3 A magyar születési mutatók egyváltozós modellezése Box-Jenkins eljárással
Mielőtt a születési mutatók alakulásának gazdasági és társadalmi hatásainak elemzését elvégezném a születési mutatók egyváltozós modellezését készítem el. Ezen elemzés során ARIMA-modellezést hajtok végre Box-Jenkins-féle módszerrel. Dolgozatomban ennek a lépésnek a célja, hogy a későbbi más változókkal vizsgált kapcsolat vizsgálat előtt jobban megismerjük a vizsgált idősort, megmutatva, hogy alakulása mennyire függ saját maga korábbi értékeitől (mennyire erős esetünkben az útfüggőség). Ily módon elkerülhető, hogy úgy elemezzünk kapcsolatvizsgálatot idősorok között, hogy esetleg tudnánk, hogy a tárgyalt idősor alakulásának oka leginkább a saját múltbeli értékeiben keresendő (Granger & Newbold, 1973).
3.1 A módszertan bemutatása
A Box-Jenkins módszer népszerűségét az idősorelemzésben az adja, hogy majdnem minden esetben használható feltétel nélküli előrejelzésre, követelményei között pusztán a gyenge stacionaritás, illetve az idősor korábbi értékeinek ismeretei szükséges, továbbá bizonyos esetekben jobb előrejelzést képesek produkálni, mint a hagyományos ökonometriai modellek (Kirchgässner & Wolters, 2007).
A Box-Jenkins-módszer lépései tradicionálisan a következők: (1.) Az idősor differenciázásával az eredeti idősor stacionerré alakítás (itt továbbra is a fentebb említett gyenge stacionaritás értendő, tehát az idősor minden egyes pontjára teljesülnie kell az első két momentumban való egyezőségnek), (2.) modell identifikálása, (3.) feltételezett modell becslése, (4.) modell-diagnosztika (Maddala, 2004). Az idősor stacionárius mivoltának eldöntése kiterjesztett Dickey-Fuller teszttel kerül eldöntésre, majd ezt követően az identifikáció (ARIMA-modellhez tartozó autoregresszív és mozgóátlag paraméterek számának meghatározása) a korrelogramok szemrevételével kerül eldöntésre. A modell-diagnosztika során szükséges ellenőrizni, hogy a reziduumok fehérzajok-e (ellenőrzése Ljung-Box-teszttel), illetve normál eloszlást követnek-e (Jarque-Bera-teszttel kerül megvizsgálásra). Amennyiben a reziduumok nem fehérzajok, tehát továbbra is maradt benne autokorreláció, úgy a modell előrejelzésre alkalmatlan. Amennyiben a hibatagok nem normáleloszlást követnek úgy a két alkalmazható becslési eljárás közül a Maximum Likelihood (ML) módszere torzított eredményt fog adni, így csak a feltételes legkisebb négyzetek eljárás (conditional sum of squares, CSS) alkalmazható.
Miután a korrelogramok szemrevételével csak a tiszta mozgóátlag-, illetve véletlen bolyongás-folyamatok azonosíthatók egyértelműen, így több lehetséges modell megbecslése ajánlott, majd a modellek illeszkedésének jóságát jellemző információs kritériumok segítségével kiválasztani a legjobb modellt.
Jelen tanulmányban további komplexitást jelent, hogy három különböző idősoron is elvégzem a modellezést, az így kapott modellek illeszkedése pedig nem összehasonlítható az információs kritériumok alapján. Ennek megoldására az alábbi módon járok el: (3.) mind a három változó esetén az utolsó 10 megfigyelés elhagyásával becslem meg a lehetséges modelleket, (4.) az így elkészült modellek közül kiválasztom Akaike-féle információs kritérium alapján a legjobb illeszkedésű modelleket idősoronként. Ezt követően ezeket a (5.) modelleket alávetem a fentebb megnevezett modell-diagnosztikai teszteknek, (6.) és elkészítem velük a modellbecslésből kihagyott 10 évre az ex post előrejelzéseket, amelyek segítségével a modellek közül kiválasztom a legkisebb átlagos abszolút százalékos hibával (mean absolute percentage error, MAPE) rendelkezőt.
3.2 Egy általános modell bemutatása
A következőben a fentebb felsorolt lépések közül az első négyet végzem el részletesen a termékenységi ráta differenciázott idősorán CSS módszerrel.5 Az identifikáció első lépése a differenciázás számának megválasztása (d). A d számú differenciázásra akkor van szükség, ha az idősor eredetileg nem stacioner, de d számú differenciázás elvégzése után már stacioner6 a kapott idősor. Mindhárom mutató esetében szemrevételezéssel is megállapítható, hogy ez nem teljesül. Az itt tárgyalt esetben a kiterjesztett Dickey-Fuller (Augmented Dickey-Fuller, ADF) teszt p-értéke 44.80%. Miután a Dickey-Fuller teszt esetében az alternatív hipotézis tartalmazza azt az állítást, hogy az idősor stacioner, így valóban most már teszttel is megállapíthatjuk, hogy ez az idősor nem stacioner, mivel trendet tartalmaz. Magát a trendet a Hodrick-Prescott szűrő segítségével is prezentálom a 3. ábrán.
