10 Counting and Classification
All over the world, every day, scientists throw away information. Sometimes this is through the removal of “outliers,” cases in the data that offend the model and are exiled. More routinely, counted things are converted to proportions before analysis. Why does analysis of proportions throw away information? Because 10/20 and ½ are the same proportion, one-half, but have very different sample sizes. Once converted to proportions, and treated as outcomes in a linear regression, the information about sample size has been destroyed.
It’s easy to retain the information about sample size. All that is needed is to model what has actually been observed, the counts instead of the proportions. (p. 291)
In this chapter, we focus on the two most common types of count models: the binomial and the Poisson.
Side note: For a nice Bayesian way to accommodate outliers in your Gaussian models, check out my blog Robust Linear Regression with Student’s \(t\)-Distribution.
10.1 Binomial regression
The basic binomial model follows the form
\[y \sim \text{Binomial} (n, p)\]
where \(y\) is some count variable, \(n\) is the number of trials, and \(p\) it the probability a given trial was a 1, which is sometimes termed a success. When \(n = 1\), then \(y\) is a vector of 0s and 1s. Presuming the logit link, models of this type are commonly termed logistic regression. When \(n > 1\), and still presuming the logit link, we might call our model an aggregated logistic regression model, or more generally an aggregated binomial regression model.
10.1.1 Logistic regression: Prosocial chimpanzees.
Load the chimpanzees data.
library(rethinking)
data(chimpanzees)
d <- chimpanzeesSwitch from rethinking to brms.
detach(package:rethinking, unload = T)
library(brms)
rm(chimpanzees)We start with the simple intercept-only logistic regression model, which follows the statistical formula
\[\begin{align*} \text{pulled_left}_i & \sim \text{Binomial} (1, p_i) \\ \text{logit} (p_i) & = \alpha \\ \alpha & \sim \text{Normal} (0, 10) \end{align*}\]In the brm() formula syntax, including a | bar on the left side of a formula indicates we have extra supplementary information about our criterion. In this case, that information is that each pulled_left value corresponds to a single trial (i.e., trials(1)), which itself corresponds to the \(n = 1\) portion of the statistical formula, above.
b10.1 <-
brm(data = d, family = binomial,
pulled_left | trials(1) ~ 1,
prior(normal(0, 10), class = Intercept),
seed = 10)You might use fixef() to get a focused summary of the intercept.
library(tidyverse)
fixef(b10.1) %>%
round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## Intercept 0.32 0.09 0.14 0.5The brms::inv_logit_scaled() function will be our alternative to the logistic() function in rethinking.
c(.18, .46) %>%
inv_logit_scaled()## [1] 0.5448789 0.6130142fixef(b10.1) %>%
inv_logit_scaled()## Estimate Est.Error Q2.5 Q97.5
## Intercept 0.579012 0.5226864 0.5350585 0.6217093With the next two chimp models, we add predictors in the usual way.
b10.2 <-
brm(data = d, family = binomial,
pulled_left | trials(1) ~ 1 + prosoc_left,
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 10), class = b)),
seed = 10)
b10.3 <-
update(b10.2,
newdata = d,
formula = pulled_left | trials(1) ~ 1 + prosoc_left + condition:prosoc_left)Compute the WAIC for each model and save the results within the brmfit objects.
b10.1 <- add_criterion(b10.1, "waic")
b10.2 <- add_criterion(b10.2, "waic")
b10.3 <- add_criterion(b10.3, "waic")Compare them with the loo_compare() and make sure to add the criterion = "waic" argument.
w <- loo_compare(b10.1, b10.2, b10.3, criterion = "waic")
print(w, simplify = F)## elpd_diff se_diff elpd_waic se_elpd_waic p_waic se_p_waic waic se_waic
## b10.2 0.0 0.0 -340.2 4.7 2.0 0.0 680.4 9.4
## b10.3 -1.0 0.4 -341.2 4.7 3.1 0.1 682.5 9.5
## b10.1 -3.8 3.1 -344.0 3.5 1.0 0.0 688.0 7.1Recall our cbind() trick to convert the differences from the \(\text{elpd}\) metric to the WAIC metric.
cbind(waic_diff = w[, 1] * -2,
se = w[, 2] * 2) %>%
round(digits = 2)## waic_diff se
## b10.2 0.00 0.00
## b10.3 2.06 0.90
## b10.1 7.57 6.21For this chapter, we’ll take our color scheme from the wesanderson package’s Moonrise2 palette.
# install.packages("wesanderson", dependencies = T)
library(wesanderson)
wes_palette("Moonrise2")
wes_palette("Moonrise2")[1:4]## [1] "#798E87" "#C27D38" "#CCC591" "#29211F"We’ll also take a few formatting cues from Edward Tufte, curtesy of the ggthemes package. The theme_tufte() function will change the default font and remove some chart junk. The theme_set() function, below, will make these adjustments the default for all subsequent ggplot2 plots. To undo this, just execute theme_set(theme_default()).
library(ggthemes)
library(bayesplot)
theme_set(theme_default() +
theme_tufte() +
theme(plot.background = element_rect(fill = wes_palette("Moonrise2")[3],
color = wes_palette("Moonrise2")[3])))Finally, here’s our WAIC plot.
w %>%
data.frame() %>%
rownames_to_column(var = "model") %>%
ggplot() +
geom_pointrange(aes(x = reorder(model, -waic), y = waic,
ymin = waic - se_waic,
ymax = waic + se_waic,
color = model),
shape = 16) +
scale_color_manual(values = wes_palette("Moonrise2")[c(1:2, 4)]) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "WAIC") +
theme(axis.ticks.y = element_blank(),
legend.position = "none")
The full model, b10.3, did not have the lowest WAIC value. Though note how wide those standard error bars are relative to the point estimates. There’s a lot of model uncertainty there. Here are the WAIC weights.
model_weights(b10.1, b10.2, b10.3,
weights = "waic")## b10.1 b10.2 b10.3
## 0.01645053 0.72480254 0.25874693Let’s look at the parameter summaries for the theory-based model.
print(b10.3)## Family: binomial
## Links: mu = logit
## Formula: pulled_left | trials(1) ~ prosoc_left + prosoc_left:condition
## Data: d (Number of observations: 504)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 0.04 0.13 -0.20 0.29 3514 1.00
## prosoc_left 0.63 0.23 0.19 1.07 2417 1.00
## prosoc_left:condition -0.12 0.27 -0.65 0.42 2510 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Here’s what the odds are multiplied by:
fixef(b10.3)[2] %>%
exp()## [1] 1.870972Given an estimated value of 4, the probability of a pull, all else equal, would be close to 1.
inv_logit_scaled(4)## [1] 0.9820138Adding the coefficient, fixef(b10.3)[2], would yield an even higher estimate.
(4 + fixef(b10.3)[2]) %>%
inv_logit_scaled()## [1] 0.9903055For our variant of Figure 10.2, we use brms::pp_average() in place of rethinking::ensemble().
# the combined `fitted()` results of the three models weighted by their WAICs
ppa <-
pp_average(b10.1, b10.2, b10.3,
weights = "waic",
method = "fitted") %>%
as_tibble() %>%
bind_cols(b10.3$data) %>%
distinct(Estimate, Q2.5, Q97.5, condition, prosoc_left) %>%
mutate(x_axis = str_c(prosoc_left, condition, sep = "/")) %>%
mutate(x_axis = factor(x_axis, levels = c("0/0", "1/0", "0/1", "1/1"))) %>%
rename(pulled_left = Estimate)
# the empirically-based summaries
d_plot <-
d %>%
group_by(actor, condition, prosoc_left) %>%
summarise(pulled_left = mean(pulled_left)) %>%
mutate(x_axis = str_c(prosoc_left, condition, sep = "/")) %>%
mutate(x_axis = factor(x_axis, levels = c("0/0", "1/0", "0/1", "1/1")))
# the plot
ppa %>%
ggplot(aes(x = x_axis)) +
geom_smooth(aes(y = pulled_left, ymin = Q2.5, ymax = Q97.5, group = 0),
stat = "identity",
fill = wes_palette("Moonrise2")[2], color = "black",
alpha = 1, size = 1/2) +
geom_line(data = d_plot,
aes(y = pulled_left, group = actor),
color = wes_palette("Moonrise2")[1], size = 1/3) +
scale_x_discrete(expand = c(.03, .03)) +
coord_cartesian(ylim = 0:1) +
labs(x = "prosoc_left/condition",
y = "proportion pulled left") +
theme(axis.ticks.x = element_blank())
McElreath didn’t show the actual pairs plot in the text. Here’s ours using mcmc_pairs().
# this helps us set our custom color scheme
color_scheme_set(c(wes_palette("Moonrise2")[3],
wes_palette("Moonrise2")[1],
wes_palette("Moonrise2")[2],
wes_palette("Moonrise2")[2],
wes_palette("Moonrise2")[1],
wes_palette("Moonrise2")[1]))
# the actual plot
mcmc_pairs(x = posterior_samples(b10.3),
pars = c("b_Intercept", "b_prosoc_left", "b_prosoc_left:condition"),
off_diag_args = list(size = 1/10, alpha = 1/6),
diag_fun = "dens")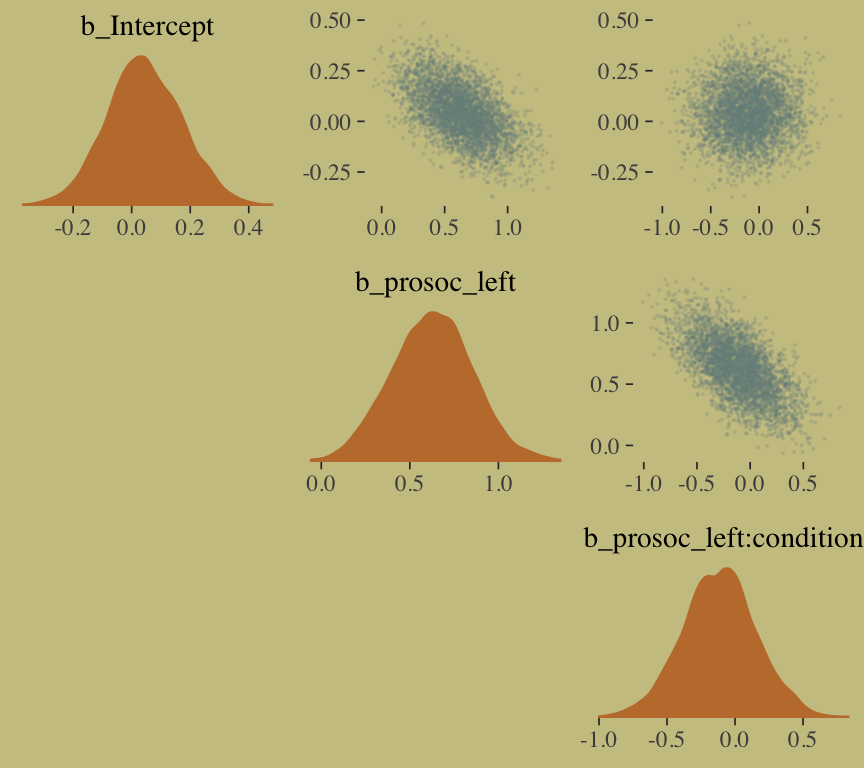
As McElreath observed, the posterior looks multivariate Gaussian.
