Capítulo 6 Trabajar con datos
6.1 Resumen
En este capítulo:
- Vamos a revisar algunas de las principales operaciones que tenemos que realizar con bases de datos para ordenarlas y para hacer algunos análisis.
- Aprenderemos cómo realizar subconjuntos de datos, lidiar con datos no disponibles (
NA), agrupar observaciones y unir bases de datos. - Familiarizarnos con las herramientas contenidas en la metalibrería
tidyverse, especialmente las libreríasdplyrytidyr.
Principales conceptos: hacer subconjuntos de datos; agrupar observaciones; unir bases de datos relacionales.
Funciones clave: filter(); select(); group_by(); summarize(); left_join().
6.1.1 Librerías
Vamos a utilizar las siguientes librerías:
library(tidyverse)
library(gapminder) # datos para ejercicios
library(readxl) # cargar archivos .xlsx
library(writexl) # guardar archivos .xlsx
library(knitr) # tablas en RMarkdown
library(haven) # cargar archivos .dta
library(janitor) # limpiar nombres de variables
library(countrycode) # codigos de pais para unir bases de datos6.1.2 Datos
Debemos descargar los siguientes archivos de datos y guardarlos en la carpeta /data de nuestro proyecto:
- Polity IV: link. Para descargar, hacer click en “Download”.
- Database of Political Institutions, 2017: link. Para descargar, hacer click en “Download”.
- Homicidios en Medellín: link. Para descargar, hacer click derecho, “Guardar como…”.
- Comunas de Medellín: link. Para descargar, hacer click derecho, “Guardar como…”.
6.2 Cargar bases de datos
Para efectos de este curso, aunque también en ciencias sociales en general, una base de datos es una recopilación de información en formato rectangular, con tres elementos esenciales:
- Filas que representan casos u observaciones.
- Columnas que representan variables o características de esos casos.
- Celdas en la intersección de filas y columnas y que contienen información (valores) sobre características de cada caso.
La mayor parte de los análisis estadísticos en ciencias sociales se realizan al hacer operaciones o aplicar funciones a bases de datos de este tipo.
Como mencionamos anteriormente, vamos a trabajar con distintas librerías del tidyverse para trabajar con bases de datos rectangulares. Estaremos utilizando varias funciones de las librerías dplyr y tidyr para transformar bases de datos y organizarlos de tal manera que podamos realizar análisis de datos exploratorios.
6.2.1 Bases de datos incluidas en R
R incluye unas cuantas bases de datos que podemos usar sin descargar primero. Ya están incluidas y disponibles en datasets, una librería que viene “pre-cargada” en cada sesión de R. La lista es extensa e incluye:
AirPassengers: viajeros mensuales en aerolíneas americanas, 1949-1960.Titanic: sobrevivientes del hundimiento del RMS Titanic.mtcars: tests de carros de la revista MotorTrend.airquality: calidad del aire en New York.iris: especies de plantas iris.
Otras bases de datos vienen en librerías que cargamos nosotros mismos. Por ejemplo, como ya cargamos tidyverse en esta sesión, podemos mirar economics, una base de datos macroeconómicos básicos de Estados Unidos:
economics## # A tibble: 574 x 6
## date pce pop psavert uempmed unemploy
## <date> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1967-07-01 507. 198712 12.6 4.5 2944
## 2 1967-08-01 510. 198911 12.6 4.7 2945
## 3 1967-09-01 516. 199113 11.9 4.6 2958
## 4 1967-10-01 512. 199311 12.9 4.9 3143
## 5 1967-11-01 517. 199498 12.8 4.7 3066
## 6 1967-12-01 525. 199657 11.8 4.8 3018
## 7 1968-01-01 531. 199808 11.7 5.1 2878
## 8 1968-02-01 534. 199920 12.3 4.5 3001
## 9 1968-03-01 544. 200056 11.7 4.1 2877
## 10 1968-04-01 544 200208 12.3 4.6 2709
## # ... with 564 more rowsEsta base de datos contiene datos en serie de tiempo -mes a mes- del desempleo en Estados Unidos, de julio de 1967 a abril de 2015 (la columna unemploy). Son en total 574 observaciones. ¿Cuál ha sido el comportamiento de este indicador en este periodo? Utilicemos ggplot2 para visualizar esta serie de tiempo.
Calculamos la tasa de desempleo dentro de la misma función (unemploy/pop) y graficamos el resultado a través del tiempo. Podemos observar claramente un pico durante la “Gran Recesión” de 2007-2009:
# datos y variables a usar
ggplot(data = economics, aes(x = date, y = unemploy/pop)) +
# tipo de gráfica: línea
geom_line(color = "darkred") 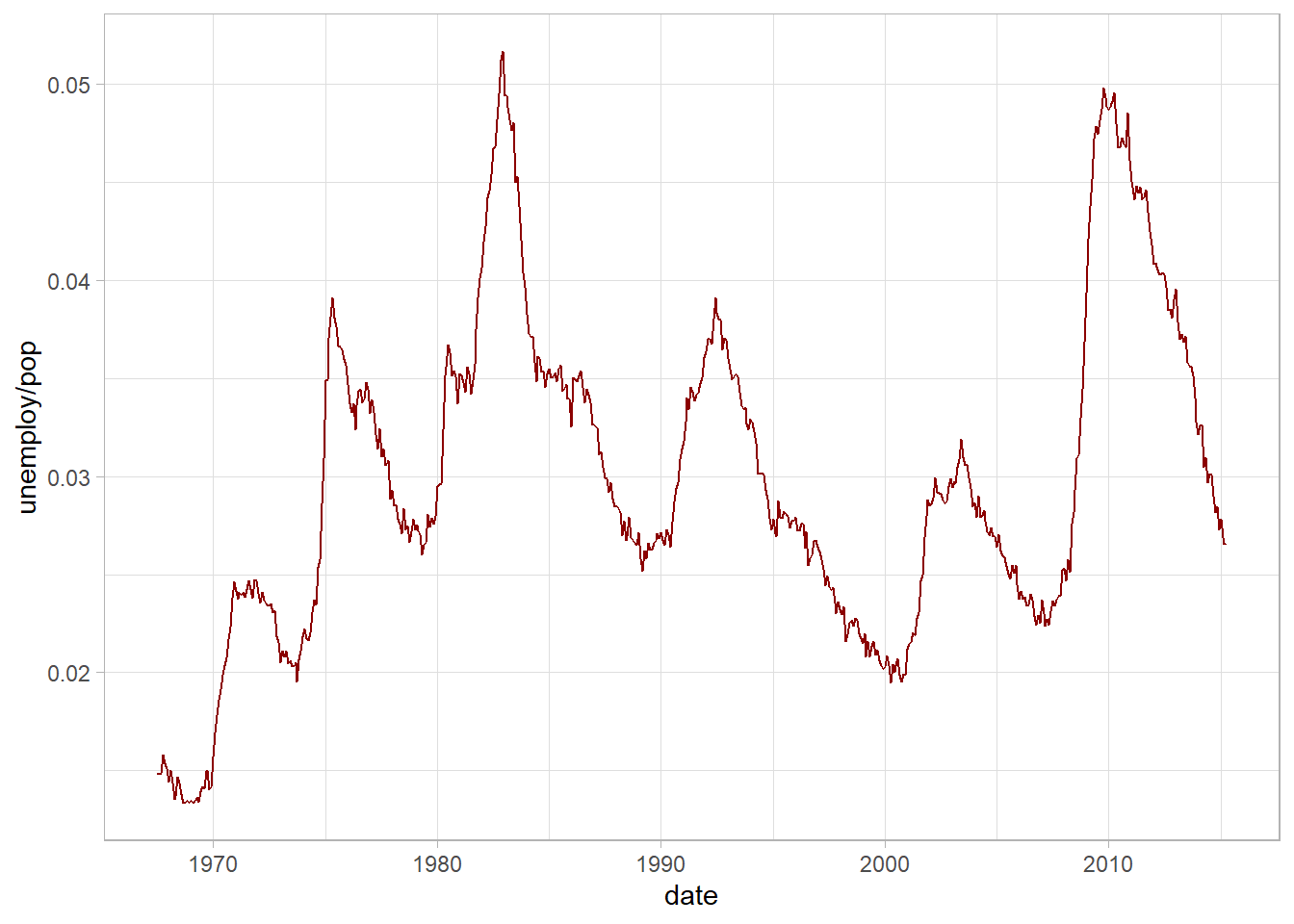
Otras librerías vienen con sus propias bases de datos. Aquí cargamos datos de la librería gapminder, que se deriva del trabajo educativo de la Gapminder Foundation. Esta librería contiene una base de datos también llamada gapminder. Veamos 10 observaciones aleatorias de esta base de datos, usando la función sample_n():
sample_n(gapminder, size = 10)## # A tibble: 10 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 El Salvador Americas 2007 71.9 6939688 5728.
## 2 Vietnam Asia 1977 55.8 50533506 714.
## 3 Australia Oceania 2007 81.2 20434176 34435.
## 4 Iceland Europe 2007 81.8 301931 36181.
## 5 Eritrea Africa 1972 44.1 2260187 514.
## 6 Jordan Asia 1957 45.7 746559 1886.
## 7 Chile Americas 1957 56.1 7048426 4316.
## 8 Turkey Europe 1957 48.1 25670939 2219.
## 9 Gambia Africa 1992 52.6 1025384 666.
## 10 Malawi Africa 1987 47.5 7824747 636.Vemos que hay información sobre expectativa de vida al nacer (lifeExp) y el PIB per cápita (gdpPercap) para 142 países en intervalos de 5 años. ¿Cuál es la relación entre estas dos variables? Podemos hacer una gráfica de dispersión:
# datos y variables
ggplot(data = gapminder, aes(x = gdpPercap, y = lifeExp)) +
# tipo de gráfica, puntos con con opacidad 50%
geom_point(alpha = 0.5, color = "darkblue") 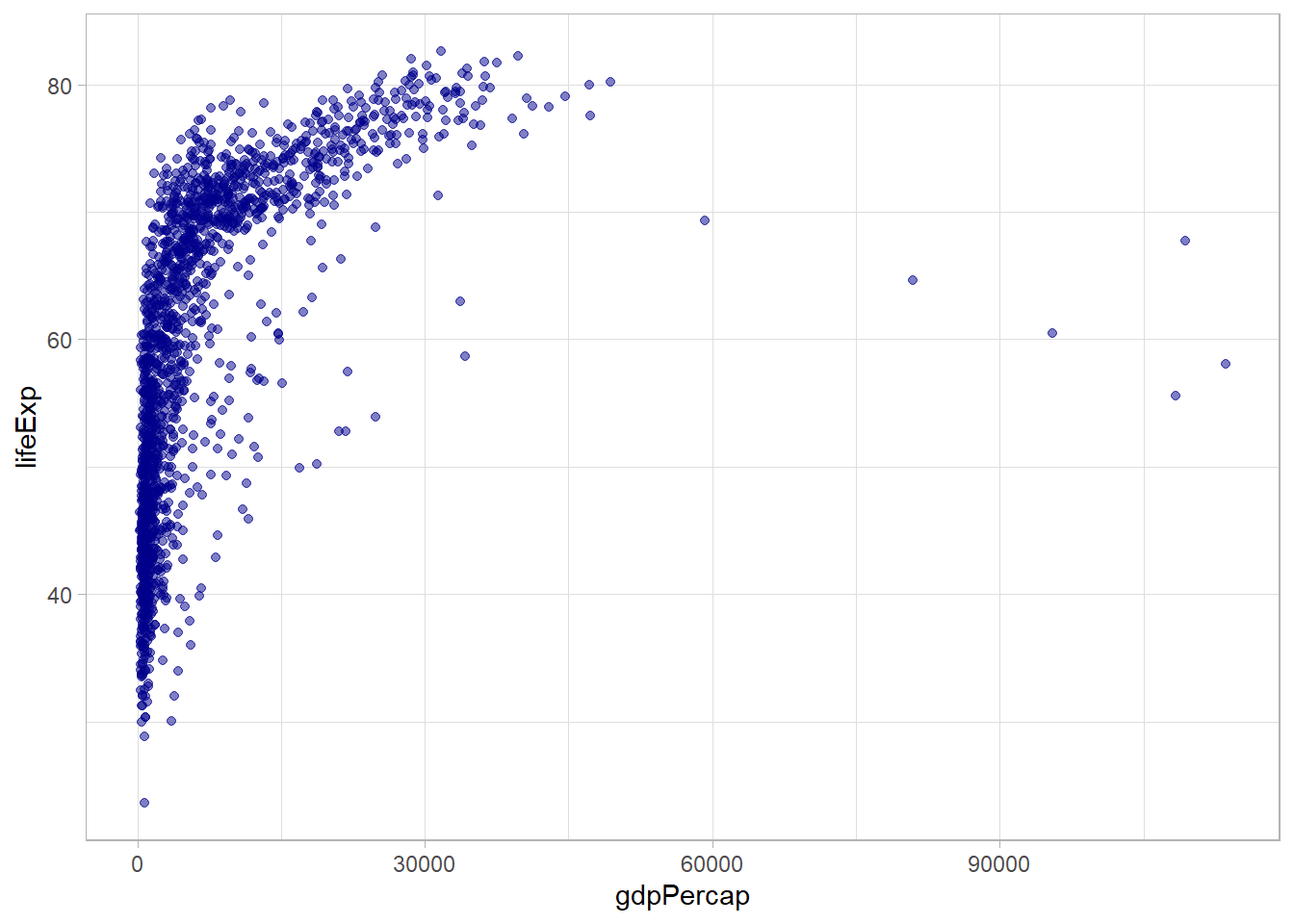
Parece que hay una relación positiva, pero no estrictamente lineal. Más bien, puede ser de tipo logarítmico, indicando rendimientos decrecientes. Nuevamente, podemos hacer la transformación de la variable gdpPercap directamente en la función ggplot() usando log():
# datos y variables
ggplot(data = gapminder, aes(x = log(gdpPercap), y = lifeExp)) +
# tipo de gráfica, puntos con con opacidad 50%
geom_point(alpha = 0.5, color = "darkgreen")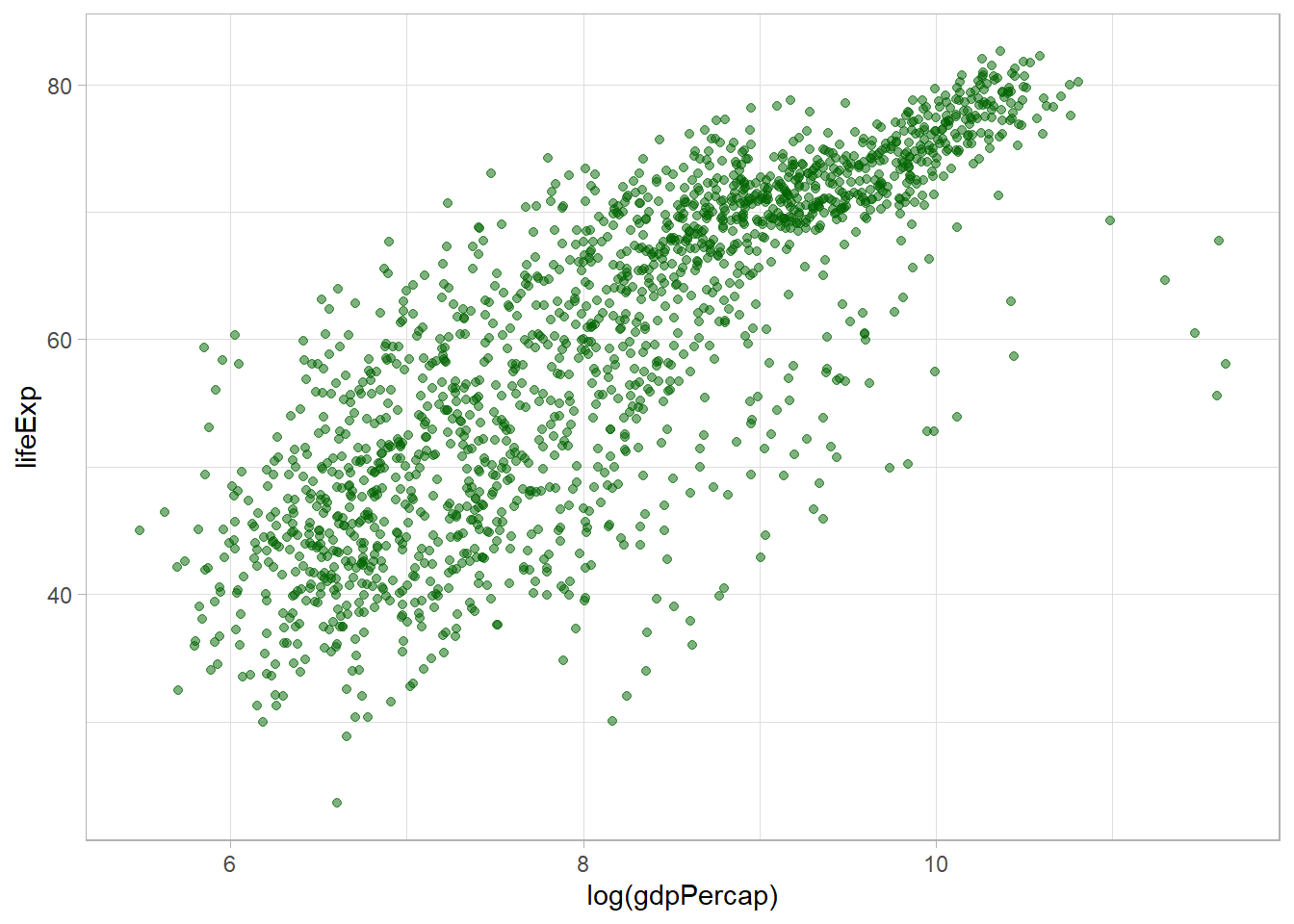
Por otro lado, si nos interesa ver la frecuencia de una variable categórica, podríamos contar cuántas observaciones (países-año) hay por continente usando la función count(), algo similar a lo que hicimos con table() en capítulos anteriores:
count(gapminder, continent)## # A tibble: 5 x 2
## continent n
## <fct> <int>
## 1 Africa 624
## 2 Americas 300
## 3 Asia 396
## 4 Europe 360
## 5 Oceania 246.2.2 Archivos locales
Es más frecuente que estemos interesados en trabajar con otros datos que recogimos o descargamos de otras fuentes. Para esto, debemos tener el archivo de datos ubicado en una carpeta en nuestro equipo, idealmente dentro del proyecto en el que estamos trabajando en RStudio. Recordemos que en este libro, vamos a utilizar la carpeta o directorio \data para esto.9 Si queremos ver qué archivos ya están en una carpeta, podemos usar la función list.files(), dándole la dirección de la carpeta:
list.files("data/")## [1] "camara2018.csv" "cede-agro.csv"
## [3] "cede-conf.csv" "cede-edu.csv"
## [5] "cede-gen.csv" "cede-gob.csv"
## [7] "cede-salud.csv" "codebooks"
## [9] "DahlDims.sav" "data.zip"
## [11] "datos_ingreso.csv" "datos_polity_dpi.csv"
## [13] "datos_taller1.csv" "DPI2017.dta"
## [15] "gapminder_america.xlsx" "gp0070_cronograma_20211.xlsx"
## [17] "gp0070_cronograma_20212.xlsx" "mde_df.csv"
## [19] "mde_homicidio.csv" "nafta.dta"
## [21] "nes_2004_data.csv" "OECD_country_data.csv"
## [23] "OECD_country_data.xls" "p4v2017.xls"
## [25] "p5v2018.xls" "riverside_final.csv"
## [27] "wb_tidy.csv"Vemos que en esta carpeta ya hay varios archivos y de varios tipos. Dependiendo del tipo de archivo (Excel, CSV, datos de Stata, etc.) utilizamos una función distinta. Las librerías readr, readxl y haven del tidyverse son nuestras amigas para este tipo de trabajos.
