Chapter 10 분석3: 주제모형
10.1 개관
문서에 빈번하는 등장하는 단어를 통해 그 문서의 주제를 추론할 수 있다. 한 문서에는 다양한 주제가 들어있다.
예를 들어, 아래 문장은 AP가 보도한 1988년 허스트재단의 링컨센터 기부 기사다.
ap_v <- c("The William Randolph Hearst Foundation will give $1.25 million to Lincoln Center, Metropolitan Opera Co., New York Philharmonic and Juilliard School. “Our board felt that we had a
real opportunity to make a mark on the future of the performing arts with these grants an act
every bit as important as our traditional areas of support in health, medical research, education
and the social services,” Hearst Foundation President Randolph A. Hearst said Monday in
announcing the grants. Lincoln Center’s share will be $200,000 for its new building, which
will house young artists and provide new public facilities. The Metropolitan Opera Co. and
New York Philharmonic will receive $400,000 each. The Juilliard School, where music and
the performing arts are taught, will get $250,000. The Hearst Foundation, a leading supporter
of the Lincoln Center Consolidated Corporate Fund, will make its usual annual $100,000
donation, too.")단어의 총빈도와 상대빈도를 계산하면, 이 문서의 주요 내용이 무엇인지 파악할 수 있다. 먼저 총빈도 상위단어를 찾아보자.
pkg_v <- c("tidyverse", "tidytext", "tidylo")
lapply(pkg_v, require, ch = T)## [[1]]
## [1] TRUE
##
## [[2]]
## [1] TRUE
##
## [[3]]
## [1] TRUEap_count <-
ap_v %>% tibble(text = .) %>%
unnest_tokens(word, text, drop = F) %>%
anti_join(stop_words) %>%
count(word, sort = T) %>% head(10)## Joining, by = "word"상대빈도를 구해보자.
먼저 문장 단위로 토큰화해 문장별 ID를 구한다음 단어 단위로 토큰화한다. 대문자 앞의 마침표와 공백("\\.\\s(?=[:upper:])")을 기준으로 구분하면 된다.
ap_tfidf <-
ap_v %>% tibble(text = .) %>%
mutate(text = str_squish(text)) %>%
unnest_tokens(sentence, text, token = "regex", pattern = "\\.\\s(?=[:upper:])") %>%
mutate(ID = row_number()) %>%
unnest_tokens(word, sentence, drop = F) %>%
anti_join(stop_words) %>%
count(ID, word, sort = T) %>%
bind_tf_idf(term = word, document = ID, n = n) %>%
arrange(-tf_idf) %>% head(10)## Joining, by = "word"ap_wlo <-
ap_v %>% tibble(text = .) %>%
mutate(text = str_squish(text)) %>%
unnest_tokens(sentence, text, token = "regex", pattern = "\\.\\s(?=[:upper:])") %>%
mutate(ID = row_number()) %>%
unnest_tokens(word, sentence, drop = F) %>%
anti_join(stop_words) %>%
count(ID, word, sort = T) %>%
bind_log_odds(feature = word, set = ID, n = n) %>%
arrange(-log_odds_weighted) %>% head(10)## Joining, by = "word"추출한 상위 10대 빈도 단어를 비교해 보자.
bind_cols(
select(ap_count, 총빈도 = word),
select(ap_tfidf, tf_idf = word),
select(ap_wlo, 가중승산비 = word)
)## # A tibble: 10 x 3
## 총빈도 tf_idf 가중승산비
## <chr> <chr> <chr>
## 1 hearst announcing hearst
## 2 foundation monday grants
## 3 lincoln 400,000 announcing
## 4 arts receive monday
## 5 center grants metropolitan
## 6 grants 250,000 opera
## 7 juilliard music philharmonic
## 8 metropolitan taught york
## 9 opera metropolitan 400,000
## 10 performing opera receive총빈도와 상대빈도를 보면, 허스트재단이 링컨아트센터에 기부금 발표한 내용이란 것을 추론할 수 있지만, 기사에는 보다 다양한 주제를 담고 있다. 기사의 내용을 읽어보면 다양한 주제가 있음을 알수 있다 (Figure 10.1).

Figure 10.1: AP 기사
기사에 포함된 단어 중 같은 색으로 구부된 단어들을 모아보면 예술, 재정, 아동, 교육 등의 주제를 나타내는 일관된 단어로 구성됐음을 알수 있다 (Figure 10.2).
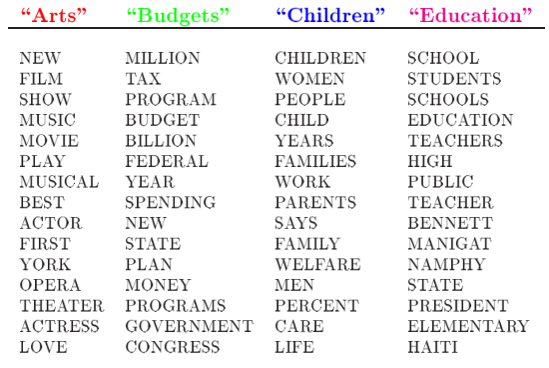
Figure 10.2: AP 기사 주제
Blei 등 일군의 전산학자들은 문서 내 단어의 확률분포를 계산해 찾아낸 일련의 단어 군집을 통해 문서의 주제를 추론하는 방법으로서 LDA(Latent Dirichlet Allocation)을 제시했다.
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3, 993-1022.
19세기 독일 수학자 러죈 디리클레(Lejeune Dirichlet, 1805 ~ 1859)가 제시한 디리클래 분포(Dirichlet distribution)를 이용해 문서에 잠재된 주제를 추론하기에 잠재 디리클레 할당(LDA: Latent Dirichlet Allocation)이라고 했다. 문서의 주제를 추론하는 방법이므로 주제모형(topic models)이라고 한다.
Beli(2012)가 설명한 LDA에 대한 직관적인 이해는 다음과 같다. Figure10.3에 제시된 논문 “Seeking life’s bare (genetics) necessities”은 진화의 틀에서 유기체가 생존하기 위해 필요한 유전자의 수를 결정하기 위한 데이터분석에 대한 내용이다. 문서(documents)에 파란색으로 표시된 ‘computer’ ‘prediction’ 등은 데이터분석에 대한 단어들이다. 분홍색으로 표시된 ‘life’ ‘organism’은 진화생물학에 대한 내용이다. 노란색으로 표시된 ’sequenced’ ’genes’는 유전학에 대한 내용이다. 이 논문의 모든 단어를 이런 식으로 분류하면 아마도 이 논문은 유전학, 데이터분석, 진화생물학 등이 상이한 비율로 혼합돼 있음을 알게 된다.
- Blei, D. M. (2012). Probabilistic topic models. Communications of the ACM, 55(4), 77-84.
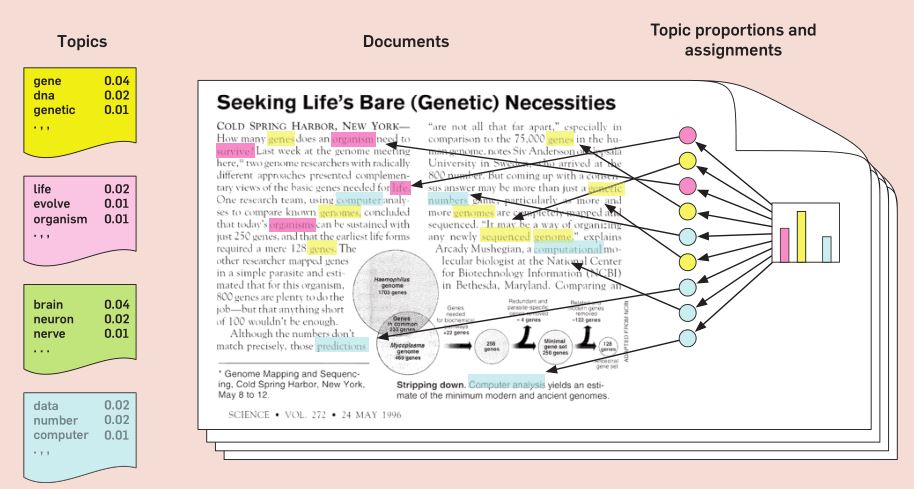
Figure 10.3: LDA의 직관적 예시
LDA에는 다음과 같은 전제가 있다.
- 말뭉치에는 단어를 통해 분포된 다수의 주제가 있다 (위 그림의 가장 왼쪽).
각 문서에서 주제를 생성하는 과정은 다음과 같다.
- 주제에 대해 분포 선택(오른쪽 히스토그램)
- 각 단어에 대해 주제의 분포 선택(색이 부여된 동그라미)
- 해당 주제를 구성하는 단어 선택(가운데 화살표)
LDA에서 정의하는 주제(topic)는 특정 단어에 대한 분포다. 예를 들어, 유전학 주제라면 유전학에 대하여 높은 확률로 분포하는 단어들이고, 진화생물학 주제라면 진화생물학에 대하여 높은 확률로 분포하는 단어들이다.
LDA에서는 문서를 주머니에 무작위로 섞여 있는 임의의 혼합물로 본다(Bag of words). 일반적으로 사용하는 문장처럼 문법이라는 짜임새있는 구조로 보는 것이 아니다. 임의의 혼합물이지만 온전하게 무작위로 섞여 있는 것은 아니다. 서로 함께 모여 있는 군집이 확률적으로 존재한다. 즉, 주제모형에서 접근하는 문서는 잠재된 주제의 혼합물로서, 각 주제를 구성하는 단어 단위가 확률적으로 혼합된 주머니(bag)인 셈이다.
- 개별 문서: 여러 주제(topic)가 섞여 있는 혼합물
- 문서마다 주제(예술, 교육, 예산 등)의 분포 비율 상이
- 주제(예: 예술)마다 단어(예: 오페라, 교향악단)의 분포 상이
주제모형의 목표는 말뭉치에서 주제의 자동추출이다. 문서 자체는 관측가능하지만, 주제의 구조(문서별 주제의 분포와 문서별-단어별 주제할당)는 감춰져 있다. 감춰진 주제의 구조를 찾아내는 작업은 뒤집어진 생성과정이라고 할 수 있다. 관측된 말뭉치를 생성하는 감춰진 구조를 찾아내는 작업이기 때문이다. 문서에 대한 사전 정보없이 문서의 주제를 분류하기 때문에 주제모형은 비지도학습(unsupervised learning) 방식의 기계학습(machine learning)이 된다.
- 기계학습(machine learing)
- 인공지능 작동방식. 투입한 데이터에서 규칙성 탐지해 분류 및 예측. 지도학습, 비지도학습, 강화학습 등으로 구분.
