Módulo 1 Revisão básica e Joins
Script da aula do Módulo intro abaixo. Download aula1.Rmd
1.1 Programação basica
1.1.1 Controle de Fluxo
Os controles de fluxo são operações definidas em todas as linguagens de programação, como por exemplo Python, C, C++, Java, Fortran, Pascal, etc. Como não podia deixar de ser, tais operações também estão definidas dentro da linguagem R.
Cada linguagem de programação tem a sua própria sintaxe, isto é, sua própria regra de como essas operações devem ser usadas. Nesta aula será abordada a sintaxe e mais detalhes sobre alguns controles de fluxo para a linguagem R.
1.1.2 Estrutura Condicional IF-ELSE
Uma instrução if permite que você execute código condicionalmente, ou seja, apenas uma parte do código será executada e apenas se alguma condição for atendida. E se parece com isso:
if (condicao) {
#comandos caso condicao seja verdadeira (TRUE)
} else {
#comandos caso condicao seja falsa (FALSE)
}ou simplesmente
if (condicao) {
#comandos caso condicao seja verdadeira (TRUE)
}Essa instrução lógica funciona analisando cada condição. O par de parênteses seguidos do if tem que ter um objeto do tipo "logical". Os comandos dentro do primeiro par de chaves serão executados caso o objeto condicao seja TRUE. Caso contrário, os comandos de dentro do par de chaves depois do else serão executados. O comando else é opcional, como foi mostrado anteriormente. No caso do else não aparecer, nada será executado caso o objeto condicao seja FALSE.
1.1.2.1 Exemplos
O exemplo a seguir terá como resultado texto impresso na tela. O que será impresso depende do valor guardado na variável x. Se x receber o valor menor que 5, um texto será impresso, caso contrário, outro texto aparecerá na tela.
#Neste caso x recebe um valor entre 1 e 10
x <- sample(1:10, 1)
if( x < 5 ){
print(paste(x,"é menor que",5))
} else {
print(paste(x,"é maior ou igual a",5))
}## [1] "2 é menor que 5"A função print() é responsável por imprimir na tela e a função paste() por concatenar textos e criar um único objeto do tipo "character". Para mais detalhes digite no console do R o comando help(print) e help(paste).
Agora considere a seguinte sequência de comandos, qual o valor da variável y ao final desse código?
x <- 3
if (x > 7){
y <- 2**x
} else {
y <- 3**x
}A resposta para esse problema é 27. O controle de fluxo if/else será usado na maioria das vezes dentro de funções ou iteradores, como será visto adiante.
É possível encadear diversos if() else em sequência:
numero <- 5
if (numero == 1) {
print("o número é igual a 1")
} else if (numero == 2) {
print("o número é igual a 2")
} else {
print("o número não é igual nem a 1 nem a 2")
}## [1] "o número não é igual nem a 1 nem a 2"1.1.3 Iteradores
A iteração ajuda quando você precisa fazer a mesma coisa com várias entradas, como por exemplo: repetir a mesma operação em colunas diferentes ou em conjuntos de dados diferentes.
Existem ferramentas como loops for e while, que são um ótimo lugar para começar porque tornam a iteração muito explícita, então é óbvio o que está acontecendo.
1.1.3.1 FOR Loops
No entanto, os loops for podem ser bastante prolixos e requerem um pouco de código que é duplicado para cada loop for o que não é algo prático de dar manutenção.
Imagine que temos um dataframe simples como:
df <- tibble(
a = sample(1:10000, 10),
b = sample(1:10000, 10),
c = sample(1:10000, 10),
d = sample(1:10000, 10)
)Para computar a mediana de cada coluna. Deve ser feito o uso da função `median``
median(df$a)## [1] 7182median(df$b)## [1] 4334.5median(df$c)## [1] 6017.5median(df$d)## [1] 6734Mas isso quebra nossa regra de ouro: nunca copie e cole mais de duas vezes. Em vez disso, poderíamos usar um loop for:
medianas <- vector("double", ncol(df)) # 1. saída (output)
for (i in seq_along(df)) { # 2. sequência (sequence)
medianas[i] <- median(df[[i]]) # 3. corpo (body)
}
medianas## [1] 7182.0 4334.5 6017.5 6734.0Todo for loop tem três componentes:
1 - A saída: saida <- vector("double", length (x)). Antes de iniciar o loop, você deve sempre alocar espaço suficiente para a saída. Isso é muito importante para a eficiência: se você aumentar o loop for a cada iteração usando c() (por exemplo), seu loop for será muito lento.
Uma maneira geral de criar um vetor vazio de determinado comprimento é a função vector(). Que possui dois argumentos: o tipo do vetor (“logical”, “integer”, “double”, “character”, etc) e o comprimento do vetor.
2 - A sequência: i em seq_along(df). Isso determina sobre o que fazer o loop: cada execução do loop for atribuirá i a um valor diferente de seq_along(df).
Você pode não ter visto seq_along() antes. É uma versão segura do familiar 1:length(l), com uma diferença importante: se você tem um vetor de comprimento zero, seq_along() faz a coisa certa:
y <- vector("double", 0)
seq_along(y)## integer(0)#> integer(0)
1:length(y)## [1] 1 0#> [1] 1 0Claro que não vai ser criado um vetor de comprimento zero deliberadamente, mas é fácil criá-los acidentalmente. Se você usar 1:length(x) em vez de seq_along(x), é provável que receba uma mensagem de erro confusa.
3 - O corpo: saida[i] <- median(df[[i]]). Este é o código que faz o trabalho. É executado repetidamente, cada vez com um valor diferente para i. A primeira iteração executará a saída[1] <- median(df[[1]]), a segunda executará a saída[2] <- median(df[[2]]) e assim por diante.
Isso é tudo que existe para o loop for! Agora é momento para praticar!
1.1.3.2 Variações em FOR Loops
Depois de ter o loop for básico em seu currículo, existem algumas variações das quais você deve estar ciente.
Existem quatro variações sobre o tema básico do loop for:
Modificar um objeto existente, em vez de criar um novo objeto.
Loop sobre nomes ou valores, em vez de índices.
Tratamento de saídas de comprimento desconhecido.
Manipulação de sequências de comprimento desconhecido.
1.1.3.3 Modificando um objeto existente
Às vezes, você deseja usar um loop for para modificar um objeto existente. Por exemplo:
df <- tibble(
a = sample(1:10000, 10),
b = sample(1:10000, 10),
c = sample(1:10000, 10),
d = sample(1:10000, 10)
)
df$a <- scale(df$a)
df$b <- scale(df$b)
df$c <- scale(df$c)
df$d <- scale(df$d)Para resolver isso com um loop for, novamente pensamos sobre os três componentes:
1 - Saída: já temos a saída - é o mesmo que a entrada!
2 - Sequência: podemos pensar em um quadro de dados como uma lista de colunas, então podemos iterar sobre cada coluna com seq_along(df).
3 - Corpo: aplicar scale()
for (i in seq_along(df)) {
df[[i]] <- scale(df[[i]])
}Normalmente, você modificará uma lista ou quadro de dados com esse tipo de loop, então lembre-se de usar [[, não [.
1.1.3.4 For loops sobre nomes e valores ao invés de índices
Existem três maneiras básicas de fazer um loop em um vetor. Até agora eu mostrei o mais geral: looping sobre os índices numéricos com for(i in seq_along(xs)) e extrair o valor com x[[i]]. Existem duas outras formas:
Faça um loop sobre os elementos: for(x in xs). Isso é mais útil se você se preocupa apenas com os efeitos colaterais, como plotar ou salvar um arquivo, porque é difícil salvar a saída de forma eficiente.
Faça um loop sobre os nomes: for(nm in names(xs)). Isso fornece um nome, que você pode usar para acessar o valor com x[[nm]]. Isso é útil se você deseja usar o nome em um título de plotagem ou um nome de arquivo. Se você estiver criando uma saída nomeada, certifique-se de nomear o vetor de resultados da seguinte forma:
results <- vector("list", length(x))
names(results) <- names(x)A iteração sobre os índices numéricos é a forma mais geral, porque dada a posição, você pode extrair o nome e o valor:
for (i in seq_along(x)) {
name <- names(x)[[i]]
value <- x[[i]]
}1.1.3.5 For loop com comprimento de saída desconhecido
Às vezes, você pode não saber o tamanho da saída. Por exemplo, imagine que você deseja simular alguns vetores aleatórios de comprimentos aleatórios. Você pode ficar tentado a resolver esse problema aumentando progressivamente o vetor:
means <- c(0, 1, 2)
output <- double()
for (i in seq_along(means)) {
n <- sample(100, 1)
output <- c(output, rnorm(n, means[[i]]))
}
str(output)## num [1:129] -0.966 0.83 1.648 -1.723 -2.189 ...Mas isso não é muito eficiente porque em cada iteração, R tem que copiar todos os dados das iterações anteriores.