In equations, the next model follows the form
\[\begin{align*} \text{pulled_left}_i & \sim \text{Binomial} (1, p_i) \\ \text{logit} (p_i) & = \alpha_{\text{actor}} + (\beta_1 + \beta_2 \text{condition}_i) \text{prosoc_left}_i \\ \alpha_{\text{actor}} & \sim \text{Normal} (0, 10) \\ \beta_1 & \sim \text{Normal} (0, 10) \\ \beta_2 & \sim \text{Normal} (0, 10) \end{align*}\]Enclosing the actor variable within factor() will produce the indexing we need to get actor-specific intercepts. Also notice we’re using the 0 + factor(actor) part of the model formula to suppress the brms default intercept. As such, the priors for all parameters in the model will be of class = b. And since we’re using the same Gaussian prior for each, we only need one line for the prior argument.
b10.4 <-
brm(data = d, family = binomial,
pulled_left | trials(1) ~ 0 + factor(actor) + prosoc_left + condition:prosoc_left ,
prior(normal(0, 10), class = b),
iter = 2500, warmup = 500, chains = 2, cores = 2,
control = list(adapt_delta = 0.9),
seed = 10)Within the tidyverse, distinct() yields the information you’d otherwise get from unique().
d %>%
distinct(actor)## actor
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7We have no need to use something like depth=2 for our posterior summary.
print(b10.4)## Family: binomial
## Links: mu = logit
## Formula: pulled_left | trials(1) ~ 0 + factor(actor) + prosoc_left + condition:prosoc_left
## Data: d (Number of observations: 504)
## Samples: 2 chains, each with iter = 2500; warmup = 500; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## factoractor1 -0.74 0.27 -1.28 -0.21 3461 1.00
## factoractor2 10.98 5.48 3.89 24.16 1870 1.00
## factoractor3 -1.05 0.29 -1.63 -0.51 3714 1.00
## factoractor4 -1.05 0.28 -1.61 -0.51 3870 1.00
## factoractor5 -0.74 0.27 -1.28 -0.21 3782 1.00
## factoractor6 0.22 0.27 -0.29 0.77 4221 1.00
## factoractor7 1.82 0.40 1.08 2.69 4221 1.00
## prosoc_left 0.84 0.26 0.35 1.35 2455 1.00
## prosoc_left:condition -0.13 0.30 -0.72 0.44 3259 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Correspondingly, brms::posterior_samples() returns an object for b10.4 that doesn’t quite follow the same structure as from rethinking::extract.samples(). We just have a typical 2-dimensional data frame.
post <- posterior_samples(b10.4)
post %>%
glimpse()## Observations: 4,000
## Variables: 10
## $ b_factoractor1 <dbl> -1.1858595, -0.4615217, -0.7064094, -0.2933396, -0.9631797, -1.0367221, -…
## $ b_factoractor2 <dbl> 7.454134, 6.917168, 7.084945, 7.208442, 16.542496, 5.172823, 8.026027, 9.…
## $ b_factoractor3 <dbl> -0.7563732, -1.3653995, -0.4588494, -0.1941674, -1.6394630, -1.2838897, -…
## $ b_factoractor4 <dbl> -0.9358261, -0.8761278, -1.0917094, -1.0846353, -1.0000311, -1.4545123, -…
## $ b_factoractor5 <dbl> -0.2041299, -0.9987514, -0.3351474, -0.3790166, -0.9260228, -1.1574304, -…
## $ b_factoractor6 <dbl> 0.68325055, -0.24779408, 0.96302540, 0.98686825, -0.36103079, 0.69365567,…
## $ b_factoractor7 <dbl> 2.9389421, 2.5470499, 1.6366450, 1.2998254, 2.6914495, 1.3223443, 0.89571…
## $ b_prosoc_left <dbl> 0.3384714, 0.8072413, 0.7844121, 1.0413892, 0.9789063, 1.3959586, 1.10938…
## $ `b_prosoc_left:condition` <dbl> 0.521824578, 0.147820067, -0.601883627, -0.619894359, 0.394578954, -0.388…
## $ lp__ <dbl> -297.4577, -292.0001, -293.5426, -300.4224, -296.1999, -292.4967, -294.35…Our variant of Figure 10.3:
post %>%
ggplot(aes(x = b_factoractor2)) +
geom_density(color = "transparent",
fill = wes_palette("Moonrise2")[1]) +
scale_y_continuous(NULL, breaks = NULL) +
labs(x = NULL,
title = "Actor 2's large and uncertain intercept",
subtitle = "Once your log-odds are above, like, 4, it's all\npretty much a probability of 1.")
Figure 10.4. shows the idiographic trajectories for four of our chimps.
# subset the `d_plot` data
d_plot_4 <-
d_plot %>%
filter(actor %in% c(3, 5:7)) %>%
ungroup() %>%
mutate(actor = str_c("actor ", actor))
# compute the model-implied estimates with `fitted()` and wrangle
f <-
fitted(b10.4) %>%
as_tibble() %>%
bind_cols(b10.4$data) %>%
filter(actor %in% c(3, 5:7)) %>%
distinct(Estimate, Q2.5, Q97.5, condition, prosoc_left, actor) %>%
select(actor, everything()) %>%
mutate(actor = str_c("actor ", actor),
x_axis = str_c(prosoc_left, condition, sep = "/")) %>%
mutate(x_axis = factor(x_axis, levels = c("0/0", "1/0", "0/1", "1/1"))) %>%
rename(pulled_left = Estimate)
# plot
f %>%
ggplot(aes(x = x_axis, y = pulled_left, group = actor)) +
geom_smooth(aes(ymin = Q2.5, ymax = Q97.5),
stat = "identity",
fill = wes_palette("Moonrise2")[2], color = "black",
alpha = 1, size = 1/2) +
geom_line(data = d_plot_4,
color = wes_palette("Moonrise2")[1], size = 1.25) +
scale_x_discrete(expand = c(.03, .03)) +
coord_cartesian(ylim = 0:1) +
labs(x = "prosoc_left/condition",
y = "proportion pulled left") +
theme(axis.ticks.x = element_blank(),
# color came from: http://www.color-hex.com/color/ccc591
panel.background = element_rect(fill = "#d1ca9c",
color = "transparent")) +
facet_wrap(~actor)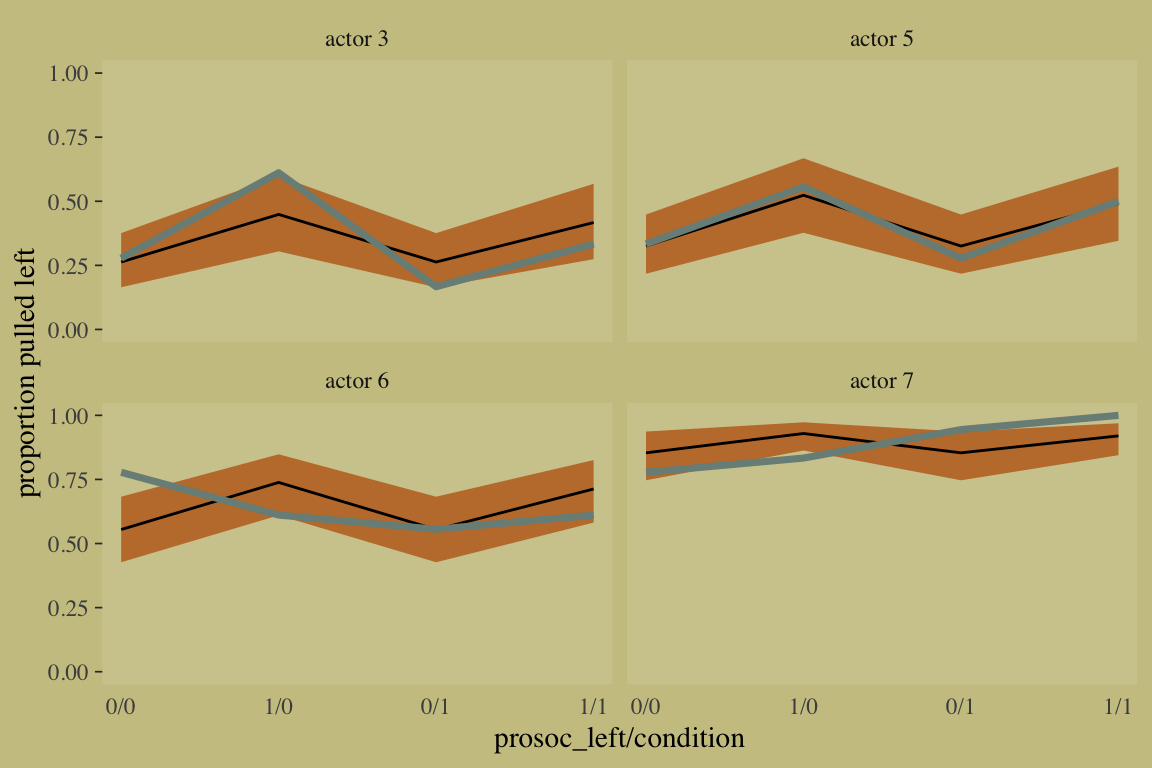
10.1.1.1 Overthinking: Using the by group_by() function.
Let’s work within the tidyverse, instead. If you wanted to compute the proportion of trials pulled_left == 1 for each combination of prosoc_left, condition, and chimp actor, you’d put those last three variables within group_by() and then compute the mean() of pulled_left within summarise().
d %>%
group_by(prosoc_left, condition, actor) %>%
summarise(`proportion pulled_left` = mean(pulled_left))## # A tibble: 28 x 4
## # Groups: prosoc_left, condition [4]
## prosoc_left condition actor `proportion pulled_left`
## <int> <int> <int> <dbl>
## 1 0 0 1 0.333
## 2 0 0 2 1
## 3 0 0 3 0.278
## 4 0 0 4 0.333
## 5 0 0 5 0.333
## 6 0 0 6 0.778
## 7 0 0 7 0.778
## 8 0 1 1 0.278
## 9 0 1 2 1
## 10 0 1 3 0.167
## # … with 18 more rowsAnd since we’re working within the tidyverse, that operation returns a tibble rather than a list.
