Chapter 6 정제도구
정제는 컴퓨터가 분석할 수 있도록 수집한 원자료(raw data)를 전처리(preprocessing)해 자료로 구성하는 단계다. 텍스트 마이닝 전과정에서 가장 많은 자원이 소모되는 부분이다. 정제실력이 텍스트마이닝 실력을 좌우한다 해도 과언이 아닐 정도로 중요하다. 정제를 잘못하면 이후 과정을 통해 얻는 결과가 모두 잘못되기 때문이다.
6.0.0.1 주요 정제 도구
정제 과정에서는 주로 문자열(string)을 조작해야 하기 때문에 dplyr패키지 뿐 아니라 정규표현식(regular expressions: regex)과 stringr패키지 등 다양한 도구를 활용한다.
stringrdplrpurrrtidyr- 연산자(operator)
- 정규표현식(regex)
6.0.0.2 토큰화(tokenization)
분석단위에 따라 텍스트를 분석할 수 있도록 잘게 나누는 과정이다. 분석 목적에 따라 글자, 단어, 복수의 단어(n-gram), 문장, 문단, 문서 등으로 나눈다. 토큰화에는 다양한 방법이 있는데, 다양한 분석단위를 지정할 수 있는 tidytext패키지의 unnest_tokens()를 이용한다. unnest_tokens()함수는 데이터프레임을 투입해 토큰화한 다음, 행(row) 하나에 토큰(token) 하나만 할당(one-token-per-row)한 정돈텍스트(tidy text) 형식으로 산출한다.
6.0.0.3 불용어(stop words) 제거
분석에 사용하지 않는 요소를 제거하는 단계다. 무엇이 불용어 대상인지는 분석 목적과 맥락에 따라 다르다. 일반적으로 불용어 대상으로 분류되는 것들은 스페이스(공백, 탭 등), 숫자, 구두점(punctuation), 및 한글자 단어, 광범하게 사용되는 일반어(대명사, 접속사 등) 등이다.
불용어는 사전으로 목록을 만들어 제거하기도 하지만 불용어 사전이 완벽할수는 없다. 분석목적과 맥락이 다양하기 때문이다. 예를 들어, “나,” “그녀,” “너” 등과 같은 대명사가 분석에 중요한 역할을 하는 경우, 대명사를 제거해서는 안된다. 또한 구두점이 글쓴이의 성격과 글의 내용에 중요한 역할을 하는 경우가 있기 때문에, 분석목적에 따라서는 구두점을 제거하지 말아야 할수도 있다.
이런 이유로 불용어 사전을 수정하거나 불용어처리에 예외를 적용하는 경우가 흔하다. 이 과정에서 stringr, dplyr 등의 패키지와 정규표현식과 연산자 등의 정제도구가 많이 쓰이므로, 이들 정제도구 사용에 익숙해져야 한다.
6.0.0.4 정규화(normalization)
의미는 같지만 표현방법이 다른 단어들을 같은 표현의 단어로 통합하는 작업이다. 어근추출과 표제어추출 등이 있다.
어근 추출(stemming)
단어에서 의미를 담고 있는 핵심부분을 추출하는 작업이다. 어근은 실질적인 의미를 나타내는 중심 부분이다. 예들 들어, “보다” “보니” “보고” 등 파생된 형태의 단어에서 어근 “보~”를 추출해야 “보다”로 통일하거나, “study” “studies” “studied”에서 “studi”를 추출해 “study”로 통일해야 정확한 분석이 가능하다.
(어근과 어간은 구분되는 개념이나, 여기서는 편의상 어간을 포괄하는 의미로 어근이라고 한다.)
기본형(표제어) 추출(lemmatization)
다양한 형태로 굴절된(inflected) 일군의 단어에서 공통적으로 기본이 되는 기본형(lemma)을 추출하는 작업이다. 대표하는 단어이므로 표제어라고도 한다. 예를 들어, “my” “me” “mine” “I”는 모두 “나”에 대한 단어이므로, “me”를 기본형으로 설정해 “my” “mine” “I”를 모두 “me”로 치환하는 작업이다.
6.0.0.5 문자형과 따옴표
R에서는 문자형(character type)을 여러 글자로 이뤄진 문자열(string)과 글자(character, letter) 하나를 구분하지 않기 때문에 겹따옴표와 홑따옴포의 구분이 없다. 다만, 혼동을 피하기 위해 겹따옴표를 기본으로 사용하고, 특수한 경우(따옴표가 본문안에 포함된 경우)에만 겹따옴표와 홑따옴표를 구분해 사용하기로 한다.
"겹따옴표 안에 '홑따옴표'가 있는 경우"
'홑따옴표 안에 "겹따옴표"가 있는 경우'
"겹따옴표와 "홑따옴표"를 구분하지 않는 경우"
'겹따옴표와 '홑따옴표'를 구분하지 않는 경우'
library(tidyverse)## -- Attaching packages --------------------------------------- tidyverse 1.3.0 --## v ggplot2 3.3.2 v purrr 0.3.4
## v tibble 3.0.4 v dplyr 1.0.2
## v tidyr 1.1.2 v stringr 1.4.0
## v readr 1.4.0 v forcats 0.5.0## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(tidytext)6.1 stringr
6.1.1 개괄
stringr패키지는 문자열을 일관된 방식으로 다루는 다양한 함수를 제공한다. stringr패키지 함수는 크게 4개 집단으로 구분할 수 있다.
패턴 일치(Pattern matching)
공백문자(Whitespace)
로케일 민감(Locale sensitive)
기타 도우미(Other helpers)
가장 많이 활용하는 함수는 문자의 패턴과 관련된 기능이다.
패턴 일치(Pattern matching)
탐지와 찾기(detect & locate)
부분선택, 추출, 일치(subset, extract & match)
변환(mutate)
결합과 분리(join & split)
6.1.1.1 패턴 일치(Pattern matching)
각 종류별 주요 함수는 다음과 같다.
6.1.1.1.1 탐지와 찾기(detect & locate)
str_detect()문자열에서 패턴의 일치여부를 찾아 논리값(TRUE FALSE)으로 산출한다.str_which()문자열에서 패턴의 인덱스를 찾아 숫자형으로 산출한다.
str_count()문자열에서 패턴과 일치하는 문자의 개수 계산str_locate()str_locate_all()문자열에서 패턴의 위치를 찾아 숫자형으로 산출한다. 여기서 찾은 정수를str_sub()를 이용해 해당 단어를 추출할 수 있다.str_locate()와str_sub()함수를 결합해 사용하기 보다str_extract()함수를 이용하는 것이 더 편리하다.
6.1.1.1.2 부분선택, 추출, 일치(subset, extract & match)
str_sub()문자벡터에서 문자열을 추출한다.str_subset()문자열에서 패턴을 찾아 해당 패턴이 포함된 요소를 산출한다.
str_extract()str_extract_all()문자열에서 일치하는 패턴을 찾아 벡터로 산출한다.str_match()str_match_all()문자열에서 일치하는 패턴을 찾아 행렬로 산출한다.
6.1.1.1.3 문자열 변환(Mutate Strings)
str_replace()str_replace_all()문자열에서 패턴을 찾아 지정된 패턴으로 치환한다.str_remove()str_remove_all()문자열에서 패턴을 찾아 제거한다.
6.1.1.1.4 결합과 분리(Join and Split)
str_c()복수의 문자열을 하나의 문자열로 결합str_split()문자열에서 패턴을 찾아 분리. 리스트 구조로 산출한다.str_split_fixed()문자열에서 패턴을 찾아 분리. 행렬 구조로 산출한다.
6.1.1.2 공백문자(Whitespace)
str_squish()문자열에서 모든 공백을 단일 스페이스 공백으로 치환.str_trim()문자열에서 좌우 공백을 단일 스페이스 공백으로 치환.
6.1.1.3 로케일 민감(Locale sensitive)
현장, 무대라는 의미의 로케일(locale)은 언어 등의 지역별로 설정된 사용환경이다. 아래 함수는 로케일 설정에 따라 산출값이 달라 질수 있다.
str_to_lower()문자열을 모두 소문자로 변환str_to_upper()문자열을 모두 대문자로 변환str_to_title()문자열에서 각 단어 첫 글자를 대문자로 변환str_to_sentence()문자열에서 각 문장 첫 글자를 대문자로 변화str_order()문자벡터에서 순서 인덱스를 숫자형으로 산출.str_sort()문자벡터를 순서대로 정렬
6.1.1.4 기타 도우미(Other helpers)
str_length()문자열의 길이 계산해 산출. 즉, 문자열에 있는 문자의 개수 계산
str_view()str_view_all()정규표현식과 일치하는 결과를 HTML로 렌더링해 산출str_conv()문자열의 인코딩 설정str_wrap()너비(width) 등을 정해 잘 포맷된 문단으로 문자열 포장
이외에도 stringr패키지에는 다양한 함수가 있으니 설명서 참고.
한 남자가 사랑하는 여인에게 보내는 연애편지로 stringr패키지의 각 함수의 사용법을 알아보자.
love_v <- c(
"You still fascinate and inspire me. :)",
"You influence me for the better ~ .",
"You’re the object of my desire, the #1 Earthly reason for my existence!!!",
" ... ",
"그대는 여전히 매혹적이고 나에게 영감을 줍니다. ^^",
"당신은 나로 하여금 더 나은 사람이 되도록 했습니다 ~.",
"당신은 내 욕망의 대상이요, 내가 이 세상에 존재하는 첫번째 이유입니다!!!~",
" "
)6.1.2 탐지와 찾기(detect & locate)
6.1.2.1 str_detect(string, pattern, negate = FALSE)
문자열에서 패턴의 일치여부를 찾아 논리값(TRUE FALSE)으로 산출한다.
love_v %>% str_detect(pattern = "그대")## [1] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSEstr_detect()함수는 논리값을 산출하므로 dplyr패키지의 filter()함수와 함께 사용해 특정 단어가 포함된 요소를 추출할 수 있다.
tibble(text = love_v) %>%
filter(str_detect(string = text, pattern = "그대"))## # A tibble: 1 x 1
## text
## <chr>
## 1 그대는 여전히 매혹적이고 나에게 영감을 줍니다. ^^!를 이용하면 특정 단어가 포함된 요소만 빼고 추출할 수 있다.
tibble(text = love_v) %>%
filter(!str_detect(string = text, pattern = "그대"))## # A tibble: 7 x 1
## text
## <chr>
## 1 "You still fascinate and inspire me. :)"
## 2 "You influence me for the better ~ ."
## 3 "You’re the object of my desire, the #1 Earthly reason for my existence!!!"
## 4 " ... "
## 5 "당신은 나로 하여금 더 나은 사람이 되도록 했습니다 ~."
## 6 "당신은 내 욕망의 대상이요, 내가 이 세상에 존재하는 첫번째 이유입니다!!!~"
## 7 " "토큰화해서 추출한 결과와 비교해보자.
tibble(text = love_v) %>%
unnest_tokens(output = word, input = text) %>%
filter(str_detect(string = word, pattern = "그대"))## # A tibble: 1 x 1
## word
## <chr>
## 1 그대는6.1.2.2 str_which(string, pattern, negate = FALSE))
문자열에서 패턴의 인덱스를 찾아 숫자형으로 산출한다.
love_v[1:3]## [1] "You still fascinate and inspire me. :)"
## [2] "You influence me for the better ~ ."
## [3] "You’re the object of my desire, the #1 Earthly reason for my existence!!!"love_v %>% str_which(pattern = "You")## [1] 1 2 3“You”가 포함된 요소가 1,2,3번째에 있다.
6.1.2.3 str_count(string, pattern = "")
문자열에서 패턴과 일치하는 문자의 개수 계산. 기본값에는 패턴지정이 안돼 있어, 패턴 지정을 안하면 각 요소에 있는 글자 길이를 모두 계산한다.
c("apple", "banana", "pear", "pinapple", "123") %>%
str_count("a")## [1] 1 3 1 1 0love_v %>% str_count(pattern = "You")## [1] 1 1 1 0 0 0 0 0love_v %>% str_count()## [1] 38 35 73 5 29 31 43 1str_count()함수는 숫자형을 산출하므로 연산자와 함께 투입하면 논리값(TRUE, FALSE)이 나온다. 따라서 filter()함수와 병용해 일정한 길이의 문자를 걸러내는데 쓸수 있다.
love_v %>% str_count() == 1## [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUEtibble(text = love_v) %>%
unnest_tokens(output = word, input = text) %>%
filter(str_count(word) > 7)## # A tibble: 3 x 1
## word
## <chr>
## 1 fascinate
## 2 influence
## 3 existence6.1.2.4 str_locate(string, pattern)
문자열에서 첫번째 패턴이 어느 위치에서 시작해 어느 위치에서 끝나는지 산출한다.
c("123 567 9123", "789 123 123", "456 789 456") %>%
str_locate(pattern = "123")## start end
## [1,] 1 3
## [2,] 5 7
## [3,] NA NA패턴 “123”은 첫째요소 1번째에서 3번째에 위치한다. 둘째 요소에 있는 “123”은 5번째에서 7번째에 위치한다. 둘째 요소의 시작위치가 4번째가 아닌 이유는 그 앞 공백 위치가 4번째이기 때문이다.
str_locate_all(string, pattern)문자열에서 모든 패턴이 어느 위치에서 시작해 어느 위치에서 끝나는지 리스트로 산출한다.
c("123 567 9123", "789 123 123", "456 789 456") %>%
str_locate_all(pattern = "123")## [[1]]
## start end
## [1,] 1 3
## [2,] 10 12
##
## [[2]]
## start end
## [1,] 5 7
## [2,] 9 11
##
## [[3]]
## start endend의 값에서 start의 값을 빼면 패턴의 길이를 계산할 수 있다. 특정 패턴의 문서상의 위치와 빈도를 계산하는데 사용할 수 있다.
6.1.3 부분선택, 추출, 일치(subset, extract & match)
6.1.3.1 str_sub(start = 1L, end = -1L)
문자벡터의 요소에서 시작과 끝나는 지점의 값으로 문자열을 추출한다.
c("123 567 9123", "789 123 123", "456 789 456") %>%
str_sub(start = 1, end = 3)## [1] "123" "789" "456"음수를 지정하면 끝나는 지점에서 역순으로 추출한다.
c("123 567 9123", "789 123 123", "456 789 456") %>%
str_sub(start = 1, end = -3)## [1] "123 567 91" "789 123 1" "456 789 4"6.1.3.2 str_subset(string, pattern, negate = FALSE)
문자열에서 패턴을 찾아 해당 패턴이 포함된 요소를 산출한다.
love_v %>% str_subset(pattern = "대")## [1] "그대는 여전히 매혹적이고 나에게 영감을 줍니다. ^^"
## [2] "당신은 내 욕망의 대상이요, 내가 이 세상에 존재하는 첫번째 이유입니다!!!~"negate =인자를 TRUE로 설정하면 해당 패턴이 없는 요소를 산출한다.
love_v %>% str_subset(pattern = "대", negate = "TRUE")## [1] "You still fascinate and inspire me. :)"
## [2] "You influence me for the better ~ ."
## [3] "You’re the object of my desire, the #1 Earthly reason for my existence!!!"
## [4] " ... "
## [5] "당신은 나로 하여금 더 나은 사람이 되도록 했습니다 ~."
## [6] " "6.1.3.3 str_extract(string, pattern)
문자열에서 일치하는 첫번째 패턴을 찾아 벡터로 산출한다. 셰익스피어의 소네트 27에서 “나”와 “너”에 대한 단어를 추출하자. \\bI\\b|m(e|y)|th(y|ee)는 정규표현식에서 “I, my, me, thee, thy”를 찾는 패턴이다. (정규표현식은 다음 장에서 자세하게 다룬다.)
sonnet27_v <- "Weary with toil I haste me to my bed,
The dear repose for limbs with travel tired;
But then begins a journey in my head
To work my mind when body's work's expired;
For then my thoughts, from far where I abide,
Intend a zealous pilgrimage to thee,
And keep my drooping eyelids open wide
Looking on darkness which the blind do see:
Save that my soul's imaginary sight
Presents thy shadow to my sightless view,
Which like a jewel hung in ghastly night
Makes black night beauteous and her old face new.
Lo! thus by day my limbs, by night my mind,
For thee, and for myself, no quietness find."
sonnet27_v %>% str_extract(pattern = "\\bI\\b|m(e|y)|th(y|ee)")## [1] "I"str_extract_all(string, pattern, simplify = FALSE)문자열에서 일치하는 모든 패턴을 찾아 리스트로 산출한다.simplify = TRUE로 설정하면 문자행렬로 산출한다.
sonnet27_v %>% str_extract_all(pattern = "\\bI\\b|m(e|y)|th(y|ee)")## [[1]]
## [1] "I" "me" "my" "my" "my" "my" "I" "thee" "my" "my"
## [11] "thy" "my" "my" "my" "thee" "my"table()함수로 추출한 각 단어의 빈도를 계산할 수 있다.
sonnet27_v %>%
str_extract_all(pattern = "\\bI\\b|m(e|y)|th(y|ee)") %>%
table()## .
## I me my thee thy
## 2 1 10 2 1이 소네트는 침대에 누워 연인을 생각하는 장면을 그렸음에도 불구하고 연인보다는 자기 자신에 대한 내용으로 가득찬 내용 임을 알 수 있다.
6.1.3.4 str_match(string, pattern)
문자열에서 일치하는 패턴을 찾아 행렬로 산출한다. str_extract()함수와 기능이 비슷하지만, 산출양식과 추출방식에서 미세한 차이가 있다. str_match()함수는 패턴의 하부패턴을 소괄호()로 묶어 주면 소괄로별로 문자열을 분리해 추출할 수 있다. .+는 임의의 요소.가 1회이상 반복+된다는 의미의 정규표현식이다.
email_v <- c("애플", "apple@ddd.com", "테슬라", "tesla@sss.com")
email_v %>% str_match(pattern = ".+@.+")## [,1]
## [1,] NA
## [2,] "apple@ddd.com"
## [3,] NA
## [4,] "tesla@sss.com"email_v %>% str_match(pattern = "(.+)@(.+)")## [,1] [,2] [,3]
## [1,] NA NA NA
## [2,] "apple@ddd.com" "apple" "ddd.com"
## [3,] NA NA NA
## [4,] "tesla@sss.com" "tesla" "sss.com"email_v %>% str_extract(pattern = "(.+)@(.+)")## [1] NA "apple@ddd.com" NA "tesla@sss.com"str_match_all(string, pattern)문자열에서 일치하는 모든 패턴을 찾아 리스트로 산출한다.
email_v %>% str_match_all(pattern = "(.+)@(.+)")## [[1]]
## [,1] [,2] [,3]
##
## [[2]]
## [,1] [,2] [,3]
## [1,] "apple@ddd.com" "apple" "ddd.com"
##
## [[3]]
## [,1] [,2] [,3]
##
## [[4]]
## [,1] [,2] [,3]
## [1,] "tesla@sss.com" "tesla" "sss.com"6.1.4 문자열 변환(Mutate Strings)
6.1.4.1 str_replace(string, pattern, replacement)
문자열에서 패턴을 찾아 첫째 요소를 지정된 패턴으로 치환한다.
c("my my my book", "my my my paper") %>%
str_replace(pattern = "my", replacement = "MY")## [1] "MY my my book" "MY my my paper"str_replace_all(string, pattern, replacement)문자열에서 패턴을 찾아 모든 요소를 지정된 패턴으로 치환한다.
c("my my my book", "my my my paper") %>%
str_replace_all(pattern = "my", replacement = "MY")## [1] "MY MY MY book" "MY MY MY paper"연산자 “또는”|과 함께 사용하면 복수의 패턴을 찾아 치환할 수 있다.
love_v %>% str_replace_all(pattern = "(my|me|내|내가|나로)", replacement = "ME")## [1] "You still fascinate and inspire ME. :)"
## [2] "You influence ME for the better ~ ."
## [3] "You’re the object of ME desire, the #1 Earthly reason for ME existence!!!"
## [4] " ... "
## [5] "그대는 여전히 매혹적이고 나에게 영감을 줍니다. ^^"
## [6] "당신은 ME 하여금 더 나은 사람이 되도록 했습니다 ~."
## [7] "당신은 ME 욕망의 대상이요, ME가 이 세상에 존재하는 첫번째 이유입니다!!!~"
## [8] " "같은 글자가 포함된 두 요소를 연산자로 결합할 때는 결합 순서에 주의한다.
love_v %>% str_replace_all(pattern = "(You|You’re)", replacement = "YOU")## [1] "YOU still fascinate and inspire me. :)"
## [2] "YOU influence me for the better ~ ."
## [3] "YOU’re the object of my desire, the #1 Earthly reason for my existence!!!"
## [4] " ... "
## [5] "그대는 여전히 매혹적이고 나에게 영감을 줍니다. ^^"
## [6] "당신은 나로 하여금 더 나은 사람이 되도록 했습니다 ~."
## [7] "당신은 내 욕망의 대상이요, 내가 이 세상에 존재하는 첫번째 이유입니다!!!~"
## [8] " "먼저 “You”를 “YOU”로 치환했기 때문에 “You”는 남아 있지 않게 된다. 따라서 그 다음에 나오는 “You’re”에 대해서는 일치하는 패턴이 없어진다. 연산자 투입 순서를 바꿔준다.
love_v %>% str_replace_all(pattern = "(You’re|You)", replacement = "YOU")## [1] "YOU still fascinate and inspire me. :)"
## [2] "YOU influence me for the better ~ ."
## [3] "YOU the object of my desire, the #1 Earthly reason for my existence!!!"
## [4] " ... "
## [5] "그대는 여전히 매혹적이고 나에게 영감을 줍니다. ^^"
## [6] "당신은 나로 하여금 더 나은 사람이 되도록 했습니다 ~."
## [7] "당신은 내 욕망의 대상이요, 내가 이 세상에 존재하는 첫번째 이유입니다!!!~"
## [8] " "6.1.4.2 str_remove(string, pattern)
문자열에서 패턴을 찾아 첫째 요소 제거한다.
