Chapter 5 Statistical Inference
Suppose we want to investigate whether a coin is fair. Let’s assign the result of each flip to the random variable, \(Y\). We’ll let \(Y\) equal 1 if the coin lands on Heads and 0 if Tails. The coin is fair if \(Pr(Y = 1)\) equals 0.50.
5.0.1 Quick Questions
Imagine we flip the coin 10 times, and we observe seven H’s and three T’s. Is there enough evidence for you to conclude that the coin is unfair?
What if we observed 5 H’s and 5 T’s, would that be enough evidence to conclude that the coin is fair?
If the coin really is fair, would we always observe 5 H’s and 5 T’s on ten flips?
5.1 Estimators, Estimands, and Sampling Distributions
Again, consider a simple linear regression model,
\[\begin{gather} Y_i = \beta_0 + \beta_1 X_i + u_i. \tag{5.1} \end{gather}\]
Recall that we a draw a sample of data (from the population) to obtain estimates of the parameters \(\beta_0\) and \(\beta_1\). OLS provides estimators \(\hat{\beta}_0\) and \(\hat{\beta}_1\). We may call the parameters (\(\beta_0\) and \(\beta_1\)) estimands.
An important observation is that estimates are random variables, because they are computed from a simple random sample of observations from the population. Consider again the example from Simple Linear Regression using CPS data to estimate the following model,
\[\begin{gather} Wages_i = \beta_0 + \beta_1 Schooling_i + u_i. \end{gather}\]
We obtained the following estimated model,
\[ \widehat{Wages} = -14.77 + 2.74 Schooling. \] However, imagine if the Bureau of Labor Statistics again sampled (from the same population of American workers) 60,000 workers and collected the same information. If we used this second sample to estimate the same regression model, would we get the same point estimate of \(\beta_1\)? Almost certainly not. However, since both samples are from the same population, both estimates would be estimates of the same estimand. There is an important concept here:
Estimates, like \(\hat{\beta}_1\), are random variables. They can take on any value among a distribution of possible values.
Using mathematics, we can characterize the probability distribution of an estimator, like \(\hat{\beta}_1\).
\[\begin{gather} \newcommand{\Var}{\operatorname{Var}} \newcommand{\Expect}{\operatorname{E}} \Expect[\hat{\beta}_1] = \beta_1 \\ \Var(\hat{\beta}_1) = \frac{1}{n} \frac{\Var\left(\left(X_i - \Expect[X]\right)u_i\right)}{\left[\Var\left(X_i\right)\right]^2} (\tag{5.2}) \end{gather}\]
We can also characterize the probability distribution of \(\hat{\beta}_1\).
The Central Limit Theorem says that \(\hat{\beta}_1\) is approximately normally distributed. The larger is the sample size, the better is the approximation.
This is a remarkable result. We do not need to know anything about the distributions of \(X\), \(Y\), or \(u\), yet we can still approximate the distribution of our estimator using this theorem.