10.1.2 Aggregated binomial: Chimpanzees again, condensed.
With the tidyverse, we use group_by() and summarise() to achieve what McElreath did with aggregate().
d_aggregated <-
d %>%
select(-recipient, -block, -trial, -chose_prosoc) %>%
group_by(actor, condition, prosoc_left) %>%
summarise(x = sum(pulled_left))
d_aggregated %>%
filter(actor %in% c(1, 2))## # A tibble: 8 x 4
## # Groups: actor, condition [4]
## actor condition prosoc_left x
## <int> <int> <int> <int>
## 1 1 0 0 6
## 2 1 0 1 9
## 3 1 1 0 5
## 4 1 1 1 10
## 5 2 0 0 18
## 6 2 0 1 18
## 7 2 1 0 18
## 8 2 1 1 18To fit an aggregated binomial model in brms, we augment the <criterion> | trials() syntax where the value that goes in trials() is either a fixed number, as in this case, or variable in the data indexing \(n\). Either way, at least some of those trials will have an \(n > 1\).
b10.5 <-
brm(data = d_aggregated, family = binomial,
x | trials(18) ~ 1 + prosoc_left + condition:prosoc_left,
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 10), class = b)),
iter = 2500, warmup = 500, cores = 2, chains = 2,
seed = 10)We might compare b10.3 with b10.5 like this.
fixef(b10.3) %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## Intercept 0.04 0.13 -0.20 0.29
## prosoc_left 0.63 0.23 0.19 1.07
## prosoc_left:condition -0.12 0.27 -0.65 0.42fixef(b10.5) %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## Intercept 0.04 0.13 -0.21 0.29
## prosoc_left 0.61 0.23 0.18 1.06
## prosoc_left:condition -0.09 0.26 -0.61 0.42A coefficient plot can offer a complimentary perspective.
library(broom)
# wrangle
tibble(model = str_c("b10.", c(3, 5))) %>%
mutate(fit = map(model, get)) %>%
mutate(tidy = map(fit, tidy)) %>%
unnest(tidy) %>%
filter(term != "lp__") %>%
# plot
ggplot() +
geom_pointrange(aes(x = model, y = estimate,
ymin = lower,
ymax = upper,
color = term),
shape = 16) +
scale_color_manual(values = wes_palette("Moonrise2")[c(1:2, 4)]) +
coord_flip() +
labs(x = NULL, y = NULL) +
theme(axis.ticks.y = element_blank(),
legend.position = "none") +
facet_wrap(~term, ncol = 1)
The two are close within simulation error.
10.1.3 Aggregated binomial: Graduate school admissions.
Load the infamous UCBadmit data.
# detach(package:brms)
library(rethinking)
data(UCBadmit)
d <- UCBadmitSwitch from rethinking to brms.
detach(package:rethinking, unload = T)
library(brms)
rm(UCBadmit)
d## dept applicant.gender admit reject applications
## 1 A male 512 313 825
## 2 A female 89 19 108
## 3 B male 353 207 560
## 4 B female 17 8 25
## 5 C male 120 205 325
## 6 C female 202 391 593
## 7 D male 138 279 417
## 8 D female 131 244 375
## 9 E male 53 138 191
## 10 E female 94 299 393
## 11 F male 22 351 373
## 12 F female 24 317 341Now compute our newly-constructed dummy variable, male.
d <-
d %>%
mutate(male = ifelse(applicant.gender == "male", 1, 0))The univariable logistic model with male as the sole predictor of admit follows the form
The second model omits the male predictor.
b10.6 <-
brm(data = d, family = binomial,
admit | trials(applications) ~ 1 + male ,
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 10), class = b)),
iter = 2500, warmup = 500, cores = 2, chains = 2,
seed = 10)
b10.7 <-
brm(data = d, family = binomial,
admit | trials(applications) ~ 1,
prior(normal(0, 10), class = Intercept),
iter = 2500, warmup = 500, cores = 2, chains = 2,
seed = 10)Compute the information criteria for each model and save the results within the brmfit objects.
b10.6 <- add_criterion(b10.6, "waic")
b10.7 <- add_criterion(b10.7, "waic")Here’s the WAIC comparison.
w <- loo_compare(b10.6, b10.7, criterion = "waic")
print(w, simplify = F)## elpd_diff se_diff elpd_waic se_elpd_waic p_waic se_p_waic waic se_waic
## b10.6 0.0 0.0 -496.2 163.8 112.9 40.4 992.5 327.6
## b10.7 -29.7 82.1 -525.9 164.8 86.3 37.6 1051.8 329.7If you prefer the difference in the WAIC metric, use our cbind() conversion method from above.
Bonus: Information criteria digression.
Let’s see what happens if we switch to the LOO.
b10.6 <- add_criterion(b10.6, "loo")## Warning: Found 7 observations with a pareto_k > 0.7 in model 'b10.6'. It is recommended to set 'reloo = TRUE'
## in order to calculate the ELPD without the assumption that these observations are negligible. This will refit
## the model 7 times to compute the ELPDs for the problematic observations directly.b10.7 <- add_criterion(b10.7, "loo")## Warning: Found 4 observations with a pareto_k > 0.7 in model 'b10.7'. It is recommended to set 'reloo = TRUE'
## in order to calculate the ELPD without the assumption that these observations are negligible. This will refit
## the model 4 times to compute the ELPDs for the problematic observations directly.If you just ape the text and use the WAIC, everything appears fine. But holy smokes look at those nasty warning messages from the loo()! One of the frightening but ultimately handy things about working with the PSIS-LOO is that it requires we estimate a Pareto \(k\) parameter, which you can learn all about in the loo-package section of the loo reference manual. As it turns out, the Pareto \(k\) can be used as a diagnostic tool. Each case in the data gets its own \(k\) value and we like it when those \(k\)s are low. The makers of the loo package get worried when those \(k\)s exceed 0.7 and as a result, loo() spits out a warning message when they do.
First things first, if you explicitly open the loo package, you’ll have access to some handy diagnostic functions.
library(loo)We’ll be leveraging those \(k\) values with the pareto_k_table() and pareto_k_ids() functions. Both functions take objects created by the loo() or psis() functions. So, before we can get busy, we’ll first make two objects with the loo().
l_b10.6 <- loo(b10.6)## Warning: Found 7 observations with a pareto_k > 0.7 in model 'b10.6'. It is recommended to set 'reloo = TRUE'
## in order to calculate the ELPD without the assumption that these observations are negligible. This will refit
## the model 7 times to compute the ELPDs for the problematic observations directly.l_b10.7 <- loo(b10.7)## Warning: Found 4 observations with a pareto_k > 0.7 in model 'b10.7'. It is recommended to set 'reloo = TRUE'
## in order to calculate the ELPD without the assumption that these observations are negligible. This will refit
## the model 4 times to compute the ELPDs for the problematic observations directly.There are those warning messages, again. Using the loo-object for model b10.6, which we’ve named l_b10.6, let’s take a look at the pareto_k_table() function.
pareto_k_table(l_b10.6) ## Pareto k diagnostic values:
## Count Pct. Min. n_eff
## (-Inf, 0.5] (good) 4 33.3% 635
## (0.5, 0.7] (ok) 1 8.3% 391
## (0.7, 1] (bad) 2 16.7% 90
## (1, Inf) (very bad) 5 41.7% 2You may have noticed that this same table pops out when you just do something like loo(b10.6). Recall that this data set has 12 observations (i.e., execute count(d)). With pareto_k_table(), we see how the Pareto \(k\) values have been categorized into bins ranging from “good” to “very bad”. Clearly, we like nice and low \(k\)s. In this example, our observations are all over the place, with 5 in the “bad” \(k\) range We can take a closer look like this:
plot(l_b10.6)
So when you plot() a loo object, you get a nice diagnostic plot for those \(k\) values, ordered by observation number. Our plot indicates cases 1, 2, 3, 11, and 12 had “very bad” \(k\) values for this model. If we wanted to further verify to ourselves which observations those were, we’d use the pareto_k_ids() function.
pareto_k_ids(l_b10.6, threshold = 1)## [1] 1 2 3 11 12Note our use of the threshold argument. Play around with it to see how it works.
If you want an explicit look at those \(k\) values, you do:
l_b10.6$diagnostics## $pareto_k
## [1] 2.29760490 1.02057506 1.58539693 0.04789929 0.42364825 0.61818010 0.78376601 0.41292102 0.47109654
## [10] 0.72698486 2.18412716 1.85392099
##
## $n_eff
## [1] 1.875425 45.003615 3.370704 3160.753814 1051.252892 391.491348 89.731920 1145.574819
## [9] 635.209403 258.696950 3.503268 7.730014The pareto_k values can be used to examine cases that are overly-influential on the model parameters, something like a Cook’s \(D_{i}\). See, for example this discussion on stackoverflow.com in which several members of the Stan team weighed in. The issue is also discussed in this paper and in this presentation by Aki Vehtari.
Anyway, the implication of all this is these values suggest model b10.6 isn’t a great fit for these data.
Part of the warning message for model b10.6 read:
It is recommended to set ‘reloo = TRUE’ in order to calculate the ELPD without the assumption that these observations are negligible. This will refit the model [\(n\)] times to compute the ELPDs for the problematic observations directly.
