8 中文文本分析
代码提供: 张柏珊 王楠
主要内容:
-1.安装拓展包和导入 -2.分词 -3.运用SQL -4.词云 -5.词频可视化
8.1 安装拓展包和导入
8.1.1 安装拓展包
library(jiebaR)## Loading required package: jiebaRDlibrary(tidyverse)
library(rvest)##
## Attaching package: 'rvest'## The following object is masked from 'package:readr':
##
## guess_encodinglibrary(wordcloud2)
library(dplyr)8.1.2 导入文档,建议用记事本,格式为UTTF-8 运用scan函数
f <- scan('zfgzbg.txt', sep = '\n', encoding = 'UTF-8', what = '')8.2 结巴分词处理
8.2.1 制作词表
8.2.1.1 标停止词
engine1 <- worker(user = "users.txt",stop_word = "stopwords.txt")
stopwords_CN <- c("被","怎么","还是","多少","得", "吗","给",
"年","月","还","个","能", "日","什么","做","没","啊",
"的", "了", "在", "是", "我", "有", "和", "就","不",
"人", "都", "一", "一个", "上", "也", "很", "到", "说",
"要", "去", "你","会", "着", "没有", "看", "好",
"自己", "这", "等","各位代表")
library('jiebaR')8.2.1.2 变量seg保存文章所有的词语
seg <- qseg[f]## Warning in `[.qseg`(qseg, f): Quick mode is depreciated, and is scheduled to be
## remove in v0.11.0. If you want to keep this feature, please submit a issue on
## GitHub page to let me know.8.2.1.3 保留字数大于1的词语
seg <- seg[nchar(seg)>1]8.2.1.4 用数据框函数讲这些词汇排成一列方便处理
m1 <- data.frame(seg)8.3 运用SQL
8.3.1 安装并载入sqldf程序包 >group by“根据一定的规则进行分组”,通过一定的规则将一个数据集划分成若干个笑的区域,然后针对若干个小区域进行数据处理 >count(1)来计数 >select检索数据
library(sqldf)## Loading required package: gsubfn## Loading required package: proto## Warning in doTryCatch(return(expr), name, parentenv, handler): unable to load shared object '/Library/Frameworks/R.framework/Resources/modules//R_X11.so':
