Chapter 5 수집: 불러오기
자료는 존재에 대한 관찰의 기록이다. 현실을 기술하거나 나타내는 상징(숫자 문자 도형 등)으로서 인식의 첫 단계다. 수집한 원자료를 정제(1차 부호화)하면 자료가 생성된다. 자료에 의미를 부여하는 2차 부호화 단계를 통해 정보가 생성된다. 자료, 즉 데이터는 추상적인 개념이다. 데이터는 데이터셋(dataset)으로 구체화해 존재한다. 데이터셋은 바이너리파일(binary file) 형태나 일반텍스트(plain text) 파일 형태로 존재한다. 바이너리 파일이란 epub나 pdf처럼 텍스트 양식정보가 포함된 파일이다. 일반텍스트파일은 txt처럼 양식 정보 없이 텍스트 정보 자체만 있는 파일이다.
웹서버에 저장된 바이너리 파일은 download.file()함수로 다운로드 받은 후 불러오기 과정을 거쳐야 데이터를 정제 분석 등의 과정을 처리할 수 있다. 일반텍스트 파일은 read_lines()함수 등을 이용해 다운로드과정을 거치지 않고 직접 불러오기 할 수 있다.
(주: 이전 설명에서는 readLines()로 설명했었다. readr의 read_lines()이 더 효율적이므로 read_lines()를 사용하기로 한다. readr은 tidyverse가 실행되면 함께 부착되는 핵심 패키지 중 하나)
5.1 바이너리 파일
인터넷은 데이터셋의 보고다. 웹사이트에 접속해 수작업으로 다운로드 받을 수 있지만, 데이터셋의 위치(웹사이트 주소 및 파일 위치)를 정확하게 알고 있으면 download.file()과 같은 함수를 이용해 다운로드 받을 수 있다.
download.file()함수 사용법은 다음과 같다.
download.file(url, # 파일의 URL
destfile, # 다운로드 받을 파일의 경로와 이름
mode # 다운로드 받는 방식. 바이너리 파일인 경우 윈도에서는 "wb"로 지정.
)
download.file()함수를 이용해 파일 받기를 해보자. epub파일이 다음 URL에 위치하고 있다. 파일명을 jikji.epub로 지정해 다운로드 받아보자.
아래 코드는 dir.create()함수로 작업디렉토리 아래 “data”폴더를 만든 다음, data폴더에 jikji.epub파일을 저장한다.
dir.create("data")
file_url <- 'https://www.dropbox.com/s/ug3pi74dnxb66wj/jikji.epub?dl=1'
# 윈도에서 mode = "wb"추가 필요
download.file(url = file_url,
destfile = "data/jikji.epub",
mode="wb")list.files(path = "data", pattern = "epub")## [1] "bunn.epub" "jikji.epub" "moby.epub" "sense.epub"jikji.epub란 파일의 데이터셋이 컴퓨터 하드디스크의 작업디렉토리 아래에 있는 data폴더에 저장됐다.
5.1.1 불러오기(이입: import)
불러오기(import)는 PC나 서버의 하드디스크에 있는 파일의 내용을 R환경으로 불러오는 작업이다. 외부 하드디스크에서 R환경 안으로 읽어 들이므로 import(불러오기 또는 이입)라고 한다. 반대로 R환경 내부의 자료를 하드디스크로 내보내는 작업을 내보내기(export: 이출)라고 한다.
EPUB(electronic publication)는 국제디지털포럼에서 제정한 개방형 전자서적 표준이다. 다양한 epub리더가 있는데, R에서는 epubr패키지의 epub()함수를 이용해 불러오기를 할 수 있다.
작업디렉토리 아래 data폴더에 있는jikji.epub파일을 epub()함수로 R환경 안으로 불러오자. 결과를 str()함수와 glimpse()함수로 결과를 비교해 보자.
install.packages("epubr")library(tidyverse)## -- Attaching packages --------------------------------------- tidyverse 1.3.0 --## v ggplot2 3.3.2 v purrr 0.3.4
## v tibble 3.0.4 v dplyr 1.0.2
## v tidyr 1.1.2 v stringr 1.4.0
## v readr 1.4.0 v forcats 0.5.0## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()library(epubr)
jikji_df <- epub("data/jikji.epub")
jikji_df %>% str()## tibble [1 x 8] (S3: tbl_df/tbl/data.frame)
## $ identifier: chr "urn:uuid:15037ed1-7721-4f33-8534-f6a7473ab654"
## $ title : chr "직지 프로젝트"
## $ creator : chr "수학방"
## $ language : chr "ko"
## $ date : chr "2013-05-10"
## $ rights : chr "크리에이티브 커먼즈 저작자표시-비영리-동일조건변경허락 2.0 대한민국"
## $ source : chr "직지프로젝트(http://www.jikji.org)"
## $ data :List of 1
## ..$ : tibble [93 x 4] (S3: tbl_df/tbl/data.frame)
## .. ..$ section: chr [1:93] "x2.xhtml" "x3.xhtml" "x4.xhtml" "x5.xhtml" ...
## .. ..$ text : Named chr [1:93] "17원 50전(十七圓五十錢)--- 젋은 화가 A의 눈물 한 방울\n\n 지은이: 나도향\n\n 출전: 개벽, <1923>\n\n 공개"| __truncated__ "B사감(舍監)과 러브레터\n\n 지은이: 현진건\n\n 출전: 조선문단 5호 <1925>\n 본문\n\n 여학교에서 교원 겸 기"| __truncated__ "경희(瓊姬)\n\n 지은이: 나혜석\n\n 출판사: 여자계1\n\n 찍은해: 1918년 3월\n\n 전산화: 1999? ~\n\n "| __truncated__ "계집 하인\n\n 지은이: 나도향\n\n 출전: 조선 문단 5월호 <1925>\n\n 공개되어 있는 내용이 없어 2009.9.22일 "| __truncated__ ...
## .. .. ..- attr(*, "names")= chr [1:93] "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/2.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/3.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/4.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/5.xhtml" ...
## .. ..$ nword : Named int [1:93] 126 11 23 7 26 12 13 15 26 36 ...
## .. .. ..- attr(*, "names")= chr [1:93] "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/2.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/3.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/4.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/5.xhtml" ...
