第 3 章 农村人力资本投资
劳动力流动、家庭收入与农村人力资本投资
library(tidyverse)
library(here)
library(fs)
library(haven)
library(broom)3.1 数据导入
我们选取了北京大学开放数据平台中的中国家庭追踪调查CFPS2的2014年数据。
cfps2014adult <- read_dta("../data/2014AllData/Cfps2014famecon_170630.dta",
encoding = "GB2312"
)3.2 数据探索
# colnames(cfps2014adult)3.3 选取变量
研究劳动力流动、家庭收入与农村人力资本投资的关系3,因此我们选取了…
vars_select <- c(
"fid14", "provcd14", "fa1",
"fa7_s_1", "fa7_s_2", "fa7_s_3", "fk1l",
"fn1_s_1", "fn1_s_2", "fn1_s_3", "fn1_s_4",
"fn101", "fn2", "fn3", "fo1", "fp510",
"fincome1_per"
)cfps2014adult %>% select(vars_select) %>% glimpse()## Observations: 13,946
## Variables: 17
## $ fid14 <dbl+lbl> 100051, 100125, 100160, 1...
## $ provcd14 <dbl+lbl> 11, 11, 12, 13, 13, 13, 4...
## $ fa1 <dbl+lbl> 1, 1, 1, 1, 5, 5, 1, 5, 5...
## $ fa7_s_1 <dbl+lbl> 78, 78, 78, 78, 78, NA, 7...
## $ fa7_s_2 <dbl+lbl> -8, -8, -8, -8, -8, NA, -...
## $ fa7_s_3 <dbl+lbl> -8, -8, -8, -8, -8, NA, -...
## $ fk1l <dbl+lbl> 0, 0, 0, 1, 1, 0, 0, 0, 0...
## $ fn1_s_1 <dbl+lbl> 78, 78, 78, 78, 78, 3, 78...
## $ fn1_s_2 <dbl+lbl> -8, -8, -8, -8, -8, -8, -...
## $ fn1_s_3 <dbl+lbl> -8, -8, -8, -8, -8, -8, -...
## $ fn1_s_4 <dbl+lbl> -8, -8, -8, -8, -8, -8, -...
## $ fn101 <dbl+lbl> -8, -8, -8, -8, -8, -1, -...
## $ fn2 <dbl+lbl> 0, 0, 0, 0, 0, 0, 0, 0, 1...
## $ fn3 <dbl+lbl> 5, 5, 5, 5, 5, NA, 1, 5, ...
## $ fo1 <dbl+lbl> 0, 0, 0, 1, 1, NA, 0, 0, ...
## $ fp510 <dbl+lbl> 5000, 3000, 0, 0, 0, 1000...
## $ fincome1_per <dbl+lbl> 23333, 400000, 30000, 440...3.4 获取标签
library(purrr)
get_var_label <- function(dta) {
labels <- map(dta, function(x) attr(x, "label"))
data_frame(
name = names(labels),
label = as.character(labels)
)
}
cfps2014adult %>% select(vars_select) %>% get_var_label()## # A tibble: 17 x 2
## name label
## <chr> <chr>
## 1 fid14 2014年家户号
## 2 provcd14 省国标码
## 3 fa1 社区性质
## 4 fa7_s_1 住房困难
## 5 fa7_s_2 住房困难
## 6 fa7_s_3 住房困难
## 7 fk1l 是否从事农业工作
## 8 fn1_s_1 您家收到哪些政府补助-选择1
## 9 fn1_s_2 您家收到哪些政府补助-选择2
## 10 fn1_s_3 您家收到哪些政府补助-选择3
## 11 fn1_s_4 您家收到哪些政府补助-选择4
## 12 fn101 政府补助总额(元)
## 13 fn2 是否收到社会捐助
## 14 fn3 领取离退休或养老金
## 15 fo1 作农活或外出打工
## 16 fp510 过去12个月教育培训支出(元)
## 17 fincome1_per 人均家庭纯收入这里多选题 fa7_s_2, fa7_s_3, fn1_s_2, fn1_s_3, fn1_s_4有没有用到呢? 还是看看原始的调查问卷比较好。
3.5 数据统计
cfps2014adult %>%
summarise_all(n_distinct) %>%
tidyr::gather(vars_name, num_distinct_answers) %>%
arrange(desc(num_distinct_answers))## # A tibble: 459 x 2
