1 Introduccion practica a la Ciencia de Datos
Al terminar este capítulo ustedes van a poder:
- Crear un proyecto en RStudio
- Cargar datos a una sesión de R
- Identificar y comprender las distintas estructuras con las que R maneja los datos1.1 Nuestra primera investigación: el precio de las propiedades en CABA
En este primer capítulo vamos a estudiar el mercado inmobiliario de la Ciudad de Buenos Aires. Más específicamente, analizaremos los movimientos de los precios en los años 2013-2017 a través de un muy interesante (y masivo) dataset que públicamente ofrece Properati1.
Más allá de que analizar los datos de las propiedades es de por sí interesante y pedagógico para introducir varias de las herramientas que vamos a utilizar, el mercado inmobiliario fue procesando varios cambios en parámetros claves como el precio del dólar y la oferta de créditos hipotecarios. Por esta razón, los precios durante los últimos años de nuestra muestra han experimentado un alza, o eso dicen las fuentes del sector.
Figure 1.1: Nota de TELAM sobre el precio de los inmuebles en CABA durante 2017
En este primer capítulo vamos a hacer uso de un dataset que tiene el precio promedio del metro cuadrado en USD para el período 2013-2017 desagregado a nivel de barrios. Este dataset se descargó del portal de datos de Properati y se manipuló para que sea apto para nuestro primer análisis.
Vamos a intentar responder dos preguntas:
- ¿Aumentaron los precios de los inmuebles (medido como USD en m2) en el 2017?
- ¿Todos los barrios aumentaron en la misma proporción o existen heterogeneidades?
Pero antes de adentrarnos en nuestra pregunta de investigación tenemos que detenernos en algunos puntos importantes.
1.2 Conociendo RStudio
RStudio es el Entorno Ingregrado de Desarrollo (IDE) que vamos a usar a lo largo de este libro, pero ¿Qué hace exactamente un IDE? ¿Para que lo necesitamos?
Un IDE es un software que nos ayuda programar de una manera más simple y eficiente. Entre algunas de sus múltiples funciones, nos sugiere qué deberíamos continuar escribiendo , nos marca dónde nos hemos confundido y administra nuestros archivos en proyectos.
Pero no existe mejor manera de aprender qué es un IDE que usándolo. Abran RStudio. Por default, deberían encontrarse con algo similar a lo que aparece en la Figura 1. RStudio divide la pantalla en cuatro paneles. Ariba a la izquierda vemos el Panel de edición de archivos, donde vamos a modificar los archivos donde guardamos nuestro código, a la derecha vemos el Panel de estructuras de datos, donde aparecen las “estructuras de datos” que están creadas (más sobre esto abajo en el documento).
Abajo a la izquierda tenemos el panel donde se visualiza la consola o terminal, que es donde vamos a ver ejecutado nuestro código y a su derecha un Panel multiuso, que será de utilidad para explorar archivos, ver la salida gráfica de nuestro código, encontrar ayuda sobre nuestros comandos, entre otras funciones.
