Chapter 5 Lab 3 - 21/10/2022
In questa lezione impareremo poi a calcolare i rendimenti e a studiarne la distribuzione utilizzano boxplot e istogramma.
Per questa lezione useremo il file denominato prices.xlsx. Procediamo quindi con l’importazione dei dati come descritto nella sezione 4.2 utilizzando l’opzione Import dataset di RStudio (pannello in alto a destra). L’oggetto prices verrà di fatto creato quando si lancia il seguente codice:
library(readxl)
prices <- read_excel("data/prices.xlsx")E’ buona pratica controllare di che tipo di oggetto si tratta (data frame)
class(prices)## [1] "tbl_df" "tbl" "data.frame"e visionare la parte iniziale e finale del data frame (per verificare l’ordinamento dai dati più vecchi a quelli più recenti)
head(prices)## # A tibble: 6 × 4
## Date A2Aadj ISPajd JUVEadj
## <dttm> <dbl> <dbl> <dbl>
## 1 2017-01-10 00:00:00 0.983 1.60 0.288
## 2 2017-01-11 00:00:00 0.999 1.60 0.290
## 3 2017-01-12 00:00:00 1.01 1.57 0.288
## 4 2017-01-13 00:00:00 1.03 1.60 0.290
## 5 2017-01-16 00:00:00 1.02 1.57 0.285
## 6 2017-01-17 00:00:00 1.02 1.57 0.288tail(prices)## # A tibble: 6 × 4
## Date A2Aadj ISPajd JUVEadj
## <dttm> <dbl> <dbl> <dbl>
## 1 2021-10-13 00:00:00 1.84 2.40 0.712
## 2 2021-10-14 00:00:00 1.85 2.43 0.726
## 3 2021-10-15 00:00:00 1.84 2.48 0.720
## 4 2021-10-18 00:00:00 1.83 2.49 0.724
## 5 2021-10-19 00:00:00 1.85 2.45 0.723
## 6 2021-10-20 00:00:00 1.88 2.47 0.728e la struttura del data frame (con le variabili quantitative num/dbl per i prezzi)
str(prices)## tibble [1,213 × 4] (S3: tbl_df/tbl/data.frame)
## $ Date : POSIXct[1:1213], format: "2017-01-10" "2017-01-11" ...
## $ A2Aadj : num [1:1213] 0.983 0.999 1.013 1.03 1.022 ...
## $ ISPajd : num [1:1213] 1.6 1.6 1.57 1.6 1.57 ...
## $ JUVEadj: num [1:1213] 0.288 0.29 0.288 0.29 0.285 ...5.1 Calcolo dei rendimenti
5.1.1 Per un singolo titolo
Come già visto nella Sezione 4.8 è utile iniziare con il calcolo dei rendimenti logaritmi utilizzando le funzioni log e diff. Calcoliamo quindi i log-rendimenti per il titolo A2A con il codice che segue:
A2Alogret = diff(log(prices$A2Aadj))