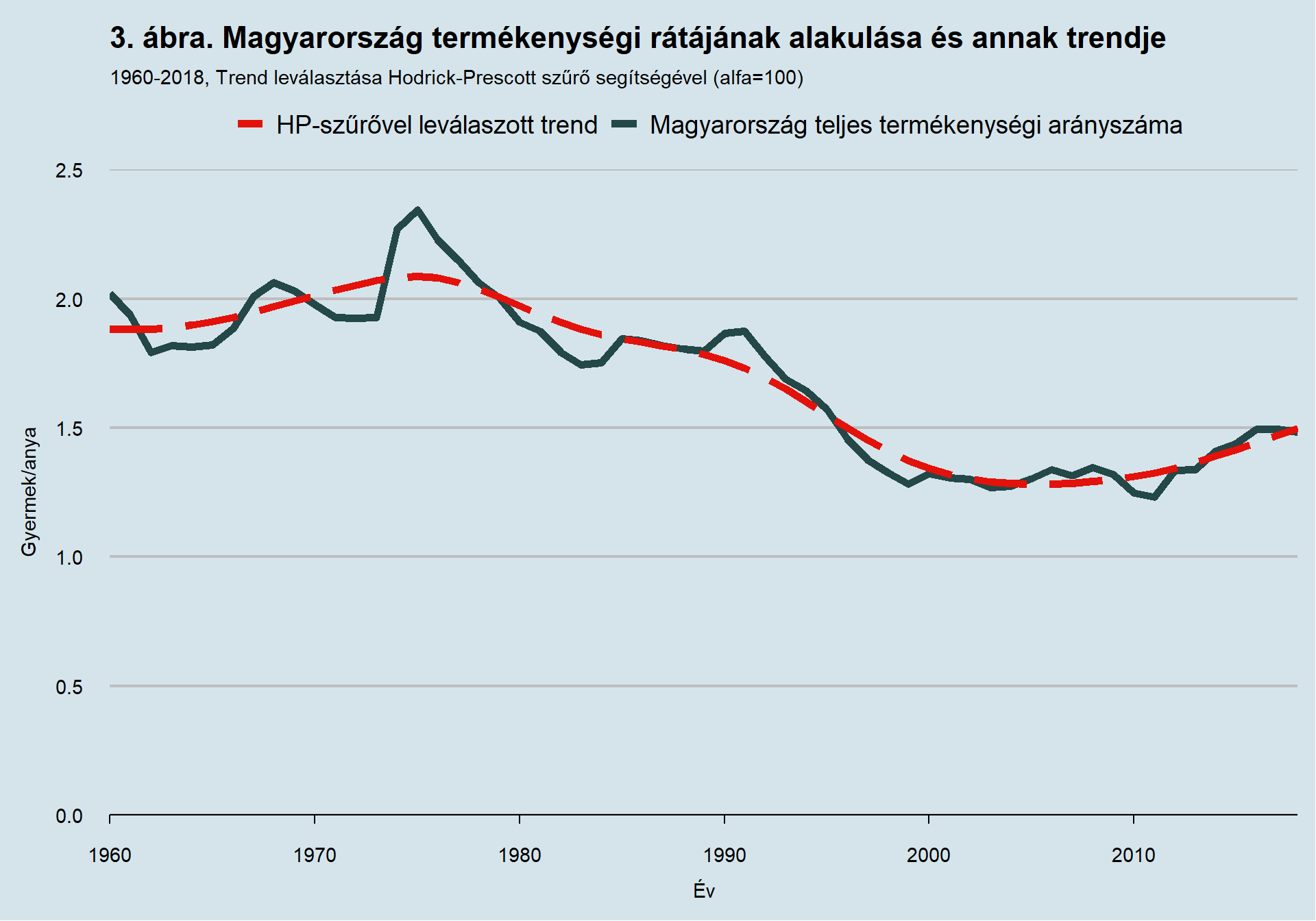
Mivel az idősor trendet tartalmaz, így annak differenciázással stacionerré tétele szükséges. Ez azt jelenti, hogy az egyes évek növekménytagjait vesszük szemügyre. Ezen az idősoron elvégezve a Dickey-Fuller tesztet a kapott p-értékünk 2,72% (trendszűréses teszt), tehát ez már stacioner. Az itt tárgyalt növekménytagokat a 4. ábra mutatja be.
