7 Višediomenzionalni tipovi podataka
7.1 Kreiranje matrice
U ovom poglavlju objašnjava se kako kreirati i strukturirati matrice u R-u, uključujući različite načine definiranja redova i stupaca, unos elemenata te postavljanje atributa poput naziva redaka i stupaca. Poglavlje također prikazuje kako koristiti vektore za kreiranje matrica i kako prilagoditi strukturu matrice za analizu podataka.
Matrice su dvodimenzionalni vektori (dakle, vrijede isti uvjeti kao i za vektore), a mogu se kreirati na više načina. Matricu je uobičajeno definirati koristeći funkciju matrix(), u kojoj je potrebno navesti podatke, broj stupaca i broj redaka. Osim toga, može se definirati način slaganja elemenata u matricu, zadano (engl. default) je slaganje po stupcu, a može se definirati slaganje po recima unosom byrow=TRUE. Podaci se mogu kreirati, a može se koristiti uvezeni skup podataka (engl. dataset) (npr. ako se uvezeni dataset zove Analiza, tada je data=Analiza, kasnije će biti više riječi o tome).
7.1.1 Kreiranje matrice koristeći izravan upis elemenata
Ukoliko postoje specifični elementi koje je potrebno upisati u matricu točno određenim redom, onda kreiranje matrice može biti napravljeno na sljedeći način:
> Mat <- matrix(c(5, 6, 8,
+ 10, 11, 15,
+ 2, 7, 3,
+ 12, 28, 19,
+ 13, 22, 24,
+ 31, 25, 8),
+ ncol = 3, byrow = TRUE)
> Mat## [,1] [,2] [,3]
## [1,] 5 6 8
## [2,] 10 11 15
## [3,] 2 7 3
## [4,] 12 28 19
## [5,] 13 22 24
## [6,] 31 25 8Pri definiranju matrice, koristi se naredba matrix(). Prvi parametar funkcije su podaci temeljem kojih se kreira matrica. Ako se podaci unose ručno, potrebno ih je unijeti kao vektor, koristeći funkciju c(). Potom je potrebno definirati broj redaka i/ili stupaca. Dovoljno je definirati samo jedno (broj redaka ili broj stupaca), ali se može definirati oboje. Potom je potrebno definirati parametar byrow. To je logički parametar koji je unaprijed zadan (engl. default) na FALSE i kao takav uvjetuje da će podaci biti očitani po stupcima, a ne po recima. Ako je definirano byrow = TRUE, tada će podaci biti očitani i zapisani u matricu po recima. Ovaj se pristup češće koristi s obzirom da je ljudima uglavnom prirodnije čitati i upisivati podatke po recima nego po stupcima.
Ako ne bismo koristili postavku byrow = TRUE, tada se automatski podrazumijeva upotreba byrow = FALSE i očitavanje i zapis podataka u matricu po stupcima. Sljedeći primjer pokazuje upravo takvu situaciju. Obratite pozornost na to da u zapisu niže također koristimo manje pregledan zapis podataka. To znači da pri kreiranju matrica zapravo nije potrebno svaki redak ili stupac buduće matrice pisati u zaseban redak i R će očitati podatke neovisno o zapisu. U pravilu, zapis nalik na prethodni primjer koristimo radi preglednosti koda i lakše provjere.
> Mat <- matrix(c(5, 6, 8, 10, 11, 15, 2, 7, 3, 12,
+ 28, 19, 13, 22, 24, 31, 25, 8),
+ ncol = 3)
> Mat## [,1] [,2] [,3]
## [1,] 5 2 13
## [2,] 6 7 22
## [3,] 8 3 24
## [4,] 10 12 31
## [5,] 11 28 25
## [6,] 15 19 8Osim toga, ako su u pitanju cjelobrojni redoslijedni elementi, onda matricu možemo kreirati i na sljedeći način:
> A <- matrix(data = 10:18, nrow = 3, ncol = 3)
> A## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 187.1.2 Matrica indeksa
Matrica koja sardži redoslijedne cijele brojeve kao elemente naziva se i matrica indeksa, zbog toga što vrijednosti elemenata odgovaraju rednim mjestima. Takve se matrice ponekad koriste u pomoćnim izračunima.
> B <- matrix(data = 1:9, nrow = 3, ncol=3, byrow=TRUE)
> B## [,1] [,2] [,3]
## [1,] 1 2 3
## [2,] 4 5 6
## [3,] 7 8 97.1.3 Kreiranje matrice iz vektora
Matrica se može kreirati i temeljem vektora. Kreirajmo malo duži vektor, na primjer,
> o <- c(a, j)
> o## [1] 1 2 3 4 5 5 10 15 20 25 1 2 3 4 5Da bi se matrica kreirala pomoću vektora, broj elemenata u vektoru mora odgovarati broju elemenata u matrici koja će se kreirati (ovdje ne funkcionira recikliranje). Zbog toga ćemo prvo provjeriti duljinu vektora.
> length(o)## [1] 15Da bi vektor pretvorili u matricu, potrebno mu je zadati dvije dimenzije, a dimenzije se zadaju pomoću funkcije dim(). U ovom slučaju, duljina vektora je 15, pa možemo kreirati matricu dimenzija, npr. \(3 \times 5\).
> dim(o) <- c(3, 5)Već pri sljedećem ispisu moguće je uočiti rezultat primjene dim(). No, obratite pozornost na to da će matrica kreirana na ovaj način uvijek biti popunjena po stupcima, a ne po recima.
> o## [,1] [,2] [,3] [,4] [,5]
## [1,] 1 4 10 25 3
## [2,] 2 5 15 1 4
## [3,] 3 5 20 2 5Ako je potrebno, tako kreiranoj matrici moguće je pridodati atribute, a nazivi stupaca i redaka mogu se pridružiti kao što je ranije prikazano.
> rownames(o) <- c("Prvi", "Drugi", "Treći")
> colnames(o) <- c("Stupac 1.", "Stupac 2.", "Stupac 3.", "Stupac 4.", "Stupac 5.")
> print(o)## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 10 25 3
## Drugi 2 5 15 1 4
## Treci 3 5 20 2 57.1.4 Dodjela atributa
Za unos naziva redaka i stupaca mogu se koristiti colnames() i rownames().
> C <- matrix(10:18, nrow = 3, ncol = 3, byrow = TRUE)
> colnames(C)<-c("A", "B", "C")
> rownames(C)<-c("1.", "2.", "3.")
> C## A B C
## 1. 10 11 12
## 2. 13 14 15
## 3. 16 17 18Nazivi stupaca i redaka matrice mogu se unijeti pomoću argumenta dimnames. Pritom je prvo potrebno kreirati listu koja će imati dva elementa: vektor naziva redaka i vektor naziva stupaca.
> C<-list(c("Crveno", "Žuto", "Zeleno"), c("Lokacija 1", "Lokacija 2"))
> matrix(data=c("DA", "NE", "N/a"), nrow = 3, ncol = 2, dimnames = C)## Lokacija 1 Lokacija 2
## Crveno "DA" "DA"
## Žuto "NE" "NE"
## Zeleno "N/a" "N/a"Obratite pozornost da je ovime prepisana prethodno kreirana matrica C. Treba voditi računa o nazivima vektora i matrica, jer R neće javljati nikakvo upozorenje ako želite promijeniti postojeći vektor ili matricu.
7.2 Rad s matricama
U ovom poglavlju obrađuju se osnovne operacije s matricama u R-u, uključujući provjeru tipa, odabir i zamjenu elemenata te različite oblike filtriranja i spajanja. Također, poglavlje pruža uvid u operacije kao što su transponiranje i množenje matrica te konverziju matrice u vektor ili podatkovni okvir, omogućujući fleksibilnost u analizi podataka. Dodatno, poglavlje naglašava važnost razumijevanja prednosti i ograničenja matrica za različite analitičke zadatke.
7.2.1 Provjera tipa matrice
Je li objekt matrica može se provjeriti koristeći is.matrix().
> is.matrix(o)## [1] TRUEOsim toga, moguće je provjeriti radi li se o matrici i koristeći class():
> class(o)## [1] "matrix" "array"Za uvid u karakteristike elemenata matrice, koristi se typeof().
> typeof(o)## [1] "double"7.2.2 Odabir elemenata matrice
Kao i kod vektora, iz matrica je moguće odabirati elemente s obzirom na njihovu poziciju.
> A[2, 3]## [1] 17Pritom prvi broj označava redak, a drugi stupac. Tako je 17 element koji pripada drugom retku i trećem stupcu matrice A. Ispis matrice moguće je odabrati i s obzirom na retke i stupce. Na primjer, ako se želi odabrati/ ispisati samo prvi redak matrice A, tada je to moguće učiniti na sljedeći način:
> A[1, ]## [1] 10 13 16> o[1, ]## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## 1 4 10 25 3Možete uočiti razliku između ispisa prvog retka matrice A kojoj nisu zadani nazivi stupaca i redaka, u odnosu na matricu o, kojoj su zadani nazivi stupaca i redaka.Ipak, uočite i to da imenovanje stupaca i redaka ne utječe na odabir.
Ako bi se, koristeći isti izraz upisao, npr. o[2,], tada bi rezultat prikazao samo drugi redak. Ako se želi ispisati više redaka, tada je to potrebno definirati npr. ovako:
> o[c(1, 2), ]## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 10 25 3
## Drugi 2 5 15 1 4Slično vrijedi i za stupce, samo će se u tom slučaju prva pozicija prije zareza ostavljati praznom.
> o[ ,1]## Prvi Drugi Treci
## 1 2 3> o[ ,c(1, 2)]## Stupac 1. Stupac 2.
## Prvi 1 4
## Drugi 2 5
## Treci 3 5> o[ ,c(3, 5)]## Stupac 3. Stupac 5.
## Prvi 10 3
## Drugi 15 4
## Treci 20 57.2.3 Zamjena elemenata matrica
Kao i kod vektora, elementi matrice mogu se zamijeniti drugim elementom. Na primjer:
> o[2, 2] <- 100
> o## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 10 25 3
## Drugi 2 100 15 1 4
## Treci 3 5 20 2 5Ako je potrebno, mogu se zamijeniti i svi elementi pojedinog retka ili stupca.
> o[ ,3] <- c(15, 20, 25)
> o## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 15 25 3
## Drugi 2 100 20 1 4
## Treci 3 5 25 2 5> o[3, ] <- c(4, 6, 26, 3, 6)
> o## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 15 25 3
## Drugi 2 100 20 1 4
## Treci 4 6 26 3 6Ako je potrebno, pri zamjeni se mogu koristiti i već prikazane operacije na vektorima.
> o[3, ]<-c(o[3, ] + 1)
> o## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 15 25 3
## Drugi 2 100 20 1 4
## Treci 5 7 27 4 7> o[ ,5] <- c(o[ ,5] * 3)
> o## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 15 25 9
## Drugi 2 100 20 1 12
## Treci 5 7 27 4 21Generalno, sve operacije u kojima se matrice pojavljuju bit će osjetljive na elemente koji nedostaju (NA), zbog čega je brisanje elemenata matrice (iako moguće) nepoželjno.
7.2.4 Filtriranje matrice - odabir elemenata prema kriteriju
Slično kao kod vektora, mogu se ispisati elementi prema zadanom kriteriju, npr. elementi veći od 10.
> o[o > 10]## [1] 100 15 20 27 25 12 217.2.5 Kreiranje matrice s ponovljenim vrijednostima i zadavanje dijagonale
Osim toga, moguće su situacije u kojima će se htjeti kreirati specifične matrice. Na primjer matrica koja sadržava sve 0, osim jedinica na dijagonali. To je moguće učiniti na sljedeći način:
> D <- matrix(0, nrow = 3, ncol = 3)
> diag(D) <-1
> D## [,1] [,2] [,3]
## [1,] 1 0 0
## [2,] 0 1 0
## [3,] 0 0 1Slično tome, moguće je učiniti i obrnuto. Na primjer, ako se želi kreirati matrica koja će sadržavati sve jedinice, osim nula na dijagonali, to je moguće na sljedeći način:
> E <-matrix(1, nrow = 3, ncol = 3)
> diag(E)<-0
> E## [,1] [,2] [,3]
## [1,] 0 1 1
## [2,] 1 0 1
## [3,] 1 1 07.2.6 Spajanje matrica
Kao što je moguće spajati vektore, tako je moguće spajati i matrice. Pritom je potrebno paziti na dimenzije matrica koje se spajaju. Matrice koje se podudaraju u broju redaka mogu se spojiti funkcijom cbind(), a matrice koje se podudaraju po broju stupaca funkcijom rbind().
Ranije kreirane matrice A i B imaju jednak broj stupaca i redaka. Provjerimo koja je razlika ako se primjenjuje spajanje po stupcu i spajanje po retku.
> AB <- rbind(A, B)
> AB## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9Prethodnom naredbom matrice su spojene po recima (r-row). Kreirana je nova matrica, AB, pri čemu matrica A tvori prva tri retka nove matrice, a matrica B sljedeća tri retka.
Sljedećom naredbom matrice se spajaju po stupcima (c-column). Tako će druga matrica biti nadodana prvoj matrici u obliku dodatna tri stupca.