Uma solução melhor é salvar os resultados em uma lista e, em seguida, combiná-los em um único vetor após a conclusão do loop:
out <- vector("list", length(means))
for (i in seq_along(means)) {
n <- sample(100, 1)
out[[i]] <- rnorm(n, means[[i]])
}
str(out)## List of 3
## $ : num [1:67] -0.0581 0.5367 -1.0679 -0.6056 -0.021 ...
## $ : num [1:100] 2.01 1.85 2.56 1.46 1.3 ...
## $ : num [1:66] 0.797 1.561 2.754 1.351 1.542 ...str(unlist(out))## num [1:233] -0.0581 0.5367 -1.0679 -0.6056 -0.021 ...1.1.3.6 For loops com comprimento de sequência desconhecido ou While
Algumas vezes, você nem sabe por quanto tempo a sequência de entrada deve ser executada. Isso é comum ao fazer simulações. Por exemplo, você pode querer fazer um loop até obter três caras seguidas. Você não pode fazer esse tipo de iteração com o loop for. Em vez disso, você pode usar um loop while. Um loop while é mais simples do que loop for porque tem apenas dois componentes, uma condição e um corpo:
while (condition) { #condição
# corpo (body)
}Um loop while também é mais geral do que um loop for, porque você pode reescrever qualquer loop for como um loop while, mas não pode reescrever todo loop while como um loop for:
for (i in seq_along(x)) {
# body
}
# Equivalent to
i <- 1
while (i <= length(x)) {
# body
i <- i + 1
}Aqui está como poderíamos usar um loop while para descobrir quantas tentativas são necessárias para obter três caras em uma linha:
flips <- 0
nheads <- 0
while (nheads < 3) {
if (sample(c("T", "H"), 1) == "H") {
nheads <- nheads + 1
} else {
nheads <- 0
}
flips <- flips + 1
}
flips## [1] 9loops while foi mencionado apenas brevemente, porque é pouco usado. Eles são usados com mais frequência no contexto de simulação. No entanto, é bom saber que eles existem para que você esteja preparado para problemas em que o número de iterações não é conhecido com antecedência.
1.2 Funções (Functions)
Uma das melhores maneiras de melhorar sua performance como cientista/analista de dados é escrever funções. As funções permitem automatizar tarefas comuns de uma forma mais poderosa e geral do que copiar e colar. Escrever uma função tem três grandes vantagens sobre o uso de copiar e colar:
1 - Você pode dar a uma função um nome elucidativo que torne seu código mais fácil de entender.
2 - Conforme os requisitos mudam, você só precisa atualizar o código em um lugar, em vez de muitos.
3 - Você elimina a chance de cometer erros incidentais ao copiar e colar (ou seja, atualizar o nome de uma variável em um lugar, mas não em outro).
Escrever boas funções é uma jornada para a vida toda. O objetivo deste módulo não é ensinar todos os detalhes esotéricos das funções, mas dar a você alguns direcionamentos pragmáticos que você pode aplicar imediatamente.
Além disso, algumas sugestões sobre como definir o estilo de seu código. Um bom estilo de código é como a pontuação correta. Você pode gerenciar sem ele, mas com certeza ele torna as coisas mais fáceis de ler! Tal como acontece com os estilos de pontuação, existem muitas variações possíveis.
1.2.1 Quando eu devo escrever uma função?
Você deve considerar escrever uma função sempre que copiou e colou um bloco de código mais de duas vezes (ou seja, agora você tem três cópias do mesmo código).
3 > 5## [1] FALSE7 > 9## [1] FALSE19 > 10## [1] TRUEmaior <- function(a,b){
if(a>b){
return(a)
}else{
return(b)
}
} Depois da função definida e compilada podemos chamá-la sem ter que digitar todo o código novamente. Veja o que acontece quando a função é chamada no console do R.
maior(3,2)## [1] 3maior(-1,4)## [1] 4maior(10,10)## [1] 10Uma segunda função pode ser criada com o intuito de receber como argumento um número natural n e retorna um array com os n primeiros múltiplos de 3.
multiplos_3 <- function(n){
vet <- NULL
for(i in 1:n){
vet[i] <- 3*i
}
return(vet)
}
multiplos_3(10)## [1] 3 6 9 12 15 18 21 24 27 30multiplos_3(15)## [1] 3 6 9 12 15 18 21 24 27 30 33 36 39 42 45Existem três etapas principais para criar uma nova função:
1 - Você precisa escolher um nome para a função. Que faça sentido para o que a função executa.
2 - Você lista as entradas, ou argumentos, para a função dentro da função. Por exemplo uma chamada poderia ser a function (x, y, z).
3 - Você coloca o código que desenvolveu no corpo da função, um {bloco que segue imediatamente a função (…).
Outra vantagem das funções é que, se nossos requisitos mudarem, só precisaremos fazer a mudança em um lugar.
Criar funções é uma parte importante do princípio “do not repeat yourself” (or DRY). Quanto mais repetição você tiver em seu código, mais lugares você precisará se lembrar de atualizar quando as coisas mudarem (e sempre mudam!) E maior será a probabilidade de você criar bugs com o tempo.
1.2.2 Funções são para humanos e computadores
É importante lembrar que as funções não são apenas para o computador, mas também para humanos. R não se importa com o que sua função é chamada, ou quais comentários ela contém, mas estes são importantes para leitores humanos.
O nome de uma função é importante. Idealmente, o nome da sua função será curto, mas evocará claramente o que a função faz. Isso é difícil! Mas é melhor ser claro do que curto, pois o preenchimento automático do RStudio facilita a digitação de nomes longos.
Geralmente, os nomes das funções devem ser verbos e os argumentos devem ser substantivos. Existem algumas exceções: substantivos estão ok se a função calcula um substantivo muito conhecido (ou seja, mean() é melhor do que compute_mean()), ou acessar alguma propriedade de um objeto (ou seja, coef() é melhor do que get_coefficients()). Um bom sinal de que um substantivo pode ser uma escolha melhor é se você estiver usando um verbo muito amplo como “obter”, “calcular” ou “determinar”. Use seu bom senso e não tenha medo de renomear uma função se você descobrir um nome melhor mais tarde.
# Muito curto
f()
# Não descritivo
my_awesome_function()
# Longo mas claro
impute_missing()
collapse_years()Se o nome da sua função for composto por várias palavras, recomendo usar “snake_case”, onde cada palavra minúscula é separada por um underscore. “camelCase” é uma alternativa popular. Escolha uma e seja consistente. O R em si não é muito consistente, mas não há nada que você possa fazer sobre isso. Certifique-se de não cair na mesma armadilha, tornando seu código o mais consistente possível.
# Não faça isso!
col_mins <- function(x, y) {}
rowMaxes <- function(y, x) {}Se você tem uma família de funções que fazem coisas semelhantes, certifique-se de que eles tenham nomes e argumentos consistentes. Use um prefixo comum para indicar que eles estão conectados. Isso é melhor do que um sufixo comum porque o preenchimento automático permite que você digite o prefixo e veja todos os membros da família.
# Faça isso
input_select()
input_checkbox()
input_text()
# Escolha não fazer isso
select_input()
checkbox_input()
text_input()1.2.3 Argumentos de função
Os argumentos para uma função normalmente se enquadram em dois conjuntos amplos: um conjunto fornece os dados para calcular e o outro fornece argumentos que controlam os detalhes do cálculo. Por exemplo:
Em
log(), os dados sãox, e o detalhe é a base do logaritmo.Em
mean(), os dados sãoxe os detalhes são quantos dados cortar das extremidades (trim) e como lidar com os valores ausentes (na.rm).
Em str_c() você pode fornecer qualquer número de strings para ..., e os detalhes da concatenação são controlados por sep e collapse.
Geralmente, os argumentos de dados devem vir primeiro. Os argumentos de detalhes devem ir no final e geralmente devem ter valores padrão. Você especifica um valor padrão da mesma maneira que chama uma função com um argumento nomeado. ## Boas práticas
1.2.4 Nomeando variáveis
Os nomes dos argumentos também são importantes. O R mais uma vez não se importa, mas os leitores de seu código (incluindo você-futuro!) sim. Geralmente você deve preferir nomes mais longos e descritivos, mas há um punhado de nomes muito comuns e muito curtos. Vale a pena memorizar estes:
x, y, z: vetores.w: um vetor de pesos.df: um quadro de dados.i, j: índices numéricos (normalmente linhas e colunas).n: comprimento ou número de linhas.p: número de colunas.
Caso contrário, considere combinar nomes de argumentos em funções R existentes. Por exemplo, use na.rm para determinar se os valores ausentes devem ser removidos.
1.2.5 Ambiente (Environment)
O último componente de uma função é seu ambiente. Isso não é algo que você precisa entender profundamente quando começa a escrever funções. No entanto, é importante saber um pouco sobre os ambientes porque eles são cruciais para o funcionamento das funções. O ambiente de uma função controla como R encontra o valor associado a um nome. Por exemplo, use esta função:
soma_xy <- function(x) {
x + y
} Em muitas linguagens de programação, isso seria um erro, porque y não é definido dentro da função. Em R, este é um código válido porque R usa regras chamadas escopo léxico para encontrar o valor associado a um nome. Uma vez que y não está definido dentro da função, R irá procurar no ambiente onde a função foi definida:
y <- 100
soma_xy(10)## [1] 110y <- 1000
soma_xy(10)## [1] 1010Este comportamento parece uma receita para bugs e de fato, você deve evitar criar funções como esta, mas em geral não causa muitos problemas (especialmente se você reiniciar o R regularmente).