The normal distribution is bell-shaped:
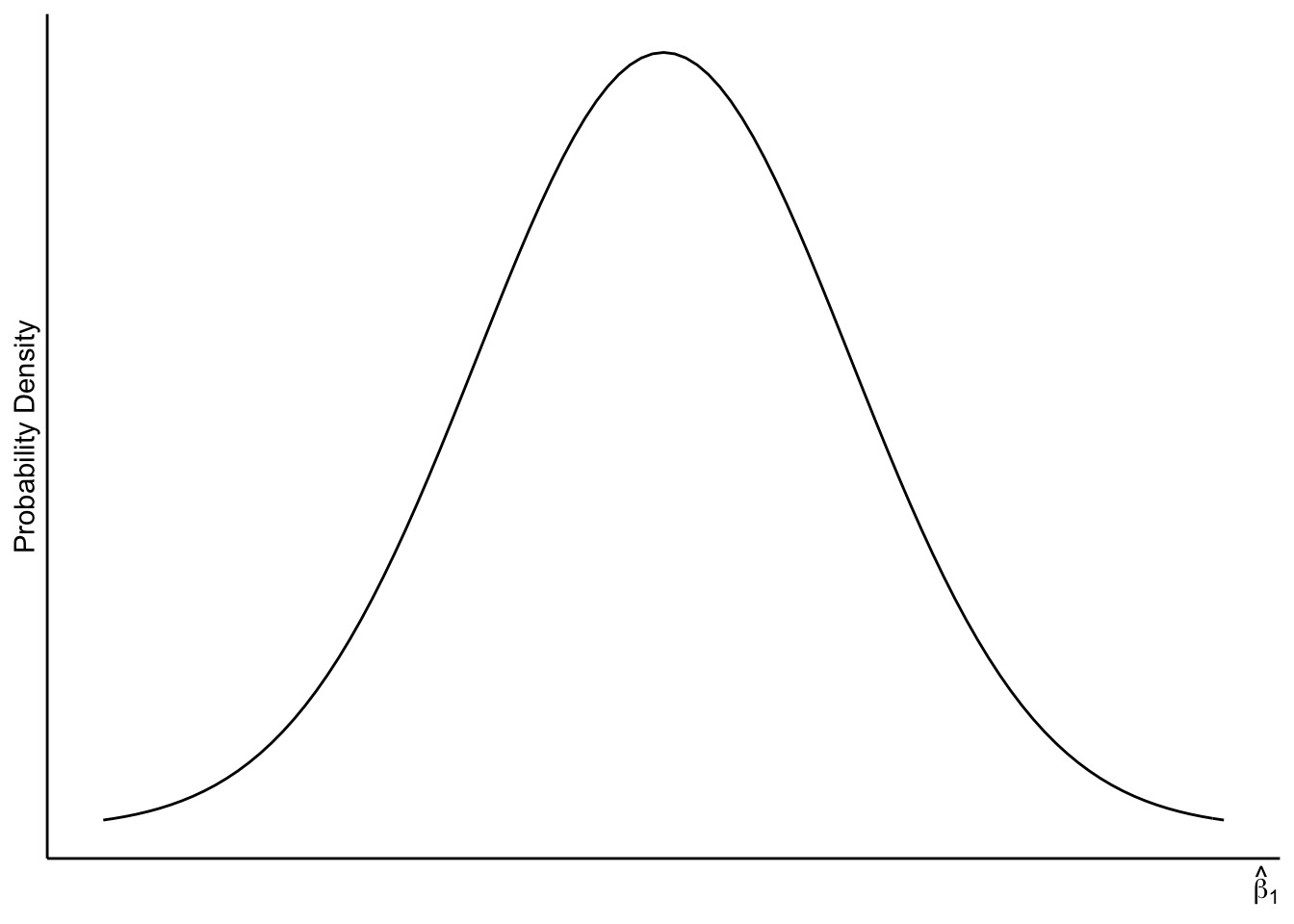
Figure 5.1: Sampling Distribution of \(\hat{\beta}_1\)
We know a lot about the distribution of \(\hat{\beta}_1\), but there seems to be one problem. We don’t know what \(\beta_1\) is. After all, that is why we collect data and estimate it!
Now you might be thinking that we have another problem with the expression for the variance of \(\hat{\beta}_1\): We don’t know the expected value of \(X\) and we don’t observe the error term for each observation (\(u_i\)). However, we can estimate the variance of \(\hat{\beta}_1\) by plugging in the sample mean of X (\(\bar{X}\)) for the population mean of X and the OLS residuals (\(\hat{u}_i\)) for the error terms!
5.1.1 Quick Questions
- What is a probability distribution function? How do we get probabilities from the bell-shaped graph above?
- Can you label \(\beta_1\) on the horizontal axis in 5.1?