> BA <- cbind(A, B)
> BA## [,1] [,2] [,3] [,4] [,5] [,6]
## [1,] 10 13 16 1 2 3
## [2,] 11 14 17 4 5 6
## [3,] 12 15 18 7 8 9U sljedećem primjeru kombinirat ćemo ranije naučene funkcije. Recimo da se odabirom svakog sedmog elementa iz vektora f želi kreirati vektor p. Nakon provjere duljine vektora, dodjeljuju mu se odgovarajuće dimenzije. Usporedbom s već kreiranim matricama, uočava se da novokreirana matrica ima jednak broj redaka kao matrica o, te se matrice p i o spajaju funkcijom cbind().
> p <- f[seq(1, 101, by=7)]
> p## [1] 100 107 114 121 128 135 142 149 156 163 170 177 184 191 198> length(p)## [1] 15> dim(p) <- c(3, 5)
> po <- cbind(o, p)
> po## Stupac 1. Stupac 2. Stupac 3. Stupac 4. Stupac 5.
## Prvi 1 4 15 25 9 100 121 142 163 184
## Drugi 2 100 20 1 12 107 128 149 170 191
## Treci 5 7 27 4 21 114 135 156 177 1987.2.7 Operacije na matricama
Nadalje, jedna od često potrebnih operacija s matricama je transponiranje t() (zamjena redaka i stupaca).
> t(po)## Prvi Drugi Treci
## Stupac 1. 1 2 5
## Stupac 2. 4 100 7
## Stupac 3. 15 20 27
## Stupac 4. 25 1 4
## Stupac 5. 9 12 21
## 100 107 114
## 121 128 135
## 142 149 156
## 163 170 177
## 184 191 198Matrice se mogu i zbrajati
> A + B## [,1] [,2] [,3]
## [1,] 11 15 19
## [2,] 15 19 23
## [3,] 19 23 27Nadalje, matrice se mogu množiti skalarom:
> 3 * A## [,1] [,2] [,3]
## [1,] 30 39 48
## [2,] 33 42 51
## [3,] 36 45 54Osim toga, matrice se mogu i množiti:
> A * B## [,1] [,2] [,3]
## [1,] 10 26 48
## [2,] 44 70 102
## [3,] 84 120 162Obratite pozornost na to da je ova operacija rezultirala množenjem odgovarajućih elemenata dviju matrica, ali ne i množenjem matrica kako se to učilo na matematici. Da biste to napravili, potrebno je koristiti operator %*%:
> A %*% B## [,1] [,2] [,3]
## [1,] 174 213 252
## [2,] 186 228 270
## [3,] 198 243 2887.2.8 Konverzija matrice u vektor
Matrice je moguće konvertirati u vektor, ali pritom treba posvetiti osobitu pozornost poretku elemenata. Na primjer, izravna transformacija u vektor rezultirat će očitavanjem elemenata po stupcu. Podsjetimo se prvo kako je definirana matrica A.
> A## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18Ako ovu matricu izravno trasformiramo u vektor, dobivamo sljedeći rezultat:
> v <- as.vector(A)
> v## [1] 10 11 12 13 14 15 16 17 18Uočava se da se u vektoru nalaze elementi matrice iščitani po stupcima. S obzirom da se u praksi matrični zapis često koristi za jednostavniju i bržu manipulaciju podataka tablica, češće ćete htjeti da elementi u vektoru budu iščitani i zapisani po recima u matrici. To se može postići međukorakom, odnosno transponiranjem matrice.
> v <- as.vector(t(A))
> v## [1] 10 13 16 11 14 17 12 15 18Nadalje, tijekom konverzije matrice u vektor, moguće je promijeniti vrijednosti matrice na način da se one umanje, uvećaju ili množe skalarom. Na primjer, ako se svi elementi matrice žele uvećati za npr. 5, tada će se to učiniti na sljedeći način:
> v <- as.vector(5 + t(A))
> v## [1] 15 18 21 16 19 22 17 20 23Također, ako se elementi žele uvećati 5 puta, tada je elemente matrice potrebno pomožiti brojem 5:
> v <- as.vector(5 * t(A))
> v## [1] 50 65 80 55 70 85 60 75 90Također, pri transformaciji u vektor, moguće je i promijeniti predznak vrijednostima elemenata matrice:
> v <- as.vector(-t(A))
> v## [1] -10 -13 -16 -11 -14 -17 -12 -15 -18Ako se vrijednosti u matrici žele uvećati, umanjiti ili množiti s različitim vrijednostima po stupcima, onda je moguće za to primijeniti vektor:
> v <- as.vector(c(1, 2, 3) * t(A))
> v## [1] 10 26 48 11 28 51 12 30 54Napomena: pri svakoj provedenoj konverziji podataka, poželjno je ispisati rezultate kako biste provjerili je li konverzija rezultirala željenim promjenama. Ovi su postupci često samo pomoćne radnje u zahtjevnijim analizama i greške u ovim koracima mogu rezultirati ozbiljnim pogrešama u konačnim rezultatima.
7.2.9 Konverzija matrice u podatkovni okvir
Matrice podataka s uključenim nazivima stupaca i redaka često su korisnije u obliku podatkovnog okvira, zato jer brojni paketi koriste upravo takvu strukturu podataka. Matrice se lako mogu spremiti u obliku podatkovnog okvira na sljedeći način:
> X <- as.data.frame(po)
> str(X)## 'data.frame': 3 obs. of 10 variables:
## $ Stupac 1.: num 1 2 5
## $ Stupac 2.: num 4 100 7
## $ Stupac 3.: num 15 20 27
## $ Stupac 4.: num 25 1 4
## $ Stupac 5.: num 9 12 21
## $ V6 : num 100 107 114
## $ V7 : num 121 128 135
## $ V8 : num 142 149 156
## $ V9 : num 163 170 177
## $ V10 : num 184 191 198Obratite pozornost na prozor Environment, u kojem se sad pojavio objekt X.
7.2.10 Izračun pokazatelja deskriptivne statistike za matrice
Osim toga, ako se izdvoji pojedini stupac matrice, na njemu se mogu izvršavati naredbe kao i na vektorima. Na primjer, ako se želi utvrditi prosjek vrijednosti prvog stupca matrice A, to se može učiniti na sljedeći način:
> mean(A[ ,1])## [1] 11Treba obratiti posebnu pozornost na to što se događa ako se ne izdvoji specifični stupac, nego se odabere mean za matricu A:
> mean(A)## [1] 14Naime, izračunata je aritmetička sredina svih elemenata matrice A, što može predstavljati problem ako postoji pojmovna razlika u vrijednostima zapisanim u stupcima matrice (tj., ako bi stupci matrice trebali predstavljati varijable).
7.3 Prednosti i nedostaci rada s matricama te najčešće greške
Nekonzistentnost dimenzija matrica
Jedna od čestih grešaka prilikom rada s matricama je pokušaj izvođenja operacija na matricama koje nemaju kompatibilne dimenzije (na primjer, pokušaj množenja dviju matrica čije dimenzije ne zadovoljavaju pravilo množenja matrica). R će vratiti grešku ako dimenzije nisu usklađene za određenu operaciju.
Neispravna primjena funkcija
Ovdje se misli na pokušaj primjene funkcija koje očekuju vektore (na primjer, sum(), mean()) izravno na matricama bez specificiranja dimenzija (redaka ili stupaca) na kojima se funkcija treba primijeniti. To može dovesti do neočekivanih rezultata, kao što je izračun prosjeka svih elemenata u matrici umjesto po stupcima ili recima.
Zaboravljanje postavke byrow prilikom kreiranja matrice:
Važno je zadati na koji će se način matrica popunjavati: po stupcima ili recima. Ako zaboravite postaviti byrow=TRUE, a namjeravali se popuniti matricu po redovima, elementi će se rasporediti po stupcima, što može rezultirati neželjenim rasporedom podataka. Štoviše, ako ne izvršite provjeru nakon kreiranja matrice, preskakanje ovog argumenta može uzrokovati veće pogreške u kasnijim izračunima.
Korištenje nespojivih tipova podataka
Budući da matrice u R-u mogu sadržavati samo jedan tip podataka, pokušaj kombiniranja brojeva i tekstualnih vrijednosti u istoj matrici rezultirat će konverzijom svih elemenata u tekstualne vrijednosti. To može izazvati probleme pri kasnijoj obradi podataka.
Pogrešno indeksiranje i odabir podataka
Pogreške u indeksiranju, poput pokušaja pristupa elementima koji ne postoje (zbog krive specifikacije indeksa) mogu dovesti do grešaka ili neočekivanih rezultata. Također, bitno je razumjeti razliku između odabira pojedinačnih elemenata, redaka ili stupaca.
Zanemarivanje atributa matrice prilikom transformacija
Prilikom konverzije matrice u vektor ili izvođenja nekih transformacija, moguće je izgubiti imena redaka i stupaca ili druge atribute matrice. Važno je biti svjestan ovih promjena i po potrebi ponovno postaviti atribute.
Matrice u R-u su moćan alat za numeričku analizu i manipulaciju podataka, ali imaju određena ograničenja koja ih čine manje fleksibilnima u odnosu na liste ili podatkovne okvire za određene vrste analiza i obrade podataka. Evo ključnih ograničenja matrica:
Homogenost tipova podataka
Jedno od glavnih ograničenja matrica jest da one mogu sadržavati samo jedan tip podataka. Ako matrica sadrži brojeve i tekstualne podatke, svi će biti prisilno pretvoreni u tekstualni tip, što može dovesti do gubitka numeričkih operacija nad tim podacima. Nasuprot tome, podatkovni okviri i liste mogu sadržavati elemente različitih tipova podataka (npr., numeričke, logičke, znakovne), što ih čini prikladnijima za složene skupove podataka koji se često nalaze u praktičnim primjenama.
Dvodimenzionalna struktura
Matrice su inherentno dvodimenzionalne, što znači da imaju ograničenje na retke i stupce. Ovo ograničenje može biti problematično kada radite s višedimenzionalnim podacima. Liste, s druge strane, mogu sadržavati složene i višedimenzionalne strukture podataka, uključujući i druge liste ili podatkovne okvire, omogućavajući time veću fleksibilnost u organizaciji podataka.
Manipulacija podacima i pristup
Podatkovni okviri u R-u su optimizirani za statističku analizu i manipulaciju podataka, s brojnim funkcijama iz različitih paketa koje olakšavaju rad s podacima. Podatkovni okviri omogućuju jednostavno filtriranje, sortiranje, grupiranje i sumiranje podataka, dok matrice nisu toliko prilagođene za takve operacije.
Pristup i indeksiranje
Iako matrice omogućuju pristup elementima, recima i stupcima putem indeksiranja, podatkovni okviri pružaju dodatnu fleksibilnost omogućujući pristup stupcima po imenu, što može biti intuitivnije i smanjiti mogućnost grešaka prilikom analize podataka.
Veličina i performanse
Za vrlo velike skupove podataka, posebno kada se radi o rijetkim matricama koje sadrže mnogo nula, specijalizirane strukture podataka poput rijetkih matrica (sparseMatrix iz paketa Matrix) mogu pružiti značajne prednosti u smislu učinkovitosti pohrane i performansa obrade. Podatkovni okviri i liste ne nude izravnu podršku za ovakve optimizacije.
Unatoč svojim ograničenjima, matrice se dalje često koristimo u mnogim scenarijima u R-u, posebice zbog njihove efikasnosti i jednostavnosti kada su u pitanju specifični tipovi analize i manipulacije podacima. Evo nekoliko situacija u kojima su matrice posebno korisne.
Linearna algebra i matematičke operacije
Matrice su idealne za izvođenje operacija linearne algebre, uključujući množenje matrica, transponiranje, izračunavanje determinanti, inverza i svojstvenih vrijednosti. U situacijama gdje su ove operacije ključne, kao što je rješavanje sustava linearnih jednadžbi, matrice su nezaobilazan alat.
Numerička analiza
Matrice se često koriste u numeričkim simulacijama i algoritmima, gdje je potrebno manipulirati velikim količinama numeričkih podataka. Primjeri: numeričko rješavanje diferencijalnih jednadžbi, optimizaciju i simulacije.
Obrada signala i slike
U obradi signala i slika, podaci su često predstavljeni kao dvodimenzionalni nizovi (na primjer, pikseli slike), gdje matrice omogućuju efikasnu obradu i analizu tih podataka, uključujući filtriranje, detekciju rubova, i segmentaciju.
Statistički modeli i multivarijatna analiza
Pri modeliranju statističkih odnosa među višedimenzionalnim podacima, matrice se koriste za predstavljanje podataka i koeficijenata u višedimenzionalnim statističkim modelima, kao što su višestruka linearna regresija, analiza varijance i faktorska analiza.
Grafovi i mreže
U analizi grafova i mreža, matrice susjedstva i incidencije koriste se za predstavljanje veza među čvorovima, što omogućava primjenu algoritama za pretraživanje grafova, pronalaženje najkraćih putova, i druge analize mrežnih struktura.
Računanje s rijetko popunjenim matricama
U situacijama gdje su podaci rijetko raspoređeni (npr., u matricama s mnogo nula), specijalizirane strukture rijetkih matrica omogućuju efikasno pohranjivanje i obradu, čineći matrice prikladnima za rad s velikim skupovima podataka u kojima je većina elemenata nula.
