7 Deskriptive Auswertungen
Nach dem Gespräch mit der Dozentin zur statistischen Analyse, lässt sich Emma zunächst Häufigkeitsauszählungen der Merkmale ausgeben. Dazu greift sie nach Internetrecherche auf das sjmisc-Paket zurück.
Zuerst lädt sie das Paket mit dem library-Befehl. Um sich etwas Arbeit zu sparen und nicht jedes Mal den Datensatz bei der Auswertung der einzelnen Variablen mit angeben zu müssen, spezifiziert Emma den Datensatz für die nachfolgenden Auswertungenf mit dem attach-Befehl . Wenn Emma nicht anderes angibt, beziehen sich die folgenden Befehle also immer auf den Datensatz “ALLBUS_21_young”, welcher im vorherigen Kapitel erstellt wurde. Emma lässt sich die Häufigkeiten für Geschlecht, politisches Interesse und Wahlabsicht auszählen.
library (sjmisc)
attach (ALLBUS_21_young) #Zugriff auf den Datensatz, damit entfällt die Angabe Datensatz$Variable
frq (sex) #Häufigkeitsauszählung der Variable sex (Geschlecht)
frq (pa02a) #Häufigkeitsauszählung der Variable pa02a (politisches Interesse)
frq (pv01) #Häufigkeitsauszählung der Variable pv01 (Wahlabsicht)#> GESCHLECHT, BEFRAGTE(R) (x) <numeric>
#> # total N=387 valid N=387 mean=1.51 sd=0.50
#>
#> Value | Label | N | Raw % | Valid % | Cum. %
#> -----------------------------------------------------
#> -9 | KEINE ANGABE | 0 | 0.00 | 0.00 | 0.00
#> 1 | MANN | 191 | 49.35 | 49.35 | 49.35
#> 2 | FRAU | 196 | 50.65 | 50.65 | 100.00
#> 3 | DIVERS | 0 | 0.00 | 0.00 | 100.00
#> <NA> | <NA> | 0 | 0.00 | <NA> | <NA>
#> POLITISCHES INTERESSE, BEFR. (ORDINAL) (x) <numeric>
#> # total N=387 valid N=386 mean=2.83 sd=0.98
#>
#> Value | Label | N | Raw % | Valid % | Cum. %
#> ---------------------------------------------------------
#> -42 | DATENFEHLER: MFN | 0 | 0.00 | 0.00 | 0.00
#> -9 | KEINE ANGABE | 0 | 0.00 | 0.00 | 0.00
#> 1 | SEHR STARK | 36 | 9.30 | 9.33 | 9.33
#> 2 | STARK | 97 | 25.06 | 25.13 | 34.46
#> 3 | MITTEL | 169 | 43.67 | 43.78 | 78.24
#> 4 | WENIG | 65 | 16.80 | 16.84 | 95.08
#> 5 | UEBERHAUPT NICHT | 19 | 4.91 | 4.92 | 100.00
#> <NA> | <NA> | 1 | 0.26 | <NA> | <NA>
#> BEFR.: WAHLABSICHT BUNDESTAGSWAHL (x) <numeric>
#> # total N=387 valid N=285 mean=18.05 sd=30.79
#>
#> Value | Label | N | Raw % | Valid % | Cum. %
#> -------------------------------------------------------------
#> -50 | NICHT WAHLBERECHTIGT | 0 | 0.00 | 0.00 | 0.00
#> -42 | DATENFEHLER: MFN | 0 | 0.00 | 0.00 | 0.00
#> -9 | KEINE ANGABE | 0 | 0.00 | 0.00 | 0.00
#> -8 | WEISS NICHT | 0 | 0.00 | 0.00 | 0.00
#> -7 | VERWEIGERT | 0 | 0.00 | 0.00 | 0.00
#> 1 | CDU-CSU | 30 | 7.75 | 10.53 | 10.53
#> 2 | SPD | 31 | 8.01 | 10.88 | 21.40
#> 3 | FDP | 44 | 11.37 | 15.44 | 36.84
#> 4 | DIE GRUENEN | 93 | 24.03 | 32.63 | 69.47
#> 6 | DIE LINKE | 29 | 7.49 | 10.18 | 79.65
#> 42 | AFD | 18 | 4.65 | 6.32 | 85.96
#> 90 | ANDERE PARTEI | 22 | 5.68 | 7.72 | 93.68
#> 91 | WUERDE NICHT WAEHLEN | 18 | 4.65 | 6.32 | 100.00
#> <NA> | <NA> | 102 | 26.36 | <NA> | <NA>7.1 Visualisierungen mit base-R-Befehlen
Die in den Häufigkeitstabellen sichtbaren Ergebnisse möchte Emma nun über Diagramme visualisieren. Zu Beginn erstellt sie für das politische Interesse ein Säulen-, ein Balken- und ein Kreisdiagramm. Dazu verwendet sie zunächst base-R-Befehle zur Graphikerstellung.
7.1.1 Säulendigramm mit base-R-Befehlen
Im ersten Schritt erstellt Emma das Säulendiagramm. Sie definiert wie auch schon oben, zuerst wieder mit attach den Datensatz, mit dem sie in den nächsten Schritten arbeiten möchte. Der Befehl barplot wird dann dafür genutzt, um ein Balkendiagramm zu erstellen. Sie muss dann aber im Code zusätzlich noch angeben, auf welcher statistischen Grundlage das Balkendiagramm erstellt werden soll. Dazu gibt sie table (pa02a) für eine einfache Häufigkeitsauszählung an. Das Ergebnis der Häufigkeitsauszählung wird in absoluten Zahlen dargestellt.
#Säulendiagramm mit base-R-Befehlen
attach (ALLBUS_21_young)
barplot (table (pa02a)) #Säulendiagramm fuer Interesse an Politik (absolute Zahlen)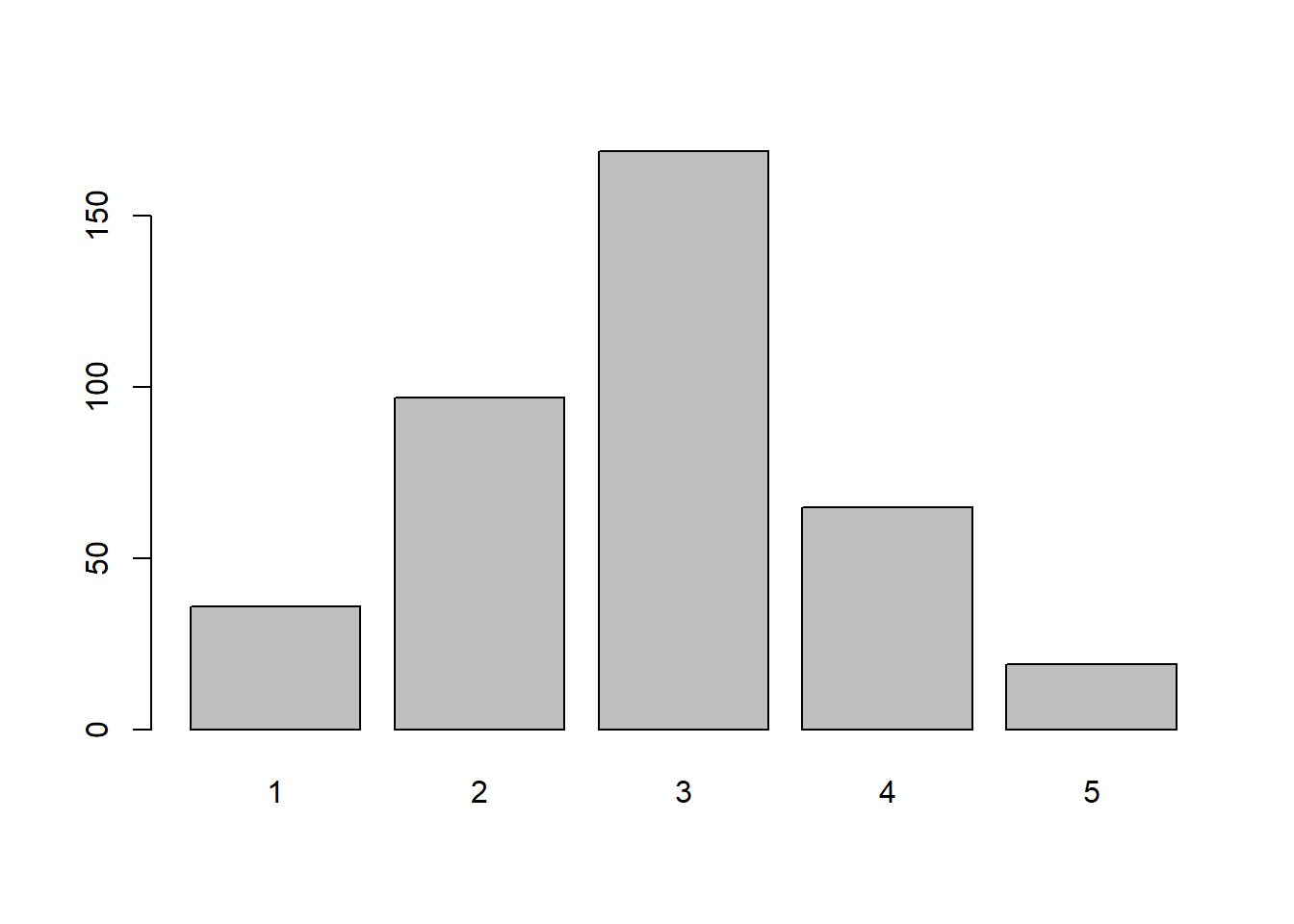
Da sich Emma auch für die prozentualen Anteile interessiert, wandelt sie ihren Code im nächsten Schritt leicht ab. Sie nutzt jetzt nicht mehr table, sondern 100*prop.table um das Säulendiagramm in relativen Zahlen (Prozentwerte) angezeigt zu bekommen.