- 인공지능 작동방식. 투입한 데이터에서 규칙성 탐지해 분류 및 예측. 지도학습, 비지도학습, 강화학습 등으로 구분.
- 지도학습(supervised learning)
- 인간이 사전에 분류한 결과를 학습해 투입한 자료에서 규칙성 혹은 경향 발견
- 비지도학습(unsupervised learning)
- 사전분류한 결과 없이 기계 스스로 투입한 자료에서 규칙성 혹은 경향 발견
- 강화학습(reinforced learning)
- 행동의 결과에 대한 피드백(보상, 처벌 등)을 통해 투입한 자료에서 규칙성 혹은 경향 발견
주제모형의 효용은 대량의 문서에서 의미구조를 닮은 주제구조를 추론해 주석을 자동으로 부여할 수 있다는데 있다.
주제모형은 다양한 패지키가 있다.
여기서는 구조적 주제모형(structural topic model)이 가능한 stm패키지를 이용한다. stm은 메타데이터를 이용한 추출한 주제에 대하여 다양한 분석을 할 수 있는 장점이 있다.
10.2 자료 준비
빅카인즈에서 다음의 조건으로 기사를 추출한다.
- 검색어: 인공지능
- 기간: 2010.1.1 ~ 2020.12.31
- 언론사: 중앙일보, 조선일보, 한겨레, 경향신문, 한국경제, 매일경제
- 분석: 분석 기사
모두 5145건이다.
10.2.1 자료 이입
다운로드한 기사를 작업디렉토리 아래 data폴더에 복사한다.
list.files("data/.")## [1] "bunn.epub"
## [2] "dfm.rds"
## [3] "jikji.epub"
## [4] "knusenti.zip"
## [5] "KnuSentiLex-master"
## [6] "moby.epub"
## [7] "newsData"
## [8] "newsData.zip"
## [9] "NewsResult_20200101-20201231.xlsx"
## [10] "NewsResult_20200601-20210531_hdm.xlsx"
## [11] "NewsResult_20200601-20210531_tsl.xlsx"
## [12] "NewsResult_20210101-20210330.xlsx"
## [13] "NewsResult_20210201-20210228.xlsx"
## [14] "NewsResult_20210330-20210330.xlsx"
## [15] "ogamdo.txt"
## [16] "ogamdo2.txt"
## [17] "poliblogs2008.csv"
## [18] "ratings.txt"
## [19] "sense.epub"
## [20] "topic.csv"파일명이 ’NewsResult_20200101-20201201.xlsx’다.
readxl::read_excel("data/NewsResult_20200101-20201231.xlsx") %>% names()## [1] "뉴스 식별자" "일자"
## [3] "언론사" "기고자"
## [5] "제목" "통합 분류1"
## [7] "통합 분류2" "통합 분류3"
## [9] "사건/사고 분류1" "사건/사고 분류2"
## [11] "사건/사고 분류3" "인물"
## [13] "위치" "기관"
## [15] "키워드" "특성추출(가중치순 상위 50개)"
## [17] "본문" "URL"
## [19] "분석제외 여부"분석에 필요한 열을 선택해 데이터프레임으로 저장한다. 분석 텍스트는 제목과 본문이다. 빅카인즈는 본문을 200자까지만 무료로 제공하지만, 학습 목적을 달성하기에는 충분하다. 제목은 본문의 핵심 내용을 반영하므로, 제목과 본문을 모두 주제모형 분석에 투입한다. 시간별, 언론사별, 분류별로 분석할 계획이므로, 해당 열을 모두 선택한다.
ai_df <-
readxl::read_excel("data/NewsResult_20200101-20201231.xlsx") %>%
select(일자, 제목, 본문, 언론사, cat = `통합 분류1`)
ai_df %>% head()## # A tibble: 6 x 5
## 일자 제목 본문 언론사 cat
## <chr> <chr> <chr> <chr> <chr>
## 1 20201~ "`사모펀드 책임` 놓고 새해부터 금융위 탓한 ~ "은성수 금융위원장과 윤석헌 금융감독원장이 한~ 매일경제~ 경제>금융_재테~
## 2 20201~ "[이광석의 디지털 이후](25)시민 자율과 자~ "ㆍ기술 민주주의\n\n\n\n얼마 전까지도 ~ 경향신문~ IT_과학>과학~
## 3 20201~ "\"소처럼 묵묵하게 경제 통합 코로나 극복\"~ "역시나 전국 광역단체장들의 2021년 새해 ~ 매일경제~ 지역>경기
## 4 20201~ "GS건설, `강릉자이 파인베뉴` 견본주택 오픈~ "GS건설은 강원도 강릉시 내곡동 102번지 ~ 매일경제~ 경제>부동산~
## 5 20201~ "디지털 강조한 금융협회장들 사회적 책임에도 `~ "\"디지털과 혁신, ESG(환경 책임 투명경~ 매일경제~ 경제>금융_재테~
## 6 20201~ "정치인 거짓말도 진실로 둔갑 딥페이크, 민주주~ "◆ AI의 역습, 딥페이크 ② ◆\n \"저~ 매일경제~ IT_과학>IT~시간열에는 연월일의 값이 있다. 월별 추이에 따른 주제를 분석할 것이므로 열의 값을 월에 대한 값으로 바꾼다. tidyverse패키지에 함께 설치되는 lubridate패키지를 이용해 문자열을 날짜형으로 변경하고 월 데이터 추출해 새로운 열 month 생성한다. lubridate는 tidyverse에 포함돼 있으나 함께 부착되지 않으므로 별도로 실행해야 한다.
library(lubridate)##
## Attaching package: 'lubridate'## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, unionas_date("20201231") %>% month()## [1] 12ymd("20201231") %>% month()## [1] 12DB에 같은 기사가 중복 등록되는 경우가 있으므로, dplyr패키지의 distinct()함수를 이용해 중복된 문서를 제거한다. .keep_all =인자의 기본값은 FALSE다. 투입한 열 이외의 열은 유지하지 않는다. 다른 변수(열)도 분석에 필요하므로 .keep_all =인자를 TRUE로 지정한다.
분석 목적에 맞게 열을 재구성한다.
library(lubridate)
ai2_df <-
ai_df %>%
# 중복기사 제거
distinct(제목, .keep_all = T) %>%
# 기사별 ID부여
mutate(ID = factor(row_number())) %>%
# 월별로 구분한 열 추가
mutate(month = month(ymd(일자))) %>%
# 기사 제목과 본문 결합
unite(제목, 본문, col = "text", sep = " ") %>%
# 중복 공백 제거
mutate(text = str_squish(text)) %>%
# 언론사 분류: 보수 진보 경제 %>%
mutate(press = case_when(
언론사 == "조선일보" ~ "종합지",
언론사 == "중앙일보" ~ "종합지",
언론사 == "경향신문" ~ "종합지",
언론사 == "한겨레" ~ "종합지",
언론사 == "한국경제" ~ "경제지",
TRUE ~ "경제지") ) %>%
# 기사 분류 구분
separate(cat, sep = ">", into = c("cat", "cat2")) %>%
# IT_과학, 경제, 사회 만 선택
filter(str_detect(cat, "IT_과학|경제|사회")) %>%
select(-cat2) ## Warning: Expected 2 pieces. Additional pieces discarded in 9 rows [262, 371,
## 1929, 2393, 2416, 2644, 3082, 3132, 4149].## Warning: Expected 2 pieces. Missing pieces filled with `NA` in 123 rows [11, 68,
## 87, 118, 153, 198, 241, 308, 362, 393, 445, 455, 483, 546, 549, 550, 551, 552,
## 577, 602, ...].ai2_df %>% head(5)## # A tibble: 5 x 7
## 일자 text 언론사 cat ID month press
## <chr> <chr> <chr> <chr> <fct> <dbl> <chr>
## 1 202012~ "`사모펀드 책임` 놓고 새해부터 금융위 탓한 금감원 은성수 금융위~ 매일경제~ 경제 1 12 경제지~
## 2 202012~ "[이광석의 디지털 이후](25)시민 자율과 자치의 상상력을 발휘 ~ 경향신문~ IT_과~ 2 12 종합지~
## 3 202012~ "GS건설, `강릉자이 파인베뉴` 견본주택 오픈 강릉 내곡동에 91~ 매일경제~ 경제 4 12 경제지~
## 4 202012~ "디지털 강조한 금융협회장들 사회적 책임에도 `앞장` \"디지털과 ~ 매일경제~ 경제 5 12 경제지~
## 5 202012~ "정치인 거짓말도 진실로 둔갑 딥페이크, 민주주의 근간 흔든다 ◆ ~ 매일경제~ IT_과~ 6 12 경제지~ai2_df %>% names()## [1] "일자" "text" "언론사" "cat" "ID" "month" "press"기사의 분류된 종류, 월 등 새로 생성한 열의 내용을 확인해보자.
ai2_df$cat %>% unique()## [1] "경제" "IT_과학" "사회"ai2_df$month %>% unique()## [1] 12 11 10 9 8 7 6 5 4 3 2 1ai2_df$press %>% unique()## [1] "경제지" "종합지"분류별, 월별로 기사의 양을 계산해보자.
ai2_df %>% count(cat, sort = T)## # A tibble: 3 x 2
## cat n
## <chr> <int>
## 1 IT_과학 1922
## 2 경제 1409
## 3 사회 460ai2_df %>% count(month, sort = T)## # A tibble: 12 x 2
## month n
## <dbl> <int>
## 1 1 382
## 2 9 379
## 3 12 366
## 4 7 345
## 5 6 335
## 6 5 334
## 7 11 311
## 8 10 306
## 9 8 287
## 10 4 277
## 11 3 268
## 12 2 201ai2_df %>% count(press, sort = T)## # A tibble: 2 x 2
## press n
## <chr> <int>
## 1 경제지 2049
## 2 종합지 174210.2.2 정제
10.2.2.1 토큰화
KoNLP패키지의 extractNoun()함수로 명사만 추출해 토큰화한다. 명사가 문서의 주제를 잘 나타내므로 주제모형에서는 주로 명사를 이용하지만, 목적에 따라서는 다른 품사(용언 등)를 분석에 투여하기도 한다.
