# Cargar el conjunto de datos 'USArrests'
data(USArrests)5 La visualización de los datos
La importancia de la visualización de datos se ha ganado espacio en diversas publicaciones y en las últimas décadas, ya que constituye una disciplina en sí misma siendo relevante porque hay un punto en el análisis de datos el cual es: los parámetros y coeficientes con los que solemos trabajar no siempre son tan simples de interpretar como pensamos. Por ejemplo, algunos autores recomiendan fuertemente graficar las predicciones del modelo ante distintos valores, antes que los coeficientes del modelo (McElreath, 2016).
5.1 Visualización de datos univariados.
Traeremos un conjunto de datos para poder utilizar, el conjunto de datos USArrests que está disponible en R para explorar visualizaciones univariadas relacionadas con la tasa de arrestos en diferentes estados de EE. UU. El conjunto de datos contiene información sobre el número de arrestos por cada 100,000 habitantes en cada uno de los 50 estados en los Estados Unidos.
5.1.1 Histograma
El código tiene como propósito crear un histograma para la variable Murder (tasa de asesinatos) en el conjunto de datos USArrests. Un histograma proporciona una representación gráfica de la distribución de frecuencias de una variable continua, dividiendo el rango de valores en intervalos (bins) y mostrando la frecuencia de observaciones en cada intervalo.
# Crear un histograma para la variable Murder
hist(USArrests$Murder, main = "Histograma de Tasa de Asesinatos", xlab = "Tasa de Asesinatos (por 100,000 habitantes)")
Interpretación: El histograma muestra la distribución de la tasa de asesinatos en los arrestos en Estados Unidos. Cada barra del histograma representa un intervalo de valores de tasas de asesinatos, y la altura de la barra indica la frecuencia de observaciones en ese intervalo. Este tipo de gráfico es útil para visualizar la forma general de la distribución y para identificar patrones en la concentración de los datos, como la presencia de sesgos, modas o la dispersión de los valores.