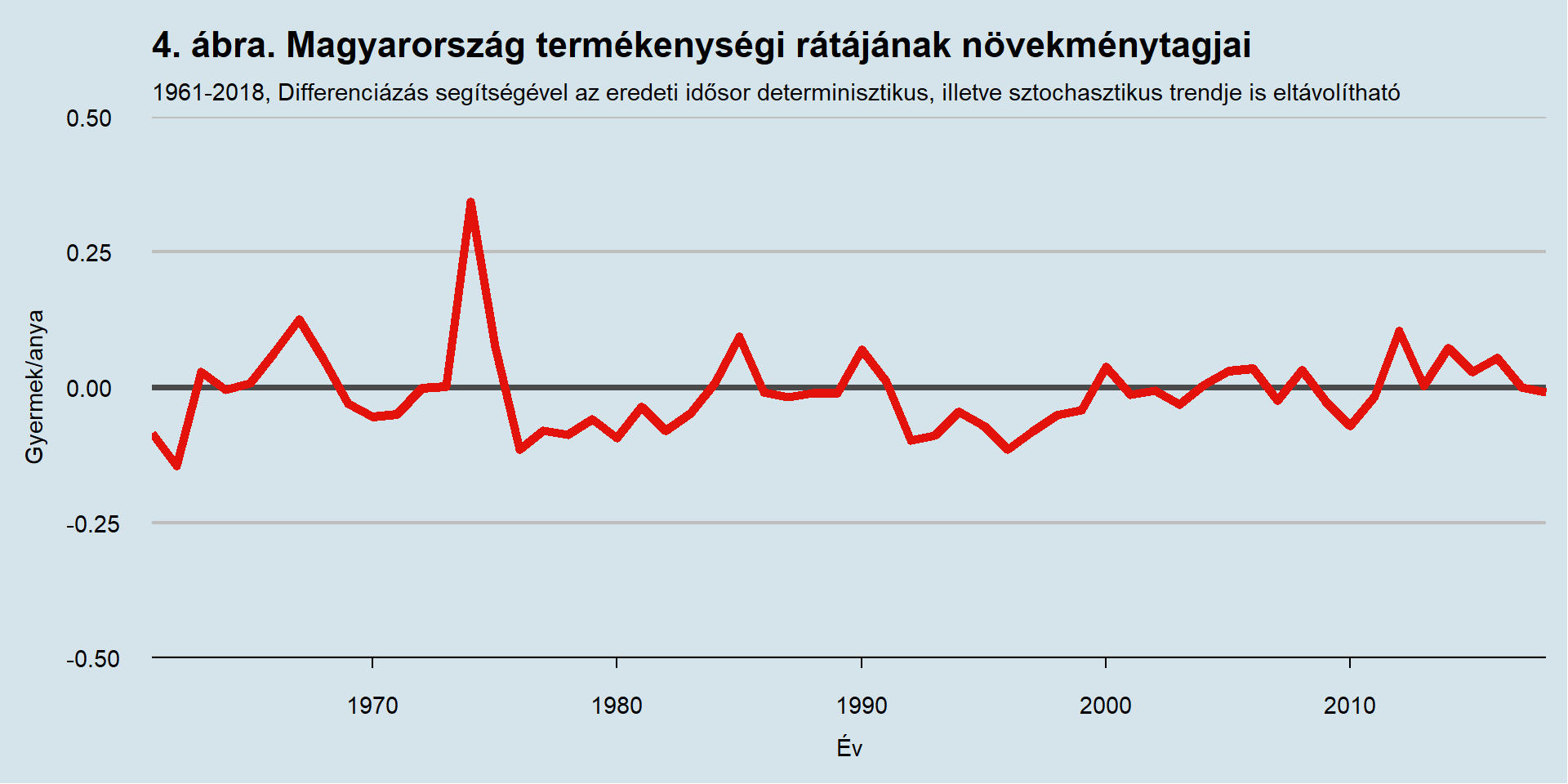
A Box-Jenkins eljárás következő lépése a korrelogramok szemrevétele.