(* 형태소 추출전에 문자 혹은 공백 이외의 요소(예: 구둣점)를 먼저 제거한다.)
library(KoNLP)## Checking user defined dictionary!ai_tk <-
ai2_df %>%
mutate(text = str_remove_all(text, "[^(\\w+|\\s)]")) %>% # 문자 혹은 공백 이외 것 제거
unnest_tokens(word, text, token = extractNoun, drop = F)
ai_tk %>% glimpse()## Rows: 202,643
## Columns: 8
## $ 일자 <chr> "20201231", "20201231", "20201231", "20201231", "20201231", "2...
## $ text <chr> "사모펀드 책임 놓고 새해부터 금융위 탓한 금감원 은성수 금융위원장과 윤석헌 금융감독원장이 한 해를 뜨겁게 ...
## $ 언론사 <chr> "매일경제", "매일경제", "매일경제", "매일경제", "매일경제", "매일경제", "매일경제", "매일경제",...
## $ cat <chr> "경제", "경제", "경제", "경제", "경제", "경제", "경제", "경제", "경제", "경제", ...
## $ ID <fct> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
## $ month <dbl> 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, ...
## $ press <chr> "경제지", "경제지", "경제지", "경제지", "경제지", "경제지", "경제지", "경제지", "경제지...
## $ word <chr> "사모", "펀드", "책임", "새해", "금융", "위", "감원", "은성", "수", "금융", "위...10.2.2.2 불용어 제거
’인공지능’으로 검색한 기사이므로, ’인공지능’관련 단어는 제거한다. 문자가 아닌 요소를 모두 제거한다. (숫자를 반드시 제거해야 하는 것은 아니다.)
ai_tk <-
ai_tk %>%
filter(!word %in% c("인공지능", "AI", "ai", "인공지능AI", "인공지능ai")) %>%
filter(str_detect(word, "[:alpha:]+")) 단어의 총빈도와 상대빈도를 살펴보자
ai_tk %>% count(word, sort = T)## # A tibble: 21,260 x 2
## word n
## <chr> <int>
## 1 한 3107
## 2 하 1611
## 3 기술 1439
## 4 기업 1426
## 5 등 1373
## 6 해 1238
## 7 년 1232
## 8 것 1002
## 9 수 989
## 10 서비스 957
## # ... with 21,250 more rows상대빈도가 높은 단어와 낮은 단어를 확인한다.
ai_tk %>% count(cat, word, sort = T) %>%
bind_log_odds(set = cat, feature = word, n = n) %>%
arrange(log_odds_weighted)## # A tibble: 29,972 x 4
## cat word n log_odds_weighted
## <chr> <chr> <int> <dbl>
## 1 IT_과학 반도체 30 -5.56
## 2 IT_과학 투자 193 -5.33
## 3 경제 전자 125 -5.31
## 4 IT_과학 펀드 9 -5.03
## 5 IT_과학 종목 4 -4.98
## 6 경제 교육 85 -4.85
## 7 IT_과학 금융 102 -4.69
## 8 IT_과학 채용 7 -4.05
## 9 IT_과학 교육 214 -3.79
## 10 IT_과학 대학 95 -3.63
## # ... with 29,962 more rowsai_tk %>% count(cat, word, sort = T) %>%
bind_tf_idf(term = word, document = word, n = n) %>%
arrange(idf)## # A tibble: 29,972 x 6
## cat word n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 IT_과학 한 1623 0.522 8.87 4.63
## 2 경제 한 1109 0.357 8.87 3.16
## 3 IT_과학 기술 876 0.609 8.87 5.40
## 4 IT_과학 하 777 0.482 8.87 4.28
## 5 경제 기업 714 0.501 8.87 4.44
## 6 IT_과학 등 678 0.494 8.87 4.38
## 7 IT_과학 기업 651 0.457 8.87 4.05
## 8 IT_과학 전자 650 0.831 8.87 7.37
## 9 IT_과학 서비스 633 0.661 8.87 5.86
## 10 IT_과학 해 630 0.509 8.87 4.51
## # ... with 29,962 more rows한글자 단어는 문서의 주제를 나타내는데 기여하지 못하는 경우도 있고, 고유명사인데 형태소로 분리돼 있는 경우도 있다. 상대빈도가 높은 단어를 살펴 특이한 단어가 있으면 형태소 추출전 단어가 무엇인지 확인한다. 특이한 경우가 없으면 한글자 단어는 모두 제거한다.
tibble데이터프레임은 문자열의 일부만 보여준다. pull()함수로 열에 포함된 문자열을 벡터로 출력하므로, 모든 내용을 확인할 수 있다.
ai_tk %>%
filter(word == "하") %>% pull(text) %>% head(3)## [1] "이광석의 디지털 이후(25)시민 자율과 자치의 상상력을 발휘 폭주하는 과학기술 말머리를 돌려라 ㆍ기술 민주주의 얼마 전까지도 우리 사회 속 기술 수용은 그리 대중의 관심사가 아니었다 대중의 기술 체감도 크지 않았다 여전히 기술은 국가의 일이었다 정확히는 주로 재벌의 성장 지표에 관심이 많은 엘리트 관료들 소관이었다 하지만 10여년 전부터 스마트 기술이 일상으로 확산되면서 상황이 많이 바뀌었다 일반인이 느끼고 감지하는 기술 경험이 확"
## [2] "베컴이 9개 언어로 말한다고 딥페이크로 입모양 바꿔 AI의 역습 딥페이크 영국을 대표하는 축구선수였던 데이비드 베컴은 2020년 말라리아 머스트 다이(Malaria Must Die)라는 비영리기구가 만든 광고에 출연해 영어뿐만 아니라 스페인어 독일어 아랍어 등 9개국어로 말라리아에 대항해 같이 싸우자는 메시지를 전달했다 물론 베컴이 9개국어를 할 리가 없다 딥페이크로 입 모양을"
## [3] "모두가 주목하는 대학 IT의 힘으로 AI의 미래로 숭실대학교 4차 산업혁명을 주도하는 글로벌 대학 한국 최초의 4년제 근대대학 숭실대학교는 4차 산업혁명 시대를 맞아 지난2017년 숭실 40을 선포 대한민국 최고의 AI 융합분야 인재 양성 대학으로 도약하기 위한 로드맵을 세웠다 개교 123주년을 맞아 AI비전을 선포한 숭실은 올해 5월 교육부가 주관하는 4차 산업혁명 혁신선도대학으로 선정되어 2년간"‘기업’ ‘기술’ 등의 단어는 총사용빈도가 높지만, 상대빈도는 낮다. 대부분의 분류에서 널리 사용된 단어다. 지금 제거할필요는 없지만, 제거가능성을 염두에 둔다.
ai_tk %>%
filter(str_length(word) > 1) -> ai2_tk
ai2_tk %>%
count(word, sort = T) ## # A tibble: 20,522 x 2
## word n
## <chr> <int>
## 1 기술 1439
## 2 기업 1426
## 3 서비스 957
## 4 개발 949
## 5 lg 796
## 6 전자 782
## 7 디지털 760
## 8 데이터 681
## 9 사업 680
## 10 투자 658
## # ... with 20,512 more rows상대빈도를 다시 확인하자.
ai2_tk %>% count(cat, word, sort = T) %>%
bind_log_odds(set = cat, feature = word, n = n) %>%
arrange(-log_odds_weighted)## # A tibble: 28,407 x 4
## cat word n log_odds_weighted
## <chr> <chr> <int> <dbl>
## 1 IT_과학 lg 669 12.6
## 2 사회 교육 286 11.2
## 3 사회 대학 166 8.70
## 4 IT_과학 세탁 215 7.33
## 5 경제 은행 146 7.16
## 6 사회 학생 94 6.92
## 7 사회 수능 23 6.86
## 8 사회 환자 77 6.67
## 9 사회 진단 92 6.43
## 10 IT_과학 건조기 160 6.40
## # ... with 28,397 more rowsai2_tk %>% count(cat, word, sort = T) %>%
bind_tf_idf(term = word, document = word, n = n) %>%
arrange(tf_idf)## # A tibble: 28,407 x 6
## cat word n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 사회 금융 2 0.005 8.83 0.0442
## 2 사회 펀드 1 0.00571 8.83 0.0505
## 3 사회 tv 1 0.00637 8.83 0.0562
## 4 사회 상품 1 0.00730 8.83 0.0645
## 5 사회 반도체 2 0.00738 8.83 0.0652
## 6 사회 클라우드 1 0.00769 8.83 0.0679
## 7 사회 투자자 1 0.00840 8.83 0.0742
## 8 사회 채용 1 0.00855 8.83 0.0755
## 9 사회 챗봇 1 0.00862 8.83 0.0761
## 10 사회 전자 7 0.00895 8.83 0.0790
## # ... with 28,397 more rows10.2.3 stm 말뭉치
install.packages("stm", dependencies = T)토큰화한 데이터프레임을 stm패키지 형식의 말뭉치로 변환한다. 이를 위해 먼저 분리된 토큰을 원래 문장에 속한 하나의 열로 저장한다.
str_flatten()은str_c()함수와 달리, 문자열을 결합해 단일 요소로 산출한다.str_c()함수에collapse =인자를 사용한 경우에 해당한다.
str_c()는 R기본함수paste0()와 비슷하다. 결측값 처리방법이 서로 다르다.
combined_df <-
ai2_tk %>%
group_by(ID) %>%
summarise(text2 = str_flatten(word, " ")) %>%
ungroup() %>%
inner_join(ai2_df, by = "ID")## `summarise()` ungrouping output (override with `.groups` argument)combined_df %>% glimpse()## Rows: 3,791
## Columns: 8
## $ ID <fct> 1, 2, 4, 5, 6, 7, 8, 9, 10, 12, 14, 15, 16, 17, 18, 19, 20, ...
## $ text2 <chr> "사모 펀드 책임 새해 금융 감원 은성 금융 위원장 윤석헌 금융 감독원 장이 사모 펀드 사태 새해 위원장 발...
## $ 일자 <chr> "20201231", "20201231", "20201231", "20201231", "20201231", "2...
## $ text <chr> "`사모펀드 책임` 놓고 새해부터 금융위 탓한 금감원 은성수 금융위원장과 윤석헌 금융감독원장이 한 해를 뜨겁...
## $ 언론사 <chr> "매일경제", "경향신문", "매일경제", "매일경제", "매일경제", "매일경제", "매일경제", "한국경제",...
## $ cat <chr> "경제", "IT_과학", "경제", "경제", "IT_과학", "IT_과학", "사회", "IT_과학", ...
## $ month <dbl> 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, ...
## $ press <chr> "경제지", "종합지", "경제지", "경제지", "경제지", "경제지", "경제지", "경제지", "종합지...textProcessor()함수로 리스트 형식의 stm말뭉치로 변환한다. ‘documents’ ‘vacab’ ’meta’등의 하부요소가 생성된다. ’meta’에 텍스트데이터가 저장돼 있다.
영문문서의 경우, textProcessor()함수로 정제과정을 수행하므로, 한글문서처럼 별도의 형태소 추출과정 바로 영문데이터프레임을 투입하면 된다.
’text2’열에 토큰화한 단어가 저장돼 있다.
만일 tm패키지나 SnowballC패키지가 설치돼 있지 않으면
library(stm)## Warning: package 'stm' was built under R version 4.0.5## stm v1.3.6 successfully loaded. See ?stm for help.