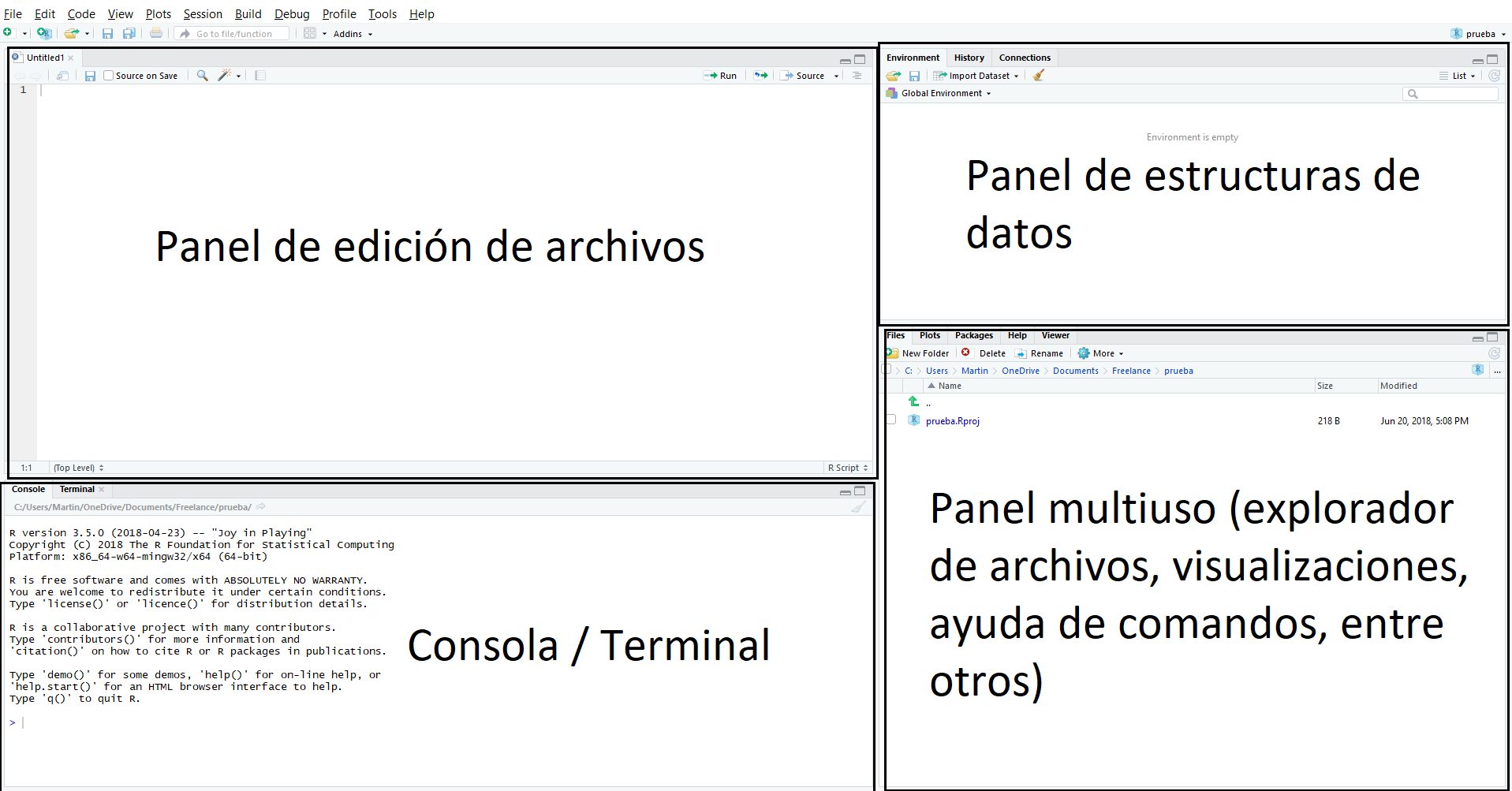
Figure 1.2: Impresión de pantalla de RStudio
Vamos a ejecutar nuestro primer código en R. En el panel de abajo a la izquierda (consola o terminal), ejecuten el siguiente código:
5 * 10 # No deberíamos necesitar a R para esto...## [1] 50Debería devolver, también en el panel de la consola, el número 50. Ya ejecutamos nuestro primer código en R, pero antes de seguir ejecutemos lo mismo de una manera un poco distinta. Escriban exactamente el mismo código, pero ahora en el Panel de edición de archivos. Una vez que lo hayan escrito, seleccionen el código completo con el mouse y presionen Control + Enter. En la consola deberían obtener exactamente el mismo resultado.
¿Qué fue lo que pasó? Nuestro código está en un archivo (que todavía no guardamos). Al seleccionar el código y apretar Control + Enter RStudio pasa este código a la consola y se ejecuta, tal como antes. Para guardar el archivo que acabamos de editar, presionen Control + S, pongan el nombre que quieran al nuevo archivo, que tendrá la terminación .R, que es como vamos a identificar a los archivos que contienen código de R.
1.2.1 Proyectos en RStudio
Hasta ahora creamos un archivo .R que tiene una sola línea de código, pero en los proyectos en los que solemos trabajar la cantidad de archivos con código y con datos se multiplica. Si no pensamos en la organización para un proyecto de ciencia de datos, el resultado puede ser un conjunto de archivos con nombres poco intuitivos en las ubicaciones más variadas dentro de nuestra computadora.
