2 Metodología adecuada para el análisis de datos
2.1 Metodología Teóricas
En el análisis de datos, las metodologías teóricas son enfoques y marcos conceptuales que se utilizan para guiar y fundamentar el proceso de análisis de datos. Estas metodologías se basan en teorías, modelos y principios bien establecidos que proporcionan un marco sólido para comprender y analizar los datos de manera sistemática.
2.2 Metodología-KDD
La metodología KDD(Knowledge Discovery in Databases), es un proceso centrado en el usuario que es altamente interactivo. Este proceso es utilizado para llevar a cabo la extracción automatizada de datos partiendo de grandes volúmenes de datos. Normalmente el proceso KDD tiene como motivación la detección de información que permita resolver los problemas o necesidades que surgen en las empresas y es a menudo solicitado por directivos y/o stakeholders.
El conocimiento que se pretende extraer con el proceso KDD debe ser no trivial, implícito, previamente desconocido y potencialmente útil, por ello se tiene una serie de pasos a seguir que son:
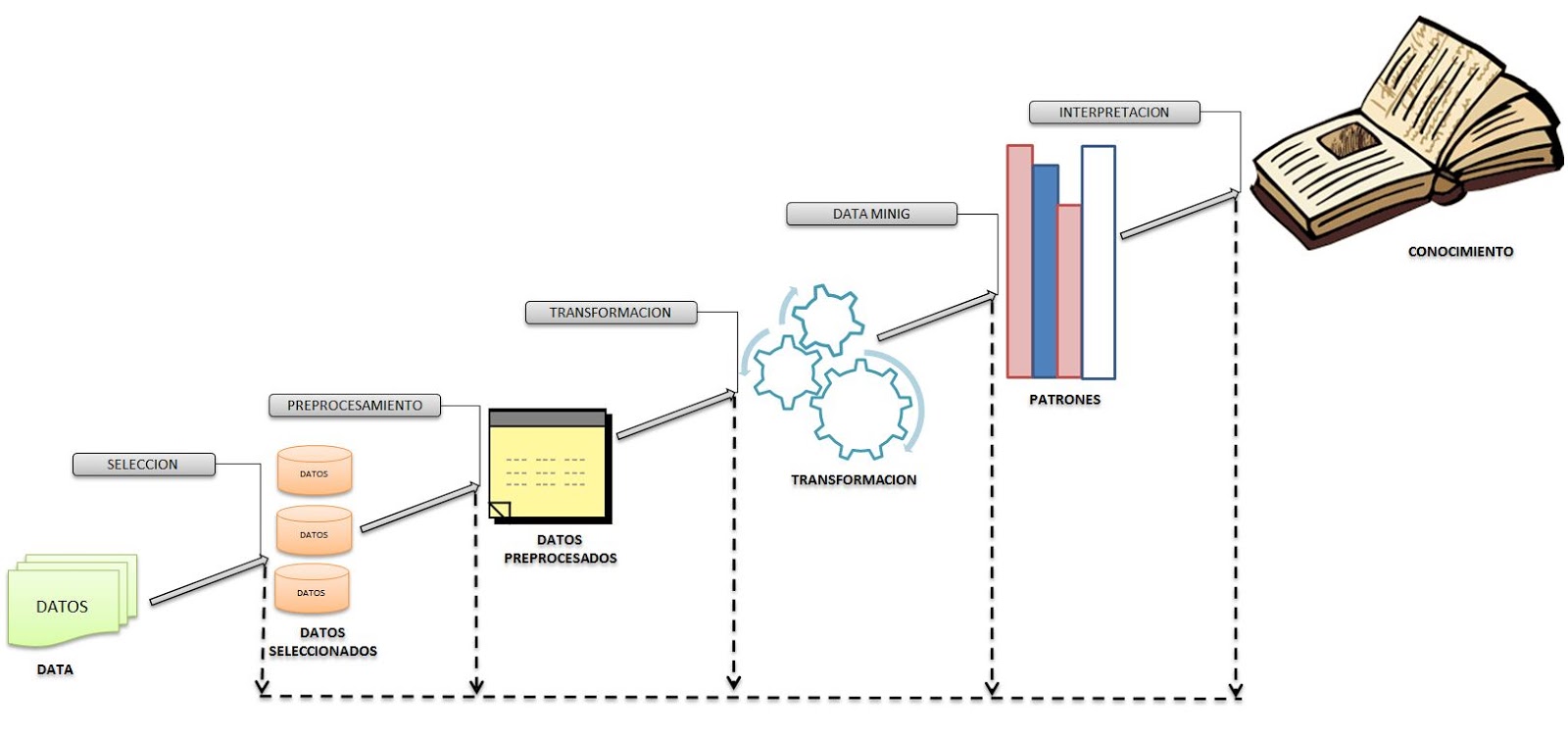
Selección: Inicialmente se recolectan datos
Preposamiento: Se recolecta datos que se utilice, verificando si la base de datos seleccionada sea coherente, confiable, relevante y esté actualizada.
Transformación: Teniendo ya seleccionados los datos que se entienden como más importantes dentro del data, se transforman para poder procesarse con mayor facilidad. el resultado de esta fase se le conoce como vista minable.
Minería de datos: En esta etapa se aplican algoritmos de minería de datos sobre la vista minable con el objeto de obtener modelos. Un modelo, en este contexto, es una representación simbólica y resumida de los datos analizados que permite extraer conclusiones a partir de ellos de manera cómoda y eficaz.
Evaluación: Se utiliza el modelo o patrón obtenidos en la fase anterior, en los cuales son analizados y evaluados para convertirse en conocimiento.
