# Crear una matriz en R
library(Matrix)
matriz <- Matrix(c(1, 2, 3, 4, 5, 6), nrow = 2)
matriz2 x 3 Matrix of class "dgeMatrix"
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6Numpy es una biblioteca ampliamente utilizada en el mundo de la programación en Python para realizar cálculos numéricos y manipulación de matrices. Aunque Numpy está diseñada para Python, en R podemos lograr funcionalidades similares para manipular matrices y realizar operaciones numéricas mediante paquetes como “base” y “Matrix”. En esta guía, exploraremos cómo realizar operaciones matriciales y numéricas similares a Numpy en R, y proporcionaremos ejemplos prácticos.
En Numpy, es común crear y manipular matrices. En R, podemos lograr esto usando la biblioteca “Matrix”. Aquí hay un ejemplo de creación de una matriz en R y cómo realizar operaciones matriciales:
# Crear una matriz en R
library(Matrix)
matriz <- Matrix(c(1, 2, 3, 4, 5, 6), nrow = 2)
matriz2 x 3 Matrix of class "dgeMatrix"
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6#Ejemplo 2
matriz <- matrix(c(10, 20, 30, 40, 50, 60, 70, 80, 90), nrow = 3)
matriz [,1] [,2] [,3]
[1,] 10 40 70
[2,] 20 50 80
[3,] 30 60 90Numpy es conocida por su capacidad de realizar operaciones numéricas en matrices. En R, podemos lograr lo mismo con vectores o matrices. A continuación se muestra un ejemplo de cómo realizar operaciones numéricas en R
# Ejemplo de operaciones numéricas en R
vector <- c(1, 2, 3, 4, 5)
suma <- sum(vector)
sum(vector)[1] 15producto <- prod(vector)
prod(vector)[1] 120#Ejemplo 1
# Crear dos matrices en R
matriz_A <- matrix(c(2, 3, 5, 7), nrow = 2, byrow = TRUE)
matriz_B <- matrix(c(11, 13, 17, 19), nrow = 2, byrow = TRUE)
# Realizar la multiplicación de matrices en R
resultado <- matriz_A %*% matriz_B
resultado [,1] [,2]
[1,] 73 83
[2,] 174 198# Mostrar la matriz original y su inversa
cat("Matriz original:\n")Matriz original:print(matriz) [,1] [,2] [,3]
[1,] 10 40 70
[2,] 20 50 80
[3,] 30 60 90# Obtener la transposición de la matriz
transpuesta <- t(matriz)
# Mostrar la matriz original y su transpuesta
cat("Matriz original:\n")Matriz original:print(matriz) [,1] [,2] [,3]
[1,] 10 40 70
[2,] 20 50 80
[3,] 30 60 90cat("Matriz transpuesta:\n")Matriz transpuesta:print(transpuesta) [,1] [,2] [,3]
[1,] 10 20 30
[2,] 40 50 60
[3,] 70 80 90#Ejemplo
# Realizar la descomposición en valores singulares (SVD)
svd_result <- svd(matriz)
svd_result$d
[1] 1.684810e+02 1.068370e+01 9.675242e-15
$u
[,1] [,2] [,3]
[1,] -0.4796712 0.77669099 0.4082483
[2,] -0.5723678 0.07568647 -0.8164966
[3,] -0.6650644 -0.62531805 0.4082483
$v
[,1] [,2] [,3]
[1,] -0.2148372 -0.8872307 -0.4082483
[2,] -0.5205874 -0.2496440 0.8164966
[3,] -0.8263375 0.3879428 -0.4082483# Obtener la matriz unitaria izquierda
U <- svd_result$u
U [,1] [,2] [,3]
[1,] -0.4796712 0.77669099 0.4082483
[2,] -0.5723678 0.07568647 -0.8164966
[3,] -0.6650644 -0.62531805 0.4082483# Obtener la matriz diagonal de valores singulares
D <- diag(svd_result$d)
D [,1] [,2] [,3]
[1,] 168.481 0.0000 0.000000e+00
[2,] 0.000 10.6837 0.000000e+00
[3,] 0.000 0.0000 9.675242e-15# Obtener la matriz unitaria derecha
V <- svd_result$v
V [,1] [,2] [,3]
[1,] -0.2148372 -0.8872307 -0.4082483
[2,] -0.5205874 -0.2496440 0.8164966
[3,] -0.8263375 0.3879428 -0.4082483NumPy ofrece varias funciones para el cálculo de estadísticas en matrices, como: Calcula el promedio de los elementos a lo largo de un eje o de todo el arreglo.
# Crear un vector de datos
datos <- c(12, 15, 18, 22, 27)
datos[1] 12 15 18 22 27# Calcular la media
media <- mean(datos)
media[1] 18.8# Crear un vector de datos
datos <- c(12, 15, 18, 22, 27)
datos[1] 12 15 18 22 27# Calcular la mediana
mediana <- median(datos)
mediana[1] 18# Crear un vector de datos
datos <- c(12, 15, 18, 22, 27)
datos[1] 12 15 18 22 27# Calcular la desviación estándar
desviacion_estandar <- sd(datos)
desviacion_estandar[1] 5.890671# Crear un vector de datos
datos <- c(12, 15, 18, 22, 27)
datos[1] 12 15 18 22 27# Calcular la varianza
varianza <- var(datos)
varianza[1] 34.7# Crear un vector de datos
datos <- c(12, 15, 18, 22, 27)
datos[1] 12 15 18 22 27# Encontrar el valor máximo
maximo <- max(datos)
maximo[1] 27# Crear un vector de datos
datos <- c(12, 15, 18, 22, 27)
datos[1] 12 15 18 22 27# Encontrar el valor mínimo
minimo <- min(datos)
minimo[1] 12La indexación y el rebanado (slicing) son técnicas utilizadas para acceder a elementos específicos o a subconjuntos de una matriz.
