2.2 Learn and use ML | 学习使用机器学习
本节内容受到 Deep Learning with Python 一书的启发。教程使用 Tensorflow 中的高级 Python API tf.keras 来构建和训练深度学习模型。学习如何利用 Keras 使用 Tensorflow,见 TensorFlow Keras Guide。
Deep Learning with Python 介绍了利用 Python 语言和强大的 Keras 库进行深度学习。本书作者是 Keras 的创始人和 Google AI 研究员 François Chollet,本书通过直观的解释和实际的案例帮助你构建对深度学习的理解。
学习机器学习的基础概念,可参考 Machine Learning Crash Course 课程。额外的 Tensorflow 和机器学习资源罗列在 Next Steps 中。
2.2.1 Basic classification | 基础分类问题
训练你的第一个的神经网络模型:基础分类问题
本节将训练一个神经网络模型用于服装图片的分类,例如运动鞋和衬衫。你可以不必对所有的细节都理解,这是一个完整的 Tensorflow 程序的快速概述以及对其细节的说明。
本节将使用 Tensorflow 的高级 API tf.keras 构建和训练模型。
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)2.2.1.1 Import the Fashion MNIST dataset | 导入 Fashion MNIST 数据集
本节使用的 Fashion MNIST 数据集包含 70,000 个共 10 个类别的灰度图像。这些图像以 28x28 的低分辨率显示不同类型的服装,如图 1.1 所示:
图 1.1: Fashion-MNIST samples (by Zalando, MIT License).
传统的 MNIST 数据集包含了手写数字 (0,1,2 等) 通常作为计算机视觉领域机器学习的 Hello, World 被使用。Fashion MNIST 数据集作为其替代品,保留了与其相同的数据格式。
本节使用 Fashion MNIST 数据集是因为其相比传统的 MNIST 数据集更具有挑战性。两个数据集都相对比较小,适用于验证一个算法是否能够正常工作,也适合我们对代码进行测试和调试。
我们将利用 60,000 张图片用于训练并利用 10,000 张图片用于验证我们的神经网络的分类准确性。你可以直接从 Tensorflow 中访问 Fashion MNIST 数据集,仅需要导入并加载数据即可:
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 5us/step
Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 7s 0us/step
Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 0us/step
Downloading data from http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 4s 1us/step载入的数据以 Numpy 的数组形式返回
train_images和train_labels数组为 训练集 的图片和对应的类别。test_images和test_labels数组为 测试集 的图片和对应的类别。
每张图片为 28x28 的 Numpy 数组,每个像素点的值介于 0 和 255 之间。标签 labels 为整形数值的数组,值介于 0 和 9 之间。这些便签值对应的衣服的类型 class 如表 1.1 所示:
| 标签 | 类别 | 类别 (中文) |
|---|---|---|
| 0 | T-shirt/top | T恤/短衫 |
| 1 | Trouser | 裤子 |
| 2 | Pullover | 套衫 |
| 3 | Dress | 裙子 |
| 4 | Coat | 大衣 |
| 5 | Sandal | 凉鞋 |
| 6 | Shirt | 衬衫 |
| 7 | Sneaker | 运动鞋 |
| 8 | Bag | 包 |
| 9 | Ankle boot | 短靴 |
每张图片被映射到一个标签上。由于类型名称 class names 并没有包含在数据集中,我们需要将其保存在变量中用于后续的绘图:
2.2.1.2 Explore the data | 探索数据
在开始训练模型之前,让我们先对数据集的格式进行初步探索。如下代码显示了在训练集中共包含 60,000 张图片,每张图片由 28x28 个像素构成:
类似的,训练集中共有 60,000 个标签:
每个标签是一个介于 0 和 9 之间的一个整数:
测试集中共包含 10,000 张图片,每张图片由 28x28 个像素构成:
训练集中共有 10,000 个标签:
2.2.1.3 Preprocess the data | 数据预处理
在训练神经网络之前,数据必须进行预处理。如果你查看训练集中的第一个图像,你会发现其像素值介于 0 和 255 之间:
图 1.2: Fashion MNIST 训练集中第一张图片
在将其喂给神经网络模型之前,我们将其值缩放到 0 和 1 之间。将其类型转换为 float 型,再除以 255,如下为对图片的预处理。特别注意的是我们需要对训练集和测试集均进行相同的预处理:
显示训练集中的前 25 张图片,并将其类型的名称显示在每张图片的下面。验证我们的数据是否格式正确,以便于构建和训练我们的模型。
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid('off')
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
图 1.3: Fashion MNIST 训练集中前 25 张图片
2.2.1.4 Build the model | 构建模型
构建神经网络模型需要设置网络中的每一层,之后再编译整个模型。
2.2.1.4.1 Setup the layers | 设置网络层级
构建一个神经网络模型的基础单元是层 (layer)。每个层从喂给他们的数据中提取信息,同时我们希望这些信息对于当前的问题是更有意义的。
大多数的深度学习模型是由一系列的 layer 构成的链条。对于大多数的 layer,例如 tf.keras.layers.Dense 包含了在训练过程中可被学习的参数。
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])网络中的第一个 layer,tf.keras.layers.Flatten 将原始的图片由一个 2d-array (28x28 像素) 转换成一个 1d-array (28 * 28 = 784)。这一层可以看做是将图像中的像素一行一行的连接起来,这一层没有参数,其目的仅是转换数据的格式。
将所有像素平坦化 (flattened) 后,后面连接了两个 tf.keras.layers.Dense 层。这两个层称之为全连接层 (densely-connected / fully-connected layer)。第一个全连接层包含 128 个神经元。第二层是一个由 10 个节点构成的 softmax 层,该层将返回一个和为 1 的包含 10 个概率值的数组。其中,每个节点的数值表示当前图片属于该类别的概率。
2.2.1.4.2 Compile the model | 编译模型
在对模型进行训练之前,我们还需要一些额外的设置。这些设置将在模型的编译 (compile) 阶段添加:
- 损失函数 (loss function):它用于衡量训练过程中模型的准确度。我们希望通过最小化损失函数来控制 (steer) 模型朝着正确的方向优化。
- 优化器 (optimizer):它控制模型如何利用输入的数据和损失函数对模型的参数进行更新。
- 度量 (metrics):它用于模型训练和测试阶段的监控。下面的例子中我们使用的是准确率 (accuracy),即被正确分类的图像的占比。
2.2.1.5 Train the model | 训练模型
训练一个神经网络模型需要如下步骤:
- 将训练数据喂给模型,在本例中,即为
train_images和train_labels数组。 - 模型学习图像和标签之间的关系。
- 利用训练好的模型对测试数据进行预测,在本例中,即为
test_images。我们通过预测值和测试集中的标签test_labels进行验证。
我们通过调用 model.fit 函数开始模型的训练,模型将会拟合 (fit) 训练集:
Epoch 1/5
60000/60000 [==============================] - 2s 36us/step - loss: 0.4975 - acc: 0.8247
Epoch 2/5
60000/60000 [==============================] - 2s 35us/step - loss: 0.3732 - acc: 0.8662
Epoch 3/5
60000/60000 [==============================] - 2s 34us/step - loss: 0.3376 - acc: 0.8764
Epoch 4/5
60000/60000 [==============================] - 2s 34us/step - loss: 0.3127 - acc: 0.8851
Epoch 5/5
60000/60000 [==============================] - 2s 34us/step - loss: 0.2960 - acc: 0.8920随着模型的训练,其损失 (loss) 和准确率 (accuray) 两个度量不断被更新。最终,模型在训练集上达到 89% 的准确率。
2.2.1.6 Evaluate accuracy | 评估准确率
下面,我们利用测试集来评估模型的性能:
可以看出,在测试集上的准确率要比在训练集上的准确率略小。这两者之间的差别即为过拟合 (overfitting),过拟合可以理解为一个机器学习模型在新的数据集上的性能要比在训练集上差的情况。
2.2.1.7 Make predictions | 进行预测
利用训练好的模型,我们可以对一些图片进行预测。
模型对测试集中的所有图片都进行了预测,在此,我们看一下第一张图片的预测结果:
array([1.6108595e-06, 3.4841499e-09, 3.6127108e-08, 1.5056702e-10,
1.7367940e-07, 7.1331444e-03, 8.0608407e-07, 7.3155247e-02,
1.2063636e-05, 9.1969693e-01], dtype=float32)预测结果是由一个包含 10 个数字的数组。其描述了模型对图片属于不同类型判别的概率 (confidence),其中具有最大概率值的标签为:
所以模型得到最可信的结果分类为 ankle boot,即 class_name[9]。我们可以检查测试集的标签看预测是否正确:
让我们画一些真实值和模型预测结果的对比图,我们将正确的预测结果标注为绿色,错误的预测结果标注为红色。
# Plot the first 25 test images, their predicted label, and the true label
# Color correct predictions in green, incorrect predictions in red
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid('off')
plt.imshow(test_images[i], cmap=plt.cm.binary)
predicted_label = np.argmax(predictions[i])
true_label = test_labels[i]
if predicted_label == true_label:
color = 'green'
else:
color = 'red'
plt.xlabel("{} ({})".format(class_names[predicted_label],