## Papers, resources, and other materials at structuraltopicmodel.comprocessed <-
ai2_df %>% textProcessor(documents = combined_df$text2, metadata = .)## Building corpus...
## Converting to Lower Case...
## Removing punctuation...
## Removing stopwords...
## Removing numbers...
## Stemming...
## Creating Output...prepDocuments()함수로 주제모형에 사용할 데이터의 인덱스(wordcounts)를 만든다.
out <-
prepDocuments(processed$documents,
processed$vocab,
processed$meta)## Removing 8945 of 12908 terms (8945 of 37860 tokens) due to frequency
## Removing 3 Documents with No Words
## Your corpus now has 3788 documents, 3963 terms and 28915 tokens.제거할수 있는 단어와 문서의 수를 plotRemoved()함수로 확인할 수 있다.
plotRemoved(processed$documents, lower.thresh = seq(0, 100, by = 5))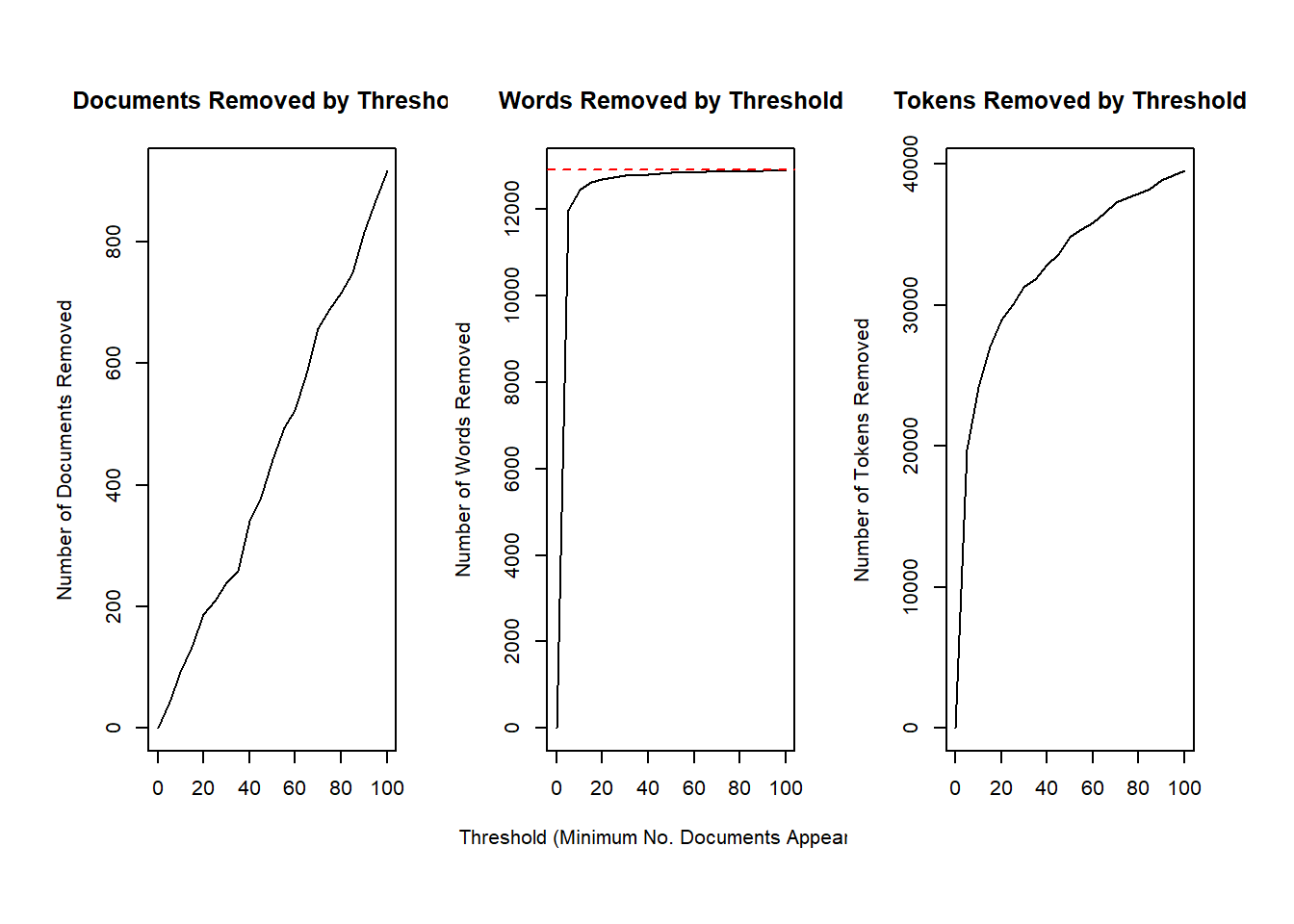
lower.thresh =로 최소값 설정하면 빈도가 낮아 제거할 용어의 수를 설정할 수 있다. 설정값을 너무 높게 잡으면 분석의 정확도가 떨어진다. 여기서는 계산 편의를 위해 설정값을 높게 잡았다.
out <-
prepDocuments(processed$documents,
processed$vocab,
processed$meta,
lower.thresh = 15)## Removing 12618 of 12908 terms (22820 of 37860 tokens) due to frequency
## Removing 133 Documents with No Words
## Your corpus now has 3658 documents, 290 terms and 15040 tokens.산출결과를 개별 객체로 저장한다. 이 객체들은 이후 모형구축에 사용된다.
docs <- out$documents
vocab <- out$vocab
meta <- out$meta10.3 분석
10.3.1 주제의 수(K) 설정
주제를 몇개로 설정할지 탐색한다. 7개와 10개를 놓고 비교해보자. searchK()함수는 주제의 수에 따라 4가지 계수를 제공한다.
배타성(exclusivity): 특정 주제에 등장한 단어가 다른 주제에는 나오지 않는 정도. 확산타당도에 해당.
의미 일관성(semantic coherence): 특정 주제에 높은 확률로 나타나는 단어가 동시에 등장하는 정도. 수렴타당도에 해당.
지속성(heldout likelihood): 데이터 일부가 존재하지 않을 때의 모형 예측 지속 정도.
잔차(residual): 투입한 데이터로 모형을 설명하지 못하는 오차.
배타성, 의미 일관성, 지속성이 높을 수록, 그리고 잔차가 작을수록 모형의 적절성 증가.
보통 10개부터 100개까지 10개 단위로 주제의 수를 구분해 연구자들이 정성적으로 최종 주제의 수 판단한다.
학습 상황이므로 계산시간을 줄이기 위해 주제의 수를 3개와 10개의 결과만 비교한다. (iteration을 200회 이상 수행하므로 계산시간이 오래 걸린다.)
백그라운드에서 계산하도록 하면, RStudio에서 다른 작업을 병행할 수 있다.
# topicN <- seq(from = 10, to = 100, by = 10)
topicN <- c(3, 10)
storage <- searchK(out$documents, out$vocab, K = topicN)## Beginning Spectral Initialization
## Calculating the gram matrix...
## Finding anchor words...
## ...
## Recovering initialization...
## ..
## Initialization complete.
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 1 (approx. per word bound = -5.235)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 2 (approx. per word bound = -5.147, relative change = 1.677e-02)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 3 (approx. per word bound = -5.113, relative change = 6.625e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 4 (approx. per word bound = -5.098, relative change = 2.984e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 5 (approx. per word bound = -5.090, relative change = 1.477e-03)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 스타트, 코로나
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, 자동차
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 대통령
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 6 (approx. per word bound = -5.086, relative change = 7.952e-04)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 7 (approx. per word bound = -5.084, relative change = 4.602e-04)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 8 (approx. per word bound = -5.083, relative change = 2.840e-04)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 9 (approx. per word bound = -5.082, relative change = 1.871e-04)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 10 (approx. per word bound = -5.081, relative change = 1.327e-04)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 스타트, 코로나
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 대통령
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 11 (approx. per word bound = -5.080, relative change = 1.020e-04)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 12 (approx. per word bound = -5.080, relative change = 8.472e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 13 (approx. per word bound = -5.080, relative change = 7.516e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 14 (approx. per word bound = -5.079, relative change = 7.045e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 15 (approx. per word bound = -5.079, relative change = 6.853e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 16 (approx. per word bound = -5.079, relative change = 6.710e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 17 (approx. per word bound = -5.078, relative change = 6.327e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 18 (approx. per word bound = -5.078, relative change = 5.604e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 19 (approx. per word bound = -5.078, relative change = 4.656e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 20 (approx. per word bound = -5.078, relative change = 3.659e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 21 (approx. per word bound = -5.077, relative change = 2.777e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 22 (approx. per word bound = -5.077, relative change = 2.095e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 23 (approx. per word bound = -5.077, relative change = 1.665e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 24 (approx. per word bound = -5.077, relative change = 1.456e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 25 (approx. per word bound = -5.077, relative change = 1.451e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 26 (approx. per word bound = -5.077, relative change = 1.638e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 27 (approx. per word bound = -5.077, relative change = 2.010e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 28 (approx. per word bound = -5.077, relative change = 2.573e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 29 (approx. per word bound = -5.077, relative change = 3.292e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 30 (approx. per word bound = -5.076, relative change = 4.071e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 31 (approx. per word bound = -5.076, relative change = 4.763e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 32 (approx. per word bound = -5.076, relative change = 5.174e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 33 (approx. per word bound = -5.076, relative change = 5.173e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 34 (approx. per word bound = -5.075, relative change = 4.819e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 35 (approx. per word bound = -5.075, relative change = 4.129e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 36 (approx. per word bound = -5.075, relative change = 3.347e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 37 (approx. per word bound = -5.075, relative change = 2.800e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 38 (approx. per word bound = -5.075, relative change = 2.522e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 39 (approx. per word bound = -5.075, relative change = 2.402e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 40 (approx. per word bound = -5.074, relative change = 2.357e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 41 (approx. per word bound = -5.074, relative change = 2.324e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 42 (approx. per word bound = -5.074, relative change = 2.281e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 43 (approx. per word bound = -5.074, relative change = 2.223e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 44 (approx. per word bound = -5.074, relative change = 2.155e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 45 (approx. per word bound = -5.074, relative change = 2.102e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 46 (approx. per word bound = -5.074, relative change = 2.096e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 47 (approx. per word bound = -5.074, relative change = 2.153e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 48 (approx. per word bound = -5.074, relative change = 2.286e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 49 (approx. per word bound = -5.073, relative change = 2.483e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 50 (approx. per word bound = -5.073, relative change = 2.710e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 51 (approx. per word bound = -5.073, relative change = 2.891e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 52 (approx. per word bound = -5.073, relative change = 2.951e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 53 (approx. per word bound = -5.073, relative change = 2.874e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 54 (approx. per word bound = -5.073, relative change = 2.696e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 55 (approx. per word bound = -5.073, relative change = 2.483e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 56 (approx. per word bound = -5.072, relative change = 2.290e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 57 (approx. per word bound = -5.072, relative change = 2.177e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 58 (approx. per word bound = -5.072, relative change = 2.176e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 59 (approx. per word bound = -5.072, relative change = 2.286e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 60 (approx. per word bound = -5.072, relative change = 2.511e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 61 (approx. per word bound = -5.072, relative change = 2.843e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 62 (approx. per word bound = -5.072, relative change = 3.253e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 63 (approx. per word bound = -5.072, relative change = 3.605e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 64 (approx. per word bound = -5.071, relative change = 3.688e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 65 (approx. per word bound = -5.071, relative change = 3.362e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 66 (approx. per word bound = -5.071, relative change = 2.797e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 67 (approx. per word bound = -5.071, relative change = 2.231e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 68 (approx. per word bound = -5.071, relative change = 1.827e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 69 (approx. per word bound = -5.071, relative change = 1.590e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 70 (approx. per word bound = -5.071, relative change = 1.503e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 71 (approx. per word bound = -5.071, relative change = 1.488e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 72 (approx. per word bound = -5.070, relative change = 1.572e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 73 (approx. per word bound = -5.070, relative change = 1.705e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 74 (approx. per word bound = -5.070, relative change = 1.903e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 75 (approx. per word bound = -5.070, relative change = 2.163e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 76 (approx. per word bound = -5.070, relative change = 2.479e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 77 (approx. per word bound = -5.070, relative change = 2.867e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 78 (approx. per word bound = -5.070, relative change = 3.310e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 79 (approx. per word bound = -5.070, relative change = 3.811e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 80 (approx. per word bound = -5.069, relative change = 4.325e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 81 (approx. per word bound = -5.069, relative change = 4.793e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 82 (approx. per word bound = -5.069, relative change = 5.118e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 83 (approx. per word bound = -5.069, relative change = 5.197e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 84 (approx. per word bound = -5.068, relative change = 5.004e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 85 (approx. per word bound = -5.068, relative change = 4.540e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 86 (approx. per word bound = -5.068, relative change = 3.940e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 87 (approx. per word bound = -5.068, relative change = 3.295e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 88 (approx. per word bound = -5.068, relative change = 2.703e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 89 (approx. per word bound = -5.067, relative change = 2.225e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 90 (approx. per word bound = -5.067, relative change = 1.834e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 91 (approx. per word bound = -5.067, relative change = 1.566e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 92 (approx. per word bound = -5.067, relative change = 1.389e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 93 (approx. per word bound = -5.067, relative change = 1.286e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 94 (approx. per word bound = -5.067, relative change = 1.252e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 95 (approx. per word bound = -5.067, relative change = 1.259e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 96 (approx. per word bound = -5.067, relative change = 1.301e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 97 (approx. per word bound = -5.067, relative change = 1.391e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 98 (approx. per word bound = -5.067, relative change = 1.485e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 99 (approx. per word bound = -5.067, relative change = 1.605e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 100 (approx. per word bound = -5.067, relative change = 1.734e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 101 (approx. per word bound = -5.067, relative change = 1.868e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 102 (approx. per word bound = -5.066, relative change = 1.988e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 103 (approx. per word bound = -5.066, relative change = 2.101e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 104 (approx. per word bound = -5.066, relative change = 2.185e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 105 (approx. per word bound = -5.066, relative change = 2.234e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 106 (approx. per word bound = -5.066, relative change = 2.233e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 107 (approx. per word bound = -5.066, relative change = 2.181e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 108 (approx. per word bound = -5.066, relative change = 2.077e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 109 (approx. per word bound = -5.066, relative change = 1.924e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 110 (approx. per word bound = -5.066, relative change = 1.737e-05)
## Topic 1: 디지털, 인공지능ai, 플랫폼, 코로나, 스타트
## Topic 2: 서비스, 스마트, 빅데이터, 산업혁명, ces
## Topic 3: 데이터, 글로벌, 솔루션, 시스템, 텔레콤
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 111 (approx. per word bound = -5.066, relative change = 1.533e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 112 (approx. per word bound = -5.065, relative change = 1.332e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 113 (approx. per word bound = -5.065, relative change = 1.156e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 114 (approx. per word bound = -5.065, relative change = 1.016e-05)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Model Converged
## Beginning Spectral Initialization
## Calculating the gram matrix...
## Finding anchor words...
## ..........
## Recovering initialization...
## ..
## Initialization complete.
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 1 (approx. per word bound = -5.222)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 2 (approx. per word bound = -5.082, relative change = 2.677e-02)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 3 (approx. per word bound = -4.977, relative change = 2.067e-02)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 4 (approx. per word bound = -4.912, relative change = 1.298e-02)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 5 (approx. per word bound = -4.876, relative change = 7.327e-03)
## Topic 1: 코로나, 온라인, 코로나바이러스, 코로나로, 가운데
## Topic 2: 건조기, 맞춤형, 신제품, 프로젝트, 이벤트
## Topic 3: 서비스, 솔루션, 텔레콤, 인공지능ai, 사이버
## Topic 4: ces, 비즈니스, 마케팅, 대학교, 모빌리티
## Topic 5: 스마트, 시스템, 브랜드, 디자인, 스마트폰
## Topic 6: 디지털, 데이터, 인공지능ai, 빅데이터, 알고리즘
## Topic 7: 반도체, 대통령, 지난해, 투자자, 대학원
## Topic 8: 스타트, 인터넷, ict, 핀테크, 실시간
## Topic 9: 플랫폼, 자동차, 산업혁명, 소프트웨어, 일자리
## Topic 10: 글로벌, 연구소, 콘텐츠, 아마존, 페이스
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 6 (approx. per word bound = -4.856, relative change = 4.089e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 7 (approx. per word bound = -4.846, relative change = 2.150e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 8 (approx. per word bound = -4.841, relative change = 1.027e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 9 (approx. per word bound = -4.839, relative change = 3.736e-04)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Model Convergedplot(storage)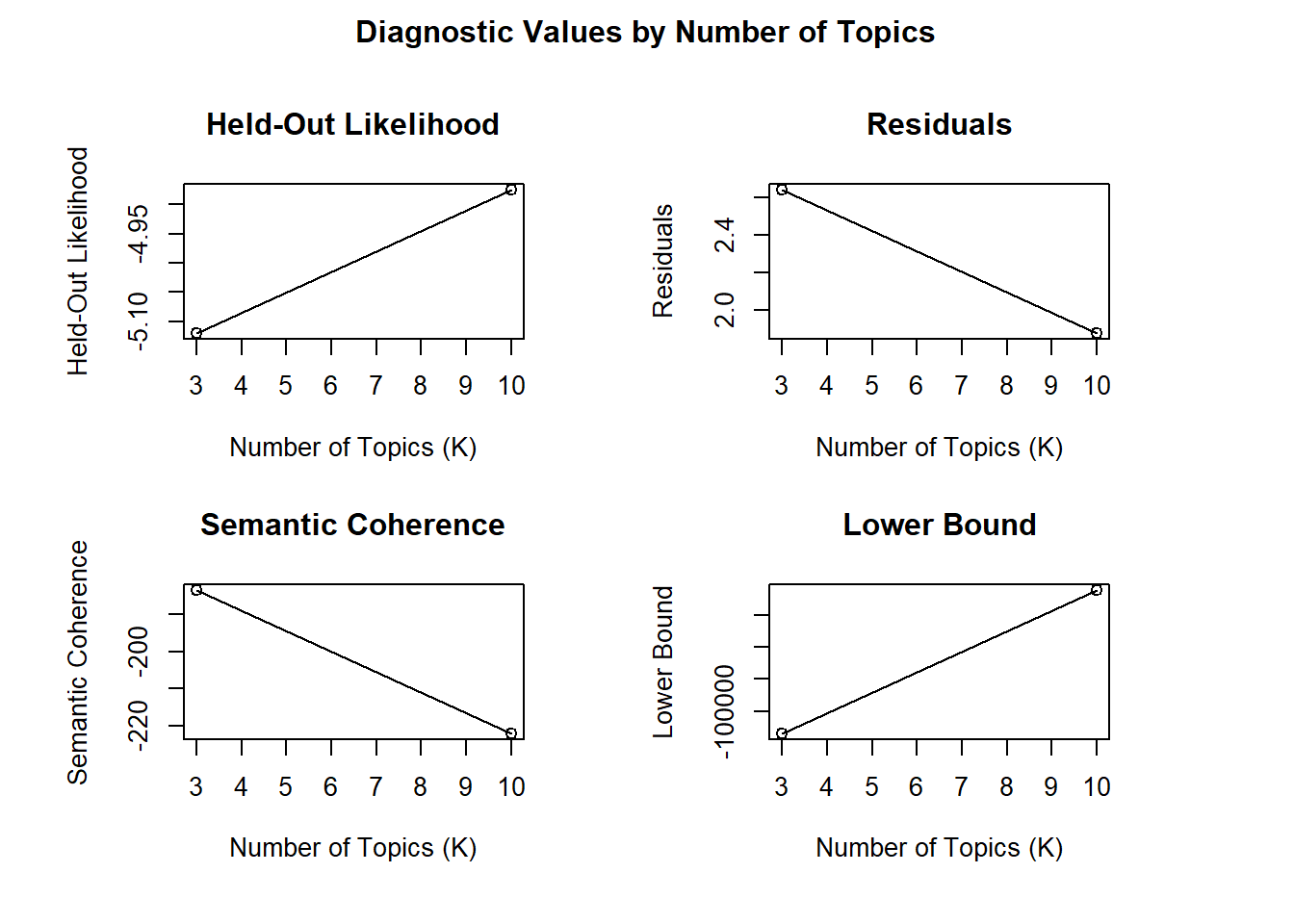
배타성, 지속성, 잔차 등 3개 지표에서 모두 주제의 수가 10개인 모형이 3개인 모형보다 우수하고, 3개인 모형은 의미일관성만 높다. 따라서 이미 10개로 분석한 모형을 그대로 이용한다.
10.3.2 주제모형 구성
docs, vocab, meta에 저장된 문서와 텍스트정보를 이용해 주제모형을 구성한다. 추출한 주제의 수는 K =인자로 설정한다. 처음에는 임의의 값을 투입한다. 이후 적절한 주제의 수를 다시 추정하는 단계가 있다.
