Chapter 1 Summary Statistics and Graphing
When confronted with a large amount of data, we seek to summarize the data into statistics that capture the essence of the data with as few numbers as possible. Graphing the data has a similar goal: to reduce the data to an image that represents all the key aspects of the raw data. In short, we seek to simplify the data in order to understand the trends while not obscuring important structure.
# Every chapter, we will load all the libraries we will use at the beginning
# of the chapter. These commands will start most every homework assignment
# for this class, and likely, every R script you write.
suppressPackageStartupMessages({
library(tidyverse)
})
# Set default behavior of ggplot2 graphs to be black/white theme
theme_set(theme_bw())For this chapter, we will consider data from a the 2005 Cherry Blossom 10 mile run that occurs in Washington DC. This data set has 8636 observations that includes the runners state of residence, official time (gun to finish, in seconds), net time (start line to finish, in seconds), age, and gender of the runners.
data(TenMileRace, package='mosaicData')
head(TenMileRace) # examine the first few rows of the data## state time net age sex
## 1 VA 6060 5978 12 M
## 2 MD 4515 4457 13 M
## 3 VA 5026 4928 13 M
## 4 MD 4229 4229 14 M
## 5 MD 5293 5076 14 M
## 6 VA 6234 5968 14 M1.1 Variable Types
We will distinguish variables into two principal categories: categorical and numerical. This distinction will become important because the manner in which we visualize and model the data will depend on the variable types. For example we use box plots to graph a continuous vs categorical variable relationship but a scatter plot for a continuous vs continuous relationship.
Categorical variables are variables whose elements take on non-numerical entries.
Examples within the
TenMileRaceset include the state and sex variables. Categorical variables are typically un-ordered, such that if we chose to order ‘NM’ before ‘AZ’ in an evaluation of the state variable, there would be no impact on our analysis. Categorical variables that have an implied order are termed ordinal variables. Examples include the common A, B, C, D, F grade-scale system. The variable entries are non-numerical, but there is an implied order that A > B > C > D > F. Such an ordering could influence the way the data is evaluated.Numerical variables are broadly classified as variables with numerical elements.
Numerical variables within theTenMileRaceset include the time, net, and age variables. Numerical variables are sub-classified as either discrete or continuous.Numerical Discrete variables are numerical variables have values coming from a countable set of possible values. Data that is numerical discrete can take on a countable number of numerical entries. Some examples are:
- The number of offspring an adult has
- The number of items in a shopping cart.
- The value of a die roll.
- The number of students in a classroom.
Discrete variables often have an upper bound on their possible value, but theoretically could be countably infinite and listed as \({0,1,2,\dots}\). Although there is no largest value within the list, the number of potential entries is still countable. Infinite valued discrete variables will serve the basis for important distributions, such as the Poisson distribution, while the finite valued variables serve as the basis for distributions such as the binomial, Bernoulli, and discrete uniform.
Continuous variables have entries that take on numerical values that lie on an interval.
Continuous variables are also numerical variables but the values come from an uncountable set of values. This distinction between Discrete and Continuous variable types is important from a statistical theory point of view, but is less helpful in statistical practice. Instead we can consider the question: “Does a fraction of a value make sense?” If so, then the data is continuous.
The TenMileRace data, the variables time and net are both recorded in
seconds, and in this case seem to conform to discrete.
However, if we had instead recorded the minutes with fractions of a minute present,
such as 75.25 minutes instead of 4515 seconds, we might realize these variables
are more likely to be considered continuous.
Continuous variables constitute a large set of distributions that will be studied,
the most commonly known being the Normal distribution.
For the Normal distribution, it is theoretically possible to see values ranging from
\((-\infty, \infty)\). This constitutes an interval, albeit a very large interval.
Thus, elements of the variables lie on an interval, and it is not possible to
list out all possible entries.
Another simple example will be the Uniform distribution, whose entries lie on the
interval \((a,b)\), where \(a\) and \(b\) are any real valued number.
Again, all potential observation of the variable can be found in the interval,
but it is not possible to list out all possible outcomes.
1.2 Randomization and Sampling
An important aspect of working within statistics is the concept that the data we are working with has been collected randomly. We think of having a population, the collection of all possible observations under consideration. We often consider population summary quantities, such as the population mean which we will denote as \(\mu\). For example, we might care about the mean age of all NAU students, or the average income of Hispanic residents of Arizona.
Usually we will not have data on all individuals within the population and we
are forced to rely on a sample. A sample is a subset of the population
for which information is gathered.
The fundamental idea in the theory of statistics is:
- The sample is a representative subset of the population and quantities calculated from the sample (called sample statistics) are reasonable estimates of the corresponding population quantity (called population parameters).
The way we select our samples is done to ensure that the sample is representative of the population and that there is no unknown lurking correlation between variables.
We will distinguish between the usually unknown population parameters and the sample estimating quantities by using Greek letters such as \(\mu, \sigma, \rho,\) or \(\beta\) for the population values and either Roman characters such as \(\bar{x}\), s, r, or b or add a “hat” on-top of the parameter such as \(\hat{\mu}, \hat{\sigma}, \hat{\rho}\) or \(\hat{\beta}\). As for the Population and sample sizes, we will use \(N\) to represent the number of individuals in the population, and \(n\) to represent the number of individuals in the sample.
1.2.1 Sampling Techniques
We will cover three broad sampling techniques that help ensure the sample is representative of the population and the randomization of the samples collected.
- Simple Random Sampling (SRS) is when every sample of size \(n\) is equally likely. In practice this almost always implemented as randomly selecting member of the population is equally-likely to be chosen.
For SRS to be used, we also ensure that every member of the population is
selected independently. Let us take the a university of having 30,000 students
enrolled to be our population of which we would like to selected 1,000 as a
sample. To use SRS, we would assign every member of the population a value
{1, 2, ..., 30,000} and then draw numbers, without replacement, from our list
of values. Such random numbers can be drawn using a random number generator,
or traditionally through the use of a random number table. Below we show a simple
method in R to draw 1,000 from 30,000 without replacement.
sample(1:30000, 1000, replace=FALSE)Using this method would ensure that we obtain a random sampling drawn from the entire University. What we cannot do is draw a student, then also draw all of their siblings. If we were to use such a method, we would be introducing correlation within our samples. We must ensure that the students are all drawn randomly and that the selection is done independently.
- Random Cluster Sampling draws entire clusters based on a division of the population.
In cluster sampling, the idea is perform a hierarchical sampling where that we will use a SRS to select clusters and then observe every individual in that cluster. For example, if we were taking a sample of NAU students, we might first randomly select a certain set of classes and then interview every student in each class. Another example would have a tree ecologist randomly select GIS locations in a study area and then measure every tree within 20 meters of the location.
Cluster sampling is usually done to make it more convenient to carry out the sample, but introduces correlation among the observations that will need to be accounted for in the statistical analysis (e.g. using mixed models).
As an example of a bad cluster sample design, let us consider cluster sampling
the TenMileRace population based on state. If one was to view this variable,
they would find there are 62 unique state identifiers. This is due to there
being several countries listed in this variable, as well as the inclusion of
Washington, DC as its own state, and because it is real data, there is also one
blank. The main concept though if we chose to cluster by state, we would produce
62 clusters, all of which are imbalanced in size. To complete cluster random sampling,
we then use SRS to draw X states from the 62 clusters produced, such as say 10
from 62. From those 10, we would sample ALL participants within those clusters.
Thus, if I were to draw the AZ cluster, I would sample all 3 participants.
If I drew the VA cluster, we would sample all 3689 participants. Although this
type of sampling is easier to produce larger samples with less randomization, we
can see that clusters can be highly imbalanced, and it is unlikely that clustering
will allow me to sub-sample from the entire population. Just in our example,
I would not gather information from 52 of the 62 states, if I only was to draw
10 clusters.
- Stratified Sampling draws samples using proportionality based on homogeneous groupings known as strata.
It is often easy to confuse Clustering and Stratified sampling, but the major difference here is that we will draw random samples from within the strata, unlike clustering where we take all individuals from the chosen clusters. Let us consider for exampling producing a random stratified sample using sex as our strata. Here, our homogeneous grouping is simply sex. Other examples might include stratifying animals by breed, stratifying the atmosphere by height above ground, or stratifying soil by depth. The main idea behind a strata is every member should be homogenized: in our example, we homogenized by ‘Male’ and ‘Female’.
| sex | n | Proportion |
|---|---|---|
| F | 4325 | 0.501 |
| M | 4311 | 0.499 |
Above shows a table for the number of ‘Male’ and ‘Female’ participants. We see that these two strata are nearly equivalent, but we suppose we want to ensure we draw the samples based on proportionality. In total, we have 8636 participants. Let us say we want to draw \(800\) of these participants, but through stratification using sex. We must then ensure that when we draw a random sample, we obtain a sub-sample that has nearly equivalent proportions to that observed in the population. We must therefore draw
| sex | Sample size |
|---|---|
| F | \(800 * 0.501 = 401\) |
| M | \(800 * 0.499 = 399\) |
And if we do this sub-sampling, then our sample proportions will necessarily be the same as our population proportions. This can have desirable consequences, mainly that stratifying ensures samples are taken from all potential sources, here the sources are the different categories within our sex variable. If I did draw samples using only SRS with no stratifying, I might get proportions of ‘Male’ and ‘Female’ that are wildly different than the original sample, and stratification forces us to not select those unrepresentative samples. Stratifying guarantees we reproduce the proportions, while sampling from all homogeneous groupings.
