Chapter 4 XML
資料記錄常用的其中一種架構
4.1 What is XML?
4.2 package: XML2
Reference: http://xml2.r-lib.org/index.html
4.3 XML document
4.3.1 Typical structure
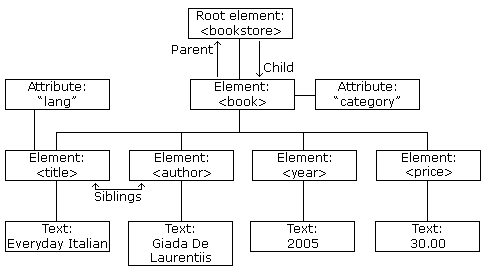
Source: XML Tree. (2019). W3schools.com. Retrieved 5 February 2019, from https://www.w3schools.com/xml/xml_tree.asp
4.3.1.1 Element
An XML element is everything from (including) the element’s start tag to (including) the element’s end tag.
帶有內容的element:
<tag> 內容文字 </tag>不帶有內容的element:
<sunnyday/>
4.3.1.2 Attribute
在< >內「非element名稱」的其他設定:如 <sunnyday temperature="25C" />
4.3.2 Example
單純文字檔,以<?xml...>開頭,附檔名通常為.xml
範例:取自 https://www.dgbas.gov.tw/public/data/open/Stat/price/PR0103A1M.xml
<?xml version="1.0" encoding="utf-8"?>
<DataSet Tab_NAME="消費者物價特殊分類指數-月" Sender_NAME="行政院主計總處">
<Obs1>
<Item>總指數(不含食物)(民國105年=100)</Item>
<TIME_PERIOD>1981M01</TIME_PERIOD>
<FREQ>M</FREQ>
<TYPE>原始值</TYPE>
<Item_VALUE>62.05</Item_VALUE>
</Obs1>
<Obs2>
<Item>總指數(不含蔬菜水果)(民國105年=100)</Item>
<TIME_PERIOD>1981M01</TIME_PERIOD>
<FREQ>M</FREQ>
<TYPE>原始值</TYPE>
<Item_VALUE>60.35</Item_VALUE>
</Obs2>
</DataSet>'<?xml version="1.0" encoding="utf-8"?>
<DataSet Tab_NAME="消費者物價特殊分類指數-月" Sender_NAME="行政院主計總處">
<Obs1>
<Item>總指數(不含食物)(民國105年=100)</Item>
<TIME_PERIOD>1981M01</TIME_PERIOD>
<FREQ>M</FREQ>
<TYPE>原始值</TYPE>
<Item_VALUE>62.05</Item_VALUE>
</Obs1>
<Obs2>
<Item>總指數(不含蔬菜水果)(民國105年=100)</Item>
<TIME_PERIOD>1981M01</TIME_PERIOD>
<FREQ>M</FREQ>
<TYPE>原始值</TYPE>
<Item_VALUE>60.35</Item_VALUE>
</Obs2>
</DataSet>' %>%
read_xml -> example4.4 XML Tree
XML documents are formed as element trees.
An XML tree starts at a root element and branches from the root to child elements.
All elements can have sub elements (child elements).
root只會有一個樹結。
4.4.1 root tree
Obtain root tree:
4.4.1.1 xml_document
檢視
由上述的結果,我們得知rootTree是個特別的xml_document class, 其文件內容記錄在{xml_document}的下方。
4.4.1.2 two classes
rootTree帶有兩個classes: xml_document跟xml_node;前者是以文字字串角度來看,後者是以樹狀結構來看。
4.4.2 sub trees
xml_node class的物件可以進行子樹(subtree)的裁剪。
4.4.2.1 裁剪子樹
xml_child(n)可裁出rootTree第一層的子樹中的第n株子樹,在範例裡有Obs1及Obs2兩株子樹可裁。
xml_child不指定n時會裁出第一顆子樹。
rootTree %>%
xml_child -> subTree1; print(subTree1)
rootTree %>%
xml_child(2) -> subTree2; print(subTree2)注意:裁剪出的子樹依然保有樹狀結構class,即保有xml_node class。(print時有
{xml_node}標示。 )
xml_node在print時會有[1],[2],…,[n],顯示下一層子樹會有幾株。要查詢有幾株子樹也可以用
xml_length():
範例:剪出Obs2下的Item_Value子樹
4.4.3 其他常用裁剪函數
4.4.3.1 xml_parent()
xml_parent()由子樹找回上層母樹
parentOfsubTree1透過
xml_child()自然可裁出subTree1
4.4.3.2 xml_siblings()
xml_siblings()會找出對應的兄弟姐妹樹
siblingsOfsubTree1和subTree2有點不同。siblingsOfsubTree1是一個list集合,subTree2是其中一個元素。雖然subTree2是唯一的sibling tree,但要siblingsOfsubTree1[[1]]才會是subTree2。
4.5 Contents
xml_contents(): xml_node tree依第一層子樹列出各別子樹原始xml文字內容
4.5.1 text
xml_text()會取出xml_contents中各element的值(即去除element tag<tag></tag>),並以字串方式保留
4.6 XPath
Reference: https://www.w3schools.com/xml/xpath_intro.asp
XPath是用來描述取得子樹的一行文字。
先前的子樹裁剪是由rootTree開始,透過xml_child(),xml_children()等,一層一層剪下去。若知道某一顆子樹的XPath,我們可以用xml_find_all(rootTree,Xpath)一行指示就取到那顆樹,較有效率。
4.6.2 練習
4.6.2.1 取出rootTree
4.6.2.2 有多少Obs
4.6.2.3 裁出第一個Obs子樹
4.6.2.4 裁出firstObsTree的Item子樹
4.6.2.5 找出firstObsItemTree的XPath
4.6.3 “/”
XPath裡/後方名字代表node element name:
/DataSet: 走到DataSet node
/DataSet/Obs: 走到DataSet node之後再走到Obs node
4.6.4 “[ ]”
/DataSet/Obs若要再走下去會有5472種走法,有時要選出符合某種條件的路就使用/DataSet/Obs[條件描述]。
條件描述為predicate。
條件描述會以每一株的contents來看
使用xml_find_first()裁出第一株子樹,並用xml_contents()看一下contents
[...]裡…必需是contents條件。
選出/DataSet/Obs中contents符合TYPE='原始值'且Item='總指數(不含食物)(民國105年=100)'
"/DataSet/Obs[TYPE='原始值' and Item='總指數(不含食物)(民國105年=100)']" %>%
xml_find_all(cpiRoot,.) -> cpiSelect; cpiSelect原本XPath
/DataSet/Obs子樹會有5472株,符合contents描述的只剩下456株。
更多可用的operators: https://www.w3schools.com/xml/xpath_operators.asp
4.7 轉成Data frame
4.7.1 Terminal nodes
Terminal nodes in XMLs are nodes that do no have any “children”. These nodes contain the information we generally want to extract into a tidy data frame.