Let’s do that.
l_b10.6_reloo <- loo(b10.6, reloo = T)Check the results.
l_b10.6_reloo##
## Computed from 4000 by 12 log-likelihood matrix
##
## Estimate SE
## elpd_loo -518.2 170.5
## p_loo 134.9 51.9
## looic 1036.4 341.1
## ------
## Monte Carlo SE of elpd_loo is NA.
##
## Pareto k diagnostic values:
## Count Pct. Min. n_eff
## (-Inf, 0.5] (good) 11 91.7% 2
## (0.5, 0.7] (ok) 1 8.3% 391
## (0.7, 1] (bad) 0 0.0% <NA>
## (1, Inf) (very bad) 0 0.0% <NA>
##
## All Pareto k estimates are ok (k < 0.7).
## See help('pareto-k-diagnostic') for details.Now that looks better. We’ll do the same thing for model b10.7.
l_b10.7_reloo <- loo(b10.7, reloo = T)Okay, let’s compare models with formal \(\text{elpd}_{\text{loo}}\) differences before and after adjusting with reloo = T.
loo_compare(l_b10.6, l_b10.7)## elpd_diff se_diff
## b10.6 0.0 0.0
## b10.7 -27.3 76.8loo_compare(l_b10.6_reloo, l_b10.7_reloo)## elpd_diff se_diff
## b10.6 0.0 0.0
## b10.7 -12.2 81.3In this case, the results are kinda similar. The standard errors for the differences are huge compared to the point estimates, suggesting large uncertainty. Watch out for this in your real-world data.
But this has all been a tangent from the central thrust of this section.
Back from our information criteria digression.
Let’s get back on track with the text. Here’s a look at b10.6, the unavailable model:
print(b10.6)## Family: binomial
## Links: mu = logit
## Formula: admit | trials(applications) ~ 1 + male
## Data: d (Number of observations: 12)
## Samples: 2 chains, each with iter = 2500; warmup = 500; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept -0.83 0.05 -0.93 -0.73 1929 1.00
## male 0.61 0.06 0.48 0.74 2527 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Here’s the relative difference in admission odds.
fixef(b10.6)[2] %>%
exp() %>%
round(digits = 2)## [1] 1.84And now we’ll compute difference in admission probabilities.
post <- posterior_samples(b10.6)
post %>%
mutate(p_admit_male = inv_logit_scaled(b_Intercept + b_male),
p_admit_female = inv_logit_scaled(b_Intercept),
diff_admit = p_admit_male - p_admit_female) %>%
summarise(`2.5%` = quantile(diff_admit, probs = .025),
`50%` = median(diff_admit),
`97.5%` = quantile(diff_admit, probs = .975))## 2.5% 50% 97.5%
## 1 0.1125269 0.1414872 0.1705231Instead of the summarise() code, we could have also used tidybayes::median_qi(diff_admit). It’s good to have options. Here’s our version of Figure 10.5.
d <-
d %>%
mutate(case = factor(1:12))
p <-
predict(b10.6) %>%
as_tibble() %>%
bind_cols(d)
d_text <-
d %>%
group_by(dept) %>%
summarise(case = mean(as.numeric(case)),
admit = mean(admit / applications) + .05)
ggplot(data = d, aes(x = case, y = admit / applications)) +
geom_pointrange(data = p,
aes(y = Estimate / applications,
ymin = Q2.5 / applications ,
ymax = Q97.5 / applications),
color = wes_palette("Moonrise2")[1],
shape = 1, alpha = 1/3) +
geom_point(color = wes_palette("Moonrise2")[2]) +
geom_line(aes(group = dept),
color = wes_palette("Moonrise2")[2]) +
geom_text(data = d_text,
aes(y = admit, label = dept),
color = wes_palette("Moonrise2")[2],
family = "serif") +
coord_cartesian(ylim = 0:1) +
labs(y = "Proportion admitted",
title = "Posterior validation check") +
theme(axis.ticks.x = element_blank())
As alluded to in all that LOO/pareto_k talk, above, this is not a great fit. So we’ll ditch the last model paradigm for one that answers the new question “What is the average difference in probability of admission between females and males within departments?” (p. 307). The statistical formula for the full model follows the form
We don’t need to coerce an index like McElreath did in the text. But here are the models.
b10.8 <-
brm(data = d, family = binomial,
admit | trials(applications) ~ 0 + dept,
prior(normal(0, 10), class = b),
iter = 2500, warmup = 500, cores = 2, chains = 2,
seed = 10)
b10.9 <-
update(b10.8,
newdata = d,
formula = admit | trials(applications) ~ 0 + dept + male)Let’s make two more loo() objects using reloo = T.
l_b10.8_reloo <- loo(b10.8, reloo = T)
l_b10.9_reloo <- loo(b10.9, reloo = T)Now compare them.
loo_compare(l_b10.6_reloo, l_b10.7_reloo, l_b10.8_reloo, l_b10.9_reloo)## elpd_diff se_diff
## b10.8 0.0 0.0
## b10.9 -4.2 2.7
## b10.6 -453.7 166.2
## b10.7 -465.9 160.6Here are the LOO weights.
model_weights(b10.6, b10.7, b10.8, b10.9,
weights = "loo") %>%
round(digits = 3)## b10.6 b10.7 b10.8 b10.9
## 0.000 0.000 0.877 0.123The parameters summaries for our multivariable model, b10.9, look like this:
fixef(b10.9) %>% round(digits = 2)## Estimate Est.Error Q2.5 Q97.5
## deptA 0.68 0.10 0.49 0.87
## deptB 0.64 0.11 0.42 0.87
## deptC -0.58 0.07 -0.72 -0.44
## deptD -0.61 0.09 -0.78 -0.45
## deptE -1.06 0.10 -1.26 -0.87
## deptF -2.64 0.16 -2.96 -2.33
## male -0.10 0.08 -0.25 0.05And on the proportional odds scale, the posterior mean for b_male is:
fixef(b10.9)[7, 1] %>% exp()## [1] 0.9033437Since we’ve been using brms, there’s no need to fit our version of McElreath’s m10.9stan. We already have that in our b10.9. But just for kicks and giggles, here’s another way to get the model summary.
b10.9$fit## Inference for Stan model: a56936c0ede77895dee7937133dd0dcd.
## 2 chains, each with iter=2500; warmup=500; thin=1;
## post-warmup draws per chain=2000, total post-warmup draws=4000.
##
## mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
## b_deptA 0.68 0.00 0.10 0.49 0.62 0.69 0.75 0.87 2186 1
## b_deptB 0.64 0.00 0.11 0.42 0.57 0.64 0.72 0.87 2236 1
## b_deptC -0.58 0.00 0.07 -0.72 -0.63 -0.58 -0.53 -0.44 3125 1
## b_deptD -0.61 0.00 0.09 -0.78 -0.67 -0.61 -0.55 -0.45 3391 1
## b_deptE -1.06 0.00 0.10 -1.26 -1.13 -1.06 -0.99 -0.87 3372 1
## b_deptF -2.64 0.00 0.16 -2.96 -2.74 -2.63 -2.52 -2.33 4162 1
## b_male -0.10 0.00 0.08 -0.25 -0.16 -0.10 -0.05 0.05 1858 1
## lp__ -70.67 0.05 1.91 -75.16 -71.69 -70.30 -69.28 -68.02 1605 1
##
## Samples were drawn using NUTS(diag_e) at Sat May 4 13:20:48 2019.
## For each parameter, n_eff is a crude measure of effective sample size,
## and Rhat is the potential scale reduction factor on split chains (at
## convergence, Rhat=1).Here’s our version of Figure 10.6, the posterior validation check.
predict(b10.9) %>%
as_tibble() %>%
bind_cols(d) %>%
ggplot(aes(x = case, y = admit / applications)) +
geom_pointrange(aes(y = Estimate / applications,
ymin = Q2.5 / applications ,
ymax = Q97.5 / applications),
color = wes_palette("Moonrise2")[1],
shape = 1, alpha = 1/3) +
geom_point(color = wes_palette("Moonrise2")[2]) +
geom_line(aes(group = dept),
color = wes_palette("Moonrise2")[2]) +
geom_text(data = d_text,
aes(y = admit, label = dept),
color = wes_palette("Moonrise2")[2],
family = "serif") +
coord_cartesian(ylim = 0:1) +
labs(y = "Proportion admitted",
title = "Posterior validation check") +
theme(axis.ticks.x = element_blank())
The model precisions are imperfect, but way more valid than before. The posterior looks reasonably multivariate Gaussian.
pairs(b10.9,
off_diag_args = list(size = 1/10, alpha = 1/6))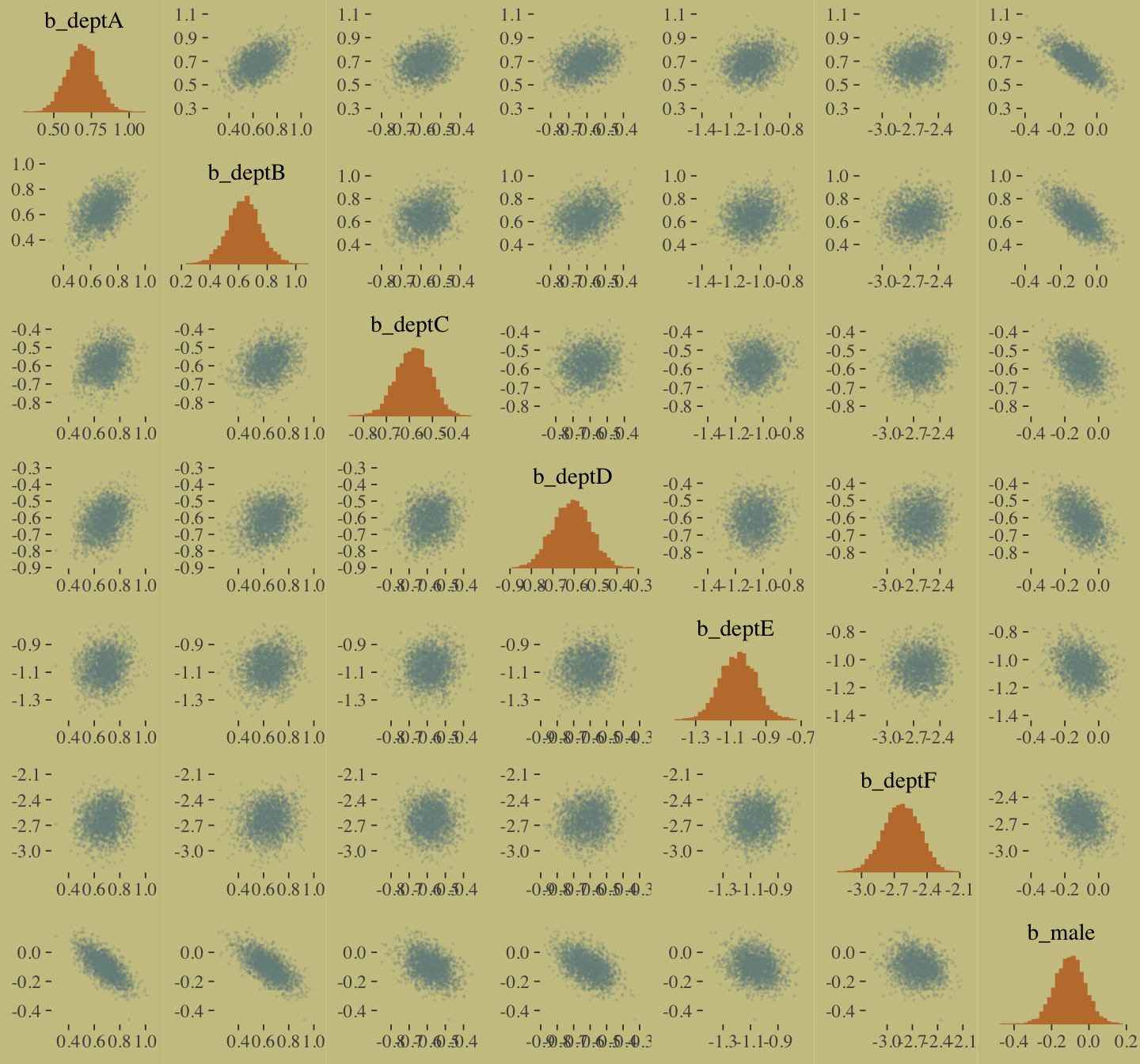
