b7.5)[2, 1] + fixef(b7.5)[4, 1] * 1## [1] 0.1607303# outside Africa
fixef(b7.5)[2, 1] + fixef(b7.5)[4, 1] * 0## [1] -0.18132227.1.4.2 Incorporating uncertainty.
To get some idea of the uncertainty around those \(\gamma\) values, we’ll need to use the whole posterior. Since \(\gamma\) depends upon parameters, and those parameters have a posterior distribution, \(\gamma\) must also have a posterior distribution. Read the previous sentence again a few times. It’s one of the most important concepts in processing Bayesian model fits. Anything calculated using parameters has a distribution. (p. 212)
Like McElreath, we’ll avoid integral calcus in favor of working with the posterior_samples().
post <- posterior_samples(b7.5)
post %>%
transmute(gamma_Africa = b_rugged + `b_rugged:cont_africa`,
gamma_notAfrica = b_rugged) %>%
gather(key, value) %>%
group_by(key) %>%
summarise(mean = mean(value))## # A tibble: 2 x 2
## key mean
## <chr> <dbl>
## 1 gamma_Africa 0.161
## 2 gamma_notAfrica -0.181And here is our version of Figure 7.5.
post %>%
transmute(gamma_Africa = b_rugged + `b_rugged:cont_africa`,
gamma_notAfrica = b_rugged) %>%
gather(key, value) %>%
ggplot(aes(x = value, group = key, color = key, fill = key)) +
geom_density(alpha = 1/4) +
scale_colour_pander() +
scale_fill_pander() +
scale_x_continuous(expression(gamma), expand = c(0, 0)) +
scale_y_continuous(NULL, breaks = NULL) +
ggtitle("Terraine Ruggedness slopes",
subtitle = "Blue = African nations, Green = others") +
theme_pander() +
theme(text = element_text(family = "Times"),
legend.position = "none")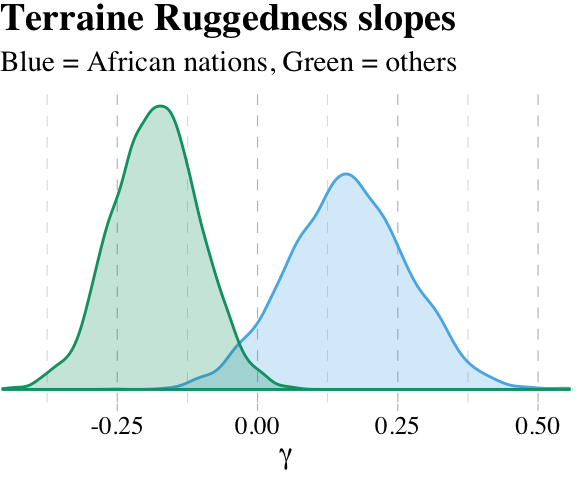
What proportion of these differences is below zero?
post %>%
mutate(gamma_Africa = b_rugged + `b_rugged:cont_africa`,
gamma_notAfrica = b_rugged) %>%
mutate(diff = gamma_Africa -gamma_notAfrica) %>%
summarise(Proportion_of_the_difference_below_0 = sum(diff < 0) / length(diff))## Proportion_of_the_difference_below_0
## 1 0.004257.2 Symmetry of the linear interaction.
Consider for example the GDP and terrain ruggedness problem. The interaction there has two equally valid phrasings.
- How much does the influence of ruggedness (on GDP) depend upon whether the nation is in Africa?
- How much does the influence of being in Africa (on GDP) depend upon ruggedness?
While these two possibilities sound different to most humans, your golem thinks they are identical. (p. 223)
7.2.1 Buridan’s interaction.
Recall the original equation.
\[\begin{align*} \text{log_gdp}_i & \sim \text{Normal} (\mu_i, \sigma) \\ \mu_i & = \alpha + \gamma_i \text{rugged}_i + \beta_2 \text{cont_africa}_i \\ \gamma_i & = \beta_1 + \beta_3 \text{cont_africa}_i \end{align*}\]Next McElreath replaced \(\gamma_i\) with the expression for \(\mu_i\).
\[\begin{align*} \mu_i & = \alpha + (\beta_1 + \beta_3 \text{cont_africa}_i) \times \text{rugged}_i + \beta_2 \text{cont_africa}_i \\ & = \alpha + \beta_1 \text{rugged}_i + \beta_3 \text{rugged}_i \times \text{cont_africa}_i + \beta_2 \text{cont_africa}_i \end{align*}\]And new we’ll factor together the terms containing \(\text{cont_africa}_i\).
\[ \mu_i = \alpha + \beta_1 \text{rugged}_i + \underbrace{(\beta_2 + \beta_3 \text{rugged}_i)}_G \times \text{cont_africa}_i \]
And just as in the text, our \(G\) term looks a lot like the original \(\gamma_i\) term.
7.2.2 Africa depends upon ruggedness.
Here is our version of McElreath’s Figure 7.6.