barplot (100*prop.table (table(pa02a))) #Säulendiagramm fuer Interesse an Politik (relative Zahlen)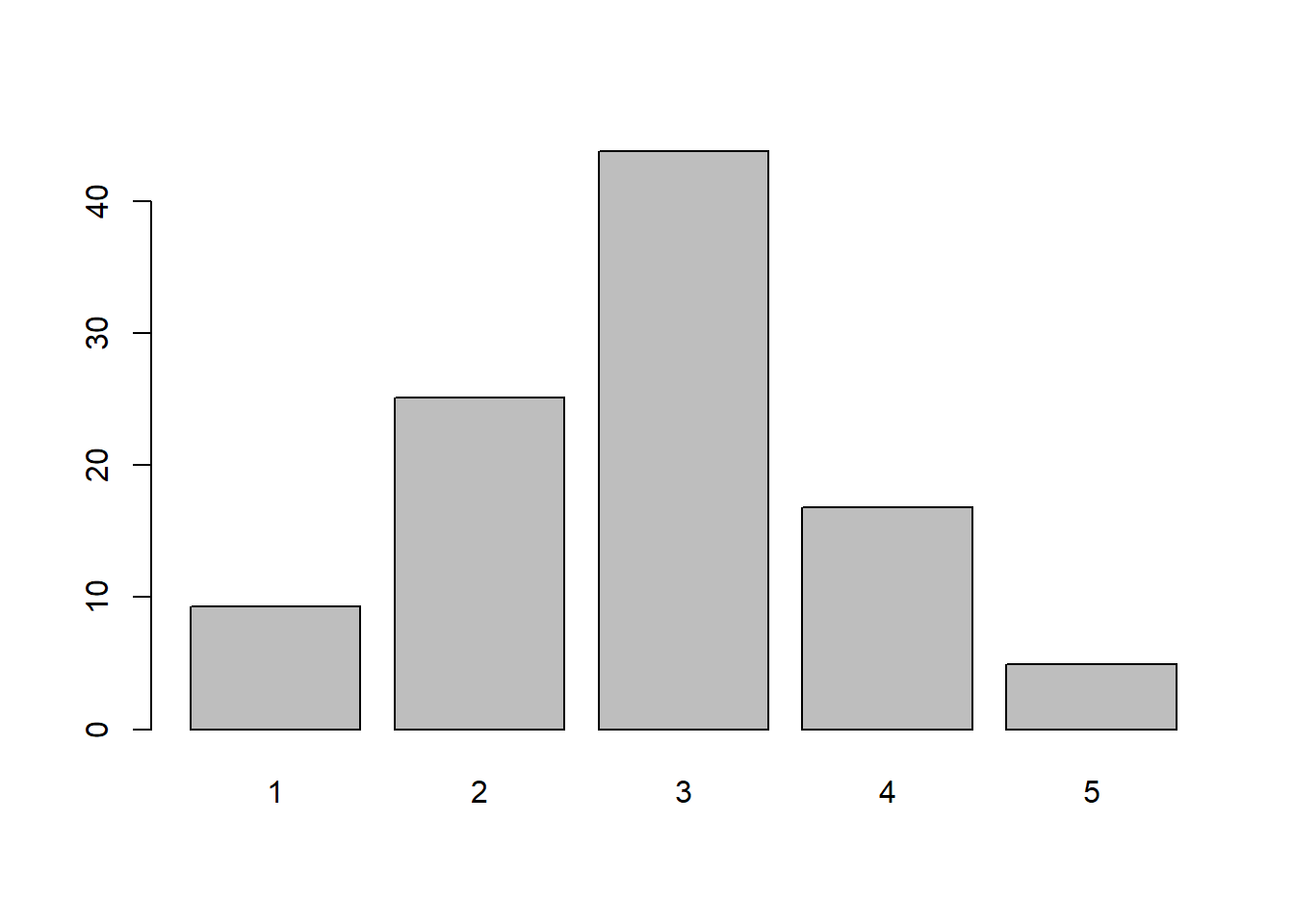
Damit hat sie ein einfaches Diagramm erstellt, das ihr einen ersten groben Überblick gibt, aber immer noch schwer zu lesen ist, wenn man die Variablenausprägungen nicht kennt. Damit die Diagramme informativer aussehen, möchte Emma diese individuell anpassen und beschriften. Dazu nutzt sie unterschiedliche Optionen in ihrem Befehl:
names=c() - Beschriftung der einzelnen Elemente der X-Achse
ylim=c() - Festlegung des Wertebereich auf der Y-Achse
cex.names () - Anpassung der Schriftgröße
main= - Festlegung eines Diagrammtitels
xlab= - Beschriftung der X-Achse
ylab= - Beschriftung der Y-Achse
col=c() - Festlegung der Farbe(n) für die Balken
grid(col=c()) - Gitternetz des Diagramms
# Säulendiagramm mit base-R-Befehlen & Beschriftungen:
barplot (100*prop.table (table(pa02a)),
names=c("sehr stark", "stark", "mittel", "wenig", "überhaupt nicht"), #Beschriftung für x-Achse
ylim=c(0,50), #Wertebereich der y-Achse
cex.names=0.9, #Schriftgröße für Beschriftung
main= "Wie stark interessieren Sie sich\n für Politik? (N=386)", #Diagrammtitel
xlab="Antwortkategorien", #X-Achsen-Titel
ylab="Prozent", #Y-Achsen-Titel
col=c("cornflowerblue")) #Farbe der Balken
grid (col=c("darkgrey")) #Gitternetz für Diagramm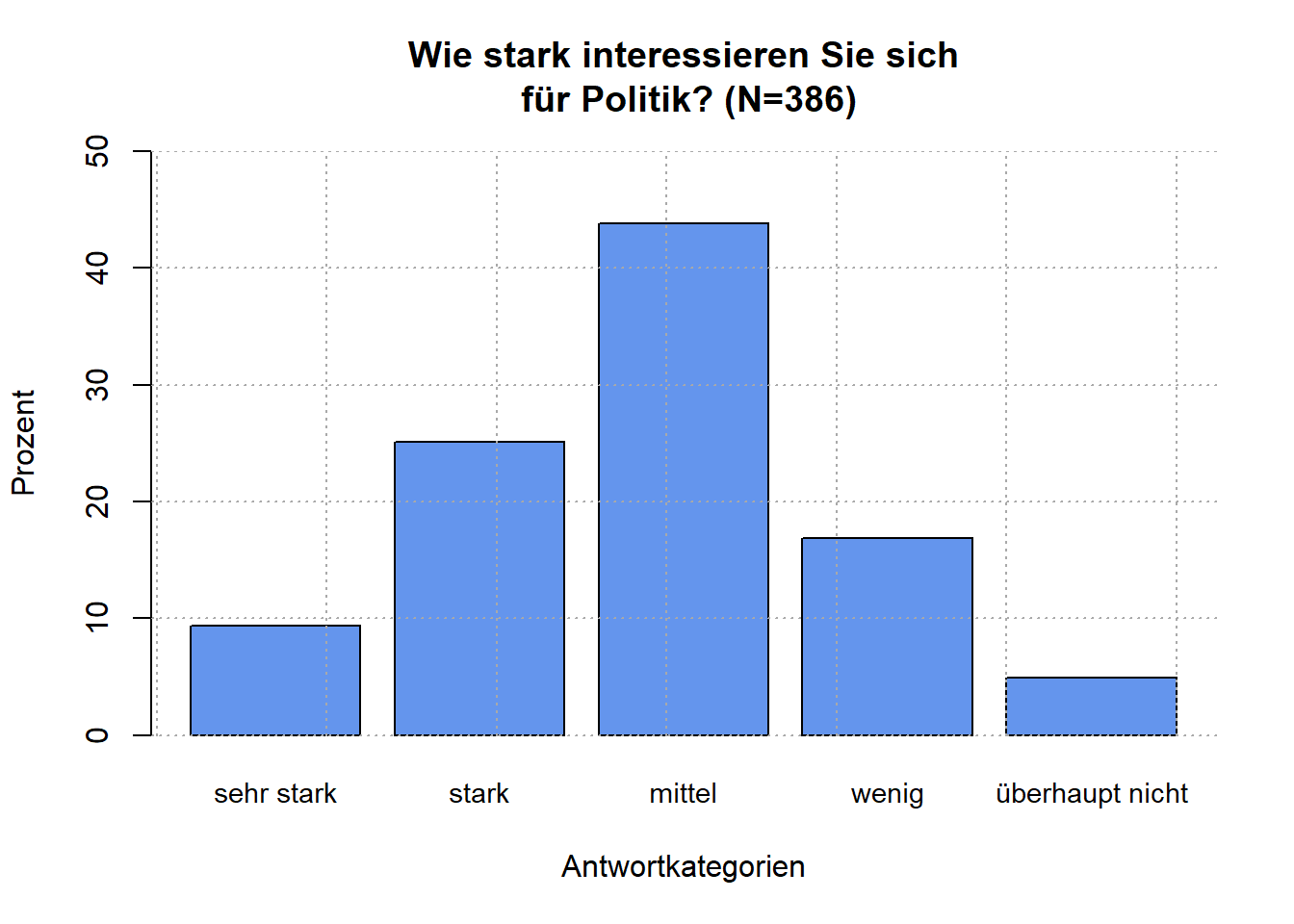
7.1.2 Darstellung als Balkendiagramm
