1 Statistica descrittiva
1.1 Popolazione, campione e variabili
Esercizio 1.1
Secondo un’indagine della Goldman Sachs, soltanto il 4% delle famiglie statunitensi ha un conto online. In un sondaggio della Cyber Dialogue riportato su USA Today si è cercato di indagare sui motivi per cui i clienti hanno chiuso il proprio conto online dopo un periodo di prova. Di seguito trovate le risposte degli intervistati alla domanda: “Perchè hai chiuso il tuo conto online?”
| Perchè hai chiuso il tuo conto online? | |
|---|---|
| Troppo complicato o richiede troppo tempo | 27% |
| Insoddisfatto dal servizio clienti | 25% |
| Non mi necessario o non mi interessa | 20% |
| Preoccupato per la sicurezza del conto | 11% |
| Troppo costoso | 11% |
| Sono preoccupato per la privacy | 5% |
Descrivere la popolazione per l’indagine della Goldman Sachs;
Descrivere la popolazione per l’indagine della Cyber Dialogue;
La risposta alla domanda considerata è qualitativa o quantitativa?
Soluzione
La popolazione di riferimento per l’indagine della Goldman Sachs è costituita da tutte le famiglie statunitensi.
La popolazione di riferimento per l’indagine della Cyber Dialogue è costituita dalle famiglie statunitensi che avevano un conto online e hanno deciso di chiuderlo.
La risposta alla domanda considerata è qualitativa.
Esercizio 1.2
In un fast food vengono venduti 3 diversi tipi di bevande: bibite, tè e caffè.
Spiegare perchè il tipo di bevanda venduta è un esempio di carattere qualitativo sconnesso.
Le bibite vengono vendute in 3 dimensioni diverse: piccola, media e grande. Di che carattere si tratta?
Soluzione
Il tipo di bevanda è un carattere qualitativo sconnesso: le sue modalità sono definite mediante sostantivi e non ammettono un ordinamento tra loro (infatti date due bevande è possibile affermare soltanto se esse sono uguali o diverse tra loro).
La dimensione della bibita è un carattere qualitativo ordinato perchè le sue modalità sono attributi non numerici, ma logicamente ordinabili (infatti una bevanda ‘piccola’ è di dimensione inferiore ad una ‘media’, che a sua volte è di dimensione inferiore ad una ‘grande’).
Esercizio 1.3
Per ognuna delle seguenti variabili dire di che tipo di variabile si tratta e la scala di misura di riferimento:
Numero di telefoni per famiglia;
Tipo di telefono usato principalmente;
Numero di telefonate al mese;
Numero medio di telefonate al mese;
Durata (in minuti) delle chiamate;
Costo mensile delle telefonate;
Esistenza di una linea telefonica collegata ad un modem.
Soluzione
quantitativo discreto, scala proporzionale.
qualitativo sconnesso, scala nominale.
quantitativo discreto, scala proporzionale.
quantitativo continuo, scala proporzionale.
quantitativo continuo, scala proporzionale.
quantitativo continuo, scala proporzionale.
qualitativo sconnesso, scala nominale.
Esercizio 1.4
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.3-1.7)
Identificare (i) le unità, (ii) le variabili e la loro tipologia, (iii) l’obiettivo principale di ricerca, (iv) la popolazione di interesse e il campione negli studi descritti qui di seguito. Discutere inoltre sulla possibilità di generalizzare i risultati dello studio alla popolazione e di stabilire dei nessi causali:
Alcuni ricercatori hanno raccolto dei dati per esaminare la relazione tra sostanze inquinanti e nascite premature nel sud della California. Durante lo studio i livelli di inquinamento dell’aria (monossido di carbonio CO, diossido di nitrogeno, ozono, particolato PM 10) sono stati misurati in apposite stazioni di monitoraggio della qualità dell’aria. E’ stata inoltre rilevata la durata della gestazione per 143196 nascite tra il 1989 e il 1993 e l’esposizione all’inquinamento dell’aria durante la gestazione è stato calcolato per ciascuna nascita. L’analisi ha mostrato che una maggiore concentrazione di PM 10 e, in misura minore, di CO possono essere associate a nascite premature.
Il metodo Buteyko è una tecnica di respirazione debole sviluppata dal medico russo Konstantin Buteyko nel 1952. L’evidenza empirica suggerisce che il metodo Buteyko aiuta a ridurre i sintomi dell’asma e a migliorare la qualità della vita. In uno studio clinico volto a dimostrare l’efficacia di questo metodo, i ricercatori hanno reclutato 600 pazienti malati asma di età compresa tra i 18 e i 69 anni che erano stati sottoposti ad una terapia medica contro l’asma. Questi pazienti sono stati suddivisi in due gruppi: uno sottoposto al metodo Buteyko, l’altro no. Sono stati rilevati degli indici di qualità della vita, di attività, di sintomi dell’asma e riduzione dei trattamenti medici su una scala da 0 a 10. In media, i pazienti del gruppo Buteyko hanno sperimentato una riduzione significativa nei sintomi dell’asma e un miglioramento di qualità della vita.
Soluzione
(i) Le unità sono 143196 nuovi nati registrati nel sud della California tra il 1989 e il 1993. (ii) Le variabili misurate sono tutte quantitative continue: monossido di carbonio CO, diossido di nitrogeno, ozono, particolato PM 10. (iii) L’obiettivo della ricerca è stabilire se c’è un’associazione tra l’esposizione all’inquinamento dell’aria e le nascite premature. (iv) La popolazione di interesse è quella di tutte le nascite nel sud della California. Il campione considera invece le 143196 nascite avvenute tra il 1989 e il 1993. Se le nascite in questo periodo di tempo possono essere considerate rappresentative di tutte le nascite del sud della California allora si può pensare che i risultati ottenuti siano generalizzabili all’intera popolazione. Tuttavia, poichè lo studio è di tipo osservazionale, non può essere usato per dimostrare una relazione di tipo causale.
(i) Le unità sono 600 pazienti adulti di età compresa tra i 18 e i 69 anni malati di asma e sotto trattamento. (ii) Le variabili misurate su una scala qualitativa ordinale da 0 a 10 (quindi trattabili come quantitative discrete) sono: indici di qualità della vita, di attività, di sintomi dell’asma e riduzione dei trattamenti medici. Inoltre viene considerata una variabile binaria che indica l’appartenenza o non appartenenza al gruppo sperimentale Buteyko. (iii) L’obiettivo della ricerca è dimostrare l’efficacia del metodo Buteyko nel miglioramento della condizione generale del malato d’asma. (iv) La popolazione di riferimento è l’insieme di tutti i pazienti di età compresa tra i 18 e i 69 anni, malati di asma e sotto trattamento. Il campione contiene 600 di questi pazienti. Se assumiamo che il campione contenga dei pazienti volontari, non possiamo pensare che sia un campione rappresentativo e quindi generalizzare i risultati all’intera popolazione. Tuttavia, la natura sperimentale dello studio consente di poter dimostrare statisticamente l’esistenza di una relazione causale.
Esercizio 1.5
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.5)
Il Sig. Ronald Aylmer Fisher era uno statistico inglese, esperto di evoluzione, biologo e genetista, che lavorò tra l’altro su un noto dataset riguardante tre tipi di fiori iris (setosa, versicolor e virginica) per i quali erano state rilevate la lunghezza e la larghezza dei sepali e lunghezza e larghezza dei petali. I dati, relativi a 50 fiori per ciascun tipo1, sono contenuti nel dataset iris (riportato in Appendice e disponibile online).

Quante sono le unità?
Quante variabili quantitative sono presenti nel dataset? Indicare quali sono, e se sono continue o discrete.
Quante variabili categoriche sono presenti nel dataset, e quali sono? Elenca le corrispondenti modalità.
1.2 Distribuzioni di frequenza
Esercizio 1.6
(dal libro di testo Introduzione alla statistica di Sheldon M. Ross, es. 1 pag.59)
I dati seguenti indicano il gruppo sanguigno di 50 donatori in un centro di raccolta del sangue.
0 A 0 AB A A 0 0 B A 0 A AB B 0 0 0 A B A A 0 A A 0
B A 0 AB A 0 0 A B A A A 0 B 0 0 A 0 A B 0 AB A 0 BRappresentare questi dati in una tabella di frequenze.
Rappresentare i dati in una tabella di frequenze relative.
Calcolare inoltre le frequenze percentuali.
Esercizio 1.7
(dal libro di testo Introduzione alla statistica di Sheldon M. Ross, es. 5 pag.35)
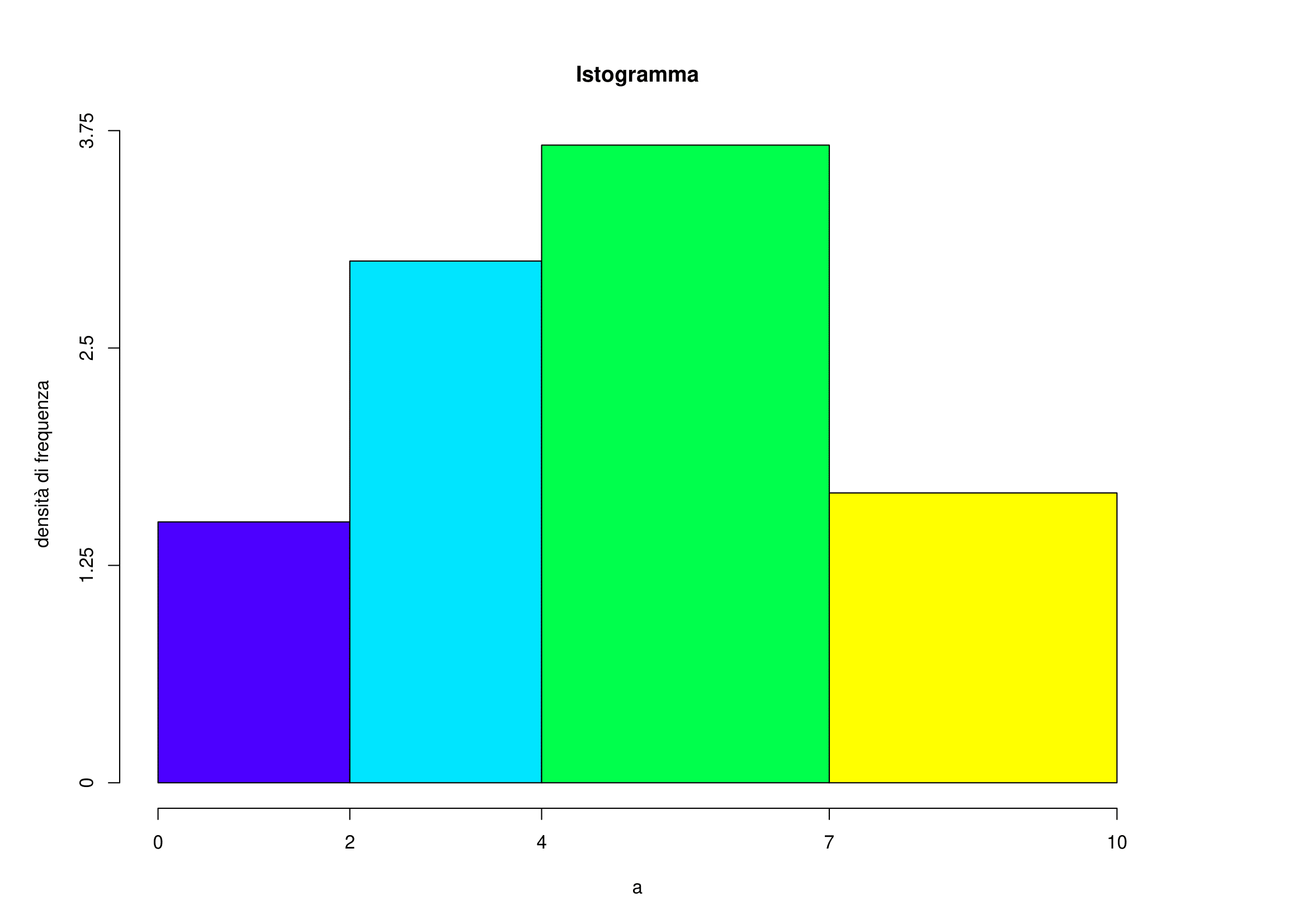
I seguenti dati indicano la concentrazione di ozono nell’aria del centro di Los Angeles durante 25 giorni consecutivi nell’estate del 1984:
6.2 9.1 2.4 3.6 1.9 1.7 4.5 4.2 3.3 5.1 6.0 1.8 2.3
4.9 3.7 3.8 5.5 6.4 8.6 9.3 7.7 5.4 7.2 4.9 6.2Costruire la distribuzione in classi utilizzando le seguenti classi:
\((0,2]\),\((2,4]\),\((4,7]\), \((7,10]\).
Esercizio 1.8
La seguente tabella riguarda la distribuzione di frequenza del costo di un pasto (espresso in euro):
| Costo di un pasto | Frequenza assoluta |
|---|---|
| \([10,15)\) | 1 |
| \([15,20)\) | 0 |
| \([20,25)\) | 2 |
| \([25,30)\) | 15 |
| \([30,35)\) | 5 |
| \([25,40)\) | 1 |
| \([40,45)\) | 3 |
| \(>45\) | 15 |
Di che tipo di carattere si tratta? E di che rappresentazione tabellare si tratta?
Che differenza c’è rispetto a quella dell’Esercizio 1.7?
Costruire le frequenze relative, percentuali.
È possibile ricostruire la corrispondente distribuzione unitaria?
Soluzione
Il carattere costo di un pasto è quantitativo continuo. La tabella precedente rappresenta la distribuzione in classi delle frequenze assolute.
La distribuzione data nell’esercizio precente è una distribuzione unitaria, quella che viene richiesto di ricavare è invece una distribuzione in classi: in questo caso possiamo notare che le classi sono chiuse a sinistra e aperte a destra e che l’ultima classe è aperta.
La seguente tabella riporta le frequenze relative e percentuali:
Costo di un pasto classi Freq. assolute \(n_i\) Freq. relative \(f_i=\frac{n_i}{n}\) Freq. percentuali \([10,15)\) 1 0.02 2% \([15,20)\) 0 0 0% \([20,25)\) 2 0.05 5% \([25,30)\) 15 0.36 36% \([30,35)\) 5 0.12 12% \([25,40)\) 1 0.02 2% \([40,45)\) 3 0.07 7% \(>45\) 15 0.36 36% Totale \(n=\)42 1 100% A partire dalla distribuzione in classi non è possibile ricostruire quella unitaria, mentre è possibile il viceversa come abbiamo visto nell’esercizio precedente.
1.3 Rappresentazioni grafiche per caratteri qualitativi
Esercizio 1.9
(dal libro di testo Introduzione alla statistica di Sheldon M. Ross, es. 1 pag.59)
Riprendendo l’Esercizio 1.6, rappresentare la distribuzione mediante un diagramma a barre.
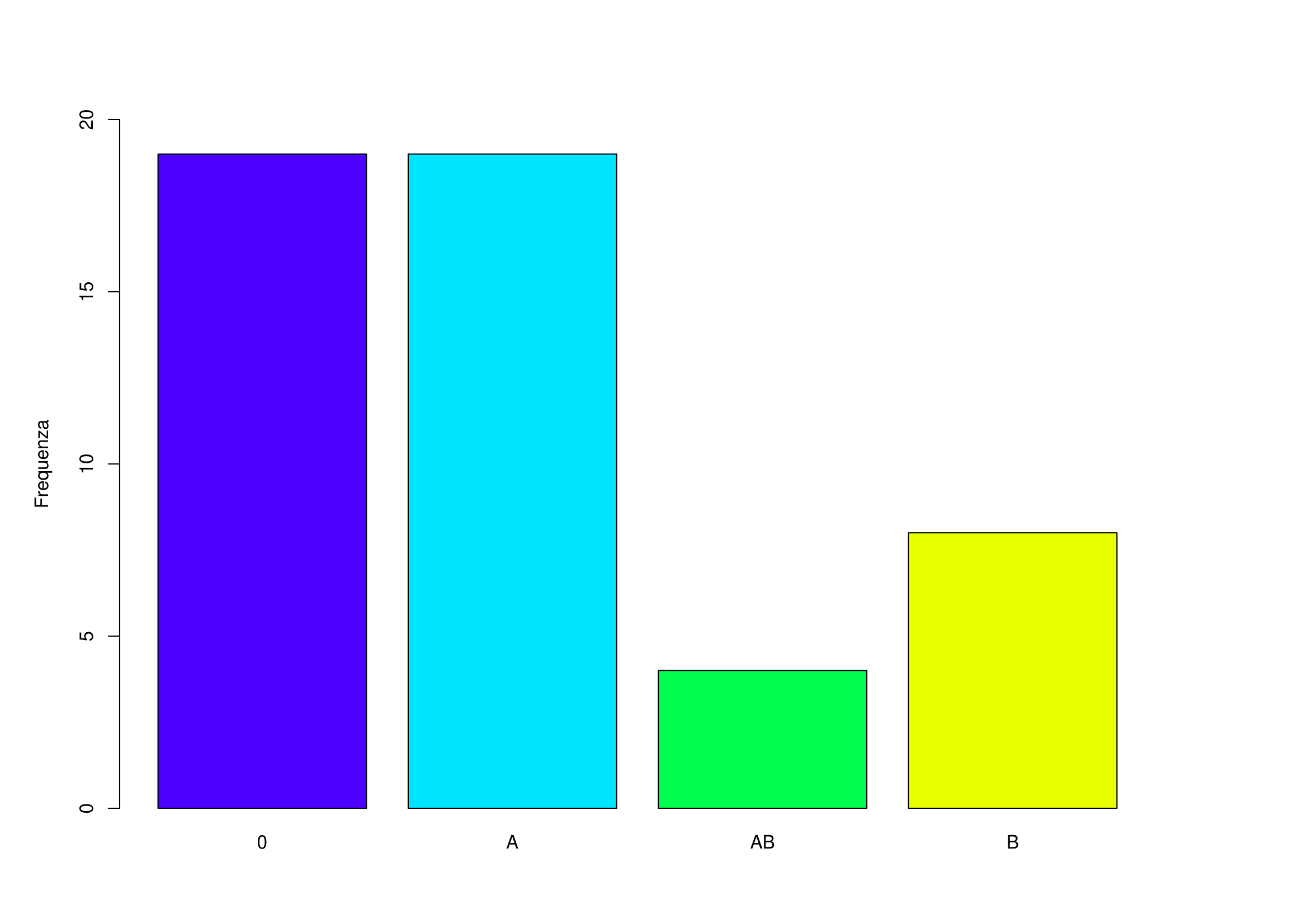
Esercizio 1.10
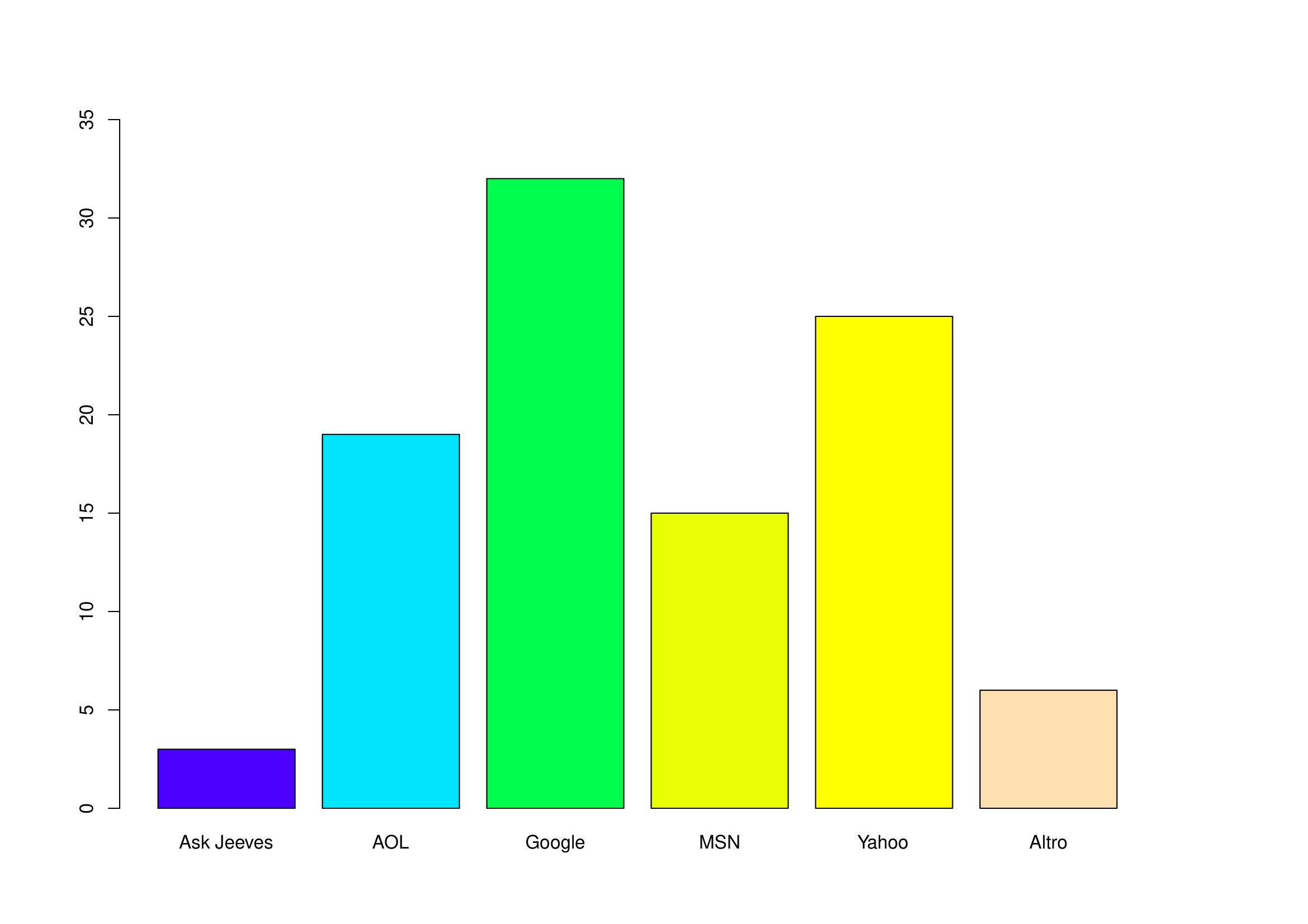
Un articolo del Wall Stree Journal del luglio 2003 discute l’influenza che Google ha avuto sul web. La tabella seguente mostra come si sono distribuite le ricerche sul web condotte nel maggio 2003 dagli utenti americani di Internet (valori percentuale).
| Fonte | Percentuale (%) |
|---|---|
| Ask Jeeves | 3 |
| AOL Time Warner | 19 |
| 32 | |
| MSN-Microsoft | ??? |
| Yahoo | 25 |
| Altro | 6 |
Completare la tabella inserendo il valore mancante.
