Chapter 1 Der Datensatz
Bevor wir Modelle zur Klassifikation der Daten nutzen, analysieren wir den Datensatz, bereiten die Daten für unsere Nutzung auf und bereinigen den Datensatz. Dazu laden wir die folgenden libraries in R.
# Import needed libraries
library(dplyr)
library(lubridate)
library(ggplot2)
library(ggthemes)
library(scales)
library(caTools)
library(MASS)
library(e1071)Im nächsten Schritt werden die Daten in R importiert. Um die Berechnungen etwas zu beschleunigen, wird eine zufällige Stichprobe mit \(N =500.000\) gezogen und gespeichert. Durch die Funktion set.seed() lässt sich das Ziehen der Stichprobe reproduzieren.
# set directory with stored csv-files
# setwd("/home/.../daten")
# # initialize data frame
# bikedata = data.frame()
#
# # extract file names
# csv_files = list.files()
#
# # Import the data
# for(file in csv_files){bikedata = rbind(bikedata,read.table(file,header=T,sep=",",stringsAsFactors = F))}
#
# draw sample
# set.seed(123)
# bikedata = sample_n(bikedata,500000)
#
# # save sample
# write.csv(bikedata,"/home/daniel/sciebo/Vortrag_Bewerbung_ASV/daten/bikedata.csv", row.names = TRUE)Im nächsten Schritt laden wir den gespeicherten Datensatz und werfen einen ersten Blick auf die Daten. Die Funktion head() wird genutzt, um die ersten Datensätze anzuzeigen.
# load sample
bikedata= read.table("bikedata.csv",header=T,sep=",",stringsAsFactors = F)
# look at the first data rows
head(bikedata)## X tripduration starttime stoptime
## 1 1 904 2018-09-04 16:43:34.5150 2018-09-04 16:58:39.2420
## 2 2 691 2018-09-20 14:04:31.8180 2018-09-20 14:16:03.1310
## 3 3 1235 2018-11-14 22:59:08.1330 2018-11-14 23:19:43.3510
## 4 4 642 2018-06-12 10:59:21.3640 2018-06-12 11:10:03.9700
## 5 5 284 2018-12-05 15:27:02.6660 2018-12-05 15:31:47.0700
## 6 6 467 2018-01-24 08:05:57.3790 2018-01-24 08:13:44.7510
## start.station.id start.station.name start.station.latitude
## 1 441 E 52 St & 2 Ave 40.75601
## 2 518 E 39 St & 2 Ave 40.74780
## 3 3539 W 116 St & Amsterdam Ave 40.80676
## 4 285 Broadway & E 14 St 40.73455
## 5 490 8 Ave & W 33 St 40.75155
## 6 519 Pershing Square North 40.75187
## start.station.longitude end.station.id end.station.name
## 1 -73.96742 492 W 33 St & 7 Ave
## 2 -73.97344 236 St Marks Pl & 2 Ave
## 3 -73.96071 3145 E 84 St & Park Ave
## 4 -73.99074 379 W 31 St & 7 Ave
## 5 -73.99393 362 Broadway & W 37 St
## 6 -73.97771 507 E 25 St & 2 Ave
## end.station.latitude end.station.longitude bikeid usertype birth.year
## 1 40.75020 -73.99093 25661 Subscriber 1984
## 2 40.72842 -73.98714 15331 Subscriber 1982
## 3 40.77863 -73.95772 34119 Subscriber 1987
## 4 40.74916 -73.99160 31092 Subscriber 1973
## 5 40.75173 -73.98754 15967 Subscriber 1988
## 6 40.73913 -73.97974 16050 Subscriber 1990
## gender
## 1 1
## 2 1
## 3 1
## 4 1
## 5 1
## 6 21.1 Erstellen neuer Variablen
Einige der Variablen des Datensatzes sind ohne eine Bearbeitung nicht für die Klassifikationsmodelle, die im nächsten Abschnitt diskutiert werden, nutzbar. Aus diesem Grund nutzen wir die gegebenen Informationen, um neue Variablen zu bestimmen.
Die Informationen in Starttime, mit Ausprägungen wie 2018-09-04 16:43:34.5150, sind für die Analyse sehr nützlich. Im Folgenden bestimmen wir aus Starttime den Wochentag, den Monat und die Uhrzeit der Ausleihe. Zusätzlich wird die Dauer der Fahrt in Minuten bestimmt sowie das Alter der Kunden.
# create tripDate field
bikedata$tripDate = as.Date(bikedata$starttime,format="%Y-%m-%d")
# convert character to POSIXct
bikedata$time = as.POSIXct(strptime(bikedata$starttime,"%Y-%m-%d %H:%M:%S"))
# extract time
bikedata$time = strftime(bikedata$time,format="%H:%M:%S")
# new variables
bikedata$wday = wday(bikedata$tripDate)
bikedata$month = factor(month(bikedata$tripDate))
bikedata$hour = as.numeric(substr(bikedata$time,1,2))
bikedata$tripMin = bikedata$tripduration/60
bikedata$age = year(today())-bikedata$birth.year
bikedata$age_group = cut(bikedata$age,breaks=c(0,29,39,49,59,69,79,100),labels=c("unter 30","< 40","< 50","< 60","< 70","< 80","80 und älter"))Im nächsten Schritt bekommen einige Variablen einfach zu interpretierende Label.
#convert gender vars to name
bikedata$gender = ifelse(bikedata$gender==1,"Männer",ifelse(bikedata$gender==2,"Frauen","Unbekannt"))
# rename weekdays
bikedata$wday = ifelse(bikedata$wday==1,"Sonntag",bikedata$wday)
bikedata$wday = ifelse(bikedata$wday==2,"Montag",bikedata$wday)
bikedata$wday = ifelse(bikedata$wday==3,"Dienstag",bikedata$wday)
bikedata$wday = ifelse(bikedata$wday==4,"Mittwoch",bikedata$wday)
bikedata$wday = ifelse(bikedata$wday==5,"Donnerstag",bikedata$wday)
bikedata$wday = ifelse(bikedata$wday==6,"Freitag",bikedata$wday)
bikedata$wday = ifelse(bikedata$wday==7,"Samstag",bikedata$wday)
bikedata$wday = factor(bikedata$wday,levels = c("Montag","Dienstag","Mittwoch","Donnerstag","Freitag","Samstag","Sonntag"))
# usertype as factor
bikedata$usertype = factor(bikedata$usertype)Aus den Informationen in start.station.latitude, start.station.longitude, end.station.latitude und end.station.longitude wird die Distanz (Luftlinie) zwischen Start und Endstation bestimmt. Dazu definieren wir folgende Funktionen:
# calculate distance between start and end stations
getDistanceFromLatLonInKm = function(lat1,lon1,lat2,lon2) {
R = 6371 # Radius of the earth in km
dLat = deg2rad(lat2-lat1) # deg2rad below
dLon = deg2rad(lon2-lon1)
a = sin(dLat/2) * sin(dLat/2) +
cos(deg2rad(lat1)) * cos(deg2rad(lat2)) *
sin(dLon/2) * sin(dLon/2)
c = 2 * atan2(sqrt(a), sqrt(1-a))
d = R * c # Distance in km
return(d)
}
deg2rad = function(deg) {
return(deg * (pi/180))
}
bikedata$dist=getDistanceFromLatLonInKm(bikedata$start.station.latitude,bikedata$start.station.longitude,
bikedata$end.station.latitude,bikedata$end.station.longitude)1.2 Bereinigung der Daten
Einige Variablen haben Ausprägungen, die wahrscheinlich aus fehlerhaften Eintragungen resultieren. Um die Schätzung unabhängig von diesen Beobachtungen zu machen, werden die betroffenen Beobachtungen aus dem Datensatz entfernt.
Wir beginnen mit tripMin. Durch die summary() Funktion können wir uns den maximalen Wert dieser Variable anzeigen lassen. Der maximale Wert entspricht ca. 1863 Stunden. Dieser Wert scheint nicht realistisch. Wir entfernen alle Ausleihen, die länger als 12 Stunden andauern.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.02 5.97 10.08 16.06 17.65 111781.68## [1] 222Für die Variable Alter entfernen wir alle Beobachtungen mit einem Alter 90 oder älter. Der maximale Wert von 136 scheint auch hier nicht realistisch.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 19.00 32.00 40.00 41.99 52.00 136.00## [1] 413Die Variable dist hat den maximalen Wert 14.83 km. Hier ist keine Bereinigung nötig. Zuletzt überprüfen wir, ob es Variablen mit missing values gibt, das ist hier aber nicht gegeben.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0000 0.8271 1.3734 1.7857 2.3031 14.8286## [1] 01.3 Deskriptive Analyse
In diesem Abschnitt führen wir eine deskriptive Analyse des Datensatzes durch, um die Variablen des Datensatzes besser zu verstehen und in den Klassifikationsmodellen benutzen zu können.