## .. ..$ nchar : Named int [1:93] 18422 5524 27801 8784 5843 9983 16631 86078 10953 12732 ...
## .. .. ..- attr(*, "names")= chr [1:93] "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/2.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/3.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/4.xhtml" "C:/Users/Public/Documents/ESTsoft/CreatorTemp/RtmpqaKukU/jikji/OEBPS/Text/5.xhtml" ...jikji_df %>% glimpse()## Rows: 1
## Columns: 8
## $ identifier <chr> "urn:uuid:15037ed1-7721-4f33-8534-f6a7473ab654"
## $ title <chr> "직지 프로젝트"
## $ creator <chr> "수학방"
## $ language <chr> "ko"
## $ date <chr> "2013-05-10"
## $ rights <chr> "크리에이티브 커먼즈 저작자표시-비영리-동일조건변경허락 2.0 대한민국"
## $ source <chr> "직지프로젝트(http://www.jikji.org)"
## $ data <list> [<tbl_df[93 x 4]>]R기본함수인 str()함수와 tidyverse에 부착된 dplyr패키지의 glimpse()함수는 둘 다 객체의 구조를 제시하지만, str()함수는 자세하게, glimpse()는 간결하게 보여준다.
epub파일에는 메타데이터와 텍스트데이터가 함께 저장돼 있다. title, source 등의 열에 EPUB문서의 메타데이터가 있다. 다운로드 받은 파일의 메타데이터를 보면 수학방에서 직지프로젝트로 한글소설 93편을 모아 전자서적으로 만든 파일이란 것을 알수 있다. 텍스트데이터는 data열에 리스트로 저장돼 있다. 리스트 구조의 첫번째 요소이므로 [[ ]]를 이용해 부분선택할 수 있다.
df <- jikji_df$data[[1]]
df %>% glimpse()## Rows: 93
## Columns: 4
## $ section <chr> "x2.xhtml", "x3.xhtml", "x4.xhtml", "x5.xhtml", "x6.xhtml",...
## $ text <chr> "17원 50전(十七圓五十錢)--- 젋은 화가 A의 눈물 한 방울\n\n 지은이: 나도향\n\n 출...
## $ nword <int> 126, 11, 23, 7, 26, 12, 13, 15, 26, 36, 6, 24, 10, 133, 10,...
## $ nchar <int> 18422, 5524, 27801, 8784, 5843, 9983, 16631, 86078, 10953, ...93행 4열의 데이터프레임이고 text열에 소설 본문이 있다. 첫번째 소설을 부분선택해 보자.
tibble(text = df$text[1]) ## # A tibble: 1 x 1
## text
## <chr>
## 1 "17원 50전(十七圓五十錢)--- 젋은 화가 A의 눈물 한 방울\n\n 지은이: 나도향\n\n 출전: 개벽, <1923>\n\n ~첫번째 소설은 나도향의 “17월 50전”이다. 이 소설에서 사용한 단어의 빈도를 분석해 시각화해보자.
library(tidytext)
library(ggplot2)
tibble(text = df$text[1]) %>%
unnest_tokens(output = word, input = text) %>%
count(word, sort = T) %>%
filter(n >=20) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n)) +
coord_flip()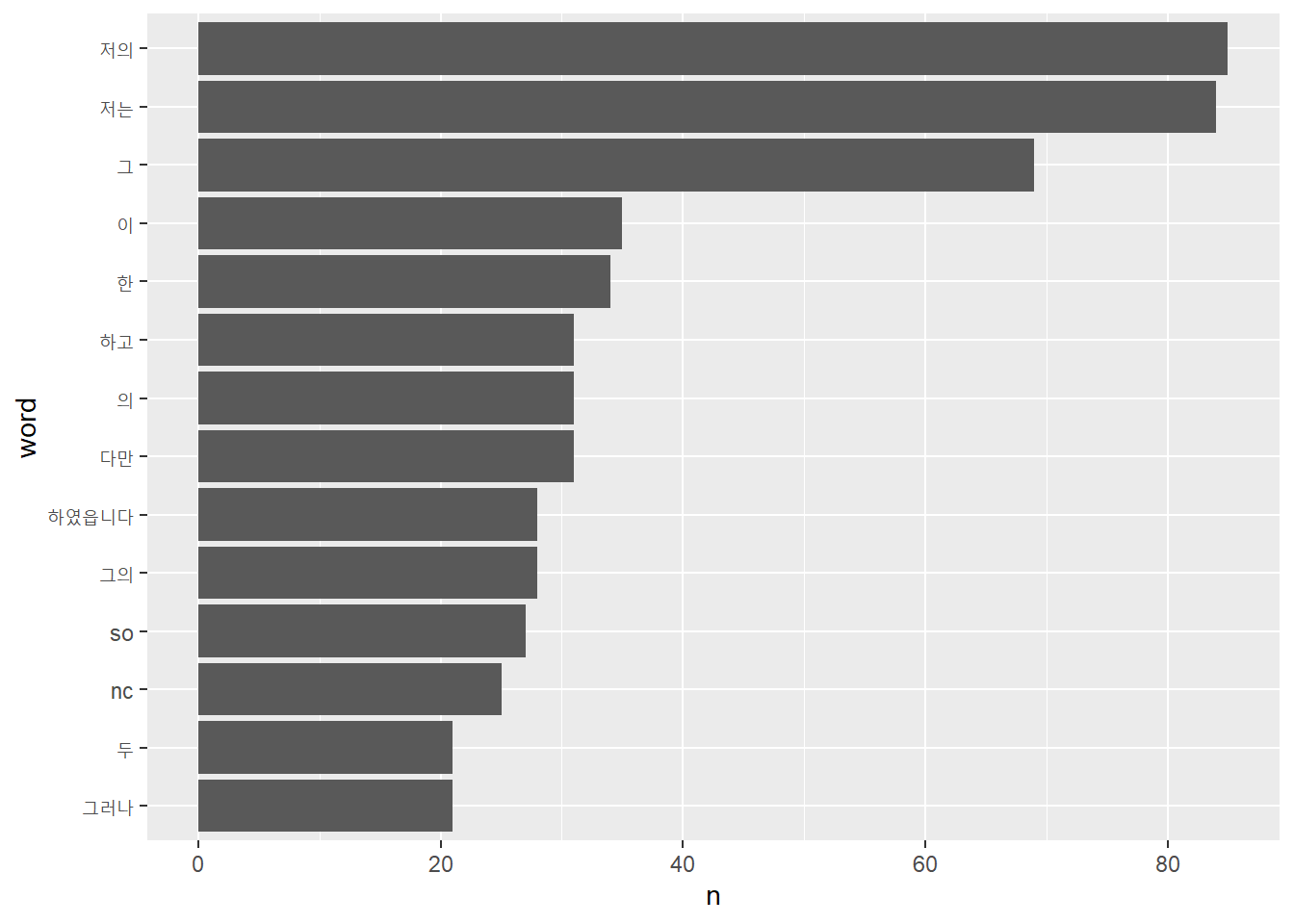
“저의 저는 그 이” 등의 단어가 많이 사용됐다. 분석 전에 정제를 충분하기 않아 의미를 파악하기 어렵다. 데이터 정제방법은 추후 자세하게 다룬다.