1.3 Graphical Summaries
1.3.1 Barcharts/Barplots (Univariate - Categorical)
If we have univariate data about a number of groups, often the best way to display it is using barplots. They have the advantage over pie-charts that groups are easily compared. The bars do NOT touch indicating that the order is not required, and the same information could be gained if we plotted them in a slightly different order. Below we compare the counts of ‘Male’ and ‘Female’ participants.
ggplot(TenMileRace, aes(x=sex)) + geom_bar()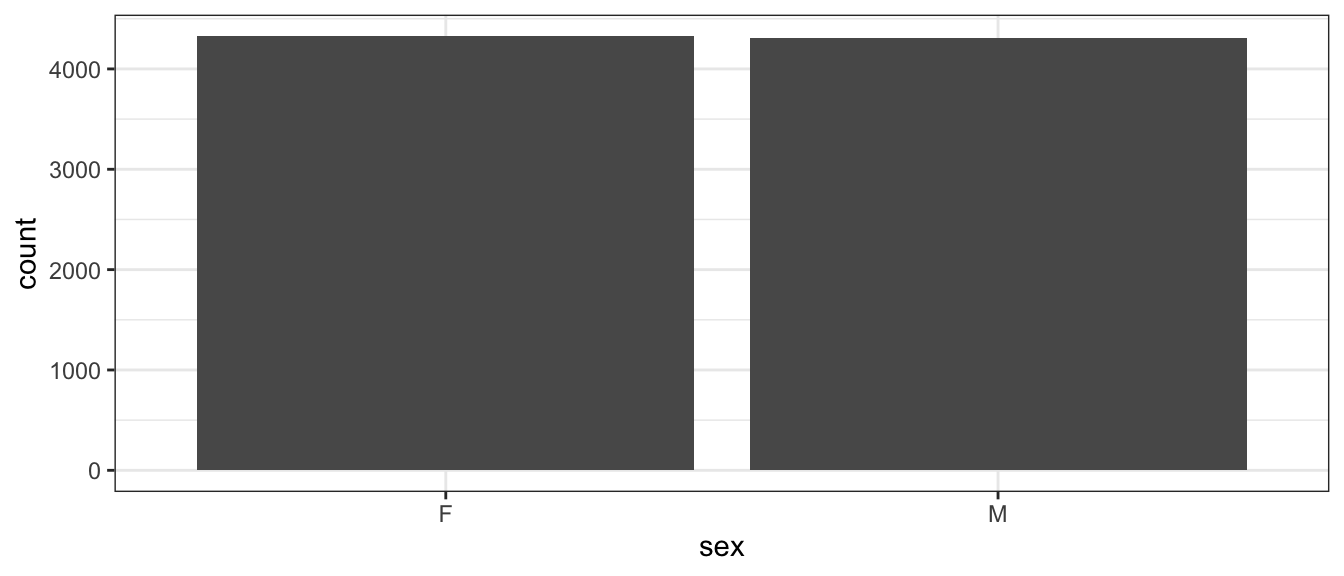
One thing that can be misleading is if the zero on the y-axis is removed. In the following graph it looks like there are twice as many female runners as male until you examine the y-axis closely. In general, the following is a very misleading graph.
ggplot(TenMileRace, aes(x=sex)) +
geom_bar() +
coord_cartesian(ylim = c(4300, 4330))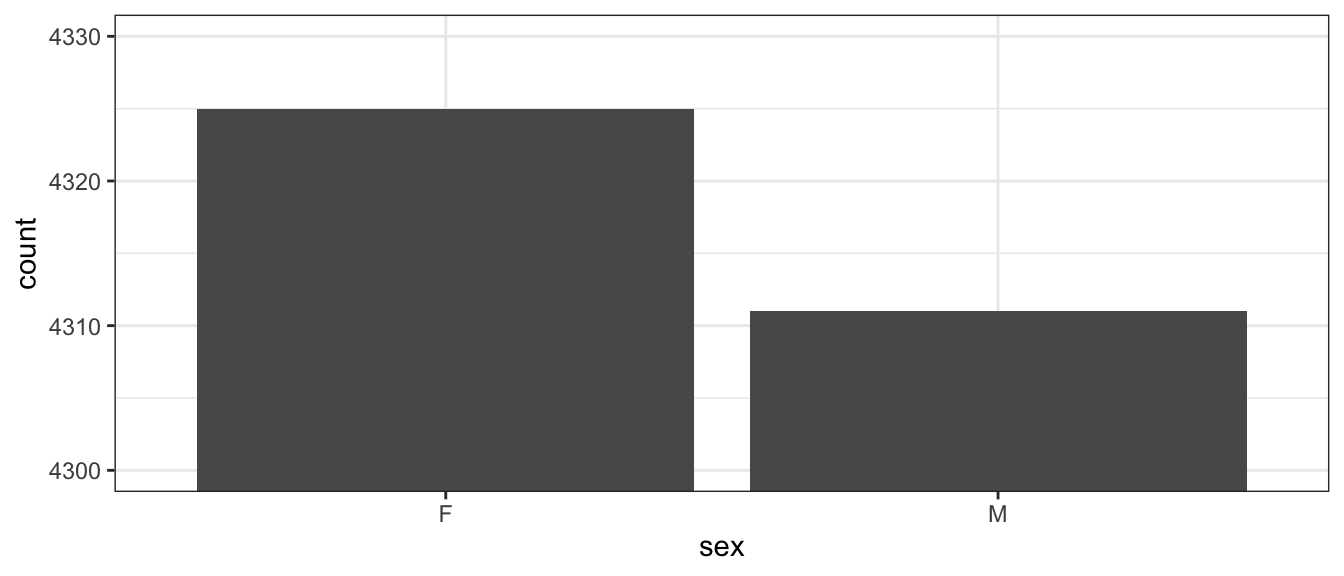
1.3.2 Histogram (Univariate - Numerical)
A histogram looks very similar to a bar plot, but is used to represent numerical data instead of categorical and therefore the bars will actually be touching.
ggplot(TenMileRace, aes(x=net)) +
geom_histogram()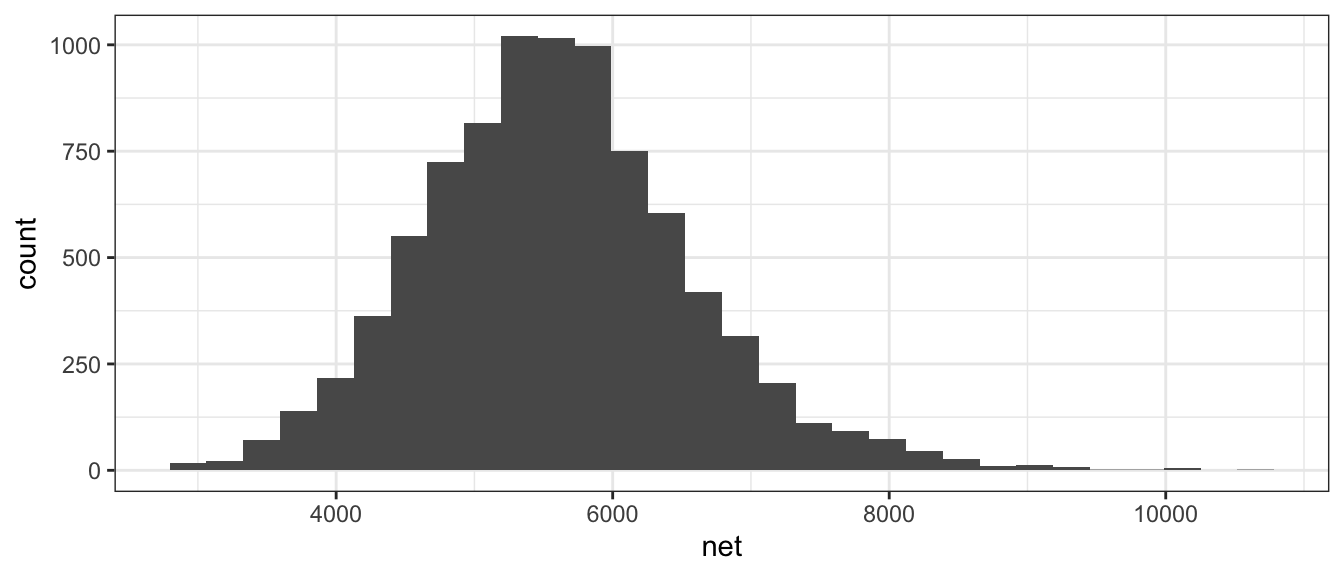
Often when a histogram is presented, the y-axis is labeled as “frequency” or “count” which is the number of observations that fall within a particular bin. However, it is often desirable to scale the y-axis so that if we were to sum up the area \((height * width)\) then the total area would sum to 1. The re-scaling that accomplishes this is
\[density=\frac{\#\;observations\;in\;bin}{total\;number\;observations}\cdot\frac{1}{bin\;width}\]
We can force the histogram created within ggplot to be display density by using the y=..density.. command.