2.3 Metodología SEMMA
La metodología SEMMA es un enfoque de análisis de datos utilizado en el campo de la minería de datos.
La metodología SEMMA proporciona una estructura organizada para el proceso de análisis de datos y es particularmente útil en contextos de minería de datos y análisis predictivo, donde el objetivo es construir modelos que puedan hacer predicciones basadas en datos históricos. SEMMA facilita la gestión de las etapas clave del análisis de datos, desde la preparación de datos hasta la construcción y evaluación de modelos.
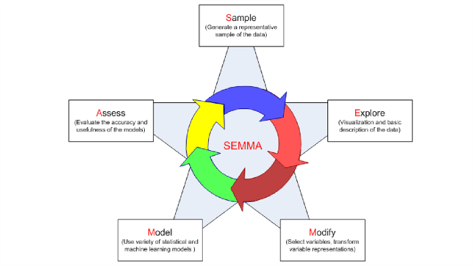
El término “SEMMA” es un acrónimo que representa las siguientes etapas secuenciales en el proceso de análisis de datos:
Sample: Es la primera etapa, donde se selecciona una muestra representativa de los datos disponibles. La muestra se utiliza para reducir la cantidad de datos con la que se trabajará en las etapas posteriores. La selección de una muestra apropiada es esencial para garantizar la validez de los resultados.
Explore: En esta fase, se exploran los datos para comprender su estructura, detectar patrones, tendencias y anomalías, y obtener una visión general de su contenido. Esto implica la visualización de datos, la identificación de correlaciones y la realización de análisis estadísticos descriptivos.
Modify: Durante esta etapa, se realizan modificaciones en los datos según sea necesario. Esto puede incluir la limpieza de datos para abordar valores atípicos, datos faltantes o errores, así como la ingeniería de características para crear nuevas variables que sean más informativas para el análisis.
Model: En esta etapa, se desarrollan modelos predictivos o descriptivos utilizando técnicas estadísticas y algoritmos de aprendizaje automático. Los modelos se ajustan a los datos de muestra para predecir o describir relaciones y patrones en los datos.
Assess: En la etapa de evaluación, se evalúan los modelos desarrollados. Esto implica medir su rendimiento, validar su capacidad para hacer predicciones precisas y determinar si cumplen con los objetivos del análisis. Se pueden utilizar métricas de rendimiento como el error cuadrático medio (MSE) o el coeficiente de determinación (R-cuadrado) para evaluar los modelos.
2.4 Metodología CRISP-DM
CRISP-DM es una metodología con propósitos generales para cualquier proyecto de MD; plantea ideas que deben parametrizarse para cada entorno de ejecución, quitando algunas cosas y adicionando otras, según sea la naturaleza y los objetivos de cada proyecto. Propone modelos genéricos que deben ser adaptados.
Esta metodología se utiliza para guiar el ciclo de vida de un proyecto de minería de datos, desde la comprensión del problema hasta la implementación de soluciones basadas en datos. CRISP-DM consta de las siguientes etapas:
- Comprensión del Negocio: En esta etapa inicial, se busca definir el problema que se va a resolver y establecer metas claras para la minería de datos.
- Comprensión de los Dato: En esta etapa, se recopilan, exploran y familiarizan con los datos disponibles. Esto implica la identificación de fuentes de datos, la evaluación de su calidad, la visualización de datos y la identificación de patrones iniciales.
- Preparación de los Datos: En esta etapa, se limpian, transforman y preparan los datos para su uso en el análisis. Esto puede incluir la eliminación de valores atípicos, la imputación de datos faltantes y la ingeniería de características.
- Modelado de Datos: Aquí es donde se aplican técnicas de minería de datos, como algoritmos de aprendizaje automático, para construir modelos predictivos o descriptivos y elegir uno que sea el mas adecuado.
- Evaluación: En esta etapa, se evalúan los modelos construidos en términos de su precisión y eficacia. Se utilizan métricas de rendimiento, como el error cuadrático medio o el área bajo la curva ROC, para medir la calidad de los modelos.
- Despliegue: Si los modelos son satisfactorios, se implementan en el entorno de producción para su uso práctico. Esto puede implicar la integración con sistemas existentes o la creación de interfaces para la toma de decisiones basadas en datos.

2.5 Metodologías Híbridas
Las metodologías híbridas son enfoques que combinan elementos de diferentes metodologías o enfoques tradicionales para adaptarse a situaciones específicas o necesidades de un proceso. Estas metodologías buscan aprovechar lo mejor de múltiples enfoques y ajustarlos para obtener el resultado más eficiente. En el ámbito del análisis de datos y la gestión de proyectos, las metodologías híbridas se utilizan para abordar situaciones en las que un enfoque único puede no ser adecuado.
2.6 Tipos de datos
Identificar y comprender los tipos de datos es fundamental para aplicar las técnicas de análisis de datos adecuadas. Teniendo los siguientes tipos de datos:
2.6.1 Datos estructurados
Los datos estructurados, son un tipo de datos que se caracterizan por tener un formato predefinido y organizado, lo que facilita su almacenamiento, gestión y análisis.
2.6.2 Datos semiestructurados
Los datos semiestructurados son un tipo de datos que se encuentra en un punto intermedio entre los datos estructurados y los datos no estructurados. Aunque no tiene datos relacionados completos, es manejable comprender la estructura y el proceso de los datos.
2.6.3 Datos no estructurados
Los datos no estructurados son un tipo de datos que carece de una estructura clara y definida. A diferencia de los datos estructurados, estos datos no estructurados no siguen un formato específico y no se pueden organizar fácilmente en filas y columnas.