Chapter 4 Use case 2: jointModel() with site-level covariates
This second use case uses the same goby data as in use case 1, except this time we will include site-level covariates that affect the sensitivity of eDNA relative to traditional surveys.
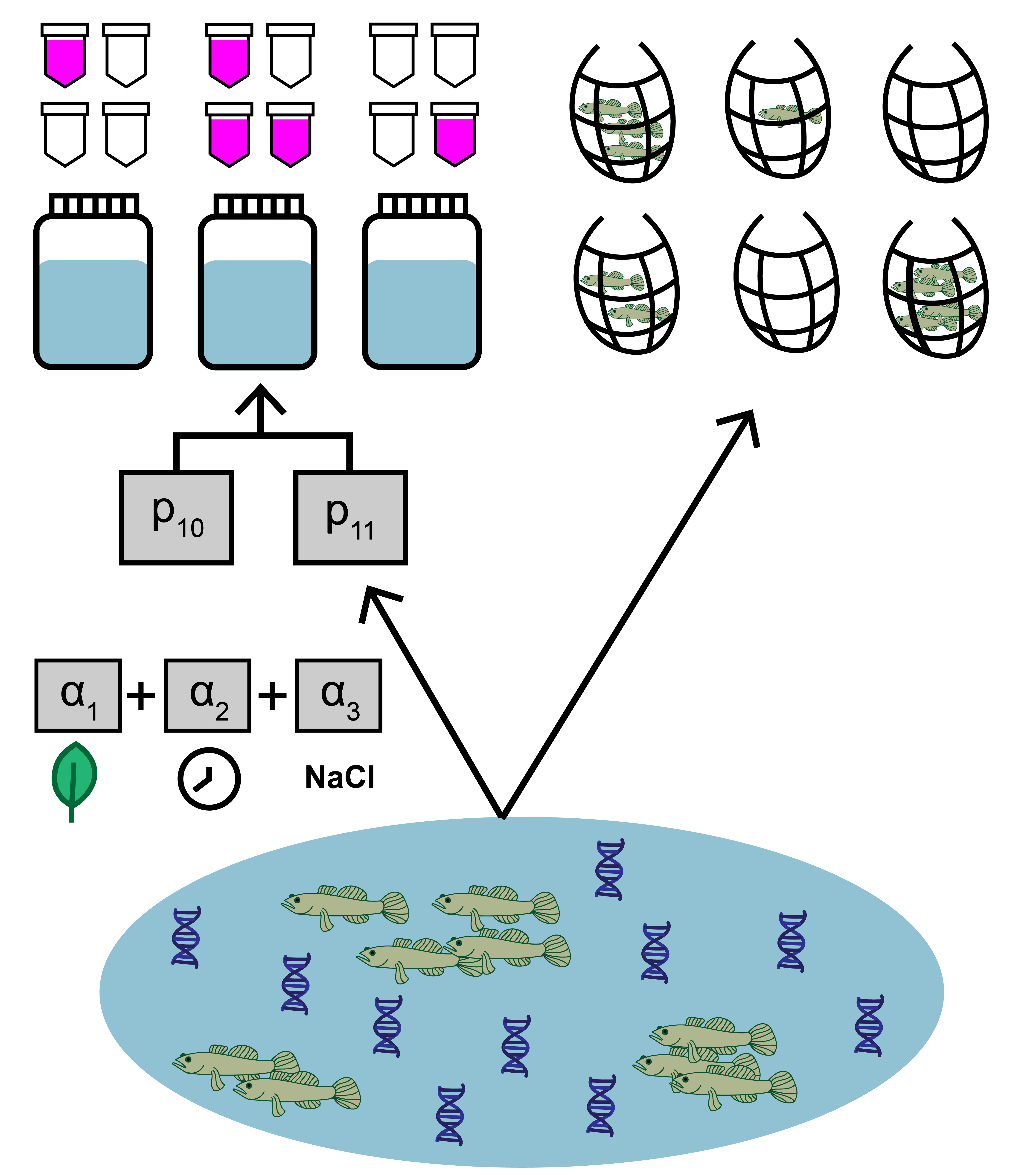
In addition to count and qPCR data, the goby data includes site-level covariates, which is optional when implementing jointModel(). Here, the data represent salinity, mean time to filter eDNA samples, density of other fish, habitat size, and vegetation presence at each site. Two important notes:
Notice that the continuous covariate data is standardized. This is useful since this data will be used in a linear regression. Similarly, one should use dummy variables for categorical variables (like the ‘Veg’ variable).