ggplot(TenMileRace, aes(x=net)) +
geom_histogram(aes(y=..density..))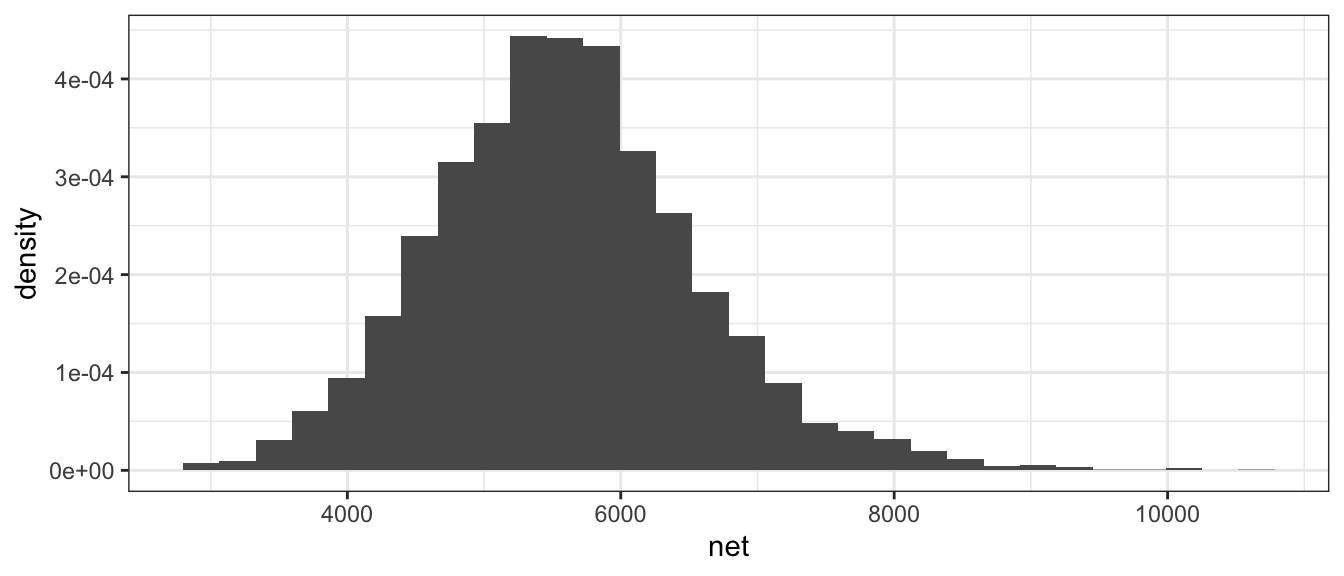
1.3.3 Boxplot (Bivariate - Categorical vs Numerical)
We often wish to compare response levels from two or more groups of interest. To do this, we often use side-by-side box plots. Notice that each observation is associated with a continuous response value and a categorical value.
ggplot(TenMileRace, aes(x=sex, y=net)) +
geom_boxplot()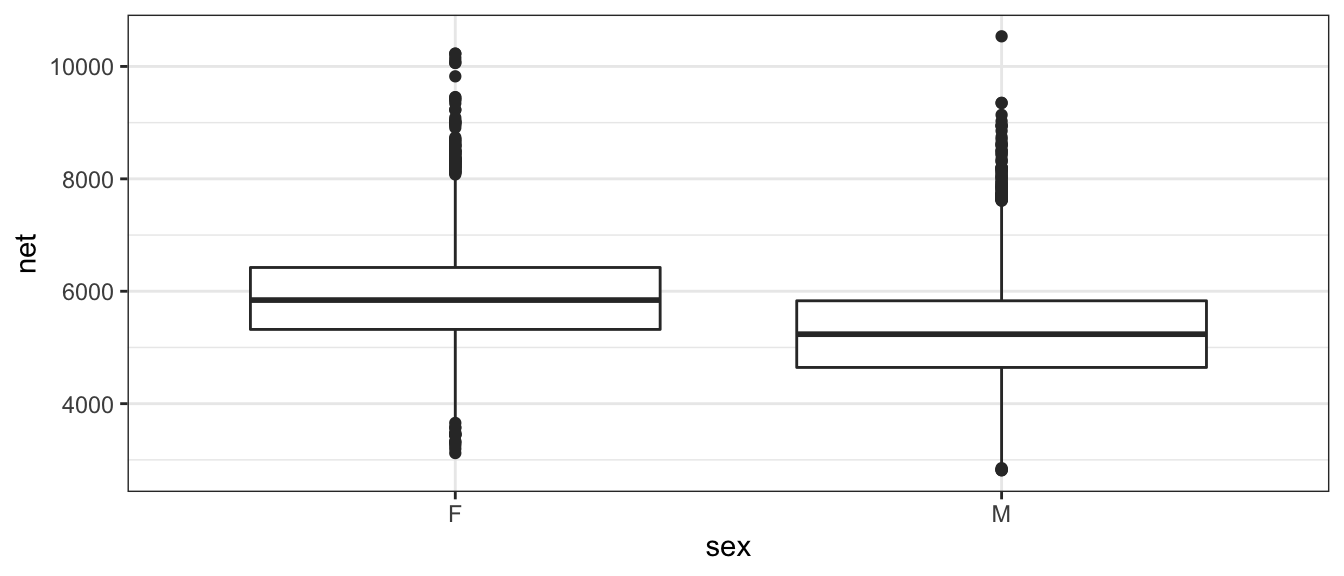
In this graph, the edges of the box are defined by the 25% and 75% percentiles. That is to say, 25% of the data is to the below of the box, 50% of the data is in the box, and the final 25% of the data is to the above of the box. The line in the center of the box represents the 50% percentile, more commonly called the median. The dots are data points that are traditionally considered outliers. We will define the Inter-Quartile Range (IQR) as the length of the box. It is conventional to define any observation more than 1.5*IQR from the box as an outlier. In the above graph it is easy to see that the median time for the males is lower than for females, but the box width (one measure of the spread of the data) is approximately the same.
Because boxplots simplify the distribution to just 5 numbers, looking at side-by-side histograms might give similar information.
ggplot(TenMileRace, aes(x=net)) +
geom_histogram() +
facet_grid( . ~ sex ) # side-by-side plots based on sex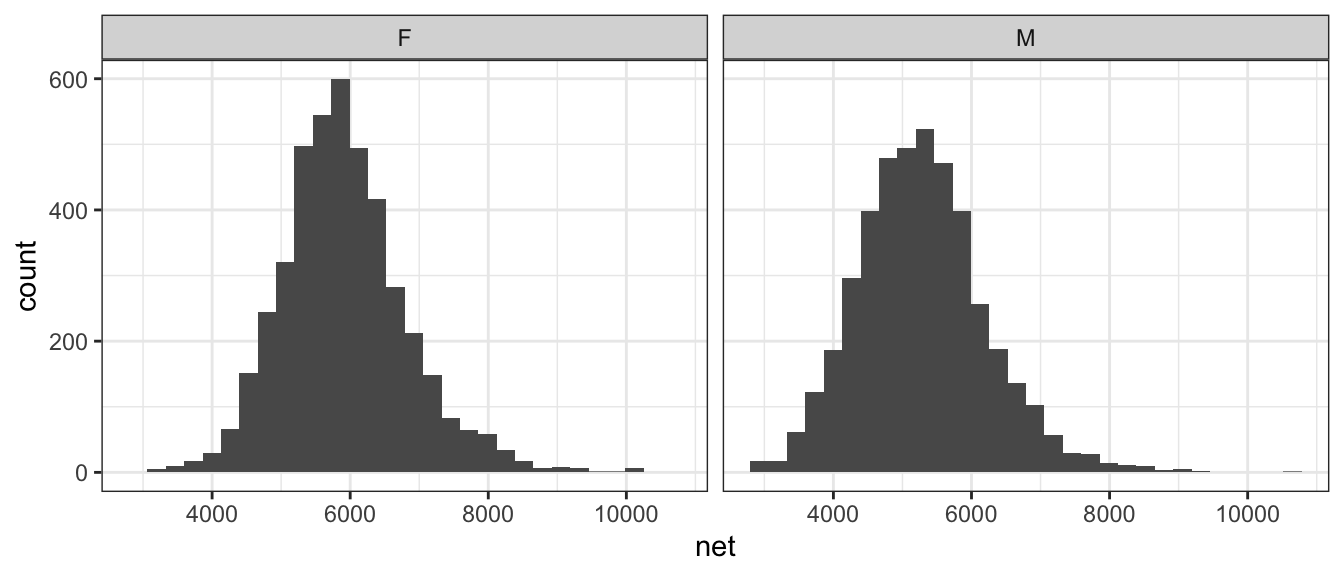
Orientation of graphs can certainly matter. In this case, it makes sense to stack the two graphs to facilitate comparisons in where the centers are and it is more obvious that the center of the female distribution is about 500 to 600 seconds higher than then center of the male distribution.