# new predictor data for `fitted()`
nd <-
tibble(rugged = rep(range(dd$rugged), times = 2),
cont_africa = rep(0:1, each = 2))
# `fitted()`
f <-
fitted(b7.5, newdata = nd) %>%
as_tibble() %>%
bind_cols(nd) %>%
mutate(ox = rep(c(-0.05, 0.05), times = 2))
# augment the `dd` data a bit
dd %>%
mutate(ox = ifelse(rugged > median(rugged), 0.05, -0.05),
cont_africa = cont_africa + ox) %>%
select(cont_africa, everything()) %>%
# plot
ggplot(aes(x = cont_africa, color = factor(ox))) +
geom_smooth(data = f,
aes(y = Estimate, ymin = Q2.5, ymax = Q97.5,
fill = factor(ox), linetype = factor(ox)),
stat = "identity",
alpha = 1/4, size = 1/2) +
geom_point(aes(y = log_gdp),
alpha = 1/2, shape = 1) +
scale_colour_pander() +
scale_fill_pander() +
scale_x_continuous("Continent", breaks = 0:1,
labels = c("other", "Africa")) +
coord_cartesian(xlim = c(-.2, 1.2)) +
ylab("log GDP from year 2000") +
theme_pander() +
theme(text = element_text(family = "Times"),
legend.position = "none")
7.3 Continuous interactions
Though continuous interactions can be more challenging to interpret, they’re just as easy to fit as interactions including dummies.
7.3.1 The data.
Look at the tulips.
library(rethinking)
data(tulips)
d <- tulips
str(d)## 'data.frame': 27 obs. of 4 variables:
## $ bed : Factor w/ 3 levels "a","b","c": 1 1 1 1 1 1 1 1 1 2 ...
## $ water : int 1 1 1 2 2 2 3 3 3 1 ...
## $ shade : int 1 2 3 1 2 3 1 2 3 1 ...
## $ blooms: num 0 0 111 183.5 59.2 ...7.3.2 The un-centered models.
The likelihoods for the next two models are
\[\begin{align*} \text{blooms}_i & \sim \text{Normal} (\mu_i, \sigma) \\ \mu_i & = \alpha + \beta_1 \text{water}_i + \beta_2 \text{shade}_i \\ \alpha & \sim \text{Normal} (0, 100) \\ \beta_1 & \sim \text{Normal} (0, 100) \\ \beta_2 & \sim \text{Normal} (0, 100) \\ \sigma & \sim \text{Uniform} (0, 100) \end{align*}\]and
\[\begin{align*} \text{blooms}_i & \sim \text{Normal} (\mu_i, \sigma) \\ \mu_i & = \alpha + \beta_1 \text{water} + \beta_2 \text{shade}_i + \beta_3 \text{water}_i \times \text{shade}_i \\ \alpha & \sim \text{Normal} (0, 100) \\ \beta_1 & \sim \text{Normal} (0, 100) \\ \beta_2 & \sim \text{Normal} (0, 100) \\ \beta_3 & \sim \text{Normal} (0, 100) \\ \sigma & \sim \text{Uniform} (0, 100) \end{align*}\]Load brms.
detach(package:rethinking, unload = T)
library(brms)
rm(tulips)Here we continue with McElreath’s very-flat priors for the multivariable and interaction models.
b7.6 <-
brm(data = d, family = gaussian,
blooms ~ 1 + water + shade,
prior = c(prior(normal(0, 100), class = Intercept),
prior(normal(0, 100), class = b),
prior(uniform(0, 100), class = sigma)),
iter = 2000, warmup = 1000, cores = 4, chains = 4,
seed = 7)## Warning: There were 58 divergent transitions after warmup. Increasing adapt_delta above 0.8 may help. See
## http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup## Warning: Examine the pairs() plot to diagnose sampling problemsb7.7 <-
update(b7.6,
formula = blooms ~ 1 + water + shade + water:shade)Much like in the text, these models yielded divergent transitions. Here, we’ll try to combat them by following Stan’s advice and “[increase] adapt_delta above 0.8.” While we’re at it, we’ll put better priors on \(\sigma\).
b7.6 <-
update(b7.6,
prior = c(prior(normal(0, 100), class = Intercept),
prior(normal(0, 100), class = b),
prior(cauchy(0, 10), class = sigma)),
control = list(adapt_delta = 0.9),
seed = 7)
b7.7 <-
update(b7.6,
formula = blooms ~ 1 + water + shade + water:shade)Increasing adapt_delta did the trick. Instead of coeftab(), we can also use posterior_summary(), which gets us most of the way there.
posterior_summary(b7.6) %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept 60.54 42.30 -21.72 145.01
## b_water 73.79 14.60 44.59 102.07
## b_shade -40.56 14.66 -69.79 -11.18
## sigma 61.61 9.38 46.70 82.54
## lp__ -169.81 1.54 -173.72 -167.87posterior_summary(b7.7) %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept -108.09 63.35 -228.52 20.66
## b_water 160.16 29.29 101.17 215.68
## b_shade 44.16 29.52 -16.11 102.54
## b_water:shade -43.15 13.73 -69.81 -15.33
## sigma 49.96 7.60 37.57 67.49
## lp__ -170.68 1.71 -174.76 -168.36This is an example where HMC yielded point estimates notably different from MAP. However, look at the size of those posterior standard deviations (i.e., ‘Est.Error’ column)! The MAP estimates are well within a fraction of those \(SD\)s.
