An important — maybe the most authoritative — classification system is developed and maintained by the United Nations. It is expressively developed for statistical purposes by the United Nations Statistics Division UNSD using the M49 methodology.
Resource 1.1 : United Nations Statistics Division M49 Classification
Manual download: The standard country or area codes for statistical use (M49) is available in different languages (English, Chinese, Russian, French, Spanish, Arabic) by clicking one of the buttons “Copy”, “Excel” or “CSV”. On this page is no URL for an programmable download with an R script available, because Javascript triggers the buttons mentioned above.
Several detailed outputs of the classifications categories (regions) and their elements (countries) in different code chunks (tabs).
To facilitate the second task I have prepared the function pb_class_scheme() and stored in “R./helper.r”.
R Code 1.2 : Inspect raw data of the UNSD M49 geoscheme classification
Code
m49_raw<-base::readRDS("data/unsd/m49_raw.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(m49_raw)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(m49_raw)
#> ******************* Using skimr::skim() ***************************
The file has 15 columns as you can also see online from the Overview page.
The many missing values (NAs) for the categories LDC, LLDC and SIDS are easy explained: These three columns are coded with an ‘x’ if the country of this row belong to this category. Recoding these three columns with 1 and 0 (1 = yes, belongs to this category, 0 = no, does not belong to this category) will reduce most of their missing values.
1.4.2 Antarctica
One missing value in the regional categories (Region, Sub-Region and Intermediate Region) is related to Antarctica which is not seen by the M49 scheme as a separated region. It has therefore no regional codes and names with the exception of the overall comprising global region. But it has M49 as well ISO-alpha codes.
1.4.3 Channel Island Sark
One of the missing values for ISO-alpha2 and ISO-alpha3 is related to Sark, which is “recognized by the United Nations Statistics Division (UNSD) as a separate territory” but was not accepted by ISO now for more than 20 years (McCarthy 2020). 2020 a new 54-page submission for an ISO code (see PDF) was applied to ISO but it seems still under consideration, because currently 3 Sark has no ISO 3166 codes.
For further processing of the M49 dataset, however, it is crucial to have a complete list of ISO Codes because these are the columns where the joining of two dataset will be linked. There exist two possibilities to get a complete list for all UN entries for the ISO codes:
The other missing value for ISO-alpha2 codes belongs to Namibia because its abbreviation NA is interpreted by R as a missing value!
1.5 Clean Data (first step)
1.5.1 Procedure
Procedure 1.1 : Clean M49 data of the UNSD geoscheme classification (first step)
Load the original M49 dataset (“m49_raw.rds”)
Remove the global codes and global names because they a redundant: All rows have global code “001” (“World”).
Shorten long names to their abbreviation (“LCD”, “LLCD” and “SIDS”).
Remove row “Antarctica” because it is not seen as separate country.
Add ISO Codes “CQ” and “SCQ” to Country or Area of Sark.
Replace NA in the column ISO-alpha2 Code” of Namibia with the string “NA”.
Recode the columns LDC, LLDC and SIDS with 0 and 1.
Relocate columns ISO-alpha3 CODE and Country or Area to the first two columns because these two columns are always relevant for the later groupings and joining with groupings from other sources.
Sort the data alphabetically by Country or Area.
1.5.2 Result (first step)
1.5.2.1 Data Structure
R Code 1.3 : Clean UNSD M49 geoscheme classification data (first step)
Code
## column renaming vector ########m49_cols=c( LDC ="Least Developed Countries (LDC)", LLDC ="Land Locked Developing Countries (LLDC)", SIDS ="Small Island Developing States (SIDS)")## clean data ###############################m49_clean<-base::readRDS("data/unsd/m49_raw.rds")|># (1)dplyr::select(-(1:2))|># (2)dplyr::rename(tidyselect::all_of(m49_cols))|># (3) dplyr::filter(`Country or Area`!="Antarctica")|># (4)dplyr::mutate( `ISO-alpha2 Code` =base::ifelse(`Country or Area`=="Sark", "CQ", `ISO-alpha2 Code`), # (5a) `ISO-alpha3 Code` =base::ifelse(`Country or Area`=="Sark", "SCQ", `ISO-alpha3 Code`), # (5b) `ISO-alpha2 Code` =base::ifelse(`Country or Area`=="Namibia", "NA", `ISO-alpha2 Code`)# (6))|>dplyr::relocate(## any_of() does not understand object names (??)tidyselect::any_of(c("ISO-alpha3 Code", "Country or Area")), .before =`Region Code`)|># (7)# .x = anonymous function; "x" = value in cols of m40_cleandplyr::mutate(dplyr::across(LDC:SIDS, ~dplyr::if_else(.x=="x", 1, 999, 0)# (8)))|>dplyr::arrange(`Country or Area`)# (9)## save new tibble ##########pb_save_data_file("unsd",m49_clean,"m49_clean.rds")## display results ##########m49_clean<-base::readRDS("data/unsd/m49_clean.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(m49_clean)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(m49_clean)
#> ******************* Using skimr::skim() ***************************
As explained above, only Sark has no value for ISO-alpha2 Code and ISO-alpha3 Code .