ggplot(TenMileRace, aes(x=net)) +
geom_histogram() +
facet_grid( sex ~ . ) # side-by-side plots based on sex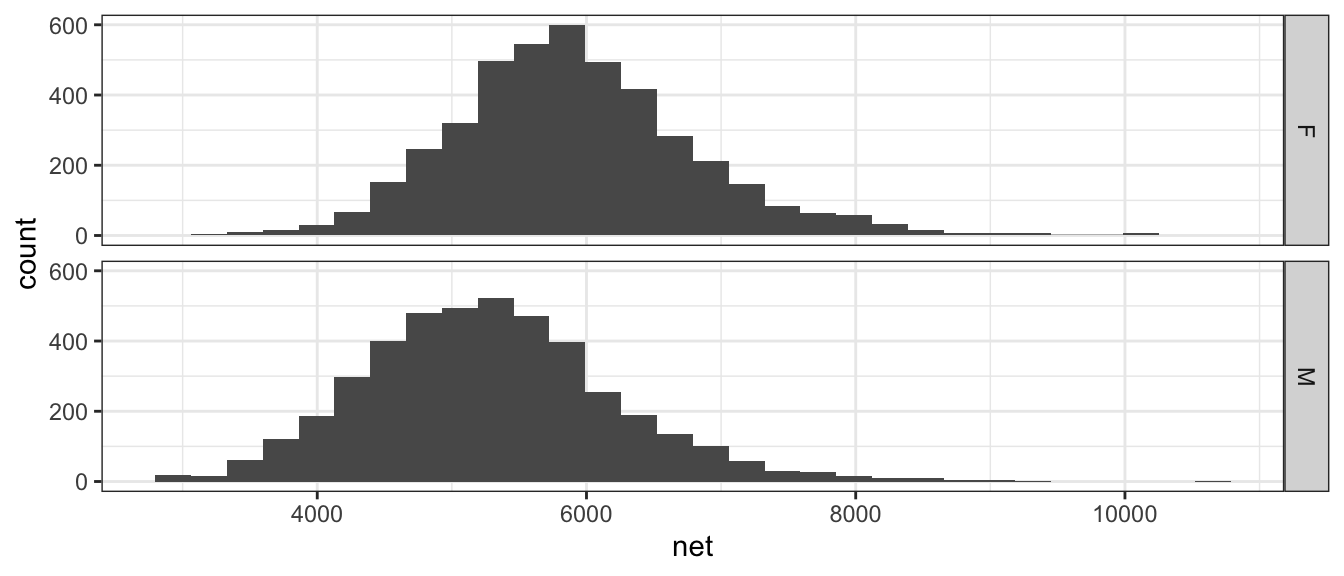
1.3.4 Scatterplot (Bivariate - Numerical vs Numerical)
Finally we might want to examine the relationship between two numerical random variables. For example, we might wish to explore the relationship between a runners age and their net time.
ggplot(TenMileRace, aes(x=age, y=net, color=sex)) +
geom_point()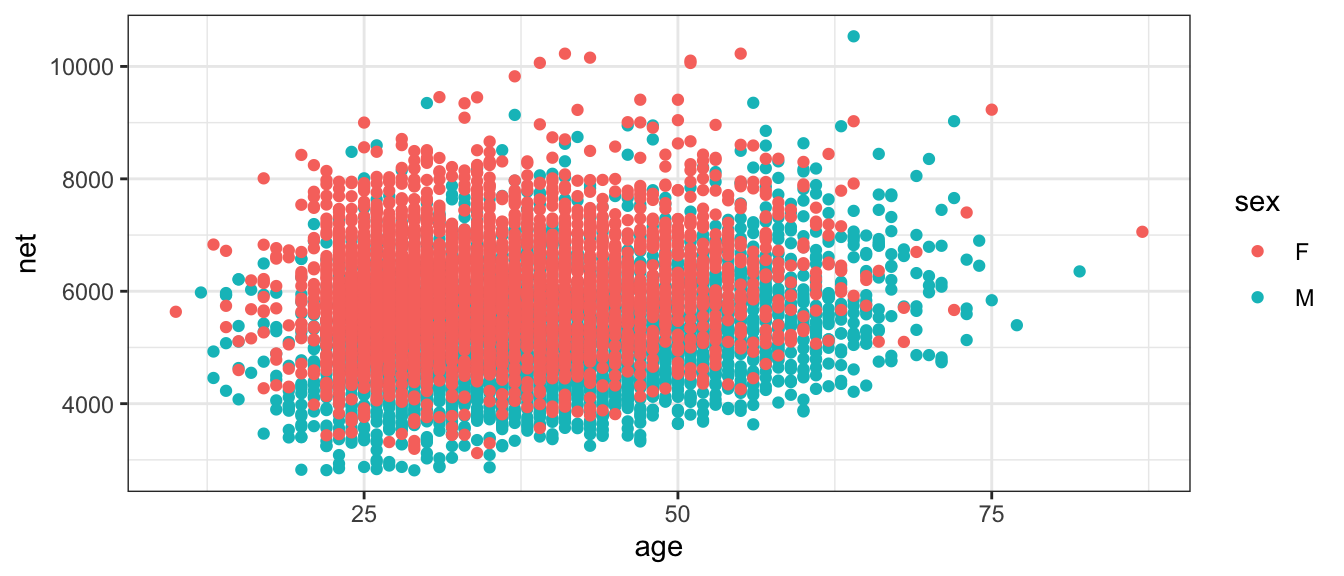
1.4 Summary Statistics
Often we want to take a set of data and summarize it using just a few numbers. These numbers are called summary statistics and different statistics measure different aspects of the data.
1.4.1 Measures of Centrality
The most basic question to ask of any dataset is ‘What is the typical value?’ There are several ways to answer that question and they should be familiar to most students.
1.4.1.1 Mean
Often called the average, or arithmetic mean, we will denote this special statistic with a bar. We define \[\bar{x}=\frac{1}{n}\sum_{i=1}^{n}x_{i}=\frac{1}{n}\left(x_{1}+x_{2}+\dots+x_{n}\right)\]
If we want to find the mean of five numbers \(\left\{ 3,6,4,8,2\right\}\) the calculation is \[\bar{x} = \frac{1}{5}\left(3+6+4+8+2\right) = \frac{1}{5}\left(23\right) = 23/5 = 4.6\]
This can easily be calculated in R by using the function mean(). We first extract the column we are interested in using the notation: DataSet$ColumnName where the $ signifies grabbing the column.
mean( TenMileRace$net ) # Simplest way of doing this calculation## [1] 5599.065# Using the dplyr package we first specify the data set
# Then specify we wish to summarize() the data set
# The summary we want to do is to calculate the mean of the 'net' column.
# and we want to name what we are about to create as Calculated.Mean
# The .groups='drop' is telling R to ungroup() the data.
TenMileRace %>%
summarise( Calculated.Mean = mean(net), .groups='drop' ) ## Calculated.Mean
## 1 5599.0651.4.1.2 Median
If the data were to be ordered, the median would be the middle most observation (or, in the case that \(n\) is even, the mean of the two middle most values).
In our simple case of five observations \(\left\{ 3,6,4,8,2\right\}\), we first sort the data into \(\left\{ 2,3,4,6,8\right\}\) and then the middle observation is clearly \(4\).
In R the median is easily calculated by the function median().
# median( TenMileRace$net )
TenMileRace %>%
summarise( Median = median(net) ) ## Median
## 1 55551.4.1.3 Mode
This is peak in the distribution. A distribution might have a single peak or multiple peaks.This measure of “center” is not often used in quantitative analyses, but is often helps provide a nice description.