cpiSelect 1st child的結構:只包含terminal nodes
4.7.2 as_list()
把cpiSelect的456株子樹轉成帶有456個elements的List。
試著把第一株樹存成data frame
.x<-cpiSelectList[[1]]
data.frame(
項目=.x$Item[[1]],
期間=.x$TIME_PERIOD[[1]],
頻率=.x$FREQ[[1]],
格式=.x$TYPE[[1]],
CPI指數=as.numeric(.x$Item_VALUE[[1]]),
stringsAsFactors = F
)寫一個函數,讓cpiSelectList中的任一個element(即cpiSelectList[[i]], i為element位置)輸入後會輸出一個一筆資料的data frame.
treeList2df<-function(.x){
data.frame(
項目=.x$Item[[1]],
期間=.x$TIME_PERIOD[[1]],
頻率=.x$FREQ[[1]],
格式=.x$TYPE[[1]],
CPI指數=as.numeric(.x$Item_VALUE[[1]]),
stringsAsFactors = F
)
}測試一下函數
使用迴圈將cpiSelectList疊成完整資料data frame
4.7.3 xmltools
xmltools::xml_dig_df()可將只有terminal nodes的nodeset轉成list of dataframes.
xml_dig_df()是個list,在應用上每個元素可以是不同結構的dataframe.
若每個dataframe有相同變數項目可推疊成一個dataframe,可透過如下的步驟完成
4.8 綜合練習
4.8.1 練習1
4.8.1.1 由Item node找出資料裡有那幾種消費者物價指數
4.8.1.2 選出「核心物價」指數「原始值」的所有Obs子樹
4.8.1.3 存出核心物價指數
4.8.2 練習2
"https://www.dgbas.gov.tw/public/data/open/localstat/009-%E5%90%84%E7%B8%A3%E5%B8%82%E5%88%A5%E5%B9%B3%E5%9D%87%E6%AF%8F%E6%88%B6%E6%89%80%E5%BE%97%E6%94%B6%E5%85%A5%E7%B8%BD%E8%A8%88.xml" %>%
read_xml() -> incomeXML4.8.2.1 轉成Data frame
incomeTreeList <- function(.x) {
data.frame(
年份=.x$Year[[1]],
臺灣地區=as.numeric(.x$臺灣地區[[1]]),
新北市=as.numeric(.x$新北市[[1]]),
臺北市=as.numeric(.x$臺北市[[1]]),
桃園市=as.numeric(.x$桃園市[[1]]),
臺中市=as.numeric(.x$臺中市[[1]]),
臺南市=as.numeric(.x$臺南市[[1]]),
高雄市=as.numeric(.x$高雄市[[1]]),
宜蘭縣=as.numeric(.x$宜蘭縣[[1]]),
新竹縣=as.numeric(.x$新竹縣[[1]]),
苗栗縣=as.numeric(.x$苗栗縣[[1]]),
彰化縣=as.numeric(.x$彰化縣[[1]]),
南投縣=as.numeric(.x$南投縣[[1]]),
雲林縣=as.numeric(.x$雲林縣[[1]]),
嘉義縣=as.numeric(.x$嘉義縣[[1]]),
屏東縣=as.numeric(.x$屏東縣[[1]]),
臺東縣=as.numeric(.x$臺東縣[[1]]),
花蓮縣=as.numeric(.x$花蓮縣[[1]]),
澎湖縣=as.numeric(.x$澎湖縣[[1]]),
基隆市=as.numeric(.x$基隆市[[1]]),
新竹市=as.numeric(.x$新竹市[[1]]),
嘉義市=as.numeric(.x$嘉義市[[1]]),
stringsAsFactors = F
)
}4.8.3 練習3: 2019 ROC
表演曲目抓取
- 2019 阿姆斯特丹皇家交響樂團曲目:https://www.concertgebouworkest.nl/en/concert/lang-lang-plays-beethoven-1