## vars_name num_distinct_answers
## <chr> <int>
## 1 fid14 13946
## 2 fresp1pid 13939
## 3 fz1pid 13932
## 4 pid_a_1 13893
## 5 fid12 12711
## 6 pid_a_2 12697
## 7 fid10 12292
## 8 total_asset 11538
## 9 fswt_natcs14 11198
## 10 fswt_natpn1014 11116
## # ... with 449 more rowscfps2014adult %>%
select(vars_select) %>%
map(~ count(data.frame(x = .x), x))## $fid14
## # A tibble: 13,946 x 2
## x n
## <dbl+lbl> <int>
## 1 100051 1
## 2 100125 1
## 3 100160 1
## 4 100286 1
## 5 100376 1
## 6 100435 1
## 7 100453 1
## 8 100551 1
## 9 100569 1
## 10 100724 1
## # ... with 13,936 more rows
##
## $provcd14
## # A tibble: 29 x 2
## x n
## <dbl+lbl> <int>
## 1 11 142
## 2 12 98
## 3 13 775
## 4 14 596
## 5 15 6
## 6 21 1381
## 7 22 271
## 8 23 474
## 9 31 1011
## 10 32 296
## # ... with 19 more rows
##
## $fa1
## # A tibble: 3 x 2
## x n
## <dbl+lbl> <int>
## 1 -1 2
## 2 1 4180
## 3 5 9764
##
## $fa7_s_1
## # A tibble: 9 x 2
## x n
## <dbl+lbl> <int>
## 1 -1 1
## 2 1 714
## 3 2 482
## 4 3 97
## 5 4 60
## 6 5 255
## 7 77 614
## 8 78 11182
## 9 NA 541
##
## $fa7_s_2
## # A tibble: 8 x 2
## x n
## <dbl+lbl> <int>
## 1 -8 13016
## 2 1 24
## 3 2 121
## 4 3 103
## 5 4 23
## 6 5 88
## 7 77 30
## 8 NA 541
##
## $fa7_s_3
## # A tibble: 8 x 2
## x n
## <dbl+lbl> <int>
## 1 -8 13269
## 2 1 3
## 3 2 7
## 4 3 38
## 5 4 12
## 6 5 48
## 7 77 28
## 8 NA 541
##
## $fk1l
## # A tibble: 2 x 2
## x n
## <dbl+lbl> <int>
## 1 0 7131
## 2 1 6815
##
## $fn1_s_1
## # A tibble: 10 x 2
## x n
## <dbl+lbl> <int>
## 1 -1 5
## 2 1 1458
## 3 2 775
## 4 3 4265
## 5 4 41
## 6 5 57
## 7 6 9
## 8 7 38
## 9 77 326
## 10 78 6972
##
## $fn1_s_2
## # A tibble: 9 x 2
## x n
## <dbl+lbl> <int>
## 1 -8 12233
## 2 1 54
## 3 2 308
## 4 3 1136
## 5 4 36
## 6 5 30
## 7 6 5
## 8 7 37
## 9 77 107
##
## $fn1_s_3
## # A tibble: 9 x 2
## x n
## <dbl+lbl> <int>
## 1 -8 13616
## 2 1 10
## 3 2 10
## 4 3 204
## 5 4 9
## 6 5 26
## 7 6 7
## 8 7 20
## 9 77 44
##
## $fn1_s_4
## # A tibble: 7 x 2
## x n
## <dbl+lbl> <int>
## 1 -8 13902
## 2 2 2
## 3 4 5
## 4 5 5
## 5 6 1
## 6 7 10
## 7 77 21
##
## $fn101
## # A tibble: 551 x 2
## x n
## <dbl+lbl> <int>
## 1 -8 6977
## 2 -2 1
## 3 -1 178
## 4 0 3
## 5 1 6
## 6 4 2
## 7 5 9
## 8 6 1
## 9 8 1
## 10 9 1
## # ... with 541 more rows
##
## $fn2
## # A tibble: 3 x 2
## x n
## <dbl+lbl> <int>
## 1 -1 2
## 2 0 13765
## 3 1 179
##
## $fn3
## # A tibble: 4 x 2
## x n
## <dbl+lbl> <int>
## 1 -1 1
## 2 1 4814
## 3 5 8590
## 4 NA 541
##
## $fo1
## # A tibble: 3 x 2
## x n