1.5.2.2 Regional Groups
As we can see from R Code 1.3 the M49 classification of the United Nations knows three different regional groups (in addition to the overall region World.)
Code Collection 1.1 : Display different regional groups
R Code 1.4 : Show Regions of the UNSD M49 Geoscheme
Code
(m49_region<-pb_class_scheme( df =base::readRDS("data/unsd/m49_clean.rds"), sel1 =rlang::quo(`Country or Area`), sel2 =rlang::quo(`Region Name`)))
“Region” is a classification scheme with 248 countries in 5 regions.
R Code 1.5 : Show Sub-regions of the UNSD M49 Geoscheme
Code
(m49_sub_region<-pb_class_scheme(df<-base::readRDS("data/unsd/m49_clean.rds"), sel1 =rlang::quo(`Country or Area`), sel2 =rlang::quo(`Sub-region Name`)))
“Sub-region” is a classification scheme with 248 countries in 17 regions.
R Code 1.6 : : Show Intermediate Regions of the UNSD M49 Geoscheme
Code
(m49_intermediate_region<-pb_class_scheme( df =base::readRDS("data/unsd/m49_clean.rds"), sel1 =rlang::quo(`Country or Area`), sel2 =rlang::quo(`Intermediate Region Name`)))
“Intermediate Region” is a classification scheme with 248 countries in 9 regions.
1.6 Clean Data (second step)
The intermediate grouping does not result into the expected 22 (with Antarctica: 23) different regions as is mentioned in many documents. See for instance the Article on Wikipedia about the UN geoscheme which features a colored world map and a list of countries grouped into the 22 different regions.
Graph 1.1: M49 Geoscheme developed and maintained by the United Nations Statistics Divisions (UNSD). (CC BY-SA 3.0, Wikimedia Commons)
The solution is that we have the NAs in Intermediate Region Name to replace with the values of the sub-regions. Additionally — as can be seen in R Code 1.6 — there is a second small problem: Three small countries are listed as an extra group “Channel Islands”. To get the official intermediate grouping we need to get rid of this group and sort all three of them into the category of “Northern Europe”.
1.6.1 Procedure
Procedure 1.2 : Clean M49 data of the UNSD geoscheme classification (second step)
Replace the NA values of Intermediate Region Name with values from the Sub-region Name column.
Replace the NA values of Intermediate Region Code with values from the Sub-region Code column.
Replace the “Channel Islands” values in Intermediate Region Name with the value of “Northern Europe”.
Replace the “Channel Islands” values (“830”) in Intermediate Region Code with the code of “Northern Europe” (“154”).
1.6.2 Result (second step)
1.6.2.1 Data Structure
R Code 1.7 : Clean UNSD M49 geoscheme classification data (second step)
Code
m49_clean2<-base::readRDS("data/unsd/m49_clean.rds")|>## replace `NA`s of intermediate regions with sub-region values ######dplyr::mutate(`Intermediate Region Name` =base::ifelse(is.na(`Intermediate Region Name`), `Sub-region Name`, `Intermediate Region Name`), # (1) `Intermediate Region Code` =base::ifelse(is.na(`Intermediate Region Code`), `Sub-region Code`, `Intermediate Region Code`), # (2)## replace ""Channel Islands" with "Northen Europe" values ###### `Intermediate Region Name` =base::ifelse(`Intermediate Region Name`=="Channel Islands", "Northern Europe", `Intermediate Region Name`), # (3) `Intermediate Region Code` =base::ifelse(`Intermediate Region Code`=="830", "154", `Intermediate Region Code`)# (4) )## save new tibble as clean2 ##########pb_save_data_file("unsd", m49_clean2, "m49_clean2.rds")## display results ##########m49_clean2<-base::readRDS("data/unsd/m49_clean2.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(m49_clean2)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(m49_clean2)
#> ******************* Using skimr::skim() ***************************
With the “trick” to replace the NAs of Intermediate Region Name with the values of Sub-regional Namecolumn we also got rid of the many NAs in that and the accompanying Intermediate Region Code column.
1.6.2.2 Intermediate Region Again
R Code 1.8 : Show correct intermediate region for the UNSD M49 Geoscheme
Code
## show new intermediate result ###############(m49_intermediate2<-pb_class_scheme( df =base::readRDS("data/unsd/m49_clean2.rds"), sel1 =rlang::quo(`Country or Area`), sel2 =rlang::quo(`Intermediate Region Name`)))
The new regional group Intermediate Region Name is a classification scheme with 248 countries in 22 regions. As Antarctica is not included the grouping with Intermediate Region Name represents the correct M49 classification.