class_names[true_label]),
color=color)
图 1.4: Fashion MNIST 训练集中前 25 张图片预测结果
最后,我们可以利用训练好的模型对一张图片进行预测。
tf.keras 模型对于一批 (batch) 数据的预测进行了优化,因此即使我们仅对一张图片进行预测,我们也需要将其添加到一个 list 中:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)之后再进行预测:
[[1.6108593e-06 3.4841494e-09 3.6127172e-08 1.5056756e-10 1.7367938e-07
7.1331505e-03 8.0608396e-07 7.3155306e-02 1.2063634e-05 9.1969681e-01]]model.predict 返回一个包含 list 的 list,其中每一个为一批数据中的一张图像的预测结果。获取上文中一批图像 (仅 1 张) 的预测结果:
结果同之前的一样,模型对其预测结果为标签 9。
2.2.2 Text classification | 文本分类
电影评论问分类:二分类问题
本节将利用电影评论文本的内容对该电影评论的正向或负向进行分类。这是一个二分类 (binary / two-class classification) 任务的案例,二分类任务是机器学习领域广泛适用的问题。
我们经使用 IMDB 数据集中 50,000 条电影评论数据构建分类模型。该数据集中包含 25,000 条训练数据和 25,000 条测试数据,训练数据和测试数据是均衡的,两者包含相同数量的正向和负向评论。
本节将使用 Tensorflow 的高级 API tf.keras 构建和训练模型。
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)2.2.2.1 Download the IMDB dataset | 下载 IMDB 数据集
IMDB 数据集已经被打包在 Tensorflow 中,同时评论 (文本序列) 已经被预处理为整型数值的序列,每个整型数值代表词典中一个具体的词。
如下代码可以将 IMDB 数据集下载到你的机器上 (或者你也可以使用已经下载好的缓存副本):
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)Downloading data from https://s3.amazonaws.com/text-datasets/imdb.npz
17465344/17464789 [==============================] - 2s 0us/step参数 num_words=10000 表示仅保留训练数据中出现频率最高的 10,000 个词。为了保证数据的易控性,我们将不常见的词进行了舍弃处理。
2.2.2.2 Explore the data | 探索数据
让我们首先来了解一下数据的格式。数据是经过预处理的,每个样本是一个整型数值的数组,表示电影评论中的文本。每个标签是 0 或 1 的整型数值,0 表示是一个负向的评论,1 表示是一个正向的评论。
评论的文本已经被转换成了数值类型,每个整型数值表示词典中一个具体的词。我们来看一下第一条评论长什么样子:
电影评论的长度各有不同。如下代码展示了第一条评论和第二条评论的长度。由于输入到神经网络模型的数据必须有相同的长度,因此我们需要在后续对其进行处理。
2.2.2.2.1 Convert the integers back to words | 将整型数值转换回文本
知道如何将整型数值转换回文本将对于我们的理解有所帮助。在此,我们构建一个工具函数 (helper function) 用于查询一个包含从整型数值到文本的映射词典。
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])Downloading data from https://s3.amazonaws.com/text-datasets/imdb_word_index.json
1646592/1641221 [==============================] - 1s 1us/step接下来我们就可以利用 decode_review 函数来显示我们第一条评论的原始文本了:
2.2.2.3 Prepare the data | 准备数据
评论数据 (整型数组) 在喂给神经网络之前需要先转换成张量 (Tensors),这种转换可以通过多种方式实现:
- 独热编码 (one-hot-encode) 可以经他们转换成由 0 和 1 构成的向量。例如,序列 [3, 5] 将会变成一个 10,000 维的向量,其中除了 3 和 5 的位置的值为 1,其他位置的值均为 0。我们将编码后的数据作为网络的第一层,一个可以处理浮点向量数据的全连接层 (Dense Layer)。但这种方式的编码会占用大量的内存空间,因为其需要存储
num_words * num_reviews大小的矩阵。 - 另一种方式,我们首先需要填补数组使得所有的数组具有相同的长度。之后,我们构建一个形状为
num_examples * max_length的整型张量。我们使用一个能够处理这个形状的嵌入层 (Embedding Layer) 作为网络的第一层。
在本节中,我们使用第二种方法进行转换。
因为需要保证所有的电影评论的长度相同,在此我们使用 pad_sequences 函数来统一长度:
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)处理之后,我们看一下不同样本的长度:
经过填补的第一条评论如下:
[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 3941
4 173 36 256 5 25 100 43 838 112 50 670 2 9
35 480 284 5 150 4 172 112 167 2 336 385 39 4
172 4536 1111 17 546 38 13 447 4 192 50 16 6 147
2025 19 14 22 4 1920 4613 469 4 22 71 87 12 16
43 530 38 76 15 13 1247 4 22 17 515 17 12 16
626 18 2 5 62 386 12 8 316 8 106 5 4 2223
5244 16 480 66 3785 33 4 130 12 16 38 619 5 25
124 51 36 135 48 25 1415 33 6 22 12 215 28 77
52 5 14 407 16 82 2 8 4 107 117 5952 15 256
4 2 7 3766 5 723 36 71 43 530 476 26 400 317
46 7 4 2 1029 13 104 88 4 381 15 297 98 32
2071 56 26 141 6 194 7486 18 4 226 22 21 134 476
26 480 5 144 30 5535 18 51 36 28 224 92 25 104
4 226 65 16 38 1334 88 12 16 283 5 16 4472 113
103 32 15 16 5345 19 178 32 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]2.2.2.4 Build the model | 构建模型
一个神经网络是由多层神经元构成的,因此在构建一个神经网络的时候,对于网络架构我们主要需确定如下两个问题:
- 网络有多少层?
- 每一层中有多少个神经元?
在示例中,输入数据是由词在词典中的位置构成的数组,待预测的标签为 0 或 1,针对这个问题,我们构建如下模型:
# input shape is the vocabulary count used for the movie reviews (10,000 words)
vocab_size = 10000
model = keras.Sequential()
model.add(keras.layers.Embedding(vocab_size, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 16) 272
_________________________________________________________________
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________所有层以序列形式的堆叠组成了最终的分类器:
- 第一层是一个嵌入层 (
EmbeddingLayer)。这一层接受整型编码的词汇表,对每个整型编码的词通过查询得到其对应的嵌入向量。这些词向量通过模型的训练可以学得。这些向量输出一维信息到输出数组中,其维度为:(batch, sequence, embedding)。 - 接下来,一个
GlobalAveragePooling1D层对不同维度的值计算均值返回一个固定长度的输出向量。该操作是一种最简单的处理可变长度输入的方法。 - 一个固定长度的输出向量被接到了一个包含 16 个隐含节点的全连接层 (
DenseLayer)。 - 最后一层是一个连接到最终一个输出节点的全连接层,使用
sigmoid作为激活函数,最后的输出结果是一个介于 0 和 1 之间的浮点数,代表概率或置信水平。
2.2.2.4.2 Loss function and optimizer | 损失函数和优化器
一个模型需要一个损失函数和一个优化器用于训练。因为这是一个二分类问题,同时模型输出一个概率 (一个单节点的,以 sigmoid 函数为激活函数的层),因此我们使用 binary_crossentropy 作为损失函数。
当然,这并不是唯一的选择,除此之外我们也可以选择 mean_squared_error 损失函数。不过,一般情况下,binary_crossentropy 损失函数在处理概率的时候效果更好。binary_crossentropy 衡量了两个概率分布之间的距离,在我们的示例中,即为真实情况的分布和预测分布之间的距离。
后面,我们将探索回归 (Regression) 问题 (例如预测房屋的价格),我们将展示如果使用另一种名为均方根误差 (Mean Suqared Error) 的损失函数。
现在,我们为模型添加一个优化器和损失函数:
2.2.2.5 Create a validation set | 构造一个验证集
在训练模型的过程中,我们希望检查模型在未知数据上的准确率。因此我们需要从原始的训练数据的 10,000 个样本中划分出来一些构成验证集。(为什么不使用测试集呢?因为我们的目标是仅利用训练数据来优化我们的模型,最后利用测试数据一次性评估模型的准确率)。
2.2.2.6 Train the model | 训练模型
我们利用训练数据训练模型 40 轮 (epochs),每一批优化使用 512 个样本,这将在全部的训练数据上循环 40 次。在训练过程中,我们可以监控模型在验证集 (10,000 个样本) 上的损失和准确率:
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)Train on 15000 samples, validate on 10000 samples
Epoch 1/40
15000/15000 [==============================] - 1s 43us/step - loss: 0.6927 - acc: 0.5121 - val_loss: 0.6919 - val_acc: 0.5169
Epoch 2/40
15000/15000 [==============================] - 0s 27us/step - loss: 0.6905 - acc: 0.5582 - val_loss: 0.6896 - val_acc: 0.5909
Epoch 3/40
15000/15000 [==============================] - 0s 26us/step - loss: 0.6880 - acc: 0.5851 - val_loss: 0.6873 - val_acc: 0.6281
......