5.1.2 Gráfico de Densidad
El código tiene como propósito crear un Gráfico de Densidad para la variable Assault (tasa de asaltos) en el conjunto de datos USArrests. Un Gráfico de Densidad proporciona una estimación visual de la distribución de probabilidad de la variable, permitiendo identificar la forma y concentración de los valores.
# Gráfico de densidad para la variable Assault
plot(density(USArrests$Assault), main = "Gráfico de Densidad de Asaltos", xlab = "Tasa de Asaltos (por 100,000 habitantes)")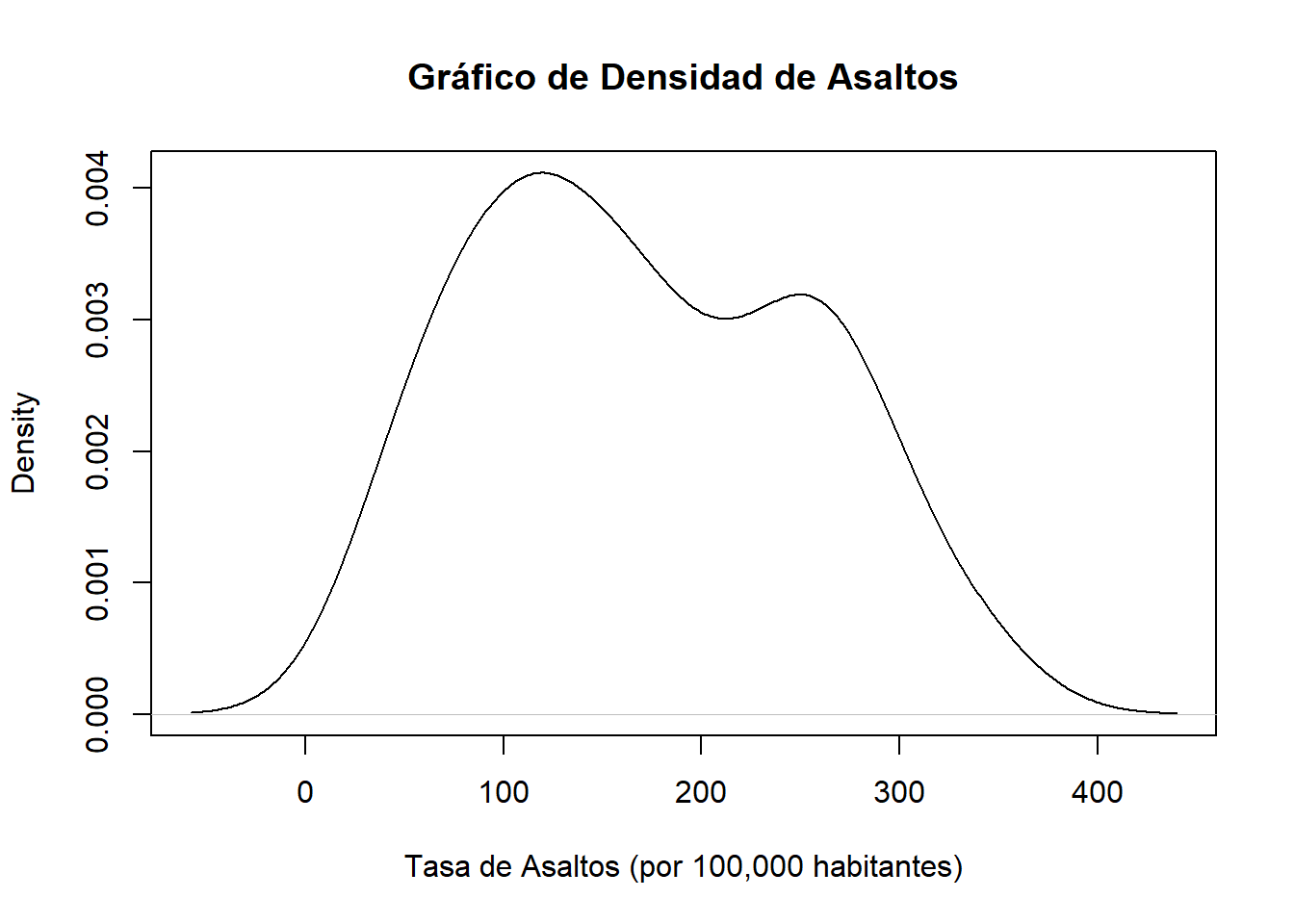
El Gráfico de Densidad muestra la forma de la distribución de la tasa de asaltos en los arrestos en Estados Unidos. La curva de densidad describe la concentración relativa de los valores de asaltos y ofrece información sobre la posible presencia de múltiples modas (picos) o sesgo en la distribución. Este tipo de gráfico es especialmente útil para obtener una comprensión visual de la variabilidad y la concentración de los datos, y para comparar distribuciones de diferentes variables o conjuntos de datos.
5.1.3 Diagrama de caja o Boxplot
El gráfico muestra la mediana, cuartiles, dispersión y posibles valores atípicos, permitiendo la identificación rápida de la simetría, forma y variabilidad de la distribución. El boxplot es una herramienta versátil en la exploración y comprensión de la variabilidad en conjuntos de datos. En el siguiente código tiene como objetivo crear un boxplot para visualizar la distribución de la variable Rape en el conjunto de datos USArrests.
# Boxplot para la variable Rape
boxplot(USArrests$Rape, main = "Boxplot de Tasa de Violación", ylab = "Tasa de Violación (por 100,000 habitantes)")
Interpretación: El boxplot muestra la distribución de la tasa de violación en los arrestos en Estados Unidos. Los elementos clave del boxplot incluyen la mediana, los cuartiles y los posibles valores atípicos. Proporciona una representación visual de la variabilidad y la dispersión en la tasa de violación, así como la presencia de posibles valores extremos.