Numpy permite indexar y realizar cortes en matrices para acceder a elementos específicos. En R, podemos hacerlo de manera similar. Aquí hay un ejemplo de cómo indexar y realizar cortes en una matriz en R:
# Ejemplo de indexación y slicing en R
matriz <- matrix(c(1, 2, 3, 4, 5, 6, 7, 8, 9), nrow = 3)
elemento <- matriz[2, 3] # Acceder al elemento en la fila 2, columna 3
fila <- matriz[2, ] # Obtener la segunda fila completa
columna <- matriz[, 3] # Obtener la tercera columna completa
resultado [,1] [,2]
[1,] 73 83
[2,] 174 198Es un paquete de R que proporciona un conjunto de funciones para realizar manipulación y transformación de datos de manera eficiente y fácil de entender. Es parte del conjunto de paquetes conocido como el “Tidyverse”, que está diseñado para ayudar a los usuarios de R a trabajar de manera más eficiente con datos estructurados. Aquí te proporcionaré información sobre dplyr, su uso, ventajas y algunos ejemplos en varios casos comunes.
Uso de dplyr: El paquete dplyr se utiliza para realizar operaciones comunes de manipulación y transformación de datos, como filtrar filas, seleccionar columnas, agregar, agrupar y ordenar datos. Algunas de las funciones principales de dplyr incluyen filter(), select(), mutate(), group_by(), summarize(), y arrange().
Ventajas de dplyr: - Sintaxis intuitiva y fácil de entender: dplyr utiliza una sintaxis que se asemeja al lenguaje natural, lo que facilita la escritura y lectura del código. - Eficiencia: dplyr está diseñado para ser rápido y eficiente en la manipulación de datos, lo que es importante cuando se trabajan con conjuntos de datos grandes. - Integración con el “Tidyverse”: dplyr se integra bien con otros paquetes del Tidyverse, como ggplot2, tidyr, y purrr, lo que permite un flujo de trabajo más consistente y poderoso. - Soporte para bases de datos: dplyr puede trabajar con bases de datos SQL, lo que permite realizar consultas directamente en bases de datos externas.
Entonces veamos los casos en las cuales usaremos esta librería:
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, uniondf <- data.frame(
name = c("Alice", "Bob", "Charlie", "David", "Eve"),
age = c(25, 32, 45, 28, 36),
sex = c("F", "M", "M", "M", "F")
)df_filtered <- df %>% filter(age > 30)
print(df_filtered) name age sex
1 Bob 32 M
2 Charlie 45 M
3 Eve 36 Fdf_selected <- df %>% select(name, age)
print(df_selected) name age
1 Alice 25
2 Bob 32
3 Charlie 45
4 David 28
5 Eve 36df_modified <- df %>% mutate(age_group = ifelse(age > 30, "Mayor de 30", "Menor de 30"))
print(df_modified) name age sex age_group
1 Alice 25 F Menor de 30
2 Bob 32 M Mayor de 30
3 Charlie 45 M Mayor de 30
4 David 28 M Menor de 30
5 Eve 36 F Mayor de 30df_summary <- df %>% group_by(sex) %>% summarize(mean_age = mean(age), count = n())
print(df_summary)# A tibble: 2 × 3
sex mean_age count
<chr> <dbl> <int>
1 F 30.5 2
2 M 35 3df_sorted <- df %>% arrange(age)
print(df_sorted) name age sex
1 Alice 25 F
2 David 28 M
3 Bob 32 M
4 Eve 36 F
5 Charlie 45 MEs un paquete en R que se utiliza para organizar y transformar datos en un formato que sea más adecuado para su análisis. Tidyr es parte del conjunto de paquetes conocidos como “tidyverse”, que están diseñados para trabajar juntos de manera coherente y facilitar el análisis de datos.
Aquí tienes información sobre tidyr, su uso, ventajas y ejemplos en varios casos:
Uso de tidyr: Tidyr se utiliza para reorganizar conjuntos de datos de manera que se ajusten al formato “tidy”, que es un formato que cumple con ciertas reglas:
Tidyr proporciona varias funciones para ayudarte a realizar estas transformaciones de datos. Las dos funciones principales son gather() (anteriormente conocida como melt) y spread().
Ventajas de tidyr: Las ventajas de tidyr incluyen:
Ejemplos en varios casos:
A continuación, te mostraré ejemplos en tres casos comunes en los que tidyr es útil:
Caso 1: Transformar datos desordenados a formato tidy
Supongamos que tienes un conjunto de datos desordenado con múltiples columnas para diferentes años:
# Crear un conjunto de datos desordenado
data <- data.frame(
País = c("A", "B"),
`2000` = c(100, 150),
`2001` = c(120, 160),
`2002` = c(130, 170)
)
# Utilizar tidyr para convertirlo a formato tidy
library(tidyr)
Attaching package: 'tidyr'The following objects are masked from 'package:Matrix':
expand, pack, unpacktidy_data <- gather(data, key = "Año", value = "Población", -País)
tidy_data País Año Población
1 A X2000 100
2 B X2000 150
3 A X2001 120
4 B X2001 160
5 A X2002 130
6 B X2002 170Este código utilizará gather() para reorganizar los datos en un formato tidy con columnas “País”, “Año” y “Población”.
Caso 2: Expandir datos en formato tidy
Supongamos que tienes un conjunto de datos tidy pero quieres expandirlo para obtener un formato más ancho:
# Crear un conjunto de datos tidy
tidy_data <- data.frame(
País = c("A", "B"),
Año = c(2000, 2000),
Población = c(100, 150)
)
# Utilizar tidyr para expandirlo
expanded_data <- spread(tidy_data, key = Año, value = Población)
expanded_data País 2000
1 A 100
2 B 150Este código utilizará spread() para expandir los datos en un formato más ancho con columnas para cada año.
Caso 3: Tratar con datos anidados
Supongamos que tienes un conjunto de datos con columnas anidadas y deseas desanidarlos:
# Crear un conjunto de datos con columnas anidadas
data <- data.frame(
País = c("A", "B"),
Datos = I(list(list(1, 2, 3), list(4, 5, 6)))
)
# Utilizar tidyr para desanidar los datos
unnested_data <- unnest(data, cols = Datos)
unnested_data# A tibble: 6 × 2
País Datos
<chr> <list>
1 A <dbl [1]>
2 A <dbl [1]>
3 A <dbl [1]>
4 B <dbl [1]>
5 B <dbl [1]>
6 B <dbl [1]>Este código utiliza unnest() para desanidar las listas en la columna “Datos”.
Espero que estos ejemplos te hayan ayudado a comprender cómo usar tidyr para transformar y organizar datos en R. Tidyr es una herramienta poderosa para manipular datos en un formato “tidy” que facilita su análisis y visualización.
