Chapter 4 데이터 기초
인식론의 틀에서 우리가 사는 세상은 세상 그 자체가 아니라, 우리 마음에 속에 비친 그림자이다. 따라서 세상은 “인식전 세상”과 “인식된 세상”으로 구분할 수 있다.
인식의 과정은 자료-정보-지식-지혜(DIKW: Data, Information, Knowledge, Wisdom) 위계론을 통해 4단계 모형으로 구성할 수 있다.
1단계: 인식전 세계에서 원자료(raw data) 수집
2단계: 원자료 정제해 자료(data)로 1차부호화
3단계: 자료를 분석해 정보(information)로 2차부호화
4단계: 정보를 지식(knowledge)으로 해석하고 지혜(wisdom)로 내면화
데이터가 저장된 데이터구조는 다양하다. 벡터(vector), 데이터프레임(data frame), 리스트(list) 등의 구조에 저장해 사용한다. 가장 기본적인 텍스트데이터 구조는 문자형으로 구성된 문자벡터다.
4.1 데이터의 값(value)과 유형(data type)
각각의 개별적 데이터의 값(value)에는 유형이 있다.
- 숫자형
- 1, 2, 3, 4, …
- 논리형
- 참
TRUE, 거짓FALSE - TRUE는
T, FALSE는F로 표기 가능 - 주의: “True,” “true” 등은 논리형이 아니라 문자형.
- 참
- 문자형
- “1,” “2,” “3,” …
- “TRUE”
- “일,” “이,” “삼,” “사,” …
- “남자,” “여자,” …
- “rose,” “pink,” …
4.2 데이터구조
데이터를 책이라고 한다면, 데이터구조는 책을 보관하는 책장이나 서랍 캐비닛 등 에 비유할 수 있다. R에서 주로 사용하는 데이터 구조는 벡터(vector), 데이터프레임(dataframe), 리스트(list) 등 3가지다. 이외에도 매트릭스(matrix)와 어레이(array)가 있다. 5가지 데이터구조를 그림으로 표현하면 다음과 같다 (Figure: 4.1).
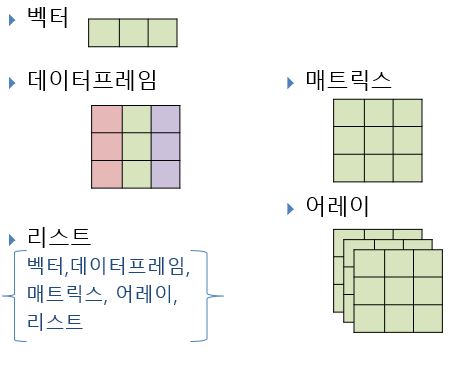
Figure 4.1: 데이터 구조
4.2.1 벡터 c()
1차원의 데이터구조다. 개별 값(요소)를 1차원의 공간에 배치하는 데이터구조다. c()함수로 벡터를 만든다. ‘c’는 combine 혹은 concatenate로서 값들을 ’결합하다’ 혹은 ’연결시키다’는 의미다.
‘사과,’ ‘배,’ ‘오렌지’ 등 3개 요소를 벡터에 저장해 ’fruit_v’에 할당해보자.
fruit_v <- c('사과', '배', '오렌지')저장하는 데이터의 유형에 따라 벡터의 종류 결정된다.
- 숫자형 데이터로만 이뤄졌으면 숫자벡터
c(1, 2, 3)
- 논리형 데이터로만 이뤄졌으면 논리벡터
c(TRUE, FALSE)
- 문자형 데이터로만 이뤄졌으면 문자벡터
c("1", "TRUE", "F", "포도", "apple")
" "나 ' '로 값의 앞뒤를 감싸면 문자형이 된다.
4.2.1.1 요인(factor)
요인은 문자형인것처럼 보이지만 본질은 숫자형인 데이터의 유형이다. 범주형(category)데이터를 다룰 때 사용하는 데이터 유형이다. 예를 들어, 성(sex)이라는 범주형 데이터는 ’남자’와 ’여자’라는 속성을 갖고 있는데, 이때, ’남자’와 ’여자’라는 데이터의 값을 문자형이 아니라 요인으로 처리하는 것이 효율적일 때가 있다.