5.1.4 Gráfico de Barras
El código tiene como objetivo agrupar la variable UrbanPop en categorías (“Baja”, “Media”, “Alta”) y crear un gráfico de barras para visualizar la frecuencia de la población urbana en cada categoría.
# Agrupar la variable UrbanPop en categorías
USArrests$UrbanPopGroup <- cut(USArrests$UrbanPop, breaks = c(0, 50, 75, 100), labels = c("Baja", "Media", "Alta"), include.lowest = TRUE)
# Crear un gráfico de barras para la variable UrbanPopGroup
barplot(table(USArrests$UrbanPopGroup),
main = "Frecuencia de Población Urbana Agrupada",
ylab = "Frecuencia",
col = rainbow(length(unique(USArrests$UrbanPopGroup))))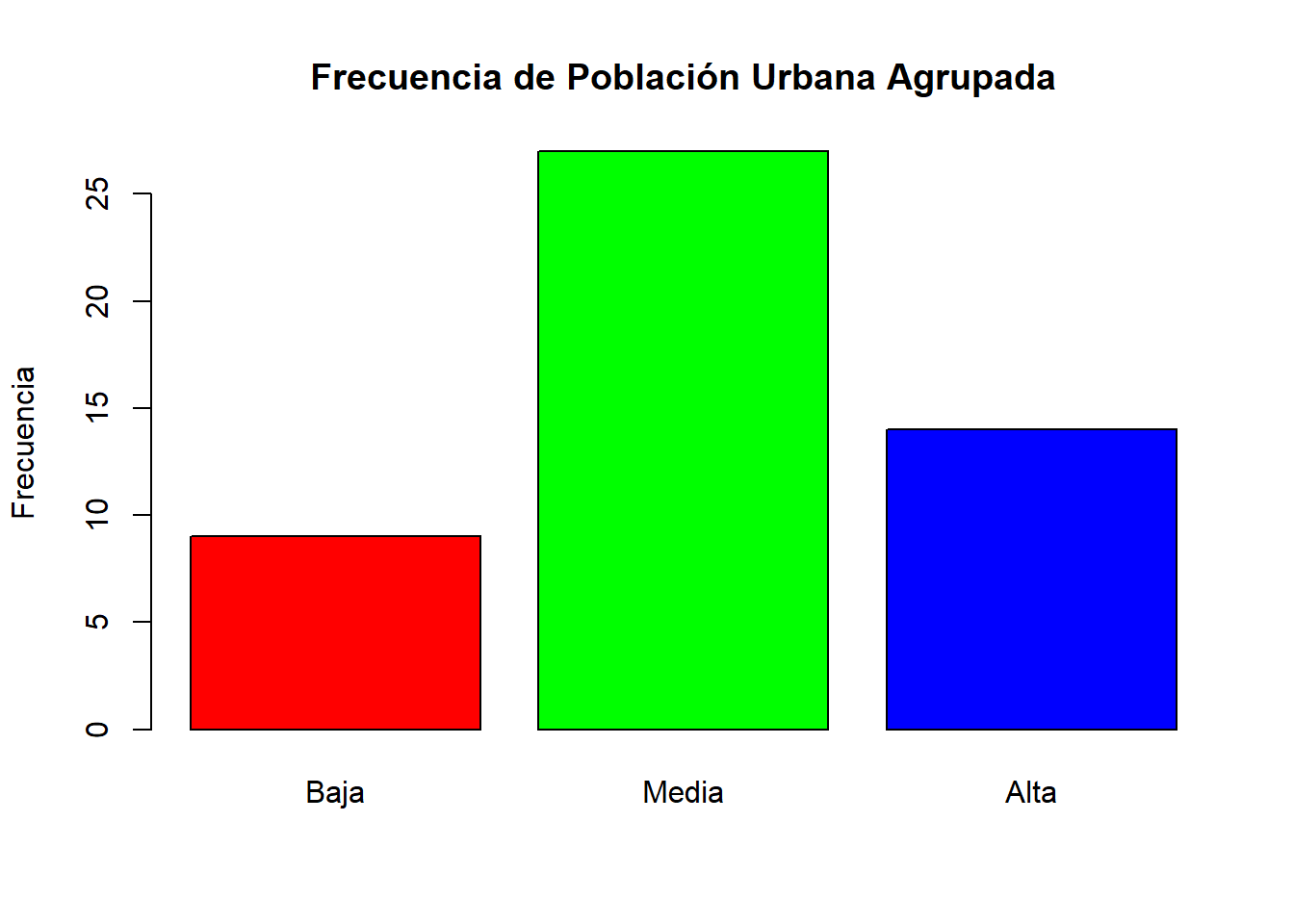
Interpretación: El gráfico de barras muestra la frecuencia de la población urbana en las categorías “Baja”, “Media” y “Alta”. Cada barra representa una categoría y su altura indica la frecuencia (número de observaciones) en esa categoría. Los colores de las barras proporcionan una distinción visual entre las categorías, permitiendo una rápida comparación de la frecuencia relativa de la población en diferentes niveles de urbanización.
5.1.5 Gráfico de Pastel
El código tiene como objetivo visualizar de manera gráfica la distribución de la población urbana en tres categorías (“Baja”, “Media”, “Alta”) a partir de la variable UrbanPop en el conjunto de datos USArrests. La creación de un gráfico de pastel permite una representación concisa y visual de la proporción de la población en cada categoría de urbanización.
# Agrupar la variable UrbanPop en categorías
USArrests$UrbanPopGroup <- cut(USArrests$UrbanPop, breaks = c(0, 50, 75, 100), labels = c("Baja", "Media", "Alta"), include.lowest = TRUE)
# Gráfico de pastel para la variable UrbanPopGroup
pie(table(USArrests$UrbanPopGroup),
main = "Distribución de Población Urbana Agrupada",
col = rainbow(length(unique(USArrests$UrbanPopGroup))),