1.7 Un Countries
The UN M49 geoscheme classification data contains 15 columns and 248 rows (= Columns or Areas). This is much more than the currently 193 member states of the United Nations. Even if we include Holy See (Vatican) and the State of Palestine, which are non-member observer states and the two controversial countries / areas (Taiwan & Kosovo) we are far from the 248 countries or areas listed in the M49 geoscheme of the United Nations.
1.7.1 Procedure
Procedure 1.3 : Add Column for UN country membership
To get only the 193 member states and the two non-member observer states (= 195 UN states) I will apply the following procedure:
Prepared a list with the names of the countries and their ISO-alpha3 codes. (The ISO-alpha3 code is important for the later joining with the cleaned data m49_clean.rds). — Done manually, no program code.
Saved this two row data file manually as “data/unsd/un_countries.csv”. — Done manually, no program code.
Load “data/unsd/un_countries.csv” into memory.
Add a new row UN (for UN member state) to the data, fill all values with “1” (= member state).
Save the result as R object un_countries.rds
Load m49_clean.rds and un_countries.rds.
Join these two data frames as tibbles fully via their ISO code columns.
Replace all NAs of the UN column (these rows did not come from the “un_countries” file) with the value “0” (= non UN member state).
Delete the redundant Country column — originally from the “un_countries” file.
Save the result as new R object m49_clean3.rds.
Inspect the result.
1.7.2 Result
Code Collection 1.2 : Display structure and content of the adapted UN M49 geoscheme dataset
The UN M49 geoscheme data contains 249 countries or areas This includes 193 UN members, 2 non-member states with observer status, Antartica and 53 dependent territories. With the exception of Sark all of this regions have ISO-alpha2 and ISO-alpha3 codes ISO-alpha2 Code and ISO-alpha3 Code. These two columns are important, because they facilitate joining data from other sources via this standardized codes. This is crucial because the spelling of the names of countries and areas is not always identical in the different sources. You can’t therefore often not join two data sets just by country or area name but needs a more systematic approach with the ISO codes.
UN M49 geoscheme classification has three regional division with 5, 17 and 22 groups (always without Antarctica and not counting the overall group “World” with code “001”).
About the three grouping we can say (always not including Antarctica):
Region: It consists of five groups representing more or less the continents. But instead of the traditional separation between Northern and Southern America it unites these two continents into the “Americas”, including also the Caribbean countries.
Sub-region: It consists of 17 groups by dividing some of the continents into very big sub-regions. For instance the many African countries are grouped only into two groups: Northern Africa and Sub-Saharan Africa. This is in contrast to the more detailed “Intermediate region” where we have Northern-, Eastern, Western, Southern and Middle Africa. On the other hand the smaller Europe is divided into four sub-regions. The sub-regional division is in my opinion therefore not a very consistent classification.
Intermediate region: It consists of 22 groups and is for statistical purposes the most detailed regional classification.
Additionally there are with LDC, LLDC and SIDS three other divisions, driven not by regional reasons but by geographical common features. As we will see in the other chapters there are — besides of the UN M49 geoscheme — other approaches for a consistent country classification.
OMNIKA DataStore is an open-access data science resource for researchers, authors, and technologists. It is 501c3 nonprofit organization whose mission is to digitize, organize, and make important (free) contents available for the general public. The service provides raw data from trusted sources, data visualizations, data analysis tools, and other digital resources.↩︎
A check with base::all.equal() turned out that the files from the two different sources (UNSD and OMNIKA) are identical.↩︎
Even if United Nations and ISO both list 249 entries (including Antarctica) there is a small difference between ISO 3166 codes and the M49 geoscheme of the UN: The UN lists Sark (without ISO codes), whereas the list of ISO includes “Taiwan (Province of China)” with the ISO codes “TW” and “TWN”.↩︎
Source Code