class(A2Alogret) #vettore!## [1] "numeric"Si noti che l’oggetto A2Alogre è un vettore. E’ possibile rappresentare graficamente la serie di log-rendimenti come segue, includendo anche nel grafico una linea orizzontale in corrispondenza di 0 che è il valore di riferimento:
plot(A2Alogret, type="l")
abline(h = 0, col="red")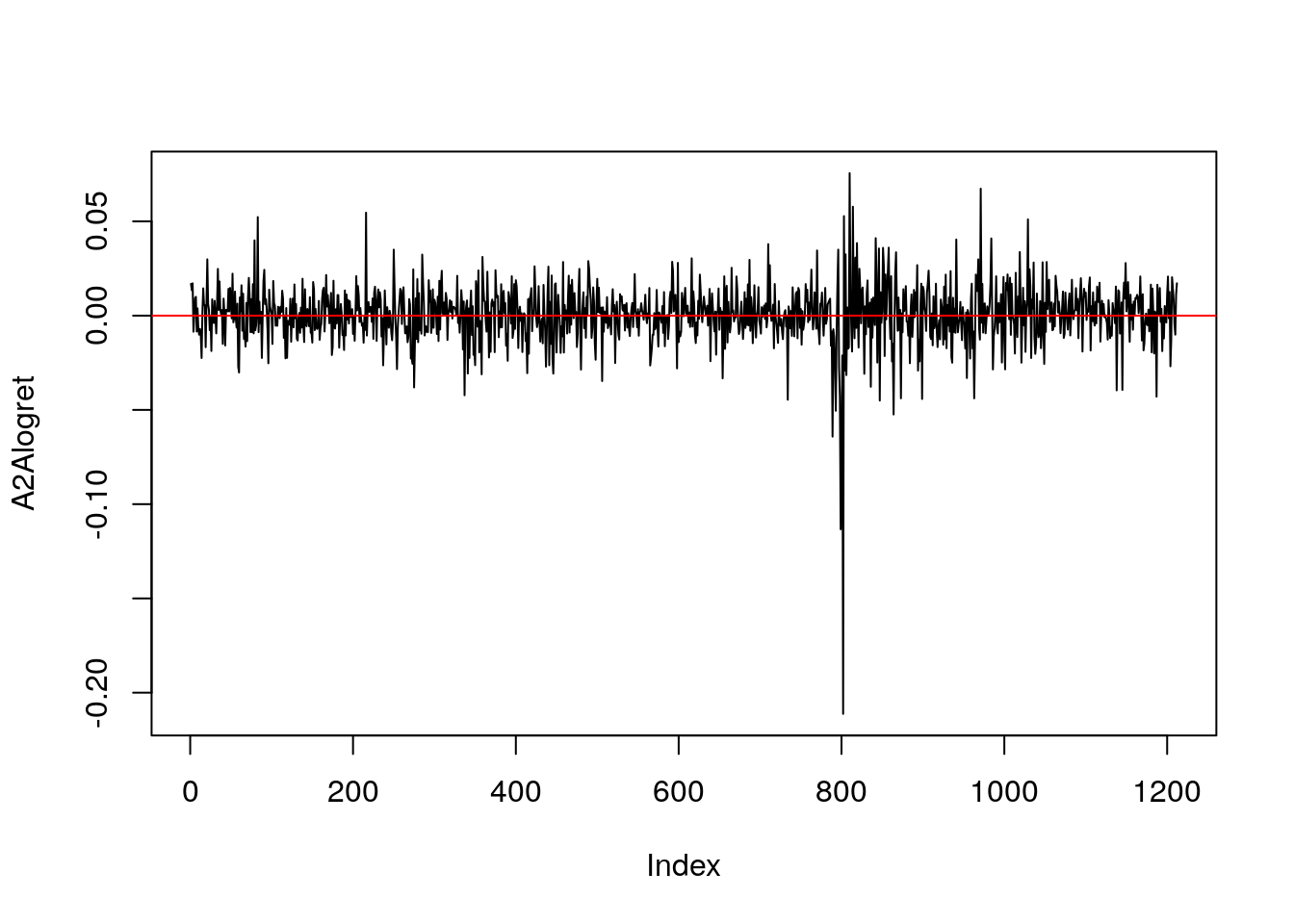
Dati i log-rendimenti \(r_t\) è possibile calcolare i rendimenti lordi e poi quelli netti utilizzando le seguenti formule: \[ R_t + 1= \exp(r_t) \]
\[ R_t = \frac{P_t}{P_{t-1}}-1 \]
Qui di seguito il codice di R per il calcolo dei rendimenti lordi e netti:
A2Agrossret = exp(A2Alogret)
A2Anetret = A2Agrossret - 1E’ possibile salvare i tre nuovi vettori in un nuovo data frame utilizzando la funzione data.frame:
A2Atutti = data.frame(A2Alogret, A2Agrossret, A2Anetret)
head(A2Atutti)## A2Alogret A2Agrossret A2Anetret
## 1 0.0168609165 1.0170039 0.0170038640
## 2 0.0134447672 1.0135356 0.0135355545
## 3 0.0171345090 1.0172821 0.0172821467
## 4 -0.0085310454 0.9915052 -0.0084947593
## 5 0.0007788307 1.0007791 0.0007791341
## 6 0.0092950844 1.0093384 0.0093384179Al dat frame appena creato manca la colonna delle date. E’ possibile aggiungere utilizzando l’operatore $ seguito dal nome della nuova colonna (in questo caso date):
A2Atutti$date = prices$Date[-1]Si ricordi che che A2Atutti e prices sono due oggetti con dimensione diversa (quando si calcolano i rendimenti si perde un’osservazione). E’ quindi necessario rimuovere la prima data tramite il codice [-1] che va a selezionare tutti i dati nel vettore delle date tranne la prima (-1).
Le tre serie storiche di rendimenti posso essere rappresentate graficamente come descritto nella Sezione 4.7:
plot(A2Atutti$A2Alogret, type="l",
ylim=c(-0.5, 1.5), ylab="Returns")
lines(A2Atutti$A2Agrossret, col="blue")
lines(A2Atutti$A2Anetret, col="red")
abline(h = 1, col="red")
abline(h = 0, col="green")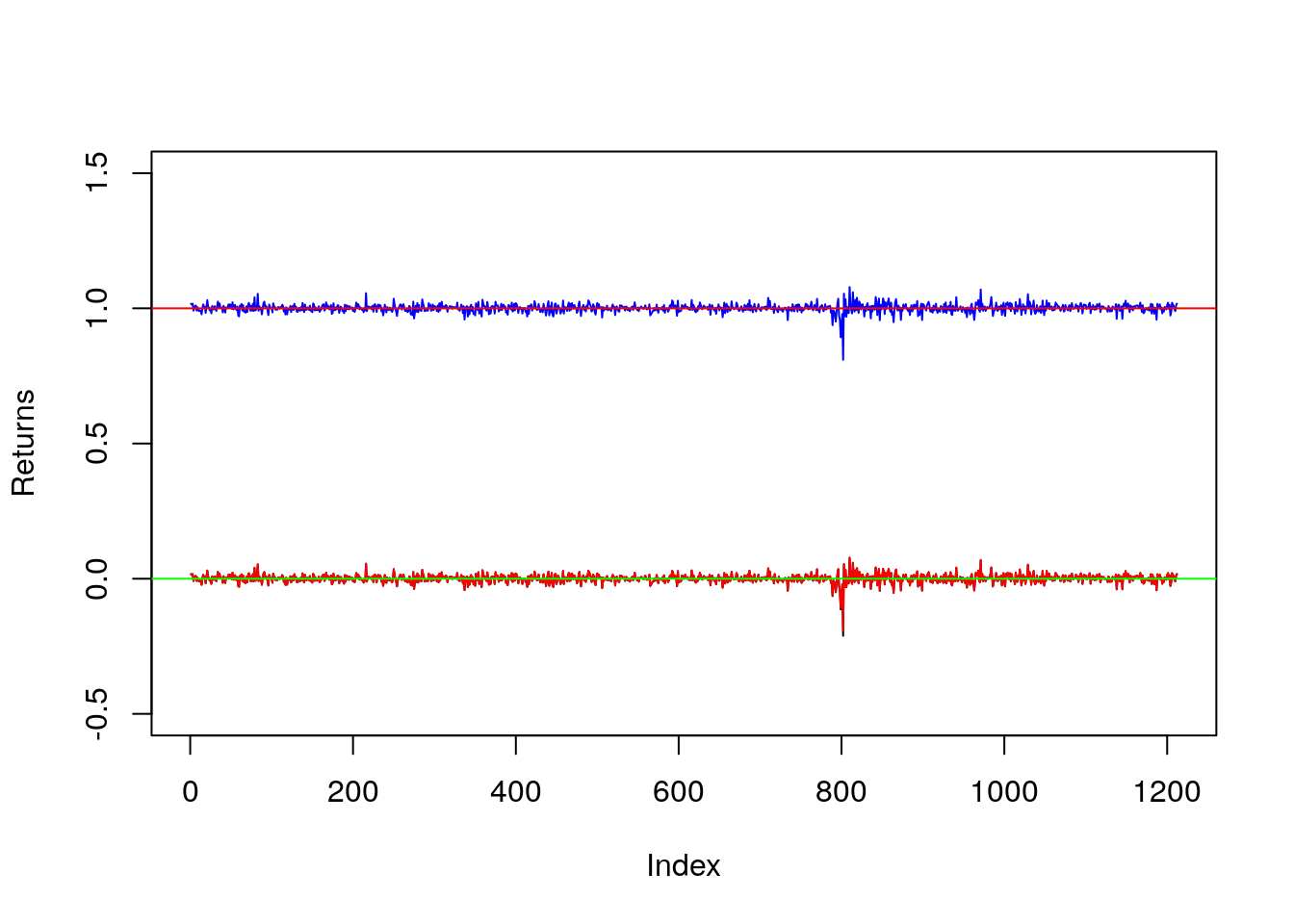
Si noti che la serie storica rossa di rendimenti logaritmici copre quasi interamente la serie storica nera dei rendimenti netti; questo è dovuto alle proprietà teoriche dei rendimenti e al fatto che \(r_t\simeq R_t\) per valori piccoli di \(R_t\).