- The standard normal distribution is a normal distribution with mean equal to zero and variance equal to one. How can we transform \(\hat{\beta}_1\) so that it has mean equal to zero and variance equal to one?
5.2 Hypothesis Testing
While we can never know exactly what \(\beta_1\) equals, we can shed light on what values might be in play and which might not be in play. We call this process inference, and it is characterized by hypothesis testing.
Hypothesis testing always follows the same formula. I’ll present the formula here in relation to \(\beta_1\), but it can be applied to any estimand.
- Assume that \(\beta_1\) equals some candidate value, \(c\).
- Find the probability of obtaining the observed point estimate, or a point estimate more extreme than the one observed (under the assumption that \(\beta_1=c\)). We call this probability the p-value.
- If this probability is sufficiently small, then we reject the candidate value.
Let’s do an example. Again, consider the population model below.
\[\begin{gather} Wages_i = \beta_0 + \beta_1 Schooling_i + u_i. \end{gather}\]
We will use the Current Population Survey data to estimate this model, and we will test whether \(\beta_1\) equals zero.
library(readxl)
ch8_cps <- read_excel("data/ch8_cps.xlsx")
est1 <- lm(ahe ~ yrseduc, data = ch8_cps)
summary(est1)##
## Call:
## lm(formula = ahe ~ yrseduc, data = ch8_cps)
##
## Residuals:
## Min 1Q Median 3Q Max
## -36.23 -8.92 -2.75 5.86 360.56
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -14.77458 0.32319 -45.71 <2e-16 ***
## yrseduc 2.74270 0.02256 121.59 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 14.12 on 59483 degrees of freedom
## Multiple R-squared: 0.1991, Adjusted R-squared: 0.199
## F-statistic: 1.478e+04 on 1 and 59483 DF, p-value: < 2.2e-16Our point estimate of \(\beta_1\) is 2.74. Now we ask, is there enough evidence to conclude that \(\beta_1\) is not zero? We formulate this test with the following notation,
\[\begin{align} &H_0: \beta_1 = 0 \\ &H_1: \beta_1 \ne 0 \end{align}\]
\(H_0\) is our null hypothesis. Here we are offering the candidate value for the estimand. In testing, we presume that the null is true for the moment. Under this presumption, we know that \(\hat{\beta}_1\) is distributed normally with mean equal to zero.
Before we continue, we need to decide what amount of evidence is enough to rule out that \(\beta_1\) equals zero. In statistics, we do this by deciding how small is “sufficiently small” in the third step of the hypothesis testing formula given above. The usual choice is 5%. In general, we label this choice \(\alpha\) and call it the significance level.
We want to ask, if \(\beta_1\) is equal to zero, what is the probability that we would observe a point estimate of \(\beta_1\) that is as different or more different than 2.74. In other words, we want the following probability, which we call the p-value:
\[\begin{gather} \text{p-value} = \Pr (| \hat{\beta}_1 - E[\hat{\beta}_1] | \ge | 2.74 - 0 |) \tag{5.3} \end{gather}\]
We know enough to ascertain this probability! We know that \(\hat{\beta}_1\) has a normal distribution (by CLT), it’s expected value is 0 (by null hypothesis), and its standard error is 0.0226. A standard error is a sample estimate of the standard deviation of \(\hat{\beta}_1\), which is obtained by plugging in \(\bar{X}\) for \(\E [X]\) and \(\hat{u}\) for \(u\) in equation (5.2) (and taking the square root).
Recall that probability distributions, like the normal distribution, are defined so that _areas beneath the curve over some interval indicate the probability of observing an outcome in that interval space.
In figure 5.2 I draw a normal distribution with the areas shaded. These shaded areas present the probability in (5.3).