모형 초기값은 init.type =인자에 “Spectral”을 투입한다. 같은 결과가 나오도록 하려면 seed =인자를 지정한다. 투입하는 값은 개인의 선호대로 한다.
stm_fit <-
stm(
documents = docs,
vocab = vocab,
K = 10, # 토픽의 수
data = meta,
init.type = "Spectral",
seed = 37 # 반복실행해도 같은 결과가 나오게 난수 고정
)## Beginning Spectral Initialization
## Calculating the gram matrix...
## Finding anchor words...
## ..........
## Recovering initialization...
## ..
## Initialization complete.
## .....................................................................................................
## Completed E-Step (1 seconds).
## Completed M-Step.
## Completing Iteration 1 (approx. per word bound = -5.209)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 2 (approx. per word bound = -5.067, relative change = 2.729e-02)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 3 (approx. per word bound = -4.961, relative change = 2.078e-02)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 4 (approx. per word bound = -4.900, relative change = 1.229e-02)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 5 (approx. per word bound = -4.865, relative change = 7.210e-03)
## Topic 1: 플랫폼, 지난해, 카카오, 네이버, 지난달
## Topic 2: 서비스, 건조기, 맞춤형, 신제품, 트렌드
## Topic 3: 서비스, 텔레콤, 브랜드, 마케팅, 디자인
## Topic 4: 데이터, 솔루션, 반도체, 인공지능ai, 인터넷
## Topic 5: 코로나, 산업혁명, 대학교, 자동차, 코로나바이러스
## Topic 6: 디지털, 대통령, 일자리, 대학원, 투자자
## Topic 7: 스타트, ces, 프로그램, 모빌리티, 중소기업
## Topic 8: 글로벌, 온라인, 부동산, 비즈니스, 스마트폰
## Topic 9: 서비스, 스마트, 시스템, 업무협약, mou
## Topic 10: 빅데이터, 소프트웨어, 전문가, 인공지능ai, 사용자
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 6 (approx. per word bound = -4.843, relative change = 4.528e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 7 (approx. per word bound = -4.832, relative change = 2.230e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 8 (approx. per word bound = -4.827, relative change = 1.028e-03)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Completing Iteration 9 (approx. per word bound = -4.826, relative change = 2.656e-04)
## .....................................................................................................
## Completed E-Step (0 seconds).
## Completed M-Step.
## Model Convergedsummary(stm_fit) %>% glimpse()## A topic model with 10 topics, 3658 documents and a 290 word dictionary.
## List of 5
## $ prob : chr [1:10, 1:7] "플랫폼" "서비스" "서비스" "데이터" ...
## $ frex : chr [1:10, 1:7] "네이버" "건조기" "텔레콤" "데이터" ...
## $ lift : chr [1:10, 1:7] "청소기" "건조기" "에어컨" "학습용" ...
## $ score : chr [1:10, 1:7] "청소기" "건조기" "에어컨" "학습용" ...
## $ topicnums: int [1:10] 1 2 3 4 5 6 7 8 9 10
## - attr(*, "class")= chr "labelTopics"summary(stm_fit)## A topic model with 10 topics, 3658 documents and a 290 word dictionary.## Topic 1 Top Words:
## Highest Prob: 플랫폼, 지난해, 카카오, 네이버, 지난달, 연구소, 실리콘밸리
## FREX: 네이버, 카카오, 연구소, 지난달, 지난해, 플랫폼, 청소기
## Lift: 청소기, 네이버는, 네이버, 네이버가, 연구소, 지난달, 카카오
## Score: 청소기, 플랫폼, 지난해, 카카오, 네이버, 연구소, 지난달
## Topic 2 Top Words:
## Highest Prob: 서비스, 건조기, 맞춤형, 신제품, 트렌드, 알고리즘, 핀테크
## FREX: 건조기, 신제품, 맞춤형, 다음달, 콜센터, 라이프스타일, 냉장고
## Lift: 건조기, 신제품, 라이프스타일, 냉장고, 콜센터, 다음달, 한국표준협회
## Score: 건조기, 서비스, 신제품, 맞춤형, 다음달, 트렌드, 콜센터
## Topic 3 Top Words:
## Highest Prob: 서비스, 텔레콤, 브랜드, 마케팅, 디자인, 스피커, 인공지능ai
## FREX: 텔레콤, 스피커, 브랜드, 아파트, 에어컨, 디자인, 마케팅
## Lift: 에어컨, 스피커, 텔레콤, 아파트, 통신사, 어르신, skt
## Score: 에어컨, 브랜드, 텔레콤, 스피커, 디자인, 마케팅, 서비스
## Topic 4 Top Words:
## Highest Prob: 데이터, 솔루션, 반도체, 인공지능ai, 클라우드, 인터넷, ict
## FREX: 데이터, 반도체, 컴퓨터, 에너지, 솔루션, 학습용, ict
## Lift: 학습용, 반도체, 데이터, 경진대회, 컴퓨터, sk하이닉스, 에너지
## Score: 학습용, 데이터, 반도체, 솔루션, 에너지, 컴퓨터, ict
## Topic 5 Top Words:
## Highest Prob: 코로나, 산업혁명, 자동차, 대학교, 코로나바이러스, 가운데, 코로나로
## FREX: 사이버, etf, 바이러스, 마스크, 코로나, 수익률, 대학교
## Lift: etf, 수익률, 사이버, 마스크, 코로나가, 재택근무, 확진자
## Score: etf, 코로나, 대학교, 산업혁명, 코로나바이러스, 자동차, 사이버
## Topic 6 Top Words:
## Highest Prob: 디지털, 대통령, 일자리, 대학원, 투자자, 프로젝트, 목소리
## FREX: 일자리, 대통령, 대학원, 디지털, 신약개발, kaist, 위원회
## Lift: 청와대, 대학원, 일자리, 신입생, 대통령, 신약개발, 한국형
## Score: 청와대, 디지털, 대통령, 대학원, 일자리, 투자자, 신약개발
## Topic 7 Top Words:
## Highest Prob: 스타트, ces, 프로그램, 모빌리티, 중소기업, 라스베이거스, 미디어
## FREX: 스타트, ces, 모빌리티, 라스베이거스, 벤처기업, 중소기업, 마켓인사이트에
## Lift: 마켓인사이트에, electron, 스타트, ces, 라스베이거스, 모빌리티, 벤처기업
## Score: 마켓인사이트에, 스타트, ces, 모빌리티, 프로그램, 라스베이거스, 전시회
## Topic 8 Top Words:
## Highest Prob: 글로벌, 온라인, 부동산, 비즈니스, 바이오, 스마트폰, 카메라
## FREX: 부동산, 글로벌, 카메라, 스마트폰, 의료기기, 영업이익, 온라인
## Lift: 자본시장, 고등학교, 카메라, 영업이익, 부동산, 의료기기, 글로벌
## Score: 자본시장, 글로벌, 온라인, 부동산, 카메라, 바이오, 영업이익
## Topic 9 Top Words:
## Highest Prob: 스마트, 시스템, 서비스, 업무협약, 차세대, mou, 지능형
## FREX: 스마트, 컴퓨팅, 지능형, 시스템, 이미지, mou, 제조업
## Lift: 운전자, 컴퓨팅, 현대차그룹은, 부회장, 스마트, 제조업, 사이언스
## Score: 운전자, 스마트, 시스템, 업무협약, mou, 서비스, 지능형
## Topic 10 Top Words:
## Highest Prob: 빅데이터, 소프트웨어, 전문가, 인공지능ai, 실시간, 사용자, 상반기
## FREX: 소프트웨어, 빅데이터, 배터리, 갤럭시, 상반기, 사용자, 미래기술
## Lift: 갤럭시, 배터리, 미래기술, 소프트웨어, 빅데이터, 솔트룩스는, 상반기
## Score: 갤럭시, 빅데이터, 소프트웨어, 전문가, 배터리, 사용자, 실시간stm패키지는 4종의 가중치를 이용해 주제별로 주요 단어를 제시한다.
- Highest probability: 각 주제별로 단어가 등장할 확률이 높은 정도. 베타() 값.
- FREX: 전반적인 단어빈도의 가중 평균. 해당 주제에 배타적으로 포함된 정도.
- Lift: 다른 주제에 덜 등장하는 정도. 해당 주제에 특정된 정도.
- score: 다른 주제에 등장하는 로그 빈도. 해당 주제에 특정된 정도.
FREX와 Lift는 드문 빈도의 단어도 분류하는 경향이 있으므로, 주로 Highest probability(베타)를 이용한다.
stm패키지의 자세한 내용은 패키지 저자 Roberts의 stm홈페이지와 해설 논문을 참조한다.
10.4 소통
분석한 모형을 통해 말뭉치에 포함된 주제와 주제별 단어의 의미가 무엇인지 전달하기 위해서는 우선 모형에 대한 해석을 제시할 수 있는 시각화가 필요하다. 이를 위해서는 먼저 주요 계수의 의미를 이해할 필요가 있다. 주제모형에서 주제별 확률분포를 나타내는 베타와 감마다.
베타 \(\beta\): 단어가 각 주제에 등장할 확률. 각 단어별로 베타 값 부여. stm모형 요약에서 제시한 Highest probability의 지표다.
감마 \(\gamma\): 문서가 각 주제에 등장할 확률. 각 문서별로 감마 값 부여.
즉, 베타와 감마 계수를 이용해 시각화하면 주제와 주제단어의 의미를 간명하게 나타낼 수 있다.
먼저 tidy()함수를 이용해 stm()함수로 주제모형을 계산한 결과를 정돈텍스트 형식으로 변환한다(줄리아 실기의 시각화 참고)
학습편의를 위해 주제의 수롤 6개로 조정해 다시 모형을 구성하자.
stm_fit <-
stm(
documents = docs,
vocab = vocab,
K = 6, # 토픽의 수
data = meta,
init.type = "Spectral",
seed = 37, # 반복실행해도 같은 결과가 나오게 난수 고정
verbose = F
)
summary(stm_fit) %>% glimpse()## A topic model with 6 topics, 3658 documents and a 290 word dictionary.