Emma ist immer noch nicht richtig zufrieden mit der Darstellung und versucht es deshalb im nächsten Schritt mit einem Balkendiagramm. Der grundlegende Code für das Balkendiagramm ist zunächst identisch zu dem für die Säulendiagramme. Es kommt lediglich eine Drehung des Diagramms um 90° hinzu. Dazu wird die Bedingung horiz=TRUE hinzugefügt. Um auch die Beschriftung der Achse anzupassen, verwendet sie die zusätzliche Bedingungen las=1.
#Balkendiagramm mit base-R-Befehlen
barplot (100*prop.table (table(pa02a)),
horiz=TRUE, #Drehung des Diagramms um 90 Grad
names=c("sehr\nstark", "stark", "mittel", "wenig", "über-\nhaupt\n nicht"), #Beschriftung für y-Achse
xlim=c(0,50), #Wertebereich der x-Achse
cex.names=0.9, #Schriftgröße für Beschriftung
main= "Wie stark interessieren Sie sich\n für Politik? (N=386)", #Diagrammtitel
xlab="Prozent", #Y-Achsen-Titel
las =1,
col=c("cornflowerblue")) #Farbe der Balken
grid (col=c("darkgrey")) #Gitternetz für Diagramm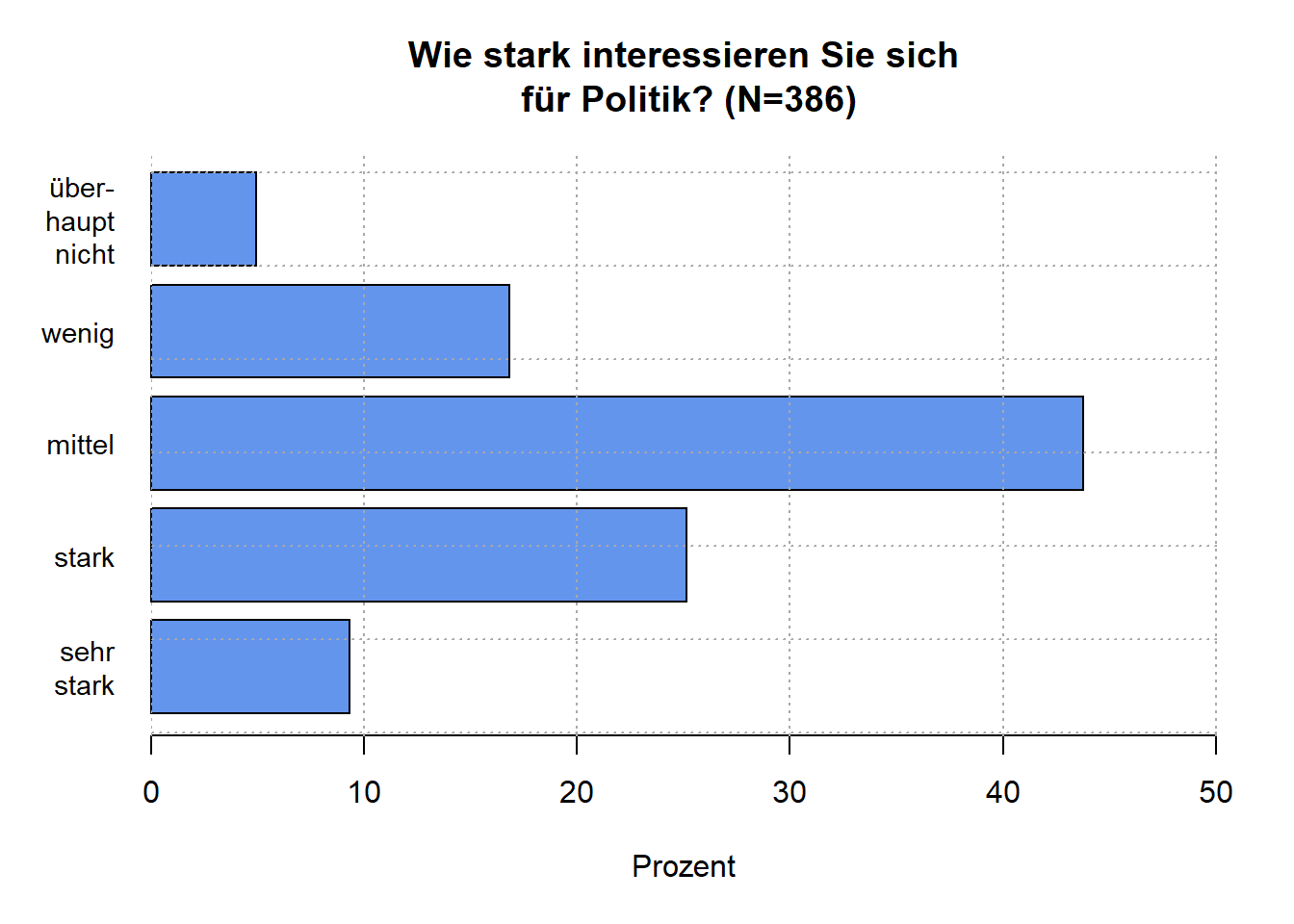
7.1.3 Darstellung als Kreisdiagramm
Als weitere Alternative für die Darstellung möchte Emma sich noch ein Kreisdiagramm ansehen, um dann entscheiden zu können, was für sie die beste Darstellung ist. Dazu ist wieder ein bisschen Vorarbeit nötig: Zuerst werden zwei Objekte für die Antwortkategorien und die Prozentwerte angelegt. Im ersten Schritt wird das Objekt “prozent” erzeugt. Hier werden die Antworten der Variablen pa02a (politisches Interesse) als Prozentwerte gespeichert. Der vorangestellte round-Befehl rundet die Prozentwerte auf eine Nachkommastelle (,1). Im zweiten Schritt wird dann das Objekt “antworten” erstellt. Die Antwortmöglichkeiten werden dabei einzeln aufgeführt und als eigenes Objekt gespeichert. Danach werden diese beide Objekte, welche Emma für die Beschriftung braucht, mit dem paste-Befehl zusammengeführt.