Di che tipo di carattere si tratta? Quali sono le unità statistiche di riferimento?
Rappresentare graficamente la distribuzione mediante un diagramma a barre.
Esercizio 1.11
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.47)
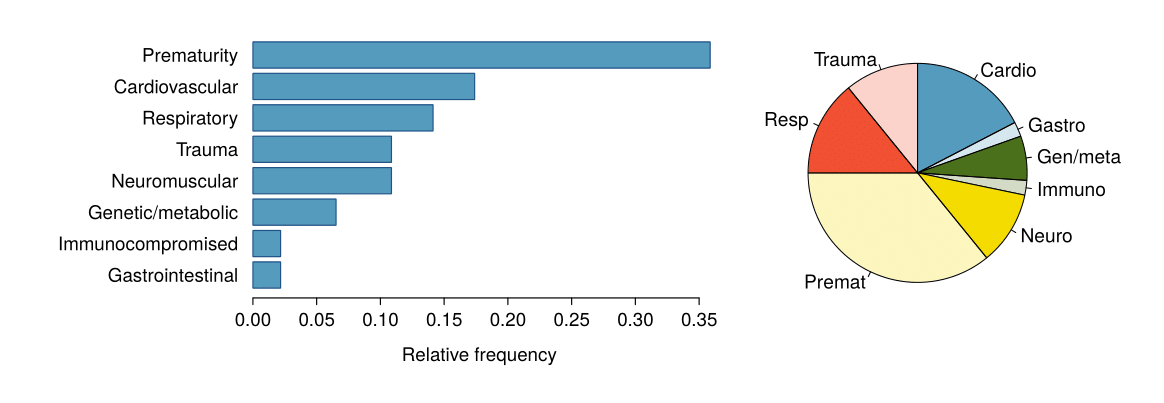
Nei grafici seguenti viene rappresentata la distribuzione della condizione medica precedente di bambini arruolati in uno studio sulla durata ottimale di una terapia antibiotica per la tracheite.
Quali sono le caratteristiche che emergono dal diagramma a barre ma non dal diagramma a torta?
Quali sono le caratteristiche che emergono dal diagramma a torta ma non dal diagramma a barre?
Quale grafico è preferibile per rappresentare questo tipo di dati?
Soluzione
Nel diagramma a barre è evidente l’ordinamento tra le categorie e vengono rappresentate le frequenze relative.
Il diagramma a torta non aggiunge altre informazioni utili a quanto mostrato nel diagramma a barre.
In genere il diagramma a barre è preferibile sia per i motivi espressi al punto a. sia perchè il confronto tra lunghezze è più immediato rispetto a quello tra aree.
1.4 Rappresentazioni grafiche e numeriche per caratteri quantitativi
Esercizio 1.12
Con riferimento all’Esercizio 1.7
Costruire l’istogramma della distribuzione.
Calcolare la media (ovvero la concentrazione media di ozono a Los Angeles nei 25 giorni considerati).
Soluzione
- Calcoliamo innanzi tutto le ampiezze delle classi e le densità di frequenza.
| concentrazione | freq. assolute \(n_i\) | ampiezze \(d_i\) | densità di frequenza \(h_i=\frac{n_i}{d_i}\) |
|---|---|---|---|
| (0,2] | 3 | 2 | 1.50 |
| (2,4] | 6 | 2 | 3.00 |
| (4,7] | 11 | 3 | 3.67 |
| (7,10] | 5 | 3 | 1.67 |
- Utilizzando la formula della media \[\begin{align} \bar{x} &= \frac{x_1 + x_2 + \cdots + x_i + \cdots + x_n }{n} = \\ &= \frac{6.2 +9.1 +2.4 +3.6 +1.9 + \cdots + 6.2}{25} = \frac{125.7}{25} = 5.028\end{align}\]
Esercizio 1.13
Nella seguente tabella sono riportati i tempi di funzionamento, in mesi prima dell’esaurimento, di un campione di batterie.
| Durata (mesi) | Frequenza |
|---|---|
| \([1,3)\) | 10 |
| \([3,6)\) | 42 |
| \([6,12)\) | 38 |
| \([12,24)\) | 8 |
Rappresentare graficamente la distribuzione.
Definire e individuare la classe modale.
Soluzione
- Calcoliamo innanzi tutto le ampiezze delle classi e le densità di frequenza.
| Durata (mesi) | Freq. \(n_i\) | Ampiezza \(d_i\) | Densità \(h_i=\frac{n_i}{d_i}\) |
|---|---|---|---|
| \([1,3)\) | 10 | 2 | 5.00 |
| \([3,6)\) | 42 | 3 | 14.00 |
| \([6,12]\) | 38 | 6 | 6.33 |
| \([12,24)\) | 8 | 12 | 0.67 |
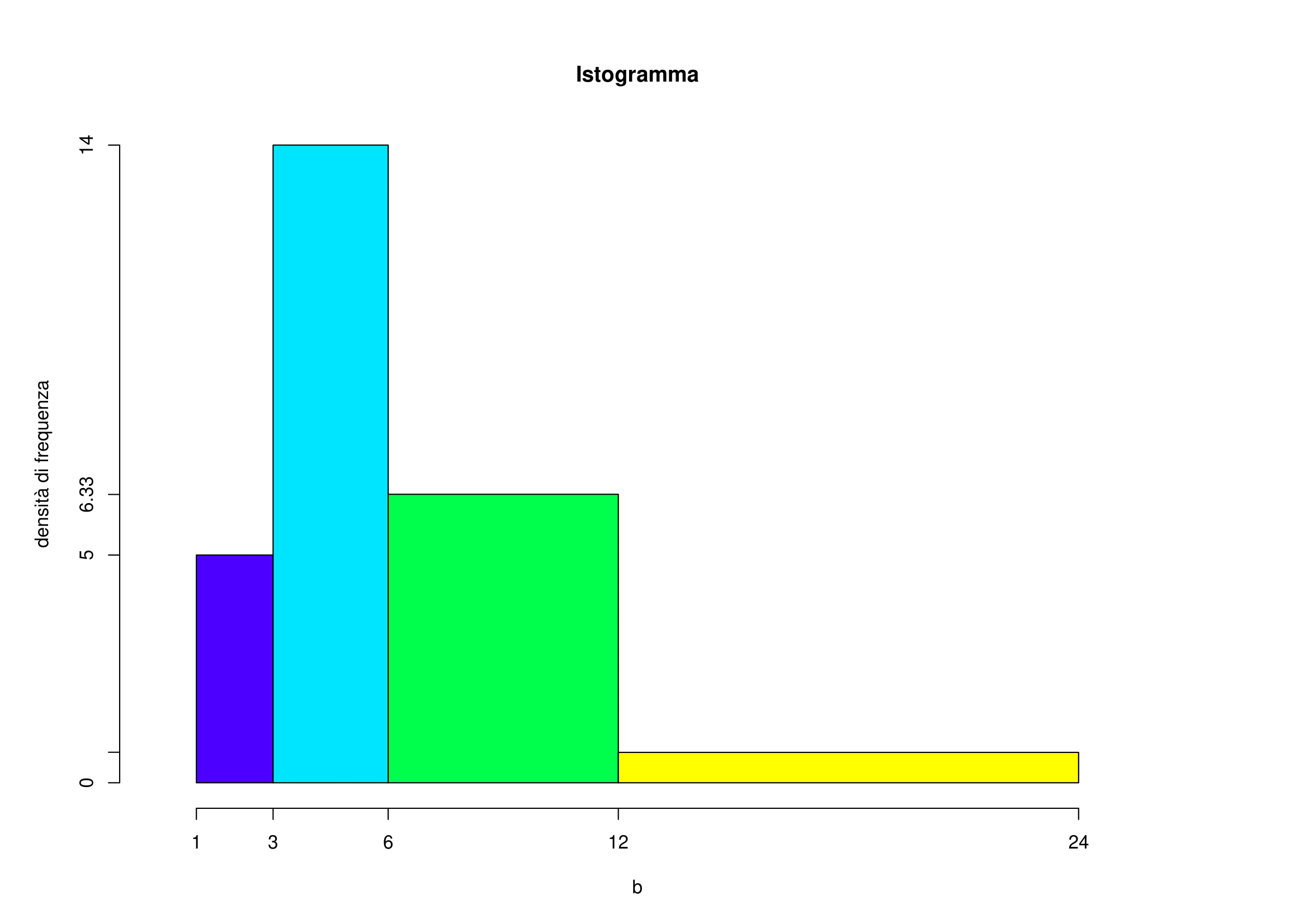
- La classe modale è la classe alla quale risulta associata la massima densità di frequenza: in questo caso è la classe \([3,6)\).
Esercizio 1.14
In un’indagine sui consumi delle auto a benzina nei percorsi urbani è stata osservata la distribuzione del numero di litri consumati per 100 Km riportata nella seguente tabella.
| Consumo (litri) | Frequenza |
|---|---|
| \([5, 10)\) | 15 |
| \([10, 15)\) | 45 |
| \([15, 25)\) | 38 |
| \([25, 35)\) | 2 |
Rappresentare graficamente la distribuzione.
Definire e individuare la classe modale.
Soluzione
- Calcoliamo innanzi tutto le ampiezze delle classi e le densità di frequenza.
| Consumo (litri) | Freq. \(n_i\) | Ampiezza \(d_i\) | Densità di Frequenza \(h_i=\frac{n_i}{d_i}\) |
|---|---|---|---|
| \([5, 10)\) | 15 | 5 | 3 |
| \([10, 15)\) | 45 | 5 | 9 |
| \([15, 25)\) | 38 | 10 | 3.8 |
| \([25, 35)\) | 2 | 10 | 0.2 |
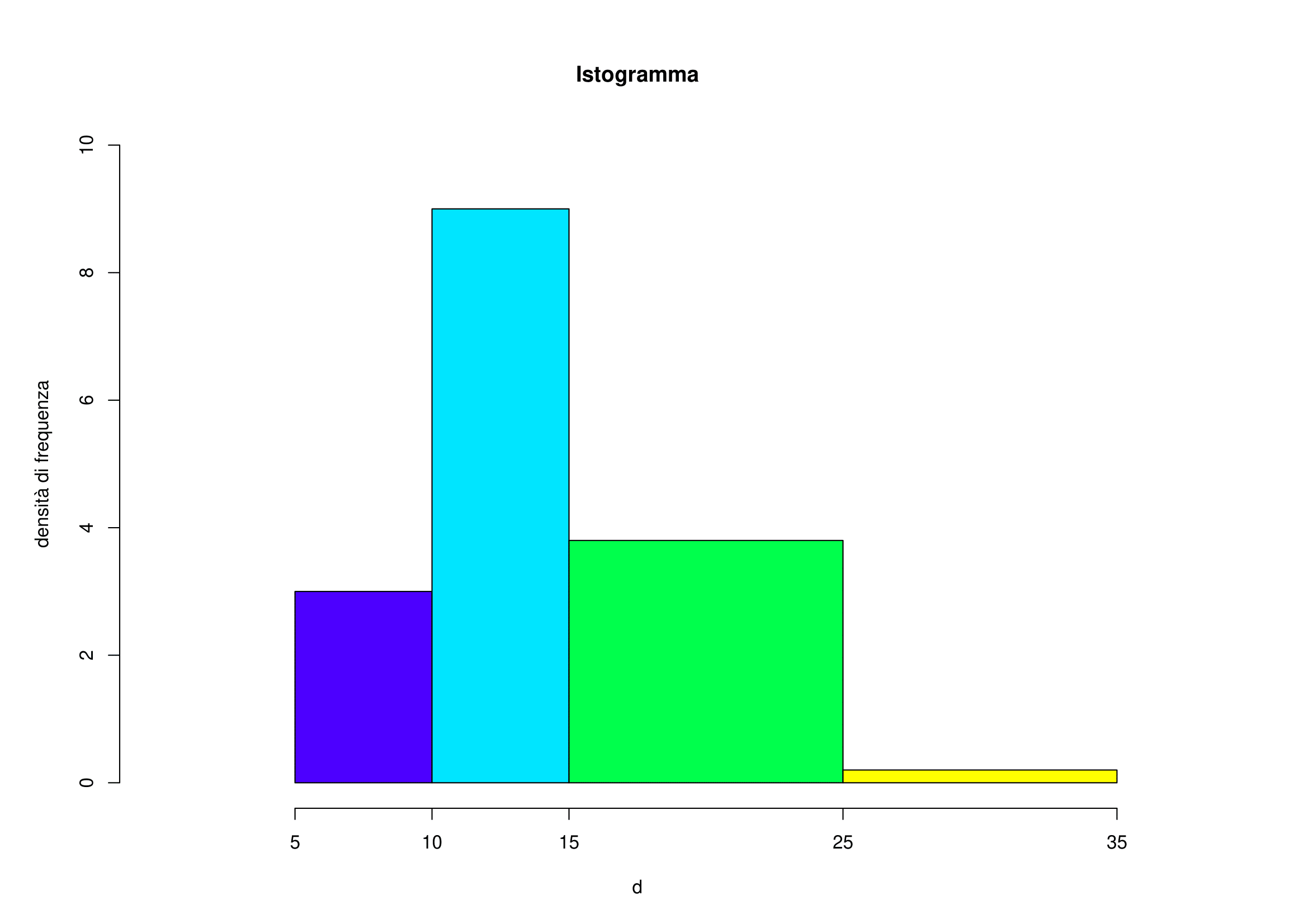
- La classe modale è la classe alla quale risulta associata la massima densità di frequenza: in questo caso è la classe \([10,15)\).
Esercizio 1.15
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.9)
È stata condotta un’indagine su 218 studenti della Duke University che hanno frequentato un corso di statistica di base nella primavera del 2012. Tra le molte altre domande, gli studenti sono stati interrogati sulla loro media dei voti (GPA) e sul numero di ore di studio settimanali (Study hours/week). Il seguente grafico a dispersione sotto mostra la relazione tra le due variabili.
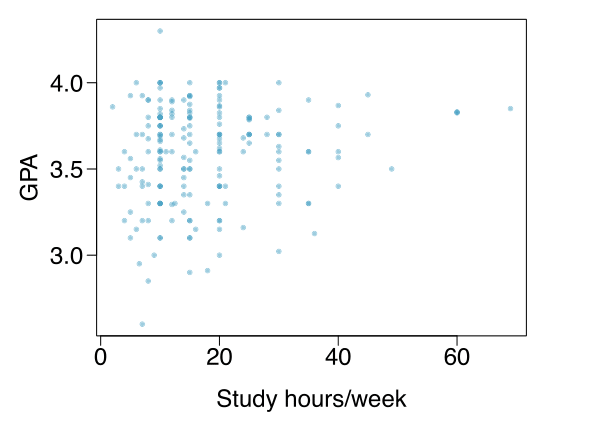
Quale è la variabile esplicativa e quale è la variabile risposta?
Descrivere la relazione tra le due variabili. Mettere in evidenza osservazioni anomale, se ci sono.
Si tratta di un esperimento o uno studio osservazionale?
Possiamo concludere che all’aumentare del numero di ore di studio aumenta la media dei voti?
Soluzione
La variabile esplicativa è il numero di ore di studio settimanali mentre la variabile risposta è la media dei voti.
C’è una relazione leggermente positiva tra le due variabili. Uno studente ha una media superiore a 4.0, quindi, si tratta di un errore. Ci sono anche alcuni studenti che riportano un numero di ore di studio settimanale inusualmente alto (60 e 70 ore/settimana). Inoltre, la variabilità della variabile media dei voti sembra essere maggiore per gli studenti che studiano meno rispetto a quelli che studiano di più. Poiché aumenta la dispersione al crescere del numero di ore di studio, è difficile valutare la forza della relazione e anche la variabilità su diversi numeri di ore di studio.
Si tratta di uno studio osservazionale
Proprio perché si tratta di uno studio osservazionale, non si può stabilire una relazione causale tra ore di studio e media dei voti.
Esercizio 1.16
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.23)
Sono stati raccolti dei dati che riguardano la durata di vita (anni) e la durata della gestazione (giorni) per 62 mammiferi. Si risponda alle seguenti domande, in base al grafico a dispersione della durata di vita rispetto ai giorni di gestazione, sotto riportato:
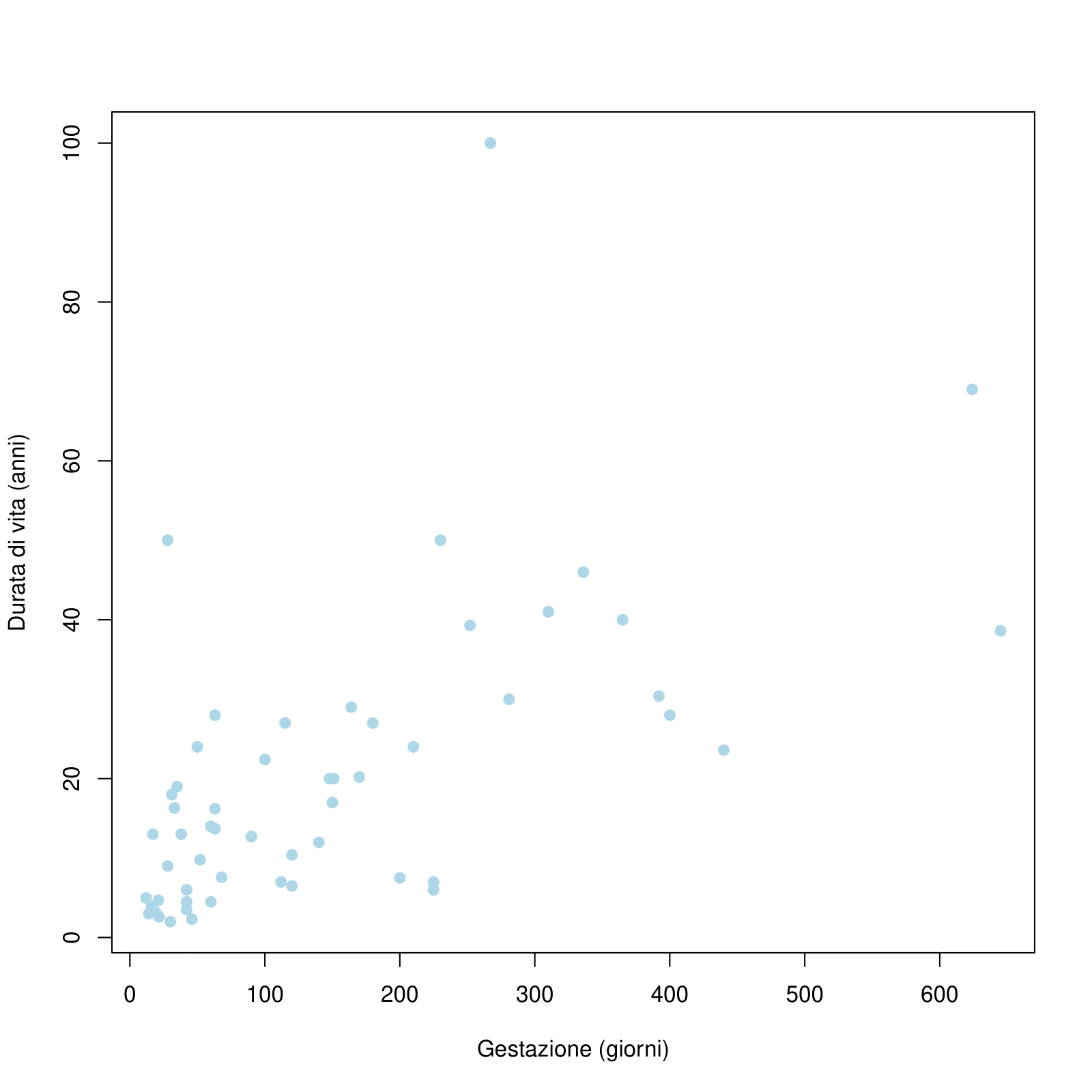
Che tipo di associazione c’è tra durata della vita e durata della gestazione?