The columns in the matrix should be named, since these identifiers will be used when fitting the model.
## Salinity Filter_time Other_fishes Hab_size Veg
## [1,] -0.7114925 -1.17 0.0 -0.2715560 0
## [2,] -0.2109183 -1.24 0.0 -0.2663009 0
## [3,] -1.1602831 -1.29 0.0 -0.2717707 0
## [4,] -0.5561419 0.11 160.9 -0.2164312 1
## [5,] -0.9876713 -0.70 113.0 4.9981956 1
## [6,] 1.2562818 -0.55 19.3 -0.2934710 0For more data formatting guidance, see section 2.1.1.
4.1 Fit the model
Now that we understand our data, let’s fit the joint model. The key arguments of this function include:
- data: list of
qPCR.K,qPCR.N,count, andsite.covmatrices - cov: character vector of site-level covariates (this model will only include mean eDNA sample filter time and salinity)
- family: probability distribution used to model the seine count data. A poisson distribution is chosen here.
- p10priors: Beta distribution parameters for the prior on the probability of false positive eDNA detection, p10. c(1,20) is the default specification. More on this later.
- q: logical value indicating the presence of multiple traditional gear types. Here, we’re only using data from one traditional method.
More parameters exist to further customize the MCMC sampling, but we’ll stick with the defaults.
# run the joint model with two covariates
goby.fit.cov1 <- jointModel(data = gobyData, cov=c('Filter_time','Salinity'),
family = 'poisson', p10priors = c(1,20), q=FALSE)goby.fit.cov1 is a list containing:
- model fit (
goby.fit.cov1$model) of the class ‘stanfit’ and can be accessed and interpreted using all functions in the rstan package. - initial values used for each chain in MCMC (
goby.fit.cov1$inits)
4.2 Model selection
We previously made a choice to include two site-level covariates. Perhaps we want to test how that model specification compares to a model specification with different site-level covariates.
# fit a new model with one site-level covariate
goby.fit.cov2 <- jointModel(data = gobyData, cov='Other_fishes',
family = 'poisson', p10priors = c(1,20), q=FALSE)We can now compare the fit of these model to our data using the jointSelect() function, which performs leave-one-out cross validation with functions from the loo package.
## elpd_diff se_diff
## model1 0.0 0.0
## model2 -27.9 23.8These results tell us that model1 has a higher Bayesian LOO estimate of the expected log pointwise predictive density (elpd_loo). This means that goby.fit.cov1 is likely a better fit to the data.
You could keep going with this further and include/exclude different covariates, or compare to a null model without covariates.
4.3 Interpret the output
4.3.1 Summarize posterior distributions
Let’s interpret goby.fit.cov1. Use jointSummarize() to see the posterior summaries of the model parameters.
## mean se_mean sd 2.5% 97.5% n_eff Rhat
## p10 0.003 0.000 0.001 0.001 0.007 17936.752 1
## alpha[1] 0.542 0.001 0.099 0.350 0.734 10214.238 1
## alpha[2] 1.021 0.001 0.118 0.788 1.249 9351.836 1
## alpha[3] -0.349 0.001 0.107 -0.559 -0.133 11165.492 1This summarizes the mean, sd, and quantiles of the posterior estimates of p10 and α, as well as the effective sample size (n_eff) and Rhat for the parameters.
The mean estimated probability of a false positive eDNA detection is 0.001. In use case 1, the scalar parameter β was used to scale the relationship between eDNA and traditional sampling, but now the vector α represents the regression covariates that scales this relationship (see model description for more). alpha[1] corresponds to the intercept of the regression with site-level covariates. alpha[2] corresponds to the regression coefficient associated with Filter_time, and alpha[3] corresponds to the regression coefficient associated with Salinity. Positive regression coefficients indicate an inverse relationship between the covariate and eDNA sensitivity.
We can also use functions from the bayesplot package to examine the posterior distributions and chain convergence.