Epoch 38/40
15000/15000 [==============================] - 0s 28us/step - loss: 0.2020 - acc: 0.9289 - val_loss: 0.2940 - val_acc: 0.8835
Epoch 39/40
15000/15000 [==============================] - 0s 29us/step - loss: 0.1968 - acc: 0.9309 - val_loss: 0.2925 - val_acc: 0.8830
Epoch 40/40
15000/15000 [==============================] - 0s 28us/step - loss: 0.1921 - acc: 0.9331 - val_loss: 0.2912 - val_acc: 0.88452.2.2.7 Evaluate the model | 评估模型
现在让我们评估一下模型的性能如何。评估将返回两个值,一个是损失 (Loss,代表了模型的误差,数值越小越好),另一个是准确率。
这种比较简单的做法最终的准确率在 87%,配合一些更高级的方法,模型的准确率可以提升至接近 95%。
2.2.2.8 Create a graph of accuracy and loss over time | 绘制准确率和损失的变化图
model.fit() 可以返回一个历史 (History) 对象,一个包含了训练过程中所发生事件的词典。
其中包含了 4 种条目,每一种代表了在训练和验证过程中被记录的度量值。我们可以使用这些数据绘制训练和验证过程中损失和准确率的变化图:
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()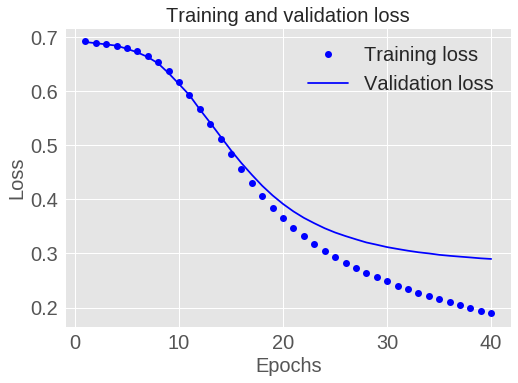
图 1.5: 训练和验证的损失
plt.clf() # clear figure
acc_values = history_dict['acc']
val_acc_values = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()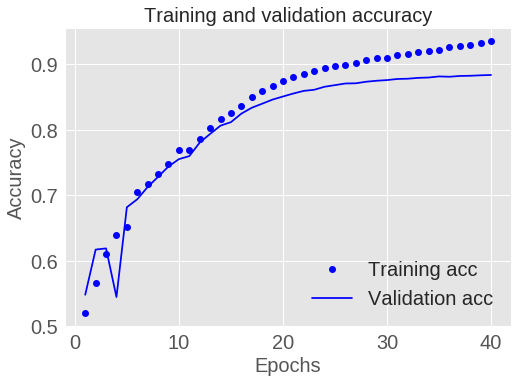
图 1.6: 训练和验证的准确率
在上图中,点为训练数据的损失和准确率,实线为验证数据的损失和准确率。
可以看出训练数据的损失随着每一轮的训练不断减小,准确率随着每一轮训练不断增加。这正是我们利用梯度下降算法进行优化时所期望的,每一轮都会最小化设置的损失。
验证数据的损失和准确率的变化略有不同,在 20 轮后似乎达到了峰值。这是过拟合的一个典型的例子,模型在训练数据上的表现要比在未见过的数据上表现更好。此时,模型过度优化并学习到了仅在训练数据上才有的模式,而这些模式并不能够在测试数据上有很好的泛化能力。
对于这个例子,我们可以通过在 20 轮后停止训练避免过拟合。后面,我们将展示如何利用一个 callback 来自动化处理这个问题。
2.2.3 Regression | 回归
在回归 (Regression) 问题中,我们的目标是预测一个连续的值,例如价格或概率。相对的,一个分类 (Classification) 问题则是预测一个离散的标签 (例如:一个图片是包含包含一个苹果还是一个橙子)。
本节我们将构建一个模型预测二十世纪 70 年代波士顿郊区的房价。为此,我们将利用一些其他的信息用于构建模型,例如:犯罪率和本地的财产税等。
本节将使用 Tensorflow 的高级 API tf.keras 构建和训练模型。
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)2.2.3.1 The Boston Housing Prices dataset | 波士顿房价数据
波士顿房价数据集已经被打包在 Tensorflow 中,下载并打乱数据:
boston_housing = keras.datasets.boston_housing
(train_data, train_labels), (test_data, test_labels) = boston_housing.load_data()
# Shuffle the training set
order = np.argsort(np.random.random(train_labels.shape))
train_data = train_data[order]
train_labels = train_labels[order]Downloading data from https://s3.amazonaws.com/keras-datasets/boston_housing.npz
57344/57026 [==============================] - 0s 3us/step2.2.3.1.1 Examples and features | 样本和特征
波士顿房价数据集要远比我们已经处理过的数据集要小,共包括了 506 个样本,其中训练样本 404 条,测试样本 102 条:
print("Training set: {}".format(train_data.shape)) # 404 examples, 13 features
print("Testing set: {}".format(test_data.shape)) # 102 examples, 13 features数据包含的 13 个特征如下:
- 人均犯罪率
- 超过 25,000 平方英尺的居住地的占比
- 每个城镇非零售业面积的占比
- Charles 河流的呀变量 (如果是河流边界则为 1,否则为 2)
- 氮氧化物浓度
- 每个住宅的平均房间数量
- 1940 年以前建造的自由住房占比
- 5 个波士顿就业中心的加权距离
- 高速公路的便捷性指数
- 每万美元的全额财产税税率
- 每个城镇小学教师的比率
- \(1000 \times (\text{Bk} - 0.63)\),其中 Bk 为城镇黑人占比
- 较差生活状态的人口占比
每个特征的数值范围不尽相同,有些特征是一个介于 0 和 1 之间的占比值,有些特征则是介于 1 和 12 或 0 到 100 之间。现实生活的数据往往就是这样,所以对数据的探索性分析和清洗就十分重要。
[7.8750e-02 4.5000e+01 3.4400e+00 0.0000e+00 4.3700e-01 6.7820e+00
4.1100e+01 3.7886e+00 5.0000e+00 3.9800e+02 1.5200e+01 3.9387e+02
6.6800e+00]利用 pandas 库可以以漂亮的格式来显示数据的前几行:
import pandas as pd
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT']
df = pd.DataFrame(train_data, columns=column_names)
df.head()| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.07875 | 45 | 3.44 | 0 | 0.437 | 6.782 | 41.1 | 3.7886 | 5 | 398 | 15.2 | 393.87 | 6.68 |
| 2 | 4.55587 | 0 | 18.10 | 0 | 0.718 | 3.561 | 87.9 | 1.6132 | 24 | 666 | 20.2 | 354.70 | 7.12 |
| 3 | 0.09604 | 40 | 6.41 | 0 | 0.447 | 6.854 | 42.8 | 4.2673 | 4 | 254 | 17.6 | 396.90 | 2.98 |
| 4 | 0.01870 | 85 | 4.15 | 0 | 0.429 | 6.516 | 27.7 | 8.5353 | 4 | 351 | 17.9 | 392.43 | 6.36 |
| 5 | 0.52693 | 0 | 6.20 | 0 | 0.504 | 8.725 | 83.0 | 2.8944 | 8 | 307 | 17.4 | 382.00 | 4.63 |
2.2.3.1.2 Labels | 标签
标签为以千美元为单位的房价。(需要注意的是此处为二十世纪七十年代中期的价格)
2.2.3.2 Normalize features | 规范化特征
在使用不同量纲和大小的特征的时候,我们建议对其进行规范化。对于每个特征,我们可以减去其均值,然后再除以其标准差:
# Test data is *not* used when calculating the mean and std.
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
train_data = (train_data - mean) / std
test_data = (test_data - mean) / std
print(train_data[0]) # First training sample, normalized[-0.39725269 1.41205707 -1.12664623 -0.25683275 -1.027385 0.72635358
-1.00016413 0.02383449 -0.51114231 -0.04753316 -1.49067405 0.41584124
-0.83648691]尽管不进行特征规范化模型也可能收敛,但这会让训练变得比较慢,同时也会让结果模型过多的依赖对于出入节点的选择。
2.2.3.3 Create the model | 构建模型
让我们开始构建模型,我们将使用一个 Sequential 模型,其包含两个全链接隐含层和一个返回单个连续值的输出层。模型的构建被封装在一个函数中 (build_model),因为稍后我们将构建第二个模型。
def build_model():
model = keras.Sequential([
keras.layers.Dense(64, activation=tf.nn.relu,
input_shape=(train_data.shape[1],)),
keras.layers.Dense(64, activation=tf.nn.relu),
keras.layers.Dense(1)
])
optimizer = tf.train.RMSPropOptimizer(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae'])
return model
model = build_model()
model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 896
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 5,121
Trainable params: 5,121
Non-trainable params: 0
_________________________________________________________________2.2.3.4 Train the model | 训练模型
我们利用训练数据对模型训练 500 轮,训练和验证的准确率被保存在 history 对象中。
# Display training progress by printing a single dot for each completed epoch.
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 500
# Store training stats
history = model.fit(train_data, train_labels, epochs=EPOCHS,
validation_split=0.2, verbose=0,
callbacks=[PrintDot()])利用 history 对象中保存的统计数据对训练过程进行可视化。我们希望据此确定训练模型花费了多长的时间。
import matplotlib.pyplot as plt
def plot_history(history):
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [1000$]')
plt.plot(history.epoch, np.array(history.history['mean_absolute_error']),
label='Train Loss')
plt.plot(history.epoch, np.array(history.history['val_mean_absolute_error']),
label = 'Val loss')
plt.legend()
plt.ylim([0,5])
plot_history(history)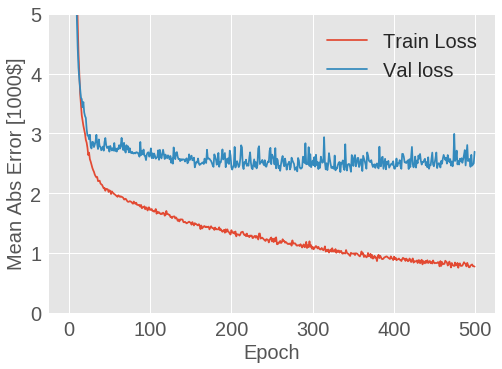
图 1.7: 波士顿房价预测模型 MAE 变化曲线
从图中可以看出,模型在 200 轮训练后几乎就不再有改进。让我们更新 model.fit 方法,使得当验证效果不再有改进时自动停止训练。我们将使用一个回调 (callback) 来在每轮训练中测试训练,如果若干轮训练未带来改进,则自动停止训练。
你可以在 这里 获得更多关于回调的信息。
model = build_model()
# The patience parameter is the amount of epochs to check for improvement.
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=20)
history = model.fit(train_data, train_labels, epochs=EPOCHS,
validation_split=0.2, verbose=0,
callbacks=[early_stop, PrintDot()])
plot_history(history)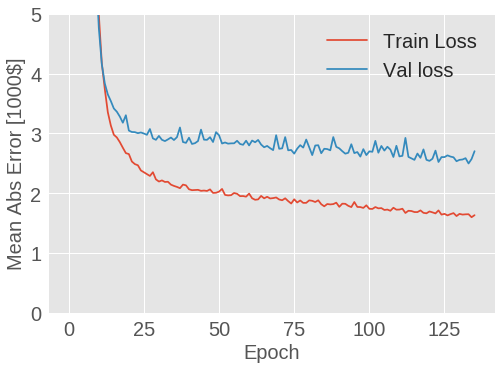
图 1.8: 波士顿房价预测模型 MAE 变化曲线
上图显示了平均的误差为 2,500 美元,效果如何?其实 2,500 美元并不是一个小数目,尤其是一些标签数据仅为 15,000 美元。
2.2.3.5 Predict | 预测
最后,我们利用测试集中的数据对一些房价进行预测:
[ 9.492763 18.1796 20.660446 33.27327 24.00824 20.649681
24.09721 21.225113 17.83197 21.656506 15.512122 15.404796
15.138904 39.677517 19.844698 19.36996 25.030819 17.653196
19.63914 24.552425 11.003424 13.472205 19.966118 14.998609
18.718044 25.505722 27.795177 27.285934 11.143001 19.670704
19.177574 15.27002 32.24345 23.417282 20.372746 8.2208185
15.965524 14.6927 17.458612 23.658459 29.821249 25.411175
13.356717 38.75688 27.357449 24.69639 25.346142 17.12498
22.083925 21.278576 32.694485 20.339231 10.553803 14.291162
32.912132 26.365799 11.496123 45.684895 33.524784 22.260208
22.794165 15.367835 14.69179 19.043844 22.491611 19.757336
13.792027 20.988216 15.325042 7.1343594 24.010147 27.490314
27.396553 14.25174 23.12503 17.15664 19.25171 21.911198
33.41672 9.918727 20.616936 34.754543 15.031564 13.140673
16.571709 18.395157 20.793179 19.235928 20.059248 30.748552
19.980759 16.391459 24.65013 39.585415 33.642494 19.128313
32.32082 47.260014 24.049652 45.643284 28.646091 17.741257 ]2.2.3.6 Conclusion | 结论
本案介绍了处理回归问题的一些方法。
- 均方根误差 (Mean Squared Error, MSE) 是一种常用于回归问题的损失函数。
- 类似的,回归问题的平均指标也与分类问题不同,常用的回归问题的评价指标为平均绝对误差 (Mean Absolute Error, MAE)。
- 当输入数据的特征有不同的量纲和取值范围时,每个格正都应该被单独规范化。
- 当没有大量的训练数据时,建议选择一个包含少量隐含层的小网络来避免过拟合。
- 早停 (Early Stopping) 是一种实用的避免过拟合的方法。
2.2.4 Overfitting and underfitting | 过拟合和欠拟合
同样,本例也将使用 tf.keras API,你可以在 TensorFlow Kears Guide 中获取更多相关信息。
在我们之前的 IDMB 电影评论分类和波士顿房价预测的案例中,可以看出验证集的准确率在一定轮数后达到一个峰值,之后便开始下降。换言之,我们的模型在训练数据上发生了过拟合 (Overfitting),因此学习如何处理过拟合将十分重要。尽管我们能够在训练数据上取得很高的准确率,但是我们真正想得到的是一个能够在测试数据 (未见过的数据) 上有更好泛化能力的模型。
过拟合的对立面是欠拟合 (Undefitting),欠拟合是指如果继续进行训练,模型在测试数据上任有改进的空间。也就是说我们的模型还并没有学习到训练数据中所有有关的模式。
当我们训练模型过长时间后,模型将开始产生过拟合,其将会学习到尽在训练集中存在并无法在测试数据上有很好的泛化能力的模式。因此我们需要寻找一个平衡点,下面我们将探讨如何训练适当的轮数,这将是一项很重要的技能。
为了方式过拟合的发生,最好的解决方案就是使用更多的训练数据,一个利用更多数据训练的模型往往能够有更好的泛化能力。但当这种情况不太现实的时候,次优的方案就是使用想正则化等类似技术,这将限制模型所存储信息的数量和类型。如果一个模型仅能够记住少量的模式,那么在优化的过程中将会促使其更多的关注那些更为有用的模式,进而使得模型能够有机会获得更好的泛化能力。
在本例中,我们将探索两种常用的正则化技术:权重正则化和 Dropout,我们将使用这两种技术来改进 IMDB 电影评论分类模型。
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)2.2.4.1 Download the IMDB dataset | 下载 IMDB 数据集
不同于之前示例中使用的 Embedding 的方法,本例中我们使用句子级别的 Multi-Hot 编码。这样的话,模型将会很快在训练数据上出现过拟合,因此我们将用其作为过拟合的演示示例,并介绍如何解决这个问题。
Multi-Hot 编码是指将数据转化成仅由 0 和 1 构成的向量。也就是说对于 [3, 5] 这样一个序列,我们会将其转换成一个 10,000 维度的向量,该向量中除了第 3 和 5 位值为 1 外,其他的值均为 0。
NUM_WORDS = 10000
(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)
def multi_hot_sequences(sequences, dimension):
# Create an all-zero matrix of shape (len(sequences), dimension)
results = np.zeros((len(sequences), dimension))
for i, word_indices in enumerate(sequences):
results[i, word_indices] = 1.0 # set specific indices of results[i] to 1s
return results
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)
test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)Downloading data from https://s3.amazonaws.com/text-datasets/imdb.npz