labels = paste(names(table(USArrests$UrbanPopGroup)), "(", table(USArrests$UrbanPopGroup), ")"))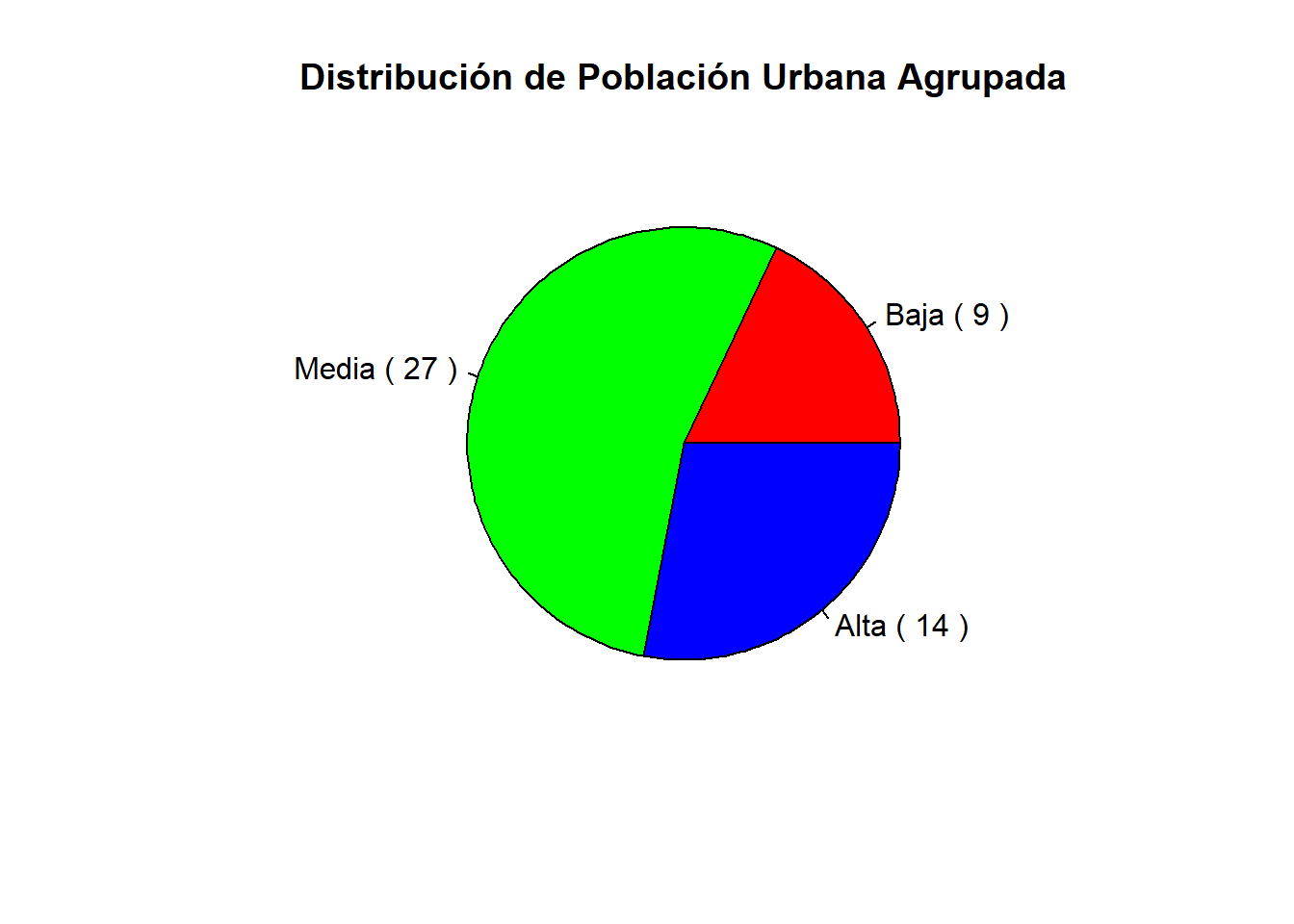
El gráfico de pastel resultante mostrará la proporción de la población urbana clasificada en las categorías “Baja”, “Media” y “Alta”. Cada sector del pastel representará una categoría, y el color y las etiquetas proporcionarán información visual sobre la distribución de la población urbana en esas categorías.
5.2 Visualización de datos bivariados
Los siguientes gráficos te permitiran explorar diferentes aspectos de la relación entre variables en el conjunto de datos gapminder. Podemos ajustar y personalizar los gráficos según las necesidades específicas y de acuerdo a las preguntas de investigación que nosotros podamos realizar a futuro.
5.2.1 Gráfico de Dispersión
El Gráfico de Dispersión creado con la función plot muestra la relación entre el ingreso per cápita (gdpPercap) y la expectativa de vida (lifeExp) para diferentes países en el conjunto de datos gapminder.
options(repos = c(CRAN = "https://cran.rstudio.com"))
install.packages("gapminder", quiet= TRUE)package 'gapminder' successfully unpacked and MD5 sums checkedlibrary(gapminder)Es útil para tener una visión rápida de cómo se distribuyen los países en términos de ingreso y expectativa de vida. Aunque es menos personalizado que los gráficos creados con ggplot2, la función base de R proporciona una forma rápida de visualizar relaciones básicas entre dos variables.
# Crear un gráfico de dispersión para la relación entre ingreso per cápita y expectativa de vida
plot(gapminder$gdpPercap, gapminder$lifeExp,
main = "Gráfico de Dispersión: Ingreso per Cápita vs Expectativa de Vida",
xlab = "Ingreso per Cápita",
ylab = "Expectativa de Vida",
col = "blue")
Interpretación: Cada punto en el gráfico representa un país. Tenemos al eje x nos representa el ingreso per cápita, y el eje que representa la expectativa de vida. Nos ayudara a visualizar la dispersión de los países en términos de ingreso y expectativa de vida.