First let’s look at the posterior distribution for p10.
library(bayesplot)
# plot posterior distribution, highlighting median and 80% credibility interval
mcmc_areas(as.matrix(goby.fit.cov1$model), pars = 'p10', prob = 0.8)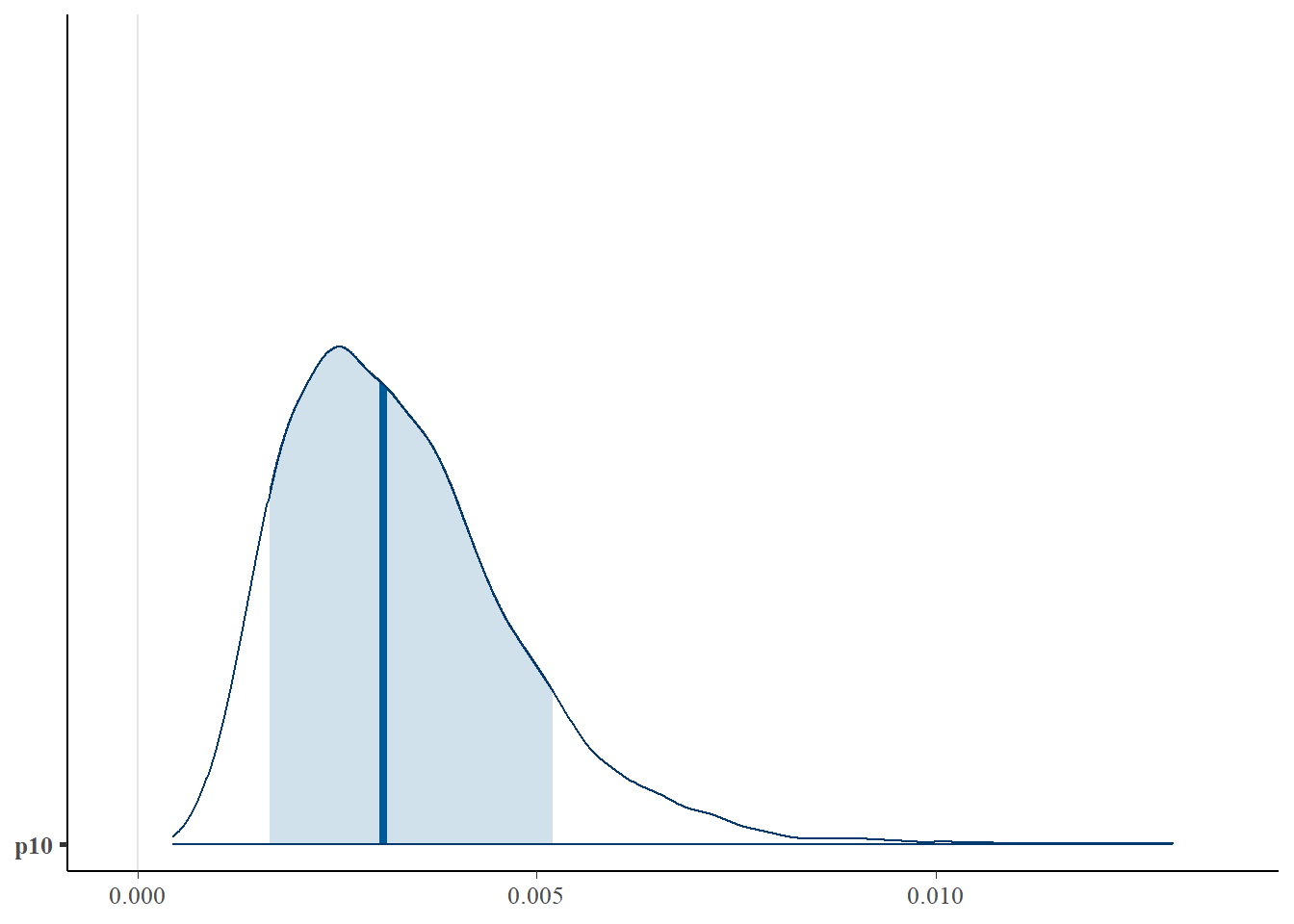
Next let’s look at chain convergence for p10 and μi=1.