17465344/17464789 [==============================] - 3s 0us/step我们来看一下转换后的的一个 Multi-Hot 编码的向量,因为词典中词的下标是按照词频逆序排序的,因此下图中可以看出在词下标 0 附近有更多的值。
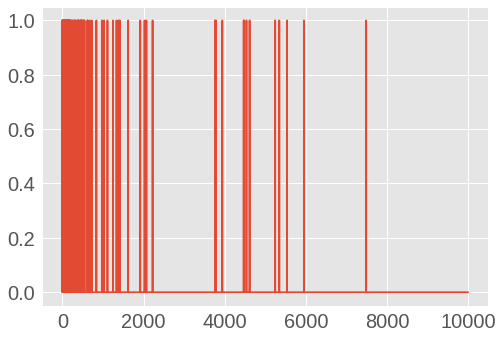
图 1.9: IMDB 电影评论第一条数据 Multi-Hot 编码
2.2.4.2 Demonstrate overfitting | 演示过拟合问题
解决过拟合问题的最简单的方式是减小模型的大小,例如模型中可学习的参数个数 (在神经网络中由网络层的个数和每层中节点的个数决定)。在深度学习中,一个模型的可学习的参数通常称之为模型的容量 (cpcity)。直观上,一个拥有更多参数的模型会有更好的记忆能力 (memorization capacity),这样就能够比较容易的学习一个从训练样本到其目标的完美的字典式 (dictionary-like) 的映射。但这种映射没有任何泛化能力,因此将无法对之前未遇见过的数据上进行预测。
要牢记:深度学习模型倾向于更好的拟合训练数据,但真正的挑战是泛化,而非拟合。
换言之,当网络仅有有限的记忆资源时,将无法很容易的学习到映射模式。当最小化损失时,网络就必须学习具有更强预测能力的压缩表示 (compressed representations)。与此同时,当模型过小时,网络将很难拟合训练数据,因此我们需要在“容量过大” (too much capacity) 和“容量不足” (not enough capacity) 之间进行权衡。
不幸的是,并没有一个完美的方案去确定一个模型的大小和结构 (例如网络的层数和每层的节点数),因此需要进行大量的实验测试不同的网络结构。
为了得到一个合适的模型大小,建议以一些相对较少的网络层数和参数开始。之后在添加新的网络的层和层中节点的过程中观察验证数据上的损失是否减小。让我们在 IMDB 电影评论分类神经网络上实验一下。
我们仅用 Dense 层构建一个简单的模型,之后再构建一个更小的模型并比较他们。
2.2.4.2.1 Create a baseline model | 构建一个基线模型
baseline_model = keras.Sequential([
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
baseline_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
baseline_model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 160016
_________________________________________________________________
dense_1 (Dense) (None, 16) 272
_________________________________________________________________
dense_2 (Dense) (None, 1) 17
=================================================================
Total params: 160,305
Trainable params: 160,305
Non-trainable params: 0
_________________________________________________________________baseline_history = baseline_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 4s - loss: 0.5334 - acc: 0.7900 - binary_crossentropy: 0.5334 - val_loss: 0.3697 - val_acc: 0.8682 - val_binary_crossentropy: 0.3697
Epoch 2/20
- 4s - loss: 0.2706 - acc: 0.9044 - binary_crossentropy: 0.2706 - val_loss: 0.2863 - val_acc: 0.8869 - val_binary_crossentropy: 0.2863
Epoch 3/20
- 4s - loss: 0.1932 - acc: 0.9313 - binary_crossentropy: 0.1932 - val_loss: 0.2855 - val_acc: 0.8861 - val_binary_crossentropy: 0.2855
......
Epoch 18/20
- 4s - loss: 0.0068 - acc: 0.9998 - binary_crossentropy: 0.0068 - val_loss: 0.9196 - val_acc: 0.8483 - val_binary_crossentropy: 0.9196
Epoch 19/20
- 4s - loss: 0.0050 - acc: 0.9999 - binary_crossentropy: 0.0050 - val_loss: 0.9538 - val_acc: 0.8489 - val_binary_crossentropy: 0.9538
Epoch 20/20
- 4s - loss: 0.0038 - acc: 0.9999 - binary_crossentropy: 0.0038 - val_loss: 0.9981 - val_acc: 0.8480 - val_binary_crossentropy: 0.99812.2.4.2.2 Create a smaller model | 构建一个小模型
让我们构建一个具有较少隐含节点的网络,并同我们刚才构建的基线模型进行比较:
smaller_model = keras.Sequential([
keras.layers.Dense(4, activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dense(4, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
smaller_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
smaller_model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 4) 40004
_________________________________________________________________
dense_4 (Dense) (None, 4) 20
_________________________________________________________________
dense_5 (Dense) (None, 1) 5
=================================================================
Total params: 40,029
Trainable params: 40,029
Non-trainable params: 0
_________________________________________________________________然后我们利用相同的数据对其进行训练:
smaller_history = smaller_model.fit(train_data,
train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 4s - loss: 0.5305 - acc: 0.7886 - binary_crossentropy: 0.5305 - val_loss: 0.4079 - val_acc: 0.8631 - val_binary_crossentropy: 0.4079
Epoch 2/20
- 4s - loss: 0.3219 - acc: 0.8942 - binary_crossentropy: 0.3219 - val_loss: 0.3231 - val_acc: 0.8802 - val_binary_crossentropy: 0.3231
Epoch 3/20
- 4s - loss: 0.2468 - acc: 0.9174 - binary_crossentropy: 0.2468 - val_loss: 0.2930 - val_acc: 0.8871 - val_binary_crossentropy: 0.2930
......
Epoch 18/20
- 4s - loss: 0.0473 - acc: 0.9914 - binary_crossentropy: 0.0473 - val_loss: 0.5047 - val_acc: 0.8584 - val_binary_crossentropy: 0.5047
Epoch 19/20
- 4s - loss: 0.0426 - acc: 0.9926 - binary_crossentropy: 0.0426 - val_loss: 0.5221 - val_acc: 0.8584 - val_binary_crossentropy: 0.5221
Epoch 20/20
- 4s - loss: 0.0386 - acc: 0.9938 - binary_crossentropy: 0.0386 - val_loss: 0.5452 - val_acc: 0.8570 - val_binary_crossentropy: 0.54522.2.4.2.3 Create a bigger model | 构建一个大模型
作为一个练习,你可以构建一个足够大的模型来观察其迅速的出现过拟合现象。接下来,让我们将一个要远比问题的空间要大得多的容量的模型加入到我们的对比测试中。
bigger_model = keras.models.Sequential([
keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dense(512, activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
bigger_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
bigger_model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_6 (Dense) (None, 512) 5120512
_________________________________________________________________
dense_7 (Dense) (None, 512) 262656
_________________________________________________________________
dense_8 (Dense) (None, 1) 513
=================================================================
Total params: 5,383,681
Trainable params: 5,383,681
Non-trainable params: 0
_________________________________________________________________依旧使用相同的数据对其进行训练:
bigger_history = bigger_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 8s - loss: 0.3434 - acc: 0.8554 - binary_crossentropy: 0.3434 - val_loss: 0.3024 - val_acc: 0.8771 - val_binary_crossentropy: 0.3024
Epoch 2/20
- 8s - loss: 0.1324 - acc: 0.9519 - binary_crossentropy: 0.1324 - val_loss: 0.3620 - val_acc: 0.8613 - val_binary_crossentropy: 0.3620
Epoch 3/20
...