7.4 Kreiranje i rad s listama
U ovom poglavlju objašnjavaju se osnovne funkcionalnosti lista u R-u, kao što su kreiranje, dodavanje i odabir elemenata te spajanje i razdvajanje lista. Liste su fleksibilni objekti koji mogu pohranjivati elemente različitih tipova, uključujući druge strukture poput vektora i matrica, što ih čini korisnima za složene podatkovne strukture. Dodatno, poglavlje naglašava prednosti i uobičajene greške pri radu s listama, omogućujući korisnicima efikasno upravljanje heterogenim podacima u analitičkim zadacima.
Nalik vektorima, liste su jednodimenzionalni objekti, ali mogu sadržavati elemente različitih tipova i mogu uključivati druge objekte (vektore, matrice, druge liste, funkcije i dr., što znači da elementi unutar liste ne moraju biti jednodimenzionalni). Zadaje se funkcijom list(). Na primjer,
> lista1 <-list(5, "Pula", a, AB)
> lista1## [[1]]
## [1] 5
##
## [[2]]
## [1] "Pula"
##
## [[3]]
## [1] 1 2 3 4 5
##
## [[4]]
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9Elementi liste naznačeni su dvostrukim uglatim zagradama i označavaju poziciju elementa u listi. Dakle, i dalje se radi o uređenom nizu i prema poziciji je moguće odabirati elemente.
> lista1[[2]]## [1] "Pula"7.4.1 Dodavanje atributa
Elementima liste možemo pridružiti nazive.
> names(lista1)<-c("broj", "grad", "vektor", "matrica")
> lista1## $broj
## [1] 5
##
## $grad
## [1] "Pula"
##
## $vektor
## [1] 1 2 3 4 5
##
## $matrica
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9Elementima liste moguće je pridodati nazive i prilikom kreiranja liste.
> lista2<-list(Drzava="Hrvatska", Grad="Hvar", Selo="Heki", Rijeka="Hudinja",
+ Jezero="Harambašić", Opcina="Hum na Sutli", Planina="Hahlići",
+ Zivotinja=c("Hrcak", "Hobotnica", "Hijena"))
> lista2## $Drzava
## [1] "Hrvatska"
##
## $Grad
## [1] "Hvar"
##
## $Selo
## [1] "Heki"
##
## $Rijeka
## [1] "Hudinja"
##
## $Jezero
## [1] "Harambašic"
##
## $Opcina
## [1] "Hum na Sutli"
##
## $Planina
## [1] "Hahlici"
##
## $Zivotinja
## [1] "Hrcak" "Hobotnica" "Hijena"7.4.2 Odabir elemenata
Odabire je moguće vršiti putem pozicije elementa i putem naziva.
> lista2[1]## $Drzava
## [1] "Hrvatska"> lista2$Drzava## [1] "Hrvatska"> lista1$matrica## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9Nadalje, možemo odabirati elemente unutar elemenata liste, na primjer:
> lista1$matrica[4, 3]## [1] 3> lista1[[3]][15]## [1] NA7.4.3 Dodavanje elemenata
Ako želimo postojeću listu proširiti za element, onda je to moguće učiniti pridruživanjem.
> lista2$Biljka <- "Hren"
> lista2## $Drzava
## [1] "Hrvatska"
##
## $Grad
## [1] "Hvar"
##
## $Selo
## [1] "Heki"
##
## $Rijeka
## [1] "Hudinja"
##
## $Jezero
## [1] "Harambašic"
##
## $Opcina
## [1] "Hum na Sutli"
##
## $Planina
## [1] "Hahlici"
##
## $Zivotinja
## [1] "Hrcak" "Hobotnica" "Hijena"
##
## $Biljka
## [1] "Hren"Također, možemo dodati element u neki od elemenata liste.
> lista2$Biljka[2] <- "Hibiskus"
> lista2## $Drzava
## [1] "Hrvatska"
##
## $Grad
## [1] "Hvar"
##
## $Selo
## [1] "Heki"
##
## $Rijeka
## [1] "Hudinja"
##
## $Jezero
## [1] "Harambašic"
##
## $Opcina
## [1] "Hum na Sutli"
##
## $Planina
## [1] "Hahlici"
##
## $Zivotinja
## [1] "Hrcak" "Hobotnica" "Hijena"
##
## $Biljka
## [1] "Hren" "Hibiskus"Ako element koji se pridružuje nije potrebno imenovati, onda se pridruživanje može izvršiti na sljedeći način:
> lista1[5] <- "50 %"
> lista1## $broj
## [1] 5
##
## $grad
## [1] "Pula"
##
## $vektor
## [1] 1 2 3 4 5
##
## $matrica
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9
##
## [[5]]
## [1] "50 %"7.4.4 Izmjena ili brisanje elementa
Ako se želi izbrisati element, onda je to moguće na sljedeći način:
> lista1[[1]] <- NULL
> lista1## $grad
## [1] "Pula"
##
## $vektor
## [1] 1 2 3 4 5
##
## $matrica
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9
##
## [[4]]
## [1] "50 %"Izmjena elementa:
> lista1[[2]] <- c(6, 7, 8, 9, 10)
> lista1## $grad
## [1] "Pula"
##
## $vektor
## [1] 6 7 8 9 10
##
## $matrica
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9
##
## [[4]]
## [1] "50 %"7.4.5 Spajanje lista
Nadalje, slično kao što se mogu spajati vektori i matrice, mogu se spajati i liste.
> lista3 <- list(lista1, lista2)
> lista3## [[1]]
## [[1]]$grad
## [1] "Pula"
##
## [[1]]$vektor
## [1] 6 7 8 9 10
##
## [[1]]$matrica
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9
##
## [[1]][[4]]
## [1] "50 %"
##
##
## [[2]]
## [[2]]$Drzava
## [1] "Hrvatska"
##
## [[2]]$Grad
## [1] "Hvar"
##
## [[2]]$Selo
## [1] "Heki"
##
## [[2]]$Rijeka
## [1] "Hudinja"
##
## [[2]]$Jezero
## [1] "Harambašic"
##
## [[2]]$Opcina
## [1] "Hum na Sutli"
##
## [[2]]$Planina
## [1] "Hahlici"
##
## [[2]]$Zivotinja
## [1] "Hrcak" "Hobotnica" "Hijena"
##
## [[2]]$Biljka
## [1] "Hren" "Hibiskus"Alternativno, liste se mogu spojiti i kombiniranjem:
> lista4 <- c(lista1, lista2)
> lista4## $grad
## [1] "Pula"
##
## $vektor
## [1] 6 7 8 9 10
##
## $matrica
## [,1] [,2] [,3]
## [1,] 10 13 16
## [2,] 11 14 17
## [3,] 12 15 18
## [4,] 1 2 3
## [5,] 4 5 6
## [6,] 7 8 9
##
## [[4]]
## [1] "50 %"
##
## $Drzava
## [1] "Hrvatska"
##
## $Grad
## [1] "Hvar"
##
## $Selo
## [1] "Heki"
##
## $Rijeka
## [1] "Hudinja"
##
## $Jezero
## [1] "Harambašic"
##
## $Opcina
## [1] "Hum na Sutli"
##
## $Planina
## [1] "Hahlici"
##
## $Zivotinja
## [1] "Hrcak" "Hobotnica" "Hijena"
##
## $Biljka
## [1] "Hren" "Hibiskus"7.4.6 Razdvajanje lista
Razdvajanje liste vršimo pomoću unlist().
> unlist(lista4)## grad vektor1 vektor2 vektor3 vektor4 vektor5 matrica1 matrica2
## "Pula" "6" "7" "8" "9" "10" "10" "11"
## matrica3 matrica4 matrica5 matrica6 matrica7 matrica8 matrica9 matrica10
## "12" "1" "4" "7" "13" "14" "15" "2"
## matrica11 matrica12 matrica13 matrica14 matrica15 matrica16 matrica17 matrica18
## "5" "8" "16" "17" "18" "3" "6" "9"
## Drzava Grad Selo Rijeka Jezero Opcina Planina
## "50 %" "Hrvatska" "Hvar" "Heki" "Hudinja" "Harambašic" "Hum na Sutli" "Hahlici"
## Zivotinja1 Zivotinja2 Zivotinja3 Biljka1 Biljka2
## "Hrcak" "Hobotnica" "Hijena" "Hren" "Hibiskus"Funkcija unlist() pretvara listu u vektor, pa možete uočiti da su svi elementi matrice zasebno odvojeni. Isprobajte primjenu unlist() na lista3 i usporedite rezultate.
Ako su listi već pridodani atributi (nazivi), oni se mogu provjeriti/ ispisati ponoću attributes() ili attr().
> attributes(lista2)## $names
## [1] "Drzava" "Grad" "Selo" "Rijeka" "Jezero" "Opcina" "Planina" "Zivotinja" "Biljka"> attr(lista1, "names")## [1] "grad" "vektor" "matrica" ""7.5 Prednosti i nedostaci rada s listama te najčešće greške
Uobičajene greške pri radu s listama
Neispravan pristup elementima: greške u pristupu elementima liste mogu se dogoditi ako koristite jednostruke uglate zagrade (
[ ]) umjesto dvostrukih ([[ ]]) za pristup elementima liste. Jednostruke zagrade vraćaju podlistu, dok dvostruke vraćaju element.Zaboravljanje heterogenosti podataka: budući da liste mogu sadržavati različite tipove podataka, nemojte zaboraviti na ovu činjenicu pri manipulaciji ili analizi podataka unutar liste, jer to može dovesti do neočekivanih rezultata ili grešaka.
Zadavanje (nepotrebno) složene strukture podataka: Ponekad korisnici nepotrebno kompliciraju strukturu podataka koristeći liste kada bi jednostavnija struktura podataka, kao što je vektor ili matrica, bila adekvatnija i efikasnija za određeni zadatak.
Prednosti korištenja lista
Fleksibilnost: liste u R-u mogu sadržavati elemente različitih tipova, uključujući brojeve, znakove, vektore, matrice, pa čak i druge liste. Ova fleksibilnost omogućava da u jednom objektu pohranimo kompleksne skupove podataka.
Strukturiranje složenih podataka: Liste su idealne za organiziranje složenih i hijerarhijskih podataka. Primjerice, možete imati listu koja sadrži podatke o različitim geografskim regijama, gdje svaki element liste predstavlja određenu regiju s vlastitom podlistom podataka relevantnih za tu regiju.
Spremanje funkcija i njihovih rezultata: Liste se mogu koristiti za spremanje niza funkcija ili čak rezultata izvršenja funkcija, što omogućava jednostavan pristup i analizu tih podataka kasnije.
Kad koristiti liste
Za rad s heterogenim podacima: liste su idealan izbor kada trebate raditi s nizom objekta različitih tipova podataka koje trebate držati zajedno.
Za složene strukture podataka: ako vaši podaci imaju složenu ili hijerarhijsku strukturu, liste omogućuju efikasno grupiranje i organizaciju tih podataka.
Kada funkcije vraćaju više od jednog rezultata: liste su korisne za spremanje rezultata funkcija koje vraćaju više od jednog objekta, omogućavajući vam da pohranite sve rezultate zajedno i pristupate im po potrebi.
7.6 Kreiranje podatkovnih okvira (data frame)
U ovom poglavlju objašnjavaju se različiti načini kreiranja podatkovnih okvira u R-u. Kroz primjere, poglavlje prikazuje četiri pristupa za konstruiranje podatkovnog okvira, ilustrirajući fleksibilnost i različite stilove kodiranja u R-u. Osim toga, naglašava važnost prilagođavanja tipa podataka unutar stupaca kako bi se izbjegle moguće greške prilikom analize.
Podatkovni okviri (data frame ili df) su uređeni dvodimenzionalni skupovi podataka koji se mogu sastojati od elemenata različitih tipova, uz uvjet da se unutar pojedinog stupca nalaze elementi istog tipa. Primjer:
## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 1. Croatia 57668 2980
## 2. France 211998 48069
## 3. China 158606 149720
## 4. Italy 93228.6 61194.6
## 5. Austria 30816 11043
## 6. Ireland 10926 8643Podaci se odnose na zadnje dostupne podatke iz 2018. godine dostupne na mrežnim stranicama Svjetske Banke, DT.INT.ARVL i ST.INT.DPRT izraženi u tisućama. Recimo da se ovi podaci žele zapisati u obliku podatkovnog okvira. Za to postoji više načina.
Prvi način:
> y <- c("Croatia", 57668.00, 2980.00,
+ "France", 211998.00, 48069.00,
+ "China", 158606.00, 149720.00,
+ "Italy", 93228.60, 61194.60,
+ "Austria", 30816.00, 11043.00,
+ "Ireland", 10926.00, 8643.00)
>
> Tablica2 <- matrix(y, nrow = 6, ncol = 3, byrow = TRUE)
> colnames(Tablica2) <- c("Drzava", "Broj_turistickih_dolazaka",
+ "Broj_turistickih_putovanja_(odlazni)")
> rownames(Tablica2) <- c("1.", "2.", "3.", "4.", "5.", "6.")