Veamos esto en acción. Carguemos los datos del proyecto Polity IV sobre democracia institucional, un conjunto de datos muy utilizado en ciencia política, pero que ha recibido críticas en los últimos años. Como los datos están en formato Excel 97-03 (el archivo tiene extensión .xls), usamos la función read_excel() de la librería readxl y le asignamos un nombre al objeto (los datos) que estamos creando de la siguiente manera:10
polity4 <- read_excel("data/p4v2017.xls")Para confirmar que todo está bien, revisemos las primeras filas del objeto que creamos imprimiendo a la consola el objeto:
polity4## # A tibble: 17,395 x 36
## cyear ccode scode country year flag fragment democ autoc polity polity2
## <dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 21800 2 USA United Sta~ 1800 0 NA 7 3 4 4
## 2 21801 2 USA United Sta~ 1801 0 NA 7 3 4 4
## 3 21802 2 USA United Sta~ 1802 0 NA 7 3 4 4
## 4 21803 2 USA United Sta~ 1803 0 NA 7 3 4 4
## 5 21804 2 USA United Sta~ 1804 0 NA 7 3 4 4
## 6 21805 2 USA United Sta~ 1805 0 NA 7 3 4 4
## 7 21806 2 USA United Sta~ 1806 0 NA 7 3 4 4
## 8 21807 2 USA United Sta~ 1807 0 NA 7 3 4 4
## 9 21808 2 USA United Sta~ 1808 0 NA 7 3 4 4
## 10 21809 2 USA United Sta~ 1809 0 NA 9 0 9 9
## # ... with 17,385 more rows, and 25 more variables: durable <dbl>, xrreg <dbl>,
## # xrcomp <dbl>, xropen <dbl>, xconst <dbl>, parreg <dbl>, parcomp <dbl>,
## # exrec <dbl>, exconst <dbl>, polcomp <dbl>, prior <dbl>, emonth <dbl>,
## # eday <dbl>, eyear <dbl>, eprec <dbl>, interim <dbl>, bmonth <dbl>,
## # bday <dbl>, byear <dbl>, bprec <dbl>, post <dbl>, change <dbl>, d4 <dbl>,
## # sf <dbl>, regtrans <dbl>Parece que todo está bien. Miremos la distribución de la variable polity2, el popular indicador combinado de democracia de Polity IV. Aquí volvemos a usar la librería ggplot2 en vez de las funciones de base, como plot() y barplot():
# datos y variables
ggplot(data = polity4, aes(x = polity2)) +
# tipo de gráfica y ancho de las barras
geom_histogram(binwidth = 1)## Warning: Removed 236 rows containing non-finite values (stat_bin).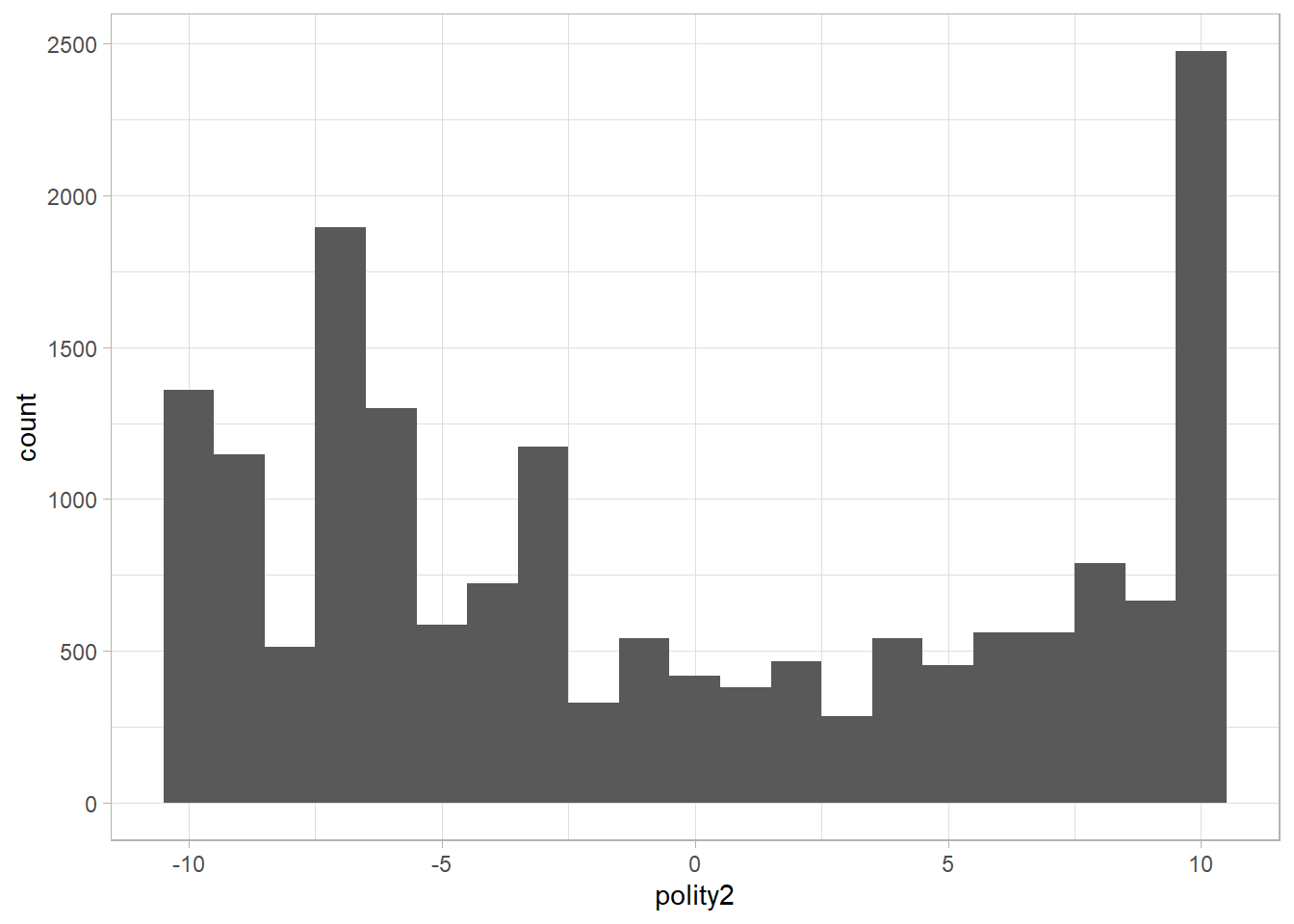
Vemos que hay más casos de democracia (valores altos del indicador) y de autocracia (valores bajos) que anocracias (valores medios).
6.2.3 Descarga web
Por último, carguemos unos datos directamente de la web, sin tener que descargarlos primero. El Uppsala Conflict Data Program (UCDP) tiene una de las bases de datos más completas sobre conflicto armado y está fácilmente disponible para su uso: el Armed Conflict Dataset. Con read_csv() podemos darle a R el URL del archivo y cargarlo como un objeto nuevo. Necesitamos una conexión a internet activa y se puede demorar unos segundos más. Lo hacemos de la siguiente manera:
ucdp <- read_csv("http://ucdp.uu.se/downloads/ucdpprio/ucdp-prio-acd-201.csv")UCDP distingue entre cuatro tipos de conflicto armado: interestatal, extraestatal, interno e interno internacionalizado. ¿Cuántos casos hay de cada tipo en la base de datos? Si leemos el libro de códigos de la base de datos, vemos que la variable type_of_conflict toma cuatro valores: 1 (inter-), 2 (extra-), 3 (intra-) y 4 (intra- internacionalizado). La prevalencia global de los conflictos armados internos es clara:
# datos y variables
ggplot(ucdp, aes(type_of_conflict)) +
# tipo de gráfica
geom_bar()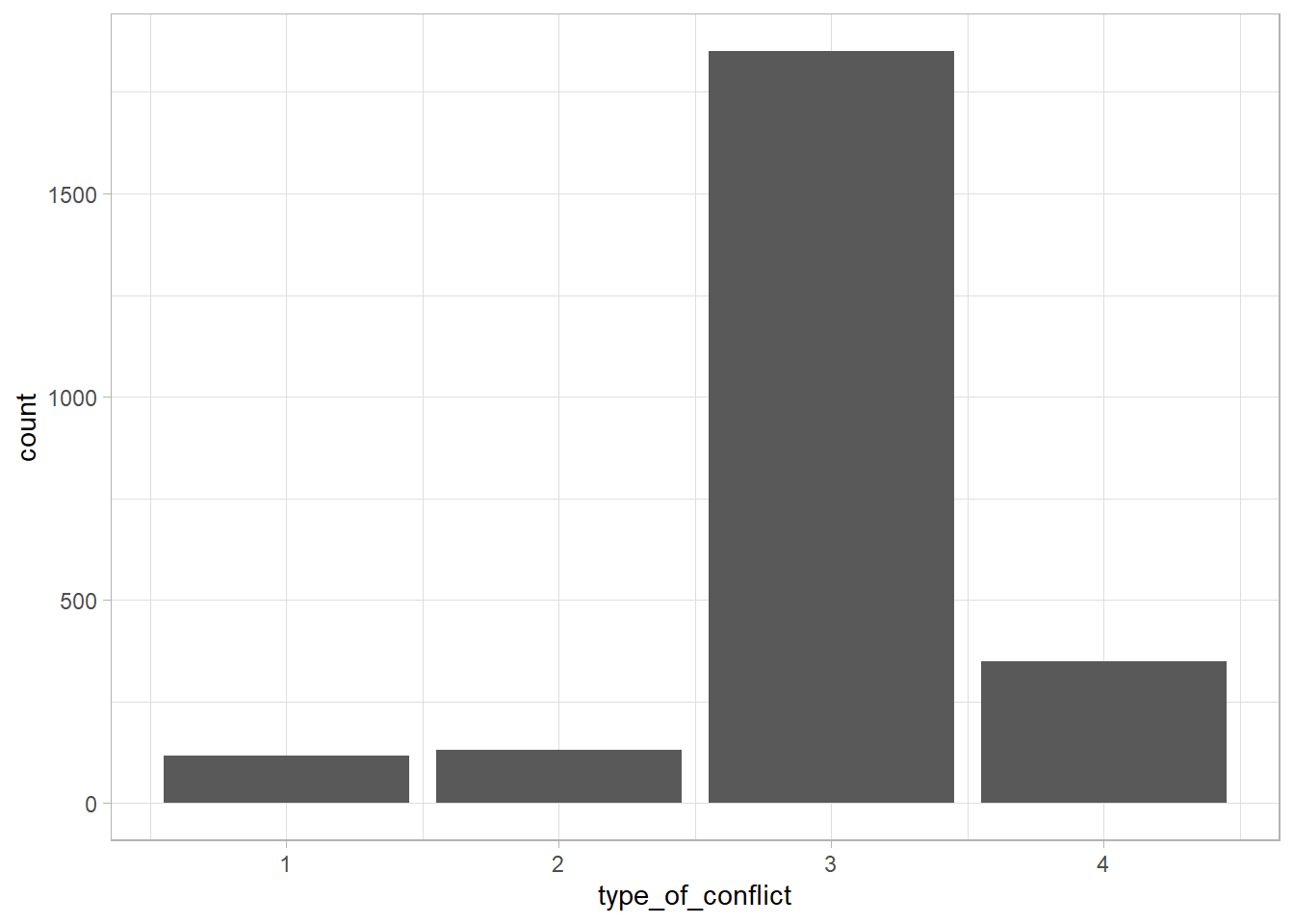
Pero esto no siempre ha sido así. Con unas líneas de código adicionales, podemos ver los cambios en el tiempo en el tipo de conflicto armado predominante a nivel global. Primero, resumimos los datos, contando (con count()) el número de conflictos por año y tipo de conflicto:
conflictos <- count(ucdp, year, type_of_conflict)
conflictos## # A tibble: 228 x 3
## year type_of_conflict n
## <dbl> <dbl> <int>
## 1 1946 1 5
## 2 1946 2 2
## 3 1946 3 8
## 4 1946 4 2
## 5 1947 1 5
## 6 1947 3 9
## 7 1948 1 5
## 8 1948 2 3
## 9 1948 3 12
## 10 1949 1 5
## # ... with 218 more rowsAhora, utilizamos esa tabla de datos resumidos para ver los cambios temporales, especificando que queremos una gráfica de barras con un color para cada tipo de conflicto:
ggplot(conflictos, aes(year, n, fill = factor(type_of_conflict))) +
# tipo de gráfica
geom_col()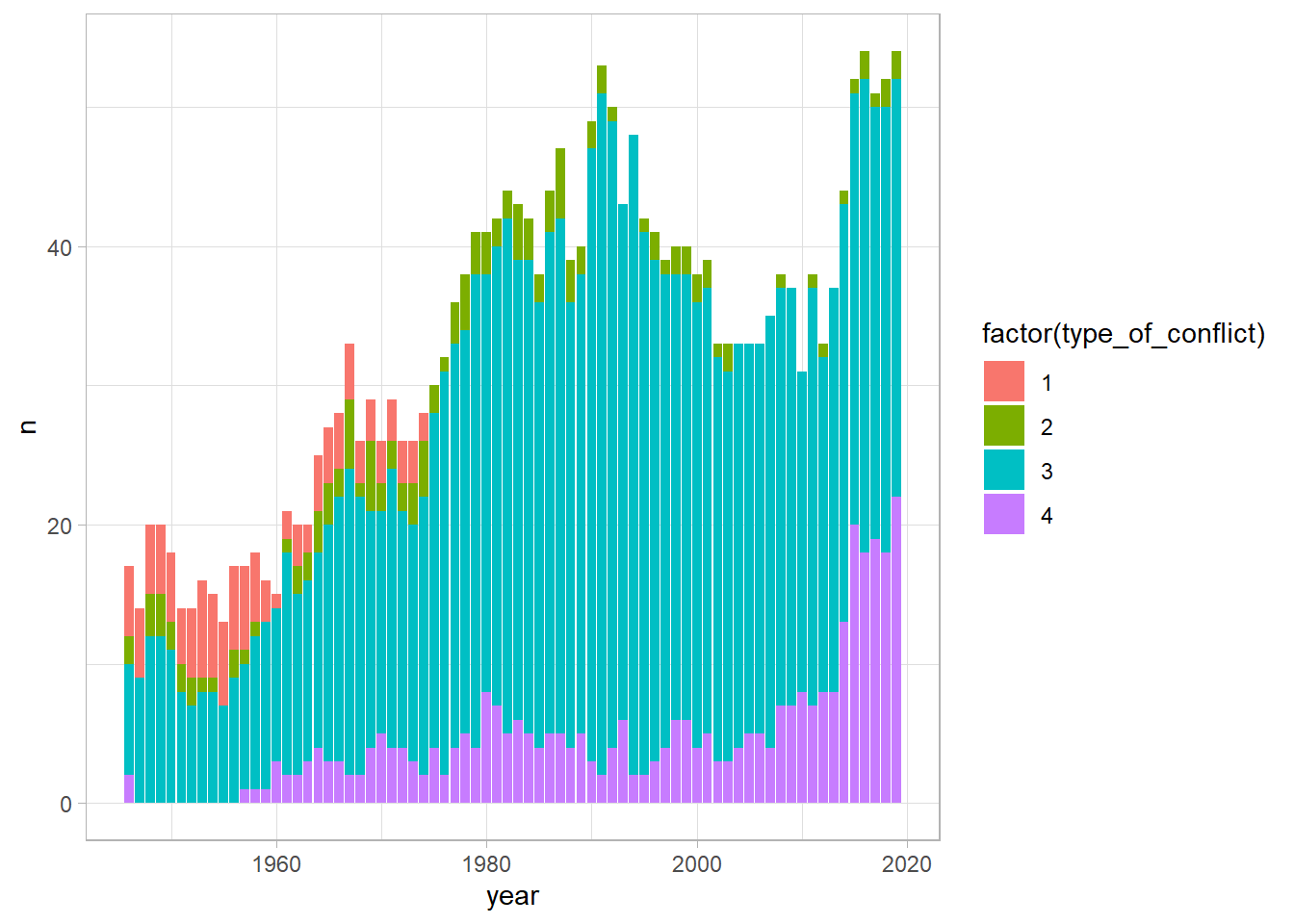
Con base en estos datos, podemos concluir que los conflictos armados internos (internacionalizados o no) se han vuelto cada vez más frecuentes, especialmente a partir del fin de la guerra fría, mientras que los conflictos entre estados son cada vez menos comunes.
Podemos hacer otras operaciones más allá de cargar datos, contar casos y hacer gráficas de estas frecuencias. A continuación, vamos a utilizar las principales herramientas del tidyverse para seleccionar, transformar . Miremos cada una de estas operaciones. Al final, veremos que, en conjunto, ofrecen una caja de herramientas potente –y necesaria– para el analista de datos políticos.
6.3 Seleccionar datos
En ocasiones, una base de datos va a tener más filas y columnas de las que necesitamos, dada una teoría y un diseño de investigación. Para esto, con frecuencia nos vemos en la necesidad de:
- Seleccionar filas (observaciones o casos).
- Organizar y ordenar estas observaciones.
- Seleccionar columnas (variables).
A continuación, revisamos estas operaciones.
6.4 Seleccionar filas: filter()
A veces no necesitamos todas las filas en una base de datos, sino que queremos concentrarnos en algunas observaciones o casos que creemos son relevantes. Por ejemplo, puede que solo queramos estudiar los países más pobres según los datos de gapminder() o solo las guerras civiles de UCDP. Para esto, la principal función que usamos es filter().
6.4.1 Seleccionar filas por condiciones
El tipo de selección más sencilla consiste en seleccionar condicionalmente filas usando evaluaciones lógicas. Por ejemplo, puede que nos interese ver solamente las observaciones para el año 2007 de la base de datos de gapminder, para lo cual usamos filter() en conjunción con el operador == (estrictamente igual a). A continuación, seleccionamos las filas que tienen exactamente el valor 2007 en la variable year:
filter(gapminder, year == 2007)## # A tibble: 142 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 2007 43.8 31889923 975.
## 2 Albania Europe 2007 76.4 3600523 5937.
## 3 Algeria Africa 2007 72.3 33333216 6223.
## 4 Angola Africa 2007 42.7 12420476 4797.
## 5 Argentina Americas 2007 75.3 40301927 12779.
## 6 Australia Oceania 2007 81.2 20434176 34435.
## 7 Austria Europe 2007 79.8 8199783 36126.
## 8 Bahrain Asia 2007 75.6 708573 29796.
## 9 Bangladesh Asia 2007 64.1 150448339 1391.
## 10 Belgium Europe 2007 79.4 10392226 33693.
## # ... with 132 more rowsAsí mismo, podemos hacer una selección según valores de más de una variable. Nos valemos de otros operadores, como & y |. El operador & es el booleano “y” (AND). Con & podemos seleccionar observaciones que cumplan dos condiciones simultáneamente (observaciones del año 2007 y expectativa de vida por encima de los 60 años):
filter(gapminder, year == 2007 & lifeExp > 60)## # A tibble: 99 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Albania Europe 2007 76.4 3600523 5937.
## 2 Algeria Africa 2007 72.3 33333216 6223.
## 3 Argentina Americas 2007 75.3 40301927 12779.
## 4 Australia Oceania 2007 81.2 20434176 34435.
## 5 Austria Europe 2007 79.8 8199783 36126.
## 6 Bahrain Asia 2007 75.6 708573 29796.
## 7 Bangladesh Asia 2007 64.1 150448339 1391.
## 8 Belgium Europe 2007 79.4 10392226 33693.
## 9 Bolivia Americas 2007 65.6 9119152 3822.
## 10 Bosnia and Herzegovina Europe 2007 74.9 4552198 7446.
## # ... with 89 more rowsSimplificando, filter() nos permite reemplazar los & por ,:
filter(gapminder, year == 2007, lifeExp > 60)## # A tibble: 99 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Albania Europe 2007 76.4 3600523 5937.
## 2 Algeria Africa 2007 72.3 33333216 6223.
## 3 Argentina Americas 2007 75.3 40301927 12779.
## 4 Australia Oceania 2007 81.2 20434176 34435.
## 5 Austria Europe 2007 79.8 8199783 36126.
## 6 Bahrain Asia 2007 75.6 708573 29796.
## 7 Bangladesh Asia 2007 64.1 150448339 1391.
## 8 Belgium Europe 2007 79.4 10392226 33693.
## 9 Bolivia Americas 2007 65.6 9119152 3822.
## 10 Bosnia and Herzegovina Europe 2007 74.9 4552198 7446.
## # ... with 89 more rowsMientras, el operador | es el booleano “o” (OR). Aquí, seleccionamos observaciones que cumplan una condición o la otra (el año 2007 o el año 1997):
filter(gapminder, year == 2007 | year == 1997)## # A tibble: 284 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1997 41.8 22227415 635.
## 2 Afghanistan Asia 2007 43.8 31889923 975.
## 3 Albania Europe 1997 73.0 3428038 3193.
## 4 Albania Europe 2007 76.4 3600523 5937.
## 5 Algeria Africa 1997 69.2 29072015 4797.
## 6 Algeria Africa 2007 72.3 33333216 6223.
## 7 Angola Africa 1997 41.0 9875024 2277.
## 8 Angola Africa 2007 42.7 12420476 4797.
## 9 Argentina Americas 1997 73.3 36203463 10967.
## 10 Argentina Americas 2007 75.3 40301927 12779.
## # ... with 274 more rowsSi tenemos muchas condiciones de tipo OR (|) usamos el operador %in% seguido de una lista de condiciones concatenadas con c() para simplificar el código, de esta manera:
# guardamos la muestra como un objeto
eurasia <- filter(gapminder, continent %in% c("Europe", "Asia"))
# revisamos con una muestra de 5 observaciones aleatorias
sample_n(eurasia, 5) ## # A tibble: 5 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Japan Asia 1982 77.1 118454974 19384.