# gender
bikedata %>% ggplot(aes(x=gender,fill=gender)) + geom_bar(alpha=.8) + theme_fivethirtyeight() + scale_fill_brewer(palette="Set2")+
theme(legend.position="none")+ggtitle(expression(atop("68% der Citi Bike Nutzer sind Männer")))+
scale_y_continuous(label=unit_format(big.mark = ".",decimal.mark = ",",suffix=""))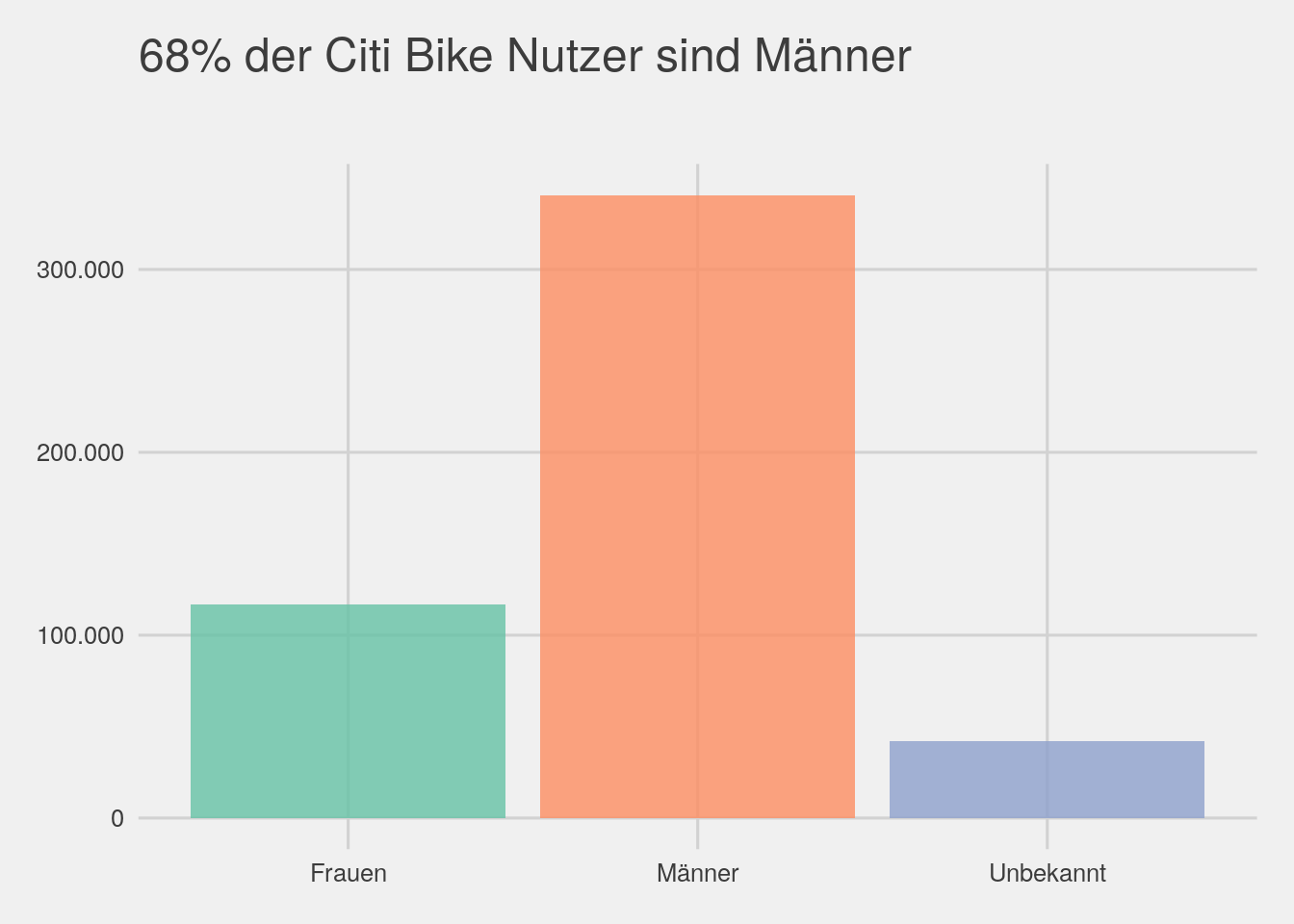
# age
bikedata %>% ggplot(aes(x=age)) + geom_density(bw=1.5)+theme_fivethirtyeight()+theme(axis.text.y=element_blank())+ggtitle("Altersverteilung der Citi Biker")+
geom_vline(xintercept=median(bikedata$age,na.rm=T),linetype="dashed",col="dark grey")+annotate("text",x=33,y=.045,label="Median = 40")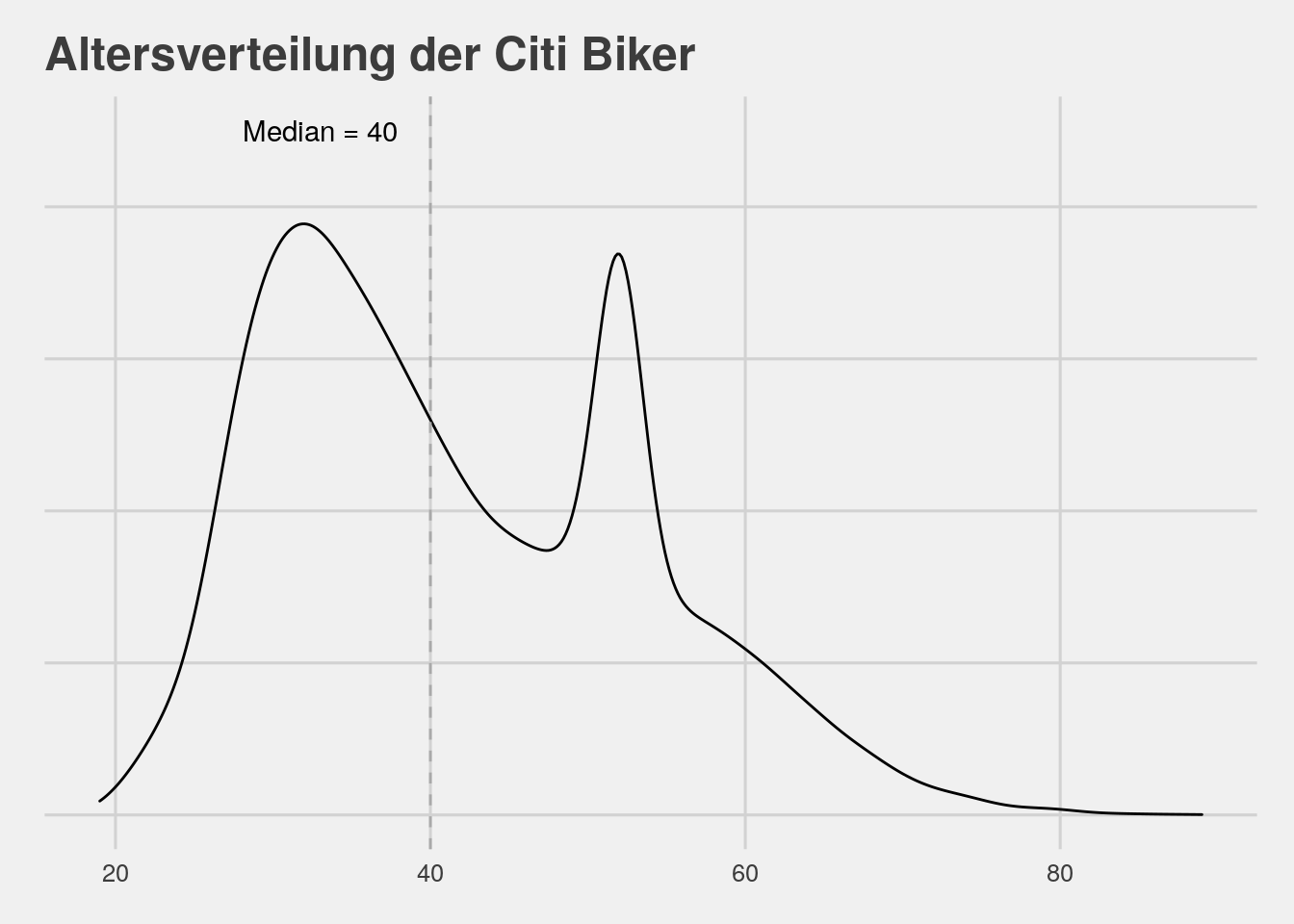
# age_group
bikedata %>% ggplot(aes(x=age_group,fill=age_group)) + geom_bar(alpha=.8)+theme_fivethirtyeight()+scale_fill_brewer(palette="Set2")+
