A Exercise solutions
A.1 Chapter 1
- 23 observations and 7 variables.
- (a) “Is there an association between air pollution exposure and preterm births?” (b) 143,196 births in Southern California between 1989 and 1993. (c) Measurements of carbon monoxide, nitrogen dioxide, ozone, and particulate matter less than 10\(\mu g/m^3\) (PM\(_{10}\)) collected at air-quality-monitoring stations as well as length of gestation. Continuous numerical variables.
- (a) “What is the effect of gamification on learning outcomes compared to traditional teaching methods?” (b) 365 college students taking a statistics course (c) Gender (categorical), level of studies (categorical, ordinal), academic major (categorical), expertise in English language (categorical, ordinal), use of personal computers and games (categorical, ordinal), treatment group (categorical), score (numerical, discrete).
- (a) Treatment: \(10/43 = 0.23 \rightarrow 23\%\). (b) Control: \(2/46 = 0.04 \rightarrow 4\%\). (c) A higher percentage of patients in the treatment group were pain free 24 hours after receiving acupuncture. (d) It is possible that the observed difference between the two group percentages is due to chance. (e) Explanatory: acupuncture or not. Response: if the patient was pain free or not.
- (a) Experiment; researchers are evaluating the effect of fines on parents’ behavior related to picking up their children late from daycare. (b) 10 cases: the daycare centers. (c) Number of late pickups (discrete numerical). (d) Week (numerical, discrete), group (categorical, nominal), number of late pickups (numerical discrete), and study period (categorical, ordinal).
- (a) 344 cases (penguins) are included in the data. (b) There are 4 numerical variables in the data: bill length, bill depth, and flipper length (measured in millimeters) and body mass (measured in grams). They are all continuous. (c) There are 3 categorical variables in the data: species (Adelie, Chinstrap, Gentoo), island (Torgersen, Biscoe, and Dream), and sex (female and male).
- (a) Airport ownership status (public/private), airport usage status (public/private), region (Central, Eastern, Great Lakes, New England, Northwest Mountain, Southern, Southwest, Western Pacific), latitude, and longitude. (b) Airport ownership status: categorical, not ordinal. Airport usage status: categorical, not ordinal. Region: categorical, not ordinal. Latitude: numerical, continuous. Longitude: numerical, continuous.
- (a) Year, number of baby girls named Fiona born in that year, nation. (b) Year (numerical, discrete), number of baby girls named Fiona born in that year (numerical, discrete), nation (categorical, nominal).
- (a) County, state, driver’s race, whether the car was searched or not, and whether the driver was arrested or not. (b) All categorical, non-ordinal. (c) Response: whether the car was searched or not. Explanatory: race of the driver.
- (a) Observational study. (b) Dog: Lucy. Cat: Luna. (c) Oliver and Lily. (d) Positive, as the popularity of a name for dogs increases, so does the popularity of that name for cats.
A.2 Chapter 2
- (a) Population mean, \(\mu_{2007} = 52\); sample mean, \(\bar{x}_{2008} = 58\). (b) Population mean, \(\mu_{2001} = 3.37\); sample mean, \(\bar{x}_{2012} = 3.59\).
- (a) Population: all births, sample: 143,196 births between 1989 and 1993 in Southern California. (b) If births in this time span at the geography can be considered to be representative of all births, then the results are generalizable to the population of Southern California. However, since the study is observational the findings cannot be used to establish causal relationships.
- (a) The population of interest is all college students studying statistics. The sample consists of 365 such students. (b) If the students in this sample, who are likely not randomly sampled, can be considered to be representative of all college students studying statistics, then the results are generalizable to the population defined above. This is probably not a reasonable assumption since these students are from two specific majors only. Additionally, since the study is experimental, the findings can be used to establish causal relationships.
- (a) Observation. (b) Variable. (c) Sample statistic (mean). (d) Population parameter (mean).
- (a) Observational. (b) Use stratified sampling to randomly sample a fixed number of students, say 10, from each section for a total sample size of 40 students.
- (a) Positive, non-linear, somewhat strong. Countries in which a higher percentage of the population have access to the internet also tend to have higher average life expectancies, however rise in life expectancy trails off before around 80 years old. (b) Observational. (c) Wealth: countries with individuals who can widely afford the internet can probably also afford basic medical care. (Note: Answers may vary.)
- (a) Simple random sampling is okay. In fact, it’s rare for simple random sampling to not be a reasonable sampling method! (b) The student opinions may vary by field of study, so the stratifying by this variable makes sense and would be reasonable. (c) Students of similar ages are probably going to have more similar opinions, and we want clusters to be diverse with respect to the outcome of interest, so this would not be a good approach. (Additional thought: the clusters in this case may also have very different numbers of people, which can also create unexpected sample sizes.)
- (a) The cases are 200 randomly sampled men and women. (b) The response variable is attitude towards a fictional microwave oven. (c) The explanatory variable is dispositional attitude. (d) Yes, the cases are sampled randomly, recruited online using Amazon’s Mechanical Turk. (e) This is an observational study since there is no random assignment to treatments. (f) No, we cannot establish a causal link between the explanatory and response variables since the study is observational. (g) Yes, the results of the study can be generalized to the population at large since the sample is random.
- (a) Simple random sample. Non-response bias, if only those people who have strong opinions about the survey responds their sample may not be representative of the population. (b) Convenience sample. Under coverage bias, their sample may not be representative of the population since it consists only of their friends. It is also possible that the study will have non-response bias if some choose to not bring back the survey. (c) Convenience sample. This will have a similar issues to handing out surveys to friends. (d) Multi-stage sampling. If the classes are similar to each other with respect to student composition this approach should not introduce bias, other than potential non-response bias.
- (a) Exam performance. (b) Light level: fluorescent overhead lighting, yellow overhead lighting, no overhead lighting (only desk lamps). (c) Wearing glasses or not.
- (a) Experiment. (b) Light level (overhead lighting, yellow overhead lighting, no overhead lighting) and noise level (no noise, construction noise, and human chatter noise). (c) Since the researchers want to ensure equal representation of those wearing glasses and not wearing glasses, wearing glasses is a blocking variable.
- Need randomization and blinding. One possible outline: (1) Prepare two cups for each participant, one containing regular Coke and the other containing Diet Coke. Make sure the cups ar identical and contain equal amounts of soda. Label the cups (regular) and B (diet). (Be sure to randomize A and B for each trial!) (2) Give each participant the two cups, one cup at a time, in random order, and ask the participant to record a value that indicates ho much she liked the beverage. Be sure that neither the participant nor the person handing out the cups knows the identity of th beverage to make this a double-blind experiment. (Answers may vary.)
- (a) Experiment. (b) Treatment: 25 grams of chia seeds twice a day, control: placebo. (c) Yes, gender. (d) Yes, single blind since the patients were blinded to the treatment they received. (e) Since this is an experiment, we can make a causal statement. However, since the sample is not random, the causal statement cannot be generalized to the population at large.
- (a) Non-responders may have a different response to this question, e.g., parents who returned the surveys likely don’t have difficulty spending time with their children. (b) It is unlikely that the women who were reached at the same address 3 years later are a random sample. These missing responders are probably renters (as opposed to homeowners) which means that they might have a lower socio-economic status than the respondents. (c) There is no control group in this study, this is an observational study, and there may be confounding variables, e.g., these people may go running because they are generally healthier and/or do other exercises.
- (a) Randomized controlled experiment. (b) Explanatory: treatment group (categorical, with 3 levels). Response variable: Psychological well-being. (c) No, because the participants were volunteers. (d) Yes, because it was an experiment. (e) The statement should say “evidence” instead of “proof”.
A.3 Chapter 3
- (a) We see the order of the categories and the relative frequencies in the bar plot. (b) There are no features that are apparent in the pie chart but not in the bar plot. (c) We usually prefer to use a bar plot as we can also see the relative frequencies of the categories in this graph.