## 2 Indonesia Asia 1962 42.5 99028000 849.
## 3 Hungary Europe 1977 70.0 10637171 11675.
## 4 Pakistan Asia 1992 60.8 120065004 1972.
## 5 Poland Europe 2007 75.6 38518241 15390.Dentro de filter() podemos utilizar estos operadores, así como otros como <, <=, > y >= e incluso funciones como max() o mean(). Por ejemplo, a continuación seleccionamos solo los casos que tengan una expectativa de vida mayor o igual a la media global de esa variable:
filter(gapminder, lifeExp >= mean(lifeExp, na.rm = TRUE))## # A tibble: 895 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Albania Europe 1962 64.8 1728137 2313.
## 2 Albania Europe 1967 66.2 1984060 2760.
## 3 Albania Europe 1972 67.7 2263554 3313.
## 4 Albania Europe 1977 68.9 2509048 3533.
## 5 Albania Europe 1982 70.4 2780097 3631.
## 6 Albania Europe 1987 72 3075321 3739.
## 7 Albania Europe 1992 71.6 3326498 2497.
## 8 Albania Europe 1997 73.0 3428038 3193.
## 9 Albania Europe 2002 75.7 3508512 4604.
## 10 Albania Europe 2007 76.4 3600523 5937.
## # ... with 885 more rowsA veces, es más fácil pedirle a R que seleccione los datos que no cumplen una condición. Para eso está el operador != (no es igual a):
filter(gapminder, continent != "Asia")## # A tibble: 1,308 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Albania Europe 1952 55.2 1282697 1601.
## 2 Albania Europe 1957 59.3 1476505 1942.
## 3 Albania Europe 1962 64.8 1728137 2313.
## 4 Albania Europe 1967 66.2 1984060 2760.
## 5 Albania Europe 1972 67.7 2263554 3313.
## 6 Albania Europe 1977 68.9 2509048 3533.
## 7 Albania Europe 1982 70.4 2780097 3631.
## 8 Albania Europe 1987 72 3075321 3739.
## 9 Albania Europe 1992 71.6 3326498 2497.
## 10 Albania Europe 1997 73.0 3428038 3193.
## # ... with 1,298 more rowsDos funciones adicionales -top_n() y top_frac- nos permiten seleccionar las primeras observaciones cuando ordenamos los datos según una variable, como cuando hacemos “Sort” u “Ordenar” en un programa como Excel. Por ejemplo, aquí seleccionamos el “top 5” de países según PIB per cápita:
top_n(gapminder, 5, gdpPercap)## # A tibble: 5 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Kuwait Asia 1952 55.6 160000 108382.
## 2 Kuwait Asia 1957 58.0 212846 113523.
## 3 Kuwait Asia 1962 60.5 358266 95458.
## 4 Kuwait Asia 1967 64.6 575003 80895.
## 5 Kuwait Asia 1972 67.7 841934 109348.Y aquí los 5 peores:
top_n(gapminder, -5, gdpPercap)## # A tibble: 5 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Congo, Dem. Rep. Africa 1997 42.6 47798986 312.
## 2 Congo, Dem. Rep. Africa 2002 45.0 55379852 241.
## 3 Congo, Dem. Rep. Africa 2007 46.5 64606759 278.
## 4 Guinea-Bissau Africa 1952 32.5 580653 300.
## 5 Lesotho Africa 1952 42.1 748747 299.Veamos el top 99.5% de los países con mayor expectativa de vida al nacer:
top_frac(gapminder, 0.005, lifeExp)## # A tibble: 8 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Australia Oceania 2007 81.2 20434176 34435.
## 2 Hong Kong, China Asia 2002 81.5 6762476 30209.
## 3 Hong Kong, China Asia 2007 82.2 6980412 39725.
## 4 Iceland Europe 2007 81.8 301931 36181.
## 5 Japan Asia 2002 82 127065841 28605.
## 6 Japan Asia 2007 82.6 127467972 31656.
## 7 Spain Europe 2007 80.9 40448191 28821.
## 8 Switzerland Europe 2007 81.7 7554661 37506.Finalmente, podemos guardar los resultados de esta selección como un objeto, para seguir trabajando con este subconjunto de los datos. Esto es altamente recomendable, para no tener que repetir el mismo código cada vez que queremos trabajar con un subconjunto de datos. Veamos dos ejemplos:
gapminder_reciente <- filter(gapminder, year %in% c(1997, 2002, 2007))
gapminder_america <- filter(gapminder, continent == "Americas")Además, si guardamos el objeto como un archivo .csv o .xlsx por ejemplo y lo cargamos después, podemos “saltarnos” muchas líneas de código en una sesión futura o en otro proyecto. Si queremos guardar un archivo de Excel, usamos la función write_xlsx() de la librería writexl, especificando la carpeta de destino y el nombre del nuevo archivo:
write_xlsx(gapminder_america, "data/gapminder_america.xlsx")Exportar datos en formato Excel de esta manera nos permite utilizarlos en ese programa o compartirlo con colegas o un público que no necesariamente tiene conocimiento de R. Sin embargo, si pensamos seguir trabajando en R, es recomendable guardar los datos como archivos de tipo RDS o CSV. Hacemos esto de la siguiente manera, usando funciones análogas de la librería readr, incluida en el tidyverse:
# guardar como archivo de datos de R
write_rds(gapminder_america, "data/gapminder_america.rds")
# guardar como archivo de datos CSV
write_csv(gapminder_america, "data/gapminder_america.csv")6.4.2 Seleccionar filas por posición
Si con filter() podemos usar valores de variables como criterios de selección, con slice() podemos seleccionar un número arbitrario de observaciones según la posición de la fila en la base de datos. Por ejemplo, si queremos solo la observación o fila número 100:
slice(gapminder, 100)## # A tibble: 1 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Bangladesh Asia 1967 43.5 62821884 721.O las observaciones de la 55 a la 65 de una base de datos:
slice(gapminder, 55:65)## # A tibble: 11 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Argentina Americas 1982 69.9 29341374 8998.
## 2 Argentina Americas 1987 70.8 31620918 9140.
## 3 Argentina Americas 1992 71.9 33958947 9308.
## 4 Argentina Americas 1997 73.3 36203463 10967.
## 5 Argentina Americas 2002 74.3 38331121 8798.
## 6 Argentina Americas 2007 75.3 40301927 12779.
## 7 Australia Oceania 1952 69.1 8691212 10040.
## 8 Australia Oceania 1957 70.3 9712569 10950.
## 9 Australia Oceania 1962 70.9 10794968 12217.
## 10 Australia Oceania 1967 71.1 11872264 14526.
## 11 Australia Oceania 1972 71.9 13177000 16789.Quizás la última observación, usando la función n():
slice(gapminder, n())## # A tibble: 1 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Zimbabwe Africa 2007 43.5 12311143 470.O todas las filas, menos de la octava observación hasta la última:
slice(gapminder, -8:-n())## # A tibble: 7 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.En cierto sentido, slice() es similar a head() y tail(), las cuales usamos para explorar las primeras y últimas filas de una base de datos:
tail(gapminder)## # A tibble: 6 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Zimbabwe Africa 1982 60.4 7636524 789.
## 2 Zimbabwe Africa 1987 62.4 9216418 706.
## 3 Zimbabwe Africa 1992 60.4 10704340 693.
## 4 Zimbabwe Africa 1997 46.8 11404948 792.
## 5 Zimbabwe Africa 2002 40.0 11926563 672.
## 6 Zimbabwe Africa 2007 43.5 12311143 470.La diferencia es que estas dos últimas funciones no pueden seleccionar filas en la mitad de una base de datos.
6.5 Reordenar filas: arrange()
Es probable que todos estemos familiarizados con la opción “Ordenar” (o “Sort”) en Excel y programas similares: nos permite ordenar datos de mayor a menor (o menor a mayor) según los valores de una variables. En el tidyverse, tenemos arrange(), una función que cambia el orden de las filas. En vez del orden alfabético por defecto de gapminder, organicemos la base de datos por PIB per cápita, de menor a mayor:
arrange(gapminder, gdpPercap)## # A tibble: 1,704 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Congo, Dem. Rep. Africa 2002 45.0 55379852 241.
## 2 Congo, Dem. Rep. Africa 2007 46.5 64606759 278.
## 3 Lesotho Africa 1952 42.1 748747 299.
## 4 Guinea-Bissau Africa 1952 32.5 580653 300.
## 5 Congo, Dem. Rep. Africa 1997 42.6 47798986 312.
## 6 Eritrea Africa 1952 35.9 1438760 329.
## 7 Myanmar Asia 1952 36.3 20092996 331
## 8 Lesotho Africa 1957 45.0 813338 336.
## 9 Burundi Africa 1952 39.0 2445618 339.
## 10 Eritrea Africa 1957 38.0 1542611 344.
## # ... with 1,694 more rowsPodemos utilizar más de una variable para ordenar los datos:
arrange(gapminder, country, year)## # A tibble: 1,704 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # ... with 1,694 more rowsSi queremos que este nuevo orden sea permanente, debemos crear un objeto nuevo o reescribir el original, como mostramos a continuación:
gapminder <- arrange(gapminder, country, year)Por último, podemos ordenar los datos de manera descendente usando el operador -. Aquí, ordenamos los datos por PIB per cápita, pero de mayor a menor:
arrange(gapminder, -gdpPercap)## # A tibble: 1,704 x 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Kuwait Asia 1957 58.0 212846 113523.
## 2 Kuwait Asia 1972 67.7 841934 109348.
## 3 Kuwait Asia 1952 55.6 160000 108382.
## 4 Kuwait Asia 1962 60.5 358266 95458.
## 5 Kuwait Asia 1967 64.6 575003 80895.
## 6 Kuwait Asia 1977 69.3 1140357 59265.
## 7 Norway Europe 2007 80.2 4627926 49357.
## 8 Kuwait Asia 2007 77.6 2505559 47307.
## 9 Singapore Asia 2007 80.0 4553009 47143.
## 10 Norway Europe 2002 79.0 4535591 44684.
## # ... with 1,694 more rows6.6 Seleccionar variables: select()
Ya vimos cómo seleccionar filas u observaciones (casos). Esta es una herramienta indispensable para asegurarnos que nuestros análisis correspondan a la muestra o muestras que más nos interesan, dados elementos como nuestra pregunta, teoría y diseño.
Por otro lado, en ocasiones no necesitamos todas las columnas que están incluidas een una base de datos. Por ejemplo, solo nos interesan las variables económicas y no las demográficas. En otras palabras, queremos eliminar unas columnas y mantener otras. Para esto, usamos la función select(). Seleccionemos solo tres columnas de gapminder:
select(gapminder, country, year, gdpPercap)## # A tibble: 1,704 x 3
## country year gdpPercap
## <fct> <int> <dbl>
## 1 Afghanistan 1952 779.
## 2 Afghanistan 1957 821.
## 3 Afghanistan 1962 853.
## 4 Afghanistan 1967 836.
## 5 Afghanistan 1972 740.
## 6 Afghanistan 1977 786.
## 7 Afghanistan 1982 978.
## 8 Afghanistan 1987 852.
## 9 Afghanistan 1992 649.
## 10 Afghanistan 1997 635.
## # ... with 1,694 more rowsPodemos usar el operador : para seleccionar un rango de variables, según el orden en que aparecen en la base de datos (aquí, desde year hasta pop):
select(gapminder, year:pop)## # A tibble: 1,704 x 3
## year lifeExp pop
## <int> <dbl> <int>
## 1 1952 28.8 8425333
## 2 1957 30.3 9240934
## 3 1962 32.0 10267083
## 4 1967 34.0 11537966
## 5 1972 36.1 13079460
## 6 1977 38.4 14880372
## 7 1982 39.9 12881816
## 8 1987 40.8 13867957
## 9 1992 41.7 16317921
## 10 1997 41.8 22227415
## # ... with 1,694 more rowsDe manera análoga a filter(), podemos seleccionar todo excepto ciertas variables. Aquí, seleccionamos todas menos continent y pop:
select(gapminder, -continent, -pop)## # A tibble: 1,704 x 4
## country year lifeExp gdpPercap
## <fct> <int> <dbl> <dbl>
## 1 Afghanistan 1952 28.8 779.
## 2 Afghanistan 1957 30.3 821.
## 3 Afghanistan 1962 32.0 853.
## 4 Afghanistan 1967 34.0 836.
## 5 Afghanistan 1972 36.1 740.
## 6 Afghanistan 1977 38.4 786.
## 7 Afghanistan 1982 39.9 978.
## 8 Afghanistan 1987 40.8 852.
## 9 Afghanistan 1992 41.7 649.
## 10 Afghanistan 1997 41.8 635.
## # ... with 1,694 more rowsLa función select() tiene unas funciones hermanas que le agregan flexibilidad y expanden lo que podemos hacer con ella. Por ejemplo, con where() podemos seleccionar variables que cumplen una condición. En el siguiente caso, selecionamos solo las columnas numéricas (según su clase en R):
select(gapminder, where(is.numeric))## # A tibble: 1,704 x 4
## year lifeExp pop gdpPercap
## <int> <dbl> <int> <dbl>
## 1 1952 28.8 8425333 779.
## 2 1957 30.3 9240934 821.
## 3 1962 32.0 10267083 853.
## 4 1967 34.0 11537966 836.
## 5 1972 36.1 13079460 740.
## 6 1977 38.4 14880372 786.
## 7 1982 39.9 12881816 978.
## 8 1987 40.8 13867957 852.
## 9 1992 41.7 16317921 649.
## 10 1997 41.8 22227415 635.
## # ... with 1,694 more rowsO podríamos seleccionar solo las columnas definidas como factores en R (variables categóricas con niveles o categorías definidas):
select(gapminder, where(is.factor))## # A tibble: 1,704 x 2
## country continent
## <fct> <fct>
## 1 Afghanistan Asia
## 2 Afghanistan Asia
## 3 Afghanistan Asia
## 4 Afghanistan Asia
## 5 Afghanistan Asia
## 6 Afghanistan Asia
## 7 Afghanistan Asia
## 8 Afghanistan Asia
## 9 Afghanistan Asia
## 10 Afghanistan Asia
## # ... with 1,694 more rowsUsando starts_with, podemos quedarnos solo con las columnas cuyo nombre comienza por una letra o una expresión en específico. Esto puede ser útil cuando tenemos columnas con nombres como indicador_a, indicador_b, indicador_c, etc. y queremos seleccionarlas. Por ejemplo, seleccionemos columnas que empiezan por “c”:
select(gapminder, starts_with("c"))## # A tibble: 1,704 x 2
## country continent
## <fct> <fct>
## 1 Afghanistan Asia
## 2 Afghanistan Asia
## 3 Afghanistan Asia
## 4 Afghanistan Asia
## 5 Afghanistan Asia
## 6 Afghanistan Asia
## 7 Afghanistan Asia
## 8 Afghanistan Asia
## 9 Afghanistan Asia
## 10 Afghanistan Asia
## # ... with 1,694 more rowsLa función ends_with() hace lo opuesto, busca columnas que terminan con ciertos patrones o expresiones:
select(gapminder, ends_with("p"))## # A tibble: 1,704 x 3
## lifeExp pop gdpPercap
## <dbl> <int> <dbl>
## 1 28.8 8425333 779.
## 2 30.3 9240934 821.
## 3 32.0 10267083 853.
## 4 34.0 11537966 836.
## 5 36.1 13079460 740.
## 6 38.4 14880372 786.
## 7 39.9 12881816 978.
## 8 40.8 13867957 852.
## 9 41.7 16317921 649.
## 10 41.8 22227415 635.
## # ... with 1,694 more rowsMientras, contains() busca columnas que tengan ciertos caracteres, sea al principio, final o en la mitad:
select(gapminder, contains("Exp"))## # A tibble: 1,704 x 1
## lifeExp
## <dbl>
## 1 28.8
## 2 30.3
## 3 32.0
## 4 34.0
## 5 36.1
## 6 38.4
## 7 39.9
## 8 40.8
## 9 41.7
## 10 41.8
## # ... with 1,694 more rows6.6.1 Renombrar columnas: rename()
Podemos renombrar columnas directamente dentro de select(), pero esto descarta de la base de datos todas las variables no renombradas explícitamente:
select(gapminder, pib_percap = gdpPercap)## # A tibble: 1,704 x 1
## pib_percap
## <dbl>
## 1 779.
## 2 821.
## 3 853.
## 4 836.
## 5 740.
## 6 786.
## 7 978.
## 8 852.
## 9 649.
## 10 635.
## # ... with 1,694 more rowsEn cambio, rename() nos permite renombrar variables y además mantener las demás:
rename(
gapminder,
# nombre_nuevo = nombre_viejo
continente = continent, ano = year, exp_vida = lifeExp,
pob = pop, pib_percap = gdpPercap
)## # A tibble: 1,704 x 6
## country continente ano exp_vida pob pib_percap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # ... with 1,694 more rows6.7 Transformar datos
Una vez tenemos una base de datos cargada en R (o sea, que está definido como un objeto en el Environment) y opcionalmente hemos seleccionado un subconjunto de interés, queremos hacer algo con esos datos. Usualmente, ese algo implica transformarlos. Hay muchas formas de transformar datos en R. Algunas de las principales son:
- Computar nuevas variables o transformar las existentes.
- Resumir datos por grupos.
- Trabajar con datos no disponibles (
NA).
A continuación, revisamos estas operaciones esenciales.
6.8 Crear y transformar variables: mutate()
Las bases de datos no siempre tienen todas las variables que necesitamos. Pero pueden tener la información necesaria para que las creemos nosotros mismos. mutate() es la principal función que usamos para crear variables o modificar variables existentes. mutate() siempre adiciona columnas nuevas a la base de datos, pero -como veremos- si queremos que queden grabadas al objeto, debemos usar el operador de asignación <-.
Como ejemplo, tomemos gapminder. Tenemos información sobre PIB per cápita (gdpPercap), pero en realidad queremos el PIB. Esa columna no existe en los datos, pero tenemos la información suficiente para construirla. El PIB per cápita se define como \(\frac{PIB}{población}\), así que si utilizamos la variable pop tenemos lo necesario para calcular el PIB:
mutate(gapminder, gdp = gdpPercap*pop)## # A tibble: 1,704 x 7
## country continent year lifeExp pop gdpPercap gdp
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779. 6567086330.
## 2 Afghanistan Asia 1957 30.3 9240934 821. 7585448670.
## 3 Afghanistan Asia 1962 32.0 10267083 853. 8758855797.
## 4 Afghanistan Asia 1967 34.0 11537966 836. 9648014150.
## 5 Afghanistan Asia 1972 36.1 13079460 740. 9678553274.
## 6 Afghanistan Asia 1977 38.4 14880372 786. 11697659231.
## 7 Afghanistan Asia 1982 39.9 12881816 978. 12598563401.
## 8 Afghanistan Asia 1987 40.8 13867957 852. 11820990309.
## 9 Afghanistan Asia 1992 41.7 16317921 649. 10595901589.
## 10 Afghanistan Asia 1997 41.8 22227415 635. 14121995875.
## # ... with 1,694 more rowsSi solo queremos mantener las variables creadas (y descartar las originales), usamos transmute(), pero rara vez queremos deshacernos de todo:
transmute(gapminder, gdp = gdpPercap*pop)## # A tibble: 1,704 x 1
## gdp
## <dbl>
## 1 6567086330.
## 2 7585448670.
## 3 8758855797.
## 4 9648014150.
## 5 9678553274.
## 6 11697659231.
## 7 12598563401.
## 8 11820990309.
## 9 10595901589.
## 10 14121995875.
## # ... with 1,694 more rowsAdemás, podemos usar muchas otras funciones, como log(), para crear nuevas variables. Por ejemplo, si queremos el logaritmo del PIB per cápita:
mutate(gapminder, gdpPercap_log = log(gdpPercap))## # A tibble: 1,704 x 7
## country continent year lifeExp pop gdpPercap gdpPercap_log
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779. 6.66
## 2 Afghanistan Asia 1957 30.3 9240934 821. 6.71
## 3 Afghanistan Asia 1962 32.0 10267083 853. 6.75
## 4 Afghanistan Asia 1967 34.0 11537966 836. 6.73
## 5 Afghanistan Asia 1972 36.1 13079460 740. 6.61
## 6 Afghanistan Asia 1977 38.4 14880372 786. 6.67
## 7 Afghanistan Asia 1982 39.9 12881816 978. 6.89
## 8 Afghanistan Asia 1987 40.8 13867957 852. 6.75
## 9 Afghanistan Asia 1992 41.7 16317921 649. 6.48
## 10 Afghanistan Asia 1997 41.8 22227415 635. 6.45
## # ... with 1,694 more rowsUsualmente, queremos que las variables recién creadas permanezcan y se vuelvan parte de la base de datos en R. Entonces, debemos reescribir el objeto (o crear uno nuevo) usando el operador de asignación <-. Breve recordatorio: si usamos el mismo nombre del objeto original, lo reescribimos, pero si usamos un nuevo nombre, creamos un objeto adicional. Veamos cómo reescribir gapminder para agregar unas nuevas variables:
gapminder <- mutate(
gapminder,
gdp = gdpPercap*pop,
gdp_log = log(gdp),
gdpPercap_log = log(gdpPercap)
)Inspeccionemos el resultado para confirmar que las nuevas columnas ahora sí quedaron guardadas en el objeto:
select(gapminder, country, year, gdp_log, gdpPercap_log)## # A tibble: 1,704 x 4
## country year gdp_log gdpPercap_log
## <fct> <int> <dbl> <dbl>
## 1 Afghanistan 1952 22.6 6.66
## 2 Afghanistan 1957 22.7 6.71
## 3 Afghanistan 1962 22.9 6.75
## 4 Afghanistan 1967 23.0 6.73
## 5 Afghanistan 1972 23.0 6.61
## 6 Afghanistan 1977 23.2 6.67
## 7 Afghanistan 1982 23.3 6.89
## 8 Afghanistan 1987 23.2 6.75
## 9 Afghanistan 1992 23.1 6.48
## 10 Afghanistan 1997 23.4 6.45
## # ... with 1,694 more rowsOtro ejemplo útil: podemos calcular valores acumulados, rezagados y adelantados de una variable. En el caso de una base de datos donde la unidad de análisis es el país-año (o sea, cada fila tiene información para un país en un año), esto nos permite calcular los valores del año anterior. Para ilustrar este procedimiento, hagamos un pequeño subconjunto de datos:
gapminder_colombia <- filter(gapminder, country == "Colombia")Ahora, creemos una serie de variables nuevas Para cada observación, queremos conocer los siguientes valores:
- PIB per cápita más alto de toda la serie (
cummax()). - El valor del PIB per cápita de la observación o año anterior (
lag()). - Esta misma variable, pero de hace 2 años (con el argumento
n =) y del año siguiente (lead()).
