Kapittel 6 Fra HTML til tekst
6.1 Fra HTML til tekst
Vi bruker pakken rvest for å jobbe med webscraping. Det er en av de vanligste pakkene i R, og hører til gruppen av tidyverse, som lager en enklere og mer oversiktlig syntaks til R-kode.
De viktigste funksjonene i rvest-pakken er:
read_html(url) # Scrape HTML-innhold fra en URL
html_nodes() # Identifiserer HTML-noder (hmtl_node() identifiserer bare en node).
html_nodes(“.class”) # Kaller en node basert på CSS-klasse.
html_nodes(“#id”) # Kaller en node basert på <div> id.
html_nodes(xpath=”xpath”) # Kaller en node basert på xpath.
html_attrs() # Identifiserer attributter, f. eks. lenker.
html_table() # Gjør om HTML-tabeller til data frames.
html_text() # Stripper vekk HTML-noder og henter bare ut teksten.Kodene vi skal se på i denne delen er disse:
- read_html(): Kaller på serveren og henter inn en nettside.
- html_node(): Velger hvilken node (dvs. html-tag) som skal leses inn. Bruk html_nodes (flertall) for å lese inn alle nodene på nettsiden som har denne taggen.
- html_text(): Ordner og strukturerer html-koden slik at vi får det i et lesbart format, her tenkt som tekst.
Framgangsmåten for å hente informasjon er slik:
- Bruk
read_htmlmed navnet på URL-en du vil hente informasjon fra inne i gåsetegn i parentes bak. - Inspiserer nettsiden for å finne ut hvilken node du vil hente informasjon fra.
- Høyreklikk på noden i HTML-strukturen og velg “copy selector”.
- Spesifiserer node i
html_node. Dette gjør du ved å lime inn det du kopierte i forrige operasjon. - Siden vi vil hente ut teksten, skriver vi
html_textetterpå.
Disse kodesnuttene fletter vi sammen med pipe-operatoren %>%.
page <- read_html("https://www.regjeringen.no/no/dokumenter/meld.-st.-2-20192020/id2702126/?ch=1")
page <- page %>%
html_node("#kap1-1") %>% # For å få hele kapittel 1
html_text()read_html("https://www.regjeringen.no/no/dokumenter/meld.-st.-2-20192020/id2702126/?ch=1") %>%
html_node("#kap1-1-p1") %>% # For å få bare avsnitt 1 i kapittel 1
html_text()## [1] "Regjeringen Solberg består av Høyre, Venstre og Kristelig Folkeparti etter at Fremskrittspartiet gikk ut av regjering i januar. Regjeringens politikk baseres på Granavolden-plattformen. I forståelse med Stortinget legger regjeringen frem Revidert nasjonalbudsjett 2020 etter ordinær tidsplan. Regjeringen vil legge frem en ny proposisjon i slutten av mai om veien videre, herunder om overgangen fra akutte krisetiltak til mer vekstfremmende tiltak. "Hva nå? Vi kunne f. eks. sjekket her hvor mange referanser som er til virusord.
virusord <- str_extract_all(page, c("([a-z]+)?([Vv]irus)([a-z]+)?")) # Henter ut alle ord som potensielt (?) begynner med bokstaver, har virus eller Virus i midten, og potensielt avsluttes med flere bokstaver.