# M49 Classification {#sec-m49}```{r}#| label: setup#| results: hold#| include: falsebase::source(file ="R/helper.R")```## Objectives {#sec-m49-objectives}:::::: {#obj-m49-objectives}::::: my-objectives::: my-objectives-headerChapter section list:::::: my-objectives-container1. Locate the file for the UN M49 geoscheme classification data, get it and save it as raw data (@sec-m49-download).2. Inspect the data thoroughly (@sec-m49-inspect-raw).3. Clean the data (first step) (@sec-m49-clean-data-1).4. Display the grouping results (@sec-m49-display-result-1).5. Clean the intermediate region to get the official results (@sec-m49-clean-data-2).6. Display the new intermediate region group (@sec-m49-display-result-2).7. List UN and non-UN member states {@sec-m49-un-member-states}8. Summary and conclusion {@sec-m49-summary}::::::::::::::## Download M49 Data {#sec-m49-download}An important --- maybe the most authoritative --- classification systemis developed and maintained by the United Nations. It is expressivelydeveloped for statistical purposes by the United Nations StatisticsDivision `r glossary("UNSD")` using the `r glossary("M49")` methodology.The result is called [Standard country or area codes for statistical use(M49)](https://unstats.un.org/unsd/methodology/m49/) and can bedownloaded manually in different languages and formats (Copy into theclipboard, Excel or CSV) from the [United Nations Methodology Overviewpage](https://unstats.un.org/unsd/methodology/m49/overview/).:::::: my-resource:::: my-resource-header::: {#lem-m49-unsd}: United Nations Statistics Division M49 Classification:::::::::: my-resource-container- [Manual download](https://unstats.un.org/unsd/methodology/m49/overview/): The standard country or area codes for statistical use (M49) is available in different languages (English, Chinese, Russian, French, Spanish, Arabic) by clicking one of the buttons "Copy", "Excel" or "CSV". On this page is no URL for an programmable download with an R script available, because Javascript triggers the buttons mentioned above.- [Automatic download by OMNIKA store](https://github.com/omnika-datastore/unsd-m49-standard-area-codes): I found with [OMNIKA DataStore](https://omnika.org/datastore)[^01-united-nations-1] an external source to download the classification file via R script[^01-united-nations-2].The `r glossary("OMNIKA")` URLs for download are:- **EXCEL**:[2022-09-24\_\_Excel_UNSD_M49.xlsx](https://github.com/omnika-datastore/unsd-m49-standard-area-codes/raw/refs/heads/main/2022-09-24__Excel_UNSD_M49.xlsx)- **CSV**:[2022-09-24\_\_CSV_UNSD_M49.csv](https://github.com/omnika-datastore/unsd-m49-standard-area-codes/raw/refs/heads/main/2022-09-24__CSV_UNSD_M49.csv):::::::::[^01-united-nations-1]: OMNIKA DataStore is an open-access data science resource for researchers, authors, and technologists. It is 501c3 nonprofit organization whose mission is to digitize, organize, and make important (free) contents available for the general public. The service provides raw data from trusted sources, data visualizations, data analysis tools, and other digital resources.[^01-united-nations-2]: A check with `base::all.equal()` turned out that the files from the two different sources (UNSD and OMNIKA) are identical.:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-classification-download}: Download the United Nations M49 Classification:::::::::: my-r-code-container<center>**Run this code chunk manually if the file still needs to bedownloaded.**</center>```{r}#| label: m49-raw#| code-fold: show#| eval: false## create folders ###########pb_create_folder(base::paste0(here::here(), "/data/"))pb_create_folder(base::paste0(here::here(), "/data/unsd"))## download m49 file ############url <-"https://github.com/omnika-datastore/unsd-m49-standard-area-codes/raw/refs/heads/main/2022-09-24__CSV_UNSD_M49.csv"downloader::download(url = url,destfile = base::paste0(here::here(), "/data/unsd/m49_raw.csv"))## create R object ###############m49_raw <- readr::read_delim(file = base::paste0(here::here(), "/data/unsd/m49_raw.csv"),delim =";" )## save as .rds file ################pb_save_data_file("unsd", m49_raw, "m49_raw.rds")```<center>(*For this R code chunk is no output available*)</center>:::::::::## Inspect M49 Data {#sec-m49-inspect-raw}To get an detailed understanding of the data structures I will providethe following two outputs of the raw-data:1. A summary statistics with `skimr::skim()` followed by inspection of the first data rows with `dplyr::glimpse()`.2. Several detailed outputs of the classifications categories (regions) and their elements (countries) in different code chunks (tabs).To facilitate the second task I have prepared the function`pb_class_scheme()` and stored in "R./helper.r".:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-inspect-raw}: Inspect raw data of the UNSD M49 geoscheme classification:::::::::: my-r-code-container```{r}#| label: inspect-m49-clean#| results: holdm49_raw <- base::readRDS("data/unsd/m49_raw.