La funzione abline aggiunge una linea costante orizzontale al grafico per \(y=1\) e \(y=0\) che rappresentano il valore di riferimento per i rendimenti lordi e netti/logaritmici (indicano nessun cambiamento nel prezzo).
5.1.2 Per tutti i titoli congiuntamente tramite apply
Utilizzando la funzione apply è possibile applicare una stessa funzione a tutte le colonne/righe di un data frame. Ciò ci permetterà di calcolare i rendimenti logaritmici per tutti i titoli congiuntamente (questo è utile quando si ha un numero elevato di colonne e si vuole evitare di ripetere molte volte copia-incolla dello stesso codice).
La funzione apply richiede tre argomenti (si veda ?apply):
X: il data frame di dati,MARGIN: un intero che può essere pari a 1 o a 2. Nel primo caso la funzione di interesse sarà applicata riga per riga, nel secondo colonna per colonna (come sarà per noi),FUN: la funzione da applicare.
Si potrebbe quindi applicare la funzione come segue:
apply(prices, 2, mean)Essendoci però in prices una colonna di testo (Date) la funzione restituisce dei messaggi di warning e nessun output utile. E’ quindi necessario rimuovere dal data frame la prima colonna. Il modo più semplice è quello di utilizzare le parentesi quadre, come visto precedentemente, utilizzando come indice di colonna la specifica -1 (che significa tutte le colonne meno la prima):
medie = apply(prices[ , -1], 2, mean)
medie## A2Aadj ISPajd JUVEadj
## 1.329637 1.808274 0.881970Si ottiene quindi con una sola riga di codice un vettore di medie. Analogamente si può procedere per il calcolo delle deviazioni standard:
stdev = apply(prices[ , -1], 2, sd)
stdev## A2Aadj ISPajd JUVEadj
## 0.2043166 0.2871477 0.2919956E infine, utilizzando i due vettori medie e stdev si può procedere con il calcolo di tutti i coefficienti di variazione:
stdev / medie## A2Aadj ISPajd JUVEadj
## 0.1536634 0.1587966 0.3310721Per il calcolo dei log rendimenti si procede quindi in due passi:
- si calcolano i log prezzi usando la funzione
log; 2) si calcolano le differenze dei log prezzi usando la funzionediff:
# 1) calcolo i log prezzi
logprezzi = apply(prices[,-1], 2, log)
head(logprezzi)## A2Aadj ISPajd JUVEadj
## [1,] -0.0174931163 0.4685438 -1.243906
## [2,] -0.0006321998 0.4669220 -1.239441
## [3,] 0.0128125674 0.4530272 -1.244226
## [4,] 0.0299470764 0.4677336 -1.239441
## [5,] 0.0214160309 0.4489038 -1.256765
## [6,] 0.0221948617 0.4489038 -1.243906# 2) calcolo i log rendimenti
logret = data.frame(apply(logprezzi, 2, diff))
head(logret)## A2Aadj ISPajd JUVEadj
## 1 0.0168609165 -0.001621803 0.004465205
## 2 0.0134447672 -0.013894794 -0.004784417
## 3 0.0171345090 0.014706338 0.004784417
## 4 -0.0085310454 -0.018829719 -0.017324368
## 5 0.0007788307 0.000000000 0.012859163
## 6 0.0092950844 -0.002482982 0.000000000class(logret)## [1] "data.frame"dim(logret)## [1] 1212 3Si noti che per il calcolo di logret si utilizza la funzione data.frame, già vista precedentemente, che permette di ottenere un oggetto di tipo data frame (mentre di default la funzione apply restituisce un oggetto di tipo matrix).
E’ possibile rappresentare graficamente le tre serie storiche dei log-rendimenti come segue:
plot(logret$A2Aadj, type = "l",
ylim = c(min(logret), max(logret)))
lines(logret$ISPajd, col = "red")
lines(logret$JUVEadj, col = "blue")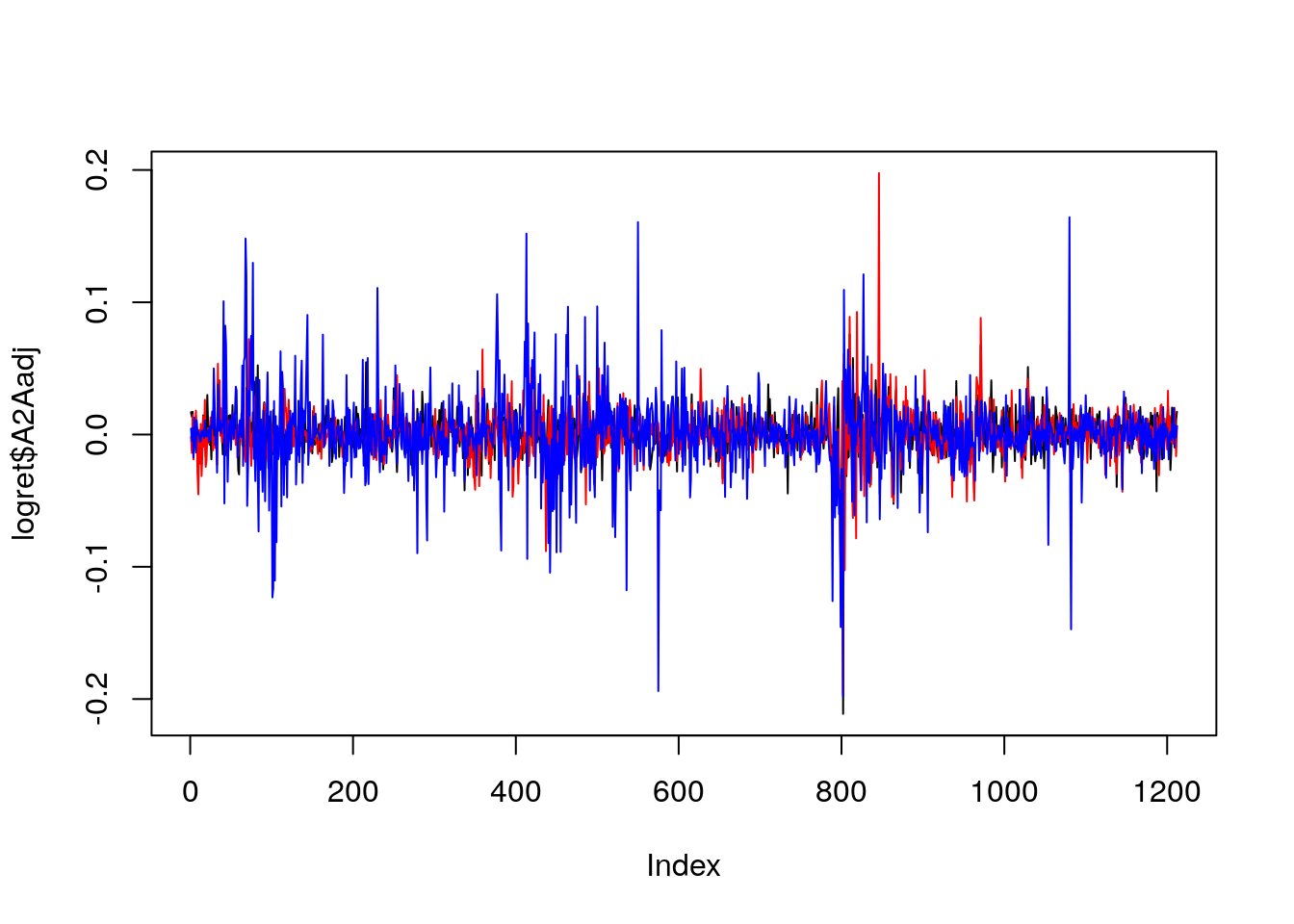
Si osserva la maggior variabilità per il titolo JUVE (maggiori e più ampie fluttuazioni).