theme(legend.position="false")+ggtitle(expression(atop("Verteilung nach Altersgruppen",atop("50% sind 39 oder jünger"))))+
scale_y_continuous(label=unit_format(big.mark = ".",decimal.mark = ",",suffix=""))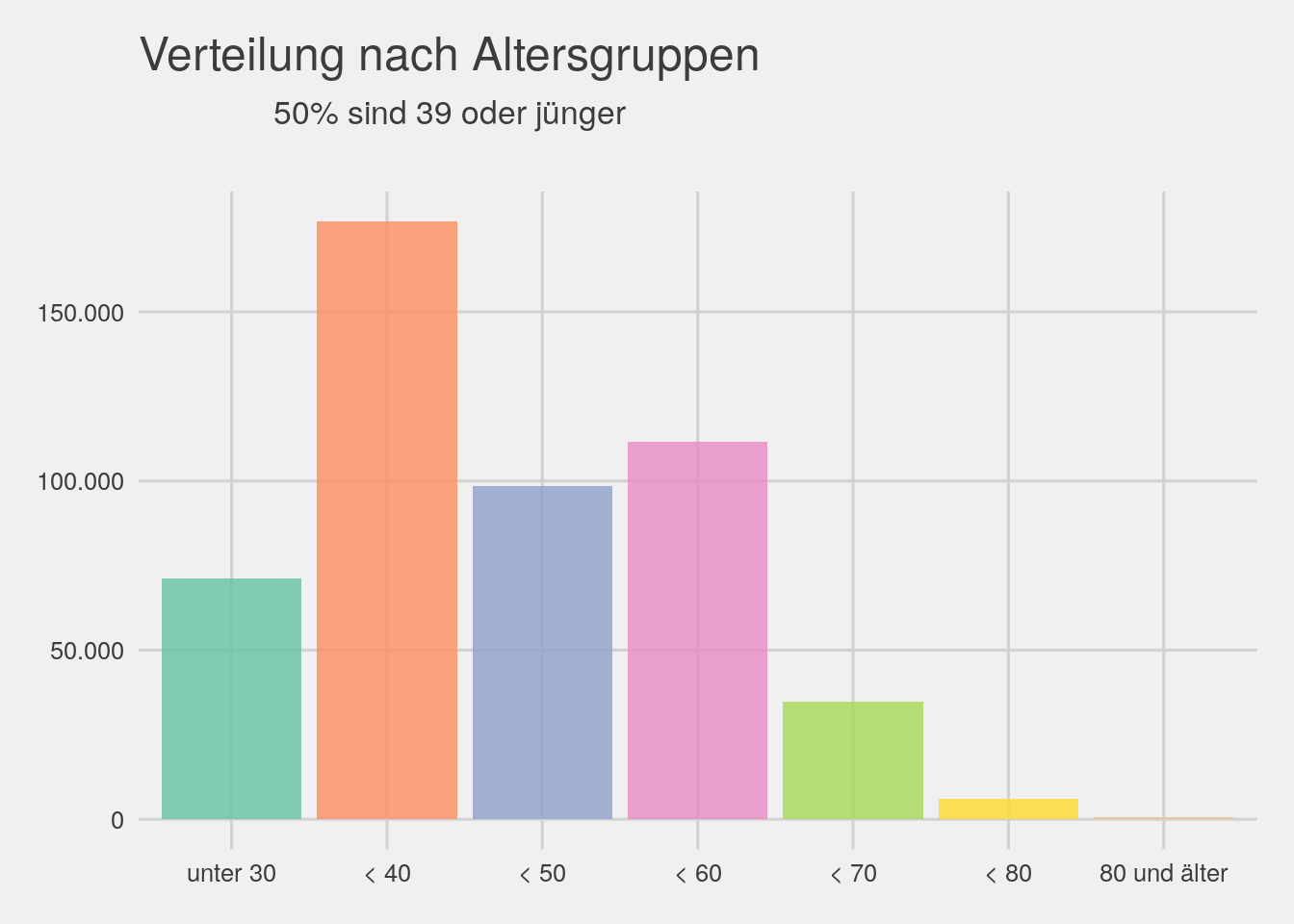
# age by gender
bikedata %>% filter(gender %in% c("Männer","Frauen")) %>% ggplot(aes(x=gender,y=age,fill=gender))+geom_boxplot(alpha=.4)+ylim(15,90)+theme_fivethirtyeight()+
theme(legend.position="none")+scale_fill_brewer(palette="Set2")+ggtitle("Altersverteilung nach Geschlecht")+annotate("text",x="Frauen",y=39,label="Median = 37")+
annotate("text",x="Männer",y=41,label="Median = 39")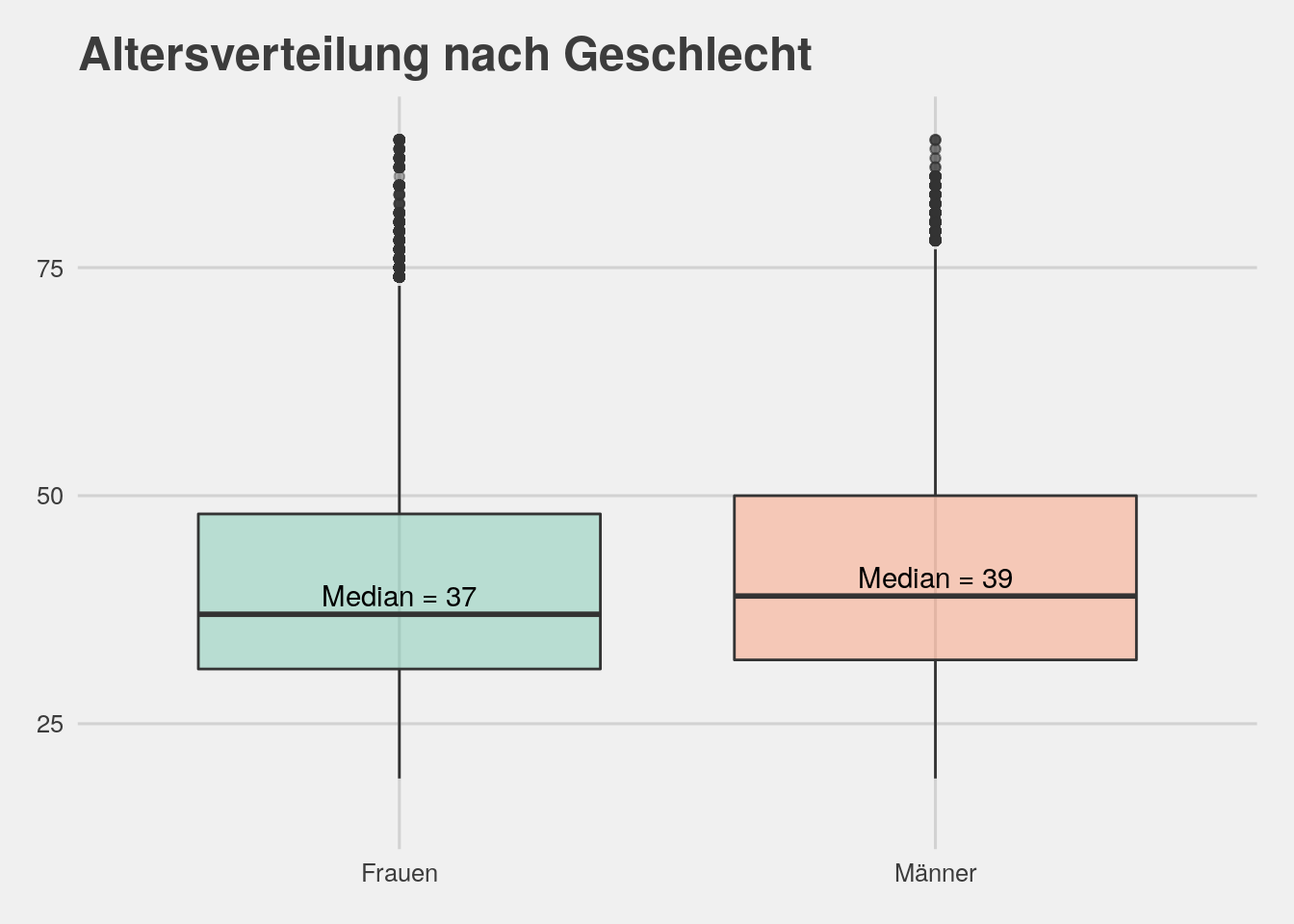
# usertype
bikedata %>% ggplot(aes(x=usertype,fill=usertype)) + geom_bar(alpha=.7)+theme_fivethirtyeight()+theme(legend.position="none")+