Usamos mutate() para realizar la operación
gapminder_colombia <- mutate(
gapminder_colombia,
gdpPercap_max = cummax(gdpPercap),
gdpPercap_lag = lag(gdpPercap),
gdpPercap_lag2 = lag(gdpPercap, n = 2),
gdpPercap_lead = lead(gdpPercap)
)
# veamos el resultado, seleccionando solo variables de interes
select(gapminder_colombia, year, gdpPercap, gdpPercap_max, gdpPercap_lag, gdpPercap_lag2, gdpPercap_lead)## # A tibble: 12 x 6
## year gdpPercap gdpPercap_max gdpPercap_lag gdpPercap_lag2 gdpPercap_lead
## <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1952 2144. 2144. NA NA 2324.
## 2 1957 2324. 2324. 2144. NA 2492.
## 3 1962 2492. 2492. 2324. 2144. 2679.
## 4 1967 2679. 2679. 2492. 2324. 3265.
## 5 1972 3265. 3265. 2679. 2492. 3816.
## 6 1977 3816. 3816. 3265. 2679. 4398.
## 7 1982 4398. 4398. 3816. 3265. 4903.
## 8 1987 4903. 4903. 4398. 3816. 5445.
## 9 1992 5445. 5445. 4903. 4398. 6117.
## 10 1997 6117. 6117. 5445. 4903. 5755.
## 11 2002 5755. 6117. 6117. 5445. 7007.
## 12 2007 7007. 7007. 5755. 6117. NAPodemos usar lag() y lead() aquí porque solo hay datos de un país y están ordenados cronológicamente por año. En paneles de datos con muchos países y años, necesitaríamos agrupar los datos por país primero, como veremos más adelante.
Un último detalle: con estas nuevas variables, podemos calcular otras cantidad de interés, como el crecimiento anual del PIB per cápita. Comparamos el PIB per cápita de un año al del año anterior:
gapminder_colombia <- mutate(
gapminder_colombia,
gdpPercap_dif = gdpPercap - gdpPercap_lag,
gdpPercap_dif_perc = gdpPercap_dif/gdpPercap_lag
)
select(gapminder_colombia, year, gdpPercap, gdpPercap_dif, gdpPercap_dif_perc)## # A tibble: 12 x 4
## year gdpPercap gdpPercap_dif gdpPercap_dif_perc
## <int> <dbl> <dbl> <dbl>
## 1 1952 2144. NA NA
## 2 1957 2324. 180. 0.0838
## 3 1962 2492. 169. 0.0725
## 4 1967 2679. 186. 0.0748
## 5 1972 3265. 586. 0.219
## 6 1977 3816. 551. 0.169
## 7 1982 4398. 582. 0.152
## 8 1987 4903. 506. 0.115
## 9 1992 5445. 541. 0.110
## 10 1997 6117. 673. 0.124
## 11 2002 5755. -362. -0.0592
## 12 2007 7007. 1251. 0.217Y podemos ver la crisis económica colombiana de finales del siglo XX:
# creamos un indicador de crecimiento negativo
gapminder_colombia <- mutate(
gapminder_colombia,
crecimiento_signo = if_else(gdpPercap_dif_perc < 0, "neg", "pos")
)
# ahora construimos la grafica
ggplot(gapminder_colombia, aes(year, gdpPercap_dif_perc, fill = crecimiento_signo)) +
geom_col()## Warning: Removed 1 rows containing missing values (position_stack).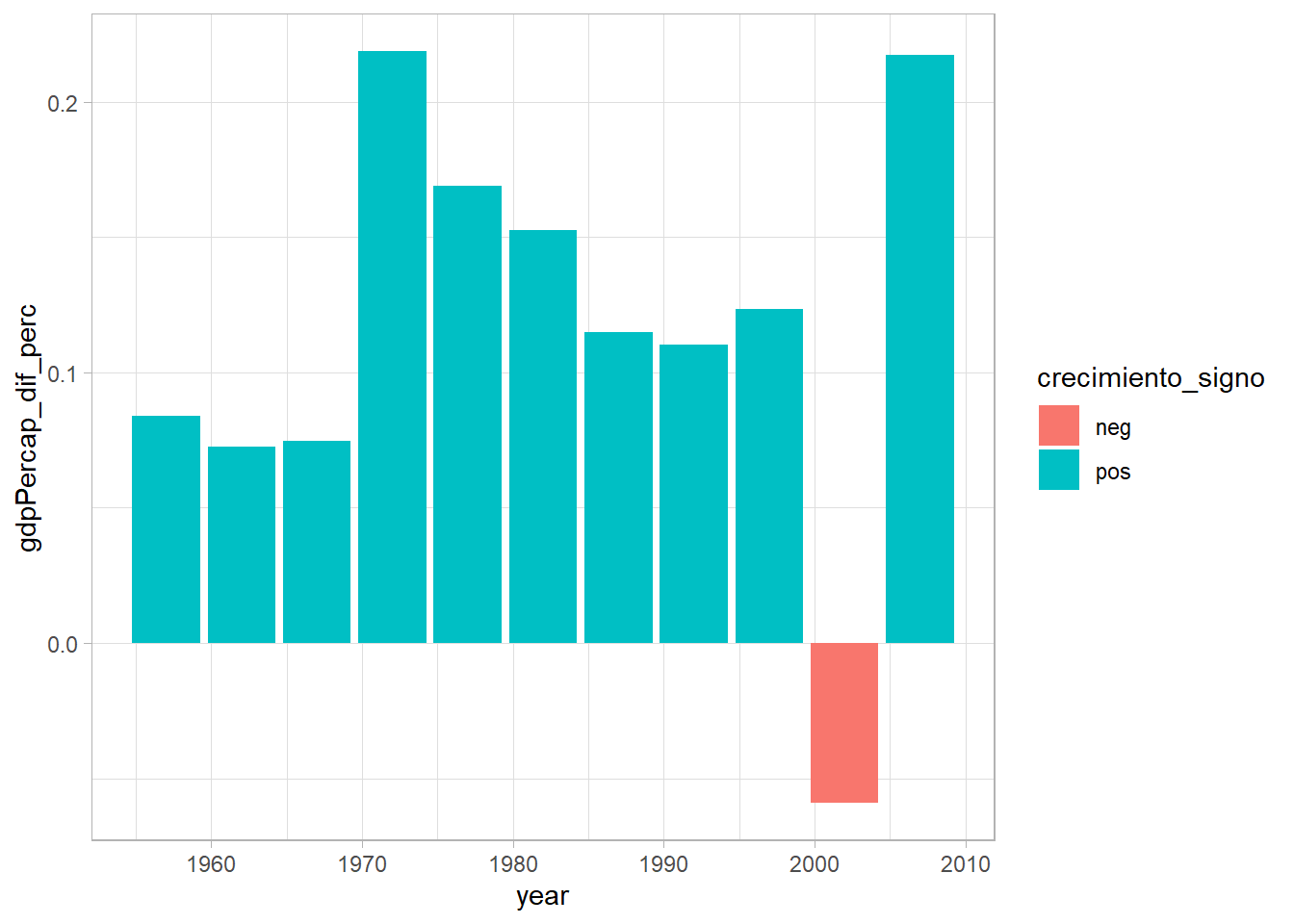
6.8.1 Cambiar clases de variables
Todos los objetos en R tienen una clase, incluyendo las columnas de una base de datos. Las principales clases de variables en R son:
numericeintegercorresponden a variables de tipo numérico, continuas y enteros.factor, variables categóricas definidas especialmente y con categorías y niveles, a veces con un orden explícito.character, a veces llamados strings, y que incluyen caracteres, texto, palabras, etc. incluyendo oraciones completas.logical, con valoresTRUEoFALSEdependiendo de si se cumple una condición.date, un formato especial para fechas.NA,NaNeInfpara datos no disponibles, que no pueden ser expresados como un número o con valor infinito.
A veces, tenemos una variable tipo caracter o texto que queremos como categórica (factor). O sucede que cargamos los datos y hay una variable numérica que R interpreta como texto. Miremos cómo cambiar tipos de variables usando los datos de PolityIV que cargamos anteriormente. Seleccionemos unas pocas variables de interés:
polity4 <- select(polity4, ccode, country, year, polity2, parreg, parcomp, exconst)
polity4## # A tibble: 17,395 x 7
## ccode country year polity2 parreg parcomp exconst
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2 United States 1800 4 4 2 7
## 2 2 United States 1801 4 4 2 7
## 3 2 United States 1802 4 4 2 7
## 4 2 United States 1803 4 4 2 7
## 5 2 United States 1804 4 4 2 7
## 6 2 United States 1805 4 4 2 7
## 7 2 United States 1806 4 4 2 7
## 8 2 United States 1807 4 4 2 7
## 9 2 United States 1808 4 4 2 7
## 10 2 United States 1809 9 2 4 7
## # ... with 17,385 more rowsHay varias funciones que nos permite hacer cambios de tipo fácilmente en conjunción con mutate(): as.numeric(), as.factor(), as.integer(), as.character(), etc. Vamos a convertir el código de país y el año a variables de tipo factor (variable categórica) y a (número) entero, respectivamente:
mutate(polity4,
ccode = as.factor(ccode),
year = as.integer(year))## # A tibble: 17,395 x 7
## ccode country year polity2 parreg parcomp exconst
## <fct> <chr> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2 United States 1800 4 4 2 7
## 2 2 United States 1801 4 4 2 7
## 3 2 United States 1802 4 4 2 7
## 4 2 United States 1803 4 4 2 7
## 5 2 United States 1804 4 4 2 7
## 6 2 United States 1805 4 4 2 7
## 7 2 United States 1806 4 4 2 7
## 8 2 United States 1807 4 4 2 7
## 9 2 United States 1808 4 4 2 7
## 10 2 United States 1809 9 2 4 7
## # ... with 17,385 more rowsSi tenemos muchas variables que aparecen con la clase incorrecta, podemos cambiarlas masivamente usando la función across() dentro de mutate(). Esta función nos permite imponer una condición para seleccionar qué variables vamos a transformar y seleccionar una función (as.factor() en este ejemplo) para aplicarle a esas variables:
mutate(
polity4,
across(
# caracteristica que tienen las variables que queremos cambiar
is.character,
# funcion que queremos aplicarles
as.factor
)
)## Warning: Predicate functions must be wrapped in `where()`.
##
## # Bad
## data %>% select(is.character)
##
## # Good
## data %>% select(where(is.character))
##
## i Please update your code.
## This message is displayed once per session.## # A tibble: 17,395 x 7
## ccode country year polity2 parreg parcomp exconst
## <dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2 United States 1800 4 4 2 7
## 2 2 United States 1801 4 4 2 7
## 3 2 United States 1802 4 4 2 7
## 4 2 United States 1803 4 4 2 7
## 5 2 United States 1804 4 4 2 7
## 6 2 United States 1805 4 4 2 7
## 7 2 United States 1806 4 4 2 7
## 8 2 United States 1807 4 4 2 7
## 9 2 United States 1808 4 4 2 7
## 10 2 United States 1809 9 2 4 7
## # ... with 17,385 more rowsLa función across() es bastante útil y permite aplicar cualquier función a un conjunto de columnas con algo en común. Como ejemplo, supongamos que por alguna razón queremos modificar los valores de las variables parreg y parcomp:
# definimos una funcion que toma una variable numerica y le suma 2
sumar2 <- function(x) {
x+2
}
# ahora modificamos las variables
mutate(
polity4,
across(
# caracteristica que tienen las variables que queremos cambiar
starts_with("par"),
# funcion que queremos aplicarles
sumar2
)
)## # A tibble: 17,395 x 7
## ccode country year polity2 parreg parcomp exconst
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2 United States 1800 4 6 4 7
## 2 2 United States 1801 4 6 4 7
## 3 2 United States 1802 4 6 4 7
## 4 2 United States 1803 4 6 4 7
## 5 2 United States 1804 4 6 4 7
## 6 2 United States 1805 4 6 4 7
## 7 2 United States 1806 4 6 4 7
## 8 2 United States 1807 4 6 4 7
## 9 2 United States 1808 4 6 4 7
## 10 2 United States 1809 9 4 6 7
## # ... with 17,385 more rows6.8.2 Variables categóricas
Ya hemos visto cómo crear nuevas variables numéricas aplicando funciones en el contexto de mutate(). Pero también podemos crear variables categóricas o cualitativas. En R, estas son llamadas “factores” (o factors). Tanto base como la librería forcats ofrecen funciones que nos ayudan a trabajar con factores.
6.8.2.1 Variable numérica a categórica
Primero, utilicemos los valores de una variable numérica para crear una categórica. Por ejemplo, clasifiquemos como “democracias” a los países que tienen un valor mayor que 5 en el indicador polity2. Para esto, la función if_else() nos permite evaluar con expresiones lógicas si se cumplen condiciones y reemplazar valores. A su vez, la función factor() le dice a R que la variable creada es categórica; es importante seguir bien los paréntesis para entender qué está pasando. Usamos <- para asegurarnos que los resultados queden guardados en polity4:
polity4 <- mutate(
polity4,
# creamos un factor llamado democracia
democracia = factor(
if_else(
# qué condición se tiene que cumplir
condition = polity2 > 5,
# qué hacer si se cumple
true = "democracia",
# qué hacer si no se cumple
false = "otro"
),
# especificamos que el factor no es ordinal
ordered = FALSE
)
)Revisamos el resultado con count() que cuenta el número de observaciones en cada categoría:
count(polity4, democracia)## # A tibble: 3 x 2
## democracia n
## <fct> <int>
## 1 democracia 5050
## 2 otro 12109
## 3 <NA> 236Podemos crear mas de dos categorías a la vez usando case_when(), la cual es una extensión de if_else(). Aquí, evaluamos si cumplen con unas condiciones y creamos una variable acordemente:
polity4 <- mutate(
polity4,
regimen = factor( # crear una nueva variable tipo factor
case_when(
# condición ~ resultado
polity2 > 5 ~ "democracia",
polity2 < -5 ~ "autocracia",
# para todos los demás casos ~ resultado
TRUE ~ "anocracia"
),
# el factor no es ordenado
ordered = FALSE
)
)
count(polity4, regimen)## # A tibble: 3 x 2
## regimen n
## <fct> <int>
## 1 anocracia 6133
## 2 autocracia 6212
## 3 democracia 5050Otra forma de hacer esto es con la función cut_number(). A continuación, la utilizamos para dividir la variable polity2 en 5 grupos o categorías con aproximadamente el mismo número de observaciones en cada una:
polity4 <- mutate(
polity4,
regimen_cut = cut_number(polity2, 5)
)
# revisamos el resultado
count(polity4, regimen_cut)## # A tibble: 6 x 2
## regimen_cut n
## <fct> <int>
## 1 [-10,-7] 4913
## 2 (-7,-4] 2607
## 3 (-4,1] 2844
## 4 (1,8] 3657
## 5 (8,10] 3138
## 6 <NA> 236Podemos darle nombre a las categorías que creamos con cut_number() y el argumento labels =:
polity4 <- mutate(
polity4,
regimen_cut = cut_number(
polity2, 5, labels = c("bajo", "med-bajo", "medio", "med-alto", "alto")
)
)
count(polity4, regimen_cut)## # A tibble: 6 x 2
## regimen_cut n
## <fct> <int>
## 1 bajo 4913
## 2 med-bajo 2607
## 3 medio 2844
## 4 med-alto 3657
## 5 alto 3138
## 6 <NA> 2366.8.2.1.1 Reordenar factores
Tenemos varias maneras de reordenar o recodificar factores; algunas son funciones de la librería forcats del tidyverse. Pueden consultar más sobre esta librería en (este sitio)[https://forcats.tidyverse.org/].