# this will plot the MCMC chains for p10 and mu at site 1
mcmc_trace(rstan::extract(goby.fit.cov1$model, permuted = FALSE),
pars = c('p10', 'mu[1]'))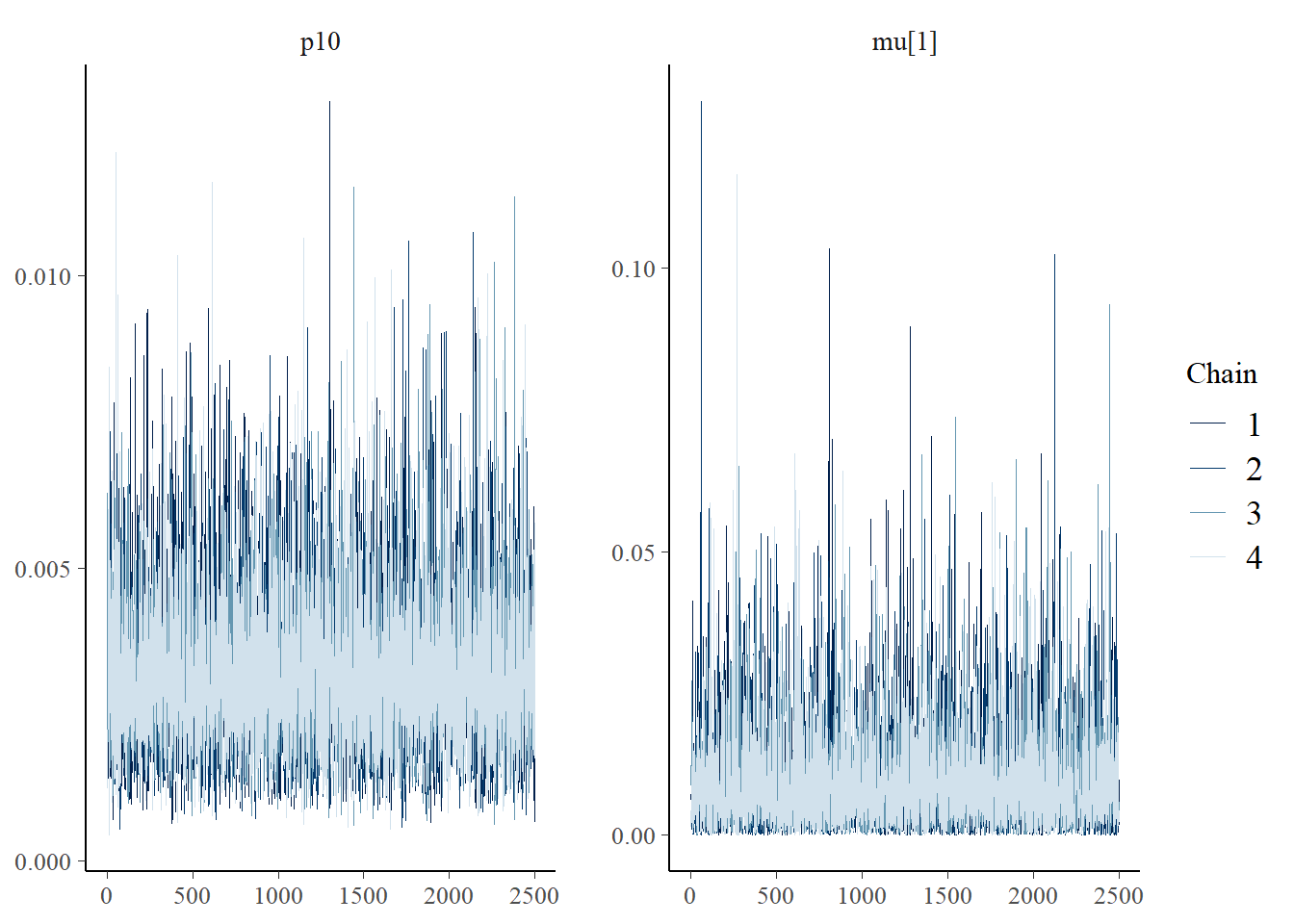
4.3.2 Effort necessary to detect presence
To further highlight the relative sensitivity of eDNA and traditional sampling, we can use detectionCalculate() to find the units of survey effort necessary to detect presence of the species. Here, detecting presence refers to producing at least one true positive eDNA detection or catching at least one individual in a traditional survey.
This function is finding the median number of survey units necessary to detect species presence if the expected catch rate, μ is 0.1, 0.5, or 1. The cov.val argument indicates the value of the covariates used for the prediction. Since the covariate data was standardized, c(0,0) indicates that the prediction is made at the mean Filter_time and Salinity values.
## mu n_traditional n_eDNA
## [1,] 0.1 24 14
## [2,] 0.5 5 4
## [3,] 1.0 3 2We can see that at the mean covariate values, it takes 14 eDNA samples or 24 seine samples to detect goby presence with 0.9 probability if the expected catch rate is 0.1.