- (a) The horizontal locations at which the age groups break into the various opinion levels differ, which indicates that likelihood of supporting protests varies by age group. Two variables may be associated. (b) Answers may vary. Political ideology/leaning and education level.
- Number of participants in each group. (b) Proportion of survival. (c) The standardized bar plot should be displayed as a way to visualize the survival improvement in the treatment versus the control group.
A.4 Chapter 4
(a) Positive association: mammals with longer gestation periods tend to live longer as well. (b) Association would still be positive. (c) No, they are not independent. See part (a).
-
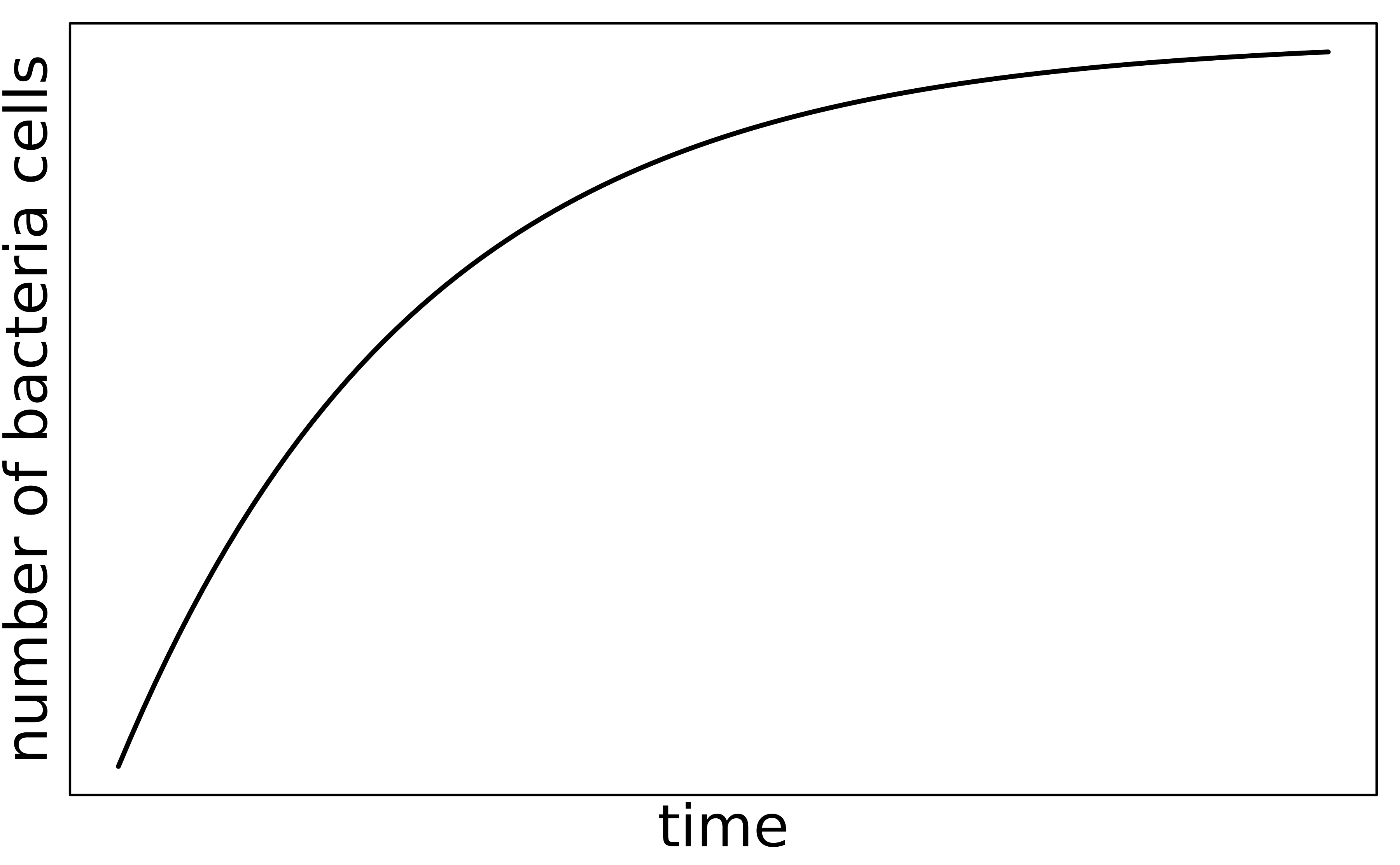
The graph below shows a ramp up period. There may also be a period of exponential growth at the start before the size of the petri dish becomes a factor in slowing growth.
(a) Decrease: the new score is smaller than the mean of the 24 previous scores. (b) Calculate a weighted mean. Use a weight of 24 for the old mean and 1 for the new mean: \((24\times 74 + 1\times64)/(24+1) = 73.6\). (c) The new score is more than 1 standard deviation away from the previous mean, so increase.
Any 10 employees whose average number of days off is between the minimum and the mean number of days off for the entire workforce at this plant.
(a) Dist B has a higher mean since \(20 > 13\), and a higher standard deviation since 20 is further from the rest of the data than 13. (b) Dist A has a higher mean since \(-20 > -40\), and Dist B has a higher standard deviation since -40 is farther away from the rest of the data than -20. (c) Dist B has a higher mean since all values in this Dist Are higher than those in Dist A, but both distribution have the same standard deviation since they are equally variable around their respective means. (d) Both distributions have the same mean since they’re both centered at 300, but Dist B has a higher standard deviation since the observations are farther from the mean than in Dist A.
(a) About 30. (b) Since the distribution is right skewed the mean is higher than the median. (c) Q1: between 15 and 20, Q3: between 35 and 40, IQR: about 20. (d) Values that are considered to be unusually low or high lie more than 1.5\(\times\)IQR away from the quartiles. Upper fence: Q3 + 1.5 \(\times\) IQR = \(37.5 + 1.5 \times 20 = 67.5\); Lower fence: Q1 - 1.5 \(\times\) IQR = \(17.5 + 1.5 \times 20 = -12.5\); The lowest AQI recorded is not lower than 5 and the highest AQI recorded is not higher than 65, which are both within the fences. Therefore none of the days in this sample would be considered to have an unusually low or high AQI.
The histogram shows that the distribution is bimodal, which is not apparent in the box plot. The box plot makes it easy to identify more precise values of observations outside of the whiskers.
(a) Right skewed, there is a natural boundary at 0 and only a few people have many pets. Center: median, variability: IQR. (b) Right skewed, there is a natural boundary at 0 and only a few people live a very long distance from work. Center: median, variability: IQR. (c) Symmetric. Center: mean, variability: standard deviation. (d) Left skewed. Center: median, variability: IQR. (e) Left skewed. Center: median, variability: IQR.
No, we would expect this distribution to be right skewed. There are two reasons for this: there is a natural boundary at 0 (it is not possible to watch less than 0 hours of TV) and the standard deviation of the distribution is very large compared to the mean.
No, the outliers are likely the maximum and the minimum of the distribution so a statistic based on these values cannot be robust to outliers.
The 75th percentile is 82.5, so 5 students will get an A. Also, by definition 25% of students will be above the 75th percentile.
(a) If \(\frac{\bar{x}}{median} = 1\), then \(\bar{x} = median\). This is most likely to be the case for symmetric distributions. (b) If \(\frac{\bar{x}}{median} < 1\), then \(\bar{x} < median\). This is most likely to be the case for left skewed distributions, since the mean is affected (and pulled down) by the lower values more so than the median. (c) If \(\frac{\bar{x}}{median} > 1\), then \(\bar{x} > median\). This is most likely to be the case for right skewed distributions, since the mean is affected (and pulled up) by the higher values more so than the median.