> Turisti1<-as.data.frame(Tablica2)
>
> #s obzirom da su podaci uneseni mješovito s obzirom na tip,
> # ako se broj turističkih dolazaka i odlazaka ne definiraju kao
> # double ili integer, preuzet će tip chr
>
> Turisti1$`Broj_turistickih_dolazaka` <- as.double(Turisti1$`Broj_turistickih_dolazaka`)
> Turisti1$`Broj_turistickih_putovanja_(odlazni)` <- as.double(Turisti1$`Broj_turistickih_putovanja_(odlazni)`)
> Turisti1## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 1. Croatia 57668 2980
## 2. France 211998 48069
## 3. China 158606 149720
## 4. Italy 93229 61195
## 5. Austria 30816 11043
## 6. Ireland 10926 8643Drugi način:
> Drzava <- c("Croatia", "France", "China", "Italy", "Austria", "Ireland")
> Br_t_dol <- c(57668, 211998, 158606, 93228, 30816, 10926)
> Br_t_odl <- c(2980, 48069, 14972, 61194, 11043, 8643)
> Turisti2 <- data.frame(Drzava, Br_t_dol, Br_t_odl)
> Turisti2## Drzava Br_t_dol Br_t_odl
## 1 Croatia 57668 2980
## 2 France 211998 48069
## 3 China 158606 14972
## 4 Italy 93228 61194
## 5 Austria 30816 11043
## 6 Ireland 10926 8643Treći način:
> D1 <- c("Croatia", 57668.00, 2980.00)
> D2 <- c("France", 211998.00, 48069.00)
> D3 <- c("China", 158606.00, 149720.00)
> D4 <- c("Italy", 93228.00, 61194.60)
> D5 <- c("Austria", 30816.00, 11043.00)
> D6 <- c("Ireland", 10926.00, 8643.00)
> Tur <- rbind(D1, D2, D3, D4, D5, D6)
> colnames(Tur) <- c("Drzava", "Broj_turistickih_dolazaka",
+ "Broj_turistickih_putovanja_(odlazni)")
> rownames(Tur) <- c("1.", "2.", "3.", "4.", "5.", "6.")
> Turisti3 <- as.data.frame(Tur)
>
> #s obzirom da su podaci uneseni mješovito s obzirom na tip,
> # ako se broj turističkih dolazaka i odlazaka ne definiraju kao
> # double ili integer, preuzet će tip chr
>
> Turisti3$`Broj_turistickih_dolazaka` <- as.double(Turisti3$`Broj_turistickih_dolazaka`)
> Turisti3$`Broj_turistickih_putovanja_(odlazni)` <- as.double(Turisti3$`Broj_turistickih_putovanja_(odlazni)`)
> Turisti3## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 1. Croatia 57668 2980
## 2. France 211998 48069
## 3. China 158606 149720
## 4. Italy 93228 61195
## 5. Austria 30816 11043
## 6. Ireland 10926 8643Četvrti način:
> Turisti4 <- data.frame(Drzava=c("Croatia", "France", "China",
+ "Italy", "Austria", "Ireland"),
+ Br_t_dol=c(57668, 211998, 158606,
+ 93228, 30816, 10926),
+ Br_t_odl=c(2980, 48069, 14972,
+ 61194, 11043, 8643))
> Turisti4## Drzava Br_t_dol Br_t_odl
## 1 Croatia 57668 2980
## 2 France 211998 48069
## 3 China 158606 14972
## 4 Italy 93228 61194
## 5 Austria 30816 11043
## 6 Ireland 10926 8643Može se uočiti da su drugi i četvrti način jednostavniji i brži za primjenu. Poanta ovih primjera je da uočite da je do rješenja moguće doći na različite načine. Dakako, neki od načina bit će elegantniji od drugih, ali važno je uočiti da ne postoji isključivo „jedan način na koji se nešto radi”. Igrajte se, isprobavajte i otkrijte svoj stil.
Već je pri unosu podataka u podatkovni okvir na prvi i treći način primijenjen jedan oblik odabira. Prije nego se pozabavimo odabirima, pogledajmo što čini podatkovni okvir.
7.7 Rad s podatkovnim okvirima
U ovom poglavlju objašnjava se rad s podatkovnim okvirima, uključujući pregled i odabir elemenata, dodavanje i brisanje podataka te filtriranje i sortiranje prema specifičnim kriterijima. Poglavlje također obuhvaća kreiranje podskupova podataka, osnovne statističke analize, kao i prikaz podataka u obliku tablica. Na kraju, razmatraju se prednosti i nedostaci podatkovnih okvira, kao i najčešće greške pri radu s njima.
7.7.1 Uvid u podatkovni okvir
Ako bismo htjeli provjeriti što podatkovni okvir sadrži, to možemo učiniti koristeći str(), head() ili tail().
> str(Turisti1)## 'data.frame': 6 obs. of 3 variables:
## $ Drzava : chr "Croatia" "France" "China" "Italy" ...
## $ Broj_turistickih_dolazaka : num 57668 211998 158606 93229 30816 ...
## $ Broj_turistickih_putovanja_(odlazni): num 2980 48069 149720 61195 11043 ...Funkcija str() daje uvid u data frame (ili df), tj. podatkovni okvir. Ovaj podatkovni okvir sastoji se od 6 opažanja za svaku od 3 varijable. Navedene su varijable, tip varijabli i ispis prvih nekoliko elemenata (slično zapisu u prozoru Environment). Dakle, podatkovni okvir je uređen varijablama i brojem opažanja. Varijable su zapisane u stupcima, a opažanja po recima.
head() će standardno rezultirati prikazom prvih 6 redaka df-a. Ako bismo uz naziv df-a dodali i broj, na primjer 3, tada bi ispis sadržavao prva tri retka.
> head(Turisti1, 3)## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 1. Croatia 57668 2980
## 2. France 211998 48069
## 3. China 158606 149720Slična je situacija s naredbom tail(), samo što standardno ispisuje posljednjih 6 redaka. Ako se uz naziv podatkovnog okvira doda broj, tada će ispisati onoliko redaka koliko je definirano brojem.
> tail(Turisti1, 2)## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 5. Austria 30816 11043
## 6. Ireland 10926 8643Nadalje, može se koristiti i glimpse() iz paketa dplyr.
> library(dplyr)
> glimpse(Turisti1)## Rows: 6
## Columns: 3
## $ Drzava <chr> "Croatia", "France", "China", "Italy", "Austria", "Ireland"
## $ Broj_turistickih_dolazaka <dbl> 57668, 211998, 158606, 93229, 30816, 10926
## $ `Broj_turistickih_putovanja_(odlazni)` <dbl> 2980, 48069, 149720, 61195, 11043, 8643Ako se podatkovni okvir pretražuje prema elementima, npr. [1,2], tada će odabrani element biti prvo opažanje pripisano drugoj varijabli (prvi redak, drugi stupac). Osim toga, češće se ispituje pojedina varijabla. Promotrimo to kroz nekoliko načina odabiranja elemenata iz podatkovnog okvira.
7.7.2 Odabir elemenata
Također, treba voditi računa da, ako se odabir ne spremi pod novim nazivom, „odabir” će se prikazati samo u ispisu (bez kreiranja novog vektora, matrice ili df-a). Najjednostavniji je način upis znaka dolara ($) nakon naziva podatkovnog okvira. Po upisu znaka dolara, pokazat će se padajući izbornik s nazivima varijabli, pri čemu se može samo kliknuti na odabranu varijablu.
> Turisti1$Drzava## [1] "Croatia" "France" "China" "Italy" "Austria" "Ireland"Slično kao kod vektora, ako je već odabran jedan stupac (varijabla) iz df-a, tada će se upisom broja u uglate zagrade izolirati taj element. Na primjer, Turisti1$Drzava[3], rezultira ispisom 3. elementa varijable Država iz podatkovnog okvira Turisti1.
> Turisti1$Drzava[3]## [1] "China"No, s obzirom da je podatkovni okvir dvodimenzionalan (ima retke i stupce), element se može odabrati i brojčanim određivanjem retka i stupca. Na primjer, Turisti1[1,2] će rezultirati ispisom elementa koji se nalazi u prvom retku i drugom stupcu.
> Turisti1[1, 2]## [1] 57668Obratite pozornost na to da Turisti1[2,1] rezultira odabirom elementa koji se nalazi u drugom retku prvog stupca. Odnosno, Turisti1[1,2] \(\neq\) Turisti1[2,1].
> Turisti1[2, 1]## [1] "France"Sljedeći je način odabira elementa upisom naziva varijable u uglate zagrade uz naziv podatkovnog okvira. Pritom treba paziti da naziv bude unutar navodnih znakova.
> Turisti1["Drzava"]## Drzava
## 1. Croatia
## 2. France
## 3. China
## 4. Italy
## 5. Austria
## 6. IrelandAko se od moguće dvije dimenzije odabere samo jedna, onda će rezultat biti prikaz retka ili stupca. Tako, na primjer, Turisti1[2,] rezultira prikazom drugog retka.
> Turisti1[2, ]## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 2. France 211998 48069Nasuprot tome, Turisti1[,2] rezultirat će prikazom drugog stupca.
> Turisti1[ ,2]## [1] 57668 211998 158606 93229 30816 109267.7.3 Dodavanje elemenata
> USA <-data.frame(Drzava = "United States",
+ Br_t_dol = 169324.92,
+ Br_t_odl = 157873.00)
> Turisti2<-rbind(Turisti2, USA)
> Turisti2## Drzava Br_t_dol Br_t_odl
## 1 Croatia 57668 2980
## 2 France 211998 48069
## 3 China 158606 14972
## 4 Italy 93228 61194
## 5 Austria 30816 11043
## 6 Ireland 10926 8643
## 7 United States 169325 157873Recimo da se za potrebe daljnje analize želi izvršiti subset europskih država. Iako je nama lako odrediti koje države pripadaju Europi, a koje drugim kontinentima, R-u je potrebno dodati podatke koji će sadržavati potrebne karakteristike. Jedan od načina je pridodavanje kontinenta svakom opažanju, a drugi je dodavanje elemenata logičkog tipa u obliku zasebne varijable. Ovdje će se iskoristiti drugi pristup. Sličan pristup može se, općenito primijeniti pri ručnom upisu i dodavanju varijable postojećem podatkovnom okviru.
> EU <- c(TRUE, TRUE, FALSE, TRUE, TRUE, TRUE, FALSE)
> Turisti2 <- cbind(Turisti2, EU)
> Turisti2## Drzava Br_t_dol Br_t_odl EU
## 1 Croatia 57668 2980 TRUE
## 2 France 211998 48069 TRUE
## 3 China 158606 14972 FALSE
## 4 Italy 93228 61194 TRUE
## 5 Austria 30816 11043 TRUE
## 6 Ireland 10926 8643 TRUE
## 7 United States 169325 157873 FALSE7.7.4 Podskup podatkovnog okvira prema kriteriju (filtriranje)
Ponekad je za daljnju analizu potreban podskup podataka, što se postiže funkcijom subset(). Na primjer, recimo da nas zanimaju samo one države koje su zabilježile više od 30 000 dolazaka turista.
> Tur_sub <- subset(Turisti1, Turisti1$`Broj_turistickih_dolazaka`>30000)
> Tur_sub## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 1. Croatia 57668 2980
## 2. France 211998 48069
## 3. China 158606 149720
## 4. Italy 93229 61195
## 5. Austria 30816 11043Ili, na primjer, ako nas zanimaju sve države osim Hrvatske, onda će to izgledati ovako:
> Tur_noCro <- subset(Turisti1, Drzava != "Croatia")
> Tur_noCro## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 2. France 211998 48069
## 3. China 158606 149720
## 4. Italy 93229 61195
## 5. Austria 30816 11043
## 6. Ireland 10926 8643Subset je moguće napraviti prema bilo kojem kriteriju kojeg je moguće zadati temeljem postojećih podataka. U nekim situacijama postojeći podaci neće biti dovoljni za potrebe analize i to će iziskivati dodavanje elemenata i/ili varijabli.
Možete stvoriti podskup temeljen na kriteriju članstva država u EU, pri čemu se koristi stupac EU kao logički vektor, na sljedeći način:
> Tur_eu <- subset(Turisti2, EU==TRUE)
> Tur_eu## Drzava Br_t_dol Br_t_odl EU
## 1 Croatia 57668 2980 TRUE
## 2 France 211998 48069 TRUE
## 4 Italy 93228 61194 TRUE
## 5 Austria 30816 11043 TRUE
## 6 Ireland 10926 8643 TRUEIako je dobiven podskup prema traženom kriteriju, može se uočiti da su nazivi redaka ostali isti kao ranije.
7.7.5 Sortiranje elemenata
Ako se elementi u podatkovnom okviru žele redoslijedno urediti prema vrijednostima pojedine varijable, tada se provodi sortiranje, koje se najčešće vrši pomoću funkcije order() i uglatih zagrada.
> Turisti2[order(Br_t_dol), ]## Drzava Br_t_dol Br_t_odl EU
## 6 Ireland 10926 8643 TRUE
## 5 Austria 30816 11043 TRUE
## 1 Croatia 57668 2980 TRUE
## 4 Italy 93228 61194 TRUE
## 3 China 158606 14972 FALSE
## 2 France 211998 48069 TRUEPrethodni je ispis rezultirao poredanim prikazom podataka iz podatkovnog okvira Turisti2.
Ako bismo htjeli provjeriti kako podatkovni okvir izgleda nakon primjene ove funkcije, to možemo učiniti koristeći str(), head() ili tail().
> str(Turisti2)## 'data.frame': 7 obs. of 4 variables:
## $ Drzava : chr "Croatia" "France" "China" "Italy" ...
## $ Br_t_dol: num 57668 211998 158606 93228 30816 ...
## $ Br_t_odl: num 2980 48069 14972 61194 11043 ...
## $ EU : logi TRUE TRUE FALSE TRUE TRUE TRUE ...Dok str daje uvid u dimenzije podatkovnog skupa, uz popis varijabli, njihovih vrsta te ispisa prvih nekoliko opažanja, head daje ispis prvih 6 redaka podatkovnog skupa.