c("my my my book", "my my my paper") %>%
str_remove(pattern = "my")## [1] " my my book" " my my paper"str_remove_all(string, pattern)문자열에서 패턴을 찾아 모든 요소 제거한다.
c("my my my book", "my my my paper") %>%
str_remove_all(pattern = "my")## [1] " book" " paper"6.1.5 결합과 분리(Join and Split)
6.1.5.1 str_c(..., sep = "", collapse = NULL)
복수의 문자열을 단일 문자열로 결합. sep =인자의 기본값은 공백없음""
str_c("You", "inspire", "me", sep = " ")## [1] "You inspire me"str_c("You", "inspire", "me")## [1] "Youinspireme"str_c("You", "inspire", "me", sep = "|")## [1] "You|inspire|me"collapse =인자를 사용해 벡터 안의 여러 문자열을 단일 문자열로 결합할 수있다.
str_c("You", "inspire", "me", collapse = "|" )## [1] "Youinspireme"“You,” “inspire,” “me”가 단일 벡터가 아니기 때문에 단일 문자열로 결합되지 않았다.
str_c( c("You", "inspire", "me"), collapse = "|" )## [1] "You|inspire|me"str_c( c("You", "inspire", "me"), collapse = "" )## [1] "Youinspireme"문자열이 여러개인 벡터끼리 결합하는 경우.
str_c(c("a", "b"), c("A", "B"))## [1] "aA" "bB"str_c(c("a", "b"), c("A", "B"), sep = "-")## [1] "a-A" "b-B"str_c(c("a", "b"), c("A", "B"), sep = "-", collapse = "")## [1] "a-Ab-B"문자열의 개수가 다른 벡터와 결합하는 경우
str_c(c("a", "b"), "C")## [1] "aC" "bC"str_c(c("a", "b"), "C", sep = "-")## [1] "a-C" "b-C"str_c(c("a", "b"), "C", sep = "-", collapse = "")## [1] "a-Cb-C"6.1.5.2 str_split(string, pattern, n = Inf, simplify = FALSE)
문자열에서 패턴을 찾아 분리해 리스트 구조로 산출한다.
str_split(string = "You inspire me", pattern = " ")## [[1]]
## [1] "You" "inspire" "me"love_v[1:2] %>% str_split(pattern = " ")## [[1]]
## [1] "You" "still" "fascinate" "and" "inspire" "me."
## [7] ":)"
##
## [[2]]
## [1] "You" "influence" "me" "for" "the" "better"
## [7] "~" "."str_split_fixed(string, pattern, n)문자열에서 패턴을 찾아 분리해 행렬 구조로 산출한다.
str_split_fixed(string = "You inspire me", pattern = " ", n = 4)## [,1] [,2] [,3] [,4]
## [1,] "You" "inspire" "me" ""str_split_fixed(string = "You inspire me", pattern = " ", n = 2)## [,1] [,2]
## [1,] "You" "inspire me"love_v[1:2] %>% str_split_fixed(pattern = " ", n = 5)## [,1] [,2] [,3] [,4] [,5]
## [1,] "You" "still" "fascinate" "and" "inspire me. :)"
## [2,] "You" "influence" "me" "for" "the better ~ ."6.1.6 공백문자(Whitespace)
공백문자는 사람 눈에는 보이지 않는 공백으로서 각각의 기능이 있다. POSIX 표준의 아스키(ASCII) 코드에 6종의 공백문자가 할당돼 있다(Table ??).
| 종류 | 아스키코드 | 문자 | 비고 |
|---|---|---|---|
| Space | 32 |
|
일반적으로 쓰이는 빈칸. 스페이스 |
| Horizontal Tab(HT) | 9 |
\t
|
일반적으로 쓰는 수평 탭 |
| New Line or Line Feed(LF) | 10 |
\n
|
줄바꿈. 다음 줄로 이동 |
| Vertical Tab(VT) | 11 |
\v
|
수직 탭 |
| Form Feed(FF) | 12 |
\f
|
다음 페이지로 이동 |
| Carriage Return(CR) | 13 |
\r
|
현재 줄의 첫 위치로 이동 |
6.1.6.1 str_squish(x)
문자열에서 모든 공백문자를 단일 스페이스로 치환한다.
whitespace_v <- " ch1 \t\n\r\v\f ch2 "
str_squish(whitespace_v)## [1] "ch1 ch2"str_squish(" String with trailing, middle, and leading white space\t")## [1] "String with trailing, middle, and leading white space"str_squish("\t\n\r\v\fString with excess, trailing and leading white space\t\n\r\v\f")## [1] "String with excess, trailing and leading white space"\s는 스페이스의 정규표현식인데, str_squish()함수는 스페이스로 인식하지 않고 “\s는 인식할 수 없는 이스케이프”는 오류메시지를 표시한다. \s가 아스키문자로 할당돼 있지 않기 때문이다.
str_squish(" ch1 \t\n\r\v\f \s ch2 ")6.1.6.2 str_trim(string, side = c("both", "left", "right"))
문자열에서 모든 종류의 공백을 단일 스페이스 공백으로 치환. 중간에 위치한 공백은 제거하지 않는다. both =c("both", "left", "right") 인자를 이용해 공백의 위치(좌, 우, 양쪽) 지정해 치환.
whitespace_v <- " ch1 \t\n\r\v\f ch2 "
str_trim(whitespace_v, side = "right")## [1] " ch1 \t\n\r\v\f ch2"str_trim(whitespace_v)## [1] "ch1 \t\n\r\v\f ch2"str_trim(" String with trailing and leading white space\t", side = "right")## [1] " String with trailing and leading white space"str_trim("\t\n\r\v\fString with trailing and leading white space\t\n\r\v\f") ## [1] "String with trailing and leading white space"6.1.7 과제
오감도에서 공백을 제거하시오.
오감도에서 숫자를 포함한 단어를 추출하시오 (숫자포함하는 정규표현식은
\\w*\\d+\\w*).오감도에서 숫자를 포함한 단어를 모두 제거하시오.
오감도에서 “아해”를 포함한 단어를 모두 찾아, “아해”로 치환하시오. (아해를 포함한 단어에 해당하는 정규표현식은
아해\\w*)
5 오감도에서 “질주”를 포함한 단어를 추출하시오.
오감도에서 “질주”를 포함한 단어를 “질주”로 치환하시오.
오감도에서 “무”를 포함한 단어를 추출하시오.
오감도에서 “무”를 포함한 단어를 “무섭다”로 치환하시오.
오감도에서 숫자가 포함된 단어를 제거하고, “아해”를 포함한 단어를 “아해”로 치환하고, “질주”를 포함한 단어를 모두 “질주”로 치환하고, “무”가 포함된 단어를 모두 “무섭다”로 치환한 다음,
ogamdo_clean_v에 할당하시오.ogamdo_clean_v를 토큰화한 다음, 한글자 단어를 제외한 다음, 가장 많이 사용한 단어의 빈도를 계산해 막대도표로 시각화하시오.
13인의 아해가 도로로 질주하오.
(길은 막다른 골목이 적당하오.)
제1의 아해가 무섭다고 그리오.
제2의 아해도 무섭다고 그리오.
제3의 아해도 무섭다고 그리오.
제4의 아해도 무섭다고 그리오.
제5의 아해도 무섭다고 그리오.
제6의 아해도 무섭다고 그리오.
제7의 아해도 무섭다고 그리오.
제8의 아해도 무섭다고 그리오.
제9의 아해도 무섭다고 그리오.
제10의 아해도 무섭다고 그리오.
제11의 아해가 무섭다고 그리오.
제12의 아해도 무섭다고 그리오.
제13의 아해도 무섭다고 그리오.
13인의 아해는 무서운 아해와 무서워하는 아해와 그렇게뿐이 모였소.
(다른 사정은 없는 것이 차라리 나았소)
그중에 1인의 아해가 무서운 아해라도 좋소.
그중에 2인의 아해가 무서운 아해라도 좋소.
그중에 2인의 아해가 무서워하는 아해라도 좋소.
그중에 1인의 아해가 무서워하는 아해라도 좋소.
(길은 뚫린 골목이라도 적당하오.)
13인의 아해가 도로로 질주하지 아니하여도 좋소.
6.2 dplyr
6.2.1 개괄
dplyr패키지는 “d(데이터) 플라이어”라는 이름에서 나타나듯, 데이터를 조작하는 종합패키지다. 데이터조작의 문법(grammar of data maminpulation)이다. 패키지에 포함된 수십여종의 동사(명령을 실행하는 함수)들이 일정한 원칙에 의해 직관적인 이름으로 구성돼 있다. “정돈된 세계” tidyverse의 핵심 패키지로서 tidyverse를 탑재하면 함께 부착된다. 데이터분석에서 가장 많이 사용하는 패키지 중 하나다.
6.2.1.1 기본 함수
mutate()transmute()데이터프레임 기존 변수(열: column)들을 계산해 열 수정, 생성, 혹은 삭제select()변수 명을 이용해 열 선택filter()값을 이용해 행(개별 케이스) 선택summarize()summarise()복수의 값을 단일 값으로 요약arrange()열의 값 순서 변경
이 5개 함수는 dplyr패키지의 핵심 동사로서 group_by()함수를 이용해 행의 같은 값끼리 묶을 수(group) 있다.
dplyr의 기본적인 사용법은 “R for Data Science”의 자료변형 참조.
6.2.2 dplyr의 구성
dplyr패키지 함수는 크게 묶음 동사, 요약 동사, 행 조작 동사, 열 조작 동사, 벡터 함수, 요약 함수, 테이블 결합 동사 등으로 구분할 수 있다. (함수와 동사는 거의 같은 의미이나 이 장에서만 편의상 데이터프레임을 입력값으로 받는 함수는 “동사”로, 벡터를 입력값으로 받는 함수는 “함수”로 표기했다.)
한 테이블
- 묶음 동사(group cases)
- 요약 동사(summarise cases)
- 요약 함수(summarize functions)
- 행 조작 동사(manipulate cases)
- 열 조작 동사(manipulate variables)
- 벡터 함수(vector functions)
두 테이블
- 테이블 결합 동사(combine tables)
- 행 결합(combine cases)
- 열 결합(combine variables)
6.2.2.1 묶음 동사(group cases)
데이터프레임 열의 행을 같은 값에 따라 하부 그룹으로 묶어 새로운 테이블(데이터프레임) 생성한다.
group_by()지정한 열에서 값이 같은 행끼리 서브그룹으로 결합(group)ungroup()group_by()로 묶은 그룹 해제
6.2.2.2 요약 동사(summrise cases)
데이터프레임 열의 값을 계산해 새로운 테이블 생성한다.
count()데이터프레임을 받아 각 변수(열)에 있는 행의 수 계산summarise()각 변수(열)의 값에 대한 기술통계 계산summarise_all()모든 열에 대하여 계산summarise_at()특정 열에 대하여 계산summarise_if()조건에 부합하는 열에 대하여 계산
6.2.2.2.1 요약 함수(summarize functions)
summarise()함수와 함께 사용하는 함수들이다. 데이터프레임의 열벡터를 입력값으로 받아 단일 행으로 산출한다.
n()열의 값 개수 계산n_distinct()열의 고유한 값 개수 계산first()열의 첫째 값last()열의 마지막 값nth()열의 n번째 값
이외에도 요약기능을 하는 다양한 R기본함수와 함께 사용한다.
head()quantile()min()max()mean()median(),sum()sd()var()등
6.2.2.3 행 조작 동사(manipulate cases)
filter()데이터프레임의 행 부분선택distinct()데이터프레임의 (동일한 복수의 행이 존재하는 경우) 고유한(unique) 행 부분선택arrange()데이터프레임의 열에서 행의 순서 정렬add_row()데이터프레임에 하나 이상의 행 추가. (주의: row가 단수)slice()데이터프레임 행의 위치를 지정해 부분 선택slice_head()slice_tail()slice_min()slice_max()slice_sample()
6.2.2.4 열 조작 동사(manipulate variables)
select()데이터프레임의 열 부분선택add_column()데이터프레임에 하나 이상의 열 추가. (주의: column이 단수)rename()열의 이름 변경mutate()데이터프레임 기존 변수(열: column)들을 계산해 새로운 열 추가
6.2.2.4.1 벡터 함수(vector functions)
mutate()함수와 함께 사용하는 함수들이다. 데이터프레임의 열벡터를 입력값으로 같은 길이의 벡터를 산출한다.
recode()열의 값 변경if_else()주어진 조건의 논리벡터를 받아 true 혹은 false에 해당하는 값 산출case_when()if_else()를 복수의 사례(case)에 적용
벡터함수는 이외에도 산술 및 논리 연산자등을 포함 매우 다양한 기능을 제공하는 함수가 있다.
6.2.2.5 테이블 결합동사
자료분석 과정에서 종종 복수의 테이블을 결합해야 한다. 두 테이블을 열 방향(좌우)으로 결합하는 동사와, 행 방향(상하)으로 결합하는 동사 군으로 구분할 수있다.
6.2.2.5.1 행 결합
bind_rows()두개의 테이블을 행 방향(상하)로 결합.intersect()두 테이블에서 일치하는 행만 결합(교집합)setdiff()두 테이블의 행에서 아래쪽 테이블의 행은 배제하고 결합(차집합)union()두 테이블에서 공통적인 행 결합(합집합) 테이블과 테이블을 행병합한다. 사전을 수정할때 사용할 수 있다.
6.2.2.5.2 열 결합
열을 결합하는 함수들은 단순결합, 변환병합, 열추출 병합 등으로 구분할 수 있다.
6.2.2.5.2.1 단순 병합
bind_cols()두개의 테이블을 열 방향(좌우)로 결합. 두 테이블 행의 수가 같아야 한다.
6.2.2.5.2.2 변환 병합(Mutating Join)
병합 후 양쪽 테이블의 값 모두 유지
inner_join()양쪽 데이터프레임에서 일치하는 행만 결합left_join()왼쪽 테이블을 기준으로 결합. 양쪽 데이터프레임에서 일치하는 행 + 왼쪽 데이터프레임 행 유지한다.right_join()오른쪽 테이블을 기준으로 결합. 양쪽 데이터프레임에서 일치하는 행 + 오른쪽 데이터프레임 행 유지full_join()양쪽 데이터프레임의 모든 행 유지 유지
6.2.2.5.2.3 열 추출 병합(Filtering Join)
병합 후 왼쪽 테이블의 값만 유지
semi_join()두 테이블에서 일치하는 행만 유지. 왼쪽 데이터프레임에서 오른쪽 데이터프레임에 있는 행 내용만 선택한다. 왼쪽 테이블 값만 유지하는 점에서inner_join()과 구분된다.anti_join()두 테이블에서 불일치하는 행만 유지. 왼쪽 데이터프레임에서 오른쪽 데이터프레임에 있는 행 내용을 제거한다.
테이블의 열 결합은 불용어를 제거하거나, 필요한 단어만 골라낼 때 사용할 수 있다. _join()계열 함수는 데이터 조작에 중요한 부분이므로 병합 방식을 잘 이해해야 한다.
6.2.2.6 동일성 확인
setequal()데이터프레임, 벡터 등 두 데이터셋의 요소가 동일한지 확인할 수 있다. 요소의 순서는 무관.
6.2.3 묶음 동사(group cases)
데이터프레임 열의 행을 같은 값에 따라 묶어 새로운 테이블(데이터프레임) 생성한다.
group_by()지정한 열에서 값이 같은 행끼리 서브그룹으로 결합(group)ungroup()group_by()로 묶은 그룹 해제
6.2.3.1 group_by()
데이터프레임을 입력값으로 받아 지정한 열에서 값이 같은 행을 하나로 결합(group)
먼저 tidytext패키지에서 제공하는 불용어 사전을 탑재해 구조를 살펴보자.
library(tidytext)
library(tidyverse)
data(stop_words)
stop_words %>% glimpse()## Rows: 1,149
## Columns: 2
## $ word <chr> "a", "a's", "able", "about", "above", "according", "accordi...
## $ lexicon <chr> "SMART", "SMART", "SMART", "SMART", "SMART", "SMART", "SMAR...행이 1,149개이고 열이 2개인 데이터프레임이다. word 열에는 불용어가 저장돼 있고, lexicon 열에는 불용어사전명의 값이 저장돼 있다.
불용어 사전의 종류를 살펴보자.
stop_words %>% distinct(lexicon)## # A tibble: 3 x 1
## lexicon
## <chr>
## 1 SMART
## 2 snowball
## 3 onixlexicon 열에 “SMART” “snowball” “onix” 등 3종의 값이 있다. 즉, tidytext패키지에 포함된 불용어사전은 SMART snowball onix 등 3종을 행방향으로 결합해 놓은 사전이다.
group_by()동사로 이 묶음 사전을 3종의 사전 별로 나눠 묶어 보자. 나눠 묶은 데이터프레임과 묶기 전 데이터프레임을 glimpse()함수로 비교해 보자.
stop_words %>% glimpse()## Rows: 1,149
## Columns: 2
## $ word <chr> "a", "a's", "able", "about", "above", "according", "accordi...
## $ lexicon <chr> "SMART", "SMART", "SMART", "SMART", "SMART", "SMART", "SMAR...stop_words %>% group_by(lexicon) %>% glimpse()## Rows: 1,149
## Columns: 2
## Groups: lexicon [3]
## $ word <chr> "a", "a's", "able", "about", "above", "according", "accordi...
## $ lexicon <chr> "SMART", "SMART", "SMART", "SMART", "SMART", "SMART", "SMAR...행과 열의 수는 같지만, group_by()로 묶은 객체에는 묶음(Groups: lexicon[3])이 설정돼 있다.
group_by()로 묶기 전후의 행의 개수를 summarise()와 n()으로 비교해 보자.
stop_words %>% summarise(wordN = n()) ## # A tibble: 1 x 1
## wordN
## <int>
## 1 1149stop_words %>% group_by(lexicon) %>% summarise(wordN = n()) ## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## lexicon wordN
## <chr> <int>
## 1 onix 404
## 2 SMART 571
## 3 snowball 1746.2.3.2 ungroup()
group_by()로 설정된 그룹 설정을 해제한다.
ungroup()으로 묶음을 해제한 결과를 묶기 전 stop_words의 결과와 비교해 보자.
stop_words %>%
group_by(lexicon) %>%
ungroup() %>%
glimpse()## Rows: 1,149
## Columns: 2
## $ word <chr> "a", "a's", "able", "about", "above", "according", "accordi...
## $ lexicon <chr> "SMART", "SMART", "SMART", "SMART", "SMART", "SMART", "SMAR...stop_words %>%
glimpse()## Rows: 1,149
## Columns: 2
## $ word <chr> "a", "a's", "able", "about", "above", "according", "accordi...
## $ lexicon <chr> "SMART", "SMART", "SMART", "SMART", "SMART", "SMART", "SMAR...stop_words %>%
group_by(lexicon) %>%
ungroup() %>%
summarise(wordN = n()) ## # A tibble: 1 x 1
## wordN
## <int>
## 1 1149stop_words %>%
summarise(wordN = n()) ## # A tibble: 1 x 1
## wordN
## <int>
## 1 11496.2.4 요약 동사와 요약 함수
요약 동사(summarise cases)
count()summarise()각 변수(열)의 값에 대한 요약 정보 계산
요약 함수(summarize functions)
summarise()함수와 함께 사용해 데이터프레임의 열벡터를 입력값으로 받아 단일 행으로 산출한다.
n(x)x열의 값 개수 계산n_distinct(x)x열의 고유한 값 개수 계산first(x)x열의 첫째 값last(x)x열의 마지막 값nth(x, n)x열의 n번째 값
head()등 다양한 R기본함수와 함께 사용가능하다.