(a) The distribution of percentage of population that is Hispanic is extremely right skewed with majority of counties with less than 10% Hispanic residents. However there are a few counties that have more than 90% Hispanic population. It might be preferable to, in certain analyses, to use the log-transformed values since this distribution is much less skewed. (b) The map reveals that counties with higher proportions of Hispanic residents are clustered along the Southwest border, all of New Mexico, a large swath of Southwest Texas, the bottom two-thirds of California, and in Southern Florida. In the map all counties with more than 40% of Hispanic residents are indicated by the darker shading, so it is impossible to discern how high Hispanic percentages go. The histogram reveals that there are counties with over 90% Hispanic residents. The histogram is also useful for estimating measures of center and spread. (c) Both visualizations are useful, but if we could only examine one, we should examine the map since it explicitly ties geographic data to each county’s percentage.
A.5 Chapter 5
- (a) The residual plot will show randomly distributed residuals around 0. The variance is also approximately constant. (b) The residuals will show a fan shape, with higher variability for smaller \(x\). There will also be many points on the right above the line. There is trouble with the model being fit here.
- (a) Strong relationship, but a straight line would not fit the data. (b) Strong relationship, and a linear fit would be reasonable. (c) Weak relationship, and trying a linear fit would be reasonable. (d) Moderate relationship, but a straight line would not fit the data. (e) Strong relationship, and a linear fit would be reasonable. (f) Weak relationship, and trying a linear fit would be reasonable.
- (a) Exam 2 since there is less of a scatter in the plot of course grade versus exam 2. Notice that the relationship between Exam 1 and the course grade appears to be slightly nonlinear. (b) (Answers may vary.) If Exam 2 is cumulative it might be a better indicator of how a student is doing in the class.
- (a) \(r = -0.7\) \(\rightarrow\) (4). (b) \(r = 0.45\) \(\rightarrow\) (3). (c) \(r = 0.06\) \(\rightarrow\) (1). (d) \(r = 0.92\) \(\rightarrow\) (2).
- (a) There is a moderate, positive, and linear relationship between shoulder girth and height. (b) Changing the units, even if just for one of the variables, will not change the form, direction or strength of the relationship between the two variables.
- (a) There is a somewhat weak, positive, possibly linear relationship between the distance traveled and travel time. There is clustering near the lower left corner that we should take special note of. (b) Changing the units will not change the form, direction or strength of the relationship between the two variables. If longer distances measured in miles are associated with longer travel time measured in minutes, longer distances measured in kilometers will be associated with longer travel time measured in hours. (c) Changing units doesn’t affect correlation: \(r = 0.636\).
- In each part, we can write the age of one partner as a linear function of the other. (a) \(age_{P1} = age_{P2} + 3\). (b) \(age_{P1} = age_{P2} - 2\). (c) \(age_{P1} = 2 \times age_{P2}\). Since the slopes are positive and these are perfect linear relationships, the correlation will be exactly 1 in all three parts. An alternative way to gain insight into this solution is to create a mock dataset, e.g., 5 women aged 26, 27, 28, 29, and 30, then find the husband ages for each wife in each part and create a scatterplot.
- Correlation: no units. Intercept: cal. Slope: cal/cm.
- Over-estimate. Since the residual is calculated as \(observed - predicted\), a negative residual means that the predicted value is higher than the observed value.
- (a) There is a positive, moderate, linear association between number of calories and amount of carbohydrates. In addition, the amount of carbohydrates is more variable for menu items with higher calories, indicating non-constant variance. There also appear to be two clusters of data: a patch of about a dozen observations in the lower left and a larger patch on the right side. (b) Explanatory: number of calories. Response: amount of carbohydrates (in grams). (c) With a regression line, we can predict the amount of carbohydrates for a given number of calories. This may be useful if only calorie counts for the food items are posted but the amount of carbohydrates in each food item is not readily available. (d) Food menu items with higher predicted protein are predicted with higher variability than those without, suggesting that the model is doing a better job predicting protein amount for food menu items with lower predicted proteins.
- (a) First calculate the slope: \(b_1 = R\times s_y/s_x = 0.636 \times 113 / 99 = 0.726\). Next, make use of the fact that the regression line passes through the point \((\bar{x},\bar{y})\): \(\bar{y} = b_0 + b_1 \times \bar{x}\). Plug in \(\bar{x}\), \(\bar{y}\), and \(b_1\), and solve for \(b_0\): 51. Solution: \(\widehat{travel~time} = 51 + 0.726 \times distance\). (b) \(b_1\): For each additional mile in distance, the model predicts an additional 0.726 minutes in travel time. \(b_0\): When the distance travelled is 0 miles, the travel time is expected to be 51 minutes. It does not make sense to have a travel distance of 0 miles in this context. Here, the \(y\)-intercept serves only to adjust the height of the line and is meaningless by itself. (c) \(R^2 = 0.636^2 = 0.40\). About 40% of the variability in travel time is accounted for by the model, i.e., explained by the distance travelled. (d) \(\widehat{travel~time} = 51 + 0.726 \times distance = 51 + 0.726 \times 103 \approx 126\) minutes. (Note: we should be cautious in our predictions with this model since we have not yet evaluated whether it is a well-fit model.) (e) \(e_i = y_i - \hat{y}_i = 168 - 126 = 42\) minutes. A positive residual means that the model underestimates the travel time. (f) No, this calculation would require extrapolation.
- (a) \(\widehat{\texttt{poverty}} = 4.60 + 2.05 \times \texttt{unemployment_rate}.\) (b) The model predicts a poverty rate of 4.60% for counties with 0% unemployment, on average. This is not a meaningful value as no counties have such low unexmployment, it just serves to adjust the height of the regression line. (c) For each additional percentage increase in unemployment rate, poverty rate is predicted to be higher, on average, by 2.05%. (d) Unemployment rate explains 46% of the variability in poverty levels in US counties. (e) \(\sqrt{0.46} = 0.678.\)
- (a) There is an outlier in the bottom right. Since it is far from the center of the data, it is a point with high leverage. It is also an influential point since, without that observation, the regression line would have a very different slope. (b) There is an outlier in the bottom right. Since it is far from the center of the data, it is a point with high leverage. However, it does not appear to be affecting the line much, so it is not an influential point. (c) The observation is in the center of the data (in the x-axis direction), so this point does not have high leverage. This means the point won’t have much effect on the slope of the line and so is not an influential point.
- (a) There is a negative, moderate-to-strong, somewhat linear relationship between percent of families who own their home and the percent of the population living in urban areas in 2010. There is one outlier: a state where 100% of the population is urban. The variability in the percent of homeownership also increases as we move from left to right in the plot. (b) The outlier is located in the bottom right corner, horizontally far from the center of the other points, so it is a point with high leverage. It is an influential point since excluding this point from the analysis would greatly affect the slope of the regression line.
- (a) True. (b) False, correlation is a measure of the linear association between any two numerical variables.
- (a) \(r = 0.7 \to (1)\) (b) \(r = 0.09 \to (4)\) (c) \(r = -0.91 \to (2)\) (d) \(r = 0.96 \to (3)\).
A.6 Chapter 6
- (a) Mean. Each student reports a numerical value: a number of hours. (b) Mean. Each student reports a number, which is a percentage, and we can average over these percentages. (c) Proportion. Each student reports Yes or No, so this is a categorical variable and we use a proportion. (d) Mean. Each student reports a number, which is a percentage like in part (b). (e) Proportion. Each student reports whether or not s/he expects to get a job, so this is a categorical variable and we use a proportion.
- (a) Alternative. (b) Null. (c) Alternative. (d) Alternative. (e) Null. (f) Alternative. (g) Null.
- (a) \(H_0: \mu = 8\) (On average, New Yorkers sleep 8 hours a night.) \(H_A: \mu < 8\) (On average, New Yorkers sleep less than 8 hours a night.) (b) \(H_0: \mu = 15\) (The average amount of company time each employee spends not working is 15 minutes for March Madness.) \(H_A: \mu > 15\) (The average amount of company time each employee spends not working is greater than 15 minutes for March Madness.)