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(m49_raw)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(m49_raw)```:::::::::## Special cases### Missing valuesThe file has 15 columns as you can also see online from the [Overviewpage](https://unstats.un.org/unsd/methodology/m49/overview/).The many missing values (`NAs`) for the categories `r glossary("LDC")`,`r glossary("LLDC")` and `r glossary("SIDS")` are easy explained: Thesethree columns are coded with an 'x' if the country of this row belong tothis category. Recoding these three columns with 1 and 0 (1 = yes,belongs to this category, 0 = no, does not belong to this category) willreduce most of their missing values.### AntarcticaOne missing value in the regional categories (Region, Sub-Region andIntermediate Region) is related to Antarctica which is not seen by theM49 scheme as a separated region. It has therefore no regional codes andnames with the exception of the overall comprising global region. But ithas M49 as well ISO-alpha codes.### Channel Island SarkOne of the missing values for ISO-alpha2 and ISO-alpha3 is related toSark, which is "recognized by the United Nations Statistics Division(UNSD) as a separate territory" but was not accepted by ISO now for morethan 20 years [@mccarthy-2020]. 2020 a new 54-page submission for an ISO code (see[PDF](https://www.sarkid.org/assets/pdf/SarkID%20Identity%20info%20v1_2.pdf)) was applied to ISO but it seems still under consideration, because currently [^01-united-nations-3] Sark has no [ISO 3166 codes](https://www.iso.org/iso-3166-country-codes.html).For further processing of the M49 dataset, however, it is crucial to have a complete list of ISO Codes because these are the columns where the joining of two dataset will be linked. There exist two possibilities to get a complete list for all UN entries for the ISO codes:1. Remove the Sark entry from the dataset.2. Add ISO-alpha2 and ISO-alpha3 for Sark.The second possibility is not so out of the hand, because it is possible that Sark will succeed finally with its application. In that case it is highly likely that it will get "CQ" for ISO-alpha2 and "SCQ" for the ISO-alpha3 Code. (The other possibility "sk" is already by Slovakia and Sercq is the original Norman dialect spelling of the island. See [After 20-year battle, Channel island Sark finally earns the right to exist on the internet with its own top-level domain](https://www.theregister.com/2020/03/23/sark_cctld_iso/)[@mccarthy-2020]).[^01-united-nations-3]: Even if United Nations and ISO both list 249 entries (including Antarctica) there is a small difference between ISO 3166 codes and the M49 geoscheme of the UN: The UN lists Sark (without ISO codes), whereas the list of ISO includes "Taiwan (Province of China)" with the ISO codes "TW" and "TWN".### NamibiaThe other missing value for ISO-alpha2 codes belongs to Namibia becauseits abbreviation `NA` is interpreted by R as a missing value!## Clean Data (first step) {#sec-m49-clean-data-1}### Procedure:::::: my-procedure:::: my-procedure-header::: {#prp-m49-clean-1}: Clean M49 data of the UNSD geoscheme classification (first step):::::::::: my-procedure-container1. Load the original M49 dataset ("m49_raw.rds")2. Remove the global codes and global names because they a redundant: All rows have global code "001" ("World").3. Shorten long names to their abbreviation ("LCD", "LLCD" and "SIDS").4. Remove row "Antarctica" because it is not seen as separate country.5. Add ISO Codes "CQ" and "SCQ" to `Country or Area` of Sark.6. Replace `NA` in the column ISO-alpha2 Code" of Namibia with the string "NA".7. Recode the columns `r glossary("LDC")`, `r glossary("LLDC")` and`r glossary("SIDS")` with 0 and 1.8. Relocate columns `ISO-alpha3 CODE` and `Country or Area` to the first two columns because these two columns are always relevant for the later groupings and joining with groupings from other sources.9. Sort the data alphabetically by `Country or Area`.:::::::::### Result (first step) {#sec-m49-display-result-1}#### Data Structure:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-clean-1}: Clean UNSD M49 geoscheme classification data (first step):::::::::: my-r-code-container```{r}#| label: clean-m49-1#| results: hold## column renaming vector ########m49_cols =c(LDC ="Least Developed Countries (LDC)", LLDC ="Land Locked Developing Countries (LLDC)", SIDS ="Small Island Developing States (SIDS)" )## clean data ###############################m49_clean <- base::readRDS("data/unsd/m49_raw.rds") |># (1) dplyr::select(-(1:2)) |># (2) dplyr::rename(tidyselect::all_of(m49_cols)) |># (3) dplyr::filter(`Country or Area`!