python
字符串前加f、r、u、b
1.字符串前加 u:后面字符串以unicode格式进行编码(表示中文),一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时出现乱码。
2.字符串前加 r:在字符串前加r可防止字符串转义
print(r"F:\Python_Easy\n4\test.py ")
print("F:\\Python_Easy\\n4\\test.py ")3.字符串前加 b:后面字符串是bytes类型。
bytes 和 str 的互相转换
str--->bytes:【str.encode('utf-8')】
bytes--->str:【bytes.decode('utf-8')】print("中文".encode(encoding="utf-8"))
print(b'\xe4\xb8\xad\xe6\x96\x87'.decode())
print(r'\xe4\xb8\xad\xe6\x96\x87')4.字符串前加 f:以f开头表示在字符串内支持大括号内的python表达式 作用:相当于format函数。
name = "帅哥"
age = 12
print(f"my name is {name},age is {age}")字符串工具
val = "a, bbbb, Guido "
val.split(",") # 字符串分割
pieces = [x.strip() for x in val.split(",")] # 字符串首尾去空格
pieces
[x.rstrip() for x in val.split(",")] # 字符串末尾去空格
[x.lstrip() for x in val.split(",")] # 字符串开头去空格
first, second, third = pieces
first + "::" + second + "::" + third # 字符串拼接
"::".join(pieces) # 字符串拼接,将字符串作为分隔符来连接其他字符串序列
"guido" in val # 字符串中是否存在某字符
val.index(",") # 字符串中某字符首次出现的位置,不存在时报错
val.find("x") # 字符串中某字符首次出现的位置,不存在时返回-1
val.rfind("b") # 字符串中某字符最后一次出现的位置,不存在时返回-1
val.count(",") # 字符串中某字符出现的次数
val.replace(",", "::") # 字符替换
val.endswith("o") # 是否以某字符结尾
val.startswith("a") # 是否以某字符开头
val.lower() # 转小写字母
val.upper() # 转大写字母
"Groß - α".casefold() # 转小写字母,包括中英文以外的语言
val.rjust(20) # 字符串按指定长度右对齐,不足的以空格填充
val.ljust(20) # 字符串按指定长度左对齐,不足的以空格填充爬虫
requests从URL获取HTML
import requests
url = "http://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2022/index.html"
response = requests.get(url)
response.encoding = "utf-8" # 指定正确的编码
html = response.text
## requests.get(url, params=None, **kwargs) params用于传递查询参数
requests.get("http://www.stats.gov.cn", params={'qt': '统计用区划代码和城乡划分代码'})
requests.get("http://www.stats.gov.cn/?qt=统计用区划代码和城乡划分代码")
## 编码问题
### 1、指定正确的编码
response.encoding = "utf-8"
### 2、使用第三方库 chardet 来自动检测网页的编码
import chardet
encoding = chardet.detect(response.content)["encoding"]
response.encoding = encodinglxml.etree解析HTML
from lxml import etree
root = etree.HTML(html)
## 使用XPath查询节点文本
root.xpath("//tr[@class=\"provincetr\"]//td//a/text()")
### 注1:以上节点路径中的双斜杠//表示当前节点下的所有符合条件的**子孙节点**
root.xpath("//tr[@class=\"provincetr\"]//text()")
### 注2:单斜杠/则会查找当前节点的**直接子节点**
root.xpath("//tr[@class=\"provincetr\"]/td/a/text()")
## 使用XPath获取节点a的href属性
root.xpath("//tr[@class=\"provincetr\"]//td//a/@href") # 返回所有a节点下的href属性值
root.xpath("//tr[@class=\"provincetr\"]//td//a")[0].attrib.get('href') # 返回第一个a节点下的href属性值get_dummies()与分段函数的结合使用
np.random.seed(12345)
values = np.random.uniform(size=10)
values
array([0.92961609, 0.31637555, 0.18391881, 0.20456028, 0.56772503,
0.5955447 , 0.96451452, 0.6531771 , 0.74890664, 0.65356987])bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
pd.cut(values, bins)
[(0.8, 1.0], (0.2, 0.4], (0.0, 0.2], (0.2, 0.4], (0.4, 0.6], (0.4, 0.6], (0.8, 1.0], (0.6, 0.8], (0.6, 0.8], (0.6, 0.8]]
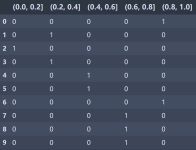
Categories (5, interval[float64, right]): [(0.0, 0.2] < (0.2, 0.4] < (0.4, 0.6] < (0.6, 0.8] < (0.8, 1.0]]pd.get_dummies(pd.cut(values, bins))
crontab 定时任务
1、bash终端输入:crontab -e
2、编辑:输入a
3、添加定时任务:
* * * * * /home/user/test.py 定时执行test.py
* * * * * /home/user/test.py > /home/user/test.log 2>&1 定时执行test.py 输出内容保存至test.log
4、退出编辑状态:Ctrl+c 退出编辑后再保存或退出
5、保存::w
6、放弃保存并退出::q!
7、保存并退出::wq
8、bash终端输入crontab -l查看已添加的定时任务
9、已安装模块,但仍提示crontab ModuleNotFoundError: No module named
进入虚拟环境:activate 环境名称
输入:which python
(tf_copy) zhouyu@zhouyu-MS-7C94:~$ which python
/home/zhouyu/anaconda3/envs/tf_copy/bin/python以上路径插入到定时执行脚本路径前:
* * * * * /home/zhouyu/anaconda3/envs/tf_copy/bin/python /home/user/test.py