- (a) (i) False. Instead of comparing counts, we should compare percentages of people in each group who suffered cardiovascular problems. (ii) True. (iii) False. Association does not imply causation. We cannot infer a causal relationship based on an observational study. The difference from part (ii) is subtle. (iv) True. (b) Proportion of all patients who had cardiovascular problems: \(\frac{7,979}{227,571} \approx 0.035\) (c) The expected number of heart attacks in the Rosiglitazone group, if having cardiovascular problems and treatment were independent, can be calculated as the number of patients in that group multiplied by the overall cardiovascular problem rate in the study: \(67,593 * \frac{7,979}{227,571} \approx 2370\). (d) (i) \(H_0\): The treatment and cardiovascular problems are independent. They have no relationship, and the difference in incidence rates between the Rosiglitazone and Pioglitazone groups is due to chance. \(H_A\): The treatment and cardiovascular problems are not independent. The difference in the incidence rates between the Rosiglitazone and Pioglitazone groups is not due to chance and Rosiglitazone is associated with an increased risk of serious cardiovascular problems. (ii) A higher number of patients with cardiovascular problems than expected under the assumption of independence would provide support for the alternative hypothesis as this would suggest that Rosiglitazone increases the risk of such problems. (iii) In the actual study, we observed 2,593 cardiovascular events in the Rosiglitazone group. In the 100 simulations under the independence model, the simulated differences were never so high, which suggests that the actual results did not come from the independence model. That is, the variables do not appear to be independent, and we reject the independence model in favor of the alternative. The study’s results provide convincing evidence that Rosiglitazone is associated with an increased risk of cardiovascular problems.
A.7 Chapter 7
- (a) The statistic is the sample proportion (0.289); the parameter is the population proportion (unknown). (b) \(\hat{p}\) and \(p\). (c) Bootstrap sample proportion. (d) 0.289. (e) Roughly (0.22, 0.35). (f) We can be 95% confident that between 22% and 35% of all YouTube videos take place outdoors.
- With 98% confidence, the true proportion of all US adult Twitter users (in 2013) who get at least some of the news from Twitter is between 0.48 and 0.56.
- (a) A or perhaps D. (b) A, B, C, or D. (c) B or C. (d) B. (e) None.
- (a) This claim is reasonable, since the entire interval lies above 50%. (b) The value of 70% lies outside of the interval, so we have convincing evidence that the researcher’s conjecture is wrong. (c) A 90% confidence interval will be narrower than a 95% confidence interval. Even without calculating the interval, we can tell that 70% would not fall in the interval, and we would reject the researcher’s conjecture based on a 90% confidence level as well.
A.8 Chapter 8
- (a) Recall that the general formula is \(point~estimate \pm z^{\star} \times SE\). First, identify the three different values. The point estimate is 45%, \(z^{\star} = 1.96\) for a 95% confidence level, and \(SE = 1.2\%\). Then, plug the values into the formula: \(45\% \pm 1.96 \times 1.2\% \quad\to\quad (42.6\%, 47.4\%)\) We are 95% confident that the proportion of US adults who live with one or more chronic conditions is between 42.6% and 47.4%. (b) (i) False. Confidence intervals provide a range of plausible values, and sometimes the truth is missed. A 95% confidence interval “misses” about 5% of the time. (ii) True. Notice that the description focuses on the true population value. (iii) True. If we examine the 95% confidence interval, we can see that 50% is not included in this interval. This means that in a hypothesis test, we would reject the null hypothesis that the proportion is 0.5. (iv) False. The standard error describes the uncertainty in the overall estimate from natural fluctuations due to randomness, not the uncertainty corresponding to individuals’ responses.
- A Z score of 0.47 denotes that the sample proportion is 0.47 standard errors greater than the hypothesized value of the population proportion.
- (a) Sampling distribution. (b) To know whether the distribution is skewed, we need to know the proportion. We’ve been told the proportion is likely above 5% and below 30%, and the success-failure condition would be satisfied for any of these values. If the population proportion is in this range, the sampling distribution will be symmetric. (c) Standard error. (d) The distribution will tend to be more variable when we have fewer observations per sample.
A.9 Chapter 9
- (a) \(H_0\): Anti-depressants do not affect the symptoms of Fibromyalgia. \(H_A\): Anti-depressants do affect the symptoms of Fibromyalgia (either helping or harming). (b) Concluding that anti-depressants either help or worsen Fibromyalgia symptoms when they actually do neither. (c) Concluding that anti-depressants do not affect Fibromyalgia symptoms when they actually do.
- (a) \(H_0\): The restaurant meets food safety and sanitation regulations. \(H_A\): The restaurant does not meet food safety and sanitation regulations. (b) The food safety inspector concludes that the restaurant does not meet food safety and sanitation regulations and shuts down the restaurant when the restaurant is actually safe. (c) The food safety inspector concludes that the restaurant meets food safety and sanitation regulations and the restaurant stays open when the restaurant is actually not safe. (d) A Type 1 Error may be more problematic for the restaurant owner since his restaurant gets shut down even though it meets the food safety and sanitation regulations. (e) A Type 2 Error may be more problematic for diners since the restaurant deemed safe by the inspector is actually not. (f) Strong evidence. Diners would rather a restaurant that meet the regulations get shut down than a restaurant that doesn’t meet the regulations not get shut down.
- The hypotheses should be about the population proportion (\(p\)), not the sample proportion. The null hypothesis should have an equal sign. The alternative hypothesis should have a not-equals sign, and it should reference the null value, \(p_0 = 0.6\), not the observed sample proportion. The correct way to set up these hypotheses is: \(H_0: p = 0.6\) and \(H_A: p \neq 0.6\).
A.10 Chapter 11
- First, the hypotheses should be about the population proportion (\(p\)), not the sample proportion. Second, the null value should be what we are testing (0.25), not the observed value (0.29). The correct way to set up these hypotheses is: \(H_0: p = 0.25\) and \(H_A: p > 0.25.\)
- (a) \(H_0 : p = 0.20,\) \(H_A : p > 0.20.\) (b) \(\hat{p} = 159/650 = 0.245.\) (c) Answers will vary. Each student can be represented with a card. Take 100 cards, 20 black cards representing those who support proposals to defund police departments and 80 red cards representing those who do not. Shuffle the cards and draw with replacement (shuffling each time in between draws) 650 cards representing the 650 respondents to the poll. Calculate the proportion of black cards in this sample, \(\hat{p}_{sim},\) i.e., the proportion of those who upport proposals to defund police departments. The p-value will be the proportion of simulations where \(\hat{p}_{sim} \geq 0.245.\) (Note: We would generally use a computer to perform the simulations.) (d) There 1 only one simulated proportion that is at least 0.245, therefore the approximate p-value is 0.001. Your p-value may vary slightly since it is based on a visual estimate. Since the p-value is smaller than 0.05, we reject \(H_0.\) The data provide convincing evidence that the proportion of Seattle adults who support proposals to defund police departments is greater than 0.20, i.e. more than one in five.
- (a) \(H_0: p = 0.5\), \(H_A: p \ne 0.5\). (b) The p-value is roughly 0.4, There is not evidence in the data (possibly because there are only 7 cats being measured!) to conclude that the cats have a preference one way or the other between the two shapes.
- (a) \(SE(\hat{p}) = 0.189\). (c) Roughly 0.188. (c) Yes. (d) No. (e) The parametric bootstrap is discrete (only a few distinct options) and the mathematical model is continuous (infinite options on a continuum).
- (a) The parametric bootstrap simulation was done with \(p=0.7\), and the data bootstrap simulation was done with \(p = 0.6.\) (b) The parametric bootstrap is centered at 0.7; the data bootstrap is centered at 0.6. (c) The standard error of the sample proportion is given to be roughly 0.1 for both histograms. (d) Both histograms are reasonably symmetric. Note that histograms which describe the variability of proportions become more skewed as the center of the distribution gets closer to 1 (or zero) because the boundary of 1.0 restricts the symmetry of the tail of the distribution. For this reason, the parametric bootstrap histogram is slightly more skewed (left).