virusord <- unlist(virusord)
virustabell <- tibble(tekst = page) %>%
tidytext::unnest_tokens(ord, tekst) %>%
count(ord, sort = TRUE) %>%
filter(ord %in% virusord)
virustabell %>%
ggplot(aes(ord, n)) +
geom_bar(stat = "identity") +
coord_flip()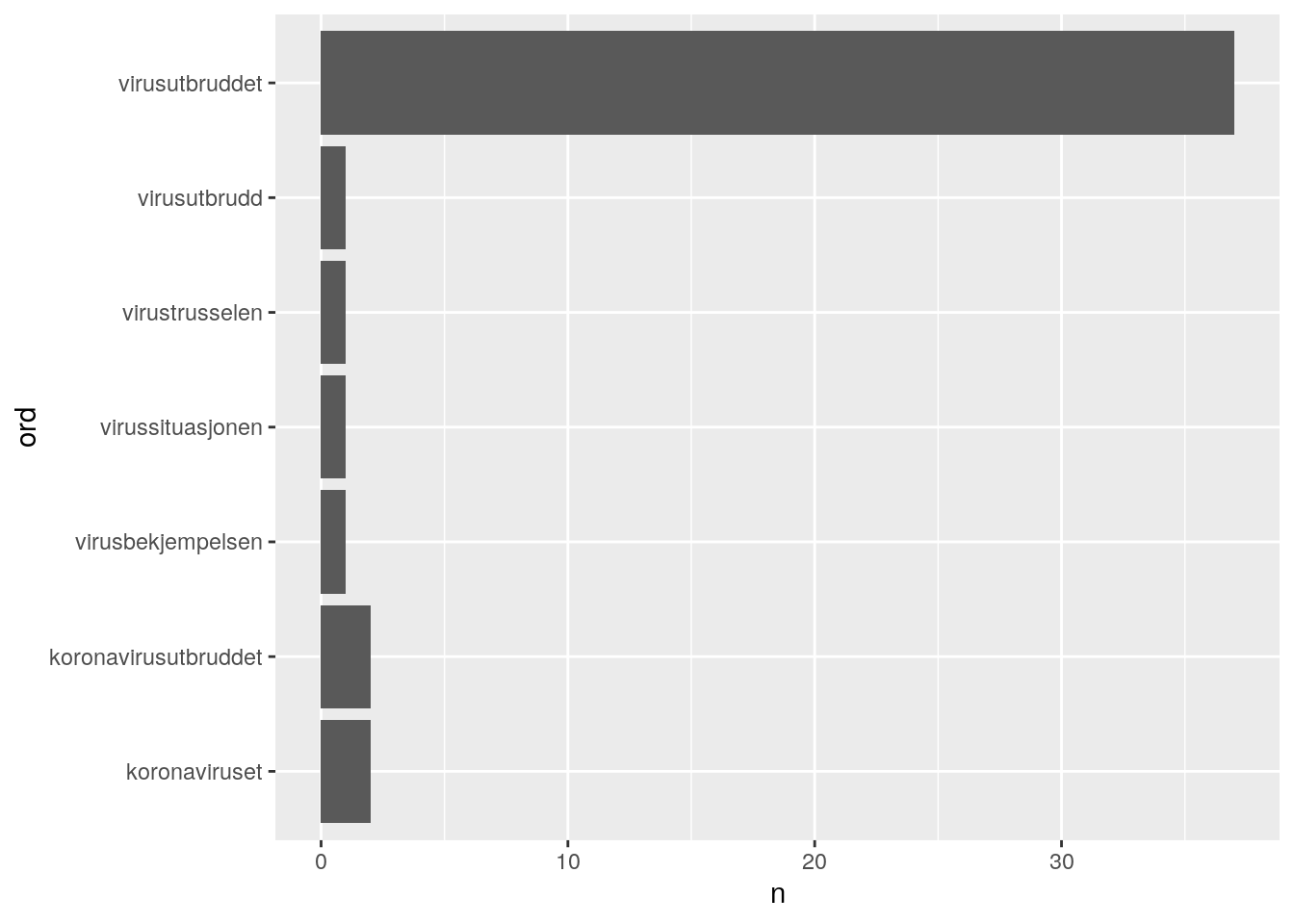
Hva skjedde i denne koden? I den siste kodechunken lager vi et plot ved hjelp av ggplot-pakken. I den midterste kodechunken prosesserer vi tekst ved hjelp av tidytext-pakken. Vi kommer ikke til å gå nærmere inn på disse delene, men for de som er interessert kan https://r4ds.had.co.nz/ og https://www.tidytextmining.com/index.html være til hjelp. Den øverste kodechunken skal vi imidlertid se nærmere, for her skjer det noe som brukes ganske mye i webscraping for å håndtere datainput fra nettsider. Vi henter ut et ord ved hjelp av regex.
Ofte ønsker vi å ta ut deler fra data vi laster ned, og det kan vi gjøre ved å bruke pakken stringr sammen med litt regex. Regex er et kodespråk som refererer til språk, og stringr-pakken er en pakke som gjør vi kan jobbe med strenger i R. Alle funksjonene i stringr-pakken starter med str_.
str_extract() # Henter ut en spesifisert del fra en string
str_extract_all() # Henter ut flere spesifiserte deler fra en string
str_replace() # Erstatter en spesifisert del fra en string
str_replace_all() # Erstatter flere spesifiserte deler fra en string
str_remove() # Tar bort en spesifisert del fra en string
str_remove_all() # Tar bort flere spesifiserte deler fra en string
str_c() # Limer sammen to strenger. (paste() eller paste0() i 'base R'.)