Si queremos especificar los niveles de un factor al crearlo, usamos el argumento "levels =" en factor(). El orden de un factor es importante, pues define la categoría base, frente a la cual comparamos e interpretamos a la hora de hacer gráficas o estimar modelos estadísticos:
polity4 <- mutate(
polity4,
regimen = factor(regimen, levels = c("democracia", "anocracia", "autocracia"))
)
count(polity4, regimen)## # A tibble: 3 x 2
## regimen n
## <fct> <int>
## 1 democracia 5050
## 2 anocracia 6133
## 3 autocracia 6212Podemos hacer algo similar -un reordenamiento manual- con fct_relevel() cuando tenemos una variable categórica que ya existe. Comparen el orden en el código y las diferencias en el resultado:
polity4 <- mutate(
polity4,
regimen = fct_relevel(regimen,
c("autocracia", "anocracia", "democracia"))
)
count(polity4, regimen)## # A tibble: 3 x 2
## regimen n
## <fct> <int>
## 1 autocracia 6212
## 2 anocracia 6133
## 3 democracia 5050Igualmente, podemos reordenar por frecuencias, trayendo al frente a la categoría con más observaciones, la cual se convierte en nuestra categoría base o de referencia. Hacemos esto con fct_infreq() y es útil cuando queremos construir una gráfica:
ggplot(polity4, aes(fct_infreq(regimen_cut))) +
geom_bar() +
coord_flip()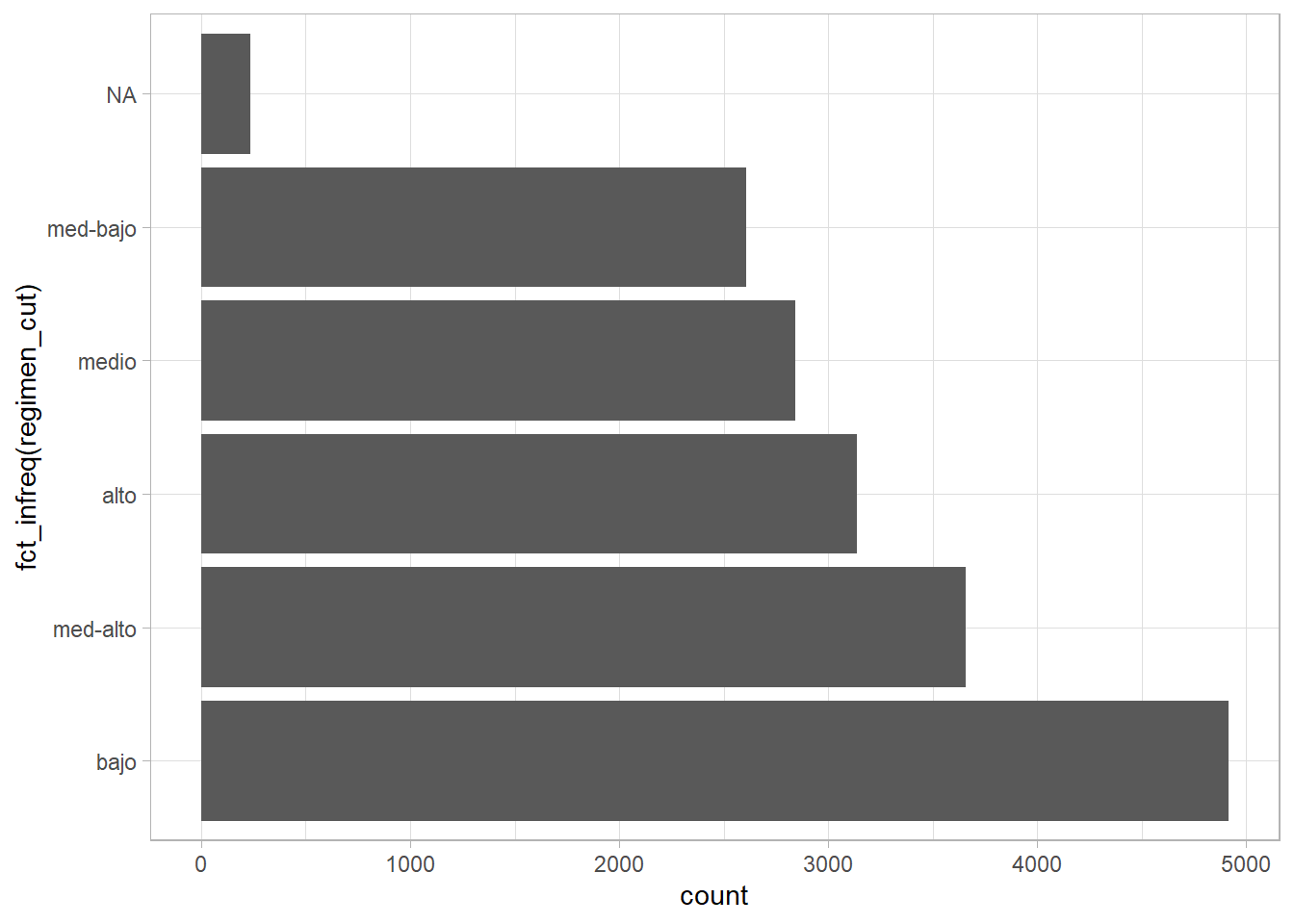
También podemos ordenar los niveles de un factor según los valores de otra variable con fct_reorder(). En la siguiente gráfica, vemos el PIB per cápita de cuatro países suramericanos para el año 2007, pero el orden de los países en la gráfica corresponde a la expectativa de vida promedio en cada país:
gapminder_sub <- filter(
gapminder,
year == max(year),
country %in% c("Colombia", "Argentina", "Peru", "Venezuela")
)
ggplot(gapminder_sub, aes(fct_reorder(country, lifeExp), gdpPercap)) +
geom_col()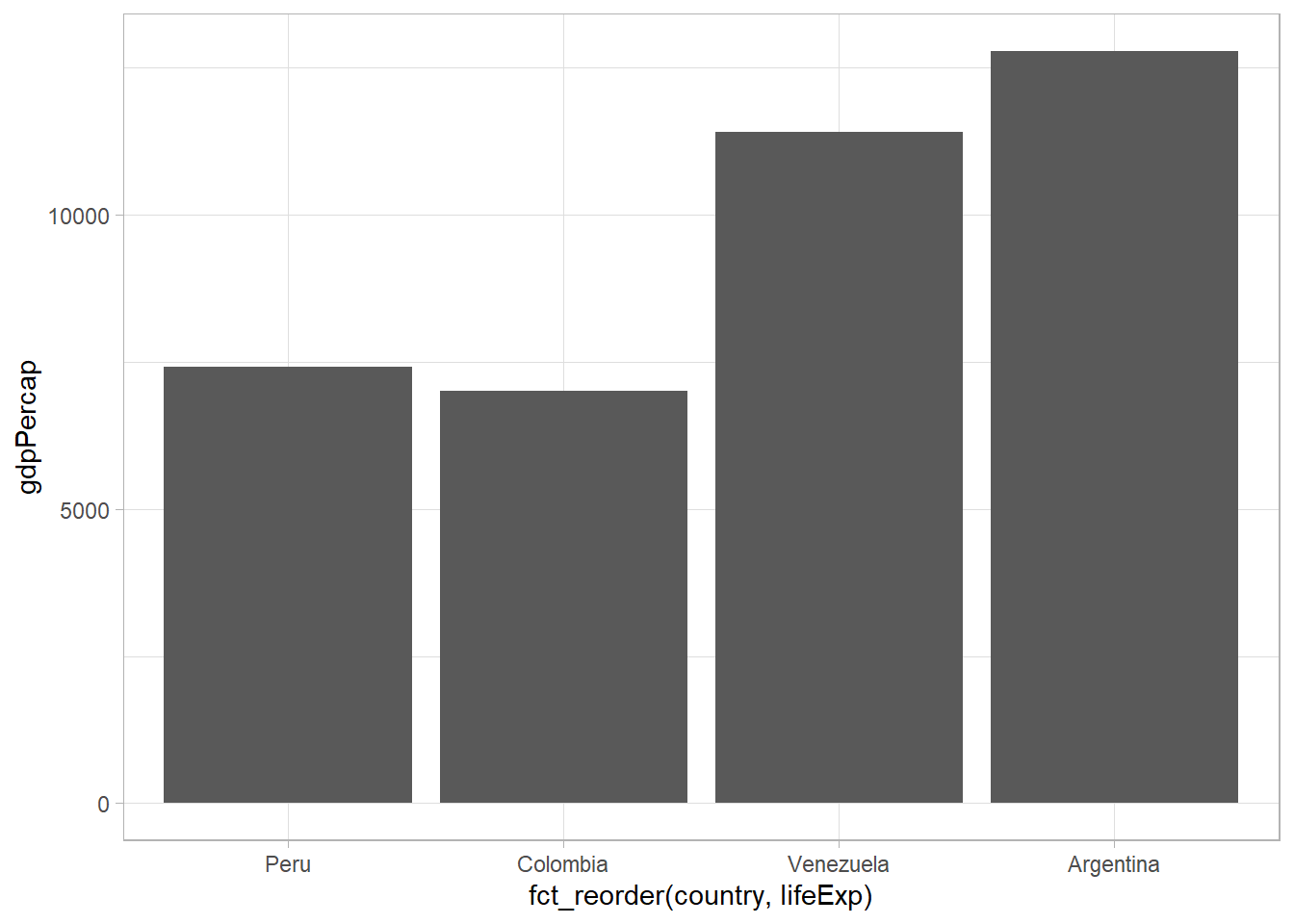
Finalmente, podemos combinar o colapsar categorías en una categoría de “otros” usando la función fct_lump(), con el argumento opcional other_level = para especificar el nombre de la categoría residual (por defecto, esta queda nombrado como “Other”):
polity4 <- mutate(
polity4,
regimen_bin = fct_lump(regimen_cut, n = 2, other_level = "otros")
)
count(polity4, regimen_bin)## # A tibble: 4 x 2
## regimen_bin n
## <fct> <int>
## 1 bajo 4913
## 2 med-alto 3657
## 3 otros 8589
## 4 <NA> 2366.9 Resumir: count(), group_by() y summarize()
Con frecuencia, nuestros datos están agrupados: las observaciones pertenecen a grupos, indicador por una variable categórica. Por ejemplo, los países del mundo están ubicados en distintos continentes. Como hemos visto con anterioridad, la función count() nos muestra el número de observaciones en cada grupo, definido por una variable categórica (factor o caracter):
count(gapminder, continent)## # A tibble: 5 x 2
## continent n
## <fct> <int>
## 1 Africa 624
## 2 Americas 300
## 3 Asia 396
## 4 Europe 360
## 5 Oceania 246.9.1 Tablas cruzadas
La función count() sirve además para hacer tablas cruzadas con dos variables categóricas. Veamos cómo funciona. Primero, creamos una nueva variable para niveles altos de PIB per cápita (aquellos países-año por encima de la media global):
gapminder <- mutate(
gapminder,
pib_dummy = if_else(
gdpPercap > mean(gdpPercap, na.rm = TRUE), "alto", "bajo"
)
)Ahora, tabulamos o “cruzamos” las variables con count():
count(gapminder, continent, pib_dummy)## # A tibble: 9 x 3
## continent pib_dummy n
## <fct> <chr> <int>
## 1 Africa alto 36
## 2 Africa bajo 588
## 3 Americas alto 92
## 4 Americas bajo 208
## 5 Asia alto 112
## 6 Asia bajo 284
## 7 Europe alto 270
## 8 Europe bajo 90
## 9 Oceania alto 24Las tablas cruzadas nos permiten ver rápidamente posibles relaciones entre variables categóricas. Por tanto, son parte central de la caja de herramientas de las ciencias sociales.
Digamos que queremos exportar la anterior tabla cruzada porque queremos incluirla en un documento externo (y por alguna razón no estamos usando RMarkdown). En este caso, una posibilidad es usar la libreria knitr y la función kable(). Primero, creamos la tabla como un objeto:
library(knitr)
tabla_cruzada <- kable(
count(gapminder, continent, pib_dummy), # datos
format = "html", # formato .html
col.names = c("Continente", "Nivel PIB", "Casos"), # nombres de columnas
caption = "Tabla cruzada" # titulo
)Y luego guardamos la tabla con write_file() de readr, especificando el directorio y el nombre del archivo al cual queremos mandar la tabla:
write_file(tabla_cruzada, "output/tabla_cruzada.doc")Luego, podemos abrir el archivo y copiar la tabla.
6.9.2 Agrupar y resumir
Aprovechamos que los datos frecuentemente pueden ser agrupados para aplicar operaciones que los resumen, dándonos información para cada grupo, definido por una variable categórica. Esto nos permitirá ver diferencias y comparar entre democracias y autocracias o entre observaciones en un grupo de tratamiento y un grupo de control experimental.
Las dos funciones que vamos a utilizar para esto son group_by() y summarize(). Por si sola, summarize() resume variables y el resultado siempre es un solo valor, al cual le damos un nuevo nombre. Por ejemplo, la media de la variable lifeExp en gapminder:
summarize(gapminder, lifeExp_media = mean(lifeExp, na.rm = TRUE))## # A tibble: 1 x 1
## lifeExp_media
## <dbl>
## 1 59.5Esta es una alternativa a:
mean(gapminder$lifeExp, na.rm = TRUE)## [1] 59.47444Por el otro lado, group_by() por si solo aparentemente no hace mucho – noten que el tibble resultante nos indica que este objeto está agrupado y que hay 142 grupos:
group_by(gapminder, country)## # A tibble: 1,704 x 10
## # Groups: country [142]
## country continent year lifeExp pop gdpPercap gdp gdp_log
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779. 6567086330. 22.6
## 2 Afghanistan Asia 1957 30.3 9240934 821. 7585448670. 22.7
## 3 Afghanistan Asia 1962 32.0 10267083 853. 8758855797. 22.9
## 4 Afghanistan Asia 1967 34.0 11537966 836. 9648014150. 23.0
## 5 Afghanistan Asia 1972 36.1 13079460 740. 9678553274. 23.0
## 6 Afghanistan Asia 1977 38.4 14880372 786. 11697659231. 23.2
## 7 Afghanistan Asia 1982 39.9 12881816 978. 12598563401. 23.3
## 8 Afghanistan Asia 1987 40.8 13867957 852. 11820990309. 23.2
## 9 Afghanistan Asia 1992 41.7 16317921 649. 10595901589. 23.1
## 10 Afghanistan Asia 1997 41.8 22227415 635. 14121995875. 23.4
## # ... with 1,694 more rows, and 2 more variables: gdpPercap_log <dbl>,
## # pib_dummy <chr>En este punto, group_by() nos permite hallar valores razagados y adelantadas por grupo, como hicimos anteriormente, pero con una base de datos en donde hay más de un grupo (más de un país en este caso específico):
select(mutate(
group_by(gapminder, country),
gdp_lag = lag(gdpPercap),
gdp_lead = lead(gdpPercap)
), country, year, gdp_lag, gdp_lead)## # A tibble: 1,704 x 4
## # Groups: country [142]
## country year gdp_lag gdp_lead
## <fct> <int> <dbl> <dbl>
## 1 Afghanistan 1952 NA 821.
## 2 Afghanistan 1957 779. 853.
## 3 Afghanistan 1962 821. 836.
## 4 Afghanistan 1967 853. 740.
## 5 Afghanistan 1972 836. 786.
## 6 Afghanistan 1977 740. 978.
## 7 Afghanistan 1982 786. 852.
## 8 Afghanistan 1987 978. 649.
## 9 Afghanistan 1992 852. 635.
## 10 Afghanistan 1997 649. 727.
## # ... with 1,694 more rowsPero, por sus poderes combinados… group_by() junto a summarize() crea uno de los “combos” mas potentes de dplyr y el tidyverse. Agrupamos los datos según una variable (usualmente categórica) y los resumimos, obteniendo una observación por grupo. Así, calculamos la media de la expectativa de vida de cada año:
summarize(
# agrupamos los datos
group_by(gapminder, year),
# creamos una columna nueva que resume una variable para cada grupo
lifeExp_media = mean(lifeExp, na.rm = TRUE)
)## # A tibble: 12 x 2
## year lifeExp_media
## <int> <dbl>
## 1 1952 49.1
## 2 1957 51.5
## 3 1962 53.6
## 4 1967 55.7
## 5 1972 57.6
## 6 1977 59.6
## 7 1982 61.5
## 8 1987 63.2
## 9 1992 64.2
## 10 1997 65.0
## 11 2002 65.7
## 12 2007 67.0A veces queremos agregar el número de observaciones hay en cada grupo, como cuando usamos count(). Simplemente agregamos otra columna y usamos n():
summarize(
group_by(gapminder, continent),
num_obs = n()
)## # A tibble: 5 x 2
## continent num_obs
## <fct> <int>
## 1 Africa 624
## 2 Americas 300
## 3 Asia 396
## 4 Europe 360
## 5 Oceania 24Digamos que queremos saber cuál ha sido el nivel de PIB per cápita más alto para cada país en la muestra:
summarize(
group_by(gapminder, country),
gdpPercap_max = max(gdpPercap, na.rm = TRUE)
)## # A tibble: 142 x 2
## country gdpPercap_max
## <fct> <dbl>
## 1 Afghanistan 978.
## 2 Albania 5937.
## 3 Algeria 6223.
## 4 Angola 5523.
## 5 Argentina 12779.
## 6 Australia 34435.
## 7 Austria 36126.
## 8 Bahrain 29796.
## 9 Bangladesh 1391.
## 10 Belgium 33693.
## # ... with 132 more rowsEl combo group_by() + summarize() es clave porque permite empezar a explorar relaciones entre variables categóricas y numéricas, algo central en las ciencias sociales. Por ejemplo, continente y PIB per cápita:
summarize(
group_by(gapminder, continent),
gdpPercap_media = mean(gdpPercap, na.rm = TRUE),
gdpPercap_desv = sd(gdpPercap, na.rm = TRUE)
)## # A tibble: 5 x 3
## continent gdpPercap_media gdpPercap_desv
## <fct> <dbl> <dbl>
## 1 Africa 2194. 2828.
## 2 Americas 7136. 6397.
## 3 Asia 7902. 14045.
## 4 Europe 14469. 9355.
## 5 Oceania 18622. 6359.Y no tiene por qué terminar ahí: combinando summarize(), group_by() y across() podemos aplicar una lista de múltiples funciones a un conjunto de variables con una característica en común:
summarize(
group_by(gapminder, continent),
# resumir variables de clase double, un tipo de variable numérica no entera
across(where(is.double),
list(media = ~mean(.x, na.rm = TRUE),
desv = ~sd(.x, na.rm = TRUE),
mediana = ~median(.x, na.rm = TRUE)))
)## # A tibble: 5 x 16
## continent lifeExp_media lifeExp_desv lifeExp_mediana gdpPercap_media
## <fct> <dbl> <dbl> <dbl> <dbl>
## 1 Africa 48.9 9.15 47.8 2194.
## 2 Americas 64.7 9.35 67.0 7136.
## 3 Asia 60.1 11.9 61.8 7902.
## 4 Europe 71.9 5.43 72.2 14469.
## 5 Oceania 74.3 3.80 73.7 18622.
## # ... with 11 more variables: gdpPercap_desv <dbl>, gdpPercap_mediana <dbl>,
## # gdp_media <dbl>, gdp_desv <dbl>, gdp_mediana <dbl>, gdp_log_media <dbl>,
## # gdp_log_desv <dbl>, gdp_log_mediana <dbl>, gdpPercap_log_media <dbl>,
## # gdpPercap_log_desv <dbl>, gdpPercap_log_mediana <dbl>Finalmente, si vamos a realizar más operaciones con los datos después de agruparlos y resumirlos, pero no queremos que sigan agrupados, usamos la función ungroup(). De lo contrario todas las operaciones siguientes se harían también por grupos:
ungroup(
summarize(
group_by(gapminder, continent),
media_pib = mean(gdpPercap, na.rm = TRUE)
)
)## # A tibble: 5 x 2
## continent media_pib
## <fct> <dbl>
## 1 Africa 2194.
## 2 Americas 7136.
## 3 Asia 7902.
## 4 Europe 14469.
## 5 Oceania 18622.6.10 Datos no disponibles: na_if(), replace_na() y drop_na()
A veces, no tenemos información para una característica de un caso. En otras palabras, hay un dato no disponible (not available). En vez de una celda en blanco, marcamos el dato específicamente como no disponible. En R, los datos no disponibles deben aparecer como NA para poder tratarlos correctamente. El valor NA es distinto al texto “NA” o cosas como “N/A”, “No disponible” y “-”.
Es supremamente importante tener en mente los valores NA y los datos no disponibles por varias razones. Resaltemos dos. Primero, es imposible calcular una media de un vector numérico (una columna con un índice de democracia, por ejemplo) si hay un valor marcado como NA o “N/A” y similares. De la misma manera, calcular una media de un vector numérico con valores como “-999” nos dará un resultado, pero errado. Segundo, algunas de las operaciones estadísticas que veremos más adelante -específicamente los modelos de regresión- asumen que no hay datos no disponibles y, por tanto, remueven automáticamente del análisis cualquier observación con valores NA en alguna de las variables de interés. Si los valores no disponibles dependen de alguna característica importante (por ejemplo, no tenemos datos sobre capacidad estatal en los países pobres) nuestro análisis podría terminar siendo sobre una muestra problemática en términos de sesgo de selección.
Las librerías dplyr y tidyr incluyen tres funciones para lidiar con valores NA: na_if(), replace_na() y drop_na(). Otras librerías como naniar ofrecen funciones adicionales. También existen técnicas avanzadas para imputar valores no disponibles, pero no las cubriremos aquí.
6.10.1 Convertir a NA
Algunas bases de datos especifican en el libro de códigos como vienen los datos no disponibles. En el caso de Polity IV, los valores -66, -77 y -88 pueden ser interpretados como valores no disponibles. Sin embargo, no vienen marcados como valores NA, así que R no los interpreta adecuadamente. Si miramos los valores de la variable exconst podemos entender un poco mejor a qué nos referimos:
count(polity4, exconst)## # A tibble: 10 x 2
## exconst n
## <dbl> <int>
## 1 -88 328
## 2 -77 214
## 3 -66 234
## 4 1 4777
## 5 2 952
## 6 3 3798
## 7 4 363
## 8 5 1316
## 9 6 758
## 10 7 4655Si intentamos hallar la media de esta variable, sin antes corregir estos tres valores, el resultado va a ser distinto, porque R los incluye en el cálculo, ya que no entiende que son NA. Más adelante veremos la diferencia.