Now let’s perform the same calculation under a condition where the Filter_time covariate value is 0.5 z-scores above the mean.
## mu n_traditional n_eDNA
## [1,] 0.1 24 23
## [2,] 0.5 5 5
## [3,] 1.0 3 3At sites with a longer eDNA sample filter time, it would now take 22 eDNA samples or 24 seine samples to detect goby presence if the expected catch rate is 0.1.
Let’s do the same for salinity.
## mu n_traditional n_eDNA
## [1,] 0.1 24 12
## [2,] 0.5 5 3
## [3,] 1.0 3 2At sites with higher salinity, it would now take 12 eDNA samples or 24 seine samples to detect goby presence if the expected catch rate is 0.1.
We can also plot these comparisons. mu.min and mu.max define the x-axis in the plot.
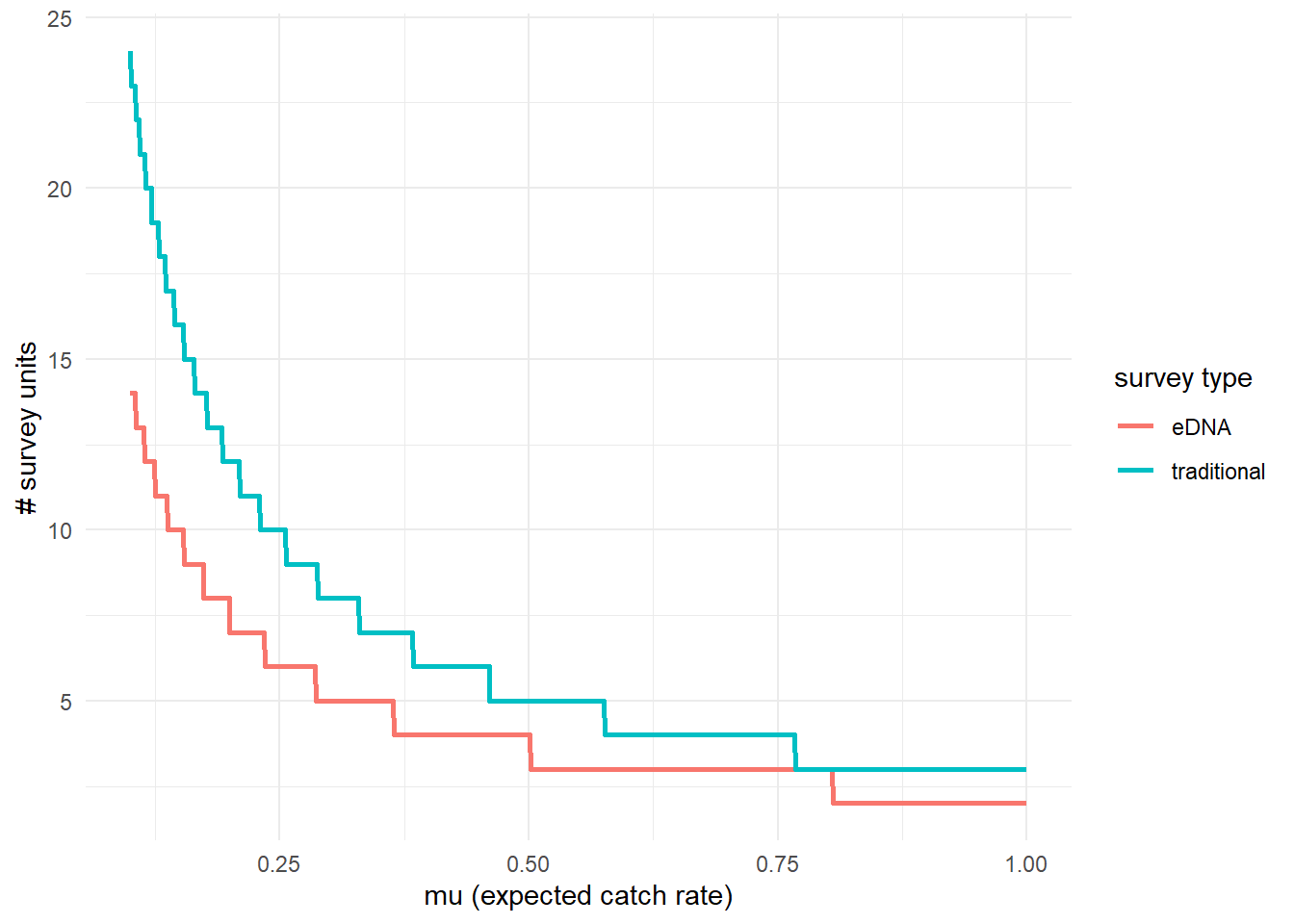
4.3.3 Calculate μcritical
The probability of a true positive eDNA detection, p11, is a function of the expected catch rate, μ. Low values of μ correspond to low probability of eDNA detection. Since the probability of a false-positive eDNA detection is non-zero, the probability of a false positive detection may be higher than the probability of a true positive detection at very low values of μ.