6.2.4.1 count(df, ..., sort = FALSE)와 summarise(df, 요약함수)
데이터프레임을 받아 각 변수(열)에 있는 행의 수 계산. summarise(df, n())과 같은 결과를 산출한다.
count()와 summarise()를 이용해 stop_words에는 몇개의 행이 있는지 계산해보자. summarise()는 새로운 테이블을 요약해 생성하므로 데이터프레임을 만들 때처럼 열의 이름을 wordN =과 같이 지정할 수 있다.
stop_words %>% count()## # A tibble: 1 x 1
## n
## <int>
## 1 1149stop_words %>% summarise(wordN = n())## # A tibble: 1 x 1
## wordN
## <int>
## 1 1149stop_word 데이프레임에는 1149개의 행이 있다. 즉, 1149개의 단어가 있다.
count()와 summarise(n())의 차이를 비교해보자.
stop_words %>% count(word, sort = T)## # A tibble: 728 x 2
## word n
## <chr> <int>
## 1 down 4
## 2 would 4
## 3 a 3
## 4 about 3
## 5 above 3
## 6 after 3
## 7 again 3
## 8 against 3
## 9 all 3
## 10 an 3
## # ... with 718 more rowsstop_words %>%
group_by(word) %>%
summarise(wordN = n()) %>%
arrange(desc(wordN))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 728 x 2
## word wordN
## <chr> <int>
## 1 down 4
## 2 would 4
## 3 a 3
## 4 about 3
## 5 above 3
## 6 after 3
## 7 again 3
## 8 against 3
## 9 all 3
## 10 an 3
## # ... with 718 more rowsstop_words %>% count(lexicon, sort = T)## # A tibble: 3 x 2
## lexicon n
## <chr> <int>
## 1 SMART 571
## 2 onix 404
## 3 snowball 174stop_words %>%
group_by(lexicon) %>%
summarise(lexN = n()) %>%
arrange(desc(lexN))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## lexicon lexN
## <chr> <int>
## 1 SMART 571
## 2 onix 404
## 3 snowball 174count()와 summarise(n())의 결과는 거의 비슷하다.
결과 중에 n열의 값은 word열 값의 개수다. “a,” “about” 등은 3개다. 사전이 3종이므로 모든 사전에 포함돼 있는 것으로 해석할 수 있지만 반드시 그렇지만도 않을 수도 있다. “down”과 “would”를 보자. 4개 있다. 즉, 한종의 사전에 중복된 어휘가 있을 수 있다는 의미다.
구체적인 내용을 확인하기 위해 먼저 stop_words에서 “down,” “would,” “about”이 들어 있는 행)만 추출해서 보자. $은 정규표현식에서 “요소의 마지막”이란 의미다.
dwa_df <- stop_words %>% filter(str_detect(word, "down$|would$|about"))
dwa_df %>% arrange(word)## # A tibble: 11 x 2
## word lexicon
## <chr> <chr>
## 1 about SMART
## 2 about snowball
## 3 about onix
## 4 down SMART
## 5 down snowball
## 6 down onix
## 7 down onix
## 8 would SMART
## 9 would SMART
## 10 would snowball
## 11 would onix“down”은 “onix”에 2건이 들어 있고, “would”는 “SMART”에 2건이 들어있다.
특정 열을 지정해 개수를 계산해보자. count()와 summarise()의 차이를 비교하자.
stop_words %>% count(word, sort = T)## # A tibble: 728 x 2
## word n
## <chr> <int>
## 1 down 4
## 2 would 4
## 3 a 3
## 4 about 3
## 5 above 3
## 6 after 3
## 7 again 3
## 8 against 3
## 9 all 3
## 10 an 3
## # ... with 718 more rowsstop_words %>%
group_by(word) %>%
summarise(wordN = n()) %>%
arrange(desc(wordN))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 728 x 2
## word wordN
## <chr> <int>
## 1 down 4
## 2 would 4
## 3 a 3
## 4 about 3
## 5 above 3
## 6 after 3
## 7 again 3
## 8 against 3
## 9 all 3
## 10 an 3
## # ... with 718 more rowsstop_words %>% count(lexicon, sort = T)## # A tibble: 3 x 2
## lexicon n
## <chr> <int>
## 1 SMART 571
## 2 onix 404
## 3 snowball 174stop_words %>%
group_by(lexicon) %>%
summarise(lexN = n()) %>%
arrange(desc(lexN))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## lexicon lexN
## <chr> <int>
## 1 SMART 571
## 2 onix 404
## 3 snowball 174count()와 summarise()의 사이에 차이가 거의 없다. summarise()를 쓰는 방식이 보다 번거로운 편이데도 summarise()를 쓰는 이유는 빈도 계산 외에 다양한 계산을 할 수 있기 때문이다.
6.2.4.2 n_distinct(x)
열벡터에 있는 고유한 값의 개수를 계산한다.
word열과 lexicon열에 고유한 값이 각각 몇개 있는지 계산해보자.
stop_words %>% summarise(n_distinct(word))## # A tibble: 1 x 1
## `n_distinct(word)`
## <int>
## 1 728stop_words %>% summarise(n_distinct(lexicon))## # A tibble: 1 x 1
## `n_distinct(lexicon)`
## <int>
## 1 3word열에는 고유한 값이 728개 있다. 즉, 고유한 단어가 728개 있다. lexicon열에는 고유한 값이 3개 있다. 즉, 사전 3종이 있다.
전체 행이 1149개인데, 고유한 단어가 728개 있으므로 일부 행이 중복됨을 알수 있다.
각 사전별 단어의 개수를 계산해 보자.
stop_words %>% count(lexicon)## # A tibble: 3 x 2
## lexicon n
## <chr> <int>
## 1 onix 404
## 2 SMART 571
## 3 snowball 174stop_words %>% group_by(lexicon) %>% summarise(wordN = n())## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## lexicon wordN
## <chr> <int>
## 1 onix 404
## 2 SMART 571
## 3 snowball 174stop_words %>% group_by(lexicon) %>% summarise(wdisN = n_distinct(word))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## lexicon wdisN
## <chr> <int>
## 1 onix 398
## 2 SMART 570
## 3 snowball 174“오닉스”에는 총 404개가 있는데, 고유한 어휘는 398개다. 6개가 중복돼 있음을 알수 있다.
6.2.4.3 요약함수 활용
summarise()는 요약함수와 함께 다양한 계산을 제공한다. stop_words의 첫번째, 마지막, 10번째 위치한 단어를 찾아보자.
stop_words %>% summarise(first(word))## # A tibble: 1 x 1
## `first(word)`
## <chr>
## 1 astop_words %>% group_by(lexicon) %>% summarise(first(word))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## lexicon `first(word)`
## <chr> <chr>
## 1 onix a
## 2 SMART a
## 3 snowball istop_words %>% group_by(lexicon) %>% summarise(head(word, 3))## `summarise()` regrouping output by 'lexicon' (override with `.groups` argument)## # A tibble: 9 x 2
## # Groups: lexicon [3]
## lexicon `head(word, 3)`
## <chr> <chr>
## 1 onix a
## 2 onix about
## 3 onix above
## 4 SMART a
## 5 SMART a's
## 6 SMART able
## 7 snowball i
## 8 snowball me
## 9 snowball mystop_words %>% summarise(last(word))## # A tibble: 1 x 1
## `last(word)`
## <chr>
## 1 yoursstop_words %>% summarise(nth(word, 10))## # A tibble: 1 x 1
## `nth(word, 10)`
## <chr>
## 1 afterstop_words %>% group_by(lexicon) %>% summarise(nth(word, 10))## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 3 x 2
## lexicon `nth(word, 10)`
## <chr> <chr>
## 1 onix alone
## 2 SMART after
## 3 snowball your6.2.5 행 조작 동사(manipulate cases)
filter()데이터프레임의 행 부분선택distinct()데이터프레임의 (동일한 복수의 행이 존재하는 경우) 고유한(unique) 행 부분선택arrange()데이터프레임의 열에서 행의 순서 정렬add_row()데이터프레임에 하나 이상의 행 추가. (주의: row가 단수)slice()데이터프레임 행의 위치를 지정해 부분 선택slice_head()slice_tail()slice_min()slice_max()slice_sample()
6.2.5.1 filter(df, ...)
데이터프레임을 입력값으로 받아, 논리값(TRUE FALSE)을 이용해 데이터프레임의 행을 부분선택한다.
stop_words에서 lexicon열의 “onix” 또는 “snowball”에 해당하는 행의 단어만 부분 선택하자.
stop_words %>% filter(lexicon == "onix")## # A tibble: 404 x 2
## word lexicon
## <chr> <chr>
## 1 a onix
## 2 about onix
## 3 above onix
## 4 across onix
## 5 after onix
## 6 again onix
## 7 against onix
## 8 all onix
## 9 almost onix
## 10 alone onix
## # ... with 394 more rowsstop_words %>% filter(word == "y")## # A tibble: 1 x 2
## word lexicon
## <chr> <chr>
## 1 y SMARTstop_words %>% filter(word == "y" | lexicon == "onix")## # A tibble: 405 x 2
## word lexicon
## <chr> <chr>
## 1 y SMART
## 2 a onix
## 3 about onix
## 4 above onix
## 5 across onix
## 6 after onix
## 7 again onix
## 8 against onix
## 9 all onix
## 10 almost onix
## # ... with 395 more rowsstop_words %>% filter(word == "y" & lexicon == "onix")## # A tibble: 0 x 2
## # ... with 2 variables: word <chr>, lexicon <chr>str_detect()함수와 함께 사용하면 정규표현식을 이용할 수 있다. “you”로 시작하는 값이 포함된 행과 반대로 이들 행만 제외한 행을 각각 선택해 보자. ^는 정규표현식에서 “요소의 시작”을 의미한다.
stop_words %>% filter(str_detect(word, "^you"))## # A tibble: 24 x 2
## word lexicon
## <chr> <chr>
## 1 you SMART
## 2 you'd SMART
## 3 you'll SMART
## 4 you're SMART
## 5 you've SMART
## 6 your SMART
## 7 yours SMART
## 8 yourself SMART
## 9 yourselves SMART
## 10 you snowball
## # ... with 14 more rowsstop_words %>% filter(!str_detect(word, "^you"))## # A tibble: 1,125 x 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a's SMART
## 3 able SMART
## 4 about SMART
## 5 above SMART
## 6 according SMART
## 7 accordingly SMART
## 8 across SMART
## 9 actually SMART
## 10 after SMART
## # ... with 1,115 more rows6.2.5.2 distinct(df)
데이터프레임을 입력값으로 받아 고유한 행을 부분 선택한다. 중복된 행을 제거하는데 사용한다.
stop_words의 word열과 lexicon열에서 중복된 행을 제거하고 고유한 행만 부분선택하자.
stop_words %>% distinct(word)## # A tibble: 728 x 1
## word
## <chr>
## 1 a
## 2 a's
## 3 able
## 4 about
## 5 above
## 6 according
## 7 accordingly
## 8 across
## 9 actually
## 10 after
## # ... with 718 more rowsstop_words %>% distinct(lexicon)## # A tibble: 3 x 1
## lexicon
## <chr>
## 1 SMART
## 2 snowball
## 3 onix6.2.5.3 arrange(df, ..., .by_group = FALSE)
데이터프레임을 입력값으로 받아 선택한 열의 행을 순서대로 정렬한다. 기본값은 오름차 순서. 내림차로 정렬하려면 desc()를 인자로 추가한다.
stop_words %>% arrange(word)## # A tibble: 1,149 x 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a snowball
## 3 a onix
## 4 a's SMART
## 5 able SMART
## 6 about SMART
## 7 about snowball
## 8 about onix
## 9 above SMART
## 10 above snowball
## # ... with 1,139 more rowsstop_words %>% arrange(desc(word))## # A tibble: 1,149 x 2
## word lexicon
## <chr> <chr>
## 1 zero SMART
## 2 z SMART
## 3 yourselves SMART
## 4 yourselves snowball
## 5 yourself SMART
## 6 yourself snowball
## 7 yours SMART
## 8 yours snowball
## 9 yours onix
## 10 your SMART
## # ... with 1,139 more rows결측값 NA는 늘 국지데이터의 마지막으로 정렬된다. desc()로 정렬 순서를 바꿔도 마지막에 위치.
tibble(c1 = c(1:2, NA), c2 = 4:6, c3 = c("a", "b", "c")) %>% arrange(c1)## # A tibble: 3 x 3
## c1 c2 c3
## <int> <int> <chr>
## 1 1 4 a
## 2 2 5 b
## 3 NA 6 ctibble(c1 = c(1:2, NA), c2 = 4:6, c3 = c("a", "b", "c")) %>% arrange(desc(c1), c2)## # A tibble: 3 x 3
## c1 c2 c3
## <int> <int> <chr>
## 1 2 5 b
## 2 1 4 a
## 3 NA 6 cgroup_by()로 묶어 정렬하기 위해서는 기본값이 FALSE인 .by_group = 인자를 TRUE로 변경한다. by_group =이 아니라 .by_group =이다. (by 앞 .주의)
stop_words %>% arrange(word, .by_group = F)
stop_words %>% arrange(word, .by_group = T)
stop_words %>% group_by(lexicon) %>% arrange(word, .by_group = T)6.2.5.4 add_row(df, ..., .before = NULL, .after = NULL)
tibble패키지의 함수로서 데이터프레임에 한개 이상의 행을 추가할 수 있다.
기본값은 끝부분 추가이다. 추가 위치를 지정하려면 .before = 혹은 .after = 인자에 추가할 위치를 지정한다.
stop_words %>% add_row(word = c("용어1", "용어2"), lexicon = "KOR", .before = 1)## # A tibble: 1,151 x 2
## word lexicon
## <chr> <chr>
## 1 용어1 KOR
## 2 용어2 KOR
## 3 a SMART
## 4 a's SMART
## 5 able SMART
## 6 about SMART
## 7 above SMART
## 8 according SMART
## 9 accordingly SMART
## 10 across SMART
## # ... with 1,141 more rowsstop_words %>% add_row(word = c("용어1", "용어2"), lexicon = c("KOR1", "KOR2"), .before = 1)## # A tibble: 1,151 x 2
## word lexicon
## <chr> <chr>
## 1 용어1 KOR1
## 2 용어2 KOR2
## 3 a SMART
## 4 a's SMART
## 5 able SMART
## 6 about SMART
## 7 above SMART
## 8 according SMART
## 9 accordingly SMART
## 10 across SMART
## # ... with 1,141 more rowsstop_words %>% add_row(word = "불용어", lexicon = "KOR", .before = 3)## # A tibble: 1,150 x 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a's SMART
## 3 불용어 KOR
## 4 able SMART
## 5 about SMART
## 6 above SMART
## 7 according SMART
## 8 accordingly SMART
## 9 across SMART
## 10 actually SMART
## # ... with 1,140 more rowsstop_words %>% add_row(word = "불용어", lexicon = "KOR", .after = 3)## # A tibble: 1,150 x 2
## word lexicon
## <chr> <chr>
## 1 a SMART
## 2 a's SMART
## 3 able SMART
## 4 불용어 KOR
## 5 about SMART
## 6 above SMART
## 7 according SMART
## 8 accordingly SMART
## 9 across SMART
## 10 actually SMART
## # ... with 1,140 more rows6.2.5.5 slice(df, ..., .)
데이터프레임 행의 위치를 지정해 부분선택(subsetting)한다. 예를 들어,투입값 n = 2:4은 2번째에서 4번째 요소를 부분선택한다.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
slice(n = 2:4)## # A tibble: 3 x 1
## word
## <chr>
## 1 inspire
## 2 me
## 3 you지정한 행을 제거하려면 음기호-사용. n = -(1:3)은 1번재부터 3번째를 제외하고 부분선택.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
slice(n = -(1:3))## # A tibble: 6 x 1
## word
## <chr>
## 1 you
## 2 influence
## 3 me
## 4 for
## 5 the
## 6 better6.2.5.5.1 slice_head(df, ..., n, prop)
첫행부터 행의 순서대로 선택. 개수(n = ) 혹은 비율(prop = )로 지정.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
slice_head(n = 3)## # A tibble: 3 x 1
## word
## <chr>
## 1 you
## 2 inspire
## 3 meprop =인자는 비율로 지정. 0.3은 첫행부터 3/10에 속하는 행 선택
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
slice_head(prop = 0.3)## # A tibble: 2 x 1
## word
## <chr>
## 1 you
## 2 inspire6.2.5.5.2 slice_tail(df, ..., n, prop)
마지막 행까지 행의 순서대로 선택
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
slice_tail(n = 3)## # A tibble: 3 x 1
## word
## <chr>
## 1 for
## 2 the
## 3 better6.2.5.5.3 slice_max(df, order_by, ..., n, prop, with_ties = TRUE)
행의 값이 최대인 행 n개 선택. 기본값은 동률(tie) 모두 표시with_ties = T
(참고: dplyr패키지에서 이제까지 쓰였던 top_n()은 곧 사용을 중지하게 된다.)
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
count(word) %>%
slice_max(n, n = 3)## # A tibble: 7 x 2
## word n
## <chr> <int>
## 1 me 2
## 2 you 2
## 3 better 1
## 4 for 1
## 5 influence 1
## 6 inspire 1
## 7 the 1prop =인자로 상위 3/10에 속하는 행 선택
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
count(word) %>%
slice_max(n, prop = 0.3)## # A tibble: 2 x 2
## word n
## <chr> <int>
## 1 me 2
## 2 you 2만일 동률중 하나만 표시하고 싶으면 with_ties = F
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
count(word) %>%
slice_max(n, n = 3, with_ties = F)## # A tibble: 3 x 2
## word n
## <chr> <int>
## 1 me 2
## 2 you 2
## 3 better 16.2.5.5.4 slice_min(df, order_by, ..., n, prop, with_ties = TRUE)
행의 값이 최소인 행 n개 선택. 기본값은 동률(tie) 모두 표시with_ties = T. (선택할 때 지정하는 열에 주의하자. 값이 들어 있는 열.)
tibble(text = "You inspire me, You influence me for the better. You, you, you ~") %>%
unnest_tokens(word, text) %>%
count(word) %>%
slice_min(n, n = 2)## # A tibble: 5 x 2
## word n
## <chr> <int>
## 1 better 1
## 2 for 1
## 3 influence 1
## 4 inspire 1
## 5 the 1tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
count(word) %>%
slice_min(n, n = 2, with_ties = F)## # A tibble: 2 x 2
## word n
## <chr> <int>
## 1 better 1
## 2 for 16.2.5.5.5 slice_sample(df, ..., n. prop., weited_by = NULL, replace = F)
단순 확률로 임의의 n개 행을 추출한다. 기본값은 비복원추출(뽑은 표본을 모집단에 다시 넣지 않는 표집). 복원추출)뽑은 표본을 모집단에 다시 넣는 표집) 하려면 replace =인자를 TRUE로 설정한다.
set.seed(37)
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
slice_sample(n = 3)## # A tibble: 3 x 1
## word
## <chr>
## 1 me
## 2 for
## 3 inspire6.2.6 열 조작 동사(manipulate variables)
select()데이터프레임의 열 부분선택add_column()데이터프레임에 하나 이상의 열 추가. (주의: column이 단수)rename()열의 이름 변경mutate()데이터프레임 기존 변수(열: column)들을 계산해 새로운 열 추가
6.2.6.1 select(df, ...)
데이터프레임을 받아 선택한 열을 부분선택한다.
stop_words %>% select(word)## # A tibble: 1,149 x 1
## word
## <chr>
## 1 a
## 2 a's
## 3 able
## 4 about
## 5 above
## 6 according
## 7 accordingly
## 8 across
## 9 actually
## 10 after
## # ... with 1,139 more rowsselect()는 연산자와 다양한 도우미 함수를 이용해 복수의 열을 효과적으로 부분선택할 수있다. 구체적인 내용은 설명서(Subset columns using their names and types)참조
6.2.6.2 add_column(df, ..., .before = NULL, .after = NULL)
tibble패키지의 함수로서 데이터프레임에 한개 이상의 열을 추가할 수 있다. 기본값은 끝부분 추가이다. 추가 위치를 지정하려면 .before = 혹은 .after = 인자에 추가할 위치를 지정한다.
stop_words_5 <- stop_words[1:5,]
stop_words_5 %>% add_column(number = 1:5)## # A tibble: 5 x 3
## word lexicon number
## <chr> <chr> <int>
## 1 a SMART 1
## 2 a's SMART 2
## 3 able SMART 3
## 4 about SMART 4
## 5 above SMART 5stop_words_5 %>% add_column(number = 1:5, .before = 1)## # A tibble: 5 x 3
## number word lexicon
## <int> <chr> <chr>
## 1 1 a SMART
## 2 2 a's SMART
## 3 3 able SMART
## 4 4 about SMART
## 5 5 above SMARTstop_words_5 %>% add_column(number = 1:5, .after = 1)## # A tibble: 5 x 3
## word number lexicon
## <chr> <int> <chr>
## 1 a 1 SMART
## 2 a's 2 SMART
## 3 able 3 SMART
## 4 about 4 SMART
## 5 above 5 SMART추가하는 열은 행의 수가 일치해야 한다. 아래 예처럼 행의 수가 일치하지 않으면 오류가 발생한다.
stop_words_5 %>% add_column(number = 1:3)
stop_words_5 %>% add_column(number = 1:7)6.2.6.3 rename(df, ... )
데이터프레임 열의 이름를 변경한다. 새로운 열의 이름을 먼저 지정한다 (예: new_name = old_name) 데이터프레임을 만드는 것에 준하는 과정을 거치기 때문이다.
tibble(ID = 1:3) %>% rename(numbers = ID)## # A tibble: 3 x 1
## numbers
## <int>
## 1 1
## 2 2
## 3 36.2.6.4 mutate(df, ... )
데이터프레임 기존 변수(열: column)들을 계산해 새로운 열 추가한다. 기존 열을 제거하려면 transmute() 이용.
stop_words %>% mutate(plus = str_c(word, "-", lexicon))## # A tibble: 1,149 x 3
## word lexicon plus
## <chr> <chr> <chr>
## 1 a SMART a-SMART
## 2 a's SMART a's-SMART
## 3 able SMART able-SMART
## 4 about SMART about-SMART
## 5 above SMART above-SMART
## 6 according SMART according-SMART
## 7 accordingly SMART accordingly-SMART
## 8 across SMART across-SMART
## 9 actually SMART actually-SMART
## 10 after SMART after-SMART
## # ... with 1,139 more rowsstop_words %>% transmute(plus = str_c(word, "-", lexicon))## # A tibble: 1,149 x 1
## plus
## <chr>
## 1 a-SMART
## 2 a's-SMART
## 3 able-SMART
## 4 about-SMART
## 5 above-SMART
## 6 according-SMART
## 7 accordingly-SMART
## 8 across-SMART
## 9 actually-SMART
## 10 after-SMART
## # ... with 1,139 more rows6.2.7 벡터 함수(vector functions)
mutate()함수와 함께 사용하는 함수들이다. 데이터프레임의 열벡터를 입력값으로 같은 길이의 벡터를 산출한다.
recode()열의 값 변경if_else()주어진 조건의 논리벡터를 받아TRUE혹은FALSE에 해당하는 값 산출case_when()if_else()를 복수의 사례(case)에 적용
벡터함수는 이외에도 산술 및 논리 연산자등을 포함 매우 다양한 기능을 제공하는 함수가 있다. 참고자료.