10.1.3.1 Overthinking: WAIC and aggregated binomial models.
McElreath wrote:
The
WAICfunction inrethinkingdetects aggregated binomial models and automatically splits them apart into 0/1 Bernoulli trials, for the purpose of calculating WAIC. It does this, because WAIC is computed point by point (see Chapter 6). So what you define as a “point” affects WAIC’s value. In an aggregated binomial each “point” is a bunch of independent trials that happen to share the same predictor values. In order for the disaggregated and aggregated models to agree, it makes sense to use the disaggregated representation. (p. 309)
To my knowledge, brms::waic() and brms::loo() do not do this, which might well be why some of our values didn’t match up with those in the text. If you have additional insight on this, please share with the rest of the class.
10.1.4 Fitting binomial regressions with glm().
We’re not here to learn frequentist code, so we’re going to skip most of this section. But model b.good is worth fitting. Here are the data.
# outcome and predictor almost perfectly associated
y <- c(rep(0, 10), rep(1, 10))
x <- c(rep(-1, 9), rep(1, 11))Fit the b.good model.
b.good <-
brm(data = list(y = y, x = x), family = binomial,
y ~ 1 + x,
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 10), class = b)),
seed = 10) Our model summary will differ a bit from the one in the text. It seems this is because of the MAP/HMC contrast and our choice of priors.
print(b.good)## Family: binomial
## Links: mu = logit
## Formula: y ~ 1 + x
## Data: list(y = y, x = x) (Number of observations: 20)
## Samples: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept -5.34 4.24 -15.14 0.43 530 1.01
## x 8.07 4.23 2.47 18.06 532 1.01
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).You might experiment with different prior \(SD\)s to see how they influence the posterior \(SD\)s. Anyways, here’s the pairs() plot McElreath excluded from the text.
pairs(b.good,
off_diag_args = list(size = 1/10, alpha = 1/6))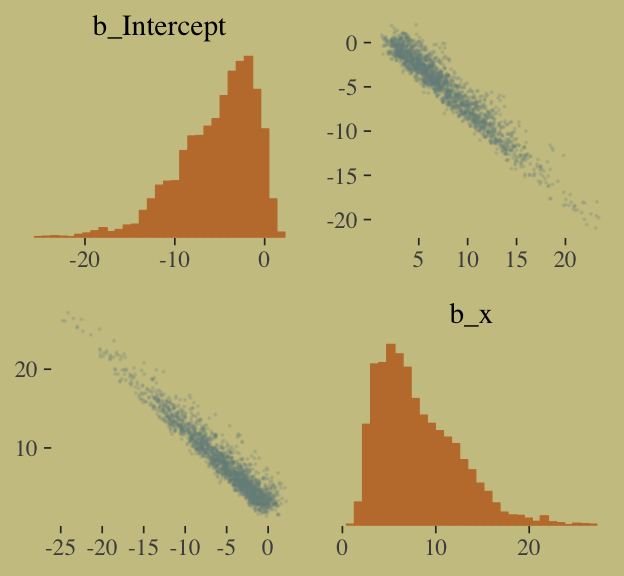
That posterior, my friends, is not multivariate Gaussian. The plot deserves and extensive quote from McElreath.
Inspecting the pairs plot (
notshown) demonstrates just how subtle even simple models can be, once we start working with GLMs. I don’t say this to scare the reader. But it’s true that even simple models can behave in complicated ways. How you fit the model is part of the model, and in principle no GLM is safe for MAP estimation. (p. 311)
10.2 Poisson regression
We’ll simulate our sweet count data.
set.seed(10) # make the results reproducible
tibble(y = rbinom(1e5, 1000, 1/1000)) %>%
summarise(y_mean = mean(y),
y_variance = var(y))## # A tibble: 1 x 2
## y_mean y_variance
## <dbl> <dbl>
## 1 0.994 0.995Yes, those statistics are virtually the same. When dealing with Poisson data, \(\mu = \sigma^2\). When you have a number of trials for which \(n\) is unknown or much larger than seen in the data, the Poisson likelihood is a useful tool. We define it like this
\[y \sim \text{Poisson} (\lambda)\]
As \(\lambda\) expresses both mean and variance because, within this model, the variance scales right along with the mean. Since \(\lambda\) is constrained to be positive, we typically use the log link. Thus the basic Poisson regression model is
\[\begin{align*} y_i & \sim \text{Poisson} (\lambda_i) \\ \text{log} (\lambda_i) & = \alpha + \beta x_i \end{align*}\]10.2.1 Example: Oceanic tool complexity.
Load the Kline data.
library(rethinking)
data(Kline)
d <- KlineSwitch from rethinking to brms.
detach(package:rethinking, unload = T)
library(brms)
rm(Kline)
d## culture population contact total_tools mean_TU
## 1 Malekula 1100 low 13 3.2
## 2 Tikopia 1500 low 22 4.7
## 3 Santa Cruz 3600 low 24 4.0
## 4 Yap 4791 high 43 5.0
## 5 Lau Fiji 7400 high 33 5.0
## 6 Trobriand 8000 high 19 4.0
## 7 Chuuk 9200 high 40 3.8
## 8 Manus 13000 low 28 6.6
## 9 Tonga 17500 high 55 5.4
## 10 Hawaii 275000 low 71 6.6Here are our new columns.
d <-
d %>%
mutate(log_pop = log(population),
contact_high = ifelse(contact == "high", 1, 0))Our statistical model will follow the form
\[\begin{align*} \text{total_tools}_i & \sim \text{Poisson} (\lambda_i) \\ \text{log} (\lambda_i) & = \alpha + \beta_1 \text{log_pop}_i + \beta_2 \text{contact_high}_i + \beta_3 \text{contact_high}_i \times \text{log_pop}_i \\ \alpha & \sim \text{Normal} (0, 100) \\ \beta_1 & \sim \text{Normal} (0, 1) \\ \beta_2 & \sim \text{Normal} (0, 1) \\ \beta_3 & \sim \text{Normal} (0, 1) \end{align*}\]The only new thing in our model code is family = poisson. brms defaults to the log() link.
b10.10 <-
brm(data = d, family = poisson,
total_tools ~ 1 + log_pop + contact_high + contact_high:log_pop,
prior = c(prior(normal(0, 100), class = Intercept),
prior(normal(0, 1), class = b)),
iter = 3000, warmup = 1000, chains = 4, cores = 4,
seed = 10) print(b10.10)## Family: poisson
## Links: mu = log
## Formula: total_tools ~ 1 + log_pop + contact_high + contact_high:log_pop
## Data: d (Number of observations: 10)
## Samples: 4 chains, each with iter = 3000; warmup = 1000; thin = 1;
## total post-warmup samples = 8000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 0.94 0.35 0.24 1.63 4087 1.00
## log_pop 0.26 0.03 0.20 0.33 4331 1.00
## contact_high -0.11 0.84 -1.74 1.53 3115 1.00
## log_pop:contact_high 0.04 0.09 -0.14 0.22 3080 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Here’s the lower triangle of the correlation matrix for the parameters.
post <-
posterior_samples(b10.10)
post %>%
select(-lp__) %>%
rename(b_interaction = `b_log_pop:contact_high`) %>%
psych::lowerCor()## b_Int b_lg_ b_cn_ b_ntr
## b_Intercept 1.00
## b_log_pop -0.97 1.00
## b_contact_high -0.12 0.11 1.00
## b_interaction 0.06 -0.07 -0.99 1.00And here’s the coefficient plot via bayesplot::mcmc_intervals():
# we'll set a renewed color theme
color_scheme_set(c(wes_palette("Moonrise2")[2],
wes_palette("Moonrise2")[1],
wes_palette("Moonrise2")[4],
wes_palette("Moonrise2")[2],
wes_palette("Moonrise2")[1],
wes_palette("Moonrise2")[1]))
post %>%
select(-lp__) %>%
rename(b_interaction = `b_log_pop:contact_high`) %>%
mcmc_intervals(prob = .5, prob_outer = .95) +
theme(axis.ticks.y = element_blank(),
axis.text.y = element_text(hjust = 0))
How plausible is it a high-contact island will have more tools than a low-contact island?
post <-
post %>%
mutate(lambda_high = exp(b_Intercept + b_contact_high + (b_log_pop + `b_log_pop:contact_high`) * 8),
lambda_low = exp(b_Intercept + b_log_pop * 8)) %>%
mutate(diff = lambda_high - lambda_low)
post %>%
summarise(sum = sum(diff > 0) / length(diff))## sum
## 1 0.95525Quite, it turns out. Behold the corresponding Figure 10.8.a.
post %>%
ggplot(aes(x = diff)) +
geom_density(color = "transparent",
fill = wes_palette("Moonrise2")[1]) +
geom_vline(xintercept = 0, linetype = 2,
color = wes_palette("Moonrise2")[2]) +
scale_y_continuous(NULL, breaks = NULL) +
labs(x = "lambda_high - lambda_low")
I’m not happy with how clunky this solution is, but one way to get those marginal dot and line plots for the axes is to make intermediary tibbles. Anyway, here’s a version of Figure 10.8.b.