ggtitle(expression(atop("Nutzertypen",atop("Customer = 24 hour/3 Day pass | Subscriber = Annual Pass")))) +
scale_y_continuous(label=unit_format(big.mark = ".",decimal.mark=",",suffix=""))+
annotate("text",x="Subscriber",y=350000,label="89% sind Subscriber")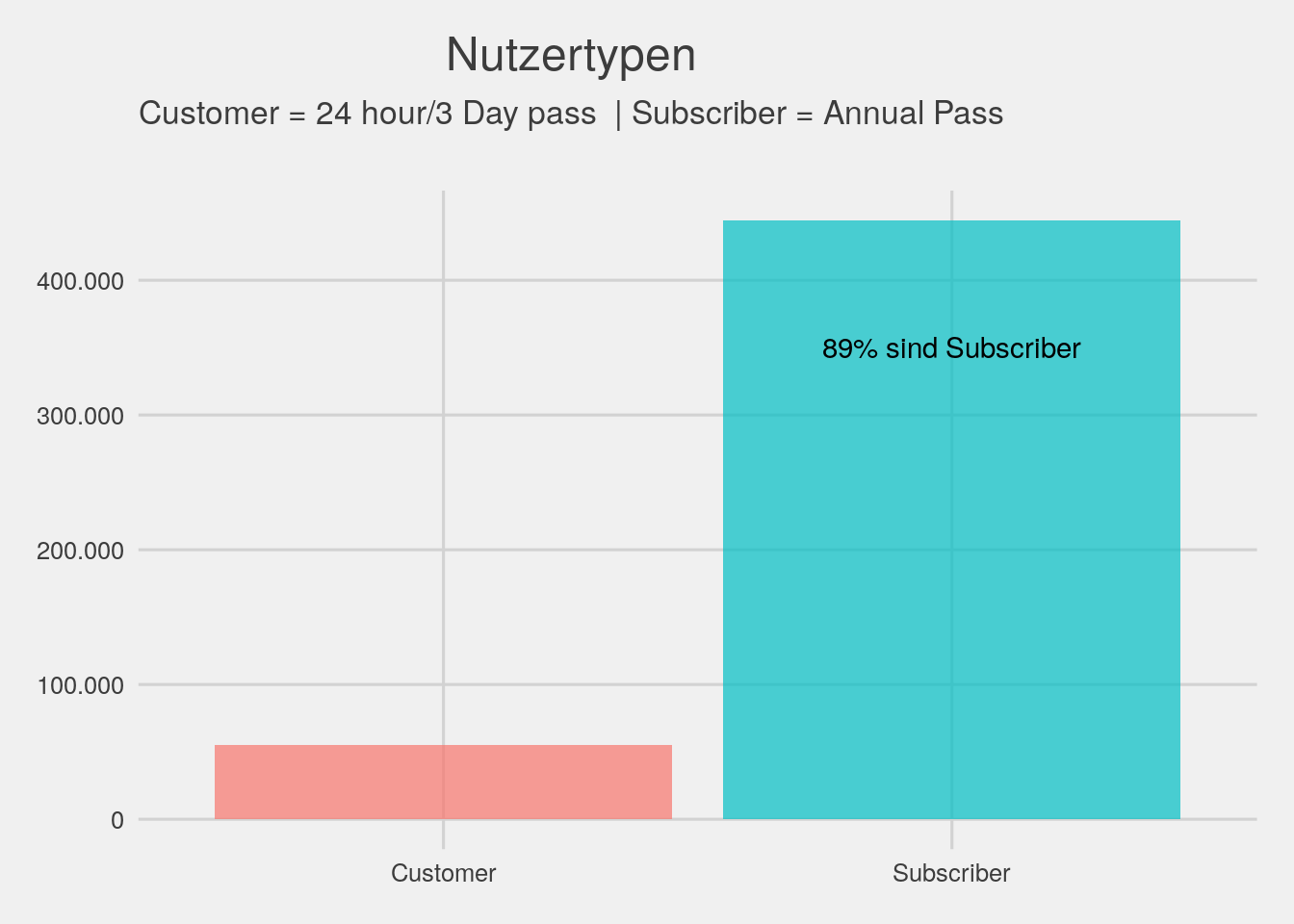
# rides by day
bikedata %>% ggplot(aes(x=wday,fill=wday))+geom_bar(alpha=.8)+theme_fivethirtyeight()+ scale_fill_brewer(palette="Set2")+theme(legend.position="none")+
ggtitle(expression(atop("In der Woche höhere Nutzung",atop("Anzahl Fahrten pro Tag"))))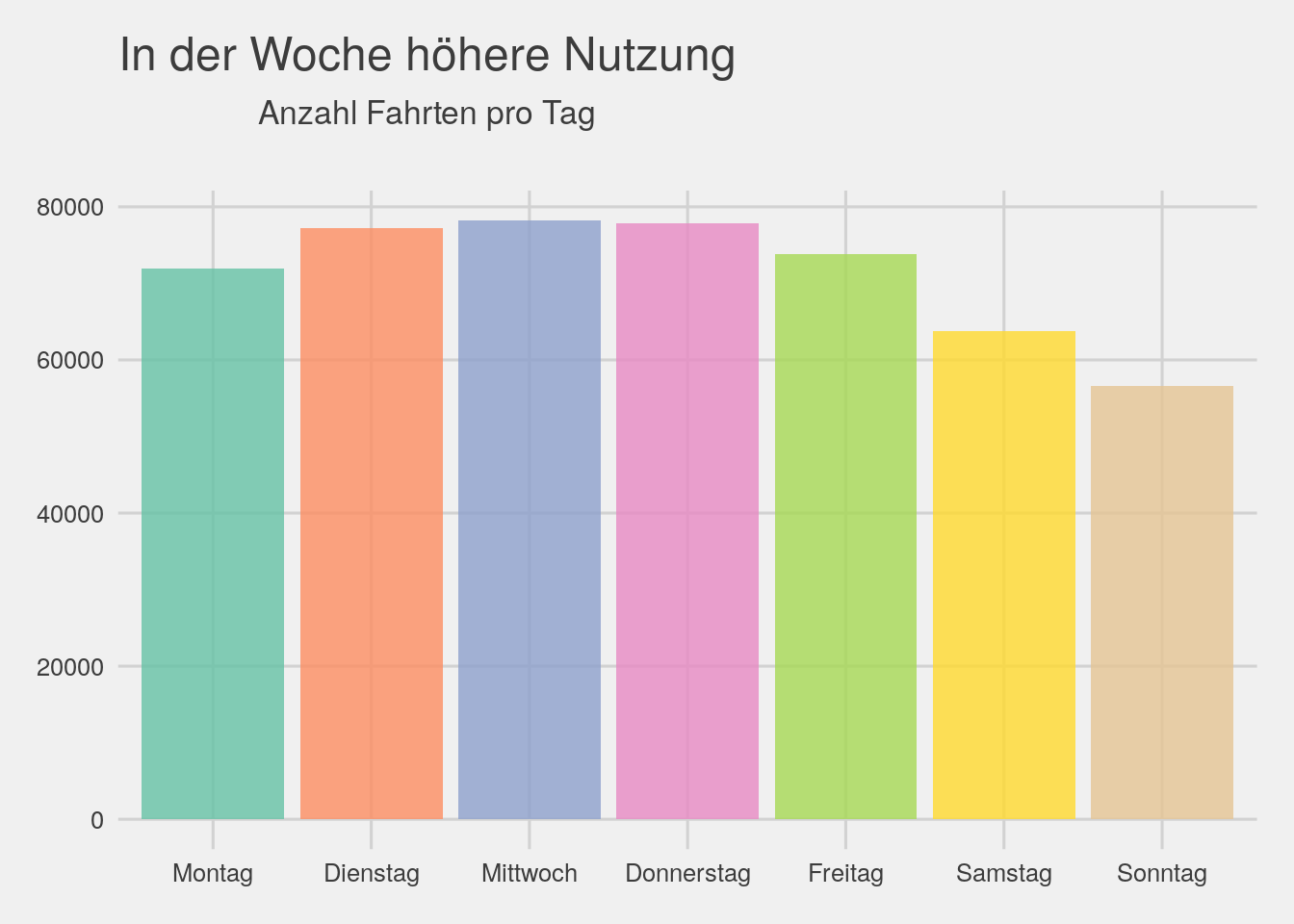
# weekday distribution, graph
bikedata %>% ggplot(aes(x=hour,fill=factor(wday))) + geom_density(alpha=.2)+facet_wrap(~wday,ncol=1)+theme_fivethirtyeight()+