## List of 5
## $ prob : chr [1:6, 1:7] "글로벌" "서비스" "플랫폼" "데이터" ...
## $ frex : chr [1:6, 1:7] "스타트" "반도체" "스마트" "데이터" ...
## $ lift : chr [1:6, 1:7] "수익성" "sk하이닉스" "에어컨" "고등학교" ...
## $ score : chr [1:6, 1:7] "청소기" "건조기" "에어컨" "데이터" ...
## $ topicnums: int [1:6] 1 2 3 4 5 6
## - attr(*, "class")= chr "labelTopics"summary(stm_fit)## A topic model with 6 topics, 3658 documents and a 290 word dictionary.## Topic 1 Top Words:
## Highest Prob: 글로벌, 스타트, 카카오, 프로그램, 지난달, 스피커, 트렌드
## FREX: 스타트, 카카오, 프로그램, 글로벌, 지난달, 컨퍼런스, 의료기기
## Lift: 수익성, 청소기, 투자유치, 카카오, 프로그램, 글로벌, 마켓인사이트에
## Score: 청소기, 스타트, 글로벌, 카카오, 프로그램, 스피커, 의료기기
## Topic 2 Top Words:
## Highest Prob: 서비스, 시스템, 반도체, 건조기, 텔레콤, 일자리, 맞춤형
## FREX: 반도체, 건조기, 텔레콤, 맞춤형, 서비스, 사용자, skt
## Lift: sk하이닉스, 개개인, 로보어드바이저, 미래기술, 배터리, 한국표준협회, 건조기
## Score: 건조기, 서비스, 반도체, 텔레콤, 시스템, 맞춤형, 일자리
## Topic 3 Top Words:
## Highest Prob: 플랫폼, 스마트, 빅데이터, 브랜드, 소프트웨어, 투자자, 실시간
## FREX: 스마트, 브랜드, 투자자, 플랫폼, 네이버, 아파트, 빅데이터
## Lift: 에어컨, 스마트, 네이버, 네이버가, 네이버는, 브랜드, 아파트
## Score: 에어컨, 플랫폼, 스마트, 빅데이터, 브랜드, 소프트웨어, 투자자
## Topic 4 Top Words:
## Highest Prob: 데이터, 인공지능ai, 솔루션, 클라우드, 업무협약, 대학원, ict
## FREX: 데이터, 대학원, 알고리즘, 연구소, 목소리, 디자인, 이벤트
## Lift: 고등학교, 데이터, 대학원, 목소리, 뷰노는, 수익률, 신입생
## Score: 데이터, 학습용, 솔루션, 인공지능ai, 대학원, 알고리즘, 클라우드
## Topic 5 Top Words:
## Highest Prob: 디지털, 코로나, 온라인, 산업혁명, 대학교, 가운데, 전문가
## FREX: 디지털, 코로나, 대학교, 코로나로, 온라인, 에너지, 바이러스
## Lift: etf, 바이러스, 사이버, 온라인, 코로나, 코로나로, digit
## Score: etf, 디지털, 코로나, 온라인, 대학교, 사이버, 산업혁명
## Topic 6 Top Words:
## Highest Prob: 지난해, 자동차, ces, 대통령, 코로나바이러스, 인터넷, 비즈니스
## FREX: 자동차, ces, 대통령, 부동산, 지난해, 라스베이거스, 전시회
## Lift: 일현지시각, 전시회, 친환경, ces, electron, rpa, 라스베이거스
## Score: ces, 대통령, 청와대, 자동차, 지난해, 부동산, 전시회10.4.1 주제별 단어 분포
베타 값을 이용해 주제별로 단어의 분포를 막대도표로 시각화하자.
td_beta <- stm_fit %>% tidy(matrix = 'beta')
td_beta %>%
group_by(topic) %>%
slice_max(beta, n = 7) %>%
ungroup() %>%
mutate(topic = str_c("주제", topic)) %>%
ggplot(aes(x = beta,
y = reorder(term, beta),
fill = topic)) +
geom_col(show.legend = F) +
facet_wrap(~topic, scales = "free") +
labs(x = expression("단어 확률분포: "~beta), y = NULL,
title = "주제별 단어 확률 분포",
subtitle = "각 주제별로 다른 단어들로 군집") +
theme(plot.title = element_text(size = 20))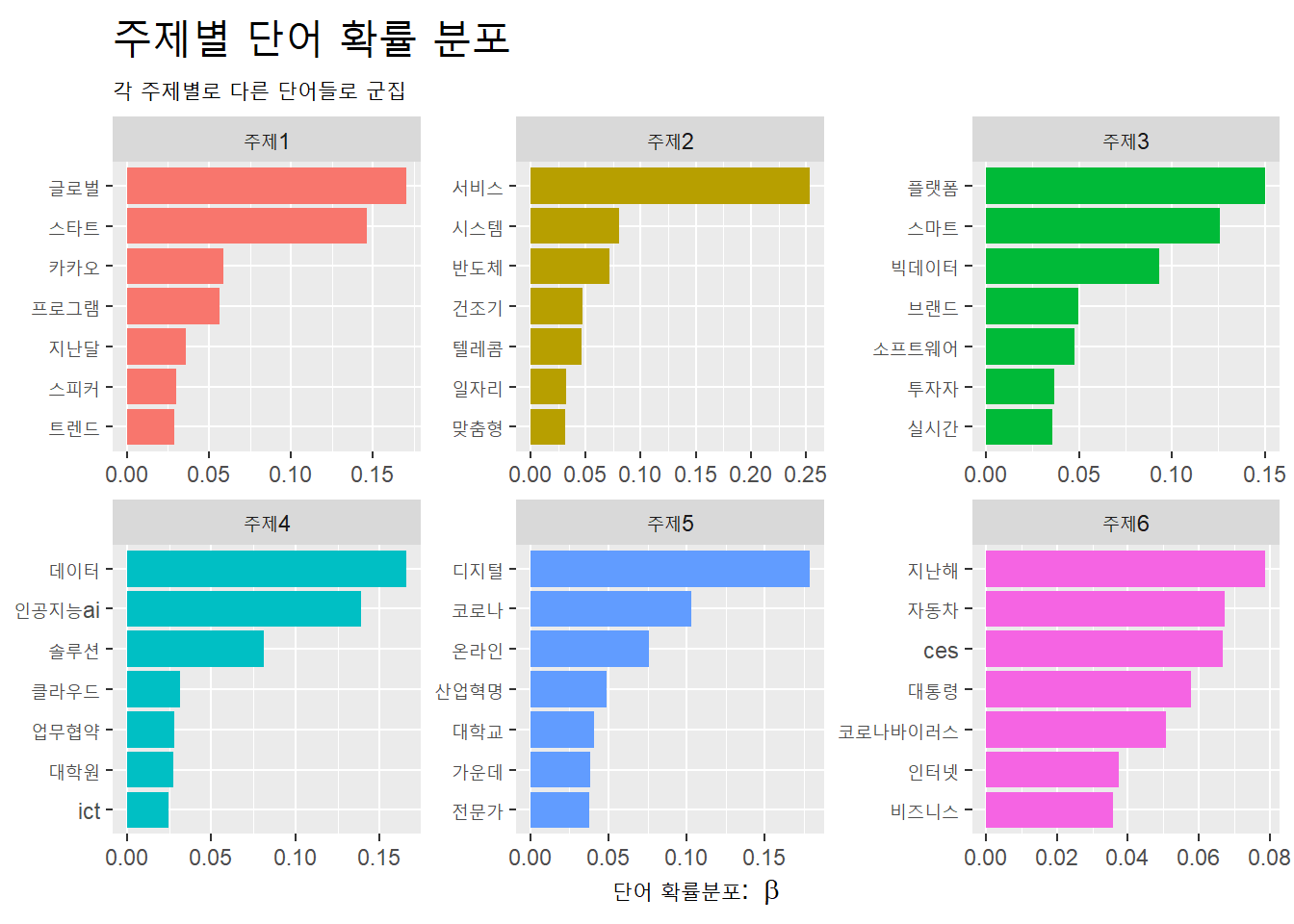
10.4.2 주제별 문서 분포
감마 값을 이용해 주제별로 문서의 분포를 히스토그램으로 시각화한다. x축과 y축에 각각 변수를 투입하는 막대도표와 달리, 히스토그램은 x축에만 변수를 투입하고, y축에는 x축 값을 구간(bin)별로 요약해 표시한다.
각 문서가 각 주제별로 등장할 확률인 감마(\(\gamma\))의 분포가 어떻게 히스토그램으로 표시되는지 살펴보자.
td_gamma <- stm_fit %>% tidy(matrix = "gamma")
td_gamma %>% glimpse()## Rows: 21,948
## Columns: 3
## $ document <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,...
## $ topic <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
## $ gamma <dbl> 0.07534948, 0.10225496, 0.09729881, 0.05099715, 0.10879445...td_gamma %>%
mutate(max = max(gamma),
min = min(gamma),
median = median(gamma))## # A tibble: 21,948 x 6
## document topic gamma max min median
## <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 1 1 0.0753 0.784 0.0239 0.122
## 2 2 1 0.102 0.784 0.0239 0.122
## 3 3 1 0.0973 0.784 0.0239 0.122
## 4 4 1 0.0510 0.784 0.0239 0.122
## 5 5 1 0.109 0.784 0.0239 0.122
## 6 6 1 0.0975 0.784 0.0239 0.122
## 7 7 1 0.107 0.784 0.0239 0.122
## 8 8 1 0.206 0.784 0.0239 0.122
## 9 9 1 0.122 0.784 0.0239 0.122
## 10 10 1 0.166 0.784 0.0239 0.122
## # ... with 21,938 more rowstd_gamma에는 문서별로 감마 값이 부여돼 있다. 1번 문서는 주제1에 포함될 확률(감마)이 0.4이고, 2번 문서는 주제1에 포함될 확률이 0.2다. 감마 값은 최저 0.04에서 최고 0.74까지 있다. 감마는 연속적인 값이므로 이 감마의 값을 일정한 구간(bin)으로 나누면, 각 감마의 구간에 문서(document)가 몇개 있는지 계산해, 감마 값에 따른 각 문서의 분포를 구할 수 있다. 연속하는 값을 구간(bin)으로 구분해 분포를 표시한 도표가 히스토그램이다.
