Chapter 2 What is Data Science?
2.1 Defining data science
Data Science is often referred to the science field that interphase scientific methods, mathematics, computer programming to extract knowledge from different forms of datasets (UC-Berkely-School-of-Information 2019). These datasets can originate from biological, chemistry, physics, pedagogy, non-science fields (e.g. business), among others. Data science integrates epicycles starting from the question to answer with the dataset to communicating the results of the data analysis(Roger Peng 2016).
2.2 Important terminology in data science
Below find definitions of some key terms in data science, which will be beneficial for us to understand during this workshop.
- epicycle: a cycle that moves around a larger cycle (Roger Peng 2016)
- programming script: file containing a series of lines of codes that are executable for specific tasks (Wikipedia 2019)
- repository: central storage system (often online) for scripts, data, and documents. Click here for more information
- algorithm: a set of rules or processes within a script. A script file could have a single or more than one algorithm (Wikipedia 2019)
- dataset: file containing the variables, and the observations (e.g. values) for each variable, to be examined in the data analysis workflow (Wickham 2014)
- variable: contains the measures underlying an attribute. Example, the **age* variable would only contain the age of a person in years (sometimes in month) (Wickham 2014)
- observation: measure within a variable arranged in the same unit (Wickham 2014)
- uncleaned (or unstructured) data: data containing errors, inaccurate points, missing values, incomplete annotations, or irrelevant data (i.e. data not needed for downstream analysis) (Wickham 2014)
- cleaned (or structured) data: dataset that contains no errors, inaccurate data points, incomplete annotations, or irrelevant data (i.e. data not needed for downstream analysis). Different types of dataset require specific approaches to become structured (e.g. cleaned) (Roger Peng 2016)
- tidy data: the data is arranged such that each column is a variable, and each row is an observation (Wickham 2014)