## dlopen(/Library/Frameworks/R.framework/Resources/modules//R_X11.so, 0x0006): Library not loaded: /opt/X11/lib/libSM.6.dylib
## Referenced from: /Library/Frameworks/R.framework/Versions/4.1-arm64/Resources/modules/R_X11.so
## Reason: tried: '/opt/X11/lib/libSM.6.dylib' (no such file), '/Library/Frameworks/R.framework/Resources/lib/libSM.6.dylib' (no such file), '/Library/Java/JavaVirtualMachines/jdk-17.jdk/Contents/Home/lib/server/libSM.6.dylib' (no such file)## Warning in system2("/usr/bin/otool", c("-L", shQuote(DSO)), stdout = TRUE):
## running command ''/usr/bin/otool' -L '/Library/Frameworks/R.framework/Resources/
## library/tcltk/libs//tcltk.so'' had status 1## Could not load tcltk. Will use slower R code instead.## Loading required package: RSQLitem2 <- sqldf('select seg,count(1)as freg from m1 group by seg')
class(m2)## [1] "data.frame"8.3.2 按顺序排列
m3=m2[order(m2$freg,decreasing = TRUE),]8.3.3 抽取频次为前一百的词语
m4=m3[1:100,]8.4 绘制词云
wordcloud2(m4,size=1,shape="star")8.5 词频可视化
8.5.1 barplot绘制排名前30的高频词 第一个参数源为数据源,第二个参数源为标签
barplot(m4$freg[1:30] , names.arg = m4$seg[1:30], col = rainbow(30))+
theme(text = element_text(family='Kai'))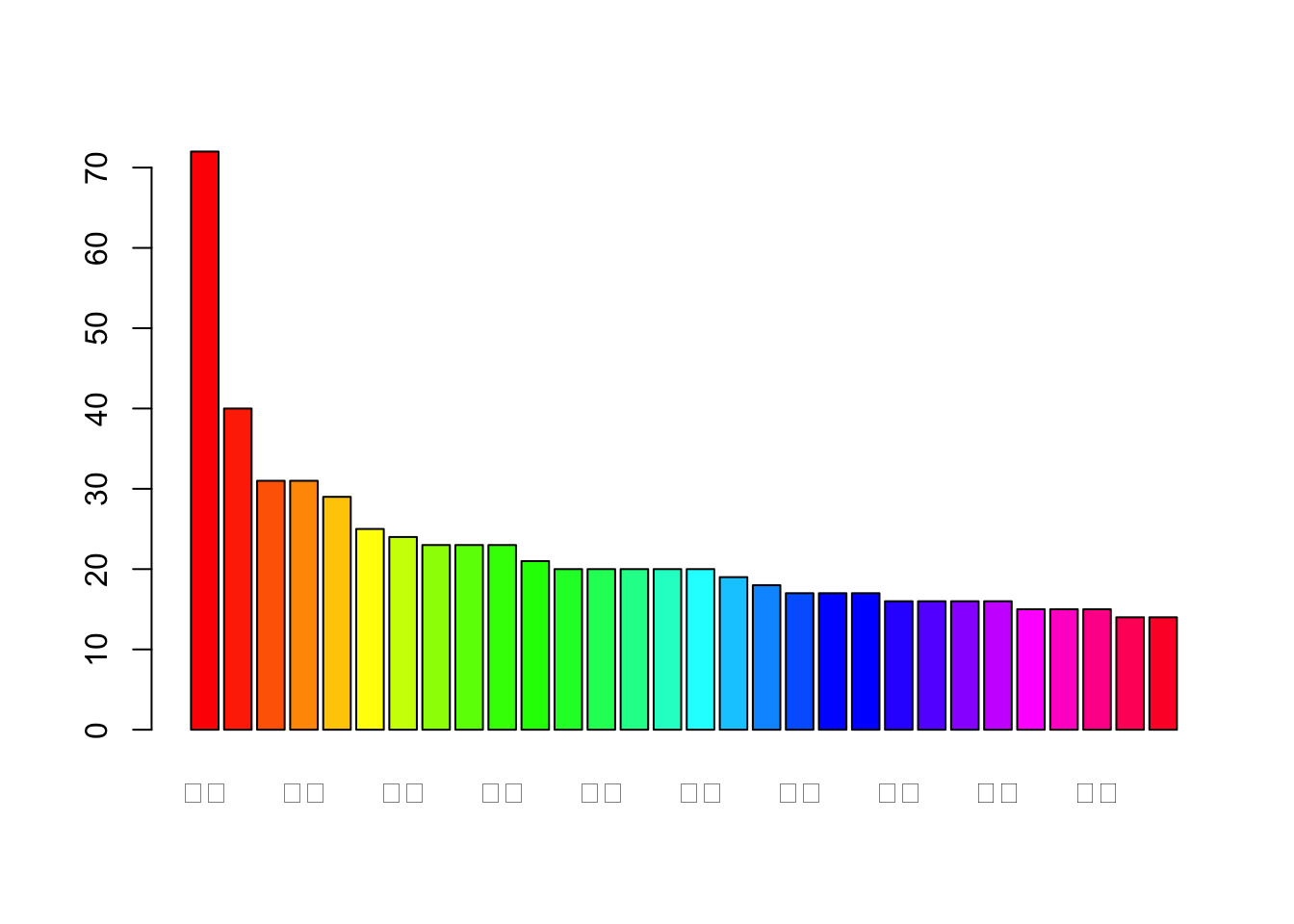
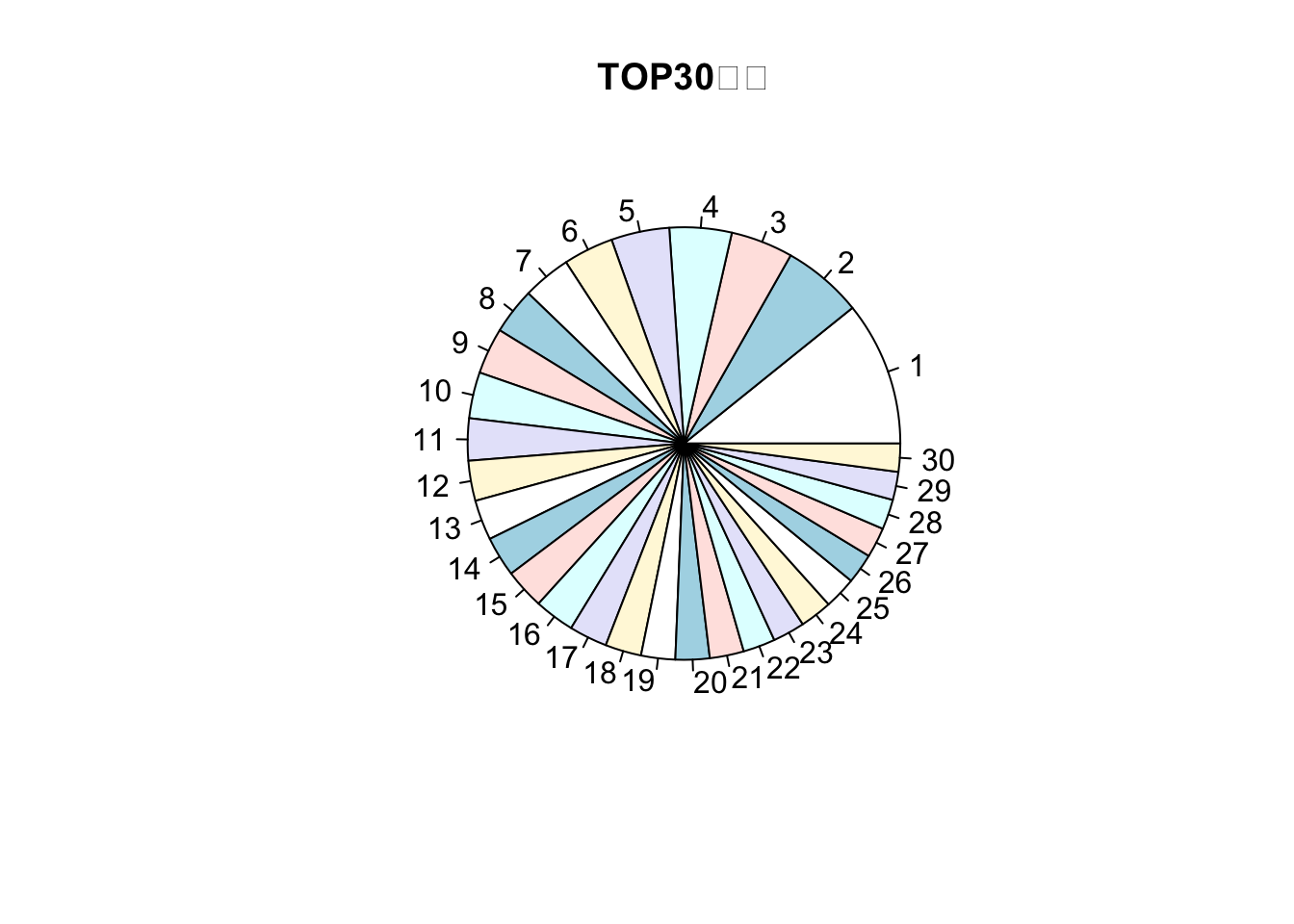
## NULL8.5.2 利用pie函数绘制饼图对高频词语进行可视化
提取数据
number <- m4$freg[1:30]
label <- m4$seg[1:30]不带比例的饼图
a <- pie(number,label,main = "TOP30词语")+
theme(text = element_text(family='Kai'))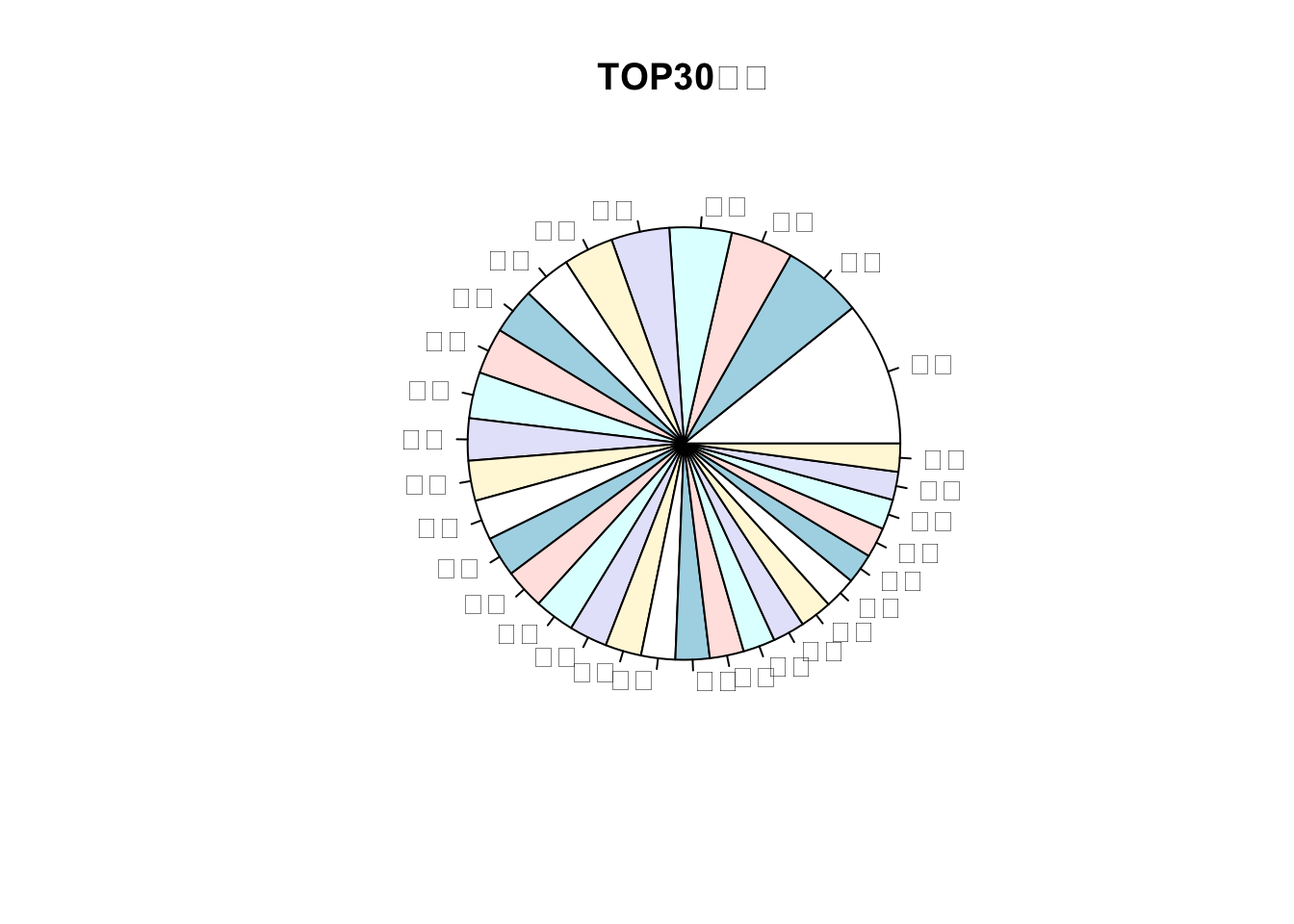
带比例的饼图
pie(number, a$label, main ="TOP30词语" )