μcritical describes the value of μ where the probability of a false positive eDNA detection equals the probability of a true positive eDNA detection. This value can be calculated using muCritical(). Here, we will calculate this value at the mean covariate values.
## $median
## [1] 0.005294315
##
## $lower_ci
## Highest Density Interval: 1.69e-03
##
## $upper_ci
## Highest Density Interval: 9.60e-03This function calculates μcritical using the entire posterior distributions of parameters from the model, and ‘HDI’ corresponds to the 90% credibility interval calculated using the highest density interval.
4.4 Initial values
By default, eDNAjoint will provide initial values for parameters estimated by the model, but you can provide your own initial values if you prefer. Here is an example of providing initial values for parameters, mu,p10, and alpha, as an input in jointModel().
# set number of chains
n.chain <- 4
# initial values should be a list of named lists
inits <- list()
for(i in 1:n.chain){
inits[[i]] <- list(
# length should equal the number of sites (dim(gobyData$count)[1]) for each chain
mu = stats::runif(dim(gobyData$count)[1], 0.01, 5),
# length should equal 1 for each chain
p10 = stats::runif(1,0.0001,0.08),
# length should equal the number of covariates plus 1 (to account for intercept in regression)
alpha = rep(0.1,length(c('Filter_time','Salinity'))+1)
)
}
# now fit the model
fit.w.inits <- jointModel(data = gobyData, cov=c('Filter_time','Salinity'),
initial_values = inits)##
## SAMPLING FOR MODEL 'joint_binary_cov_pois' NOW (CHAIN 1).
## Chain 1:
## Chain 1: Gradient evaluation took 0.0001 seconds
## Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1 seconds.
## Chain 1: Adjust your expectations accordingly!
## Chain 1:
## Chain 1:
## Chain 1: Iteration: 1 / 3000 [ 0%] (Warmup)
## Chain 1: Iteration: 500 / 3000 [ 16%] (Warmup)
## Chain 1: Iteration: 501 / 3000 [ 16%] (Sampling)
## Chain 1: Iteration: 1000 / 3000 [ 33%] (Sampling)
## Chain 1: Iteration: 1500 / 3000 [ 50%] (Sampling)
## Chain 1: Iteration: 2000 / 3000 [ 66%] (Sampling)
## Chain 1: Iteration: 2500 / 3000 [ 83%] (Sampling)
## Chain 1: Iteration: 3000 / 3000 [100%] (Sampling)
## Chain 1:
## Chain 1: Elapsed Time: 2.402 seconds (Warm-up)
## Chain 1: 4.639 seconds (Sampling)
## Chain 1: 7.041 seconds (Total)
## Chain 1:
##
## SAMPLING FOR MODEL 'joint_binary_cov_pois' NOW (CHAIN 2).
## Chain 2:
## Chain 2: Gradient evaluation took 9.2e-05 seconds
## Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0.92 seconds.
## Chain 2: Adjust your expectations accordingly!
## Chain 2:
## Chain 2:
## Chain 2: Iteration: 1 / 3000 [ 0%] (Warmup)
## Chain 2: Iteration: 500 / 3000 [ 16%] (Warmup)
## Chain 2: Iteration: 501 / 3000 [ 16%] (Sampling)
## Chain 2: Iteration: 1000 / 3000 [ 33%] (Sampling)
## Chain 2: Iteration: 1500 / 3000 [ 50%] (Sampling)
## Chain 2: Iteration: 2000 / 3000 [ 66%] (Sampling)
## Chain 2: Iteration: 2500 / 3000 [ 83%] (Sampling)
## Chain 2: Iteration: 3000 / 3000 [100%] (Sampling)
## Chain 2:
## Chain 2: Elapsed Time: 2.029 seconds (Warm-up)
## Chain 2: 4.233 seconds (Sampling)
## Chain 2: 6.262 seconds (Total)
## Chain 2:
##
## SAMPLING FOR MODEL 'joint_binary_cov_pois' NOW (CHAIN 3).
## Chain 3:
## Chain 3: Gradient evaluation took 9.4e-05 seconds
## Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 0.94 seconds.