Qualche statistica descrittiva può essere ottenuta con il seguente codice:
summary(logret)## A2Aadj ISPajd JUVEadj
## Min. :-0.2112382 Min. :-0.1958118 Min. :-0.1980986
## 1st Qu.:-0.0076642 1st Qu.:-0.0082247 1st Qu.:-0.0115276
## Median : 0.0012598 Median : 0.0002749 Median : 0.0006789
## Mean : 0.0005349 Mean : 0.0003585 Mean : 0.0007638
## 3rd Qu.: 0.0090198 3rd Qu.: 0.0087727 3rd Qu.: 0.0130212
## Max. : 0.0755707 Max. : 0.1976145 Max. : 0.1642638Se si è interessati a calcolare un quantile diverso da quelli riportati da summary (che riporta solo i quantili di ordine 0.25, 0.5, 0.75 ovvero i quartili) si può utilizzare la funzione quantile (vedere ?quantile). Ad esempio per calcolare il quantile di ordine 0.8:
# per una singola colonna
quantile(logret$A2Aadj, 0.8)## 80%
## 0.01180501# per più colonne
apply(logret, 2, quantile, 0.8)## A2Aadj ISPajd JUVEadj
## 0.01180501 0.01151315 0.017308635.2 Boxplot
Il boxplot è un utile strumento grafico per lo studio di una distribuzione e per il confronto tra distribuzioni diverse.