6.2.7.1 recode(x, old1 = "new1", old2 = "new2")
벡터를 받아 투입한 벡터의 값을 지정한 값으로 치환한다. 투입순서에 주의한다. old를 new로 교체한다. 문자열을 입력값으로 받아 pattern, replacement 순서로 지정하는 str_replace()와 투입순서가 유사하다. 반면, 데이터프레임을 입력값으로 받는 동사들(예: rename(), mutate() 등)은 new = old다. 데이터프레임은 열의 이름을 지정해 생성하므로 바뀔 이름을 먼저 배치한다.
c("You", "inspire", "me") %>% recode(inspire = "INSPIRE")## [1] "You" "INSPIRE" "me"숫자형 값을 바꿀때는 숫자에 백틱으로 인용한다. 치환하는 값의 유형이 일치해야 한다. 정수에는 정수로, 실수에는 실수로, 문자에는 문자로. 불일치하는 경우 NA 산출.
1:4 %>% recode(`4` = 10)## Warning: Unreplaced values treated as NA as .x is not compatible. Please specify
## replacements exhaustively or supply .default## [1] NA NA NA 101:4 %>% recode(`4` = 10L)## [1] 1 2 3 10c(1.3, 2.5) %>% recode(`1.3` = 10)## [1] 10.0 2.5백틱대신 따옴표를 해도 작동한다.
c("You", "inspire", "me") %>% recode("inspire" = "INSPIRE")## [1] "You" "INSPIRE" "me"1:4 %>% recode("4" = 10L)## [1] 1 2 3 10c(1.3, 2.5) %>% recode("1.3" = 5.5)## [1] 5.5 2.5mutate(df, columnName = recode(column, old = "new))데이터프레임의 값을 바꾸기 위해서는mutate()동사와 함께 사용한다.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
mutate(recoded = recode(word,
inspire = "INSPIRE",
better = "BETTER"))## # A tibble: 9 x 2
## word recoded
## <chr> <chr>
## 1 you you
## 2 inspire INSPIRE
## 3 me me
## 4 you you
## 5 influence influence
## 6 me me
## 7 for for
## 8 the the
## 9 better BETTER바꾼 값의 열만 남기려면 생성된 열의 이름을 투입한 열의 이름과 같도록 지정.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
mutate(word = recode(word,
inspire = "INSPIRE",
better = "BETTER"))## # A tibble: 9 x 1
## word
## <chr>
## 1 you
## 2 INSPIRE
## 3 me
## 4 you
## 5 influence
## 6 me
## 7 for
## 8 the
## 9 BETTERstr_replace() 대비 recode()의 장점은 여러 문자열을 개별적으로 변환한다는데 있다. str_replace()는 한번에 하나만 변환한다.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
mutate(word = str_replace_all(word, "inspire", "INSPIRE")) %>%
mutate(word = str_replace_all(word, "better", "BETTER"))recode() 대비 str_replace()의 장점은 투입문자열에 정규표현식 가능.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
mutate(recoded = str_replace(word, ".*", "IN"))## # A tibble: 9 x 2
## word recoded
## <chr> <chr>
## 1 you IN
## 2 inspire IN
## 3 me IN
## 4 you IN
## 5 influence IN
## 6 me IN
## 7 for IN
## 8 the IN
## 9 better IN반면, recode()는 투입문자열에 정규표현식을 받지 못한다.
tibble(text = "You inspire me, You influence me for the better.") %>%
unnest_tokens(word, text) %>%
mutate(recoded = recode(word, ".* " = "IN"))## # A tibble: 9 x 2
## word recoded
## <chr> <chr>
## 1 you you
## 2 inspire inspire
## 3 me me
## 4 you you
## 5 influence influence
## 6 me me
## 7 for for
## 8 the the
## 9 better better6.2.7.2 if_else(condition, true, false, missing = NULL)
주어진 조건의 논리벡터를 받아 true 혹은 false에 해당하는 값 산출
c("희", "노", "애", "락") %>%
str_detect("희|애|락") %>%
if_else("긍정","부정")## [1] "긍정" "부정" "긍정" "긍정"6.2.7.3 case_when(...)
if_else()를 복수의 사례(case)에 적용. \\byou.*는 정규표현식에서 “you로 시작하는,” .*sel.*은 “sel이 포함돼 있는,” \\byoung.*은 “young으로 시작하는”을 나타낸다.
you_v <- c("you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves", "young", "younger", "youngest")
case_when(
str_detect(you_v, "\\byou.*") ~ "you",
str_detect(you_v, ".*sel.*") ~ "self",
str_detect(you_v, "\\byoung.*") ~ "young"
)## [1] "you" "you" "you" "you" "you" "you" "you" "you" "you" "you" "you" "you"의도와 달리 모든 값이 “you”로 바뀌었다. 치환 순서 때문이다. str_detect(you_v, "\\byou.*") ~ "you"가 가장 먼저 배치돼 모두 “you”로 바꾸었다. 일반적인 설정은 가장 뒤에 배치한다.
you_v <- c("you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves", "young", "younger", "youngest")
case_when(
str_detect(you_v, ".*sel.*") ~ "self",
str_detect(you_v, "\\byoung.*") ~ "young",
str_detect(you_v, "\\byou.*") ~ "you",
)## [1] "you" "you" "you" "you" "you" "you" "you" "self" "self"
## [10] "young" "young" "young"6.2.8 테이블 결합동사(행방향)
자료분석 과정에서 종종 복수의 테이블을 결합해야 한다. 두 테이블을 열 방향(좌우)으로 결합하는 동사와, 행 방향(상하)으로 결합하는 동사 군으로 구분할 수 있다. 먼저 행방향 결합부터 다룬다.
bind_rows()두개의 테이블을 행 방향(상하)로 결합. 두 테이블 열의 수가 같아야 한다.intersect()두 테이블에서 일치하는 행만 결합(교집합)setdiff()두 테이블의 행에서 아래쪽 테이블의 행은 배제하고 결합(차집합)union()두 테이블에서 공통적인 행 결합(합집합)
6.2.8.1 bind_rows(x, y, .id = NULL)
두개의 테이블을 행 방향(상하)로 결합한다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "V", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "W", 1,
)
bind_rows(x = a_df, y = b_df)## # A tibble: 6 x 4
## A B C D
## <chr> <chr> <dbl> <dbl>
## 1 a t 1 NA
## 2 b u 2 NA
## 3 CC V 3 NA
## 4 a t NA 3
## 5 b u NA 2
## 6 DD W NA 1.id =인자를 이용해 결합된 데이터프레임에 열을 생성해 결합하기 전 데이터프레임 이름을 지정할 수 있다. id 앞에 .이 있다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "V", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "W", 1,
)
bind_rows(dfA = a_df, dfB = b_df, .id = "dfID")## # A tibble: 6 x 5
## dfID A B C D
## <chr> <chr> <chr> <dbl> <dbl>
## 1 dfA a t 1 NA
## 2 dfA b u 2 NA
## 3 dfA CC V 3 NA
## 4 dfB a t NA 3
## 5 dfB b u NA 2
## 6 dfB DD W NA 16.2.8.2 intersect(x, y)
두 테이블에서 일치하는 행만 결합(교집합). 열의 이름과 수가 일치해야 한다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "V", 3,
)
b_df <- tribble(
~A, ~B, ~C,
"a", "t", 3,
"b", "u", 2,
"DD", "W", 1,
)
intersect(x = a_df, y = b_df)## # A tibble: 1 x 3
## A B C
## <chr> <chr> <dbl>
## 1 b u 26.2.8.3 setdiff(x, y)
두 테이블의 행에서 아래쪽 테이블의 행은 배제하고 결합(차집합)
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "V", 3,
)
b_df <- tribble(
~A, ~B, ~C,
"a", "t", 3,
"b", "u", 2,
"DD", "W", 1,
)
setdiff(x = a_df, y = b_df)## # A tibble: 2 x 3
## A B C
## <chr> <chr> <dbl>
## 1 a t 1
## 2 CC V 36.2.8.4 union()
두 테이블에서 공통적인 행 결합(합집합)
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "V", 3,
)
b_df <- tribble(
~A, ~B, ~C,
"a", "t", 3,
"b", "u", 2,
"DD", "W", 1,
)
union(x = a_df, y = b_df)## # A tibble: 5 x 3
## A B C
## <chr> <chr> <dbl>
## 1 a t 1
## 2 b u 2
## 3 CC V 3
## 4 a t 3
## 5 DD W 16.2.9 테이블 결합동사(열방향)
두 테이블을 열 방향(좌우)으로 결합하는 동사들이다. 두 테이블을 단순하게 결합하는 열 결합 외에 “열추출 병합”과 “변환 병합”이 있다.
열 결합
bind_cols()두개의 테이블을 열 방향(좌우)로 결합. 두 테이블 행의 수가 같아야 한다.
열 추출 병합(Filtering Join) 병합 후 왼쪽 테이블의 값만 유지
anti_join()두 테이블에서 불일치하는 행만 유지. 왼쪽 데이터프레임에서 오른쪽 데이터프레임에 있는 행 내용을 제거한다.semi_join()두 테이블에서 일치하는 행만 유지. 왼쪽 데이터프레임에서 오른쪽 데이터프레임에 있는 행 내용만 선택한다. 왼쪽 테이블 값만 유지하는 점에서inner_join()과 구분된다.
변환 병합(Mutating Join) 병합 후 양쪽 테이블의 값 모두 유지
inner_join()양쪽 데이터프레임에서 일치하는 행만 결합left_join()양쪽 데이터프레임에서 일치하는 행 + 왼쪽 데이터프레임 행 유지right_join()양쪽 데이터프레임에서 일치하는 행 + 오른쪽 데이터프레임 행 유지full_join()양쪽 데이터프레임의 모든 행 유지 유지
6.2.9.1 bind_cols(...)
두 데이터프레임을 단순하게 열 방향으로 결합한다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "V", 3,
)
b_df <- tribble(
~A, ~B, ~C,
"a", "t", 3,
"b", "u", 2,
"DD", "W", 1,
)
bind_cols(a_df, b_df)## New names:
## * A -> A...1
## * B -> B...2
## * C -> C...3
## * A -> A...4
## * B -> B...5
## * ...## # A tibble: 3 x 6
## A...1 B...2 C...3 A...4 B...5 C...6
## <chr> <chr> <dbl> <chr> <chr> <dbl>
## 1 a t 1 a t 3
## 2 b u 2 b u 2
## 3 CC V 3 DD W 16.2.9.2 열 추출 병합(Filtering Join)
병합 후 왼쪽 테이블의 값만 유지
6.2.9.2.1 anti_join(x, y, by = NULL)
양쪽 데이터프레임에서 열의 이름이 값은 열의 값을 비교해 값이 다른 행만 결합한다. 왼쪽 데이터프레임에서 오른쪽 데이터프레임에 있는 행 내용을 제거할 때 사용한다.
불용어사전으로 불용어제거할 때 사용. 투입데이터프레임에서 불용어사전데이터프레임의 행을 배제해 결합한다.
결합하는 기준은 열의 이름이 같은 열이다. 아래 예시에서는 “A”열과 “B”열의 이름이 같다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
anti_join(x = a_df, y = b_df)## Joining, by = c("A", "B")## # A tibble: 1 x 3
## A B C
## <chr> <chr> <dbl>
## 1 CC v 3열의 이름이 같아도 값이 다르면 다른 행으로 취급한다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "UU", 2,
"DD", "w", 1,
)
anti_join(x = a_df, y = b_df)## Joining, by = c("A", "B")## # A tibble: 2 x 3
## A B C
## <chr> <chr> <dbl>
## 1 b u 2
## 2 CC v 3결합하는 기준 열을 지정하려면 by =인자를 이용한다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "UU", 2,
"DD", "w", 1,
)
anti_join(x = a_df, y = b_df, by = "A")## # A tibble: 1 x 3
## A B C
## <chr> <chr> <dbl>
## 1 CC v 36.2.9.2.2 semi_join(x, y, by = NULL)
왼쪽 데이터프레임에서 오른쪽 데이터프레임에 있는 행 내용만 선택.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
semi_join(a_df, b_df)## Joining, by = c("A", "B")## # A tibble: 2 x 3
## A B C
## <chr> <chr> <dbl>
## 1 a t 1
## 2 b u 26.2.9.3 변환 결합(Mutating Join)
양쪽 테이블의 값이 병합 후 유지
6.2.9.3.1 inner_join(x, y, by = NULL, suffix = c(."x, ".y"))
양쪽 데이터프레임에서 일치하는 행만 결합한다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
inner_join(x = a_df, y = b_df)## Joining, by = c("A", "B")## # A tibble: 2 x 4
## A B C D
## <chr> <chr> <dbl> <dbl>
## 1 a t 1 3
## 2 b u 2 2by =인자로 결합할 기준 열을 지졍하면, 지정한 열만을 기준 열로 이용한다. 중복되는 열의 이름의 접미사 기본값은 .x와 .y다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
inner_join(x = a_df, y = b_df, by = "A")## # A tibble: 2 x 5
## A B.x C B.y D
## <chr> <chr> <dbl> <chr> <dbl>
## 1 a t 1 t 3
## 2 b u 2 u 2중복되는 열의 이름의 접미사 기본값을 바꾸려면 suffix =인자를 이용한다.
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
inner_join(x = a_df, y = b_df, by = "A", suffix = c("_1", "_2" ))## # A tibble: 2 x 5
## A B_1 C B_2 D
## <chr> <chr> <dbl> <chr> <dbl>
## 1 a t 1 t 3
## 2 b u 2 u 26.2.9.3.2 left_join(x, y, by = NULL, suffix = c(."x, ".y"))
양쪽 데이터프레임에서 일치하는 행 + 왼쪽 데이터프레임 행 유지
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
left_join(x = a_df, y = b_df)## Joining, by = c("A", "B")## # A tibble: 3 x 4
## A B C D
## <chr> <chr> <dbl> <dbl>
## 1 a t 1 3
## 2 b u 2 2
## 3 CC v 3 NA6.2.9.3.3 right_join(x, y, by = NULL, suffix = c(."x, ".y"))
양쪽 데이터프레임에서 일치하는 행 + 오른쪽 데이터프레임 행 유지
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
right_join(x = a_df, y = b_df)## Joining, by = c("A", "B")## # A tibble: 3 x 4
## A B C D
## <chr> <chr> <dbl> <dbl>
## 1 a t 1 3
## 2 b u 2 2
## 3 DD w NA 16.2.9.3.4 full_join(x, y, by = NULL, suffix = c(."x, ".y"))
양쪽 데이터프레임의 모든 행 유지 유지
a_df <- tribble(
~A, ~B, ~C,
"a", "t", 1,
"b", "u", 2,
"CC", "v", 3,
)
b_df <- tribble(
~A, ~B, ~D,
"a", "t", 3,
"b", "u", 2,
"DD", "w", 1,
)
full_join(x = a_df, y = b_df)## Joining, by = c("A", "B")## # A tibble: 4 x 4
## A B C D
## <chr> <chr> <dbl> <dbl>
## 1 a t 1 3
## 2 b u 2 2
## 3 CC v 3 NA
## 4 DD w NA 16.2.10 연습1
stop_words는 불용어가 포함돼 있는 데이터프레임이다. 셰익스피어의 <소네트27>과stop_words을_join()해 불용어를 제거하려고 한다. 어느_join()을 이용해야 하는가?
- semi_join
- anti_join
- inner_join
- left_join
- right_join
- full_join
- <소네트27>에서 불용어를 제거한 다음 단어 빈도를 계산해 막대도표로 시각화 하시오.
sonnet27_v <- "Weary with toil I haste me to my bed,
The dear repose for limbs with travel tired;
But then begins a journey in my head
To work my mind when body's work's expired;
For then my thoughts, from far where I abide,
Intend a zealous pilgrimage to thee,
And keep my drooping eyelids open wide
Looking on darkness which the blind do see:
Save that my soul's imaginary sight
Presents thy shadow to my sightless view,
Which like a jewel hung in ghastly night
Makes black night beauteous and her old face new.
Lo! thus by day my limbs, by night my mind,
For thee, and for myself, no quietness find."
tibble(text = sonnet27_v) %>%
unnest_tokens(word, text) %>%
anti_join(stop_words) %>%
count(word, sort = T) %>%
filter(n > 1) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n)) +
coord_flip() +
ggtitle("Sonnet27 Word Frequency")## Joining, by = "word"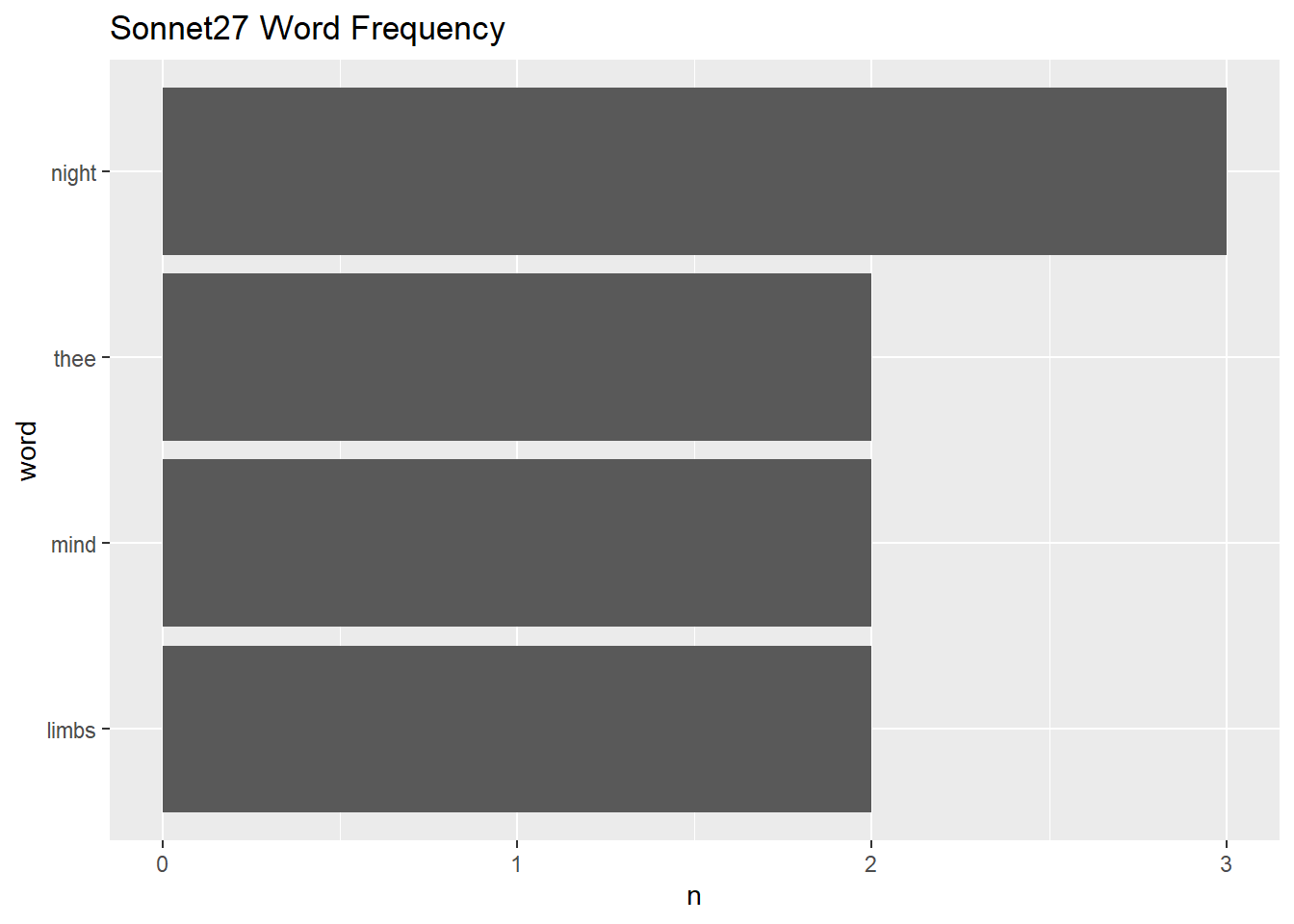
textdata패키지를 설치한다. `get_sentments()함수를 이용해 3종(“afinn,” “bing,” “nrc”)의 영문 감정어의 구조를 파악하자. 처음 설치하고 실행한다면, 사전 다운로드를 할것인지 묻는다. “1: Yes”를 선택해 다운로드 받는다.
install.packages("textdata")library(tidytext)
get_sentiments("afinn")## # A tibble: 2,477 x 2
## word value
## <chr> <dbl>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2
## 7 abhor -3
## 8 abhorred -3
## 9 abhorrent -3
## 10 abhors -3
## # ... with 2,467 more rowsget_sentiments("bing")## # A tibble: 6,786 x 2
## word sentiment
## <chr> <chr>
## 1 2-faces negative
## 2 abnormal negative
## 3 abolish negative
## 4 abominable negative
## 5 abominably negative
## 6 abominate negative
## 7 abomination negative
## 8 abort negative
## 9 aborted negative
## 10 aborts negative
## # ... with 6,776 more rowsget_sentiments("nrc")## # A tibble: 13,901 x 2
## word sentiment
## <chr> <chr>
## 1 abacus trust
## 2 abandon fear
## 3 abandon negative
## 4 abandon sadness
## 5 abandoned anger
## 6 abandoned fear
## 7 abandoned negative
## 8 abandoned sadness
## 9 abandonment anger
## 10 abandonment fear
## # ... with 13,891 more rows세 감정사전 모두 word열에 감정어가 들어 있다. afinn에는 감정 값이 숫자형으로 value열에 저장돼 있다. bing과 nrc에는 감정 값이 문자형으로 sentiment열에 저장돼 있다.