# intermediary tibbles for our the dot and line portoin of the plot
point_tibble <-
tibble(x = c(median(post$b_contact_high), min(post$b_contact_high)),
y = c(min(post$`b_log_pop:contact_high`), median(post$`b_log_pop:contact_high`)))
line_tibble <-
tibble(parameter = rep(c("b_contact_high", "b_log_pop:contact_high"), each = 2),
x = c(quantile(post$b_contact_high, probs = c(.025, .975)),
rep(min(post$b_contact_high), times = 2)),
y = c(rep(min(post$`b_log_pop:contact_high`), times = 2),
quantile(post$`b_log_pop:contact_high`, probs = c(.025, .975))))
# the plot
post %>%
ggplot(aes(x = b_contact_high, y = `b_log_pop:contact_high`)) +
geom_point(color = wes_palette("Moonrise2")[1],
size = 1/10, alpha = 1/10) +
geom_point(data = point_tibble,
aes(x = x, y = y)) +
geom_line(data = line_tibble,
aes(x = x, y = y, group = parameter))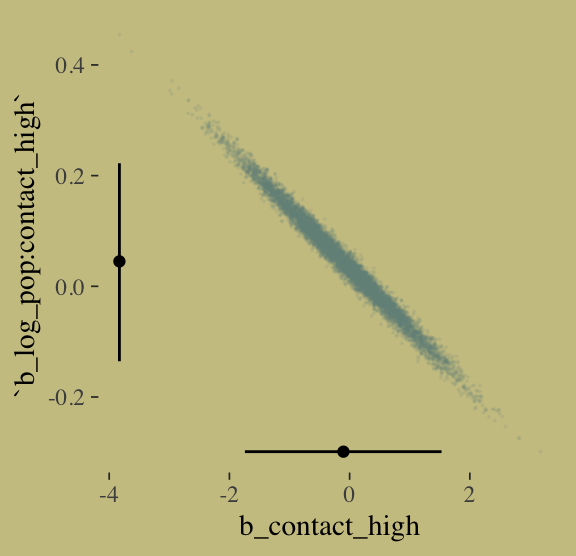
Here we deconstruct model b10.10, bit by bit.
# no interaction
b10.11 <-
update(b10.10, formula = total_tools ~ 1 + log_pop + contact_high)
# no contact rate
b10.12 <-
update(b10.10, formula = total_tools ~ 1 + log_pop)
# no log-population
b10.13 <-
update(b10.10, formula = total_tools ~ 1 + contact_high)
# intercept only
b10.14 <-
update(b10.10, formula = total_tools ~ 1,
seed = 10)I know we got all excited with the LOO, above. Let’s just be lazy and go WAIC. [Though beware, the LOO opens up a similar can of worms, here.]
b10.10 <- add_criterion(b10.10, criterion = "waic")
b10.11 <- add_criterion(b10.11, criterion = "waic")
b10.12 <- add_criterion(b10.12, criterion = "waic")
b10.13 <- add_criterion(b10.13, criterion = "waic")
b10.14 <- add_criterion(b10.14, criterion = "waic")Now compare them.
w <- loo_compare(b10.10, b10.11, b10.12, b10.13, b10.14, criterion = "waic")
cbind(waic_diff = w[, 1] * -2,
se = w[, 2] * 2) %>%
round(digits = 2)## waic_diff se
## b10.11 0.00 0.00
## b10.10 0.75 1.35
## b10.12 4.86 8.29
## b10.14 62.07 34.55
## b10.13 71.30 47.08Let’s get those WAIC weights, too.
model_weights(b10.10, b10.11, b10.12, b10.13, b10.14, weights = "waic") %>%
round(digits = 2)## b10.10 b10.11 b10.12 b10.13 b10.14
## 0.39 0.56 0.05 0.00 0.00Now wrangle w a little and make the WAIC plot.
w %>%
data.frame() %>%
rownames_to_column(var = "model") %>%
ggplot(aes(x = reorder(model, -waic),
y = waic,
ymin = waic - se_waic,
ymax = waic + se_waic,
color = model)) +
geom_pointrange(shape = 16, show.legend = F) +
scale_color_manual(values = wes_palette("Moonrise2")[c(1, 2, 1, 1, 1)]) +
coord_flip() +
labs(x = NULL, y = NULL,
title = "WAIC") +
theme(axis.ticks.y = element_blank())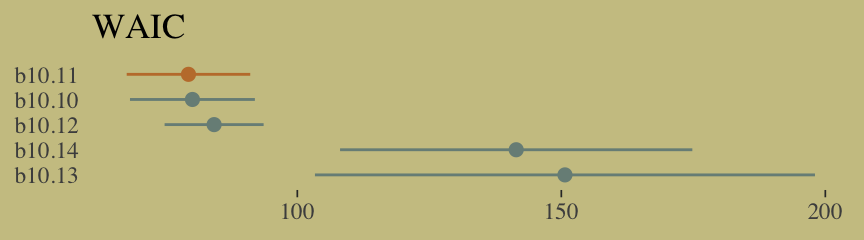
Here’s our version of Figure 10.9. Recall, to do an “ensemble” posterior prediction in brms, one uses the pp_average() function. I know we were just lazy and focused on the WAIC. But let’s play around, a bit. Here we’ll weight the models based on the LOO by adding a weights = "loo" argument to the pp_average() function. If you check the corresponding section of the brms reference manual, you’ll find several weighting schemes.
nd <-
tibble(contact_high = 0:1) %>%
expand(contact_high,
log_pop = seq(from = 6.5, to = 13, length.out = 50))
ppa <-
pp_average(b10.10, b10.11, b10.12,
weights = "loo",
method = "fitted",
newdata = nd) %>%
as_tibble() %>%
bind_cols(nd)
ppa %>%
ggplot(aes(x = log_pop,
group = contact_high)) +
geom_smooth(aes(y = Estimate, ymin = Q2.5, ymax = Q97.5,
fill = contact_high, color = contact_high),
stat = "identity",
alpha = 1/4, size = 1/2) +
geom_text(data = d,
aes(y = total_tools,
label = total_tools,
color = contact_high),
size = 3.5) +
coord_cartesian(xlim = c(7.1, 12.4),
ylim = c(12, 70)) +
labs(x = "log population",
y = "total tools",
subtitle = "Blue is the high contact rate; black is the low.") +
theme(legend.position = "none",
panel.border = element_blank())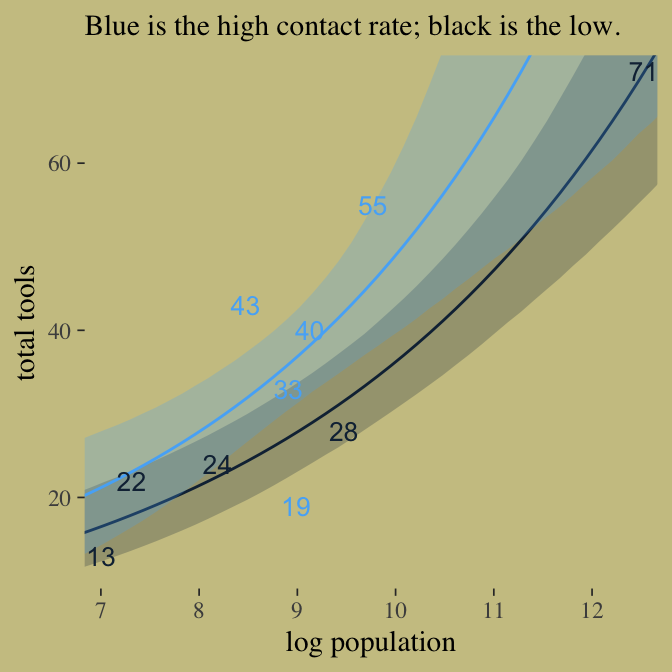
In case you were curious, here are those LOO weights:
model_weights(b10.10, b10.11, b10.12,
weights = "loo")## b10.10 b10.11 b10.12
## 0.37857139 0.57188875 0.0495398610.2.2 MCMC islands.
We fit our analogue to m10.10stan, b10.10, some time ago.
print(b10.10)## Family: poisson
## Links: mu = log
## Formula: total_tools ~ 1 + log_pop + contact_high + contact_high:log_pop
## Data: d (Number of observations: 10)
## Samples: 4 chains, each with iter = 3000; warmup = 1000; thin = 1;
## total post-warmup samples = 8000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 0.94 0.35 0.24 1.63 4087 1.00
## log_pop 0.26 0.03 0.20 0.33 4331 1.00
## contact_high -0.11 0.84 -1.74 1.53 3115 1.00
## log_pop:contact_high 0.04 0.09 -0.14 0.22 3080 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Center log_pop.
d <-
d %>%
mutate(log_pop_c = log_pop - mean(log_pop))Now fit the log_pop-centered model.
b10.10_c <-
brm(data = d, family = poisson,
total_tools ~ 1 + log_pop_c + contact_high + contact_high:log_pop_c,
prior = c(prior(normal(0, 10), class = Intercept),
prior(normal(0, 1), class = b)),
iter = 3000, warmup = 1000, chains = 4, cores = 4,
seed = 10)print(b10.10_c)## Family: poisson
## Links: mu = log
## Formula: total_tools ~ 1 + log_pop_c + contact_high + contact_high:log_pop_c
## Data: d (Number of observations: 10)
## Samples: 4 chains, each with iter = 3000; warmup = 1000; thin = 1;
## total post-warmup samples = 8000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 3.31 0.09 3.13 3.49 6035 1.00
## log_pop_c 0.26 0.04 0.19 0.33 6024 1.00
## contact_high 0.28 0.12 0.06 0.52 6606 1.00
## log_pop_c:contact_high 0.06 0.17 -0.26 0.38 6718 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).We’ll use mcmc_pairs(), again, for Figure 10.10.a.