## <dbl+lbl> <int>
## 1 0 8032
## 2 1 5373
## 3 NA 541
##
## $fp510
## # A tibble: 295 x 2
## x n
## <dbl+lbl> <int>
## 1 -2 1
## 2 -1 85
## 3 0 7273
## 4 9 1
## 5 10 2
## 6 20 3
## 7 30 2
## 8 40 1
## 9 50 10
## 10 55 1
## # ... with 285 more rows
##
## $fincome1_per
## # A tibble: 5,789 x 2
## x n
## <dbl+lbl> <int>
## 1 0.2500 1
## 2 0.5000 1
## 3 0.8333 1
## 4 1.6667 1
## 5 2.6667 1
## 6 3.3333 2
## 7 5.0000 2
## 8 6.2500 1
## 9 8.0000 2
## 10 9.0000 1
## # ... with 5,779 more rows# map_if(is.character, ~count(data.frame(x = .x), x) )3.6 缺失值
library(naniar)
cfps2014adult %>%
select(vars_select) %>%
miss_var_summary()## # A tibble: 17 x 3
## variable n_miss pct_miss
## <chr> <int> <dbl>
## 1 fincome1_per 1245 8.93
## 2 fa7_s_1 541 3.88
## 3 fa7_s_2 541 3.88
## 4 fa7_s_3 541 3.88
## 5 fn3 541 3.88
## 6 fo1 541 3.88
## 7 fid14 0 0
## 8 provcd14 0 0
## 9 fa1 0 0
## 10 fk1l 0 0
## 11 fn1_s_1 0 0
## 12 fn1_s_2 0 0
## 13 fn1_s_3 0 0
## 14 fn1_s_4 0 0
## 15 fn101 0 0
## 16 fn2 0 0
## 17 fp510 0 0library(visdat)
cfps2014adult %>%
select(vars_select) %>%
vis_dat()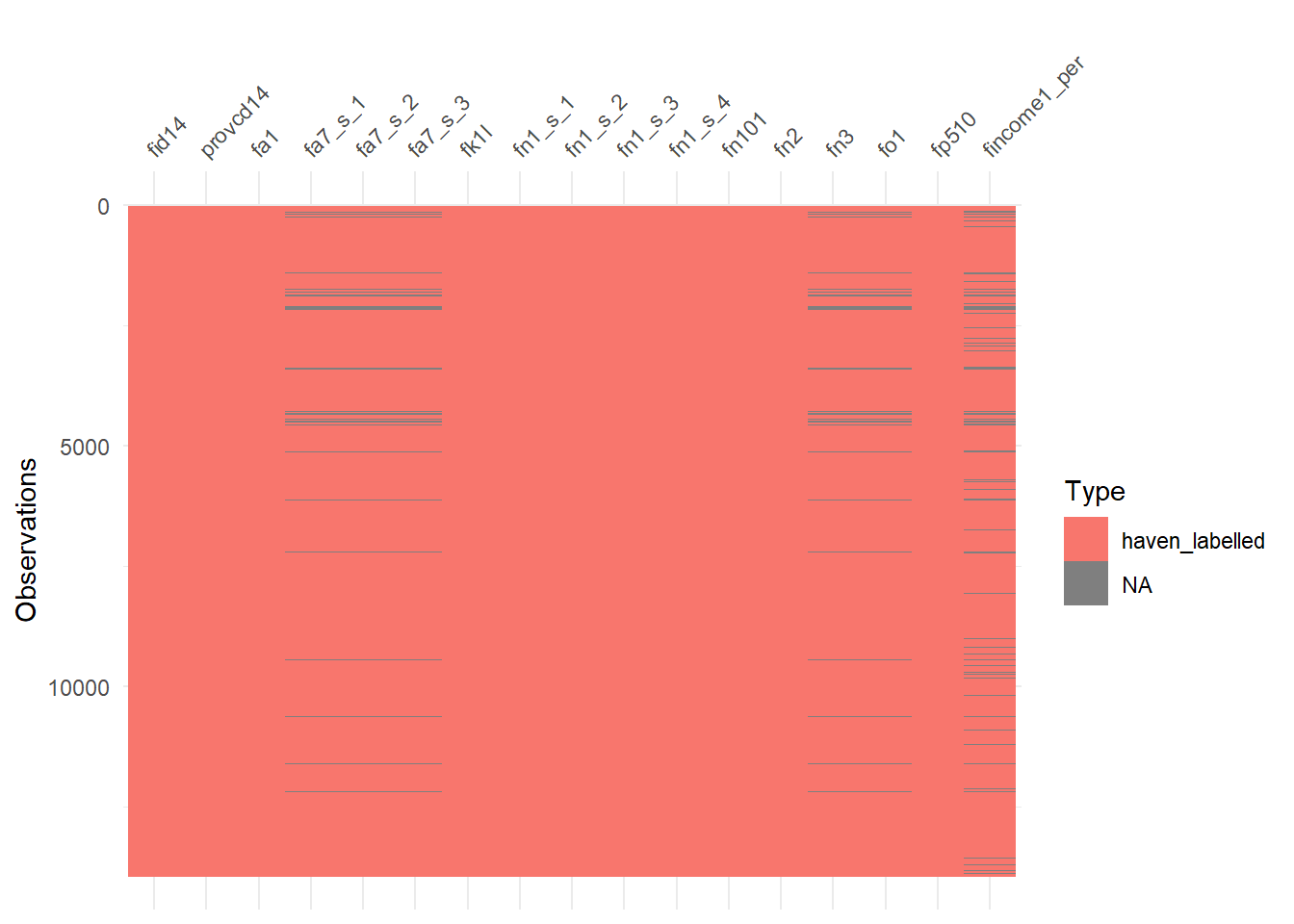
3.7 数据规整
我们是这样做数据规整和清洗的:
- 问卷题目
- 变量统计
- 信息提取
- 代码实现
tb <- cfps2014adult %>%
select(vars_select)3.7.1 fid14
tb %>% count(fid14)## # A tibble: 13,946 x 2
## fid14 n
## <dbl+lbl> <int>
## 1 100051 1
## 2 100125 1
## 3 100160 1
## 4 100286 1
## 5 100376 1
## 6 100435 1
## 7 100453 1
## 8 100551 1
## 9 100569 1
## 10 100724 1
## # ... with 13,936 more rows数据清洗: 检查是否有重复的
#tb %>% distinct(fid14, .keep_all = TRUE)
tb %>%
group_by(fid14) %>%
filter(n() > 1)## # A tibble: 0 x 17
## # Groups: fid14 [0]
## # ... with 17 variables: fid14 <dbl+lbl>,
## # provcd14 <dbl+lbl>, fa1 <dbl+lbl>,
## # fa7_s_1 <dbl+lbl>, fa7_s_2 <dbl+lbl>,
## # fa7_s_3 <dbl+lbl>, fk1l <dbl+lbl>,
## # fn1_s_1 <dbl+lbl>, fn1_s_2 <dbl+lbl>,
## # fn1_s_3 <dbl+lbl>, fn1_s_4 <dbl+lbl>,
## # fn101 <dbl+lbl>, fn2 <dbl+lbl>, fn3 <dbl+lbl>,
## # fo1 <dbl+lbl>, fp510 <dbl+lbl>,
## # fincome1_per <dbl+lbl>3.7.2 provcd14
tb %>% count(provcd14)## # A tibble: 29 x 2
## provcd14 n
## <dbl+lbl> <int>
## 1 11 142
## 2 12 98
## 3 13 775
## 4 14 596
## 5 15 6
## 6 21 1381
## 7 22 271
## 8 23 474
## 9 31 1011
## 10 32 296
## # ... with 19 more rows数据清洗: 创建虚拟变量
# 虚拟变量
fastDummies::dummy_cols("provcd14") 3.7.3 fa1

tb %>% count(fa1)## # A tibble: 3 x 2
## fa1 n
## <dbl+lbl> <int>
## 1 -1 2
## 2 1 4180
## 3 5 9764数据清洗: 过滤符合情形的fa1 == 5
filter(fa1 == 5) 3.7.4 fa7