Utilizzando una singola variabile si procede come segue:
boxplot(logret$A2Aadj)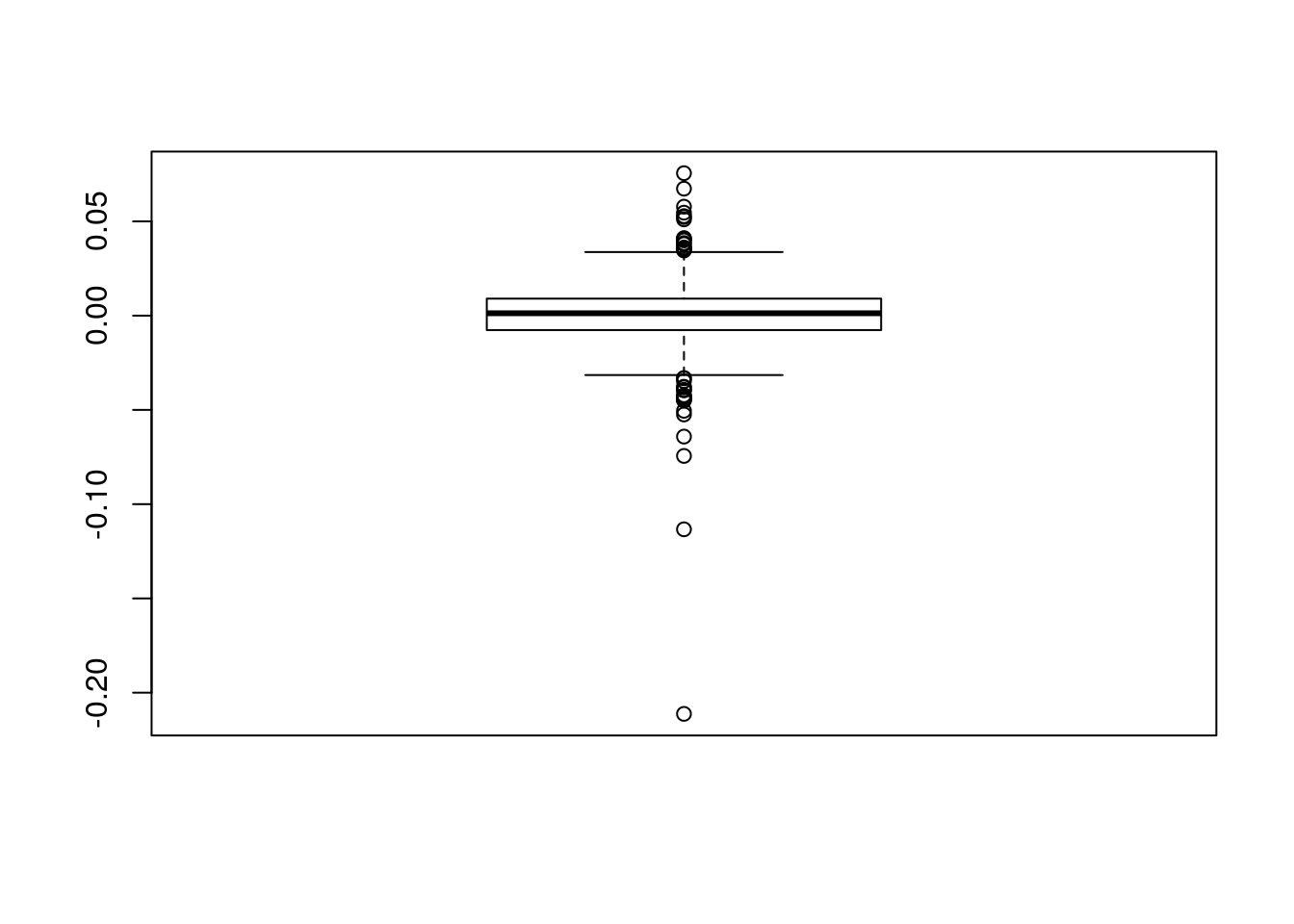
Si ricorda che i baffi del boxplot sono posizionati in corrispondenza del terzo quartile + 1.5\(*\)differenza intequartile (baffo superiore) e del primo quartile - 1.5\(*\)differenza interquartile. I punti rappresentano quindi osservazioni estreme (o outliers). In alternativa è possibile posizionare i baffi del boxplot in corrispondenza del valore minimo e massimo della distribuzione utilizzando l’opzione range:
boxplot(logret$A2Aadj, range = 0)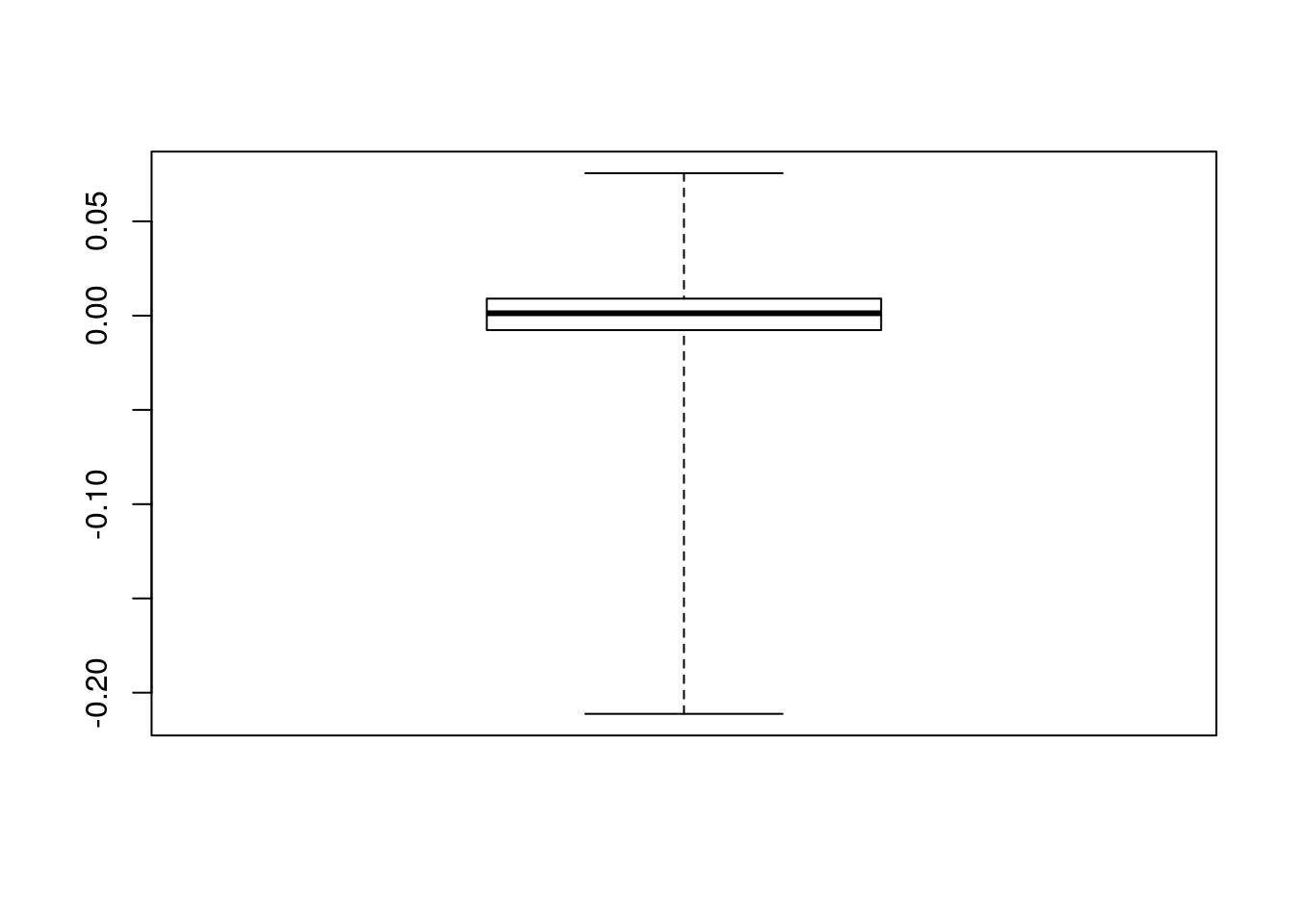
E’ anche possibile confrontare le diverse distribuzioni di rendimenti logaritmici applicando la funzione boxplot all’interno data frame:
boxplot(logret,
col = rainbow(3))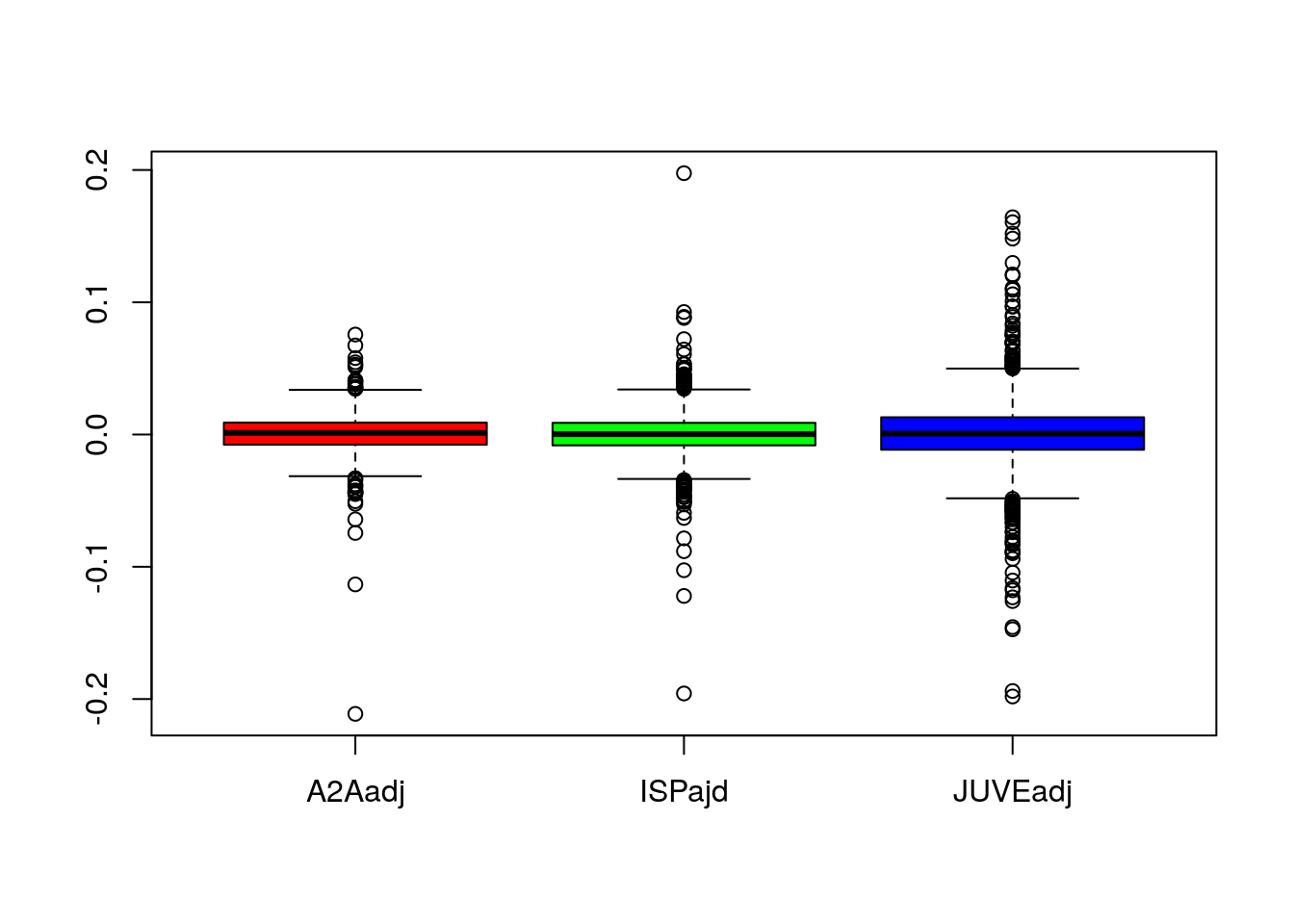
L’opzione rainbow(3) permette di scegliere 3 colori da una palette di colori denominata rainbow.