1.3 Manipulação de dados com dplyr
Esta seção, trataremos do pacote dplyr, que é um dos pacotes mais importantes da coleção tidyverse. Ele traz uma “gramática” específica de manipulação de dados, provendo um conjunto de funções que ajudam a resolver os desafios mais comuns na manipulação de dados. O objetivo é que você se familiarize com as funções do pacote dplyr; com as tarefas que elas executam; e veja exemplos de como aplicá-las a data.frames.
Para tanto vamos utilizar três datasets que vamos citar e descrever abaixo:
- Chess game dataset
Este é um conjunto de pouco mais de 20.000 jogos coletados de uma seleção de usuários no site Lichess.org.
tb_chess_game <- read_csv(file="https://raw.githubusercontent.com/brunolucian/cursoBasicoR/master/datasets/chess_games.csv")##
## -- Column specification ------------------------------------------------------------------------------------------------------------------------------------------
## cols(
## id = col_character(),
## rated = col_logical(),
## created_at = col_double(),
## last_move_at = col_double(),
## turns = col_double(),
## victory_status = col_character(),
## winner = col_character(),
## increment_code = col_character(),
## white_id = col_character(),
## white_rating = col_double(),
## black_id = col_character(),
## black_rating = col_double(),
## moves = col_character(),
## opening_eco = col_character(),
## opening_name = col_character(),
## opening_ply = col_double()
## )## # A tibble: 20,058 x 16
## id rated created_at last_move_at turns victory_status winner increment_code white_id white_rating black_id black_rating moves opening_eco opening_name
## <chr> <lgl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
## 1 TZJHL~ FALSE 1.50e12 1.50e12 13 outoftime white 15+2 bourgris 1500 a-00 1191 d4 d5 c~ D10 Slav Defense~
## 2 l1NXv~ TRUE 1.50e12 1.50e12 16 resign black 5+10 a-00 1322 skinner~ 1261 d4 Nc6 ~ B00 Nimzowitsch ~
## 3 mIICv~ TRUE 1.50e12 1.50e12 61 mate white 5+10 ischia 1496 a-00 1500 e4 e5 d~ C20 King's Pawn ~
## 4 kWKvr~ TRUE 1.50e12 1.50e12 61 mate white 20+0 daniamu~ 1439 adivano~ 1454 d4 d5 N~ D02 Queen's Pawn~
## 5 9tXo1~ TRUE 1.50e12 1.50e12 95 mate white 30+3 nik2211~ 1523 adivano~ 1469 e4 e5 N~ C41 Philidor Def~
## 6 MsoDV~ FALSE 1.50e12 1.50e12 5 draw draw 10+0 trelynn~ 1250 frankli~ 1002 e4 c5 N~ B27 Sicilian Def~
## 7 qwU9r~ TRUE 1.50e12 1.50e12 33 resign white 10+0 capa_jr 1520 daniel_~ 1423 d4 d5 e~ D00 Blackmar-Die~
## 8 RVN0N~ FALSE 1.50e12 1.50e12 9 resign black 15+30 daniel_~ 1413 soultego 2108 e4 Nc6 ~ B00 Nimzowitsch ~
## 9 dwF3D~ TRUE 1.50e12 1.50e12 66 resign black 15+0 ehabfan~ 1439 daniel_~ 1392 e4 e5 B~ C50 Italian Game~
## 10 afoMw~ TRUE 1.50e12 1.50e12 119 mate white 10+0 daniel_~ 1381 mirco25 1209 e4 d5 e~ B01 Scandinavian~
## # ... with 20,048 more rows, and 1 more variable: opening_ply <dbl>- Netflix dataset
Programas de TV e filmes listados no Netflix Este conjunto de dados consiste em programas de TV e filmes disponíveis no Netflix a partir de 2019. O conjunto de dados é coletado do Flixable, um mecanismo de busca Netflix de terceiros.
Em 2018, eles lançaram um relatório interessante que mostra que o número de programas de TV na Netflix quase triplicou desde 2010. O número de filmes do serviço de streaming diminuiu em mais de 2.000 títulos desde 2010, enquanto seu número de programas de TV quase triplicou. Será interessante explorar o que todos os outros insights podem ser obtidos no mesmo conjunto de dados.
tb_netflix <- read_csv("https://raw.githubusercontent.com/brunolucian/cursoBasicoR/master/datasets/netflix_titles.csv")##
## -- Column specification ------------------------------------------------------------------------------------------------------------------------------------------
## cols(
## show_id = col_character(),
## type = col_character(),
## title = col_character(),
## director = col_character(),
## cast = col_character(),
## country = col_character(),
## date_added = col_character(),
## release_year = col_double(),
## rating = col_character(),
## duration = col_character(),
## listed_in = col_character(),
## description = col_character()
## )## # A tibble: 7,787 x 12
## show_id type title director cast country date_added release_year rating duration listed_in description
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
## 1 s1 TV Sh~ 3% <NA> João Miguel, Bianca Compara~ Brazil August 14,~ 2020 TV-MA 4 Seaso~ International ~ In a future where the elite inh~
## 2 s2 Movie 7:19 Jorge Mic~ Demián Bichir, Héctor Bonil~ Mexico December 2~ 2016 TV-MA 93 min Dramas, Intern~ After a devastating earthquake ~
## 3 s3 Movie 23:59 Gilbert C~ Tedd Chan, Stella Chung, He~ Singapo~ December 2~ 2011 R 78 min Horror Movies,~ When an army recruit is found d~
## 4 s4 Movie 9 Shane Ack~ Elijah Wood, John C. Reilly~ United ~ November 1~ 2009 PG-13 80 min Action & Adven~ In a postapocalyptic world, rag~
## 5 s5 Movie 21 Robert Lu~ Jim Sturgess, Kevin Spacey,~ United ~ January 1,~ 2008 PG-13 123 min Dramas A brilliant group of students b~
## 6 s6 TV Sh~ 46 Serdar Ak~ Erdal Besikçioglu, Yasemin ~ Turkey July 1, 20~ 2016 TV-MA 1 Season International ~ A genetics professor experiment~
## 7 s7 Movie 122 Yasir Al ~ Amina Khalil, Ahmed Dawood,~ Egypt June 1, 20~ 2019 TV-MA 95 min Horror Movies,~ After an awful accident, a coup~
## 8 s8 Movie 187 Kevin Rey~ Samuel L. Jackson, John Hea~ United ~ November 1~ 1997 R 119 min Dramas After one of his high school st~
## 9 s9 Movie 706 Shravan K~ Divya Dutta, Atul Kulkarni,~ India April 1, 2~ 2019 TV-14 118 min Horror Movies,~ When a doctor goes missing, his~
## 10 s10 Movie 1920 Vikram Bh~ Rajneesh Duggal, Adah Sharm~ India December 1~ 2008 TV-MA 143 min Horror Movies,~ An architect and his wife move ~
## # ... with 7,777 more rows- Games sales dataset
Este conjunto de dados contém uma lista de videogames com vendas superiores a 100.000 cópias.
tb_game_sales <- read_csv("https://raw.githubusercontent.com/brunolucian/cursoBasicoR/master/datasets/vgsales.csv")##
## -- Column specification ------------------------------------------------------------------------------------------------------------------------------------------
## cols(
## Rank = col_double(),
## Name = col_character(),
## Platform = col_character(),
## Year = col_character(),
## Genre = col_character(),
## Publisher = col_character(),
## NA_Sales = col_double(),
## EU_Sales = col_double(),
## JP_Sales = col_double(),
## Other_Sales = col_double(),
## Global_Sales = col_double()
## )## # A tibble: 16,598 x 11
## Rank Name Platform Year Genre Publisher NA_Sales EU_Sales JP_Sales Other_Sales Global_Sales
## <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 Wii Sports Wii 2006 Sports Nintendo 41.5 29.0 3.77 8.46 82.7
## 2 2 Super Mario Bros. NES 1985 Platform Nintendo 29.1 3.58 6.81 0.77 40.2
## 3 3 Mario Kart Wii Wii 2008 Racing Nintendo 15.8 12.9 3.79 3.31 35.8
## 4 4 Wii Sports Resort Wii 2009 Sports Nintendo 15.8 11.0 3.28 2.96 33
## 5 5 Pokemon Red/Pokemon Blue GB 1996 Role-Playing Nintendo 11.3 8.89 10.2 1 31.4
## 6 6 Tetris GB 1989 Puzzle Nintendo 23.2 2.26 4.22 0.58 30.3
## 7 7 New Super Mario Bros. DS 2006 Platform Nintendo 11.4 9.23 6.5 2.9 30.0
## 8 8 Wii Play Wii 2006 Misc Nintendo 14.0 9.2 2.93 2.85 29.0
## 9 9 New Super Mario Bros. Wii Wii 2009 Platform Nintendo 14.6 7.06 4.7 2.26 28.6
## 10 10 Duck Hunt NES 1984 Shooter Nintendo 26.9 0.63 0.28 0.47 28.3
## # ... with 16,588 more rowsConforme os próprios autores do pacote apontam, quando trabalhamos com dados, nós precisamos:
Descobrir o que desejamos fazer;
Descrever essas tarefas na forma de um programa de computador;
Executar o programa.