5.2 일반텍스트(plain text) 파일
서버에 일반텍스트파일(txt)로 저장돼 있으면 다운로드 과정을 거치지 않고, 직접 불러오기를 할 수 있다.
프로젝트 구텐베르크는 인류가 생성한 정보를 디지털로 저장하고 배포하는 프로젝트다. 자원봉사자들이 문자와 음성을 디지털로 올리고 있다. 대부분 영어권의 문학작품이다.
프로젝트 구텐베르크는 일반텍스트, HTML, epub, 음성 등 다양한 형식으로 제공하고 있다 (Figure ??).
(#fig:data8, gutenberg)프로젝트 구텐베르크의 모비딕
프로젝트 구텐베르크에서 일반텍스트파일로 저장된 멜빌의 <모비딕>을 불러오자. 일반텍스트 파일은 read_lines()함수를 이용한다.
(readr패키지의 read_lines()함수의 내용은 readr 문서 참조)
moby_url <- 'https://www.gutenberg.org/files/2701/2701-0.txt'
moby_v <- read_lines(moby_url)moby_v %>% glimpse()
moby_v %>% head(3)
moby_v %>% tail(3)일반텍스트 파일은 scan()함수를 통해서도 읽을 수 있다. scan함수에는 인자를 데이터의 유형what =(이 경우에는 “character”)과 구분자sep =를 지정해야 한다. 기본값은 공백이다. sep =인자에 값을 지정하지 않으면 띄어쓰기를 기준으로 구분해서 읽어온다.
moby_scan <- scan(moby_url, what = "character")moby_scan %>% head()만일, 행을 구분하여 읽어 오려면 구분자를 개행(new line) 공백문자인 \n으로 지정한다.
moby_scan_n <- scan(moby_url, what = "character", sep= "\n")moby_scan_n %>% head()함수의 자세한 사용법은 ?함수명으로 도움말을 이용하자.
scan()함수는 문자형 문서 뿐아니라, 숫자형, 논리형 문서도 읽어 올수 있다. 반면, read_lines()함수는 문자형 데이터만 읽어 올수 있다.
5.3 HTML 파일
HTML(HyperText Markup Language)문서는 웹브라우저를 이용해 열람할 수 있도록 한 형식의 문서다. HTML은 웹페이지를 만드는 언어로서 풀어쓰면 초본문(HyperText) 표식달기(Markup) 언어(Language)다. R이나 자바와 같은 프로그래밍언어가 아니라 마크업언어다. 본문(text)에 표식(Mark)을 달아(up) 문서의 구조와 내용을 지정한다.
일반적인 문서는 순차적으로 연결돼 있지만, 초본문(HypterText)은 본문과 본문이 마크업(링크 또는 하이퍼링크(hyperlink))을 통해 비순차적으로 연결돼 있다. 순차적인 연결을 뛰어넘는(초월한 Hyper) 문서이므로 초본문이라고 한다.
HTLM문서는 tidytverse패키지와 함께 설치되는 rvest패키지에서 제공하는 read_html()함수 등을 이용해 내용을 추출할 수 있다. rvest패키지는 tidytverse와 함께 설치돼도 부착되지는 않기 때문에 library()함수로 R환경에 탑재해야 한다.
rvest패키지의 함수는 3종류로 구분할 수 있다. (자세한 내용은 다음 장에서 다룬다.)
- HTML문서 불러오기
read_html()
- HTML문서에서 HTML요소 추출
html_node()html_nodes()
- HTML요소에서 내용 혹은 속성의 값 추출
html_text()html_table()html_attr()html_attrs()
5.3.1 HTML문서 불러오기 read_html()
프로젝트 구텐베르크에서 HTML형식으로 된 <모비딕>을 불러오자.
library(rvest)
moby_url_h <- 'https://www.gutenberg.org/files/2701/2701-h/2701-h.htm'moby_html <- read_html(moby_url_h)
moby_html여러 HTML 요소(element)가 포함된 HTML문서가 산출된다. <head>와 <body> 등의 태그(tag)가 보인다. 이처럼 HTML문서는 태그(tag)로 문서의 내용이 마크업돼 있다.
5.3.2 HTLM요소 추출하기 html_node()
html_node()함수를 이용해 <body>섹션 안의 HTML요소들을 추출하자.
moby_html %>% html_node("body")5.3.3 내용 추출하기 html_text
html_text()함수를 이용해 본문을 추출하자.
moby_html %>% html_node("body") %>% html_text()read_html() -> html_node() -> html_text()의 순서는 HTML문서 불러오기의 기본 구조이므로 잘 기억해두자. 다음 장에서 보다 자세하게 다룬다.
5.4 내보내기(export: 이출)
R환경 내의 객체는 메모리에 올려져 있기 때문에, R세션이 종료되면 함께 사라진다. 추후 사용하기 위해서는 하드디스크에 저장해 둬야 한다.
R은 기본값(default)으로 R환경 내의 객체를 이미지로 저장한다. 기본값으로 저장된 이미지는 .RData 파일에 저장돼 있다. (2.8.2 R환경내 객체를 다루는 함수 참조)
특정 객체를 저장하기 위해서는 데이터구조에 따라 접근이 다르다. 문자형데이터는 readr패키지의 write_lines()함수를 이용한다.