- package (or library): units, in the case of the R language, that contain reusable R functions, include documentation, examples, and often, samples of data to implement the functions
- version control: the approach of saving every version of a giving file, document, etc. In many platforms that implement version control, each version of a file or change gets a unique identifier
2.3 The epicycle of data science
Drs. Roger Peng and Elizabeth Matsui (the latter was one of my co-mentors as a postdoctoral fellow at Johns Hopkins University School of Public Health), in their book “The Art of Data Science” provide a good representation of the epicycles of data science (Roger Peng 2016).
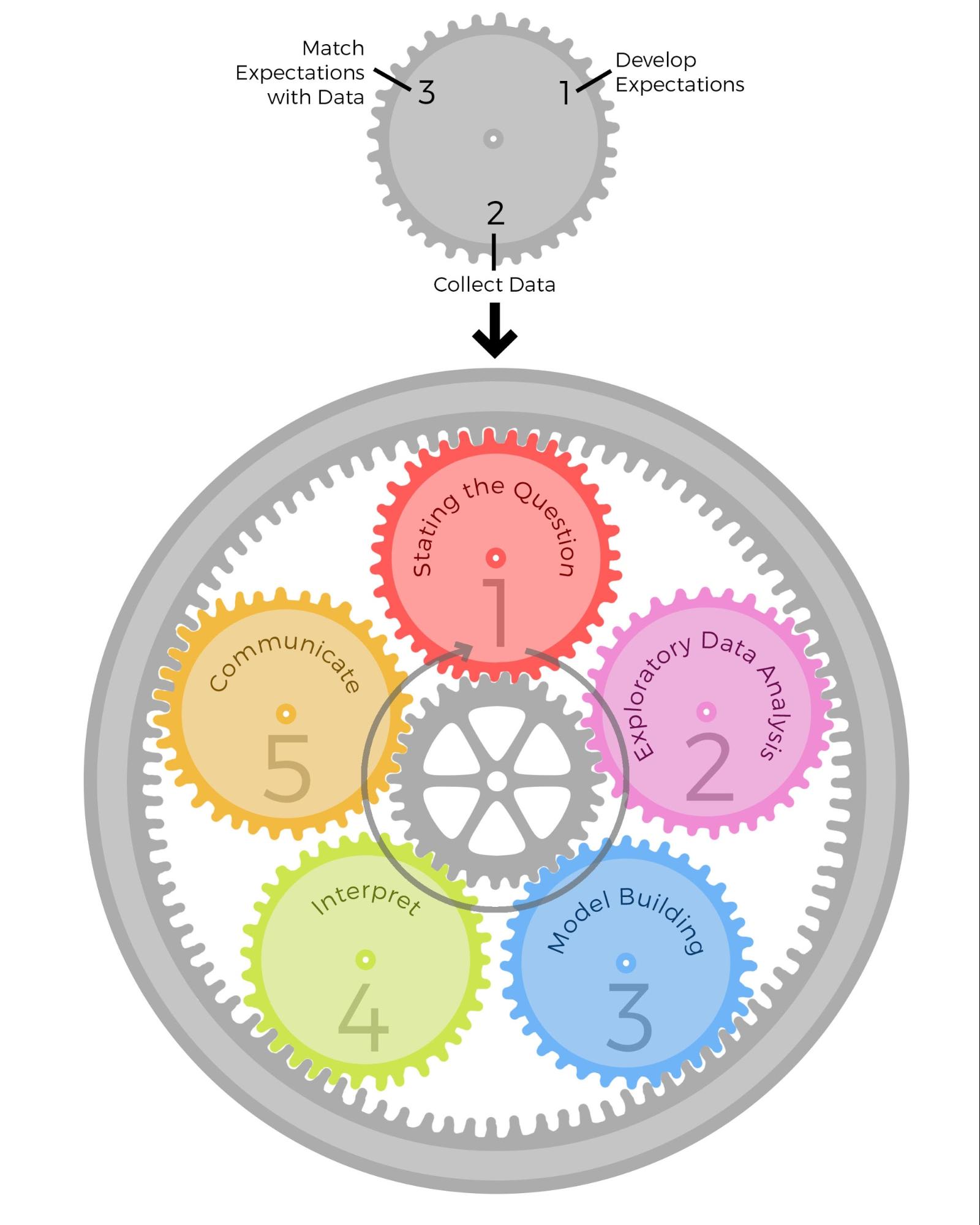
The Epicycles of data science, from the book the Art of Data Science (Peng 2016)
During a workflow of data science, which include from 1) elaborating the question to be answer with the data, 2) exploring the data, 3) develop statistical models with the data, 4) interpreting the models based on the output, and 5) and communicating the models, results, and interpretation, we can see the following:
- First (1), we have to set an expectation (or more than one expectation)
- Second (2), we must collect the data to evaluate the expectation(s)
- Third (3), we must determine if the expectation(s) match with the data (we have available) or not
Below is a table by Drs. Roger Peng and Elizabeth Matsui (Roger Peng 2016) with more examples of 1) the expectation(s), 2) collecting information to evaluate the expectation(s), and 3) determining if the expectation(s) is/are met
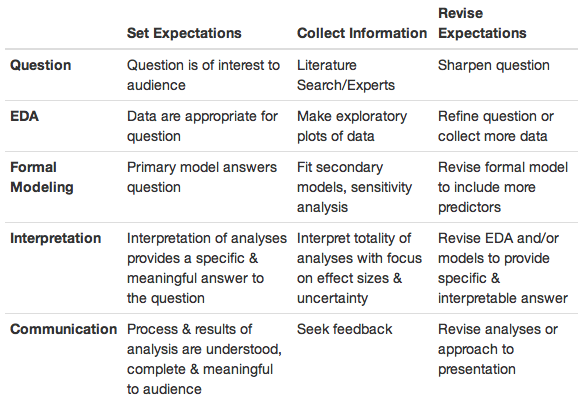
Table of the epicycles of data science (Peng 2016)
References
UC-Berkely-School-of-Information. 2019. What Is Data Science? https://datascience.berkeley.edu/about/what-is-data-science/.
Roger Peng, Elizabeth Matsui. 2016. The Art of Data Science. 1st ed. Boca Raton, Florida: Lulu Press. https://leanpub.com/artofdatascience.
Wikipedia. 2019. Script Language. (Accessed on Jan 21st, 2019). https://en.wikipedia.org/wiki/Scripting_language#cite_note-ecma262-1.
Wickham, Hadley. 2014. “Tidy Data.” Journal Statistical Software 59 (10). https://www.jstatsoft.org/article/view/v059i10.