str_to_lower() # Setter alle bokstaver i en string til lav bokstav
str_to_upper() # Setter alle bokstaver i en string til stor bokstav
str_trim() # Tar bort whitespace fra en string
str_split() # Splitter en string i to. (strsplit i 'base R'.)Regex: Regex står for “Regular Expression”, og kalles ofte for “regulære uttrykk” på norsk. Regex gjør det mulig å beskrive en string utfra et mønster - det ligger altså et abstraksjonsnivå opp fra vanlig språk. For eksempel, vi har en serie med e-poster som ser slik ut:
bfu@ssb.no rts@ssb.no pol@ssb.no put@ssb.no amy@ssb.no
Strukturen i disse e-postene er veldig like. Alle starter på tre bokstaver, så kommer en alfrakrøll, deretter ssb.no. Siden dette følger et spesielt mønster, kan vi beskrive det i regex. Nedenfor ser vi at vi kan spesifisere generelle mønstre innenfor klammeparentes i en string, f. eks. [a-z], som indikerer små bokstaver.
eposter_string <- c("Vi må huske å sende ut eposter til bfu@ssb.no og rts@ssb.no. Det er ikke så viktig med pol@ssb.no, for han kan vi også nå via pelle@gmail.com. Dersom dere får tid kan dere også kontakte påt@ssb.no og AMY@ssb.no, som jobber med nettsiden ssb.no.")Vi må huske å sende ut eposter til bfu@ssb.no og rts@ssb.no. Det er ikke så viktig med pol@ssb.no, for han kan vi også nå via pelle@gmail.com. Dersom dere får tid kan dere også kontakte påt@ssb.no og AMY@ssb.no, som jobber med nettsiden ssb.no.*
str_extract_all(eposter_string, "ssb.no") # Vi får med alle steder i teksten der 'ssb.no' dukker opp## [[1]]
## [1] "ssb.no" "ssb.no" "ssb.no" "ssb.no" "ssb.no" "ssb.no"str_extract_all(eposter_string, "[a-z]@ssb.no") # Vi får med alle steder i teksten der en liten bokstav følges av 'ssb.no'## [[1]]
## [1] "u@ssb.no" "s@ssb.no" "l@ssb.no" "t@ssb.no"str_extract_all(eposter_string, "[a-z]+@ssb.no") # Vi får med alle steder i teksten der en eller flere små bokstaver følges av 'ssb.no'## [[1]]
## [1] "bfu@ssb.no" "rts@ssb.no" "pol@ssb.no" "t@ssb.no"str_extract_all(eposter_string, "[a-zA-Z]+@ssb.no") # Vi får med alle steder i teksten der en eller flere små eller store bokstaver følges av 'ssb.no'## [[1]]
## [1] "bfu@ssb.no" "rts@ssb.no" "pol@ssb.no" "t@ssb.no" "AMY@ssb.no"str_extract_all(eposter_string, "[a-zA-ZÆæØøÅå]+@ssb.no") # Vi får med alle steder i teksten der en eller flere små eller store bokstaver følges av 'ssb.no', pluss at vi inkluderer Æ Ø Å i både små og store bokstaver## [[1]]
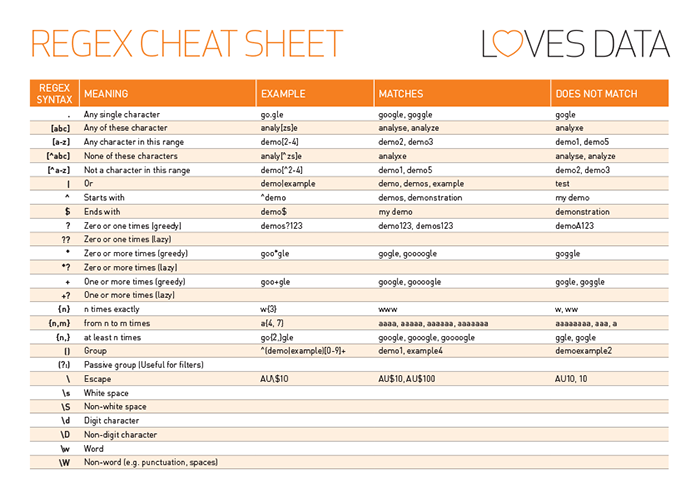
## [1] "bfu@ssb.no" "rts@ssb.no" "pol@ssb.no" "påt@ssb.no" "AMY@ssb.no"Regex gir mange muligheter, men siden det handler om å se mønstre på en spesiell måte (det er en nokså intuitiv prosess), er det er mengdetrening som gjør at man kan bruke det effektivt. Bildet under gir et eksempel på regex syntax.
6.2 Oppgave 1
- Gå inn på www.ssb.no
- Trykk deg inn på en artikkel.
- Høyreklikk, velg «inspiser» og undersøk HTML-koden.
- Hent ut teksten fra artikkelen via
rvest-pakken. - Prøv å bruke både html_node() og html_nodes(). Hva blir forskjellen?