주제별로 문서의 분포를 감마 값에 따라 히스토그램으로 시각해하자. geom_histogram()함수에서 bins =인자의 기본값은 30이다. 즉, bin을 30개로 나눠 분포를 그린다.
td_gamma %>%
ggplot(aes(x = gamma, fill = as.factor(topic))) +
geom_histogram(bins = 100, show.legend = F) +
facet_wrap(~topic) +
labs(title = "주제별 문서 확률 분포",
y = "문서(기사)의 수", x = expression("문서 확률분포: "~(gamma))) +
theme(plot.title = element_text(size = 20))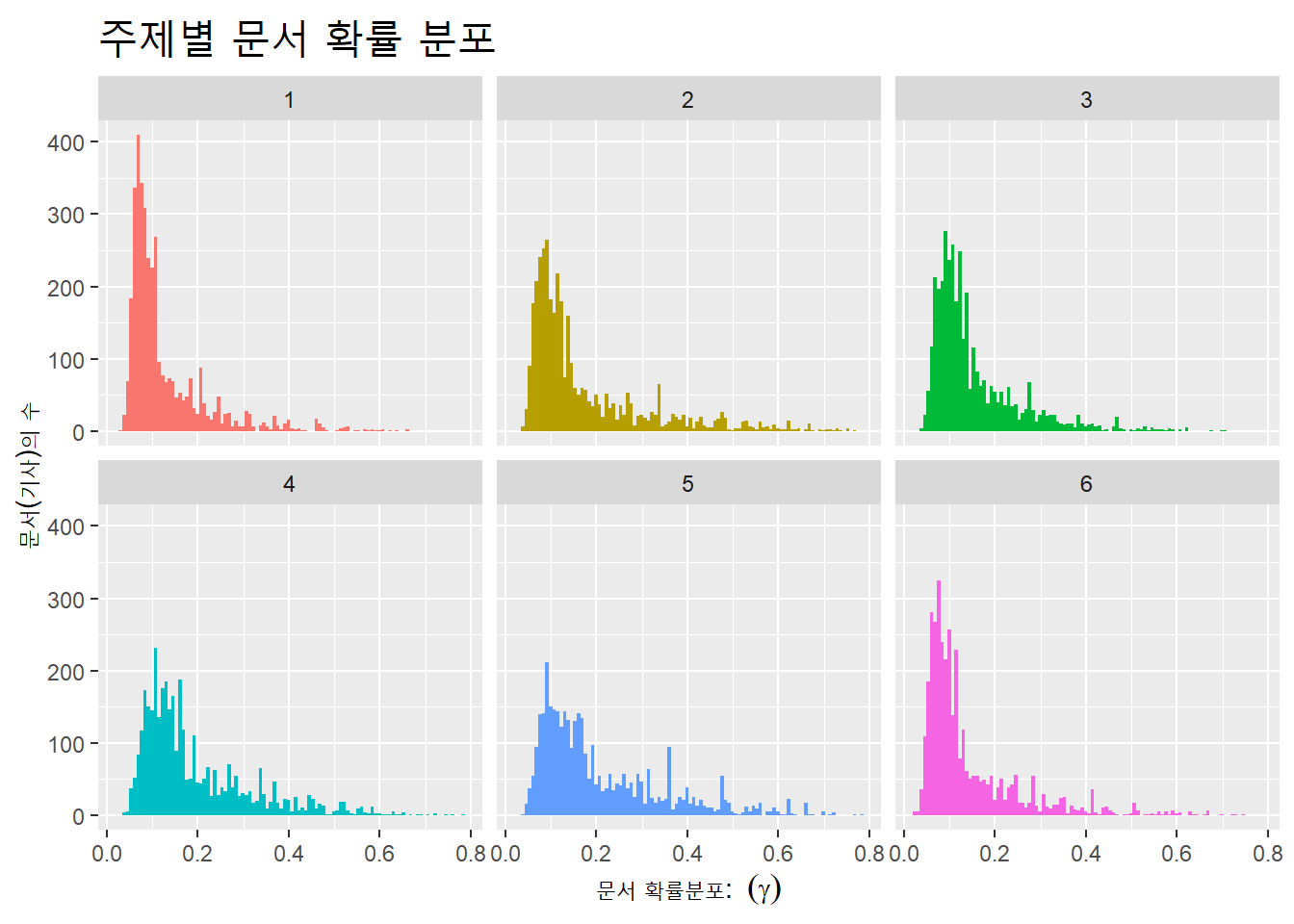
감마가 높은 문서(기사)가 많지 않고, 대부분 낮은 값에 치우쳐 있다. ‘인공지능’ 단일 검색어로 추출한 말뭉치이기 때문이다.
10.4.3 주제별 단어-문서 분포
주제별로 감마의 평균값을 구하면 비교적 각 주제와 특정 문서와 관련성이 높은 순서로 주제를 구분해 표시할 수 있다. 또한 각 주제 별로 대표 단어를 표시할 수 있다. 가장 간단하게 주제별로 단어와 문서의 분포를 표시하는 방법은 stm패키지에서 제공하는 plot()함수다.
stm plot()함수는 type =인자에 ‘summary’ ‘labels’ ‘perspective’ ‘hist’ 등을 투입해 다양한 방식으로 결과를 탐색할 수 있다. 기본적인 정보는 ’summary’를 통해 제시한다.
plot(stm_fit, type = "summary", n = 5)
위 결과를 ggplot2 패키지로 시각화하는 방법은 다음과 같다.
- 주제별 상위 5개 단어 추출해 데이터프레임에 저장.
- 문서의 감마 평균값 주제별로 계산해 주제별 상위 단어 데이터프레임과 결합
10.4.3.1 주제별 상위 5개 단어 추출
td_beta에서 주제별로 상위 5개 단어 추출해 top_terms에 할당한다. 각 주제별로 그룹을 묶어 list형식으로 각 상위단어 5개를 각 주제에 리스트로 묶어준 다음, 다시 데이터프레임의 열로 바꿔준다.
top_terms <-
td_beta %>%
group_by(topic) %>%
slice_max(beta, n = 5) %>%
select(topic, term) %>%
summarise(terms = str_flatten(term, collapse = ", ")) ## `summarise()` ungrouping output (override with `.groups` argument)10.4.3.2 주제별 감마 평균 계산
td_gamma에서 각 주제별 감마 평균값 계산해 top_terms(주제별로 추출한 상위 5개 단어 데이터프레임)와 결합해 gamma_terms에 할당한다.
gamma_terms <-
td_gamma %>%
group_by(topic) %>%
summarise(gamma = mean(gamma)) %>%
left_join(top_terms, by = 'topic') %>%
mutate(topic = str_c("주제", topic),
topic = reorder(topic, gamma))## `summarise()` ungrouping output (override with `.groups` argument)결합한 데이터프레임을 막대도표에 표시한다. 문서 확률분포 평균값과 주제별로 기여도가 높은 단어를 표시한다. 주제별로 문서의 확률분포와 단어의 확률분포를 한눈에 볼수 있다. X축을 0에서 1까지 설정한 이유는 구간을 국소로 설정할 경우, 막대도표가 크기가 상대적으로 크게 보여 결과적으로 데이터의 왜곡이 되기 때문이다.
gamma_terms %>%
ggplot(aes(x = gamma, y = topic, fill = topic)) +
geom_col(show.legend = F) +
geom_text(aes(label = round(gamma, 2)), # 소수점 2자리
hjust = 1.4) + # 라벨을 막대도표 안쪽으로 이동
geom_text(aes(label = terms),
hjust = -0.05) + # 단어를 막대도표 바깥으로 이동
scale_x_continuous(expand = c(0, 0), # x축 막대 위치를 Y축쪽으로 조정
limit = c(0, 1)) + # x축 범위 설정
labs(x = expression("문서 확률분포"~(gamma)), y = NULL,
title = "인공지능 관련보도 상위 주제어",
subtitle = "주제별로 기여도가 높은 단어 중심") +
theme(plot.title = element_text(size = 20))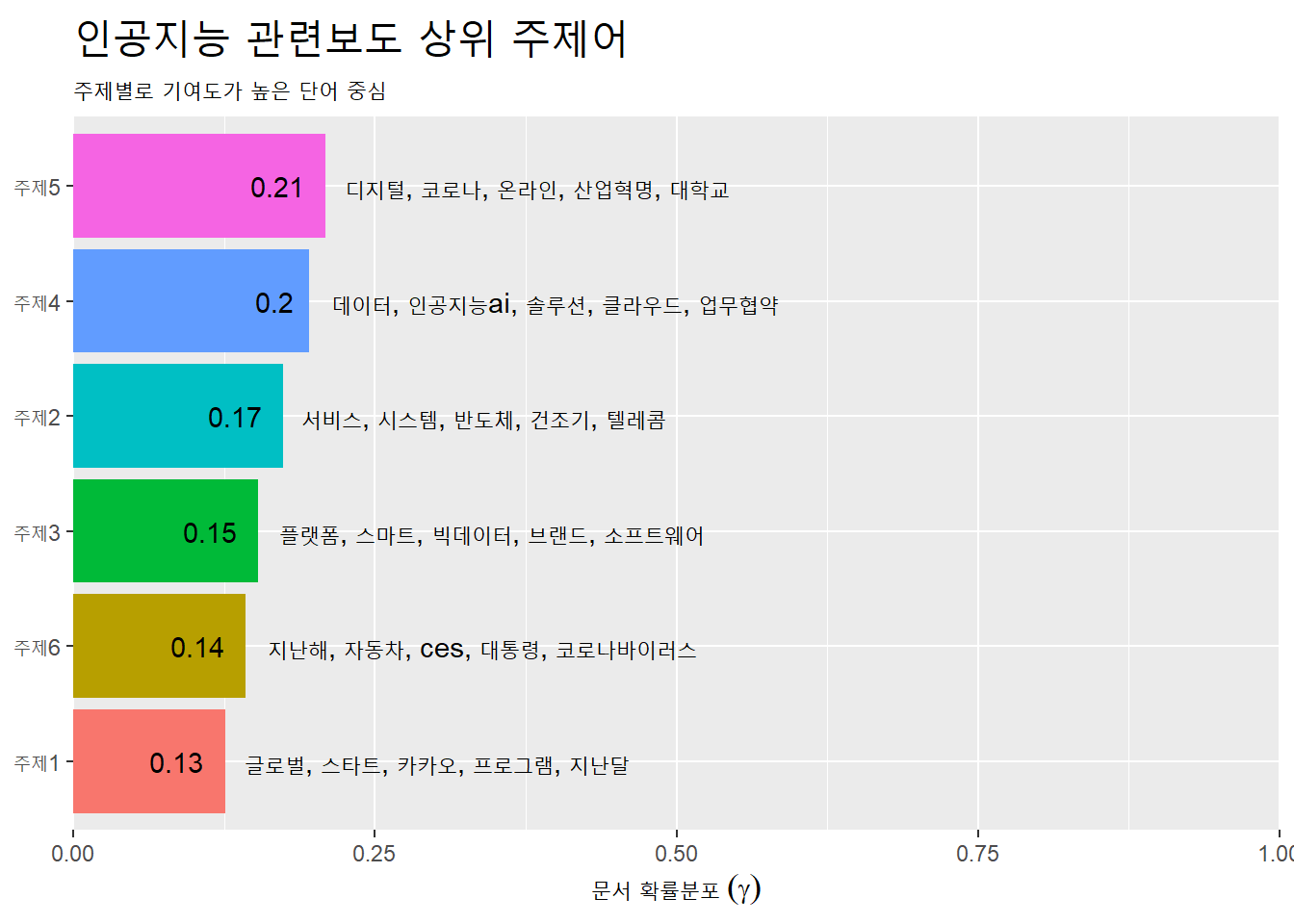
10.4.4 과제
관심있는 검색어를 이용해 빅카인즈에서 기사를 검색해 수집한 기사의 주제모형을 구축한다.
구축한 주제 모형에 대해 시각화한다(주제별 단어분포, 주제별 문서분포, 주제별 단어-문서 분포)