5.2.2 Gráfico de burbujas
El gráfico de burbujas muestra la relación entre el ingreso per cápita (eje x) y la expectativa de vida (eje y). Cada burbuja representa un país, y su tamaño está determinado por la población del país. El color de las burbujas indica el continente al que pertenecen.
Instalaremos algunos paquetes necesarios para realizar los graficos:
# Instalar y cargar el paquete 'ggplot2' para el gráfico de burbujas
install.packages("ggplot2", quiet= TRUE)package 'ggplot2' successfully unpacked and MD5 sums checkedlibrary(ggplot2)
install.packages("gapminder", quiet= TRUE)Warning: package 'gapminder' is in use and will not be installedlibrary(gapminder)
data(gapminder)# Crear un gráfico de burbujas para la relación entre ingreso per cápita, expectativa de vida y población
ggplot(gapminder, aes(x = gdpPercap, y = lifeExp, size = pop, color = continent)) +
geom_point(alpha = 0.7) +
scale_size_continuous(range = c(2, 20)) +
labs(title = "Gráfico de Burbujas: Ingreso per Cápita vs Expectativa de Vida",
x = "Ingreso per Cápita",
y = "Expectativa de Vida",
size = "Población",
color = "Continente")
Interpretación: Se puede observar cómo se distribuyen los países en función de su ingreso per cápita y expectativa de vida. Las burbujas más grandes representan países con una población más grande, y el color proporciona información adicional sobre la ubicación geográfica de los países.
5.2.3 Gráfico de líneas
EL gráfico de líneas muestra la evolución temporal del ingreso per cápita para diferentes países a lo largo de los años. Cada línea representa un país, y el color de la línea indica el continente al que pertenece.
data(gapminder)# Crear un gráfico de líneas para la evolución temporal del ingreso per cápita
ggplot(gapminder, aes(x = year, y = gdpPercap, group = country, color = continent)) +
geom_line() +
labs(title = "Gráfico de Líneas: Evolución Temporal del Ingreso per Cápita",
x = "Año",
y = "Ingreso per Cápita",
color = "Continente")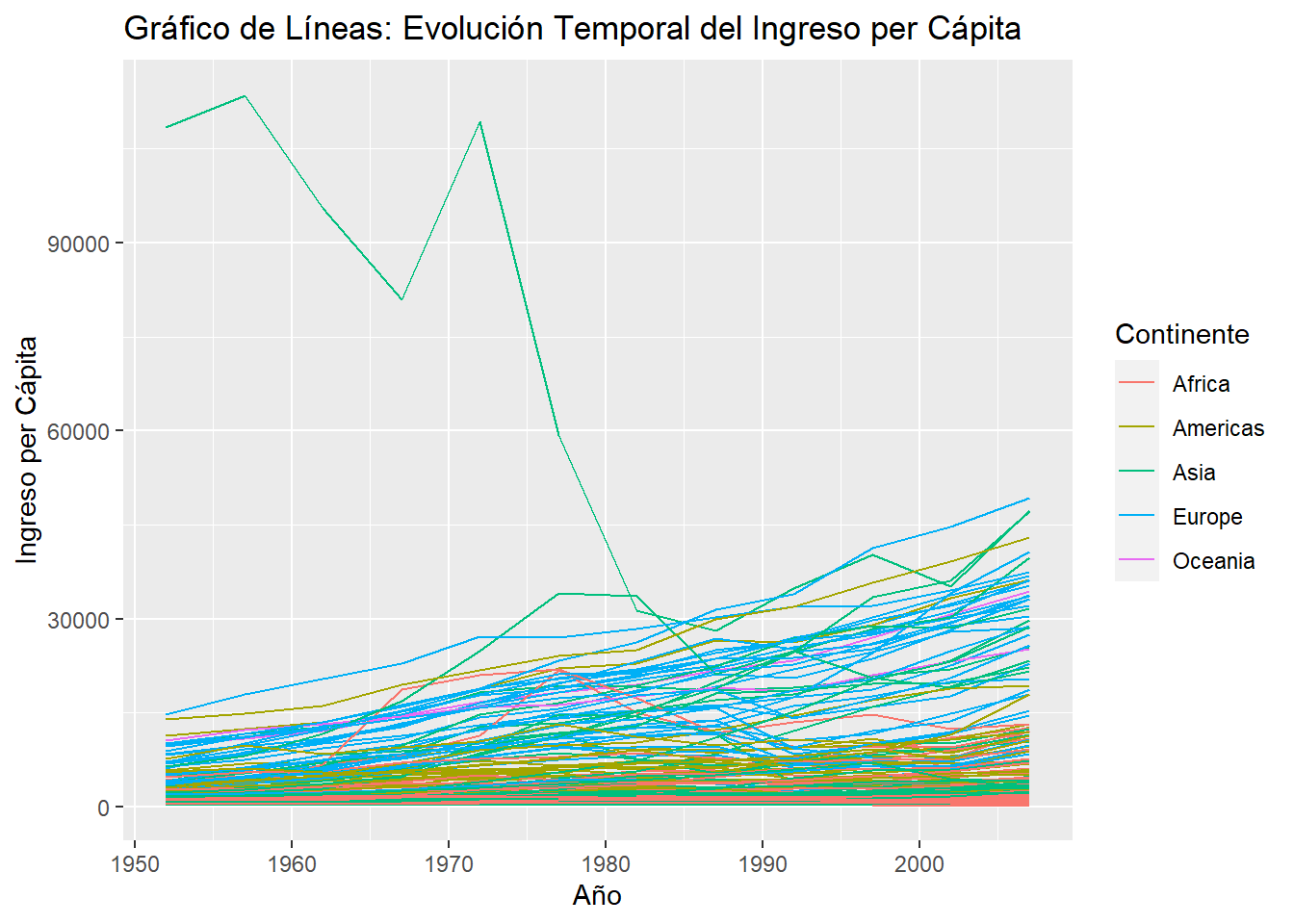
Interpretación: Puedes observar cómo cambia el ingreso per cápita de cada país a lo largo del tiempo. Las líneas que pertenecen al mismo color representan países del mismo continente, permitiendo comparar tendencias continentales en el ingreso per cápita.