Epoch 18/20
- 8s - loss: 1.7077e-05 - acc: 1.0000 - binary_crossentropy: 1.7077e-05 - val_loss: 0.8456 - val_acc: 0.8720 - val_binary_crossentropy: 0.8456
Epoch 19/20
- 8s - loss: 1.5273e-05 - acc: 1.0000 - binary_crossentropy: 1.5273e-05 - val_loss: 0.8518 - val_acc: 0.8721 - val_binary_crossentropy: 0.8518
Epoch 20/20
- 8s - loss: 1.3756e-05 - acc: 1.0000 - binary_crossentropy: 1.3756e-05 - val_loss: 0.8578 - val_acc: 0.8721 - val_binary_crossentropy: 0.85782.2.4.2.4 Plot the training and validation loss | 绘制训练和验证的损失
下图中,实线表示的是训练集的损失,虚线表示的是验证集的损失 (请记住,越小的验证集损失表示模型越好)。从图中可以看出,较小的模型要迟于基线模型发生过拟合,同时在发生过拟合后其性能的下降程度也相对缓慢。
def plot_history(histories, key='binary_crossentropy'):
plt.figure(figsize=(16,10))
for name, history in histories:
val = plt.plot(history.epoch, history.history['val_'+key],
'--', label=name.title()+' Val')
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
label=name.title()+' Train')
plt.xlabel('Epochs')
plt.ylabel(key.replace('_',' ').title())
plt.legend()
plt.xlim([0,max(history.epoch)])
plot_history([('baseline', baseline_history),
('smaller', smaller_history),
('bigger', bigger_history)])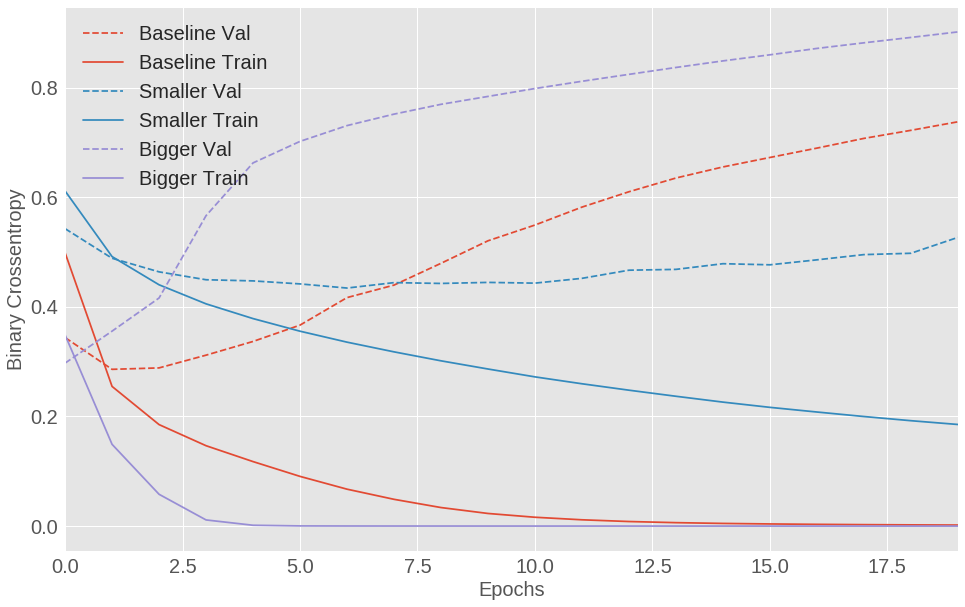
图 1.10: IMDB 电影评论分类模型训练集和测试集损失对比 (基线模型,大模型,小模型)
可以发现,大的网络在一开始便发生了过拟合,在之后其过拟合的更为严重。当网络的容量越大时,其也容易拟合训练数据 (即训练集的损失很快变小),但越容易发生过拟合 (即验证集和训练集之间的损失差别增大)。
2.2.4.3 Strategies | 应对策略
2.2.4.3.1 Add weight regularization | 添加权重正则项
你也许熟悉奥卡姆剃刀原则:如果对于一个事务有两种解释,往往是“最简单”的,也就是有更少假设的那个往往是正确的。这对于通过神经网络学习到的模型同样适用:给定一些训练数据和一个网络结构,有很多种组合的权重 (即很多个模型) 可以解释数据中的模式,那么越简单的模型相比于复杂的模型越不容易发生过拟合现象。
在这里,一个“简单的模型”的含义就是模型参数值的分布的熵比较小 (或者说一个模型具有更少的参数)。因此,减轻过拟合的一种常见方法是通过添加一个强制权重仅能取到一些小的值的约束,这样做将会使得权重的分布更加的“正则” (Regular)。这种做法称之为权重正则化 (Weight Regularization),其具体做法是在网络的损失函数中添加和权重大小相关的代价。如下为两种常用的形式:
- L1 正则,增加的代价与权重系数的绝对值成正比 (即与权重的 L1 范数成正比)。
- L2 正则,增加的代价与权重系数的平方项成正比 (即与权重的 L2 范数成正比)。L2 正则化在神经网络中也称之为权重衰减。不要让不同的叫法把你弄混,权重衰减和 L2 正则化是完全相同的概念。
在 tf.keras 中,权重正则化是通过给没一层添加一个权重正则化实例实现的。现在,让我们为模型添加 L2 权重正则化。
l2_model = keras.models.Sequential([
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
activation=tf.nn.relu),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
l2_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy', 'binary_crossentropy'])
l2_model_history = l2_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.5311 - acc: 0.8050 - binary_crossentropy: 0.4901 - val_loss: 0.3865 - val_acc: 0.8766 - val_binary_crossentropy: 0.3450
Epoch 2/20
- 3s - loss: 0.3099 - acc: 0.9095 - binary_crossentropy: 0.2654 - val_loss: 0.3353 - val_acc: 0.8880 - val_binary_crossentropy: 0.2886
Epoch 3/20
- 3s - loss: 0.2582 - acc: 0.9274 - binary_crossentropy: 0.2096 - val_loss: 0.3324 - val_acc: 0.8865 - val_binary_crossentropy: 0.2824
...