(주: 이전 설명에서는 writeLines()로 설명했었다. write_lines()이 더 효율적이므로 write_lines()를 사용하기로 한다.)
- write_lines(x, file, sep = “” na = “NA,” append = FALSE, path = deprecated())
아래 코드를 실행하면 작업디렉토리 아래의 data폴더가 생성되고, 그 안에 ogamdo.txt파일이 생성된다.
ogamdo_txt <- "13인의 아해가 도로로 질주하오.
(길은 막다른 골목이 적당하오.)
제1의 아해가 무섭다고 그리오.
제2의 아해도 무섭다고 그리오.
제3의 아해도 무섭다고 그리오.
제4의 아해도 무섭다고 그리오.
제5의 아해도 무섭다고 그리오.
제6의 아해도 무섭다고 그리오.
제7의 아해도 무섭다고 그리오.
제8의 아해도 무섭다고 그리오.
제9의 아해도 무섭다고 그리오.
제10의 아해도 무섭다고 그리오.
제11의 아해가 무섭다고 그리오.
제12의 아해도 무섭다고 그리오.
제13의 아해도 무섭다고 그리오.
13인의 아해는 무서운 아해와 무서워하는 아해와 그렇게뿐이 모였소.(다른 사정은 없는 것이 차라리 나았소)
그중에 1인의 아해가 무서운 아해라도 좋소.
그중에 2인의 아해가 무서운 아해라도 좋소.
그중에 2인의 아해가 무서워하는 아해라도 좋소.
그중에 1인의 아해가 무서워하는 아해라도 좋소.
(길은 뚫린 골목이라도 적당하오.)
13인의 아해가 도로로 질주하지 아니하여도 좋소."
# dir.create("data")
ogamdo_txt %>% write_lines("data/ogamdo.txt")파일이 생성돼 있는지 획인해보자.
list.files(path = "data",
pattern = "ogamdo")## [1] "ogamdo.txt" "ogamdo2.txt"파일을 만들었으면, read_lines()함수로 읽어 보자.
read_lines("data/ogamdo.txt")## [1] "13인의 아해가 도로로 질주하오."
## [2] "(길은 막다른 골목이 적당하오.)"
## [3] ""
## [4] "제1의 아해가 무섭다고 그리오."
## [5] "제2의 아해도 무섭다고 그리오."
## [6] "제3의 아해도 무섭다고 그리오."
## [7] "제4의 아해도 무섭다고 그리오."
## [8] "제5의 아해도 무섭다고 그리오."
## [9] "제6의 아해도 무섭다고 그리오."
## [10] "제7의 아해도 무섭다고 그리오."
## [11] "제8의 아해도 무섭다고 그리오."
## [12] "제9의 아해도 무섭다고 그리오."
## [13] "제10의 아해도 무섭다고 그리오."
## [14] "제11의 아해가 무섭다고 그리오."
## [15] "제12의 아해도 무섭다고 그리오."
## [16] "제13의 아해도 무섭다고 그리오."
## [17] "13인의 아해는 무서운 아해와 무서워하는 아해와 그렇게뿐이 모였소.(다른 사정은 없는 것이 차라리 나았소)"
## [18] ""
## [19] "그중에 1인의 아해가 무서운 아해라도 좋소."
## [20] "그중에 2인의 아해가 무서운 아해라도 좋소."
## [21] "그중에 2인의 아해가 무서워하는 아해라도 좋소."
## [22] "그중에 1인의 아해가 무서워하는 아해라도 좋소."
## [23] ""
## [24] "(길은 뚫린 골목이라도 적당하오.)"
## [25] "13인의 아해가 도로로 질주하지 아니하여도 좋소."문자가 깨진다. 컴퓨터에 설정된 문자 인코딩과 R환경에 설정된 문자 인코딩이 맞지 않기 때문이다.
5.5 인코딩(encoding: 부호화)
컴퓨터는 0과 1의 디지털로 데이터를 처리하기 때문에 인간의 언어를 컴퓨터가 처리할 수 있도록 하기 위해서는 개별 문자(character)에 대해 각각 이진부호를 부여한다. 디지털로 부호화(encoding)해 인간의 언어를 컴퓨터가 이해할 수 있도록 하는 것이다.
대표적인 사례가 아스키(ASCII: American Starndard Code for Information Interchange, 미국정보교환표준부호)다. 알파벳, 숫자, 자주 사용하는 특수문자 등 128개에 0부터 127까지 값을 부여했다. 예를 들어, A에는 65(이진법: 1000001), 0에는 48(이진법: 0110000)을 부여했다.
인간이 사용하는 문자는 128개를 훨씬 뛰어넘기 때문에, ASCII를 확장해 다양한 문자 인코딩(character encoding)을 이용하고 있다. 한글문자는 두가지 인코딩이 쓰인다. UTF-8과 CP-949다. UTF-8은 “ㄱ ㄴ ㅏ ㅑ” 등 각 자모에 코드를 부여한 조합형 인코딩이다. CP-949는 “가 불 힣” 등 완성된 한글문자 11,720개에 코드를 부여한 확장 인코딩이다. 당초 한글 완성형 인코딩으로 쓰이던 EUC-KR다. EUC-KR은 한글 문자 2,350개에만 코드를 부여해 한글표현이 부족하기 때문에 마이크로소프트는 이를 확장한 CP-949를 사용하고 있다.
운영체제 혹은 웹페이지마다 사용하는 인코딩이 다르다. 마이크로소프트는 CP-949를 사용하는 반면, 애플은 UTF-8을 사용한다. 대다수의 웹페이지는 UTF-8을 이용한다. 국내 웹페이지 중에는 EUC-KR을 사용하는 경우도 있다.
언어권별로 고유의 인코딩을 사용한다.인코딩이 맞지 않는다면, 문자가 깨져 읽을 수 없다. 한국의 한글, 일본의 가나, 중국의 한자와 같은 문자는 멀티바이트 문자인데, 영어권에서 개발한 프로그램이 멀티바이트문자 인코딩을 지원하지 않아 한글, 가나, 한자 등의 깨치는 경우가 드물지 않게 생긴다.
