Chapter 5 Procesando los datos
Habitualmente tendremos que trabajar los datos para arreglarlos. Este proceso, que en castellano podría llamarse “limpieza” o procesado de datos, se conoce en inglés como data munging or data wrangling.
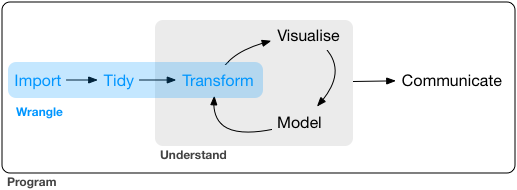
Procesar datos. Fuente: https://r4ds.had.co.nz/wrangle-intro.html
Se suele decir que el procesado/limpieza de los datos suele ocupar un 80% del tiempo de un análisis de datos. Quizás sea una cifra un poco exagerada, pero, en cualquier caso, es una tarea que ocupa tiempo y que puede llegar a ser tediosa y frustante si no se dispone de las herramientas adecuadas.
Aprenderemos a limpiar y transformar datos en R. Priorizaremos la nueva forma de hacer las cosas en R (o workflow) conocido como tidyverse. Es mucho más eficiente que R-Base
5.1 Tidyverse
Con la palabra tidyverse se hace referencia a una nueva forma de afrontar el análisis de datos en R. Se hace uso de un grupo de paquetes que trabajan en armonía porque comparten ciertos principios, como por ejemplo, la forma de estructurar los datos. La mayoría de estos paquetes han sido desarrollados por (o al menos con la colaboración de Hadley Wickham, un “dios” de R.
5.2 The pipe (%>%)
El operador ‘%>%’ es básico en el tidyverse, ya que permite encadenar llamadas a funciones para así realizar de forma sencilla transformaciones de datos complejas. En palabras, lo que hace este operador es pasar el elemento que está a su izquierda como un argumento de la función que tiene a la derecha;
Se entiende mejor con un ejemplo sencillo. Las siguientes dos instrucciones de R hacen exactamente lo mismo: permiten ver las 7 primeras filas de la base de datos iris.
Esto está bien, pero no supone ninguna ventaja, sólo es una forma distinta de ejecutar o llamar a una función. Lo importante para nosotros es que las pipes se pueden encadenar.
El operador pipe podemos leerlo como “entonces” y permite encadenar sucesivas llamadas a funciones. Por ejemplo:
La anterior linea de código R hace: - 1 coge los datos del dataframe ‘df’ y selecciona (o filtra) las filas que cumplen que el valor de ‘X1’ es mayor que 100, entonces (o después) - 2 agrupa los datos por la variable ‘X2’, entonces - 3 calcula la media de ‘X3’
En conjunto, encadenando las 3 funciones hemos seleccionado las filas de las personas que tienen un salario (X1) mayor de 100, agrupado las filas que cumplen esta condición por genero (X2) y calculado la media para cada uno de los grupos; es decir, hemos calculado la media salarial para Hombres y Mujeres, teniendo en cuenta sólo a los individuos con salario superior a 100.
5.3 Principales pkgs del tidyverse
Los principales packages del tidyverse son:
- readr: para importar datos
- tidyr: para convertir los datos a tidy data
- dplyr: para manipular datos
- ggplot2: para hacer gráficos
- purrr: para functional programming ( no nos interesa)
Todos estos pkgs se han agrupado en un solo package, el ‘tidyverse’ package. por lo tanto solamente debemos instalara este último. Recordamos como se hace esto?