Che tipo di associazione ci si potrebbe aspettare se gli assi del plot fossero invertiti?
La durata di vita e la durata di gestazione sono indipendenti? Motivare la risposta.
Esercizio 1.17
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.25)
Indicare quale dei seguenti grafici mostra
associazione positiva
associazione negativa
assenza di associazione
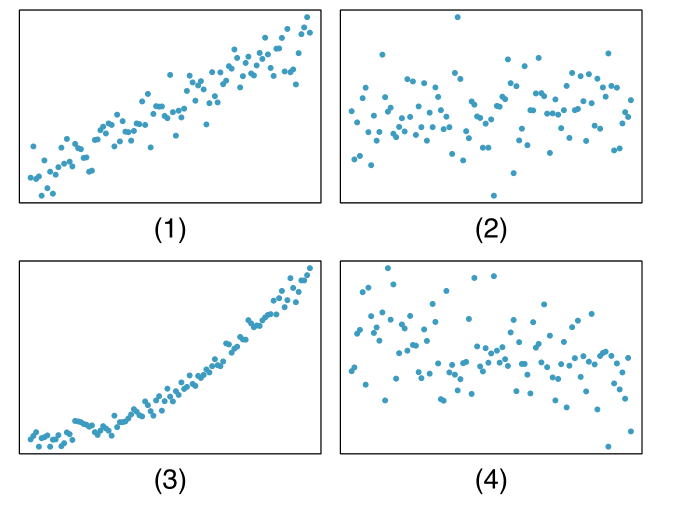
Determinare inoltre se le associazioni positive e negative sono lineari o non lineari.
Esercizio 1.18
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.29)
È stata condotta un’indagine per studiare l’abitudine al fumo dei residenti UK. Di seguito sono riportati gli istogrammi relativi alle distribuzioni di numero di sigarette fumate durante i giorni della settimana (amount weekdays) e durante il fine settimana (amount weekends), escludendo i non fumatori. Descrivere le due distribuzioni e confrontarle.
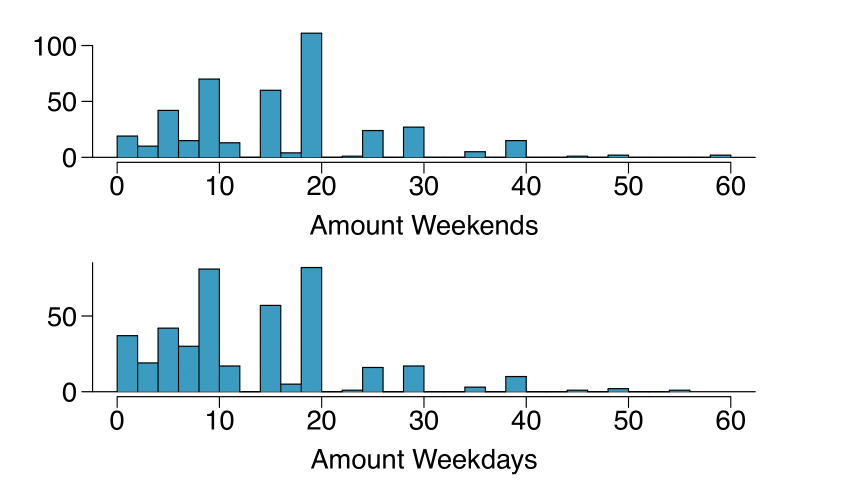
Soluzione
Entrambe le distribuzioni sono asimmetriche a destra e bimodali: una moda in corrispondenza di 10 sigarette e l’altra di 20 sigarette; ciò è dovuto al fatto che gli intervistati tendono a rispondere arrotondando a mezzo pacchetto o un pacchetto intero. La mediana di ciascuna distribuzione è tra 10 e 15 sigarette. In entrambi il range interquartile ha un’ampiezza intorno a 10-15. Ci sono delle osservazioni anomale in corrispondenza di 40 sigarette al giorno. Inoltre, sembra che coloro che fumano solo poche sigarette (da 0 a 5) fumano di più durante la settimana che durante il fine settimana.
Esercizio 1.19
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.37)
Descrivere le tre distribuzioni degli istogrammi riportati di seguito e associare ciascun istogramma al boxplot corrispondente.
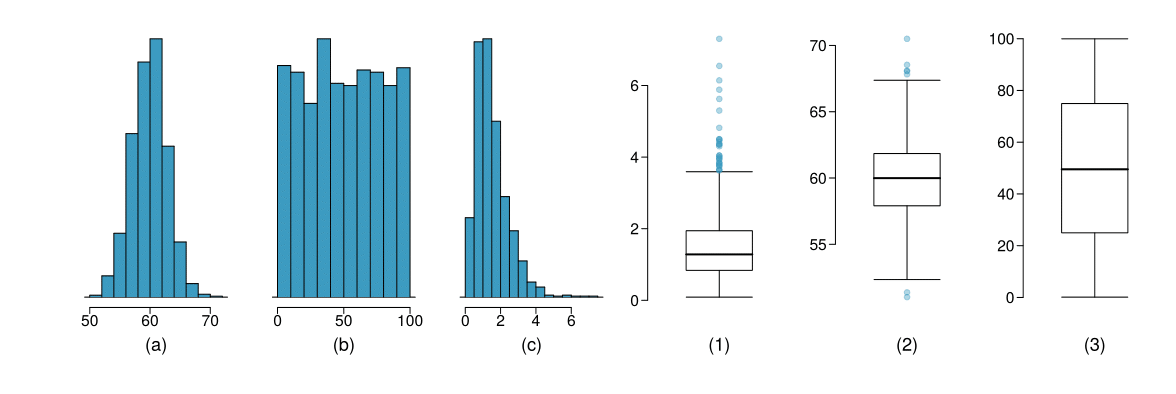
Soluzione
Distribuzione unimodale, simmetrica, centrata intorno al valore 60 con una standard deviation approssimativamente pari a 3. Il boxplot corrispondente è il numero 2.
Distribuzione simmetrica e approssimativamente uniforme tra 0 e 100. Il boxplot corrispondente è il numero 3.
Distribuzione asimmetrica a destra, unimodale, centrata attorno al valore 1.5 con la maggior parte delle osservazioni tra 0 e 3 e una frazione molto piccola di osservazioni al di sopra di 5.
Esercizio 1.20
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.39)
Confrontare i due grafici riportati sotto. Quali caratteristiche della distribuzione si possono rilevare dall’istogramma e non dal boxplot? Quali caratteristiche sono evidenti nel boxplot e non nell’istogramma?
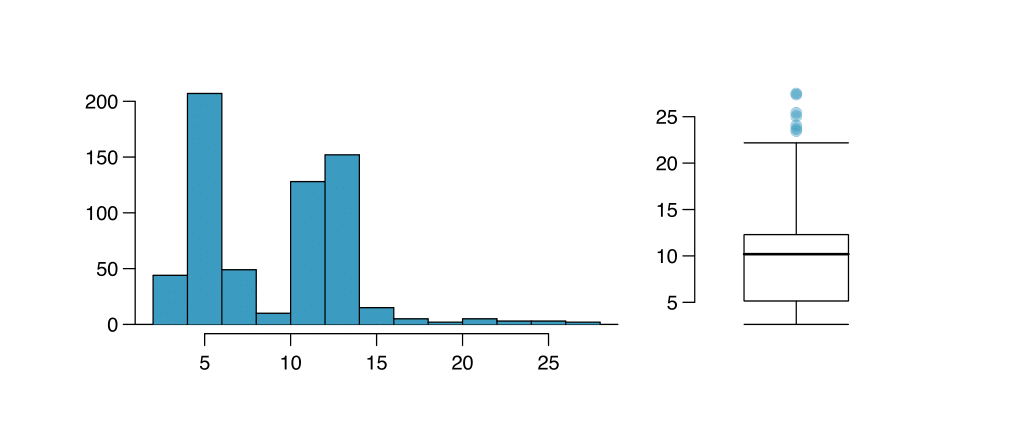
Esercizio 1.21
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.43)
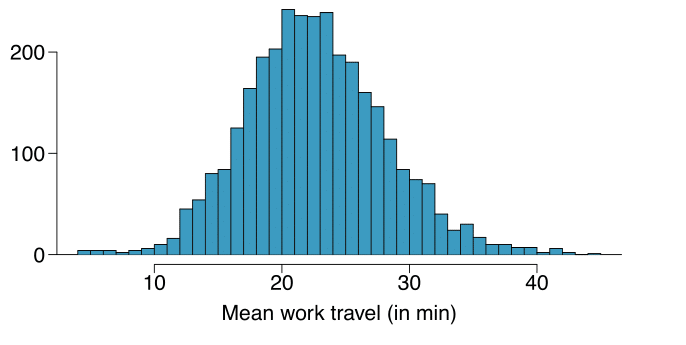
L’istrogramma riportato sotto è relativo alla distribuzione dei tempi medi di pendolarismo (mean work travel) in 3,143 contee US nel 2010. Descrivere la distribuzione e discutere se una trasformazione logaritmica può essere indicata per questi dati.
Soluzione
La distribuzione è unimodale e simmetrica con media pari a circa 25 minuti e deviazione standard pari a circa 5 minuti. Non sembra esserci nessuna contea con tempi particolarmente alti o bassi. Poichè la distribuzione è già unimodale e simmetrica, una trasformazione logaritmica non è necessaria.
1.5 Moda, media, mediana e quantili
Esercizio 1.22
I dati seguenti riguardano il tempo impiegato per prepararsi al mattino:
| 52 | 44 | 43 | 44 | 40 | 29 | 31 | 39 | 35 | 39 |
Di che tipo di carattere si tratta?
Calcolare la moda di questa distribuzione;
Calcolare la media di questa distribuzione;
Calcolare la mediana;
Calcolare il primo e il terzo quartile di questa distribuzione.
Soluzione
Il tempo impiegato per prepararsi è un carattere quantitativo continuo.
Costruendo la tabella di frequenza corrispondente alla distribuzione unitaria dei tempi, ci accorgiamo che le modalità 39 e 44 si presentano entrambe due volte (le altre tutte una volta), quindi la distribuzione ha due mode: 39 e 44.
Calcoliamo la media aritmetica: \[\bar{x} = \frac{52 +44 +43 +44 +40 +29 +31 +39 +35 +39}{10} = 39.6\]
Per calcolare la mediana, innanzi tutto ordiniamo le 10 osservazioni disponibili:
29 31 35 39 39 40 43 44 44 52Poi, dal momento che \(n = 10\) è pari, consideriamo le osservazioni che occupano le posizioni \(n/2\) e \(n/2+1\), cioè rispettivamente 39 e 40 e ne calcoliamo la semisomma. La mediana è quindi 39.5.
- Per calcolare il primo quartile, consideriamo la prima metà della distribuzione (costituita dalle prime 5 osservazioni) e ne calcoliamo la mediana:
Q1 = 35Dopodichè ripetiamo lo stesso procedimento sulla seconda metà della distribuzione e otteniamo
Q3 = 44Esercizio 1.23
Di seguito viene riportata la distribuzione dei rendimenti del 2003 di 9 fondi comuni specializzati in aziende di piccole dimensioni:
| 37.3 | 39.2 | 44.2 | 44.5 | 53.8 | 56.6 | 59.3 | 62.4 | 66.5 |
Di che tipo di carattere si tratta?
Di che tipo di distribuzione si tratta?
Calcolare la moda di questa distribuzione;
Calcolare la media;
Calcolare la mediana.
Soluzione
Si tratta di un carattere quantitativo continuo.
La distribuzione riportata è una distribuzione per unità.
In questo caso la moda della distribuzione non è definita in quanto ogni unità presenta una modalità distinta dalle altre, quindi ciascuna modalità si presenta con frequenza 1.
La media è pari a \[\bar{x} = \frac{37.3+ 39.2 +44.2 +44.5+ 53.8 +56.6+ 59.3+ 62.4 +66.5}{9} = 51.53\]
Per calcolare la mediana innanzi tutto ordiniamo le 9 osservazioni disponibili:
37.3 39.2 44.2 44.5 53.8 56.6 59.3 62.4 66.5
poi, dal momento che \(n = 9\) è dispari, la mediana è definita come l’osservazione che occupa la posizione \((n+1)/2 = 5\), ovvero \(53.8\).
Esercizio 1.24
Di seguito sono riportate gli importi (in dollari) relativi alle bollette mensili pagate da un campione casuale di 50 utenti di provider commerciali di Internet nell’agosto del 2002:
| 20 | 40 | 22 | 22 | 21 | 21 | 20 | 10 | 20 | 20 |
| 20 | 13 | 18 | 50 | 20 | 18 | 15 | 8 | 22 | 26 |
| 22 | 10 | 20 | 22 | 22 | 21 | 15 | 23 | 30 | 12 |
| 9 | 20 | 40 | 22 | 29 | 19 | 15 | 20 | 20 | 20 |
| 20 | 15 | 19 | 21 | 14 | 22 | 21 | 35 | 20 | 22 |
Di che carattere si tratta?
Costruire la distribuzione in classi di questo carattere, utilizzando le seguenti classi: \((7.96,18.5]\), \((18.5,29]\), \((29,39.5]\) e \((39.5,50]\);
Determinare la classe modale.
Soluzione
Si tratta di un carattere quantitativo continuo.
La distribuzione di frequenza in classi è
Bollette (dollari) Freq. assoluta \(n_i\) Ampiezza \(d_i\) Densità \(h_i=\frac{n_i}{d_i}\) (7.96,18.5] 13 10.54 1.23 (18.5,29] 32 10.50 3.05 (29,39.5] 2 10.50 0.19 (39.5,50] 3 10.50 0.29 La classe modale è la classe alla quale è associata la massima densità di frequenza (notare che le ampiezze delle classi non sono tutte uguali), ovvero la classe (18.5,29].
Esercizio 1.25
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.41)
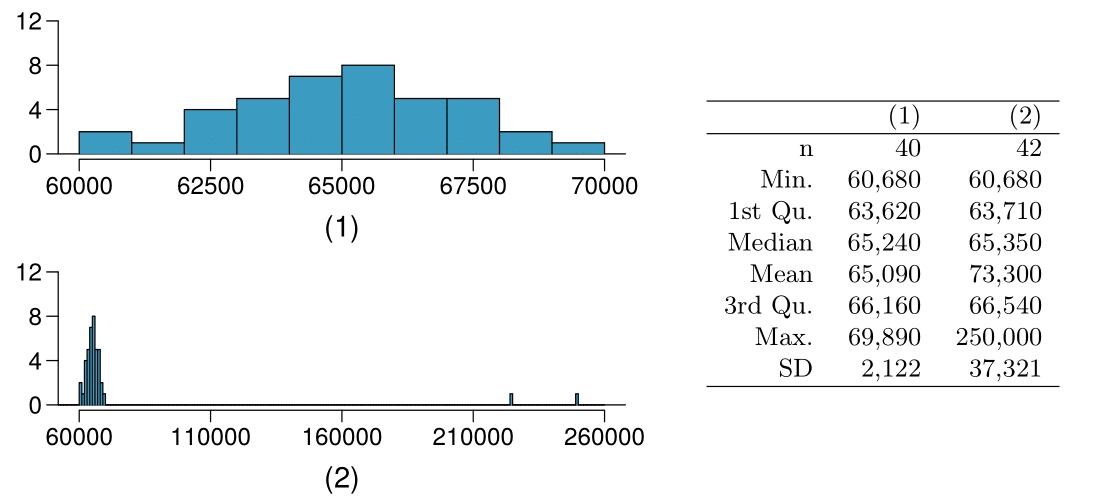
Il primo istogramma rappresentato di seguito mostra la distribuzione dei redditi annui di 40 clienti di un bar. Due nuovi clienti hanno rispettivamente un reddito annuo di 225000 \(\$\) e 250000 \(\$\). Il secondo istogramma mostra la nuova distribuzione e la tabella riporta alcune statistiche riassuntive.
Quale indice rappresenta meglio il tipico reddito dei 42 clienti? La media o la mediana? Cosa rivela questa osservazione rispetto alla robustezza di queste due misure?
Quale indice rappresenta meglio la variabilità nella distribuzione del reddito dei 42 clienti? La deviazione standard o il range interquartilico? Cosa rivela questa osservazione rispetto alla robustezza di queste due misure?
Esercizio 1.26
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.33)
Per ciascuna parte, confrontare le distribuzioni (1) e (2) basandosi su mediane e range interquartile. Non è necessario calcolare queste statistiche, ma semplicemente confrontarle, spiegare il proprio ragionamento.
(1) 3, 5, 6, 7, 9
(2) 3, 5, 6, 7, 20(1) 3, 5, 6, 7, 9
(2) 3, 5, 8, 7, 9(1) 1, 2, 3, 4, 5
(2) 6, 7, 8, 9, 10(1) 0, 10, 50, 60, 100
(2) 0, 100, 500, 600, 1000
Soluzione
Entrambe le distribuzioni hanno la stessa mediana e stesso range interquartile
La seconda distribuzione ha una mediana più alta e un range interquartile più alto
La seconda distribuzione ha una mediana più alta e stesso range interquartile.
La seconda distribuzione ha una mediana più alta e un range interquartile più ampio.
1.6 Gli indici di variabilità
Esercizio 1.27
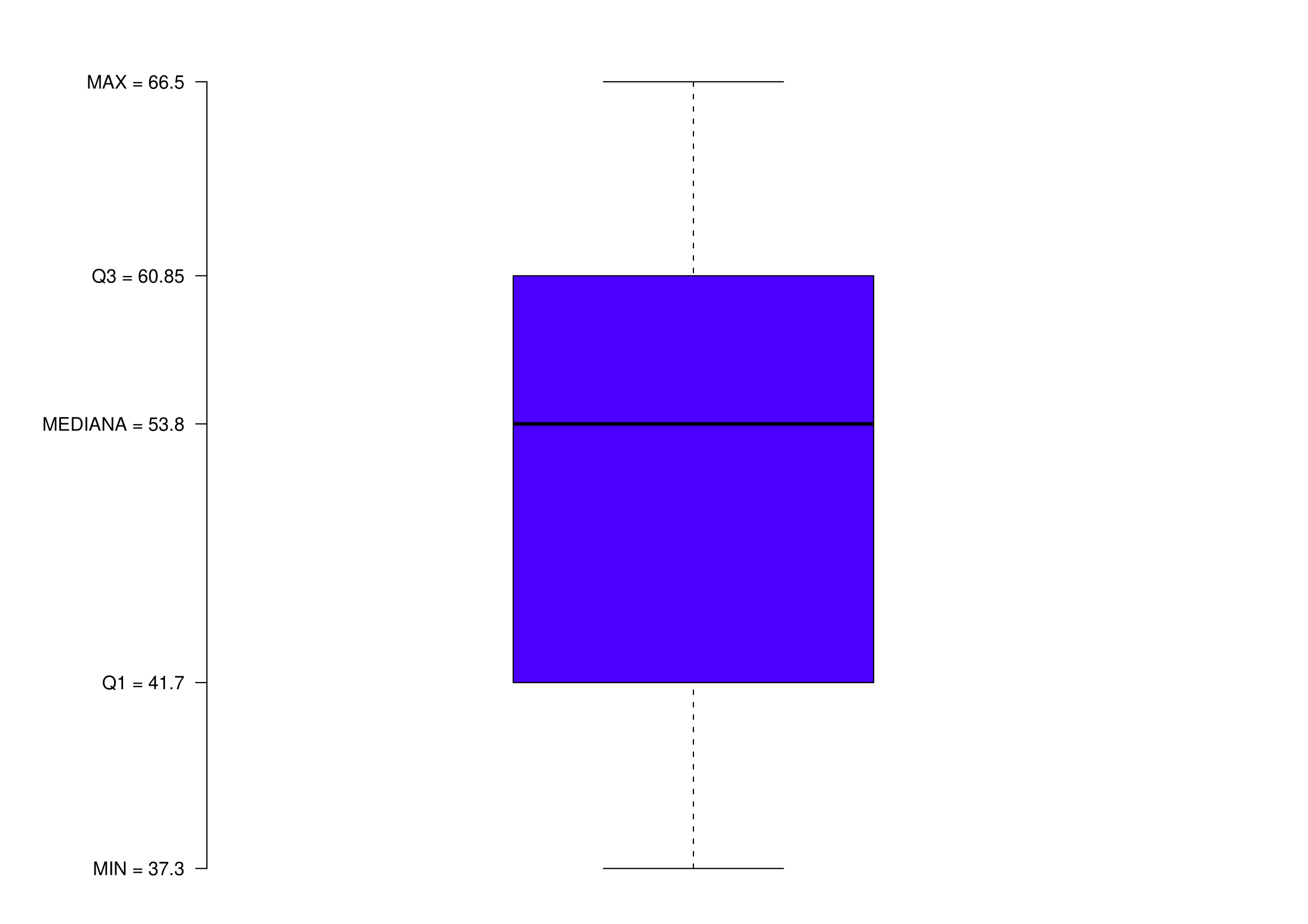
Riprendendo l’Esercizio 1.23, consideriamo i rendimenti del 2003 per i fondi comuni ad alto rischio specializzati in aziende di piccole dimensioni.