Para ayudar a corregir al menos parcialmente este problema, RStudio ofrece la posibilidad de guardar todos los archivos vinculados a un proyecto en una misma dirección de nuestra computadora. De esta manera, evitamos tener que recordar dónde guardamos los archivos y podemos movernos rápidamente de proyecto en proyecto.
Crear un nuevo proyecto en RStudio es realmente simple. Solo tienen que ir a File -> New Project... -> New Directory -> New Project. Allí deben elegir un nombre para el proyecto y hacer click en Create Project ¡Listo! Ya creamos nuestro primer proyecto. Nuestra pantalla ahora debería estar dividida en cuatro paneles.
¿Recuerdan la carpeta donde crearon el proyecto? Una vez que lo hayan hecho, ejecuten el siguiente código desde el panel de abajo a la izquierda:
getwd()¿Qué sucedió? Les devolvió la dirección de la carpeta donde está este proyecto. De ahora en más, todo lo que guarden o a lo que intenten acceder desde el proyecto de RStudio se hará dentro de este directorio. Esto trae muchos beneficios que iremos viendo de aquí en adelante.
1.3 Importando datos a R
Cargar los datos a la sesión de R - es decir cuando abrimos RStudio - es una de las tareas más importantes ¡no hay ciencia de datos sin datos! En esta sección vamos a ver distintas formas de cargar los datos y veremos dónde aparecen visualmente en RStudio.
1.3.1 Comma Separated Values
Uno de los formatos más conocidos para guardar datos son los archivos separados por comas (CSV). El formato consiste simplemente en elementos separados por algún delimitador, en general una coma, que terminan formando una matriz. Veamos un ejemplo con el precio de los inmuebles por año y barrio:
precioAvisos <- read.csv(file = 'https://raw.githubusercontent.com/martintinch0/CienciaDeDatosParaCuriosos/master/data/precioBarrios.csv',
sep=';',
stringsAsFactors = FALSE)En este código hicimos muchas cosas ¿no? Pero antes de empezar a explicar lo que acaban de ejecutar, fijense qué pasó en el panel de arriba a la derecha: deberían tener una fila que dice “precioAvisos” con 48 observaciones 6 variables. Si descargan el csv que acabamos de cargar directamente a R y lo abren, por ejemplo, con excel van a ver también que tiene 48 observaciones y 6 variables ¡Hicimos nuestra primera carga de datos a R!
¿Cómo lo hicimos? Con la ayuda de la función read.csv. ¿Qué es una función? Una función no es otra cosa que un conjunto de código que no vemos, pero que podemos usar de la siguiente manera: le damos algo y nos devuelve otra cosa.
Una función en los lenguajes de programación es una “caja” que procesa algo que le damos (input) y nos devuelve algo (output).
¿Qué le damos a una función? Le pasamos valores. En este caso, file, sep y stringsAsFactors. ¿Qué nos devuelve? Lo que hay en ese archivo (file) separado por el caracter que nosotros le pasamos (sep). Por el momento, dejaremos stringsAsFactors de un lado.
Pero ¿Cómo aparecieron esos datos en un objeto con un nombre precioAvisos? Eso lo hicimos con la ayuda de <-, nuestra forma de asignar resultados de funciones a objetos.
El operador de asignación
<-“pasa” o asigna lo que sea que está a su derecha a un objeto que está a su izquierda. En nuestro ejemplo. a la izquierda esta “precioAvisos”, que es como se llamará nuestro objeto, y a la derecha está nuestra primera función “read.csv()”
1.4 ¿Cómo R organiza los datos?
Hagan click en “precioAvisos”, en el panel de arriba a la derecha ¿Qué ven? Este es tan solo uno de los objetos que tiene R para ir guardando datos. La función class() nos ayuda para saber qué usó R para guardar estos datos:
class(precioAvisos)## [1] "data.frame"En este caso, vemos que es un data.frame, un caso específico - y muy importante - de las estructuras de datos u objetos de R. Se trata de un caso un poco complejo, vayamos un poco para atrás y veamos las estructuras de datos más simples que maneja R. Luego veremos que se relacionan con los data.frame.