El paquete ggplot2 es una poderosa librería de visualización de datos en R, diseñada por Hadley Wickham, que se utiliza para crear gráficos de alta calidad y personalizables. Aquí tienes un resumen del concepto, cómo aplicarlo, sus ventajas y ejemplos de sus diversos usos:
ggplot2 es una librería de R que se basa en el sistema de “gramática de gráficos”. Esto significa que te permite construir gráficos de manera declarativa, definiendo cómo quieres que se vea tu visualización mediante capas de elementos geométricos y estilísticos. Es altamente personalizable y permite crear una amplia gama de tipos de gráficos.
Para utilizar ggplot2, primero debes cargar el paquete con library(ggplot2). Luego, puedes crear un objeto de gráfico usando la función ggplot() y agregar capas (geoms) y ajustes estilísticos (aes) para personalizar tu gráfico. Puedes visualizar tus datos de diferentes maneras mediante la combinación de funciones como geom_point(), geom_bar(), geom_line(), etc.
#Cargar el paquete ggplot2
library(ggplot2)
# Datos
datos <- data.frame(Categoria = c("A", "B", "C", "D"),
Valor = c(20, 40, 15, 30))
# Crear el gráfico
ggplot(datos, aes(x = Categoria, y = Valor)) +
geom_bar(stat = "identity") +
geom_text(aes(label = Valor), vjust = -0.5) +
labs(title = "Gráfico de Barras", x = "Categoría", y = "Valor")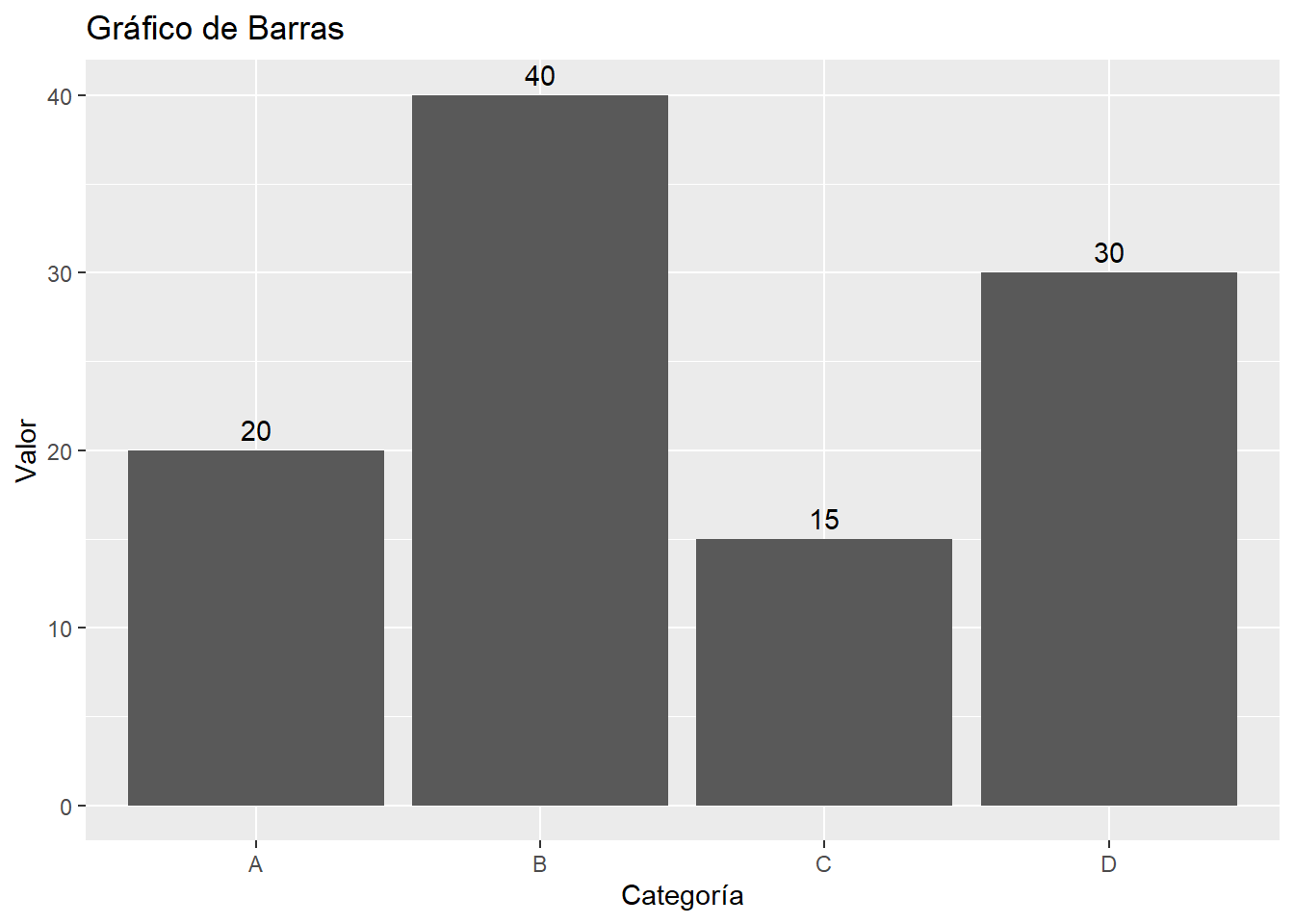
# Datos
datos <- data.frame(Mes = c("Enero", "Febrero", "Marzo", "Abril"),
A = c(10, 5, 12, 8),
B = c(5, 15, 8, 10),
C = c(8, 7, 10, 12))
# Reorganizar los datos en formato largo
datos_largos <- tidyr::gather(datos, Categoria, Valor, -Mes)
# Crear el gráfico de barras apiladas
ggplot(datos_largos, aes(x = Mes, y = Valor, fill = Categoria)) +