Definire i 5 numeri di sintesi della distribuzione;
Disegnare il boxplot della distribuzione;
Calcolare la varianza e la deviazione standard della distribuzione;
Calcolare il coefficiente di variazione.
Soluzione
- I cinque numeri di sintesi sono:
Minimo: 37.3,
Primo Quartile: 41.7,
Mediana: 53.8,
Terzo Quartile:60.85,
Massimo: 66.5.- Ecco il boxplot corrispondente:
Ricordando che la media è pari a \(\bar{x} = 51.53\), calcoliamo la varianza, ovvero: \[\begin{aligned} s^2 &=& \frac{\sum\limits_{i=1}^n (x_i -\bar{x})^2}{n-1} = 111.395\end{aligned}\] La deviazione standard è quindi \[s = \sqrt{s^2} = \sqrt{111.395} = 10.554\]
Il coefficiente di variazione è \[CV = \frac{s}{\bar{x}} \cdot 100 = 0.205 \cdot 100 = 20.5 \%\]
Esercizio 1.28
Il direttore operativo di un’azienda di consegna di pacchi sta pensando all’acquisto di un nuovo parco di autocarri. Quando i pacchi sono depositati negli autocarri in attesa della consegna, si deve tenere conto di 2 vincoli principali: il peso (in chilogrammi) e il volume (in metri cubi) di ciascun pacco. Si considera un campione di 200 pacchi per cui si osserva un peso medio di 9 Kg, con uno scarto quadratico medio di 1.5 Kg, e un volume medio di 2.7 metri cubi, con uno scarto quadratico medio di 0.6 metri cubi. Come è possibile confrontare la variabilità del peso e del volume?
Soluzione
Peso e volume sono espressi in unità di misura diverse: si deve quindi prendere in considerazione la variabilità relativa delle osservazioni. Per il peso, il coefficiente di variazione è \[CV_{P}= \frac{s}{\bar{x}} \cdot 100 = \frac{1.5}{9} \cdot 100=16.67\%\] per il volume è pari a \[CV_{V}=\frac{s}{\bar{x}} \cdot 100 = \frac{0.6}{2.7}\cdot100=22.22\%\] Pertanto rispetto alla media, il volume dei pacchi più variabile del peso.
Esercizio 1.29
Consideriamo la distribuzione in classi ricavata all’Esercizio 1.24
| Classi | \(n_{i}\) |
|---|---|
| (7.96,18.5] | 13 |
| (18.5,29] | 32 |
| (29,39.5] | 2 |
| (39.5,50] | 3 |
Calcolare varianza e deviazione standard di questo carattere.
Soluzione
Per calcolare la varianza abbiamo bisogno delle quantità riportate nella seguente tabella (\(\tilde{x}_i\) indica il valore centrale della classe i-esima):
| Classi | \(n_{i}\) | \(\tilde{x}_i\) | \(f_{i}\) | \(\tilde{x}_i^2\) | \(\tilde{x}_i^2 f_{i}\) |
|---|---|---|---|---|---|
| \((7.96,18.5]\) | 13 | 13.23 | 0.26 | 175.0329 | 45.51 |
| \((18.5,29]\) | 32 | 23.75 | 0.64 | 564.0625 | 361 |
| \((29,39.5]\) | 2 | 34.25 | 0.04 | 1173.0625 | 46.92 |
| \((39.5,50]\) | 3 | 44.75 | 0.06 | 2002.5625 | 120.15 |
| Totale | 50 | 1 | 573.58 |
La media è pari a \[\bar{x} = (13.23 \cdot 0.26)+(23.75 \cdot 0.64)+(34.25 \cdot 0.04)+(44.75 \cdot 0.06)=22.69\] e quindi la varianza è \[s^2=\frac{n}{n-1}\left(\sum_{i}\tilde{x}_{i}^{2}f_{i}-\bar{x}^{2}\right) = \frac{50}{49}\left(573.58 - (22.69)^2\right) = 59.94\] e la deviazione standard \[s = \sqrt{s^2} = \sqrt{59.94} = 7.74\]
Esercizio 1.30
Riprendendo dall’Esercizio 1.13 i dati sui tempi di funzionamento di un campione di batterie,
Calcolare il valore di opportuni indici di posizione e di variabilità.
Come variano gli indici di posizione e di variabilità se il tempo di funzionamento è espresso in settimane (assumendo, per approssimazione, che ciascun mese sia composto esattamente da quattro settimane)?
Se si utilizza il coefficiente di variazione per misurare la variabilità, vi è differenza se si utilizza un’unità di misura diversa (mesi o settimane)? Motivare la risposta.
Soluzione
Calcoliamo innanzi tutto le quantità riportate in tabella:
Durata (mesi) Frequenza \(\tilde{x}_i\) \(f_i\) \(\tilde{x}_i^2\) \(\tilde{x}_i^2 f_{i}\) (1,3] 10 2 0.10 4 0.4 (3,6] 42 4.5 0.43 20.25 8.71 (6,12] 38 9 0.39 81 31.59 (12,24] 8 18 0.08 324 25.92 Totale 98 1 66.62
La media è \[\bar{x} = (2 \cdot 0.1)+(4.5 \cdot 0.43)+(9 \cdot 0.39)+(18 \cdot 0.08)=7.085\] e la varianza \[s^2=\frac{n}{n-1}\left(\sum_{i}\tilde{x}_{i}^{2}f_{i}-\bar{x}^{2}\right) = \frac{98}{97}\left(66.62 - (7.085)^2\right) = 16.59\] e la deviazione standard \[s = \sqrt{s^2} = \sqrt{16.59} = 4.07\]
Esprimere il tempo in settimane anzichè in mesi significa cambiare unità di misura. Per le proprietà della media (linearità) sappiamo che per calcolare la durata media in settimane è sufficiente moltiplicare la durata media in mesi per l’opportuno coefficiente (4), ovvero: \[\bar{x}_{settimane} = \bar{x}_{mesi} \cdot 4 = 7.085 \cdot 4 = 28.34\] Per quanto riguarda la varianza abbiamo invece: \[s^2_{settimane} = s^2_{mesi} \cdot 4^2 = 16.59 \cdot 16 = 265.44\]
In entrambi i casi il coefficiente di variazione è pari a \[CV = s / \bar{x} \cdot 100= 4.07 /7.085 \cdot 100= 0.57 \cdot 100 = 57 \%\] perchè non dipende dall’unità di misura.
Esercizio 1.31
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.31)
Si consideri un campione casuale di 5 fumatori per i quali sono state rilevate le variabili riportate nella seguente tabella:
| Sesso | Età | Stato civile | Reddito lordo | quantità (weekend) | quantità (giorni feriali) |
|---|---|---|---|---|---|
| F | 51 | Coniugato/a | 2.600-5.200 | 20 | 20 |
| M | 24 | Celibe/Nubile | 10.400-15.600 | 20 | 15 |
| F | 33 | Coniugato/a | 10.400-15.600 | 20 | 10 |
| F | 17 | Celibe/Nubile | 2.600-5.200 | 20 | 15 |
| F | 76 | Vedovo/a | 2.600-5.200 | 20 | 20 |
Determinare la quantità media di sigarette fumate nei giorni feriali e nei weekend dai 5 fumatori.
Determinare la deviazione standard della quantità di sigarette fumate nei giorni feriali e nei weekend dai 5 fumatori. La variabilità è maggiore nei weekend o nei giorni feriali?
1.7 Proprietà delle medie
Esercizio 1.32
A 10 studenti universitari viene chiesto il numero di esami superati in un anno. La distribuzione unitaria è la seguente:
4 0 7 1 5 5 0 2 0 12Calcolare il numero medio di esami;
Se alle informazioni fornite dai 10 studenti si aggiungono quelle di altri 20 studenti, la media aritmetica risulta pari a 5. Determinare la media del numero di esami superati dal secondo gruppo di 20 studenti.
Soluzione
Calcoliamo la media aritmetica del numero di esami: \[\bar{x}_A = \frac{4 +0 +7 +1+ 5+ 5+ 0+ 2+ 0+ 12 }{10} =3.6\]
Se indichiamo con \(\bar{x}_{TOT} = 5\) il numero medio di esami del campione complessivo, con \(\bar{x}_A\) il numero medio di esami nel primo gruppo di numerosità \(n_A=10\) e con \(\bar{x}_B\) il numero medio di esami nel secondo gruppo di numerosità \(n_B=20\), otteniamo: \[\bar{x}_{TOT} = \frac{n_A \cdot \bar{x}_A + n_B \cdot \bar{x}_B }{n_A+ n_B} = \frac{10\cdot3.6+20\cdot\bar{x}_B}{10+20} = 5\] In questo caso però conosciamo la media complessiva e dalla formula precedente possiamo ricavare quella del secondo gruppo in questo modo: \[\bar{x}_B = \frac{5\cdot30-10\cdot3.6}{20} = 5.7\]
Esercizio 1.33
Un uomo d’affari nell’ultimo mese è andato in viaggio a Londra per 10 volte. Il costo medio del biglietto aereo è 120, con una varianza pari a 7. Se l’uomo avesse prenotato tutti i voli da Londra, sapendo che il cambio è 1 euro = 0.87 sterline e che c’è un costo fisso della commissione pari a una sterlina per ciascun cambio, quanto avrebbe speso? Calcolare il costo medio in sterline e la varianza.
Esercizio 1.34
(dal libro di testo OpenIntro Statistics di Diez et al., es. 1.27)
In una classe di 25 studenti, 24 hanno svolto un esame in classe e un solo studente è stato sottoposto a una prova di recupero il giorno successivo. Il professore ha valutato il primo blocco di esami, per i quali il punteggio medio è risultato di 74 punti con una deviazione standard di 8.9 punti. La prova di recupero dello studente del giorno dopo ha riportato un punteggio di 64 punti.
Il punteggio del nuovo studente fa aumentare o diminuire il punteggio medio?
Quale è la nuova media?
Il punteggio del nuovo studente fa aumentare o diminuire la deviazione standard?
Soluzione
Il punteggio del nuovo studente fa diminuire il punteggio medio.
La media complessiva si ottiene come media ponderata della media dei 24 studenti e del nuovo punteggio con pesi pari a 24 e 1 rispettivamente: \((24*74+1*64)/(24+1) = 73.6\).
Il punteggio del nuovo studente fa aumentare la deviazione standard, perchè dista dalla media precendente più di una deviazione standard.
1.8 I numeri indice
Esercizio 1.35
Nella tabella sono riportate le quantità di acciaio di prima fabbricazione prodotte in Italia negli anni del periodo 1976-1981:
| Anni | Acciaio di prima fabbricazione |
|---|---|
| 1976 | 23447 |
| 1977 | 23334 |
| 1978 | 24283 |
| 1979 | 24250 |
| 1980 | 26501 |
| 1981 | 24777 |
Calcolare il numero indice semplice con base 1976 per la produzione di acciaio nell’anno 1977 (ossia \(_{1976}I_{1977}\)) e intepretare tale indice.
Calcolare il numero indice semplice con base 1976 per la produzione di acciaio nell’anno 1980 (ossia \(_{1976}I_{1980}\)) e intepretare tale indice.
Soluzione
\(_{1976}I_{1977}=\frac{23334}{23447} 100=0.994 100=99.4 \%\) La produzione di acciaio nel 1977 ha subito un lievissimo decremento rispetto a quella dell’anno precedente: il decremento assoluto rispetto all’anno precedente è pari a 100-99.4=0.6%.
\(_{1976}I_{1980}=\frac{26501}{23447} 100=1.129 100=112.9 \%\) La produzione di acciaio nel 1980 ha subito un incremento rispetto alla produzione di acciaio nel 1976; l’incremento è del 12.9%.
Esercizio 1.36
L’Indice dei prezzi alla produzione dei prodotti industriali (base 2005 - Istat) a luglio e ad agosto 2009 è stato pari, rispettivamente, a 107.3 e 107.9. Qual è stato l’incremento percentuale che il fenomeno ha subito tra i due mesi?
Esercizio 1.37
Nel 2008 La variazione percentuale, calcolata rispetto all’anno precedente, del Prodotto Interno Lordo italiano è stata pari a \(-1.04\%\). Sapendo che nel 2008 il PIL valeva 1276439 milioni di euro, qual era il valore del PIL nel 2007?
Esercizio 1.38
Nella tabella seguente sono riportati i tassi d’inflazione (cioè le variazioni percentuali rispetto allo stesso mese dell’anno precedente) registrati ad agosto 2009 in alcune città.
| città | variazione \(\%\) |
|---|---|
| Torino | 0.0 |
| Milano | -0.6 |
| Trieste | +1.8 |
| Roma | +0.2 |
| Reggio Calabria | +1.3 |
| Bologna | -0.5 |
| Firenze | -0.5 |
Quali informazioni possiamo trarre dal confronto tra i dati? Quale è stata la città col più elevato livello dei prezzi?
Soluzione
Rispetto ad agosto 2008, tra le città considerate, Trieste è quella in cui i prezzi hanno subito una maggiore accelerazione, Milano quella in cui i prezzi sono diminuiti con più elevata velocità, mentre a Torino non è stata riscontrata alcuna variazione.
Non siamo in grado di rispondere alla seconda domanda, poichè i dati disponibili danno informazioni solo sul cambiamento che il fenomeno prezzi ha subito tra i due mesi, non sul livello.
Esercitazione 1.1
Rapporti statistici
Esercizio 1.1.1
La seguente tabella riporta i dati relativi alla raccolta (in migliaia di tonnellate) di rifiuti urbani per area geografica nell’anno 2010 (fonte Istat):
| Area Geografica | Raccolta Indifferenziata | Raccolta Differenziata | Rifiuti Ingombranti | Totale | Abitanti (migliaia) |
|---|---|---|---|---|---|
| Nord | 7167 | 7271 | 370 | 14808 | 27663 |
| Centro | 5258 | 1985 | 81 | 7324 | 11321 |
| Sud | 8133 | 2194 | 21 | 10348 | 20896 |
| Italia | 20558 | 11450 | 472 | 32480 | 59880 |
- Si determini la composizione percentuale delle varie tipologie di rifiuto per ciascuna delle aree considerate.
- Quali tra gli abitanti delle tre aree geografiche considerate tendono a produrre il maggior quantitativo di rifiuti? Si specifichi la tipologia di rapporto statistico utile a rispondere a questa domanda.
- Si riconosca la natura del rapporto statistico: \[\frac{\mathrm{rifiuti \ indifferenziati \ al \ nord}}{\mathrm{rifiuti \ indifferenziati \ al \ sud}}\] e se ne interpreti il significato.
Esercizio 1.1.2
Nella seguente tabella sono riportati:
- il numero di sportelli bancari presenti in alcune provincie lombarde e in Italia negli anni dal 2003 al 2007 (fonte Banca d’Italia);
- la superficie delle provincie lombarde considerate, espressa in \(km^2\) (fonte Istat);
- la popolazione residente nel 2003 in ciascuna provincia lombarda considerata (fonte Istat).
|
\(n°\) sportelli
|
|||||||
|---|---|---|---|---|---|---|---|
| Provincia | 2003 | 2004 | 2005 | 2006 | 2007 | Superficie | Popolazione |
| Lodi (LO) | 132 | 133 | 137 | 142 | 150 | 782.25 | 200554 |
| Milano (MI) | 2313 | 2342 | 2378 | 2458 | 2530 | 1984.39 | 3721428 |
| Pavia (PV) | 310 | 314 | 319 | 322 | 331 | 3964.73 | 497233 |
| Sondrio (SO) | 120 | 121 | 124 | 127 | 128 | 3211.3 | 177568 |
| Altre provincie | 2966 | 3030 | 3110 | 3196 | 3314 | 14919.58 | 4510862 |
| Lombardia | 5841 | 5940 | 6068 | 6245 | 6453 | 24862.85 | 9108645 |
| ITALIA | 30502 | 30946 | 31498 | 33333 | 32225 | ||
- Si riconosca la natura del rapporto statistico: \[\frac{n°\mathrm{ \ di \ sportelli \ in \ provincia \ di \ Lodi \ nel \ 2005}}{n° \mathrm{ \ di \ sportelli \ in \ Lombardia \ nel \ 2005}}\] e se interpreti il significato.
- Si riconosca la natura del rapporto statistico: \[\frac{n° \mathrm{\ di\ sportelli\ in\ provincia\ di\ Milano\ nel\ 2007}}{n° \mathrm{\ di\ sportelli\ in\ provincia\ di\ Sondrio\ nel\ 2007}}\] e se interpreti il significato.
- Relativamente all’anno 2007, utilizzando un opportuno rapporto statistico, si valuti la densità degli sportelli bancari sul territorio delle provincie di Milano e di Sondrio.
- Si ricavi il numero di sportelli bancari per mille abitanti relativamente alle provincie di Milano e di Sondrio nell’anno 2003, riconoscendo la natura del rapporto statistico utilizzato.
Soluzioni esercitazione 1.1
Esercizio 1.1.1
-
Rapporti di composizione (intravedere distribuzioni parziali):
Area Geografica Raccolta Indifferenziata Raccolta Differenziata Rifiuti Ingombranti Nord 0.4839951 0.4910184 0.0249865 Centro 0.7179137 0.2710268 0.0110595 Sud 0.7859490 0.2120216 0.0020294 Italia 0.6329433 0.3525246 0.0145320 -
Per confrontare la produzione di rifiuti è opportuno eliminare l’influenza del numero di abitanti; quindi, si utilizza un rapporto di derivazione (gli abitanti producono rifiuti) in particolare di seguito si calcolano i rifiuti prodotti ogni mille abitanti. Gli abitanti dell’Italia centrale tendono a produrre più rifiuti.
Totale Abitanti (migliaia) Rapporto di derivazione 14808 27663 0.5352999 7324 11321 0.6469393 10348 20896 0.4952144 32480 59880 0.5424182 - È un rapporto di coesistenza perché si confrontano valori associati a due modalità di uno stesso carattere, in questo caso l’area geografica. Il rapporto è pari a \(0.8812\) e indica che per ogni tonnellata (o migliaia di tonnellate) di rifiuti indifferenziati prodotta al sud vengono prodotte \(0.8812\) tonnellate di rifiuti indifferenziati al nord.
Esercizio 1.1.2
- Lodi è in Lombardia, quindi gli sportelli di Lodi sono parte degli sportelli della Lombardia, rapporto di composizione. \[\frac{137}{6068}=0.0226\] Gli sportelli della provincia di Lodi nel 2005 costituivano il \(2.26\%\) degli sportelli di tutta la Lombardia.
-
Milano e Sondrio sono due province distinte, rapporto di coesistenza. Nel 2007, per ogni sportello nella provincia di Sondrio ce ne erano \(\frac{2530}{128}=10.7656\) nella provincia di Milano.
-
Rapporti di densità.
Nel 2007, nella provincia di Milano c’erano \(\frac{2530}{1984.39}=1.2375\) sportelli per chilometro quadrato.
Nel 2007, nella provincia di Sondrio c’erano \(\frac{128}{3211.90}=0.0399\) sportelli per chilometro quadrato. -
Rapporti di derivazione ipotizzando che la numerosità della popolazione sia causa del numero di sportelli bancari.
Nel 2003, nella provincia di Milano c’erano \(\frac{2313}{3721428}\cdot 1000=0.6215\) sportelli ogni mille abitanti.
Nel 2003, nella provincia di Sondrio c’erano \(\frac{120}{177568}\cdot 1000=0.6758\) sportelli ogni mille abitanti.
Esercitazione 1.2
Frequenze e rappresentazioni grafiche
Esercizio 1.2.1
Un certo materiale è stato sottoposto a un esperimento termico. Durante l’esperimento è stata rilevata 60 volte la sua temperatura \(X\) (in gradi Celsius). La distribuzione di frequenze di \(X\) è riportata nella seguente tabella:
| Classi \(X\) | Frequenze |
|---|---|
| \([5, 10]\) | 8 |
| \((10, 13]\) | 18 |
| \((13, 17]\) | 8 |
| \((17, 25]\) | 16 |
| \((25, 40]\) | 10 |
| Totale | 60 |
-
Indicare il tipo di carattere e la scala di misurazione.
-
Calcolare le frequenze cumulate e interpretare la quarta di esse.
-
Rappresentare la distribuzione di frequenze relative.
-
Calcolare la frequenza relativa della classe \([11,20)\).
-
Rappresentare la funzione di ripartizione di \(X\).
Esercizio 1.2.2
La seguente tabella riporta la distribuzione degli utenti di due social network A e B secondo il numero \(X\) di post in un determinato pomeriggio:
| Valori di \(X\) | Frequenze di A | Frequenze di B |
| 0 | 7 | 3 |
| 1 | 9 | 4 |
| 2 | 16 | 8 |
| 3 | 25 | 10 |
| 4 | 23 | 15 |
| 5 | 20 | 40 |
| Totale | 100 | 80 |
-
Indicare il tipo di carattere e la scala di misurazione.
-
Rappresentare le due distribuzioni di frequenze in modo tale che siano confrontabili.
-
In quale social network sono stati pubblicati più post tra gli utenti considerati?
-
Rappresentare la funzione di ripartizione di \(X\) considerando come collettivo statistico entrambi i social network.