> head(Turisti2)## Drzava Br_t_dol Br_t_odl EU
## 1 Croatia 57668 2980 TRUE
## 2 France 211998 48069 TRUE
## 3 China 158606 14972 FALSE
## 4 Italy 93228 61194 TRUE
## 5 Austria 30816 11043 TRUE
## 6 Ireland 10926 8643 TRUEfunkcija head() zadano (engl. default) prikazuje prvih 6 redaka podatkovnog okvira, a taj se broj može promijeniti, na primjer:
> head(Turisti2, 3)## Drzava Br_t_dol Br_t_odl EU
## 1 Croatia 57668 2980 TRUE
## 2 France 211998 48069 TRUE
## 3 China 158606 14972 FALSEFunkcija tail() prikazuje posljednjih 6 redaka podatkovnog okvira, a može se podesiti i drugačiji broj redaka ovisno o potrebama.
> tail(Turisti2)## Drzava Br_t_dol Br_t_odl EU
## 2 France 211998 48069 TRUE
## 3 China 158606 14972 FALSE
## 4 Italy 93228 61194 TRUE
## 5 Austria 30816 11043 TRUE
## 6 Ireland 10926 8643 TRUE
## 7 United States 169325 157873 FALSEOno što se može uočiti iz pregleda podatkovnog okvira jest da nije došlo do promjene u poretku. Da bi promjena u poretku bila evidentirana, potrebno je kreirati novi podatkovni okvir.
> Tur_ord <- Turisti2[order(Br_t_dol), ]
> Tur_ord## Drzava Br_t_dol Br_t_odl EU
## 6 Ireland 10926 8643 TRUE
## 5 Austria 30816 11043 TRUE
## 1 Croatia 57668 2980 TRUE
## 4 Italy 93228 61194 TRUE
## 3 China 158606 14972 FALSE
## 2 France 211998 48069 TRUEFunkcija sort() ne primjenjuje se na podatkovnom okviru, nego na vektorima, tako da ovdje nije od koristi.
> Turisti2[order(Drzava), ]## Drzava Br_t_dol Br_t_odl EU
## 5 Austria 30816 11043 TRUE
## 3 China 158606 14972 FALSE
## 1 Croatia 57668 2980 TRUE
## 2 France 211998 48069 TRUE
## 6 Ireland 10926 8643 TRUE
## 4 Italy 93228 61194 TRUEObratite pozornost na to da je order() moguće primijeniti i na elementima tipa character. Nadalje, funkcija order() će uvijek sortirati vrijednosti silazno, ako drugačije nije navedeno. Redoslijed prema kriteriju uzlaznog povećavanja vrijednosti elemenata odlaznih turista moguće je zadati:
> Turisti2[order(Br_t_odl, decreasing = TRUE), ]## Drzava Br_t_dol Br_t_odl EU
## 4 Italy 93228 61194 TRUE
## 2 France 211998 48069 TRUE
## 3 China 158606 14972 FALSE
## 5 Austria 30816 11043 TRUE
## 6 Ireland 10926 8643 TRUE
## 1 Croatia 57668 2980 TRUE7.7.6 Brisanje elemenata
Nadalje, tijekom pripreme podataka za analizu može se pojaviti potreba za brisanjem elemenata, opažanja ili varijabli. Brisanje elementa zapravo se vrši putem zamjene elementa s oznakom za nedostupnu vrijednost (Not Available/Missing Values), koja predstavlja logičku konstantu duljine 1, a R ju tumači kao indikator nepostojeće vrijednosti.
> Turisti2[5, 4] <- NA
> Turisti2## Drzava Br_t_dol Br_t_odl EU
## 1 Croatia 57668 2980 TRUE
## 2 France 211998 48069 TRUE
## 3 China 158606 14972 FALSE
## 4 Italy 93228 61194 TRUE
## 5 Austria 30816 11043 NA
## 6 Ireland 10926 8643 TRUE
## 7 United States 169325 157873 FALSEBrisanje stupca:
> Turisti2$EU <- NULL
> Turisti2## Drzava Br_t_dol Br_t_odl
## 1 Croatia 57668 2980
## 2 France 211998 48069
## 3 China 158606 14972
## 4 Italy 93228 61194
## 5 Austria 30816 11043
## 6 Ireland 10926 8643
## 7 United States 169325 157873Napomena: Izmjene vezane za dodavanje i brisanje elemenata izravno utječu na postojeći dataset, bez potrebe za kreiranjem novog objekta.
Drugi način odnosi se na prikaz bez pojedinog stupca i tehnički taj stupac neće biti obrisan, samo neće biti prikazan.
> Turisti2[-2]## Drzava Br_t_odl
## 1 Croatia 2980
## 2 France 48069
## 3 China 14972
## 4 Italy 61194
## 5 Austria 11043
## 6 Ireland 8643
## 7 United States 157873Da bi se stupac izbrisao koristeći ovaj pristup, potrebno je kreirati novi objekt:
> Tur_odl <- Turisti2[-2]Na sličan način, mogu se brisati reci ili samo ukloniti iz prikaza.
> Tur0 <- Turisti1[-1, ]
> Tur0## Drzava Broj_turistickih_dolazaka Broj_turistickih_putovanja_(odlazni)
## 2. France 211998 48069
## 3. China 158606 149720
## 4. Italy 93229 61195
## 5. Austria 30816 11043
## 6. Ireland 10926 8643Također, moguće je ukloniti više opažanja istovremeno, navodeći pripadajuće retke na prvom mjestu unutar uglatih zagrada, koristeći funkciju combine.
> Tur_noEU <- Turisti2[-c(1, 2, 4, 5, 6), ]
> Tur_noEU## Drzava Br_t_dol Br_t_odl
## 3 China 158606 14972
## 7 United States 169325 157873Osim toga, moguće je izvršiti i kombinaciju pretraživanja po varijablama i zamjenu elementa, na primjer:
> #Za Br_t_dol Francuske, želi se zamijeniti postojeća vrijednost s NA
> Turisti2$Br_t_dol[Turisti2$Drzava == "France"] <- NA
> Turisti2## Drzava Br_t_dol Br_t_odl
## 1 Croatia 57668 2980
## 2 France NA 48069
## 3 China 158606 14972
## 4 Italy 93228 61194
## 5 Austria 30816 11043
## 6 Ireland 10926 8643
## 7 United States 169325 157873Iako u ovako jednostavnim primjerima, ovakav pristup djeluje suvišno, u zahtjevnijim skupovima podataka koji broje tisuće elemenata, ovaj je pristup često učinkovitiji.
7.7.7 Učitavanje podatkovnog okvira sadržanog u R-u
Postoje neki podatkovni okviri koji su već uključeni u R, a brojni su uključeni u različite pakete. Jedan od češće korištenih podatkovnih okvira za vježbu i primjere je iris. Podatkovni okvir iris sadrži opažanja o duljini i širini latica za tri vrste cvijeća iris (Iris setosa, versicolor i virginica). U spomenutom podatkovnom okviru postoji 150 opažanja (redaka) i 5 varijabli (stupaca), s nazivima: Sepal.Length, Sepal.Width, Petal.Length, Petal.Width i Species.
Podatkovni okvir koji je sadržan u R-u ili nekom od već instaliranih paketa može se pozvati koristeći naredbu data(), na primjer, na sljedeći način:
> data("iris")Prvo, nakon što upišete data i otvorite zagradu, nudi se izbor dostupnih podatkovnih okvira. Drugo, ako vas zanimaju detalji o pojedinom podatkovnom okviru, potrebno je naziv upisati u tražilicu u prozoru Help (donji desni prozor).
Provjerimo kako skup podataka izgleda.
> str(iris)## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...> head(iris, 5)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosaAko ne želimo stalno koristiti operator $ u kombinaciji s nazivom podatkovnog okvira, korisna je funkcija attach(). Ta će funkcija pridružiti podatkovni okvir R-ovom putu traženja, što omogućuje izravno pozivanje varijabli putem imena.
> attach(iris)7.7.8 Izračun pokazatelja deskriptivne statistike
Izračunajmo nekoliko jednostavnih pokazatelja.
> mean(Sepal.Length)## [1] 5.8> fivenum(Sepal.Width)## [1] 2.0 2.8 3.0 3.3 4.4> sd(Sepal.Length)## [1] 0.83Kombinacija statističkih pokazatelja, s naglaskom na mjere središnje tendencije, može se dobiti naredbom summary().
> summary(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## Min. :4.3 Min. :2.0 Min. :1.0 Min. :0.1 setosa :50
## 1st Qu.:5.1 1st Qu.:2.8 1st Qu.:1.6 1st Qu.:0.3 versicolor:50
## Median :5.8 Median :3.0 Median :4.3 Median :1.3 virginica :50
## Mean :5.8 Mean :3.1 Mean :3.8 Mean :1.2
## 3rd Qu.:6.4 3rd Qu.:3.3 3rd Qu.:5.1 3rd Qu.:1.8
## Max. :7.9 Max. :4.4 Max. :6.9 Max. :2.5Ako želimo izračunati uobičajene pokazatelje deskriptivne statistike, to možemo učiniti na način da izračunamo svaki od pokazatelja, a rezultate pohranimo u listu rezultata.
> mean_Sepal.Length <- mean(Sepal.Length)
> median_Sepal.Length <- median(Sepal.Length)
> mode_Sepal.Length <- as.numeric(names(sort(table(Sepal.Length),
+ decreasing = TRUE))[1])
>
> # Kvartili
> quartiles <- quantile(Sepal.Length)
>
> # Mjere disperzije
> range_Sepal.Length <- diff(range(Sepal.Length))
> iqr_Sepal.Length <- IQR(Sepal.Length)
> mad_Sepal.Length <- mad(Sepal.Length)
> var_Sepal.Length <- var(Sepal.Length)
> sd_Sepal.Length <- sd(Sepal.Length)
> cv_Sepal.Length <- sd_Sepal.Length / mean_Sepal.Length * 100
>
> # Mjere oblika distribucije
> library(e1071)
> skewness_Sepal.Length <- skewness(Sepal.Length)
> kurtosis_Sepal.Length <- kurtosis(Sepal.Length)
>
> # Prikaz rezultata
> mjere_deskriptivne_statistike_Sepal.Length <- list(
+ Prosjek = mean_Sepal.Length,
+ Medijan = median_Sepal.Length,
+ Mod = mode_Sepal.Length,
+ PrviKvartil = quartiles[2],
+ TreciKvartil = quartiles[4],
+ Raspon = range_Sepal.Length,
+ IQR = iqr_Sepal.Length,
+ MAD = mad_Sepal.Length,
+ Varijanca = var_Sepal.Length,
+ StandardnaDevijacija = sd_Sepal.Length,
+ KoeficijentVarijacije = cv_Sepal.Length,
+ Asimetrija = skewness_Sepal.Length,
+ Zaobljenost = kurtosis_Sepal.Length
+ )
>
> mjere_deskriptivne_statistike_Sepal.Length## $Prosjek
## [1] 5.8
##
## $Medijan
## [1] 5.8
##
## $Mod
## [1] 5
##
## $PrviKvartil
## 25%
## 5.1
##
## $TreciKvartil
## 75%
## 6.4
##
## $Raspon
## [1] 3.6
##
## $IQR
## [1] 1.3
##
## $MAD
## [1] 1
##
## $Varijanca
## [1] 0.69
##
## $StandardnaDevijacija
## [1] 0.83
##
## $KoeficijentVarijacije
## [1] 14
##
## $Asimetrija
## [1] 0.31
##
## $Zaobljenost
## [1] -0.61Ovdje korištene naredbe mogu se primjenjivati samo na vektorima. To znači da bismo koristeći ovakav pristup morali računati sve ove pokazatelje zasebno, za svaku varijablu u podatkovnom okviru.
Alternativno, postoje dva paketa koja se najčešće koriste za opisivanje podataka. Oba paketa koja će se ovdje prikazati mogu se koristiti za izračun pokazatelja deskriptivne statistike pojedine varijable (zapisane u vektoru) ili više varijabli zajedno (zapisanih u podatkovnom okviru).
Prvi je paket psych, a izračunati pokazatelji deskriptivne statistike dohvaćaju se naredbom describe(). Za više mogućnosti podešavanja, pročitajte stranice pomoći paketa.
> library(psych)
> pokazatelji_iris <- describe(iris, IQR = TRUE)
> knitr::kable(pokazatelji_iris, align = "c")| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se | IQR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sepal.Length | 1 | 150 | 5.8 | 0.83 | 5.8 | 5.8 | 1.04 | 4.3 | 7.9 | 3.6 | 0.31 | -0.61 | 0.07 | 1.3 |
| Sepal.Width | 2 | 150 | 3.1 | 0.44 | 3.0 | 3.0 | 0.44 | 2.0 | 4.4 | 2.4 | 0.31 | 0.14 | 0.04 | 0.5 |
| Petal.Length | 3 | 150 | 3.8 | 1.77 | 4.3 | 3.8 | 1.85 | 1.0 | 6.9 | 5.9 | -0.27 | -1.42 | 0.14 | 3.5 |
| Petal.Width | 4 | 150 | 1.2 | 0.76 | 1.3 | 1.2 | 1.04 | 0.1 | 2.5 | 2.4 | -0.10 | -1.36 | 0.06 | 1.5 |
| Species* | 5 | 150 | 2.0 | 0.82 | 2.0 | 2.0 | 1.48 | 1.0 | 3.0 | 2.0 | 0.00 | -1.52 | 0.07 | 2.0 |
Drugi paket odnosi se na summarytools, koji sadrži naredbu descr(). Ova naredba sadrži brojne mogućnosti podešavanja, uključujući i podešavanja outputa. Ovdje su uključeni argumenti stats = “all” i style = “rmarkdown” radi ilustracije. Više mogućnosti naći ćete na stranicama pomoći paketa, odnosno ove naredbe.