geom_bar(stat = "identity") +
labs(title = "Gráfico de Barras Apiladas", x = "Mes", y = "Valor") +
scale_fill_brewer(palette = "Set3")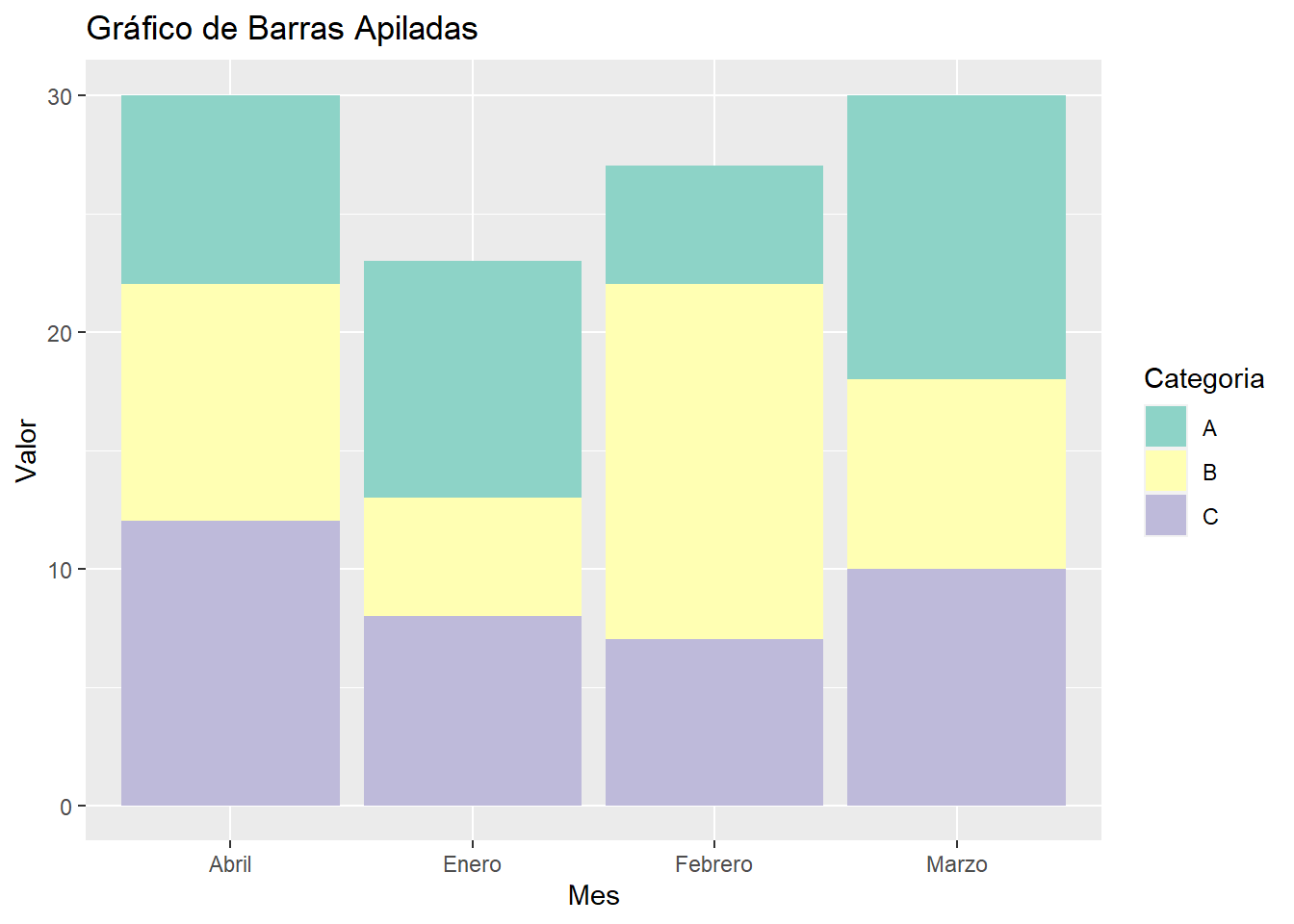
3.1 Gráficos de barras apiladas en horizontal
# Datos
datos <- data.frame(Categoria = c("A", "B", "C"),
Valor_1 = c(15, 20, 10),
Valor_2 = c(8, 12, 6))
# Reorganizar los datos en formato largo
datos_largos <- tidyr::gather(datos, Mes, Valor, -Categoria)
datos_largos Categoria Mes Valor
1 A Valor_1 15
2 B Valor_1 20
3 C Valor_1 10
4 A Valor_2 8
5 B Valor_2 12
6 C Valor_2 63.2 Crear un gráfico de barras apiladas horizontal
ggplot(datos_largos, aes(x = Categoria, y = Valor, fill = Mes)) +
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "Gráfico de Barras Apiladas Horizontal", x = "Valor", y = "Categoría") +