O pacote dplyr torna estes passos mais rápidos e fáceis de executar, pois:
ao invés de disponibilizar uma imensidão de funções, igual temos no R base e outros pacotes, ele restringe nossas opções e com isso nos ajuda a raciocinar de forma mais direta sobre o que desejamos e podemos fazer com os dados;
provém “verbos” (ou funções) mais simples, ou seja, funções que correspondem às tarefas mais comuns de manipulação de dados, ajudando-nos assim a traduzir pensamentos em código;
utiliza backends (códigos de final de processo, ou seja, mais próximos ao usuário) eficientes, de modo que gastamos menos tempo esperando pelo computador.
O pacote dplyr proporciona uma função para cada “verbo” considerado importante em manipulação de dados:
filter()para selecionar “casos” baseados em seus valores;arrange()para reordenar os “casos”;select()e rename() para selecionar variáveis baseadas em seus nomes;mutate()etransmute()para adicionar novas variáveis que são funções de variáveis já existentes nos dados;summarise()ousummarize()para condensar multiplos valores em um único;group_by()embora não seja considerado um dos “verbos”, serve para agruparmos os dados em torno de uma ou mais variáveis. As funções consideradas “verbos” podem ser utilizadas antes ou após o agrupamentodos dados.
Veremos agora alguns exemplos de aplicação destas funções.
library(dplyr)Note que pelo print que temos novamente um tibble, que é uma forma moderna de data.frame implementada pelo pessoal do tidyverse . Este formato é particularmente útil para grandes datasets porque só é impresso na tela as primeiras linhas e diversos resumos/informações sobre nossas variáveis. Para converter data.frames em tibbles, usamos as_tibble().
1.3.1 Filtrando linhas com filter()
filter() permite fazer um subset das linhas de um tibble/dataframe. Como todos os verbos simples de dplyr, o primeiro argumento será um tibble (ou data.frame). O segundo argumento e os subsequentes se referem a variáveis dentro do data.frame, em que se selecionam as linhas onde a expressão é verdadeira (TRUE).
Vamos selecionar todos as linhas em que o jogador que estava com as peças pretas foi o vencedor da partida:
filter(tb_chess_game, winner == "black")## # A tibble: 9,107 x 16
## id rated created_at last_move_at turns victory_status winner increment_code white_id white_rating black_id black_rating moves opening_eco opening_name
## <chr> <lgl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
## 1 l1NXv~ TRUE 1.50e12 1.50e12 16 resign black 5+10 a-00 1322 skinner~ 1261 d4 Nc6 ~ B00 Nimzowitsch ~
## 2 RVN0N~ FALSE 1.50e12 1.50e12 9 resign black 15+30 daniel_~ 1413 soultego 2108 e4 Nc6 ~ B00 Nimzowitsch ~
## 3 dwF3D~ TRUE 1.50e12 1.50e12 66 resign black 15+0 ehabfan~ 1439 daniel_~ 1392 e4 e5 B~ C50 Italian Game~
## 4 Vf5fK~ FALSE 1.50e12 1.50e12 38 resign black 20+60 daniel_~ 1381 subham7~ 1867 e4 e6 d~ C02 French Defen~
## 5 HRti5~ FALSE 1.50e12 1.50e12 60 resign black 5+40 daniel_~ 1381 roman12~ 1936 e4 e6 N~ C00 French Defen~
## 6 2fEjS~ FALSE 1.50e12 1.50e12 31 resign black 8+0 daniel_~ 1381 alkhan 1607 e4 e6 Q~ C00 French Defen~
## 7 guanv~ FALSE 1.50e12 1.50e12 43 resign black 15+15 sureka_~ 1141 shivang~ 1094 e4 e5 N~ C57 Italian Game~
## 8 PmpkW~ FALSE 1.50e12 1.50e12 52 resign black 15+15 shivang~ 1094 sureka_~ 1141 e4 e5 N~ C50 Four Knights~
## 9 EwaK0~ FALSE 1.50e12 1.50e12 66 mate black 15+16 sureka_~ 1141 shivang~ 1094 e4 e5 N~ C50 Four Knights~
## 10 yrSDo~ FALSE 1.50e12 1.50e12 101 resign black 15+15 shivang~ 1094 slam_me~ 1300 e4 e5 N~ C41 Philidor Def~
## # ... with 9,097 more rows, and 1 more variable: opening_ply <dbl>filter(tb_chess_game, winner == "black", black_rating < 1500)## # A tibble: 2,947 x 16
## id rated created_at last_move_at turns victory_status winner increment_code white_id white_rating black_id black_rating moves opening_eco opening_name
## <chr> <lgl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
## 1 l1NXv~ TRUE 1.50e12 1.50e12 16 resign black 5+10 a-00 1322 skinner~ 1261 d4 Nc6 e~ B00 Nimzowitsch ~
## 2 dwF3D~ TRUE 1.50e12 1.50e12 66 resign black 15+0 ehabfan~ 1439 daniel_~ 1392 e4 e5 Bc~ C50 Italian Game~
## 3 guanv~ FALSE 1.50e12 1.50e12 43 resign black 15+15 sureka_~ 1141 shivang~ 1094 e4 e5 Nf~ C57 Italian Game~
## 4 PmpkW~ FALSE 1.50e12 1.50e12 52 resign black 15+15 shivang~ 1094 sureka_~ 1141 e4 e5 Nf~ C50 Four Knights~
## 5 EwaK0~ FALSE 1.50e12 1.50e12 66 mate black 15+16 sureka_~ 1141 shivang~ 1094 e4 e5 Nf~ C50 Four Knights~
## 6 yrSDo~ FALSE 1.50e12 1.50e12 101 resign black 15+15 shivang~ 1094 slam_me~ 1300 e4 e5 Nf~ C41 Philidor Def~
## 7 mCij4~ TRUE 1.50e12 1.50e12 13 resign black 10+0 shivang~ 1113 ivangon~ 1423 e4 c5 d4~ B21 Sicilian Def~
## 8 srz9Q~ TRUE 1.50e12 1.50e12 54 mate black 10+10 mannat1 1328 shivang~ 1038 d4 d5 Nc~ D01 Queen's Pawn~
## 9 NS6cc~ TRUE 1.50e12 1.50e12 53 resign black 10+10 shivang~ 1056 biyaniv~ 1156 d4 d5 c4~ D10 Slav Defense
## 10 M3vpf~ TRUE 1.50e12 1.50e12 66 mate black 10+10 shivang~ 1077 chinmay~ 1148 d4 d5 c4~ D06 Queen's Gamb~
## # ... with 2,937 more rows, and 1 more variable: opening_ply <dbl>filter(tb_chess_game, winner == "black" | opening_eco =="A10")## # A tibble: 9,178 x 16
## id rated created_at last_move_at turns victory_status winner increment_code white_id white_rating black_id black_rating moves opening_eco opening_name
## <chr> <lgl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
## 1 l1NXv~ TRUE 1.50e12 1.50e12 16 resign black 5+10 a-00 1322 skinner~ 1261 d4 Nc6 ~ B00 Nimzowitsch ~
## 2 RVN0N~ FALSE 1.50e12 1.50e12 9 resign black 15+30 daniel_~ 1413 soultego 2108 e4 Nc6 ~ B00 Nimzowitsch ~
## 3 dwF3D~ TRUE 1.50e12 1.50e12 66 resign black 15+0 ehabfan~ 1439 daniel_~ 1392 e4 e5 B~ C50 Italian Game~
## 4 Vf5fK~ FALSE 1.50e12 1.50e12 38 resign black 20+60 daniel_~ 1381 subham7~ 1867 e4 e6 d~ C02 French Defen~
## 5 HRti5~ FALSE 1.50e12 1.50e12 60 resign black 5+40 daniel_~ 1381 roman12~ 1936 e4 e6 N~ C00 French Defen~
## 6 2fEjS~ FALSE 1.50e12 1.50e12 31 resign black 8+0 daniel_~ 1381 alkhan 1607 e4 e6 Q~ C00 French Defen~
## 7 guanv~ FALSE 1.50e12 1.50e12 43 resign black 15+15 sureka_~ 1141 shivang~ 1094 e4 e5 N~ C57 Italian Game~
## 8 PmpkW~ FALSE 1.50e12 1.50e12 52 resign black 15+15 shivang~ 1094 sureka_~ 1141 e4 e5 N~ C50 Four Knights~
## 9 EwaK0~ FALSE 1.50e12 1.50e12 66 mate black 15+16 sureka_~ 1141 shivang~ 1094 e4 e5 N~ C50 Four Knights~
## 10 yrSDo~ FALSE 1.50e12 1.50e12 101 resign black 15+15 shivang~ 1094 slam_me~ 1300 e4 e5 N~ C41 Philidor Def~
## # ... with 9,168 more rows, and 1 more variable: opening_ply <dbl>1.3.2 Ordenando linhas com arrange()
arrange() funciona de modo semelhante a filter, mas ao invés de filtrar e selecionar linhas, ele apenas as reordena de acordo com alguma condição que passamos. Essa função recebe um data.frame e um conjunto de column names pelo qual vai ordenar. Se você fornecer mais de um nome de coluna, cada coluna adicional passada será usada como critério de desempate.