> library(summarytools)
> descr(iris, stats = "all", style = "rmarkdown", size = 150)## ### Descriptive Statistics
## #### iris
## **N:** 150
##
## | | Petal.Length | Petal.Width | Sepal.Length | Sepal.Width |
## |----------------:|-------------:|------------:|-------------:|------------:|
## | **Mean** | 3.76 | 1.20 | 5.84 | 3.06 |
## | **Std.Dev** | 1.77 | 0.76 | 0.83 | 0.44 |
## | **Min** | 1.00 | 0.10 | 4.30 | 2.00 |
## | **Q1** | 1.60 | 0.30 | 5.10 | 2.80 |
## | **Median** | 4.35 | 1.30 | 5.80 | 3.00 |
## | **Q3** | 5.10 | 1.80 | 6.40 | 3.30 |
## | **Max** | 6.90 | 2.50 | 7.90 | 4.40 |
## | **MAD** | 1.85 | 1.04 | 1.04 | 0.44 |
## | **IQR** | 3.50 | 1.50 | 1.30 | 0.50 |
## | **CV** | 0.47 | 0.64 | 0.14 | 0.14 |
## | **Skewness** | -0.27 | -0.10 | 0.31 | 0.31 |
## | **SE.Skewness** | 0.20 | 0.20 | 0.20 | 0.20 |
## | **Kurtosis** | -1.42 | -1.36 | -0.61 | 0.14 |
## | **N.Valid** | 150.00 | 150.00 | 150.00 | 150.00 |
## | **Pct.Valid** | 100.00 | 100.00 | 100.00 | 100.00 |7.7.9 Pretvaranje varijable u faktor unutar postojećeg podatkovnog okvira
Kako bi se ilustrirala pretvorba varijable u faktor, koristit će se podatkovni okvir mtcars, dostupan u R-u. S obzirom da je unaprijed instaliran s R-om i dostupan u osnovnoj instalaciji, može se odmah koristiti bez dodatnih preuzimanja ili instalacija. mtcars predstavlja tehničke karakteristike 32 automobila iz 1973. i 1974. godine, koji su bili uključeni u američki časopis Motor Trend.
> data(mtcars)
> head(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21 6 160 110 3.9 2.6 16 0 1 4 4
## Mazda RX4 Wag 21 6 160 110 3.9 2.9 17 0 1 4 4
## Datsun 710 23 4 108 93 3.8 2.3 19 1 1 4 1
## Hornet 4 Drive 21 6 258 110 3.1 3.2 19 1 0 3 1
## Hornet Sportabout 19 8 360 175 3.1 3.4 17 0 0 3 2
## Valiant 18 6 225 105 2.8 3.5 20 1 0 3 1> str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...Ovdje su cyl (broj cilindara) i gear (broj brzina) numeričke varijable, ali se i cjelobrojne kvantitativne varijable mogu tretirati kao kategorije za potrebe analize. Pritom traba imati u vidu da je to prikladan/ praktičan odabir samo ako te varijabli sadrže mali broj modaliteta. Nadalje, varijabla vs označava tip motora, a varijabla am razlikuje automatski i ručni prijenos.
> mtcars$cyl <- factor(mtcars$cyl, levels = c(4, 6, 8), ordered = TRUE,
+ labels = c("4_cilindra", "6_cilindara", "8_cilindara"))
> mtcars$gear <- factor(mtcars$gear, levels = c(3, 4, 5), ordered = TRUE,
+ labels = c("3_brzine", "4_brzine", "5_brzina"))
> mtcars$vs <- factor(mtcars$vs,
+ labels = c("V_motor", "Linijski_motor"))
> mtcars$am <- factor(mtcars$am,
+ labels = c("Automatski_prijenos", "Ručni_prijenos"))Ako želimo sad provjeriti kako podatkovni okvir izgleda, možemo koristiti str().
> str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : Ord.factor w/ 3 levels "4_cilindra"<"6_cilindara"<..: 2 2 1 2 3 2 3 1 1 2 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : Factor w/ 2 levels "V_motor","Linijski_motor": 1 1 2 2 1 2 1 2 2 2 ...
## $ am : Factor w/ 2 levels "Automatski_prijenos",..: 2 2 2 1 1 1 1 1 1 1 ...
## $ gear: Ord.factor w/ 3 levels "3_brzine"<"4_brzine"<..: 2 2 2 1 1 1 1 2 2 2 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...S obzirom da se faktori tretiraju kao kvalitativne varijable, možemo kreirati tablicu kontingencije. Ta tablica bilježi apsolutne frekvencije svake kombinacije modaliteta promatranih dviju varijabli.
> table(mtcars$am, mtcars$gear)##
## 3_brzine 4_brzine 5_brzina
## Automatski_prijenos 15 4 0
## Rucni_prijenos 0 8 5No, faktori su češće korisni za ispitivanje karakteristika podskupina, a to se može napraviti putem izračuna pokazatelja deskriptivne statistike za svaku skupinu. U datasetu mtcars, varijabla mpg (engl. miles per gallon ili milje po galonu) mjeri efikasnost potrošnje goriva automobila. Veća vrijednost označava bolju ekonomičnost goriva. Varijabla hp (engl. horsepower ili konjska snaga) mjeri snagu motora automobila te veće vrijednosti označavaju snažnije motore.
> library(psych)
> deskr_stat <- describeBy(mtcars[, c("mpg", "hp")], group = mtcars$am)
> t(deskr_stat$Automatski_prijenos)## mpg hp
## vars 1.000 2.000
## n 19.000 19.000
## mean 17.147 160.263
## sd 3.834 53.908
## median 17.300 175.000
## trimmed 17.118 161.059
## mad 3.113 77.095
## min 10.400 62.000
## max 24.400 245.000
## range 14.000 183.000
## skew 0.014 -0.014
## kurtosis -0.803 -1.210
## se 0.880 12.367> t(deskr_stat$Rucni_prijenos)## mpg hp
## vars 1.000 2.00
## n 13.000 13.00
## mean 24.392 126.85
## sd 6.167 84.06
## median 22.800 109.00
## trimmed 24.382 114.73
## mad 6.672 63.75
## min 15.000 52.00
## max 33.900 335.00
## range 18.900 283.00
## skew 0.053 1.36
## kurtosis -1.455 0.56
## se 1.710 23.31Ovdje je upotrijebljena naredba describeBy() iz paketa psych, koja računa statističke pokazatelje za svaku grupu određenu faktorom.Ova naredba pohranjuje rezultate u listu, spremljenu pod nazivom deskr_stat. Ovdje se pozivaju i transponiraju sažeci Automatski_prijenos i Rucni_prijenos odvojeno, radi preglednijeg ispisa.
Nadalje, faktori mogu biti korisni i za kreiranje grafičkih prikaza temeljem kojih možemo dobiti detaljnije uvide. Recimo da nas zanimaju uvidi u distribuciju konjskih snaga motora s obzirom na to imaju li ručni ili automatski prijenos.
> boxplot(hp ~ am, data = mtcars,
+ xlab = "Tip prijenosa",
+ ylab = "Snaga motora (hp)",
+ col = c("lightblue", "lightgreen"))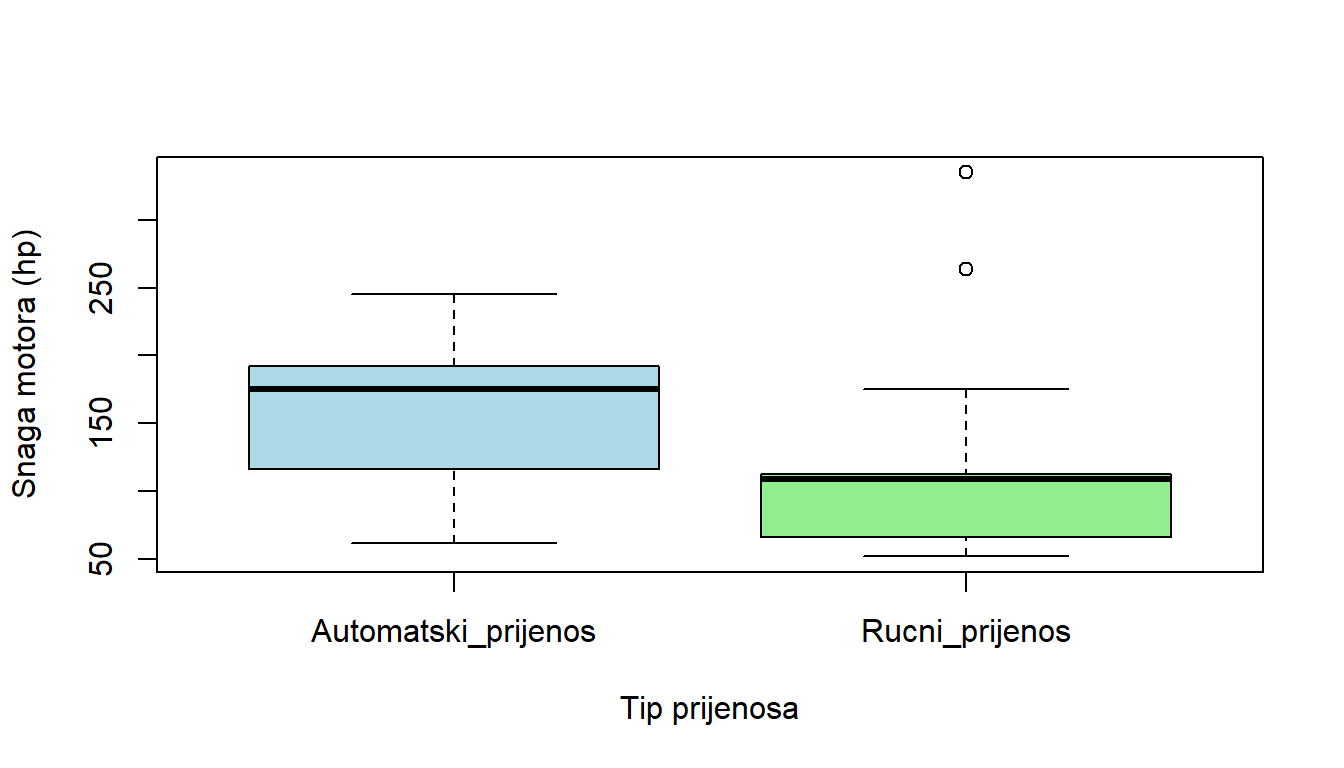
Korištenje faktora omogućuje podjelu podataka na temelju kategorija, što donosi nekoliko važnih prednosti iz perspektive analize podataka. Box-plotovi na grafikonu jasno pokazuju distribuciju snage motora (hp) između vozila s automatskim i ručnim prijenosom - dakle, omogućuje vizualnu usporedbu dviju grupa, odnosno distribucija dviju grupa. Ovdje možemo vidjeti da vozila s ručnim prijenosom imaju nižu medijalnu vrijednost snage motora, dok vozila s automatskim prijenosom pokazuju viši medijan i širi interkvartil.
Osim toga, u ovom slučaju faktorizacija pomaže u identifikaciji varijabilnosti. Možemo uočiti da su vrijednosti snage motora za vozila s ručnim prijenosom grupirane bliže medijanu, što ukazuje na manju varijabilnost. Nasuprot tome, vozila s automatskim prijenosom imaju širi raspon varijacija, što ukazuje na veću raznolikost u snazi motora.
Nadalje, iz perspektive upotrebe R-a, faktori pojednostavljuju proces grupiranja i daljnju manipulaciju podacima. Ako je varijabla am postavljena kao faktor, podaci se lako mogu filtrirati, grupirati i analizirati pomoću funkcija dostupnih u paketima tapply, dplyr ili ggplot2.
Evo još jednog primjera, recimo da želimo kreirati stupčasti dijagram broja brzina prijenosa (gear) s obzirom na to kakav je motor (vs).