## Chain 3: Adjust your expectations accordingly!
## Chain 3:
## Chain 3:
## Chain 3: Iteration: 1 / 3000 [ 0%] (Warmup)
## Chain 3: Iteration: 500 / 3000 [ 16%] (Warmup)
## Chain 3: Iteration: 501 / 3000 [ 16%] (Sampling)
## Chain 3: Iteration: 1000 / 3000 [ 33%] (Sampling)
## Chain 3: Iteration: 1500 / 3000 [ 50%] (Sampling)
## Chain 3: Iteration: 2000 / 3000 [ 66%] (Sampling)
## Chain 3: Iteration: 2500 / 3000 [ 83%] (Sampling)
## Chain 3: Iteration: 3000 / 3000 [100%] (Sampling)
## Chain 3:
## Chain 3: Elapsed Time: 2.384 seconds (Warm-up)
## Chain 3: 4.396 seconds (Sampling)
## Chain 3: 6.78 seconds (Total)
## Chain 3:
##
## SAMPLING FOR MODEL 'joint_binary_cov_pois' NOW (CHAIN 4).
## Chain 4:
## Chain 4: Gradient evaluation took 0.000205 seconds
## Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 2.05 seconds.
## Chain 4: Adjust your expectations accordingly!
## Chain 4:
## Chain 4:
## Chain 4: Iteration: 1 / 3000 [ 0%] (Warmup)
## Chain 4: Iteration: 500 / 3000 [ 16%] (Warmup)
## Chain 4: Iteration: 501 / 3000 [ 16%] (Sampling)
## Chain 4: Iteration: 1000 / 3000 [ 33%] (Sampling)
## Chain 4: Iteration: 1500 / 3000 [ 50%] (Sampling)
## Chain 4: Iteration: 2000 / 3000 [ 66%] (Sampling)
## Chain 4: Iteration: 2500 / 3000 [ 83%] (Sampling)
## Chain 4: Iteration: 3000 / 3000 [100%] (Sampling)
## Chain 4:
## Chain 4: Elapsed Time: 1.837 seconds (Warm-up)
## Chain 4: 4.529 seconds (Sampling)
## Chain 4: 6.366 seconds (Total)
## Chain 4:
## Refer to the eDNAjoint guide for visualization tips: https://bookdown.org/abigailkeller/eDNAjoint_vignette/tips.html#visualization-tips## $chain1
## $chain1$mu_trad
## [1] 2.04393687 2.13858200 0.83867409 1.82922529 4.21995384 1.38082632 4.28211934
## [8] 3.53658081 4.16123419 3.76859712 1.33127074 4.55114092 2.33118368 0.81521753
## [15] 4.47183180 2.04776085 2.64797997 0.66674815 1.39890668 1.00416212 0.68292900
## [22] 3.09098650 0.59747924 2.53917391 1.64250020 4.37446245 0.11000119 0.08903043
## [29] 0.49631369 1.36427525 1.63104675 2.30288276 4.69588402 0.60685573 3.98933093
## [36] 4.26983533 4.46034743 0.47263531 0.89076780
##
## $chain1$mu
## [1] 2.04393687 2.13858200 0.83867409 1.82922529 4.21995384 1.38082632 4.28211934
## [8] 3.53658081 4.16123419 3.76859712 1.33127074 4.55114092 2.33118368 0.81521753
## [15] 4.47183180 2.04776085 2.64797997 0.66674815 1.39890668 1.00416212 0.68292900
## [22] 3.09098650 0.59747924 2.53917391 1.64250020 4.37446245 0.11000119 0.08903043
## [29] 0.49631369 1.36427525 1.63104675 2.30288276 4.69588402 0.60685573 3.98933093
## [36] 4.26983533 4.46034743 0.47263531 0.89076780
##
## $chain1$log_p10
## [1] -3.772597
##
## $chain1$alpha
## [1] 0.1 0.1 0.1
##
##
## $chain2
## $chain2$mu_trad
## [1] 3.01635005 2.06144046 4.83685517 1.67723976 2.74920443 0.07283268 0.94866626
## [8] 4.02085528 3.78160175 2.44499350 0.93607497 2.77077091 