Si nota che i rendimenti di JUVE presentano una maggiore variabilità rispetto agli altri titoli. La distribuzione risulta inoltre caratterizzata da un numero più elevato di valori estremi (positivi e negativi). Per tutti i titoli la mediana è vicino a zero e i baffi risultano simmetrici rispetto alla scatola.
5.3 Istogramma
L’asimmetria è evidente anche dalla rappresentazione grafica della distribuzione tramite istogramma:
hist(logret$A2Aadj)
abline(v=mean(logret$A2Aadj),col="blue")
abline(v=median(logret$A2Aadj),col="red")
abline(v=quantile(logret$A2Aadj, 0.9),col="violet")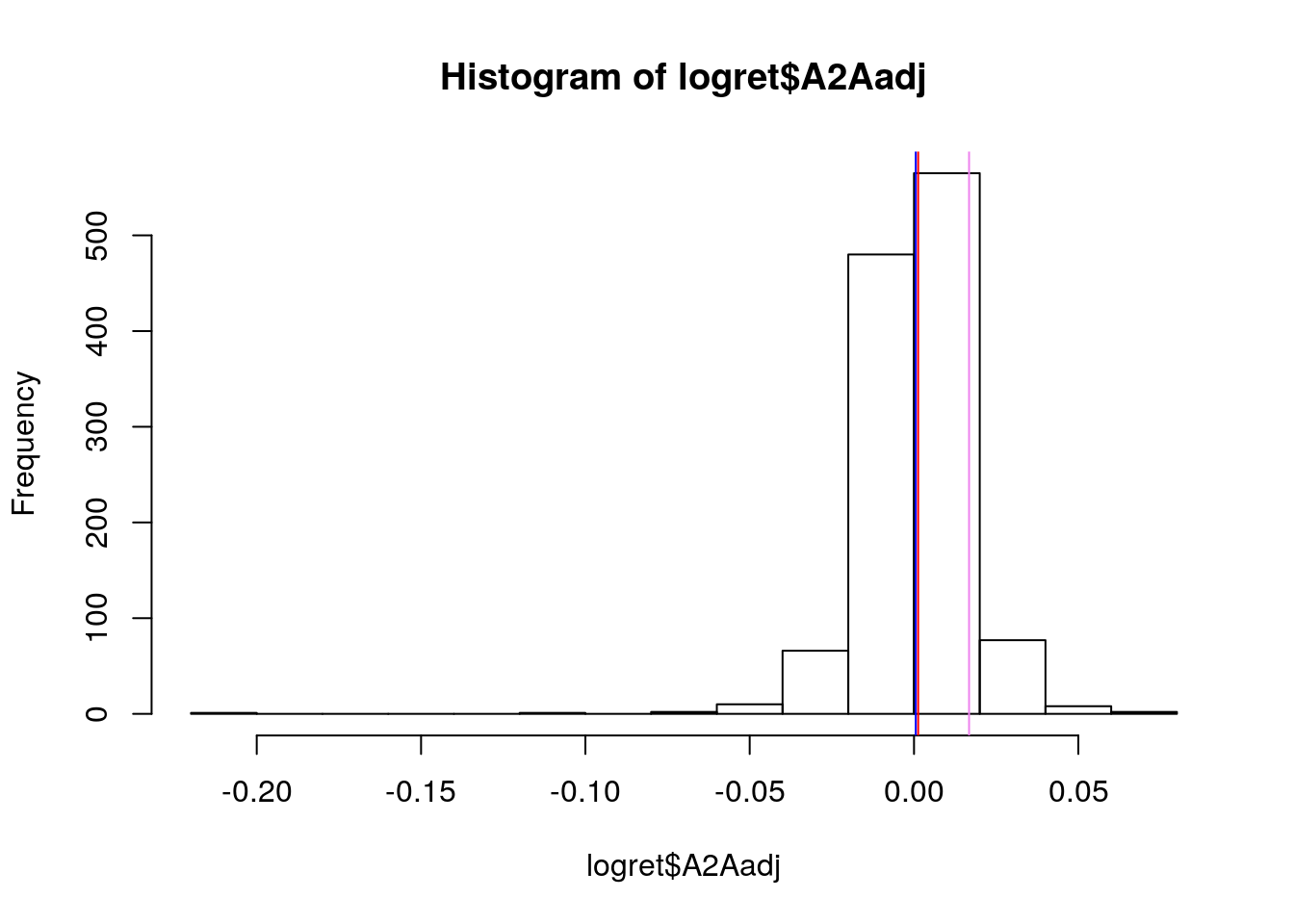
L’istogramma riporta sull’asse delle x i valori dei rendimenti in classi e sull’asse delle y le corrispondente frequenze (i.e. numero di giorni). La funzione abline è utilizzata qui per aggiungere 3 linee verticali costanti in corrispondenza della media, della mediana e del novantesimo quantile della distribuzione. In particolare,
quantile(logret$A2Aadj, 0.9)## 90%
## 0.01675133rappresenta il valore dei rendimenti logaritmici che divide in due la distribuzione, con 90% dei dati a sinistra e 10% a destra.