- 셰익스피어 afinn감정사전과 소네트27을 결합해 소네트27의 감정단어를 추출해 감정단어 빈도를 계산하려고한다. 다음 중 어느
_join()을 이용해야 할까? 왜?
- semi_join
- anti_join
- inner_join
- left_join
- right_join
- full_join
만일, semi_join()을 선택했다면 왜 적절한선택이 아닐까 잘 생각해 보자. 감정사전에 있는 감정 값을 유지하려면 inner_join()을 해야 한다.
- afinn bing nrc감정사전을 이용해 <소네트27>에 어떤 감정단어가 사용됐는지 살펴보자.
sonnet27_tk <- tibble(text = sonnet27_v) %>%
unnest_tokens(word, text)
sonnet27_tk %>% inner_join(get_sentiments("afinn")) %>% arrange(desc(value))## Joining, by = "word"## # A tibble: 10 x 2
## word value
## <chr> <dbl>
## 1 dear 2
## 2 zealous 2
## 3 save 2
## 4 like 2
## 5 jewel 1
## 6 darkness -1
## 7 blind -1
## 8 no -1
## 9 weary -2
## 10 tired -2sonnet27_tk %>% inner_join(get_sentiments("bing")) %>% arrange(desc(sentiment))## Joining, by = "word"## # A tibble: 14 x 2
## word sentiment
## <chr> <chr>
## 1 work positive
## 2 like positive
## 3 beauteous positive
## 4 weary negative
## 5 toil negative
## 6 haste negative
## 7 tired negative
## 8 expired negative
## 9 zealous negative
## 10 darkness negative
## 11 blind negative
## 12 imaginary negative
## 13 hung negative
## 14 ghastly negativesonnet27_tk %>% inner_join(get_sentiments("nrc")) %>% arrange(desc(sentiment))## Joining, by = "word"## # A tibble: 29 x 2
## word sentiment
## <chr> <chr>
## 1 intend trust
## 2 zealous trust
## 3 save trust
## 4 weary sadness
## 5 darkness sadness
## 6 black sadness
## 7 dear positive
## 8 repose positive
## 9 journey positive
## 10 zealous positive
## # ... with 19 more rows- <소네트27>에서 각 감정별로 등장한 빈도도 살펴보자.
sonnet27_tk %>% inner_join(get_sentiments("afinn")) %>% count(value)## Joining, by = "word"## # A tibble: 4 x 2
## value n
## <dbl> <int>
## 1 -2 2
## 2 -1 3
## 3 1 1
## 4 2 4sonnet27_tk %>% inner_join(get_sentiments("bing")) %>% count(sentiment)## Joining, by = "word"## # A tibble: 2 x 2
## sentiment n
## <chr> <int>
## 1 negative 11
## 2 positive 3sonnet27_tk %>% inner_join(get_sentiments("nrc")) %>% count(sentiment)## Joining, by = "word"## # A tibble: 9 x 2
## sentiment n
## <chr> <int>
## 1 anger 1
## 2 anticipation 2
## 3 disgust 1
## 4 fear 3
## 5 joy 3
## 6 negative 8
## 7 positive 5
## 8 sadness 3
## 9 trust 3- 3종의 감정사전로 추출한 <소네트27>의 감정단어를 각각 sonnet27_afinn, sonnet27_bing, sonnet27_nrc에 할당하자.
sonnet27_afinn <- sonnet27_tk %>% inner_join(get_sentiments("afinn"))## Joining, by = "word"sonnet27_bing <- sonnet27_tk %>% inner_join(get_sentiments("bing")) ## Joining, by = "word"sonnet27_nrc <- sonnet27_tk %>% inner_join(get_sentiments("nrc")) ## Joining, by = "word"- 3종의 사전에 공통적으로 등장하는 감정단어를 찾고 싶다. 어느
_join()을 이용해야 할까?
- semi_join
- anti_join
- inner_join
- left_join
- right_join
- full_join
- 3종의 사전을 각각 결합해 공통적으로 등장하는 감정단어를 살펴보자. 먼저 각각 2종씩결합해보자.
inner_join(sonnet27_afinn, sonnet27_bing)## Joining, by = "word"## # A tibble: 6 x 3
## word value sentiment
## <chr> <dbl> <chr>
## 1 weary -2 negative
## 2 tired -2 negative
## 3 zealous 2 negative
## 4 darkness -1 negative
## 5 blind -1 negative
## 6 like 2 positiveinner_join(sonnet27_afinn, sonnet27_nrc)## Joining, by = "word"## # A tibble: 15 x 3
## word value sentiment
## <chr> <dbl> <chr>
## 1 weary -2 negative
## 2 weary -2 sadness
## 3 dear 2 positive
## 4 tired -2 negative
## 5 zealous 2 joy
## 6 zealous 2 positive
## 7 zealous 2 trust
## 8 darkness -1 anger
## 9 darkness -1 fear
## 10 darkness -1 negative
## 11 darkness -1 sadness
## 12 blind -1 negative
## 13 save 2 joy
## 14 save 2 positive
## 15 save 2 trustinner_join(sonnet27_bing, sonnet27_nrc)## Joining, by = c("word", "sentiment")## # A tibble: 6 x 2
## word sentiment
## <chr> <chr>
## 1 weary negative
## 2 tired negative
## 3 expired negative
## 4 darkness negative
## 5 blind negative
## 6 ghastly negativebing과 nrc는 열의 이름이 sentiment로 동일해 bing의 값만 남고, nrc의 값은 사라졌다. by =인자로 공통된 열을 지정하면, 공통되지 않은 열이 유지된다.
inner_join(sonnet27_bing, sonnet27_nrc,
by = "word")## # A tibble: 16 x 3
## word sentiment.x sentiment.y
## <chr> <chr> <chr>
## 1 weary negative negative
## 2 weary negative sadness
## 3 haste negative anticipation
## 4 tired negative negative
## 5 expired negative negative
## 6 zealous negative joy
## 7 zealous negative positive
## 8 zealous negative trust
## 9 darkness negative anger
## 10 darkness negative fear
## 11 darkness negative negative
## 12 darkness negative sadness
## 13 blind negative negative
## 14 ghastly negative disgust
## 15 ghastly negative fear
## 16 ghastly negative negative- 새로 생긴 열의 이름에 어느 사전에 있었던 것이지 표시하고 싶다.
suffix =인자를 이용해보자.
inner_join(sonnet27_bing, sonnet27_nrc,
by = "word",
suffix = c("_bing", "_nrc"))## # A tibble: 16 x 3
## word sentiment_bing sentiment_nrc
## <chr> <chr> <chr>
## 1 weary negative negative
## 2 weary negative sadness
## 3 haste negative anticipation
## 4 tired negative negative
## 5 expired negative negative
## 6 zealous negative joy
## 7 zealous negative positive
## 8 zealous negative trust
## 9 darkness negative anger
## 10 darkness negative fear
## 11 darkness negative negative
## 12 darkness negative sadness
## 13 blind negative negative
## 14 ghastly negative disgust
## 15 ghastly negative fear
## 16 ghastly negative negative- 사전3종의 결과를 모두 결합해보자.
inner_join(sonnet27_afinn, sonnet27_bing) %>%
inner_join(sonnet27_nrc, by = "word", suffix = c("_bing", "_nrc"))## Joining, by = "word"## # A tibble: 11 x 4
## word value sentiment_bing sentiment_nrc
## <chr> <dbl> <chr> <chr>
## 1 weary -2 negative negative
## 2 weary -2 negative sadness
## 3 tired -2 negative negative
## 4 zealous 2 negative joy
## 5 zealous 2 negative positive
## 6 zealous 2 negative trust
## 7 darkness -1 negative anger
## 8 darkness -1 negative fear
## 9 darkness -1 negative negative
## 10 darkness -1 negative sadness
## 11 blind -1 negative negative사전마다 감정단어의 극성에 대한 값이 조금씩 다르다. 특히, zealous는 afin과 nrc는 긍정감정으로 분류했는데, bing은 부정감정으로 취급했다.
- 3종의 감정사전에 모두 들어 있는 감정단어를 보고 싶다. 어느 결합을 이용해야 할까?
- semi_join
- anti_join
- inner_join
- left_join
- right_join
- full_join
- 3종의 사전에 모두 포함된 감정단어를 추출해보자.
full_dic <- full_join(sonnet27_afinn, sonnet27_bing) %>%
full_join(sonnet27_nrc, by = "word", suffix = c("_bing", "_nrc"))## Joining, by = "word"full_dic## # A tibble: 37 x 4
## word value sentiment_bing sentiment_nrc
## <chr> <dbl> <chr> <chr>
## 1 weary -2 negative negative
## 2 weary -2 negative sadness
## 3 dear 2 <NA> positive
## 4 tired -2 negative negative
## 5 zealous 2 negative joy
## 6 zealous 2 negative positive
## 7 zealous 2 negative trust
## 8 darkness -1 negative anger
## 9 darkness -1 negative fear
## 10 darkness -1 negative negative
## # ... with 27 more rows- 3종 사전을 결합한 사전을 이용해 <소네트27>에 등장한 감정단어의 빈도를 계산하시오.
tibble(text = sonnet27_v) %>%
unnest_tokens(word, text) %>%
inner_join(full_dic) %>%
count(word, sort = T) %>%
filter(n > 1) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n)) +
coord_flip() +
ggtitle("Sonnet27 Emotion Words")## Joining, by = "word"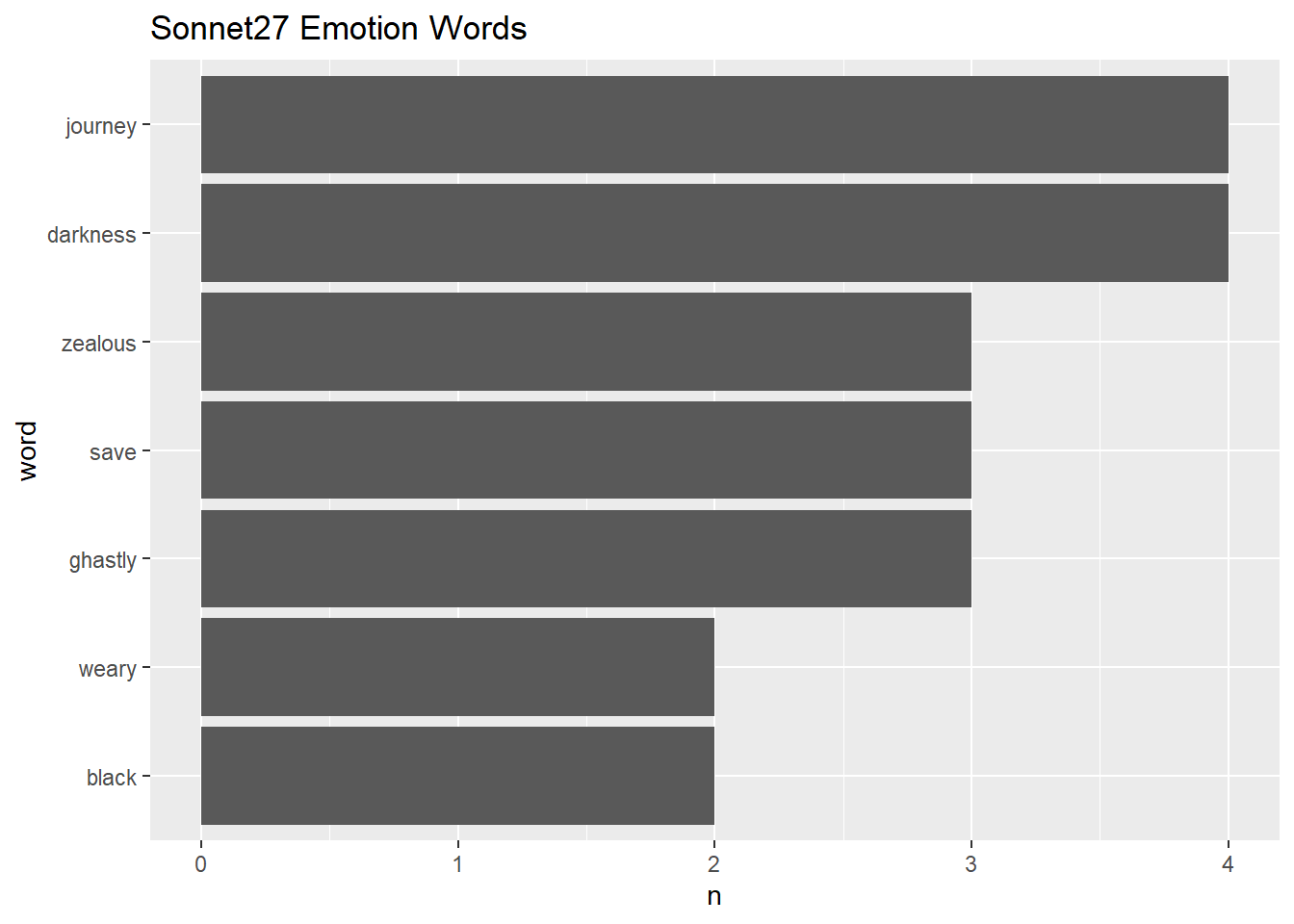
- bing과 nrc사전을 행방향으로 결합한 결과와 열방향으로 결합한 결과를 비교해보자.
library(tidyverse)
bind_rows(BING = sonnet27_bing, NRC = sonnet27_nrc, .id = "DIC")## # A tibble: 43 x 3
## DIC word sentiment
## <chr> <chr> <chr>
## 1 BING weary negative
## 2 BING toil negative
## 3 BING haste negative
## 4 BING tired negative
## 5 BING work positive
## 6 BING expired negative
## 7 BING zealous negative
## 8 BING darkness negative
## 9 BING blind negative
## 10 BING imaginary negative
## # ... with 33 more rowsfull_join(sonnet27_bing, sonnet27_nrc, by = "word")## # A tibble: 35 x 3
## word sentiment.x sentiment.y
## <chr> <chr> <chr>
## 1 weary negative negative
## 2 weary negative sadness
## 3 toil negative <NA>
## 4 haste negative anticipation
## 5 tired negative negative
## 6 work positive <NA>
## 7 expired negative negative
## 8 zealous negative joy
## 9 zealous negative positive
## 10 zealous negative trust
## # ... with 25 more rowsintersect(sonnet27_bing, sonnet27_nrc)## # A tibble: 6 x 2
## word sentiment
## <chr> <chr>
## 1 weary negative
## 2 tired negative
## 3 expired negative
## 4 darkness negative
## 5 blind negative
## 6 ghastly negativeinner_join(sonnet27_bing, sonnet27_nrc, by = "word")## # A tibble: 16 x 3
## word sentiment.x sentiment.y
## <chr> <chr> <chr>
## 1 weary negative negative
## 2 weary negative sadness
## 3 haste negative anticipation
## 4 tired negative negative
## 5 expired negative negative
## 6 zealous negative joy
## 7 zealous negative positive
## 8 zealous negative trust
## 9 darkness negative anger
## 10 darkness negative fear
## 11 darkness negative negative
## 12 darkness negative sadness
## 13 blind negative negative
## 14 ghastly negative disgust
## 15 ghastly negative fear
## 16 ghastly negative negativeinner_join(sonnet27_bing, sonnet27_nrc, by = c("word", "sentiment"))## # A tibble: 6 x 2
## word sentiment
## <chr> <chr>
## 1 weary negative
## 2 tired negative
## 3 expired negative
## 4 darkness negative
## 5 blind negative
## 6 ghastly negativesemi_join(sonnet27_bing, sonnet27_nrc)## Joining, by = c("word", "sentiment")## # A tibble: 6 x 2
## word sentiment
## <chr> <chr>
## 1 weary negative
## 2 tired negative
## 3 expired negative
## 4 darkness negative
## 5 blind negative
## 6 ghastly negativesetdiff(sonnet27_bing, sonnet27_nrc)## # A tibble: 8 x 2
## word sentiment
## <chr> <chr>
## 1 toil negative
## 2 haste negative
## 3 work positive
## 4 zealous negative
## 5 imaginary negative
## 6 like positive
## 7 hung negative
## 8 beauteous positiveunion(sonnet27_bing, sonnet27_nrc)## # A tibble: 37 x 2
## word sentiment
## <chr> <chr>
## 1 weary negative
## 2 toil negative
## 3 haste negative
## 4 tired negative
## 5 work positive
## 6 expired negative
## 7 zealous negative
## 8 darkness negative
## 9 blind negative
## 10 imaginary negative
## # ... with 27 more rows6.2.11 연습2
소설 <오만과 편견(Pride and Prejudice)>에서 감정사전bing을 이용해 긍정감정과 부정감정 단어의 빈도를 막대도표로 시각화해보자.