인코딩이 맞지 않아 문자가 깨진다면 readr패키지의 guess_encoding()함수를 이용해 인코딩이 무엇인지 확인할 수 있다. readr패키지는 tidyverse패키지에 부착돼 있으므로, tidyverse패키지를 실행한다.
library(tidyverse)
guess_encoding("data/ogamdo.txt") ## # A tibble: 1 x 2
## encoding confidence
## <chr> <dbl>
## 1 UTF-8 1다양한 인코딩 가능성을 제시됐다. 만일 특정 인코딩에 대한 확신이 높다면, 그 인코딩을 선택한다. 인코딩은 iconv()나 enc2utf8()함수로 변경할 수 있다.
iconv(x, from = "", to = "", sub = NA, mark = TRUE, toRaw = FALSE)enc2utf8(x)
read_lines("data/ogamdo.txt") %>% iconv("utf-8")## [1] "13인의 아해가 도로로 질주하오."
## [2] "(길은 막다른 골목이 적당하오.)"
## [3] ""
## [4] "제1의 아해가 무섭다고 그리오."
## [5] "제2의 아해도 무섭다고 그리오."
## [6] "제3의 아해도 무섭다고 그리오."
## [7] "제4의 아해도 무섭다고 그리오."
## [8] "제5의 아해도 무섭다고 그리오."
## [9] "제6의 아해도 무섭다고 그리오."
## [10] "제7의 아해도 무섭다고 그리오."
## [11] "제8의 아해도 무섭다고 그리오."
## [12] "제9의 아해도 무섭다고 그리오."
## [13] "제10의 아해도 무섭다고 그리오."
## [14] "제11의 아해가 무섭다고 그리오."
## [15] "제12의 아해도 무섭다고 그리오."
## [16] "제13의 아해도 무섭다고 그리오."
## [17] "13인의 아해는 무서운 아해와 무서워하는 아해와 그렇게뿐이 모였소.(다른 사정은 없는 것이 차라리 나았소)"
## [18] ""
## [19] "그중에 1인의 아해가 무서운 아해라도 좋소."
## [20] "그중에 2인의 아해가 무서운 아해라도 좋소."
## [21] "그중에 2인의 아해가 무서워하는 아해라도 좋소."
## [22] "그중에 1인의 아해가 무서워하는 아해라도 좋소."
## [23] ""
## [24] "(길은 뚫린 골목이라도 적당하오.)"
## [25] "13인의 아해가 도로로 질주하지 아니하여도 좋소."가장 많이 사용하는 인코딩이 UTF-8이므로 R스튜디오의 인코딩 기본값(Defalt text encoding)을 UTF-8로 설정하면 편리하다.
R Studio(1.4)의 상단 메뉴 [Tools]를 클릭하면 열리는 풀다운메뉴에서 [Global Options] 선택하면 창이 새로 열린다. [Code] 선택하고 [Saving] 탭 클릭하면 인코딩 기본값(Defalt text encoding)을 지정할 수 있는 창이 열린다.
이 방법이 안되면 R Studio 상단 메뉴 [File]을 클릭하면 열리는 풀다운 메뉴에서 [Reopen with Encoding ]를 클릭하면 창(Choose Encoding)이 열린다. [UTF-8] 선택 후 [Set as default encoding for source files] 옆 박스에 체크 후 [OK]버튼을 클릭한다.
5.6 테이블구조 문서
테이블 구조 문서는 자료의 값이 행과 열에 저장돼 있는 문서다.
CSV(comma-separated value): 파일 안의 값들이 콤마
,로 구분된 테이블 형식.read_csv()TSV(tab-separated value): 파일 안의 값들이 탭
으로 구분된 테이블 형식.read_tsv()FWF(fixed width format): 파일 안의 값들이 고정된 간격으로 구분된 테이블 형식.
파일 형식에 따라 불러오기에 사용하는 함수가 다르다. csv파일은 tidyverse패키지에 부착되는 readr패키지의 read_csv()함수를 이용한다. R기본함수로 제공되는 read.csv()보다 처리속도가 빠르고 재현성이 좋다.
readr패키지 `사용설명서
테이블구조 문서와 일반텍스트 문서의 차이를 살펴보자. 먼저, 테이블형식의 파일 tibble.csv을 생성해 하드디스크에 저장하자. 파일의 내용은 앞서 만든 벡터 ogamdo_txt를 데이터프레임으로 만들어 이용하자.
df <- tibble(text = ogamdo_txt)
df## # A tibble: 1 x 1
## text
## <chr>
## 1 "13인의 아해가 도로로 질주하오.\n(길은 막다른 골목이 적당하오.)\n\n제1의 아해가 무섭다고 그리오.\n제2의 아해도 무섭다고 그리~# 생성된 데이터프레임 파일로 저장
write_csv(df, "tibble.csv")
# 생성된 파일 표시
list.files(pattern = "tibble")## [1] "tibble.csv" "tibble.txt"생성된 파일을 readLines()와 read_csv()함수로 읽어 들여 결과를 비교해 보자.
먼저 readLines()
readLines("tibble.csv")## [1] "text"
## [2] "\"13\xec씤\xec쓽 \xec븘\xed빐媛\u0080 \xeb룄濡쒕줈 吏덉<\xed븯\xec삤."
## [3] "(湲몄\x9d\u0080 留됰떎瑜\xb8 怨⑤ぉ\xec씠 \xec쟻\xeb떦\xed븯\xec삤.)"
## [4] ""
## [5] "\xec젣1\xec쓽 \xec븘\xed빐媛\u0080 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [6] "\xec젣2\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [7] "\xec젣3\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [8] "\xec젣4\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [9] "\xec젣5\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [10] "\xec젣6\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [11] "\xec젣7\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [12] "\xec젣8\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [13] "\xec젣9\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [14] "\xec젣10\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [15] "\xec젣11\xec쓽 \xec븘\xed빐媛\u0080 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [16] "\xec젣12\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [17] "\xec젣13\xec쓽 \xec븘\xed빐\xeb룄 臾댁꽠\xeb떎怨\xa0 洹몃━\xec삤."