arrange(tb_chess_game, white_rating)## # A tibble: 20,058 x 16
## id rated created_at last_move_at turns victory_status winner increment_code white_id white_rating black_id black_rating moves opening_eco opening_name
## <chr> <lgl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
## 1 YwaFf~ TRUE 1.50e12 1.50e12 61 mate white 10+0 ragnarl~ 784 joe-bro~ 970 e4 e5 Nf~ C40 King's Knig~
## 2 XJoTQ~ TRUE 1.50e12 1.50e12 2 resign black 10+0 crazysc~ 784 tahsink~ 1006 e4 e5 C20 King's Pawn~
## 3 APnsy~ FALSE 1.40e12 1.40e12 27 resign black 20+12 lucatie~ 788 val4 1307 Nf3 e6 d~ A04 Zukertort O~
## 4 lWZQs~ TRUE 1.49e12 1.49e12 62 resign black 15+15 natalua 793 marigw 961 d4 d5 b4~ D00 Queen's Paw~
## 5 t6GU6~ TRUE 1.49e12 1.49e12 144 resign black 15+0 epicche~ 795 busines~ 1157 f4 e6 e4~ C00 French Defe~
## 6 yRIvg~ TRUE 1.50e12 1.50e12 23 resign white 0+25 mr_zilg~ 798 hash_13~ 1157 e4 g6 Nf~ B06 Modern Defe~
## 7 yRIvg~ TRUE 1.50e12 1.50e12 23 resign white 0+25 mr_zilg~ 798 hash_13~ 1157 e4 g6 Nf~ B06 Modern Defe~
## 8 q5xbB~ TRUE 1.41e12 1.41e12 6 resign black 10+8 canabid~ 801 fisherm~ 1223 e4 Nc6 d~ B00 King's Pawn~
## 9 wr2hp~ FALSE 1.39e12 1.39e12 92 mate black 20+8 allieka~ 807 moty1 1076 d4 d5 e3~ D00 Queen's Paw~
## 10 4Oie3~ TRUE 1.50e12 1.50e12 47 mate white 10+0 mata1234 808 joe-bro~ 973 e3 d5 b3~ A00 Van't Kruij~
## # ... with 20,048 more rows, and 1 more variable: opening_ply <dbl>Se quiser ordenar de forma decrescente, utilize a função desc(nome_da_coluna) dentro de arrange(). Isso seria particularmente interessante se você quisesse ordenar os dados na coluna final do maior volume para o maior.
arrange(tb_chess_game, desc(white_rating), desc(black_rating) )## # A tibble: 20,058 x 16
## id rated created_at last_move_at turns victory_status winner increment_code white_id white_rating black_id black_rating moves opening_eco opening_name
## <chr> <lgl> <dbl> <dbl> <dbl> <chr> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
## 1 Y1oXT~ FALSE 1.49e12 1.49e12 20 resign white 30+30 justice~ 2700 yourede~ 1486 e4 c6 d4~ B18 Caro-Kann De~
## 2 qIn8f~ TRUE 1.48e12 1.48e12 149 resign white 5+5 blitzbu~ 2622 milancu~ 2188 e4 Nc6 N~ B00 Nimzowitsch ~
## 3 upN6B~ FALSE 1.50e12 1.50e12 69 resign white 10+15 lance55~ 2621 chessma~ 2206 e4 c5 Nf~ B90 Sicilian Def~
## 4 TVQun~ FALSE 1.50e12 1.50e12 40 resign black 10+15 lance55~ 2621 danny77 2150 e4 e5 Nf~ C43 Russian Game~
## 5 fPm9l~ FALSE 1.50e12 1.50e12 58 outoftime black 10+10 lance55~ 2621 danny77 2150 d3 d5 Nf~ A06 Zukertort Op~
## 6 woqCH~ FALSE 1.50e12 1.50e12 42 resign black 10+15 lance55~ 2621 danny77 2139 e4 e5 Nf~ C59 Italian Game~
## 7 lh41y~ FALSE 1.50e12 1.50e12 49 resign white 5+60 lance55~ 2621 lukarpov 1802 d4 Nf6 c~ D57 Queen's Gamb~
## 8 zA4LD~ FALSE 1.50e12 1.50e12 77 resign white 15+0 lance55~ 2621 lukarpov 1802 d4 Nf6 c~ D57 Queen's Gamb~
## 9 HWw4e~ FALSE 1.50e12 1.50e12 14 resign white 10+25 lance55~ 2621 theches~ 1770 e4 e5 Nf~ C57 Italian Game~
## 10 2hNUH~ FALSE 1.50e12 1.50e12 47 outoftime white 10+25 lance55~ 2621 koryaki~ 1715 e4 e5 Nf~ C59 Italian Game~
## # ... with 20,048 more rows, and 1 more variable: opening_ply <dbl>1.3.3 Selecionando colunas com select()
Geralmente trabalhamos com grandes datasets com muitas colunas, mas somente algumas poucas colunas serão de nosso interesse. select() nos permite rapidamente focar num subconjunto dos dados. O melhor é que podemos utilizar operações - que normalmente só funcionam com as posições das colunas - direto nos nomes das variáveis.
# Seleção por nome
select(tb_netflix, title, country, rating)## # A tibble: 7,787 x 3
## title country rating
## <chr> <chr> <chr>
## 1 3% Brazil TV-MA
## 2 7:19 Mexico TV-MA
## 3 23:59 Singapore R
## 4 9 United States PG-13
## 5 21 United States PG-13
## 6 46 Turkey TV-MA
## 7 122 Egypt TV-MA
## 8 187 United States R
## 9 706 India TV-14
## 10 1920 India TV-MA
## # ... with 7,777 more rows# Selecionando todas as colunas num intervalo de colunas (inclusive)
select(tb_netflix, title:release_year)## # A tibble: 7,787 x 6
## title director cast country date_added release_year
## <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 3% <NA> João Miguel, Bianca Comparato, Michel Gomes, Rodolfo Valente, Vaneza Oliveira, Rafael Lozano, Vivi~ Brazil August 14, 20~ 2020
## 2 7:19 Jorge Michel ~ Demián Bichir, Héctor Bonilla, Oscar Serrano, Azalia Ortiz, Octavio Michel, Carmen Beato Mexico December 23, ~ 2016
## 3 23:59 Gilbert Chan Tedd Chan, Stella Chung, Henley Hii, Lawrence Koh, Tommy Kuan, Josh Lai, Mark Lee, Susan Leong, Be~ Singapore December 20, ~ 2011
## 4 9 Shane Acker Elijah Wood, John C. Reilly, Jennifer Connelly, Christopher Plummer, Crispin Glover, Martin Landau~ United St~ November 16, ~ 2009
## 5 21 Robert Luketic Jim Sturgess, Kevin Spacey, Kate Bosworth, Aaron Yoo, Liza Lapira, Jacob Pitts, Laurence Fishburne~ United St~ January 1, 20~ 2008
## 6 46 Serdar Akar Erdal Besikçioglu, Yasemin Allen, Melis Birkan, Saygin Soysal, Berkan Sal, Metin Belgin, Ayça Eren~ Turkey July 1, 2017 2016
## 7 122 Yasir Al Yasi~ Amina Khalil, Ahmed Dawood, Tarek Lotfy, Ahmed El Fishawy, Mahmoud Hijazi, Jihane Khalil, Asmaa Ga~ Egypt June 1, 2020 2019
## 8 187 Kevin Reynolds Samuel L. Jackson, John Heard, Kelly Rowan, Clifton Collins Jr., Tony Plana United St~ November 1, 2~ 1997
## 9 706 Shravan Kumar Divya Dutta, Atul Kulkarni, Mohan Agashe, Anupam Shyam, Raayo S. Bakhirta, Yashvit Sancheti, Greev~ India April 1, 2019 2019
## 10 1920 Vikram Bhatt Rajneesh Duggal, Adah Sharma, Indraneil Sengupta, Anjori Alagh, Rajendranath Zutshi, Vipin Sharma,~ India December 15, ~ 2008
## # ... with 7,777 more rows# Selecionando todas as colunas exceto aquelas em um intervalo (inclusive)
select(tb_netflix, -(date_added:description))## # A tibble: 7,787 x 6
## show_id type title director cast country
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 s1 TV Show 3% <NA> João Miguel, Bianca Comparato, Michel Gomes, Rodolfo Valente, Vaneza Oliveira, Rafael Lozano, Viviane Porto, ~ Brazil
## 2 s2 Movie 7:19 Jorge Michel ~ Demián Bichir, Héctor Bonilla, Oscar Serrano, Azalia Ortiz, Octavio Michel, Carmen Beato Mexico
## 3 s3 Movie 23:59 Gilbert Chan Tedd Chan, Stella Chung, Henley Hii, Lawrence Koh, Tommy Kuan, Josh Lai, Mark Lee, Susan Leong, Benjamin Lim Singapore
## 4 s4 Movie 9 Shane Acker Elijah Wood, John C. Reilly, Jennifer Connelly, Christopher Plummer, Crispin Glover, Martin Landau, Fred Tata~ United Sta~
## 5 s5 Movie 21 Robert Luketic Jim Sturgess, Kevin Spacey, Kate Bosworth, Aaron Yoo, Liza Lapira, Jacob Pitts, Laurence Fishburne, Jack McGe~ United Sta~
## 6 s6 TV Show 46 Serdar Akar Erdal Besikçioglu, Yasemin Allen, Melis Birkan, Saygin Soysal, Berkan Sal, Metin Belgin, Ayça Eren, Selin Ulu~ Turkey
## 7 s7 Movie 122 Yasir Al Yasi~ Amina Khalil, Ahmed Dawood, Tarek Lotfy, Ahmed El Fishawy, Mahmoud Hijazi, Jihane Khalil, Asmaa Galal, Tara E~ Egypt
## 8 s8 Movie 187 Kevin Reynolds Samuel L. Jackson, John Heard, Kelly Rowan, Clifton Collins Jr., Tony Plana United Sta~
## 9 s9 Movie 706 Shravan Kumar Divya Dutta, Atul Kulkarni, Mohan Agashe, Anupam Shyam, Raayo S. Bakhirta, Yashvit Sancheti, Greeva Kansara, ~ India
## 10 s10 Movie 1920 Vikram Bhatt Rajneesh Duggal, Adah Sharma, Indraneil Sengupta, Anjori Alagh, Rajendranath Zutshi, Vipin Sharma, Amin Hajee~ India
## # ... with 7,777 more rowsDICA: Existem helper functions que podemos usar dentro de select(). São funções que lembram o funcionamento de uma regular expression (Vamos ver no curso avançado com mais detalhes) para identificarmos nomes de colunas que atendem a determinado critério. São muito úteis com grandes datasets: starts_with(), ends_with(), matches() e contains().