Anyway, let’s look at WAIC.
b7.6 <- add_criterion(b7.6, "waic")
b7.7 <- add_criterion(b7.7, "waic")
w <- loo_compare(b7.6, b7.7, criterion = "waic")
print(w, simplify = F)## elpd_diff se_diff elpd_waic se_elpd_waic p_waic se_p_waic waic se_waic
## b7.7 0.0 0.0 -146.7 4.0 4.6 1.2 293.5 7.9
## b7.6 -5.4 2.6 -152.1 3.8 4.1 1.1 304.2 7.7Here we use our cbind() trick to convert the difference from the \(\text{elpd}\) metric to the more traditional WAIC metric.
cbind(waic_diff = w[, 1] * -2,
se = w[, 2] * 2)## waic_diff se
## b7.7 0.00000 0.000000
## b7.6 10.71164 5.246709Why not compute the WAIC weights?
model_weights(b7.6, b7.7, weights = "waic")## b7.6 b7.7
## 0.004698423 0.995301577As in the text, almost all the weight went to the interaction model, b7.7.
7.3.3 Center and re-estimate.
To center a variable means to create a new variable that contains the same information as the original, but has a new mean of zero. For example, to make centered versions of
shadeandwater, just subtract the mean of the original from each value. (p. 230, emphasis in the original)
Here’s a tidyverse way to center the predictors.
d <-
d %>%
mutate(shade_c = shade - mean(shade),
water_c = water - mean(water))Now refit the models with our shiny new centered predictors.
b7.8 <-
brm(data = d, family = gaussian,
blooms ~ 1 + water_c + shade_c,
prior = c(prior(normal(130, 100), class = Intercept),
prior(normal(0, 100), class = b),
prior(cauchy(0, 10), class = sigma)),
iter = 2000, warmup = 1000, chains = 4, cores = 4,
control = list(adapt_delta = 0.9),
seed = 7)
b7.9 <-
update(b7.8,
formula = blooms ~ 1 + water_c + shade_c + water_c:shade_c)Check out the results.
posterior_summary(b7.8) %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept 128.97 11.58 105.40 151.69
## b_water_c 74.31 14.27 46.11 102.59
## b_shade_c -40.73 14.52 -69.06 -12.14
## sigma 61.42 9.14 46.34 82.07
## lp__ -168.93 1.49 -172.68 -167.03posterior_summary(b7.9) %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## b_Intercept 128.97 9.60 110.14 147.94
## b_water_c 74.91 11.49 52.52 97.77
## b_shade_c -41.17 11.40 -63.29 -18.25
## b_water_c:shade_c -51.63 14.10 -79.00 -22.52
## sigma 49.46 7.56 37.36 67.45
## lp__ -168.51 1.75 -172.95 -166.27And okay fine, if you really want a coeftab()-like summary, here’s a way to do it.
tibble(model = str_c("b7.", 8:9)) %>%
mutate(fit = purrr::map(model, get)) %>%
mutate(tidy = purrr::map(fit, broom::tidy)) %>%
unnest(tidy) %>%
filter(term != "lp__") %>%
select(term, estimate, model) %>%
spread(key = model, value = estimate) %>%
mutate_if(is.double, round, digits = 2)## # A tibble: 5 x 3
## term b7.8 b7.9
## <chr> <dbl> <dbl>
## 1 b_Intercept 129. 129.
## 2 b_shade_c -40.7 -41.2
## 3 b_water_c 74.3 74.9
## 4 b_water_c:shade_c NA -51.6
## 5 sigma 61.4 49.5Anyway, centering helped a lot. Now, not only do the results in the text match up better than those from Stan, but the ‘Est.Error’ values are uniformly smaller.
7.3.3.1 Estimation worked better.
Nothing to add, here.
7.3.3.2 Estimates changed less across models.
On page 231, we read:
The interaction parameter always factors into generating a prediction. Consider for example a tulip at the average moisture and shade levels, 2 in each case. The expected blooms for such a tulip is:
\[\mu_i | \text{shade}_{i = 2}, \text{water}_{i = 2} = \alpha + \beta_\text{water} (2) + \beta_\text{shade} (2) + \beta_{\text{water} \times \text{shade}} (2 \times 2)\]
So to figure out the effect of increasing water by 1 unit, you have to use all of the \(\beta\) parameters. Plugging in the [HMC] values for the un-centered interaction model, [
b7.7], we get:
\[\mu_i | \text{shade}_{i = 2}, \text{water}_{i = 2} = -107.1 + 159.9 (2) + 44.0 (2) -43.2 (2 \times 2)\]
With our brms workflow, we use fixef() to compute the predictions.
k <- fixef(b7.7)
k[1] + k[2] * 2 + k[3] * 2 + k[4] * 2 * 2## [1] 127.3211Even though or HMC parameters differ a bit from the MAP estimates McElreath reported in the text, the value they predicted matches quite closely with the one in the text. Same thing for the next one.
k <- fixef(b7.9)
k[1] + k[2] * 0 + k[3] * 0 + k[4] * 0 * 0## [1] 128.9692Here are the coefficient summaries for the centered model.
print(b7.9)## Family: gaussian
## Links: mu = identity; sigma = identity
## Formula: blooms ~ water_c + shade_c + water_c:shade_c
## Data: d (Number of observations: 27)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 128.97 9.60 110.14 147.94 4377 1.00
## water_c 74.91 11.49 52.52 97.77 5905 1.00
## shade_c -41.17 11.40 -63.29 -18.25 4235 1.00
## water_c:shade_c -51.63 14.10 -79.00 -22.52 5055 1.00
##
## Family Specific Parameters:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## sigma 49.46 7.56 37.36 67.45 3159 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).7.3.4 Plotting implied predictions.
Now we’re ready for the bottom row of Figure 7.7. Here’s our variation on McElreath’s tryptych loop code, adjusted for brms and ggplot2.