scale_fill_brewer(palette = "Set2")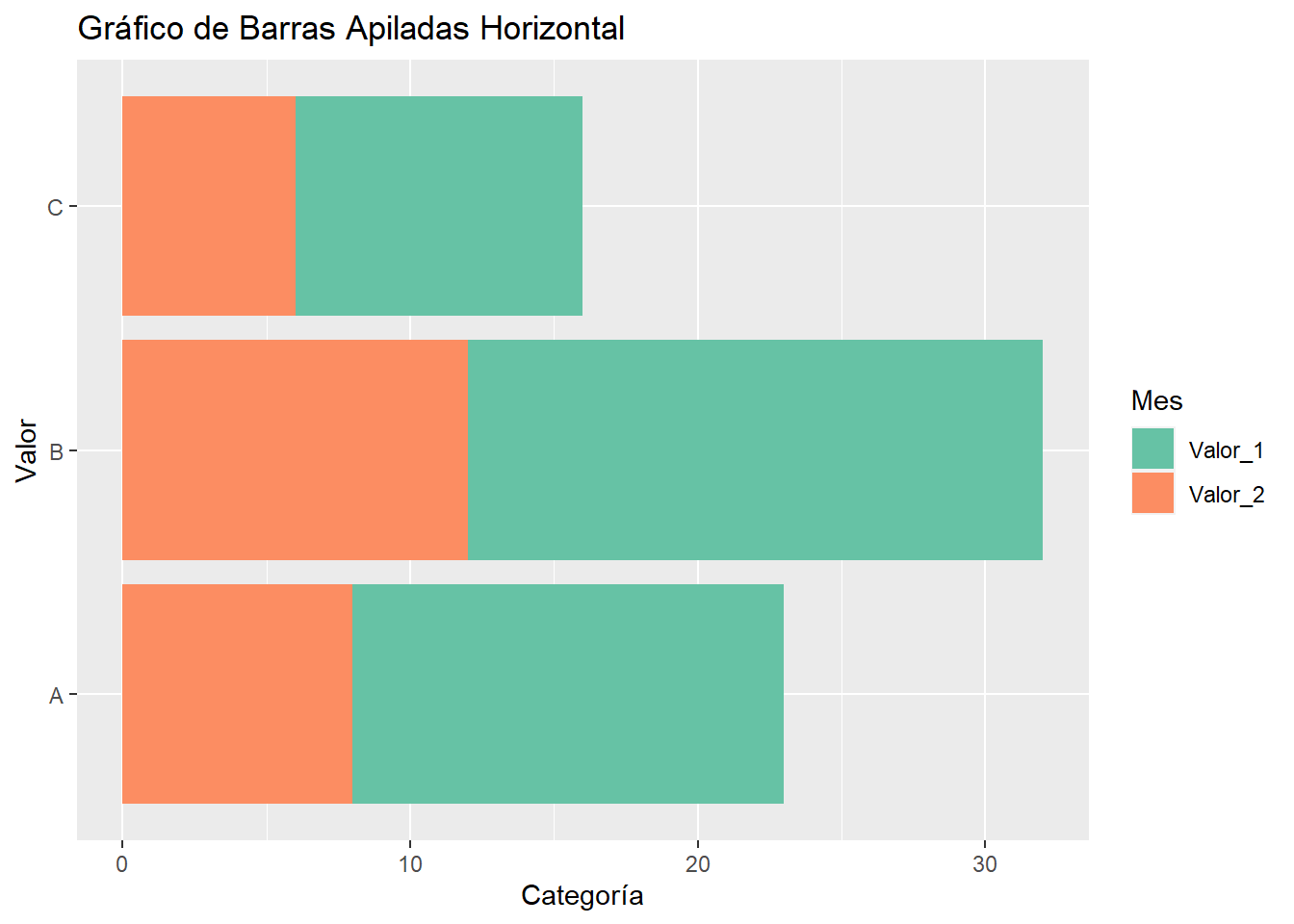
# Datos
set.seed(123)
fecha <- seq(as.Date("2023-01-01"), by = "months", length.out = 12)
valor <- cumsum(runif(12, min = 0, max = 10))
datos <- data.frame(Fecha = fecha, Valor = valor)
# Crear el gráfico
ggplot(datos, aes(x = Fecha, y = Valor)) +
geom_line(color = "blue", size = 1) +
labs(title = "Gráfico de Líneas", x = "Fecha", y = "Valor")Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.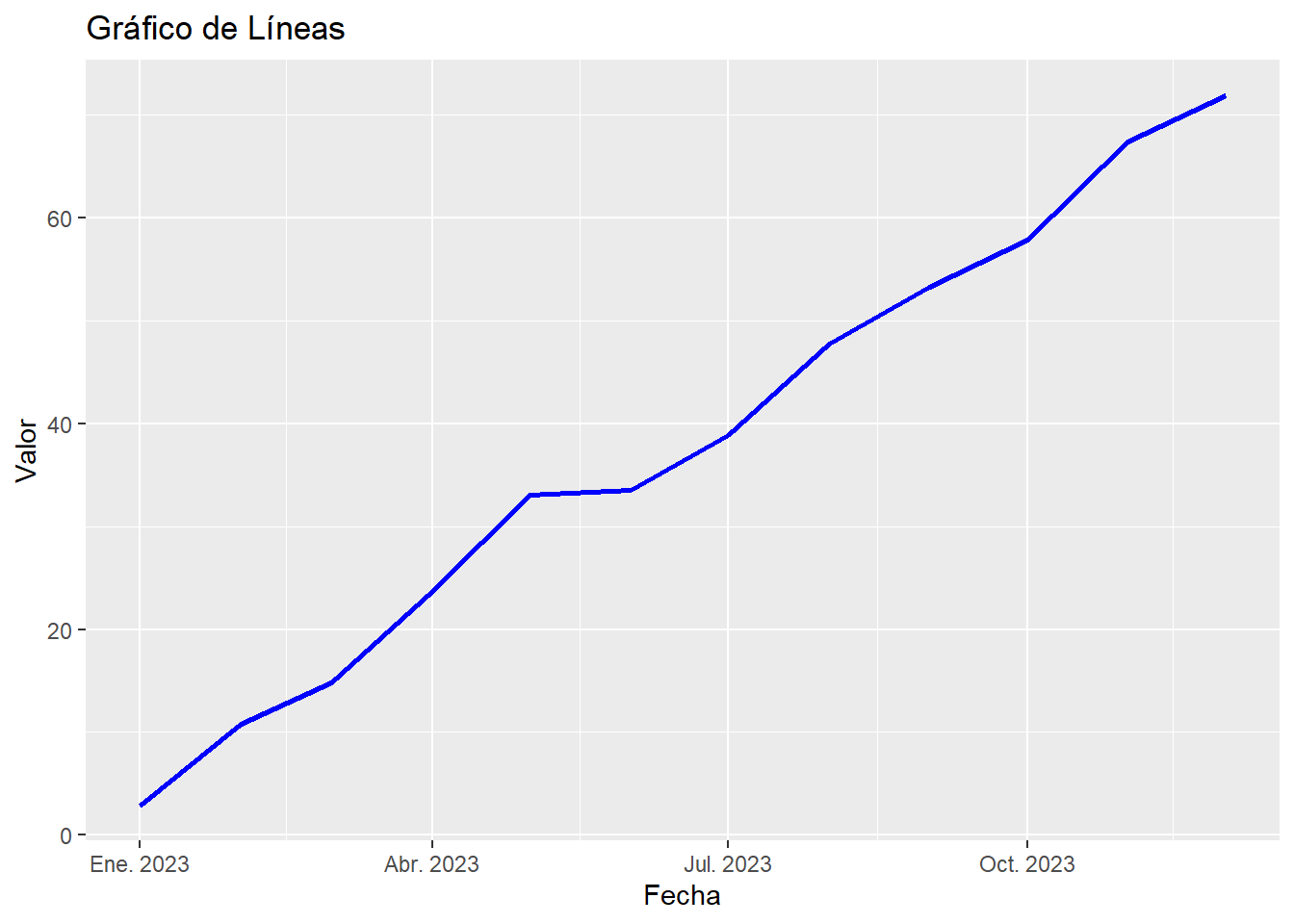
# Datos
set.seed(123)
fecha <- seq(as.Date("2023-01-01"), by = "months", length.out = 12)
valor <- cumsum(runif(12, min = 0, max = 10))
datos <- data.frame(Fecha = fecha, Valor = valor)
# Crear el gráfico
ggplot(datos, aes(x = Fecha, y = Valor, fill = "Área Bajo la Curva")) +
geom_area() +
labs(title = "Gráfico de Áreas", x = "Fecha", y = "Valor") +