When creating a histogram from a set of data, often the choice of binwidth will affect the modes of the graph. Consider the following graphs of \(n=200\) data points, where we have slightly different binwidths.
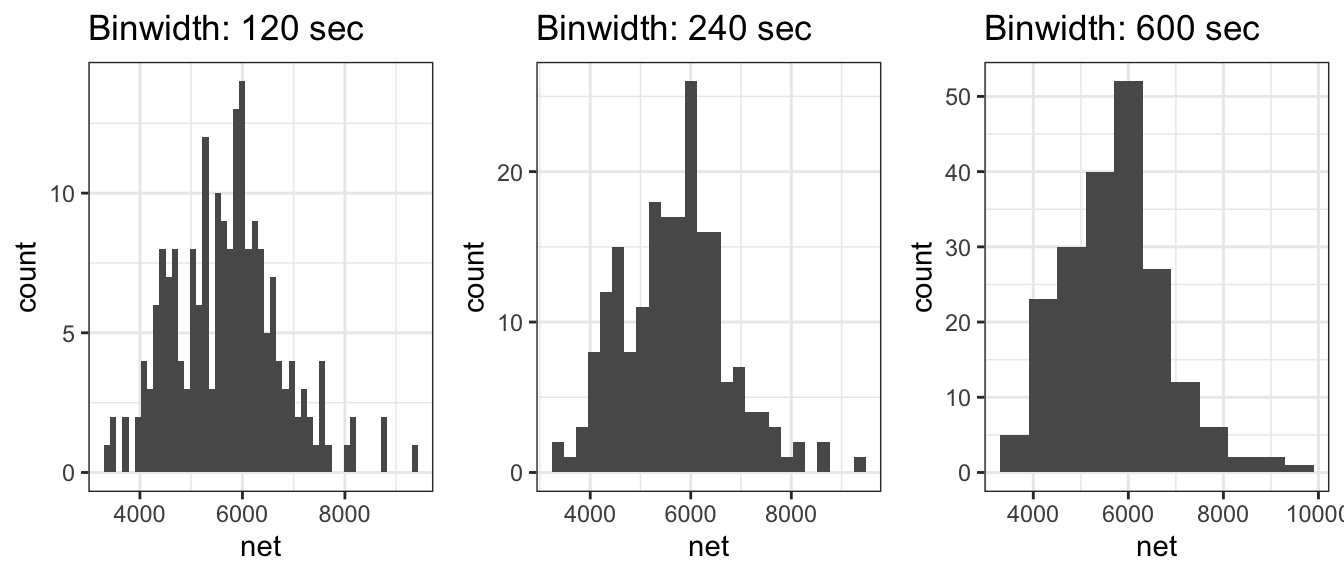
With the two smaller binwidths, sample randomness between adjacent bins obscures the overall shape and we have many different modes. However the larger binwidth results in a histogram that more effectively communicates the shape of the distribution and has just a single mode at around 6000 seconds. When making histograms, the choice of binwidth (or equivalently, the number of bins) should not be ignored and a balance should be struck between simplifying the data too much vs seeing too much of the noise resulting from the sample randomness.
1.4.1.4 Examples
- Suppose a retired professor were to become bored and enroll in the author’s
STA 570 course, how would that affect the mean and median age of the STA 570 students?
- The mean would move much more than the median. Suppose the class has 5 people right now, ages 21, 22, 23, 23, 24 and therefore the median is 23. When the retired professor joins, the ages will be 21, 22, 23, 23, 24, 72 and the median will remain 23. However, the mean would move because we add in such a large outlier. Whenever we are dealing with skewed data, the mean is pulled toward the outlying observations.
- In 2010, the median NFL player salary was $770,000 while the mean salary was $1.9 million. Why the difference?
- Because salary data is skewed by superstar players that make huge salaries (in excess of $20,000,000) while the minimum salary for a rookie is $375,000. Financial data often reflects a highly skewed distribution and the median is often a better measure of centrality in these cases.
1.4.2 Measures of Spread
The second question to ask of a dataset is ‘How much spread is in the data?’ The fancier (and eventually more technical) word for spread is ‘variability’. As with centrality, there are several ways to measure this.
1.4.2.1 Range
Range is the distance from the largest to the smallest value in the dataset.
TenMileRace %>% summarise( Range = max(net) - min(net) )## Range
## 1 7722We usually aren’t interested in the range because it can be highly affected by
a single observation. For example, in the TenMileRace data, only two runners
out of 8600 were in their 80s, but the range is calculated using the most extreme
values of a 10 and 87 year old even though the majority of the runners were between
28 and 44.
1.4.2.2 Inter-Quartile Range (IQR)
The p-th percentile is the observation (or observations) that has at most \(p\) percent of the observations below it and \((1-p)\) above it, where \(p\) is between 0 and 100. The median is the \(50\)th percentile. Often we are interested in splitting the data into four equal sections using the \(25\)th, \(50\)th, and \(75\)th percentiles (which, because it splits the data into four sections, we often call these the \(1\)st, \(2\)nd, and \(3\)rd quartiles).
In general we could be interested in dividing the data up into an arbitrary number of sections, and refer to those as quantiles of my data.
quantile( TenMileRace$net ) # gives the 5-number summary by default## 0% 25% 50% 75% 100%
## 2814 4950 5555 6169 10536The IQR is defined as the distance between the \(3\)rd and \(1\)st quantiles.
# IQR( TenMileRace$net )
TenMileRace %>% summarise( CalcIQR = IQR(net) ) ## CalcIQR
## 1 1219Notice that we’ve defined IQR before when we looked at boxplots, and that the IQR is exactly the length of the box.
1.4.3 Variance
One way to measure the spread of a distribution is to ask “what is the typical distance of an observation to the mean?” We could define the \(i\)th deviation as \[e_{i}=x_{i}-\bar{x}\] and then ask what is the average deviation? The problem with this approach is that the sum (and thus the average) of all deviations is always 0. \[\sum_{i=1}^{n}(x_{i}-\bar{x}) = \sum_{i=1}^{n}x_{i}-\sum_{i=1}^{n}\bar{x} = n\frac{1}{n}\sum_{i=1}^{n}x_{i}-n\bar{x} = n\bar{x}-n\bar{x} = 0\]
The big problem is that about half the deviates are negative and the others are positive. What we really care is the distance from the mean, not the sign. So we could either take the absolute value, or square it.
There are some really good theoretical reasons to chose the square option. Squared terms are easier to deal with computationally when compared to absolute values. More importantly, the spread of the normal distribution is parameterized via squared distances from the mean. Because the normal distribution is so important, we’ve chosen to define the sample variance so it matches up with the natural spread parameter of the normal distribution. So we square the deviations and find the average deviation size (approximately) and call that the sample variance. \[s^{2}=\frac{1}{n-1}\sum_{i=1}^{n}\left(x_{i}-\bar{x}\right)^{2}\] Why do we divide by \(n-1\) instead of \(n\)?
- If we divide by \(n\), then on average, we would tend to underestimate the population variance \(\sigma^{2}\).
- The reason is because we are using the same set of data to estimate
\(\sigma^{2}\) as we did to estimate the population mean (\(\mu\)). If we could use
\[\frac{1}{n}\sum_{i=1}^{n}\left(x_{i}-\mu\right)^{2}\] as the estimator, we would be fine. But because we have to replace \(\mu\) with \(\bar{x}\) we have to pay a price. - Because the estimation of \(\sigma^{2}\) requires the estimation of one other quantity, we have used one degree of freedom on estimating the mean and we need to adjust the formula accordingly.
In later chapters we’ll give this quantity a different name, so we’ll introduce the necessary vocabulary here. Let \(e_{i}=x_{i}-\bar{x}\) be the error left after fitting the sample mean. This is the deviation from the observed value to the “expected value” \(\bar{x}\). We can then define the Sum of Squared Error as \[SSE=\sum_{i=1}^{n}e_{i}^{2}\] and the Mean Squared Error as \[MSE=\frac{SSE}{df}=\frac{SSE}{n-1}=s^{2}\] where \(df=n-1\) is the appropriate degrees of freedom.
Calculating the variance of our small sample of five observations \(\left\{ 3,6,4,8,2\right\}\), recall that the sample mean was \(\bar{x}=4.6\)
| \(x_i\) | \((x_i-\bar{x})\) | \((x_i-\bar{x})^2\) |
|---|---|---|
| 3 | -1.6 | 2.56 |
| 6 | 1.4 | 1.96 |
| 4 | -0.6 | 0.36 |
| 8 | 3.4 | 11.56 |
| 2 | -2.6 | 6.76 |
| Sum = 0 | SSE = 23.2 |
and so the sample variance is \[s^2 = \frac{SSE}{n-1} = \frac{23.2}{(n-1)} = \frac{23.2}{4}=5.8\]
Clearly this calculation would get very tedious to do by hand and computers will
be much more accurate in these calculations. In R, the sample variance is easily
calculated by the function var(). Given below is an example calculation done
using dplyr commands.