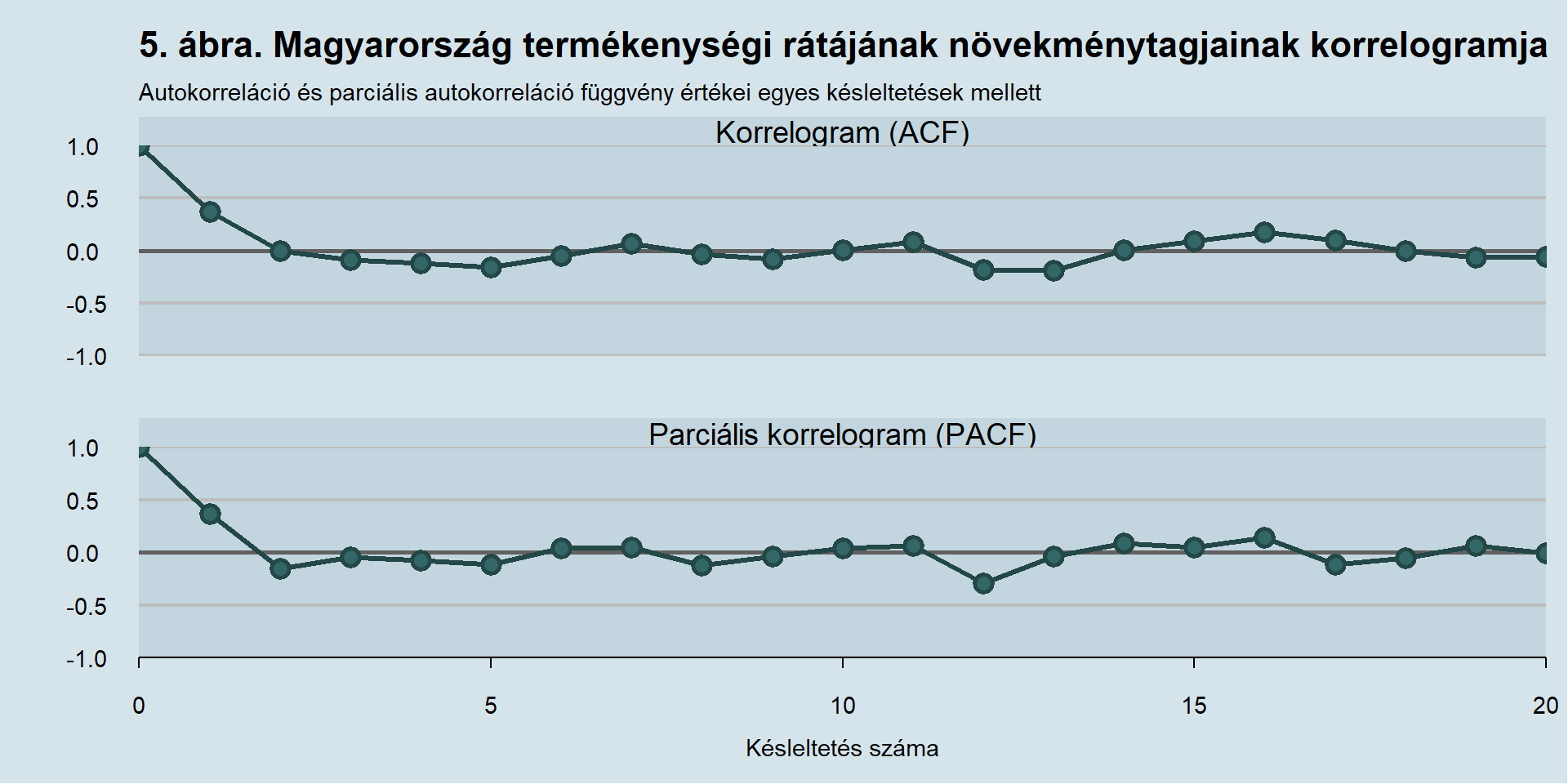
Jelen esetben mind a korrelogram (ACF), mind a paricális korrelogram (PACF) letörik már az első késleltetés után, tehát nem egy tiszta mozgóátlag- vagy véletlen bolyongás-folyamattal állunk szemben. Érdemes több modellt is becsülni, majd Akaike-féle információs kritérium alapján dönteni. Néhány így megfontolásra kerülő modell és a hozzájuk tartozó információs kritérium értékét mutatja be az 2. táblázat.
| Modell | AIC |
|---|---|
| ARMA (2, 2) konstans nélkül | -242.885 |
| ARMA (0, 0) konstans nélkül | -240.849 |
| ARMA (1, 0) konstans nélkül | -245.811 |
| ARMA (0, 1) konstans nélkül | -247.251 |
| ARMA (0, 0) konstanssal | -241.485 |
| ARMA (1, 1) konstans nélkül | -243.801 |
| ARMA (0, 2) konstans nélkül | -244.906 |
| ARMA (1, 2) konstans nélkül | -242.047 |
| ARMA (0, 1) konstanssal | -248.674 |
| ARMA (1, 1) konstanssal | -245.643 |
| ARMA (0, 2) konstanssal | -246.473 |
| ARMA (1, 0) konstanssal | -247.669 |
| ARMA (1, 2) konstanssal | -244.050 |
Az információs kritérium hibajellegű mutató, így a modellezés során cél a minimalizálása, ebből következik, hogy jelen esetben a legjobb modell az ARMA (0, 1), azaz a termékenységi ráta növekménytagjára egy mozgóátlag modell illeszkedik a legjobban. Mielőtt felhasználnánk a modell szükséges ellenőrizni a reziduumok autokorrelálatlanságát. A Ljung-Box teszt-statisztika p-értéke 93,75%, ahol a nullhipotézis szerint a maradéktagok autokorrelálatlanok, tehát ez a modell felhasználható előrejelzési célokra.