Esercizio 1.2.3
In uno stabilimento lavorano 224 operai, di cui 160 sono uomini e 64 sono donne. La seguente tabella riporta la distribuzione degli operai secondo il tempo \(X\) (in secondi) impiegato per produrre un pezzo:
| Classi di \(X\) | Frequenze (uomini) | Frequenze (donne) |
| \([10,15)\) | 20 | 16 |
| \([15,20)\) | 84 | 30 |
| \([20,30)\) | 46 | 16 |
| \([30,45)\) | 10 | 2 |
| Totale | 160 | 64 |
-
Si rappresentino le due distribuzioni di frequenze in modo che possano essere confrontate.
-
Si calcoli la frequenza assoluta degli uomini che impiegano tra 15 e 35 secondi per produrre un pezzo.
-
Si calcoli la frequenza relativa degli operai (uomini e donne) che impiegano \([20,30)\) secondi a produrre un pezzo.
-
Rappresentare la funzione di ripartizione di \(X\) per entrambe le due sottopopolazioni.
-
Calcolare qual è la proporzione di uomini che impiegano più di 25 secondi a produrre un pezzo.
Soluzioni esercitazione 1.2
Esercizio 1.2.1
| \(j\) | Classi \(X\) | \(n_j\) | \(N_j\) | \(d_j\) | \(f_j=\frac{n_j}{N}\) | \(\frac{h_j}{N}=\frac{f_j}{d_j}\) | \(F_j\) |
| 1 | \([5, 10]\) | 8 | 8 | 5 | 0.133 | 0.027 | 0.133 |
| 2 | \((10, 13]\) | 18 | 26 | 3 | 0.3 | 0.1 | 0.433 |
| 3 | \((13, 17]\) | 8 | 34 | 4 | 0.133 | 0.033 | 0.566 |
| 4 | \((17, 25]\) | 16 | 50 | 8 | 0.267 | 0.033 | 0.833 |
| 5 | \((25, 40]\) | 10 | 60 | 15 | 0.167 | 0.011 | 1 |
| Totale | 60 |
- Carattere quantitativo continuo su scala di intervalli: lo 0 della scala Celsius è convenzionale e non rappresenta l’assenza di calore, quindi il calore a 30°C non è il doppio del calore a 15°C.
- \(N_4=50\) indica che ci sono 50 rilevazioni nelle quali si è osservata una temperatura minore o uguale a 25°Celsius.
- Istogramma, le frequenze relative sono rappresentate dall’area dei rettangoli pertanto bisogna calcolare le frequenze relative specifiche. Le ampiezze delle classi di un carattere continuo sono; \[d_j=l_j^+-l_j^-\]
- \[\begin{align}\frac{h_j}{N}([11,20)) & = (13-11)\cdot\frac{h_2}{N}+\frac{h_3}{N}+(20-17)\cdot\frac{h_4}{N}=\\ & = 2\cdot 0.1+0.133+3\cdot 0.033 = 0.2 + 0.133+0.099=0.432\end{align}\]
- Funzione di ripartizione a scalini con altezze pari alla colonna \(F_j\).
Esercizio 1.2.2
|
\(X\)
|
|||||
|---|---|---|---|---|---|
| Valori di \(X\) | \(f_j^A\) | \(f_j^B\) | \(n_j\) | \(N_j\) | \(F_j\) |
| 0 | 0.07 | 0.0375 | 10 | 10 | 0.056 |
| 1 | 0.09 | 0.05 | 13 | 23 | 0.128 |
| 2 | 0.16 | 0.1 | 24 | 47 | 0.261 |
| 3 | 0.25 | 0.125 | 35 | 82 | 0.456 |
| 4 | 0.23 | 0.1875 | 38 | 120 | 0.667 |
| 5 | 0.2 | 0.5 | 60 | 180 | 1 |
| Totale | 1 | 1 | 180 | ||
- Carattere quantitativo discreto su scala di rapporti, 0 post indicano assenza di attività sul social network, quindi è uno zero assoluto.
- Le due popolazioni hanno un numero diverso di osservazioni, quindi bisogna considerare le frequenze relative (fare un cenno alle tabelle a doppia entrata e confrontare le frequenze relative, per confrontare le distribuzioni di X nei due social network). Aste.
- Nel primo social network sono stati pubblicati \(0\cdot 7+1\cdot 9+2\cdot 16+3\cdot 25+4\cdot 23+5\cdot 20=308\) post, nel secondo social network sono stati pubblicati \(0\cdot 3+1\cdot 4+2\cdot 8+3\cdot 10+4\cdot 15+5\cdot 40=310\) post.
- Funzione di ripartizione a segmenti con altezze pari alla colonna \(F_j\).
Esercizio 1.2.3
| Classi di \(X\) | \(f_j^U\) | \(f_j^D\) | \(d_j\) | \(\frac{h_j^D}{N^U}\) | \(\frac{h_j^D}{N^U}\) | \(F_j^U\) | \(F_j^D\) |
| \([10,15)\) | 0.125 | 0.25 | 5 | 0.025 | 0.05 | 0.125 | 0.25 |
| \([15,20)\) | 0.525 | 0.469 | 5 | 0.105 | 0.069 | 0.65 | 0.719 |
| \([20,30)\) | 0.287 | 0.25 | 10 | 0.029 | 0.038 | 0.937 | 0.969 |
| \([30,45)\) | 0.063 | 0.031 | 15 | 0.004 | 0.002 | 1 | 1 |
| Totale | 1 | 1 |
- Istogramma di frequenze relative.
- \[f^U([15,35])=0.525+0.287+5\cdot 0.004=0.832\] \[n^U([15,35])=0.832\cdot 160 =133.12\]
- \[f([20,30))=\frac{46+16}{224}=\frac{62}{224}=0.277\]
- Funzioni di ripartizione a segmenti rispettivamente con altezze pari alle colonne \(F_j^U\) e \(F_j^D\)
-
\[F^U(x)\begin{equation}\begin{cases}0, & \mathrm{per\ }x<l_1^-\\ F^U_{j-1}+\frac{h^U_j}{N^U}(x-l_j^-), & \mathrm{per\ }l_j^-\leq x<l_j^+,\,\, j=1,2,\ldots,k\\ 1, & \mathrm{per\ }x\geq l_k^+\end{cases}\end{equation}\] \(x=25\) cade nella terza classe, quindi \(j=3\): \[\begin{align}F^U(25)& = F^U_{3-1}+\frac{h_3^U}{N^U}(25-l_3^-)=\\ & = 0.650+0.029\cdot(25-20)=\\ &= 0.650+0.145=0.795 \end{align}\] Questa è la proporzione di uomini che impiega al più 25 secondi a produrre un pezzo.
Per sapere qual è la proporzione di uomini che impiegano più di 25 secondi a produrre un pezzo è necessario fare il complemento a 1: \(1 – 0.795 = 0.205\)
Esercitazione 1.3
Medie analitiche e medie lasche
Per gli esercizi da 1 a 4 la fonte dei dati è: Banca d’Italia – Indagine campionaria, “Indagine sui bilanci delle famiglie italiane”, anno 2006.
La base di dati è costituita da 7768 famiglie, 19551 individui, dei quali 13009 percettori di reddito.
Esercizio 1.3.1
Si consideri il carattere \(X=\)“titolo di studio”. Di seguito è riportata la distribuzione di frequenze. Si individuino mediana, quartili, decili e moda.
| \(j\) |
|
\(n_j\) |
|---|---|---|
| 1 | Nessuno | 2293 |
| 2 | Licenza elementare | 4240 |
| 3 | Licenza media inferiore | 5671 |
| 4 | Licenza media superiore | 5738 |
| 5 | Laurea triennale | 146 |
| 6 | Laurea magistrale | 1421 |
| 7 | Specializzazione post-laurea | 42 |
| Totale | 19551 |
Esercizio 1.3.2
Si considerino i seguenti 10 individui e il carattere \(X=\)“età in anni compiuti”. Si individuino mediana, quartili, moda e media aritmetica.
| \(x_{1}\) | \(x_{2}\) | \(x_{3}\) | \(x_{4}\) | \(x_{5}\) | \(x_{6}\) | \(x_{7}\) | \(x_{8}\) | \(x_{9}\) | \(x_{10}\) |
| 58 | 36 | 32 | 86 | 52 | 60 | 56 | 19 | 37 | 51 |
Esercizio 1.3.3
La seguente tabella riporta la distribuzione di frequenze dell’età in anni compiuti \(X\) circoscritta all’intervallo \([31,40]\). Si individuino mediana, quartili, moda e media aritmetica.
| \(x_j\) | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | Totale |
| \(n_j\) | 222 | 227 | 227 | 215 | 201 | 294 | 259 | 282 | 271 | 276 | 2474 |
Esercizio 1.3.4
Si considerino ora le 7768 famiglie. Per ognuna di esse si osserva il reddito disponibile netto \(X\) espresso in migliaia di euro. I dati sono stati raggruppati in classi. Si individuino mediana, quartili, moda e media aritmetica. Si verifichi la somma dagli scarti dalla media aritmetica.
| \(j\) |
|
\(n_j\) |
| 1 | \((0,50]\) | 6696 |
| 2 | \((50,100]\) | 958 |
| 3 | \((100,150]\) | 80 |
| 4 | \((150,350]\) | 26 |
| 5 | \((350,850]\) | 8 |
| Totale | 7768 |
Esercizio 1.3.5
Nel mese di dicembre, in un comune italiano sono state rilevate le temperature di una giornata ad intervalli regolari di 3 ore. La seguente tabella riporta i valori osservati espressi in gradi Celsius:
| \(j\) | \(x_j\) |
|---|---|
| 1 | 8 |
| 2 | 6 |
| 3 | 6 |
| 4 | 6 |
| 5 | 11 |
| 6 | 12 |
| 7 | 10 |
| 8 | 10 |
Si calcoli la media aritmetica. Che valore assumerebbe la media aritmetica se le temperature fossero espresse in gradi Kelvin? E se fossero espresse in gradi Fahrenheit? Si discuta la natura del carattere e delle scale citate. \(x_6=12°\,C\) è il doppio di \(x_2=6°\,C\)? Si ricordano le relazioni esistenti tra le scale di misurazione della temperatura \[K=C+273.15\] \[F=\frac{9}{5} K-459.67\]
Lo zero assoluto corrisponde a \(0°\,K\).
Esercizio 1.3.6
Si consideri una popolazione suddivisa in tre gruppi \(A, B\) e \(C\). Si calcoli la media aritmetica di ogni gruppo e la media dell’intera popolazione e si verifichi la proprietà associativa della media aritmetica.
|
|
|
Esercizio 1.3.7
Un automobilista, nel fare un percorso di \(N=100\,Km\), viaggia a velocità diverse. Percorre \(20\,Km\) a una velocità di \(50\,Km/h\), \(30\,Km\) a \(80\,Km/h\) e altri \(50\,Km\) li percorre a \(60\,Km/h\). Valutare la velocità media che lascia invariato il tempo di percorrenza del tragitto.
Soluzioni esercitazione 1.3
Esercizio 1.3.1
\(X=\) titolo di studio. Con \(x_j\) indichiamo la \(j\)-esima modalità, \(j=1,2,\ldots,K\). Il carattere presenta \(K=7\) modalità distinte. Le modalità devono essere ordinate.
| \(j\) |
|
\(n_j\) | \(C_j\) |
|---|---|---|---|
| 1 | Nessuno | 2293 | 2293 |
| 2 | Licenza elementare | 4240 | 6533 |
| 3 | Licenza media inferiore | 5671 | 12204 |
| 4 | Licenza media superiore | 5738 | 17942 |
| 5 | Laurea triennale | 146 | 18088 |
| 6 | Laurea magistrale | 1421 | 19509 |
| 7 | Specializzazione post-laurea | 42 | 19551 |
| \(N=19551\) |
Mediana: \(Pos(Me)=\frac{N+1}{2}=9776\), \(Me=x_{(9776)}=\) Licenza media inferiore.
Per trovare quartili decili e centili si segue la stessa procedura ma cambiano le posizioni delle modalità.
Quartili: \(l\cdot\frac{N+1}{4}\) per \(l=1,2,3\). Decili: \(l\cdot \frac{N+1}{10}\) per \(l=1,2,\ldots,9\). Notare la corrispondenza tra media e secondo quartile.
Esempi: \(Pos(Q_1)=4888\), \(Pos(Q_3)=14664\), \(Pos(D_3)=5865.6\cong 5866\). Per avere una posizione esatta arrotondare sempre per eccesso.
La moda è la modalità che presenta frequenza più elevata, in questo caso \(Moda =\) Licenza media superiore. È opportuno discuterne la rappresentatività, a tale scopo si valuta la sua frequenza relativa \(f_4=\frac{n_4}{N}=\frac{5738}{19551}=0.2935\). La moda rappresenta il \(23.35\%\) della popolazione.
Esercizio 1.2.2
Per determinare mediana e i quartili è necessario ordinare le osservazioni
| \(i\) | \(x_{(i)}\) |
| 1 | 19 |
| 2 | 32 |
| 3 | 36 |
| 4 | 37 |
| 5 | 51 |
| 6 | 52 |
| 7 | 56 |
| 8 | 58 |
| 9 | 60 |
| 10 | 86 |
| Totale | 487 |
\(N\) pari, quindi la mediana corrisponde al valore centrale tra le osservazioni in posizione \(\frac{N}{2}\) e \(\frac{N}{2}+1\) , ovvero a \(m=\frac{x_{(5)}+x_{(6)}}{2}=51.5\). Il primo quartile invece \(x_{\left( \frac{N+1}{4}\right)}=x_{(2.75)}=x_{(2)}+0.75\cdot \left(x_{(3)}-x_{(2)}\right)=32+0.75\cdot1=32.75\). Il terzo quartile: \(x_{\left(3\cdot \frac{N+1}{4}\right) }=x_{(8.25)}=x_{(8)}+0.25\cdot\left(x_{(9)}-x_{(8)}\right) =58+0.25⋅2=58.5\). La moda corrisponde all’osservazione maggiormente frequente. Non essendoci ripetizioni la distribuzione è amodale. \[M_1= \frac{487}{10}=48.7.\]
Esercizio 1.3.3
| \(j\) | \(x_j\) | \(n_j\) | \(N_j\) | \(x_j\cdot n_j\) |
| 1 | 31 | 222 | 222 | 6882 |
| 2 | 32 | 227 | 449 | 7264 |
| 3 | 33 | 227 | 676 | 7491 |
| 4 | 34 | 215 | 891 | 7310 |
| 5 | 35 | 201 | 1092 | 7035 |
| 6 | 36 | 294 | 1386 | 10584 |
| 7 | 37 | 259 | 1645 | 9583 |
| 8 | 38 | 282 | 1927 | 10716 |
| 9 | 39 | 271 | 2198 | 10569 |
| 10 | 40 | 276 | 2474 | 11040 |
| Totale | 2474 | 88474 |
I valori sono già ordinati ma per valutare i quantili ora si devono tenere d’occhio le frequenze cumulate.
\[m=q\left(\frac{1}{2}\right)=\begin{cases}x_h,& \text{se } \frac{N}{2}>N_{h-1}\\ \frac{1}{2}(x_{h-1}+x_{h}),&\text{se }\frac{N}{2}=N_{h-1}\end{cases}\] \[\frac{N}{2}=1237>1092=N_5, \quad h=6,\quad m=x_h=x_6=36\] \[q_1=q\left(\frac{1}{4}\right)=q(0.25)\] \[\frac{N}{4}=618.5>449=N_2,\quad h=3,\quad q_1=x_3=33\] \[q_3=q\left(\frac{3}{4}\right)=q(0.75)\] \[\frac{3}{4}N=1855.5>1645=N_7,\quad h=8,\quad q_3=x_8=38\] \[M_1=\frac{1}{N}\sum_{j=1}^k x_jn_j=\frac{88474}{2474}=35.7615\]
Esercizio 1.3.4
| \(j\) | \(n_j\) | \(x_j^c\) | \(l^-_j\) | \(N_j\) | \(x_j^c\cdot n_j\) | \(x_j^c-M_1\) | \((x_j^c-M_1)\cdot n_j\) |
| 1 | 6696 | 25 | 0 | 6696 | 167400 | -8.5415 | -57193.5633 |
| 2 | 958 | 75 | 50 | 7654 | 71850 | 41.4585 | 39717.2889 |
| 3 | 80 | 125 | 100 | 7734 | 10000 | 91.4585 | 7316.6838 |
| 4 | 26 | 250 | 150 | 7760 | 6500 | 216.4585 | 5627.9222 |
| 5 | 8 | 600 | 350 | 7768 | 4800 | 566.4585 | 4531.6684 |
| Totale | 7768 | 260550 | 907.4585 |
\[M_1=\mu=\frac{260550}{7768}=33.5415\] \[q\left(\frac{l}{v}\right)=l^-_h+\frac{N\cdot\frac{l}{v}-N_{h-1}}{N_h-N_{h-1}}[l_h^+-l_h^-]\] \[m=q(0.5)\] \[0.5\cdot N=3384>0,\quad h=1\] \[m=q(0.5)=0+\frac{3884-0}{6696-0}(50-0)=29.0024\] \[q_1=q(0.25)\] \[0.25\cdot N=1942>0,\quad h=1\] \[q_1=q(0.25)=0+\frac{1942-0}{6696-0}(50-0)=14.5012\] \[q_3=q(0.75)\] \[0.75\cdot N=5826>0, h=1\] \[q_3=q(0.75)=0+\frac{5826-0}{6696-0}(50-0)=43.5039\]
La classe modale corrisponde alla prima e rappresenta il \(\frac{6696}{7768}=86,2 \%\) del collettivo.
Esercizio 1.3.5
| \(j\) | \(x_j\) |
|---|---|
| 1 | 8 |
| 2 | 6 |
| 3 | 6 |
| 4 | 6 |
| 5 | 11 |
| 6 | 12 |
| 7 | 10 |
| 8 | 10 |
| Media | \(8.625\) |
In Kelvin \(8.625+273.15=281.775\) e in Fahrenheit \(\frac{9}{5}\cdot 281.775-459.67=47.525\).
Esercizio 1.3.6
| \(A\) | \(B\) | \(C\) | Totale | |
|---|---|---|---|---|
| 12 | 90 | 98 | ||
| 34 | 76 | 34 | ||
| 45 | 34 | 23 | ||
| 12 | 45 | 64 | ||
| 75 | 34 | |||
| 83 | ||||
| Somma | 178 | 245 | 336 | 759 |
| Media | \(35.6\) | \(61.25\) | \(56\) | \(50.6\) |
Esercizio 1.3.7
\[T=\sum_{j=1}^k t_j = \sum_{j=1}^k \frac{l_j}{v_j}\] \[ \sum_{j=1}^k \frac{l_j}{\overline{v}}= \sum_{j=1}^k \frac{l_j}{v_j}\] \[ \frac{1}{\overline{v}}=\frac{\displaystyle \sum_{j=1}^k \frac{l_j}{v_j}}{\displaystyle \sum_{j=1}^k l_j}\] \[\overline{v}=\frac{\displaystyle \sum_{j=1}^kl_j}{\displaystyle \sum_{j=1}^k \frac{l_j}{v_j}}\] È una specie di media armonica ponderata delle velocità, con pesi pari alle lunghezze dei diversi tratti.
| \(j\) | \(v_j\) | \(l_j\) | \(t_j\) |
|---|---|---|---|
| 1 | 50 | 20 | 0.4 |
| 2 | 80 | 30 | 0.375 |
| 3 | 60 | 50 | 0.833 |
| Totale | 100 | 1.608 |
\[\overline{v}=\frac{100}{1.608}=62.1891 \,\frac{Km}{h}\]
Esercitazione 1.4
Esercizio 1.4.1
La seguente tabella riporta la distribuzione di 351 imprese secondo il fatturato \(X\) del 2017 (in milioni di Euro):
| Classi di \(X\) | Frequenze |
|---|---|
| \((0,0.6]\) | 170 |
| \((0.6,1]\) | 148 |
| \((1,1.2]\) | 23 |
| \((1.2,1.4]\) | 10 |
| Totale | 351 |
- Si individui la classe modale del carattere \(X\).
- Si forniscano il primo ed il terzo quartile di \(X\) e di commentino i valori ottenuti.
- Si calcoli la differenza interquartile e si commenti il valore ottenuto.
- Si calcoli la media aritmetica del carattere \(X\) e si commenti il valore ottenuto.
- Alle aziende precedentemente considerate, sono state aggiunte altre 134 aziende il cui fatturato del 2017 è mediamente pari a 420000 Euro. Si determini il fatturato medio di tutte le 485 imprese.
- Come varierebbe il risultato precedente se i valori fossero espressi in migliaia di Dollari statunitensi? Si consideri che un Euro vale 1.23 Dollari statunitensi (dato 2017).
Esercizio 1.4.2
Sono stati rilevati i ritardi (espressi in minuti) dei treni di una linea ferroviaria in un determinato giorno. Le diverse rilevazioni sono state classificate a seconda direzione di percorrenza dei treni. La seguente tabella riporta le distribuzioni di frequenza.
| Ritardo | Andata | Ritorno | Totale |
|---|---|---|---|
| \((0,5]\) | 14 | 10 | 24 |
| \((5,10]\) | 9 | 8 | 17 |
| \((10,20]\) | 7 | 7 | 14 |
| \((20,30]\) | 2 | 3 | 5 |
| Totale | 32 | 28 | 60 |
- Si calcoli lo scostamento medio assoluto dalla media aritmetica dei ritardi.
- Si valuti quale gruppo presenta maggiore variabilità.