ToyData <- data.frame( x=c(3,6,4,8,2) )
#var(ToyData$x)
ToyData %>% summarise( s2 = var(x) )## s2
## 1 5.8For the larger TenMileRace data set, the variance of the net time to complete
the race is calculated just as easily.
TenMileRace %>% summarise( s2 = var(net) )## s2
## 1 940233.51.4.3.1 Standard Deviation
The biggest problem with the sample variance statistic is that the units are the original units-squared. That means if you are looking at data about car fuel efficiency, then the values would be in mpg\(^{2}\) which are units that I can’t really understand. The solution is to take the positive square root, which we will call the sample standard deviation. \[s=\sqrt{s^{2}}\]
Why do we even bother to define the variance? Mathematically the variance is more useful and most distributions (such as the normal) are defined by the variance term. Practically, standard deviation is easier to think about and becomes an informative quantity when discussing sample error.
The sample standard deviation is important enough for R to have a function
sd() that will calculate it for you.
# sd( TenMileRace$net )
TenMileRace %>% summarise( s = sd(net) )## s
## 1 969.65641.4.3.2 Coefficient of Variation
While the IQR and standard deviation are the most common ways to evaluate spread, they are not the only measures. Suppose we had a group of animals and the sample standard deviation of the animals lengths was 15 cm. If the animals were elephants, you would be amazed at their uniformity in size, but if they were insects, you would be astounded at the variability. To account for that, the coefficient of variation takes the sample standard deviation and divides by the absolute value of the sample mean (to keep everything positive)
\[CV=\frac{s}{\vert\bar{x}\vert}\]
Below is sample code to quickly grab the summary metrics of interest, with a calculation of the CV.
TenMileRace %>%
summarise( s = sd(net),
xbar = mean(net),
CV = s / abs(xbar) )## s xbar CV
## 1 969.6564 5599.065 0.1731818One final example showing how we can get information about grouped variables. Here, we would like to to calculate the same summary statistics as above, but would like to know them specificall for each factor with sex; that is, we want to compare ‘Male’ and ‘Female’.
# Previously using dplyr notation didn't help too much, but if we wanted
# to calculate the statistics separately for each sex, the dplyr solution
# is MUCH easier.
TenMileRace %>% # Summarize the Ten Mile Race Data
group_by(sex) %>% # Group actions using sex
summarise( xbar = mean(net), #
s = sd(net), #
cv = s / abs(xbar) ) # Calculate three different summary stats## `summarise()` ungrouping output (override with `.groups` argument)## # A tibble: 2 x 4
## sex xbar s cv
## <fct> <dbl> <dbl> <dbl>
## 1 F 5916. 902. 0.152
## 2 M 5281. 930. 0.1761.4.3.3 Empirical Rules
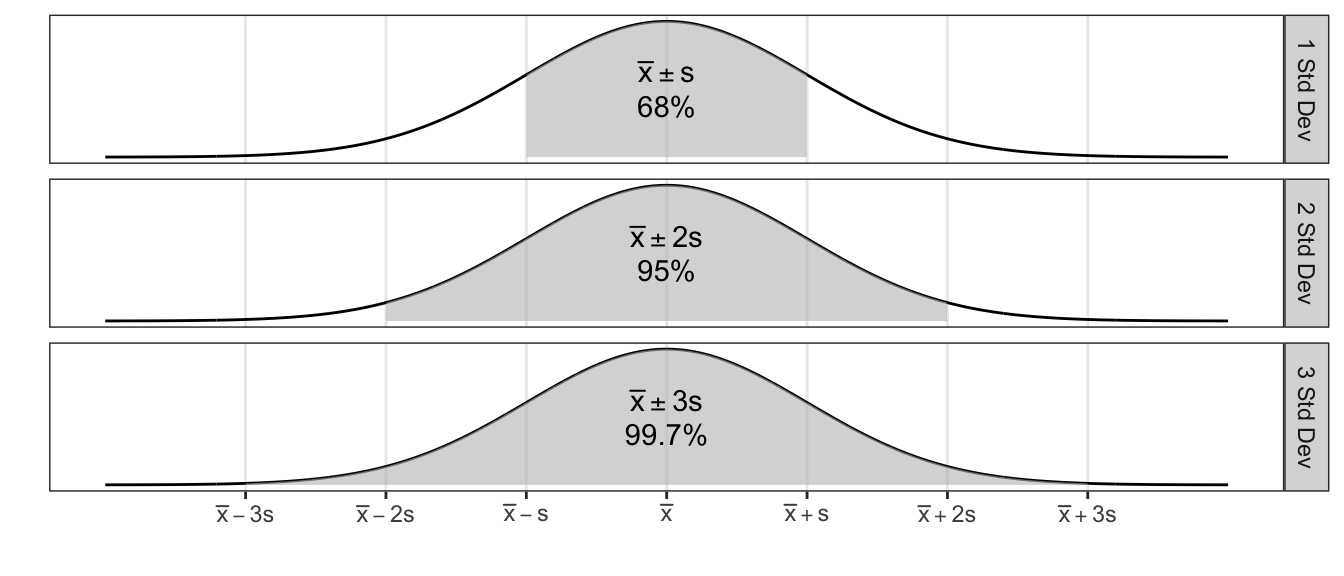
For any data that are normally distributed (or approximately normal), the following are resourceful rules of thumb:
| Interval | Approximate percent of Measurements |
|---|---|
| \(\bar{x}\pm s\) | 68% |
| \(\bar{x}\pm 2s\) | 95% |
| \(\bar{x}\pm 3s\) | 99.7% |
1.5 Shape
Vocabulary for discussing the shape of a distribution is discussed. These descriptors can be very useful for understanding the distribution, and as understanding develops, also tell us about relationships between the mean and median, or other informative quantities.
1.5.1 Symmetry
A distribution is said to be symmetric if there is a point along the x-axis (which we’ll call \(\mu\)) which acts as a mirror. Mathematically, a distribution is symmetric around \(m\) if and only if \(f( -\lvert x-\mu \rvert ) = f( \lvert x-\mu \rvert )\). The following graphs give the point of symmetry marked with a red line.
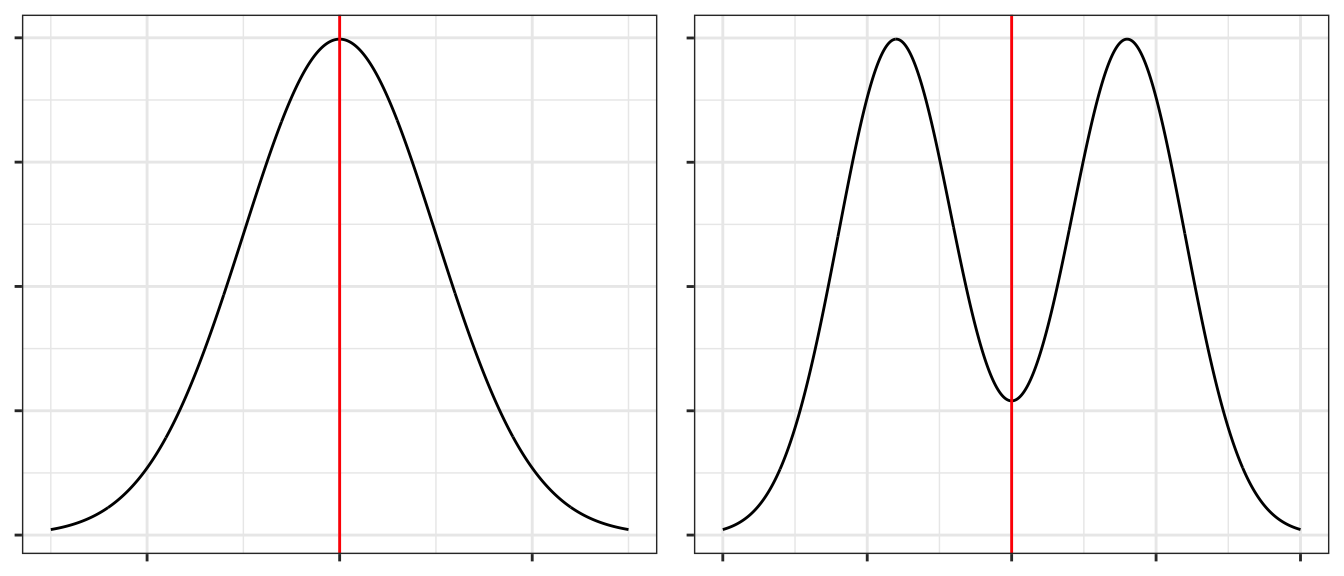
A distribution that is not symmetric is said to be asymmetric.