Ahora, cambiemos estos valores a NA usando la función na_if() dentro de mutate():
polity4 <- mutate(
polity4,
# variable nueva; podríamos reescribir la original
exconst_mod = na_if(exconst, "-66")
)
# revisamos que los convertimos a NA
count(polity4, exconst_mod) ## # A tibble: 10 x 2
## exconst_mod n
## <dbl> <int>
## 1 -88 328
## 2 -77 214
## 3 1 4777
## 4 2 952
## 5 3 3798
## 6 4 363
## 7 5 1316
## 8 6 758
## 9 7 4655
## 10 NA 234Comparemos los resultados, calculando la media de la variable original y la corregida:
summarize(
polity4,
media_exconst = mean(exconst, na.rm = TRUE),
media_exconst_mod = mean(exconst_mod, na.rm = TRUE)
)## # A tibble: 1 x 2
## media_exconst media_exconst_mod
## <dbl> <dbl>
## 1 0.141 1.04Este cambio a NA lo podemos realizar para una variable solamente, para varias (con across()) o para toda la base de datos. A continuación, vemos cómo realizar el cambio para todas las columnas de una base de datos – deben estar seguros de que esto tiene sentido:
polity4 <- na_if(polity4, "-66") Como -77 y -88 también pueden ser vistos como NA, repetimos la operaciones:
polity4 <- na_if(polity4, "-77")
polity4 <- na_if(polity4, "-88")
count(polity4, exconst)## # A tibble: 8 x 2
## exconst n
## <dbl> <int>
## 1 1 4777
## 2 2 952
## 3 3 3798
## 4 4 363
## 5 5 1316
## 6 6 758
## 7 7 4655
## 8 NA 776En realidad, esta operación es un “hack” y los desarrolladores de tidyverse recomiendan usar across() así:
mutate(
polity4,
across(everything(), ~na_if(.x, "-77"))
)## # A tibble: 17,395 x 12
## ccode country year polity2 parreg parcomp exconst democracia regimen
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <fct>
## 1 2 United States 1800 4 4 2 7 otro anocracia
## 2 2 United States 1801 4 4 2 7 otro anocracia
## 3 2 United States 1802 4 4 2 7 otro anocracia
## 4 2 United States 1803 4 4 2 7 otro anocracia
## 5 2 United States 1804 4 4 2 7 otro anocracia
## 6 2 United States 1805 4 4 2 7 otro anocracia
## 7 2 United States 1806 4 4 2 7 otro anocracia
## 8 2 United States 1807 4 4 2 7 otro anocracia
## 9 2 United States 1808 4 4 2 7 otro anocracia
## 10 2 United States 1809 9 2 4 7 democracia democrac~
## # ... with 17,385 more rows, and 3 more variables: regimen_cut <fct>,
## # regimen_bin <fct>, exconst_mod <dbl>6.10.2 Reemplazar NA con otro valor
Puede suceder que hay valores que aparecen como NA pero que sabemos que no lo son. Por ejemplo, puede que sean igual a un valor de 0 y no indiquen realmente una falta de datos o información. Para tratar con estas situaciones, usamos replace_na(). Aquí creamos una variable nueva donde los valores NA de la columna exconst_mod pasan a ser 0:
polity4 <- mutate(
polity4,
exconst_mod2 = replace_na(exconst_mod, 0)
)
count(polity4, exconst_mod2)## # A tibble: 8 x 2
## exconst_mod2 n
## <dbl> <int>
## 1 0 776
## 2 1 4777
## 3 2 952
## 4 3 3798
## 5 4 363
## 6 5 1316
## 7 6 758
## 8 7 46556.10.3 Descartar NA
Por último, si queremos descartar las observaciones que tienen valores NA en una o varias variables, usamos la función drop_na(). Nuevamente, es aplicable para una variable -descartar observaciones con NA en esa columna en particular- o para toda la base de datos -descartar observaciones con NA en cualquier variable o columna. Comparemos el número de observaciones de nuestra base de datos cuando descartamos filas con NA en la variable country:
nrow(drop_na(polity4, country))## [1] 17395Con el número de filas restantes cuando descartamos filas con NA en cualquier columna:
nrow(drop_na(polity4))## [1] 166196.11 Simplificar código: tuberías %>%
Ya que revisamos las principales formas de trabajar con datos, quizás nos parezca que nuestro código a veces se vuelve engorroso y largo. En particular, se vuelve difícil hacerle seguimiento a todos los paréntesis incluidos cuando aplicamos varias funciones como group_by(), summarize() y mutate(). En esta sección, damos un paso gigantesco hacia la simplificación de nuestro código a través del uso del operador %>%.
El operador %>% (pipe, tubo o tubería) sirve para simplificar nuestro código. Viene de la librería magrittr y de pronto el logo de esta librería nos ayuda a entender la referencia en el nombre:
Logo de la librería magrittr.
El pipe es usado extensamente en el tidyverse – si cargamos esta librería, automáticamente podemos usar %>% sin necesidad de cargar magrittr. Para entender la utilidad de los pipes, comparemos tres formas de usar varias funciones al mismo tiempo:
- Anidadas: se vuelve confuso tener tantos paréntesis.
head(arrange(select(filter(gapminder, year == 2007, continent == "Americas"), country, gdpPercap), desc(gdpPercap)))## # A tibble: 6 x 2
## country gdpPercap
## <fct> <dbl>
## 1 United States 42952.
## 2 Canada 36319.
## 3 Puerto Rico 19329.
## 4 Trinidad and Tobago 18009.
## 5 Chile 13172.
## 6 Argentina 12779.Romper el código en líneas -como hemos hecho hasta ahora- ayuda un poco a entender qué está pasando, pero sigue exigiendo jugar una ronda de “veo, veo”:
head(
arrange(
select(
filter(gapminder, year == 2007, continent == "Americas"), where(
is.numeric
)
),
desc(gdpPercap)
)
)## # A tibble: 6 x 7
## year lifeExp pop gdpPercap gdp gdp_log gdpPercap_log
## <int> <dbl> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2007 78.2 301139947 42952. 1.29e13 30.2 10.7
## 2 2007 80.7 33390141 36319. 1.21e12 27.8 10.5
## 3 2007 78.7 3942491 19329. 7.62e10 25.1 9.87
## 4 2007 69.8 1056608 18009. 1.90e10 23.7 9.80
## 5 2007 78.6 16284741 13172. 2.14e11 26.1 9.49
## 6 2007 75.3 40301927 12779. 5.15e11 27.0 9.46- Paso a paso: es ineficiente, pues estamos crenado nuevos objetos “intermedios” o temporales que luego debemos eliminar (para eso está
rm()) o, de lo contrario, ocupan memoria en nuestro equipo.
gapminder_2007 <- filter(gapminder, year == 2007, continent == "Americas")
gapminder_2007 <- select(gapminder_2007, where(is.numeric))
gapminder_2007 <- arrange(gapminder_2007, desc(gdpPercap))
head(gapminder_2007)## # A tibble: 6 x 7
## year lifeExp pop gdpPercap gdp gdp_log gdpPercap_log
## <int> <dbl> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2007 78.2 301139947 42952. 1.29e13 30.2 10.7
## 2 2007 80.7 33390141 36319. 1.21e12 27.8 10.5
## 3 2007 78.7 3942491 19329. 7.62e10 25.1 9.87
## 4 2007 69.8 1056608 18009. 1.90e10 23.7 9.80
## 5 2007 78.6 16284741 13172. 2.14e11 26.1 9.49
## 6 2007 75.3 40301927 12779. 5.15e11 27.0 9.46rm(gapminder_2007)- Pipes: se puede leer como “… y entonces…”. Tomamos un objeto, le aplicamos una función y entonces se lo pasamos a otra función y hacemos algo más. Se leen izquierda-derecha y de arriba-abajo, si partimos el código en líneas. El objeto que pasamos por el pipe entra como primer argumento de la siguiente función.
Empecemos con un ejemplo sencillo:
# tomar un vector numérico
c(1, 1, 2, 3, 5, 8, 13, 21) %>%
# encontrar la media
mean() %>%
# redondear el resultado
round() ## [1] 7Pueden usarse como “tuberías” que conectan varias funciones, como filter(), select() y arrange(), cada una construyendo sobre los resultados que arroja la anterior, para analizar una base de datos paso a paso en un solo bloque de código legible:
# tomar una base de datos
gapminder %>%
# filtrar por valores de year y continent
filter(year == 2007, continent == "Americas") %>%
# seleccionar solo las variables numericas
select(where(is.numeric)) %>%
# ordenar descendente segun gdpPercap
arrange(desc(gdpPercap)) %>%
# ver las primeras filas del resultado
head() ## # A tibble: 6 x 7
## year lifeExp pop gdpPercap gdp gdp_log gdpPercap_log
## <int> <dbl> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2007 78.2 301139947 42952. 1.29e13 30.2 10.7
## 2 2007 80.7 33390141 36319. 1.21e12 27.8 10.5
## 3 2007 78.7 3942491 19329. 7.62e10 25.1 9.87
## 4 2007 69.8 1056608 18009. 1.90e10 23.7 9.80
## 5 2007 78.6 16284741 13172. 2.14e11 26.1 9.49
## 6 2007 75.3 40301927 12779. 5.15e11 27.0 9.46Las funciones del tidyverse están diseñadas para trabajar con el operador %>%; por eso, el primer argumenta de estas funciones siempre es una base de datos. Si usamos una función con una sintáxis distinta, podemos usar . para seguir usando los pipes. Por ejemplo, en un modelo de regresión lineal usando la función básica lm(), el argumento data = no es el primero, en pero la función summary() (para ver los resultados del modelo) sí. Luego:
gapminder %>%
lm(lifeExp ~ gdpPercap, data = .) %>%
summary()##
## Call:
## lm(formula = lifeExp ~ gdpPercap, data = .)
##
## Residuals:
## Min 1Q Median 3Q Max
## -82.754 -7.758 2.176 8.225 18.426
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 5.396e+01 3.150e-01 171.29 <2e-16 ***
## gdpPercap 7.649e-04 2.579e-05 29.66 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 10.49 on 1702 degrees of freedom
## Multiple R-squared: 0.3407, Adjusted R-squared: 0.3403
## F-statistic: 879.6 on 1 and 1702 DF, p-value: < 2.2e-16Con tuberías más largas, podemos responder a preguntas interesantes y comparaciones relevantes de forma más eficiente, siempre teniendo claro cuáles fueron los pasos que seguimos.
Por ejemplo, digamos que queremos encontrar la media continental del PIB per cápita en el último año para el que tenemos información, porque estamos interesados en explorar la variación espacial en la riqueza de las naciones. ¿Cómo lo hacemos? ¡Pues armamos una tubería con group_by() y summarize()! Ya sabemos que comparar medias entre dos grupos nos permite ver la relación entre una variable numérica y una categórica:
gapminder %>%
# el ultimo año presente en los datos
filter(year == max(year, na.rm = TRUE)) %>%
# agrupar por continente
group_by(continent) %>%
# hacemos un resumen
summarize(
pib_media = mean(gdpPercap, na.rm = TRUE),
pib_mediana = median(gdpPercap, na.rm = TRUE),
pib_max = max(gdpPercap, na.rm = TRUE),
pib_min = min(gdpPercap, na.rm = TRUE),
pib_de = sd(gdpPercap, na.rm = TRUE),
num_casos = n()
)## # A tibble: 5 x 7
## continent pib_media pib_mediana pib_max pib_min pib_de num_casos
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
## 1 Africa 3089. 1452. 13206. 278. 3618. 52
## 2 Americas 11003. 8948. 42952. 1202. 9713. 25
## 3 Asia 12473. 4471. 47307. 944 14155. 33
## 4 Europe 25054. 28054. 49357. 5937. 11800. 30
## 5 Oceania 29810. 29810. 34435. 25185. 6541. 2O quizás nos interesa saber cuál es el promedio de varios indicadores de la base de datos de Polity IV para cada tipo de régimen (usando la variable categórica que creamos anteriormente en este capítulo):
polity4 %>%
# solo unos años
filter(year %in% c(1997:2017)) %>%
# agrupamos por tipo de régimen (demo-anocracia-auto)
group_by(regimen) %>%
# hacemos un resumen
summarize(
media_polity2 = mean(polity2, na.rm = TRUE),
media_parreg = mean(parreg, na.rm = TRUE),
media_parcomp = mean(parcomp, na.rm = TRUE)
)## # A tibble: 3 x 4
## regimen media_polity2 media_parreg media_parcomp
## <fct> <dbl> <dbl> <dbl>
## 1 autocracia -7.61 3.90 1.43
## 2 anocracia 0.309 2.80 2.75
## 3 democracia 8.51 3.29 4.23Con across() seleccionamos variables a resumir si cumplen alguna condición. En este ejemplo además incluimos ungroup() al final porque creemos que podríamos hacer más operaciones, pero no necesariamente a nivel de grupos:
polity4 %>%
filter(year %in% c(1997:2017)) %>% # solo unos años
group_by(regimen) %>% # agrupamos por tipo de régimen (demo-ano-auto)
# hacemos un resumen para ciertas variables
summarize(
across(
where(is.numeric), ~mean(.x, na.rm = TRUE)
)
) %>%
ungroup()## # A tibble: 3 x 9
## regimen ccode year polity2 parreg parcomp exconst exconst_mod exconst_mod2
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 autocracia 616. 2006. -7.61 3.90 1.43 1.94 1.94 1.94
## 2 anocracia 540. 2007. 0.309 2.80 2.75 3.52 3.52 3.03
## 3 democracia 382. 2007. 8.51 3.29 4.23 6.53 6.53 6.53Vale la pena acostumbrarse a cerrar un pipe como este con ungroup() si queremos seguir la tubería sin hacer operaciones por grupo; de lo contrario todas las operaciones adicionales se harían por grupos.
6.11.1 Tablas cruzadas con %>%
Las tablas cruzados que hicimos arriba también se benfician del uso de pipes. Hagamos una tabla que cuente y muestre la relación entre la variable continente (continent) y la variable binaria de nivel de ingreso alto o bajo que construimos anteriormente (pib_dummy). Ahora, además de la frecuencia de observaciones por grupo, queremos las proporciones por grupo. Combinamos varias funciones usando pipes:
tabla2 <- gapminder %>%
count(continent, pib_dummy) %>%
group_by(continent) %>%
mutate(prop = round(n/sum(n), 2))
tabla2## # A tibble: 9 x 4
## # Groups: continent [5]
## continent pib_dummy n prop
## <fct> <chr> <int> <dbl>
## 1 Africa alto 36 0.06
## 2 Africa bajo 588 0.94
## 3 Americas alto 92 0.31
## 4 Americas bajo 208 0.69
## 5 Asia alto 112 0.28
## 6 Asia bajo 284 0.72
## 7 Europe alto 270 0.75
## 8 Europe bajo 90 0.25
## 9 Oceania alto 24 1Al final, exportamos el resultado a un archivo de Word:
tabla2 %>%
kable(
format = "html",
col.names = c("Continente", "Nivel PIB", "Casos", "Prop."),
caption = "Tabla cruzada",
format.args = list(decimal.mark = ",")
) %>%
write_file("output/tabla2.doc")6.11.2 Agregación: cambiar niveles de análisis
Otro uso común de group_by() seguido de summarize() es para agregar datos. Al agrupar y resumir podemos cambiar el nivel de análisis. Por ejemplo, en vez de país-año podemos pasar la base de datos gapminder al nivel continente-año: cada fila sería un continente en un año y las columnas son resúmenes (la media en este caso) de toda slas observaciones en cada continente. Por cierto, porque el inglés británico existe, tanto summarize() como summarise() son válidas:
gapminder_cont <- gapminder %>%
group_by(continent, year) %>%
summarise(across(lifeExp:gdp, ~mean(.x, na.rm = TRUE))) %>%
ungroup()## `summarise()` has grouped output by 'continent'. You can override using the `.groups` argument.gapminder_cont %>%
sample_n(10)## # A tibble: 10 x 6
## continent year lifeExp pop gdpPercap gdp
## <fct> <int> <dbl> <dbl> <dbl> <dbl>
## 1 Americas 1992 69.6 29570964. 8045. 489899820623.
## 2 Africa 1957 41.3 5093033. 1385. 7359188796.
## 3 Africa 1972 47.5 7305376. 2340. 15072241974.
## 4 Europe 2002 76.7 19274129. 21712. 436448815097.
## 5 Asia 1952 46.3 42283556. 5195. 34095762654.
## 6 Asia 1992 66.5 94948248. 8640. 307100497486.
## 7 Asia 1987 64.9 87006690. 7608. 241784763369.
## 8 Asia 1957 49.3 47356988. 5788. 47267432088.
## 9 Asia 2007 70.7 115513752. 12473. 627513635079.
## 10 Americas 1962 58.4 17330810. 4902. 169153069442.Por último, estos pipes y los verbos que hemos utilizado sirven para hacer gráficas de manera eficiente y clara, lo cual veremos con más detalle en capítulos siguientes:
gapminder_cont %>% # tomar datos
ggplot(mapping = aes(x = log(gdpPercap), y = lifeExp)) + # seleccionar variables
geom_point(color = "darkblue") + # gráfica de dispersion
labs(x = "PIB per cápita (USD, log.)", y = "Expectativa de vida al nacer (años)") # titulos de los ejes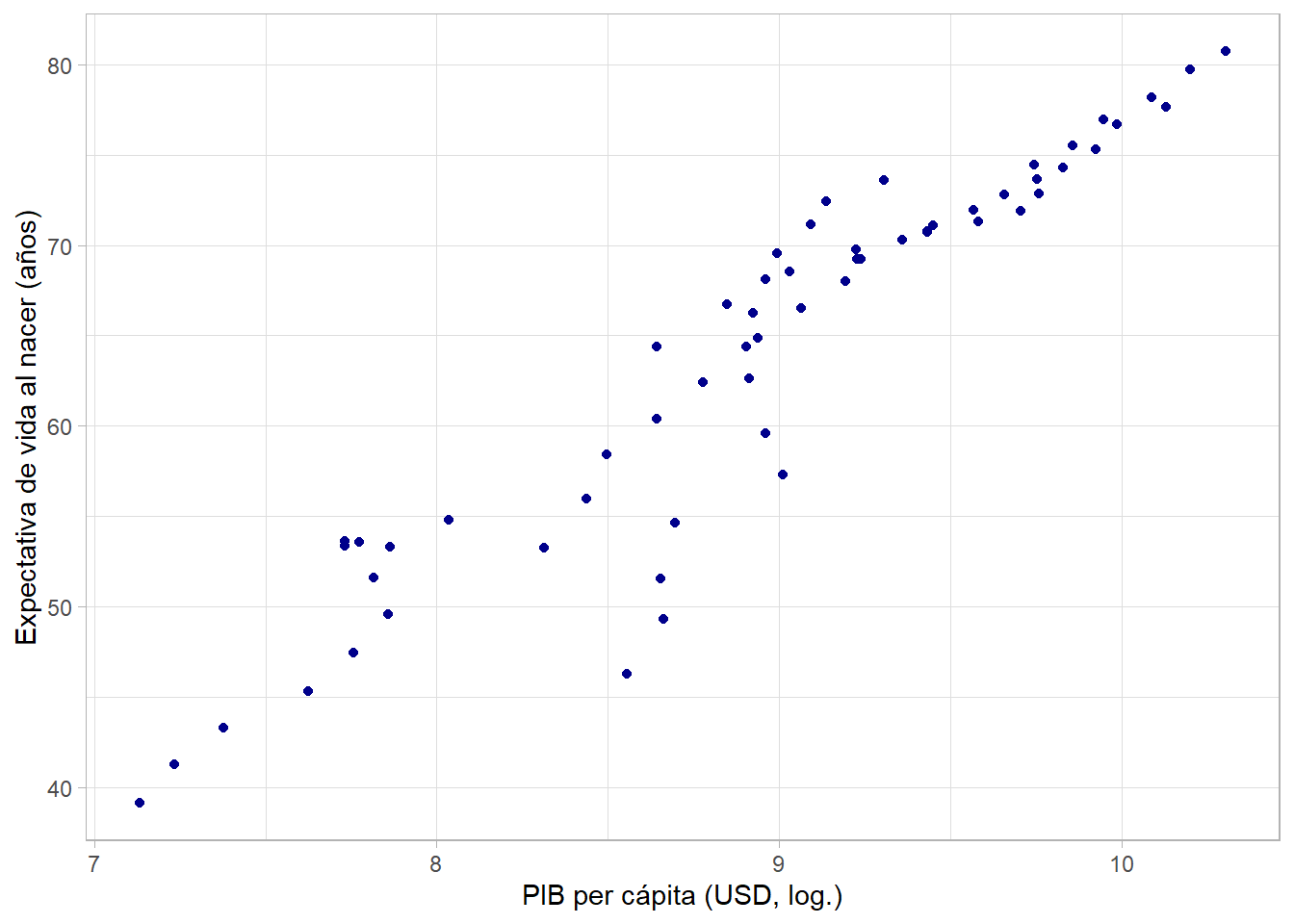
Construyamos una gráfica similar, pero trabajando con los datos a nivel-país año:
gapminder %>% # tomar datos
filter(year %in% c(1962, 1972, 1982, 1992, 2002)) %>% # filtrar para incluir ciertos anos
ggplot(mapping = aes(x = log(gdpPercap), y = lifeExp)) + # seleccionar variables
geom_point(color = "darkblue", alpha = 0.5) + # gráfica de dispersion, transparencia 50%
labs(x = "PIB per cápita (USD, log.)", y = "Expectativa de vida al nacer (años)") # titulos de los ejes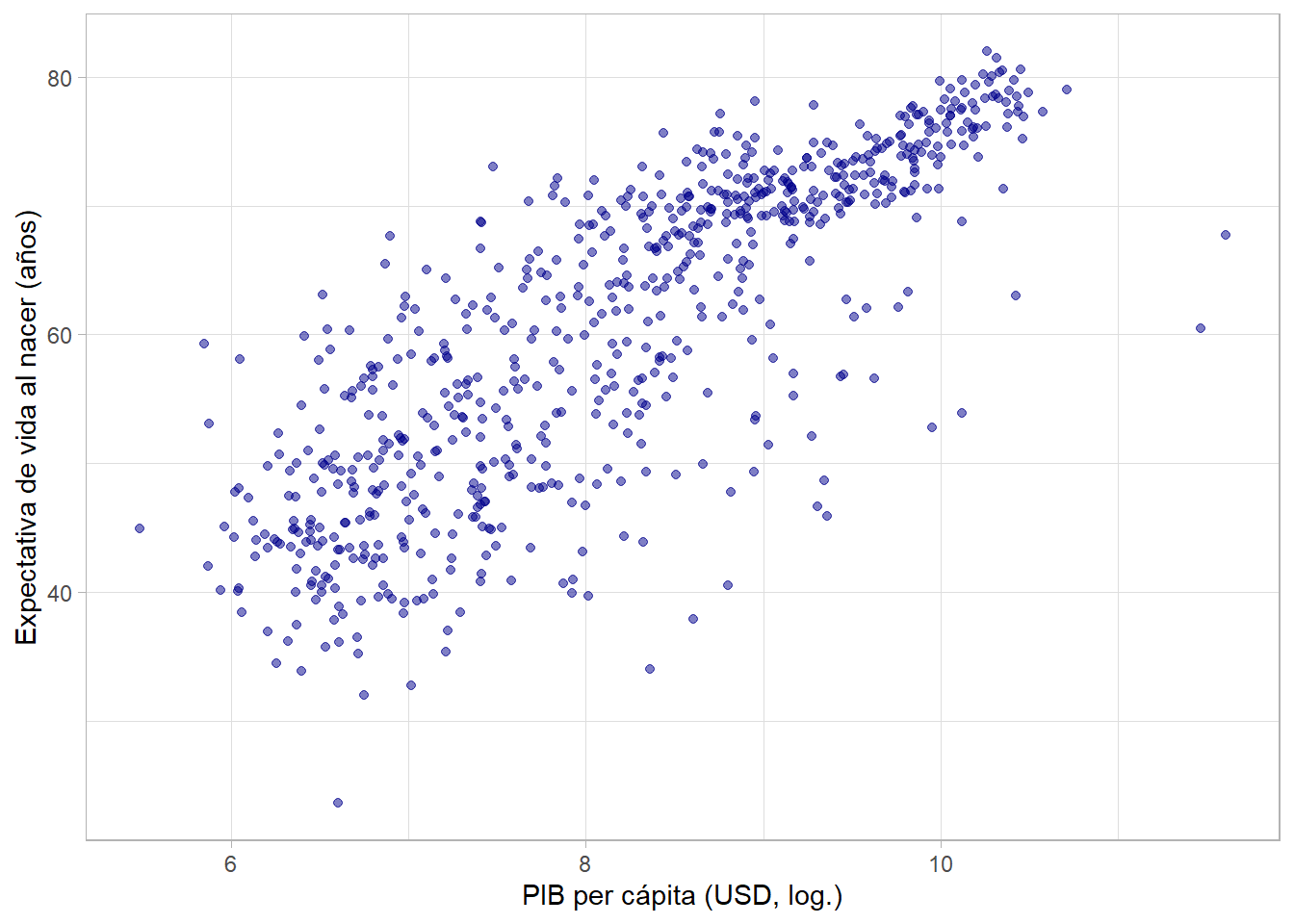
Finalmente, si queremos ver las trayectorias de los distintos continentes, usamos el agumento color = de ggplot() para graficar una línea de color distinto para cada grupo:
gapminder_cont %>%
ggplot(aes(year, log(gdpPercap), color = continent)) +
geom_line() +
labs(x = "Año", y = "PIB per cápita (USD, log.)", color = "Continente")
6.12 Ordenar y reformatear: pivot_()
Muy frecuentemente, los datos que encontramos están desordenados. Por ejemplo, usualmente debemos corregir los NA, cambiar el tipo de una variable, recodificar un factor para cambiar la categoría base o quizás calcular un pedazo de información faltante.