变量 fa7_s_2, fa7_s_3没有用到? 还是看看原始的调查问卷比较好。问卷调查是这样设计的: 这道题是多选题,最多选3项。因此就会出现(1,2,3),(2,4,6), (1,4,5) …这答案,分别用 fa7_s_1, fa7_s_2, fa7_s_3存放。如果少于三项(缺失的、只选1项或者2项的)就左对齐依次存放, 即从fa7_s_1开始存放。
| fa7_s_1 | fa7_s_2 | fa7_s_3 |
|---|---|---|
| 78 | ||
| 2 | ||
| 2 | 3 | |
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 1 | 3 | 6 |
也就是说,我们可以是否有住房困难,只需要通过fa7_s_1即可。
tb %>% count(fa7_s_1)## # A tibble: 9 x 2
## fa7_s_1 n
## <dbl+lbl> <int>
## 1 -1 1
## 2 1 714
## 3 2 482
## 4 3 97
## 5 4 60
## 6 5 255
## 7 77 614
## 8 78 11182
## 9 NA 541数据清洗:
删除
fa7_s_1缺失值行filter(!is.na(fa7_s_1))删除
fa7_s_1包含c(-10, -8, -2, -1)的行并根据
fa7_s_1住房困难,新建housing变量
# 删除缺失值
filter(!is.na(fa7_s_1)) %>%
# 住房困难fa7_s
filter(!fa7_s_1 %in% c(-10, -8, -2, -1)) %>%
# 新建housing变量
mutate(housing = if_else(fa7_s_1 %in% c(78) | fa7_s_2 %in% c(78) | fa7_s_3 %in% c(78), 0, 1)) 3.7.5 fk1l

tb %>% count(fk1l)## # A tibble: 2 x 2
## fk1l n
## <dbl+lbl> <int>
## 1 0 7131
## 2 1 6815数据清洗: 无
3.7.6 fn1

tb %>% count(fn1_s_1)## # A tibble: 10 x 2
## fn1_s_1 n
## <dbl+lbl> <int>
## 1 -1 5
## 2 1 1458
## 3 2 775
## 4 3 4265
## 5 4 41
## 6 5 57
## 7 6 9
## 8 7 38
## 9 77 326
## 10 78 6972fn1与fa7情况类似。fn1_s_1, fn1_s_2, fn1_s_3, fn1_s_4主要用到fn1_s_1。 换句话说只有fn1_s_1包含了1到7,就说明收到政府补助。
数据清洗:
- 删除
fn1_s_1缺失值和 c(-10, -9, -8, -2, -1) 行
# 过滤
filter(!fn1_s_1 %in% c(-10, -9, -8, -2, -1)) %>%3.7.7 fn101

tb %>% count(fn101)## # A tibble: 551 x 2
## fn101 n
## <dbl+lbl> <int>
## 1 -8 6977
## 2 -2 1
## 3 -1 178
## 4 0 3
## 5 1 6
## 6 4 2
## 7 5 9
## 8 6 1
## 9 8 1
## 10 9 1
## # ... with 541 more rows数据清洗:
将-8替换为0,并删除缺失值和c(-1, -2, -9, -10)行,
求政府补助总额+1的自然对数
# 替换
mutate_at(vars(fn101), funs(replace(., . == -8, 0))) %>%
# 家庭收到政府补助
filter(!fn101 %in% c(-1, -2, -9, -10)) %>%3.7.8 fn2

tb %>% count(fn2)## # A tibble: 3 x 2
## fn2 n
## <dbl+lbl> <int>
## 1 -1 2
## 2 0 13765
## 3 1 179数据清洗: 删除-1
# 否收到社会捐助
filter(!fn2 %in% c(-1)) %>%3.7.9 fn3

tb %>% count(fn3)## # A tibble: 4 x 2
## fn3 n
## <dbl+lbl> <int>
## 1 -1 1
## 2 1 4814
## 3 5 8590
## 4 NA 541数据清洗: 删除-1和NA 所在的行
# 是否有人领取离退休金和养老金
filter(!fn3 %in% c(-1, NA)) 3.7.10 fo1

tb %>% count(fo1)## # A tibble: 3 x 2
## fo1 n
## <dbl+lbl> <int>
## 1 0 8032
## 2 1 5373
## 3 NA 541数据清洗: 删除缺失值
# 是否打工
filter(!is.na(fo1)) %>%3.7.11 fp510

tb %>% count(fp510)## # A tibble: 295 x 2
## fp510 n
## <dbl+lbl> <int>
## 1 -2 1
## 2 -1 85
## 3 0 7273
## 4 9 1
## 5 10 2
## 6 20 3
## 7 30 2
## 8 40 1
## 9 50 10
## 10 55 1
## # ... with 285 more rows数据清洗:
删除c(-10, -9, -8, -2, NA) 这种答案,