Per ottenere i valori con cui è costruito l’istogramma (estremi delle classi e relative frequenze) si può usare:
hist(logret$A2Aadj, plot = FALSE)## $breaks
## [1] -0.22 -0.20 -0.18 -0.16 -0.14 -0.12 -0.10 -0.08 -0.06 -0.04 -0.02 0.00
## [13] 0.02 0.04 0.06 0.08
##
## $counts
## [1] 1 0 0 0 0 1 0 2 10 66 480 565 77 8 2
##
## $density
## [1] 0.04125413 0.00000000 0.00000000 0.00000000 0.00000000 0.04125413
## [7] 0.00000000 0.08250825 0.41254125 2.72277228 19.80198020 23.30858086
## [13] 3.17656766 0.33003300 0.08250825
##
## $mids
## [1] -0.21 -0.19 -0.17 -0.15 -0.13 -0.11 -0.09 -0.07 -0.05 -0.03 -0.01 0.01
## [13] 0.03 0.05 0.07
##
## $xname
## [1] "logret$A2Aadj"
##
## $equidist
## [1] TRUE
##
## attr(,"class")
## [1] "histogram"E’ anche possibile cambiare il numero di classi attraverso l’opzione breaks. Si può in particolare specificare un numero diverso di classi della stessa ampiezza (ad esempio 3):
hist(logret$A2Aadj, breaks = 3)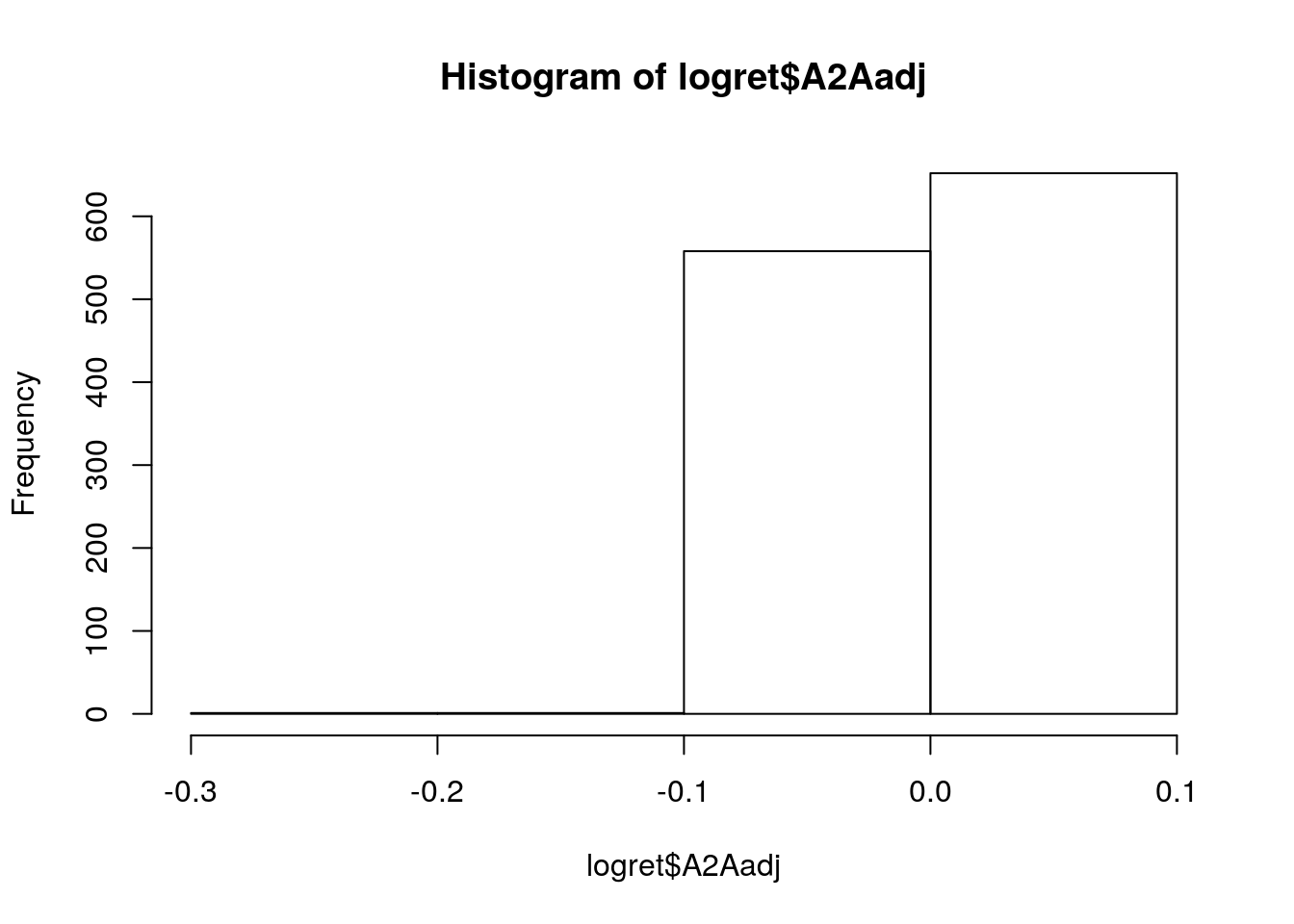 In particolare, specificando un numero intero positivo la funzione
In particolare, specificando un numero intero positivo la funzione hist calcolerà poi il numero ottimale di classi più vicino a quanto specificato (per questo motivo può succedere che il numero di classi nel grafico sia leggermento diverso rispetto a quanto specificato).