Otro paso habitual es “limpiar” los nombres de las variables. No es recomendable tener espacios o caracteres especiales en los nombres de las variables y en general de los objetos en R. La librería janitor facilita hacer estos cambios con la función clean_names(), la cual automáticamente cambia el formato del nombre de las variables a snake_case en donde todos los caracteres están en minúsculas y los espacios son reemplazados por guiones bajos. Veamos qué hace esta función con gapminder:
gapminder %>%
clean_names()## # A tibble: 1,704 x 10
## country continent year life_exp pop gdp_percap gdp gdp_log
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779. 6567086330. 22.6
## 2 Afghanistan Asia 1957 30.3 9240934 821. 7585448670. 22.7
## 3 Afghanistan Asia 1962 32.0 10267083 853. 8758855797. 22.9
## 4 Afghanistan Asia 1967 34.0 11537966 836. 9648014150. 23.0
## 5 Afghanistan Asia 1972 36.1 13079460 740. 9678553274. 23.0
## 6 Afghanistan Asia 1977 38.4 14880372 786. 11697659231. 23.2
## 7 Afghanistan Asia 1982 39.9 12881816 978. 12598563401. 23.3
## 8 Afghanistan Asia 1987 40.8 13867957 852. 11820990309. 23.2
## 9 Afghanistan Asia 1992 41.7 16317921 649. 10595901589. 23.1
## 10 Afghanistan Asia 1997 41.8 22227415 635. 14121995875. 23.4
## # ... with 1,694 more rows, and 2 more variables: gdp_percap_log <dbl>,
## # pib_dummy <chr>Lidiar con NA y nombres de variables es sencillo. Más complejo es asegurarse que una base de datos estén ordenadas (“tidy data”): cada fila debe ser una observacion y cada columna una variable. Es el principio rector del tidyverse(). A veces, decimos que una base de datos en formato tidy está en formato “largo”, en oposición a “ancho”. Por ejemplo, gapminder está en formato largo y tidy. Cada fila es una observación, cada columna una variable:
sample_n(gapminder, 10)## # A tibble: 10 x 10
## country continent year lifeExp pop gdpPercap gdp gdp_log
## <fct> <fct> <int> <dbl> <int> <dbl> <dbl> <dbl>
## 1 Mauritius Africa 1972 62.9 851334 2575. 2.19e 9 21.5
## 2 Mexico Americas 2002 74.9 102479927 10742. 1.10e12 27.7
## 3 Uganda Africa 2002 47.8 24739869 928. 2.30e10 23.9
## 4 Cambodia Asia 1952 39.4 4693836 368. 1.73e 9 21.3
## 5 Zambia Africa 1962 46.0 3421000 1453. 4.97e 9 22.3
## 6 Burkina Faso Africa 1977 46.1 5889574 743. 4.38e 9 22.2
## 7 Australia Oceania 1982 74.7 15184200 19477. 2.96e11 26.4
## 8 Kenya Africa 1977 56.2 14500404 1268. 1.84e10 23.6
## 9 Paraguay Americas 1982 66.9 3366439 4259. 1.43e10 23.4
## 10 Senegal Africa 2007 63.1 12267493 1712. 2.10e10 23.8
## # ... with 2 more variables: gdpPercap_log <dbl>, pib_dummy <chr>A continuación, vamos a crear un ejemplo sencillo de datos desordenados en formato ancho:
ancho <- tibble(
pais = c("Colombia", "Argentina", "Brazil"),
indicador_2000 = rnorm(3, 2),
indicador_2010 = rnorm(3, 3),
indicador_2020 = rnorm(3, 4)
)
ancho## # A tibble: 3 x 4
## pais indicador_2000 indicador_2010 indicador_2020
## <chr> <dbl> <dbl> <dbl>
## 1 Colombia 2.12 2.33 3.34
## 2 Argentina 2.55 4.67 3.86
## 3 Brazil 1.55 4.13 3.37Comparemos con los mismos datos en formato largo. Según el principio tidy, debería haber tres columnas: pais, indicador y ano. Aquí, en vez de hacerlo completamente “a mano”, usamos expand_grid() para repetir los nombres de país y años, para luego agregar el indicador.
largo <- expand_grid(
pais = c("Colombia", "Argentina", "Brazil"),
ano = c(2000, 2010, 2020)
) %>%
mutate(indicador = rnorm(9, 3))
largo## # A tibble: 9 x 3
## pais ano indicador
## <chr> <dbl> <dbl>
## 1 Colombia 2000 2.91
## 2 Colombia 2010 3.16
## 3 Colombia 2020 3.44
## 4 Argentina 2000 2.58
## 5 Argentina 2010 4.78
## 6 Argentina 2020 3.65
## 7 Brazil 2000 2.77
## 8 Brazil 2010 2.98
## 9 Brazil 2020 3.70Pero, ¿cómo hacemos para pasar fácilmente de un formato al otro? Para reformatear datos de esta manera hacemos uso de funciones de la librería tidyr. Usamos pivot_wider() para pasar de largo a ancho y pivot_longer() para hacer lo contrario.
6.12.1 Largo a ancho
Ocasionalmente, tenemos datos en formato largo y queremos pasarlos a un forma más ancha. Esto puede ser porque queremos hacer una tabla para presentar la información (una tabla muy larga es difícil de leer) o porque queremos cambiar el nivel de análisis de los datos (“agregarlos”) para analizarlos o graficarlos. Usamos pivot_wider():
gapminder_ancho <- gapminder %>%
pivot_wider(
# especificar columnas que identifican cada observacion
id_cols = country,
# de donde salen los nombres de las nuevas columnas
names_from = year,
# opcional: un prefijo para las nuevas variables
names_prefix = "year_",
# de donde salen los valores de las nuevas celdas
values_from = lifeExp,
)
gapminder_ancho## # A tibble: 142 x 13
## country year_1952 year_1957 year_1962 year_1967 year_1972 year_1977 year_1982
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Afghan~ 28.8 30.3 32.0 34.0 36.1 38.4 39.9
## 2 Albania 55.2 59.3 64.8 66.2 67.7 68.9 70.4
## 3 Algeria 43.1 45.7 48.3 51.4 54.5 58.0 61.4
## 4 Angola 30.0 32.0 34 36.0 37.9 39.5 39.9
## 5 Argent~ 62.5 64.4 65.1 65.6 67.1 68.5 69.9
## 6 Austra~ 69.1 70.3 70.9 71.1 71.9 73.5 74.7
## 7 Austria 66.8 67.5 69.5 70.1 70.6 72.2 73.2
## 8 Bahrain 50.9 53.8 56.9 59.9 63.3 65.6 69.1
## 9 Bangla~ 37.5 39.3 41.2 43.5 45.3 46.9 50.0
## 10 Belgium 68 69.2 70.2 70.9 71.4 72.8 73.9
## # ... with 132 more rows, and 5 more variables: year_1987 <dbl>,
## # year_1992 <dbl>, year_1997 <dbl>, year_2002 <dbl>, year_2007 <dbl>6.12.2 Ancho a largo:
Es más común tener que pasar de ancho (desordenado) a largo (ordenado). Usamos pivot_longer() para realizar este reformateo:
gapminder_largo <- gapminder_ancho %>%
pivot_longer(
# cuales variables vamos a transformar
cols = -country,
# nombre de la nueva columna de las viejas columnas
names_to = "year",
# opcional: si las variables a transformar tienen un prefijo
names_prefix = "year_",
# nombre de la nueva columna que contiene los valores de las celdas
values_to = "lifeExp"
) %>%
arrange(country, year)
gapminder_largo## # A tibble: 1,704 x 3
## country year lifeExp
## <fct> <chr> <dbl>
## 1 Afghanistan 1952 28.8
## 2 Afghanistan 1957 30.3
## 3 Afghanistan 1962 32.0
## 4 Afghanistan 1967 34.0
## 5 Afghanistan 1972 36.1
## 6 Afghanistan 1977 38.4
## 7 Afghanistan 1982 39.9
## 8 Afghanistan 1987 40.8
## 9 Afghanistan 1992 41.7
## 10 Afghanistan 1997 41.8
## # ... with 1,694 more rowsComo ejemplo final, convertimos el ejemplo que construimos arriba:
ancho %>%
pivot_longer(
-pais,
names_to = "ano",
names_prefix = "indicador_",
values_to = "indicador"
)## # A tibble: 9 x 3
## pais ano indicador
## <chr> <chr> <dbl>
## 1 Colombia 2000 2.12
## 2 Colombia 2010 2.33
## 3 Colombia 2020 3.34
## 4 Argentina 2000 2.55
## 5 Argentina 2010 4.67
## 6 Argentina 2020 3.86
## 7 Brazil 2000 1.55
## 8 Brazil 2010 4.13
## 9 Brazil 2020 3.376.12.3 Ejercicio: datos del Banco Mundial
La librería tidyr incluye unos datos del Banco Mundial que vamos a utilizar para dar un ejemplo más avanzado:
world_bank_pop## # A tibble: 1,056 x 20
## country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ABW SP.URB.TO~ 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4
## 2 ABW SP.URB.GR~ 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2
## 3 ABW SP.POP.TO~ 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5
## 4 ABW SP.POP.GR~ 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1
## 5 AFG SP.URB.TO~ 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6
## 6 AFG SP.URB.GR~ 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0
## 7 AFG SP.POP.TO~ 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7
## 8 AFG SP.POP.GR~ 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0
## 9 AGO SP.URB.TO~ 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7
## 10 AGO SP.URB.GR~ 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0
## # ... with 1,046 more rows, and 11 more variables: 2007 <dbl>, 2008 <dbl>,
## # 2009 <dbl>, 2010 <dbl>, 2011 <dbl>, 2012 <dbl>, 2013 <dbl>, 2014 <dbl>,
## # 2015 <dbl>, 2016 <dbl>, 2017 <dbl>Los datos está en formato ancho. Nuestro objetivo es tener una base de datos donde cada variable esté en una columna y cada fila sea una observación. Nuestro problema es que el año está en multiples columnas, en vez de tener su propia columna. Entonces, usamos pivot_longer():
pop2 <- world_bank_pop %>%
pivot_longer(
# comillas para que R entienda que son nombres de columnas, no valores
`2000`:`2017`,
names_to = "year",
values_to = "value"
)
pop2## # A tibble: 19,008 x 4
## country indicator year value
## <chr> <chr> <chr> <dbl>
## 1 ABW SP.URB.TOTL 2000 42444
## 2 ABW SP.URB.TOTL 2001 43048
## 3 ABW SP.URB.TOTL 2002 43670
## 4 ABW SP.URB.TOTL 2003 44246
## 5 ABW SP.URB.TOTL 2004 44669
## 6 ABW SP.URB.TOTL 2005 44889
## 7 ABW SP.URB.TOTL 2006 44881
## 8 ABW SP.URB.TOTL 2007 44686
## 9 ABW SP.URB.TOTL 2008 44375
## 10 ABW SP.URB.TOTL 2009 44052
## # ... with 18,998 more rowsAún así, tenemos que considerar la variable indicator:
pop2 %>%
count(indicator)## # A tibble: 4 x 2
## indicator n
## <chr> <int>
## 1 SP.POP.GROW 4752
## 2 SP.POP.TOTL 4752
## 3 SP.URB.GROW 4752
## 4 SP.URB.TOTL 4752Aquí:
SP.POP.GROWes la tasa de crecimiento poblacional.SP.POP.TOTLes la población total.SP.URB.*es lo mismo, pero para áreas urbanas
Dividamos indicator en dos variables, área (total o urbana) y
la variable en sí (población o crecimiento). Para esto, usamos la función separate():
pop3 <- pop2 %>%
separate(indicator, c(NA, "area", "variable"))
pop3## # A tibble: 19,008 x 5
## country area variable year value
## <chr> <chr> <chr> <chr> <dbl>
## 1 ABW URB TOTL 2000 42444
## 2 ABW URB TOTL 2001 43048
## 3 ABW URB TOTL 2002 43670
## 4 ABW URB TOTL 2003 44246
## 5 ABW URB TOTL 2004 44669
## 6 ABW URB TOTL 2005 44889
## 7 ABW URB TOTL 2006 44881
## 8 ABW URB TOTL 2007 44686
## 9 ABW URB TOTL 2008 44375
## 10 ABW URB TOTL 2009 44052
## # ... with 18,998 more rowsAhora podemos terminar de limpiar los datos al convertir los valores TOTAL y GROW en variables/columnas propias:
wb_tidy <- pop3 %>%
pivot_wider(names_from = variable, values_from = value)
wb_tidy## # A tibble: 9,504 x 5
## country area year TOTL GROW
## <chr> <chr> <chr> <dbl> <dbl>
## 1 ABW URB 2000 42444 1.18
## 2 ABW URB 2001 43048 1.41
## 3 ABW URB 2002 43670 1.43
## 4 ABW URB 2003 44246 1.31
## 5 ABW URB 2004 44669 0.951
## 6 ABW URB 2005 44889 0.491
## 7 ABW URB 2006 44881 -0.0178
## 8 ABW URB 2007 44686 -0.435
## 9 ABW URB 2008 44375 -0.698
## 10 ABW URB 2009 44052 -0.731
## # ... with 9,494 more rowsO, en un solo bloque de código con pipes:
world_bank_pop %>%
pivot_longer(
# comillas para que R entienda que son nombres de columnas, no valores
`2000`:`2017`,
names_to = "year",
values_to = "value"
) %>%
separate(indicator, c(NA, "area", "variable")) %>%
pivot_wider(
names_from = variable,
values_from = value
)## # A tibble: 9,504 x 5
## country area year TOTL GROW
## <chr> <chr> <chr> <dbl> <dbl>
## 1 ABW URB 2000 42444 1.18
## 2 ABW URB 2001 43048 1.41
## 3 ABW URB 2002 43670 1.43
## 4 ABW URB 2003 44246 1.31
## 5 ABW URB 2004 44669 0.951
## 6 ABW URB 2005 44889 0.491
## 7 ABW URB 2006 44881 -0.0178
## 8 ABW URB 2007 44686 -0.435
## 9 ABW URB 2008 44375 -0.698
## 10 ABW URB 2009 44052 -0.731
## # ... with 9,494 more rowsPor último, para usar los datos más adelante sin tener que repetir este proceso, guardamos los datos como archivo con extensión .csv:
write_csv(wb_tidy, "data/wb_tidy.csv")6.13 Combinar/unir: _join()
Otro problema de datos común: tenemos dos bases de datos relacionadas, de pronto porque ambas incluyen información sobre los mismos casos, y queremos combinarlas. Volvamos a los datos de Polity IV:
polity4## # A tibble: 17,395 x 13
## ccode country year polity2 parreg parcomp exconst democracia regimen
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <fct> <fct>
## 1 2 United States 1800 4 4 2 7 otro anocracia
## 2 2 United States 1801 4 4 2 7 otro anocracia
## 3 2 United States 1802 4 4 2 7 otro anocracia
## 4 2 United States 1803 4 4 2 7 otro anocracia
## 5 2 United States 1804 4 4 2 7 otro anocracia
## 6 2 United States 1805 4 4 2 7 otro anocracia
## 7 2 United States 1806 4 4 2 7 otro anocracia
## 8 2 United States 1807 4 4 2 7 otro anocracia
## 9 2 United States 1808 4 4 2 7 otro anocracia
## 10 2 United States 1809 9 2 4 7 democracia democrac~
## # ... with 17,385 more rows, and 4 more variables: regimen_cut <fct>,
## # regimen_bin <fct>, exconst_mod <dbl>, exconst_mod2 <dbl>Pero esta base de datos solo tiene informacion sobre algunas características institucionales de la democracia. ¿Qué pasa si queremos explorar la relación de estas medidas con otros factores? Necesitaríamos unirla con otra base de datos que tenga información sobre los mismos casos (o un subconjunto de estos). Por ejemplo, miremos la base de datos Database of Political Institutions. Cargamos el archivo (con extensión .dta de Stata, que abrimos cortesía de la librería haven), seleccionamos unas variables y hacemos un poco de limpieza de estos usando los trucos que aprendimos:
dpi <- read_dta("data/DPI2017.dta") %>%
select(countryname, ifs, year, system, pr, numopp) %>%
zap_labels() %>% # quita las etiquetas de variable de Stata
na_if("-999")
sample_n(dpi, 10)## # A tibble: 10 x 6
## countryname ifs year system pr numopp
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Sweden SWE 1990 2 1 172
## 2 Togo TGO 2003 1 0 8
## 3 Paraguay PRY 1981 0 1 20
## 4 Barbados BRB 1993 2 0 10
## 5 Singapore SGP 1992 2 0 4
## 6 Ecuador ECU 2005 0 1 41
## 7 PRK PRK 2010 1 NA 0
## 8 Cuba CUB 1986 1 NA 0
## 9 Zambia ZMB 2015 0 0 85
## 10 Iran IRN 1979 0 NA 0Ahora tenemos dos bases de datos y queremos unirlas o combinarlas. Seguimos tres pasos para alcanzar este objetivo.
- Encontrar variables en común.
- Combinar las dos bases de datos.
- Guardar el resultado como un nuevo objeto en R.
6.13.1 Variables en común
Debe haber variables en común para poder unir dos bases de datos. También debemos pensar en la unidad de análisis: ¿a qué corresponde cada fila en las bases de datos?
En este ejemplo, ambas bases de datos están en un formato largo de país-año: cada fila es un país observado en un año (repetidamente, o sea, es un panel). Entonces, podemos usar el año y el nombre de los de países para unir las bases de datos pues son elementos en común. Por un lado, polity4 y dpi ambas tienen la columna year que representa el año de la observación.