并根据是否为0,新建变量Y(=是否人力资本投资),
并计算教育支出+1的自然对数
# 过去12月的教育支出
filter(!fp510 %in% c(-10, -9, -8, -2, NA)) %>%
# 是否进行人力资本投入
mutate(Y = if_else(fp510 %in% c(0), 0, 1)) %>%
# 教育支出计算其自然对数
mutate(ln_fp510 = log(fp510 + 1)) %>%3.7.12 fincome1_per

tb %>% count(fincome1_per)## # A tibble: 5,789 x 2
## fincome1_per n
## <dbl+lbl> <int>
## 1 0.2500 1
## 2 0.5000 1
## 3 0.8333 1
## 4 1.6667 1
## 5 2.6667 1
## 6 3.3333 2
## 7 5.0000 2
## 8 6.2500 1
## 9 8.0000 2
## 10 9.0000 1
## # ... with 5,779 more rows数据清洗: 删除其中缺失值,并求自然对数
# 删除缺失值
filter(!is.na(fincome1_per)) %>%
# 家庭人均收入fincome1_per的自然对数
mutate(ln_fincome1_per = log(fincome1_per)) 3.8 代码实现
| 变量 | 数据清洗 |
|---|---|
| fa1 | 过滤符合情形的fa1 == 5 |
| fa7_s_1 | 删除缺失值行filter(!is.na(fa7_s_1)) |
| fa7_s_1 | 删除包含c(-10, -8, -2, -1)的行 + 并根据住房困难多选题,新建housing变量 |
| fn1_s_1 | 删除缺失值和 c(-10, -9, -8, -2, -1) 行 |
| fn101 | 将-8替换为0,并删除缺失值和c(-1, -2, -9, -10)行, 并求政府补助总额+1的自然对数 |
| fn2 | 删除-1 |
| fn3 | 删除-1和NA 所在的行 |
| fo1 | 删除缺失值 |
| fp510 | 删除c(-10, -9, -8, -2, NA) 这种答案,并根据是否为0,新建变量Y(=是否人力资本投资), 并计算教育支出+1的自然对数 |
| fincome1_per | 删除其中缺失值,并求自然对数 |
| provcd14 | 创建省份的虚拟变量 |
针对数据探索过程中发现的问题,我们一一做相应的数据规整处理。
a <- cfps2014adult %>%
select(vars_select) %>%
# 过滤符合情形的
filter(fa1 == 5) %>%
# 删除缺失值
filter(!is.na(fa7_s_1)) %>%
# 住房困难fa7_s
filter(!fa7_s_1 %in% c(-10, -8, -2, -1)) %>%
# 新建housing变量
# mutate(housing = if_else(fa7_s_1 == 78 | fa7_s_2 == 78 | fa7_s_3 == 78, 0, 1)) %>%
mutate(housing = if_else(fa7_s_1 %in% c(78) | fa7_s_2 %in% c(78) | fa7_s_3 %in% c(78), 0, 1)) %>% #
# 过滤
filter(!fn1_s_1 %in% c(-10, -9, -8, -2, -1)) %>%
# 替换
mutate_at(vars(fn101), funs(replace(., . == -8, 0))) %>%
# 家庭收到政府补助
filter(!fn101 %in% c(-1, -2, -9, -10)) %>%
# 否收到社会捐助
filter(!fn2 %in% c(-1)) %>%
# 是否有人领取离退休金和养老金
filter(!fn3 %in% c(-1, NA)) %>%
# 是否打工
filter(!is.na(fo1)) %>%
# 过去12月的教育支出
filter(!fp510 %in% c(-10, -9, -8, -2, NA)) %>%
# 是否进行人力资本投入
# mutate(Y = if_else(fp510 == 0, 0, 1)) %>%
mutate(Y = if_else(fp510 %in% c(0), 0, 1)) %>%
# 删除缺失值
filter(!is.na(fincome1_per)) %>%
# 虚拟变量
fastDummies::dummy_cols("provcd14") %>%
# 家庭人均收入fincome1_per的自然对数
mutate(ln_fincome1_per = log(fincome1_per)) %>%
# 政府补助总额+1的自然对数
mutate(ln_fn101 = log(fn101 + 1)) %>%
# 教育支出计算其自然对数
mutate(ln_fp510 = log(fp510 + 1)) %>%
# 是否外出打工与收入对数的交乘项
mutate(fo1xln_fincome1_per = ln_fincome1_per * fo1) %>%
# 收入的自然对数的二次项
mutate(ln_fincome1_perxln_fincome1_per = ln_fincome1_per * ln_fincome1_per)交乘项的意义?