# loop over values of `water_c` and plot predictions
shade_seq <- -1:1
for(w in -1:1){
# define the subset of the original data
dt <- d[d$water_c == w, ]
# defining our new data
nd <- tibble(water_c = w, shade_c = shade_seq)
# use our sampling skills, like before
f <-
fitted(b7.9, newdata = nd) %>%
as_tibble() %>%
bind_cols(nd)
# specify our custom plot
fig <-
ggplot() +
geom_smooth(data = f,
aes(x = shade_c, y = Estimate, ymin = Q2.5, ymax = Q97.5),
stat = "identity",
fill = "#CC79A7", color = "#CC79A7", alpha = 1/5, size = 1/2) +
geom_point(data = dt,
aes(x = shade_c, y = blooms),
shape = 1, color = "#CC79A7") +
coord_cartesian(xlim = range(d$shade_c),
ylim = range(d$blooms)) +
scale_x_continuous("Shade (centered)", breaks = c(-1, 0, 1)) +
labs("Blooms",
title = paste("Water (centered) =", w)) +
theme_pander() +
theme(text = element_text(family = "Times"))
# plot that joint
plot(fig)
}
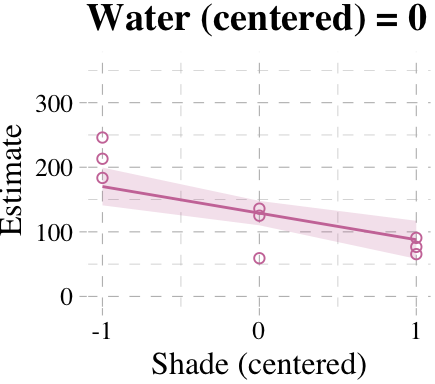
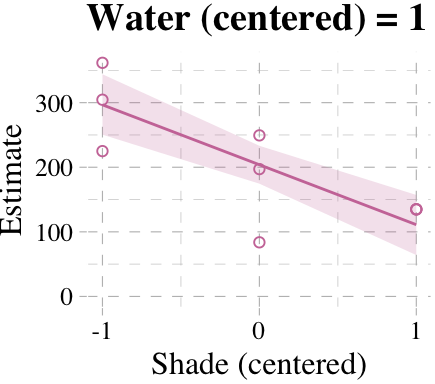
But we don’t necessarily need a loop. We can achieve all of McElreath’s Figure 7.7 with fitted(), some data wrangling, and a little help from ggplot2::facet_grid().
# `fitted()` for model b7.8
fitted(b7.8) %>%
as_tibble() %>%
# add `fitted()` for model b7.9
bind_rows(
fitted(b7.9) %>%
as_tibble()
) %>%
# we'll want to index the models
mutate(fit = rep(c("b7.8", "b7.9"), each = 27)) %>%
# here we add the data, `d`
bind_cols(bind_rows(d, d)) %>%
# these will come in handy for `ggplot2::facet_grid()`
mutate(x_grid = paste("water_c =", water_c),
y_grid = paste("model: ", fit)) %>%
# plot!
ggplot(aes(x = shade_c)) +
geom_smooth(aes(y = Estimate, ymin = Q2.5, ymax = Q97.5),
stat = "identity",
fill = "#CC79A7", color = "#CC79A7", alpha = 1/5, size = 1/2) +
geom_point(aes(y = blooms, group = x_grid),
shape = 1, color = "#CC79A7") +
coord_cartesian(xlim = range(d$shade_c),
ylim = range(d$blooms)) +
scale_x_continuous("Shade (centered)", breaks = c(-1, 0, 1)) +
ylab("Blooms") +
theme_pander() +
theme(text = element_text(family = "Times"),
panel.background = element_rect(color = "black")) +
facet_grid(y_grid ~ x_grid)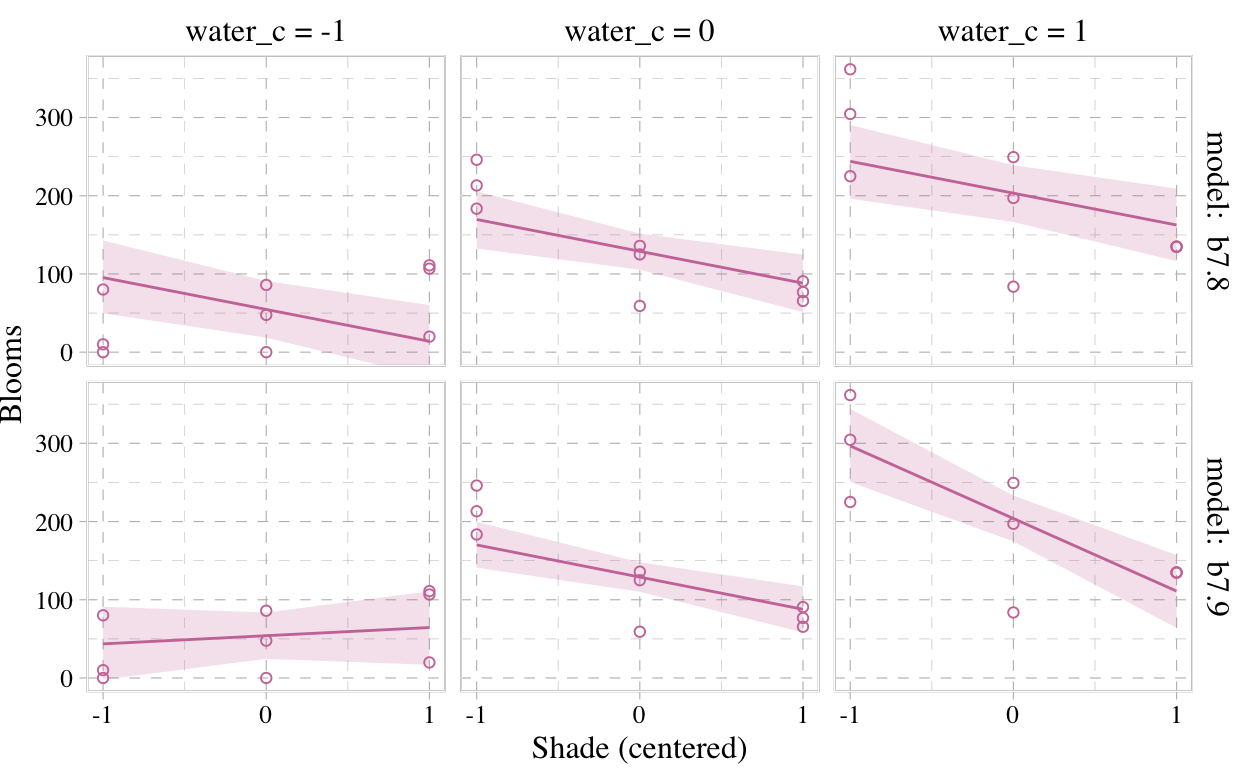
7.4 Interactions in design formulas
The brms syntax generally follows the design formulas typical of lm(). Hopefully this is all old hat.