5.2.4 Gráfico de barras agrupadas
Compara el número de observaciones (países) para combinaciones de continente y año, mostrando la distribución de los datos en relación con el ingreso per cápita y la expectativa de vida.
# Crear un gráfico de barras agrupadas para comparar ingreso per cápita y expectativa de vida por continente
ggplot(gapminder, aes(x = continent, fill = factor(year))) +
geom_bar(stat = "count", position = "dodge") +
labs(title = "Barras Agrupadas: Ingreso per Cápita y Expectativa de Vida por Continente",
x = "Continente",
y = "Conteo",
fill = "Año")
Interpretación: Cada barra agrupada representa una combinación de continente y año, y la altura de cada barra indica cuántos países pertenecen a esa combinación. Puedes observar la distribución de los países en función del continente y año, proporcionando una visión general de cómo se distribuyen las observaciones en la muestra.
5.3 Visualización de datos bivariados multivariados.
Utilizaremos el conjunto de datos mtcars, que contiene información sobre diferentes modelos de automóviles. Vamos a explorar algunas visualizaciones bivariadas y multivariadas.
5.3.1 Gráfico de Dispersiones (Bivariado)
Visualizar la relación entre la potencia del motor (hp) y la eficiencia en millas por galón (mpg) de diferentes modelos de automóviles.
# Gráfico de dispersión entre la eficiencia en millas por galón (mpg) y la potencia bruta (hp)
plot(mtcars$hp, mtcars$mpg, main = "Gráfico de Dispersión: Potencia vs Eficiencia",
xlab = "Potencia (hp)", ylab = "Eficiencia (mpg)", pch = 19, col = "blue")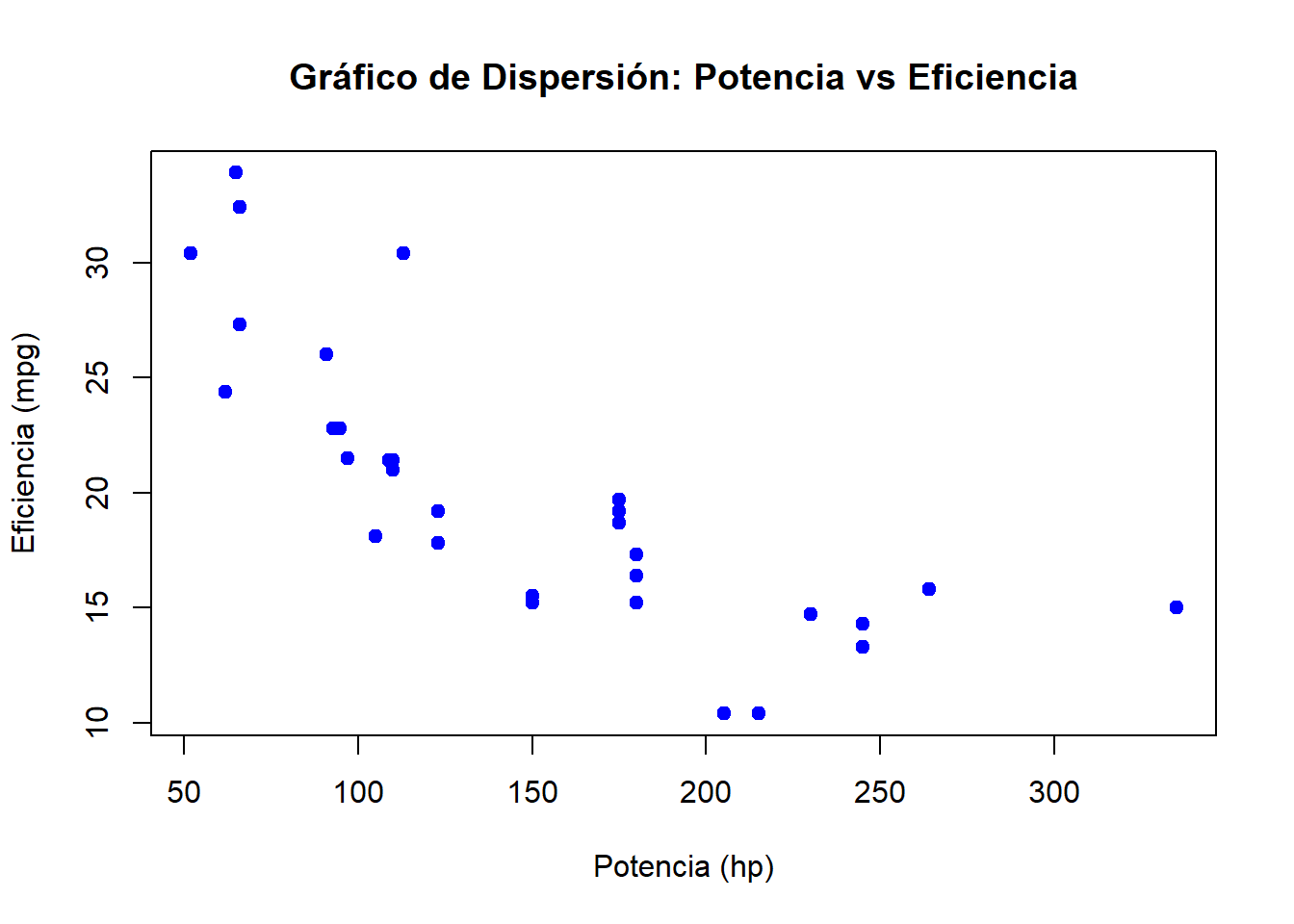
Interpretación: El gráfico de dispersión muestra cómo la potencia del motor se relaciona con la eficiencia en millas por galón. Se puede observar si hay una tendencia general, dispersión o patrones específicos.