="Antarctica") |># (4) dplyr::mutate(`ISO-alpha2 Code`= base::ifelse(`Country or Area`=="Sark", "CQ", `ISO-alpha2 Code`), # (5a)`ISO-alpha3 Code`= base::ifelse(`Country or Area`=="Sark", "SCQ", `ISO-alpha3 Code`), # (5b)`ISO-alpha2 Code`= base::ifelse(`Country or Area`=="Namibia", "NA", `ISO-alpha2 Code`) # (6) ) |> dplyr::relocate(## any_of() does not understand object names (??) tidyselect::any_of(c("ISO-alpha3 Code", "Country or Area")), .before =`Region Code`) |># (7)# .x = anonymous function; "x" = value in cols of m40_clean dplyr::mutate(dplyr::across( LDC:SIDS, ~ dplyr::if_else(.x =="x", 1, 999, 0) # (8) )) |> dplyr::arrange(`Country or Area`) # (9)## save new tibble ##########pb_save_data_file("unsd", m49_clean,"m49_clean.rds")## display results ##########m49_clean <- base::readRDS("data/unsd/m49_clean.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(m49_clean)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(m49_clean)```------------------------------------------------------------------------As explained above, only Sark has no value for `ISO-alpha2 Code` and`ISO-alpha3 Code` .:::::::::#### Regional GroupsAs we can see from @cnj-m49-clean-1 the M49 classification of the UnitedNations knows three different regional groups (in addition to theoverall region `World`.):::::::::::::::::::: my-code-collection::::: my-code-collection-header::: my-code-collection-icon:::::: {#exm-m49-show-regional-groups}: Display different regional groups:::::::::::::::::::::::: my-code-collection-container::::::::::::::: panel-tabset###### Region:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-show-region-group}: Show Regions of the UNSD M49 Geoscheme:::::::::: my-r-code-container```{r}#| label: show-m49-region( m49_region <-pb_class_scheme(df = base::readRDS("data/unsd/m49_clean.rds"),sel1 = rlang::quo(`Country or Area`),sel2 = rlang::quo(`Region Name`) ))```------------------------------------------------------------------------"Region" is a classification scheme with **`r sum(m49_region$x$data$N)`countries in `r length(m49_region$x$data$N)` regions**.:::::::::###### Sub-region:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-show-sub-regional-groups}: Show Sub-regions of the UNSD M49 Geoscheme:::::::::: my-r-code-container```{r}#| label: show-m49-sub-region( m49_sub_region <-pb_class_scheme( df <- base::readRDS("data/unsd/m49_clean.rds"),sel1 = rlang::quo(`Country or Area`),sel2 = rlang::quo(`Sub-region Name`) ))```------------------------------------------------------------------------"Sub-region" is a classification scheme with**`r sum(m49_sub_region$x$data$N)` countries in`r length(m49_sub_region$x$data$N)` regions**.:::::::::###### Intermediate:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-show-intermediate-regional-groups}: : Show Intermediate Regions of the UNSD M49 Geoscheme:::::::::: my-r-code-container```{r}#| label: show-m49-intermediate-region( m49_intermediate_region <-pb_class_scheme(df = base::readRDS("data/unsd/m49_clean.rds"),sel1 = rlang::quo(`Country or Area`),sel2 = rlang::quo(`Intermediate Region Name`) ))```------------------------------------------------------------------------"Intermediate Region" is a classification scheme with**`r sum(m49_intermediate_region$x$data$N)` countries in`r length(m49_intermediate_region$x$data$N)` regions**.::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::## Clean Data (second step) {#sec-m49-clean-data-2}The intermediate grouping does not result into the expected 22 (withAntarctica: 23) different regions as is mentioned in many documents. Seefor instance the [Article on Wikipedia about the UNgeoscheme](https://en.wikipedia.org/wiki/United_Nations_geoscheme) whichfeatures a [colored worldmap](https://en.wikipedia.org/wiki/United_Nations_geoscheme#/media/File:United_Nations_geographical_subregions.png)and a list of countries grouped into the 22 different regions.