먼저 텍스트를 확보해 문자벡터로 저장한 다음 구조를 살펴보자.
pp_v <- read_lines("https://www.gutenberg.org/files/1342/1342-0.txt")
pp_v %>% glimpse()## chr [1:14580] "The Project Gutenberg eBook of Pride and Prejudice, by Jane Austen" ...pp_v[500:510]## [1] " “for a kingdom! Upon my honour, I never met with so many pleasant"
## [2] " girls in my life as I have this evening; and there are several of"
## [3] " them you see uncommonly pretty.”"
## [4] ""
## [5] " “_You_ are dancing with the only handsome girl in the room,” said"
## [6] " Mr. Darcy, looking at the eldest Miss Bennet."
## [7] ""
## [8] " “Oh! She is the most beautiful creature I ever beheld! But there"
## [9] " is one of her sisters sitting down just behind you, who is very"
## [10] " pretty, and I dare say very agreeable. Do let me ask my partner"
## [11] " to introduce you.”"문자벡터를 토큰화하고 감정사전 bing을 이용해 감정어를 추출한다.
pp_bing <- tibble(text = pp_v) %>%
unnest_tokens(word, text) %>%
inner_join(get_sentiments("bing"))## Joining, by = "word"pp_bing[100:110,]## # A tibble: 11 x 2
## word sentiment
## <chr> <chr>
## 1 fatigued negative
## 2 excellent positive
## 3 kindness positive
## 4 pleasant positive
## 5 love positive
## 6 afraid negative
## 7 sufficient positive
## 8 satisfactory positive
## 9 ingenious positive
## 10 skill positive
## 11 intelligence positive감정어의 빈도를 막대도표로 시각화한다.
pp_bing %>%
count(word, sentiment, sort = TRUE ) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n, fill = sentiment)) +
coord_flip()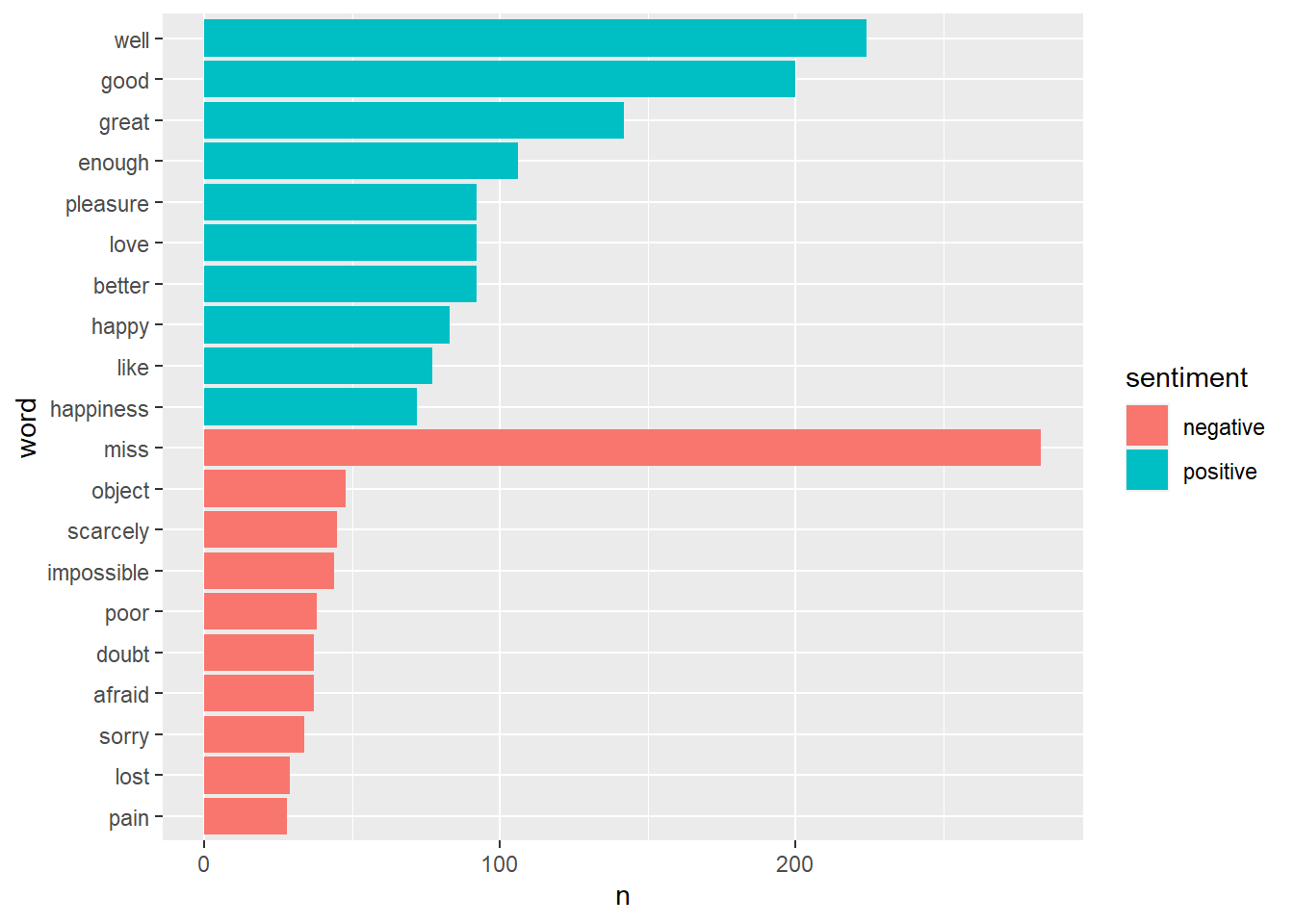
긍정어와 부정어를 구분해서 시각화 해보자. ggplot2패키지의 facet_wrap()함수를 이용한다.
pp_bing %>%
count(word, sentiment, sort = TRUE ) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n, fill = sentiment), show.legend = F) +
coord_flip() +
facet_wrap(~sentiment)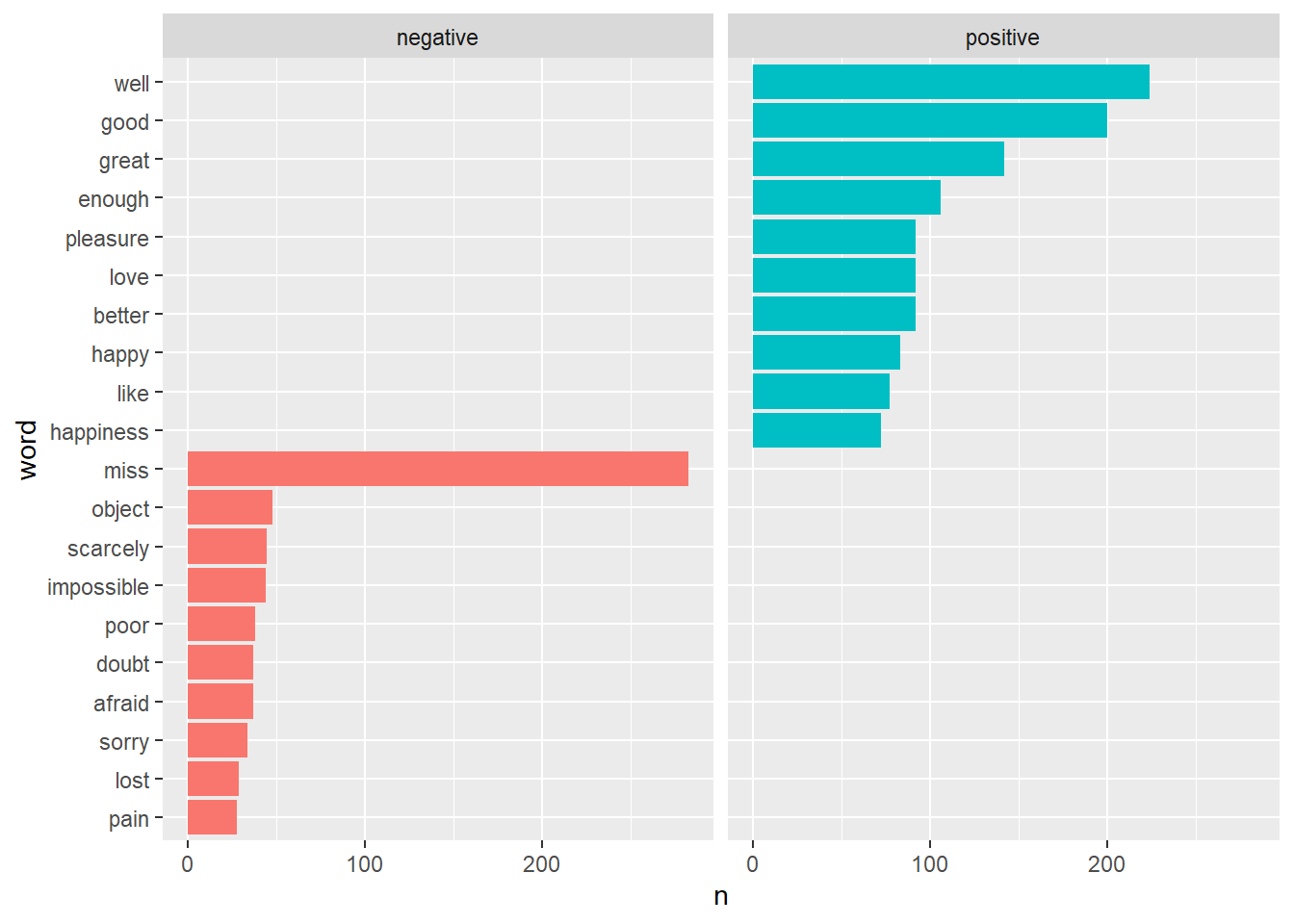
X축의 부정단어와 긍정단어 라벨을 두개의 도표로 분리해 표시하자. scales =인자를 “free”로 지정한다. 기본값은 “fixed”다.
pp_bing %>%
count(word, sentiment, sort = TRUE ) %>%
group_by(sentiment) %>%
slice_max(n, n = 10) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n, fill = sentiment), show.legend = F) +
coord_flip() +
facet_wrap(~sentiment, scales = "free")+
ggtitle("<오만과 편견>의 긍정과 부정감정 단어 빈도") +
xlab("감정단어") + ylab("단어빈도") +
theme(plot.title = element_text(size = 17))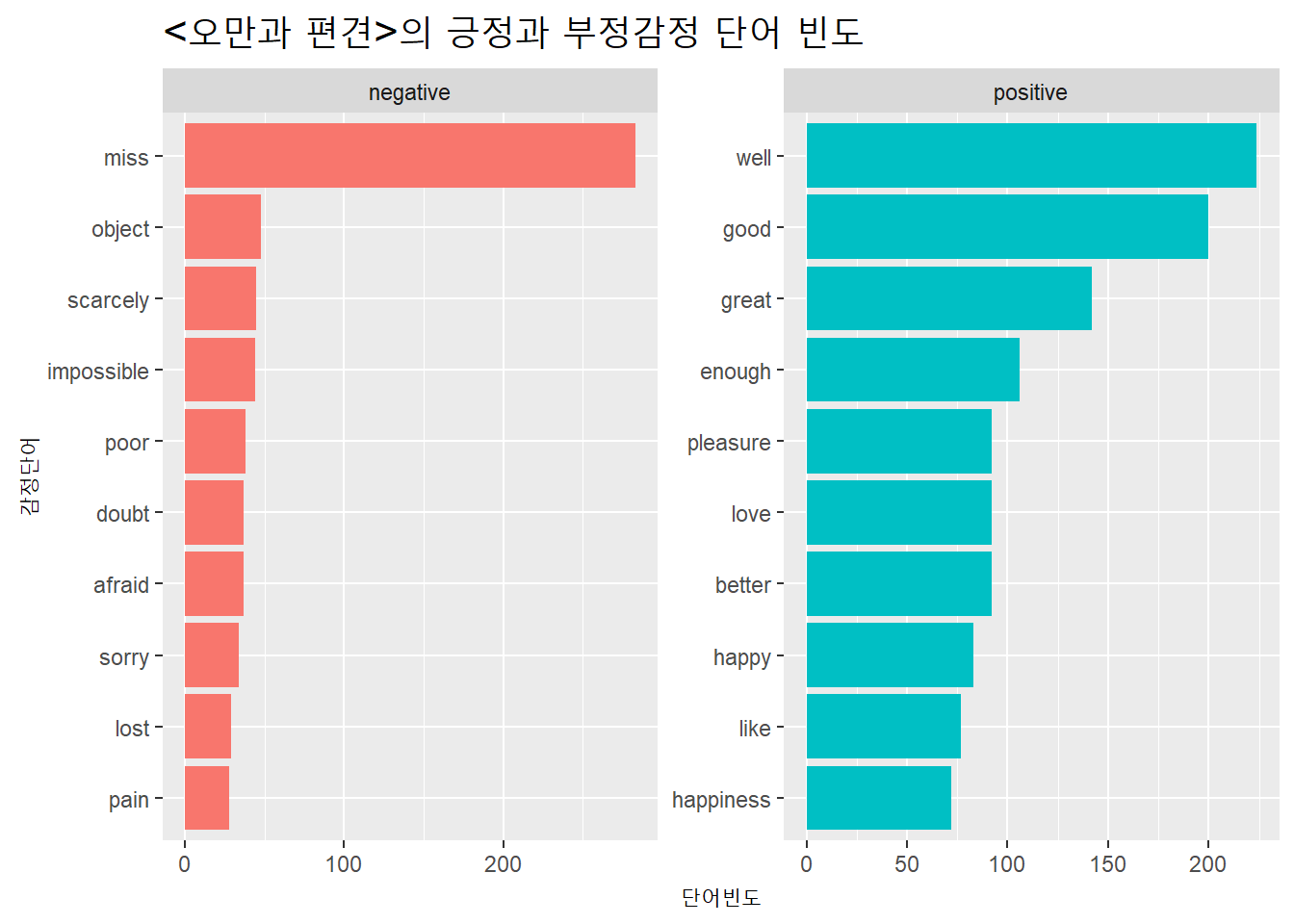
6.2.11.1 과제
영문문서를 자유롭게 선택해 감정사전으로 감정단어를 추출해 긍정단어와 부정단어의 빈도를 시각화하시오. 감정사전을 bing, afinn, nrc를 각각 적용해 결과를 비교하시오.
6.3 purrr
6.3.1 개괄
R의 함수형 프로그래밍(functional programming) 도구다. 즉, 함수를 인자로 받는 함수들의 패키지다. 함수를 반복해서 실행해야 할때 유용하다. 대표 함수가 map()이다. R기본함수의 apply()에 해당한다(정확하게는 lapply()).
6.3.1.1 반복계산
map()map2()pmap()
6.3.1.2 산출유형별
map_chr()문자벡터map_dbl()더블(숫자)벡터map_int()정수벡터map_lgl()논리벡터map_dfc()데이터프레임(열방향)map_dfr()데이터프레임(행방향)
6.3.1.3 리스트 재구성
flatten()리스트의 위계 단계를 줄여준다.flatten_chr()리스트를 문자벡터로flatten_dbl()리스트를 더블(숫자)벡터로flatten_int()리스트를 정수벡터로flatten_lgl()리스트를 논리벡터로flatten_dfc()리스트를 데이터프레임(열방향)으로flatten_dfr()리스트를 데이터프레임(행방향)으로
6.3.2 반복계산
6.3.2.1 map(.x, .f)
벡터나 리스트의 각 요소.x에 대해 순차적으로 함수나 공식(formula).f를 적용해 리스트로 산출한다.
rnorm(n, mean, sd)은 정규분포를 이루는 숫자벡터 n개를 무작위로 생성. 평균과 표준편차 기본값은 각각 0과 1. (비록 평균과 표준편차를 각각 0과 1로 설정했지만, 무작위로 생성된 숫자이므로 평균과 표준편차를 계산하면 0과 1의 근사치가 나온다.)
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
df
df$a %>% mean()
df$b %>% mean()
df$c %>% mean()
df$d %>% mean()map()은 함수를 인자로 받아 함수의 반복적인 실행을 하도록 한다.
df %>% map(mean)리스트로 산출되므로 리스트를 풀려면 flatten_함수를 이용한다. 여기서는 숫자벡터이므로 flatten_dbl()을 이용한다.
df %>% map(mean) %>% flatten_dbl()산출하는 데이터의 유형별로 선택할 수 있는 다양한 종류의 map_계열 함수가 있다.
df %>% map_dbl(mean)투입하는 .f인자를 함수가 아닌 공식(formula)를 투입할 때는 ~사용.
map(1:2, ~rnorm(n = 3, mean = .))
map(1:2, ~rnorm(n = 3, mean = ., sd = 10))6.3.2.2 map2(.x, .y, .f., ...)
복수의 인자를 투입할 수 있다.
map2(1:2, 11:12, rnorm, n = 3)
map2(1:2, 11:12, ~rnorm(n = 3, mean = ., sd = .))6.3.2.3 pmap(.l, .f, ...)
3개 이상의 인자를 투입할 수 있다. 리스트를 생성할 때 인자의 이름을 지정하지 않으면, 지정된 순서대로 투입한다.
arg_l <- list(1:2, 11:12, 21:22)
arg_l %>% pmap(rnorm)
arg_l %>% pmap(~rnorm(n = ., mean = ., sd = .))리스트의 요소 명을 인자의 이름으로 지정하면, 해당 인자로 투입된다.
arg_l <- list(mean = 11:12, n = 1:2, sd = 21:22)
arg_l %>% pmap(rnorm)
arg_l %>% pmap(~rnorm(n = ., mean = ., sd = .))6.4 tidyr
6.4.1 개괄
tidyr패키지의 목표는 자료를 정돈된 방식으로 만들 수 있도록 하는 것이다. 정돈된 자료(tidy data)는:
- 모든 열이 변수(variable)
- 모든 행은 관측값(observation)
- 각 셀에는 하나의 값(value)
정돈된 자료에 대비하여 뒤섞인(messy) 데이터셋은:
- 데이터프레임 중에는 열의 헤더가 변수가 아니라 값인 경우
- 복수의 변수가 하나의 열에 저장돼 있는 경우
- 변수가 행과 열에 저장돼 있는 경우
- 여러 유형의 관측값이 단일 테이블에 저장돼 있는 경우
- 단일 관측값이 복수의 테이블에 저장돼 있는 경우
tidyr패키지는 데이터셋을 정돈된 방식과 뒤섞인 방식 사이를 상호 변환하는 함수들의 모음이다.
축전환(Pivoting), 분리와 결합, 결측값처리, 테이블화(rectangling), 네스팅(nesting) 등 다양한 영역의 기능을 수행하는 함수가 있다. 여기서는 축전환과 분리와 결합을 다룬다.
자세한 내용은 Tidy data문서 참조
6.4.1.1 축전환(pivoting)
pivot_longer()데이터프레임에서 열의 일련의 헤더를 한 열의 값으로 전환pivot_wider()데이터프레임에서 한 열의 값을 열의 헤더로 전환
6.4.1.2 분리와 결합
separate()정규표현식을 이용해 하나의 열을 복수의 열로 분리separate_rows()하나의 행에 있는 값을 복수의 행으로 분리extract()열에 포함돼 있는 문자벡터에서 특정 값을 추출해 열로 분리unite()복수의 열을 하나의 열로 결합
6.4.1.3 결측값NA 처리
drop_na()데이터프레임에서 결측값이 포함된 행 제거fill()데이터프레임에서 결측값을 인접한 행의 값으로 대체replace_na()데이터프레임에서 결측값을 지정한 값으로 대체
6.4.2 축전환(pivoting)
축이란 의미의 pivot은 회전하는 물체의 중심을 잡아주는 축이란 의미다. 테이블에서 축전환(pivoting)이라고 하면, 테이블을 상하로 긴 축의 구조로 전환하는pivot_longer()와, 테이블을 좌우로 넒은 축의 구조로 전환하는 pivot_wider()가 있다.
기존에는 gather()나 spread()가 축전환 함수로 사용됐으나,tidyrverse패키지에서 pivot_longer()와 pivot_wider()를 도입해 사용성을 개선했다. gather()와 spread() 함수는 tidyr패키지에 남아 있어 계속 쓸수는 있지만 업데이트가 되지는 않는다.
6.4.2.1 pivot_longer(df, cols, names_to, values_to)
열의 헤더가 변수가 아니라 값으로 설정된 데이터프레임을 열의 헤더를 열 안의 값으로 전환한다.
열의 헤더에 값이 저장돼 있는 데이터프레임을 이 값들을 한 변수의 값으로 저정된 데이터프레임을 만들어보자. 자동차 모델 3종(A, B, C)이 2000년, 2001년, 2002년에 각각 화재가 발생한 빈도다.
df <- tribble(
~model, ~`2000`, ~`2001`, ~`2002`,
"A", 100, 300, 400,
"B", 400, 500, 600,
"C", 900, 1000, 1200
)
df## # A tibble: 3 x 4
## model `2000` `2001` `2002`
## <chr> <dbl> <dbl> <dbl>
## 1 A 100 300 400
## 2 B 400 500 600
## 3 C 900 1000 1200연도를 별도의 열로 잡지 않고, 각 연도를 별개의 열로 구성돼 있다. 즉, 이 데이터프레임은 축이 좌우로 넓게 퍼져 있다. 이 축을 상하로 길게(_longer) 전환해보자.
데이터프레임의 헤더가 값이므로, names_to =인자를 이용해 헤더의 값을 단일 열(“year”)의 값으로 전환하고, values_to =인자를 이용해 각 헤더별로 분산돼 있는 값을 단일 열(“case”)의 값으로 전환한다.
long_df <- df %>%
pivot_longer(cols = 2:4, names_to = "year", values_to = "case")
long_df## # A tibble: 9 x 3
## model year case
## <chr> <chr> <dbl>
## 1 A 2000 100
## 2 A 2001 300
## 3 A 2002 400
## 4 B 2000 400
## 5 B 2001 500
## 6 B 2002 600
## 7 C 2000 900
## 8 C 2001 1000
## 9 C 2002 12006.4.2.2 pivot_wider(df, names_from, values_from)
이번에는 다시 열의 값을 데이터프레임의 헤더로 전환하자. 단일 열에 길게 분포돼 있는 값을 헤더로 넓게 전환하므로 pivot_wider()함수를 이용한다. 헤더의 이름이 특정 열(year)에서 유래했으므로 names_frome =인자를 이용하고, 각 헤더의 값이 특정 열(case)에서 유래했으므로 values_from =인자를 이용한다.
long_df %>%
pivot_wider(names_from = year, values_from = case)## # A tibble: 3 x 4
## model `2000` `2001` `2002`
## <chr> <dbl> <dbl> <dbl>
## 1 A 100 300 400
## 2 B 400 500 600
## 3 C 900 1000 1200주의 : pivot_longer()의 names_to =에서는 값이 되는 것이므로 문자형(“year”)으로 투입한다. 반면, pivot_wider()의 names_from =에서는 열의 헤더이므로 변수형(year)으로 투입한다.
6.4.3 분리와 결합
복수의 변수가 하나의 열에 저장돼 있거나, 단일 변수가 여러 열에 거져 저장돼 있는 경우가 있다. 복수의 변수가 열 하나에 저장돼 있으면 복수의 열로 분리하고, 단일 변수가 열 여러 곳에 걸져 저장돼 있으면 하나의 열로 결합한다.