Vamos por exemplo selecionar todas as colunas que começam com a letra d:
select(tb_netflix, starts_with("d"))## # A tibble: 7,787 x 4
## director date_added duration description
## <chr> <chr> <chr> <chr>
## 1 <NA> August 14, 2020 4 Seaso~ In a future where the elite inhabit an island paradise far from the crowded slums, you get one chance to join the 3%~
## 2 Jorge Michel G~ December 23, 20~ 93 min After a devastating earthquake hits Mexico City, trapped survivors from all walks of life wait to be rescued while t~
## 3 Gilbert Chan December 20, 20~ 78 min When an army recruit is found dead, his fellow soldiers are forced to confront a terrifying secret that's haunting t~
## 4 Shane Acker November 16, 20~ 80 min In a postapocalyptic world, rag-doll robots hide in fear from dangerous machines out to exterminate them, until a br~
## 5 Robert Luketic January 1, 2020 123 min A brilliant group of students become card-counting experts with the intent of swindling millions out of Las Vegas ca~
## 6 Serdar Akar July 1, 2017 1 Season A genetics professor experiments with a treatment for his comatose sister that blends medical and shamanic cures, bu~
## 7 Yasir Al Yasiri June 1, 2020 95 min After an awful accident, a couple admitted to a grisly hospital are separated and must find each other to escape — b~
## 8 Kevin Reynolds November 1, 2019 119 min After one of his high school students attacks him, dedicated teacher Trevor Garfield grows weary of the gang warfare~
## 9 Shravan Kumar April 1, 2019 118 min When a doctor goes missing, his psychiatrist wife treats the bizarre medical condition of a psychic patient, who kno~
## 10 Vikram Bhatt December 15, 20~ 143 min An architect and his wife move into a castle that is slated to become a luxury hotel. But something inside is determ~
## # ... with 7,777 more rowsselect() pode ser usada inclusive para renomear variáveis:
select(tb_netflix, listed_category = listed_in)## # A tibble: 7,787 x 1
## listed_category
## <chr>
## 1 International TV Shows, TV Dramas, TV Sci-Fi & Fantasy
## 2 Dramas, International Movies
## 3 Horror Movies, International Movies
## 4 Action & Adventure, Independent Movies, Sci-Fi & Fantasy
## 5 Dramas
## 6 International TV Shows, TV Dramas, TV Mysteries
## 7 Horror Movies, International Movies
## 8 Dramas
## 9 Horror Movies, International Movies
## 10 Horror Movies, International Movies, Thrillers
## # ... with 7,777 more rowsA nova variável será chamada listed_category e receberá toda a informação da original listed_in.
No entanto, select() “abandona” todas as demais variáveis quando você faz uma renomeação. É melhor então é usar rename():
rename(tb_netflix, listed_category = listed_in)## # A tibble: 7,787 x 12
## show_id type title director cast country date_added release_year rating duration listed_category description
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
## 1 s1 TV Sh~ 3% <NA> João Miguel, Bianca Compa~ Brazil August 14~ 2020 TV-MA 4 Seaso~ International TV Sh~ In a future where the elite i~
## 2 s2 Movie 7:19 Jorge Mic~ Demián Bichir, Héctor Bon~ Mexico December ~ 2016 TV-MA 93 min Dramas, Internation~ After a devastating earthquak~
## 3 s3 Movie 23:59 Gilbert C~ Tedd Chan, Stella Chung, ~ Singapo~ December ~ 2011 R 78 min Horror Movies, Inte~ When an army recruit is found~
## 4 s4 Movie 9 Shane Ack~ Elijah Wood, John C. Reil~ United ~ November ~ 2009 PG-13 80 min Action & Adventure,~ In a postapocalyptic world, r~
## 5 s5 Movie 21 Robert Lu~ Jim Sturgess, Kevin Space~ United ~ January 1~ 2008 PG-13 123 min Dramas A brilliant group of students~
## 6 s6 TV Sh~ 46 Serdar Ak~ Erdal Besikçioglu, Yasemi~ Turkey July 1, 2~ 2016 TV-MA 1 Season International TV Sh~ A genetics professor experime~
## 7 s7 Movie 122 Yasir Al ~ Amina Khalil, Ahmed Dawoo~ Egypt June 1, 2~ 2019 TV-MA 95 min Horror Movies, Inte~ After an awful accident, a co~
## 8 s8 Movie 187 Kevin Rey~ Samuel L. Jackson, John H~ United ~ November ~ 1997 R 119 min Dramas After one of his high school ~
## 9 s9 Movie 706 Shravan K~ Divya Dutta, Atul Kulkarn~ India April 1, ~ 2019 TV-14 118 min Horror Movies, Inte~ When a doctor goes missing, h~
## 10 s10 Movie 1920 Vikram Bh~ Rajneesh Duggal, Adah Sha~ India December ~ 2008 TV-MA 143 min Horror Movies, Inte~ An architect and his wife mov~
## # ... with 7,777 more rows1.3.4 Adicionando novas colunas com mutate()
Além de selecionar conjuntos de colunas existentes, é geralmente útil adicionar novas colunas que são funções de colunas já presentes no tibble/dataframe. Veja um exemplo com mutate(), onde queremos calcular o preço por unidade de volume:
mutate(tb_game_sales,
part_na_sales = NA_Sales/Global_Sales,
)## # A tibble: 16,598 x 12
## Rank Name Platform Year Genre Publisher NA_Sales EU_Sales JP_Sales Other_Sales Global_Sales part_na_sales
## <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 Wii Sports Wii 2006 Sports Nintendo 41.5 29.0 3.77 8.46 82.7 0.501
## 2 2 Super Mario Bros. NES 1985 Platform Nintendo 29.1 3.58 6.81 0.77 40.2 0.723
## 3 3 Mario Kart Wii Wii 2008 Racing Nintendo 15.8 12.9 3.79 3.31 35.8 0.442
## 4 4 Wii Sports Resort Wii 2009 Sports Nintendo 15.8 11.0 3.28 2.96 33 0.477
## 5 5 Pokemon Red/Pokemon Blue GB 1996 Role-Playing Nintendo 11.3 8.89 10.2 1 31.4 0.359
## 6 6 Tetris GB 1989 Puzzle Nintendo 23.2 2.26 4.22 0.58 30.3 0.767
## 7 7 New Super Mario Bros. DS 2006 Platform Nintendo 11.4 9.23 6.5 2.9 30.0 0.379
## 8 8 Wii Play Wii 2006 Misc Nintendo 14.0 9.2 2.93 2.85 29.0 0.483
## 9 9 New Super Mario Bros. Wii Wii 2009 Platform Nintendo 14.6 7.06 4.7 2.26 28.6 0.510
## 10 10 Duck Hunt NES 1984 Shooter Nintendo 26.9 0.63 0.28 0.47 28.3 0.951
## # ... with 16,588 more rowsmutate() nos permite ainda nos referir a colunas que acabamos de criar no mesmo comando. Vamos salvar esta alteração em um novo tibble, chamado tb_game_sales_trans
tb_game_sales_trans <- mutate(tb_game_sales,
part_na_sales = NA_Sales/Global_Sales,
part_eu_sales = EU_Sales/Global_Sales,
part_jp_sales = JP_Sales/Global_Sales,
part_os_sales = Other_Sales/Global_Sales
)Se só nos interessarem as novas variáveis, usaríamos transmute():
transmute(tb_game_sales,
part_na_sales = NA_Sales/Global_Sales,
part_eu_sales = EU_Sales/Global_Sales,
part_jp_sales = JP_Sales/Global_Sales,
part_os_sales = Other_Sales/Global_Sales
)## # A tibble: 16,598 x 4
## part_na_sales part_eu_sales part_jp_sales part_os_sales
## <dbl> <dbl> <dbl> <dbl>
## 1 0.501 0.351 0.0456 0.102
## 2 0.723 0.0890 0.169 0.0191
## 3 0.442 0.360 0.106 0.0924
## 4 0.477 0.334 0.0994 0.0897
## 5 0.359 0.283 0.326 0.0319
## 6 0.767 0.0747 0.139 0.0192
## 7 0.379 0.308 0.217 0.0966
## 8 0.483 0.317 0.101 0.0982
## 9 0.510 0.247 0.164 0.0790
## 10 0.951 0.0223 0.00989 0.0166
## # ... with 16,588 more rows1.3.5 Modificando entradas com mutate() ou transmute() + case_when()
case_when() é uma função do pacote dplyr que nos permite modificar as variáveis a partir de uma sequência de condições que devem ser respeitadas.