예를 들어 보자. “male,” “female,” “female,” “male” 등 4개 값을 벡터로 만들어 sex_v에 할당하면, sex_v는 문자벡터가 된다. 4개의 문자요소가 생성된다.
sex_v <- c("male", "female", "female", "male")
typeof(sex_v)## [1] "character"class(sex_v)## [1] "character"문자벡터를 factor()함수로 요인으로 만들면 ’male female female male ’이라는 글자는 그대로 보이나, " "가 사라진 것을 알수 있다. typeof()로 유형을 확인하면 정수(integer)라고 제시한다. 컴퓨터내부에서 female과 male을 각각 숫자(1과 2)로 처리했기 때문이다. 정수 1과 2에 대해 각각 female과 male이라는 “이름”을 부여한 셈이다. 이때 정수 1과 2에 부여된 값을 “이름”이라고 하지 않고 “level”이라고 한다. 즉, 문자 “female”을 1로 처리하고, ’female’이란 이름(level)에 부여하고, 문자 “male”은 2로 처리하고, ’male’이란 이름(level)을 부여한 것이다.
factor(sex_v)## [1] male female female male
## Levels: female maletypeof(factor(sex_v))## [1] "integer"문자벡터뿐 아니라 숫자벡터로 요인으로 만들어 처리하면 효율적인 경우가 많다.
num_v <- c(1, 2, 1, 2)
typeof(num_v)## [1] "double"class(num_v)## [1] "numeric"숫자형(numeric)은 “double(더불형)”과 “integer(정수형)”로 구분한다. 더블형은 소숫점이 있고, 정수형은 소숫점이 없다. 정수임을 명확하게 표현히기 위해서는 1L 30L처럼 숫자 뒤에 L을 붙인다.
factor(num_v)## [1] 1 2 1 2
## Levels: 1 2typeof(factor(num_v))## [1] "integer"4.2.1.2 부분선택(subsetting)
’fruit_v’에 할당된 세개의 값에는 위치가 숫자로 부여돼 있다. 따라서 그 위치에 대한 숫자로 해당 요소만 부분선택(subset)할 수 있다. 첫번째 요소를 부분선택 해보자.
fruit_v[1]## [1] "사과"첫번째와 세번째 요소를 부분선택하려면 숫자벡터를 만들어 실행하면 된다.
fruit_v[c(1, 3)]## [1] "사과" "오렌지"특정 요소를 제외하고 부분선택하려면 -기호를 이용한다. fruit_v에서 첫번째와 세번째 요소를 제외해 부분선택해보자.
fruit_v[-c(1, 3)]## [1] "배"4.2.1.3 연습
- 문자 ’참가자1, 참가자2, 참가자3’으로 이뤄진 문자벡터를 만들어 id_v에 할당하시오.
id_v <- c("참가자1", "참가자2", "참가자3")- 숫자 ’32, 33, 45’로 이뤄진 숫자벡터를 만들어 age_v에 할당하시오
age_v <- c(32, 33, 45)- 논리값 ’TRUE, FALSE, TRUE’로 이뤄진 논리벡터를 만들어 status_v에 할당하시오.
status_v <- c(TRUE, FALSE, TRUE)- 숫자 ’60, 56, 50’으로 이뤄진 숫자벡터를 만들어 weight_v에 할당하시오.
weight_v <- c(60, 56, 30)- 숫자 ’167, 160, 155’로 이뤄진 숫자벡터를 만들어 height_v에 할당하시오.
height_v <- c(167, 160, 155)4.2.2 데이터프레임 data.frame()
행과 열로 구성된 2차원의 데이터구조다. 1차원 데이터구조인 벡터를 모아 만든다. data.frame()함수로 만든다. 앞서 만든 문자벡터, 숫자벡터, 논리벡터 5개를 이용해 데이터프레임을 만들어 ’df’에 할당해 보자. str()함수는 데이터구조를 보여준다. ’structure’의 준말이다. summary()함수로는 요약한 내용을 볼수 있다.