1.5.2 Unimodal or Multi-modal
Recall one measure of centrality was mode. If there is just a single mode, then we refer to the distribution as unimodal. If there is two or more we would refer to it as bimodal or multi-modal.
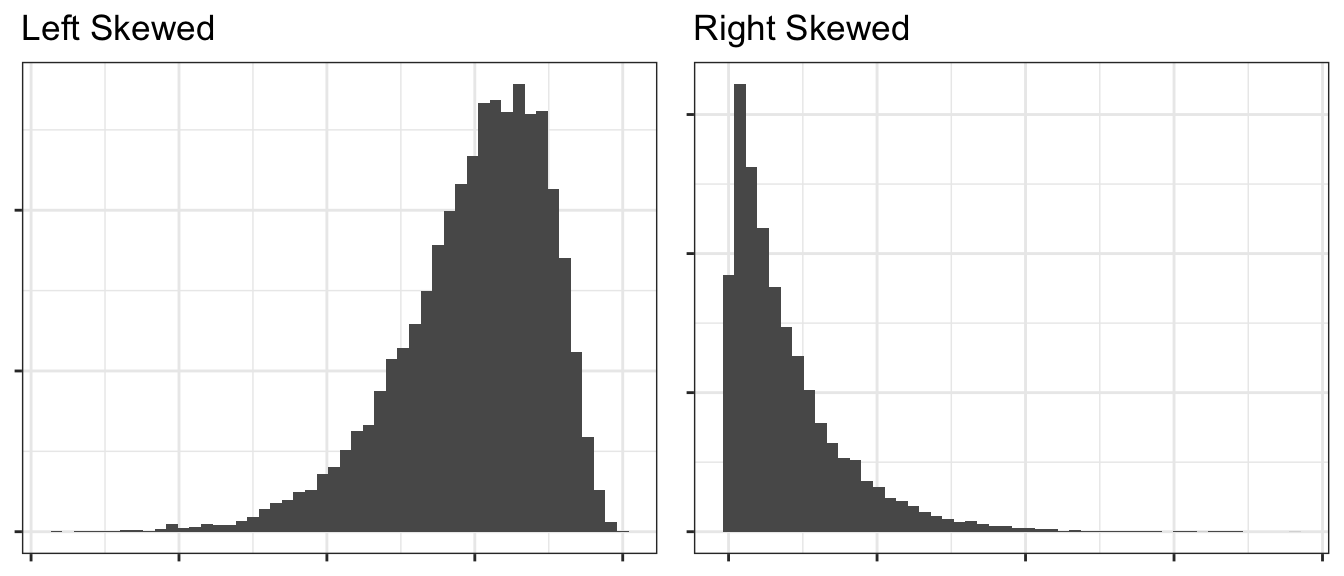
1.5.3 Skew
If a distribution has a heavier tail on one side or the other, we refer to it as a skewed distribution and the direction of the skew is towards the heavier tail. Usually (but not always), an asymmetric distribution is skewed.
1.6 Exercises
O&L 3.21. The ratio of DDE (related to DDT) to PCB concentrations in bird eggs has been shown to have had a number of biological implications. The ratio is used as an indication of the movement of contamination through the food chain. The paper “The ratio of DDE to PCB concentrations in Great Lakes herring gull eggs and its us in interpreting contaminants data” reports the following ratios for eggs collected at 13 study sites from the five Great Lakes. The eggs were collected from both terrestrial and aquatic feeding birds.
Source Type DDE to PCB Ratio Terrestrial 76.50, 6.03, 3.51, 9.96, 4.24, 7.74, 9.54, 41.70, 1.84, 2.5, 1.54 Aquatic 0.27, 0.61, 0.54, 0.14, 0.63, 0.23, 0.56, 0.48, 0.16, 0.18 - By hand, compute the mean and median separately for each type of feeder.
- Using your results from part (a), comment on the relative sensitivity of the mean and median to extreme values in a data set.
- Which measure, mean or median, would you recommend as the most appropriate measure of the DDE to PCB level for both types of feeders? Explain your answer.
O&L 3.31. Consumer Reports in its June 1998 issue reports on the typical daily room rate at six luxury and nine budget hotels. The room rates are given in the following table.
Hotel Type Nightly Rate Luxury 175, 180, 120, 150, 120, 125 Budget 50, 50, 49, 45, 36, 45, 50, 50, 40 - By hand, compute the means and standard deviations of the room rates for each class of hotel.
- Give a practical reason why luxury hotels might have higher variability than the budget hotels. (Don’t just say the standard deviation is higher because there is more spread in the data, but rather think about the Hotel Industry and why you might see greater price variability for upscale goods compared to budget items.)
Use R to confirm your calculations in problem 1 (the pollution data). Show the code you used and the subsequent output. It will often be convenient for me to give you code that generates a data frame instead of uploading an Excel file and having you read it in. The data can be generated using the following commands:
PolutionRatios <- data.frame( Ratio = c(76.50, 6.03, 3.51, 9.96, 4.24, 7.74, 9.54, 41.70, 1.84, 2.5, 1.54, 0.27, 0.61, 0.54, 0.14, 0.63, 0.23, 0.56, 0.48, 0.16, 0.18 ), Type = c( rep('Terrestrial',11), rep('Aquatic',10) ) ) head( PolutionRatios ) # Print out some data to confirm column names.## Ratio Type ## 1 76.50 Terrestrial ## 2 6.03 Terrestrial ## 3 3.51 Terrestrial ## 4 9.96 Terrestrial ## 5 4.24 Terrestrial ## 6 7.74 TerrestrialHint: for computing the means and medians for each type of feeder separately, the
group_by()command we demonstated earlier in the chapter is convenient.Use R to confirm your calculations in problem 2 (the hotel data). Show the code you used and the subsequent output. The data can be loaded into a data frame using the following commands Show the code you used and the subsequent output:
Hotels <- data.frame( Price = c(175, 180, 120, 150, 120, 125, 50, 50, 49, 45, 36, 45, 50, 50, 40), Type = c( rep('Luxury',6), rep('Budget', 9) ) ) head( Hotels ) # Print out some data to confirm the column names.## Price Type ## 1 175 Luxury ## 2 180 Luxury ## 3 120 Luxury ## 4 150 Luxury ## 5 120 Luxury ## 6 125 LuxuryFor the hotel data (problem 2 and 4), create side-by-side box-and-whisker plots to compare the prices.
For each of the following, mark if it is Continuous or Discrete.
- \(\underline{\hspace{1in}}\) Milliliters of tea drunk per day.
- \(\underline{\hspace{1in}}\) Different brands of soda drunk over the course of a year.
- \(\underline{\hspace{1in}}\) Number of days per week that you are on-campus for any amount of time.
- \(\underline{\hspace{1in}}\) Number of grizzly bears individuals genetically identified from a grid of hair traps in Glacier National Park.
Match the following histograms to the appropriate boxplot.