Por otro lado, es recomendable usar códigos de país, en vez de nombres, ya que los códigos tienen estándares y los nombres no tanto (y dependen del idioma también). Los códigos de país de dpi, que están en la columna ifs, siguen el estándar del Fondo Monetario Internacional (FMI). Por tanto, convertimos los codigos de polity4 a ese formato, apoyándonos en la libreria countrycode. Creamos una nueva variable que aloja los códigos de país según el estándar del FMI, usando los códigos de país que ya había en polity4 (la columna ccode, que sigue el estándar numérico del Correlates of War, COW) como fuente.
polity4 <- polity4 %>%
mutate(
ifs = as.character(countrycode(
# variable de origen
sourcevar = ccode,
# formato de origen: COW numerico
origin = "cown",
# formato de destino: estandar ISO 3 caracteres
destination = "iso3c"
))
) %>%
select(ifs, ccode, year, polity2, regimen)## Warning in countrycode(sourcevar = ccode, origin = "cown", destination = "iso3c"): Some values were not matched unambiguously: 89, 99, 245, 260, 265, 267, 269, 271, 315, 324, 329, 332, 335, 337, 342, 345, 347, 348, 364, 525, 529, 564, 678, 680, 730, 769, 817, 818polity4## # A tibble: 17,395 x 5
## ifs ccode year polity2 regimen
## <chr> <dbl> <dbl> <dbl> <fct>
## 1 USA 2 1800 4 anocracia
## 2 USA 2 1801 4 anocracia
## 3 USA 2 1802 4 anocracia
## 4 USA 2 1803 4 anocracia
## 5 USA 2 1804 4 anocracia
## 6 USA 2 1805 4 anocracia
## 7 USA 2 1806 4 anocracia
## 8 USA 2 1807 4 anocracia
## 9 USA 2 1808 4 anocracia
## 10 USA 2 1809 9 democracia
## # ... with 17,385 more rows6.13.2 Combinar bases de datos
Ya tenemos la primera parte del proceso: encontramos variables en común. Para unir o combinar las bases de datos, usamos la familia de funciones *_join() de dplyr.
Existen varios tipos de “joins”. Podemos ejecutar ?dplyr::join para ver todas las opciones. Hay dos grandes categorías, cada una con varios tipos de “joins” o combinaciones. Asumiendo que x y y son dos bases de datos relacionadas con variables en común, tenemos:
- Joins para “mutar” datos: todas toman dos bases de datos (X y Y) y las combinan Combinar variables de X y de Y
left_join(x, y): El mas comun es left_join(X, Y) Mantiene todas las filas de X y todas las columnas de X y Y Filas de X sin pareja en Y tienen NA en las nuevas columnasinner_join(x, y): Mantiene solo las filas de X que tienen pareja en Y y todas las columnas de X y Y Si hay multiples parejas, mantiene todas las combinacionesright_join(x, y): Complemento de left_join() Mantiene todas las filas de Y y todas las columnas de X y Y Filas de Y sin pareja en X tienen NA en las nuevas columnasfull_join(x, y): Combinacion completa Mantiene todas las filas y columnas de X y Y. Si no hay parejas, da NA en esas columnas
- Joins para “filtrar” datos: unir para mantener las filas de X
semi_join(x, y): Todas las filas de X con pareja en Y Solo columnas de Xanti_join(x, y): Todas las filas de X sin pareja en Y Solo columnas de X
Usualmente, utilizamos left_join(), la cual es la más común y cubre la mayoría de nuestras necesidades. Esta función une las dos bases de datos, agregando las columnas de una (aquí, dpi) a la otra (polity4). Este “join” mantiene todas las filas de la primera base de datos (polity4), las filas de ambas que coinciden (según las variables en común que especificamos) y todas las columnas de las dos bases de datos. Las filas de la primera base de datos que no tienen una “pareja” en la otra, aparecen con valores NA en las nuevas columnas (las de dpi que se agregan a polity4). Revisamos mirando algunos países:
datos <- polity4 %>%
left_join(
dpi,
# variables para combinar; deben tener el mismo nombre y tipo
by = c("ifs", "year")
)
datos %>%
select(ifs, year, polity2, regimen, pr, numopp) %>%
sample_n(10)## # A tibble: 10 x 6
## ifs year polity2 regimen pr numopp
## <chr> <dbl> <dbl> <fct> <dbl> <dbl>
## 1 SWE 1919 10 democracia NA NA
## 2 CHN 1994 -7 autocracia NA 0
## 3 AFG 2015 -1 anocracia 0 0
## 4 GTM 1912 -9 autocracia NA NA
## 5 NPL 1956 -7 autocracia NA NA
## 6 HTI 1974 -10 autocracia NA NA
## 7 KEN 1970 -7 autocracia NA NA
## 8 FRA 1866 -6 autocracia NA NA
## 9 URY 1961 8 democracia NA NA
## 10 CHN 1968 -9 autocracia NA NAPodemos guardar o exportar este nuevo objeto en diversos formatos. Por ejemplo, write_excel_csv() crea archivos .csv para Excel:
write_excel_csv(datos, file = "data/datos_polity_dpi.csv")Unir estas dos bases nos permite evaluar más hipótesis. Podríamos sugerir que la presencia de una oposición fuerte (en términos de su presencia en el legislativo) lleva a un nivel de democracia más alto en términos de límites al ejecutivo. O al revés: cuando hay niveles de democracia liberal altos en los que se limita el poder del ejecutivo, es más probable que la oposición creza. Pero, ¿sí hay alguna asociación empírica entre el número de curules que tiene la oposición y el nivel de democracia de un país?
datos %>%
ggplot(aes(x = factor(polity2), y = numopp)) +
geom_boxplot() +
labs(x = "Indicador de democracia", y = "Número de curules de la oposición")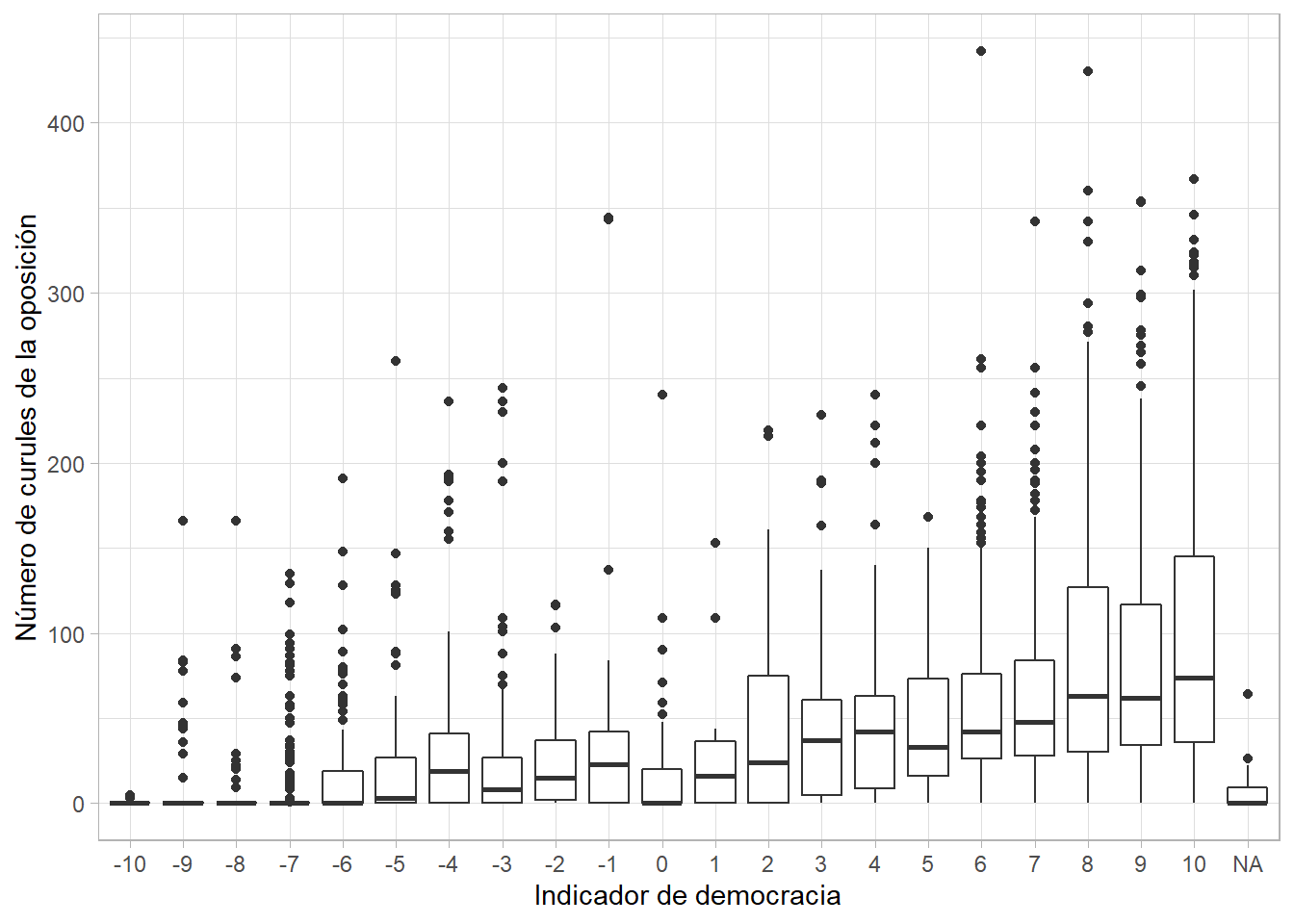
¿Qué conclusiones podemos sacar?
6.13.3 Homicidios en Medellin
Un último ejemplo para entender cómo unir bases de datos y lo que esto nos permite hacer. Supongamos que estamos interesados en analizar los homicidios de Medellín por zona a través del tiempo. Sin embargo, solo tenemos datos sobre homicidios en Medellin (tomados del SISC) en formato comuna-año. ¡No podemos hacer el análisis por zona si no tenemos una columna que nos indique la zona a la que pertenece cada observación!
homicidio <- read_csv("data/mde_homicidio.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## cod_comuna = col_character(),
## ano = col_double(),
## homicidios_total = col_double(),
## homicidios_jovenes = col_double()
## )homicidio## # A tibble: 335 x 4
## cod_comuna ano homicidios_total homicidios_jovenes
## <chr> <dbl> <dbl> <dbl>
## 1 01 2003 119 83
## 2 01 2004 36 26
## 3 01 2005 24 16
## 4 01 2006 23 16
## 5 01 2007 24 15
## 6 01 2008 39 20
## 7 01 2009 180 113
## 8 01 2010 133 82
## 9 01 2011 25 18
## 10 01 2012 37 22
## # ... with 325 more rowsAfortunadamente, encontramos un archivo .csv que contiene el listado comunas y corregimientos de Medellín y las zonas a las que pertenecen. Está en formato comuna-año para preparar un panel de datos y podemos usarlo para añadir a los datos sobre homicidios las variables cod_zona y nom_zona. Esto nos ahorra tener que clasificar las observaciones a mano.
mde <- read_csv("data/mde_df.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## cod_comuna = col_character(),
## ano = col_double(),
## nom_comuna = col_character(),
## cod_zona = col_double(),
## nom_zona = col_character()
## )mde## # A tibble: 420 x 5
## cod_comuna ano nom_comuna cod_zona nom_zona
## <chr> <dbl> <chr> <dbl> <chr>
## 1 01 2000 Popular 1 Zona 1 - Nororiental
## 2 02 2000 Santa Cruz 1 Zona 1 - Nororiental
## 3 03 2000 Manrique 1 Zona 1 - Nororiental
## 4 04 2000 Aranjuez 1 Zona 1 - Nororiental
## 5 05 2000 Castilla 2 Zona 2 - Noroccidental
## 6 06 2000 Doce de Octubre 2 Zona 2 - Noroccidental
## 7 07 2000 Robledo 2 Zona 2 - Noroccidental
## 8 08 2000 Villa Hermosa 3 Zona 3 - Centroriental
## 9 09 2000 Buenos Aires 3 Zona 3 - Centroriental
## 10 10 2000 La Candelaria 3 Zona 3 - Centroriental
## # ... with 410 more rowsEn ambas bases de datos hay codigos de comuna y años en común. Y las variables tienen la misma clase (caracter y numérico, respectivamente). Están relacionadas y podemos unirlas; queremos unirlas porque nos interesan los homicidios por zona, no por comuna. Como ya habíamos mencionado, podemos especificar las columnas que queremos usar para combinar las bases de datos (las columnas que identifican a cada observación). Si tienen nombres distintos en las dos bases de datos, podemos ser más explícitos usando "nombre_en_x" = "nombre_en_y".
mde_right <- left_join(
homicidio, mde,
by = c("cod_comuna" = "cod_comuna", "ano" = "ano")
)
mde_right## # A tibble: 335 x 7
## cod_comuna ano homicidios_total homicidios_jovenes nom_comuna cod_zona
## <chr> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 01 2003 119 83 Popular 1
## 2 01 2004 36 26 Popular 1
## 3 01 2005 24 16 Popular 1
## 4 01 2006 23 16 Popular 1
## 5 01 2007 24 15 Popular 1
## 6 01 2008 39 20 Popular 1
## 7 01 2009 180 113 Popular 1
## 8 01 2010 133 82 Popular 1
## 9 01 2011 25 18 Popular 1
## 10 01 2012 37 22 Popular 1
## # ... with 325 more rows, and 1 more variable: nom_zona <chr>Ahora tenemos la información necesaria para nuestro análisis. Empezamos usando group_by() y summarize() para agregar los datos a nivel de zona-año: ahora, tenemos el número de homicidios por zona en cada año:
mde_zonas <- mde_right %>%
# agrupar por zona y ano
group_by(nom_zona, ano) %>%
summarize(
# homicidios por comuna y ano
homicidios_total = sum(homicidios_total, na.rm = TRUE)
) %>%
ungroup() %>%
# eliminar NA
drop_na() ## `summarise()` has grouped output by 'nom_zona'. You can override using the `.groups` argument.mde_zonas## # A tibble: 112 x 3
## nom_zona ano homicidios_total
## <chr> <dbl> <dbl>
## 1 Corregimientos 2003 57
## 2 Corregimientos 2004 14
## 3 Corregimientos 2005 20
## 4 Corregimientos 2006 15
## 5 Corregimientos 2007 14
## 6 Corregimientos 2008 17
## 7 Corregimientos 2009 106
## 8 Corregimientos 2010 150
## 9 Corregimientos 2011 253
## 10 Corregimientos 2012 205
## # ... with 102 more rowsPor último, construimos una gráfica con funciones de ggplot2, capa por capa: una serie de tiempo anual de los homicidios en la ciudad, zona a zona (color = nom_zona crea una línea por zona de la ciudad). Agregamos títulos, cambiamos colores, etc. y guardamos la gráfica como un archivo con extensión .png usando ggsave():
mde_zonas %>%
# asignar variables
ggplot(aes(x = ano, y = homicidios_total, color = nom_zona)) +
# gráfica de lineas
geom_line(size = 1, alpha = 0.75) +
# etiquetas de eje X
scale_x_continuous(breaks = seq(min(mde_right$ano), max(mde_right$ano))) +
labs(
# título
title = "Heterogeneidad temporal y espacial del homicidio en Medellín",
# subtítulo
subtitle = "Homicidios por zona, 2003-2018",
# pie de imagen
caption = "Fuente: Elaboración propia con datos del \nSistema de Información para la Seguridad y Convivencia (SISC).",
# títulos de ejes y leyenda
x = NULL, y = "Número de homicidios", color = NULL
) +
# mover leyenda
theme(legend.position = "bottom") 
6.14 Repaso
Trabajar con bases de datos:
- Cargar datos: usamos las funciones incluidas en
readr,readxlohaven. - Limpiar:
na_if()para convertir aNA. - Seleccionar y realizar subconjuntos de datos:
- Columnas/variables/propiedades con
select(). - Filas/observaciones/casos con
filter().
- Columnas/variables/propiedades con
- Crear/modificar variables:
%>%(“pipes”) para pasar objetos a las funciones y concatenar varias funciones seguidas.mutate()para crear nuevas variables usando variables existentes, por ejemplo, para crear proporciones y porcentajes.across())para crear/cambiar múltiples variables al mismo tiempo.as.numeric(),as.factor(),as.integer(),as.character()para cambiar la clase de una variable.if_else()crea una variable dummy/binaria.case_when()crea una variable nominal u ordinal con más de 2 categorías.factor()y funcionesfct_*()para crear un factor o cambiar su orden y categorías.
- Resumir y agregar datos con
group_by()ysummarize(). ¡No olviden desagrupar conungroup()! - Modificar la estructura de bases de datos:
- Cambiar de formato largo a ancho con
pivot_longer()ypivot_wider(). - Combinar dos bases de datos relacionadas con
left_join()y similares.
- Cambiar de formato largo a ancho con
6.15 Taller: manejo de datos
6.15.1 Crear una base de datos
Construir, guardar e imprimir a la consola un objeto tibble en R llamado datos_pib que contenga la siguiente información en filas y columnas:
- Colombia es un país democrático en América con un PIB per cápita de 6,651 USD y una expectativa de vida de 77 años.
- En el régimen dictatorial de Corea del Norte, ubicado en Asia, la expectativa de vida es de unos 67 años.
- En España, una democracia europea, la expectativa de vida es 83 años y el PIB per cápita es de 30,524 dólares.
- El PIB per cápita de Arabia Saudí, una dictadura en Asia donde la expectativa de vida es 73 años, es de 23,219 USD.
- En Sudán, el PIB per cápita es de 977 dólares y la expectativa de vida es 61 años; este país es una dictadura africana.
Usando datos_pib, encontrar (1.0 punto):
- El promedio del PIB per cápita para toda la muestra.
- La correlación de esta variable con la expectativa de vida al nacer.
6.15.2 Mostrar relaciones
Usando la función apropiada, cargar el archivo de datos datos_taller1.csv como un objeto tipo tibble. El archivo está disponible aquí y recuerden moverlo a la carpeta "data/.
La base de datos incluye las siguientes variables tomadas de Varieties of Democracy, v. 10:
vdem_country_name: nombre del país.year: año de la observación.v2x_polyarchy: indicador (numérico) de democracia electoral.v2elparlel: tipo de sistema electoral; puede tomar cuatro valores: mayoritario, representación proporcional y “otros” (incluye mixtos).v2psoppaut: indicador (numérico) de grado de autonomía de partidos en la oposición.v2elmulpar: indicador (binario) de multipartidismo; puede tomar dos valores: “no/limitado” y “sí”.
Usando estos datos y las funciones apropiadas en R (1.0 punto):
- Construir una tabla cruzada que cuente cuántos casos con sistemas mayoritarios tienen sistemas multipartidistas.
- Construir e interpretar una gráfica sencilla que muestre la relación entre el grado de autonomía de la oposición y el nivel de democracia electoral.
6.15.3 Seleccionar observaciones
Cargar a la sesión de R la base de datos que piensan utilizar en el proyecto de investigación del curso. Utilizar las funciones y operadores apropiados para seleccionar las filas (casos) potencialmente interesantes o relevantes para la investigación. Guardar este subconjunto de datos (un “subset”) como un objeto nuevo (1.0 punto).
- Bono: Convertir todos los nombres de columna a
snake_case(usando funciones, no a mano). Esto les ahorrará dolores de cabeza a largo plazo si tienen columnas con nombres como2010 Ingresoo similares. - Bono: mostrar que los valores
NAde las variables de interés -si los hay- están codificados apropiadamente (no como-999,"N/A"o similares). Esto les ahorrará dolores de cabeza a largo plazo.
6.15.4 Seleccionar variables
Usando el objeto creado en el punto anterior (el subconjunto de datos), utilizar las funciones y operadores apropiados para seleccionar las variables que tengan más sentido para su investigación. Guardar este subconjunto de datos como un objeto tipo tibble. Después, exportar este objeto como un archivo de datos .rds en la carpeta output/ (1.0 punto). Esto les ahorrará tener que ejecutar el código para recodificar y seleccionar los datos cada vez que quieran analizarlos. Sin embargo, probable que tengan que volver a este código y modificarlo a medida que cambian las necesidades del proyecto.
6.15.5 Medias de grupos
Usando el objeto creado en los dos puntos anteriores, estimar la media de una variable numérica de interés teórico (puede ser una variable independiente o dependiente) y comparar la media de esta variable para por lo menos dos grupos o categorías de interés teórico. Interpretar los resultados (1.0 punto).
- Bono: realizar e interpretar una prueba \(t\) de Student para evaluar si estas dos medias son diferentes en términos estadísticos. Pista: la librería
inferofrece una función para hacerlo, pero R ya incluye una. - Bono: realizar e interpretar una tabla cruzada de dos variables y utilizar una prueba \(\chi^{2}\) para evaluar si las dos variables son independientes. Pista: la librería
inferofrece una función para hacerlo, pero R ya incluye una.
Si estamos en RStudio Cloud, debemos empezar por subirlos y ubicarlos en una carpeta dentro del proyecto. Vamos al panel inferior derecho, pestaña
Files, click enUploady seguimos las indicaciones.↩︎También los podemos cargar usando los menús del programa; el asistente para cargar datos en RStudio (pestaña
Environment, opciónImport Dataset) es bastante bueno y nos arroja código que después debemos copiar en un Rmarkdown o R script para replicar nuestros análisis.↩︎