- (a) The parametric bootstrap for testing. The data bootstrap distribution for confidence intervals. (b) \(H_0: p = 0.7;\) \(H_A: p \ne 0.7.\) p-value \(> 0.05.\) There is no evidence that the proportion of full-time statistics majors who work is different from 70%. (c) We are 98% confident that the true proportion of all full-time student statistics majors who work at least 5 hours per week is between 35% and 80%. (d) Using \(z^\star = 2.33\), the 98% confidence interval is 0.367 to 0.833.
- (a) False. Doesn’t satisfy success-failure condition. (b) True. The success-failure condition is not satisfied. In most samples we would expect \(\hat{p}\) to be close to 0.08, the true population proportion. While \(\hat{p}\) can be much above 0.08, it is bound below by 0, suggesting it would take on a right skewed shape. Plotting the sampling distribution would confirm this suspicion. (c) False. \(SE_{\hat{p}} = 0.0243\), and \(\hat{p} = 0.12\) is only \(\frac{0.12 - 0.08}{0.0243} = 1.65\) SEs away from the mean, which would not be considered unusual. (d) True. \(\hat{p}=0.12\) is 2.32 standard errors away from the mean, which is often considered unusual. (e) False. Decreases the SE by a factor of \(1/\sqrt{2}\).
- (a) True. See the reasoning of 6.1(b). (b) True. We take the square root of the sample size in the SE formula. (c) True. The independence and success-failure conditions are satisfied. (d) True. The independence and success-failure conditions are satisfied.
- (a) False. A confidence interval is constructed to estimate the population proportion, not the sample proportion. (b) True. 95% CI: \(82\%\ \pm\ 2\%\). (c) True. By the definition of the confidence level. (d) True. Quadrupling the sample size decreases the SE and ME by a factor of \(1/\sqrt{4}\). (e) True. The 95% CI is entirely above 50%.
- With a random sample, independence is satisfied. The success-failure condition is also satisfied. \(ME = z^{\star} \sqrt{ \frac{\hat{p} (1-\hat{p})} {n} } = 1.96 \sqrt{ \frac{0.56 \times 0.44}{600} }= 0.0397 \approx 4\%.\)
- (a) No. The sample only represents students who took the SAT, and this was also an online survey. (b) (0.5289, 0.5711). We are 90% confident that 53% to 57% of high school seniors who took the SAT are fairly certain that they will participate in a study abroad program in college. (c) 90% of such random samples would produce a 90% confidence interval that includes the true proportion. (d) Yes. The interval lies entirely above 50%.
- (a) We want to check for a majority (or minority), so we use the following hypotheses: \(H_0: p = 0.5\) and \(H_A: p \neq 0.5\). We have a sample proportion of \(\hat{p} = 0.55\) and a sample size of \(n = 617\) independents. Since this is a random sample, independence is satisfied. The success-failure condition is also satisfied: \(617 \times 0.5\) and \(617 \times (1 - 0.5)\) are both at least 10 (we use the null proportion \(p_0 = 0.5\) for this check in a one-proportion hypothesis test). Therefore, we can model \(\hat{p}\) using a normal distribution with a standard error of \(SE = \sqrt{\frac{p(1 - p)}{n}} = 0.02\). (We use the null proportion \(p_0 = 0.5\) to compute the standard error for a one-proportion hypothesis test.) Next, we compute the test statistic: \(Z = \frac{0.55 - 0.5}{0.02} = 2.5.\) This yields a one-tail area of 0.0062, and a p-value of \(2 \times 0.0062 = 0.0124.\) Because the p-value is smaller than 0.05, we reject the null hypothesis. We have strong evidence that the support is different from 0.5, and since the data provide a point estimate above 0.5, we have strong evidence to support this claim by the TV pundit. (b) No. Generally we expect a hypothesis test and a confidence interval to align, so we would expect the confidence interval to show a range of plausible values entirely above 0.5. However, if the confidence level is misaligned (e.g., a 99% confidence level and a \(\alpha = 0.05\) significance level), then this is no longer generally true.
- (a) \(H_0: p = 0.5\). \(H_A: p > 0.5\). Independence (random sample, \(<10\%\) of population) is satisfied, as is the success-failure conditions (using \(p_0 = 0.5\), we expect 40 successes and 40 failures). \(Z = 2.91\) \(\to\) p- value \(= 0.0018\). Since the p-value \(< 0.05\), we reject the null hypothesis. The data provide strong evidence that the rate of correctly identifying a soda for these people is significantly better than just by random guessing. (b) If in fact people cannot tell the difference between diet and regular soda and they randomly guess, the probability of getting a random sample of 80 people where 53 or more identify a soda correctly would be 0.0018.
- (a) The sample is from all computer chips manufactured at the factory during the week of production. We might be tempted to generalize the population to represent all weeks, but we should exercise caution here since the rate of defects may change over time. (b) The fraction of computer chips manufactured at the factory during the week of production that had defects. (c) Estimate the parameter using the data: \(\hat{p} = \frac{27}{212} = 0.127\). (d) Standard error (or \(SE\)). (e) Compute the \(SE\) using \(\hat{p} = 0.127\) in place of \(p\): \(SE \approx \sqrt{\frac{\hat{p}(1 - \hat{p})}{n}} = \sqrt{\frac{0.127(1 - 0.127)}{212}} = 0.023\). (f) The standard error is the standard deviation of \(\hat{p}\). A value of 0.10 would be about one standard error away from the observed value, which would not represent a very uncommon deviation. (Usually beyond about 2 standard errors is a good rule of thumb.) The engineer should not be surprised. (g) Recomputed standard error using \(p = 0.1\): \(SE = \sqrt{\frac{0.1(1 - 0.1)}{212}} = 0.021\). This value isn’t very different, which is typical when the standard error is computed using relatively similar proportions (and even sometimes when those proportions are quite different!).
- (a) The visitors are from a simple random sample, so independence is satisfied. The success-failure condition is also satisfied, with both 64 and \(752 - 64 = 688\) above 10. Therefore, we can use a normal distribution to model \(\hat{p}\) and construct a confidence interval. (b) The sample proportion is \(\hat{p} = \frac{64}{752} = 0.085\). The standard error is \(SE = \sqrt{\frac{0.085 (1 - 0.085)}{752}} = 0.010.\) (c) For a 90% confidence interval, use \(z^{\star} = 1.65\). The confidence interval is \(0.085 \pm 1.65 \times 0.010 \to (0.0685, 0.1015)\). We are 90% confident that 6.85% to 10.15% of first-time site visitors will register using the new design.
A.11 Chapter 12
- (a) The parameter is \(p_{Asican-Indian} - p_{Chinese}.\) The statistic is \(\hat{p}_{Asian-Indian} - \hat{p}_{Chinese} = 223/4373 - 279/4736 = -0.008\) (b) Roughly 0.005. (c) \(H_0: p_{Asian-Indian} - p_{Chinese} = 0;\), \(H_A: p_{Asian-Indian} - p_{Chinese} \ne 0.\) The evidence is borderline but worth further study. There is not strong evidence that the true difference in proportion of current smokers is different across the two ethnic groups.
- (a) Roughly 0.00625. (b) We are 95% confident that the true proportion of Filipino Americans who are current smokers is between 5.28 and 7.72 percentage points higher in the control vaccine group than the proportion of Chinese Americans who smoke. (c) We are 95% confident that the true proportion of Filipino Americans who are current smokers is between 5.2 and 7.7 percentage points higher in the control vaccine group than the proportion of Chinese Americans who smoke.
- (a) While the standard errors of the difference in proportion across the two graphs are roughly the same (approximately 0.012), the centers are not. Computational method A is centered at 0.07 (the difference in the observed sample proportions) and Computational method B is centered at 0. (b) What is the difference between the proportions of Bachelor’s and Associate’s students who believe that the COVID-19 pandemic will negatively impact their ability to complete the degree? (c) Is the proportion of Bachelor’s students who believe that their ability to complete the degree will be negatively impacted by the COVID-19 pandemic different than that of Associate’s students?