## [18] "13\xec씤\xec쓽 \xec븘\xed빐\xeb뒗 臾댁꽌\xec슫 \xec븘\xed빐\xec\x99\u0080 臾댁꽌\xec썙\xed븯\xeb뒗 \xec븘\xed빐\xec\x99\u0080 洹몃젃寃뚮퓧\xec씠 紐⑥\x98\u0080\xec냼.(\xeb떎瑜\xb8 \xec궗\xec젙\xec\x9d\u0080 \xec뾾\xeb뒗 寃껋씠 李⑤씪由\xac \xeb굹\xec븯\xec냼)"
## [19] ""
## [20] "洹몄쨷\xec뿉 1\xec씤\xec쓽 \xec븘\xed빐媛\u0080 臾댁꽌\xec슫 \xec븘\xed빐\xeb씪\xeb룄 醫뗭냼."
## [21] "洹몄쨷\xec뿉 2\xec씤\xec쓽 \xec븘\xed빐媛\u0080 臾댁꽌\xec슫 \xec븘\xed빐\xeb씪\xeb룄 醫뗭냼."
## [22] "洹몄쨷\xec뿉 2\xec씤\xec쓽 \xec븘\xed빐媛\u0080 臾댁꽌\xec썙\xed븯\xeb뒗 \xec븘\xed빐\xeb씪\xeb룄 醫뗭냼."
## [23] "洹몄쨷\xec뿉 1\xec씤\xec쓽 \xec븘\xed빐媛\u0080 臾댁꽌\xec썙\xed븯\xeb뒗 \xec븘\xed빐\xeb씪\xeb룄 醫뗭냼."
## [24] ""
## [25] "(湲몄\x9d\u0080 \xeb슟由\xb0 怨⑤ぉ\xec씠\xeb씪\xeb룄 \xec쟻\xeb떦\xed븯\xec삤.)"
## [26] "13\xec씤\xec쓽 \xec븘\xed빐媛\u0080 \xeb룄濡쒕줈 吏덉<\xed븯吏\u0080 \xec븘\xeb땲\xed븯\xec뿬\xeb룄 醫뗭냼.\""문자가 깨진 것은 인코딩이 맞지 않기 때문이다. guess_encoding()함수를 이요해 인코딩을 확인하자.
guess_encoding("tibble.csv")## # A tibble: 1 x 2
## encoding confidence
## <chr> <dbl>
## 1 UTF-8 1readLines("tibble.csv", encoding = "UTF-8")## [1] "text"
## [2] "\"13인의 아해가 도로로 질주하오."
## [3] "(길은 막다른 골목이 적당하오.)"
## [4] ""
## [5] "제1의 아해가 무섭다고 그리오."
## [6] "제2의 아해도 무섭다고 그리오."
## [7] "제3의 아해도 무섭다고 그리오."
## [8] "제4의 아해도 무섭다고 그리오."
## [9] "제5의 아해도 무섭다고 그리오."
## [10] "제6의 아해도 무섭다고 그리오."
## [11] "제7의 아해도 무섭다고 그리오."
## [12] "제8의 아해도 무섭다고 그리오."
## [13] "제9의 아해도 무섭다고 그리오."
## [14] "제10의 아해도 무섭다고 그리오."
## [15] "제11의 아해가 무섭다고 그리오."
## [16] "제12의 아해도 무섭다고 그리오."
## [17] "제13의 아해도 무섭다고 그리오."
## [18] "13인의 아해는 무서운 아해와 무서워하는 아해와 그렇게뿐이 모였소.(다른 사정은 없는 것이 차라리 나았소)"
## [19] ""
## [20] "그중에 1인의 아해가 무서운 아해라도 좋소."
## [21] "그중에 2인의 아해가 무서운 아해라도 좋소."
## [22] "그중에 2인의 아해가 무서워하는 아해라도 좋소."
## [23] "그중에 1인의 아해가 무서워하는 아해라도 좋소."
## [24] ""
## [25] "(길은 뚫린 골목이라도 적당하오.)"
## [26] "13인의 아해가 도로로 질주하지 아니하여도 좋소.\""열의 이름 “text”가 본문의 일부로 산출된다.
이제 read_csv()함수로 읽어보자.
read_csv("tibble.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## text = col_character()
## )## # A tibble: 1 x 1
## text
## <chr>
## 1 "13인의 아해가 도로로 질주하오.\n(길은 막다른 골목이 적당하오.)\n\n제1의 아해가 무섭다고 그리오.\n제2의 아해도 무섭다고 그리~1행 1열의 데이터프레임 형식으로 산출됐다. 열의 이름이 “text”로 잡혀 있고, 열에는 문자벡터가 들어 있다.
데이터의 유형이 벡터인지, 데이터프레임인지 등 사용한 함수가 산출해주는 데이터 구조가 무엇인지 잘 기억해 두자. 데이터의 유형은 class()함수, str()함수, 혹은 glimpse()함수로 확인할 수 있다. 객체이름을 정할 때 _와 함께 객체의 구조를 포함하면 이후 작업할 때 혼란을 피할 수 있을 뿐 아니라, 다른 함수 이름과 중복되는 일을 피할 수 있다.(2.6. 코딩스타일 참조)
read_csv("tibble.csv") %>% class()##
## -- Column specification --------------------------------------------------------
## cols(
## text = col_character()
## )## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"read_csv("tibble.csv") %>% str()##
## -- Column specification --------------------------------------------------------
## cols(
## text = col_character()
## )## tibble [1 x 1] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ text: chr "13인의 아해가 도로로 질주하오.\n(길은 막다른 골목이 적당하오.)\n\n제1의 아해가 무섭다고 그리오.\n제2의 아해도 "| __truncated__
## - attr(*, "spec")=
## .. cols(
## .. text = col_character()
## .. )library(tidyverse)
read_csv("tibble.csv") %>% glimpse()##
## -- Column specification --------------------------------------------------------
## cols(
## text = col_character()
## )## Rows: 1
## Columns: 1
## $ text <chr> "13인의 아해가 도로로 질주하오.\n(길은 막다른 골목이 적당하오.)\n\n제1의 아해가 무섭다고 그리오.\n...5.7 기타 파일 형식
R기본함수외에 불러오기와 내보내기을 지원하는 다양한 패키지가 있다. 대표적인 패키지가 rio다. 스위스 나이프처럼 불러오기와 내보내기에 필요한 대부분의 함수를 제공한다. 정돈된 세계tidyverse에서도 다양한 패키지를 제공한다. 여기서는 정돈된 세계의 원리를 따르기 때문에 tidyverse패키지에 포함된 패키지를 이용한다.