Nachdem die Vorarbeit geschafft ist, beginnt Emma mit der Erstellung des Kreisdiagramms. Dazu nutzt sie den pie-Befehl. Für eine ansprechende Gestaltung fügt sie wieder einige Bedingungen hinzu:
labels= - ermöglicht ihr die Beschriftung des Diagramms. Emma kann dafür jetzt das eben erstellte Objekt “Beschriftung” nutzen.
main= - Diagrammtitel
col=c() - Farben der Kreissektoren
#Kreisdiagramm mit base-R-Befehlen
prozent <- round((prop.table (table(pa02a))*100),1) #Abspeichern der Prozentwert als separates Objekt
antworten <- c("sehr stark", "stark", "mittel", "wenig", "überhaupt nicht") #Antwortoptionen als separates Objekt
beschriftung <- paste(antworten, prozent, "%", sep=" ") #Zusammenführung beider Objekte
pie(table(pa02a), #Kreisdiagramm
labels = beschriftung, #Beschriftung basiert auf dem zusammengeführten Objekt "beschriftung"
main = "Wie stark interessieren Sie sich\n für Politik? (N=386)", #Diagrammtitel
col = c("red", "orange", "yellow", "blue", "black")) #Farbe der Kreissektoren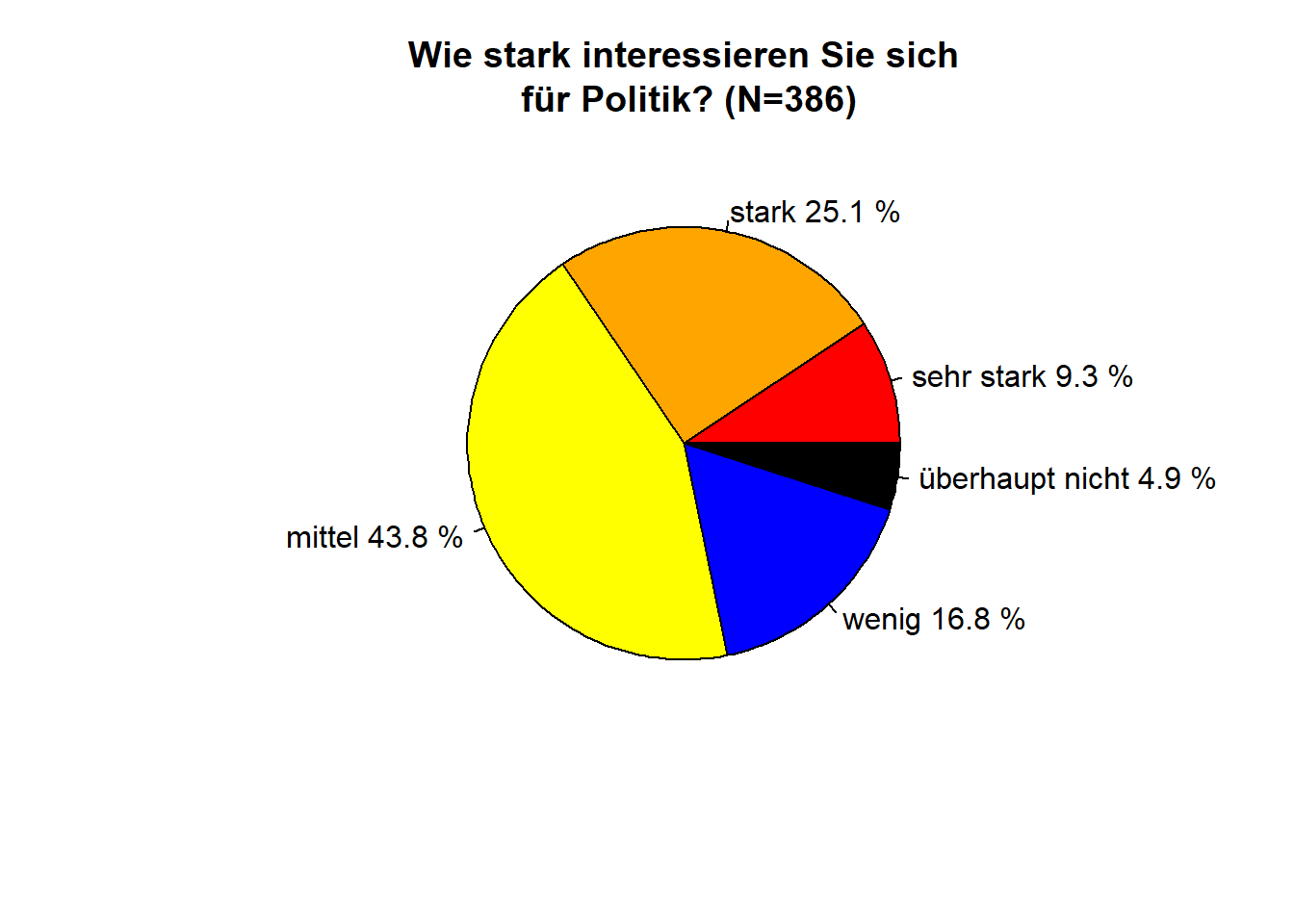
7.2 Visualisierung mit dem ggplot2-package
Emma hat von ihrer Dozentin den Tipp bekommen, für Visualisierungen das im tidyverse-Paket enthaltene Paket “ggplot2” zu nutzen, weil dieses eine noch bessere Individualisierung der Graphiken ermöglicht.
7.2.1 Säulendiagramm mit absoluten Werten
Emma arbeitet jetzt mit ggplot2. Auch hier wählt sie zuerst den Datensatz auf den sie zugreifen möchte, aus. Im zweiten Schritt filtert sie mit dem Befehl filter(!is.na(pa02a)) die fehlenden Werte der Variable “Politisches Interesse” aus dem Datensatz heraus. Sie fügt dann über die weiteren Bedingungen ein, wie das Diagramm aussehen soll.
ggplot(aes(x = sjlabelled::as_label(pa02a))) - ist die Grundlage für das Diagramm. Die ausgewählte Variable wird als Plot dargestellt. Es werden die gespeicherten Wertelabels verwendet.
geom_bar(width=0.5, fill=“Cornflowerblue”) - gibt die Form des Diagramms an. In diesem Fall ein Säulendiagramm (geom_bar), mit einer Balkenbreite von 0.5 (width=0.5) und der Füllfarbe “cornflowerblue” (fill=“cornflowerblue).
labs () - gibt die Möglichkeit verschiedene Beschriftungen am Diagramm vorzunehmen. Emma nutzt die Beschriftung für die X-Achse, Y-Achse, gibt dem Diagramm einen Titel sowie Untertitel und fügt noch die Quelle des Datensatzes hinzu.