> freq_table <- table(mtcars$gear, mtcars$vs)
>
> barplot(
+ freq_table,
+ beside = TRUE, # Prikazuje stupce jedan pored drugog
+ col = c("skyblue", "lightgreen", "orange"),
+ legend.text = c("3 brzine", "4 brzine", "5 brzina"),
+ args.legend = list(x = "top"),
+ xlab = "Broj brzina",
+ ylab = "Broj vozila"
+ )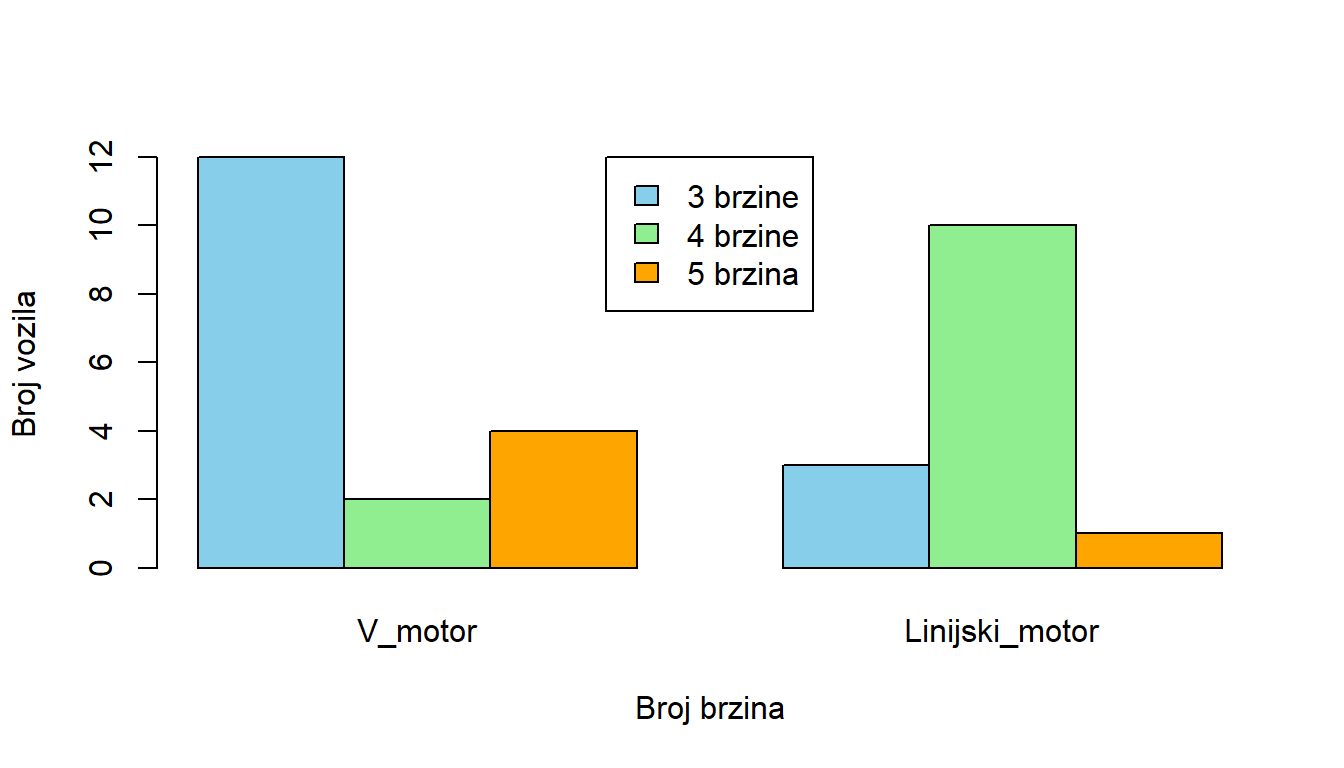
U ovom primjeru, kreiran je stupčasti dijagram koji usporedno prikazuje broj vozila s V_motorom i linijskim_motorom prema broju brzina. Možemo odmah primijetiti razlike u popularnosti pojedinih kombinacija (npr. v_motor s 3 brzine je češći od linijskog_motora s 3 brzine).
Ovi primjeri ilustrirali su upotrebu faktora pri analizi podataka u sklopu podatkovnih okvira. Dodatne primjere ilustracija i analize podataka možete naći u poglavljima “Jednostavne vizualizacije” i “Primjer upravljanja podacima.”
7.7.10 Pretvaranje podatkovnog okvira u tablicu
Podatkovni okvir je najčešće korištena struktura pri analizi podataka. A sad, promotrimo mogućnosti kreiranja tablice. Iako se čitav podatkovni okvir može pretvoriti u tablicu (koristeći as.table()), to nije korisno ni preporučljivo. Češće će biti korisno izolirati elemente koji se žele prikazati u tablici.
> table(iris$Species)##
## setosa versicolor virginica
## 50 50 50> table(Sepal.Length, Species)## Species
## Sepal.Length setosa versicolor virginica
## 4.3 1 0 0
## 4.4 3 0 0
## 4.5 1 0 0
## 4.6 4 0 0
## 4.7 2 0 0
## 4.8 5 0 0
## 4.9 4 1 1
## 5 8 2 0
## 5.1 8 1 0
## 5.2 3 1 0
## 5.3 1 0 0
## 5.4 5 1 0
## 5.5 2 5 0
## 5.6 0 5 1
## 5.7 2 5 1
## 5.8 1 3 3
## 5.9 0 2 1
## 6 0 4 2
## 6.1 0 4 2
## 6.2 0 2 2
## 6.3 0 3 6
## 6.4 0 2 5
## 6.5 0 1 4
## 6.6 0 2 0
## 6.7 0 3 5
## 6.8 0 1 2
## 6.9 0 1 3
## 7 0 1 0
## 7.1 0 0 1
## 7.2 0 0 3
## 7.3 0 0 1
## 7.4 0 0 1
## 7.6 0 0 1
## 7.7 0 0 4
## 7.9 0 0 1Iskoristimo prethodno kreiran podatkovni okvir za drugačiji prikaz.
> table(Turisti2$Drzava)##
## Austria China Croatia France Ireland Italy United States
## 1 1 1 1 1 1 1> table(Turisti2$Drzava, Turisti2$Br_t_dol)##
## 10926 30816 57668 93228 158606 169324.92
## Austria 0 1 0 0 0 0
## China 0 0 0 0 1 0
## Croatia 0 0 1 0 0 0
## France 0 0 0 0 0 0
## Ireland 1 0 0 0 0 0
## Italy 0 0 0 1 0 0
## United States 0 0 0 0 0 1Dakle, kroz ovih nekoliko primjera možete uočiti da funkcija table()* koristi zadane varijable kao zaglavlja i predstupce, dok elementi tablice predstavljaju apsolutne frekvencije. Iako u slučaju Turisti2 ne dobivamo informativnu tablicu, u nekim će situacijama ovaj pristup biti vrlo koristan, osobito za kvalitativne varijable.
7.8 Prednosti i nedostaci rada s podatkovnim okvirima te najčešće greške
Prednosti podatkovnih okvira
Svestranost: podatkovni okviri podržavaju stupce različitih tipova podataka, što ih čini idealnim za rad s heterogenim podacima tipičnim za većinu stvarnih analitičkih zadataka.
Jednostavnost upotrebe: Sintaksa za manipulaciju podatkovnim okvirima je intuitivna, a R nudi bogat skup funkcija za njihovu obradu, učitavanje, čišćenje, transformaciju, agregaciju i vizualizaciju.
Integracija s alatima za analizu podataka: mnogi paketi u R-u dizajnirani su upravo za rad s podatkovnim okvirima, uključujući popularne pakete za analizu podataka poput dplyr, tidyr i ggplot2.
Nedostaci podatkovnih okvira
Performanse i memorija
Podatkovni okviri nisu uvijek najefikasniji način za pohranu i obradu podataka, posebno kad je riječ o vrlo velikim skupovima podataka. U takvim slučajevima, alternativne strukture podataka kao što su tibbles (moderniji oblik podatkovnih okvira) ili data.table mogu pružiti bolje performanse.
Ograničenja dvodimenzionalnosti
Podatkovni okviri su prvenstveno dvodimenzionalne strukture. To ih može ograničiti u radu s višedimenzionalnim skupovima podataka.
Uobičajene greške
Pogrešan tip podataka u stupcima: ponekad, prilikom učitavanja ili transformacije podataka, stupci podatkovnog okvira mogu biti promijenjeni u pogrešan tip podataka, što može utjecati na analizu.
Neispravno indeksiranje i pristup elementima: razlika između pristupa podacima pomoću [ ], [[ ]], i $ može biti zbunjujuća. To dalje može dovesti do neispravnog odabira ili promjena podataka.
Neadekvatno upravljanje vrijednostima koje nedostaju: Vrijednosti koje nedostaju (NA) mogu uzrokovati probleme prilikom izvođenja statističkih analiza ili vizualizacije podataka.
Najčešća upotreba podatkovnih okvira
Eksploracijska analiza podataka: Podatkovni okviri su osnovni alat za istraživanje, obradu i sažimanje podataka.
Statistička analiza: Većina statističkih modela u R-u, poput linearnih i logističkih regresija, prirodno radi s podatkovnim okvirima.
Vizualizacija podataka: Alati za vizualizaciju, kao što je ggplot2, dizajnirani su za rad s podatkovnim okvirima, olakšavajući izradu složenih grafikona.
Učitavanje i manipulacija podacima: Podatkovni okviri su često korišten format za učitavanje, čišćenje i pripremu podataka prije dublje analize.
7.9 Kreiranje tablica
U ovom poglavlju objašnjava se kreiranje tablica, uključujući postupke za formatiranje i ispis tablica pomoću funkcija te razmatranje tibblea kao moderne alternative podatkovnim okvirima. Poglavlje naglašava važnost čitljivosti i prilagodbe tablica, kao i upotrebu tibblea za jednostavnije manipulacije i bolju integraciju s paketima iz tidyverse ekosustava. Osim toga, daje se pregled uobičajenih grešaka pri formatiranju i pružaju se smjernice za najbolje prakse u kreiranju tablica, čime se olakšava predstavljanje podataka na jasan i estetski prihvatljiv način.
Tablica s početka priče, koja prikazuje osnovne tipove podataka kreirana je kao matrica i ispisana koristeći paket knitr (Xie and al 2023) i naredbu kable(). Sad će se prikazati točno kako.
> library(knitr)
> x <- c("double", "1, 2.33, 50.99, 3e10", "realni brojevi",
+ "integer", "5l, -2, 5387l", "cijeli brojevi",
+ "character", "slova, oznake, 50 %, pa}", "znakovni tip",
+ "logical", "TRUE, FALSE, T, F", "logički",
+ "complex", "1+5i, 5-2i", "kompleksni brojevi",
+ "raw", "as.raw(11)", "sirovi")
>
> Tablica <- matrix(x, nrow = 6, ncol = 3, byrow = TRUE)
> colnames(Tablica) <- c("Naziv", "Primjer", "Vrsta")
> rownames(Tablica) <- c("1.", "2.", "3.", "4.", "5.", "6.")
> T<-as.table(Tablica)
> knitr::kable(T)| Naziv | Primjer | Vrsta | |
|---|---|---|---|
| 1. | double | 1, 2.33, 50.99, 3e10 | realni brojevi |
| 2. | integer | 5l, -2, 5387l | cijeli brojevi |
| 3. | character | slova, oznake, 50 %, pa} | znakovni tip |
| 4. | logical | TRUE, FALSE, T, F | logicki |
| 5. | complex | 1+5i, 5-2i | kompleksni brojevi |
| 6. | raw | as.raw(11) | sirovi |
U prvom koraku, kreiran je vektor koji sadrži sve podatke. Potom je vektor konvertiran u matricu odgovarajućih dimenzija. Potom su kreirani zaglavlje i predstupac, odnosno stupcima i recima su pridruženi nazivi. Tad je matrica spremljena kao tablica. Pozivom knitr::kable() ispisuje se tablica koja je pregledna i obogaćena izmjenično obojanim recima za lakše čitanje.
Usporedimo to s ispisom tablice bez posljednje naredbe, to jest bez upotrebe knitr paketa. Rezultat je ispis tablice, ali u usporedbi s prvom tablicom djeluje manje pregledno.
> x <- c("double", "1, 2.33, 50.99, 3e10", "realni brojevi",
+ "integer", "5l, -2, 5387l", "cjeli brojevi",
+ "character", "slova, oznake, 50 %, pa}", "znakovni tip",
+ "logical", "TRUE, FALSE, T, F", "logički",
+ "complex", "1+5i, 5-2i", "kompleksni brojevi",
+ "raw", "as.raw(11)", "sirovi")
>
> Tablica <- matrix(x, nrow = 6, ncol = 3, byrow = TRUE)
> colnames(Tablica) <- c("Naziv", "Primjer", "Vrsta")
> rownames(Tablica) <- c("1.", "2.", "3.", "4.", "5.", "6.")
> T<-as.table(Tablica)
> T## Naziv Primjer Vrsta
## 1. double 1, 2.33, 50.99, 3e10 realni brojevi
## 2. integer 5l, -2, 5387l cjeli brojevi
## 3. character slova, oznake, 50 %, pa} znakovni tip
## 4. logical TRUE, FALSE, T, F logicki
## 5. complex 1+5i, 5-2i kompleksni brojevi
## 6. raw as.raw(11) siroviNadalje, maleni podatkovni okvir može se ispisati kao tablica, ako se takva tablica namjerava predstaviti na primjer, u izvješću. Ranije je tako kreiran podatkovni okvir Tur_eu, kojeg možemo ispisati u obliku tablice:
> knitr::kable(Tur_eu)| Drzava | Br_t_dol | Br_t_odl | EU | |
|---|---|---|---|---|
| 1 | Croatia | 57668 | 2980 | TRUE |
| 2 | France | 211998 | 48069 | TRUE |
| 4 | Italy | 93228 | 61194 | TRUE |
| 5 | Austria | 30816 | 11043 | TRUE |
| 6 | Ireland | 10926 | 8643 | TRUE |
Možete uočiti da je u ovom slučaju preskočen korak konverzije i koristi se samo tablični ispis. Također, ako se želi prilagoditi ispis u obliku tablice, tada se nazivi država mogu staviti u predstupac u kojem se trenutno nalaze samo redni brojevi.