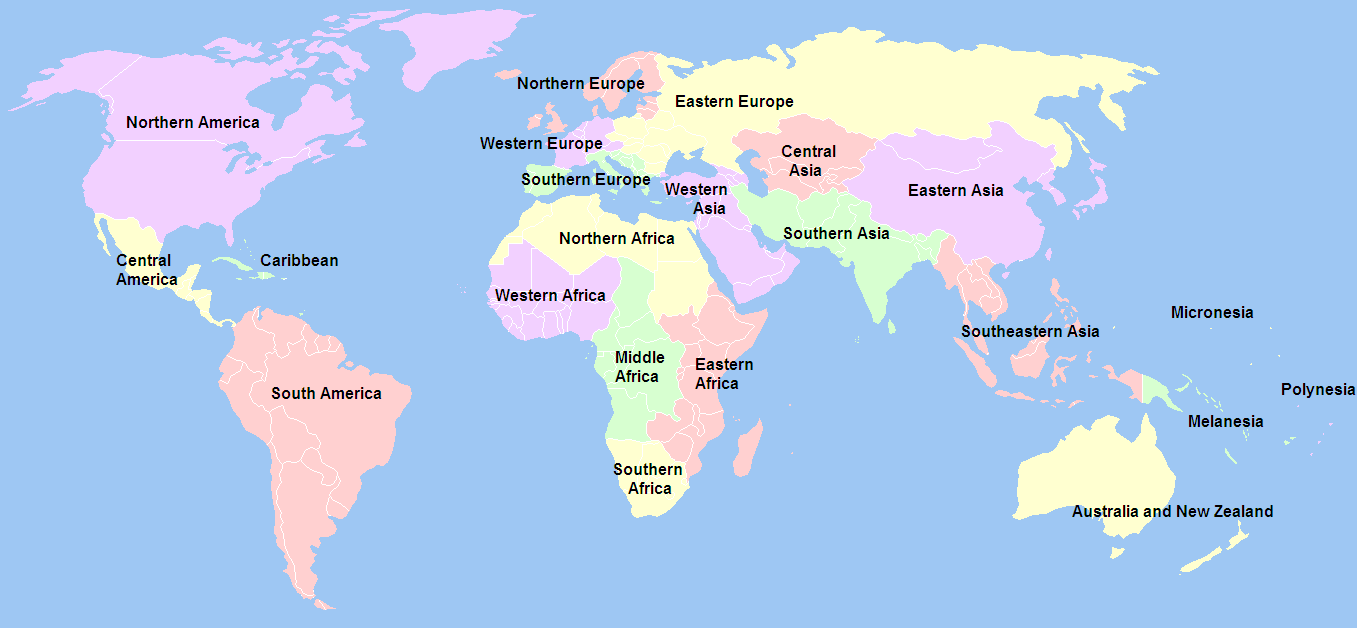{#fig-chap01_UN_geographical_subregionsfig-alt="22 geographical sub-regions as defined by the UNSD are shown with different colors. Antarctica is not shown."fig-align="center" width="100%"}The solution is that we have the `NA`s in `Intermediate Region Name` toreplace with the values of the sub-regions. Additionally --- as can beseen in @cnj-m49-show-intermediate-regional-groups --- there is a secondsmall problem: Three small countries are listed as an extra group"Channel Islands". To get the official intermediate grouping we need toget rid of this group and sort all three of them into the category of"Northern Europe".### Procedure:::::: my-procedure:::: my-procedure-header::: {#prp-m49-cnj-clean-2}: Clean M49 data of the UNSD geoscheme classification (second step):::::::::: my-procedure-container1. Replace the `NA` values of `Intermediate Region Name` with values from the `Sub-region Name` column.2. Replace the `NA` values of `Intermediate Region Code` with values from the `Sub-region Code` column.3. Replace the "Channel Islands" values in `Intermediate Region Name` with the value of "Northern Europe".4. Replace the "Channel Islands" values ("830") in`Intermediate Region Code` with the code of "Northern Europe" ("154").:::::::::### Result (second step) {#sec-m49-display-result-2}#### Data Structure:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-clean-2}: Clean UNSD M49 geoscheme classification data (second step):::::::::: my-r-code-container```{r}#| label: clean-m49-2#| results: holdm49_clean2 <- base::readRDS("data/unsd/m49_clean.rds") |>## replace `NA`s of intermediate regions with sub-region values ###### dplyr::mutate(`Intermediate Region Name`= base::ifelse(is.na(`Intermediate Region Name`), `Sub-region Name`, `Intermediate Region Name`), # (1)`Intermediate Region Code`= base::ifelse(is.na(`Intermediate Region Code`), `Sub-region Code`, `Intermediate Region Code`), # (2)## replace ""Channel Islands" with "Northen Europe" values ######`Intermediate Region Name`= base::ifelse(`Intermediate Region Name`=="Channel Islands", "Northern Europe", `Intermediate Region Name`), # (3)`Intermediate Region Code`= base::ifelse(`Intermediate Region Code`=="830", "154", `Intermediate Region Code`) # (4) )## save new tibble as clean2 ##########pb_save_data_file("unsd", m49_clean2, "m49_clean2.rds")## display results ##########m49_clean2 <- base::readRDS("data/unsd/m49_clean2.rds")glue::glue("******************* Using skimr::skim() ***************************")skimr::skim(m49_clean2)glue::glue("")glue::glue("****************** Using dplyr::glimpse() *************************")dplyr::glimpse(m49_clean2)```:::::::::With the "trick" to replace the `NA`s of `Intermediate Region Name` withthe values of `Sub-regional Name`column we also got rid of the many`NA`s in that and the accompanying `Intermediate Region Code` column.#### Intermediate Region Again:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-show-intermediate-region-2}: Show correct intermediate region for the UNSD M49 Geoscheme:::::::::: my-r-code-container```{r}#| label: show-intermediate2-region#| results: hold## show new intermediate result ###############( m49_intermediate2 <-pb_class_scheme(df = base::readRDS("data/unsd/m49_clean2.rds"),sel1 = rlang::quo(`Country or Area`),sel2 = rlang::quo(`Intermediate Region Name`) )) ```:::::::::The new regional group `Intermediate Region Name` is a classificationscheme with **`r sum(m49_intermediate2$x$data$N)` countries in`r length(m49_intermediate2$x$data$N)` regions**. As Antarctica is notincluded the grouping with `Intermediate Region Name` represents thecorrect M49 classification.## Un Countries {#sec-m49-un-member-states}The UN M49 geoscheme classification data contains 15 columns and 248rows (= Columns or Areas). This is much more than the [currently 193member states of the UnitedNations](https://www.worldatlas.com/geography/how-many-countries-are-there-in-the-world.html).Even if we include Holy See (Vatican) and the State of Palestine, whichare non-member observer states and the two controversial countries /areas (Taiwan & Kosovo) we are far from the 248 countries or areaslisted in the M49 geoscheme of the United Nations.