a %>% map_df(~ sum(is.na(.)))## # A tibble: 1 x 51
## fid14 provcd14 fa1 fa7_s_1 fa7_s_2 fa7_s_3 fk1l
## <int> <int> <int> <int> <int> <int> <int>
## 1 0 0 0 0 0 0 0
## # ... with 44 more variables: fn1_s_1 <int>,
## # fn1_s_2 <int>, fn1_s_3 <int>, fn1_s_4 <int>,
## # fn101 <int>, fn2 <int>, fn3 <int>, fo1 <int>,
## # fp510 <int>, fincome1_per <int>, housing <int>,
## # Y <int>, provcd14_53 <int>, provcd14_13 <int>,
## # provcd14_14 <int>, provcd14_11 <int>,
## # provcd14_21 <int>, provcd14_32 <int>,
## # provcd14_33 <int>, provcd14_34 <int>,
## # provcd14_36 <int>, provcd14_44 <int>,
## # provcd14_37 <int>, provcd14_41 <int>,
## # provcd14_43 <int>, provcd14_51 <int>,
## # provcd14_45 <int>, provcd14_31 <int>,
## # provcd14_61 <int>, provcd14_12 <int>,
## # provcd14_23 <int>, provcd14_35 <int>,
## # provcd14_62 <int>, provcd14_64 <int>,
## # provcd14_22 <int>, provcd14_50 <int>,
## # provcd14_52 <int>, provcd14_42 <int>,
## # provcd14_15 <int>, ln_fincome1_per <int>,
## # ln_fn101 <int>, ln_fp510 <int>,
## # fo1xln_fincome1_per <int>,
## # ln_fincome1_perxln_fincome1_per <int># or
# a %>% summarise_at(1:5, ~sum(is.na(.)))
a %>% summarise_all(~ sum(is.na(.)))## # A tibble: 1 x 51
## fid14 provcd14 fa1 fa7_s_1 fa7_s_2 fa7_s_3 fk1l
## <int> <int> <int> <int> <int> <int> <int>
## 1 0 0 0 0 0 0 0
## # ... with 44 more variables: fn1_s_1 <int>,
## # fn1_s_2 <int>, fn1_s_3 <int>, fn1_s_4 <int>,
## # fn101 <int>, fn2 <int>, fn3 <int>, fo1 <int>,
## # fp510 <int>, fincome1_per <int>, housing <int>,
## # Y <int>, provcd14_53 <int>, provcd14_13 <int>,
## # provcd14_14 <int>, provcd14_11 <int>,
## # provcd14_21 <int>, provcd14_32 <int>,
## # provcd14_33 <int>, provcd14_34 <int>,
## # provcd14_36 <int>, provcd14_44 <int>,
## # provcd14_37 <int>, provcd14_41 <int>,
## # provcd14_43 <int>, provcd14_51 <int>,
## # provcd14_45 <int>, provcd14_31 <int>,
## # provcd14_61 <int>, provcd14_12 <int>,
## # provcd14_23 <int>, provcd14_35 <int>,
## # provcd14_62 <int>, provcd14_64 <int>,
## # provcd14_22 <int>, provcd14_50 <int>,
## # provcd14_52 <int>, provcd14_42 <int>,
## # provcd14_15 <int>, ln_fincome1_per <int>,
## # ln_fn101 <int>, ln_fp510 <int>,
## # fo1xln_fincome1_per <int>,
## # ln_fincome1_perxln_fincome1_per <int># library(visdat)
# vis_miss(a)library(naniar)
a %>%
miss_var_summary() %>%
filter(n_miss > 0)## # A tibble: 0 x 3
## # ... with 3 variables: variable <chr>, n_miss <int>,
## # pct_miss <dbl>df <- a %>% select(
Y, fo1, fo1xln_fincome1_per, ln_fincome1_per,
ln_fincome1_perxln_fincome1_per, ln_fn101,
fn2, fk1l, housing, fn3,
starts_with("provcd14_")
)
df %>%
map(~ count(data.frame(x = .x), x))## $Y
## # A tibble: 2 x 2
## x n
## <dbl> <int>
## 1 0 4577
## 2 1 4363
##
## $fo1
## # A tibble: 2 x 2
## x n
## <dbl+lbl> <int>
## 1 0 4426
## 2 1 4514
##
## $fo1xln_fincome1_per
## # A tibble: 3,223 x 2
## x n
## <dbl+lbl> <int>
## 1 -0.6931 1
## 2 0.0000 4426
## 3 3.4812 1
## 4 3.9120 1
## 5 4.4248 1
## 6 4.6333 1
## 7 4.8283 1
## 8 4.9618 1
## 9 5.0106 2
## 10 5.1160 1
## # ... with 3,213 more rows
##
## $ln_fincome1_per
## # A tibble: 5,105 x 2
## x n
## <dbl+lbl> <int>
## 1 -1.3863 1
## 2 -0.6931 1
## 3 -0.1823 1
## 4 0.5108 1
## 5 0.9808 1
## 6 1.2040 1
## 7 1.6094 2
## 8 2.0794 1
## 9 2.1972 1
## 10 2.3354 1
## # ... with 5,095 more rows
##
## $ln_fincome1_perxln_fincome1_per
## # A tibble: 5,105 x 2
## x n
## <dbl+lbl> <int>
## 1 0.03324 1
## 2 0.26094 1