df <- data.frame(id_v, age_v, status_v, weight_v, height_v)
str(df)## 'data.frame': 3 obs. of 5 variables:
## $ id_v : chr "참가자1" "참가자2" "참가자3"
## $ age_v : num 32 33 45
## $ status_v: logi TRUE FALSE TRUE
## $ weight_v: num 60 56 30
## $ height_v: num 167 160 155summary(df)## id_v age_v status_v weight_v
## Length:3 Min. :32.00 Mode :logical Min. :30.00
## Class :character 1st Qu.:32.50 FALSE:1 1st Qu.:43.00
## Mode :character Median :33.00 TRUE :2 Median :56.00
## Mean :36.67 Mean :48.67
## 3rd Qu.:39.00 3rd Qu.:58.00
## Max. :45.00 Max. :60.00
## height_v
## Min. :155.0
## 1st Qu.:157.5
## Median :160.0
## Mean :160.7
## 3rd Qu.:163.5
## Max. :167.0“‘data.frame’: 3 obs. of 5 variables:”이라고 요약해 준다. 3개 행(row)과 5개 열(column)로 이뤄진 데이터프레임이란 의미다.
“obs.”는 observation의 준말이다. 자료를 수집하면 행에는 개별 사례를 투입하고 변수를 열에 투입하기 때문에 행은 “obs.” 열을 “variables”이라고 표현했다 (Figure: 4.3).
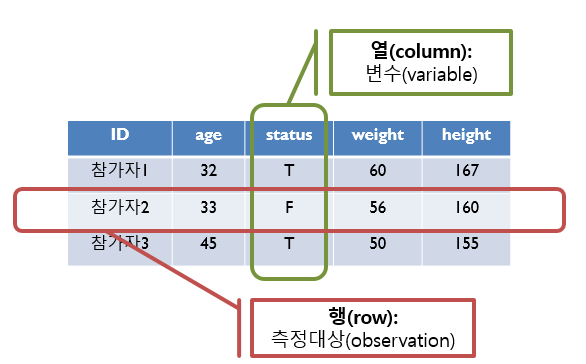
Figure 4.2: 행렬 구조의 데이터프레임
데이터프레임을 엑셀같은 스프레드시트 방식의 행렬로 보고 싶으면 View()함수를 이용한다. 별도의 창에서 행렬로 정렬된 데이터프레임이 열린다 (Figure: 4.3).
View(df)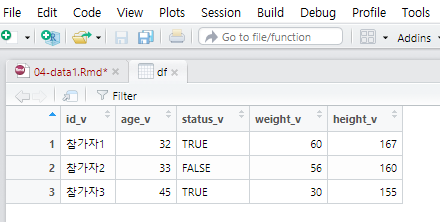
Figure 4.3: View()함수로 보는 데이터프레임
데이터프레임 열이름의 기본값은 열벡터의 이름이 그대로 사용된다. 별도로 이름을 부여할수도 있다.
df <- data.frame(ID = id_v,
age = age_v,
status = status_v,
weight = weight_v,
height = height_v)
str(df)## 'data.frame': 3 obs. of 5 variables:
## $ ID : chr "참가자1" "참가자2" "참가자3"
## $ age : num 32 33 45
## $ status: logi TRUE FALSE TRUE
## $ weight: num 60 56 30
## $ height: num 167 160 1554.2.2.1 부분선택(subsetting)
데이터프레임은 열벡터로 이뤄져 있기 때문에 [ ]로 부분선택하면 해당 열이 부분선택된다.