In alternativa è possibile specificare a mano gli estremi delle classi prescelte (ad esempio \([-0.25,0.05]\), \((0.05,0]\), \((0, 0.03]\). \((0.03, max]\)):
hist(logret$A2Aadj,
breaks = c(-0.25, 0.05, 0, 0.03, max(logret$A2Aadj)))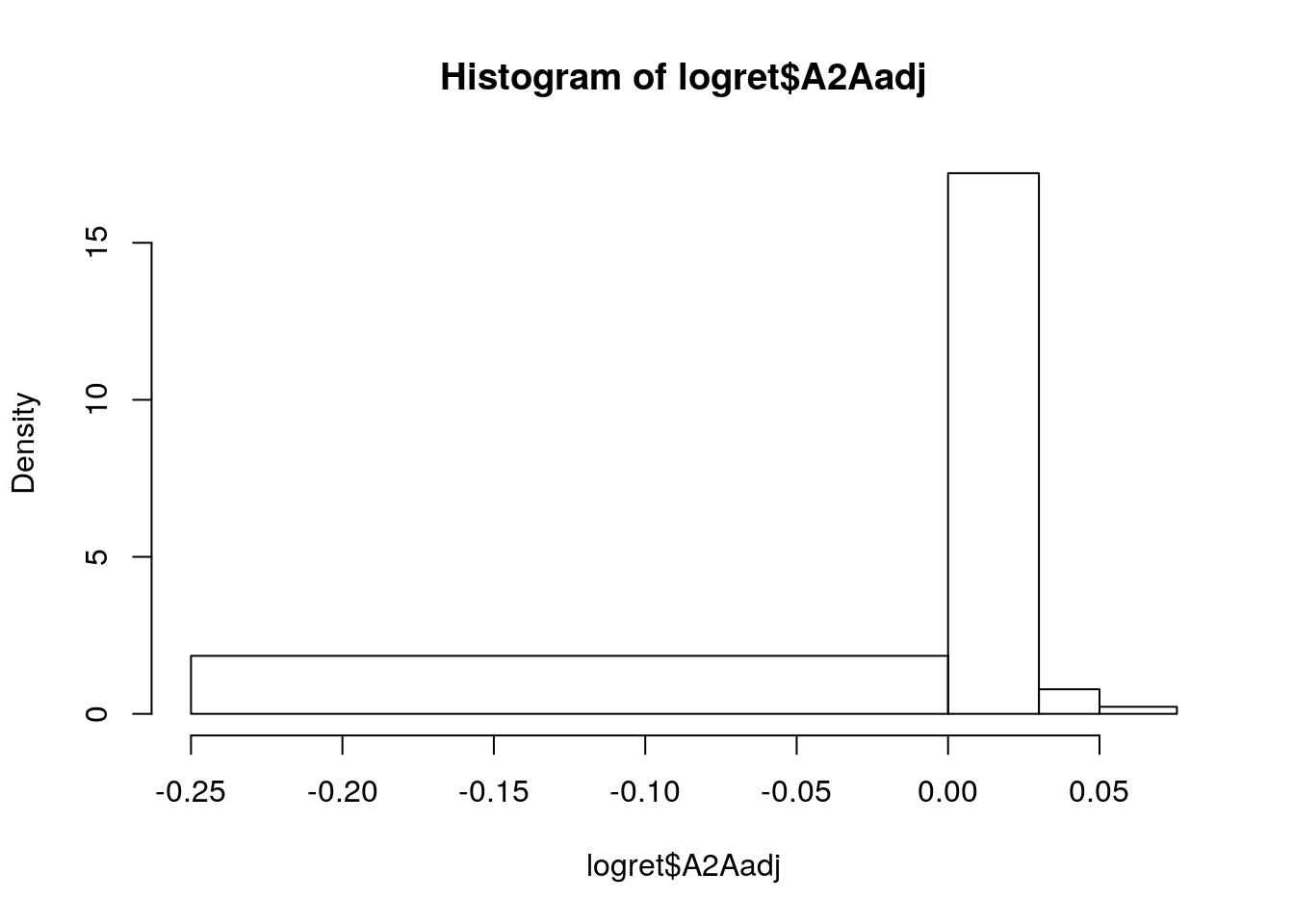 In questo caso sull’asse delle y è riportata la
In questo caso sull’asse delle y è riportata la Density (invece della Frequency) data dal rapporto tra la frequenza relativa (Frequency/1212) e l’ampiezza di ogni classe. In questo caso l’altezza delle barre tiene conto dell’ampiezza di classe; inoltre l’area di tutte le barre è pari a 1.
5.4 Indice campionario di asimmetria e curtosi
La formula per il calcolo dell’indice di asimmetria (skewness) è data da \[ sk = \frac{\frac{\sum_{i=1}^n (x_i-\bar x)^3}{n}}{\sigma^3} \] dove \(\bar x\) rappresenta la media aritmetica e \(\sigma\) la standard deviation (scarto quadratico medio) dei dati. In R l’indice può essere calcolato come segue:
mean((logret$A2Aadj - mean(logret$A2Aadj ))^3) / sd(logret$A2Aadj )^3## [1] -2.206542Essendo l’indice negativo, si può quindi concludere che la distribuzione dei rendimenti logaritmici è caratterizzata da asimmetria negativa (coda lunga a sinistra).
La curtosi campionaria può essere calcolata usando la seguente formula: \[ kur = \frac{\frac{\sum_{i=1}^n (x_i-\bar x)^4}{n}}{\sigma^4} \]
mean((logret$A2Aadj - mean(logret$A2Aadj))^4) / sd(logret$A2Aadj)^4## [1] 31.29707Essendo l’indice superiore a 3 si è in presenza di una distribuzione con code più pesanti rispetto alla normale e con picco più pronunciato.
5.5 Esercizi Lab 3
5.5.1 Esercizio 1
Il file AdjclosepricesLab3.csv contiene i prezzi giornalieri aggiustati per il periodo dal 01-09-2016 al 27-08-2020 per i seguenti indici: NASDAQ Composite (IXIC), Dow Jones Industrial Average (DJI), Gold (Gold) e CBOE Volatility Index (VIX). Fonte: Yahoo Finance.
- Importare i dati in R e verificare la struttura dei dati.
- Calcolare, usando il minor numero possibile di righe di codice, i rendimenti lordi per tutti le variabili. Creare un nuovo data frame che contiene i rendimenti lordi. Calcolare il rendimento lordo medio per ogni variabile.
- Rappresentare graficamente le serie storiche dei rendimenti lordi. Commentare il grafico.
- Rappresentare graficamente la distribuzione marginale dei dati utilizzando i boxplot (in una singola finestra). Commentare il grafico.
- Rifare il grafico del punto precedente dopo aver eliminato i dati relativi a VIX. Cosa si osserva?
- Ricordando come sono definiti i baffi del boxplot, calcolare il numero di valori estremi (i punti nel boxplot) per ogni titolo. Quale titolo presenta il numero maggiore di valori estremi?
- Rappresentare l’istogramma per i rendimenti di IXIC. Commentare il grafico.
- Calcolare per tutte le variabili l’indice di skewness e curtosi. Commentare i valori.