7.5 Summary Bonus: marginal_effects()
The brms package includes the marginal_effects() function as a convenient way to look at simple effects and two-way interactions. Recall the simple univariable model, b7.3:
b7.3$formula## log_gdp ~ 1 + ruggedWe can look at the regression line and its percentile-based intervals like so:
marginal_effects(b7.3)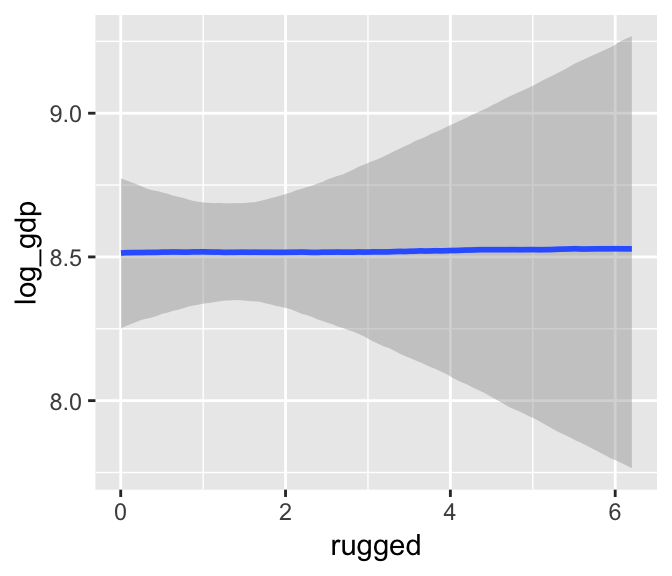
If we nest marginal_effects() within plot() with a points = T argument, we can add the original data to the figure.
plot(marginal_effects(b7.3), points = T)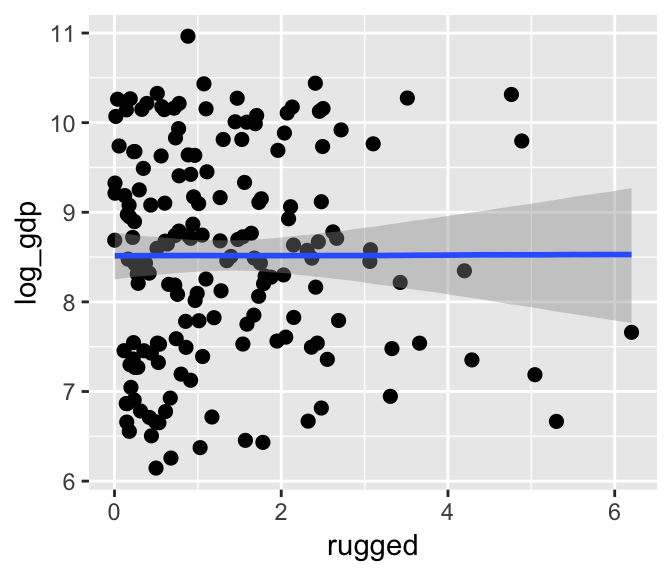
We can further customize the plot. For example, we can replace the intervals with a spaghetti plot. While we’re at it, we can use point_args to adjust the geom_jitter() parameters.
plot(marginal_effects(b7.3,
spaghetti = T, nsamples = 200),
points = T,
point_args = c(alpha = 1/2, size = 1))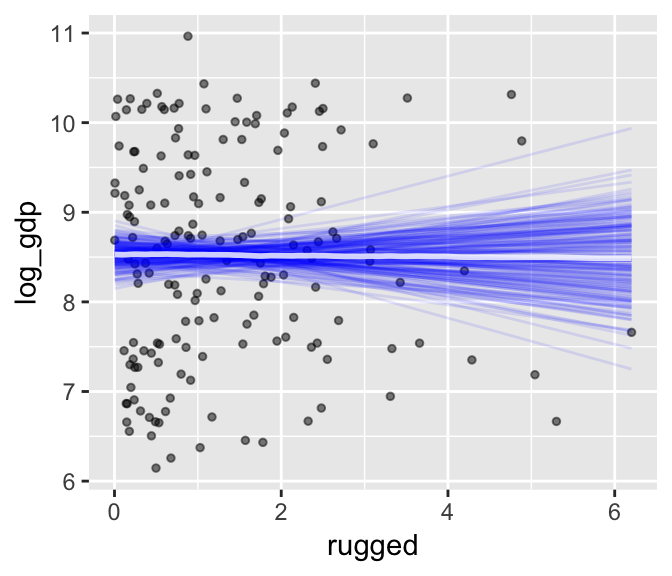
With multiple predictors, things get more complicated. Consider our multivariable, non-interaction model, b7.4.