Ezzel a modellel elkészítve az ex post előrejelzést 2009-tól 2018-ig terjedő időszakra és azt a valós értékekkel összevetve kapjuk, hogy ennek a modellnek a MAPE mutatója 6,16%, amely a modell előrejelző képességét adja meg.
3.3 Modellbecslés
A fentebb ismertetett eljárást végrehajtottam mind a három születési mutatón, amelyeket ez a dolgozat tárgyal. Első lépés az idősorok stacionerré tétele. Ehhez az idősorok 4 esetén futattam kiterjesztett Dickey-Fuller tesztet: (1) a transzformálatlan idősorokon, (2) az idősorok növekménytagjain, (3) az idősorok természetes alapú logaritmussal történő transzformáltjaikon, Magyarországon (4) a természetes alapú logaritmus után differenciázott idősorokon7. A trendet tartalmazó segédregresszióval futatott tesztek eredményét a 3. táblázat tartalmazza.
| Születési mutató | Transzformáció | ADF-teszthez tartozó p-érték |
|---|---|---|
| Összes születés | x | 24.93% |
| Összes születés | diff(x) | 4.06% |
| Összes születés | log(x) | 22.90% |
| Összes születés | diff(log(x)) | 4.85% |
| Ezer főre eső születés | x | 25.06% |
| Ezer főre eső születés | diff(x) | 3.36% |
| Ezer főre eső születés | log(x) | 22.92% |
| Ezer főre eső születés | diff(log(x)) | 4.49% |
| TTA | x | 44.80% |
| TTA | diff(x) | 2.72% |
| TTA | log(x) | 50.05% |
| TTA | diff(log(x)) | 5.68% |
A 3. táblázatból megállapítható, hogy 5%-os szignifikanciaszinten az éves összes születésszám és az ezer főre eső születésszám differenciázott, illetve logdifferenciázott transzformációja tekinthető stacionernek. Mindazonáltal a teljes termékenységi arányszám logdifferenciázott transzformációjának tesztjéhez tartozó p-érték is csak éppen meghaladja az 5%-os értéket, ezért mindhárom mutató esetében a differenciázott és logdifferenciázott idősorokon is elvégzem a Box-Jenkins eljárást. Az így kapott eredmények a 4. táblázatban láthatók.
| Születési mutató | Transzformáció | Illesztett modell | Becslés módszere | MAPE | Ljung-Box (p-érték) | Jarque-Bera (p-érték) |
|---|---|---|---|---|---|---|
| Összes születés | diff(x) | ARMA (1, 0) | ML | 10.24% | 90.39% | 0.00% |
| Összes születés | diff(x) | ARMA (0, 1) | CSS | 10.50% | 86.79% | 0.00% |
| Összes születés | log(diff(x)) | ARMA (1, 0) | ML | 33.17% | 97.35% | 0.00% |
| Összes születés | log(diff(x)) | ARMA (1, 0) | CSS | 22.27% | 95.40% | 0.00% |
| Ezer főre eső születés | diff(x) | ARMA (0, 1) | ML | 8.77% | 85.52% | 0.00% |
| Ezer főre eső születés | diff(x) | ARMA (0, 1) | CSS | 8.82% | 85.17% | 0.00% |
| Ezer főre eső születés | log(diff(x)) | ARMA (1, 0) | ML | 32.77% | 94.48% | 0.00% |
| Ezer főre eső születés | log(diff(x)) | ARMA (2, 0) | CSS | 20.27% | 93.08% | 0.00% |
| TTA | diff(x) | ARMA (0, 1) | ML | 6.16% | 94.02% | 0.00% |
| TTA | diff(x) | ARMA (0, 1) | CSS | 6.16% | 93.75% | 0.00% |
| TTA | log(diff(x)) | ARMA (0, 1) | ML | 30.75% | 97.68% | 0.00% |
| TTA | log(diff(x)) | ARMA (2, 0) | CSS | 20.76% | 97.53% | 0.00% |
Megjegyzés: az itt felsorolt modellek egyike sem tartalmaz konstanst. Ennek oka, hogy a differenciázást követően az idősor a nulla körül ingadozik, így a konstans nélküli modellek Akaike-féle információs kritériuma kivétel nélkül mindig alacsonyabb volt.