아래 4개 패키지는 tidyverse패키지와 함께 설치되지만, 이용하기 위해서는 library()함수로 따로 실행해야 한다.
readxlxls ghrdms xlsx 파일 불러오기havenSPSS, SAS, STATA 파일 불러오기jasonliteJSON형식 파일 불러오기xml2XML 형식 파일 불러오기
이외에 tidyverse에서 제공하지 않는 파일형식은 패키지는 따로 설치해야 한다.
5.8 연습
프로젝트 구텐베르크에서 허먼 멜빌(Herman Melville)의 <모비딕>(Moby dick)과 제인 오스틴(Jane Austin)의 <감성과 감수성>(Sense and Sensitiviy)를 다운로드 받아, <모비딕>과 <감성과 감수성>의 내용을 비교해보자.
- URL
moby_url <- 'https://www.gutenberg.org/ebooks/2701.epub.noimages'
download.file(url = moby_url,
destfile = "data/moby.epub",
mode="wb")
sense_url <- 'https://www.gutenberg.org/ebooks/161.epub.noimages'
download.file(url = sense_url,
destfile = "data/sense.epub",
mode="wb")list.files(path = "data", pattern = "epub")## [1] "bunn.epub" "jikji.epub" "moby.epub" "sense.epub"epub("data/moby.epub") %>% glimpse()## Rows: 1
## Columns: 9
## $ rights <chr> "Public domain in the USA."
## $ identifier <chr> "http://www.gutenberg.org/2701"
## $ creator <chr> "Herman Melville"
## $ title <chr> "Moby Dick; Or, The Whale"
## $ language <chr> "en"
## $ subject <chr> "Whaling -- Fiction"
## $ date <chr> "2001-07-01"
## $ source <chr> "https://www.gutenberg.org/files/2701/2701-h/2701-h.htm"
## $ data <list> [<tbl_df[26 x 4]>]“title,” `source" 등의 열은 EPUB문서의 메타데이터이다. 메타데이터를 보면 프로젝트 구텐베르크로 만든 멜빌의 <모비딕>이란 것을 알수 있다. “data”열에 리스트로 저장된 소설 데이터를 부분선택하자.
epub("data/moby.epub")$data[[1]] %>% glimpse()## Rows: 26
## Columns: 4
## $ section <chr> "item5", "item6", "item7", "item8", "item9", "item10", "ite...
## $ text <chr> "The Project Gutenberg eBook of Moby-Dick; or The Whale, by...
## $ nword <int> 4465, 9400, 8639, 12185, 7717, 8449, 9397, 7971, 8133, 1091...
## $ nchar <int> 27068, 52039, 48661, 68556, 43338, 48592, 54367, 45748, 475...26행 4열의 데이터프레임이고 text열에 소설 본문이 있다. EPUB문서에 공통적으로 적용되는 형식이다.
<모비딕>과 <감성과 감수성>에서 사용한 단어의 빈도를 시각화해보자.