SE CONDIÇÃO1 VERDADEIRA ~ FAÇA TAL COISA;
SENÃO ~ FAÇA OUTRA COISAEla substitui as estruturas condicionais nativas do R (função ifelse()) e é inspirada na declaração equivalente em SQL CASE WHEN. Os argumentos da função case_when() obedecem à seguinte estrutura: operação condicional ~ novo valor. No lado esquerdo do ~, você tem a comparação a ser feita. No lado direito, temos o novo valor a ser atribuído caso o resultado da comparação seja TRUE. Você pode tratar, inclusive, mais de uma condição, desde que parta do caso mais específico para o mais geral.
case_when(
condição1 ~ "novo_valor1",
condição2 ~ "novo_valor2",
condição3 ~ "novo_valor3",
TRUE ~ "valor para os demais casos não atendidos pelas condições acima"
)Geralmente, no contexto de análise de dados com dplyr, utilizamos case_when() dentro de uma função mutate() ou transmute (que traz a apenas a nova coluna criada), uma vez que pretendemos alterar as entradas de uma coluna, alterando, portanto, a própria coluna.
No tibble tb_games_sales, vamos criar uma nova coluna de caracteres chamada nivel, em que classificaremos um valor em: alto se NA_sales > mean(NA_sales); baixo se NA_sales < mean(NA_sales) ou razoavel nos demais casos:
transmute(tb_game_sales,
nivel_na =
case_when(
NA_sales > mean(NA_Sales) ~ "alto",
NA_sales < mean(NA_Sales) ~ "baixo",
TRUE ~ "razoável"
))1.3.6 Sumarizando valores com summarise()
O último “verbo” de dplyr é summarise() (ou summarize). Ele colapsa um tibble/dataframe em uma única linha.
summarise(tb_game_sales,
max_venda_na = max(NA_Sales, na.rm = TRUE)
)## # A tibble: 1 x 1
## max_venda_na
## <dbl>
## 1 41.5DICA: O parâmetro na.rm = TRUE dentro da função max() serve para que esta desconsidere os valores falatantes (NA) ao calcular a máximo Do contrário, na existência de missing values NA, a função sempre retornará NA. Isso também vale para outras funções matemáticas de funcionamento vetorizado, como sum(), mean e min, por exemplo.
Dependendo do seu objetivo, pode ser mais útil utilizar o “verbo” group_by() que veremos mais a frente. Com ele poderemos calcular o valor médio por plataforma por exemplo.
1.4 Estrutura do dplyr
Note que a sintaxe e funcionamento de todos os verbos de dplyr apresentados até aqui são bem similares:
o primeiro argumento é um tibble/dataframe;
os argumentos subsequentes descrevem o que fazer com os dados. Podemos nos referir às colunas do tibble/dataframe diretamente sem a necessidade de usar
$ou indexação por[].o resultado é um novo tibble/dataframe.
Juntas, essas propriedades facilitam encadear múltiplos passos simples para alcançar um resultado complexo. O restante do que dplyr faz, vem de aplicar as 5 funções que vimos até aqui a diferentes tipos de dados. Ao invpes de trabalharmos com dados desagregados, vamos passar a trabalhar agora com dados agrupados por uma ou mais variáveis.
1.4.1 Operações agrupadas
Os verbos de dplyr tornam-se ainda mais poderosos quando os aplicamos a grupos de observações dentro de um conjunto de dados. Fazemos isso com a função group_by(). Ela “quebra” o dataset em grupos específicos de linhas. No início, não vemos qualquer alteração. É como se elas ficassem em segundo plano. No entanto, ao aplicarmos algum dos verbos principais no dataset “alterado” por group_by, eles automaticamente serão aplicados por grupo ou “by group”.
O uso de agrupamento afeta o resultado dos verbos principais da seguinte forma:
select()agrupado é o mesmo que não agrupado, exceto pelo fato que as variáveis de agrupamento são sempre preservadas.arrange()agrupado é mesmo que não agrupado, a não ser que usemos.by_group = TRUE, caso em que ordena primeiro pelas variáveis de agrupamento;mutate()efilter()são bastante úteis em conjunto com window functions (comorank()oumin(x) == x) (Ver vignette de “window-functions” dodplyr);summarise()calcula o sumário para cada grupo.
No exemplo a seguir, nós separamos o dataset por Platform, contando o número de registros para cada um das plataformas (count = n()), computando a valor médio por plataforma (valor_medio_plataforma = mean(Global_Sales, na.rm = TRUE)).
by_platform <- group_by(tb_game_sales, Platform)
valor_medio_plataforma <- summarise(
by_platform,
count = n(),
mvp = mean(Global_Sales, na.rm = TRUE)
)Note que summarise() é normalmente utilizada com aggregate functions, as quais recebem um vetor de valores e retornam um único número. Há muito exemplos úteis do base R que podem ser utilizados, como min(), max(), mean(), sum(), sd(), median(), etc. dplyr fornece mais algumas outras bem úteis:
n(): número de observações no grupo atual;n_distinct(x): número de valores únicos em x;first(x),last(x)enth(x, n)funcionam de forma similar ax[1],x[length(x)]ex[n], mas nos dão maior controle sobre resultado caso algum valor seja missing.
1.4.2 Cuidados com os nomes de variáveis
Uma das melhores características do pacote dplyr é que podemos nos referir as variáveis de um tibble ou dataframe como se fossem variáveis regulares (aquelas que estão no Global Environment). No entanto, a sintaxe de referência para nomes de colunas escondem algumas diferenças entre os verbos. Por exemplo, um nome ou valor de coluna passado para select() não tem o mesmo significado do que teria em mutate().
Veja formas equivalentes do ponto de vista de dplyr:
select(tb_chess_game, victory_status)## # A tibble: 20,058 x 1
## victory_status
## <chr>
## 1 outoftime
## 2 resign
## 3 mate
## 4 mate
## 5 mate
## 6 draw
## 7 resign
## 8 resign
## 9 resign
## 10 mate
## # ... with 20,048 more rowsselect(tb_chess_game, 6)## # A tibble: 20,058 x 1
## victory_status
## <chr>
## 1 outoftime
## 2 resign
## 3 mate
## 4 mate
## 5 mate
## 6 draw
## 7 resign
## 8 resign
## 9 resign
## 10 mate
## # ... with 20,048 more rowsSe houver uma variável no Global Environment com o mesmo nome de uma coluna de nosso tibble/dataframe, o dplyr dará prioridade à variável que está no tibble.
victory_status <- "Vencedor"
select(tb_chess_game, victory_status)## # A tibble: 20,058 x 1
## victory_status
## <chr>
## 1 outoftime
## 2 resign
## 3 mate
## 4 mate
## 5 mate
## 6 draw
## 7 resign
## 8 resign
## 9 resign
## 10 mate
## # ... with 20,048 more rows1.5 Usando o Pipe %>%
dplyr é funcional no sentido de que os chamados às funções não tem efeitos colaterais. Ou seja, você sempre precisa salvar seus resultados. Isso faz com que não tenhámos um código tão elegante, especialmente quando vamos fazer várias operações.