1.4.1 Vectores
R organiza a los datos en diferentes estructuras según el dominio de los datos. El dominio no es otra cosa que los valores que una variable puede llegar a tomar. Por ejemplo, si una variable solo puede tomar números reales y enteros, R pondrá esa variable en un vector númerico o integer, para ser más preciso.
Un vector es la estructura más básica con la que vamos a lidiar. Un vector no es otra cosa que una colección numerada de valores, es decir una estructura que puede contener uno o más valores, y puede accederse a través de índices que denotan el orden de cada número dentro del vector ¿Simple, no? Creemos nuestro primer vector
primerVector <- c(20,40,60,80,100)Ya está: el objeto primerVector es un vector númerico que tiene cinco elementos: 20, 40, 60, 80 y 100. Como les prometí, el vector es una colección numerada de valores, por lo que podemos acceder a cualquiera de los valores llamando al objeto por su nombre y escribiendo la posición entre corchetes [] (la numeración arranca desde 1 en R)
primerVector[3] # Devuelve el valor del elemento en la tercera posición de nuestro vector## [1] 60La mayor parte de nuestros datos no consiste solo en números, sino en datos mixtos: números, texto, variables categóricas, variables lógicas. Todos estos tipos de datos pueden ser representados en nuestros versátiles vectores:
vectorTexto <- c("Croacia","Argentina","Nigeria","Islandia")
vectorLogico <- c(FALSE, TRUE, TRUE, FALSE)Los vectores de texto no requieren demasiada discusión: son vectores cuyos elementos son texto. Por su parte, los vectores lógicos quizás sí requieran algo de explicación. Los elementos de estos vectores solo pueden tomar los valores TRUE o FALSE, y resultan de mucha utilidad para hacer preguntas del estilo ¿Es este vector un vector de texto?
is.character(vectorTexto)## [1] TRUEVolvamos a nuestros datos sobre los precios de los inmuebles. Ya comentamos que había seis variables, pero no dijimos que a su vez son ¡6 vectores!. Uno es CHARACTER, como nuestro vectorTexto anterior, cinco son INTEGER, o numeric, como nuestro primer_vector y el último es sfc_MULTIPOLYGON (vamos a ver un poco más en detalle este último tipo de vector en próximas clases) ¿Cómo podemos acceder a ellos? La llave es el operador $
precios2017 <- precioAvisos$USDm2_2017
str(precios2017) # ¿Los 100 barrios porteños en realidad son 48?## num [1:48] 1946 2299 1989 1920 3199 ...¿Qué fue lo que hicimos? Creamos el objeto precios2017 al que le asignamos (<-) el vector/variable USDm2_2017 que está en el Data Frame precioAvisos (vamos a ver más sobre los Data Frame más adelante). Al usar la función str() (son las primeras tres letras de la palabra structure en inglés) vemos que se trata de un vector integer (o númerico) con 48 elementos ¡La misma cantidad de observaciones que tenemos en precioAvisos!
Ahora es donde las cosas se ponen un poco más interesantes. Podemos hacer múltiples operaciones aritméticas sobre este vector de una manera muy simple:
str(precios2017*2) # Multiplicación## num [1:48] 3891 4598 3978 3839 6398 ...str(precios2017/4) # División## num [1:48] 486 575 497 480 800 ...str(precios2017 - 20) # Resta por solo un número## num [1:48] 1926 2279 1969 1900 3179 ...str(precios2017 - precios2017) # Resta con otro vector de igual tamaño## num [1:48] 0 0 0 0 0 0 0 0 0 0 ...Una de las ventajas de R es su vectorización. En las operaciones anteriores vimos como múltiplicar, dividir, restar o cualquier otra operación aritmética se aplica de manera individual sobre cada uno de los elementos de los vectores, con lo cual la operación se hace elemento por elemento.