2.78276236 4.13368673
## [15] 0.78000261 0.88399910 3.33101891 4.96586164 3.27106349 0.40887031 1.86665386
## [22] 2.04405172 3.07021541 0.62712856 4.18949439 4.20857730 1.62403515 1.51708704
## [29] 3.71060991 1.33882569 0.59757919 0.30688147 0.02004547 1.31292310 0.11612407
## [36] 1.79071353 2.38124515 0.26818945 3.27737829
##
## $chain2$mu
## [1] 3.01635005 2.06144046 4.83685517 1.67723976 2.74920443 0.07283268 0.94866626
## [8] 4.02085528 3.78160175 2.44499350 0.93607497 2.77077091 2.78276236 4.13368673
## [15] 0.78000261 0.88399910 3.33101891 4.96586164 3.27106349 0.40887031 1.86665386
## [22] 2.04405172 3.07021541 0.62712856 4.18949439 4.20857730 1.62403515 1.51708704
## [29] 3.71060991 1.33882569 0.59757919 0.30688147 0.02004547 1.31292310 0.11612407
## [36] 1.79071353 2.38124515 0.26818945 3.27737829
##
## $chain2$log_p10
## [1] -3.080158
##
## $chain2$alpha
## [1] 0.1 0.1 0.1
##
##
## $chain3
## $chain3$mu_trad
## [1] 0.8794226 1.0186518 3.7261763 3.1065839 1.7779727 4.7689924 0.5885190 4.8133300
## [9] 4.6733623 1.5499288 0.7457254 3.1389496 0.7198004 1.1160017 3.1807162 2.1938935
## [17] 4.6646939 1.5674118 3.7160366 2.0399502 3.4711256 1.8639314 4.9833057 4.0642200
## [25] 0.7002595 0.2942121 3.8189961 0.7851154 2.5977143 3.9956082 3.7263295 1.1804083
## [33] 1.9211221 3.9175265 4.6037509 3.9741671 2.4296695 0.3311350 0.3262873
##
## $chain3$mu
## [1] 0.8794226 1.0186518 3.7261763 3.1065839 1.7779727 4.7689924 0.5885190 4.8133300
## [9] 4.6733623 1.5499288 0.7457254 3.1389496 0.7198004 1.1160017 3.1807162 2.1938935
## [17] 4.6646939 1.5674118 3.7160366 2.0399502 3.4711256 1.8639314 4.9833057 4.0642200
## [25] 0.7002595 0.2942121 3.8189961 0.7851154 2.5977143 3.9956082 3.7263295 1.1804083
## [33] 1.9211221 3.9175265 4.6037509 3.9741671 2.4296695 0.3311350 0.3262873
##
## $chain3$log_p10
## [1] -2.8294
##
## $chain3$alpha
## [1] 0.1 0.1 0.1
##
##
## $chain4
## $chain4$mu_trad
## [1] 4.4877811 2.1727203 4.8477993 4.9769401 2.1355919 2.4980598 1.1584333 2.0122739
## [9] 4.6931959 1.6861870 1.4401861 2.4905163 1.2097323 2.1351682 0.9459020 2.8799340
## [17] 2.7651233 3.4719783 4.5412596 3.0174997 2.6866175 4.1852320 3.0637430 2.9050648
## [25] 2.7907714 4.7318266 0.5644405 1.6773707 0.3710265 1.7159281 0.2033197 2.6271268
## [33] 4.0964929 0.1488295 4.8786893 0.3042488 3.2843939 2.6484452 1.3460973
##
## $chain4$mu
## [1] 4.4877811 2.1727203 4.8477993 4.9769401 2.1355919 2.4980598 1.1584333 2.0122739
## [9] 4.6931959 1.6861870 1.4401861 2.4905163 1.2097323 2.1351682 0.9459020 2.8799340
## [17] 2.7651233 3.4719783 4.5412596 3.0174997 2.6866175 4.1852320 3.0637430 2.9050648
## [25] 2.7907714 4.7318266 0.5644405 1.6773707 0.3710265 1.7159281 0.2033197 2.6271268
## [33] 4.0964929 0.1488295 4.8786893 0.3042488 3.2843939 2.6484452 1.3460973
##
## $chain4$log_p10
## [1] -3.553015
##
## $chain4$alpha
## [1] 0.1 0.1 0.1