5.3.2 Matriz de Dispersión (Multivariado)
Visualizar la relación entre varias variables numéricas (en este caso, mpg, hp, wt, qsec) en una matriz, permitiendo la exploración multivariada.
# Matriz de dispersión para múltiples variables numéricas
pairs(mtcars[, c("mpg", "hp", "wt", "qsec")], main = "Matriz de Dispersión: Variables Seleccionadas")
Interpretación: La matriz de dispersión muestra gráficos de dispersión para cada par de variables seleccionadas. Puede identificar patrones, correlaciones y distribuciones en las relaciones entre estas variables.
5.3.3 Gráfico de Burbujas (Bivariado Multivariado)
Visualizar la relación entre el peso (wt), la eficiencia en millas por galón (mpg) y la potencia del motor (hp) utilizando burbujas para representar la potencia.
# Gráfico de burbujas entre mpg, wt y hp
library(ggplot2)
ggplot(mtcars, aes(x = wt, y = mpg, size = hp, color = hp)) +
geom_point(alpha = 0.7) +
scale_size_continuous(range = c(2, 15)) +
labs(title = "Gráfico de Burbujas: Peso, Eficiencia y Potencia",
x = "Peso (wt)", y = "Eficiencia (mpg)", size = "Potencia (hp)", color = "Potencia (hp)")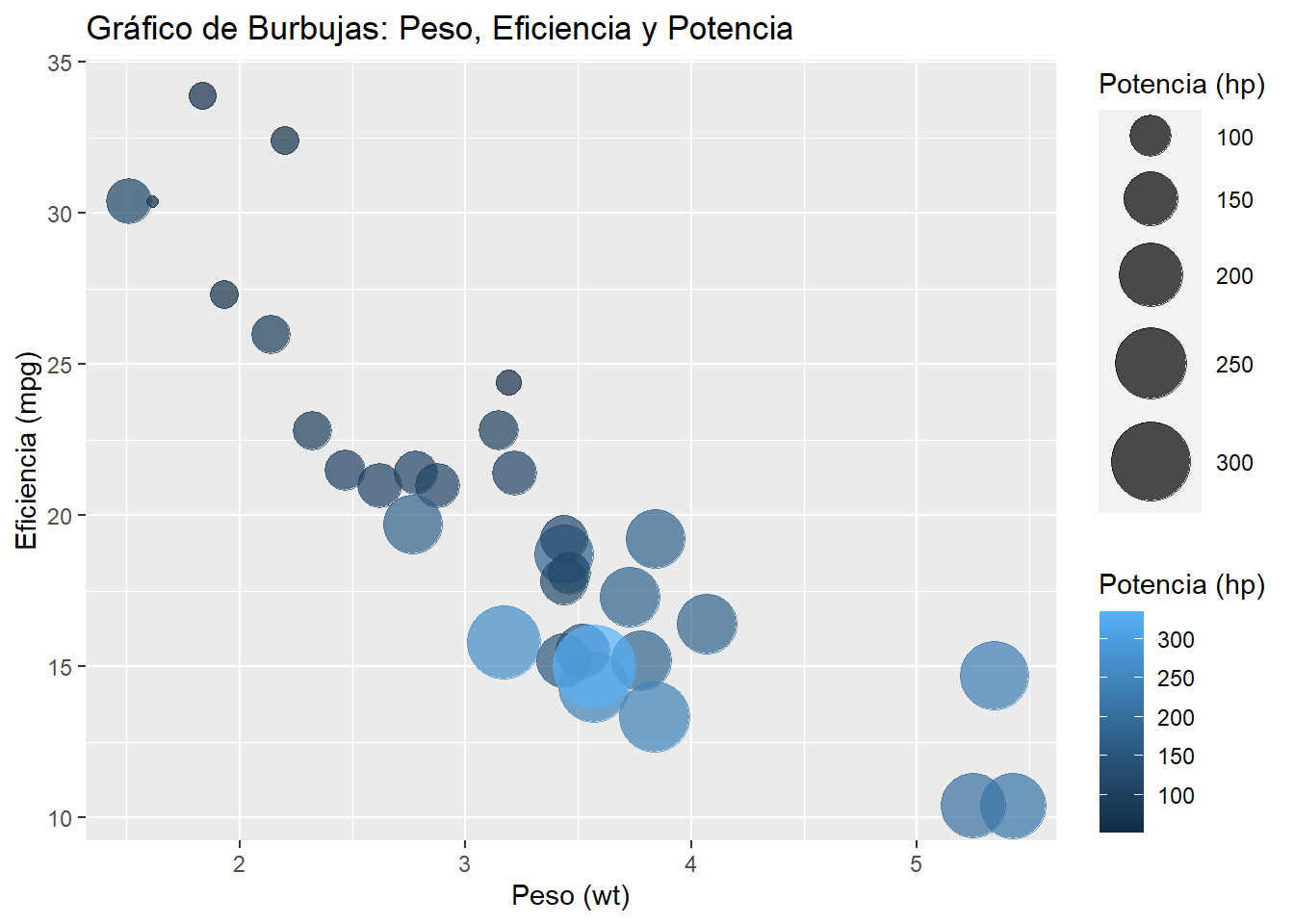
Interpretación: Burbujas más grandes indican modelos con mayor potencia. El color también indica la potencia, y la posición en el gráfico muestra cómo el peso y la eficiencia están relacionados.
5.3.4 Gráfico de Correlación
Visualizar la matriz de correlación entre las variables numéricas (mpg, hp, wt, qsec) para entender las relaciones lineales entre ellas.
Instalamos y cargamos la libreri “corrplot”
install.packages("corrplot", quiet= TRUE)package 'corrplot' successfully unpacked and MD5 sums checkedlibrary(corrplot)corrplot 0.92 loaded# Calcular la matriz de correlación
cor_matrix <- cor(mtcars[, c("mpg", "hp", "wt", "qsec")])