#Säulendiagramm mit absoluten Werten
ALLBUS_21_young%>% #Zugriff auf Datensatz
filter(!is.na(pa02a)) %>% #Herausfiltern der fehlenden Werte
ggplot(aes(x = sjlabelled::as_label(pa02a))) + #Plot der Variable "pa02", dabei werden die abgespeicherten Wertelabels genutzt
geom_bar(width=0.5, fill="Cornflowerblue")+ #als Säulendiagramm
labs (x= "Antwortkategorien", #Beschriftung X-Achse
y= "Anzahl", #Beschriftung Y-Achse
title="Wie stark interessieren Sie sich für Politik? (N=386)", #Diagrammtitel
subtitle = "ALLBUS 2021", #Untertitel
caption = "Quelle: ALLBUS 2021, https://doi.org/10.4232/1.14002") #Quelle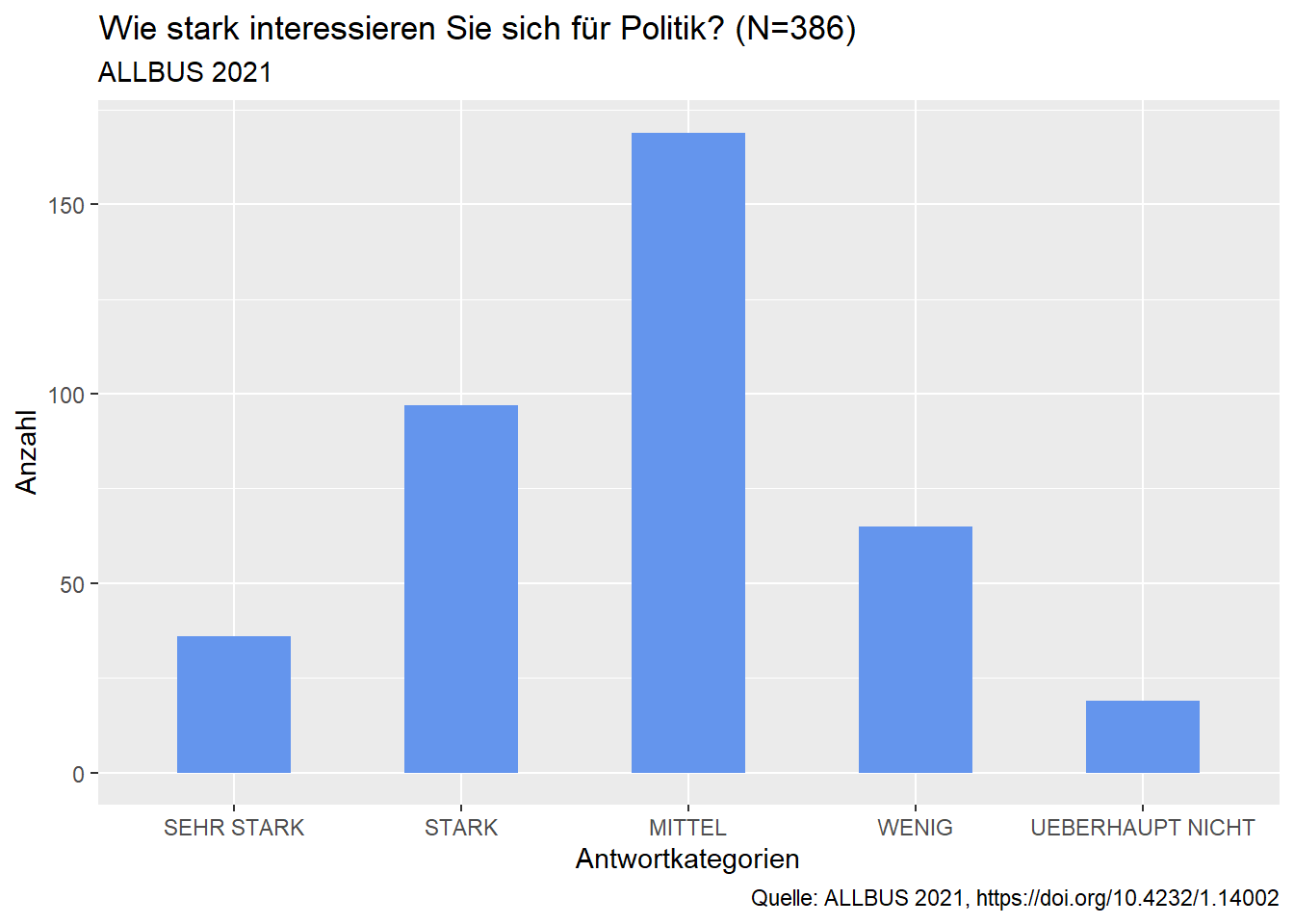
7.2.2 Säulendiagramm mit Prozentwerten
Auch hier greift Emma zuerst wieder auf den Datensatz zu und filtert die fehlenden Werte heraus. Dann berechnet Emma die prozentuierten Werte. Dazu nutzt sie:
count (pa02a = sjlabelled::as_label(pa02a)) - zählt die Häufigkeit der gewählten Variable aus.
mutate (pct =prop.table (n)) - berechnet die prozentualen Anteile zur vorherigen Auszählung.
geom_bar (stat =“identity”, width=0.5, fill=“cornflowerblue”) - wird dann wieder genutzt um, das Säulendiagramm zu erstellen und gestalten.
geom_text(vjust = -1.5, size = 3.8) - wird genutzt, um die %-Werte oberhalb der Säulen anzuzeigen.
scale_y_continuous(labels=scales::percent_format(), limits = c(0, 0.6)) - wird genutzt, um die Beschriftung der y-Achse anzupassen. Die y-Werte werden mit %-Zeichen ausgegeben und haben einen Wertebereich (limits) von 0 (=0%) bis 0.6 (=60%).
Der Skriptteil “scales::” ist eine Besonderheit. Hier wird nur für diese eine Befehlszeile das scale-package verwendet. Mit den beiden Doppelpunkten wird eine derartige Verwendung von Paketen im R-Script angezeigt.
Die weiteren Beschriftungen hat Emma wie bei den Diagrammen mit absoluten Werten vorgenommen.