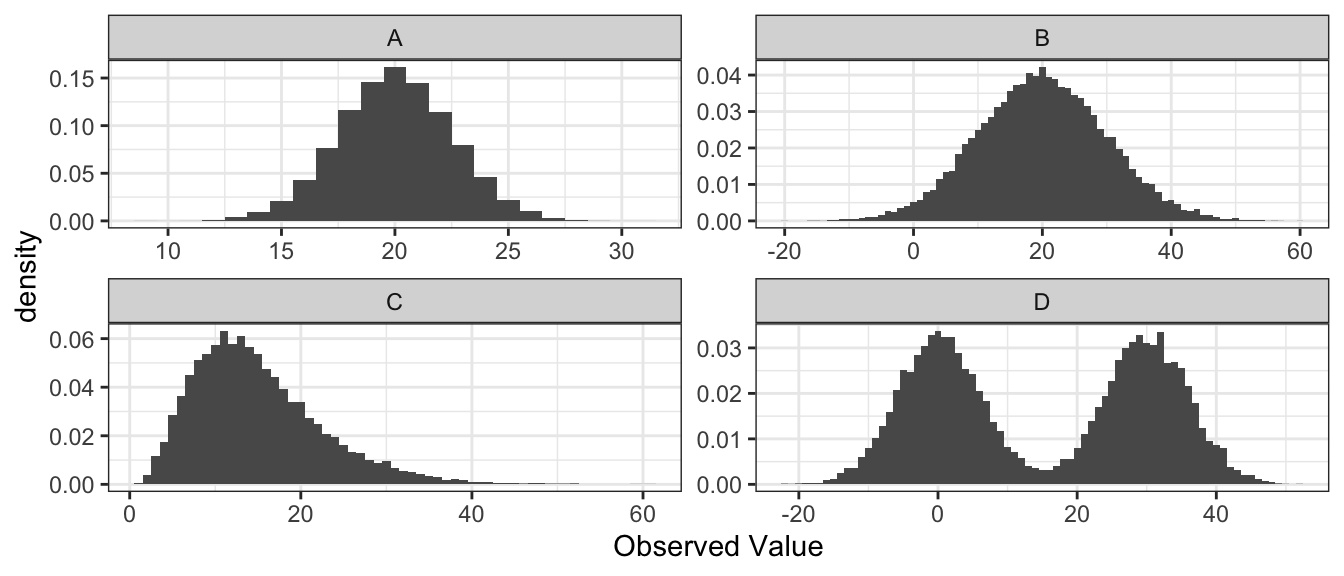
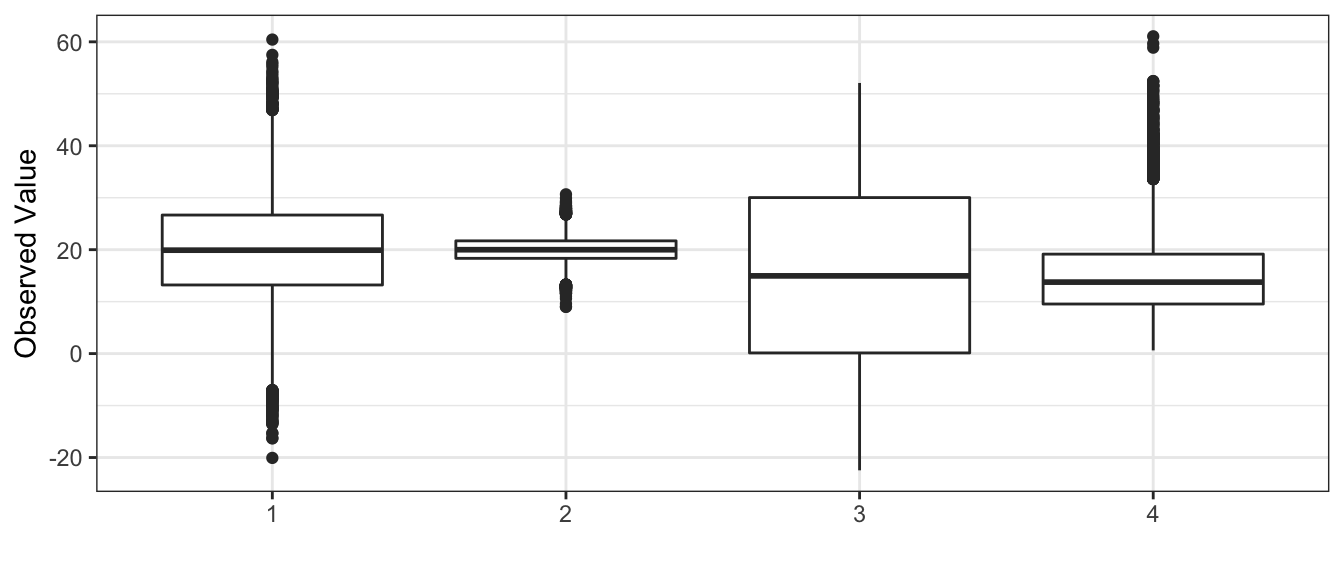
- Histogram A goes with boxplot __________
- Histogram B goes with boxplot __________
- Histogram C goes with boxplot __________
- Histogram D goes with boxplot __________
Twenty-five employees of a corporation have a mean salary of $62,000 and the sample standard deviation of those salaries is $15,000. If each employee receives a bonus of $1,000, does the standard deviation of the salaries change? Explain your reasoning.
The chemicals in clay used to make pottery can differ depending on the geographical region where the clay originated. Sometimes, archaeologists use a chemical analysis of clay to help identify where a piece of pottery originated. Such an analysis measures the amount of a chemical in the clay as a percent of the total weight of the piece of pottery. The box plots below summarize analyses done for three chemicals—X, Y, and Z—on pieces of pottery that originated at one of three sites: I, II, or III.
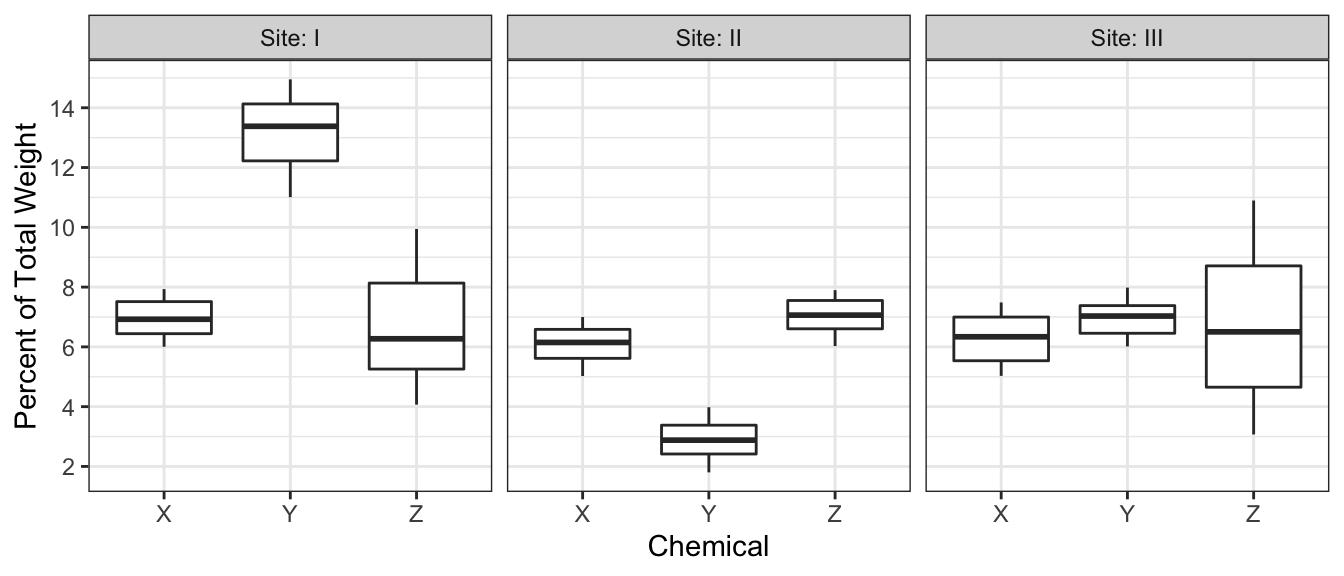
- For chemical Z, describe how the percents found in the pieces of pottery are similar and how they differ among the three sites.
- Consider a piece of pottery known to have originated at one of the three
sites, but the actual site is not known.
- Suppose an analysis of the clay reveals that the sum of the percents of the three chemicals X, Y, and Z is \(20.5\%\). Based on the box plots, which site—I, II, or III—is the most likely site where the piece of pottery originated? Justify your choice.
- Suppose only one chemical could be analyzed in the piece of pottery. Which chemical—X, Y, or Z— would be the most useful in identifying the site where the piece of pottery originated? Justify your choice.
The efficacy of a new heart medication is being tested by evaluating its effect on a wide range of individuals. For each individual in the study the following characteristics are recorded prior to being given the medication: Gender, Ethnicity, Age (years), Height (m), Weight (kg), Blood Pressure (mmHg), Heart Rate (bpm). Determine the type of variable for each characteristic, briefly justify each answer.
Grapes from a vineyard with 500 vines in Napa Valley are to be sampled. The investigator chooses to sample one grape from 100 different vines. What type of sampling is being done? Justify your response.
R Experiment. Use the code below to generate 100 samples from a normal distribution. The normal distribution has a mean of 10 and a variance of 2. Be sure to include the set.seed function so all answers are the same.
set.seed(10) rand.sample<-rnorm(100, 10, 2)Use R to calculate the mean, median, variance, and IQR of rand.sample. Assign each value to variables with the names step1.mean, step1.median, step1.var, step1.IQR and have them output to the file.
Do the mean and median calculated match the expected value of 10? Discuss why there may be discrepancies between the population mean and the sample mean.
Next use the following code to augment rand.sample. This effectively adds two outliers to rand.sample.
rand.sample.2<-c(rand.sample, 250, 250)Use R to calculate the mean, median, variance, and IQR of rand.sample.2 and save them as variables named step2.mean, step2.median, step2.var, step2.IQR. Be sure to display all resulting summary statistics in the final RMD output.
Discuss the differences in the statistics computed for rand.sample and rand.sample.2. Which statistics seem more resilient to the outliers?