Epoch 18/20
- 3s - loss: 0.1500 - acc: 0.9706 - binary_crossentropy: 0.0879 - val_loss: 0.5189 - val_acc: 0.8564 - val_binary_crossentropy: 0.4565
Epoch 19/20
- 3s - loss: 0.1489 - acc: 0.9710 - binary_crossentropy: 0.0864 - val_loss: 0.5229 - val_acc: 0.8573 - val_binary_crossentropy: 0.4600
Epoch 20/20
- 3s - loss: 0.1455 - acc: 0.9731 - binary_crossentropy: 0.0824 - val_loss: 0.5336 - val_acc: 0.8545 - val_binary_crossentropy: 0.4705l2(0.001) 表示权重矩阵中所有的系数都将添加 0.001 * weight_coefficient_value 的值到网络的整体损失中。注意,这种惩罚项尽在训练过程中添加,所以网络在训练阶段要比测试时有更大的损失值。
下面是 L2 正则化惩罚的影响:
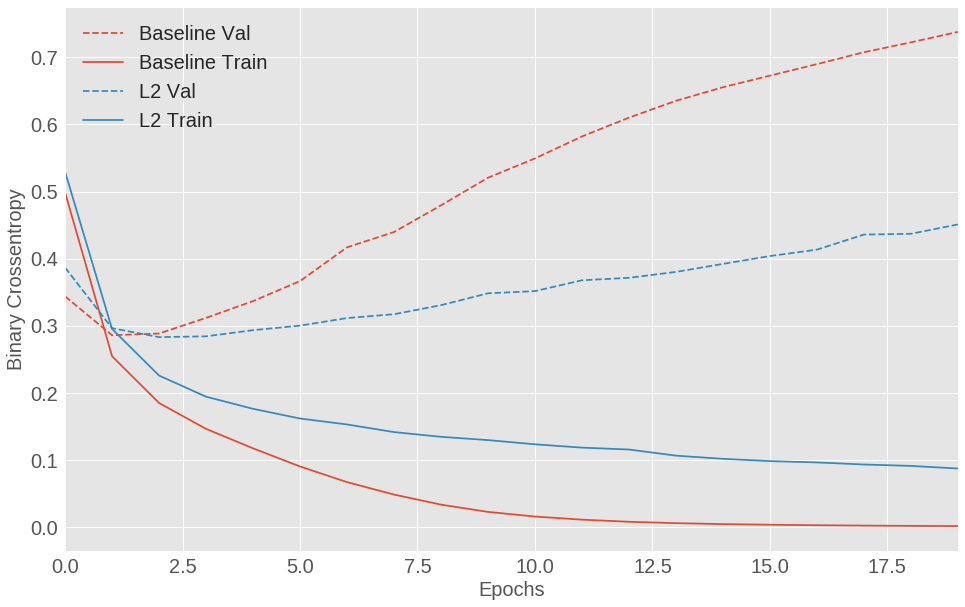
图 1.11: IMDB 电影评论分类模型训练集和测试集损失对比 (基线模型,带有 L2 正则化的模型)
从图中可以看出,带有 L2 正则化的模型要比基线模型能够更好的抑制过拟合的发生,尽管两个模型的参数数量是相同的。
2.2.4.3.2 Add dropout | 添加 Dropout
Dropout 是在神经网络中一种最有效和最常用的正则化技术,其是由 Hinton 和他在多伦多大学的学生一同发明的。Dropout 会在其应用的层上在训练时随机的删除 (Dropping Out) 一些输出的特征。例如,一个给定的层训练时对于一个给定的输入返回的结果为 [0.2, 0.5, 1.3, 0.8, 1.1],当添加 Dropout 后,这个向量将会有随机分布的零值,例如:[0, 0.5, 1.3, 0, 1.1]。删除比例 (Dropout Rate) 即为特征被零值化的占比,通常我们会将其设置在 0.2 到 0.5 之间。在测试阶段,将不会有节点的值被删除,而是会一个与删除比例相同的因子进行缩放来平衡其比训练阶段有更多的激活节点。
在 tf.kears 中,我们可以通过添加一个 Dropout 层来引入 Dropout,其将被添加在没一层输出的前面。
让我们为 IMDB 网络添加两个 Dropout 层,在来观察一下过拟合的抑制情况:
dpt_model = keras.models.Sequential([
keras.layers.Dense(16, activation=tf.nn.relu, input_shape=(10000,)),
keras.layers.Dropout(0.5),
keras.layers.Dense(16, activation=tf.nn.relu),
keras.layers.Dropout(0.5),
keras.layers.Dense(1, activation=tf.nn.sigmoid)
])
dpt_model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy','binary_crossentropy'])
dpt_model_history = dpt_model.fit(train_data, train_labels,
epochs=20,
batch_size=512,
validation_data=(test_data, test_labels),
verbose=2)Train on 25000 samples, validate on 25000 samples
Epoch 1/20
- 3s - loss: 0.6201 - acc: 0.6434 - binary_crossentropy: 0.6201 - val_loss: 0.4856 - val_acc: 0.8500 - val_binary_crossentropy: 0.4856
Epoch 2/20
- 3s - loss: 0.4636 - acc: 0.7932 - binary_crossentropy: 0.4636 - val_loss: 0.3426 - val_acc: 0.8808 - val_binary_crossentropy: 0.3426
Epoch 3/20
- 3s - loss: 0.3612 - acc: 0.8564 - binary_crossentropy: 0.3612 - val_loss: 0.2963 - val_acc: 0.8847 - val_binary_crossentropy: 0.2963
...
Epoch 18/20
- 3s - loss: 0.0881 - acc: 0.9622 - binary_crossentropy: 0.0881 - val_loss: 0.4971 - val_acc: 0.8749 - val_binary_crossentropy: 0.4971
Epoch 19/20
- 3s - loss: 0.0839 - acc: 0.9645 - binary_crossentropy: 0.0839 - val_loss: 0.5331 - val_acc: 0.8735 - val_binary_crossentropy: 0.5331
Epoch 20/20
- 3s - loss: 0.0805 - acc: 0.9650 - binary_crossentropy: 0.0805 - val_loss: 0.5524 - val_acc: 0.8724 - val_binary_crossentropy: 0.5524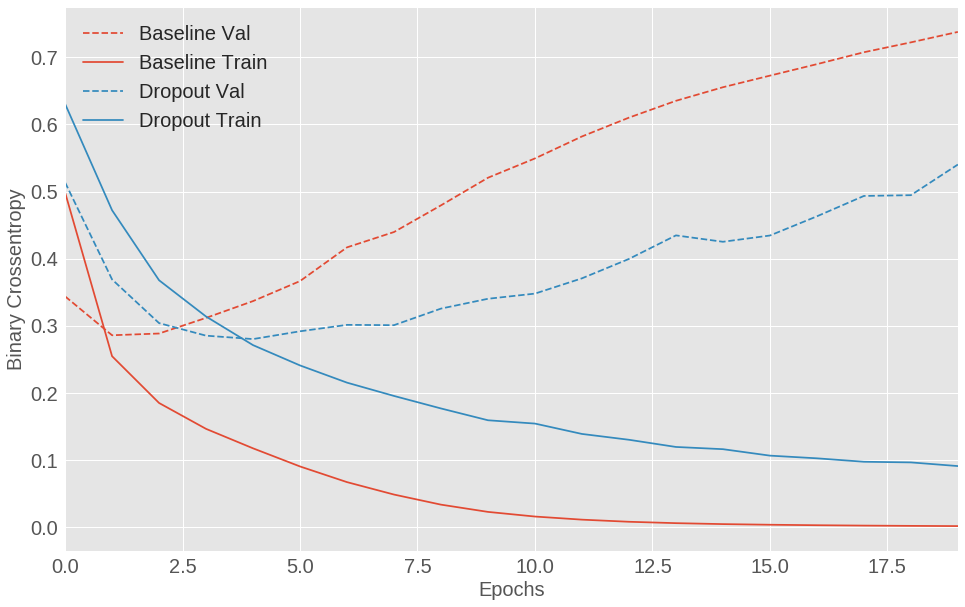
图 1.12: IMDB 电影评论分类模型训练集和测试集损失对比 (基线模型,带有 Dropout 的模型)
添加 Dropout 后较之基线模型有明显的改进。
以下是防止神经网络过拟合的常用方法:
- 获取更多的数据。
- 减少网络的容量。
- 添加权重正则化。
- 添加 Dropout。
以及本节为介绍的数据扩张 (data-augmentation) 和批标准化 (batch normalization)。
2.2.5 Save and resotre models | 保存和恢复模型
在模型的训练中和训练后均可以对其进行保存,这就意味着你可以复用一个训练好的模型,而无需重新对其进行训练。保存同样意味着你可以将其分享给他人用于复现你的工作。当我们发表研究成果的时候,大多数的机器学习实践者会分享:
- 用于构建模型的代码
- 训练好的模型权重和参数
这些数据的共享能够帮助其他人更好的理解你的模型是如何工作的,并使用他们自己的数据进行新的尝试。
2.2.5.1 Options | 选项
根据使用的 API 的不同,有多种保存 Tensorflow 模型的方法。本节将继续使用 tf.keras 高级 API 构建和训练 Tensorflow 模型。对于其他的情况,请参见 Save and Restore 和 Saving in eager。
2.2.5.2 Setup | 设置
2.2.5.2.1 Install and imports | 安装和导入
安装和导入 Tensorflow 及其依赖:
pip install -q h5py pyyaml 2.2.5.2.2 Get an example dataset | 获取示例数据集
我们将使用 MNIST 数据集 来训练我们的模型并展示如何保存训练好的权重。为了加快进度,我们仅使用前 1000 个样本:
from __future__ import absolute_import, division, print_function
import os
import tensorflow as tf
from tensorflow import keras
tf.__version__2.2.5.2.3 Define a model | 定义一个模型
让我们来构建一个简单的模型来展示如何保存和载入权重。
# Returns a short sequential model
def create_model():
model = tf.keras.models.Sequential([
keras.layers.Dense(512, activation=tf.nn.relu, input_shape=(784,)),
keras.layers.Dropout(0.2),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
return model
# Create a basic model instance
model = create_model()
model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 401920
_________________________________________________________________
dropout (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
_________________________________________________________________2.2.5.3 Save checkpoints during training | 保存检查点
最基本的使用方法就是在模型训练过程中和结束时自动保存检查点 (checkpoints)。这样的话你就可以复用一个训练好的模型而无需重新训练它,或者从上次训练中断的地方继续训练。
tf.kears.callbacks.ModelCheckpoint 是一个完成此项任务的回调方法 (callback)。这个回调方法接受一系列参数来配置检查点。
2.2.5.3.1 Checkpoint callback usage | 检查点回调使用
训练模型并将 ModelCheckpoint 回调传给训练函数:
checkpoint_path = "training_1/cp.ckpt"
checkpoint_dir = os.path.dirname(checkpoint_path)
# Create checkpoint callback
cp_callback = tf.keras.callbacks.ModelCheckpoint(checkpoint_path,
save_weights_only=True,
verbose=1)
model = create_model()
model.fit(train_images, train_labels, epochs = 10,
validation_data = (test_images,test_labels),
callbacks = [cp_callback]) # pass callback to trainingTrain on 1000 samples, validate on 1000 samples
Epoch 1/10
1000/1000 [==============================] - 1s 854us/step - loss: 1.1579 - acc: 0.6660 - val_loss: 0.7072 - val_acc: 0.7880
Epoch 00001: saving model to training_1/cp.ckpt
Epoch 2/10
1000/1000 [==============================] - 0s 427us/step - loss: 0.4262 - acc: 0.8850 - val_loss: 0.5777 - val_acc: 0.8160
...
