Chapter 3 Ergebnisse
Die Ergebnisse der 50 Schätzungen zeigen, dass die logistische Regression hier die besten Resultate liefert. Für alle Schätzer gilt, dass die Klassifizierungsgüte nicht sehr stark von der Aufteilung des Datensatzes abhängt.
## [1] 0.9409656## [1] 0.9398138## [1] 0.9141194## [1] 0.9360614# plot all N results
# initialize data frame
results = data.frame()
res = c("log_reg","lda","qda","bayes")
# Combine results
for(i in res){results = rbind(results,data.frame(get(i),i))}
names(results) = c("Fit","Estimator")
#estimation results
results%>% ggplot(aes(x=Estimator,y=Fit,fill=Estimator))+geom_boxplot(alpha=.5)+theme_fivethirtyeight()+theme(legend.position="none")+
ggtitle(expression(atop("Es gibt keine große Streuung bei allen Schätzern")))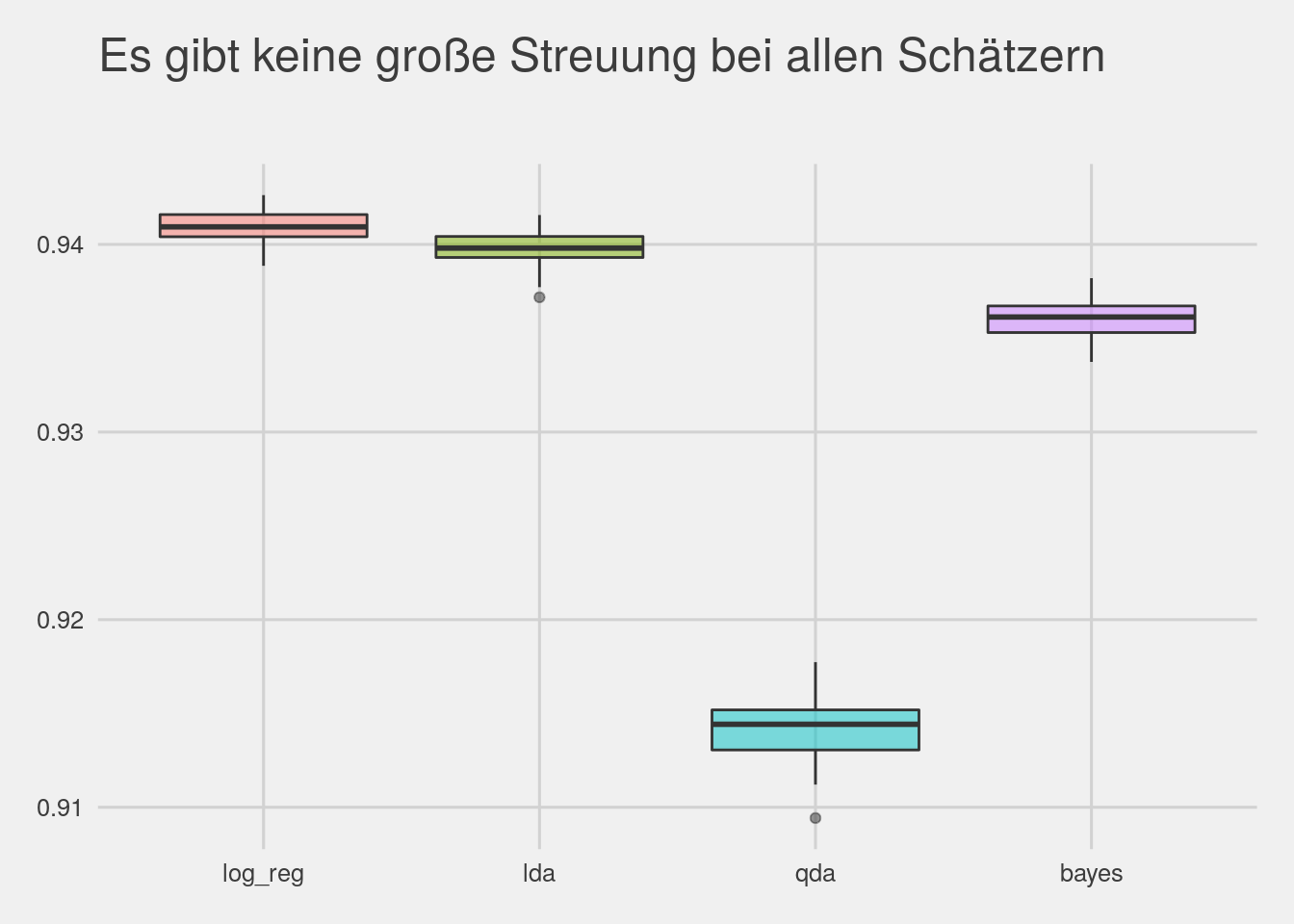
Mögliche Erweiterung: Wir haben hier nur parametrische Modelle genutzt, um die Daten zu klassifizieren. Darüber hinaus könnten zum Beispiel Methoden, die Entscheidungsbäume nutzen, wie Bagging oder Random Forest, genutzt werden.