6.4.3.1 separate(df, col, into, sep = [^[:alnum:]]+)
데이터프레임을 입력값으로 받아 분리할 열(col)을 어떻게 나눌지 지정해(into) 분리한다. 문자벡터를 분리하는 기본값은 sep = "[^[:alnum:]]+"이다. [^[:alnum:]]+은 문자와 숫자가 아닌 연속하는 값을 의미하는 정규표현식이다.
tb <- tibble(email = c(NA, "apple@ddd.com", "tesla@ttt.com", "amazon@rrr.com"),
status = str_c("g", "xxx", 1:4))
tb## # A tibble: 4 x 2
## email status
## <chr> <chr>
## 1 <NA> gxxx1
## 2 apple@ddd.com gxxx2
## 3 tesla@ttt.com gxxx3
## 4 amazon@rrr.com gxxx4tb %>% separate(col = email,
into = c("id", "comp", "type"))## # A tibble: 4 x 4
## id comp type status
## <chr> <chr> <chr> <chr>
## 1 <NA> <NA> <NA> gxxx1
## 2 apple ddd com gxxx2
## 3 tesla ttt com gxxx3
## 4 amazon rrr com gxxx4분리자가 문자나 숫자면 별도로 지정한다.
tb %>% separate(col = status,
into = c("s1", "s2"),
sep = "xxx")## # A tibble: 4 x 3
## email s1 s2
## <chr> <chr> <chr>
## 1 <NA> g 1
## 2 apple@ddd.com g 2
## 3 tesla@ttt.com g 3
## 4 amazon@rrr.com g 46.4.3.2 separate_rows(df, ..., sep = "[^[:alnum:].]+", convert = FALSE)
하나의 행에 복수의 관측값이 포함돼 있는 경우 각 관측값을 복수의 행으로 분리한다.
tbr <- tibble(year = c(1999, 2000),
email = c("apple@ddd.com", "tesla@ttt.com, amazon@rrr.com"),
stat = c("1", "2,3"))
tbr## # A tibble: 2 x 3
## year email stat
## <dbl> <chr> <chr>
## 1 1999 apple@ddd.com 1
## 2 2000 tesla@ttt.com, amazon@rrr.com 2,3tbr %>% separate_rows(email)## # A tibble: 6 x 3
## year email stat
## <dbl> <chr> <chr>
## 1 1999 apple 1
## 2 1999 ddd.com 1
## 3 2000 tesla 2,3
## 4 2000 ttt.com 2,3
## 5 2000 amazon 2,3
## 6 2000 rrr.com 2,3tbr %>% separate_rows(stat)## # A tibble: 3 x 3
## year email stat
## <dbl> <chr> <chr>
## 1 1999 apple@ddd.com 1
## 2 2000 tesla@ttt.com, amazon@rrr.com 2
## 3 2000 tesla@ttt.com, amazon@rrr.com 3pivot_longer()와 유사하나, pivot_longer()는 여러 열을 하나의 나눠 저장하고, separate_rows()는 하나의 열에 있는 값을 여러 열로 분리.
6.4.3.3 extract(df, col, into, regex = "([[:alnum:]]+)", remove = TRUE, convert = FALSE, ...)
열에 포함돼 있는 문자벡터에서 특정 값만을 추출해 열로 분리한다.
tb %>% extract(col = email,
into = "id")## # A tibble: 4 x 2
## id status
## <chr> <chr>
## 1 <NA> gxxx1
## 2 apple gxxx2
## 3 tesla gxxx3
## 4 amazon gxxx4separate()도 비슷한 결과를 산출하나 작동방식이 다르다.
tb %>% separate(col = email,
into = "id")## Warning: Expected 1 pieces. Additional pieces discarded in 3 rows [2, 3, 4].## # A tibble: 4 x 2
## id status
## <chr> <chr>
## 1 <NA> gxxx1
## 2 apple gxxx2
## 3 tesla gxxx3
## 4 amazon gxxx4extract()는 분리자(sep =)로 구분하지 않고 정규표현식(regext =)과 일치하는 값들을 추출한다. extract()의 정규표현식 기본값도 ([[:alnum:]]+)로서 연속하는 숫자와 문자 그룹 중 한 요소다. 다른 정규표현식을 투입할 때도 소괄호로 묶어 () 그룹설정을 해야 한다. (^\\w{2})은 연속하는 2개의 문자를 그룹으로 묶은 정규표현식이다.
tb %>% extract(col = email,
into = "id",
regex = "(^\\w{2})")## # A tibble: 4 x 2
## id status
## <chr> <chr>
## 1 <NA> gxxx1
## 2 ap gxxx2
## 3 te gxxx3
## 4 am gxxx46.4.3.4 unite(df, col, ..., sep = "_", remove = TRUE, na.rm = FALSE)
separate()의 역에 해당한다. 여러 열(...)에 걸쳐 저장된 값을 하나의 열(col)로 결합한다. 결합 기본값은 sep = "_"다. 결합할 열(...)의 선택은 selection()동사에서 활용하는 함수를 이용한다 (설명서).
tb2 <- tibble(id = c("apple", "tesla", "amazon"),
comp = c("ddd", "ttt", "rrr"),
type = "com")
tb2## # A tibble: 3 x 3
## id comp type
## <chr> <chr> <chr>
## 1 apple ddd com
## 2 tesla ttt com
## 3 amazon rrr comtb2 %>% unite(col = "newID")## # A tibble: 3 x 1
## newID
## <chr>
## 1 apple_ddd_com
## 2 tesla_ttt_com
## 3 amazon_rrr_comtb2 %>% unite(col = "newID", id:type)## # A tibble: 3 x 1
## newID
## <chr>
## 1 apple_ddd_com
## 2 tesla_ttt_com
## 3 amazon_rrr_comtb2 %>% unite(col = "newID", c(id, type))## # A tibble: 3 x 2
## newID comp
## <chr> <chr>
## 1 apple_com ddd
## 2 tesla_com ttt
## 3 amazon_com rrr6.4.4 연습1
- 셰익스피어의 <소네트27>의 긍정감정과 부정감정의 정도를 분석해보자. 먼저 감정어를 추출(토큰화, 감정사전결합)하고, 감정어의 빈도를 계산한다. 감정어의 빈도계산은
count()를 이용하는 방법도 있지만, 여기서는 축전환을 이용해 계산해보자. 먼저, bing사전을 이용해 <소네트27>에서 감정어를 추출해 s27_bing에 할당하자.
sonnet27_v <- "Weary with toil I haste me to my bed,
The dear repose for limbs with travel tired;
But then begins a journey in my head
To work my mind when body's work's expired;
For then my thoughts, from far where I abide,
Intend a zealous pilgrimage to thee,
And keep my drooping eyelids open wide
Looking on darkness which the blind do see:
Save that my soul's imaginary sight
Presents thy shadow to my sightless view,
Which like a jewel hung in ghastly night
Makes black night beauteous and her old face new.
Lo! thus by day my limbs, by night my mind,
For thee, and for myself, no quietness find."
s27_bing <- tibble(text = sonnet27_v) %>%
unnest_tokens(word, text) %>%
inner_join(get_sentiments("bing"))## Joining, by = "word"s27_bing## # A tibble: 14 x 2
## word sentiment
## <chr> <chr>
## 1 weary negative
## 2 toil negative
## 3 haste negative
## 4 tired negative
## 5 work positive
## 6 expired negative
## 7 zealous negative
## 8 darkness negative
## 9 blind negative
## 10 imaginary negative
## 11 like positive
## 12 hung negative
## 13 ghastly negative
## 14 beauteous positive생성된 s27_bing은 word열에 감정어가 저장돼 있고, sentiment열에 negative와 positive 값이 저장돼 있다. sentiment열을 축전환해 word열의 값을 negative와 positive열에 저장하자.
s27_bing %>% pivot_wider(
names_from = sentiment,
values_from = word
) ## Warning: Values are not uniquely identified; output will contain list-cols.
## * Use `values_fn = list` to suppress this warning.
## * Use `values_fn = length` to identify where the duplicates arise
## * Use `values_fn = {summary_fun}` to summarise duplicates## # A tibble: 1 x 2
## negative positive
## <list> <list>
## 1 <chr [11]> <chr [3]>데이터프레임의 각 열에 리스트로 저장돼 있다. purrr패키지의 flatten()함수를 이용하면 리스트의 위계구조를 한단계를 줄일 수 있다.
s27_bing %>%
pivot_wider(names_from = sentiment,
values_from = word) %>%
flatten()## Warning: Values are not uniquely identified; output will contain list-cols.
## * Use `values_fn = list` to suppress this warning.
## * Use `values_fn = length` to identify where the duplicates arise
## * Use `values_fn = {summary_fun}` to summarise duplicates## $negative
## [1] "weary" "toil" "haste" "tired" "expired" "zealous"
## [7] "darkness" "blind" "imaginary" "hung" "ghastly"
##
## $positive
## [1] "work" "like" "beauteous"s27_bing에서 부정감정어와 긍정감정서의 수를 계산해보자. purrr패키지의 map()함수를 이용하면 함수를 인자로 받아 연산을 반복적으로 수행할 수 있다. map_dfc() 혹은 map_dfr()함수를 이용하면 데이터프레임으로 산출할 수 있다.
s27_bing %>%
pivot_wider(names_from = sentiment,
values_from = word) %>%
flatten() %>%
map_dfc(length)## Warning: Values are not uniquely identified; output will contain list-cols.
## * Use `values_fn = list` to suppress this warning.
## * Use `values_fn = length` to identify where the duplicates arise
## * Use `values_fn = {summary_fun}` to summarise duplicates## # A tibble: 1 x 2
## negative positive
## <int> <int>
## 1 11 3이 결과를 막대도표로 시각화하자. 막대도표로 시각화 하기 위해서는 x변수와 y변수가 필요하다. 변수의 값이 데이터프레임의 헤더에 저장돼 있으므로, 한 변수내의 값으로 변경해야 한다. 사용가능한 방법은?
s27_bing %>%
pivot_wider(names_from = sentiment,
values_from = word) %>%
flatten() %>%
map_dfc(length) %>%
pivot_longer(cols = negative:positive,
names_to = "emotion",
values_to = "n"
) ## Warning: Values are not uniquely identified; output will contain list-cols.
## * Use `values_fn = list` to suppress this warning.
## * Use `values_fn = length` to identify where the duplicates arise
## * Use `values_fn = {summary_fun}` to summarise duplicates## # A tibble: 2 x 2
## emotion n
## <chr> <int>
## 1 negative 11
## 2 positive 3이제 막대도표로 시각화할 수 있다. 제목, x축과 y축의 라벨 및 각 막대의 색을 설정하자.
s27_bing %>%
pivot_wider(names_from = sentiment,
values_from = word) %>%
flatten() %>%
map_dfc(length) %>%
pivot_longer(cols = negative:positive,
names_to = "emotion",
values_to = "n"
) %>%
ggplot() + geom_col(aes(emotion, n), fill = c("red", "blue")) +
coord_flip()+
ggtitle("<소네트27>의 부정어와 긍정어 빈도") +
ylab("감정어 빈도") + xlab("감정 극성")+
theme(plot.title = element_text(size = 20))## Warning: Values are not uniquely identified; output will contain list-cols.
## * Use `values_fn = list` to suppress this warning.
## * Use `values_fn = length` to identify where the duplicates arise
## * Use `values_fn = {summary_fun}` to summarise duplicates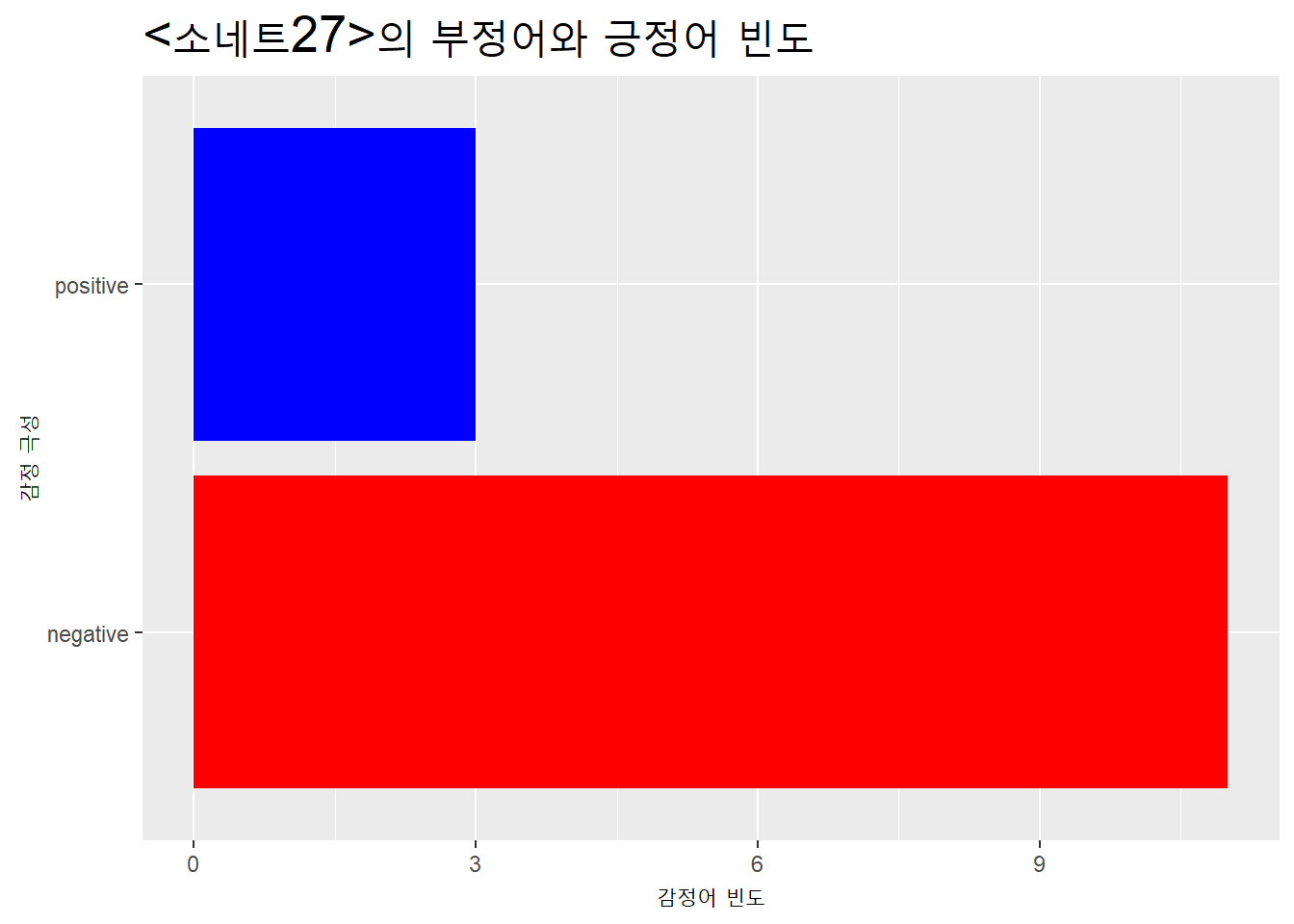
6.4.5 연습2
- 셰익스피어의 <소네트27>를 2그램으로 토큰화 해 불용어를 제거하시오. 2그램토큰의 불용어를 제거하기 위해서는 먼저 1그램으로 분리해 불용어를 제거한 다음, 다시 2그램으로 결합한다.
먼저, 2그램으로 토큰화한 후 s27_tk에 할당하자.
s27_tk <- tibble(text = sonnet27_v) %>%
unnest_tokens(word, text, token = "ngrams", n = 2)
s27_tk## # A tibble: 110 x 1
## word
## <chr>
## 1 weary with
## 2 with toil
## 3 toil i
## 4 i haste
## 5 haste me
## 6 me to
## 7 to my
## 8 my bed
## 9 bed the
## 10 the dear
## # ... with 100 more rows불용어 사전에는 불용어가 1gram으로 저장돼 있다. 2그램 토큰을 1그램 토큰으로 분리한 다음, 불용어 사전으로 제거한 후, 다시 2그램으로 결합하자. 열이 2개(word1, word2)이므로 anti_join()으로 불용어를 제거하기 힘들다. 불용어가 있는 열을 부분선택해 걸러내자. filter() 사용.
s27_tk %>%
separate(word, into = c("word1", "word2"), sep = " ") %>%
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word) ## # A tibble: 17 x 2
## word1 word2
## <chr> <chr>
## 1 dear repose
## 2 travel tired
## 3 body's work's
## 4 work's expired
## 5 abide intend
## 6 zealous pilgrimage
## 7 drooping eyelids
## 8 soul's imaginary
## 9 imaginary sight
## 10 thy shadow
## 11 sightless view
## 12 jewel hung
## 13 ghastly night
## 14 night makes
## 15 makes black
## 16 black night
## 17 night beauteous“with” “i” “me” 등 불용어 사전에 포함돼 있던 어휘가 모두 제거했다. 분리했던 열을 다시 결합해 2그램의 빈도를 계산하자.
s27_tk %>%
separate(word, into = c("word1", "word2"), sep = " ") %>%
filter(!word1 %in% stop_words$word,
!word2 %in% stop_words$word) %>%
unite(word, c(word1, word2), sep = " ") %>%
count(word, sort = T)## # A tibble: 17 x 2
## word n
## <chr> <int>
## 1 abide intend 1
## 2 black night 1
## 3 body's work's 1
## 4 dear repose 1
## 5 drooping eyelids 1
## 6 ghastly night 1
## 7 imaginary sight 1
## 8 jewel hung 1
## 9 makes black 1
## 10 night beauteous 1
## 11 night makes 1
## 12 sightless view 1
## 13 soul's imaginary 1
## 14 thy shadow 1
## 15 travel tired 1
## 16 work's expired 1
## 17 zealous pilgrimage 1빈도는 모두 1회다. 불용어들은 대개 자주 사용하는 어휘이기 때문에 대다수의 단어가 불용어와 결합돼 있기 때문이다. 불용어를 제거한 n그램은 주의해서 해석해야 한다.
6.4.5.1 과제
영문 문서(구텐베르크 프로젝트 등) 중 하나를 골라 선택한 문서의 감정단어의 빈도를 nrc사전을 이용해 시각화하시오.
6.5 연산자(operators)
- 산술연산자(Arithmatic Operators)
- 관계연산자(Relational Operators)
- 논리연산자(Logical Operators)
- 포함 연산자(Inclusion Operator)
6.5.1 산술연산자(Arithmatic Operators)
+더하기(addition)2+3-빼기(substraction)3-2*곱하기(multiplication)3*2^ 또는 **제곱(exponentiation) 37^3 37**3/나누기(division)5/25를 2로 나누면 2.5%%나머지(modulus)5%%25를 2로 나누면 나머지는 1%/%몫(integer modulus)5%%25를 2로 나누면 몫은 2
x <- c(10, 20, 30, 40, 50)
x + 1## [1] 11 21 31 41 51x - 1## [1] 9 19 29 39 49x * 2## [1] 20 40 60 80 100x / 2## [1] 5 10 15 20 25x %% 3## [1] 1 2 0 1 2x %/% 3## [1] 3 6 10 13 166.5.1.1 재활용(recycle) 연산
c(10, 20, 30, 40) + 1## [1] 11 21 31 413 + c(10, 20, 30, 40)## [1] 13 23 33 43c(10, 20, 30, 40) + c(1, 2)## [1] 11 22 31 42c(3, 4) + c(10, 20, 30, 40)## [1] 13 24 33 44c(10, 20, 30, 40) + c(1, 2, 3)## Warning in c(10, 20, 30, 40) + c(1, 2, 3): 두 객체의 길이가 서로 배수관계에 있지
## 않습니다## [1] 11 22 33 416.5.2 관계연산자(Relational Operators)
연산결과를 논리형(TRUE or FALSE)으로 산출한다.
<보다 작은(less than)>보다 큰(Greater than)<=이하(Less than or equal to)>=이상(Greater than or equal to)==같은(Equal to)!=같지 않은(Not equal to)
x <- c(10, 20, 30)
x < 20## [1] TRUE FALSE FALSEx > 20## [1] FALSE FALSE TRUEx <= 20## [1] TRUE TRUE FALSEx >= 20## [1] FALSE TRUE TRUEx == 20## [1] FALSE TRUE FALSEx != 20## [1] TRUE FALSE TRUE20 < x## [1] FALSE FALSE TRUE20 > x## [1] TRUE FALSE FALSE20 <= x## [1] FALSE TRUE TRUE20 >= x## [1] TRUE TRUE FALSE20 == x## [1] FALSE TRUE FALSE20 != x## [1] TRUE FALSE TRUE6.5.3 논리연산자(Logical Operators)
!아닌(NOT) (“0”은FALSE, 0이 아닌 값은TRUE로 취급한다.)&그리고(AND)&&요소형 그리고(첫째 요소만 연산)|또는(OR)||요소형 또는(첫째 요소만 연산)
x <- c(TRUE, FALSE, 0, 6)
y <- c(FALSE, TRUE, FALSE, TRUE)
!x## [1] FALSE TRUE TRUE FALSEx&y## [1] FALSE FALSE FALSE TRUEx&&y## [1] FALSEx|y## [1] TRUE TRUE FALSE TRUEx||y## [1] TRUE6.5.4 포함 연산자(Inclusion Operator)
6.5.4.1 %in%
“~ 포함된”이란 의미다. A%in%B는 A에 B의 요소가 포함돼 있는지 여부를 논리값으로 산출한다.
c(10, 20, 30, 40, 50) %in% c(40, 50)## [1] FALSE FALSE FALSE TRUE TRUEc(10, 20, 30, 40, 50) %in% c(40, 50, 60, 70)## [1] FALSE FALSE FALSE TRUE TRUE- 논리값을 산출하므로
filter()함수와 함께 이용해 특정 문자 선택 혹은 제거에 활용할 수 있다.filter(string %in% c("a","b","c"))투입한 문자벡터에서 지정된 자(예: a b c)를 필터(즉, 걸러내 이것들만 남김).filter(!string %in% c("a","b","c"))투입한 문자벡터에서 지정된 문자(예: a b c)만 빼고 필터(즉, 이것들만 빼고 남김).
text_v <- "You still fascinate and inspire me.