- (a) 26 Yes and 94 No in Nevaripine and 10 Yes and 110 No in Lopinavir group. (b) \(H_0: p_N = p_L\). There is no difference in virologic failure rates between the Nevaripine and Lopinavir groups. \(H_A: p_N \ne p_L\). There is some difference in virologic failure rates between the Nevaripine and Lopinavir groups. (c) Random assignment was used, so the observations in each group are independent. If the patients in the study are representative of those in the general population (something impossible to check with the given information), then we can also confidently generalize the findings to the population. The success-failure condition, which we would check using the pooled proportion (\(\hat{p}_{pool} = 36/240 = 0.15\)), is satisfied. \(Z = 2.89\) \(\to\) p-value \(=0.0039\). Since the p-value is low, we reject \(H_0\). There is strong evidence of a difference in virologic failure rates between the Nevaripine and Lopinavir groups. Treatment and virologic failure do not appear to be independent.
- (a) Standard error: \(SE = \sqrt{\frac{0.79(1 - 0.79)}{347} + \frac{0.55(1 - 0.55)}{617}} = 0.03.\) Using \(z^{\star} = 1.96\), we get: \(0.79 - 0.55 \pm 1.96 \times 0.03 \to (0.181, 0.299).\) We are 95% confident that the proportion of Democrats who support the plan is 18.1% to 29.9% higher than the proportion of Independents who support the plan. (b) True.
- (a) In effect, we’re checking whether men are paid more than women (or vice-versa), and we’d expect these outcomes with either chance under the null hypothesis: \(H_0: p = 0.5\) and \(H_A: p \neq 0.5.\) We’ll use \(p\) to represent the fraction of cases where men are paid more than women. (b) There isn’t a good way to check independence here since the jobs are not a simple random sample. However, independence doesn’t seem unreasonable, since the individuals in each job are different from each other. The success-failure condition is met since we check it using the null proportion: \(p_0 n = (1 - p_0) n = 10.5\) is greater than 10. We can compute the sample proportion, \(SE\), and test statistic: \(\hat{p} = 19 / 21 = 0.905\) and \(SE = \sqrt{\frac{0.5 \times (1 - 0.5)}{21}} = 0.109\) and \(Z = \frac{0.905 - 0.5}{0.109} = 3.72.\) The test statistic \(Z\) corresponds to an upper tail area of about 0.0001, so the p-value is 2 times this value: 0.0002. Because the p-value is smaller than 0.05, we reject the notion that all these gender pay disparities are due to chance. Because we observe that men are paid more in a higher proportion of cases and we have rejected \(H_0\), we can conclude that men are being paid higher amounts in ways not explainable by chance alone. If you’re curious for more info around this topic, including a discussion about adjusting for additional factors that affect pay, please see the following video by Healthcare Triage: youtu.be/aVhgKSULNQA.
- (a) \(H_0: p = 0.5\). \(H_A: p \neq 0.5\). Independence (random sample) is satisfied, as is the success-failure conditions (using \(p_0 = 0.5\), we expect 40 successes and 40 failures). \(Z = 2.91\) \(\to\) the one tail area is 0.0018, so the p-value is 0.0036. Since the p-value \(< 0.05\), we reject the null hypothesis. Since we rejected \(H_0\) and the point estimate suggests people are better than random guessing, we can conclude the rate of correctly identifying a soda for these people is significantly better than just by random guessing. (b) If in fact people cannot tell the difference between diet and regular soda and they were randomly guessing, the probability of getting a random sample of 80 people where 53 or more identify a soda correctly (or 53 or more identify a soda incorrectly) would be 0.0036.
- Before we can calculate a confidence interval, we must first check that the conditions are met. There aren’t at least 10 successes and 10 failures in each of the four groups (treatment/control and yawn/not yawn), \((\hat{p}_C - \hat{p}_T)\) is not expected to be approximately normal and therefore cannot calculate a confidence interval for the difference between the proportions of participants who yawned in the treatment and control groups using large sample techniques and a critical Z score.
- (a) False. The confidence interval includes 0. (b) False. We are 95% confident that 16% fewer to 2% Americans who make less than $40,000 per year are not at all personally affected by the government shutdown compared to those who make $40,000 or more per year. (c) False. As the confidence level decreases the width of the confidence level decreases as well. (d) True.
- (a) Type 1. (b) Type 2. (c) Type 2.
- No. The samples at the beginning and at the end of the semester are not independent since the survey is conducted on the same students.
- (a) The proportion of the normal curve centered at -0.1 with a standard deviation of 0.15 that is less than -2 * standard error is 0.09. (b) The proportion of the normal curve centered at -0.4 with a standard deviation of 0.145 that is less than 2 * standard error is 0.78. (c) The proportion of the normal curve centered at -0.1 with a standard deviation of 0.0671 that is less than 2 * standard error is 0.31. (d) The proportion of the normal curve centered at -0.4 with a standard deviation of 0.0678 that is less than 2 * standard error is 1. (e) The larger the value of \(\delta\) and the larger the sample size, the more likely that the future study will lead to sample proportions which are able to reject the null hypothesis.
A.12 Chapter 13
- (a) Average sleep of 20 in sample vs. all New Yorkers. (b) Average height of students in study vs all undergraduates.
- (a) Use the sample mean to estimate the population mean: 171.1. Likewise, use the sample median to estimate the population median: 170.3. (b) Use the sample standard deviation (9.4) and sample IQR (\(177.8-163.8 = 14\)). (c) \(Z_{180} = 0.95\) and \(Z_{155} = -1.71.\) Neither of these observations is more than two standard deviations away from the mean, so neither would be considered unusual. (d) No, sample point estimates only estimate the population parameter, and they vary from one sample to another. Therefore we cannot expect to get the same mean and standard deviation with each random sample. (e) We use the standard error of the mean to measure the variability in means of random samples of same size taken from a population. The variability in the means of random samples is quantified by the standard error. Based on this sample, \(SE_{\bar{x}} = \frac{9.4}{\sqrt{507}} = 0.417.\)
- (a) The kindergartners will have a smaller standard deviation of heights. We would expect their heights to be more similar to each other compared to a group of adults’ heights. (b) The standard error of the mean will depend on the variability of individual heights. The standard error of the adult sample averages will be around 9.4/\(\sqrt{100}\) = 0.94cm. The standard error of the kindergartner sample averages will be smaller.
- (a) \(df=6-1=5\), \(t_{5}^{\star} = 2.02\). (b) \(df=21-1=20\), \(t_{20}^{\star} = 2.53\). (c) \(df=28\), \(t_{28}^{\star} = 2.05\). (d) \(df=11\), \(t_{11}^{\star} = 3.11\).
- (a) 0.085, do not reject \(H_0\). (b) 0.003, reject \(H_0\). (c) 0.438, do not reject \(H_0\). (d) 0.042, reject \(H_0\).
- (a) Roughly 0.1 weeks. (b) Roughly (38.45 weeks, 38.85 weeks). (c) Roughly (38.49 weeks, 38.91 weeks).
- (a) False (b) False. (c) True. (d) False.
- The mean is the midpoint: \(\bar{x} = 20\). Identify the margin of error: \(ME = 1.015\), then use \(t^{\star}_{35} = 2.03\) and \(SE = s/ \sqrt{n}\) in the formula for margin of error to identify \(s = 3\).
- (a) \(H_0\): \(\mu = 8\) (New Yorkers sleep 8 hrs per night on average.) \(H_A\): \(\mu \neq 8\) (New Yorkers sleep less or more than 8 hrs per night on average.) (b) Independence: The sample is random. The min/max suggest there are no concerning outliers. \(T = -1.75\). \(df=25-1=24\). (c) p-value \(= 0.093\). If in fact the true population mean of the amount New Yorkers sleep per night was 8 hours, the probability of getting a random sample of 25 New Yorkers where the average amount of sleep is 7.73 hours per night or less (or 8.27 hours or more) is 0.093. (d) Since p-value \(>\) 0.05, do not reject \(H_0\). The data do not provide strong evidence that New Yorkers sleep more or less than 8 hours per night on average. (e) Yes, since we did not rejected \(H_0\).