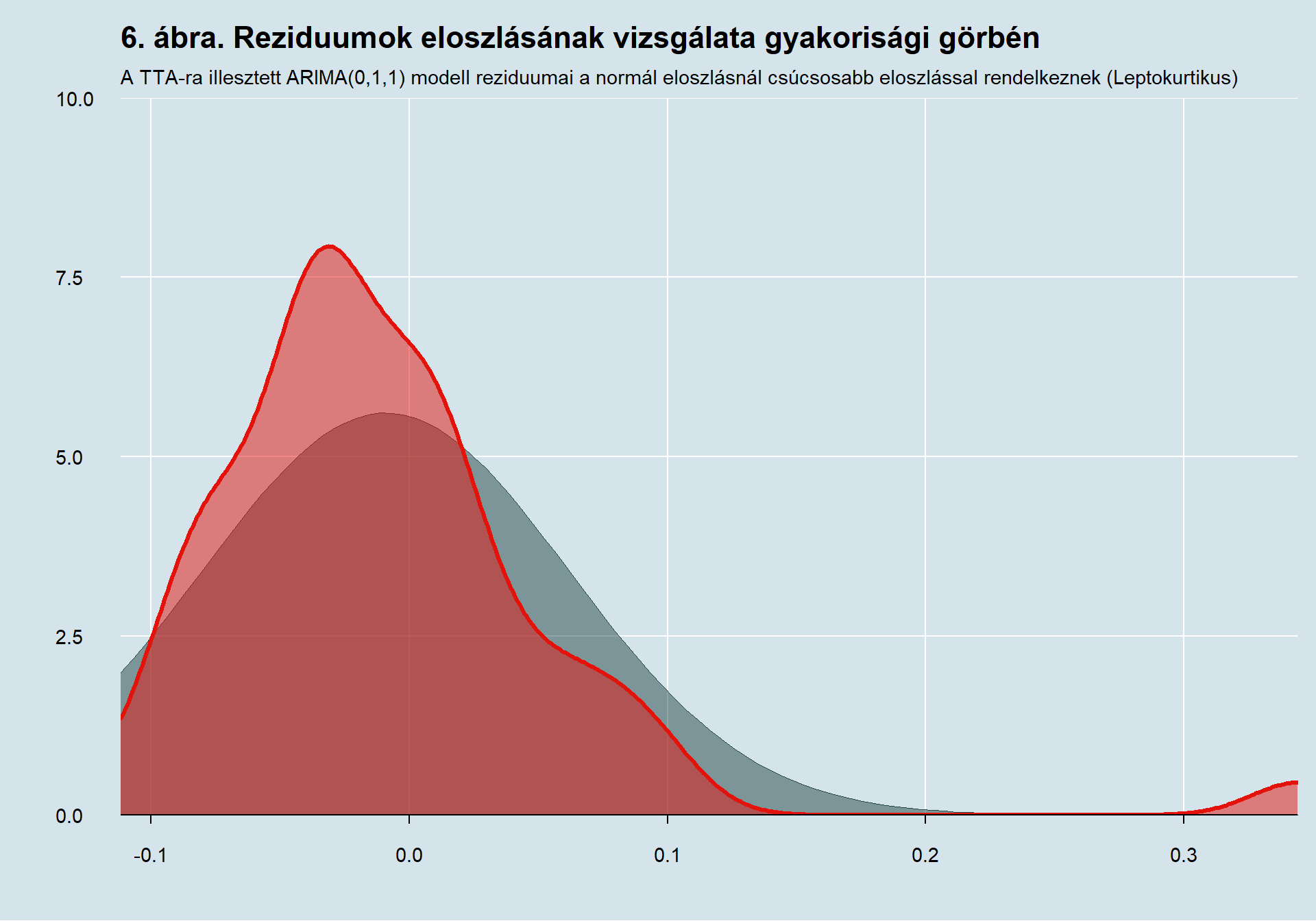
A 4. táblázatban a Jarque-Bera tesztek p-értékei is feltüntetésre kerültek, mivel ez lényeges abból a szempontból, hogy alkalmazható-e Maximum Likehood (ML) módszerrel készített becslés, amely látható módon néhány esetben jobb MAPE mutatóval rendelkezik, mint a feltételes legkisebb négyzetek módszer (CSS). Mivel a Jarque-Bera tesztek p-értékei rendre 0 körül alakulnak, így mindegyik idősor modellezésénél a CSS módszert szükséges alkalmazni. A reziduumok gyakorisági görbéjének leptokurtikus (azonos várható értékkel és szórással rendelkező normális eloszlásnál csúcsosabb eloszlású) eloszlását a 6. ábra mutatja be. Az ábrán látszódik, hogy a hibatagok eloszlása a normális eloszlásnál csúcsosabb és balra ferde, így a lehetséges modellek köre a CSS becslést alkalmazókra szűkül.