theme(legend.position="none",axis.text.y=element_blank(),plot.title=element_text(hjust=.5)) +
ggtitle(expression(atop("Zeitliche Verteilung der Nutzung",atop("In der Woche gibt es morgens (8:00-9:00) and abends (17:00-18:00) Spitzen"))))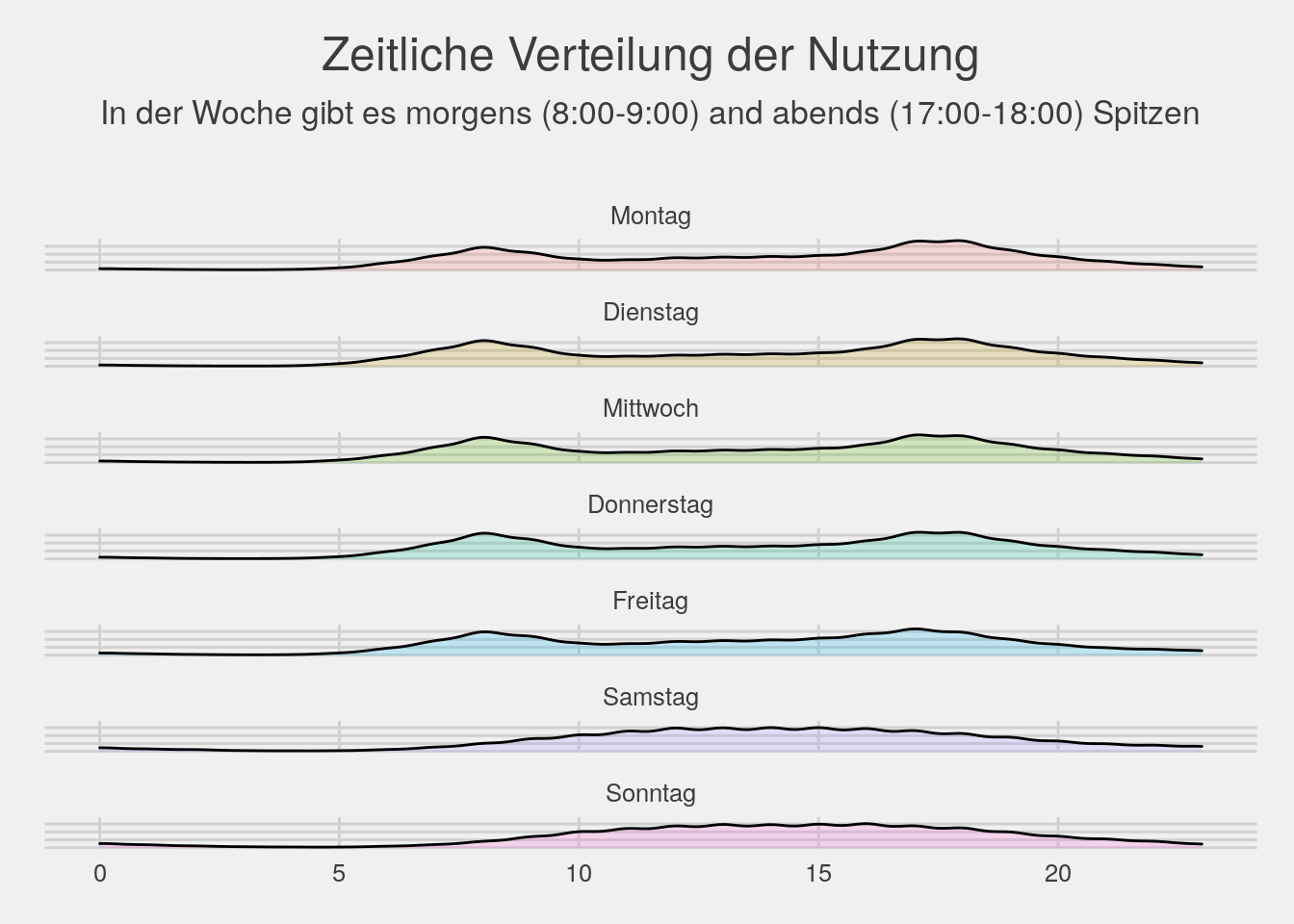
# weekday distribution
bikedata %>% ggplot(aes(x=wday,y=tripMin,fill=wday))+geom_boxplot(alpha=.5)+ylim(0,30)+theme_fivethirtyeight()+scale_fill_brewer(palette="Set2")+
theme(legend.position="none")+ggtitle("Am Wochenende werden die Fahrräder länger genutzt")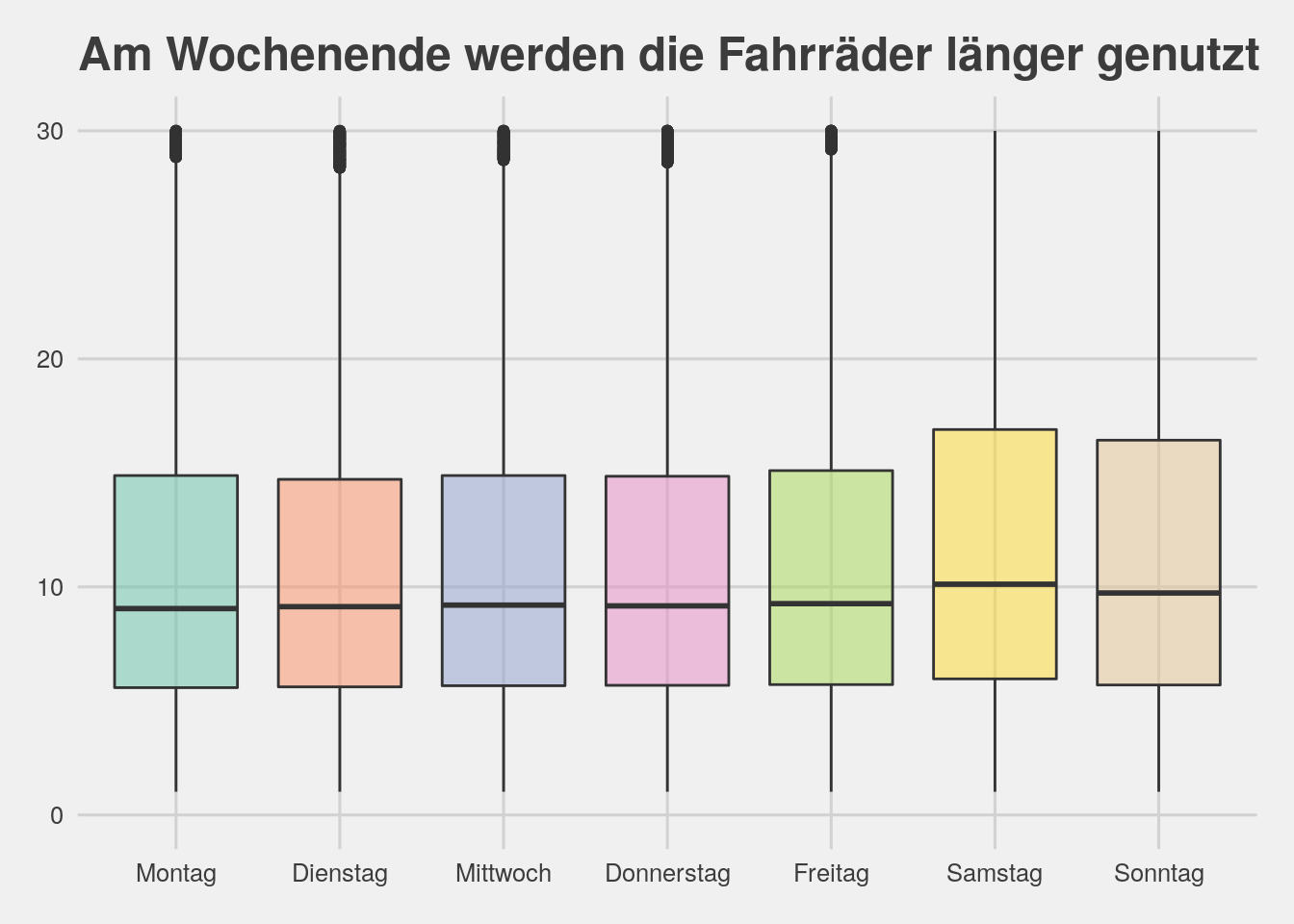
#time of day distribution by usertype
bikedata %>% ggplot(aes(x=hour,group=usertype,fill=usertype)) + geom_density(alpha=.3) + theme_fivethirtyeight() +
theme(legend.title=element_blank(),axis.text.y=element_blank())+