# Visualizar la matriz de correlación con corrplot
library(corrplot)
corrplot(cor_matrix, method = "color", addCoef.col = "black", tl.col = "black", tl.srt = 45)
Interpretación: El gráfico de correlación muestra la fuerza y la dirección de las correlaciones entre pares de variables. Los colores y los números indican la magnitud y la dirección de la correlación. Por ejemplo, valores cercanos a 1 indican una correlación positiva fuerte.
5.3.5 Gráfico de Radar (Multivariado)
Comparar múltiples variables (mpg, hp, wt, qsec) para los modelos de automóviles utilizando un gráfico de radar.
# Cargar el paquete 'fmsb' si aún no está instalado
install.packages("fmsb", quiet= TRUE)package 'fmsb' successfully unpacked and MD5 sums checkedlibrary(fmsb)# Instalar el paquete spider si aún no está instalado
install.packages("spider", quiet= TRUE)package 'spider' successfully unpacked and MD5 sums checkedlibrary(spider)# Instalar el paquete 'fmsb' si aún no está instalado
install.packages("fmsb", quiet= TRUE)Warning: package 'fmsb' is in use and will not be installedlibrary(fmsb)# Seleccionar variables numéricas para el gráfico de radar
df_radar <- mtcars[, c("mpg", "hp", "wt", "qsec")]
# Normalizar los datos entre 0 y 1 para el gráfico de radar
df_radar_norm <- as.data.frame(scale(df_radar))
# Crear el gráfico de radar
radarchart(df_radar_norm)
Interpretación: El gráfico de radar muestra visualmente cómo se comparan los modelos de automóviles en términos de múltiples variables. Cada eje del polígono representa una variable, y la forma del polígono proporciona información sobre las diferencias en los niveles de cada variable. Esto ayuda a identificar patrones y diferencias en las características de diferentes modelos de automóviles. En este caso, las variables han sido normalizadas para que tengan la misma escala en el gráfico de radar.