- With a larger critical value, the confidence interval ends up being wider. This makes intuitive sense as when we have a small sample size and the population standard deviation is unknown, we should have a wider interval than if we knew the population standard deviation, or if we had a large enough sample size.
- (a) We will conduct a 1-sample \(t\)-test. \(H_0\): \(\mu = 5\). \(H_A\): \(\mu \neq 5\). We’ll use \(\alpha = 0.05\). This is a random sample, so the observations are independent. To proceed, we assume the distribution of years of piano lessons is approximately normal. \(SE = 2.2 / \sqrt{20} = 0.4919\). The test statistic is \(T = (4.6 - 5) / SE = -0.81\). \(df = 20 - 1 = 19\). The one-tail area is about 0.21, so the p-value is about 0.42, which is bigger than \(\alpha = 0.05\) and we do not reject \(H_0\). That is, we do not have sufficiently strong evidence to reject the notion that the average is 5 years. (b) Using \(SE = 0.4919\) and \(t_{df = 19}^{\star} = 2.093\), the confidence interval is (3.57, 5.63). We are 95% confident that the average number of years a child takes piano lessons in this city is 3.57 to 5.63 years. (c) They agree, since we did not reject the null hypothesis and the null value of 5 was in the \(t\)-interval.
A.13 Chapter 14
- The hypotheses should use population means (\(\mu\)) not sample means (\(\bar{x}\)), the null hypothesis should set the two population means equal to each other, the alternative hypothesis should be two-tailed and use a not equal to sign.
- \(H_0: \mu_{0.99} = \mu_{1}\) and \(H_A: \mu_{0.99} \ne \mu_{1}.\) p-value \(<\) 0.05, reject \(H_0.\) The data provide convincing evidence that the difference in population averages of price per carat of 0.99 carats and 1 carat diamonds are different.
- (a) We are 95% confident that the population average price per carat of 0.99 carat diamonds is $2 to $23 lower than the population average price per carat of 1 carat diamonds. (b) We are 95% confident that the population average price per carat of 0.99 carat diamonds is $2.20 to $21.80 lower than the population average price per carat of 1 carat diamonds.
- The difference is not zero (statistically significant), but there is no evidence that the difference is large (practically significant), because the interval provides values as low as 1 lb.
- \(H_0: \mu_{0.99} = \mu_{1}\) and \(H_A: \mu_{0.99} \ne \mu_{1}\). Independence: Both samples are random and represent less than 10% of their respective populations. Also, we have no reason to think that the 0.99 carats are not independent of the 1 carat diamonds since they are both sampled randomly. Normality: The distributions are not extremely skewed, hence we can assume that the distribution of the average differences will be nearly normal as well. \(T_{22} = 2.23\), p-value = 0.0131. Since p-value less than 0.05, reject \(H_0\). The data provide convincing evidence that the difference in population averages of price per carat of 0.99 carats and 1 carat diamonds are different.
- We are 95% confident that the population average price per carat of 0.99 carat diamonds is $2.96 to $22.42 lower than the population average price per carat of 1 carat diamonds.
- (a) \(\mu_{\bar{x}_1} = 15\), \(\sigma_{\bar{x}_1} = 20 / \sqrt{50} = 2.8284.\) (b) \(\mu_{\bar{x}_2} = 20\), \(\sigma_{\bar{x}_1} = 10 / \sqrt{30} = 1.8257.\) (c) \(\mu_{\bar{x}_2 - \bar{x}_1} = 20 - 15 = 5\), \(\sigma_{\bar{x}_2 - \bar{x}_1} = \sqrt{\left(20 / \sqrt{50}\right)^2 + \left(10 / \sqrt{30}\right)^2} = 3.3665.\) (d) Think of \(\bar{x}_1\) and \(\bar{x}_2\) as being random variables, and we are considering the standard deviation of the difference of these two random variables, so we square each standard deviation, add them together, and then take the square root of the sum: \(SD_{\bar{x}_2 - \bar{x}_1} = \sqrt{SD_{\bar{x}_2}^2 + SD_{\bar{x}_1}^2}.\)
- (a) Chicken fed linseed weighed an average of 218.75 grams while those fed horsebean weighed an average of 160.20 grams. Both distributions are relatively symmetric with no apparent outliers. There is more variability in the weights of chicken fed linseed. (b) \(H_0: \mu_{ls} = \mu_{hb}\). \(H_A: \mu_{ls} \ne \mu_{hb}\). We leave the conditions to you to consider. \(T=3.02\), \(df = min(11, 9) = 9\) \(\to\) p-value \(= 0.014\). Since p-value \(<\) 0.05, reject \(H_0\). The data provide strong evidence that there is a significant difference between the average weights of chickens that were fed linseed and horsebean. (c) Type 1 Error, since we rejected \(H_0\). (d) Yes, since p-value \(>\) 0.01, we would not have rejected \(H_0\).
- \(H_0: \mu_C = \mu_S\). \(H_A: \mu_C \ne \mu_S\). \(T = 3.27\), \(df=11\) \(\to\) p-value \(= 0.007\). Since p-value \(< 0.05\), reject \(H_0\). The data provide strong evidence that the average weight of chickens that were fed casein is different than the average weight of chickens that were fed soybean (with weights from casein being higher). Since this is a randomized experiment, the observed difference can be attributed to the diet.
- \(H_0: \mu_{T} = \mu_{C}\). \(H_A: \mu_{T} \ne \mu_{C}\). \(T=2.24\), \(df=21\) \(\to\) p-value \(= 0.036\). Since p-value \(<\) 0.05, reject \(H_0\). The data provide strong evidence that the average food consumption by the patients in the treatment and control groups are different. Furthermore, the data indicate patients in the distracted eating (treatment) group consume more food than patients in the control group.
A.14 Chapter 15
- Paired, data are recorded in the same cities at two different time points. The temperature in a city at one point is not independent of the temperature in the same city at another time point
- (a) Since it’s the same students at the beginning and the end of the semester, there is a pairing between the datasets, for a given student their beginning and end of semester grades are dependent. (b) Since the subjects were sampled randomly, each observation in the men’s group does not have a special correspondence with exactly one observation in the other (women’s) group. (c) Since it’s the same subjects at the beginning and the end of the study, there is a pairing between the datasets, for a subject student their beginning and end of semester artery thickness are dependent. (d) Since it’s the same subjects at the beginning and the end of the study, there is a pairing between the datasets, for a subject student their beginning and end of semester weights are dependent.
- False. While it is true that paired analysis requires equal sample sizes, only having the equal sample sizes isn’t, on its own, sufficient for doing a paired test. Paired tests require that there be a special correspondence between each pair of observations in the two groups.
- The data are paired, since this is a before-after measurement of the same trees, so we will construct a confidence interval using the differences summary statistics. But before we proceed with a confidence interval, we must first check conditions: Independent: this is satisfied since the trees were randomly sampled. Normality: since \(n = 50 \geq 30\), we only need consider whether there are any particularly extreme outliers. None are mentioned, and it doesn’t seem like we’d expect to observe any such cases from data of this type, so we’ll consider this condition to be satisfied. With the conditions satisfied, we can proceed with calculations. First, compute the standard error and degrees of freedom: \(SE = \frac{7.2}{\sqrt{50}} = 1.02\) and \(df = 50 - 1 = 49\). Next, we find \(t^{\star} = 2.68\) for a 99% confidence interval using a \(t\)-distribution with 49 degrees of freedom, and then we construct the confidence interval: \(\bar{x} \pm t^{\star} \times SE = 12.5 \pm 2.68 \times 1.02 = (9.77, 15.23)\). We are 99% confident that the average growth of young trees in this area during the 10-year period was 9.77 to 15.23 feet.
- (a) No. (b) Yes. (c) No. (d) No and yes. (e) Yes.