A feltételes legkisebb négyzetek módszerével becsült modellek közül legjobb előrejelző képességűnek tekintem a legkisebb átlagos abszolút százalékos hibával rendelkezőt. Ez a modell pedig az előző alfejezetben is tárgyalt teljes termékenységi arányszám növekménytagjain futatott mozgóátlag modell. Ennek a mozgóátlag-modellnek egyetlen paramétere van, amelynek értéke 0,4503. A modellel ezután ex ante előrejelzést készítek, tehát olyan évekre becsülök, amelyek a mintán kívülre esnek8. Ehhez már felhasználom a 2009-2018-ig terjedő időszak megfigyeléseit is. Így a termékenységi arányszámra illesztett ARIMA (0, 1, 1) modell mozgóátlag paraméterének értéke 0,4040-re csökken. Az ezzel a modellel készített ex ante előrejelzést a 7. ábra mutatja be.
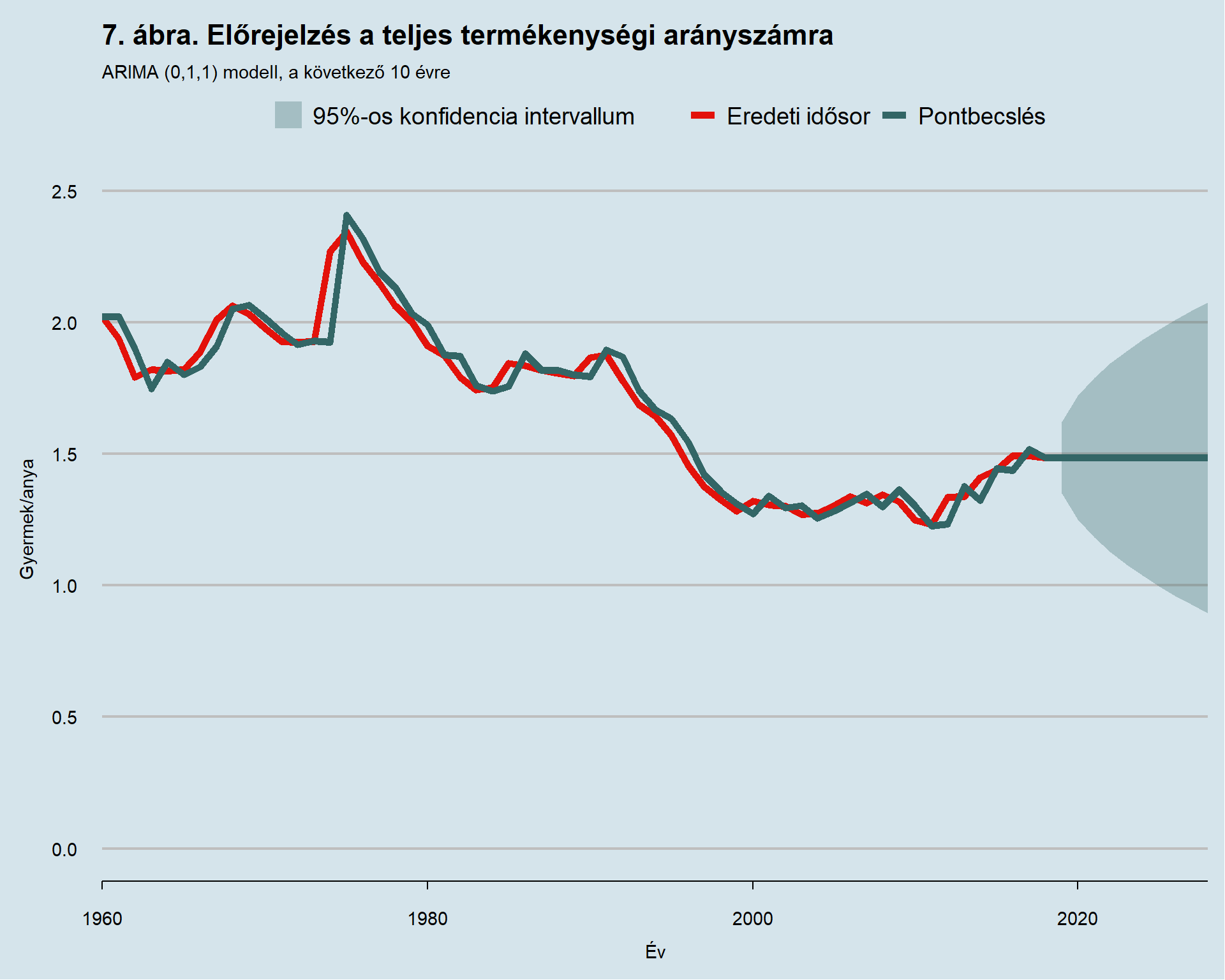
Miután a modell egy egyszerű mozgóátlag-modell a differenciázott idősoron, így előrejelzése az első évre való becslés után az, hogy az idősor nem változik tovább. Azaz csak statikus előrejelzés esetén mutat nullától különböző növekménytagot, dinamikus előrejelzése az egyszerű változatlanság. Azonban maga a modell paramétere elemzésre továbbra is felhasználható és igazából ez volt a modell választás mögötti eredeti megfontolás is.