Epoch 00008: saving model to training_1/cp.ckpt
Epoch 9/10
1000/1000 [==============================] - 0s 325us/step - loss: 0.0477 - acc: 0.9970 - val_loss: 0.4131 - val_acc: 0.8680
Epoch 00009: saving model to training_1/cp.ckpt
Epoch 10/10
1000/1000 [==============================] - 0s 282us/step - loss: 0.0374 - acc: 1.0000 - val_loss: 0.3991 - val_acc: 0.8750
Epoch 00010: saving model to training_1/cp.ckpt这将产生一些列的 Tensorflow 检查点文件,并在每一轮训练结束时更新他们:
ls {checkpoint_dir}checkpoint cp.ckpt.data-00000-of-00001 cp.ckpt.index构建一个新的未训练的模型,当仅用权重恢复一个模型的时候,你必须保证新的模型与原来的模型有相同的架构了。正因为具有相同的模型架构,我们才能够在不同的实例中共享这些权重。
现在构建一个新的未训练的模型,并利用测试集对其进行测试。一个未训练的模型仅能表现出一个随机的性能水平 (大约 10% 的准确率):
model = create_model()
loss, acc = model.evaluate(test_images, test_labels)
print("Untrained model, accuracy: {:5.2f}%".format(100*acc))接下来,我们从检查点载入权重,并重新测试:
2.2.5.3.2 Checkpoint callback options | 检查点回调选项
回调函数提供了多个选项用于指定检查点的唯一名称,调整保存检查点的频率等。
构建一个新的模型,每 5 轮保存一个单独的检查点文件:
# include the epoch in the file name. (uses `str.format`)
checkpoint_path = "training_2/cp-{epoch:04d}.ckpt"
checkpoint_dir = os.path.dirname(checkpoint_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(
checkpoint_path, verbose=1, save_weights_only=True,
# Save weights, every 5-epochs.
period=5)
model = create_model()
model.fit(train_images, train_labels,
epochs = 50, callbacks = [cp_callback],
validation_data = (test_images,test_labels),
verbose=0)Epoch 00005: saving model to training_2/cp-0005.ckpt
Epoch 00010: saving model to training_2/cp-0010.ckpt
...
Epoch 00045: saving model to training_2/cp-0045.ckpt
Epoch 00050: saving model to training_2/cp-0050.ckpt现在,我们来看一下保存的检查点文件 (以修改日期进行排序):
import pathlib
# Sort the checkpoints by modification time.
checkpoints = pathlib.Path(checkpoint_dir).glob("*.index")
checkpoints = sorted(checkpoints, key=lambda cp:cp.stat().st_mtime)
checkpoints = [cp.with_suffix('') for cp in checkpoints]
latest = str(checkpoints[-1])
checkpoints[PosixPath('training_2/cp-0030.ckpt'),
PosixPath('training_2/cp-0035.ckpt'),
PosixPath('training_2/cp-0040.ckpt'),
PosixPath('training_2/cp-0045.ckpt'),
PosixPath('training_2/cp-0050.ckpt')]让我们重置模型,并载入最后一个检查点文件进行测试:
2.2.5.4 What are these files? | 这些是什么文件
上面的代码将权重信息保存到了一系列检查点格式的二进制文件中,其中仅包含了训练权重。检查点文件包括:
- 一个或多个包含模型权重的分片文件
- 一个包含了权重分布在不同分片文件中的索引文件
如果你尽在单台机器上进行训练,则仅有一个分片文件,其文件名将以 .data-00000-of-00001 结尾。
2.2.5.5 Manually save weights | 手动保存权重
上述代码中介绍了如何将训练好的权重载入模型。
手动对模型参数进行保存也十分简单,使用 Model.save_weights 函数即可。
2.2.5.6 Save the entire model | 保存整个模型
我们还可以将整个模型保存到一个文件中,包括权重,模型的配置信息,甚至是优化器的配置信息。这将有助于我们在没有原始代码的情况下,保存模型的检查点和后续的继续训练。
保存一个包含全部信息的模型在 Keras 中十分有用,我们可以在 Tensorflow.js 中载入训练好的模型并在浏览器中进行训练和测试。
Keras 提供了一种名为 HDF5 的简单存储格式标准。之于我们的目标,我们可以将保存的模型视为一个单一的二进制文件。
model = create_model()
model.fit(train_images, train_labels, epochs=5)
# Save entire model to a HDF5 file
model.save('my_model.h5')Epoch 1/5
1000/1000 [==============================] - 1s 744us/step - loss: 1.1814 - acc: 0.6570
Epoch 2/5
1000/1000 [==============================] - 0s 340us/step - loss: 0.4349 - acc: 0.8770
Epoch 3/5
1000/1000 [==============================] - 0s 265us/step - loss: 0.2951 - acc: 0.9150
Epoch 4/5
1000/1000 [==============================] - 0s 220us/step - loss: 0.2068 - acc: 0.9430
Epoch 5/5
1000/1000 [==============================] - 0s 212us/step - loss: 0.1573 - acc: 0.9610现在我们利用这个文件来恢复我们的模型:
# Recreate the exact same model, including weights and optimizer.
new_model = keras.models.load_model('my_model.h5')
new_model.summary()_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_12 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_6 (Dropout) (None, 512) 0
_________________________________________________________________
dense_13 (Dense) (None, 10) 5130
=================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
_________________________________________________________________检查一下模型的准确性:
loss, acc = new_model.evaluate(test_images, test_labels)
print("Restored model, accuracy: {:5.2f}%".format(100*acc))利用这种方法,我们可以保存:
- 模型的权重信息
- 模型的配置信息 (架构)
- 优化器的配置信息
Keras 通过检查整个架构来保存模型。目前还不能够保存 Tensorflow 的优化器 (tf.train),如果使用了其中的代码,需要在模型载入后重新对其进行编译,这将丢失掉优化器的状态信息。
2.2.5.7 What’s Next | 接下来
本节我们简单介绍了 tf.keras 中如何保存和载入。
- 在 tf.keras guide 中可以找到更多有关
tf.keras保存和载入的介绍。 - 在 Saving in eager 中可以找到有关在动态图中保存和载入的介绍。
- 在 Save and Restore 中可以找到更底层的 Tensorflow 保存和载入的介绍。