- (a) Let \(diff = 2018 - 1948\). Then, \(H_0: \mu_{diff} = 0\) and \(H_A: \mu_{diff} \ne 0\). (b) The observed average of difference is just outside the randomized differences. (c) Since the p-value \(<\) 0.05, reject \(H_0\). The data provide convincing evidence of a difference between the average number of 90F degree days in 2018 and the average number of 90F degree days in 1948.
- (a) For each observation in one dataset, there is exactly one specially corresponding observation in the other dataset for the same geographic location. The data are paired. (b) \(H_0: \mu_{\text{diff}} = 0\) (There is no difference in average number of days exceeding 90F in 1948 and 2018 for NOAA stations.) \(H_A: \mu_{\text{diff}} \neq 0\) (There is a difference.) (c) Locations were randomly sampled, so independence is reasonable. The sample size is at least 30, so we’re just looking for particularly extreme outliers: none are present (the observation off left in the histogram would be considered a clear outlier, but not a particularly extreme one). Therefore, the conditions are satisfied. (d) \(SE = 17.2 / \sqrt{197} = 1.23\). \(T = \frac{2.9 - 0}{1.23} = 2.36\) with degrees of freedom \(df = 197 - 1 = 196\). This leads to a one-tail area of 0.0096 and a p-value of about 0.019. (e) Since the p-value is less than 0.05, we reject \(H_0\). The data provide strong evidence that NOAA stations observed more 90F days in 2018 than in 1948. (f) Type 1 Error, since we may have incorrectly rejected \(H_0\). This error would mean that NOAA stations did not actually observe a decrease, but the sample we took just so happened to make it appear that this was the case. (g) No, since we rejected \(H_0\), which had a null value of 0.
- (a) \(SE = 1.23\) and \(z^{\star} = 1.65\). \(2.9 \pm 1.65 \times 1.23 \to (0.87, 4.93)\). (b) We are 90% confident that there was an increase of 0.87 to 4.93 in the average number of days that hit 90F in 2018 relative to 1948 for NOAA stations. (c) Yes, since the interval lies entirely above 0.
- (a)These data are paired. For example, the Friday the 13th in say, September 1991, would probably be more similar to the Friday the 6th in September 1991 than to Friday the 6th in another month or year. (b) Let \(\mu_{\textit{diff}} = \mu_{sixth} - \mu_{thirteenth}\). \(H_0: \mu_{\textit{diff}} = 0\). \(H_A: \mu_{\textit{diff}} \ne 0\). (c) Independence: The months selected are not random. However, if we think these dates are roughly equivalent to a simple random sample of all such Friday 6th/13th date pairs, then independence is reasonable. To proceed, we must make this strong assumption, though we should note this assumption in any reported results. Normality: With fewer than 10 observations, we would need to see clear outliers to be concerned. There is a borderline outlier on the right of the histogram of the differences, so we would want to report this in formal analysis results. (d) \(T = 4.93\) for \(df = 10 - 1 = 9\) \(\to\) p-value = 0.001. (e) Since p-value \(<\) 0.05, reject \(H_0\). The data provide strong evidence that the average number of cars at the intersection is higher on Friday the 6\(^{\text{th}}\) than on Friday the 13\(^{\text{th}}\). (We should exercise caution about generalizing the interpetation to all intersections or roads.) (f) If the average number of cars passing the intersection actually was the same on Friday the 6\(^{\text{th}}\) and \(13^{th}\), then the probability that we would observe a test statistic so far from zero is less than 0.01. (g) We might have made a Type 1 Error, i.e., incorrectly rejected the null hypothesis.
A.15 Chapter 16
- Alternative.
- (a) Means across original data are more variable. (b) Standard deviation of egg lengths are about the same for both plots. (c) F statistic is bigger for the original data.
- \(H_0\): \(\mu_1 = \mu_2 = \cdots = \mu_6\). \(H_A\): The average weight varies across some (or all) groups. Independence: Chicks are randomly assigned to feed types (presumably kept separate from one another), therefore independence of observations is reasonable. Approx. normal: the distributions of weights within each feed type appear to be fairly symmetric. Constant variance: Based on the side-by-side box plots, the constant variance assumption appears to be reasonable. There are differences in the actual computed standard deviations, but these might be due to chance as these are quite small samples. \(F_{5,65} = 15.36\) and the p-value is approximately 0. With such a small p-value, we reject \(H_0\). The data provide convincing evidence that the average weight of chicks varies across some (or all) feed supplement groups.
- (a) \(H_0\): The population mean of MET for each group is equal to the others. \(H_A\): At least one pair of means is different. (b) Independence: We don’t have any information on how the data were collected, so we cannot assess independence. To proceed, we must assume the subjects in each group are independent. In practice, we would inquire for more details. Normality: The data are bound below by zero and the standard deviations are larger than the means, indicating very strong skew. However, since the sample sizes are extremely large, even extreme skew is acceptable. Constant variance: This condition is sufficiently met, as the standard deviations are reasonably consistent across groups. (c) Since p-value is very small, reject \(H_0\). The data provide convincing evidence that the average MET differs between at least one pair of groups.
- (a) \(H_0\): Average GPA is the same for all majors. \(H_A\): At least one pair of means are different. (b) Since p-value \(>\) 0.05, fail to reject \(H_0\). The data do not provide convincing evidence of a difference between the average GPAs across three groups of majors. (c) The total degrees of freedom is \(195 + 2 = 197\), so the sample size is \(197+1=198\).
- (a) False. As the number of groups increases, so does the number of comparisons and hence the modified significance level decreases. (b) True. (c) True. (d) False. We need observations to be independent regardless of sample size.
- (a) Left is Dataset B. (b) Right is Dataset A.
A.16 Chapter 18
- (a) \(H_0: \beta_1 = 0\), \(H_A: \beta_1 \ne 0\). (b) The observed slope of 0.604 is not a plausible value, the p-value is extremely small, and the null hypothesis can be rejected. c. The p-value is also extremely small.
- (a) Roughly 0.53 to 0.67. (b) For individuals with one cm larger shoulder girth, their average height is predicted to be between 0.53 and 0.67 cm taller, with 98% confidence.
- (a) \(H_0: \beta_1 = 0\), \(H_A: \beta_1 \ne 0\). (b) The observed slope of 2.559 is not a plausible value, the p-value is extremely small, and the null hypothesis can be rejected. (c) The p-value is also extremely small.
- (a) Rough 90% confidence interval is 1.9 to 3.1. (b) For a one unit (one percentage point) increase in poverty across given metropolitan areas, the predicted average annual murder rate will be between 1.9 and 3.1 persons per million larger, with 90% confidence.
- (a) \(H_0: \beta_1 = 0\), \(H_A: \beta_1 \ne 0\). (b) The p-value is roughly 0.45 which is much bigger than 0.05. The null hypothesis cannot be rejected.There is no evidence with these data that there is a linear relationship between a father’s age and the baby’s weight. (c) The p-value of 0.449 is quite similar. The hypothesis test conclusion is the same, the data do not support a linear model.
- (a) Rough 95% confidence interval is (-.008, 0.016). (b) 95% confident that for individuals with fathers who are one year older, their average weight is predicted to be between -0.008 and 0.016 pounds heavier.
- (a) \(H_0\): The true slope coefficient of body weight is zero (\(\beta_1 = 0\)). \(H_A\): The true slope coefficient of body weight is different than zero (\(\beta_1 \neq 0\)). (b) The p-value is extremely small (zero to 4 decimal places), which is lower than the significance level of 0.05. With such a low p-value, we reject \(H_0\). The data provide strong evidence that the true slope coefficient of body weight is greater than zero and that body weight is positively associated with heart weight in cats. (c) (3.539, 4.529). We are 95% confident that for each additional kilogram in cats’ weights, we expect their hearts to be heavier by 3.539 to 4.529 grams, on average. (d) Yes, we rejected the null hypothesis and the confidence interval lies above 0.
- (a) \(r = \sqrt{0.292} \approx -0.54\). We know the correlation is negative due to the negative association shown in the scatterplot. (b) The residuals appear to be fan shaped, indicating non-constant variance. Therefore a simple least squares fit is not appropriate for these data.