ggtitle(expression(atop("Nutzertypen unterscheiden sich in zeitlicher Nutzung",atop("Customer = 24 hour/3 Day pass | Subscriber = Annual Pass"))))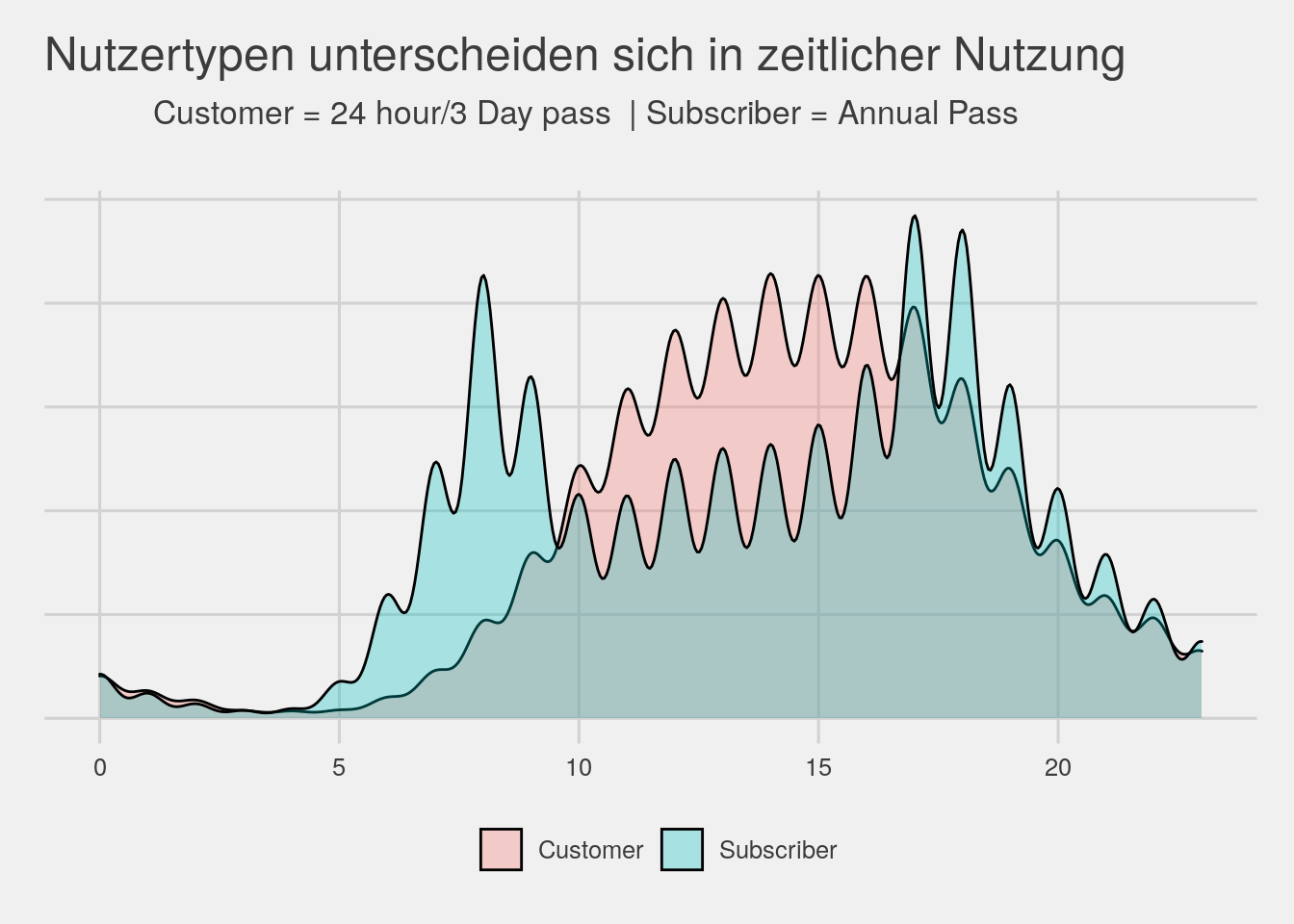
#time of day distribution by usertype, weekday
bikedata %>% filter(wday %in% c("Montag","Dienstag","Sonntag")) %>% ggplot(aes(x=hour,group=usertype,fill=usertype)) + geom_density(alpha=.3) + facet_wrap(~wday,ncol=1) + theme_fivethirtyeight() +
theme(legend.title=element_blank(),axis.text.y=element_blank(),plot.title=element_text(hjust=.5)) +
ggtitle(expression(atop("Subscribers nutzen Citi Bikes für den Weg zur Arbeit")))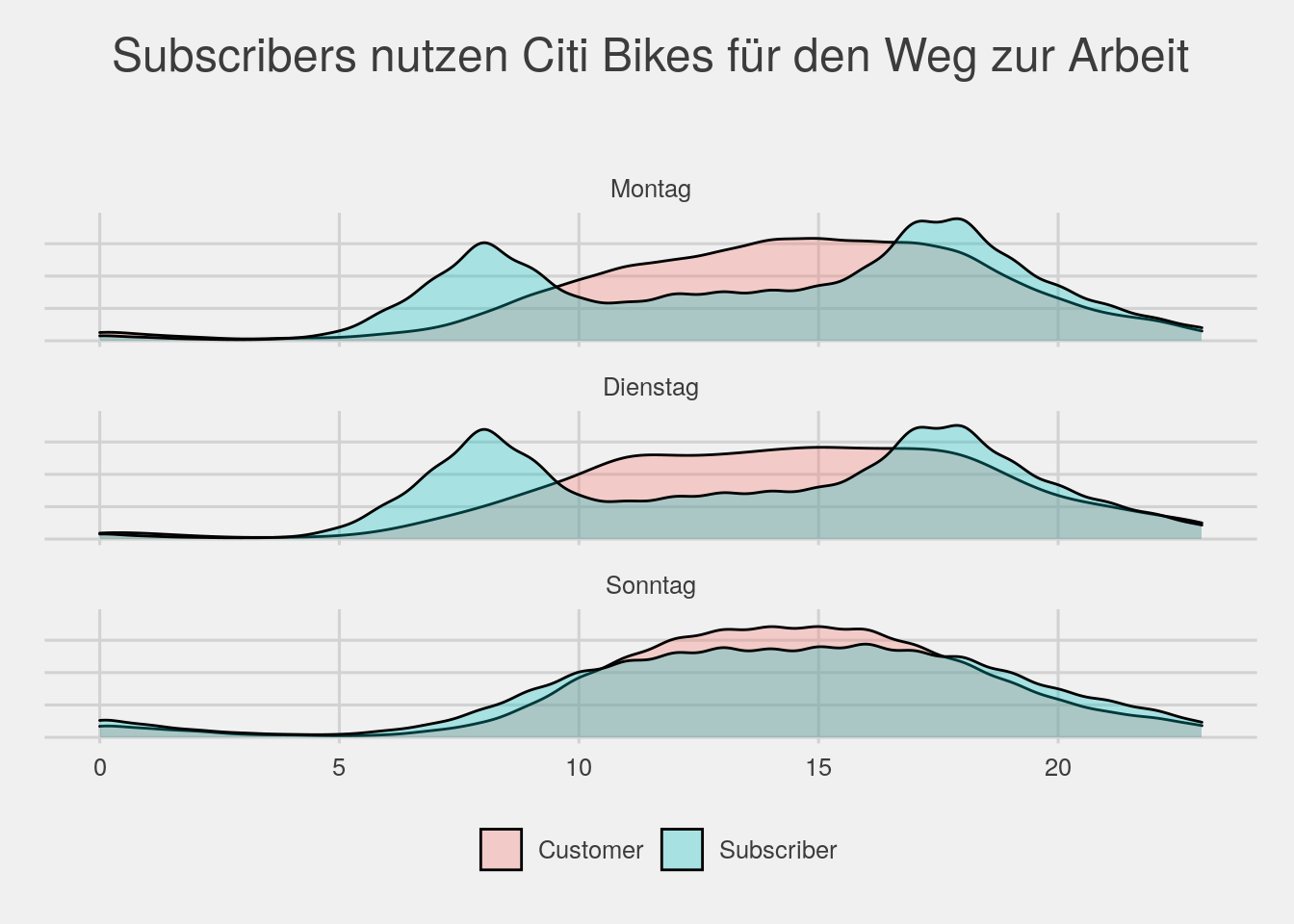
# trip duration by usertype
bikedata %>% ggplot(aes(x=usertype,y=tripMin,fill=usertype))+geom_boxplot(alpha=.5)+ylim(0,70)+theme_fivethirtyeight()+