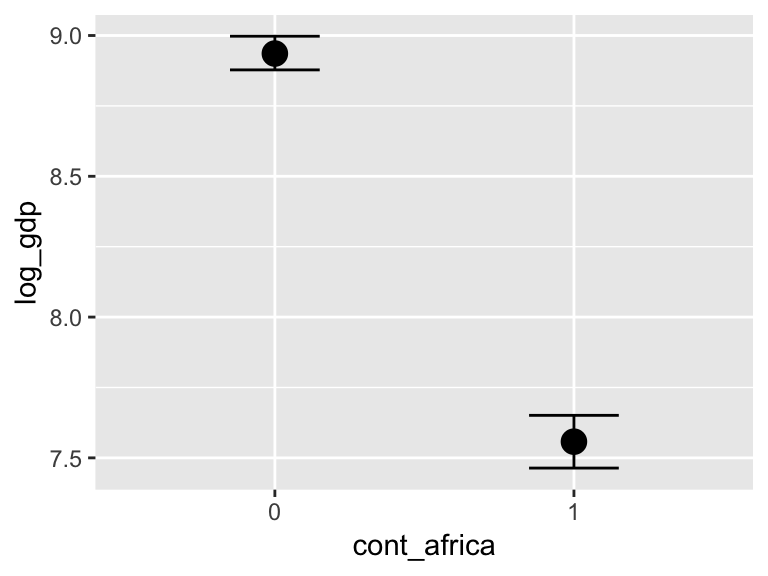
b7.4$formula## log_gdp ~ rugged + cont_africamarginal_effects(b7.4)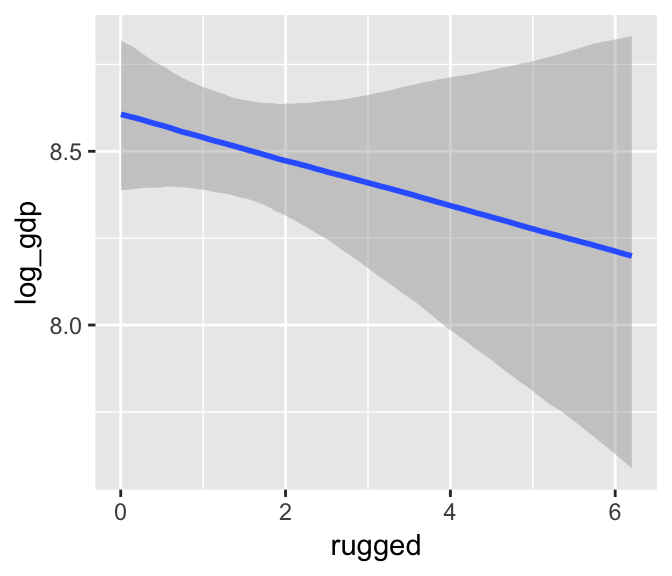

We got one plot for each predictor, controlling the other predictor at zero. Note how the plot for cont_africa treated it as a continuous variable. This is because the variable was saved as an integer in the original data set:
b7.4$data %>%
glimpse()## Observations: 170
## Variables: 3
## $ log_gdp <dbl> 7.492609, 8.216929, 9.933263, 9.407032, 7.792343, 9.212541, 10.143191, 10.274…
## $ rugged <dbl> 0.858, 3.427, 0.769, 0.775, 2.688, 0.006, 0.143, 3.513, 1.672, 1.780, 0.388, …
## $ cont_africa <int> 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0,…One way to fix that is to adjust the data set and refit the model.
d_factor <-
b7.4$data %>%
mutate(cont_africa = factor(cont_africa))
b7.4_factor <- update(b7.4, newdata = d_factor)Using the update() syntax often speeds up the re-fitting process.
marginal_effects(b7.4_factor)

Now our second marginal plot more clearly expresses the cont_africa predictor as categorical.
Things get more complicated with the interaction model, b7.5.
b7.5$formula## log_gdp ~ rugged + cont_africa + rugged:cont_africamarginal_effects(b7.5)

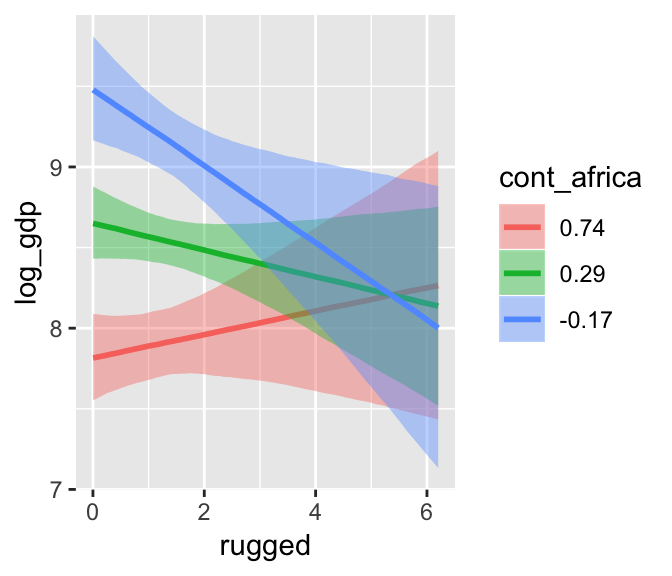
The marginal_effects() function defaults to expressing interactions such that the first variable in the term–in this case, rugged–is on the x axis and the second variable in the term–cont_africa, treated as an integer–is depicted in three lines corresponding its mean and its mean +/- one standard deviation. This is great for continuous variables, but incoherent for categorical ones. The fix is, you guessed it, to refit the model after adjusting the data.
d_factor <-
b7.5$data %>%
mutate(cont_africa = factor(cont_africa))
b7.5_factor <- update(b7.5, newdata = d_factor)Just for kicks, we’ll use probs = c(.25, .75) to return 50% intervals, rather than the conventional 95%.