# this helps us set our custom color scheme
color_scheme_set(c(wes_palette("Moonrise2")[3],
wes_palette("Moonrise2")[1],
wes_palette("Moonrise2")[2],
wes_palette("Moonrise2")[2],
wes_palette("Moonrise2")[1],
wes_palette("Moonrise2")[1]))
# the actual plot
mcmc_pairs(x = posterior_samples(b10.10),
pars = c("b_Intercept", "b_log_pop", "b_contact_high", "b_log_pop:contact_high"),
off_diag_args = list(size = 1/10, alpha = 1/10),
diag_fun = "dens")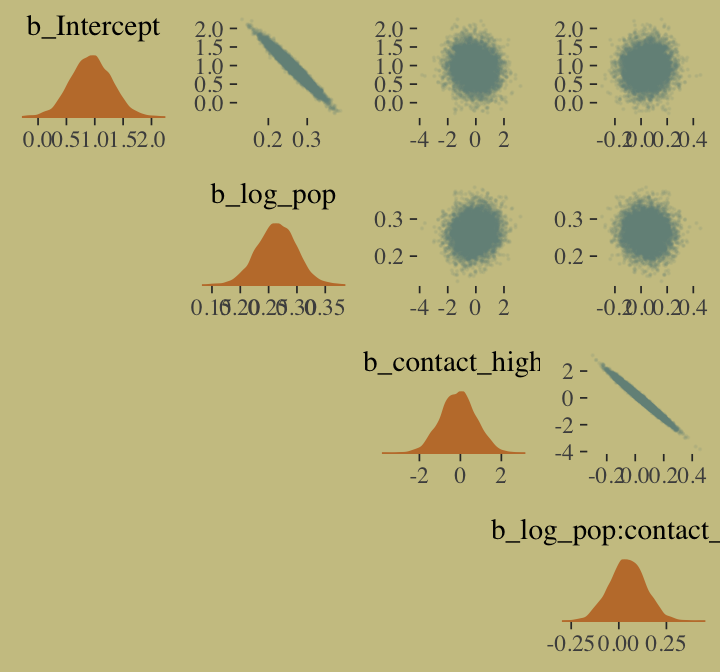
And now behold Figure 10.10.b.
mcmc_pairs(x = posterior_samples(b10.10_c),
pars = c("b_Intercept", "b_log_pop_c", "b_contact_high", "b_log_pop_c:contact_high"),
off_diag_args = list(size = 1/10, alpha = 1/10),
diag_fun = "dens")
If you really want the correlation point estimates, use psych::lowerCorr().
psych::lowerCor(posterior_samples(b10.10)[, 1:4])## b_Int b_lg_ b_cn_ b__:_
## b_Intercept 1.00
## b_log_pop -0.97 1.00
## b_contact_high -0.12 0.11 1.00
## b_log_pop:contact_high 0.06 -0.07 -0.99 1.00psych::lowerCor(posterior_samples(b10.10_c)[, 1:4])## b_Int b_l__ b_cn_ b___:
## b_Intercept 1.00
## b_log_pop_c -0.48 1.00
## b_contact_high -0.77 0.36 1.00
## b_log_pop_c:contact_high 0.09 -0.19 -0.24 1.0010.2.3 Example: Exposure and the offset.
For the last Poisson example, we’ll look at a case where the exposure varies across observations. When the length of observation, area of sampling, or intensity of sampling varies, the counts we observe also naturally vary. Since a Poisson distribution assumes that the rate of events is constant in time (or space), it’s easy to handle this. All we need to do, as explained on page 312 [of the text], is to add the logarithm of the exposure to the linear model. The term we add is typically called an offset. (p. 321, emphasis in the original)
Here we simulate our data.
set.seed(10)
num_days <- 30
y <- rpois(num_days, 1.5)
num_weeks <- 4
y_new <- rpois(num_weeks, 0.5 * 7)Let’s make them tidy and add log_days.
(
d <-
tibble(y = c(y, y_new),
days = c(rep(1, num_days), rep(7, num_weeks)),
monastery = c(rep(0, num_days), rep(1, num_weeks))) %>%
mutate(log_days = log(days))
)## # A tibble: 34 x 4
## y days monastery log_days
## <int> <dbl> <dbl> <dbl>
## 1 1 1 0 0
## 2 1 1 0 0
## 3 1 1 0 0
## 4 2 1 0 0
## 5 0 1 0 0
## 6 1 1 0 0
## 7 1 1 0 0
## 8 1 1 0 0
## 9 2 1 0 0
## 10 1 1 0 0
## # … with 24 more rowsWith the brms package, you use the offset() syntax, in which you put a pre-processed variable like log_days or the log of a variable, such as log(days).
b10.15 <-
brm(data = d, family = poisson,
y ~ 1 + offset(log_days) + monastery,
prior = c(prior(normal(0, 100), class = Intercept),
prior(normal(0, 1), class = b)),
iter = 2500, warmup = 500, cores = 2, chains = 2,
seed = 10)The model summary:
print(b10.15)## Family: poisson
## Links: mu = log
## Formula: y ~ 1 + offset(log_days) + monastery
## Data: d (Number of observations: 34)
## Samples: 2 chains, each with iter = 2500; warmup = 500; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept 0.30 0.16 -0.04 0.61 3168 1.00
## monastery -1.10 0.31 -1.72 -0.52 3340 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).The model summary helps clarify that when you use offset(), brm() fixes the value. Thus there is no parameter estimate for the offset(). It’s a fixed part of the model not unlike the \(\nu\) parameter of the Student-\(t\) distribution gets fixed to infinity when you use the Gaussian likelihood.
Here we’ll compute the posterior means and 89% HDIs with tidybayes::mean_hdi().
library(tidybayes)
posterior_samples(b10.15) %>%
transmute(lambda_old = exp(b_Intercept),
lambda_new = exp(b_Intercept + b_monastery)) %>%
gather() %>%
mutate(key = factor(key, levels = c("lambda_old", "lambda_new"))) %>%
group_by(key) %>%
mean_hdi(value, .width = .89) %>%
mutate_if(is.double, round, digits = 2)## # A tibble: 2 x 7
## key value .lower .upper .width .point .interval
## <fct> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 lambda_old 1.37 0.99 1.7 0.89 mean hdi
## 2 lambda_new 0.47 0.27 0.66 0.89 mean hdiAs McElreath pointed out in the text, “Your estimates will be slightly different, because you got different randomly simulated data” (p. 322).
10.3 Other count regressions
The next two of the remaining four models are maximum entropy distributions for certain problem types. The last two are mixtures, of which we’ll see more in the next chapter.
10.3.1 Multinomial.
When more than two types of unordered events are possible, and the probability of each type of event is constant across trials, then the maximum entropy distribution is the multinomial distribution. [We] already met the multinomial, implicitly, in Chapter 9 when we tossed pebbles into buckets as an introduction to maximum entropy. The binomial is really a special case of this distribution. And so its distribution formula resembles the binomial, just extrapolated out to three or more types of events. If there are \(K\) types of events with probabilities \(p_1, …, p_K\), then the probability of observing \(y_1, …, y_K\) events of each type out of \(n\) trials is (p. 323):
\[\text{Pr} (y_1, ..., y_K | n, p_1, ..., p_K) = \frac{n!}{\prod_i y_i!} \prod_{i = 1}^K p_i^{y_i}\]
Compare that equation with the simpler version in section 2.3.1 (page 33 in the text).
10.3.1.1 Explicit multinomial models.
“The conventional and natural link is this context is the multinomial logit. This link function takes a vector of scores, one for each \(K\) event types, and computed the probability of a particular type of event \(K\) as” (p. 323, emphasis in the original)
\[\text{Pr} (k |s_1, s_2, ..., s_K) = \frac{\text{exp} (s_k)}{\sum_{i = 1}^K \text{exp} (s_i)}\]
Let’s simulate the data.
library(rethinking)
# simulate career choices among 500 individuals
n <- 500 # number of individuals
income <- 1:3 # expected income of each career
score <- 0.5 * income # scores for each career, based on income
# next line converts scores to probabilities
p <- softmax(score[1], score[2], score[3])
# now simulate choice
# outcome career holds event type values, not counts
career <- rep(NA, n) # empty vector of choices for each individual
set.seed(10)
# sample chosen career for each individual
for(i in 1:n) career[i] <- sample(1:3, size = 1, prob = p)Here’s what the data look like.
career %>%
as_tibble() %>%
ggplot(aes(x = value %>% as.factor())) +
geom_bar(size = 0, fill = wes_palette("Moonrise2")[2])
Switch out rethinking for brms.
detach(package:rethinking, unload = T)
library(brms)Here’s my naïve attempt to fit the model in brms.
b10.16 <-
brm(data = list(career = career),
family = categorical(link = logit),
career ~ 1,
prior(normal(0, 5), class = Intercept),
iter = 2500, warmup = 500, cores = 2, chains = 2,
seed = 10)This differs from McElreath’s m10.16. Most obviously, this has two parameters. McElreath’s m10.16 only has one. If you have experience with these models and know how to reproduce McElreath’s results in brms, please share your code.
print(b10.16)## Family: categorical
## Links: mu2 = logit; mu3 = logit
## Formula: career ~ 1
## Data: list(career = career) (Number of observations: 500)
## Samples: 2 chains, each with iter = 2500; warmup = 500; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## mu2_Intercept 0.49 0.14 0.23 0.76 1220 1.00
## mu3_Intercept 1.01 0.12 0.77 1.25 1263 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Here’s the second data simulation, this time based on McElreath’s R code 10.58.
library(rethinking)
n <- 100
set.seed(10)
# simulate family incomes for each individual
family_income <- runif(n)
# assign a unique coefficient for each type of event
b <- (1:-1)
career <- rep(NA, n) # empty vector of choices for each individual
for (i in 1:n) {
score <- 0.5 * (1:3) + b * family_income[i]
p <- softmax(score[1], score[2], score[3])
career[i] <- sample(1:3, size = 1, prob = p)
}Switch out rethinking for brms.
detach(package:rethinking, unload = T)
library(brms)Here’s the brms version of McElreath’s m10.17.
b10.17 <-
brm(data = list(career = career, # note how we used a list instead of a tibble
family_income = family_income),
family = categorical(link = logit),
career ~ 1 + family_income,
prior = c(prior(normal(0, 5), class = Intercept),
prior(normal(0, 5), class = b)),
iter = 2500, warmup = 500, cores = 2, chains = 2,
seed = 10)Happily, these results cohere with the rethinking model.
print(b10.17)## Family: categorical
## Links: mu2 = logit; mu3 = logit
## Formula: career ~ 1 + family_income
## Data: list(career = career, family_income = family_incom (Number of observations: 100)
## Samples: 2 chains, each with iter = 2500; warmup = 500; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## mu2_Intercept 1.03 0.55 0.02 2.11 2758 1.00
## mu3_Intercept 1.04 0.54 0.02 2.13 2753 1.00
## mu2_family_income -1.77 1.00 -3.72 0.16 2931 1.00
## mu3_family_income -1.72 0.99 -3.76 0.13 2846 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).McElreath described the parameters as “on a scale that is very hard to interpret” (p. 325). Indeed.