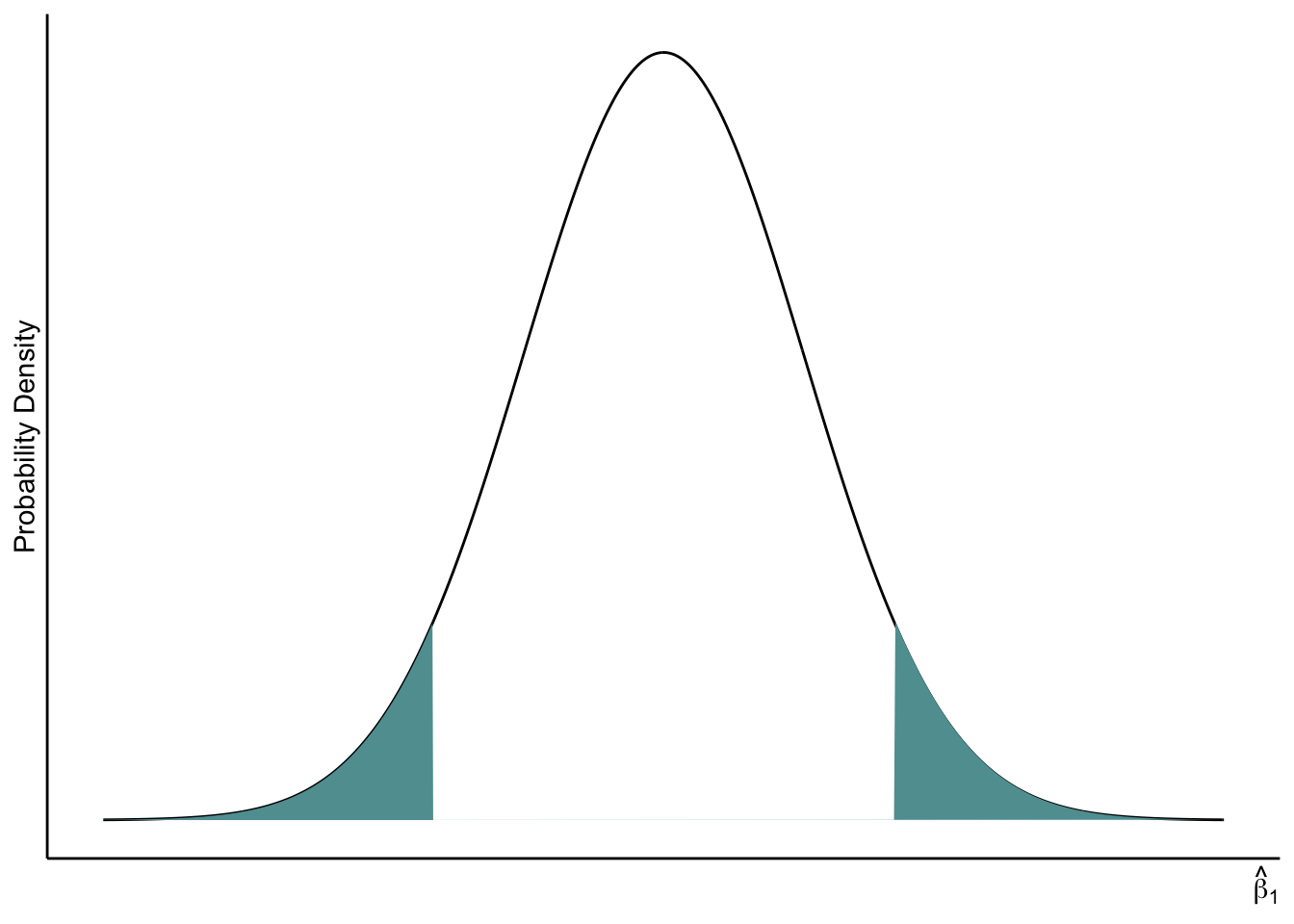
Figure 5.2: Two-tailed p-value
Since the normal distribution is symmetric, the p-value equals two times the area in one tail:
\[\begin{align} \text{p-value} &= \Pr (| \hat{\beta}_1 - E[\hat{\beta}_1] | \ge | 2.74 - 0 |) \\ &= 2 \Pr (\hat{\beta}_1 - E[\hat{\beta}_1] \le -2.74) \end{align}\]
Finding areas underneath a curve is challenging. However, there is a trick. We can map \(\hat{\beta}_1\) to a standard normal random variable. The standard normal random variable has mean equal to zero and standard deviation equal to 1. Then, we can look up the desired area in a z-table. Z-tables provide these areas for specified values of \(z\), usually from -3 to 3, in 0.01-unit increments. Z tables are everywhere, and they all provide the same information, so you can use any of them. Here is one.