> #prvi stupac dodijelimo novom vektoru
> predst <- Tur_eu[ , 1]
>
> #Kreiramo dataftame koristeći stupce broja odlazaka i dolazaka turista
> tabl <-Tur_eu[ , c(2:3)]
>
> #pridružujemo novi vektor nazivima redaka tabl
> rownames(tabl) <- predst
>
> #ispisujemo tabl
> knitr::kable(tabl)| Br_t_dol | Br_t_odl | |
|---|---|---|
| Croatia | 57668 | 2980 |
| France | 211998 | 48069 |
| Italy | 93228 | 61194 |
| Austria | 30816 | 11043 |
| Ireland | 10926 | 8643 |
Za razliku od tabličnog ispisa, funkcija table() u R-u služi za kreiranje tablica frekvencija, koje prikazuju koliko se puta pojavljuje svaka jedinstvena vrijednost unutar jednog vektora ili kombinacije više vektora. Ovo je osnovna naredba za analizu kvalitativnih podataka i vrlo je korisna za brze uvide u distribuciju podataka. Kad se koristi s jednim vektorom, table() broji pojavljivanja svake jedinstvene vrijednosti. Za dva vektora, stvara tablicu kontingence koja prikazuje učestalosti kombinacija tih varijabli.
Kako bi se ilustrirala upotreba tablica, koristit će se podaci o nekretninama, Real_estate prikupljeni sa stranice Zillow, koja procjenjuje cijene nekretnina u SAD-u. Ovdje će se koristiti dio podataka vezan za Saratogu, pripremljen za analizu Zillow Internal, ožujak 2013., Dick De Veaux, 7. listopada 2015..
> nekretnine <- read.delim("http://sites.williams.edu/rdeveaux/files/2014/09/Saratoga.txt")
> glimpse(nekretnine)## Rows: 1,728
## Columns: 16
## $ Price <int> 132500, 181115, 109000, 155000, 86060, 120000, 153000, 170000, 90000, 122900, 325000, 120000, 858~
## $ Lot.Size <dbl> 0.09, 0.92, 0.19, 0.41, 0.11, 0.68, 0.40, 1.21, 0.83, 1.94, 2.29, 0.92, 8.97, 0.11, 0.14, 0.00, 0~
## $ Waterfront <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0~
## $ Age <int> 42, 0, 133, 13, 0, 31, 33, 23, 36, 4, 123, 1, 13, 153, 9, 88, 9, 0, 82, 17, 12, 21, 1, 24, 16, 28~
## $ Land.Value <int> 50000, 22300, 7300, 18700, 15000, 14000, 23300, 14600, 22200, 21200, 12600, 22300, 4800, 3100, 30~
## $ New.Construct <int> 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0~
## $ Central.Air <int> 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0~
## $ Fuel.Type <int> 3, 2, 2, 2, 2, 2, 4, 4, 3, 2, 4, 2, 3, 2, 4, 2, 4, 2, 4, 4, 3, 3, 2, 4, 3, 4, 4, 4, 4, 4, 4, 2, 2~
## $ Heat.Type <int> 4, 3, 3, 2, 2, 2, 3, 2, 4, 2, 2, 2, 4, 3, 2, 3, 2, 2, 3, 2, 4, 4, 2, 2, 4, 2, 3, 2, 2, 2, 3, 2, 2~
## $ Sewer.Type <int> 2, 2, 3, 2, 3, 2, 2, 2, 2, 1, 2, 2, 2, 3, 2, 3, 2, 1, 2, 2, 2, 3, 2, 2, 3, 2, 2, 2, 3, 2, 2, 2, 3~
## $ Living.Area <int> 906, 1953, 1944, 1944, 840, 1152, 2752, 1662, 1632, 1416, 2894, 1624, 704, 1383, 1300, 936, 1300,~
## $ Pct.College <int> 35, 51, 51, 51, 51, 22, 51, 35, 51, 44, 51, 51, 41, 57, 41, 57, 41, 71, 35, 35, 35, 39, 39, 39, 3~
## $ Bedrooms <int> 2, 3, 4, 3, 2, 4, 4, 4, 3, 3, 7, 3, 2, 3, 3, 3, 3, 4, 2, 3, 3, 3, 3, 3, 3, 4, 3, 4, 4, 3, 2, 3, 3~
## $ Fireplaces <int> 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 1, 1~
## $ Bathrooms <dbl> 1.0, 2.5, 1.0, 1.5, 1.0, 1.0, 1.5, 1.5, 1.5, 1.5, 1.0, 2.0, 1.0, 2.0, 1.5, 1.0, 1.5, 2.5, 1.0, 1.~
## $ Rooms <int> 5, 6, 8, 5, 3, 8, 8, 9, 8, 6, 12, 6, 4, 5, 8, 4, 7, 12, 6, 6, 7, 4, 7, 6, 4, 10, 6, 5, 10, 7, 4, ~Ovaj podatkovni okvir sadrži 16 varijabli, od kojih svaka predstavlja različite aspekte podataka o nekretninama. Pri kreiranju tablice naredbom table(), možemo koristiti jednu ili dvije varijable. Za potrebe kreiranja tablice, prvo ćemo iskoristiti dvije varijable: Waterfront (binarna varijabla, odgovara na pitanje nalazi li se nekretnina uz obalu) i Fireplaces (broj kamina). Iako je broj kamina kvantitativna cjelobrojna varijabla, poprima samo četiri vrijednosti, što omogućuje jednostavan prikaz putem tablice.
> nekretnine$Waterfront <- factor(nekretnine$Waterfront, levels = c(0, 1), labels = c("Ne", "Da"))
> nekretnine$Fireplaces <- factor(nekretnine$Fireplaces, levels = c(0, 1, 2, 3, 4))
> table("Uz obalu" = nekretnine$Waterfront, "Broj kamina" = nekretnine$Fireplaces)## Broj kamina
## Uz obalu 0 1 2 3 4
## Ne 733 934 42 2 2
## Da 7 8 0 0 0Odabrane varijable pretvorili smo u faktore. Možete uočiti kako je i broj kamina (koji sadrži mali broj cjelobrojnih vrijednosti) pretvoren u faktor za potrebe kreiranja ove tablice.
Naredbom table() kreirana je tablica kontingencije. Lako možemo uočiti da postoji relativno malo nekretnina uz obalu te one sadrže jedan ili niti jedan kamin. Na primjer, od svih promatranih nekretnina, 42 nekretnine nisu uz obalu i imaju po dva kamina.
> #table(nekretnine)Naredba table(nekretnine), očekivano bi rezultirala greškom - jer, kao što je ranije navedeno, table() podržava analizu jedne ili dviju varijabli.
primijenimo na jednu varijablu, rezultat će biti apsolutne frekvencije za svaki modalitet obilježja.
> table(nekretnine$Fireplaces)##
## 0 1 2 3 4
## 740 942 42 2 2Iako se table() koristi za analizu i sažimanje podataka jedne ili dviju varijabli, pretvorba u tablicu putem as.table() može se koristiti i za prezentaciju izračunatih pokazatelja u izvještajima ili dokumentima. Rezultati analiza prikazani u obliku tablica (frekvencije, odnosi među varijablama i sl.) postaju jasniji i čitljiviji, što je korisno kao podloga za interpretaciju i dijeljenje rezultata s drugima.
> pokazatelji_nekretnine <- as.table(summary(nekretnine[,1:5]))
> kable(pokazatelji_nekretnine)| Price | Lot.Size | Waterfront | Age | Land.Value | |
|---|---|---|---|---|---|
| Min. : 5000 | Min. : 0.0 | Ne:1713 | Min. : 0 | Min. : 200 | |
| 1st Qu.:145000 | 1st Qu.: 0.2 | Da: 15 | 1st Qu.: 13 | 1st Qu.: 15100 | |
| Median :189900 | Median : 0.4 | NA | Median : 19 | Median : 25000 | |
| Mean :211967 | Mean : 0.5 | NA | Mean : 28 | Mean : 34557 | |
| 3rd Qu.:259000 | 3rd Qu.: 0.5 | NA | 3rd Qu.: 34 | 3rd Qu.: 40200 | |
| Max. :775000 | Max. :12.2 | NA | Max. :225 | Max. :412600 |
Za rad s tablicama, funkcija as.table() može pretvoriti rezultate analiza ili matricu u tablični format. Ovo je korisno za prikaz sažetaka podataka kada želite naglasiti učestalosti ili odnose između varijabli. Međutim, table() i as.table() nisu prikladni za konverziju cijelih data frame-ova u tablični format.
Iako se ne radi o tablicama, nego o oblicima podatkovnih okvira, tibble se često spominje kao alternativa tablicama. Tibble je moderna verzija podatkovnog okvira u R-u, koja je dio tidyverse paketa. Tibble je dizajniran da bude jednostavniji i učinkovitiji za upotrebu u analizi podataka, posebice u kontekstu tidyverse filozofije i funkcija.
Jedan od glavnih razloga za korištenje tibble u kontekstu tablica je to što ispisuje podatke na čitljiviji način u konzoli. Naime, prikazuju samo prvi dio velikih skupova podataka i bolje upravljaju širinom stupaca.Nadalje, za razliku od tradicionalnih podatkovnih okvira, tibble ne pretvara znakove u faktore automatski. To je korisno jer sprječava neočekivane probleme koji proizlaze iz neželjenih tipova podataka.
Ostale prednosti tibblea se odnose na kreiranje podskupova (ne rezultiraju jednodimenzionalnim strukturama, kao što su vektori, što je čest slučaj s klasičnim podatkovnim okvirima). Osim toga, tibble omogućuju imena stupaca koja nisu valjana u standardnim R podatkovnim okvirima, kao što su prazni znakovi ili simboli. Moguće ih je dalje obrađivati i vizualizirati s drugim tidyverse paketima kao što su dplyr, ggplot2, tidyr i druge, što olakšava obradu podataka i vizualizaciju.
> library(tibble)
>
> tibi <- tibble(
+ Drzava = Tur_eu[,1],
+ Dolasci = Tur_eu[,2],
+ Odlasci = Tur_eu[,3]
+ )
>
> tibi## # A tibble: 5 x 3
## Drzava Dolasci Odlasci
## <chr> <dbl> <dbl>
## 1 Croatia 57668 2980
## 2 France 211998 48069
## 3 Italy 93228 61194
## 4 Austria 30816 11043
## 5 Ireland 10926 86437.10 Prednosti i nedostaci tablica te najčešće greške
Prednosti kreiranja tablica u R-u
Poboljšana čitljivost (upotreba funkcija kao što je
kable()iz knitr paketa omogućuje nam stvaranje tablica koje su čitljive i estetski ugodne, što je posebno korisno za izvještavanje i dijeljenje rezultata),Fleksibilnost i prilagodba (R nudi širok spektar mogućnosti za prilagodbu tablica, uključujući stiliziranje, formatiranje i dodavanje zaglavlja, što omogućava precizno prilagođavanje izgleda tablica potrebama korisnika),
Integracija s drugim R paketima (tablice kreirane u R-u lako se integriraju s drugim paketima za analizu i vizualizaciju podataka, omogućujući relativno glatku suradnju između različitih koraka analitičkog procesa).
Uobičajene greške pri kreiranju tablica
Neadekvatno formatiranje (zanemarivanje detalja formatiranja, poput širine stupaca ili poravnanja teksta, može rezultirati tablicama koje su teške za čitanje),
Pogrešno rukovanje velikim skupovima podataka (pokušaj prikaza prevelikog broja redaka ili stupaca bez odgovarajućeg prilagođavanja može dovesti do nepreglednih tablica koje ne stanu na stranicu ili zaslon),
Zanemarivanje prednosti tibblea (neiskorištavanje prednosti tibblea može rezultirati manje efikasnim radom s podacima, posebno kad je riječ o velikim skupovima podataka ili kad je potrebna integracija s tidyverse ekosustavom).
Zabuna oko razlike između tablice i podatkovnog okvira (u alatima kao što su MS Excel, Google Sheets ili Libre Calc, često se tablice poistovjećuju s podatkovnim okvirima - iako i u tim alatima postoje razlike, zamjena najčešće neće rezultirati greškama. No, taj pristup ne smijete prenijeti na rad u R-u. U R-u ni na koji način nije opravdano čitav df spremiti kao tablicu, jer će to bitno otežati daljnju analizu ili rezultirati greškama.)
Najbolje prakse za kreiranje tablica
Koristite kable() za osnovne potrebe (za jednostavne potrebe prikazivanja podataka, funkcija
kable()iz knitr paketa je često dovoljna i pruža dobru ravnotežu između jednostavnosti i fleksibilnosti).Isprobajte paket gt za složenije tablice (za složenije potrebe, poput stvaranja visoko prilagođenih tablica za publikacije, paket gt nudi napredne mogućnosti stiliziranja i prilagodbe),
Prilagodite izgled tablice korisničkim potrebama (uvijek prilagodite izgled tablice tako da odgovara kontekstu u kojem će biti korištena, bilo da je to seminarski rad, esej, izvještaj ili prezentacija),
Razmotrite korištenje tibblea za rad s podacima (tibble, modernija verzija podatkovnog okvira, nudi bolje performanse i veću fleksibilnost pri radu s podacima, što može olakšati kreiranje i manipulaciju tablicama).