theme(legend.position="none")+ggtitle(expression(atop("Subscribers nutzen die Fahrräder kürzer",atop("Minuten pro Nutzung"))))+
annotate("text",x="Customer",y=23,label="Median = 21,4")+annotate("text",x="Subscriber",y=11.5,label="Median = 9,3")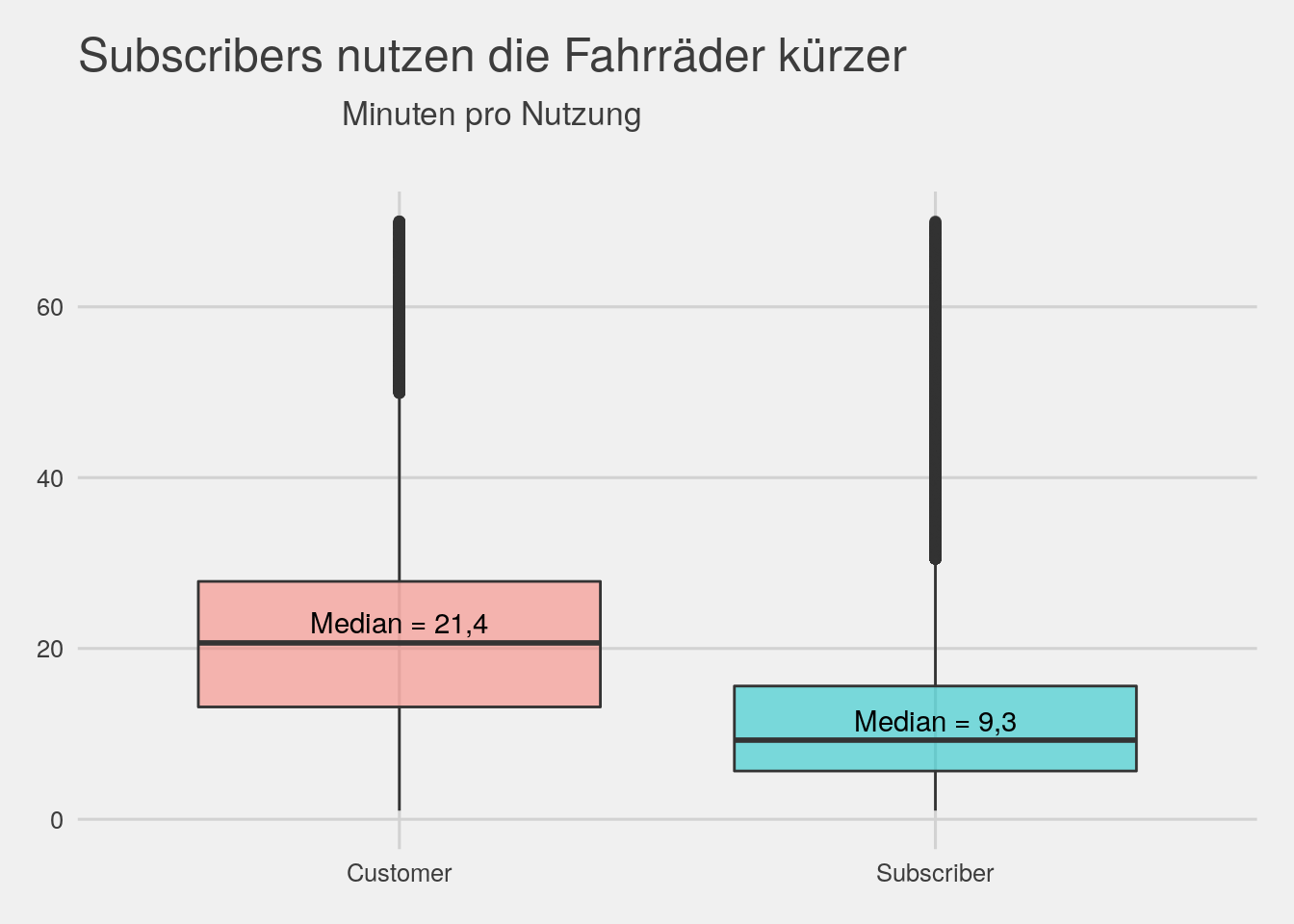
# weekday distribution, dist
bikedata %>% ggplot(aes(x=dist,fill=factor(wday))) + geom_density(alpha=.2)+facet_wrap(~wday,ncol=1)+theme_fivethirtyeight()+
theme(legend.position="none",axis.text.y=element_blank(),plot.title=element_text(hjust=.5)) +
ggtitle(expression(atop("Abstand zwischen Start- und Endstation",atop("Keine Unterschiede zwischen Arbeitstagen und Wochenende"))))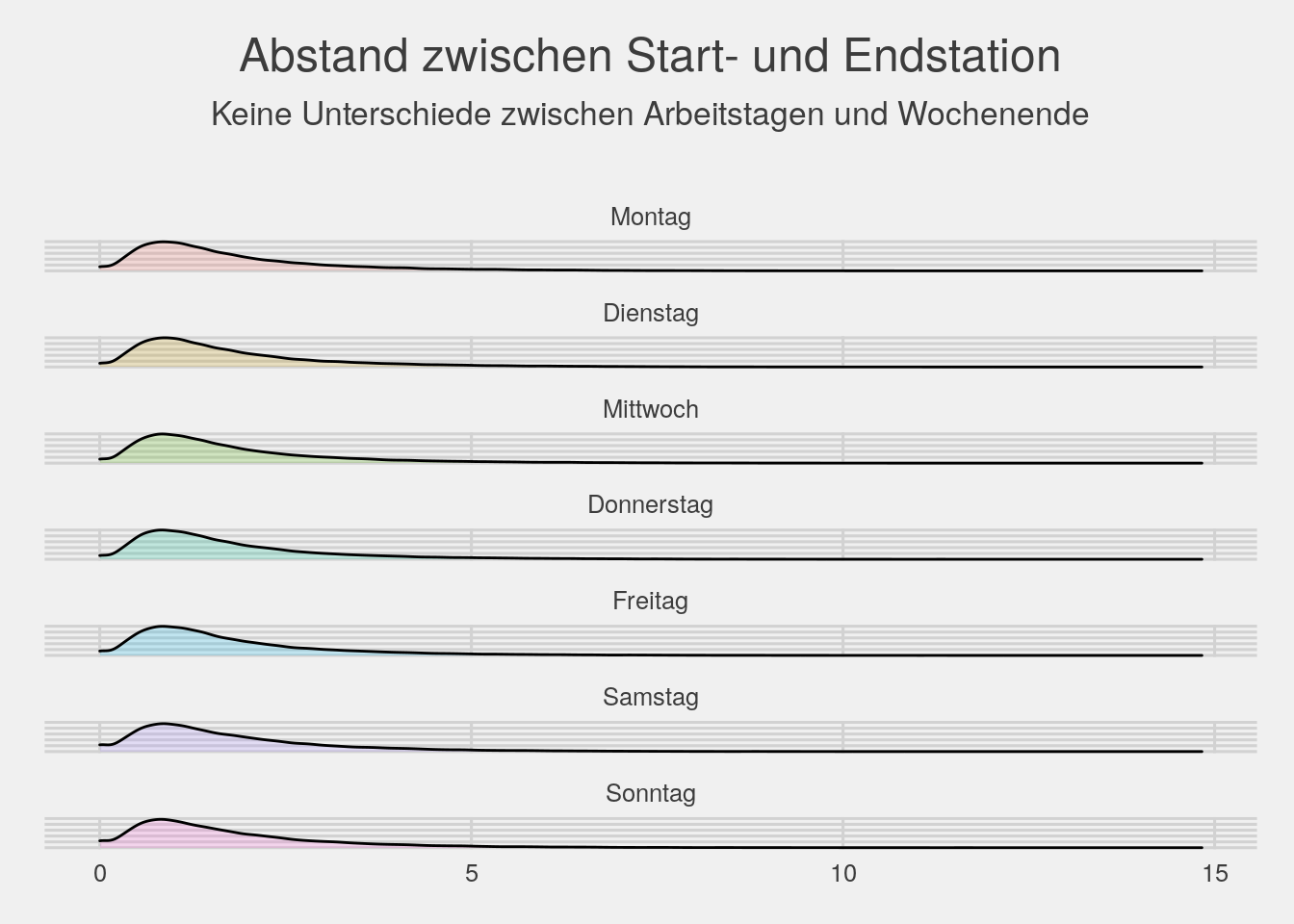
#dist by usertype
bikedata %>% ggplot(aes(x=dist,group=usertype,fill=usertype)) + geom_density(alpha=.3) + theme_fivethirtyeight() +