The mapping from \(\hat{\beta}_1\) to \(z\) is pretty easy. We only need to subtract the mean (\(\text{E} [\hat{\beta}_1]\)) and then divide by the standard error (\(\text{SE} (\hat{\beta}_1)\)). Remember, we get \(\text{E} [\hat{\beta}_1]\) from our null hypothesis, since \(\text{E} [\hat{\beta}_1]\) equals \(\beta_1\). (The expected value of the estimate equals the estimand.)
We’ll call this mapped value the test statistic and label it \(t\).
\[\begin{gather} t = \frac{\hat{\beta}_1 - \text{E} [\hat{\beta}_1]}{\text{SE} (\hat{\beta}_1)} \end{gather}\]
In our example, we’ll have \(t = \frac{2.74 - 0}{0.023} = 119.13\). Because I am going to grab the area in the left tail and multiply it by two, I’ll need to look up the \(-119.13\). In other words, have the following:
\[\begin{align} \text{p-value} &= \Pr (| \hat{\beta}_1 - E[\hat{\beta}_1] | \ge | 2.74 - 0 |) \\ &= 2 \Pr (\hat{\beta}_1 - E[\hat{\beta}_1] \le -2.74) \\ &= 2\Pr \left(\frac{\hat{\beta}_1 - E[\hat{\beta}_1]}{\text{SE}(\hat{\beta}_1)} \le \frac{-2.74}{0.023}\right) \\ &= 2\Pr (z \le -119.13) \end{align}\]
This particular z score is off the charts. The smallest value that is on the linked z-table above is -3.9. The area remaining under the normal distribution to the left of 3.9 is 0.00005. Even after multiplying this number by 2, the resulting p-value is less than 0.05:
\[\begin{gather} \text{p-value} < 0.0001 \end{gather}\]
Thus, if \(\beta_1\) were equal to zero, the probability of observing an estimate that is as different (from zero) or more different (than zero) than the one we observed (-2.74) is less than 0.01%. In other words, the null were true, it would be very unlikely to get an estimate like the one we obtained. This is sufficiently unlikely (less than 0.05) and so we reject \(H_0\). We conclude that \(\beta_1\) is not zero.
When we reject a null hypothesis that \(\beta_1=0\), we say that the estimate (\(\hat{\beta}_1\)) is statistically significant. This is short hand for “statistically significantly different from zero.”
5.2.1 Questions
Consider the following estimated regression model. I’ve included standard errors in parenthesis beneath the corresponding coefficient estimate.
\[ Y = \underset{(4.1)}{87.3} - \underset{(8.5)}{13.5}X \] 1. What is the estimated effect of \(X\) on \(Y\)?
- Is there enough evidence to conclude that the effect \(X\) in nonzero?
5.3 t-table or z-table?
We used a standard normal table (z-table) to obtain our p-value. That’s because the central limit theorem (CLT) says that if the sample size is large enough, then \(\hat{\beta}_1\) is approximately normally distributed. So, why would we ever use the Student t-distribution?
Student’s t theorem provides the exact (not approximate) distribution of \(\hat{\beta}_1\) (in this case) provided that the regressor and the error term are normally distributed.1 These normality assumptions are aggressive, which is to say that in many cases they are unlikely to be true. (Do you think years of schooling is normally distributed? What about the contribution to wages of all the other factors?)