df[2] # `df`데이터프레임의 2번째 열 부분선택. ## age
## 1 32
## 2 33
## 3 45df[2:4] # `df`데이터프레임의 2~4번째 열 부분선택## age status weight
## 1 32 TRUE 60
## 2 33 FALSE 56
## 3 45 TRUE 30데이터프레임은 행과 열로 이뤄져 있으므로, 부분선택할 때 행와 열을 나눠 지정할 수 있다.
- n행 m열 선택 : df[n, m]
df[1, ] # `df` 데이터프레임의 1행 부분선택## ID age status weight height
## 1 참가자1 32 TRUE 60 167df[c(1,2), ] # df` 데이터프레임의 1행과 2행 부분선택## ID age status weight height
## 1 참가자1 32 TRUE 60 167
## 2 참가자2 33 FALSE 56 160df[ ,2] # `df` 데이터프레임의 2열 부분선택## [1] 32 33 45df[ ,c(2,3)] # `df` 데이터프레임의 2열과 3열 부분선택## age status
## 1 32 TRUE
## 2 33 FALSE
## 3 45 TRUEdf[2,c(3:5)] # `df` 데이터프레임의 2행과 3~5열 부분선택## status weight height
## 2 FALSE 56 160데이터프레임은 열벡터(열을 구성하는 벡터)들의 합이므로, $기호와 열의 이름을 이용해 부분선택할 수 있다. ’ID’열과 ’height’열을 열의 이름으로 부분선택해보자.
df$ID## [1] "참가자1" "참가자2" "참가자3"df$height## [1] 167 160 155열 부분선택은 dplyr패키지의 select()함수를 이용하면 편리하다.
library(dplyr)
select(df, ID, age) # ID와 age열 선택## ID age
## 1 참가자1 32
## 2 참가자2 33
## 3 참가자3 45select(df, status:height) # status열부터 height열까지 순서대로 모두 포함해 선택## status weight height
## 1 TRUE 60 167
## 2 FALSE 56 160
## 3 TRUE 30 155select(df, -c(ID, age)) # ID열과 age열만 제외하고 선택## status weight height
## 1 TRUE 60 167
## 2 FALSE 56 160
## 3 TRUE 30 155dplyr패키지의 filter()함수를 이용하면 행을 부분선택할수 있다. ID열의 ’참가자1’과 같은 행에 있는 행을 선택해 보자.
- 주의:
=는<-와 같은 의미로 ’할당하다’가 된다. “같다”는 의미는==다.
filter(df, ID == "참가자1") ## ID age status weight height
## 1 참가자1 32 TRUE 60 167!기호를 이용하면 ’~을 제외하고’라는 의미가 된다. ID열에서 “참가자1”과 같은 행의 행을 제외하고 부분선택해 보자.
filter(df, !ID == "참가자1")## ID age status weight height
## 1 참가자2 33 FALSE 56 160
## 2 참가자3 45 TRUE 30 1554.2.2.2 파이프(pipe) %>%
dplyr패키지는 magrittr패키지의 파이프%>%를 이용한다. 파이프는 앞의 값을 ’파이핑’해 뒤로 전달해 주는 기능을 한다.
예를 들어 select(df, ID, age)를 파이핑하면 df %>% select(ID, age)가 된다. filter(df, ID == "참가자1")를 파이핑해 코딩하면 df %>% filter(ID == "참가자1")이 된다.
파이핑을 이용하면 select()와 filter()를 연속적으로 연결할 수 있다. df 데이터프레임에서 ’status’가 TRUE인 행에서 ID, age, weight열을 부분선택하자.
df %>%
filter(status == TRUE) %>%
select(ID, age, weight) ## ID age weight
## 1 참가자1 32 60
## 2 참가자3 45 304.2.3 리스트 list()
만일 벡터를 구성하는 요소의 수가 다르면?
data.frame(a = 1:3, b = 1:4)Error in data.frame(a = 1:3, b = 1:4) : arguments imply differing number of rows: 3, 4라며
행의 수가 맞지 않아 생기는 오류가 생긴다.