theme(legend.title=element_blank(),axis.text.y=element_blank())+
ggtitle(expression(atop("Nutzertypen unterscheiden sich in gefahrener Distanz",atop("Customer = 24 hour/3 Day pass | Subscriber = Annual Pass"))))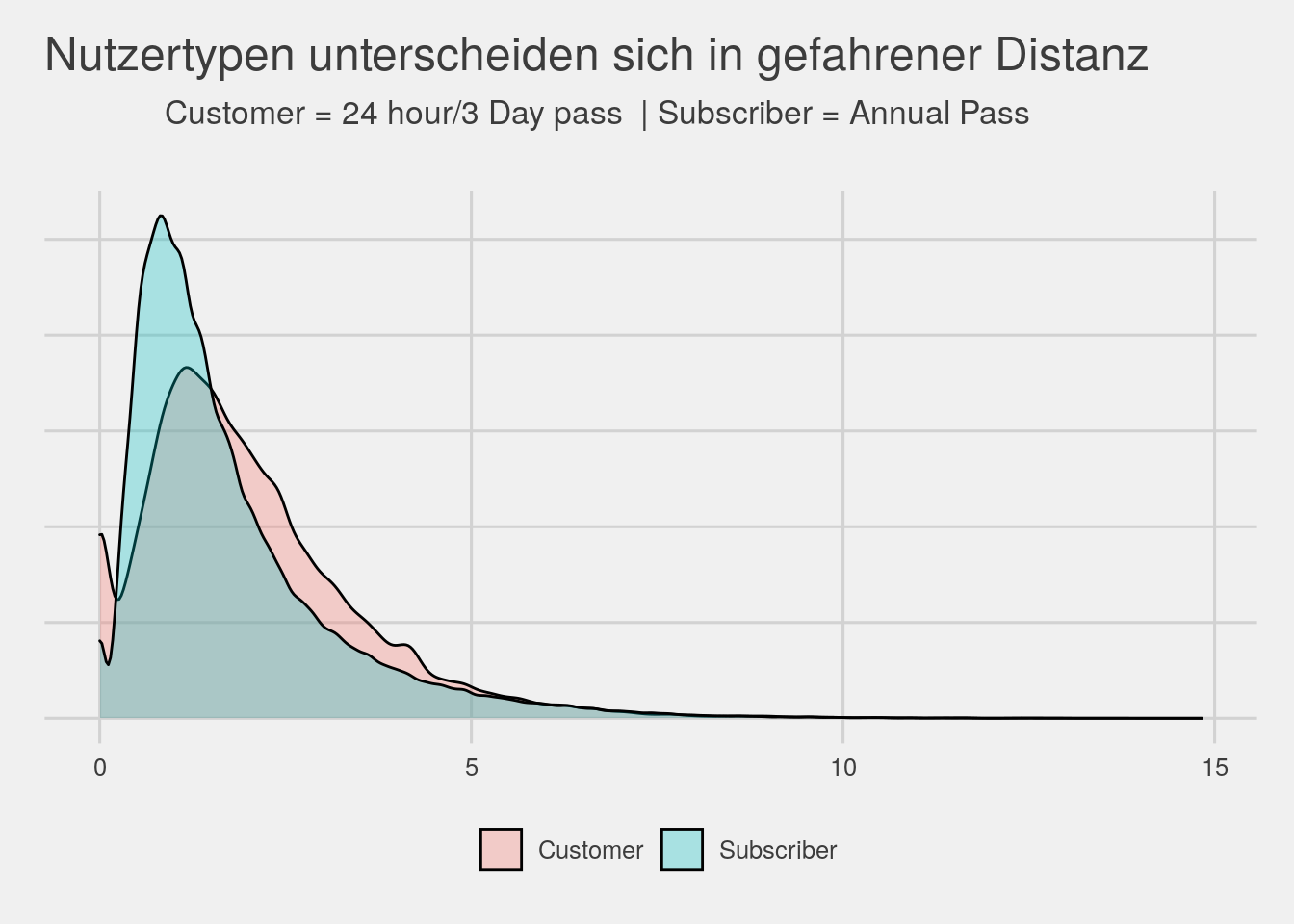
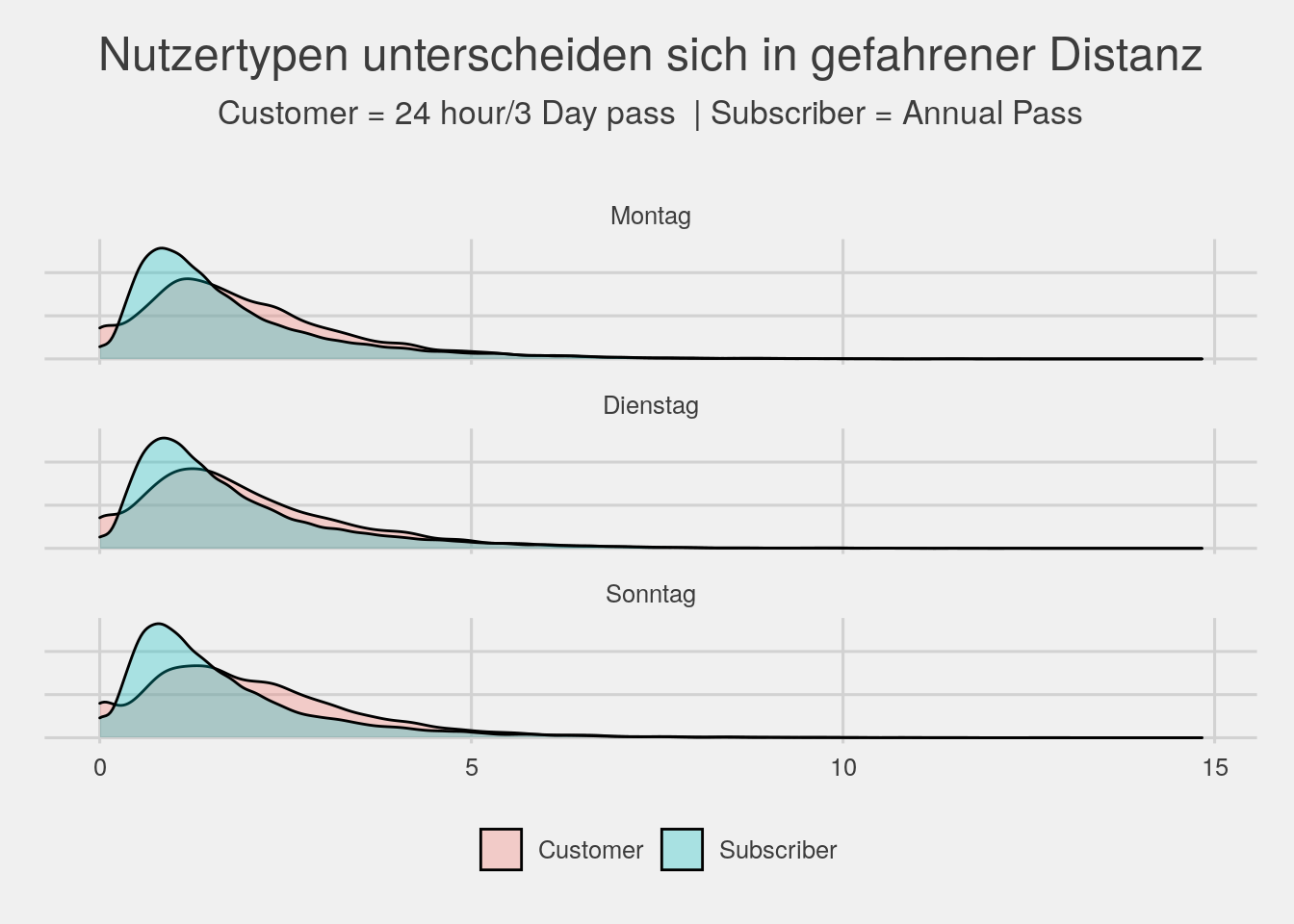
#dist by usertype, weekday
bikedata %>% filter(wday %in% c("Montag","Dienstag","Sonntag")) %>% ggplot(aes(x=dist,group=usertype,fill=usertype)) + geom_density(alpha=.3) + facet_wrap(~wday,ncol=1) + theme_fivethirtyeight() +
theme(legend.title=element_blank(),axis.text.y=element_blank(),plot.title=element_text(hjust=.5))+
ggtitle(expression(atop("Nutzertypen unterscheiden sich in gefahrener Distanz",atop("Customer = 24 hour/3 Day pass | Subscriber = Annual Pass"))))