Nevertheless, it is common to use t-distribution values for p-vales and to call the test on \(\beta_1\) that I’ve presented here a simple t-test. We will also call this a simple t-test, but when looking up p-values manually with a table, we’ll just use a z-table for ease. In cases where the sample size is really large (>100), the two distributions are very close. However, the two-tailed p-value provided in the R printout resulting from the summary command will is based on the t-distribution.
5.4 Confidence Intervals
We can ask, what are all of the values that we would reject or fail to reject as candidates in the null hypothesis? This is precisely the content contained in a confidence interval.
At the 5% significance level, we fail to reject a null hypothesis (in favor of the two-sided alternative) whenever the test statistic is smaller than 1.96 in absolute value. Using algebra, we can back out the corresponding null candidates that we would fail to reject.
\[\begin{gather} \left|\frac{\hat{\beta}_1 - c}{\text{SE} (\hat{\beta}_1)}\right| < 1.96 \\ \rightarrow \hat{\beta}_1 - 1.96\text{SE} (\hat{\beta}_1) < c < \hat{\beta}_1 + 1.96\text{SE} (\hat{\beta}_1) \end{gather}\]
Recall our estimated model from above. I’ve put the standard errors from R’s regression output in parenthesis beneath the corresponding coefficient estimates.
\[ \widehat{Wages} = \underset{(0.32)}{-14.77} + \underset{(0.02)}{2.74} Schooling. \]
The 95% confidence interval for the coefficient on schooling (\(\beta_1\)) is,
\[\begin{align} \text{95% C.I.} &= 2.74 \pm 1.96 \times(0.02) \\ &= \left[2.70, 2.78\right] \end{align}\]
This means that we would reject any candidate value in the null hypothesis that is less than 2.70 or greater than 2.78. Therefore, not only can we conclude that \(\beta_1\) is nonzero, we can also conclude that \(\beta_1\) is positive, since we would reject any negative candidates, too.
This is an important observation:
If we reject a zero-valued null hypothesis, then we can conclude that the estimand has the same sign as the estimate.
5.4.1 Question
Consider again the estimated model,
\[ Y = \underset{(4.1)}{87.3} - \underset{(8.0)}{13.5}X \] 1. What is the 95% confidence interval for the effect of \(X\)? 2. Can you conclude that the effect of X is negative? Why or why not?
5.4.2 The meaning of failing to reject \(H_0\)
If we fail to reject a null hypothesis, it means that there was not enough evidence to affirm the alternative. We are not concluding that the null is true, neither are we “accepting” the null. In many cases, there is a lot of evidence against the null hypothesis, but not quite enough. This happens if the p-value is 12%, for example.
Another way to understand this is through the confidence interval. The confidence interval contains the set of candidate values for the null hypothesis that we would fail to reject. If failure to reject meant “accepting” the null, then we would need to accept a set of values for \(\beta_1\). However, \(\beta_1\) is strictly one number and not a set of numbers.
5.5 Type 1 and Type 2 errors
A hypothesis test can go wrong in two ways. A type 1 error occurs when we reject a null hypothesis that is true. The probability of a type 1 error equals the significance level of the test, which is usually 5%. (We usually denote significance levels with the Greek letter \(\alpha\).) This means that out of 100 various tests in which the null is actually true, we will falsely reject about 5 of them. For this reason, we will almost never use the word “proved” when it comes to empirical observations. We wouldn’t want to say that we’ve “proved” that more schooling is associated with higher wages, because there is a possibility that we have a type 1 error.
Some may be tempted to infer that ANY time we reject the null, there is an \(\alpha\)-% chance that we are mistaken. That would be wrong, however. There is an \(\alpha\)-% chance of of falsely rejecting the null if the null is actually true, but we don’t know whether the null is true or not!