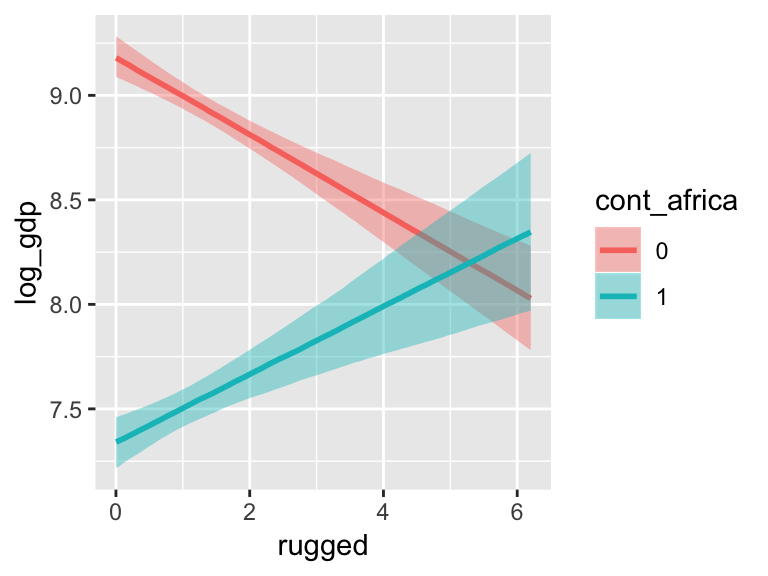
marginal_effects(b7.5_factor,
probs = c(.25, .75))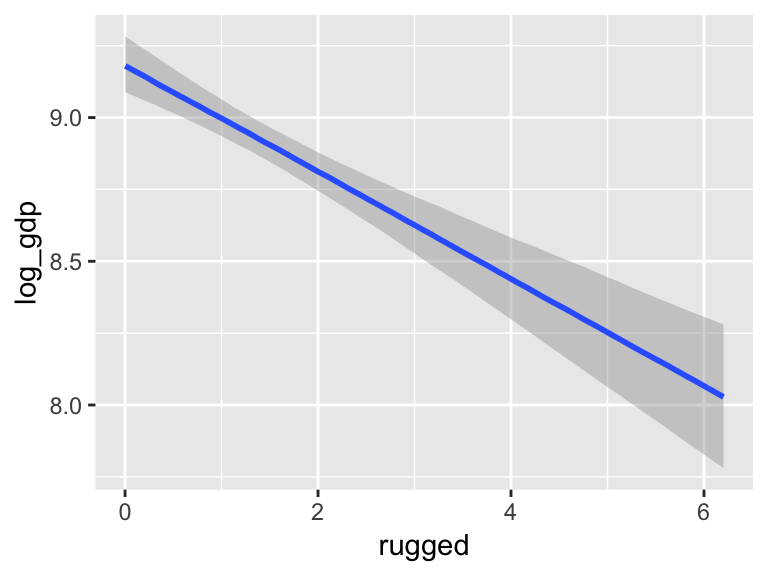
With the effects argument, we can just return the interaction effect, which is where all the action’s at. While we’re at it, we’ll use plot() to change some of the settings.
plot(marginal_effects(b7.5_factor,
effects = "rugged:cont_africa",
spaghetti = T, nsamples = 150),
points = T,
point_args = c(alpha = 2/3, size = 1), mean = F)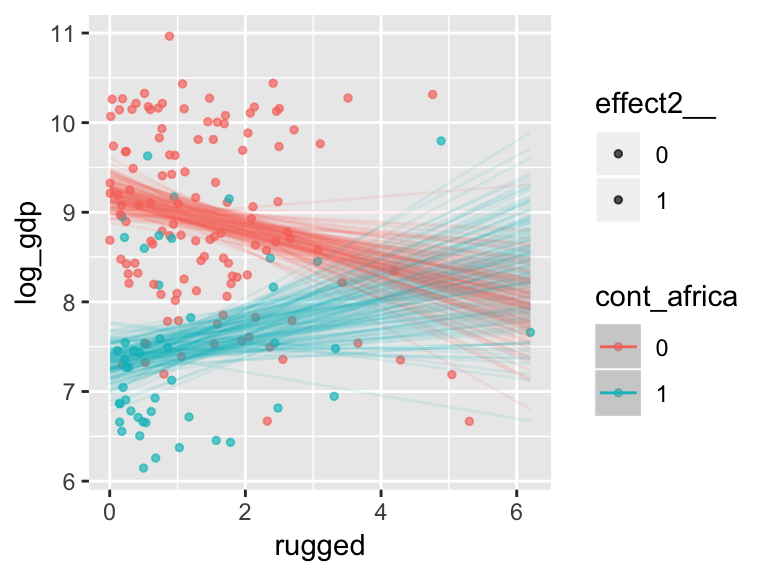
Note, the ordering of the variables matters for the interaction term. Consider our interaction model for the tulips data.