Para dar uma solução elegante ao problema, dplyr utiliza o operador pipe %>% do pacote magritrr. x %>% f(y) equivale a f(x, y). Então, podemos utilizar esse operador para reescrever múltiplas operações que podemos ler da esquerda para direita e de cima para baixo.
tb_game_sales %>%
group_by(Platform) %>%
summarise(count = n(),
mvp = mean(Global_Sales, na.rm = TRUE))## # A tibble: 31 x 3
## Platform count mvp
## <chr> <int> <dbl>
## 1 2600 133 0.730
## 2 3DO 3 0.0333
## 3 3DS 509 0.486
## 4 DC 52 0.307
## 5 DS 2163 0.380
## 6 GB 98 2.61
## 7 GBA 822 0.387
## 8 GC 556 0.359
## 9 GEN 27 1.05
## 10 GG 1 0.04
## # ... with 21 more rowsDICA: Note que o nome do tibble ou dataframe só precisa ser informado uma única vez logo ao início do processo.
1.6 Juntando bases
Podemos juntar duas tabelas a partir de uma (coluna) chave utilizando a função left_join().
orders <- read_csv("https://raw.githubusercontent.com/brunolucian/CursoIntermediarioR/main/Dados/olist_orders_dataset.csv")##
## -- Column specification ------------------------------------------------------------------------------------------------------------------------------------------
## cols(
## order_id = col_character(),
## customer_id = col_character(),
## order_status = col_character(),
## order_purchase_timestamp = col_datetime(format = ""),
## order_approved_at = col_datetime(format = ""),
## order_delivered_carrier_date = col_datetime(format = ""),
## order_delivered_customer_date = col_datetime(format = ""),
## order_estimated_delivery_date = col_datetime(format = "")
## )items <- read_csv("https://raw.githubusercontent.com/brunolucian/CursoIntermediarioR/main/Dados/olist_order_items_dataset.csv")##
## -- Column specification ------------------------------------------------------------------------------------------------------------------------------------------
## cols(
## order_id = col_character(),
## order_item_id = col_double(),
## product_id = col_character(),
## seller_id = col_character(),
## shipping_limit_date = col_datetime(format = ""),
## price = col_double(),
## freight_value = col_double()
## )Basta usar a função left_join() utilizando a coluna order_id como chave. Observe que as colunas itens aparece agora no fim da tabela.
orders_items <- left_join(orders, items, by="order_id")
orders_items## # A tibble: 113,425 x 14
## order_id customer_id order_status order_purchase_tim~ order_approved_at order_delivered_ca~ order_delivered_cu~ order_estimated_de~ order_item_id product_id
## <chr> <chr> <chr> <dttm> <dttm> <dttm> <dttm> <dttm> <dbl> <chr>
## 1 e481f51c~ 9ef432eb62~ delivered 2017-10-02 10:56:33 2017-10-02 11:07:15 2017-10-04 19:55:00 2017-10-10 21:25:13 2017-10-18 00:00:00 1 87285b348~
## 2 53cdb2fc~ b0830fb474~ delivered 2018-07-24 20:41:37 2018-07-26 03:24:27 2018-07-26 14:31:00 2018-08-07 15:27:45 2018-08-13 00:00:00 1 595fac2a3~
## 3 47770eb9~ 41ce2a54c0~ delivered 2018-08-08 08:38:49 2018-08-08 08:55:23 2018-08-08 13:50:00 2018-08-17 18:06:29 2018-09-04 00:00:00 1 aa4383b37~
## 4 949d5b44~ f88197465e~ delivered 2017-11-18 19:28:06 2017-11-18 19:45:59 2017-11-22 13:39:59 2017-12-02 00:28:42 2017-12-15 00:00:00 1 d0b61bfb1~
## 5 ad21c59c~ 8ab97904e6~ delivered 2018-02-13 21:18:39 2018-02-13 22:20:29 2018-02-14 19:46:34 2018-02-16 18:17:02 2018-02-26 00:00:00 1 65266b2da~
## 6 a4591c26~ 503740e9ca~ delivered 2017-07-09 21:57:05 2017-07-09 22:10:13 2017-07-11 14:58:04 2017-07-26 10:57:55 2017-08-01 00:00:00 1 060cb1934~
## 7 136cce7f~ ed0271e0b7~ invoiced 2017-04-11 12:22:08 2017-04-13 13:25:17 NA NA 2017-05-09 00:00:00 1 a1804276d~
## 8 6514b8ad~ 9bdf08b4b3~ delivered 2017-05-16 13:10:30 2017-05-16 13:22:11 2017-05-22 10:07:46 2017-05-26 12:55:51 2017-06-07 00:00:00 1 4520766ec~
## 9 76c6e866~ f54a9f0e6b~ delivered 2017-01-23 18:29:09 2017-01-25 02:50:47 2017-01-26 14:16:31 2017-02-02 14:08:10 2017-03-06 00:00:00 1 ac1789e49~
## 10 e69bfb5e~ 31ad1d1b63~ delivered 2017-07-29 11:55:02 2017-07-29 12:05:32 2017-08-10 19:45:24 2017-08-16 17:14:30 2017-08-23 00:00:00 1 9a78fb986~
## # ... with 113,415 more rows, and 4 more variables: seller_id <chr>, shipping_limit_date <dttm>, price <dbl>, freight_value <dbl>Além da função left_join(), também são muito utilizadas as funções right_join() e full_join().
right_join(): retorna todas as linhas da baseye todas as colunas das basesxey. Linhas deysem correspondentes emxreceberãoNAna nova base.full_join(): retorna todas as linhas e colunas dexey. Valores sem correspondência entre as bases receberãoNAna nova base.
A figura a seguir esquematiza as operações dessas funções:
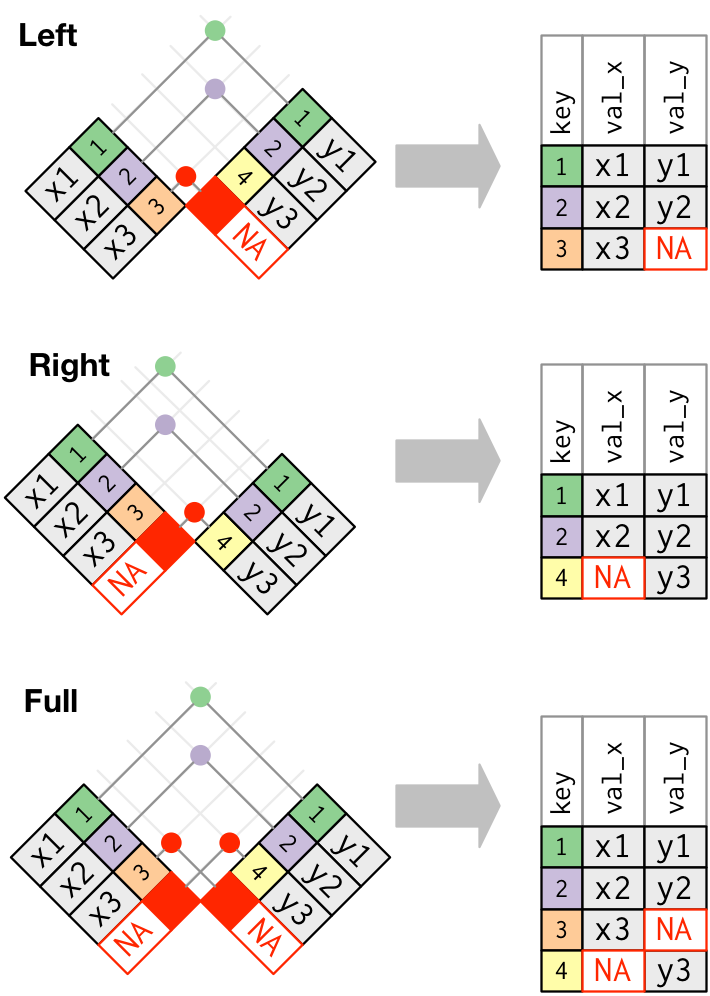
1.7 Execícios
Usando os dados da Olist apresentados neste módulo responda:
- Em que cidades os consumidores moram?
- Qual o valor médio dos pedidos?
- As pessoas preferem pagar com boleto ou cartão?
- Em quantas parcelas?
- Em que datas há mais vendas?
1.8 Referências da seção
Wickham H.; François, R.; Henry, L.; Müller K. (2019). dplyr: A Grammar of Data Manipulation. R package version 0.8.1. URL https://CRAN.R-project.org/package=dplyr.
Wickham H.; François, R.; Henry, L.; Müller K. (2020). dplyr vignette: Introduction. URL http://dplyr.tidyverse.org.
Wickham, H.; Grolemund, G. (2016). R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. O’Reilly Media. december 2016. 522 pages. Disponível em: https://www.r4ds.co.nz.