scale_fill_manual(values = "blue")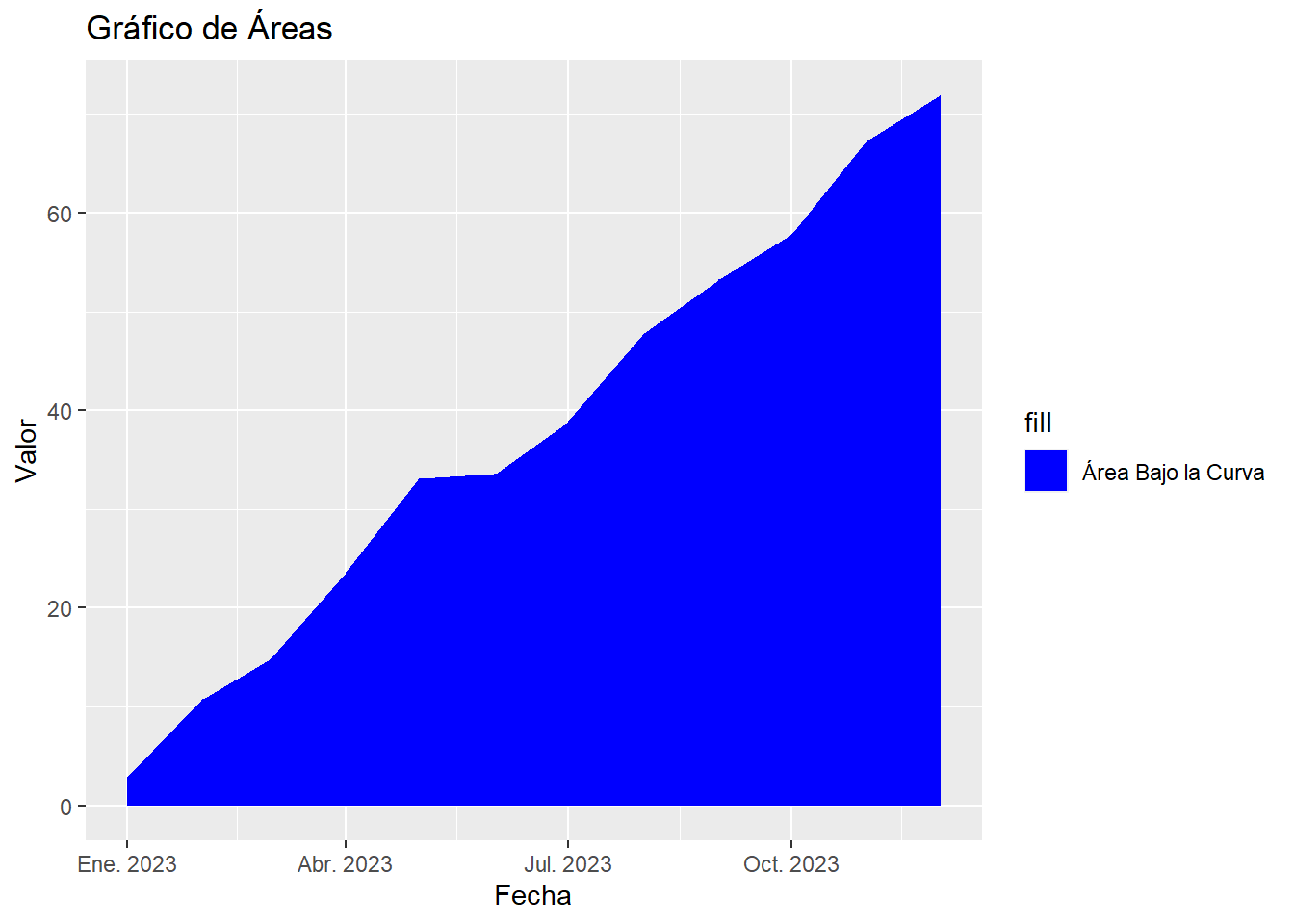
# Datos
datos <- data.frame(Categoria = c("A", "B", "C", "D"),
Valor = c(20, 40, 15, 30))
# Crear el gráfico
ggplot(datos, aes(x = "", y = Valor, fill = Categoria)) +
geom_bar(stat = "identity") +
coord_polar(theta = "y") +
labs(title = "Gráfico de Pastel")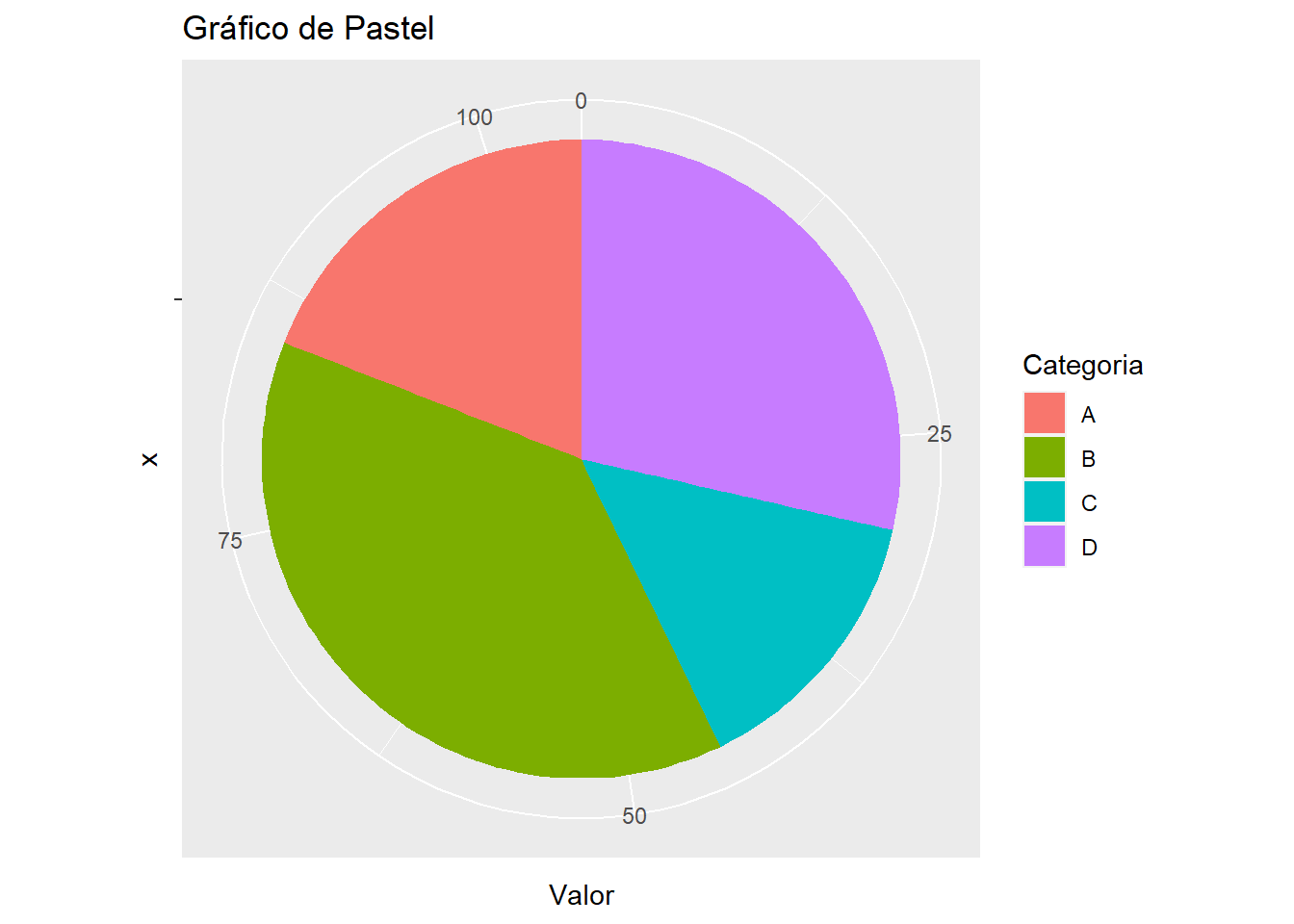
library(ggplot2)
set.seed(123)
data <- data.frame(x = rnorm(100), y = rnorm(100))
ggplot(data, aes(x, y)) +
geom_point() +
geom_smooth(method = "lm")`geom_smooth()` using formula = 'y ~ x'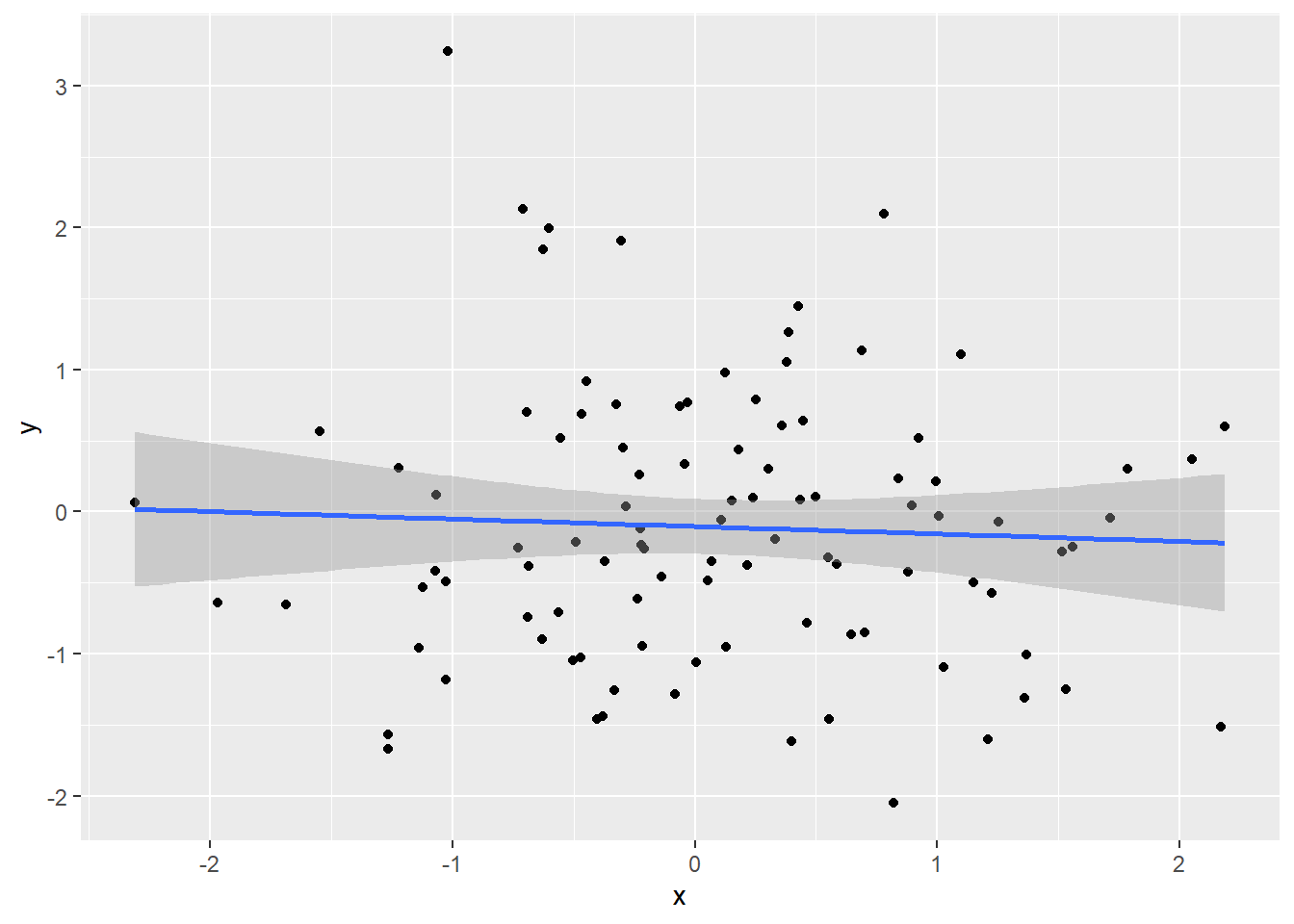
library(ggplot2)
set.seed(456)
data <- data.frame(time = 1:10, value = rnorm(10), group = factor(rep(1:2, each = 5)))
ggplot(data, aes(x = time, y = value, color = group)) +
geom_line() +