A type 2 error occurs when we fail to reject a null that is false. This equals one minus the power of the test. The power of a test equals the probability that the null is rejected whenever it is false. Power depends on the actual value of the estimand, which is unknown in practice. However, mathematics can shed light on which tests offer the most power for a given level of significance. The simple t-test that we have presented here is generally the favorite when testing hypotheses concerning a single coefficient, like \(\beta_1\).
5.6 One-tailed tests, we don’t need ’em
There is such a thing as a one-tailed test. Here is an example:
\[\begin{align} &H_0: \beta_1 \le 0 \\ &H_1: \beta_1 > 0 \\ \end{align}\]
This test asks whether there is enough information to conclude that \(\beta_1\) is positive. You might think that this is an attractive alternative to the two-tailed version. After all, it would be better to know whether the effect of \(X\) on \(Y\) (which is what \(\beta_1\) represents) is positive or negative, not just that it is different than zero.
However, this tests comes with some cost: We won’t be able to affirm that \(\beta_1\) is negative if that is the case. If we fail to reject the null in this one-tailed test, we can only conclude that there is not enough evidence to affirm that \(\beta_1\) is positive, and failing to reject a null is not grounds for acceptance of the null.
Also, don’t be tempted to choose the alternative hypothesis to be positive or negative based on the sign of the point estimate of \(\beta_1\). This reasoning is circular: using the data to inform the hypothesis that the same data will then be used to test. If you do this, the effective Type 1 error rate will be twice as large as advertised.
When would it be a good idea to use a one-tailed test? You can use it only when you really do not care whether you can detect a positive or negative coefficient. However, if you would be interested to know whether an estimand is positive or negative, then use a two-tailed test! In this class, always use a two-tailed test.
5.7 Robust Standard Errors
