5 Data Pipeline
Our pipeline is entirely orchestrated through Spotify’s Luigi. We have 5 different original sources of data:
- The current distribution of government officials in the Public Federal Administration (APF)
- All public procurement contracts available in Compranet
- All buying units listed in Compranet
- Shell companies identified by the Tax department
- Salary codes for officials in the APF
All 5 sources are downloaded in parallel when the pipeline is triggered. Once we have all clean names for public officials, we construct our last data source, by scraping the interest declaration for each one of those names, and parsing the work experience section.
knitr::include_graphics("images/pipeline.png")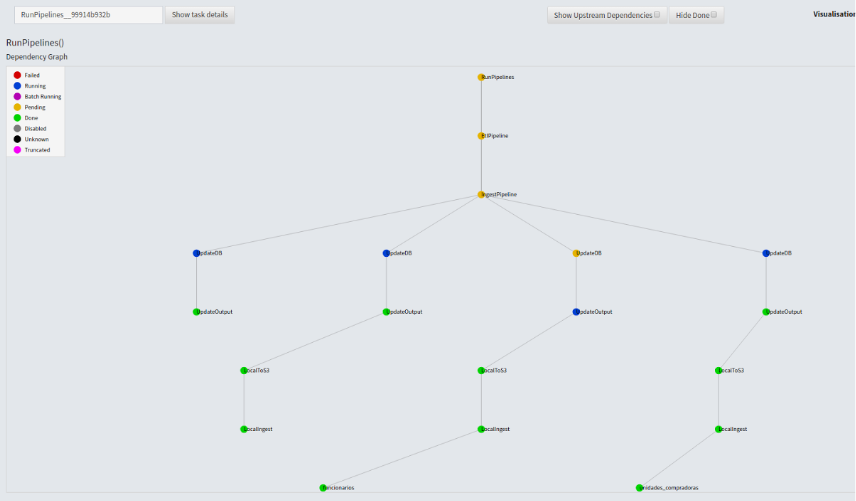
Once we had the initial ingest, we added a scrapping code that stores the ingest folder and modifies the rawschemes and, after applying some cleanse and homologation rules, adds new information to the databases.When the merge is completed and the history of bureaucrats is created, the data is isgested into neo4j, alsoinitialized within docker-compose.Finally, the pipeline runs the models described in the next section.