#Säulendiagramm mit prozentualen Werten
ALLBUS_21_young %>% #Zugriff auf Datensatz
filter(!is.na(pa02a)) %>% #Herausfiltern der fehlenden Werte
count (pa02a = sjlabelled::as_label(pa02a)) %>% #Absolute Häufigkeiten der Variable pa02a
mutate (pct =prop.table (n)) %>% #Berechnung der prozentualen Häufigkeiten
ggplot(aes(x = pa02a, y = pct, label = scales::percent(pct))) + #Plot der Variable pa02a und ihrer prozentualen Häufigkeiten
geom_bar (stat ="identity", width=0.5, fill="cornflowerblue")+ #Säulendiagramm der erzeugten Berechnungen
geom_text(vjust = -1.5,
size = 3.8)+ #Hinzufügen der Prozentwerte oberhalb der Säulen
scale_y_continuous(labels=scales::percent_format(), limits = c(0, 0.6))+
labs (x= "Antwortkategorien", #Beschriftung X-Achse
y= "Prozentualer Anteil", #Beschriftung Y-Achse
title="Wie stark interessieren Sie sich für Politik? (N=386)", #Diagrammtitel
subtitle = "ALLBUS 2021", #Untertitel
caption = "Quelle: ALLBUS 2021, https://doi.org/10.4232/1.14002") #Quelle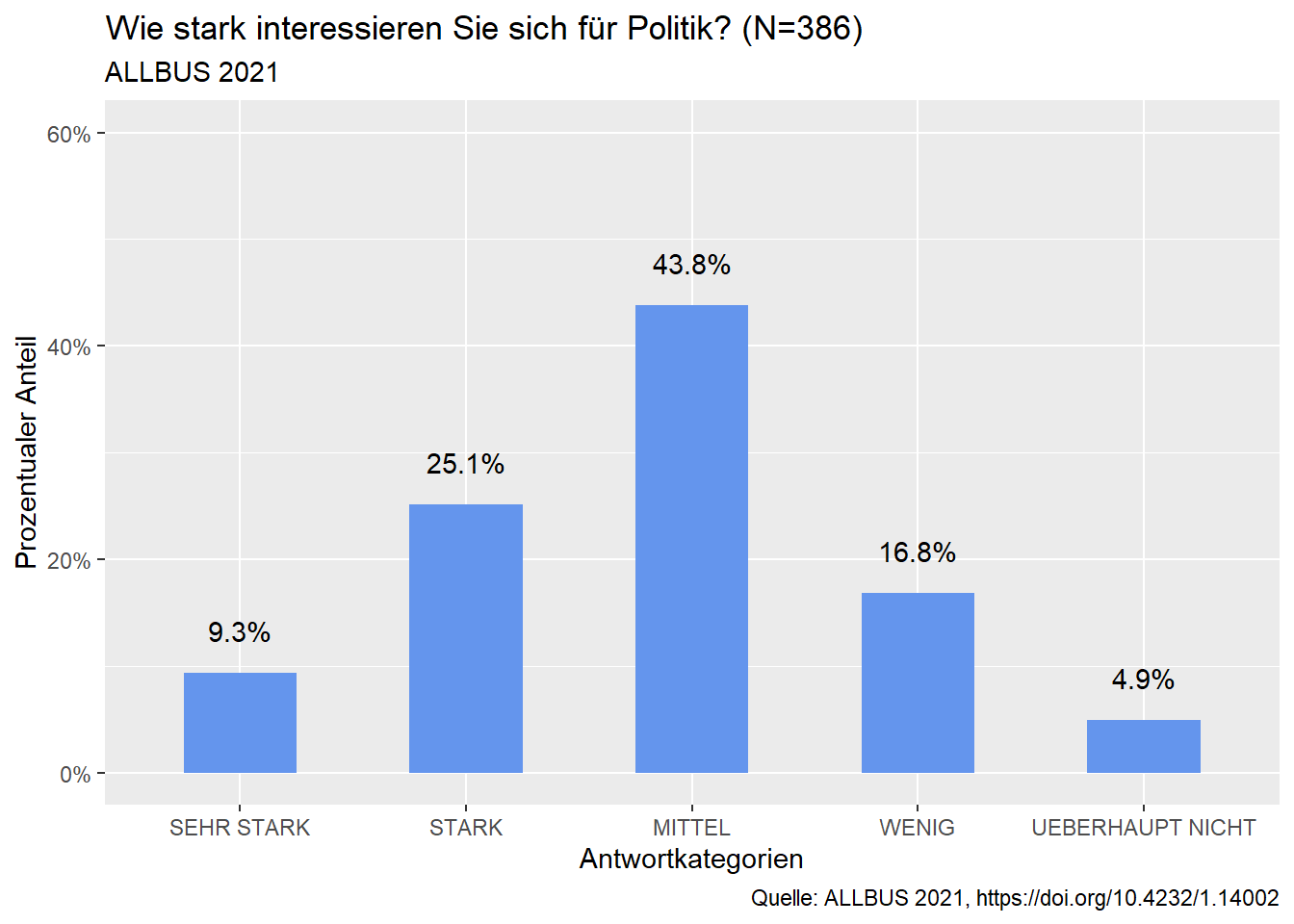
Nachdem Emma sich das politische Interesse der sie interessierenden Altersgruppe im Säulendiagramm angeschaut hat, erstellt sie ein weiteres Diagramm zur Parteienpräferenz (Frage: “Was würden Sie wählen, wenn am nächsten Sonntag Bundestagswahl wäre?”).
Dabei geht sie grundsätzlich ähnlich wie auch beim vorherigen Diagramm vor. Sie möchte allerdings die Balken in unterschiedlichen Farben einfärben und orientiert sich dabei an den typischen Farben mit denen die Parteien dargestellt werden. Deshalb gibt sie folgende Bedingung mit ein:
geom_bar (stat =“identity”, width=0.5, fill= c(“black”, “red”, “yellow”, “green”, “purple”, “cornflowerblue”, “slategrey”, “darkgrey”))
Außerdem möchte Emma die Koordinatenachsen tauschen. Die Prozentwerte sollen auf der X-Achse abzulesen sein. Dazu verwendet sie die Bedingung:
coord_flip()
#Säulendiagramm mit prozentualen Werten
ALLBUS_21_young %>%
filter(!is.na(pv01)) %>% #Herausfiltern der fehlenden Werte
count (pv01 = sjlabelled::as_label(pv01)) %>% #Absolute Häufigkeiten der Variable pv01
mutate (pct =round(prop.table (n),3)) %>% #Berechnung der prozentualen Häufigkeiten
ggplot(aes(x = pv01, y = pct, label = scales::percent(pct))) + #Plot der Variable pv01 und ihrer prozentualen Häufigkeiten, Prozentwerte werden als Label für die Y-Achse übernommen
geom_bar (stat ="identity", width=0.5, fill= c("black", "red", "yellow", "green", "purple", "cornflowerblue", "slategrey", "darkgrey"))+ #Säulendiagramm der erzeugten Berechnungen
geom_text(hjust = -0.5,
size = 3.0)+ #Hinzufügen der Prozentwerte rechts der Säulen
scale_y_continuous(labels=scales::percent_format(), limits = c(0, 0.5))+