10.3.1.2 Multinomial in disguise as Poisson.
Here we fit a multinomial likelihood by refactoring it to a series of Poissons. Let’s retrieve the Berkeley data.
library(rethinking)
data(UCBadmit)
d <- UCBadmit
rm(UCBadmit)
detach(package:rethinking, unload = T)
library(brms)Fit the models.
# binomial model of overall admission probability
b_binom <-
brm(data = d, family = binomial,
admit | trials(applications) ~ 1,
prior(normal(0, 100), class = Intercept),
iter = 2000, warmup = 1000, cores = 3, chains = 3,
seed = 10)
# Poisson model of overall admission rate and rejection rate
b_pois <-
brm(data = d %>%
mutate(rej = reject), # 'reject' is a reserved word
family = poisson,
mvbind(admit, rej) ~ 1,
prior(normal(0, 100), class = Intercept),
iter = 2000, warmup = 1000, cores = 3, chains = 3,
seed = 10)Note, the mvbind() syntax made b_pois a multivariate Poisson model. Starting with version 2.0.0, brms supports a variety of multivariate models. Anyway, here are the implications of b_pois.
# extract the samples
post <- posterior_samples(b_pois)
# wrangle
post %>%
transmute(admit = exp(b_admit_Intercept),
reject = exp(b_rej_Intercept)) %>%
gather() %>%
# plot
ggplot(aes(x = value, y = key, fill = key)) +
geom_halfeyeh(point_interval = median_qi, .width = .95,
color = wes_palette("Moonrise2")[4]) +
scale_fill_manual(values = c(wes_palette("Moonrise2")[1],
wes_palette("Moonrise2")[2])) +
labs(title = " Mean admit/reject rates across departments",
x = "# applications",
y = NULL) +
theme(legend.position = "none",
axis.ticks.y = element_blank())
The model summaries:
print(b_binom)## Family: binomial
## Links: mu = logit
## Formula: admit | trials(applications) ~ 1
## Data: d (Number of observations: 12)
## Samples: 3 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 3000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## Intercept -0.46 0.03 -0.52 -0.40 1219 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).print(b_pois)## Family: MV(poisson, poisson)
## Links: mu = log
## mu = log
## Formula: admit ~ 1
## rej ~ 1
## Data: d %>% mutate(rej = reject) (Number of observations: 12)
## Samples: 3 chains, each with iter = 2000; warmup = 1000; thin = 1;
## total post-warmup samples = 3000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## admit_Intercept 4.98 0.02 4.94 5.03 2194 1.00
## rej_Intercept 5.44 0.02 5.41 5.48 2591 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).Here’s the posterior mean for the probability of admission, based on b_binom.
fixef(b_binom)[ ,"Estimate"] %>%
inv_logit_scaled()## [1] 0.387497Happily, we get the same value within simulation error from model b_pois.
k <-
fixef(b_pois) %>%
as.numeric()
exp(k[1]) / (exp(k[1]) + exp(k[2]))## [1] 0.3876675The formula for what we just did in code is
\[p_{\text{admit}} = \frac{\lambda_1}{\lambda_1 + \lambda_2} = \frac{\text{exp} (\alpha_1)}{\text{exp} (\alpha_1) + \text{exp} (\alpha_2)}\]
10.3.2 Geometric.
Sometimes a count variable is a number of events up until something happened. Call this “something” the terminating event. Often we want to model the probability of that event, a kind of analysis known as event history analysis or survival analysis. When the probability of the terminating event is constant through time (or distance), and the units of time (or distance) are discrete, a common likelihood function is the geometric distribution. This distribution has the form:
\[\text{Pr} (y | p) = p (1 - p) ^{y - 1}\]
where \(y\) is the number of time steps (events) until the terminating event occurred and \(p\) is the probability of that event in each time step. This distribution has maximum entropy for unbounded counts with constant expected value. (pp. 327–328)
Here we simulate exemplar data.
# simulate
n <- 100
set.seed(10)
x <- runif(n)
set.seed(10)
y <- rgeom(n, prob = inv_logit_scaled(-1 + 2 * x))In case you’re curious, here are the data.
list(y = y, x = x) %>%
as_tibble() %>%
ggplot(aes(x = x, y = y)) +
geom_point(size = 3/5, alpha = 2/3)
We fit the geometric model using family = geometric(link = log).
b10.18 <-
brm(data = list(y = y, x = x),
family = geometric(link = log),
y ~ 0 + intercept + x,
prior = c(prior(normal(0, 10), class = b, coef = intercept),
prior(normal(0, 1), class = b)),
iter = 2500, warmup = 500, chains = 2, cores = 2,
seed = 10)The results:
print(b10.18, digits = 2)## Family: geometric
## Links: mu = log
## Formula: y ~ 0 + intercept + x
## Data: list(y = y, x = x) (Number of observations: 100)
## Samples: 2 chains, each with iter = 2500; warmup = 500; thin = 1;
## total post-warmup samples = 4000
##
## Population-Level Effects:
## Estimate Est.Error l-95% CI u-95% CI Eff.Sample Rhat
## intercept 0.75 0.24 0.26 1.20 1322 1.00
## x -1.62 0.51 -2.58 -0.61 1286 1.00
##
## Samples were drawn using sampling(NUTS). For each parameter, Eff.Sample
## is a crude measure of effective sample size, and Rhat is the potential
## scale reduction factor on split chains (at convergence, Rhat = 1).It turns out brms uses a different parameterization for the geometric distribution than rethinking does. It follows the form
\[f(y_i) = {y_i \choose y_i} \bigg (\frac{\mu_i}{\mu_i + 1} \bigg )^{y_i} \bigg (\frac{1}{\mu_i + 1} \bigg )\]
Even though the parameters brms yielded look different from those in the text, their predictions describe the data well. Here’s the marginal_effects() plot:
plot(marginal_effects(b10.18),
points = T,
point_args = c(size = 3/5, alpha = 2/3),
line_args = c(color = wes_palette("Moonrise2")[1],
fill = wes_palette("Moonrise2")[1]))
Session info
sessionInfo()## R version 3.5.1 (2018-07-02)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS High Sierra 10.13.6
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] parallel stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] tidybayes_1.0.4 loo_2.1.0 broom_0.5.1 bayesplot_1.6.0
## [5] ggthemes_4.0.1 wesanderson_0.3.6.9000 forcats_0.3.0 stringr_1.4.0
## [9] dplyr_0.8.0.1 purrr_0.2.5 readr_1.1.1 tidyr_0.8.1
## [13] tibble_2.1.1 tidyverse_1.2.1 brms_2.8.8 Rcpp_1.0.1
## [17] rstan_2.18.2 StanHeaders_2.18.0-1 ggplot2_3.1.1
##
## loaded via a namespace (and not attached):
## [1] colorspace_1.3-2 ggridges_0.5.0 rsconnect_0.8.8 rprojroot_1.3-2
## [5] ggstance_0.3 markdown_0.8 base64enc_0.1-3 rstudioapi_0.7
## [9] listenv_0.7.0 svUnit_0.7-12 DT_0.4 fansi_0.4.0
## [13] mvtnorm_1.0-10 lubridate_1.7.4 xml2_1.2.0 bridgesampling_0.6-0
## [17] codetools_0.2-15 mnormt_1.5-5 knitr_1.20 shinythemes_1.1.1
## [21] jsonlite_1.5 shiny_1.1.0 compiler_3.5.1 httr_1.3.1
## [25] backports_1.1.4 assertthat_0.2.0 Matrix_1.2-14 lazyeval_0.2.2
## [29] cli_1.0.1 later_0.7.3 htmltools_0.3.6 prettyunits_1.0.2
## [33] tools_3.5.1 igraph_1.2.1 coda_0.19-2 gtable_0.3.0
## [37] glue_1.3.1.9000 reshape2_1.4.3 cellranger_1.1.0 nlme_3.1-137
## [41] crosstalk_1.0.0 psych_1.8.4 xfun_0.3 globals_0.12.4
## [45] ps_1.2.1 rvest_0.3.2 mime_0.5 miniUI_0.1.1.1
## [49] gtools_3.8.1 future_1.12.0 MASS_7.3-50 zoo_1.8-2
## [53] scales_1.0.0 colourpicker_1.0 hms_0.4.2 promises_1.0.1
## [57] Brobdingnag_1.2-6 inline_0.3.15 shinystan_2.5.0 yaml_2.1.19
## [61] gridExtra_2.3 stringi_1.4.3 dygraphs_1.1.1.5 pkgbuild_1.0.2
## [65] rlang_0.3.4 pkgconfig_2.0.2 matrixStats_0.54.0 HDInterval_0.2.0
## [69] evaluate_0.10.1 lattice_0.20-35 rstantools_1.5.1 htmlwidgets_1.2
## [73] labeling_0.3 processx_3.2.1 tidyselect_0.2.5 plyr_1.8.4
## [77] magrittr_1.5 bookdown_0.9 R6_2.3.0 generics_0.0.2
## [81] foreign_0.8-70 pillar_1.3.1 haven_1.1.2 withr_2.1.2
## [85] xts_0.10-2 abind_1.4-5 modelr_0.1.2 crayon_1.3.4
## [89] arrayhelpers_1.0-20160527 utf8_1.1.4 rmarkdown_1.10 grid_3.5.1
## [93] readxl_1.1.0 callr_3.1.0 threejs_0.3.1 digest_0.6.18
## [97] xtable_1.8-2 httpuv_1.4.4.2 stats4_3.5.1 munsell_0.5.0
## [101] shinyjs_1.0