\(\tau_0^2\) is the variance of random intercepts,
\(\tau_1^2\) is the variance of random slopes,
\(\rho\) is the correlation between intercepts and slopes.
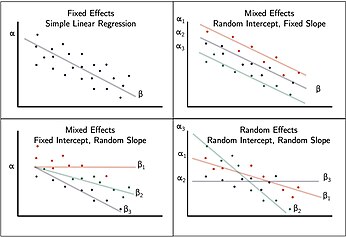
This structure allows us to model not just variation in starting points (intercepts) and rates of change (slopes), but also how they are related (e.g., do groups with higher baselines tend to change faster?).
Linear mixed model fit by REML ['lmerMod']
Formula: lead ~ week + (week | id)
Data: placebo_data
REML criterion at convergence: 1053.3
Scaled residuals:
Min 1Q Median 3Q Max
-2.20808 -0.49837 -0.02268 0.47100 2.30541
Random effects:
Groups Name Variance Std.Dev. Corr
id (Intercept) 23.3113 4.8282
week 0.1581 0.3976 0.02
Residual 4.5016 2.1217
Number of obs: 200, groups: id, 50
Fixed effects:
Estimate Std. Error t value
(Intercept) 25.68536 0.72018 35.665
week -0.37213 0.08437 -4.411
Correlation of Fixed Effects:
(Intr)
week -0.164
The correlation \(rho\) between \((\beta_{0i} \beta_{1i}) = 0.02\).
The 95% CIs of the subject-specific slopes does not include zero in the distribution. This we reject the null that a child’s lead levels do not increase with time.
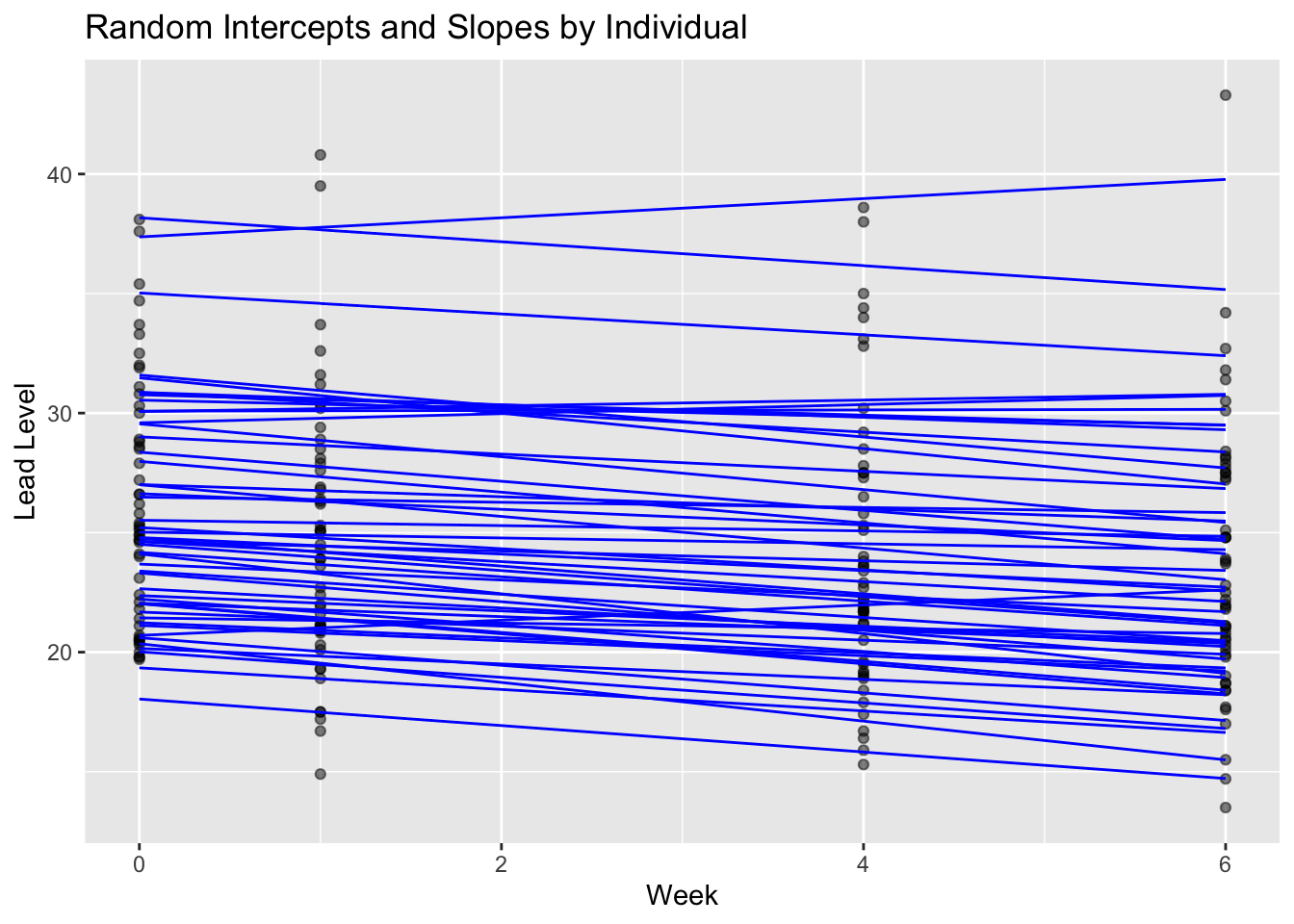
Below we visualize the individual trajectories based on both fixed effects and random intercepts and slopes.
library(ggplot2)ggplot(placebo_data, aes(x = week, y = lead, group = id)) +geom_point(alpha =0.5) +geom_line(aes(y =predict(fit_random)), color ="blue") +labs(title ="Random Intercepts and Slopes by Individual",x ="Week", y ="Lead Level")
Comparing Models
We take the random-intercept model as the baseline and ask: do subjects also differ in their trajectories (slopes)? In other words, does adding a random slope improve fit over a random-intercept-only model?