labs (x= "Antwortkategorien", #Beschriftung X-Achse
y= "Prozentualer Anteil", #Beschriftung Y-Achse
title="Wahlabsicht Bundestagswahl? (N=285)", #Diagrammtitel
subtitle = "ALLBUS 2021", #Untertitel
caption = "Quelle: ALLBUS 2021, https://doi.org/10.4232/1.14002")+#Quelle
coord_flip()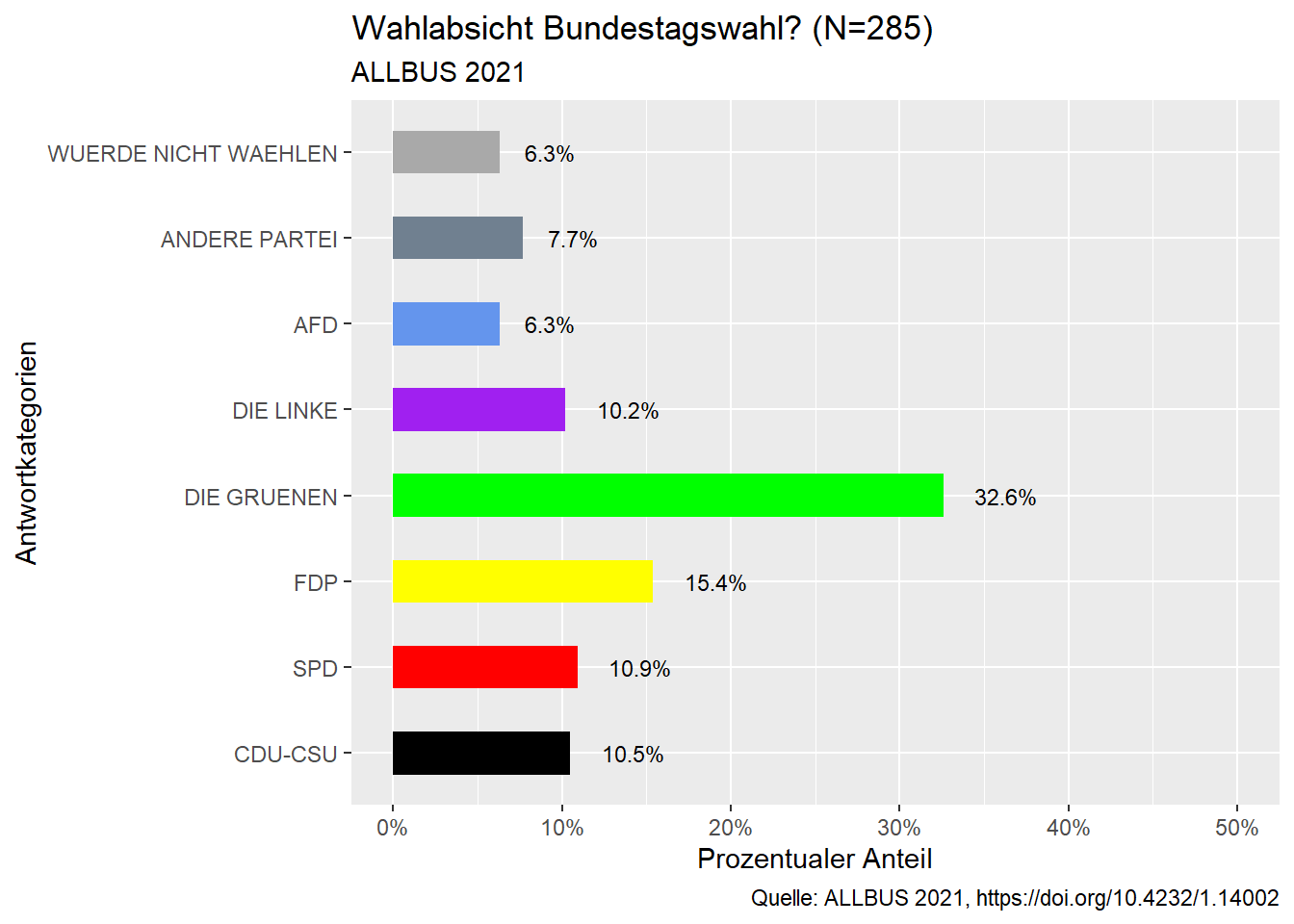
7.2.3 Gruppierte Diagramme
Nach dem Gespräch mit der Dozentin versucht sich Emma an einer Visualisierung der Unterschiede zwischen den Altersgruppen. Dazu erstellt Sie mit ihrem Datensatz “ALLBUS_21_Analyse” ein gruppiertes Säulendiagramm für das politische Interesse der beiden erzeugten Altersgruppen.
Sie greift wieder zuerst auf den Datensatz zu und filtert die fehlenden Werte heraus. Bevor sie weitermachen kann, muss sie nun die Gruppierung festlegen. Dazu nutzt sie die Bedingung:
group_by(age_group) - damit wird das Diagramm anhand der Variable “age_group” gruppiert, d.h. je nach Altersgruppe verschiedene Säulen erzeugt. Im Datensatz gibt es die beiden Gruppen “18-25jährige” und “älter als 25 Jahre”.
Dann fährt Emma wie auch schon beim vorherigen Diagramm mit der Prozentuierung fort und gibt die Bedingungen für die Darstellung ein. Dabei wird die Variable pa02a auf der X-Achse dargestellt und die berechneten %-Werte für die Y-Achse übernommen. Es wird das Säulendiagramm erzeugt und beschriftet. Als neue Beschriftung fügt Emma jetzt außerdem eine Legende hinzu, welche auch wieder individuell gestaltet wird:
scale_fill_manual (name=‘Altersgruppen’, labels=c(‘18 - 25ährige’,‘älter als 25 Jahre’), values=c(“#0072B2”, “#D55E00”))
Die Legende bekommt die Bezeichnung “Altersgruppe”. Sie wird aufgeteilt in die beiden Gruppen “18-25jährige” und “älter als 25 Jahre. Es werden dann noch die Farben für die jeweiligen Balken im Diagramm angegeben. Die weitere Beschriftung orientiert sich an den Beschriftungen der vorherigen Diagramme.
ALLBUS_21_Analyse %>% #Zugriff auf Datensatz
filter(!is.na(pa02a), !is.na(age_group)) %>% #Herausfiltern der fehlenden Werte
group_by(age_group) %>% #Gruppierung der Daten nach Variable age_group
count (pa02a = sjlabelled::as_label(pa02a)) %>% #Absolute Häufigkeiten der Variable pa02a
mutate (pct =round (prop.table (n),3)) %>% #Berechnung der prozentualen Häufigkeiten
ggplot(aes(x = pa02a, y = pct, label = scales::percent(pct), fill=age_group)) + #Plot der Variable pa02a und ihrer prozentualen Häufigkeiten, , Prozentwerte werden als Label für die Y-Achse übernommen
geom_bar (position=position_dodge(),stat ="identity", width=0.9)+ #Säulendiagramm der erzeugten Berechnungen
scale_y_continuous(labels=scales::percent_format(), limits = c(0, 0.6))+