Esercizio 1.4.3
Gli incassi \(X\) (in milioni di euro) di 5 punti vendita di una catena di grandi magazzini sono i seguenti: \[11.5;\,2.3;\, 5.5;\,8.9; \,9.7\]
- Si determinino il campo di variazione e la differenza interquartile di \(X\).
- Si calcoli lo scarto quadratico medio di \(X\) e si commenti il valore ottenuto.
- Sia \(Y\) gli incassi (in milioni di euro) dopo l’applicazione di un’imposta proporzionale del \(10\%\) e un’imposta fissa di 10000 euro. Si determini lo scarto quadratico medio di \(Y\).
- Si calcoli la differenza media semplice di \(X\) e si commenti il valore ottenuto.
Esercizio 1.4.4
La seguente tabella riporta la distribuzione delle retribuzioni mensili \(X\) (in migliaia di euro) di 42 dipendenti di un’azienda. I dati sono raggruppati in classi e per ogni classe è riportato anche il totale di \(X\).
| Classi | N.ro Dipendenti | Totale di classe |
|---|---|---|
| \((0,1]\) | 4 | 3.40 |
| \((1,1.5]\) | 14 | 19.60 |
| \((1.5,2]\) | 21 | 34.65 |
| \((2,4]\) | 3 | 8.10 |
| Totale | 42 | 65.75 |
- Si calcoli lo scostamento medio assoluto dalla media aritmetica di \(X\).
- Si calcoli il coefficiente di variazione di \(X\) e si commenti il valore ottenuto.
- Si calcoli la differenza media semplice di \(X\) e si commenti il valore ottenuto.
Soluzioni esercitazione 1.4
Esercizio 1.4.1
| \(j\) | \(\overline{x}_j\) | \(n_j\) | \(d_j\) | \(h_j\) | \(N_j\) | \(\overline{x}_jn_j\) | \(F_j\) |
| 1 | 0.3 | 170 | 0.6 | 283.33 | 170 | 51 | 0.4843 |
| 2 | 0.8 | 148 | 0.4 | 370 | 318 | 118.4 | 0.906 |
| 3 | 1.1 | 23 | 0.2 | 115 | 341 | 23.5 | 0.9715 |
| 4 | 1.3 | 10 | 0.2 | 20 | 351 | 13 | 1 |
| Totale | 351 | 207.7 |
# ES 1
rm(list = ls())
breaks <- c(0, 0.6, 1, 1.2, 1.4)
n <- c(170, 148, 23, 10)
k <- length(n)
N <- sum(n)
x <- c(breaks[-1] + breaks[-k-1])/2
d <- c(breaks[-1] - breaks[-k-1])
h <- round(n / d, 2)
Nc <- cumsum(n)
Fj <- Nc / N-
Dalle frequenze specifiche \(h_j\) si osserva che la classe modale è la seconda \((0.6, 1]\) e rappresenta il \(42.17\%\) delle imprese considerate. (disegnare istogramma)
## [1] 0.4216524barplot(h, width = d, space = 0, col = 'lightblue', border='blue', names.arg = c("(0,0.6]", "(0.6,1]", "(1,1.2]", "(1.2,1.4]"), main='Istogramma frequenze')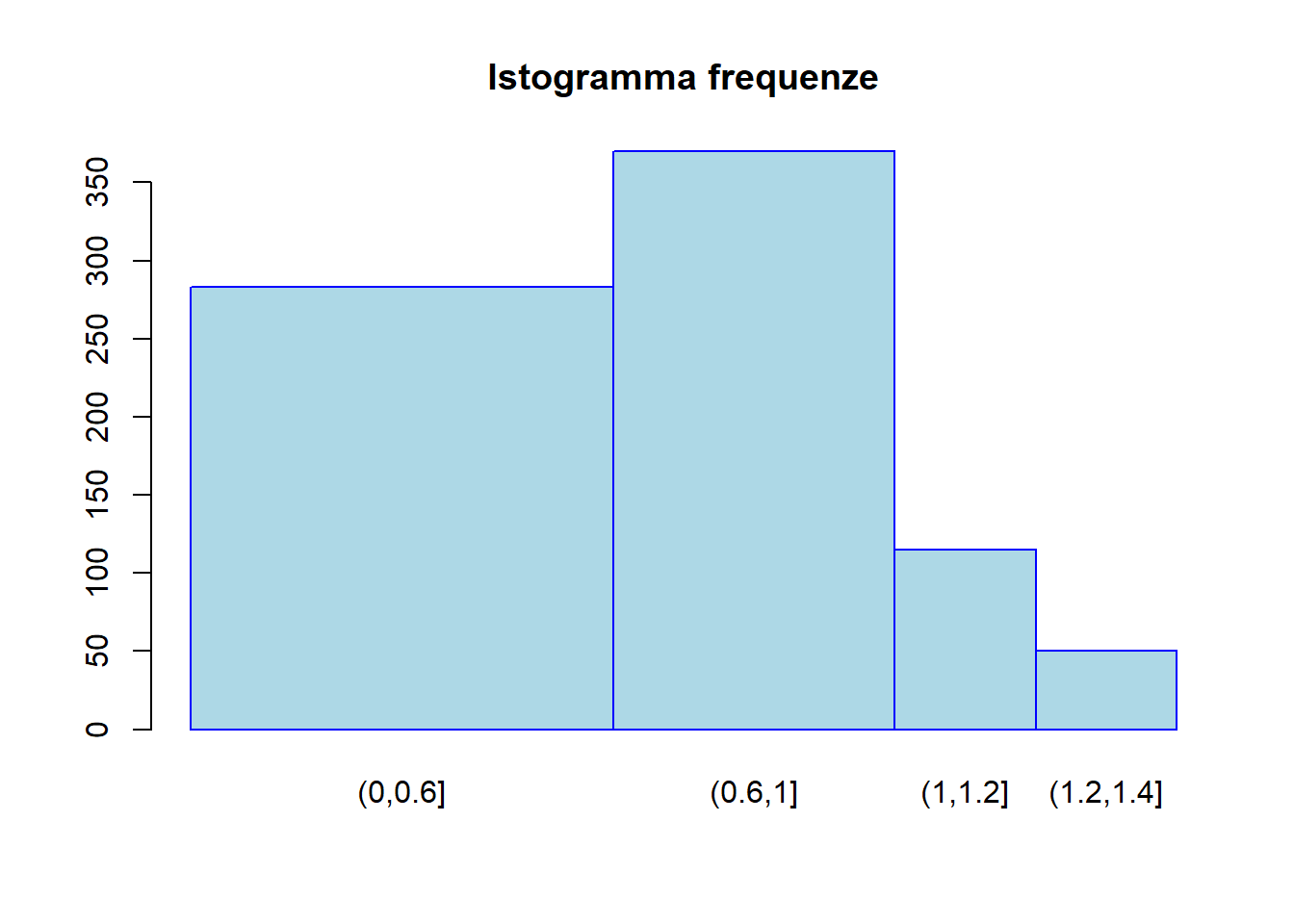
-
Primo quartile \[\frac{N}{4}=87.75>0;\quad h=1\] \[q_1=l_1^-+\frac{\frac{N}{4}-N_0}{N_1-N_0}\cdot [l_1^+-l_1^- ]=0+\frac{87.75-0}{170-0}\cdot [0,6-0]=0.3097\] Un quarto delle imprese considerate ha un fatturato minore di 309700 Euro. \[3 \cdot \frac{N}{4}=263.25>170;\quad h=2\] \[q_3=l_2^-+\frac{3\cdot\frac{N}{4}-N_1}{N_2-N_1}\cdot [l_2^+-l_2^- ]=0.6+\frac{263.25-170}{318-170}\cdot [1-0,6]=0.8520\] Tre quarti delle imprese considerate ha un fatturato minore di 852000 Euro. (disegnare funzione di ripartizione)
## [1] 87.75## [1] 0.3097## [1] 263.25## [1] 2## [1] 0.852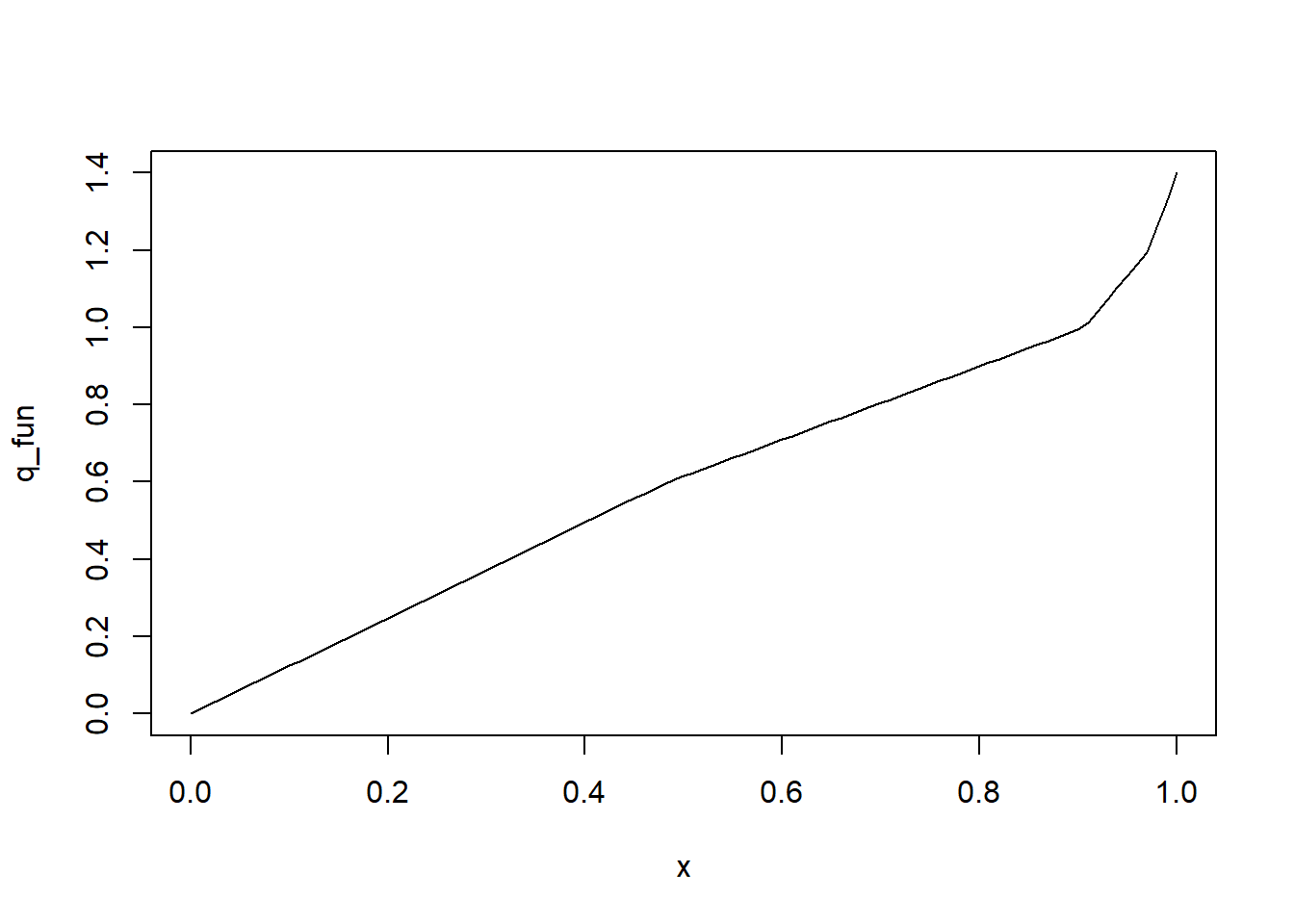
## [1] 0.3097059 0.8520270plot(q_fun(0.25*c(0,1,2,3,4)),0.25*c(0,1,2,3,4), xlab = "Quantili", ylab="Funzione di ripartizione", axes = F, col="black", pch=19, main="Funzione di ripartizione") box() axis(1, at=q_fun(0.25*c(0,1,2,3,4)), labels=c(0,round(q_fun(0.25*c(1,2,3)),2),1)) axis(2, at=0.25*c(0,1,2,3,4), labels=0.25*c(0,1,2,3,4)) for(i in 1:4){ segments(q_fun(0.25*(i-1)),0.25*(i-1), q_fun(0.25*i), 0.25*(i-1), col = 'black') }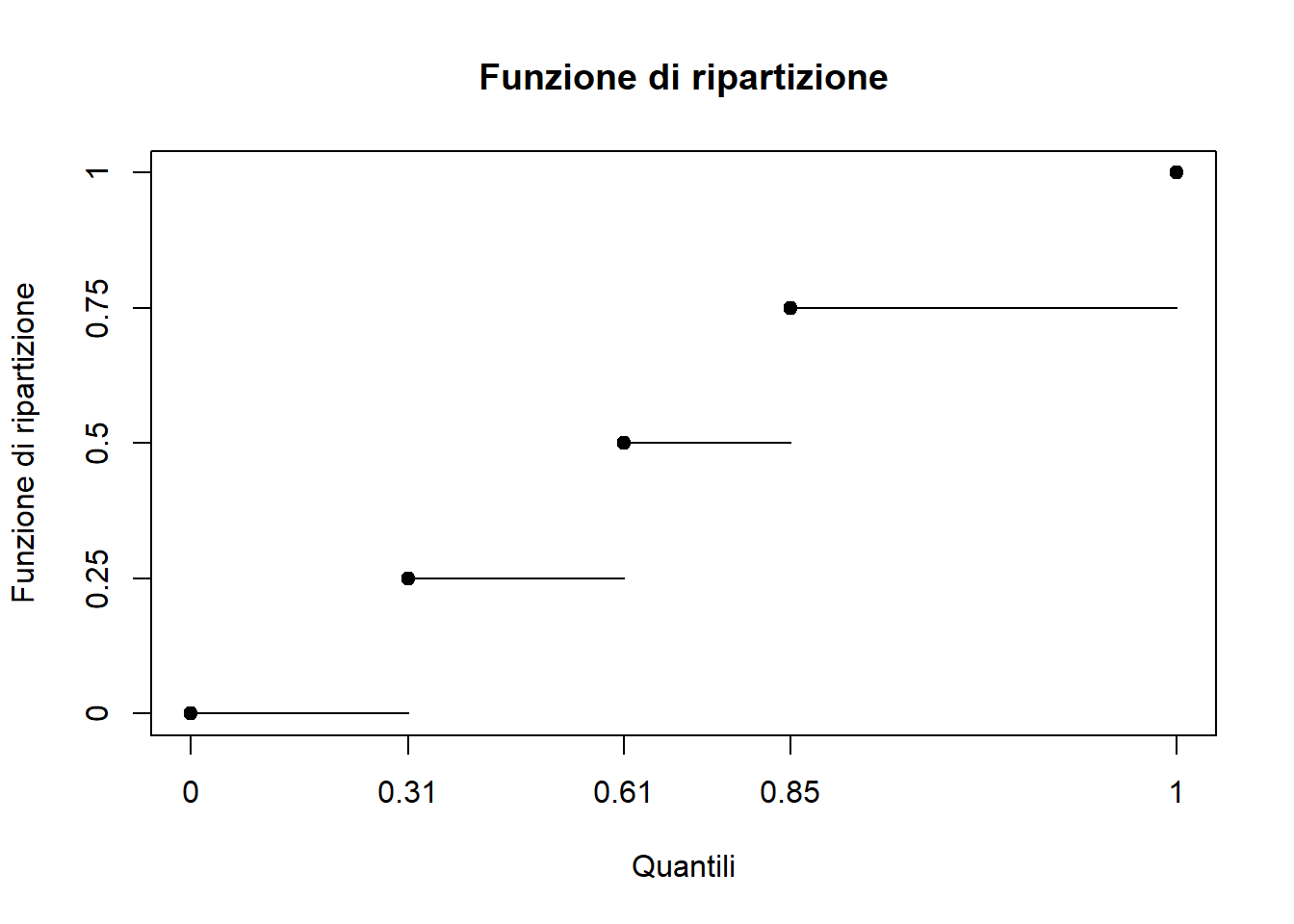
-
\[Q_3-Q_1=0.8520-0.3097=0.5423\] Il 50% dei fatturati “centrali” sono compresi in un intervallo di ampiezza pari a 542300 Euro.
## [1] 0.5423 -
\[ \overline{x}=\frac{\displaystyle\sum_{ j=1}^kx_j n_j}{N}=\frac{207.7}{351}=0.5917\] Mediamente le imprese hanno fatturato 591738 Euro ciascuna.
## [1] 0.5917379 -
Proprietà associativa della media aritmetica. \[M_1=\frac{M_1^{(1)}\cdot N_1+M_1^{(2)}\cdot N_2}{N_1+N_2}=\frac{0.5917\cdot351+0.42\cdot134}{485}=0.5443\quad\mathrm{milioni \ di \ Euro}\]
## [1] 0.5442887 -
Linearità della media aritmetica. \[Y=a+bX\Rightarrow M_1(Y)=a+bM_1(X)\] \[a=0, \quad b=1.23\] \[M_1(Y)=1.23\cdot 0.5443=0.6695\quad \mathrm{milioni \ di \ Dollari \ statunitensi}\]
## [1] 0.6694751
Esercizio 1.4.2
Tabella sulla distribuzione totale
| \(j\) | \(\overline{x}_j\) | \(n_j\) | \(\overline{x}_jn_j\) | \(|\overline{x}_j-\mu|\) | \(|\overline{x}_j-\mu|n_j\) |
|---|---|---|---|---|---|
| 1 | 2.5 | 24 | 60.0 | 6.2083 | 149.0000 |
| 2 | 7.5 | 17 | 127.5 | 1.2083 | 20.5417 |
| 3 | 15 | 14 | 210.0 | 6.2917 | 88.0833 |
| 4 | 25 | 5 | 125.0 | 16.2917 | 81.4583 |
| Totale | N = 60 | 522.5 | 339.0833 |
# ES 2
rm(list = ls())
breaks <- c(0, 5, 10, 20, 30)
nA <- c(14, 9, 7, 2)
nR <- c(10, 8, 7, 3)
nTot <- nA+nR
N <- sum(nTot)
k <- length(nA)
N_A <- sum(nA)
N_R <- sum(nR)
x <- c(breaks[-1] + breaks[-k-1])/2
d <- c(breaks[-1] - breaks[-k-1])-
Calcoliamo la media aritmetica \[\mu=\frac{\displaystyle \sum_{j=1}^kx_jn_j}{N}=\frac{552.5}{60}=8.7083\]
## [1] 8.708333Mediamente i ritardi sono pari a 9.2083 minuti.
Quindi calcoliamo \(S_\mu\) \[S_\mu=\frac{\displaystyle \sum_{j=1}^k|x_j-\mu|n_j}{N}=\frac{339.0833}{60}=5.6514\]
Mediamente i ritardi si discostano dalla media aritmetica di 5.6514 minuti.## [1] 5.651389 -
Calcoliamo ora le medie e le varianze di ogni singolo gruppo.
Tabella sulla distribuzione dei treni “Andata”\(j\) \(\overline{x}_j\) \(n_{jA}\) \(\overline{x}_j n_{jA}\) \(\overline{x}_j^2\) \(\overline{x}^2_{j}n_{jA}\) 1 2.5 14 35.0 6.25 87.50 2 7.5 9 67.5 56.25 506.25 3 15 7 105.0 225 1575.00 4 25 2 50.0 625 1250.00 Totale \(N_A=32\) 257.5 3418.75 \[\overline{x}_A=\frac{\displaystyle \sum_{j=1}^k\overline{x}_jn_{jA}}{N_A}=\frac{257.5}{32}=8.046\] \[\sigma_A^2=\frac{\displaystyle \sum_{j=1}^k \overline{x}^2_{j}n_{jA}}{N_A}-\overline{x}^2_A=\frac{3418.75}{32}-8.0469^2=42.0837\]
## [1] 8.046875## [1] 42.08374Tabella sulla distribuzione dei treni “Ritorno”
\(j\) \(\overline{x}_j\) \(n_{jR}\) \(\overline{x}_j n_{jR}\) \(\overline{x}_j^2\) \(\overline{x}^2_{j}n_{jR}\) 1 2.5 10 25 6.25 62.5 2 7.5 8 60 56.25 450.0 3 15 7 105 225 1575.0 4 25 3 75 625 1875.0 Totale \(N_R=28\) 265 3962.5 \[\overline{x}_R=\frac{\displaystyle \sum_{j=1}^k\overline{x}_jn_{jR}}{N_R}=\frac{265}{28}=9.4843\] \[\sigma_R^2=\frac{\displaystyle \sum_{j=1}^k \overline{x}^2_{j}n_{jR}}{N_R}-\overline{x}^2_R=\frac{3962.5}{28}-9.4843^2=51.9452\]
## [1] 9.464286## [1] 51.94515Per confrontare la variabilità dei gruppi dobbiamo usare un indice percentuale. \[\sigma_A=\sqrt{\sigma_A^2}=6.4872\,\,\mathrm{minuti}, \quad CV_A=\frac{\sigma_A}{\overline{x}_A}\cdot 100=80.62\%\] \[\sigma_R=\sqrt{\sigma_R^2}=7.2073\,\,\mathrm{minuti}, \quad CV_R=\frac{\sigma_R}{\overline{x}_R}\cdot 100=76.15\%\] C’è meno variabilità nel secondo gruppo.