### Procedure:::::: my-procedure:::: my-procedure-header::: {#prp-m49-un-countries}: Add Column for UN country membership:::::::::: my-procedure-containerTo get only the 193 member states and the two non-member observer states(= 195 UN states) I will apply the following procedure:1. Prepared a list with the names of the countries and their ISO-alpha3 codes. (The ISO-alpha3 code is important for the later joining with the cleaned data `m49_clean.rds`). --- Done manually, no program code.2. Saved this two row data file manually as "data/unsd/un_countries.csv". --- Done manually, no program code.3. Load "data/unsd/un_countries.csv" into memory.4. Add a new row `UN` (for UN member state) to the data, fill all values with "1" (= member state).5. Save the result as R object `un_countries.rds`6. Load `m49_clean.rds` and `un_countries.rds`.7. Join these two data frames as tibbles fully via their ISO code columns.8. Replace all `NA`s of the `UN` column (these rows did not come from the "un_countries" file) with the value "0" (= non UN member state).9. Delete the redundant `Country` column --- originally from the "un_countries" file.10. Save the result as new R object `m49_clean3.rds`.11. Inspect the result.:::::::::### Result::::::: my-code-collection::::: my-code-collection-header::: my-code-collection-icon:::::: {#exm-m49-show-clean3-file}: Display structure and content of the adapted UN M49 geoscheme dataset:::::::::::::: my-code-collection-container::: panel-tabset###### Structure:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-add-un-member-state-column}: Add column with UN membership:::::::::: my-r-code-container```{r}#| label: get-un-countries#| results: holdun_countries <- readr::read_csv("data/unsd/un_countries.csv",show_col_types =FALSE) |># (3) dplyr::mutate(UN =1) # (4)pb_save_data_file("unsd", un_countries, "un_countries.rds") # (5)x <- base::readRDS("data/unsd/m49_clean2.rds") # (6a)y <- base::readRDS("data/unsd/un_countries.rds") # (6b)m49_clean3 <- dplyr::full_join( x, y, dplyr::join_by(`ISO-alpha3 Code`== Code) ) |># (7) dplyr::mutate(UN = base::ifelse(base::is.na(UN), 0, UN) ) |># (8) dplyr::select(-Country) # (9)pb_save_data_file("unsd", m49_clean3, "m49_clean3.rds") # (10)skimr::skim(m49_clean3) # (11)```:::::::::###### UN members:::::: my-r-code:::: my-r-code-header::: {#cnj-m49-show-un-member-states}: List the 193 UN member states (plus Vatican and Palestine asnon-member observers):::::::::: my-r-code-container```{r}#| label: list-un-membersbase::readRDS("data/unsd/m49_clean3.rds") |> dplyr::filter(UN ==1) |> dplyr::select(1,2,4,8) |> DT::datatable()```:::::::::###### Non-UN members:::::: my-r-code:::: my-r-code-header::: {#cnj-show-non-un-member-states}: List the 193 UN member states (plus Vatican and Palestine asnon-member observers):::::::::: my-r-code-container```{r}#| label: list-non-un-membersbase::readRDS("data/unsd/m49_clean3.rds") |> dplyr::filter(UN ==0) |> dplyr::select(1,2,4,8) |> DT::datatable()```:::::::::::::::::::::::::## Summary {#sec-m49-summary}The UN M49 geoscheme data contains 249 countries or areas This includes193 UN members, 2 non-member states with observer status, Antartica and 53dependent territories. With the exception of Sark all of this regions have ISO-alpha2 andISO-alpha3 codes `ISO-alpha2 Code` and `ISO-alpha3 Code`. These two columns are important, becausethey facilitate joining data from other sources via this standardized codes. This iscrucial because the spelling of the names of countries and areas isnot always identical in the different sources. You can't therefore oftennot join two data sets just by country or area name but needs a moresystematic approach with the ISO codes.UN M49 geoscheme classification has three regional division with 5, 17and 22 groups (always without Antarctica and not counting the overallgroup "World" with code "001").About the three grouping we can say (always not including Antarctica):- **Region**: It consists of five groups representing more or less the continents. But instead of the traditional separation between Northern and Southern America it unites these two continents into the "Americas", including also the Caribbean countries.- **Sub-region**: It consists of 17 groups by dividing some of the continents into very big sub-regions. For instance the many African countries are grouped only into two groups: Northern Africa and Sub-Saharan Africa. This is in contrast to the more detailed "Intermediate region" where we have Northern-, Eastern, Western, Southern and Middle Africa. On the other hand the smaller Europe is divided into four sub-regions. The sub-regional division is in my opinion therefore not a very consistent classification.- **Intermediate region**: It consists of 22 groups and is for statistical purposes the most detailed **regional** classification.Additionally there are with `r glossary("LDC")`, `r glossary("LLDC")` and `r glossary("SIDS")` three other divisions, driven not by regional reasons but by geographical common features. As we will see in the other chapters there are --- besides of the UN M49 geoscheme --- other approaches for a consistent country classification.

{kind=link}