moby_v <- epub("data/moby.epub")$data[[1]]$text
sense_v <- epub("data/sense.epub")$data[[1]]$text
tibble(text = moby_v) %>%
unnest_tokens(output = word, input = text) %>%
count(word, sort = T) %>%
filter(n >=30) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n)) +
coord_flip() +
theme_minimal()
tibble(text = sense_v) %>%
unnest_tokens(output = word, input = text) %>%
count(word, sort = T) %>%
filter(n >=30) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n)) +
coord_flip() +
theme_classic()
사용빈도를 상위 12개 어휘로 국한해 보자. slice_max()함수를 이용한다.
(top_n()함수는 dplyr()패키지에서 사용중지 예정.)
moby_v <- epub("data/moby.epub")$data[[1]]$text
tibble(text = moby_v) %>%
unnest_tokens(output = word, input = text) %>%
count(word, sort = T) %>%
slice_max(n, n = 12) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n)) +
coord_flip() +
labs(title = "Moby Dick") +
theme_bw() 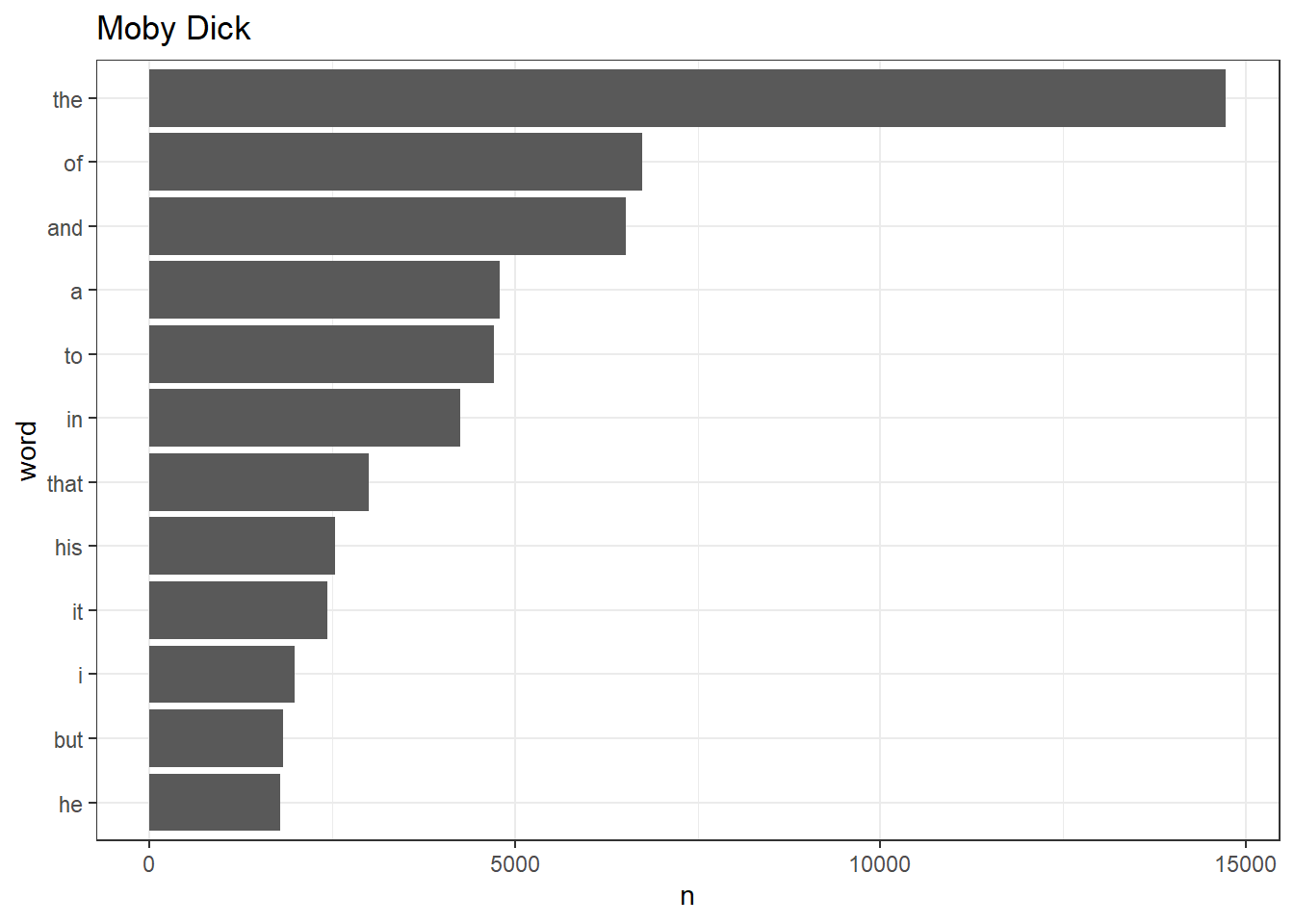
sense_v <- epub("data/sense.epub")$data[[1]]$text
tibble(text = sense_v) %>%
unnest_tokens(output = word, input = text) %>%
count(word, sort = T) %>%
slice_max(n, n = 12) %>%
mutate(word = reorder(word, n)) %>%
ggplot() + geom_col(aes(word, n)) +
coord_flip() +
labs(title = "Sense and Sensibility") +
theme_light()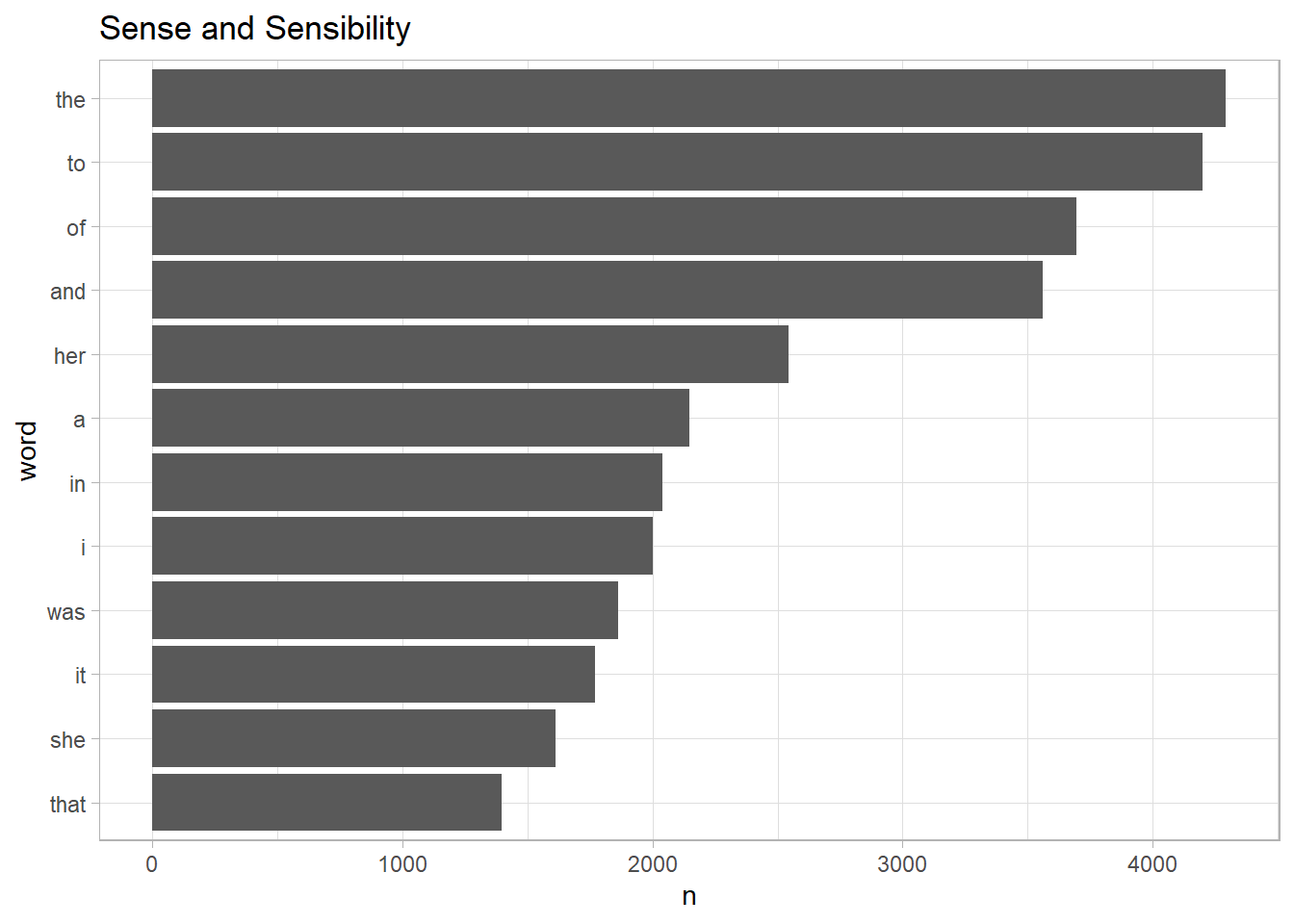
<모비딕>과 <감성과 감수성> 모두 the of and 등처럼 관사 전치사 등이 공동적으로 많이 사용됐지만, <모비딕>에는 his he가 많이 사용됐고, <감성과 감수성>에는 her she가 많이 사용됐다.
5.8.1 과제
data폴더에 다운로드받은 jikji.epub파일에서 소설 두 편을 선택해 자주 사용한 단어의 빈도를 시각화하시오. 두 편의 분석 결과를 비교해 설명하시오.