## 3 0.48045 1
## 4 0.96203 1
## 5 1.44955 1
## 6 1.92181 1
## 7 2.59029 2
## 8 4.32408 1
## 9 4.82780 1
## 10 5.45397 1
## # ... with 5,095 more rows
##
## $ln_fn101
## # A tibble: 483 x 2
## x n
## <dbl+lbl> <int>
## 1 0.0000 3020
## 2 0.6931 5
## 3 1.6094 2
## 4 1.7918 8
## 5 1.9459 1
## 6 2.1972 1
## 7 2.3026 1
## 8 2.3979 4
## 9 2.4849 1
## 10 2.7081 1
## # ... with 473 more rows
##
## $fn2
## # A tibble: 2 x 2
## x n
## <dbl+lbl> <int>
## 1 0 8816
## 2 1 124
##
## $fk1l
## # A tibble: 2 x 2
## x n
## <dbl+lbl> <int>
## 1 0 2794
## 2 1 6146
##
## $housing
## # A tibble: 2 x 2
## x n
## <dbl> <int>
## 1 0 7500
## 2 1 1440
##
## $fn3
## # A tibble: 2 x 2
## x n
## <dbl+lbl> <int>
## 1 1 2937
## 2 5 6003
##
## $provcd14_53
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8607
## 2 1 333
##
## $provcd14_13
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8367
## 2 1 573
##
## $provcd14_14
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8491
## 2 1 449
##
## $provcd14_11
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8925
## 2 1 15
##
## $provcd14_21
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8129
## 2 1 811
##
## $provcd14_32
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8744
## 2 1 196
##
## $provcd14_33
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8701
## 2 1 239
##
## $provcd14_34
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8744
## 2 1 196
##
## $provcd14_36
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8753
## 2 1 187
##
## $provcd14_44
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8228
## 2 1 712
##
## $provcd14_37
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8386
## 2 1 554
##
## $provcd14_41
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 7886
## 2 1 1054
##
## $provcd14_43
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8729
## 2 1 211
##
## $provcd14_51
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8437
## 2 1 503
##
## $provcd14_45
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8705
## 2 1 235
##
## $provcd14_31
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8546
## 2 1 394
##
## $provcd14_61
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8746
## 2 1 194
##
## $provcd14_12
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8915
## 2 1 25
##
## $provcd14_23
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8797
## 2 1 143
##
## $provcd14_35
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8809
## 2 1 131
##
## $provcd14_62
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 7760
## 2 1 1180
##
## $provcd14_64
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8938
## 2 1 2
##
## $provcd14_22
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8812
## 2 1 128
##
## $provcd14_50
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8857
## 2 1 83
##
## $provcd14_52
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8651
## 2 1 289
##
## $provcd14_42
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8840
## 2 1 100
##
## $provcd14_15
## # A tibble: 2 x 2
## x n
## <int> <int>
## 1 0 8937
## 2 1 33.9 Probit 模型
Probit 模型
\[ \Pr(Y=1 \mid X) = \Phi(X^T\beta), \]
这里 \(\Phi\) 为累积分布函数.
加入模型之前,有两点需要考虑
是否需要转换因子类型?
是否需要做标准化处理?
data <- df %>%
mutate_at(vars(fo1, fn2, fk1l, housing, fn3), as.factor) %>%
mutate_at(vars(
fo1xln_fincome1_per, ln_fincome1_per,
ln_fincome1_perxln_fincome1_per, ln_fn101
), funs((. - mean(.)) / sd(.)))