이처럼 구성 요소의 길이가 다르면 리스트 형식의 데이터터구조에 담아야 한다.
list(a = 1:3, b = 1:4)## $a
## [1] 1 2 3
##
## $b
## [1] 1 2 3 4데이터프레임은 길이가 같은 열벡터로만 만들지만, 리스트는 벡터, 데이터프레임, 리스트 등 모든 형식의 데이터구조를 이용해 만들수 있다. 리스트는 이것 저것 넣어두는 서랍장이라 할수 있다.
cha <- "리스트"
number <- c(25, 26, 18, 39)
string <- c("one", "two", "three", "four")
df2 <- data.frame(number, string)
list_l <- list(CH = cha, NU = number, ST = string, DF = df2)
str(list_l)## List of 4
## $ CH: chr "리스트"
## $ NU: num [1:4] 25 26 18 39
## $ ST: chr [1:4] "one" "two" "three" "four"
## $ DF:'data.frame': 4 obs. of 2 variables:
## ..$ number: num [1:4] 25 26 18 39
## ..$ string: chr [1:4] "one" "two" "three" "four"4.2.3.1 부분선택
리스트에는 다른 데이터구조가 하부요소로 포함돼 있기 때문에 부분선택할 때 [ ]와 [[ ]]를 이용한다. 앞서 만든 리스트 ’list_l’의 2번째 요소를 [ ]와 [[ ]]로 각각 부분선택해 결과를 비교해보자.
list_l[2] %>% typeof()## [1] "list"list_l[[2]]## [1] 25 26 18 39[ ]로 부분선택하면 리스트 구조를 유지한 채 부분선택한다. [[ ]]로 부분선택하면 구성요소의 구조(예기서는 벡터)로 부분선택한다.
데이터프레임이 리스트의 구성요소일때는 $와 [ ]를 함께 사용하거나 [[ ]]와 [ ]를 함께 이용한다.
list_l$DF[2] # 리스트 list_l의 DF요소에서 2번재 열 부분선택## string
## 1 one
## 2 two
## 3 three
## 4 fourlist_l[[4]][2] # 리스트 list_l의 DF요소의 4번재 요소 중 2번째 열 부분선택## string
## 1 one
## 2 two
## 3 three
## 4 four4.2.4 매트릭스와 어레이
벡터를 2차원 구조로 구성한 데이터구조가 매트릭스이고, 3차원 구조로 구성한 데이터구조가 어레이다. 거꾸로 표현하면, 벡터는 1차원 어레이, 매트릭스는 2차원 어레이, 어레이는 3차원 어레이라고도 할수 있다.
4.2.4.1 매트릭스 matrix()
벡터에 행과 열을 지정해 만든다. 1부터 20까지의 숫자로 이뤄진 벡터를 5개 행으로 이뤄진 매트릭스를 만들면 다음과 같다.
matrix(1:20, nrow = 5)## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 7 12 17
## [3,] 3 8 13 18
## [4,] 4 9 14 19
## [5,] 5 10 15 20열을 지정해 만들수도 있다.
matrix(1:20, ncol = 10)## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 1 3 5 7 9 11 13 15 17 19
## [2,] 2 4 6 8 10 12 14 16 18 204.2.4.2 어레이 array()
기본 속성은 매트릭스와 같다. 2개 차원만 지정하면 매트릭스가 된다. 차원은 dim =인자를 이용한다. 1부터 6까지의 숫자벡터를 2행 3열의 매트릭스로 만들어 보자.
matrix(1:6, nrow = 2)## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6array(1:6, dim = c(2, 3))## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 63차원 어레이를 만들려면 차원dim =을 3개 지정한다. 1에서 24까지의 숫자벡터를 2행과 3열로 이뤄전 3차원 어레이를 만들어 보자.
array(1:24, dim = c(2, 3, 4))## , , 1
##
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 7 9 11
## [2,] 8 10 12
##
## , , 3
##
## [,1] [,2] [,3]
## [1,] 13 15 17
## [2,] 14 16 18
##
## , , 4
##
## [,1] [,2] [,3]
## [1,] 19 21 23
## [2,] 20 22 24