## [1] 0.8061761## [1] 0.7615259
Esercizio 1.4.3
| \(i\) | \(x_{(i)}\) | \(F_i\) | \(x_{(i)}^2\) |
|---|---|---|---|
| 1 | 2.3 | 0.2 | 5.29 |
| 2 | 5.5 | 0.4 | 30.25 |
| 3 | 8.9 | 0.6 | 79.21 |
| 4 | 9.7 | 0.8 | 94.09 |
| 5 | 11.5 | 1 | 132.25 |
| Totale | 37.9 | 341.09 |
-
\[\Delta_C = x_{(N)}-x_{(1)}=11.5-2.3=9.2\,\,\mathrm{milioni \ di \ euro}\] \[ \frac{N}{4}=1.25>1;\quad h=2;\quad q_1=x_{(2)}=5.5\] \[3\cdot \frac{N}{4}=3.75>3;\quad h=4;\quad q_3=x_{(4)}=9.7\] \[\Delta_q=q_3-q_1=4.2 \,\,\mathrm{milioni \ di \ euro}\]
## [1] 1.25## [1] 3.75## [1] 4.2 -
\[\overline{x}=\frac{37.9}{5}=7.58 \,\, \mathrm{milioni \ di \ euro}\] \[M_1(X^2)=\frac{341.09}{5}=68.218\] \[Var(X)=[(X-\overline{x})^2]=M_1(X^2)-\overline{x}^2=68.218-7.58^2=10.7616\] \[\sigma=\sqrt{Var(X)}=3.2805\,\,\mathrm{milioni \ di \ euro}\] Gli incassi dei punti vendita differiscono dal valore medio di 3.2805 milioni di euro.
## [1] 7.58## [1] 68.218## [1] 10.7616## [1] 3.280488 -
\[Y=a+bX\Rightarrow \sigma(Y)=|b|\sigma(X)\] \[a=0.01,\quad b=0.9\] \[\sigma(Y)=0.9\cdot3.2805=2.9524\,\,\mathrm{milioni \ di\ euro}\]
## [1] 2.952439 -
\[\Delta = \frac{2}{N(N-1)}\sum_{i=2}^N\sum_{j=1}^{i-1} |x_i-x_j|\]
\(|x_i-x_j|\) 2.3 5.5 8.9 9.7 11.5 Totale 2.3 0 5.5 3.2 0 8.9 6.6 3.4 0 9.7 7.4 4.2 0.8 0 11.5 9.2 6 2.6 1.8 0 Totale 42.5 \[\Delta=\frac{2}{4\cdot5}45.2=4.52\] Gli incassi dei punti vendita differiscono tra loro di 4.52 milioni di Euro
## [,1] [,2] [,3] [,4] [,5] ## [1,] 0.0 3.2 6.6 7.4 9.2 ## [2,] 3.2 0.0 3.4 4.2 6.0 ## [3,] 6.6 3.4 0.0 0.8 2.6 ## [4,] 7.4 4.2 0.8 0.0 1.8 ## [5,] 9.2 6.0 2.6 1.8 0.0## [1] 45.2## [1] 4.52
Esercizio 1.4.4
| \(j\) | \(n_j\) | \(t_j\) | \(N_j\) | \(x_j\) | \(|x_j-\mu|\) | \(|x_j-\mu|n_j\) | \(x_j^2\) | \(x_j^2n_j\) |
|---|---|---|---|---|---|---|---|---|
| 1 | 4 | 3.40 | 4 | 0.85 | 0.7155 | 2.8620 | 0.7225 | 2.8900 |
| 2 | 14 | 19.60 | 18 | 1.4 | 0.1655 | 2.3170 | 1.96 | 27.4400 |
| 3 | 21 | 34.65 | 39 | 1.65 | 0.0845 | 1.7745 | 2.7225 | 57.1725 |
| 4 | 3 | 8.10 | 42 | 2.7 | 1.1345 | 3.4035 | 7.29 | 21.8700 |
| 42 | 65.75 | 10.3570 | 109.3725 |
# ES 4
rm(list = ls())
brk <- c(0, 1, 1.5, 2, 4)
n <- c(4, 14, 21, 3)
t <- c(3.4, 19.6, 34.65, 8.1)
x <- t/n
k <- length(n)-
Notare che \(x_jn_j=t_j\) e quindi il loro totale è il numeratore della media aritmetica. \[μ=\frac{65.75}{42}=1.5655\,\,\mathrm{migliaia\ di\ euro}\] Per calcolare \(S_μ\) è più coerente utilizzare i valori centrali come valori rappresentativi della classe \[S_μ=\frac{\displaystyle \sum_{j=1}^k|x_j-μ| n_j}{N}=\frac{10.3570}{42}=0.2466\,\,\mathrm{migliaia\ di\ euro} \]
## [1] 1.5655## [1] 0.85 1.40 1.65 2.70## [1] 0.7155 0.1655 0.0845 1.1345## [1] 2.8620 2.3170 1.7745 3.4035## [1] 10.357## [1] 0.2466 -
\[CV=M_2 \left(\frac{|X-\mu|}{\mu}\cdot 100\right)=\frac{\sigma}{\mu}\cdot 100\] Ora come valori rappresentativi prendiamo i valori medi di classe, pari al totale di classe diviso per le rispettive frequenze. Notare che $x_j n_j=t_j $ e quindi il loro totale è il numeratore della media aritmetica.
\[\begin{align} \sigma^2 & = M_2 (X)^2-M_1 (X)^2=\frac{109.3725}{42}-1.5655^2=0.1533\\ \sigma & =0.3916\,\,\mathrm{migliaia\ di\ euro}\\ CV & =0.2501\cdot 100=25.01\%\end{align}\]
Mediamente i valori di \(X\) si discostano dalla media del 25.01%.
## [1] 0.1533169## [1] 0.391557## [1] 25.01163 -
\[\Delta=\frac{2}{N(N-1)}\sum_{i=2}^k\sum_{j=1}^{i-1}|x_i-x_j|n_in_j\]
\(|x_i-x_j|n_in_j\) 0.85 1.4 1.65 2.7 0.85 \(0\) 4 1.4 \(0.55\cdot56\) \(0\) 14 1.65 \(0.80\cdot84\) \(0.25\cdot294\) \(0\) 21 2.7 \(1.85\cdot12\) \(1.30\cdot42\) \(1.05\cdot63\) \(0\) 3 4 14 21 3 314.45 ## [1] 0.85 1.40 1.65 2.70## [1] 4 14 21 3## [,1] [,2] [,3] [,4] ## [1,] 0.00 0.55 0.80 1.85 ## [2,] 0.55 0.00 0.25 1.30 ## [3,] 0.80 0.25 0.00 1.05 ## [4,] 1.85 1.30 1.05 0.00## [,1] [,2] [,3] [,4] ## [1,] 16 56 84 12 ## [2,] 56 196 294 42 ## [3,] 84 294 441 63 ## [4,] 12 42 63 9## [1] 314.45## [1] 0.3652149## [1] 0.1166448
Esercitazione 1.5
(continua gli esercizi della esercitazione 1.4)
Esercizio 1.5.1
Gli incassi \(X\) (in milioni di euro) di 5 punti vendita di una catena di grandi magazzini sono i seguenti:
| A | B | C | D | E |
| 11.5 | 2.3 | 5.5 | 8.9 | 9.7 |
- Si tracci il diagramma di Lorenz e si calcoli il rapporto di concentrazione di Gini commentando il risultato ottenuto.
- Si commenti il punto di coordinate \((p_3; q_3)\).
-
Senza effettuare calcoli si dica come varierebbe l’indice di concentrazione se:
- Il punto vendita B dovesse incassare 3 milioni di euro in più e il punto vendita E incassare 3 milioni di euro in meno.
- Il punto vendita D dovesse incassare 2 milioni di euro in meno e il punto vendita A incassare 2 milioni di euro in più.
- Tutti i punti vendita dovessero incassare 1 milione di euro in meno.
- Tutti i punti vendita dovessero incassare 1 milione di euro in più.
- I conferimenti fossero espressi in milioni di Dollari Statunitensi.
Esercizio 1.5.2
La seguente tabella riporta la distribuzione delle retribuzioni mensili \(X\) (in migliaia di euro) di 42 dipendenti di un’azienda. I dati sono raggruppati in classi e per ogni classe è riportato anche il totale di \(X\).
| Classi | N.ro Dipendenti | Totale di classe |
| \((0,1]\) | 4 | 3.4 |
| \((1,1.5]\) | 14 | 19.6 |
| \((1.5,2]\) | 21 | 34.65 |
| \((2,4]\) | 3 | 8.1 |
| Totale | 42 | 65.75 |
- Si tracci il diagramma di Lorenz.
- Si commenti il punto di coordinate \((p_2;q_2)\).
Esercizio 1.5.3
La seguente tabella riporta la distribuzione di 100 progetti di ricerca rispetto alle risorse finanziarie (in migliaia di Euro) impiegate. Si tracci il diagramma di Lorenz.
| Classi | N.ro Progetti |
| \((0,10]\) | 62 |
| \((10,25]\) | 28 |
| \((25,50]\) | 6 |
| \((50,80]\) | 4 |
| Totale | 100 |
Esercizio 1.5.4
La seguente tabella riporta le distribuzioni di frequenze delle nazionalità dei dipendenti di due aziende. Si determinino per entrambe le squadre l’indice di eterogeneità di Gini e l’indice di entropia.
| Azienda | Italia | Francia | Germania | Gran Bretagna | Spagna | Totale |
| A | 23 | 54 | 67 | 21 | 10 | 175 |
| B | 34 | 12 | 43 | 78 | 14 | 181 |
Soluzioni esercitazione 1.5
Esercizio 1.5.1
## [1] 1.25## [1] 3.75## [1] 4.2## [,1] [,2] [,3] [,4] [,5]
## [1,] 0.0 3.2 6.6 7.4 9.2
## [2,] 3.2 0.0 3.4 4.2 6.0
## [3,] 6.6 3.4 0.0 0.8 2.6
## [4,] 7.4 4.2 0.8 0.0 1.8
## [5,] 9.2 6.0 2.6 1.8 0.0## [1] 45.2## [1] 0.2982## [1] 0.1393 0.1942 0.1594 0.1034 0.0000## [1] 0.5963| \(j\) | \(x_{(i)}\) | \(\sum_ix_{(i)}\) | \(q_i\) | \(p_i=\frac{i}{n}\) | \(p_i-q_i\) |
|---|---|---|---|---|---|
| 1 | 2.3 | 2.3 | 0.0607 | 0.2 | 0.1393 |
| 2 | 5.5 | 7.8 | 0.2058 | 0.4 | 0.1942 |
| 3 | 8.9 | 16.7 | 0.4406 | 0.6 | 0.1594 |
| 4 | 9.7 | 26.4 | 0.6966 | 0.8 | 0.1034 |
| 5 | 11.5 | 37.9 | 1 | 1 | 0 |
| Totale | 37.9 | 0.5963 |
plot(c(0,P),c(0,Q), type = 'l', xlab = expression(p[i]),
ylab = expression(q[i]))
segments(0,0,1,1, lty=2)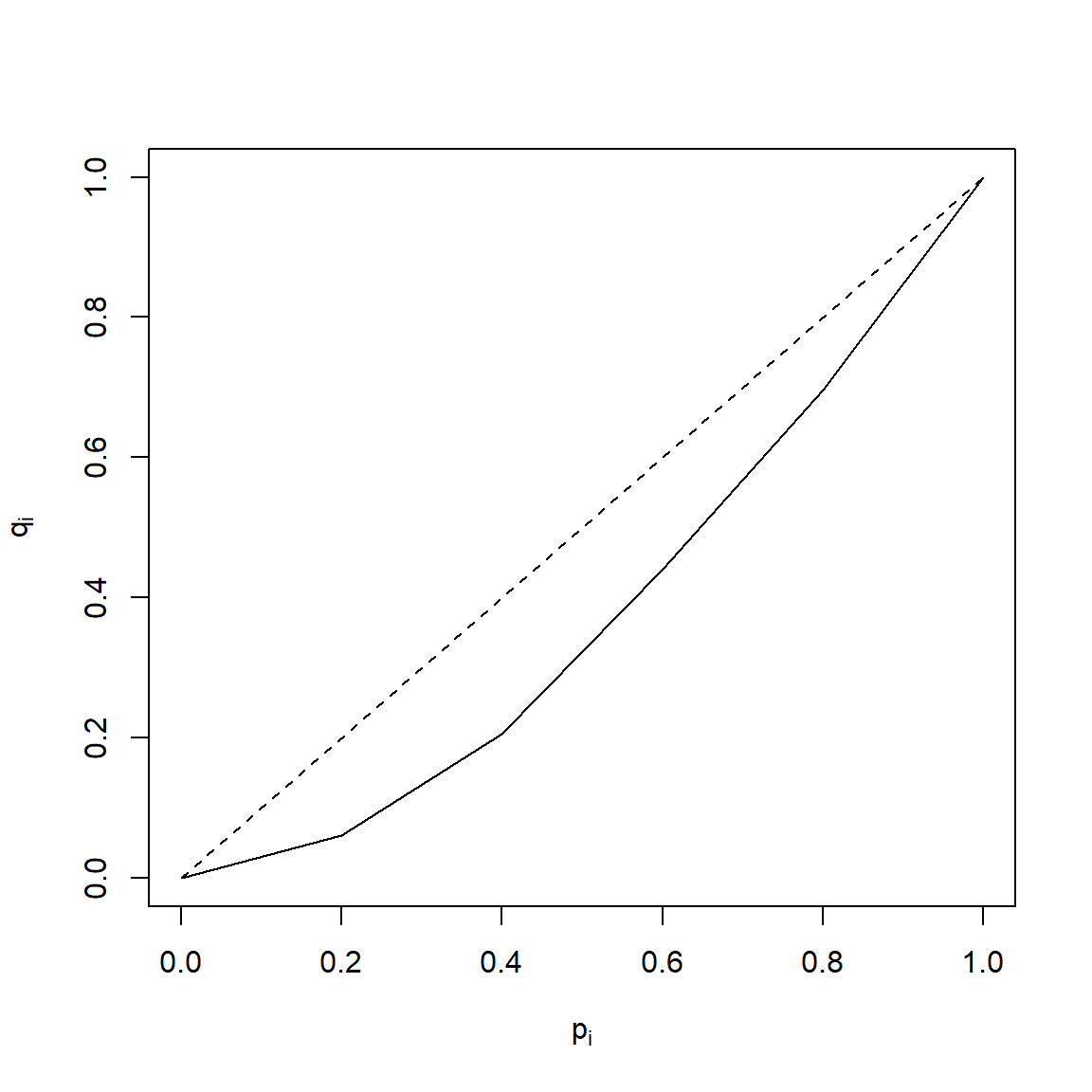
-
Dall’esercitazione precedente \[\Delta=4.52\,\,\mathrm{milioni\ di\ euro}\] \[M_1(X)=7.58\,\,\mathrm{milioni\ di\ euro}\] quindi, sapendo che \[G=\frac{\Delta}{2M_1}\] e l’indice di Gini è \[G=\frac{4.52}{2\cdot 7.58}=0.2982\]
La concentrazione è pari al 29.82% del suo massimo valore teorico.
Ma possiamo calcolarlo anche attraverso la sua definizione: \[G=\frac{2}{N-1}\sum_{i=1}^{N-1}(P_i-Q_i)=\frac{2}{4}\cdot0.5963=0.2982\] - Il punto \((p_3;q_3 )=(0.6;\,0.4406)\) indica che il 60% dei punti vendita ha incassato il 44,06% dell’incasso complessivo della catena di grandi magazzini.
-
Commenti
B aveva incassato di meno di E, per cui l’operazione è analoga a un trasferimento perequativo che comporta una diminuzione dell’indice di concentrazione.
D aveva incassato di meno di A, per cui l’operazione è analoga a un trasferimento concentrativo che comporta un aumento dell’indice di concentrazione.
L’operazione corrisponderebbe alla sottrazione di una costante a tutti i valori, pertanto la concentrazione aumenterebbe.
L’operazione corrisponderebbe alla somma di una costante a tutti i valori, pertanto la concentrazione diminuirebbe.
L’operazione corrisponderebbe alla moltiplicazione di tutti i valori per una costante, una trasformazione di scala, pertanto la concentrazione non varierebbe.
Esercizio 1.5.2
rm(list = ls())
n <- c(4,14,21,3)
t <- c(3.4,19.6,34.65,8.1)
N <- cumsum(n)
x <- t/n
P <- N/N[length(N)]
sum_t <- cumsum(t)
Q <- sum_t/sum_t[length(sum_t)]
P_Q <- P-Q
P_Q## [1] 0.04352707 0.07876154 0.05176534 0.00000000## [1] 0.07876154 0.05176534 0.00000000## [1] 0.1741083 1.7120406 2.7410646 0.1552960## [1] 4.78251| \(j\) | \(n_j\) | \(t_j\) | \(N_j\) | \(x_j=\frac{t_j}{n_j}\) | \(P_j=\frac{N_j}{N}\) | \(\sum_j t_j\) | \(Q_j\) | \(d_j=P_j-Q_j\) | \(h_j=d_j+d_{j-1}\) | \(h_j\cdot n_j\) |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | \(-\) | \(-\) | ||||||
| 1 | 4 | 3.4 | 4 | 0.85 | 0.0952 | 3.4 | 0.0517 | 0.0435 | 0.0435 | 0.1741 |
| 2 | 14 | 19.6 | 18 | 1.4 | 0.4286 | 23 | 0.3498 | 0.0788 | 0.1223 | 1.712 |
| 3 | 21 | 34.65 | 39 | 1.65 | 0.9286 | 57.65 | 0.8768 | 0.0518 | 0.1305 | 2.7411 |
| 4 | 3 | 8.1 | 42 | 2.7 | 1 | 65.75 | 1 | 0 | 0.0518 | 0.1553 |
| 42 | 65.75 | 4.7825 |
plot(c(0,P),c(0,Q), type = 'l', xlab = expression(p[j]),
ylab = expression(q[j]))
segments(0,0,1,1, lty=2)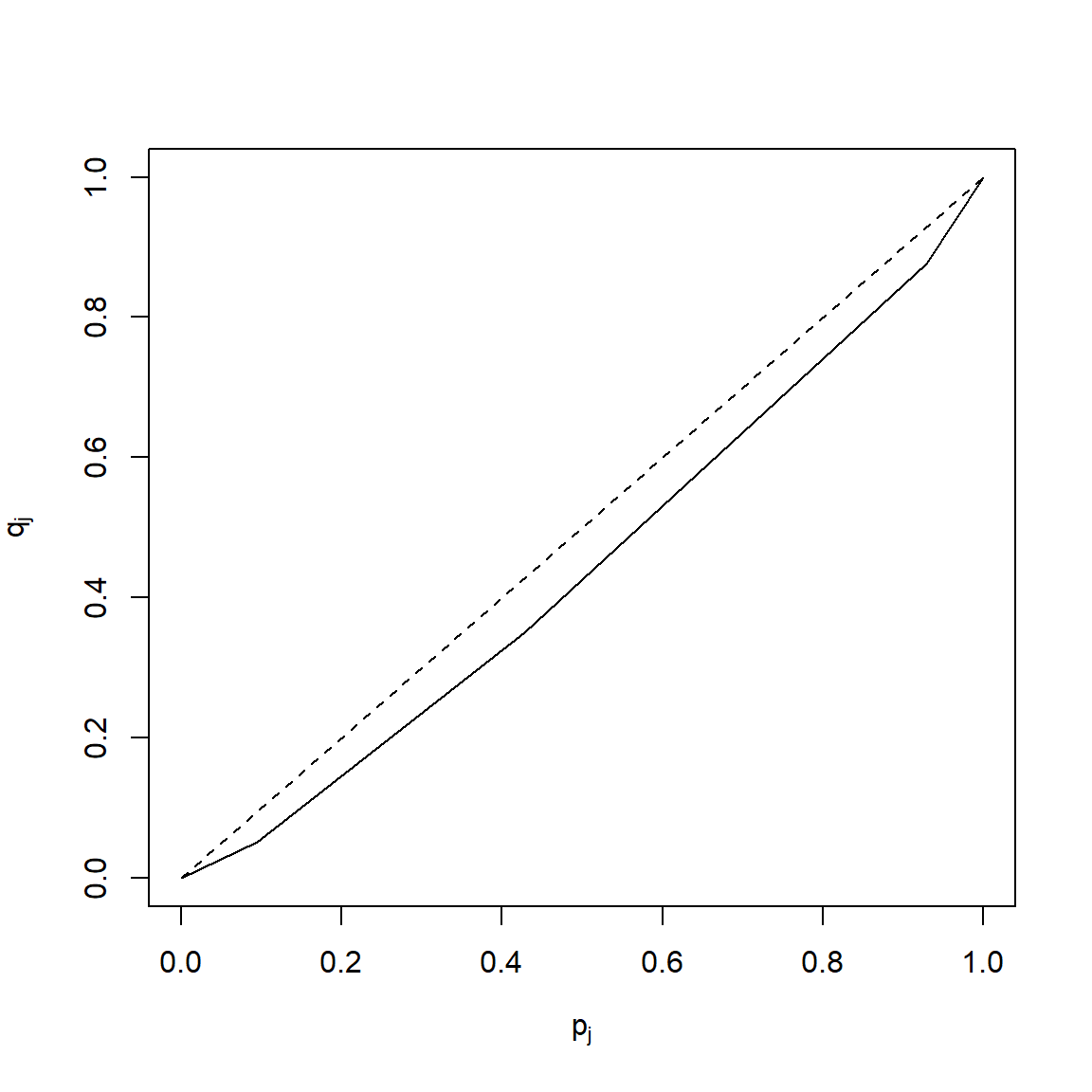
-
BONUS! Dall’esercitazione precedente \[\Delta=0.3652\,\, \mathrm{migliaia\ di\ euro}\] \[M_1=1.5655\,\, \mathrm{migliaia\ di\ euro}\] quindi \[G=\frac{0.3652}{2\cdot 1.5655}=0.1166\] La concentrazione è pari al 11.66% del suo massimo valore teorico.