labs(title = "Evolución de dos grupos a lo largo del tiempo")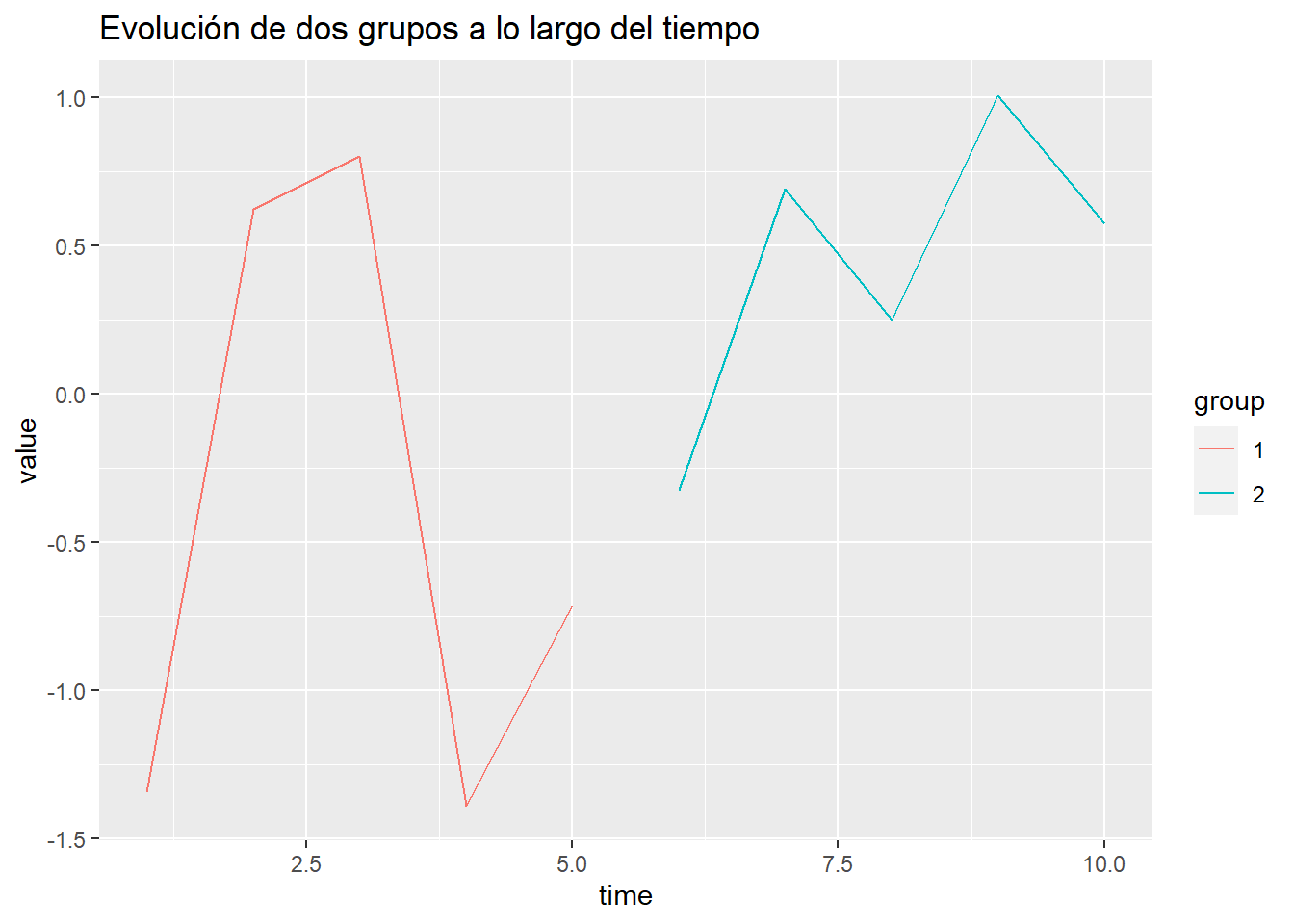
library(ggplot2)
set.seed(789)
data <- data.frame(group = rep(c("A", "B", "C"), each = 30),
value = rnorm(90))
ggplot(data, aes(x = group, y = value)) +
geom_boxplot() +
labs(title = "Distribución de valores en diferentes grupos")
# Datos de ejemplo
set.seed(123)
datos <- data.frame(Grupo = rep(c("A", "B", "C"), each = 100),
Valor = rnorm(300))
# Crear un gráfico de violín
ggplot(datos, aes(x = Grupo, y = Valor, fill = Grupo)) +
geom_violin() +
labs(title = "Gráfico de Violín", x = "Grupo", y = "Valor") +
scale_fill_brewer(palette = "Set3")
Estos ejemplos ilustran la versatilidad de ggplot2 para crear diversos tipos de gráficos de manera efectiva y personalizada. Puedes adaptar estas ideas a tus propios conjuntos de datos y necesidades de visualización.