Typical standard errors reported by R’s `lm()’ function are homoskedastic-only standard errors. Homoskedastic-only standard errors work only when the errors (\(u's\)) have constant variance regardless of regressor (\(X\)).
Consider again the scatter plot with line of best fit below. Let’s compare the variation of the residuals for workers with 10 years of schooling and 16 years of schooling. We can use range which is another measure of variation. Consider the difference between the maximum residual and minimum residual for workers in these two groups.
## `geom_smooth()` using formula 'y ~ x'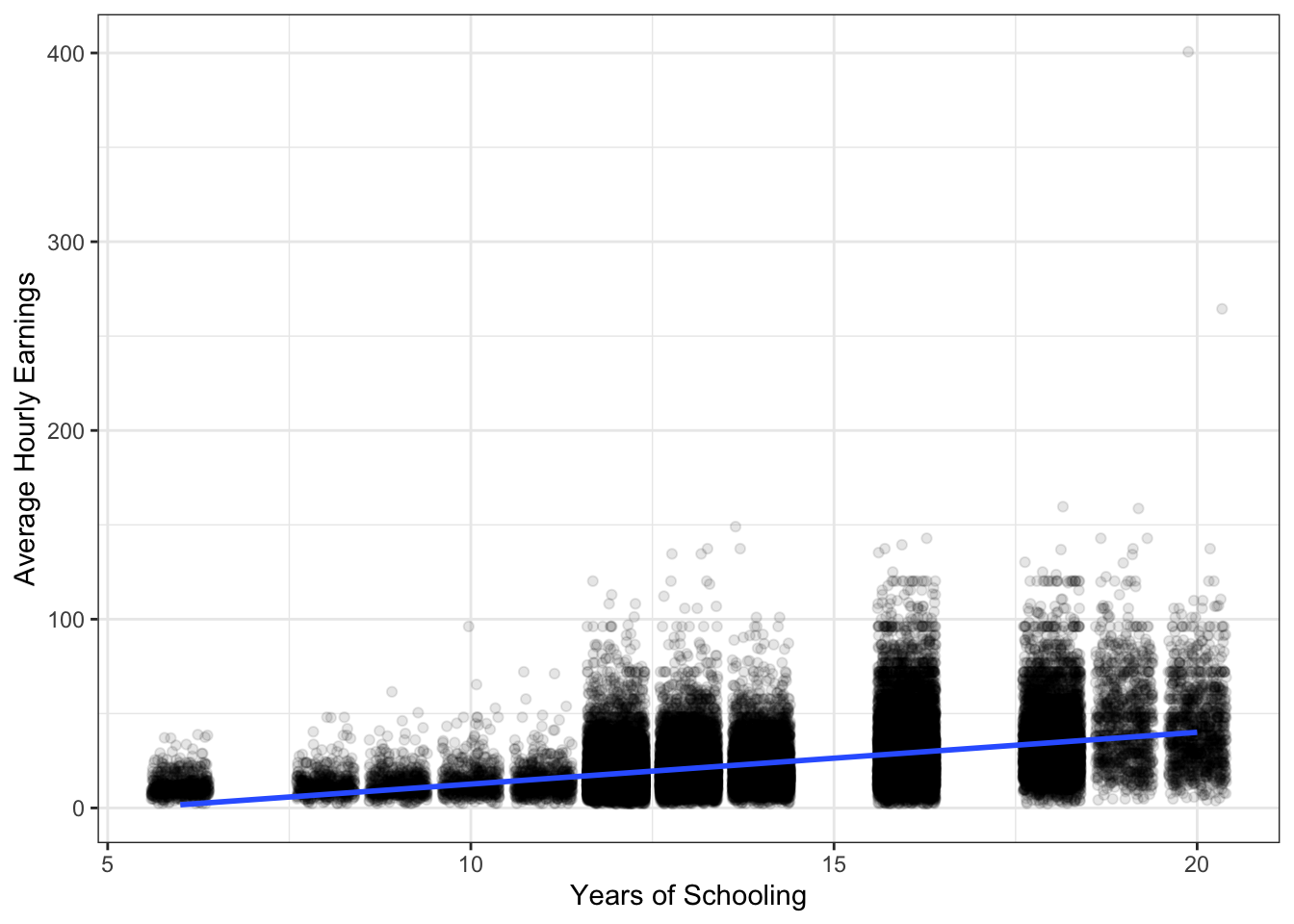
Visually it looks like the variation in the residuals is larger among workers with more schooling. This isn’t very surprising, but it is likely that homoskedastic-only standard errors are not appropriate. In this case, we say the errors (\(u's\)) are likely heteroskedastic.
Heteroskedastic-robust standard errors are an alternative to homoskedastic-only standard errors. Robust standard errors work fairly well even when the errors are homoskedastic. Therefore, I recommend using robust standard errors, by default.
In R, you can use lm_robust() from the estimatr package to return robust standard errors. From now on, I’ll use lm_robust() unless I am only interested in the estimated coefficients and will not need the standard errors.
library(estimatr)
mod_robustse <- lm_robust(ahe ~ yrseduc, data = ch8_cps)
summary(mod_robustse)##
## Call:
## lm_robust(formula = ahe ~ yrseduc, data = ch8_cps)
##
## Standard error type: HC2
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|) CI Lower CI Upper DF
## (Intercept) -14.775 0.34712 -42.56 0 -15.455 -14.094 59483
## yrseduc 2.743 0.02627 104.42 0 2.691 2.794 59483
##
## Multiple R-squared: 0.1991 , Adjusted R-squared: 0.199
## F-statistic: 1.09e+04 on 1 and 59483 DF, p-value: < 2.2e-16This result took some hard work, since the standard deviation of the regressor is unknown. Sometimes, folks start to believe that this is when you should use a t-distribution: When the standard deviation is unknown. However, the underlying random variable must also be normally distributed in order to justify using the t-distribtion.↩︎