Hagamos algo que sea útil para describir la distribución de los precios de los inmuebles ¿Cuál es el valor mínimo del metro cuadrado? ¿Cuál es el máximo? ¿Cuál es el precio promedio? Las funciones min(), max() y mean() hacen el trabajo por nosotros.
resumen_2017 <- c(min(precios2017), max(precios2017), mean(precios2017))
resumen_2017## [1] 872.7541 6070.3288 2203.11191.4.2 Listas y Data Frames
Otras estructuras de datos importantes en R son las listas y Data Frames:
- Las listas son objetos que contienen a su vez un conjunto ordenados de objetos.
- Los Data Frames son un caso específico de listas.
1.4.2.1 Listas
Las listas tienen la posibilidad de almacenar objetos con distinta clase. Es decir, es posible crear una lista en la cual se almacenan otras estructuras de datos con clases distintas:
lista1 <- list(Nombres = c("Fernando","Martín"), Apellido="Montané", tienehijos = FALSE,
edad = 26)
lista1## $Nombres
## [1] "Fernando" "Martín"
##
## $Apellido
## [1] "Montané"
##
## $tienehijos
## [1] FALSE
##
## $edad
## [1] 26En este caso creamos una lista que se llama lista1 y almacena 4 vectores. El primero, es un vector Nombres que contiene dos elementos de clase character. El segundo, un vector de un solo elemento, Apellido de clase character. El tercero, un vector lógico de un elemento ( tienehijos ). Finalmente, el vector edad, que posee un elemento númerico.
En las listas hay que acceder a los objetos, que puede ser cualquiera de las estructuras que vimos hasta ahora (incluyendo las listas). Para acceder a ellos existen al menos 3 formas:
- Usando el signo $
lista$Nombres - Usando doble corchetes e indicando la posición del objeto buscado
lista[[1]] - Usando doble corchetes e indicando el nombre del objeto buscado
lista[['Nombres']]
lista1$Nombres## [1] "Fernando" "Martín"lista1[[1]]## [1] "Fernando" "Martín"lista1[['Nombres']]## [1] "Fernando" "Martín"1.4.2.2 Data Frames
¡Ahora estamos en condiciones de explicar qué es un Data Frame! Como se adelantó, un Data Frame es un caso específico de listas. En la gran mayoría de las aplicaciones se puede describir como una matriz en la cual variables (columnas) pueden ser de distintas clases.
df <- data.frame(Nombres = c('Juan','Pedro','Ana','Delfina'),
Edad = c(21,46,58,27),
EstadoCivil = c('Soltero','Casado','Casado','Soltero'),
SecundarioCompleto = c(TRUE, FALSE, TRUE, TRUE))
df## Nombres Edad EstadoCivil SecundarioCompleto
## 1 Juan 21 Soltero TRUE
## 2 Pedro 46 Casado FALSE
## 3 Ana 58 Casado TRUE
## 4 Delfina 27 Soltero TRUEstr(df) # Resumen del objeto## 'data.frame': 4 obs. of 4 variables:
## $ Nombres : chr "Juan" "Pedro" "Ana" "Delfina"
## $ Edad : num 21 46 58 27
## $ EstadoCivil : chr "Soltero" "Casado" "Casado" "Soltero"
## $ SecundarioCompleto: logi TRUE FALSE TRUE TRUEEl comando str nos devuelve un resumen de las variables del data frame, incluyendo sus clases. Si prestan atención, el vector numérico Edad y el lógico SecundarioCompleto tienen la clase esperada, pero los vectores de caracteres Edad y SecundarioCompleto dice Factor w/2 o w/4 levels ¿Qué es esto?
La clase Factor es un caso específico de vectores. En esta clase de vectores, las variables solo pueden tomar un conjunto de valores predeterminados, es decir que tienen una categoría. Estas categorías se llaman levels en R.