scale_fill_manual (name='Altersgruppen',
labels=c('18 - 25ährige','älter als 25 Jahre'),
values=c("#0072B2", "#D55E00"))+#Manuelle Gestaltung der Legende
geom_text(position=position_dodge(.9), vjust = -1.5, size = 2.5)+ #Anzeige der Prozentwerte über den Säulen
labs (x= "Antwortkategorien", #Beschriftung X-Achse
y= "Prozentualer Anteil", #Beschriftung Y-Achse
title="Wie stark interessieren Sie sich für Politik? (N=386)", #Diagrammtitel
subtitle = "ALLBUS 2021 - nach Altersgruppen", #Untertitel
caption = "Quelle: ALLBUS 2021, https://doi.org/10.4232/1.14002") #Quelle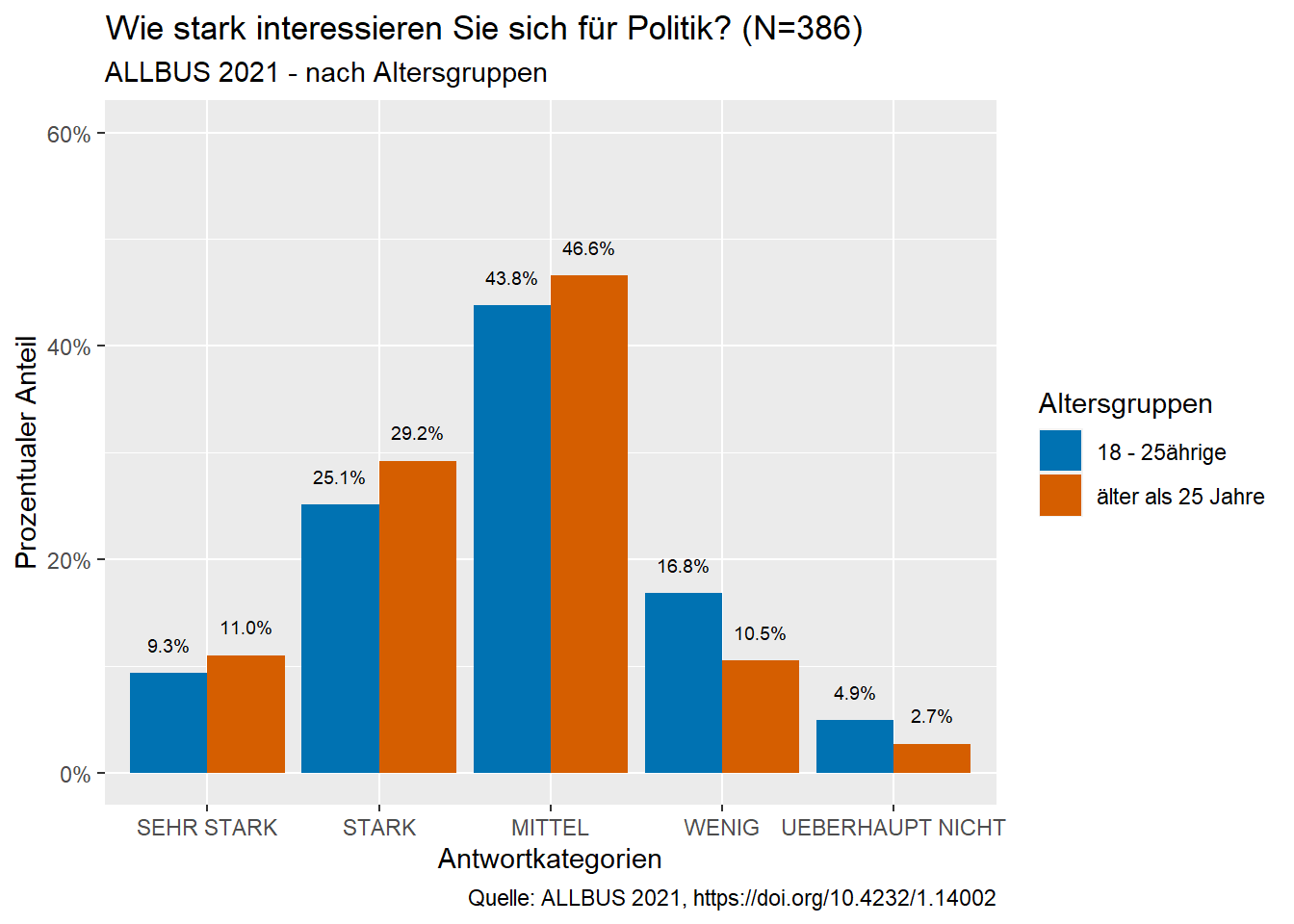
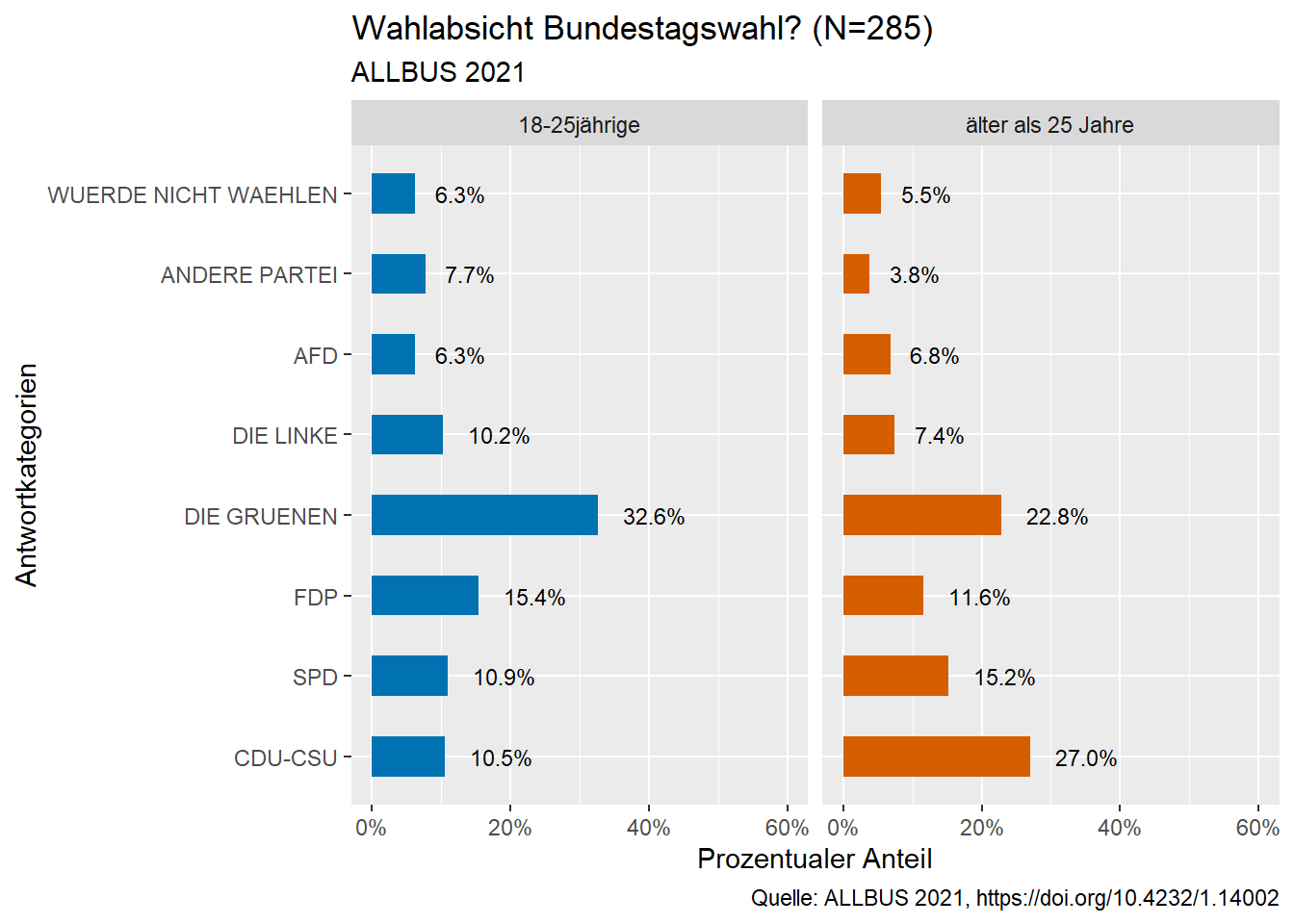
Einen ähnlichen Vergleich nimmt Sie bei der Parteienpräferenz (wenn am nächsten Sonntag Bundestagswahl wäre) vor. Hier stellt sie die entsprechenden Diagramme für die beiden Altersgruppen nebeneinander dar.
Dazu kann Emma ihren bereits vorhandenen Code nutzen und muss diesen nur etwas anpassen. Sie greift auch hier wieder auf den Datensatz zu, filtert die fehlende Werte heraus, gruppiert die Variable, prozentuiert die Werte und gibt an, wie das Diagramm dargestellt werden soll.
Um die beiden Altersgruppen nebeneinander darzustellen, verwendet sie folgende Bedingung: facet_wrap (~age_group)
Außerdem unterdrückt sie die Legende, da die Gruppierung in den beiden Diagrammen erklärt wird:
theme(legend.position=“none”)
library (tidyverse)
ALLBUS_21_Analyse %>% #Zugriff auf Datensatz
filter(!is.na(pv01), !is.na(age_group)) %>% #Herausfiltern der fehlenden Werte
group_by(age_group) %>% #Gruppierung der Daten nach Variable age_group
count (pv01 = sjlabelled::as_label(pv01)) %>% #Absolute Häufigkeiten der Variable pv01
mutate (pct = round (prop.table (n),3)) %>% #Berechnung der prozentualen Häufigkeiten
ggplot(aes(fill= age_group, x = pv01, y = pct, label = scales::percent(pct))) + #Plot der Variable pv01 und ihrer prozentualen Häufigkeiten
geom_bar (stat ="identity", width=0.5)+ #Säulendiagramm der erzeugten Berechnungen
facet_wrap (~age_group)+ # erzeugt nach Altersgruppen getrennte Diagramme
scale_fill_manual (values=c("#0072B2", "#D55E00"))+ #Festlegung der Säulenfarbe
theme(legend.position="none") +#Unterdrückung der Legende
geom_text(hjust = -0.4, size = 3.0)+ #Hinzufügen der Prozentwerte rechst neben den Säulen
scale_y_continuous(labels=scales::percent_format(), limits = c(0, 0.6))+
labs (x= "Antwortkategorien", #Beschriftung X-Achse
y= "Prozentualer Anteil", #Beschriftung Y-Achse
title="Wahlabsicht Bundestagswahl? (N=285)", #Diagrammtitel
subtitle = "ALLBUS 2021", #Untertitel
caption = "Quelle: ALLBUS 2021, https://doi.org/10.4232/1.14002")+#Quelle
coord_flip() #Drehung des Diagramms