You influence me for the better.
You’re the object of my desire, the #1 Earthly reason for my existence."
tibble(text = text_v) %>%
unnest_tokens(output = word, input = text) %>%
filter(word %in% c("still", "and"))## # A tibble: 2 x 1
## word
## <chr>
## 1 still
## 2 andtibble(text = text_v) %>%
unnest_tokens(output = word, input = text) %>%
filter(!word %in% c("still", "and"))## # A tibble: 23 x 1
## word
## <chr>
## 1 you
## 2 fascinate
## 3 inspire
## 4 me
## 5 you
## 6 influence
## 7 me
## 8 for
## 9 the
## 10 better
## # ... with 13 more rows6.6 정규표현식(regular expressions)
정규표현식은 문자열의 패턴을 간결하고도 일관되게 기술하는 방식이다. 다양한 기능문자를 이용해 일반문자의 검색과 치환을 보다 효율적으로 할수 있다. 주요 기능문자는 다음과 같다. (기능문자는 메타문자 혹은 특수문자라고도 한다.)
\이스케이프(escape)
이스케이프 이후의 일반문자는 기능문자, 이스케이프 이후의 기능문자는 일반문자임을 의미한다.
예를 들어, 영문자 “d” 앞에 \를 넣어 \d로 표시하면 영문자 “d”앞에 \가 있기 때문에 \d는 영문자 “d”가 아니라 숫자를 의미하는 기능문자가 된다. \w \s \b도 마찬가지.
반대로 부정을 의미하는 !을 느낌표로 사용하기 위해서는 \!처럼 이스케이프문자가 앞에 와야 느낌표 일반문자로 인식한다.
주의
\가 기능문자임을 알려야 하므로 \는 또 다른 \와 함께 쓰여야 한다. 따라서 실제로 쓰일 때는 \\를 두번 투입해 \\d나 \\!처럼 사용한다.
정규표현식의 종류는 다음 7종류로 구분할 수있다.
6.6.0.1 일치하는 문자
.임의의 한 요소 (new line은 예외)\w단어문자 + 숫자 =[:alnum:]= 한국에선[a-zA-Z가-힣]\W단어문자가 아닌 요소
\d숫자(digit) =[:digit:]=[0-9]\D숫자가 아닌 요소 =[^0-9]
[:alpha:]단어문자[:lower:]=[a-z][:upper:]=[A-Z]
[:punct:]구두점[:graph:]단어문자, 숫자, 구두점\b단어문자의 경계.
6.6.0.2 공백문자(whiatespace)
\n줄바꿈(new line)\ttab\s아스키코드에 등록된 공백문자 6종(빈칸및\t\n\r\f\v)\S공백문자가 아닌 요소
[:space:]=\s[:blank:]빈칸과\t- 아스키 공백문자 중
\n\r\f및v는 해당 안됨
- 아스키 공백문자 중
주의1
\n \t \r \v \f에는 ASCII코드가 9~13까지 할당돼 있는 단독문자다 (Table ??). \n과 \t 앞에 \를 붙여 \\n \\t로 투입하면, \n과 \t는 일반문자로 표시된다.
반면, 정규표현식에서 일반문자에 \문자를 더해 기능문자로 작동하는 \w \s \d \b는 \를 더하면 기능문자가 된다.
주의2
stringr패키지 함수와 달리, R기본함수 중 다수는 [[:digit:]]처럼 대괄호를 2개 설정하도록 돼 있다.
6.6.0.3 또는(alternates)
대괄호[ ]는 집합이나 범위를 나타낸다.
|또는[ ]~중 하나(one of)[^ ]~만 제외(anything but) ** 대괄호 없는^는 문자열 요소의 첫부분[ - ]~부터 ~까지 범위(range)
6.6.0.4 묶음(groups)
( )소괄호 안은 하나의 요소를 묶임을 의미
6.6.0.5 앵커(anchors)
^문자열의 시작$문자열의 종료
6.6.0.6 주변(look around)
(?= )이어지는(followed by)(?!= )이어지지 않는(not followed by)(?<= )선행하는(preceded by)(?<! )선행하지 않는(not preceded by)
6.6.0.7 반복일치(quantifiers)
중괄호 { }는 횟수를 나타낸다.
{n}선행요소가 n회( exactly n){n,}선행요소가 n회 또는 그 이상(n or more){n,m}선행요소가 n회와 m회 사이(between n and m)?선행요소가 0회 또는 1회(zero or one) ={0,1}*선행요소가 0회 또는 그 이상(zero or more) ={0,}+선행요소가 1회 또는 그 이상(one or more) ={1,}
주의
앵커는 문자열 전체의 시작과 종료를 나타낸다. 따라서, 문자열 내 특정 단어만 지정할 때는 \\b 사용
기타
stringr패키지의 str_view()와 str_view_all()함수를 이용해 정규표현식과 일반문자가 어떻게 부합하는지 확인할 수 있다. HTML로 렌더링해 산출.
str_view()각 문자열에서 정규표현식의 패턴과 일치하는 첫째 요소를 HTML로 렌더링해 표시.str_view_all()각 문자열에서 정규표현식의 패턴과 일치하는 모든 요소를 HTML로 렌더링해 표시.
6.6.1 일반문자와 기능문자
일반문자를 겹따옴표에 넣어 패턴으로 투입.
txt2_v <- c(
"newline\n\n,tab\t\t,CR\r\r,FF\f\fVT\v\v,space space",
"abcABC가나다123구두점!@#%&*()_{}:;/?기타$^+<>`~",
"가다aaaaapppP 8e.A pear... 123"
)
str_view_all(txt2_v, pattern = "s") 일반문자에 이스케이프문자\를 투입하면 기능문자가 된다.
str_view_all(txt2_v, pattern = "\\s") 일반문자로서 \문자와 함께 기능문자 역할을 하는 문자는 \s외에도 \d \b 등이 있다.
str_view_all(txt2_v, pattern = "\\d\\b") 기능문자를 패턴으로 투입한다.
str_view_all(txt2_v, pattern = ".") 기능문자에 이스케이프문자\를 투입하면 일반문자가 된다.
str_view_all(txt2_v, pattern = "\\.") 6.6.2 일치하는 문자(Match Characters)
.임의의 한 요소 (new line은 예외).\w단어문자 + 숫자 =[:alnum:]= 한국에선[a-zA-Z가-힣]\W단어나 숫자가 아닌 요소
\d숫자(digit) =[:digit:]=[0-9]\D숫자가 아닌 요소 =[^0-9]
[:alpha:]단어문자. 영어권에선[a-zA-Z]한국어권에선[가-힣][:lower:]=[a-z][:upper:]=[A-Z]
[:punct:]구두점[:graph:]단어문자, 숫자, 구두점\b단어문자의 경계.
6.6.2.1 .
임의의 한 요소(new line 제외).
str_view_all(txt2_v, ".") 일반문자 “e” 및 “e” 앞뒤 임의의 한 요소
str_view_all(txt2_v, ".e.")일반문자 “.”하나와 임의 요소 하나
str_view_all(txt2_v, "\\..") 일반문자“.” 두개가 포함된 문자열
str_view_all(txt2_v, "\\.\\.") 일반문자 “.” 한개가 포함된 문자열
str_view_all(txt2_v, "\\.") 6.6.2.2 \w [:alpha:] [:lower:] [:upper:]
글자 5개가 포함된 문자열
str_view_all(txt2_v, "\\w\\w\\w\\w\\w") 글자 2개가 포함된 문자열
str_view_all(txt2_v, "[:alpha:][:alpha:]")영문 소문자 한개
str_view_all(txt2_v, "[:lower:]")str_view_all(txt2_v, "[a-z]") str_view_all(txt2_v, "[:upper:]")str_view_all(txt2_v, "[A-Z]") 6.6.2.3 \d
숫자 하나
str_view_all(txt2_v, "\\d") str_view_all(txt2_v, "[:digit:]")str_view_all(txt2_v, "[0-9]") 임의의 숫자 하나 이외의 요소
str_view_all(txt2_v, "\\D") str_view_all(txt2_v, "[^0-9]") 임의의 문자 혹은 숫자 하나
str_view_all(txt2_v, "[:alnum:]") 일반문자 “다”와 임의의 문자 혹은 숫자
str_view_all(txt2_v, "다[:alnum:]") 6.6.2.4 [:punct:] [:graph:]
구두점(?, !, $ 등)이 포함된 문자열
str_view_all(txt2_v, "[:punct:]") txt2_v <- c(
"newline\n\n,tab\t\t,CR\r\r,FF\f\fVT\v\v,space space",
"abcABC가나다123구두점!@#%&*()_{}:;/?기타$^+<>`~",
"가지 aaaaapppP 8e.A pear... 123"
)
str_view_all(txt2_v, "[:graph:]")6.6.3 공백문자(whitespace)
\n줄바꿈(new line)\ttab\s아스키코드에 등록된 공백문자 6종(빈칸및\t\n\r\fv)\S공백문자가 아닌 요소
[:space:]=\s[:blank:]빈칸과\t- 아스키 공백문자 중
\n\r\f및v는 해당 안됨
- 아스키 공백문자 중
\t은 탭 하나
txt2_v <- c(
"newline\n\n,tab\t\t,CR\r\r,FF\f\fVT\v\v,space space",
"abcABC가나다123구두점!@#%&*()_{}:;/?기타$^+<>`~",
"가지 aaaaapppP 8e.A pear... 123"
)
str_view_all(txt2_v, "\t")\\s와 [:space:]는 공백문자(whitespace) 6종(space 및 \t\n\v\r\f) 문자 하나
str_view_all(txt2_v, "\\s") str_view_all(txt2_v, "[:space:]")[:blank:]는 공백문자(whitespace) 6종(space 및 \t\n\v\r\f) 중 space와 \t만 해당.
str_view_all(txt2_v, "[:blank:]") 6.6.4 또는
대괄호[ ]는 집합이나 범위 표시
|또는[ ]~중 하나(one of)[^ ]~만 제외(anything but) ** 대괄호 없는^는 문자열 요소의 첫부분[ - ]~부터 ~까지 범위(range)
모음 중 하나
txt2_v <- c(
"newline\n\n,tab\t\t,CR\r\r,FF\f\fVT\v\v,space space",
"abcABC가나다123구두점!@#%&*()_{}:;/?기타$^+<>`~",
"가지 aaaaapppP 8e.A pear... 123"
)
str_view_all(txt2_v, "[aeiou]") “abcABC가나다” 제외(anything but)
str_view_all(txt2_v, "[^abcABC가나다]") str_view_all(txt2_v, "[a-e]") # "a" 부터 "e" 까지6.6.5 묶음
( )소괄호 안은 하나의 요소
“ap” 또는 “e”와 그 다음의 “p”
c("apple", "eeeppp", "table") %>%
str_view_all("(ap|e)p")6.6.6 앵커
^문자열의 시작$문자열의 종료
가장 앞에 있는 “a”
txt2_v <- c(
"newline\n\n,tab\t\t,CR\r\r,FF\f\fVT\v\v,space space",
"abcABC가나다123구두점!@#%&*()_{}:;/?기타$^+<>`~",
"가지 aaaaapppP 8e.A pear... 123"
)
str_view_all(txt2_v, "^a")가장 뒤에 있는 “e”
str_view_all(txt2_v, "e$")문자열 내에서 특정 단어와 정확하게 일치하는 문자는 \\b 이용.
c("단어, 단어", "단어", "단어단어") %>%
str_view_all("\\b단어\\b")^와 $는 문자열 전체의 앞과 뒤를 지정
c("단어, 단어", "단어", "단어단어") %>%
str_view_all("^단어$")6.6.7 주변(look around)
(?= )이어지는(followed by)(?!= )이어지지 않는(not followed by)(?<= )선행하는(preceded by)(?<! )선행하지 않는(not preceded by)
뒤에 “P”가 있는 “a”
c("aaaPPP", "PPPaaa") %>%
str_view_all("a(?=P)")뒤에 “P”가 없는 “a”
c("aaaPPP", "PPPaaa") %>%
str_view_all("a(?!P)")앞에 “e”가 있는 “T”
c("eeeTTT", "TTTeee") %>%
str_view_all("(?<=e)T")앞에 “e”가 없는 “T”
c("eeeTTT", "TTTeee") %>%
str_view_all("(?<!e)T")6.6.8 반복일치
중괄호 { }는 횟수 혹은 범위
{n}선행요소가 n회( exactly n){n,}선행요소가 n회 또는 그 이상(n or more){n,m}선행요소가 n회와 m회 사이(between n and m)?선행요소가 0회 또는 1회(zero or one) ={0,1}*선행요소가 0회 또는 그 이상(zero or more) ={0,}+선행요소가 1회 또는 그 이상(one or more) ={1,}
qt_v <- "aaaaaa, taaaaaa, ta, ttttaaaaa, ttttt"“a”가 3개.
str_view_all(qt_v, "ta{3}") “a”가 2개 또는 그 이상
str_view_all(qt_v, "ta{2,}")“a”가 1회 또는 그 이상.
str_view_all(qt_v, "ta{1,}") str_view_all(qt_v, "ta+") “a”가 0회 또는 그 이상.
str_view_all(qt_v, "ta{0,}") str_view_all(qt_v, "ta*") “a”가 1회와 3회사이
str_view_all(qt_v, "ta{1,3}") “a”가 0회와 1회 사이
str_view_all(qt_v, "ta{0,1}")str_view_all(qt_v, "ta?")6.6.9 유용한 정규표현식
- 알파벳 대문자로 시작하는 글자 (반복기호
+(one or more) 사용)
str_view_all("You and I inFluence Him ~", "\\b[A-Z][a-z]+")- 한글자도 포함하려면 반복기호를
*(zero or more)로 변경
str_view_all("You and I inFluence Him ~", "\\b[A-Z][a-z]*")[:graph:]*연속하는 임의 숫자 문자 구두점
str_view_all("123-\nABadc-\t4567 가나다 I 가", "[:graph:]*")- 연속하는 문자와 숫자가 아닌 요소들
[^[:alnum:]]+
str_view_all("You influence me @@@ 123 ~~~ ^^ ㅋㅋㅋ ", "[^[:alnum:]]+" )//b[0-9]*$\\b숫자만.^[0-9]*&는 한
str_view_all("123-\nABadc234-\t4567 가나다", "\\b[0-9]*\\b")\\b[a-zA-Z]*\\b영문자만
str_view_all("123-\nABadc234-\t4567 가나다 abcd ABCD adGGG", "\\b[a-zA-Z]*\\b")\\b[가-힣]*\\b한글만
str_view_all("123-\nABadc234-\t4567 가나다 abcd ABCD adGGG", "\\b[가-힣]*\\b")\\b[a-zA-Z가-힣]*\\b영문자와 한글만
str_view_all("123-\nABadc234-\t4567 가나다 abcd ABCD adGGG", "\\b[a-zA-Z가-힣]*\\b")6.6.10 연습
- 정규표현식으로 주민등록번호를 표현하시오. 하이픈(“-”) 앞뒤로 숫자 6개만 지정하시오.
ssn_v <- c("900230-1234567, 901030-2234567",
"902230-3234567",
"901030-6234567, 901050-4234567")
str_view_all(ssn_v, "\\d{6}-\\d{7}") - 앞 6자리 중 3,4번째는 월, 5,6번째는 일이므로, 숫자의 범위가 월은 1부터 12까지로 일은 1부터 31까지로 정해져 있다. 월일의 범위를 지정한 정규표현식을 제시하시오.
str_view_all(ssn_v, "\\d{2}(0[1-9]|1[0-2])[0-3][0-9]-\\d{7}") .+@.+은@앞뒤로 임의 문자를 지정하므로 이메일에 표현이 될수 있다. 이를 조금 더 정교화해, 도메인의 종류(예: .com, .info)까지 지정한 이메일에 대한 정규표현식을 제시하시오.
email1_v <- c("apple@ddd.kr, tesla@sss.com, amazon@ttt.info, MS@x.com")
str_view_all(email1_v, "\\b[:graph:]*@[:graph:]*\\.[a-zA-Z]{2,4}\\b")- “무서”로 시작하는 문자열을 추출하시오.
mu_v <- c("두렵고 무서움", "무서운", "무서운 꿈에", "무서워서", "무리야")
mu_v %>% str_subset("^무서")## [1] "무서운" "무서운 꿈에" "무서워서"- “무서”로 시작하는 모든 단어를 추출하시오.
mu_v %>% str_extract("\\b무서\\w*\\b")## [1] "무서움" "무서운" "무서운" "무서워서" NA- “무서”가 포함된 문자열을 추출하시오.
mu_v %>% str_subset("무서")## [1] "두렵고 무서움" "무서운" "무서운 꿈에" "무서워서"- 영문에서 “나”를 표현하는 단어는 “I, my, me, mine”뿐 아니라, “I’ll, I’ve, I’d, myself” 등이 있다. “나”를 표현하는 단어를 모두 “ME”로 변환하시오.
tst_v <- c("I am, I, my, me, mine, I'll, I've, I'd, myself",
"i am, i, i'm, i've",
"interesting, INCH, mean, myopia")
str_view_all(tst_v, "(i|I)")str_view_all(tst_v, "^(i|I)")str_view_all(tst_v, "\\b(i|I)\\b")str_replace_all(tst_v, "\\b(i|I)\\b", "ME")## [1] "ME am, ME, my, me, mine, ME'll, ME've, ME'd, myself"
## [2] "ME am, ME, ME'm, ME've"
## [3] "interesting, INCH, mean, myopia"“I’m” 등을 “ME’m”이 아니라 “ME”가 되게 하자.
str_view_all(tst_v, "\\b(i|I)[:punct:][:alpha:]+\\b")가능한 패턴을 모두 만들어 저장하자.
meword_v <- c("\\b(i|I)\\b|\\bmy\\b|\\bme\\b|\\bmine\\b|\\b(i|I)[:punct:][:alpha:]+\\b|\\bmysel\\w+\\b")
str_view_all(tst_v, meword_v)정규표현식 패턴 \\b(i|I)[:punct:][:alpha:]+\\b을 단독으로 투입해면 “I’m” 등을 “ME’m”이 아니라 “ME”가 되게 하는데, 다른 정규표현식 패턴과 함께 투입하면, “ME’m”가 된다.
처리 순서 때문이다. \\b(i|I)\\b로 “I”와 “i”를 “ME”로 먼저 바꾸어 놓은 상태라 “I’m”등이 사라지게 된다. 따라서 순서를 바꿔 \\b(i|I)\\b를 뒤로 배치한다.
meword_v <- c("\\b(i|I)[:punct:][:alpha:]+\\b|\\bmysel\\w+\\b|\\b(i|I)\\b|\\bmy\\b|\\bme\\b|\\bmine\\b")
str_view_all(tst_v, meword_v)이제 모두 “나”와 관련된 단어를 “ME”로 바꾸자.
tst_v <- c("I am, I, my, me, mine, I'll, I've, I'd, myself",
"i am, i, i'm, i've",
"interesting, INCH, mean, myopia")
meword_v <- c("\\b(i|I)[:punct:][:alpha:]+\\b|\\bmysel\\w+\\b|\\b(i|I)\\b|\\bmy\\b|\\bme\\b|\\bmine\\b")
str_replace_all(tst_v, meword_v, "ME")## [1] "ME am, ME, ME, ME, ME, ME, ME, ME, ME"
## [2] "ME am, ME, ME, ME"
## [3] "interesting, INCH, mean, myopia"- 파일명 뒤의 4자리 숫자가 파일이 생성된 연도다. 정규표현식을 이용해 2001년 이후에 생성된 파일명만 추출하시오.
file_v <- c("file1999.txt", "file2000.txt", "file2001.txt", "file2002.txt",
"file2003.txt", "file2004.txt", "file2005.txt", "file2006.txt")
str_subset(file_v, "file[0-9]{3}[1-6]")## [1] "file2001.txt" "file2002.txt" "file2003.txt" "file2004.txt" "file2005.txt"
## [6] "file2006.txt"Cheat Sheet: https://www.rstudio.com/resources/cheatsheets/↩︎
Useful Regex Patterns: https://projects.lukehaas.me/regexhub/↩︎