Internamente R transforma estas variables y les asigna un número entero, que son los valores que nos devolvió el comando str. Sin embargo, estos números hacen referencia a una categoría que tiene un nombre. En nuestro caso ¿Tiene sentido que los dos vectores con texto sean Factores?. Respuesta: no. El estado civil de una persona sí puede segmentarse en categorías que se repiten, pero no es el caso de los nombres. Para evitar que R transforme nuestros vectores character en Factor lo que hay que hacer cuando definimos un Data Frame es decírselo a R con el parámetro stringsAsFactors:
df <- data.frame(Nombres = c('Juan','Pedro','Ana','Delfina'),
Edad = c(21,46,58,27),
EstadoCivil = c('Soltero','Casado','Casado','Soltero'),
SecundarioCompleto = c(TRUE, FALSE, TRUE, TRUE),
stringsAsFactors = FALSE)
df## Nombres Edad EstadoCivil SecundarioCompleto
## 1 Juan 21 Soltero TRUE
## 2 Pedro 46 Casado FALSE
## 3 Ana 58 Casado TRUE
## 4 Delfina 27 Soltero TRUEstr(df) # Resumen del objeto. Ahora ya no tenemos Factors.## 'data.frame': 4 obs. of 4 variables:
## $ Nombres : chr "Juan" "Pedro" "Ana" "Delfina"
## $ Edad : num 21 46 58 27
## $ EstadoCivil : chr "Soltero" "Casado" "Casado" "Soltero"
## $ SecundarioCompleto: logi TRUE FALSE TRUE TRUELos vectores Factor son de mucha utilidad, especialmente cuando se trabaja con modelos estadísticos en R. Vamos a verlos en otras aplicaciones más adelante.
Ahora ya tenemos los elementos suficientes como para definir más concretamente qué es un Data Frame: es un conjunto de listas, que en su versión más usual contienen un vector cada una de un mismo largo (mismas cantidad de observaciones), pero que pueden almacenar variables de distinto dominio. Esto es algo muy útil para la mayor parte de datasets con los que se trabaja.
1.5 Inspeccionando nuestros datos
¿Cómo sabemos qué datos tenemos cargados? Tenemos al menos dos funciones que sirven para inspeccionar rápidamente los datos. Por un lado, podemos usar la función View() (Notar la V mayúscula al principio de la función). Lo que hay que hacer es pasarle uno de nuestros objetos que están cargados, y nos devuelve la tabla entera en el panel de edición.
View(precioAvisos) # Debería abrirse una tabla dentro del panel de ediciónDeberían ver una matriz con 6 columnas y unas 48 filas. Las filas representan observaciones (en este caso, barrios), mientras que las columnas hacen referencia a las variables, que tienen los siguientes nombres: BARRIOS, USDm2_2013, USDm2_2014, USDm2_2015, USDm2_2016, USDm2_2017 y geometry ¿Qué significan?
- BARRIOS: es una variable que indica cuál es el nombre del barrio al que pertenece cada observación
- USDm2_201x: estás 5 columnas hacen referencia al valor promedio de los inmuebles creados en cada año para cada barrio (período 2013-2017)
Otra función que puede ser muy útil para describir nuestros objetos, que ya hemos usado anteriormente, es str(). Nos devuelve las primeras observaciones de cada una de las variables, también la clase de nuestro objeto, la cantidad de observaciones (o filas), que en este caso son 48, y la cantidad de variables (o columnas), que son 6. También nos indica la clase de cada una de las variables, que en este caso son int o num. Para entender bien las clases de datos y las diversas estructuras que los contienen tenemos que ir un casillero más atrás y explicar cómo es R organiza las cosas.
str(precioAvisos) ## 'data.frame': 48 obs. of 6 variables:
## $ BARRIOS : chr "AGRONOMIA" "ALMAGRO" "BALVANERA" "BARRACAS" ...
## $ USDm2_2013: num 1749 2034 1893 2229 2620 ...
## $ USDm2_2014: num 1458 1930 1818 1901 2544 ...
## $ USDm2_2015: num 1689 2086 1858 2390 2695 ...
## $ USDm2_2016: num 2057 1950 1834 1751 3287 ...
## $ USDm2_2017: num 1946 2299 1989 1920 3199 ...1.6 Retomando nuestro ejercicio: ¿Cuánto aumentaron las viviendas?
Ya estamos en condiciones de hacer un par de cálculos más y ver si efectivamente, como en la noticia principal, las propiedades aumentaron de precio en 2017. Para esto, no tenemos que hacer nada nuevo, usando el operador $, que nos deja elegir el vector de nuestro data.frame, solo tenemos que hacer una división.