Akaike’s Information Criterion
A common way to compare candidate models fit to the same data is AIC. It is a popular approach to choosing which variables should be in the model. Note lower is better, where rule of thumb (RoT) is a different of 2+ is substantially better.
\[
AIC = -2l(\mathbf{\hat{\theta}}) + 2p
\] where \(l(\mathbf{\hat{\theta}})\) is the log-likelihood for all parameters \(\mathbf{\theta}\) and \(p\) is the number of parameters.
Likelihood Ratio Test (Nested models)
When one model is a special case of another (e.g., in the case of nested models), use a LRT:
A larger \(\Lambda\) indicates the full model fits better.
It is important to note\(REML\) removes information about \(\beta\) so REML log-likelihoods are not directly comparable when your models have different fixed effects (not apples-to-apples). For model comparisons both uses the maximum likelihood so use \(REML=FALSE\) to set the parameter estimation to MLE.
Here are some important caveats when using AIC or LRT:
AIC is a relative measure. A lower AIC only says “better than the other model on this data,” not “good.”
Must be comparable fits. Same dataset, same likelihood. Don’t compare ML vs REML.
LRT requires nested models. You can’t use it for non-nested comparisons.
Asymptotic reference: The \(\chi^2\) approximation can be poor in small samples. This makes p-values too large (favors simpler models).
Model Comparison for TLC data
With the random-intercept model as our baseline, we now ask whether children also differ in their rates of change over time. Using the TLC data, we’ll fit (1) a random-intercept (RI) model and (2) a random-intercept-plus-slope (RI+RS) model, then compare them by likelihood (AIC and LRT). To make the comparison valid, we’ll fit both models by ML (REML = FALSE). Lower AIC and a significant LRT would support adding the random slope.
We compared the RI vs RI+RS model using ML fits and LRT.
The \(\chi^2(2) = 5.3, \text{p-value} = 0.071\rightarrow\) adding a random slope yields only marginal improvement and is not significant at \(\alpha = 0.05\).
AIC: \(RI = 2703, RI+RS = 2702 \rightarrow\), Change in AIC is 1 (RoT \(\geq 2\)). So this change is trivial.
There is limited evidence that the subject-specific slopes are needed. The tiny AIC gain and the non-significant chi-square test would suggest to retain the random-intercept-only model.
Summary
Section
Description
Model: random intercepts + slopes
For subject \(i\) and observation \(j\): \(y_{ij} = (\beta_0+\theta_{0i}) + (\beta_1+\theta_{1i})\,x_{ij} + \epsilon_{ij}, \qquad \epsilon_{ij}\stackrel{iid}{\sim}N(0,\sigma^2).\) Here \(\beta_0,\beta_1\) are population (fixed) effects; \(\theta_{0i}\) and \(\theta_{1i}\) are subject-specific deviations (random intercept and random slope).
Random-effects covariance
\(\begin{pmatrix}\theta_{0i}\\ \theta_{1i}\end{pmatrix}\sim N\!\left(\begin{pmatrix}0\\0\end{pmatrix},\; \begin{pmatrix}\tau_0^2 & \rho\,\tau_0\tau_1\\ \rho\,\tau_0\tau_1 & \tau_1^2\end{pmatrix}\right).\)\(\tau_0^2\): variability in intercepts; \(\tau_1^2\): variability in slopes; \(\rho\): correlation between intercepts and slopes (e.g., do higher baselines change faster/slower?).
Fitting & interpretation (R)
Example: `lmer(lead ~ week + (week …)`. Fixed effects \((\beta_0,\beta_1)\) give the population intercept and average rate of change. Random-effect variances \((\tau_0^2,\tau_1^2)\) quantify between-subject heterogeneity in starting level and trajectory; \(\rho\) summarizes their association.
Visualizing trajectories
Overlay predicted lines per subject using predict(fit) to show how intercepts and slopes vary across individuals while following the population trend.
Model comparison (RI vs RI+RS)
AIC (lower is better):\(\mathrm{AIC}=-2\ell(\hat\theta)+2p\); a difference \(\gtrsim 2\) is a common rule-of-thumb for meaningful improvement. LRT (nested models):\(\Lambda=2\{\ell(\text{full})-\ell(\text{reduced})\}\), compare to \(\chi^2\) with df = parameter difference. Use ML for comparison: fit both models with REML = FALSE.
TLC example (results)
Comparing random-intercept (RI) vs random-intercept+random-slope (RI+RS): LRT \(\chi^2(2)=5.3,\; p=0.071\) (not significant at \(\alpha=0.05\)); AIC: \(\text{RI}=2703,\ \text{RI+RS}=2702\) (ΔAIC = 1, trivial). Conclusion: limited evidence to include a random slope; RI model is adequate here.