Inoltre \[R=\frac{4.7842}{42}=0.1139\] \[G=\frac{N-1}{N}R=0.116688\approx 0.1167\] - \((p_2;q_2)=(0.4286,0.3498)\) il 42.86% dei dipendenti dell’azienda percepisce il 34.98% delle retribuzioni mensili.
Esercizio 1.5.3
# ES 3
rm(list = ls())
x <- c(5,17.5,37.5,65)
n <- c(62,28,6,4)
N <- cumsum(n)
P <- N/N[length(N)]
t <- x*n
sum_t <- cumsum(t)
Q <- sum_t/sum_t[length(sum_t)]
P_Q <- P-Q
h <- c(P_Q[1])
for(i in 2:length(P_Q)) h[i] <- P_Q[i]+P_Q[i-1]
hn <- h*n
sum(hn)## [1] 45.14397| \(j\) | \(x_j\) | \(n_j\) | \(N_j\) | \(P_j\) | \(x_jn_j\) | \(\sum_jx_jn_j\) | \(Q_j\) | \(d_j=P_j-Q_j\) | \(h_j=d_j+d_{j-1}\) | \(h_j\cdot n_j\) |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | \(-\) | \(-\) | ||||||
| 1 | 5 | 62 | 62 | 0.62 | 310 | 310 | 0.2412 | 0.3788 | 0.3788 | 23.4828 |
| 2 | 17.5 | 28 | 90 | 0.9 | 490 | 800 | 0.6226 | 0.2774 | 0.6562 | 18.3732 |
| 3 | 37.5 | 6 | 96 | 0.96 | 225 | 1025 | 0.7977 | 0.1623 | 0.4398 | 2.6386 |
| 4 | 65 | 4 | 100 | 1 | 260 | 1285 | 1 | 0 | 0.1623 | 0.6493 |
| Totale | 100 | 1285 | 45.144 |
plot(c(0,P),c(0,Q), type = 'l', xlab = expression(p[i]),
ylab = expression(q[i]))
segments(0,0,1,1, lty=2)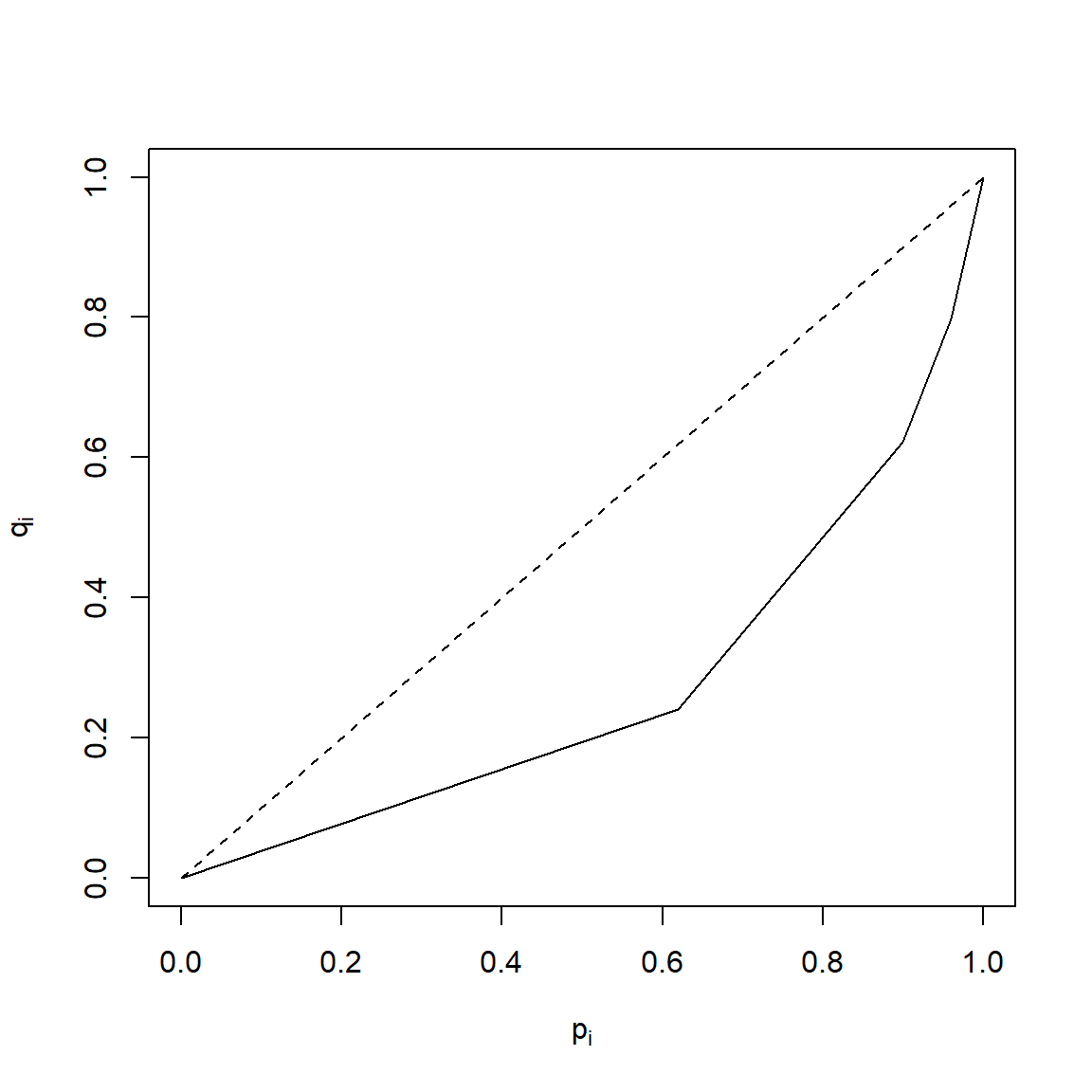
Bonus: \[R=\frac{45.2546}{100}=0.4525\] \[G=\frac{45.2546}{99}=0.4571\] La concentrazione è pari al 45.71% del suo massimo teorico.
Esercizio 1.5.4
# Es 4
rm(list = ls())
nA <- c(23, 54, 67, 21, 10)
nB <- c(34, 12, 43, 78, 14)
names(nA) <- names(nB) <- c("Ita", "Fran", "Ger", "GB", "Spa")
fA <- nA / sum(nA); fA## Ita Fran Ger GB Spa
## 0.13142857 0.30857143 0.38285714 0.12000000 0.05714286## Ita Fran Ger GB Spa
## 0.017273469 0.095216327 0.146579592 0.014400000 0.003265306## [1] 0.2767347## [1] 0.7232653## Ita Fran Ger GB Spa
## -2.0292918 -1.1758019 -0.9600934 -2.1202635 -2.8622009## Ita Fran Ger GB Spa
## -0.2667069 -0.3628189 -0.3675786 -0.2544316 -0.1635543## [1] -1.41509## Ita Fran Ger GB Spa
## 0.18784530 0.06629834 0.23756906 0.43093923 0.07734807## Ita Fran Ger GB Spa
## 0.035285858 0.004395470 0.056439059 0.185708617 0.005982723## [1] 0.2878117## [1] 0.7121883## Ita Fran Ger GB Spa
## -1.6721365 -2.7135904 -1.4372969 -0.8417882 -2.5594397## Ita Fran Ger GB Spa
## -0.3141030 -0.1799065 -0.3414573 -0.3627596 -0.1979677## [1] -1.396194| \(j\) | \(f_A\) | \(f_A^2\) | \(\mathrm{ln}f_A\) | \(f_A\mathrm{ln}f_A\) | \(f_B\) | \(f_B^2\) | \(\mathrm{ln}f_B\) | \(f_B\mathrm{ln}f_B\) | |
| Ita | 1 | 0.1314 | 0.0173 | -2.0293 | -0.2667 | 0.1878 | 0.0353 | -1.6721 | -0.3141 |
| Fran | 2 | 0.3086 | 0.0952 | -1.1758 | -0.3628 | 0.0663 | 0.0044 | -2.7136 | -0.1799 |
| Ger | 3 | 0.3829 | 0.1466 | -0.9601 | -0.3676 | 0.2376 | 0.0564 | -1.4373 | -0.3415 |
| GB | 4 | 0.12 | 0.0144 | -2.1203 | -0.2544 | 0.4309 | 0.1857 | -0.8418 | -0.3628 |
| Spa | 5 | 0.0571 | 0.0033 | -2.8622 | -0.1636 | 0.0773 | 0.006 | -2.5594 | -0.198 |
| Totale | 1 | 0.2767 | -1.4151 | 1 | 0.2878 | -1.3962 |
\[e_{1A}=1-0.2767=0.7233\] \[e_{2A}=1.4151\] \[e_{1B}=1-0.2878=0.7122\] \[e_{2B}=1.3962\]
Esercitazione 1.6
Esercizio 1.6.1
La seguente tabella riporta le serie storiche mensili dei valori (in migliaia di Euro) dei contratti stipulati dalle due filiali di Milano (\(X\)) e Torino (\(Y\)) di un’azienda nel corso dell’ultimo semestre del 2017:
| Mese | \(X\) | \(Y\) |
|---|---|---|
| Luglio | 203 | 231 |
| Agosto | 158 | 143 |
| Settembre | 87 | 134 |
| Ottobre | 114 | 123 |
| Novembre | 225 | 214 |
| Dicembre | 253 | 249 |
| Totale | 1040 | 1094 |
- Si calcolino le medie aritmetiche di \(X\) e \(Y\).
- Si calcolino i tassi di variazione medi mensili di \(X\) e \(Y\) per l’intero periodo.
- Quali conclusioni si possono dedurre dai risultati ottenuti nei due punti precedenti?
Esercizio 1.6.2
I redditi annui (in migliaia di Euro) di 7 individui sono dati da \[26,\,\,21,\,\,58,\,\,33,\,\,35,\,\,19,\,\,41.\] Si stabilisca se la distribuzione dei redditi è simmetrica rispetto alla mediana. In caso contrario si calcoli l’indice di verso di asimmetria.
Esercizio 1.6.3
La seguente tabella riporta gli esiti di un esame \(X\) di 484 studenti suddivisi in base al corso di studi \(Y\).
|
\(Y\)
|
||||
|---|---|---|---|---|
| \(X\) | C1 | C2 | C3 | Totale |
| Insufficiente | 39 | 42 | 24 | 105 |
| Sufficiente | 45 | 65 | 76 | 186 |
| Buono | 53 | 44 | 39 | 136 |
| Ottimo | 23 | 18 | 16 | 57 |
| Totale | 160 | 169 | 155 | 484 |
- Si determini la mediana di \(X\).
- Si determini la moda di \(Y\) e se ne valuti la rappresentatività.
- Si calcolino le distribuzioni di frequenze relative parziali e la distribuzione di frequenze relative marginali del carattere \(X\).
- Si stabilisca, giustificando la risposta, se fra i due caratteri considerati esiste indipendenza distributiva. In caso di risposta negativa, si costruisca la tabella delle frequenze congiunte in modo che i due caratteri risultino indipendenti.
- Si fornisca un indice che misuri il grado di dipendenza tra \(X\) e \(Y\).
Si consideri ora il carattere \(Z=\)“voto conseguito all’esame”, esso può essere organizzato in classi in base alle modalità del carattere \(X\).
\[\begin{equation*}Z=\begin{cases}[0,17]\quad\,\,\, \mathrm{per\ } X=\mathrm{``Insufficiente"}\\ [18,21]\quad \mathrm{per\ } X=\mathrm{``Sufficiente"}\\ [22,26]\quad \mathrm{per\ } X=\mathrm{``Buono"}\\ [27,30]\quad\mathrm{per\ } X=\mathrm{``Ottimo"}\end{cases}\end{equation*}\]
- Si valuti il grado di dipendenza in media di \(Z\) da \(Y\) commentando il risultato ottenuto.
Soluzioni esercitazione 1.6
Esercizio 1.6.1
- \[\overline{x}=\frac{1040}{6}=173.3333\,\,\mathrm{mila\ Euro\ al\ mese}\] \[\overline{y}=\frac{1094}{6}=182.3333\,\,\mathrm{mila\ Euro\ al\ mese}\]
- \[\overline{V}_X=\sqrt[5]{\frac{253}{203}}-1=0.0450\] \[\overline{V}_Y=\sqrt[5]{\frac{249}{231}}-1=0.0151\]
-
Mediamente, ogni mese la filiale di Torino a prodotto contratti per un valore superiore rispetto alla filiale di Milano.
Mediamente il valore dei contratti prodotti dalla filiale di Milano è cresciuto del 4.5% al mese, mentre per quelli prodotti dalla filiale di Torino il valore è cresciuto mediante dell’1.51% al mese.
Esercizio 1.6.2
Valori ordinati: \[19,\,\, 21,\,\, 26,\,\, \mathbf{\underline{33}},\,\, 35,\,\, 41,\,\, 58\] La mediana è pari a 33. Ora si immagini che i dati siano una distribuzione di frequenze con frequenze unitarie e facciamo la rappresentazione grafica.
rm(list = ls())
val <- c(26,21,58,33,35,19,41)
val <- sort(val)
n <- length(val)
plot(val, rep(1/n,n), xlab='X', ylab='frequenze relative specifiche',
ylim = c(0,1), type = 'h', axes = F, lwd=2)
segments(median(val),0,median(val),1/n, col = 'red', lwd = 2)
box()
axis(1, at = val, labels = val)
axis(2, at = seq(0,1,0.2)) Affinché la distribuzione sia simmetrica deve verificarsi che \(frs(Me+c)=frs(Me-c),\,\forall c>0.\) Assumendo \(c=2\), \(frs(Me+c)=frs(35)=0.142\neq frs(Me-c)=frs(31)=0\). Quindi la distribuzione non è simmetrica rispetto la mediana.
Affinché la distribuzione sia simmetrica deve verificarsi che \(frs(Me+c)=frs(Me-c),\,\forall c>0.\) Assumendo \(c=2\), \(frs(Me+c)=frs(35)=0.142\neq frs(Me-c)=frs(31)=0\). Quindi la distribuzione non è simmetrica rispetto la mediana.
Inoltre, si nota che le osservazioni a destra della mediana si allontanano di più di quelle alla sua sinistra, pertanto ci possiamo aspettare asimmetria positiva (media maggiore della mediana).
Per verificare ciò calcoliamo l’indice di verso di asimmetria: \[a_1=(M_1-Me)=(33.2857-33)=0.2857\]
Esercizio 1.6.3
|
\(Y\)
|
||||
|---|---|---|---|---|
| \(X\) | C1 | C2 | C3 | Totale |
| Insufficiente | 39 | 42 | 24 | 105 |
| Sufficiente | 45 | 65 | 76 | 186 |
| Buono | 53 | 44 | 39 | 136 |
| Ottimo | 23 | 18 | 16 | 57 |
| Totale | 160 | 169 | 155 | 484 |
-
La posizione della mediana è \(\frac{N+1}{2}=242.2\). Le frequenze cumulate del carattere \(X\) sono:
Pertanto, la mediana corrisponde alla modalità “Sufficiente”.\(X\) \(C_i\) Insufficiente 105 Sufficiente 291 Buono 427 Ottimo 484 - La moda del carattere Y corrisponde alla modalità con frequenza più elevata, essa è C2 con 169 studenti. Essa rappresenta il 34.92% della popolazione.
-
\(Y\)
\(X\) C1 C2 C3 Totale Insufficiente 0.2438 0.2485 0.1548 0.2169 Sufficiente 0.2812 0.3846 0.4903 0.3843 Buono 0.3312 0.2604 0.2516 0.281 Ottimo 0.1437 0.1065 0.1032 0.1178 Totale 1 1 1 1 -
Le distribuzioni parziali di \(X\) sono tutte diverse tra di loro e sono diverse dalla distribuzione marginale, pertanto \(X\) non è indipendente in distribuzione da \(Y\). Nel caso non si fossero già calcolate le distribuzioni parziali per rispondere a questa domanda è sufficiente calcolare una frequenza congiunta teorica nel caso di indipendenza distributiva \(\hat{n}_{ij}=\frac{n_{i.}n_{.j}}{N}\) e mostrare che questa è diversa da quelle effettive. Si noti che è sufficiente trovare un’eccezione per confermare che non c’è indipendenza distributiva.
\(Y\)
\(X\) C1 C2 C3 Totale Insufficiente 34.71 36.66 33.63 105 Sufficiente 61.49 64.95 59.57 186 Buono 44.96 47.49 43.55 136 Ottimo 18.84 19.9 18.25 57 Totale 160 169 155 484 -
\[M_2\left(|\rho|\right)=\left\{\frac{1}{N}\sum_{i=1}^r\sum_{j=1}^c|\rho_{ij}|^2\cdot\hat{n}_{ij}\right\}^{\frac{1}{2}}=\left\{\frac{1}{N}\sum_{i=1}^r\sum_{j=1}^c\left|\frac{C_{ij}}{\hat{n}_{ij}}\right|^2\cdot\hat{n}_{ij}\right\}^{\frac{1}{2}}=\left\{\frac{1}{N}\sum_{i=1}^r\sum_{j=1}^c\frac{C_{ij}^2}{\hat{n}_{ij}}\right\}^{\frac{1}{2}}\]
Contingenze assolute \(C_{ij}=n_{ij}-\hat{n}_{ij}\)
\[C_{ij}^2\]\(Y\)\(X\) C1 C2 C3 Totale Insufficiente 4.29 5.34 -9.63 0 Sufficiente -16.49 0.05 16.43 0 Buono 8.04 -3.49 -4.55 0 Ottimo 4.16 -1.9 -2.25 0 Totale 0 0 0 0 \(Y\)\(X\) C1 C2 C3 Insufficiente 18.4 28.52 92.74 Sufficiente 271.92 0 269.94 Buono 64.64 12.18 20.7 Ottimo 17.31 3.61 5.06 \[\frac{C_{ij}^2}{\hat{n}_{ij}}\]
\[M_2(|\rho|)=\sqrt{\frac{16.5665}{484}}=0.1850\] mediamente le frequenze effettive si discostano da quelle teoriche di indipendenza distributiva del 18.5%.\(Y\)\(X\) C1 C2 C3 Insufficiente 0.5302 0.7778 2.7576 Sufficiente 4.4222 0 4.5316 Buono 1.4378 0.2565 0.4754 Ottimo 0.9186 0.1814 0.2774 -
È necessario sostituire le classi di \(Z\) con il loro valore centrale per poter calcolare le medie parziali.
\(Y\)
\(Z\) C1 C2 C3 Totale 8.5 39 42 24 105 19.5 45 65 76 186 24 53 44 39 136 28.5 23 18 16 57 Totale 160 169 155 484 Medie parziali \[\overline{z}_1=19.6; \quad \overline{z}_2=18.9;\quad \overline{z}_3=19.86\]
Media complessiva di Z \[\overline{z}=19.44\]
Varianze parziali di Z \[\sigma_1^2=47.96;\quad \sigma_2^2=43.47;\quad \sigma_3^2=31.99\]
Varianza complessiva di Z \[\sigma^2=41.4\]
Varianza fra le medie \[\begin{align*}V_F & =\frac{\displaystyle\sum_{j=1}^c(\overline{z}_j-\overline{z})^2 n_{.j}}{N}=\\ &=\frac{(19.6-19.44)^2\cdot 160+(18.9-19.44)^2\cdot 169+(19.86-19.44)^2\cdot 155}{484}=\\ &=\frac{80.7312}{484}=0.1668 \end{align*}\]
Varianza nei gruppi \[V_N=\frac{\displaystyle\sum_{j=1}^c\sigma_j^2 n_{.j}}{N}=\frac{47.96\cdot160+43.47\cdot169+31.99\cdot155}{484}=\frac{20037.6}{484}=41.4\]
Verifica \[V_T=\sigma_Z^2=\frac{198924}{484}=41.4\simeq V_F+V_N=\frac{20118.3312}{484}=41.5668\]
Le differenze sono dovute a errori di arrotondamento.
\[\eta_{Z│Y}^2=\frac{V_F}{V_T} =\frac{0.1638}{40.15}=0.004\] Il grado di dipendenza in media è pari allo 0.4% del suo massimo valore teorico. (consiglio: a meno che non venga chiesto di verificare la scomposizione della varianza, scegliere tra \(V_T\), \(V_N\) e \(V_F\) e scegliere le due che si preferisce e ricavare la terza dalle altre due).
Foto di rtclauss su Flickr, Iris.; R.A Fisher. “The Use of Multiple Measurements in Taxonomic Problems”. In: Annals of Eugenics 7 (1936), pp. 179-188↩︎