mean(precioAvisos$USDm2_2017)/mean(precioAvisos$USDm2_2016) - 1## [1] 0.05299051Según nuestros datos, aumentaron 5,3% en 2017. Coincidimos con la nota, pero nos da un poco menos que lo esperado. Veamos ahora cuál fue la variación de los barrios: recuerden que R puede vectorizar la operación. Vamos a agregarle una nueva columna a nuestro data frame, combinando lo que aprendimos hoy
precioAvisos$variacion2017 <- precioAvisos$USDm2_2017/precioAvisos$USDm2_2016 - 1
View(precioAvisos)Ordenen desde el visor a las variaciones por barrio ¿Qué pasó? Si miran con atención, el precio de los inmuebles en Villa Soldati, para nuestra muestra, cayó un 63%. Claro que esto tiene un impacto sobre el cálculo de la variación en 2017. No se preocupen, en el próximo capítulo, con la ayuda de tidyverse vamos a poder ver qué pasa con esto.
¿Qué pueden decir sobre la heterogeneidad en los barrios? ¿Cuáles crecieron más y cuáles menos?
1.7 Conclusiones
Los datos públicos a los que accedimos nos permitieron responder las dos preguntas iniciales:
- En primer lugar, se observó un incremento en los precios de los inmuebles en USD durante el 2017 en comparación al 2016. Este aumento fue de aproximadamente 5,3%, según un promedio simple de las variaciones barriales.
- En segundo lugar, las variaciones en los precios exhiben una importante heterogeneidad regional, con algunos barrios ubicados en la parte noroeste (Villa Pueyrredón, Villa Ortúzar, Chacarita, Colegiales) y sudeste (Nueva Pompeya, Parque Chacabuco, Boedo) de la capital aumentando más que el resto.
1.8 Ejercicios
- ¿Cuál fue la variación de los precios de los inmuebles entre 2016 y 2015?
- ¿Cuál fue la variación de los precios de los inmuebles entre 2017 y 2013?
- ¿Cuál fue el barrio que más creció entre 2017 y 2013?
- ¿Cuál fue el barrio que menos creció entre 2017 y 2013?
- ¿Cual es el año en el que los precios de la ciudad fueron más altos? ¿Cuál fue ese valor?
1.9 Extensión: cargando y guardando datos de otros formatos
1.9.1 Microsoft Excel
Para bien o para mal, las planillas de Excel están por todos lados. Es importante saber cómo cargarlas a R y poder trabjar con ellas desde aquí. Para esto, vamos a necesitar la ayuda de un paquete de datos de R (en el Capítulo 2 pueden aprender qué es un paquete de datos) y descargar un archivo excel. En el ejemplo suponemos que este archivo está disponible en la carpeta principal del proyecto y que ya tienen instalado el paquete readxl.
library(readxl)
datos <- read_excel(path = 'child_mortality_0_5_year_olds_dying_per_1000_born.xlsx',
sheet = 1)Si inspeccionan el archivo datos con str(), glimpse() o View() van a poder ver qué tipo de datos hay en lo que leímos desde R. Solo necesitamos pasarle dos argumentos: la dirección (path) y el número o nombre de hoja (en este caso, la primera). Esta función tiene muchos otros parámetros para adaptarnos al formato que tenga la hoja de excel. Pueden averiguar más preguntando de esta manera: ?read_excel()
¿Cómo guardamos los datos a excel? Existen muchas alternativas para hacerlo, entre ellas la función write_xlsx que brinda el paquete writexl ¿Por qué? Porque otras alternativas tienen diveresas dependencias, como rJava, que requiere tener instalado Java versión 64 bits en la computadora y muchas veces no es fácil darse cuenta de esto. La instalación de este paquete solo debe hacerse una vez, como se explicará en los capítulos que siguen.
install.packages("writexl")Una vez que lo instalaron, ya podemeos usar la función para escribir archivos xlsx luego de usar library(writexl).
library(writexl)
write_xlsx(x = datos ,path = 'Mortalidad Infaitl.xlsx')Este video resume en unos pocos minutos gran parte de lo que vamos a ver acá y es recomendable↩