Fontos észben tartani, hogy ez az ARMA (0, 1) modell a differenciázott idősoron, tehát a teljes termékenységi rátának egyik évről másik évre való abszolút eltérésén értelmezett. Egy ARMA modell autoregresszív és mozgóátlag paraméterekből épül fel. Mikor a következő évre való értéket becsüli, akkor az autoregresszív paraméter a korábbi év konkrét értékével szorzandó össze, míg a mozgóátlag a korábbi évre vonatkozó becslés hibatagjával9. Az autoregresszív tag tulajdonképpen azt reprezentálja, hogy egyik évben egy kilengés hosszabb ideig eltéríti a mutatót az eredeti pályáról, mint ahogyan az egy tisztán mozgóátlag-folyamatnál játszódna le. Ezen modell alapján arra a következtetésre jutunk, hogy egy olyan hipotetikus esetben mikor a termékenységi ráta nyugalmi helyzetben van és egyik évben az értéke sokk hatására elváltozik, akkor a következő évben még a mutatónak a sokk mértéken 40%-nyi azonos irányú változására lehet számítani, majd a kilengés hatása teljesen eltűnik. Ez a jellegzetesség látható például, amikor 1967-ben 0,125 gyermek/anya egységnyivel nőtt TTA értéke a korábbi évhez képest, a következő évben szintén nőtt még 0,051 egységgel, majd 4 éven át csökkenés következett. 1973-ban nem történt változás, 1974-ben nőtt 0,34 egységgel, majd 1975-ben már csak 0,07 egységgel, 1976-ban meg már csökkent. Hasonló módon 1976-ban 0,11 egységgel csökkent a ráta, majd a következő évben a csökkenés mértéke már 0,08 egységre mérséklődött, később teljesen ugyanezek a számokat látjuk 1996-ban és a következő években. Természetesen számos ellenpéldát is lehetne hozni, azonban az látszik, hogy a nagyobb volumenű változások okozta kilengések után hamar megáll az impulzus10.
Azért választottam az alábbi idősort az általános bemutatáshoz, mert ez lesz a legkisebb MAPE-vel rendelkező modell, amelyet majd a későbbiekben fejtek ki.↩
Csakúgy, mint korábban továbbra is gyenge stacionaritást értek stacionaritás alatt.↩
A logdifferenciázás az idősorelemzés gyakran használt eszköze annak köszönhetően, hogy relatív kismértékű változások esetén értéke közelítőleg megegyezik a százalékos növekedés értékével. (Kirchgässner & Wolters, 2007)↩
Bár számításaimat úgy készítettem el, hogy a későbbiekben új adatok ismeretében könnyen reprodukálható legyen, jelen tanulmányban az adatok letöltése és a dolgozat megjelenése között nem ellenőriztem, hogy a KSH közölt-e már későbbi adatok, így csak az 1960-tól 2018-ig terjedő időszakot vizsgálom.↩
Illetőlegesen korábbi évek, amennyiben több autoregresszív, vagy mozgóátlag paramétert is tartalmaz a modell.↩
Bár előrejelzésre valóban nem túl „szerencsés” egy mozgóátlag-modell, mert csak annyit, mond, hogy a most még hatást kifejtő impulzusok le fognak csengeni, mivel az újakat nem határozzuk meg a modellnek exogén módon, így a 2 évvel későbbi időszakra nem mond túl sokat. Ennek ellenére a mozgóátlag-modell jelleg is egy plusz információ az idősorról. Annyival legalábbis biztosan előrébb sikerült mozdítani az elemzést, hogy Granger és Newbold ajánlása alapján elkerültük, hogy olyan dolgot magyarázzunk külső változókkal, amiket saját magukkal is teljes egészében meglehet.↩