b7.9$formula## blooms ~ water_c + shade_c + water_c:shade_cThe plot tells a slightly different story, depending on whether you specify effects = "shade_c:water_c" or effects = "water_c:shade_c".
plot(marginal_effects(b7.9,
effects = "shade_c:water_c"),
points = T)
plot(marginal_effects(b7.9,
effects = "water_c:shade_c"),
points = T)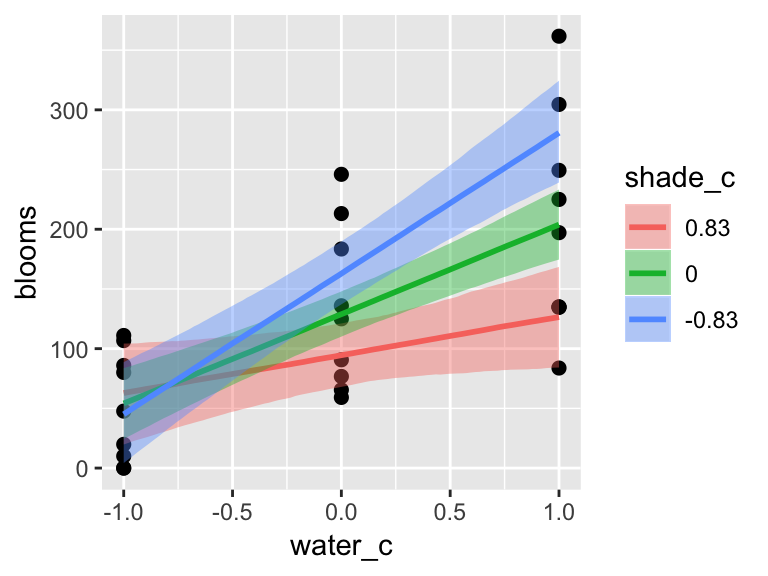
One might want to evaluate the effects of the second term in the interaction–water_c, in this case–at values other than the mean and the mean +/- one standard deviation. When we reproduced the bottom row of Figure 7.7, we expressed the interaction based on values -1, 0, and 1 for water_c. We can do that, here, by using the int_conditions argument. It expects a list, so we’ll put our desired water_c values in just that.
ic <-
list(water.c = c(-1, 0, 1))
plot(marginal_effects(b7.9,
effects = "shade_c:water_c",
int_conditions = ic),
points = T)
Session info
sessionInfo()## R version 3.5.1 (2018-07-02)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS High Sierra 10.13.6
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] parallel stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] ggthemes_4.0.1 forcats_0.3.0 stringr_1.4.0 dplyr_0.8.0.1
## [5] purrr_0.2.5 readr_1.1.1 tidyr_0.8.1 tibble_2.1.1
## [9] tidyverse_1.2.1 brms_2.8.8 Rcpp_1.0.1 rstan_2.18.2
## [13] StanHeaders_2.18.0-1 ggplot2_3.1.1
##
## loaded via a namespace (and not attached):
## [1] nlme_3.1-137 matrixStats_0.54.0 xts_0.10-2 lubridate_1.7.4
## [5] threejs_0.3.1 httr_1.3.1 rprojroot_1.3-2 tools_3.5.1
## [9] backports_1.1.4 utf8_1.1.4 R6_2.3.0 DT_0.4
## [13] lazyeval_0.2.2 colorspace_1.3-2 withr_2.1.2 tidyselect_0.2.5
## [17] gridExtra_2.3 prettyunits_1.0.2 processx_3.2.1 Brobdingnag_1.2-6
## [21] compiler_3.5.1 rvest_0.3.2 cli_1.0.1 xml2_1.2.0
## [25] shinyjs_1.0 labeling_0.3 colourpicker_1.0 bookdown_0.9
## [29] scales_1.0.0 dygraphs_1.1.1.5 mvtnorm_1.0-10 ggridges_0.5.0
## [33] callr_3.1.0 digest_0.6.18 rmarkdown_1.10 base64enc_0.1-3
## [37] pkgconfig_2.0.2 htmltools_0.3.6 readxl_1.1.0 htmlwidgets_1.2
## [41] rlang_0.3.4 rstudioapi_0.7 shiny_1.1.0 generics_0.0.2
## [45] zoo_1.8-2 jsonlite_1.5 crosstalk_1.0.0 gtools_3.8.1
## [49] inline_0.3.15 magrittr_1.5 loo_2.1.0 bayesplot_1.6.0
## [53] Matrix_1.2-14 fansi_0.4.0 munsell_0.5.0 abind_1.4-5
## [57] stringi_1.4.3 yaml_2.1.19 MASS_7.3-50 pkgbuild_1.0.2
## [61] plyr_1.8.4 grid_3.5.1 promises_1.0.1 crayon_1.3.4
## [65] miniUI_0.1.1.1 lattice_0.20-35 haven_1.1.2 pander_0.6.2
## [69] hms_0.4.2 knitr_1.20 ps_1.2.1 pillar_1.3.1
## [73] igraph_1.2.1 markdown_0.8 shinystan_2.5.0 codetools_0.2-15
## [77] reshape2_1.4.3 stats4_3.5.1 rstantools_1.5.1 glue_1.3.1.9000
## [81] evaluate_0.10.1 modelr_0.1.2 httpuv_1.4.4.2 cellranger_1.1.0
## [85] gtable_0.3.0 assertthat_0.2.0 xfun_0.3 mime_0.5
## [89] xtable_1.8-2 broom_0.5.1 coda_0.19-2 later_0.7.3
## [93] rsconnect_0.8.8 shinythemes_1.1.1 bridgesampling_0.6-0