# glimpse(data)probit_t <- glm(
formula = Y ~ .,
family = binomial(link = "probit"), # canonical link function
data = data
)tidy(probit_t)## # A tibble: 37 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) -1.90e+11 1.58e+12 -0.120 9.04e- 1
## 2 fo11 1.51e+ 0 2.87e- 1 5.25 1.55e- 7
## 3 fo1xln_finco~ -6.43e- 1 1.46e- 1 -4.41 1.03e- 5
## 4 ln_fincome1_~ 7.16e- 2 9.43e- 2 0.760 4.47e- 1
## 5 ln_fincome1_~ -4.22e- 2 9.74e- 2 -0.433 6.65e- 1
## 6 ln_fn101 -9.56e- 3 1.56e- 2 -0.611 5.41e- 1
## 7 fn21 -1.14e- 1 1.17e- 1 -0.974 3.30e- 1
## 8 fk1l1 1.94e- 1 3.30e- 2 5.88 4.15e- 9
## 9 housing1 2.69e- 1 3.78e- 2 7.13 9.79e-13
## 10 fn35 1.96e- 1 2.97e- 2 6.60 4.02e-11
## # ... with 27 more rows3.10 边际影响
library(mfx)
probitmfx(formula = Y ~ ., data = data)## Call:
## probitmfx(formula = Y ~ ., data = data)
##
## Marginal Effects:
## dF/dx Std. Err.
## fo11 0.54796 NA
## fo1xln_fincome1_per -0.25647 NA
## ln_fincome1_per 0.02857 2.90282
## ln_fincome1_perxln_fincome1_per -0.01683 NA
## ln_fn101 -0.00381 NA
## fn21 -0.04510 NA
## fk1l1 0.07718 61.02366
## housing1 0.10698 NA
## fn35 0.07798 98.87063
## provcd14_53 1.00000 0.00000
## provcd14_13 1.00000 0.00000
## provcd14_14 1.00000 0.00000
## provcd14_11 1.00000 0.00000
## provcd14_21 1.00000 0.00000
## provcd14_32 1.00000 0.00000
## provcd14_33 1.00000 0.00000
## provcd14_34 1.00000 0.00000
## provcd14_36 1.00000 0.00000
## provcd14_44 1.00000 0.00000
## provcd14_37 1.00000 0.00000
## provcd14_41 1.00000 0.00000
## provcd14_43 1.00000 0.00000
## provcd14_51 1.00000 0.00000
## provcd14_45 1.00000 0.00000
## provcd14_31 1.00000 0.00000
## provcd14_61 1.00000 0.00000
## provcd14_12 1.00000 0.00000
## provcd14_23 1.00000 0.00000
## provcd14_35 1.00000 0.00000
## provcd14_62 1.00000 0.00000
## provcd14_64 1.00000 0.00000
## provcd14_22 1.00000 0.00000
## provcd14_50 1.00000 0.00000
## provcd14_52 1.00000 0.00000
## provcd14_42 1.00000 0.00000
## provcd14_15 1.00000 0.00000
## z P>|z|
## fo11 NA NA
## fo1xln_fincome1_per NA NA
## ln_fincome1_per 0.01 0.99
## ln_fincome1_perxln_fincome1_per NA NA
## ln_fn101 NA NA
## fn21 NA NA
## fk1l1 0.00 1.00
## housing1 NA NA
## fn35 0.00 1.00
## provcd14_53 Inf <2e-16 ***
## provcd14_13 Inf <2e-16 ***
## provcd14_14 Inf <2e-16 ***
## provcd14_11 Inf <2e-16 ***
## provcd14_21 Inf <2e-16 ***
## provcd14_32 Inf <2e-16 ***
## provcd14_33 Inf <2e-16 ***
## provcd14_34 Inf <2e-16 ***
## provcd14_36 Inf <2e-16 ***
## provcd14_44 Inf <2e-16 ***
## provcd14_37 Inf <2e-16 ***
## provcd14_41 Inf <2e-16 ***
## provcd14_43 Inf <2e-16 ***
## provcd14_51 Inf <2e-16 ***
## provcd14_45 Inf <2e-16 ***
## provcd14_31 Inf <2e-16 ***
## provcd14_61 Inf <2e-16 ***
## provcd14_12 Inf <2e-16 ***
## provcd14_23 Inf <2e-16 ***
## provcd14_35 Inf <2e-16 ***
## provcd14_62 Inf <2e-16 ***
## provcd14_64 Inf <2e-16 ***
## provcd14_22 Inf <2e-16 ***
## provcd14_50 Inf <2e-16 ***
## provcd14_52 Inf <2e-16 ***
## provcd14_42 Inf <2e-16 ***
## provcd14_15 Inf <2e-16 ***
## ---
## Signif. codes:
## 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## dF/dx is for discrete change for the following variables:
##
## [1] "fo11" "fn21" "fk1l1"
## [4] "housing1" "fn35" "provcd14_53"
## [7] "provcd14_13" "provcd14_14" "provcd14_11"
## [10] "provcd14_21" "provcd14_32" "provcd14_33"
## [13] "provcd14_34" "provcd14_36" "provcd14_44"
## [16] "provcd14_37" "provcd14_41" "provcd14_43"
## [19] "provcd14_51" "provcd14_45" "provcd14_31"
## [22] "provcd14_61" "provcd14_12" "provcd14_23"
## [25] "provcd14_35" "provcd14_62" "provcd14_64"
## [28] "provcd14_22" "provcd14_50" "provcd14_52"
## [31] "provcd14_42" "provcd14_15"或者
# library(margins)
# m <- margins(probit_t)
# plot(m)重复的是这一篇文章↩